1. مقدمه
تطبیق نقشه داده های مسیر برای بسیاری از کاربردهای حمل و نقل هوشمند، مانند ردیابی وسیله نقلیه، تجزیه و تحلیل جریان ترافیک، تشخیص حالت های حمل و نقل و برنامه ریزی مسیر ضروری است [ 1 ، 2 ، 3 ، 4 ، 5 ، 6 ]. دادههای مسیر شامل نقاط مکانیابی است که بر اساس سیستمهای ماهوارهای ناوبری جهانی (GNSS) توسط یک برنامه ردیابی بر روی یک وسیله نقلیه یا هر شی دیگری ثبت شدهاند، و تطبیق نقشه برای دادههای مسیر در صورتی که حرکت در امتداد یک شبکه تحرک شناخته شده باشد، اعمال میشود [ 7 ] ]. الگوریتمهای تطبیق نقشه محتملترین بخش شبکه تحرک را برای هر نقطه GNSS در دادههای مسیر تعیین میکنند [ 5 ،8 ، 9 ].
الگوریتم های تطبیق نقشه موجود، رویکردهای متعددی را برای رسیدگی به خطاهای تطبیق نقشه در نظر می گیرند [ 10 ، 11 ]. با این حال، آنها هنوز هم به دلایل زیادی مستعد خطا هستند، مانند وقوع اجتناب ناپذیر خطاهای سیستماتیک GNSS، از جمله سیگنال های مسدود شده و اثرات چند مسیری (خطای اندازه گیری) [ 4 ، 12 ، 13 ]، مسیرهای GNSS با نرخ نمونه پایین (خطای نمونه گیری) [ 10 ]، محدودیت در کارایی الگوریتم های تطبیق نقشه آنلاین، داده های نقشه ناقص [ 14 ]، خطاهای تطبیق در اتصالات [ 11 ]، و تطبیق با شبکه های تحرک اشتباه [ 8 ، 10 ، 11 ،12 ].
برنامه های کاربردی فوق الذکر به الگوریتم های تطبیق نقشه آنلاین یا آفلاین نیاز دارند [ 6 ]. الگوریتم های تطبیق نقشه آنلاین محتمل ترین بخش شبکه تحرک را به محض ثبت نقطه GNSS تولید می کنند [ 15 ، 16 ]. برعکس، الگوریتمهای آفلاین از مجموعهای از نقاط GNSS از قبل ثبتشده برای شناسایی مسیری که جسم متحرک طی میکند در آینده استفاده میکنند [ 5 ، 6 ]]. این مقاله به تطبیق نقشه آفلاین می پردازد. در این مورد، شناسایی خطای تطبیق نقشه در حضور داده های مسیر حقیقت زمینی (مثلاً حالت و مسیر سفر) ساده خواهد بود. با این حال، فقدان معمولی دادههای واقعی، شناسایی و تعیین کمیت خطاهای تطبیق نقشه را دشوارتر میکند. در حال حاضر، تطبیق نقشه آفلاین برای بازرسی بصری باز است، که یک فرآیند بصری اعتبار سنجی توسط استدلال انسانی را امکان پذیر می کند. استفاده از این فرآیند برای شناسایی خطاهای تطبیق نقشه زمانی که تعداد زیادی از مسیرها پردازش می شوند، کاری پر زحمت است.
بنابراین، برای این مورد عدم وجود حقیقت زمین، ابتدا یک خطای تطبیق نقشه را تعریف میکنیم : وقتی یک بخش منطبق با نقشه، که در یک مسیر مطابق با نقشه گنجانده شده است، یک رفتار سفر غیرواقعی را نشان میدهد، آنگاه تطبیق این بخش به عنوان یک خطا. در نتیجه، خطاهای تطبیق نقشه را میتوان با شمارش تعداد بخشهای تطبیق نادرست (یا غیرمنطقی) اندازهگیری کرد . با در دست داشتن این دو تعریف، سؤال تحقیقاتی زیر را مطرح میکنیم: چگونه میتوانیم به طور خودکار خطاهای تطبیق نقشه را شناسایی و کمیت کنیم، زمانی که حقیقت زمینی در دسترس نیست؟
ما یک تکنیک شناسایی خطای خودکار مقیاسپذیر را ارائه میکنیم که خطای تطبیق نقشه را با شمارش تعداد بخشهای منطبق نادرست (یا غیرمنطقی) کمّی میکند. شناسایی خودکار خطا بر اساس یک رویکرد یادگیری بدون نظارت مبتنی بر نظریه گراف اجرا می شود، به طوری که نیازی به مداخله انسانی نیست. روش پیشنهادی به عنوان یک مؤلفه در یک ابزار منبع باز مبتنی بر پایتون پیادهسازی میشود که همچنین به فرد اجازه میدهد تا به صورت تعاملی مسیر منطبق بر نقشه مجموعه نقطه مسیر را تجزیه و تحلیل کند ( شکل 1 ). به دلیل فقدان دادههای حقیقت پایه، تحلیل بصری به فرد اجازه میدهد تا این حقیقت پایه را مشخص کند و از این حقیقت پایه برای تحلیل عملکرد تکنیک جدید خود استفاده کند.
ابزار پیادهسازی شده در شکل 1 میتواند به عنوان یک ابزار کاملا مستقل عمل کند زمانی که هدف صرفهجویی در نیروی انسانی باشد. با این حال، یک بازرسی بصری هدایتشده برای شناسایی خودکار خطاهای تطبیق نقشه میتواند کیفیت فرآیند خودکار را بیشتر بهبود بخشد. سهم عمده این مقاله، با این حال، الگوریتم خودکار برای شناسایی آفلاین خطاها در تطبیق نقشه است. این الگوریتم مقیاس پذیر است زیرا نیازی به دخالت انسان ندارد. فقط برای بررسی کیفیت یا اندازهگیری عملکرد، یک جزء تجزیه و تحلیل بصری در دسترس است.
بقیه مقاله به شرح زیر سازماندهی شده است. بخش 2 تکنیک های تطبیق نقشه فعلی را شرح می دهد. بخش 3 نظریه مربوطه را در رابطه با خطاها در تطبیق نقشه توضیح می دهد. بخش 4 روش ما را برای شناسایی نقاط GNSS که به اشتباه نگاشت شده اند ارائه می کند. بخش 5 تکنیک ها و نتایج تجربی را برای اعتبارسنجی روش ما و اندازه گیری عملکرد آن شرح می دهد. نتیجه گیری در بخش 6 ارائه شده است.
2. بررسی ادبیات
دو رویکرد اصلی برای تطبیق نقشه در ادبیات وجود دارد: (1) رویکردهای مبتنی بر هندسه و (2) رویکردهای مبتنی بر آمار.
2.1. تطبیق نقشه مبتنی بر هندسه
رویکردهای مبتنی بر هندسه، تطبیق نقشه را بر اساس ویژگیهای هندسی خاص (مثلاً نزدیکی) نقاط GNSS و شکل بخشهای جاده انجام میدهند. رویکردهای رایج تطبیق نقشه نقطه به نقطه (تطبیق نقاط GNSS با نزدیکترین گره شبکه جاده ای) [ 17 ]، تطبیق نقشه نقطه به منحنی (تطبیق نزدیکترین نقطه همراه با یک بخش جاده) [ 18 ] انطباق نقشه منحنی به منحنی (تطبیق مجموعه ای از نقاط همراه با یک بخش جاده) [ 19 ]، و تطبیق مبتنی بر فاصله فریشت [ 20 ] (نقاط GNSS ثبت شده بر روی بخش های جاده با نزدیکترین فاصله فرشت مطابقت داده می شود. ) [ 1 ، 21 ، 22 ، 23]. رویکرد مبتنی بر فاصله فرشه نتایج بهتری نسبت به سایر روشهای تطبیق نقشه هندسی دارد [ 3 ]. با این حال، رویکرد مبتنی بر فاصله Fréchet فرض میکند که مسیر کامل قبل از فرآیند تطبیق ثبت میشود. از این رو، این رویکرد قادر به ترسیم تطابق در زمان واقعی نیست [ 1 ]. علاوه بر این، تطبیق نقشه مبتنی بر هندسه دارای محدودیتهایی در تقاطعهای جادهای است و اغلب بخشهایی را که مطابقت نادرست دارند تولید میکند [ 10 ].
2.2. تطبیق نقشه مبتنی بر آمار
در رویکردهای مبتنی بر آمار، دقت تطبیق نقشه با استفاده از مدلهای آماری مختلف، به عنوان مثال، مدل پنهان مارکوف (HMM) بهبود یافته است [ 5 ، 10 ، 13 ]. هدف HMM تطبیق هر اندازهگیری مکان با محتملترین بخش جاده با یافتن محتملترین مسیر در شبکه راه است [ 5 ، 13 ]. HMM احتمالات حاکم بر اندازهگیریهای حالت و احتمالات حاکم بر انتقال بین حالتها (بخشهای جاده) را در هر زمان در نظر میگیرد [ 5 ، 13 ]]. HMM احتمال انتشار را با مدلسازی نویز اندازهگیری و احتمالات انتقال را با مدلسازی فاصله بین اندازهگیریهای GNSS و مسیر احتمالی محاسبه میکند [ 5 ، 7 ، 9 ، 24 ]. الگوریتم Viterbi برای محاسبه بهترین مسیر از طریق شبکه HMM استفاده می شود [ 5 ، 13 ، 24 ، 25 ]. روش دیگر، استفاده از یک نسخه دو طرفه از الگوریتم دایکسترا منجر به دقت مشابهی می شود [ 9 ]. تطبیق نقشه مبتنی بر HMM نیز در تطبیق نقشه آنلاین استفاده می شود [ 15 ، 16 ، 26]. بهبود در تطبیق نقشه مبتنی بر HMM با استفاده از مدل مارکوف پنهان مبتنی بر بخش در شبکههای جادهای متراکمتر انجام شده است [ 13 ]. رویکرد دیگر بر روی اتصالات متمرکز است که در آن الگوریتم می تواند بخش جاده اشتباه را ترسیم کند [ 8 ].
یکی دیگر از چالش های اصلی که اغلب به آن پرداخته نمی شود، کشف تطبیق نقشه و تشخیص حالت حمل و نقل است [ 4 ، 12 ]. با توجه به ادبیات فعلی، تشخیص حالت و تطبیق نقشه عمدتاً از دو مرحله تشکیل شده است [ 12 ]: (1) نقاط GNSS بر اساس چندین بخش تک وجهی مرتب می شوند و پس از آن (2) تطبیق نقشه و تشخیص حالت برای هر بخش تک وجهی جداگانه انجام می شود. هنگامی که بخش های تک وجهی به درستی توسط یک الگوریتم تشخیص حالت شناسایی نمی شوند، نقاط GNSS با بخش اشتباهی از شبکه تحرک مطابقت داده می شوند [ 8 ، 12 ]]. علاوه بر این، بخشبندی حالت معمولاً منطق سفر را در نظر نمیگیرد. به عنوان مثال، انتقال بین دو حالت وسیله نقلیه بدون راه رفتن امکان پذیر نیست [ 4 ]. الگوریتم های تشخیص حالت بسته به قدرت سیگنال GNSS و پراکندگی داده های جمع آوری شده ضعیف عمل می کنند [ 4 ، 12 ]. بنابراین، نقاط GNSS بدون برچسب با حالت های سفر و القا شده با خطای سیستماتیک منجر به تطبیق نقشه اشتباه می شود [ 8 ].
به طور خلاصه، همه الگوریتمهای موجود ممکن است برخی از نقاط GNSS را به دلیل عوامل زیادی مانند خطاهای اندازهگیری در نقاط GNSS، نرخ نمونهبرداری پایین از نقاط GNSS، محدودیتها در منابع محاسباتی برای تطبیق نقشه آنلاین و توپولوژی پیچیده، به اشتباه برخی از نقاط GNSS را در یک بخش جاده اشتباه نگاشت کنند. در تقاطع های جاده ای [ 10 ]. چالش اجتناب از خطاهای تطبیق نقشه تا به امروز به طور سیستماتیک حل نشده است. روش های اخیر تطبیق نقشه تا به 92 %92%دقت برای نرخ نمونه بالا (زیر 1 دقیقه) و تا 82 درصد82%دقت برای نرخ نمونه پایین (یک تا دو دقیقه) از نقاط ثبت شده GNSS، به ترتیب [ 10 ]. بنابراین، احتمال یک خطای تطبیق نقشه باقیمانده به دلیل رویکردهای تصادفی روشهای موجود وجود دارد [ 11 ]. تا جایی که ما می دانیم، هیچ روشی برای شناسایی این خطاهای تطبیق نقشه باقی مانده پیشنهاد نشده است. برای غلبه بر چالش ذکر شده در بالا در شناسایی خطا در بخشهای همسان نقشه، ما یک رویکرد مبتنی بر استدلال را برای شناسایی و کمی کردن خطاهای تطبیق نقشه پیشنهاد میکنیم.
3. مفاهیم شناسایی خطای تطبیق نقشه
در این بخش، ابتدا در مورد اینکه چگونه خطاهای تطبیق نقشه باقیمانده را می توان مشخص کرد ( بخش 3.1 ) بحث می کنیم. این مشخصهسازی اجازه میدهد تا خطای کمی را در یک سری نقطه مسیر مطابق با نقشه رسمیسازی کنیم ( بخش 3.2 ) و یک فاصله ویرایشی برای این کمیسازی معرفی کنیم ( بخش 3.3 ).
3.1. خطای کیفی در تطبیق نقشه
خطای کیفی در تطبیق نقشه نیاز به مشخصه ایستایی دارد. به عنوان مثال، آیا خودرویی که پشت چراغ قرمز توقف می کند، حرکت خود را بین دو فعالیت ثابت قطع می کند؟ این امر مستلزم در نظر گرفتن زمینه حرکت است، یعنی حالت سفر حرکت قبل و بعد از توقف و آستانههای خاص مد برای مدت زمان قابل قبول این توقفها. اغلب، این مسیرها در فواصل زمانی منظم نمونه برداری می شوند، اگرچه نمونه برداری در فواصل زمانی منظم و نمونه برداری نامنظم نیز امکان پذیر است. استراتژیهای نمونهگیری منظم همچنین میتواند شکافهایی را در ضبطهای آنها نشان دهد. ما دستهبندیهای زیر از رفتار سفر غیرواقعی را در نظر گرفتهایم که با خطاهای کیفی در الگوریتم تطبیق نقشه منعکس میشوند:
رفتار غیرواقعی سفر در یک بخش منطبق بر نقشه به سه دلیل اصلی رخ میدهد: (1) خطای اندازهگیری در نقاط جمعآوریشده GNSS (از آنجایی که نقاط جمعآوریشده GNSS در معرض خطای اندازهگیری قرار میگیرند، موقعیتهای واقعی ناشناخته باقی میمانند، و در نتیجه بخشهای نادرست تطبیق داده میشوند. [ 27 ])؛ (2) توپولوژی پیچیده و اطلاعات نقشه ناقص در شبکه جاده [ 11 ]، که منجر به محاسبات احتمال انتقال اشتباه در هر دو روش آماری و مبتنی بر فاصله می شود [ 5 ]]; and (iii) mismatch of travel mode and road network type (e.g., map-matching of a car route on a public transport network) [12]. As a result of map-matching, in a map-matched route, there will be two types of map-matched segments: (i) correctly map-matched segments (reflects realistic travel behavior) and (ii) incorrectly map-matched segments (reflects unrealistic travel behavior).
3.2. خطای کمی در تطبیق نقشه
ما پس از اینکه یک الگوریتم نگاشت مسیر تخمینی و بخش های مطابق با نقشه را تولید کرد، کمی خطاهای نگاشت کیفی را پیشنهاد می کنیم. فرض کنید یک مسیر T حاوی تعداد d از نقاط داده GNSS ثبت شده باشد، د≥ 2�≥2، به طوری که j�نقطه داده ( د≥ j ≥ 1�≥�≥1) شامل تاپل است <ایکسj،yj،تیj><��,��,��>، جایی که ایکسj��و yj��مختصات مکان نقطه j (به عنوان مثال، طول و عرض جغرافیایی، به ترتیب)، و تیj��مهر زمانی رکورد مکان است. اجازه دهید E مجموعه یال ها و V مجموعه رئوس در نمودار جهت دار (دیگراف) شبکه راه باشد. G = ( V، ای)�=(�,�). سپس:
در اینجا، لبهها بخشهای جاده را بر روی نقشه نشان میدهند، بخش کاندید احتمالی تطبیق نقشه. ما به اصطلاح لبه در زمینه یک نمودار و به یک بخش در زمینه داده های نقشه اشاره خواهیم کرد. مسیر حقیقت زمینی یک داده مسیر T دنباله ای از بخش های جاده متصل مسیر طی شده روی نقشه است. برای این، فرض می کنیم که نقشه کامل است.
فرض کنید R دنبالهای از بخشهای نقشه حقیقت زمین از دادههای مسیر T باشد. از این رو، R شامل دنباله ای از بخش های جاده متصل است، به عنوان مثال، بخش های نقشه، که انتظار می رود به درستی با نقاط GNSS ثبت شده در همان بخش نقشه تطبیق داده شوند. اجازه دهید R داشته باشد n ≥ 1�≥1لبه ها، و اجازه دهید Vآر⊂ V��⊂�زیر مجموعه ای از رئوس G باشد به طوری که یک زیرگراف متصل القایی وجود داشته باشد جیآر��که مجموعه راس آن است Vآر��و که لبه مجموعه Eآر= {r1، ⋯ ،rn} ⊆ E��={�1,⋯,��}⊆�به طوری که اتصال راس κ (جیآر) = 1�(��)=1-یعنی جیآر��1-راس متصل است. مجموعه برش یا جداکننده راس از جیآر��حاوی حداقل یک راس است که حذف آن رندر می شود جیآر��قطع شده. بنابراین، مسیر حقیقت زمینی R = (r1→r2→ ⋯rn)�=(�1→�2→⋯��)پیاده روی در نمودار است جیآر��.
اجازه دهید مسیر مطابق با نقشه باشد آرˆ�^برای مسیر T شامل مجموعه ای از m ≥ 1�≥1لبه ها: {rˆ1، ⋯ ،rˆمتر} ⊆ E{�^1,⋯,�^�}⊆�. بدین ترتیب، آرˆ= (rˆ1→rˆ2→ ⋯rˆمتر)�^=(�^1→�^2→⋯�^�). تطبیق نقشه تضمین می کند که برای مجموعه ای از نقاط داده GNSS توسط مختصات داده شده است { (ایکسj،yj) }{(��,��)}مجموعه ای منطبق از بخش های جاده وجود دارد {rˆمن=( p , q)من}{�^�=(�,�)�}جایی که (پمن،qمن) ∈ V(��,��)∈�و ( p , q)من∈ E(�,�)�∈�. مجموعه نقاط موقعیت یک رابطه عملکردی ذهنی با مجموعه بخشهای منطبق بر نقشه دارد به طوری که چندین نقطه را میتوان با یک بخش جاده تطبیق داد.
برای یک مسیر درست مطابق با نقشه، آرˆ= آر�^=�دارای یک دنباله متناهی از بخش های منطبق بر نقشه است به طوری که هر کدام من ( i ≥ 2 ) _�th(�≥2)بخش منطبق بر نقشه rˆمن�^�(با رئوس پمن��و qمن��) یک لبه حادثه خواهد داشت rˆمن – 1�^�−1جایی که:
یک خطای تطبیق نقشه رخ می دهد اگر:
معادله ( 3 ) بیانگر این است که با توجه به حقیقت پایه R ، هر تفاوتی از آرˆ�^می تواند به عنوان یک خطای تطبیق نقشه شناسایی و برچسب گذاری شود. معادله ( 3 ) در ادامه به این واقعیت اشاره دارد که آرˆ≠ آر�^≠�را دنبال می کند qمن – 1≠پمن��−1≠��در یک خطای تطبیق نقشه
3.3. کمی سازی مبتنی بر فاصله ویرایش
فاصله ویرایش یک متریک رشته ای است که حداقل تعداد عملیات مورد نیاز برای تبدیل یک رشته به رشته دیگر را اندازه می گیرد [ 28 ]. خطاهای تطبیق نقشه شناسایی شده را می توان با محاسبه فاصله ویرایش بین R و آرˆ�^، به عنوان مثال، با کمی کردن ویرایش های تک بخش (درج، حذف، یا جایگزینی) بین دنباله های R و آرˆ�^. ما فاصله Levenshtein را در میان فواصل ویرایش های مختلف اعمال می کنیم، زیرا این سه عملیات ویرایش را برآورده می کند [ 28 ].
فاصله لونشتاین بین دو راه R و آرˆ�^از طول ها | R ||�|و ∣∣آرˆ∣∣|�^|را می توان به ترتیب توسط lev ( R ,آرˆ)lev(�,�^)، جایی که
جایی که دم راه رفتن همان راه رفتنی است که با لبه اول آن کوتاه شده است. اولین لبه یا عنصر سر یک واک R است R [ 0 ]�[0]. بنابراین، فاصله Levenshtein تعداد عدم تطابق بین حقیقت زمین و مسیر مطابق نقشه را ارزیابی می کند.
ما چهار نوع خطای رایج در الگوریتمهای تطبیق نقشه را دستهبندی میکنیم ( شکل 2 ، شکل 3 ، شکل 4 و شکل 5 )، که همگی رفتار سفر غیرواقعی را در یک بخش مطابق با نقشه نشان میدهند. در شکل ها، نقاط ثبت شده GNSS به صورت نقاط آبی و بخش های مطابق نقشه با خطوط سبز نشان داده شده اند. هر بخش منطبق دارای یک شماره شناسایی بخش منحصر به فرد در دنباله سفر است که به رنگ سیاه نشان داده شده است. دسته بندی های رایج شناسایی شده از خطاهای تطبیق نقشه به شرح زیر است:
-
خطای Cat-I : این نوع خطا زمانی رخ می دهد که بخش های نادرست تطبیق داده شده یک طرفه باشند یا از مسیر واقعی آویزان باشند ( شکل 2 ). با مراجعه به معادله ( 2 )، خطای Cat-I در قسمت منطبق با نقشه من رخ می دهد.rˆمن: (پمن،qمن)�^�:(��,��)از آرˆ�^زمانی که شرایط زیر صادق باشد:
چنین بخشهای منطبق بر نقشه نشان میدهند که مسافر باید از انتهای بخش بپرد ( qمن��) بازگشت به آغاز خود ( پمن��) به منظور بازگشت به مسیر اصلی. یک مثال گویا از خطای Cat-I در شکل 2 نشان داده شده است .
-
خطای Cat-II : این نوع خطا زمانی رخ می دهد که خطوط جدا شده با نقاط GNSS مطابقت داده شوند ( شکل 3 ). خطای Cat-II در قسمت منطبق با نقشه I رخ می دهدrˆمتر: (پمتر،qمتر)�^�:(��,��)از آرˆ�^زمانی که شرایط زیر صادق باشد:
چنین بخش های تطبیق شده با نقشه نشان می دهد که مسافر باید در آن بخش جدا شده سرعت بی نهایت داشته باشد. یک مثال گویا از خطای Cat-II در شکل 3 نشان داده شده است . توجه داشته باشید که رفتار حرکتی اساسی کاملا قانونی و از نظر فیزیکی امکان پذیر است.
-
خطای Cat-III : این نوع خطا زمانی رخ می دهد که ناپیوستگی هایی در مسیر منطبق به دلیل پراکندگی نقاط داده ثبت شده وجود داشته باشد ( شکل 4 ). خطای Cat – III در قسمت منطبق شده با نقشه رخ می دهدrˆمن: (پمن،qمن)�^�:(��,��)از آرˆ�^زمانی که شرایط زیر صادق باشد:
چنین بخشهای منطبق بر نقشه نشان میدهد که مسافر باید در حین عبور از یک بخش به بخش جدا شده بعدی، سرعت بینهایتی داشته باشد. تصویر خطای Cat-III در شکل 4 نشان داده شده است .
-
خطای Cat-IV : گاهی اوقات، بخش های منطبق بر نقشه به دلیل خطای اندازه گیری در نقاط ثبت شده، به طور مبهم توسط الگوریتم انتخاب می شوند ( شکل 5 ). این موارد خاص از خطاهای Cat-II و Cat-III هستند :
معادله ( 8 ) مستقل از شرط است rˆمن∈ ر�^�∈�یا rˆمن∉ R�^�∉�. چنین بخشهای منطبق بر نقشه نشان میدهند که مسافر باید همزمان در هر دو بخش باشد، گویی که حضور همزمان در دو خط مختلف وجود دارد. همانطور که در شکل 5 نشان داده شده است، این نوع خطا یک خطای Cat-IV است .
با این حال، در غیاب یک مسیر مطابق با نقشه حقیقت زمینی ( R )، خطاهای تطبیق نقشه (به عنوان مثال، خطاهای Cat-I-IV ) تنها با تجزیه و تحلیل بصری قابل شناسایی هستند. آرˆ�^بر اساس استدلال عقل سلیم با دانش R و آرˆ�^، فاصله لونشتاین را می توان با استفاده از رابطه ( 4 ) محاسبه کرد.
4. محاسبه برآورد خطای تطبیق نقشه
ما یک روش دو مرحلهای مستقل برای تخمین اینکه آیا یک بخش با نقشه مطابقت دارد پیشنهاد میکنیم rˆمن�^�به احتمال زیاد اشتباه است یا خیر ما هر بخش مطابق با نقشه را در آن برچسب گذاری می کنیم آرˆ�^همانطور که به درستی تطبیق یا نادرست تطبیق داده شده است. مرحله 1 : برآورد اثر نویز اندازه گیری در نقاط ثبت شده GNSS بر روی بخش های مطابق نقشه. مرحله 2 : شناسایی رفتار غیرواقعی سفر به دلیل توالی نامعقول در مسیر مطابق با نقشه. با ترکیب هر دو مرحله 1 و مرحله 2 ، ما هر بخش مطابق با نقشه را به عنوان مطابقت صحیح یا نادرست برچسب گذاری می کنیم. ما از فاصله ویرایش Levenshtein به عنوان اندازه گیری کمی این خطا استفاده می کنیم.
4.1. مرحله 1: شناسایی بخش های منطبق با نقشه تحت تأثیر نقاط GNSS پر سر و صدا
در مرحله 1، هدف ما این است که تشخیص دهیم آیا یک بخش مطابق با نقشه تحت تأثیر خطای اندازه گیری در نقاط GNSS قرار می گیرد یا خیر. تمام نقاط ثبت شده GNSS دارای مقداری خطای اندازه گیری هستند. برای برخی از نقاط، خطای اندازه گیری در کیفیت قابل قبولی برای تطبیق نقشه است. بقیه نقاط در ریزه کاری تطبیق نقشه نیستند. مقدار آستانه برای قابل قبول بودن خطای اندازه گیری القایی برای طبقه بندی نقاط GNSS ناشناخته است. از این رو، ما یک تکنیک طبقهبندی بدون نظارت جدید را برای طبقهبندی نقاط ثبتشده GNSS به دو دسته توسعه دادیم: (i) نقاط اشتباه قابل قبول و (ب) نقاط اشتباه غیرقابل قبول (یا نقاط کاملاً اشتباه). ما یک برچسبگذاری باینری برای هر نقطه GNSS و به دنبال آن طبقهبندی انجام میدهیم. سپس،شکل 6 یک نمودار جریان را برای شناسایی خطاهای تطبیق نقشه و نقاط اشتباه GNSS نشان می دهد.
برای شکل، یک پایگاه داده از نقاط خام GNSS { ( x ، y، تی ) }{(�,�,�)}و یک نمودار شبکه جاده ایG were used by a map-matching algorithm to generate the sequences of matched segments آرˆ�^. ما ویژگی های مربوطه را که با استفاده از نقطه داده ثبت شده به دست می آیند تعریف می کنیم (ایکسj،yj،تیj)(��,��,��)و بخش مطابق با نقشه مربوطه rˆj�^�. این مقادیر ویژگی برای طبقه بندی های باینری بدون نظارت نقاط GNSS استفاده می شود { ( x ، y، تی ) }{(�,�,�)}برای فیلتر کردن نقاط اشتباه غیرقابل قبول از نقاط با خطای کمتر. هر نقطه GNSS دارای یک بخش منطبق با نقشه مربوطه است، و یک نگاشت surjection بین مجموعه نقاط GNSS و مجموعه قطعات مطابق نقشه وجود دارد: چندین نقطه GNSS ممکن است با یک بخش منطبق شود. بسته به حالت آماری نقاط برچسبگذاریشده GNSS مطابق با آن بخش، یک برچسبگذاری باینری برای هر بخش مطابق با نقشه در مسیر انجام دادیم. بنابراین، ما به مرحله 1 شناسایی بخش های نادرست تطبیق می رسیم.
4.1.1. مهندسی ویژگی
در مدل مبتنی بر HMM، انتقال و احتمال انتشار هر بخش مطابق با نقشه به (i) فاصله متعامد یک نقطه GNSS از مجموعه بخشهای احتمالی و (ب) احتمال خطای اندازهگیری در هر نقطه GNSS بستگی دارد. از این رو، طبقهبندی هر نقطه GNSS بر اساس دو معیار (یا ویژگی) به دست میآید: (1) فاصله یک نقطه GNSS از بخش تطبیقشده با نقشه و (ب) چقدر احتمال دارد که نقطه GNSS خراب شود. ویژگیها ویژگیهای قابل اندازهگیری فردی رویدادی هستند که در اینجا در فرآیند تطبیق نقشه مشاهده میشوند. هر ویژگی از یک نقطه GNSS (به T ) و بخش نگاشت مربوطه مشتق شده است. بنابراین، هر ویژگی نقطه j تابعی از ( p , q،جj)(�,�,��)جایی که جj= (ایکسj،yj)��=(��,��). ما دو ویژگی را برای طبقه بندی های مورد بحث در بخش های فرعی زیر تعریف کرده ایم: (i) فاصله متعامد و (ii) نویز تخمینی.
فاصله متعامد
میتوانیم یک خط مستقیم از نقاط بنویسیم p , q�,�مانند: fمن= p + K( p − q)��=�+�(�−�)، که در آن bold به معنای بردار و K ثابت است. سپس فاصله متعامد نقطه j امین GNSS از fمن��را می توان به صورت زیر محاسبه کرد:
نویز تخمینی
ما از یک فیلتر کالمن [ 29 ] برای تخمین نویز نقاط ثبت شده GNSS ناشی از خطای اندازه گیری استفاده می کنیم. اگر بتوانیم موقعیت واقعی یک نقطه GNSS ثبت شده را تخمین بزنیم، نویز را می توان تعیین کرد. یک فیلتر کالمن معمولی موقعیت واقعی بعدی را بر اساس موقعیت واقعی فعلی و موقعیت تخمینی فعلی با استفاده از دو فرآیند، یک فرآیند پیشبینی و یک فرآیند تصحیح تخمین میزند [ 29 ]. فرآیند پیشبینی در مهر زمانی j با معادلات زیر کنترل میشود.
جایی که ایکس�بردار حالت است. ایکسˆ�^بردار حالت تخمینی؛ پj��ماتریس واریانس-کوواریانس برای حالت j . پ0�0ماتریس واریانس کوواریانس اولیه؛ س�کوواریانس فرآیند، یعنی نویز گاوسی در پیشبینی ن( 0 ,q2)�(0,�2)، که در آن q انحراف استاندارد خطای فرآیند [ 30 ] است. و آj��ماتریس انتقال زمانی است. اگر دتیj=تیj–تیj − 1���=��−��−1، سپس:
فرآیند تصحیح در حالت j با مجموعه معادلات زیر کنترل می شود.
جایی که کj��ماتریس بهره کالمن در حالت j است، اچ�ماتریس اندازه گیری برای فرآیند مشاهده، زj��مشاهدات در حالت j و مه��ماتریس کوواریانس خطای اندازه گیری، یعنی نویز گاوسی در اندازه گیری ن( 0 ,σ2)�(0,�2)، جایی که σ�انحراف استاندارد خطای اندازه گیری است [ 14 ]. ما موقعیت تخمینی را دریافت خواهیم کرد جˆj=(ایکسˆj،yˆj)“�^�=(�^�,�^�)′از جانب ایکسˆj�^�. بنابراین، ما چهارمین ویژگی خود را به عنوان نویز تخمینی در استخراج کردیم جj��مانند:
4.1.2. طبقه بندی بدون نظارت-مبتنی بر یادگیری
هنگامی که مقادیر ویژگی هر نقطه GNSS را در داده مسیر T استخراج کردیم، یک مجموعه داده آموزشی آماده کردیم. Uتی��برای طبقه بندی نقاط J.Uتی��دارای 2 ستون و ردیف J. هر ردیف j از مجموعه داده آموزشیUتی��دارای مقادیر ویژگی است {oj،ηˆj}{��,�^�}و بدون برچسب است (یعنی خطای قابل قبول در نقاط GNSS را نمی دانیم). از این رو، ما از یادگیری بدون نظارت برای طبقه بندی نقاط GNSS استفاده کردیم Uتی��با استفاده از مدل مخلوط گاوسی [ 31 ]. مدلهای مخلوط گاوسی (GMMs) مدلهای احتمالی هستند، که در آن هر خوشه با یک توزیع احتمال چند متغیره طبیعی مطابقت دارد. الگوریتم های خوشه بندی GMM مرزهای نرم را تعریف می کنند. هدف GMM پیشنهادی انجام خوشهبندی باینری نقاط GNSS بر اساس برخی ویژگیها برای جداسازی نقاط اشتباه GNSS غیرقابل قبول از نقاط GNSS خطای قابل قبول است. مراکز خوشه برچسب های باینری نقاط ثبت شده GNSS، 1 برای نقاط خطای قابل قبول و 0 برای نقاط خطای قابل قبول را نشان می دهند. ما نقاط GNSS مرتبط با هر بخش مطابق نقشه را شناسایی کردیم. سپس به یک بخش منطبق بر نقشه، برچسبی بر اساس رویکرد مبتنی بر رأی اختصاص داده میشود: برچسبهایی که بیشترین اکثریت را دارند برنده میشوند. هر بخش در Uتی��بر اساس برچسب اکثر نقاط GNSS مرتبط با بخش، 0 (به درستی تطبیق داده شده) یا 1 (تطابق نادرست) برچسب گذاری شدند.
4.2. مرحله 2: شناسایی رفتار غیرواقعی سفر به دلیل بی نظمی های توپولوژیکی
هدف این مرحله تخمین حقیقت زمینی R از روی استآرˆ�^. مسیری که به درستی با نقشه تطبیق داده شده است (زمانی که R =آرˆ�=�^) دارای خواص راه رفتن در دیگراف G است. از این رو، آرˆ�^نمی تواند قطع شود، نمی تواند شامل چندین مؤلفه باشد، و نمی تواند یک قطعه یک طرفه (معادله ( 5 )) یا یک پنجه یک طرفه در G داشته باشد. در نظریه گراف، یک پنجه اس3�3ستاره ای با سه لبه است. اس3�3درختی است با یک گره داخلی و 2 برگ، یعنی یک گراف دوبخشی کامل اس1 ، 3�1,3. وجود مولفه های متعدد و/یا پنجه های یک طرفه در یک مسیر مطابق با نقشه آرˆ�^به عنوان بی نظمی توپولوژیکی در یک مسیر سفر پرداخته می شود. از این رو، در مرحله 2 ، هدف ما تشخیص این است که آیا یک بخش منطبق با نقشه به دلیل بینظمیهای توپولوژیکی خود تولید شده در مسیر مطابق با نقشه، رفتار سفر غیرواقعی ایجاد میکند یا خیر. ما برچسبگذاری بخشهایی را پیشنهاد میکنیم که به اشتباه با روشهای زیر مطابقت داشته باشند:
4.2.1. تجزیه و تحلیل اجزای متصل
یک مؤلفه متصل، یک زیرگراف با حداکثر اتصال یک گراف است. ما به دنبال تعداد اجزای متصل در مسیر مطابق نقشه گشتیم آرˆ�^. به این ترتیب، ما میتوانیم ناپیوستگیها را در مسیر مطابق با نقشه و بخشهای منطبق با نقشه که مسئول Cat-II هستند تعیین کنیم., Cat-III, and Cat-IV error.
4.2.2. تشخیص پنجه
در تئوری گراف، ستاره ای با سه لبه، پنجه نامیده می شود . از آنجایی که بخش های آویزان یک طرفه مسئول خطاهای Cat-I هستند ، حقیقت زمین R باید بدون پنجه باشد. پس از اتمام مرحله 2 ، هر بخش را وارد کنید Uتی��برچسب 0 (به درستی مطابقت داده شده) یا 1 (نادرست تطبیق داده شده) خواهد بود. ما یک پایگاه داده جدید ایجاد می کنیم Lتی��برای ذخیره خروجی مرحله 2 پس از برچسب زدن.
5. عملکرد شناسایی خطای تطبیق نقشه خودکار
در این بخش، اعتبار روش و عملکرد آن را با استفاده از داده های مسیر GeoLife [ 32 ] مورد بحث قرار می دهیم. از آنجایی که دادههای GeoLife اصولاً چندوجهی هستند، اما با حالت حمل و نقل برچسبگذاری شدهاند، ما فقط مجموعه دادههای برچسبگذاری شده درایو/ماشین را انتخاب کردیم تا چالشهای تطبیق نقشه جداگانه را اشتباه نگیریم. مجموعه داده تجربی ما T از GeoLife شامل 23 مجموعه داده در مجموع است 15 , 04715,047نقاط GNSS علاوه بر این، ما از تطبیق نقشه مبتنی بر HMM پیشرفته [ 5 ] استفاده کردیم که 1296 بخش مطابق با نقشه را تولید کرد.
5.1. ایجاد حقیقت پایه از بازرسی بصری
اعتبارسنجی و ارزیابی عملکرد شناسایی خطای خودکار به دادههای حقیقت زمینی برای بخشهای مطابق نقشه نیاز دارد. از آنجایی که حقیقت زمینی دادههای بخش منطبق بر نقشه با مجموعه دادههای مسیر بزرگ [ 14 ، 32 ] در دسترس نیست، ما بازرسی بصری بخشهای تطبیقشده با نقشه را اعمال میکنیم، و معیارهای توالی معقول توصیف شده در بالا را به کار میگیریم.
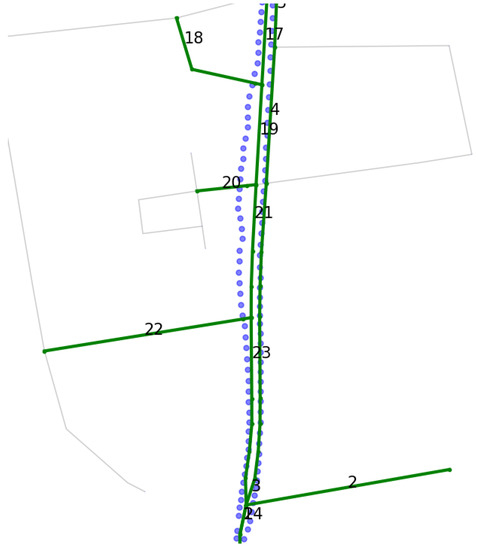
به عنوان مثال، در شکل 7 ، بخشی از داده های مسیر مجموعه داده 4 ارائه شده است، که در آن ما می توانیم به صورت بصری بخش های نادرست مطابق با نقشه را از استدلال انسانی شناسایی کنیم. ناپیوستگیهای بین بخشهای 8 و 9 نشاندهنده خطای Cat-III، و ناپیوستگیهای بین بخشهای 5 و 6 بر اساس معادلات ( 7 ) و ( 8 ) خطای Cat-IV را نشان میدهند. یک فرد برای سفر از بخش 5 به 6 و از بخش 8 به 9 به سرعت بی نهایت نیاز دارد.
هنگامی که یک خطا به صورت بصری شناسایی شد، هر بخش که به اشتباه با نقشه مطابقت دارد را برچسب گذاری می کنیم rˆه�^�. بنابراین، ما یک مجموعه داده حقیقت پایه ایجاد می کنیم جیتی��، که در آن هر بخش تطبیق شده با نقشه T به صورت دستی به عنوان 0 (اگر به درستی مطابقت داشته باشد) یا 1 (اگر مطابقت نادرست باشد) برچسب گذاری می شود.
برای تحقق بازرسی بصری، ما یک ابزار تعاملی مبتنی بر نقشه توسعه دادهایم ( شکل 8 ). نقاط ثبت شده GNSS به صورت نقاط قرمز و بخش های مطابق با نقشه به صورت نشانگرهای آبی با اعداد بازشو نشان داده می شوند. این ابزار تعاملات کاربر را ردیابی می کند، مانند شکل، که در آن بخش منطبق بر نقشه 6388 به عنوان یک خطای درستی زمین توسط یک بازرس انسانی کلیک شده است.
5.2. استفاده از حقیقت پایه برای اعتبارسنجی و ارزیابی عملکرد
روش پیشنهادی ما بخشهای تطبیقشده با نقشه را بهعنوان درست یا نادرست با نقشه تطبیق برچسبگذاری میکند و ایجاد میکند LT��. مقایسه کردیم Lتی��با مجموعه داده حقیقت زمینی جیتی��و تحلیل خطای روش ما را انجام داد. برای این تحلیل، ما از معیارهای خطای معمول استفاده کردیم:
-
مثبت واقعی ( TP ): روش پیشنهادی به درستی یک بخش اشتباه را با توجه به حقیقت زمین شناسایی می کند.
-
مثبت کاذب ( FP ): روش پیشنهادی زمانی که خطایی در تطبیق نقشه وجود نداشته باشد، خطا را نشان می دهد.
-
منفی کاذب ( FN ): روش پیشنهادی نشان دهنده خطای مشاهده شده در تطبیق نقشه نیست.
-
منفی واقعی ( TN ): روش پیشنهادی به درستی یک بخش را به عنوان غیر اشتباه برچسب گذاری کرد.
بگویید مسیر حقیقت زمینی R دارای n بخش و مسیر مطابق با نقشه است آرˆ�^دارای m بخش، از آن ها، مترسی��( ≤ متر≤�) بخش ها به درستی مطابقت دارند. اجازه دهید خطای مشاهده شده (صحت زمین) در تطبیق نقشه در رخ دهد مترo b sEr o r _���������از بخش ها سپس:
ما دو معیار خطا را برای ارزیابی دقت الگوریتم تطبیق نقشه تعریف کردهایم: (1) درصد خطای الگوریتم تطبیق نقشه. εمم���و (ب) درصد خطای نتیجه مدل εپم���. اجازه دهید مترˆسی�^�تعداد بخش هایی باشد که به درستی برچسب گذاری شده اند. سپس:
در شکل 7 ، مجموعه داده 4 دارای پنج بخش مطابق با نقشه است. از این رو، m = 5�=5. خطای Cat-III بین بخش های 8 و 9 و خطای Cat-IV بین بخش های 5 و 6 برابر است با مترo b sEr o r _= 2���������=2. روش خودکار خطای Cat-III را به درستی شناسایی کرد، اما خطای Cat-IV شناسایی نشد. از این رو، مترˆسی= 1�^�=1، با یک مثبت واقعی و یک مثبت کاذب. بدین ترتیب،
ما اعتبار خود را با مقایسه تحلیل حساسیت (نرخ مثبت واقعی) و تحلیل ویژگی (نرخ منفی واقعی) به پایان خواهیم رساند.
5.3. نتایج عملکرد شناسایی خودکار خطا
تصاویر خطاهای شناسایی شده در شکل 9 ، شکل 10 ، شکل 11 و شکل 12 ارائه شده است. تمام نقاط آبی نشان دهنده نقاط ثبت شده GNSS هستند. بخشهایی که بهطور نادرست با نقشه تطبیق داده شدهاند بهعنوان نتایج تخمین بهعنوان خطوط قرمز نشان داده میشوند. بخش های مطابق نقشه به درستی تخمین زده شده با خطوط سبز نشان داده می شوند.
-
در شکل 9 ، یک خطای Cat-I با یک خط قرمز با بخش های 2، 22، 20 و 18 شناسایی و برجسته شده است.
-
در شکل 10 ، یک خطای Cat-II شناسایی و با یک خط قرمز با بخش 22 مشخص شده است.
-
در شکل 11 ، یک خطای Cat-III با خطوط قرمز با بخش های 16 و 15 و خط سبز 14 شناسایی و برجسته شده است، زیرا با روش ما شناسایی نشده است.
-
در شکل 12 ، یک خطای Cat-IV با خط قرمز با بخش های 11 و 10 مشخص و برجسته شده است.
به این ترتیب، ما 23 مسیر منطبق با نقشه فقط درایو از GeoLife را با شمارش کل بخش های حقیقت زمین مقایسه کرده ایم (n), the observed errors in map-matching ( مترo b sEr o r _���������)، اشتباهات به درستی تخمین زده شده ( مترˆسی�^�) مثبت کاذب (خطاهای تخمینی نادرست) و منفی کاذب (خطاهای تخمین زده نشده) در روش پیشنهادی. سپس، ما محاسبه کرده ایم εمم���و εپم���بر اساس معادلات ( 21 ) و ( 22 ). نتایج در جدول 1 ارائه شده است که بر اساس مقادیر مرتب شده است εمم���به ترتیب صعودی
ما یک ماتریس تطبیق دو بعدی ( جدول 1 ) برای تجسم عملکرد روش پیشنهادی استخراج کردهایم. هر ردیف از ماتریس تطبیق نمونه های مشاهده شده را نشان می دهد، یعنی برچسب حقیقت زمینی بخش های مطابق نقشه: (i) بدون خطا و (ii) با خطا. هر ستون از ماتریس تطبیق نمونههای تخمینی را نشان میدهد، یعنی برچسبهای تخمینی بخشهای تطبیقشده با نقشه با استفاده از روش پیشنهادی: (i) بخشهایی که بدون خطا تخمین زده شدهاند و (ii) بخشهایی که با خطا برآورد شدهاند. بنابراین، یک ماتریس تطبیق با استفاده از روش پیشنهادی، معیار کمی از بخشهای برچسبگذاریشده اشتباه روی نقشه را ارزیابی میکند. یک ماتریس تطبیقی تولید شده برای روش پیشنهادی در جدول 2 ارائه شده است که در آن P و N ارائه شده استدر پرانتز به ترتیب موارد مثبت و منفی را نشان می دهد.
روش پیشنهادی ما بر اساس نمرات زیر که پس از ارزیابی ماتریس تطبیق پیشنهادی به دست آمد، ارزیابی شد: AUC (مساحت زیر منحنی) – ROC (ویژگی عملکرد گیرنده)، نرخ مثبت واقعی ( TPR )، نرخ منفی واقعی ( TNR )، پیش بینی مثبت مقدار ( PPV )، میزان حذف نادرست ( FOR )، امتیاز F 1، و دقت کلی ( ACC )، همانطور که در معادلات ( 25 )–( 31 ) تعریف شده است:
6. نتیجه گیری
شناسایی خطاها در فرآیندهای تطبیق نقشه آنلاین و آفلاین برای برنامه های حمل و نقل هوشمند مرتبط، از جمله رفتار رانندگی و تحلیل جریان ترافیک، شناسایی تغییرات در شبکه خیابان ها و برنامه ریزی مسیرهای حمل و نقل مهم است. در این مقاله، ما یک روش برای شناسایی آن خطاهای تطبیق نقشه در فرآیندهای آفلاین پیشنهاد کردهایم. ما در مورد تئوری شناسایی خطای تطبیق نقشه بحث کرده ایم. سپس یک نوع شناسی از چهار نوع رایج خطاهای تطبیق نقشه که از خطاهای اندازه گیری و توپولوژی نقشه پیچیده ناشی می شوند، معرفی و رسمیت دادیم. ما به توسعه تئوری برای شناسایی بخشهای منطبق با نقشه اشتباه در دادههای مسیر مطابق با نقشه بر اساس طبقهبندی بدون نظارت و به دنبال یک رویکرد تئوری گراف برای شناسایی رفتار سفر غیرواقعی ادامه دادیم. بدین ترتیب، به سوال تحقیق ما می توان پاسخ مثبت داد: ما می توانیم به طور خودکار خطاهای تطبیق نقشه را شناسایی و کمیت کنیم زمانی که حقیقت اصلی در دسترس نیست. فراتر از شناسایی، ما همچنین می توانیم این خطاها را با استفاده از طبقه بندی پیشنهادی طبقه بندی کنیم.
ما روش شناسی خود را با استفاده از داده های دنیای واقعی جمع آوری شده در پروژه GeoLife تأیید کرده ایم. نتایج اعتبارسنجی نشان میدهد که روش ما در هنگام وجود خطاهای تطبیق نقشه، امتیاز دقت خوبی دارد: این روش به دقت متوسط 91٪ در شناسایی خودکار خطاهای تطبیق نقشه دست مییابد. این نتیجه نشان میدهد که روش ما میتواند به طور موثر به تحلیلگران کمک کند تا تلاشهای انسانی در کنترل کیفیت تطبیق نقشه را با حاشیه زیادی کاهش دهند. با انتخاب زیرمجموعه مسیر تکوجهی GeoLife، دادههایی را ارزیابی کردیم که قبلاً باید با الگوریتمهای تطبیق نقشه (یعنی ارائه یک خط پایه سخت) بهتر کار کنند، و با این حال وجود و توانایی روش خود را برای شناسایی خطاهای مهم نشان دادیم. روش های تطبیق نقشه فعلی مقدار خطاهای بالقوه ای که باید با استفاده از روش پیشنهادی قابل تشخیص باشد، احتمالاً برای مسیرهای چندوجهی، مشاهده شده در شبکه های تحرک چندوجهی، به طور قابل توجهی بیشتر است. روش پیشنهادی و روش طبقهبندی خطا برای این مسیرها و خطاها معتبر است.
به عنوان محدودیت روش ما، بخشهایی را که به اشتباه با نقشه مطابقت داده شدهاند، بدون اصلاح شناسایی کردیم. اگرچه روش ما یک گام نظری و عملی به سمت شناسایی خطای تطبیق نقشه کمک می کند، تحقیقات بیشتر در مورد مهندسی ویژگی و الگوریتم های طبقه بندی می تواند بر محدودیت های فعلی غلبه کند. در کار آینده، بررسی معیارهای عملکرد مدل ما در خطاهای Cat-I تا Cat-IV به طور جداگانه جالب خواهد بود. اگرچه روش پیشنهادی با تطبیق نقشه آفلاین استفاده می شود، اما می تواند در تطبیق نقشه آنلاین نیز به کار رود (به عنوان مثال، با استفاده از یک رویکرد مبتنی بر شبیه سازی زمان واقعی با داده های Geolife).















بدون دیدگاه