

کلید واژه ها:
تطبیق آدرس ؛ تجزیه آدرس ; یادگیری ماشینی ؛ یادگیری عمیق ؛ پردازش زبان طبیعی ; کدگذاری جغرافیایی آدرس
1. مقدمه
2. مواد و روشها
2.1. منابع داده و استراتژی های جستجو
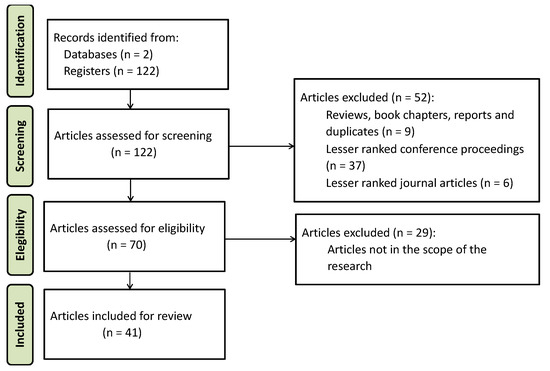
2.2. مراحل غربالگری
-
حذف نقدها، فصلهای کتاب، گزارشها و سایر موارد تکراری (مثلاً: مقالاتی که به عنوان فصلهای کتاب در مجموعههای Springer “مطالعات در هوش محاسباتی” منتشر شدهاند).
-
طبق رتبهبندی کنفرانس ارائهشده در https://www.conferenceranks.com/ (در 9 نوامبر 2021) (به عنوان مثال: کنفرانس بینالمللی محاسبات طبیعی) حذف کنفرانسهایی که به عنوان «A» رتبهبندی نشدهاند (از آوریل 2021)، ;
-
طبق شاخص رتبه مجله SCImago ( https://www.scimagojr.com/ (دسترسی در 9 نوامبر 2021)) به عنوان Q1 یا Q2 رتبه بندی نشده است (از آوریل 2021) (به عنوان مثال: مجله جنگل روسیه علوم پایه)؛
-
حذف مقالاتی که در حیطه تحقیق نبوده اند (مثلاً: مقالاتی که با ورودی های غیر مرتبط با آدرس ها سروکار دارند).
2.3. ابزار
3. نتایج و بحث
3.1. نتایج
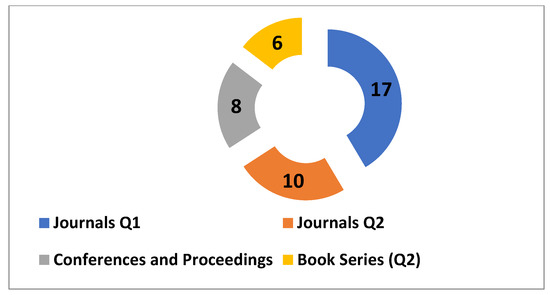
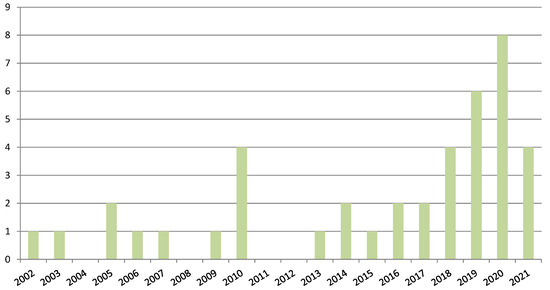
3.1.1. محل انتشار مقالات برگزیده
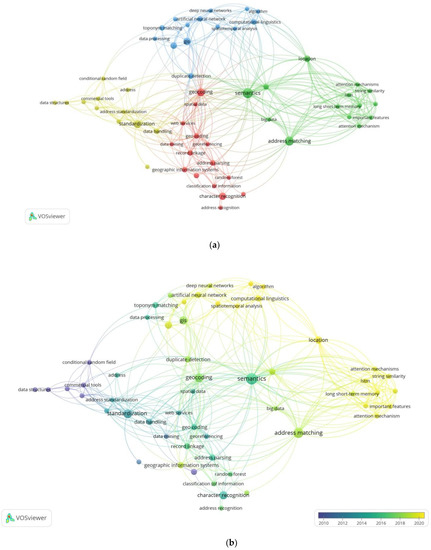
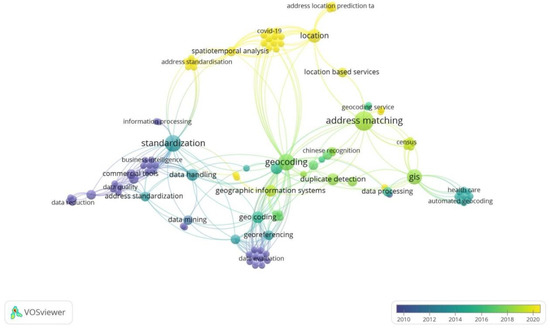
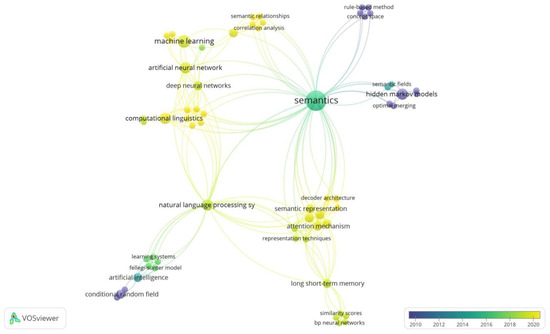
3.1.2. تجزیه و تحلیل وقوع کلمه کلیدی
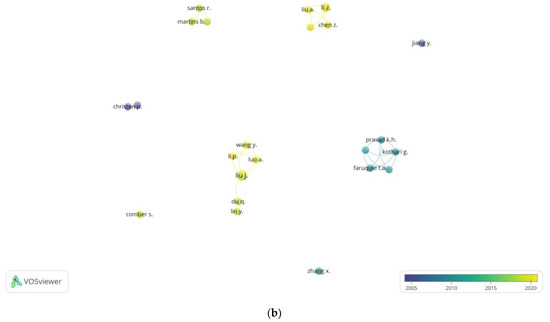
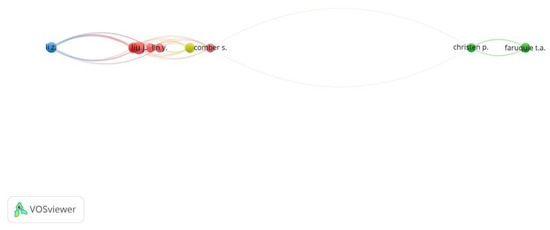
3.1.3. تحلیل هم نویسندگی
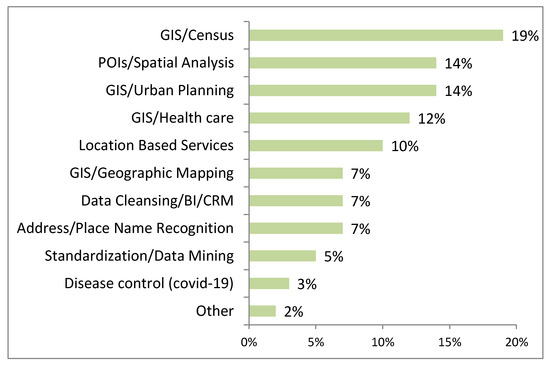
3.1.4. تحلیل کاربرد و روشها
3.2. بحث و پژوهش آینده
3.2.1. بررسی مفصل ادبیات
در مورد استفاده از HMM در زمینه آدرسهای مسکونی، حالتهای پنهان مربوط به هر بخش از آدرس است و مشاهدات شامل نشانههایی است که به هر کلمه از رشته آدرس ورودی اختصاص داده شده است (پس از اعمال برخی روشهای تمیز کردن)، که ممکن است بر اساس جداول جستجو و قوانین سخت کد شده [ 6 ] باشد. به عنوان مثال، آدرس “17 Epping St Smithfield New South Wales 2987″، پس از تمیز کردن و نشانه گذاری، به موارد زیر تبدیل می شود:
که در آن «NU» برای اعداد دیگر، «LN» برای نامهای محل (شهر، حومه)، «WT» برای نوع مسیر (خیابان، جاده، خیابان، و غیره)، «TR» برای قلمرو (ایالت، منطقه)، و ‘رایانه’ برای کد پستی (پستی) [ 6 ] (ص. 6). به منظور تعیین، با استقرای آماری، محتملترین ترتیب «گسترشکنندگان» فرضی در پشت دنباله مشاهدهشده، از مجموعهای از مثالهای آموزشی برای یادگیری هم ماتریس انتقال و هم ماتریس مشاهده، از طریق رویکرد حداکثر احتمال استفاده میشود. از آنجایی که ارزیابی احتمال هر مسیر ممکن از نظر محاسباتی غیرممکن است (برای N حالت و مشاهدات T ، N T مسیرهای مختلف وجود دارد)، از الگوریتم Viterbi برای یافتن محتمل ترین مسیر از طریق مدل استفاده می شود.48 ]. به این ترتیب، محتملترین توالی حالتها، بر اساس ماتریسهای انتقال و انتشار آموزشدیده قبلی، بالاترین احتمال وقوع را نشان میدهد، همانطور که در زیر نشان داده شده است، که در آن نمادهای مشاهده در پرانتز قرار دارند و احتمالات انتشار زیر خط کشیده شدهاند [ 6 ] (ص. 7):
-
یک لایه رمزگذاری ورودی، که بردارهای آدرس ورودی را رمزگذاری می کند و نمایش های سطح بالاتر را با استفاده از مدل حافظه کوتاه مدت دو طرفه (BiLSTM) استخراج می کند.
-
یک لایه مدلسازی استنتاج محلی، که استنتاج محلی یک جفت آدرس را با استفاده از یک مدل توجه تجزیهپذیر اصلاحشده انجام میدهد [ 72 ].
-
یک لایه ترکیب استنتاج، مسئول استنتاج سراسری بین دو رکورد آدرس مقایسه شده بر اساس استنتاج محلی آنها، که در آن از میانگین و حداکثر ادغام برای خلاصه کردن استنتاج محلی و خروجی یک بردار نهایی با طول ثابت استفاده می شود.
-
در نهایت، یک لایه پیشبینی، بر اساس یک پرسپترون چند لایه (MLP) متشکل از سه لایه کاملاً متصل با واحد خطی اصلاحشده (ReLU)، tanh و توابع فعالسازی softmax، برای خروجی نتایج پیشبینی جفتهای آدرس (یعنی اینکه آیا وجود دارد یا خیر) استفاده میشود. مطابقت دارد یا نه).
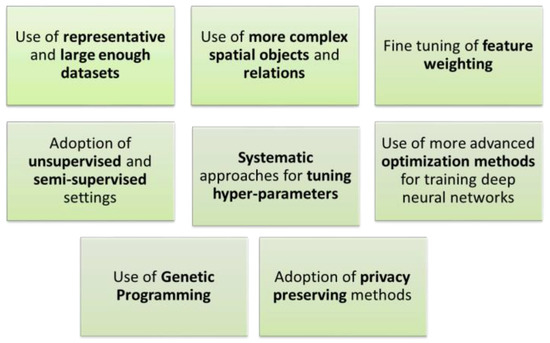
3.2.2. شکاف های تحقیقاتی
4. نتیجه گیری
ضمیمه الف. تحلیل کاربرد و روشها
| شناسه. [مرجع.] | نویسندگان، انتشارات سال | کاربرد | مواد و روش ها |
| 1 [ 9 ] | لین و همکاران، 2019 | ژئوکدینگ | Word2vec; LSTM دو جهته (مدل ESIM) |
| 2 [ 52 ] | فو و همکاران، 2005 | بخش بندی و تشخیص رشته کاراکتر آدرس دست نویس | مدل پنهان مارکوف (HMM) |
| 3 [ 55 ] | دانی و همکاران، 2010 | استاندارد سازی آدرس بهبود کیفیت داده ها | قوانین Ripple Down (RDR)؛ میدان تصادفی شرطی (CRF) |
| 4 [ 51 ] | کریستن و همکاران، 2006 | ژئوکدینگ | یادگیری تجزیه کننده آدرس بر اساس مدل های پنهان مارکوف و موتور تطبیق مبتنی بر قانون |
| 5 [ 62 ] | جیانگ و همکاران، 2007 | سیستم تشخیص آدرس | سیستم مبتنی بر درخت پسوند |
| 6 [ 75 ] | آهنگ، 2013 | خدمات مبتنی بر مکان | درک زبان طبیعی |
| 7 [ 61 ] | گوو و همکاران، 2009 | استاندارد سازی آدرس | روش استانداردسازی آدرس متن آزاد با ارتباط معنایی پنهان (LaSA). |
| 8 [ 69 ] | پی لی و همکاران، 2020 | ژئوکدینگ | شبکه عصبی دو طرفه واحد بازگشتی (GRU). |
| 9 [ 27 ] | والفورد، 2019 | ژئوکدینگ سوابق سرشماری تاریخی | روش چهار مرحلهای نیمه خودکار برای ژئوکد کردن آدرسهای سرشماری تاریخی |
| 10 [ 76 ] | ورما و کائور، 2015 | تشخیص کاراکتر از سند دست نویس | شبکه های عصبی |
| 11 [ 58 ] | جی لیو و همکاران، 2019 | مبارزه با کلاهبرداری مالی | LM-LSTM-CRF |
| 12 [ 77 ] | چوی و همکاران، 2017 | پیوند رکورد احتمالی؛ وضوح موجودیت | توابع شباهت (مثلاً Jaro-Winkler)؛ مدل Fellegi-Sunter |
| 13 [ 29 ] | شان و همکاران، 2019 | خدمات مبتنی بر مکان | معماری رمزگشای رمزگشا با دو شبکه LSTM و مکانیزم توجه |
| 14 [ 54 ] | کامبر، 2019 | کاربردهای فضایی اجتماعی-اقتصادی | CRF; توابع تشابه رشته; جنگل تصادفی |
| 15 [ 28 ] | شاه و همکاران، 2014 | کدگذاری جغرافیایی برای تحقیقات بهداشت عمومی | روش های ژئوکدینگ |
| 16 [ 57 ] | واینمن، 2017 | تراز نقشه تاریخی و تشخیص نام نامی | شناسه متن CRF نیمه مارکوف. CNN مبتنی بر کافه |
| 17 [ 7 ] | شان و همکاران، 2020 | خدمات مبتنی بر مکان | معماری رمزگشای رمزگشا با دو شبکه LSTM و مکانیزم توجه. GCN |
| 18 [ 20 ] | خو و همکاران، 2020 | مدیریت و استفاده از آدرس های غیر استاندارد | نمایش رمزگذار دو طرفه از ترانسفورماتورها (BERT). الگوریتم خوشهبندی با ابعاد بالا برای ترکیب اطلاعات معنایی و مکانی |
| 19 [ 64 ] | Q. Liu و همکاران، 2018 | تشخیص رشته کاراکتر آدرس دست نویس | شبکه عصبی عمیق برای تشخیص کاراکتر (CNN)؛ دانش خاص دامنه برای تشخیص آدرس |
| 20 [ 40 ] | X. Li و همکاران، 2014 | ثبت پیوند | HMM |
| 21 [ 1 ] | جاویدانه و همکاران، 2020 | ارزیابی تاثیر سیستم های آدرس دهی رسمی بر کسب دانش فضایی | شبیه سازی مبتنی بر عامل اکتساب دانش فضایی |
| 22 [ 5 ] | لی و همکاران، 2020 | ژئوکدینگ | Regex برای تجزیه آدرس. ماشین بردار پشتیبانی (SVM)، جنگل تصادفی (RF)، تقویت گرادیان شدید (XGB) برای تطبیق آدرس |
| 23 [ 44 ] | سانتوس و همکاران، 2017 | بازیابی اطلاعات جغرافیایی | 13 معیار شباهت رشته های مختلف. روشهای یادگیری ماشینی نظارت شده برای ترکیب امتیازات (ماشینهای بردار پشتیبانی، جنگلهای تصادفی، درختان بسیار تصادفی، درختان افزایش یافته گرادیان) |
| 24 [ 3 ] | کامبر و آریباس بل، 2019 | ثبت پیوند | word2vec; CRF ها |
| 25 [ 65 ] | H. Li و همکاران، 2019 | تجزیه آدرس های غیر استاندارد | مدلهای پیشبینی ساختار عصبی با متغیرهای پنهان (ساختارهای درختی پنهان و ساختارهای زنجیرهای منظم) |
| 26 [ 6 ] | کلیساها و همکاران، 2002 | ثبت پیوند | HMM |
| 27 [ 37 ] | ژانگ و همکاران، 2020 | خدمات مبتنی بر مکان | برت; CRF |
| 28 [ 22 ] | وی و همکاران، 2016 | تشخیص آدرس دست نویس غیر استاندارد | روش مبتنی بر درخت در سطح کلمه (WLT). |
| 29 [ 56 ] | تانگ و همکاران، 2010 | وضوح نام نامی | رویکرد تجزیه جغرافیایی مبتنی بر CRF. رویکرد کدگذاری جغرافیایی بر اساس تطبیق فازی جزئی |
| 30 [ 78 ] | Nagabhushan و همکاران، 2005 | اتوماسیون پستی | پایگاه دانش نمادین سیستم اعتبارسنجی آدرس را پشتیبانی می کند |
| 31 [ 35 ] | سانتوس و همکاران، 2018 | تشخیص نام نامی | GRU های دو طرفه |
| 32 [ 59 ] | کوثری و همکاران، 2010 | پاکسازی آدرس (با انتقال نظارت) | فرآیند دیریکله سلسله مراتبی |
| 33 [ 63 ] | تیان و همکاران، 2016 | ژئوکدینگ | مدل درخت آدرس; تطبیق فازی لوسن |
| 34 [ 21 ] | پنگ و همکاران، 2020 | پیشگیری و کنترل همه گیر COVID-19 | الگوریتم تطبیق آدرس وزنی تقسیم بندی کلمه با در نظر گرفتن انواع معناشناسی |
| 35 [ 8 ] | لو و همکاران، 2021 | آدرس استاندارد سازی POI | GRU; همبستگی فضایی |
| 36 [ 70 ] | چن و همکاران، 2021 | تطبیق معنایی آدرس | توجه-Bi-LSTM-CNN |
| 37 [ 66 ] | کومارلاس و همکاران، 2018 | افزایش تطابق آدرس | CRF; ژئوکدینگ؛ اقدامات شباهت |
| 38 [ 68 ] | کورتس و همکاران، 2021 | بهبود نرخ تطبیق کدگذاری جغرافیایی آدرسهای ساختیافته | عبارات منظم و روشهای مبتنی بر فرهنگ لغت برای استانداردسازی و غنیسازی آدرس. ژئوکدینگ |
| 39 [ 67 ] | کایو و تالبوت، 2003 | ارزیابی خطای موقعیت در ژئوکدینگ خودکار آدرسهای مسکونی | GIS |
| 40 [ 2 ] | چنگ و همکاران، 2021 | مکان یابی POI در مجموعه داده های بزرگ | ترکیبی از شباهت های متعدد (رشته ای، معنایی و فضایی). الگوریتم استدلال فضایی مبتنی بر شبکه |
| 41 [ 79 ] | فلورچیک و همکاران، 2010 | مدیریت شهری | معماری ژئوکدینگ مرکب، بر اساس روزنامهها، خدمات کاداستر و خدمات کدگذاری آدرس |
منابع
- جاویدانه، ع. کریمی پور، ف. علینقی، ن. چقدر از آدرس ها یاد می گیریم؟ در نحو، معناشناسی و عمل شناسی سیستم های آدرس دهی. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 317. [ Google Scholar ] [ CrossRef ]
- چنگ، آر. لیائو، جی. Chen, J. مکان یابی سریع POI در مجموعه داده های بزرگ از توضیحات بر اساس تطبیق آدرس بهبود یافته و نمایش های کیفی فشرده. ترانس. GIS 2021 ، 1-26. [ Google Scholar ] [ CrossRef ]
- کامبر، اس. Arribas-Bel، D. نوآوری های یادگیری ماشین در تطبیق آدرس: مقایسه عملی Word2vec و CRFs. ترانس. GIS 2019 ، 23 ، 334-348. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سان، ی. جی، م. جین، اف. وانگ، اچ. پاسخهای عمومی به آلودگی هوا در استان شاندونگ با استفاده از دادههای شکایت آنلاین. ISPRS Int. J. Geo-Inf. 2021 ، 10 ، 126. [ Google Scholar ] [ CrossRef ]
- تره فرنگی.؛ Claridades، ARC; لی، جی. بهبود الگوریتم ژئوکدینگ مبتنی بر خیابان با استفاده از تکنیک های یادگیری ماشین. Appl. علمی 2020 ، 10 ، 5628. [ Google Scholar ] [ CrossRef ]
- کلیساها، تی. کریستن، پی. لیم، ک. Zhu، JX آماده سازی داده های نام و آدرس برای پیوند رکورد با استفاده از مدل های پنهان مارکوف. BMC Med. آگاه کردن. تصمیم می گیرد. ماک 2002 ، 2 ، 9. [ Google Scholar ] [ CrossRef ] [ PubMed ] [ نسخه سبز ]
- شان، اس. لی، ز. یانگ، کیو. لیو، آ. ژائو، ال. لیو، جی. Chen, Z. آموزش نمایش نشانی جغرافیایی برای تطبیق آدرس. شبکه جهانی وب. 2020 ، 23 ، 2005–2022. [ Google Scholar ] [ CrossRef ]
- لو، ا. لیو، جی. لی، پی. وانگ، ی. Xu، S. استاندارد آدرس چینی POI بر اساس GRU و همبستگی فضایی و در ترکیب رویدادهای اضطراری چند منبعی اعمال می شود. بین المللی J. Image Data Fusion 2021 ، 12 ، 319-334. [ Google Scholar ] [ CrossRef ]
- لین، ی. کانگ، م. وو، ی. دو، س. لیو، تی. معماری یادگیری عمیق برای تطبیق آدرس معنایی. بین المللی جی. جئوگر. Inf. علمی 2019 ، 34 ، 559-576. [ Google Scholar ] [ CrossRef ]
- وانگ، جی. دنگ، اچ. لیو، بی. هو، ا. لیانگ، جی. فن، ال. ژنگ، ایکس. وانگ، تی. لی، جی. ارزیابی سیستماتیک پیشرفت تحقیق در مورد پردازش زبان طبیعی در پزشکی در 20 سال گذشته: مطالعه کتاب سنجی در Pubmed. جی. مد. Internet Res. 2020 ، 22 ، e16816. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ملو، اف. مارتینز، بی. ژئوکدینگ خودکار اسناد متنی: بررسی رویکردهای فعلی. ترانس. GIS 2017 ، 21 ، 3-38. [ Google Scholar ] [ CrossRef ]
- کاید، م. داکوری، س. علی، AA استخراج آدرس پستی از وب: یک نظرسنجی جامع . Springer: Dordrecht, The Netherlands, 2021. [ Google Scholar ] [ CrossRef ]
- بارینگتون-لی، سی. Millard-Ball، A. نقشه راه تولید شده توسط کاربر جهان بیش از 80٪ کامل شده است. PLoS ONE 2017 , 12 , e0180698. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- یاسین، م. بوشمین، دی. لاویولت، اف. Lamontagne، L. استفاده از جاسازی زیرکلمه برای تجزیه آدرس چند ملیتی. در مجموعه مقالات ششمین کنگره IEEE در علم و فناوری اطلاعات 2020 (CiSt)، اگادیر-اسائویرا، مراکش، 5 تا 12 ژوئن 2021. [ Google Scholar ]
- گلدبرگ، DW; ویلسون، جی پی؛ Knoblock، CA از متن به مختصات جغرافیایی: وضعیت فعلی ژئوکدینگ. URISA J. 2007 ، 19 ، 33-46. [ Google Scholar ]
- صفحه، MJ; مک کنزی، جی. Bossuyt، PM; بوترون، آی. هافمن، تی سی؛ مالرو، سی دی; شمسیر، ال. تتزلاف، جی.ام. آکل، EA; برنان، SE; و همکاران بیانیه PRISMA 2020: دستورالعمل به روز شده برای گزارش بررسی های سیستماتیک. PLoS Med. 2021 ، 18 ، 372. [ Google Scholar ] [ CrossRef ]
- ون اک، نیوجرسی؛ Waltman, L. Software Survey: VOSviewer، یک برنامه کامپیوتری برای نقشه برداری کتابسنجی. Scientometrics 2010 ، 84 ، 523-538. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- باستیان، م. هیمن، اس. Jacomy, M. Gephi: یک نرم افزار منبع باز برای کاوش و دستکاری شبکه ها. Icwsm 2009 ، 361-362. [ Google Scholar ]
- لین، ی. کانگ، م. او، ب. تحلیل الگوی فضایی کیفیت آدرس: مطالعه ای بر تأثیر گسترش سریع شهری در چین. محیط زیست طرح. ب مقعد شهری. علوم شهر 2019 ، 48 ، 728-740. [ Google Scholar ] [ CrossRef ]
- خو، ال. دو، ز. مائو، آر. ژانگ، اف. لیو، R. GSAM: یک مدل شبکه عصبی عمیق برای استخراج بازنمایی محاسباتی آدرسهای چینی با ویژگی جغرافیایی. محاسبه کنید. محیط زیست سیستم شهری 2020 ، 81 ، 101473. [ Google Scholar ] [ CrossRef ]
- پنگ، ام. لی، ز. لیو، اچ. منگ، سی. Li, Y. روش ژئوکدینگ وزنی بر اساس تقسیم بندی کلمات چینی و کاربرد آن در مکان یابی فضایی پیشگیری و کنترل همه گیر COVID-19. Wuhan Daxue Xuebao (Xinxi Kexue Ban)/Geomat. Inf. علمی دانشگاه ووهان 2020 ، 46 ، 808-815. [ Google Scholar ]
- وی، ایکس. لو، اس. ون، ی. Lu, Y. تشخیص آدرس چینی دستنویس با تغییرات نوشتاری. تشخیص الگو Lett. 2016 ، 73 ، 68-75. [ Google Scholar ] [ CrossRef ]
- بورنمن، ال. Wohlrabe, K. Normalization of Citation Impact in Economics ; انتشارات بین المللی Springer: برلین/هایدلبرگ، آلمان، 2019؛ جلد 120. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بابالولا، ا. موسی، س. آکینلولو، ام تی؛ Haupt، TC بررسی کتابسنجی پیشرفتها در تحقیقات مدلسازی اطلاعات ساختمان (BIM). J. Eng. دس تکنولوژی 2021 . [ Google Scholar ] [ CrossRef ]
- برایبار دیز، ای. لونا، م. اودریوزولا، دکتر Llorente، I. تاثیر اجتماعی نقشه برداری: تحلیل کتاب سنجی. پایداری 2020 ، 12 ، 9389. [ Google Scholar ] [ CrossRef ]
- لیو، ایکس. تحلیل استنادی، جفت کتابشناختی و استناد مستقیم: کدام رویکرد استنادی جبهه پژوهش را دقیقتر نشان میدهد؟ مربا. Soc. Inf. علمی تکنولوژی 2013 ، 64 ، 1852-1863. [ Google Scholar ] [ CrossRef ]
- والفورد، NS، سوابق تاریخی سرشماری جمعیت بریتانیا را به قرن بیست و یکم می آورد: روشی برای کدگذاری جغرافیایی خانوارها و افراد در آدرس های اولیه قرن بیستم. مردمی Space Place 2019 , 25 , e2227. [ Google Scholar ] [ CrossRef ]
- شاه، تی. بل، اس. ویلسون، ک. ژئوکدینگ برای تحقیقات بهداشت عمومی: مقایسه تجربی دو سرویس کدگذاری جغرافیایی اعمال شده در شهرهای کانادا. می توان. Geogr. 2014 ، 58 ، 400-417. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شان، اس. لی، ز. کیانگ، ی. لیو، ا. Xu, J. DeepAM: نمایش آدرس معنایی عمیق برای تطبیق آدرس . انتشارات بین المللی Springer: برلین/هایدلبرگ، آلمان، 2019؛ جلد 3. [ Google Scholar ] [ CrossRef ]
- چانگ، جی. گلچهره، سی. چو، ک. Bengio، Y. ارزیابی تجربی شبکههای عصبی بازگشتی دروازهای در مدلسازی توالی. arXiv 2014 ، arXiv:1412.3555. [ Google Scholar ]
- هوکرایتر، اس. اورگن اشمیدهابر، جی. حافظه کوتاه مدت بلند. محاسبات عصبی 1997 , 9 , 17351780. [ Google Scholar ] [ CrossRef ]
- واسوانی، ع. Shazeer، N. پارمار، ن. Uszkoreit، J. جونز، ال. گومز، AN; قیصر، ال. Polosukhin، I. توجه تمام چیزی است که شما نیاز دارید. در مجموعه مقالات سی و یکمین کنفرانس سیستم های پردازش اطلاعات عصبی (NIPS 2017)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 دسامبر 2017؛ صفحات 5998-6008. [ Google Scholar ]
- دولین، جی. چانگ، مگاوات؛ تره فرنگی.؛ Toutanova، K. BERT: پیش آموزش ترانسفورماتورهای عمیق دو جهته برای درک زبان. در مجموعه مقالات NAACL-HLT 2019، مینیاپولیس، MN، ایالات متحده آمریکا، 2-7 ژوئن 2019؛ جلد 1، ص 4171–4186. [ Google Scholar ]
- Thekumparampil، KK; وانگ، سی. اوه، اس. شبکه عصبی گراف مبتنی بر توجه لی، LJ برای یادگیری نیمه نظارتی. arXiv 2018 , arXiv:1803.03735. [ Google Scholar ]
- سانتوس، آر. موریتا-فلورس، پی. کالادو، پی. مارتینز، بی. تطبیق نام از طریق شبکه های عصبی عمیق. بین المللی جی. جئوگر. Inf. علمی 2018 ، 32 ، 324-348. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گوری، م. منفردینی، جی. اسکارسلی، اف. مدلی جدید برای یادگیری در حوزه های گراف. Proc. بین المللی Jt. Conf. شبکه عصبی 2005 ، 2 ، 729-734. [ Google Scholar ] [ CrossRef ]
- ژانگ، اچ. رن، اف. لی، اچ. یانگ، آر. ژانگ، اس. Du، Q. روش شناسایی عناصر آدرس جدید در تطبیق آدرس چینی بر اساس یادگیری عمیق. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 745. [ Google Scholar ] [ CrossRef ]
- Rabiner, LR A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proc. IEEE 1989 ، 77 ، 257-286. [ Google Scholar ] [ CrossRef ]
- قهرمانی، ز. مقدمه ای بر مدل های پنهان مارکوف و شبکه های بیزی. بین المللی ج. تشخیص الگو. آرتیف. هوشمند 2001 ، 15 ، 9-42. [ Google Scholar ] [ CrossRef ]
- لی، ایکس. کاردس، اچ. وانگ، ایکس. Sun، A. تجزیه آدرس مبتنی بر HMM با تولید دادههای آموزشی مصنوعی عظیم. بین المللی Conf. Inf. بدانید. مدیریت Proc. 2014 ، 33-36. [ Google Scholar ] [ CrossRef ]
- لافرتی، جی. مک کالوم، ا. Pereira، F. میدان های تصادفی شرطی: مدل های احتمالی برای قطعه بندی و برچسب گذاری داده های توالی چکیده. در مجموعه مقالات هجدهمین کنفرانس بین المللی یادگیری ماشین 2001، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 28 ژوئن تا 1 ژوئیه 2001. ص 282-289. [ Google Scholar ]
- Blei، DM; Ng، AY؛ جردن، MI; والاچ، اچ ام. هینتون، جنرال الکتریک؛ اوسیندرو، اس. Teh، Y.-W. فیلدهای تصادفی شرطی: مقدمه. محاسبات عصبی 2004 ، 18 ، 1-9. [ Google Scholar ] [ CrossRef ]
- بورگاتی، SP مرکزیت و جریان شبکه. Soc. شبکه 2005 ، 27 ، 55-71. [ Google Scholar ] [ CrossRef ]
- سانتوس، آر. موریتا-فلورس، پی. مارتینز، بی. آموزش ترکیب معیارهای تشابه رشتههای متعدد برای تطبیق مؤثر نامهای. بین المللی جی دیجیت. زمین 2017 ، 11 ، 913-938. [ Google Scholar ] [ CrossRef ]
- Levenshtein، کدهای باینری VI که قادر به تصحیح حذف، درج و معکوس هستند. Sov. فیزیک دوکل. 1966 ، 10 ، 707-710. [ Google Scholar ] [ CrossRef ]
- Jaro، MA پیشرفت در روش ثبت-پیوند به عنوان تطبیق سرشماری 1985 تمپا، فلوریدا. مربا. آمار دانشیار 1989 ، 84 ، 414-420. [ Google Scholar ] [ CrossRef ]
- وینکلر، معیارهای مقایسهکننده رشتههای WE و قوانین تصمیمگیری پیشرفته در مدل پیوند رکورد Fellegi-Sunter. Proc. فرقه Surv. Res. صبح. آمار دانشیار 1990 ، 354-359. [ Google Scholar ]
- Forney، GD الگوریتم ویتربی. Proc. IEEE 1973 ، 61 ، 268-278. [ Google Scholar ] [ CrossRef ]
- مک کالوم، ا. فرایتاگ، دی. Pereira، F. مدلهای مارکوف حداکثر آنتروپی برای استخراج و بخشبندی اطلاعات. در مجموعه مقالات هفدهمین کنفرانس بین المللی یادگیری ماشین، 2000، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 29 ژوئن تا 2 ژوئیه 2000. [ Google Scholar ]
- وانگ، ام. هابرلند، وی. یو، آ. مارتین، ای. هاروید، جی. Bishop, JM تجزیه کننده آدرس احتمالی با استفاده از فیلدهای تصادفی شرطی و دستور زبان منظم تصادفی. در مجموعه مقالات شانزدهمین کنفرانس بین المللی IEEE 2016 در کارگاه های داده کاوی (ICDMW)، بارسلون، اسپانیا، 12 تا 15 دسامبر 2016. [ Google Scholar ] [ CrossRef ]
- کریستن، پی. ویلمور، آ. کلیساها، T. یک سیستم جغرافیایی کدگذاری احتمالی با استفاده از یک فایل آدرس مبتنی بر بسته. در داده کاوی ؛ Springer: برلین/هایدلبرگ، آلمان، 2006; جلد 3755، صص 130–145. [ Google Scholar ] [ CrossRef ]
- فو، س. دینگ، XQ; لیو، سی اس; Jiang, Y. الگوریتم تقسیم بندی و تشخیص مبتنی بر مدل مارکوف پنهان برای رشته های کاراکتر آدرس دست نوشته چینی. Proc. بین المللی Conf. Doc. مقعدی تشخیص دهد. ICDAR 2005 ، 2005 ، 590-594. [ Google Scholar ] [ CrossRef ]
- میکولوف، تی. چن، ک. کورادو، جی. Dean, J. برآورد کارآمد بازنمایی کلمات در فضای برداری. arXiv 2013 , arXiv:1301.3781. [ Google Scholar ]
- Comber, S. نشان دادن سودمندی نوآوری های یادگیری ماشین در تطبیق آدرس با کاربردهای اجتماعی-اقتصادی فضایی. منطقه 2019 ، 6 ، 17–37. [ Google Scholar ] [ CrossRef ]
- دانی، MN; فاروکی، TA; گارگ، آر. کوثری، جی. موهانیا، MK; پراساد، خ. Subramaniam، LV; Swamy، VN یک روش کسب دانش برای بهبود کیفیت داده در تعاملات خدمات. در مجموعه مقالات کنفرانس بین المللی IEEE در سال 2010 در محاسبات خدمات، میامی، FL، ایالات متحده آمریکا، 5 تا 10 ژوئیه 2010. صص 346-353. [ Google Scholar ] [ CrossRef ]
- تانگ، ایکس. چن، ایکس. ژانگ، ایکس. تحقیق در مورد تفکیک نام های نامی در متن چینی. Wuhan Daxue Xuebao (Xinxi Kexue Ban)/Geomat. Inf. علمی دانشگاه ووهان 2010 ، 35 ، 930-935. [ Google Scholar ]
- واینمن، جی. مدلهای جغرافیایی و سبک برای چینش نقشههای تاریخی و تشخیص نام نامی. در مجموعه مقالات چهاردهمین کنفرانس بین المللی IAPR در سال 2017 در تجزیه و تحلیل و شناسایی اسناد (ICDAR)، کیوتو، ژاپن، 9 تا 15 نوامبر 2017؛ ص 957-964. [ Google Scholar ] [ CrossRef ]
- لیو، جی. وانگ، جی. ژانگ، سی. یانگ، ایکس. دنگ، ج. زو، آر. نان، ایکس. Chen, Q. محاسبه شباهت آدرس چینی بر اساس برچسب گذاری خودکار سطح زمین شناسی Jing ; انتشارات بین المللی Springer: چم، سوئیس، 2019; جلد 2. [ Google Scholar ] [ CrossRef ]
- کوثری، جی. فاروکی، TA; Subramaniam، LV; پراساد، خ. Mohania، MK انتقال نظارت برای بهبود استانداردسازی آدرس. در مجموعه مقالات بیستمین کنفرانس بین المللی شناسایی الگوی 2010، استانبول، ترکیه، 23 تا 26 اوت 2010. صص 2178–2181. [ Google Scholar ] [ CrossRef ]
- Teh، YW; جردن، MI; بیل، ام جی. Blei، DM فرآیندهای دیریکله سلسله مراتبی. مربا. آمار دانشیار 2006 ، 101 ، 1566-1581. [ Google Scholar ] [ CrossRef ]
- گوا، اچ. زو، اچ. گوا، ز. ژانگ، XX; سو، زی. استانداردسازی آدرس با انجمن معنایی پنهان. در مجموعه مقالات پانزدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، پاریس، فرانسه، 28 ژوئن تا 1 ژوئیه 2009. صص 1155-1163. [ Google Scholar ] [ CrossRef ]
- جیانگ، ی. دینگ، ایکس. Ren, Z. سیستم تشخیص آدرس چینی دستنویس مبتنی بر درخت پسوند. در مجموعه مقالات نهمین کنفرانس بین المللی تجزیه و تحلیل و شناسایی اسناد (ICDAR 2007)، کوریتیبا، برزیل، 23 تا 26 سپتامبر 2007. جلد 1، ص 292-296. [ Google Scholar ] [ CrossRef ]
- تیان، کیو. رن، اف. هو، تی. لیو، جی. لی، آر. Du، Q. استفاده از روش تطبیق آدرس چینی بهینه برای توسعه یک سرویس کدگذاری جغرافیایی: مطالعه موردی شنژن، چین. ISPRS Int. J. Geo-Inf. 2016 ، 5 ، 65. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لیو، کیو. وانگ، دی. لو، اچ. لی، سی. تشخیص نویسه چینی دستنویس بر اساس دانش خاص دامنه . انتشارات بین المللی Springer: برلین/هایدلبرگ، آلمان، 2018; جلد 2، ص 221-231. [ Google Scholar ] [ CrossRef ]
- لی، اچ. لو، دبلیو. زی، پی. Li, L. تجزیه آدرس عصبی چینی. در مجموعه مقالات کنفرانس 2019 بخش آمریکای شمالی انجمن زبانشناسی محاسباتی: فناوریهای زبان انسانی، مینیاپولیس، MN، ایالات متحده آمریکا، 2 تا 7 ژوئن 2019؛ جلد 1، ص 3421–3431. [ Google Scholar ]
- کومارلاس، آی. کروشک، آ. موزلی، سی. Naumann, F. Experience: Enhancing Address Match with Geocoding and Similarity Measure Selection. J. Data Inf. کیفیت 2018 ، 10 ، 1-16. [ Google Scholar ] [ CrossRef ]
- کایو، MR; تالبوت، خطای موقعیتی در رمزگذاری خودکار آدرسهای مسکونی. بین المللی J. Health Geogr. 2003 ، 2 ، 1-12. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- Cortes، TR; دا سیلویرا، IH; Junger، WL بهبود نرخ تطبیق کدگذاری جغرافیایی آدرسهای ساختاریافته در ریودوژانیرو، برزیل. Cad. Saude Publica 2021 , 37 , e00039321. [ Google Scholar ] [ CrossRef ]
- لی، پی. لو، ا. لیو، جی. وانگ، ی. ژو، جی. دنگ، ی. Zhang, J. شبکه عصبی واحد بازگشتی دردار دوطرفه برای بخش بندی عناصر آدرس چینی. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 635. [ Google Scholar ] [ CrossRef ]
- چن، جی. چن، جی. او، X. مائو، جی. چن، جی. رویکرد یادگیری تضاد عمیق برای تطبیق معنایی آدرس. Appl. علمی 2021 ، 11 ، 7608. [ Google Scholar ] [ CrossRef ]
- چن، کیو. لینگ، ز. جیانگ، اچ. زو، ایکس. وی، اس. Inkpen، D. Enhanced LSTM for Natural Language Inference. در مجموعه مقالات پنجاه و پنجمین نشست سالانه انجمن زبانشناسی محاسباتی، ونکوور، بریتیش کلمبیا، کانادا، 30 ژوئیه تا 4 اوت 2017؛ جلد 1، ص 1657–1668. [ Google Scholar ] [ CrossRef ]
- پریخ، AP; تاکستروم، او. داس، دی. Uszkoreit, J. یک مدل توجه تجزیه پذیر برای استنتاج زبان طبیعی. arXiv 2016 , arXiv:1606.01933. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Koza, JR برنامه نویسی ژنتیکی: در مورد برنامه ریزی کامپیوترها با استفاده از انتخاب طبیعی . مطبوعات MIT: کمبریج، MA، ایالات متحده آمریکا، 1992. [ Google Scholar ]
- Araujo، L. برنامه ریزی ژنتیکی برای پردازش زبان طبیعی. ژنت برنامه. ماخ تکامل پذیر. 2020 ، 21 ، 11-32. [ Google Scholar ] [ CrossRef ]
- آهنگ، Z. الگوریتم تطبیق آدرس بر اساس درک زبان طبیعی چینی. J. Remote Sens. 2013 ، 17 ، 788-801. [ Google Scholar ]
- ورما، ا. Kaur, G. شناسایی شخصیت از سند دستنویس با استفاده از شبکههای عصبی. بین المللی J. Appl. مهندس Res. 2015 ، 10 ، 37574–37579. [ Google Scholar ]
- چوی، SCT; لین، ی. Mulrow، E. مقایسه نرم افزار و خدمات دامنه عمومی برای پیوند رکورد احتمالی و استانداردسازی آدرس. لکت. یادداشت ها محاسبه. علمی 2017 ، 10344 ، 51-66. [ Google Scholar ] [ CrossRef ]
- نگابوشان، پ. انگادی، س. آنامی، ساختار داده نمادین BS برای نمایش آدرس پستی و اعتبارسنجی آدرس از طریق پایگاه دانش نمادین. لکت. یادداشت ها محاسبه. علمی 2005 ، 3776 ، 388-394. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فلورچیک، ای جی؛ لوپز-پلیسر، FJ; مورو مدرانو، پی. نوگراس-ایسو، جی. Zarazaga-Soria، FJ Semantic Selection of Georeferencing Services for Urban Management. الکترون. J. Inf. تکنولوژی ساخت و ساز 2010 ، 15 ، 111-121. [ Google Scholar ]



بدون دیدگاه