

خلاصه
چندین منطقه از زمین که سرشار از نفت و گاز طبیعی هستند نیز دارای ذخایر عظیم نمک در زیر سطح هستند. به دلیل این ارتباط، دانستن مکانهای دقیق ذخایر بزرگ نمک برای شرکتهای درگیر در اکتشاف نفت و گاز بسیار مهم است. برای مکان یابی اجسام نمک، تصویربرداری لرزه ای حرفه ای مورد نیاز است. این تصاویر توسط متخصصان انسانی تجزیه و تحلیل می شوند که منجر به رندرهای بسیار ذهنی و بسیار متغیر می شود. برای ایجاد انگیزه در اتوماسیون و افزایش دقت این فرآیند، شرکت ژئوفیزیک TGS-NOPEC (TGS) اسپانسر یک مسابقه Kaggle شده است که در نیمه دوم سال 2018 برگزار شد. این مسابقه بسیار محبوب بود و 3221 نفر و تیم را جمع آوری کرد. داده های مسابقه شامل مجموعه آموزشی از 4000 تکه تصویر لرزه ای و ماسک های تقسیم بندی مربوطه بود. مجموعه تست شامل 18، 000 وصله تصویر لرزه ای مورد استفاده برای ارزیابی (همه تصاویر 101 × 101 پیکسل هستند). اطلاعات عمق محل نمونه نیز برای هر پچ تصویر لرزه ای ارائه شد. روش ارائه شده در این مقاله بر اساس مشارکت نویسنده است و بر آموزش یک شبکه عصبی کانولوشنال عمیق (CNN) برای تقسیمبندی معنایی تکیه دارد. معماری شبکه پیشنهادی از مدل U-Net در ترکیب با معماری ResNet و DenseNet الهام گرفته شده است. برای درک بهتر ویژگیهای معماری پیشنهادی، یک سری آزمایش با استفاده از رویکردهای استاندارد شده با استفاده از چارچوب آموزشی مشابه انجام شد. نتایج نشان داد که معماری پیشنهادی قابل مقایسه و در بیشتر موارد بهتر از این مدلهای تقسیمبندی است. اطلاعات عمق محل نمونه نیز برای هر پچ تصویر لرزه ای ارائه شد. روش ارائه شده در این مقاله بر اساس مشارکت نویسنده است و بر آموزش یک شبکه عصبی کانولوشنال عمیق (CNN) برای تقسیمبندی معنایی تکیه دارد. معماری شبکه پیشنهادی از مدل U-Net در ترکیب با معماری ResNet و DenseNet الهام گرفته شده است. برای درک بهتر ویژگیهای معماری پیشنهادی، یک سری آزمایش با استفاده از رویکردهای استاندارد شده با استفاده از چارچوب آموزشی مشابه انجام شد. نتایج نشان داد که معماری پیشنهادی قابل مقایسه و در بیشتر موارد بهتر از این مدلهای تقسیمبندی است. اطلاعات عمق محل نمونه نیز برای هر پچ تصویر لرزه ای ارائه شد. روش ارائه شده در این مقاله بر اساس مشارکت نویسنده است و بر آموزش یک شبکه عصبی کانولوشنال عمیق (CNN) برای تقسیمبندی معنایی تکیه دارد. معماری شبکه پیشنهادی از مدل U-Net در ترکیب با معماری ResNet و DenseNet الهام گرفته شده است. برای درک بهتر ویژگیهای معماری پیشنهادی، یک سری آزمایش با استفاده از رویکردهای استاندارد شده با استفاده از چارچوب آموزشی مشابه انجام شد. نتایج نشان داد که معماری پیشنهادی قابل مقایسه و در بیشتر موارد بهتر از این مدلهای تقسیمبندی است. روش ارائه شده در این مقاله بر اساس مشارکت نویسنده است و بر آموزش یک شبکه عصبی کانولوشنال عمیق (CNN) برای تقسیمبندی معنایی تکیه دارد. معماری شبکه پیشنهادی از مدل U-Net در ترکیب با معماری ResNet و DenseNet الهام گرفته شده است. برای درک بهتر ویژگیهای معماری پیشنهادی، یک سری آزمایش با استفاده از رویکردهای استاندارد شده با استفاده از چارچوب آموزشی مشابه انجام شد. نتایج نشان داد که معماری پیشنهادی قابل مقایسه و در بیشتر موارد بهتر از این مدلهای تقسیمبندی است. روش ارائه شده در این مقاله بر اساس مشارکت نویسنده است و بر آموزش یک شبکه عصبی کانولوشنال عمیق (CNN) برای تقسیمبندی معنایی تکیه دارد. معماری شبکه پیشنهادی از مدل U-Net در ترکیب با معماری ResNet و DenseNet الهام گرفته شده است. برای درک بهتر ویژگیهای معماری پیشنهادی، یک سری آزمایش با استفاده از رویکردهای استاندارد شده با استفاده از چارچوب آموزشی مشابه انجام شد. نتایج نشان داد که معماری پیشنهادی قابل مقایسه و در بیشتر موارد بهتر از این مدلهای تقسیمبندی است. برای درک بهتر ویژگیهای معماری پیشنهادی، یک سری آزمایش با استفاده از رویکردهای استاندارد شده با استفاده از چارچوب آموزشی مشابه انجام شد. نتایج نشان داد که معماری پیشنهادی قابل مقایسه و در بیشتر موارد بهتر از این مدلهای تقسیمبندی است. برای درک بهتر ویژگیهای معماری پیشنهادی، یک سری آزمایش با استفاده از رویکردهای استاندارد شده با استفاده از چارچوب آموزشی مشابه انجام شد. نتایج نشان داد که معماری پیشنهادی قابل مقایسه و در بیشتر موارد بهتر از این مدلهای تقسیمبندی است.
کلید واژه ها:
یادگیری عمیق ؛ شبکه های عصبی کانولوشنال ; تقسیم بندی معنایی ; تصویربرداری لرزه ای ; رسوبات نمک
1. معرفی
تصویربرداری لرزه ای امکان تجسم سازه های زیرزمینی را فراهم می کند و از آن در کشف ذخایر سوخت هیدروکربنی استفاده می شود. این بر اساس انتشار امواج صوتی است که بر روی ساختارهای زیرزمینی منعکس میشوند و با استفاده از دستگاههای گیرنده به نام ژئوفون روی سطحی شناسایی میشوند ( شکل 1 را ببینید ). سیگنال صوتی منعکس شده برای پردازش بیشتر ثبت می شود که منجر به نمایش سه بعدی (3D) ساختار سنگ های زیرزمینی می شود [ 1 ]]. تصاویر لرزه ای مرز انواع سنگ ها را نشان می دهد. از نظر تئوری، قدرت سیگنال رد شده با تفاوت در خواص فیزیکی سنگ ها در نقطه تماس مستقیماً متناسب است. این عملاً به این معنی است که تصاویر لرزه ای حاوی اطلاعاتی در مورد مرزهای بین نهشته های سنگی هستند، در حالی که آنها اطلاعات بسیار کمی در مورد خود سنگ ها دارند [ 2 ]. تصاویر لرزه ای در اکتشاف ذخایر سوخت هیدروکربنی با کمک به شناسایی سنگ های مخزن بالقوه استفاده می شود و به همین دلیل است که شناسایی رسوبات نمک نقش مهمی ایفا می کند. توسعه گنبدهای نمکی ( شکل 2 را ببینید) می تواند سنگ های اطراف را تغییر شکل دهد و تله هایی را تشکیل دهد که نفت و گاز طبیعی را در خود نگه می دارد. رسوبات نمکی ویژگی هایی دارند که شناسایی آنها را هم ساده و هم دشوار می کند. چگالی نمک معمولاً حدود 2.14 گرم بر سانتی متر مکعب است که کمتر از اکثر سنگ های مجاور است. سرعت لرزه ای نمک حدود 4.5 کیلومتر بر ثانیه معمولاً بزرگتر از سنگ های اطراف است. این تفاوت باعث انعکاس شدید در مرز رسوب نمک می شود. رسوب نمک معمولاً یک فرم آمورف بدون ساختار داخلی خاص است، به این معنی که معمولاً انعکاس زیادی در خود رسوب وجود ندارد، مگر اینکه از سنگ دیگری که در داخل آن به دام افتاده است بیاید [ 2 ].
هدف شرکت ژئوفیزیک TGS-NOPEC (TGS) با حمایت رقابت Kaggle [ 2 ]، توسعه الگوریتمی بود که بتواند هر پیکسل را در یک پچ تصویر لرزه ای 101×101 به عنوان نمک یا نمک طبقه بندی کند. داده های ارائه شده برای آموزش شامل 4000 قطعه تصویر لرزه ای به همراه ماسک های باینری مناسب است که مناطق نمکی را به تصویر می کشد. برای اهداف آزمایش و امتیازدهی، 18000 وصله تصویر لرزهای اضافی ارائه شد. علاوه بر این، برای هر پچ تصویر لرزه ای، اطلاعات عمق (به فوت) ارائه می شود. تصویر مجموعه داده در شکل 3 نشان داده شده است ، که در آن چندین جفت تکه های تصویر لرزه ای و ماسک های مربوطه، همراه با اطلاعات عمق، نشان داده شده است.
نحوه بیان آن مشکل را در دسته بندی معنایی قرار می دهد. تقسیم بندی معنایی یکی از مشکلات کلیدی در بینایی کامپیوتر است و نشان دهنده گام بعدی طبیعی فراتر از طبقه بندی تصویر و محلی سازی اشیا است. شبکههای عصبی کانولوشنال عمیق (CNN) [ 3 ] با موفقیت برای هر سه مشکل استفاده شدهاند. سیانانها سه ایده معماری را با هم ترکیب میکنند که آنها را تا حدی نسبت به ترجمه و تحریف تغییرناپذیر میسازد: میدانهای دریافتی محلی، اشتراکگذاری وزنها و نمونهبرداری فرعی فضایی [ 4 ]]. CNN های عمیق قادر به ایجاد سلسله مراتبی از ویژگی ها هستند که آنها را برای کارهای طبقه بندی مناسب می کند، به طوری که برای محلی سازی و تقسیم بندی معنایی اشیاء در تصاویر. اگرچه CNN ها از دهه 1990 شناخته شده بودند، CNN های عمیق در سال 2012 زمانی که شبکه ای به نام AlexNet [ 5 ] برنده چالش تشخیص تصویری در مقیاس بزرگ ImageNet شد [ 6 ] در کانون توجه قرار گرفت.] (از این پس ImageNet نامیده می شود). AlexNet به خطای پنج گانه برتر 15.3% دست یافت که 10.8% بهتر از راه حل رتبه دوم بود. این نتیجه با آموزش با استفاده از واحدهای پردازش گرافیکی (GPU) امکان پذیر شد که نقطه عطفی برای پیشرفت یادگیری عمیق محسوب می شود. در سالهای بعد، پیشرفت قابلتوجهی در معماریهای عمیق CNN صورت گرفت که منجر به نتایج طبقهبندی بسیار بهتری در چالش ImageNet شد. در سال 2013، ZFNet [ 7 ] با خطای 14.8 درصدی برنده شد. سهم اصلی نویسندگان این شبکه نه در نتیجه طبقه بندی بلکه در توسعه تکنیک تجسم با نگاشت فیلترهای آموخته شده به وصله های تصویر است. سال بعد پیشرفت بزرگی را به همراه داشت و دو راه حل قابل توجه داشت. VGGNet [ 8] در حالی که سادگی و عمق را ترویج میکرد، 7.3% خطای پنج را دریافت کرد. برنده در سال 2014 GoogLeNet [ 9 ] با 6.7 درصد از پنج درصد برتر بود. جالب است بدانید که GoogLeNet نه تنها بسیار دقیق تر است، بلکه 12 برابر پارامترهای کمتری نسبت به AlexNet دارد. در سال بعد، خطا به 3.6 درصد کاهش یافت که تقریباً دو برابر بهتر از سال قبل است. به لطف معماری ResNet [ 10 ] بود که از سادگی VGGNet با معرفی باقیمانده ها الهام گرفته شد که آموزش کارآمد CNN های عمیق را امکان پذیر کرد. برنده سال 2015، تنوع ResNet با 152 لایه بود.
معماریهای CNN برای طبقهبندی از اهمیت ویژهای برخوردار هستند، زیرا میتوان آنها را نسبتاً به راحتی گسترش داد و برای تقسیمبندی معنایی استفاده کرد. بسیاری از معماری های مختلف [ 11 ، 12 ، 13 ، 14 ، 15 ، 16 ، 17 ، 18 ] وجود دارند که در چند سال گذشته برای مقابله با این مشکل به وجود آمده اند. در این مقاله، یک معماری جدید پیشنهاد شده است که در نتیجه شرکت نویسنده در مسابقه TGS [ 2 ] آمده است. معماری تکامل مدل U-Net [ 14 ] را نشان می دهد که برخی از ایده های ResNet [ 10 ] و DenseNet [ 19 ] را ادغام می کند.] معماری ها از آنجایی که معرفی این معماری باعث بهبود قابل توجه امتیاز رقابت در مقایسه با وانیلی U-Net شد، یک سری آزمایشهای پس از مسابقه با استفاده از مدلهای تقسیمبندی استاندارد شده با چارچوب آموزشی موجود انجام شد. نتایج نشان داد که معماری پیشنهادی قابل مقایسه و در بیشتر موارد بهتر از مدلهای تقسیمبندی آزمایش شده است.
این مقاله به شرح زیر سازماندهی شده است: بخش 2 یک نمای کلی از کار مرتبط در مورد تقسیم بندی معنایی و شناسایی رسوبات نمکی را ارائه می دهد. در بخش 3 ، روش پیشنهادی با ارائه معماری CNN استفاده شده و برخی جزئیات پیاده سازی توضیح داده شده است. نتایج به دست آمده در بخش 4 ارائه و مورد بحث قرار گرفته است. در نهایت، بخش 5 نتیجه گیری را ارائه می کند.
2. کارهای مرتبط
مسئله تجزیه و تحلیل تصاویر لرزه ای و شناسایی نمک محققان بسیاری را به خود جذب می کند. به طور معمول برای تمام مشکلات بینایی کامپیوتری، رویکرد سنتی برای تجزیه و تحلیل تصاویر لرزه ای بر اساس دست ساز استخراج کننده های مختلف و پردازش بعدی پاسخ های مناسب است. در یکی از اولین مقالات در این زمینه، پیتاس و کوتروپولوس [ 20 ] روشی مبتنی بر تحلیل بافت برای تقسیم بندی معنایی تصاویر لرزه ای پیشنهاد کردند. روشهای مبتنی بر ویژگیهای بافت در سالهای اخیر امکانپذیر هستند [ 21 ، 22 ]. هارپر و کلاپ [ 23] روش هایی را پیشنهاد کرد که در آنها می توان ویژگی های مختلف تصویر لرزه ای را محاسبه کرد و برای شناسایی رسوبات نمک استفاده کرد. روشی مبتنی بر محاسبه ویژگی های جدید تصویر لرزه ای نیز توسط شفیق و همکاران استفاده شده است. [ 24 ]. تجزیه و تحلیل تصاویر لرزه ای سه بعدی موضوع تحقیق در [ 25 ، 26 ، 27 ] بود. Amin و Deriche [ 25 ] روشی را بر اساس استفاده از آشکارساز لبه چند جهته سه بعدی پیشنهاد می کنند. Wu [ 26 ] برای شناسایی مرزهای رسوب نمک بر محاسبه احتمال تکیه می کند. دی و همکاران [ 27 ] خوشه بندی چند ویژگی را با استفاده از k پیشنهاد می کند-به معنای الگوریتم برای شناسایی مرزهای رسوب نمک. استفاده از تکنیک های یادگیری ماشین برای شناسایی چهار سازه لرزه ای مشخصه بر اساس ویژگی های لرزه ای مختلف استخراج شده از تصویر توسط Wrona و همکاران پیشنهاد شد. [ 28 ].
معماریهای عمیق CNN برای طبقهبندی، که در سالهای اخیر بوجود آمدهاند، میتوانند نسبتاً به راحتی گسترش داده شوند و برای تقسیمبندی معنایی استفاده شوند. شبکه کاملاً کانولوشنال (FCN) [ 11 ] یکی از اولین راهحلها را به دنبال آن مسیر نشان میدهد. یک FCN با حذف لایههای طبقهبندیکننده بالایی CNN، افزودن یک لایه کانولوشن برای کاهش تعداد فیلترها به تعداد کلاسهای خروجی، و نمونهبرداری از نقشه ویژگی بهدستآمده برای مطابقت با اندازه ورودی شبکه ساخته میشود. از آنجایی که مولفه فضایی آخرین نقشه ویژگی CNN چندین برابر کوچکتر از اندازه ورودی است، برای دستیابی به نتایج بهتر می توان یک ابر ستون تشکیل داد [ 12 ].] با استفاده از نقشه های ویژگی به دست آمده از چندین مرحله CNN. تعداد فیلترها در هر نقشه ویژگی با لایههای کانولوشنی اضافی برابر میشود و پس از نمونهبرداری به اندازه معین، از یک عملیات جمعآوری برای ساخت یک ابر ستون استفاده میشود که برای طبقهبندی در سطح پیکسل استفاده میشود.
معماری های پیچیده تر CNN برای تقسیم بندی معنایی DeconvNet [ 13 ] و U-Net [ 14 ] هستند.]. هر دو شبکه یک ایده معماری مشابه دارند: شبکه از بخش های رمزگذار و رمزگشا تشکیل شده است. در مورد DeconvNet، به ترتیب شبکه های کانولوشن و دکانولوشن نامیده می شوند. بخش رمزگذار اساساً یک CNN طبقهبندی شده با قسمت بالایی حذف شده است، در حالی که رمزگشا دارای ساختاری آینهای با بلوکهایی است که از لایههای کانولوشن upsampling یا جابجایی و به دنبال آن لایههای کانولوشن تشکیل شده است. معماری U-Net، علاوه بر این، اتصالات پرش را معرفی میکند که امکان کپی و الحاق نقشههای ویژگی رمزگذار قبلی را به نقشههای ویژگی رمزگشای نمونهبرداری شده مربوطه فراهم میکند، بنابراین لایههای کانولوشن رمزگشا هر دو را پردازش میکنند. یک رویکرد بسیار مشابه، با تفاوت های جزئی، توسط معماری SegNet [ 15 ] ترویج می شود.
مدلهای یادگیری عمیق برای تقسیمبندی معنایی به طور فزایندهای در پردازش خودکار تصاویر سنجش از دور برای استخراج ردپای ساختمان [ 29 ، 30 ، 31 ]، استخراج جاده [ 32 ]، تشخیص کاربری زمین [ 33 ]، و غیره محبوب میشوند. با انگیزه نتایج خوب در بسیاری از موارد سیانانها در حال تبدیل شدن به انتخاب پیشفرض محققان برای تقسیمبندی تصاویر لرزهای و شناسایی رسوبات نمک هستند. تعداد زیادی مقاله [ 34 , 35 , 36 , 37 , 38 , 39 , 40 , 41] در سال 2018 و 2019 از این ادعا پشتیبانی می کند. Dramsch و Lüthje [ 34 ] چندین CNN عمیق طبقه بندی را با یادگیری انتقال برای شناسایی 9 بافت لرزه ای مختلف از تکه های 65 × 65 پیکسل ارزیابی کردند. دی و همکاران [ 35 ] با استفاده از یک شبکه عصبی دکانولوشنال با سه لایه کانولوشنال و سه لایه دکانولوشنال برای تسریع در تفسیر لرزه ای به همین مشکل پرداخت. همان نویسندگان [ 36 ] با استفاده از یک رویکرد طبقه بندی به مشکل ترسیم بدن نمک پرداختند. آنها به CNN با دو لایه کانولوشن و دو لایه کاملاً متصل، که با وصلههای تصویری 32×32 تغذیه میشد، تکیه کردند. والدلند و همکاران [ 37] روشی را برای شناسایی اجسام نمک از دادههای لرزهای سه بعدی با طبقهبندی مکعبهای ۶۵ × ۶۵ × ۶۵ با استفاده از یک CNN سفارشی پیشنهاد کرد. زنگ و همکاران [ 38 ] روشی را برای شناسایی بدنه نمک با استفاده از شبکه تقسیمبندی U-Net در ترکیب با شبکه طبقهبندی ResNet برای ترسیم اجسام نمک با دقت بالا پیشنهاد کرد. شی و همکاران [ 39 ] مشکل استخراج بدنه نمک را به عنوان تقسیمبندی تصویر سهبعدی مورد بررسی قرار داد و یک رویکرد کارآمد مبتنی بر CNN عمیق با معماری رمزگذار-رمزگشا پیشنهاد کرد. آنها یک CNN را با وصله های 128 × 128 تغذیه کردند و یک ماسک نمک در هر پیکسل را پیش بینی کردند. وو و همکاران [ 40 ] این رویکرد را به سه بعدی گسترش داد و مستقیماً 128 × 128 × 128 مکعب داده را برای پیشبینی اجسام نمک پردازش کرد. در نهایت مقاله ای از باباخین و همکاران. [ 41] باید مورد تأکید قرار گیرد زیرا راه حل اول را در چالش TGS توصیف می کند [ 2 ]. عنصر کلیدی موفقیت آنها یک روش نیمه نظارت شده بود که از داده های بدون برچسب (آزمون) برای خودآموزی چند مرحله ای استفاده می کرد. در دور اول آموزش، آنها فقط از دادههای برچسبدار موجود استفاده کردند، پس از آن، در دورهای بعدی مدل را بر روی دادههای برچسبگذاریشده موجود آموزش دادند و شبهبرچسبهای مطمئن را برای دادههای بدون برچسب پیشبینی کردند. معماری مورد استفاده آنها از رمزگذارهای ResNet-34 [ 10 ] و ResNeXt-50 [ 42 ] با ماژولهای scSE [ 43 ]، ماژول توجه هرمی (FPA) [ 44 ] بعد از آخرین بلوک رمزگذار و ابر ستونها [ 12 ] استفاده میکرد.] برای پیش بینی ماسک تقسیم بندی.
رویکرد پیشنهادی در این مقاله برخلاف رویکردهای طبقهبندی ارائهشده در [ 34 ، 36 ] از بخشبندی CNN استفاده میکند. پیشبینی به جای رویکردهای [ 37 ، 40 ] که مکعبهای داده سهبعدی را پردازش میکنند، روی تصاویر دو بعدی انجام میشود. این مبتنی بر یک معماری شبکه جدید است که در بخش بعدی ارائه شده است که آن را از [ 35 ، 38 ، 39 ، 41 ] متمایز می کند.
3. شرح روش
این بخش معماری شبکه پیشنهادی را ارائه میکند که در نتیجه شرکت نویسنده در رقابت Kaggle با حمایت TGS ظاهر شد. جزییات فنی مربوط به اجرای شبکه و روش آموزش اعمال شده نیز در این بخش گنجانده شده است.
3.1. معماری شبکه
معماری شبکه ای که نهایی را تولید کرد، یعنی بهترین راه حل ارائه شده توسط نویسنده در مسابقه TGS، در شکل 4 نشان داده شده است . معماری ارائه شده از U-Net [ 14 ] سرچشمه می گیرد و شامل تغییرات خاصی است که در جستجو برای بهبود امتیاز انجام شده است.
همانطور که از شکل 4 مشاهده می شود ، شبکه عمدتاً از سه نوع بلوک (C، D و U) تشکیل شده است. بلوک C رایج ترین و پیچیده ترین بلوک در شبکه است. این بلوک از 5 لایه کانولوشن با اندازه هسته 3×3 تشکیل شده است. بلوک با استفاده از دو پارامتر ایجاد میشود: تعداد فیلترهای ورودی ( f ) و تعداد فیلترهای خروجی ( p ). 4 لایه اول تعداد فیلترهای یکسانی دارند ( f ) و با استفاده از افزودن قبل از فعال سازی ReLU، “نزدیک جفت” شده اند. لایه آخر، پنجم دارای فیلترهای p است و کاربرد اصلی آن تنظیم تعداد فیلترهای خروجی به مقدار دلخواه است. جفت خاص نقشه های خروجی لایه ها از ResNet الهام گرفته شده است [ 10] و معماری های DenseNet [ 19 ]، اگرچه «سیم کشی» خاص سهم اصلی است. علاوه بر لایههای کانولوشنال که قبلاً ذکر شد، بلوک C شامل نرمالسازی دستهای و لایههای فعالسازی ReLU نیز میشود. تعداد فیلترها در لایه های کانولوشن بلوک های C با استفاده از پارامتر n تعریف می شود که نشان دهنده تعداد فیلترها در اولین لایه های کانولوشن است. آزمایش ها با مقادیر زیر برای n انجام شد : 16، 24، و 32.
D-block دومین نوع بلوک است که استفاده می شود و می توان آن را در قسمت رمزگذار شبکه که همیشه به دنبال C-block دنبال می شود، یافت. مسئولیت D-block کم کردن نمونه ابعاد فضایی نقشه ویژگی با ضریب 2 با استفاده از لایه MaxPool است. همچنین شامل لایه Dropout با نرخ ترک تحصیل 20٪ است که برای افزایش استحکام مدل آموزش دیده و جلوگیری از تمرین بیش از حد استفاده می شود. ترک تحصیل فقط در مرحله آموزش اعمال می شود و نشان دهنده ابطال (تنظیم مقادیر روی 0) درصد معینی (نرخ انصراف) از نقشه ویژگی ورودی است. این امر شبکه را مجبور می کند که ویژگی های ورودی بیشتری را هنگام ساخت ویژگی های سطح بالاتر در نظر بگیرد.
U-block در قسمت رمزگشای شبکه یافت می شود و به نوعی با D-block در قسمت رمزگذار مطابقت دارد. U-block برای بُعد فضایی نمونه برداری نقشه ویژگی ورودی با ضریب 2 استفاده می شود که با تکرار هر ستون و سطر به دست می آید. مسئولیت دوم U-block الحاق یک نقشه ویژگی که قبلاً نمونه برداری شده است با یک نقشه ویژگی خروجی از بلوک C مناسب رمزگذار (نشان داده شده با خط چین در شکل 4 ) است.
خروجی نهایی شبکه با اعمال یک پیچیدگی 1×1، با 1 فیلتر و فعال سازی سیگموئید در خروجی آخرین بلوک C به دست می آید. پیچیدگی 1 × 1 برای کاهش تعداد فیلترها به خروجی شبکه مورد نظر استفاده می شود، در حالی که فعال سازی سیگموئید مقادیر خروجی در هر پیکسل را به بازه (0، 1) محدود می کند. مقادیر مربوطه به مقادیر 0 یا 1 گرد می شوند تا ماسک خروجی نهایی تولید شود.
3.2. اجرا و آموزش
برای پیاده سازی معماری پیشنهادی، زبان برنامه نویسی پایتون و کتابخانه Keras [ 45 ] انتخاب شدند. Keras یک کتابخانه سطح بالا است که یک رابط ساده برای پیاده سازی شبکه های عصبی عمیق را مشخص می کند و در این مورد، به عنوان یک موتور پشتیبان بر TensorFlow [ 46 ] متکی است. پیادهسازی شبکه خاص از API عملکردی Keras استفاده میکند و هر یک از بلوکهای معماری پیشنهادی در یک تابع پایتون جداگانه پیادهسازی میشوند. کد منبع پروژه را می توانید در https://github.com/a-milosavljevic/tgs-salt-identification بیابید .
آموزش در 80 درصد از مجموعه آموزشی اولیه انجام شد، در حالی که 20 درصد باقی مانده برای اعتبارسنجی استفاده شد. به طور دقیقتر، دادهها به 5 برابر تقسیم شدند، بنابراین 5 شبکه با استفاده از فولدهای مختلف برای اعتبارسنجی آموزش داده شدند. پیشبینی نهایی با استفاده از مجموعهای متشکل از 5 شبکه بهدست آمد که خروجیهای مربوطه جمعبندی شدند، بر تعداد شبکههای موجود در مجموعه تقسیم شدند و سپس برای تولید یک ماسک باینری گرد شدند. برای اینکه مجموعههای اعتبارسنجی در مقایسه با مجموعه آموزشی نماینده نگه داشته شوند، قبل از تقسیم دادهها به 5 برابر، نمونهها بر اساس تعداد پیکسلهای نمک در ماسک مرتب شدند. پس از آن، تصاویر با گرفتن 5 نمونه در یک زمان و تخصیص آنها به هر یک از 5 چین اختصاص داده شده تقسیم شدند.
تکنیک افزایش داده ها در دو مرحله آموزش و آزمون (مرحله آماده سازی نتایج) به کار گرفته شد. در مرحله آموزش، افزایش داده ها در دو سطح اعمال شد. سطح اول نشان دهنده دو برابر شدن تعداد نمونه های آموزشی با چرخش افقی تمام تصاویر و ماسک های مربوطه است. سطح دوم افزایش دادهها از تبدیلهای تصادفی تصویر استفاده میکرد که شامل ترجمه، و مقیاسگذاری و تغییر شدت بود. تبدیل ترجمه بر این واقعیت استوار است که تصاویر ورودی 101 × 101 هستند، در حالی که ورودی شبکه 128 × 128 است. در 25 درصد موارد، تصویر در مرکز قرار داشت، یعنی ترجمه 13 پیکسل در هر دو جهت داشت. در 75 درصد بقیه موارد، تصویر با مقادیر تصادفی بین 0 تا 27 در هر دو جهت ترجمه شد. ترجمه مناسب نیز روی ماسک مربوطه اعمال شد. علاوه بر ترجمه، قسمت پر نشده ورودی شبکه (و خروجی مورد انتظار) توسط تصویر و ماسک آینهسازی پر شد. تبدیل های مربوط به مقادیر تصویر شامل مقیاس بندی شدت با ضرب مقادیر تصویر با مقدار تصادفی بین 0.8-1.2، مانند تغییر شدت با افزودن مقدار تصادفی از محدوده ± 0.2 است.
افزایش زمان تست (TTA) به شرح زیر عمل می کند. برای هر تصویر در مجموعه آزمایشی، خروجی شبکه از نظر تغییرات اصلی و برگردان افقی ارزیابی می شود. در حالت دوم، خروجی نیز برگردانده شده و با خروجی اصلی میانگین می شود. هنگامی که نه تنها یک، بلکه مجموعه شبکهها استفاده میشود، میانگینگیری برای همه خروجیهای شبکه قبل از عملیات آستانهگذاری انجام میشود که ماسک تقسیمبندی نهایی را تولید میکند.
برای آموزش شبکه، بهینه ساز Adam [ 47 ] (بهینه ساز ماژول ) و تابع باینری_متقابل از دست دادن ( تلفات ماژول ) استفاده شد. به عنوان متریک برای انتخاب مدل بهینه تابع binary_accuracy از معیارهاماژول اعمال شد. این متریک درصد پیکسل های به درستی طبقه بندی شده را نشان می دهد. همچنین، متریک تقاطع بیش از اتحادیه (IoU) ردیابی شده و با تقسیم تعداد پیکسلهای موجود در تقاطع حقیقت زمین و ماسکهای پیشبینیشده و تعداد پیکسلها در اتحاد دو ماسک محاسبه میشود. متریک IoU معمولاً برای مسائل تقسیم بندی استفاده می شود و متریک رقابت بر اساس آن بود، اما نتایج کمی بهتر با استفاده از دقت باینری برای انتخاب مدل بهینه به دست آمد.
برای کنترل فرآیندهای آموزشی، از اشیاء پاسخ به تماس Keras استفاده شد. کلاس های مناسب بخشی از ماژول callbacks و راه حل پیشنهادی مورد استفاده هستند: ReduceLROnPlateau ، EarlyStopping ، ModelCheckpoint ، و CSVLogger . ReduceLROnPlateau برای کاهش نرخ یادگیری با استفاده از یک عامل خاص استفاده می شود، زمانی که در تعداد معینی از دوره ها پارامتر خاصی که ردیابی می شود بهبود نیافته است. در راه حل پیشنهادی، دقت باینری در مجموعه اعتبارسنجی ردیابی شد و اگر پس از 10 دوره آموزش هیچ پیشرفتی وجود نداشت، نرخ یادگیری 0.1 کاهش مییابد. مقدار اولیه نرخ یادگیری 10-3 بود. توقف زودهنگامهمانطور که از نامش پیداست، برای پایان دادن به تمرین با استفاده از مکانیزمی مشابه با مکانیسمی که قبلا توضیح داده شد، استفاده شد. در راه حل پیشنهادی، توقف اولیه پس از 30 دوره زمانی که دقت باینری در مجموعه اعتبار سنجی بهبود نمی یابد، فعال شد. CSVLogger برای ثبت تلفات و دقت های آموزشی و اعتبارسنجی در طول فرآیند آموزش استفاده شد. در نهایت، ModelCheckpoint برای ثبت بهترین مدل اندازهگیری شده با استفاده از دقت باینری در مجموعه اعتبارسنجی استفاده میشود. هر بار که دقت بهبود مییابد، یک مدل ذخیره میشود، بنابراین وقتی آموزش به پایان میرسد، مدلی که بهترین عملکرد را در مجموعه اعتبارسنجی داشته باشد، به دست میآید.
4. نتایج و بحث
همه مسابقات میزبانی Kaggle دارای مدت زمان، قوانین، مجموعه داده ها و معیاری برای ارزیابی ارسال هستند. در مورد مجموعه دادههای آموزشی مسابقه TGS شامل 4000 تکه تصویر لرزهای و ماسکهای تقسیمبندی مربوطه با اندازه 101 × 101 پیکسل است. مجموعه آزمایشی که برای ارزیابی مدل استفاده می شود از 18000 تکه تصویر لرزه ای تشکیل شده است. برای تمام تکه های تصویر لرزه ای، اطلاعات عمق (به فوت) محل نمونه ارائه شده است. نتایج مسابقه شامل ماسک هایی است که برای هر پچ تصویر آزمایشی تخمین زده می شود. ماسکهای تقسیمبندی باینری با استفاده از رمزگذاری طول اجرا (RLE) کدگذاری میشوند و با استفاده از فایل مقادیر استاندارد جدا شده با کاما (CSV) ارسال میشوند.
این مسابقه از 19 ژوئیه تا 20 اکتبر 2018 به طول انجامید. هر روز امکان ارسال حداکثر پنج راه حل وجود داشت که با استفاده از معیارهای مشخص شده در مسابقه امتیاز می گیرند. امتیاز اولیه (عمومی) بر اساس 34 درصد داده های آزمون داده می شود. بهترین نتیجه یک شرکت کننده، جایگاه او را در تابلوی امتیازات عمومی تعیین می کند. نتایج نهایی پس از پایان مسابقه اعلام می شود و بر اساس 66 درصد باقی مانده از داده های آزمون است. امتیاز نهایی فقط برای دو راه حل انتخاب شده توسط یک شرکت کننده محاسبه می شود و از ارزش بهتر برای قرار دادن شرکت کننده در جدول امتیازات نهایی (خصوصی) استفاده می شود. یک هفته قبل از پایان مسابقات امکان ادغام تیم ها وجود دارد که منجر به ادغام نتایج فردی آنها شده است.
مزیت اصلی مسابقه ای که به این ترتیب سازماندهی شده است، توانایی آزمایش و ارزیابی فوری بسیاری از ایده ها در مدت زمان کوتاه و همچنین سنجش کیفیت راه حل خود در مقایسه با سایر شرکت کنندگان با سطح بالا است. از عینیت
4.1. نتایج مسابقه
نتایج به دست آمده با شبکه پیشنهادی در رتبه 14 درصد برتر قرار گرفت، یعنی به عنوان 446 از 3221 شرکت کننده. قبل از ارائه نتایج، لازم است معیارهای استفاده شده توسط مسابقه برای ارزیابی آثار ارسالی معرفی شود. این معیار براساس میانگین مقادیر IoU در 10 آستانه از 0.5 تا 0.95 با گام 0.05 بود. به عنوان مثال، در آستانه 0.5، اگر مقدار IoU بزرگتر از 0.5 باشد، ماسک پیش بینی شده به عنوان یک ضربه حساب می شود.
اگر T نشان دهنده ماسک حقیقت زمین باشد، در حالی که Y نشان دهنده ماسک پیش بینی شده است، در هر مقدار آستانه t دقت P(t) با استفاده از قانون زیر محاسبه می شود:
پ( t ) =⎧⎩⎨⎪⎪⎪⎪⎪⎪⎪⎪0 ,0 ,1 ،منo U( تی، ی) > t ،| تی| = 0 ∧ | Y| > 0| تی| > 0 ∧ | Y| = 0| تی| = 0 ∧ | Y| = 0| تی| > 0 ∧ | Y| > 0.پ(تی)={0،|تی|=0∧|�|>00،|تی|>0∧|�|=01،|تی|=0∧|�|=0من��(تی،�)>تی،|تی|>0∧|�|>0.
در نهایت، متریک ارزیابی M ماسک پیشبینیشده با میانگین دقت محاسبهشده در تمام 10 آستانه محاسبه میشود:
م=110∑9k = 0پ( 0.5 + 0.05 k ) .م=110∑ک=09پ(0.5+0.05ک).
یک نمای کلی از نتایج برای پیکربندی های مختلف در رابطه با تعداد شبکه ها در مجموعه و تعداد فیلترها در اولین لایه کانولوشن (پارامتر n ) در جدول 1 ارائه شده است. همراه با نمرات خصوصی که مبنای رتبه بندی نهایی بود، نمرات عمومی مربوطه که در طول مسابقه قابل مشاهده بود نیز نشان داده شده است. برای مقاصد مقایسه، امتیاز راه حل برنده [ 41 ] نیز نشان داده شده است. تعداد کل راه حل های ارسال شده برای تیم برنده 316 بود، در حالی که نویسنده 42 مورد ارسالی داشت.
در نتایج ارائه شده دو روند قابل مشاهده است. روند اول افزایش امتیاز با تعداد فیلترهای کانولوشنال (پارامتر n ) است، در حالی که گرایش دوم نشان میدهد که افزودن شبکههای بیشتر به یک مجموعه نیز نتیجه میدهد. بهترین نویسنده از 25 شبکه استفاده کرده است که ممکن است تعجب آور به نظر برسد. این تلاش در آخرین لحظه برای افزایش امتیاز با ترکیب همه مدلهای آموزش دیده قبلی بود. به عنوان مقایسه، راه حل برنده از مجموعه 40 شبکه بدست آمد.
مواردی که از نتایج ارائه شده قابل مشاهده نیست، تلاش های بی شماری است که موفقیت آمیز نبوده است. این تلاشها شامل معماریهای دیگر، توابع و معیارهای تلفات مختلف برای انتخاب بهترین مدل، برخی تلاشهای پسپردازش شامل عملیات مورفولوژی، روشهای دیگر برای افزایش دادهها و غیره است.
به عنوان تصویری از فرآیندهای آموزشی، شکل 5 دو نمودار را نشان می دهد که دقت و معیارهای IoU را در مجموعه های آموزشی و اعتبارسنجی در طول یک دور آموزش نشان می دهد.
4.2. تحلیل های پس از مسابقه
قضاوت در مورد معماری مدل فقط با مقایسه نتایج رقابت بهترین رویکرد نیست زیرا بسیاری از چیزهای دیگر بر امتیاز نهایی تأثیر می گذارند. به همین دلیل، پس از پایان رقابت، چند آزمایش انجام شد تا ببینند مدلهای تقسیمبندی مختلف، با استفاده از چارچوب آموزشی موجود، در مقایسه با مدل پیشنهادی چگونه رتبهبندی میشوند. خوشبختانه، به لطف کتابخانه Github پاول یاکوبوسکی به نام مدلهای تقسیمبندی [ 48 ]، این کار نسبتاً آسان بود. مدلهای تقسیمبندی یک کتابخانه پایتون مبتنی بر Keras هستند که چهار معماری تقسیمبندی محبوب و دهها ستون فقرات از پیش آموزشدیده ImageNet را پیادهسازی میکنند که میتوانند به راحتی در مدل تقسیمبندی انتخابی ترکیب شوند. معماری های پشتیبانی شده شامل U-Net است که قبلاً ذکر شد [ 14]، مانند شبکه هرمی ویژگی (FPN) [ 16 ]، لینک نت [ 17 ]، و شبکه تجزیه صحنه هرمی (PSPNet) [ 18 ].
وقتی نوبت به انتخاب ستون فقرات میرسد، کتابخانه مدلهای تقسیمبندی طیفی از مدلهای از پیش آموزشدیدهشده در مجموعه دادههای ILSVRC ImageNet 2012 را پشتیبانی میکند. برای آزمایش ها از ستون فقرات ResNet-34 [ 10 ] استفاده می شود. از آنجایی که شبکه ResNet اندازه نقشه های ویژگی را چهار بار در دو لایه اول کاهش می دهد، برای حفظ دقت نقشه خروجی پیش بینی شده، تصاویر ورودی دو بار با افزودن لایه UpSampling2D در ورودی ارتقاء داده شدند و اندازه خروجی را با اعمال AvgPool2D در خروجی تنظیم کنید. شکل 6 برای تصویر). روش مشابهی برای دو برابر کردن اندازه تصاویر ورودی در راه حل برنده استفاده شد، همانطور که در [ 41 ] توضیح داده شد.
مقایسه مدل های تقسیم بندی مختلف در جدول 2 ارائه شده است . برای هر یک از مدلها، تعداد کل لایهها و فیلترهای کانولوشنی-نمرات عمومی و خصوصی نشان داده شده است. برای اهداف امتیاز دهی، مجموعه هایی از پنج شبکه استفاده شد که در آن هر یک از شبکه ها با استفاده از تاهای مختلف به عنوان مجموعه اعتبار سنجی آموزش داده شدند. فرآیند آموزش، از جمله افزایش داده ها در مرحله تمرین و آماده سازی نتایج، مشابه آنچه در مسابقه استفاده شده بود و قبلاً به تفصیل در بخش 3.2 توضیح داده شد، بود.. دو ورودی اول با نتایج به دست آمده با استفاده از شبکه شرح داده شده در این مقاله مطابقت دارد. ورودی اول نشاندهنده نتیجه بهدستآمده در طول مسابقه است، در حالی که ورودی دوم توسط یک شبکه کمی تغییر یافته تولید شده است که لایههای حذف در بلوکهای D را حذف میکند. در نهایت، چهار ورودی آخر با مدل های پیاده سازی شده با استفاده از کتابخانه Yakubovskiy مطابقت دارد. FPN، LinkNet و PSPNet با استفاده از پارامترهای پیشفرض ساخته شدند، در حالی که مدل U-Net با فیلترهای 512، 256، 128، 64، و 32 در هر یک از بلوکهای رمزگشا ساخته شد که دو برابر پیشفرض است. این تغییر برای دادن قدرت مشابه به U-Net، از نظر تعداد فیلترهای کانولوشنال، با فیلترهای مدل اصلی ارائه شد.
با نگاهی به نمرات ارائه شده در جدول 2می توان متوجه شد که مقادیر تفاوت چندانی ندارند. بهترین نمره عمومی توسط مدل FPN به دست می آید در حالی که برنده در بخش نمره خصوصی مدل پیشنهادی بدون لایه های انصرافی بود. جالب اینجاست که با نگاهی به نمرات عمومی، مدل اصلی بدون تغییر امتیاز کمی بهتر داشت. نتایج همچنین نشان داد که معماری اصلی U-Net نسبت به معماری پیشنهادی قدرتمندتر است، حتی اگر از رمزگذار ResNet-34 از پیش آموزش دیده به عنوان ستون فقرات استفاده کند. مدل FPN قابل مقایسه و حتی بهترین نتیجه را در بخش عمومی نشان داد که از فیلترهای پیچیده تری نسبت به مدل های پیشنهادی و U-Net استفاده می کرد. در نهایت، لینک نت و پی اس پی نت کمی بدتر از مدل پیشنهادی عمل کردند، اما قابل ذکر است که PSPNet از فیلترهای کانولوشنال حدود دو برابر کمتر از مدل های دیگر استفاده می کند.
برای بررسی بیشتر نحوه رفتار این مدلهای تقسیمبندی، خروجیها تجسم و مقایسه شدند. شکل 7 شش تصویر نمونه را به همراه ماسک رسوبات نمک واقعی زمین و ماسک های خروجی برای هر یک از مدل ها نشان می دهد. نمونهها برای نشان دادن برخی موارد آسان و برخی سخت انتخاب شدهاند. نمونهها از مجموعههای اعتبارسنجی انتخاب شدند، بنابراین خروجیها توسط شبکههایی تولید میشوند که این ورودیها را در طول آموزش مشاهده نکردهاند.
سه نمونه اول را می توان به عنوان نمونه های آسان در نظر گرفت، به عنوان مثال، همه خروجی های مدل ها تطابق بسیار خوبی با تصویر حقیقت زمین نشان می دهند. نمونه چهارم کمی پیچیده تر است، بنابراین تمایز بین مدل ها را می توان مشاهده کرد، با این حال بیشتر “شکل درست” را نشان می دهد. دو نمونه آخر نماینده موارد سختی هستند که در آن عدم تطابق واقعی رخ می دهد. تصاویر حقیقت زمینی برای هر دو نمونه وجود رسوبات نمکی را نشان نمی دهند، اما تصاویر خروجی مقدار زیادی از آن را دارند. یافتن راهی برای کاهش وقوع چنین مواردی به نظر یک جهت تحقیقاتی خوب است.
برای مقایسه با نمودارهای آموزشی مدل اصلی که در شکل 5 نشان داده شده است، نمودارهای مربوط به دقت و متریک IoU در شکل 8 ، شکل 9 ، شکل 10 ، شکل 11 و شکل 12 ارائه شده است. شکل 8 نمودارهایی را برای مدل اصلی بدون انصراف نشان می دهد، در حالی که شکل 9 ، شکل 10 ، شکل 11 و شکل 12نمودارهایی را برای مدلهای تقسیمبندی Yakubovskiy به ترتیب U-Net، FPN، LinkNet و PSPNet نشان میدهد. مجدداً، داده های نمودار از آموزش مدل پنجم (آخرین پارتیشن) گرفته شده است و خط قرمز در (a) بهترین دوره دقت را هنگام ذخیره مدل نشان می دهد. از آنجایی که از چارچوب آموزشی مشابهی استفاده می شود، همه این نمودارها رفتار مشابهی را نشان می دهند. نوسانات معیارهای اعتبار سنجی در ابتدا قوی تر است، و سپس با کاهش نرخ یادگیری تثبیت می شود. به نظر می رسد که نوسانات برای مدل اصلی کوچکترین هستند ( شکل 5) و این احتمالاً به دلیل ترک تحصیل است که اعمال شده است. اگر متریک IoU را برای مجموعه آموزشی مقایسه کنیم، می توان متوجه شد که، پس از اولین دوره آموزش، مدل های ما ~50٪ می گیرند در حالی که مدل های Yakubovskiy به ~60٪ می رسد. این رفتار را می توان با این واقعیت توضیح داد که مدل های Yakubovskiy از یک رمزگذار ResNet-34 از پیش آموزش دیده استفاده می کنند که به آنها یک تقویت اولیه می دهد.
5. نتیجه گیری ها
در این مقاله، رویکردی برای شناسایی رسوبات نمک زیرزمینی بر روی تصاویر لرزه ای با استفاده از CNN عمیق برای تقسیم بندی ارائه شده است. تخیل لرزه ای و شناسایی نمک نقش مهمی در کشف نفت و گاز ایفا می کند، در حالی که خودکارسازی فرآیند تجزیه و تحلیل آنها برای شرکت های درگیر در اکتشاف سوخت هیدروکربنی بسیار مهم است.
این مقاله در نتیجه شرکت نویسنده در مسابقه Kaggle تحت حمایت TGS [ 2]. راه حلی که دارای امتیاز 0.85241 در تابلوی امتیازات خصوصی است بر اساس معماری اصلی تقسیم بندی CNN است که در مقاله توضیح داده شده است. معماری پیشنهادی از مدل U-Net مشتق شده است که مسئول امتیاز اولیه نویسنده 0.76996 بود. از آنجایی که بهبود قابل توجه بود، برای درک بهتر ویژگیهای معماری پیشنهادی، یک سری آزمایشهای پس از مسابقه برای مقایسه نتایج بهدستآمده با نتایج بهدستآمده با رویکردهای استاندارد شده با استفاده از چارچوب آموزشی مشابه انجام شد. نتایج نشان میدهد که رویکرد پیشنهادی قابل مقایسه و در بیشتر موارد بهتر از این مدلهای تقسیمبندی است. مجموعه پنج مدل معماری پیشنهادی بدون لایههای انصرافی بهترین امتیاز خصوصی 0.85219 را داشت. در حالی که گروه مبتنی بر FPN بهترین امتیاز عمومی 0.83623 را ثبت کرد. شایان ذکر است که مدلهای تقسیمبندی مورد استفاده در مقایسه، از یادگیری انتقال استفاده میکنند، یعنی از رمزگذارهای ResNet-34 که روی مجموعه داده ImageNet 2012 از قبل آموزش داده شدهاند، استفاده میکنند.
برای کارهای آینده، چندین جهت قابل بررسی است. اولین مورد این است که با جایگزین کردن رمزگذار فعلی با مقداری شبکه از پیش آموزش دیده، یادگیری انتقال را به معماری پیشنهادی اعمال کنید و فقط بخش رمزگشا را حفظ کنید. جهت دوم تلاش برای بهبود معیارهای شناسایی نمک با آموزش مدلهای طبقهبندی اضافی است که پیشبینی میکنند آیا یک پچ نمک دارد یا نه، بنابراین مدل تقسیمبندی به صورت مشروط استفاده میشود. در نهایت، جهت سوم این است که معماری را بر روی برخی از داده های دیگر آزمایش کنید و ببینید که آیا آن را حفظ می کند یا خیر.
منابع
- Chevron.com: تخیل لرزه ای. در دسترس آنلاین: https://www.chevron.com/stories/seismic-imaging (در 17 نوامبر 2019 قابل دسترسی است).
- Kaggle.com: چالش شناسایی نمک TGS، رسوبات نمک در زیر سطح زمین. در دسترس آنلاین: https://www.kaggle.com/c/tgs-salt-identification-challenge (در 17 نوامبر 2019 قابل دسترسی است).
- LeCun، Y.; بوزر، بی. دنکر، جی. هندرسون، دی. هوارد، آر. هابارد، دبلیو. Jackel, L. تشخیص ارقام دستنویس با یک شبکه پس انتشار. در پیشرفت در سیستم های پردازش اطلاعات عصبی 2 ; انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، 1990; صص 396-404. [ Google Scholar ]
- LeCun، Y.; Bengio، Y. شبکههای Convolutional برای تصاویر، گفتار و سریهای زمانی. هندب نظریه مغز شبکه عصبی. 1995 ، 3361 ، 1995. [ Google Scholar ]
- کریژفسکی، آ. سوتسکور، آی. هینتون، GE ImageNet طبقه بندی با شبکه های عصبی کانولوشن عمیق. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، دریاچه تاهو، اسپانیا، 3 تا 8 دسامبر 2012. جلد 2، ص 1097–1105. [ Google Scholar ]
- روساکوفسکی، او. دنگ، ج. سو، اچ. کراوز، جی. ستایش، س. ما، س. هوانگ، ز. کارپاتی، ا. خسلا، ع. برنشتاین، ام. و همکاران چالش تشخیص بصری در مقیاس بزرگ ImageNet. بین المللی جی. کامپیوتر. Vis. 2015 ، 115 ، 211-252. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Zeiler، MD; Fergus, R. تجسم و درک شبکه های کانولوشن. در یادداشت های سخنرانی در علوم کامپیوتر (شامل یادداشت های سخنرانی های فرعی در هوش مصنوعی و یادداشت های سخنرانی در بیوانفورماتیک) ؛ LNCS; Springer: Cham, Switzerland, 2014; جلد 8689، صص 818–833. [ Google Scholar ]
- سیمونیان، ک. Zisserman, A. شبکه های پیچیده بسیار عمیق برای تشخیص تصویر در مقیاس بزرگ. در مجموعه مجموعه مقالات سومین کنفرانس بینالمللی در مورد بازنماییهای یادگیری، ICLR 2015 — مجموعه مقالات پیگیری کنفرانس، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 7 تا 9 مه 2015; ICLR: لندن، بریتانیا، 2015. [ Google Scholar ]
- سگدی، سی. لیو، دبلیو. جیا، ی. سرمانت، پ. رید، اس. آنگلوف، دی. ایرهان، د. ونهوک، وی. رابینوویچ، الف. با پیچیدگی ها عمیق تر می رویم. در مجموعه مقالات کنفرانس IEEE Computer Society on Computer Vision and Pattern Recognition، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. IEEE: Piscataway, NJ, USA, 2015; صفحات 1-9. [ Google Scholar ]
- او، ک. ژانگ، ایکس. رن، اس. Sun, J. یادگیری باقیمانده عمیق برای تشخیص تصویر. در مجموعه مقالات کنفرانس IEEE Computer Society در مورد دید رایانه و تشخیص الگو، لاس وگاس، NV، ایالات متحده، 27-30 ژوئن 2016. IEEE: Piscataway, NJ, USA, 2016; صص 770-778. [ Google Scholar ]
- لانگ، جی. شلهامر، ای. دارل، تی. شبکه های کاملاً پیچیده برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. CVPR: واشنگتن، WA، ایالات متحده آمریکا، 2015; صص 3431–3440. [ Google Scholar ]
- حریهاران، بی. آربلاز، پ. گیرشیک، آر. Malik, J. Hypercolumns برای تقسیم بندی شی و محلی سازی ریز دانه. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. CVPR: واشنگتن، WA، ایالات متحده آمریکا، 2015; صص 447-456. [ Google Scholar ]
- نه، اچ. هونگ، اس. هان، بی. یادگیری شبکه دکانولوشن برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر (ICCV)، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. IEEE: Piscataway, NJ, USA, 2015; صص 1520-1528. [ Google Scholar ]
- رونبرگر، او. فیشر، پی. Brox، T. U-Net: شبکههای کانولوشن برای تقسیمبندی تصویر پزشکی. در یادداشت های سخنرانی در علوم کامپیوتر (شامل یادداشت های سخنرانی های فرعی در هوش مصنوعی و یادداشت های سخنرانی در بیوانفورماتیک) ؛ Springer: Cham, Switzerland, 2015; جلد 9351، ص 234–241. [ Google Scholar ]
- بدرینارایانان، وی. کندال، ا. Cipolla، R. SegNet: معماری رمزگذار-رمزگشای پیچیده پیچیده برای تقسیم بندی تصویر. IEEE Trans. الگوی مقعدی ماخ هوشمند 2017 ، 39 ، 2481-2495. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کریلوف، آ. او، ک. گیرشیک، آر. Dollár, P. یک معماری واحد برای نمونه و تقسیم بندی معنایی. در دسترس آنلاین: https://presentations.cocodataset.org/COCO17-Stuff-FAIR.pdf (دسترسی در 19 نوامبر 2019).
- چاوراسیا، ا. Culurciello، E. LinkNet: بهرهبرداری از نمایشهای رمزگذار برای تقسیمبندی معنایی کارآمد. در مجموعه مقالات IEEE Visual Communications and Image Processing 2017، VCIP 2017، سنت پترزبورگ، FL، ایالات متحده آمریکا، 10–13 دسامبر 2017؛ موسسه مهندسین برق و الکترونیک: Piscataway، NJ، ایالات متحده، 2018; صص 1-4. [ Google Scholar ]
- ژائو، اچ. شی، ج. Qi، X. وانگ، ایکس. شبکه تجزیه صحنه هرم جیا، جی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ IEEE: Piscataway، نیوجرسی، ایالات متحده آمریکا، 2017؛ صص 2881-2890. [ Google Scholar ]
- هوانگ، جی. لیو، ز. ون در ماتن، ال. Weinberger، KQ شبکه های کانولوشنال به هم پیوسته متراکم. در مجموعه مقالات سی امین کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، CVPR 2017، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ موسسه مهندسین برق و الکترونیک: Piscataway، NJ، ایالات متحده، 2017; صص 2261-2269. [ Google Scholar ]
- پیتاس، آی. کوتروپولوس، سی. یک رویکرد مبتنی بر بافت برای تقسیمبندی تصاویر لرزهای. تشخیص الگو 1992 ، 25 ، 929-945. [ Google Scholar ] [ CrossRef ]
- هگازی، تی. AlRegib، G. ویژگی های بافت برای تشخیص اجسام نمک در داده های لرزه ای. در مجموعه مقالات انجمن ژئوفیزیکدانان اکتشافی نمایشگاه بین المللی و هشتاد و چهارمین نشست سالانه SEG 2014، دنور، CO، ایالات متحده آمریکا، 26-31 اکتبر 2014. انجمن ژئوفیزیکدانان اکتشافی: تولسا، OK، ایالات متحده آمریکا، 2014; ص 405-408. [ Google Scholar ]
- شفیق، م. وانگ، ز. امین، ع. هگازی، تی. دریچه، م. AlRegib, G. تشخیص سطوح مرزی گنبد نمکی در حجمهای لرزهای مهاجرتشده با استفاده از گرادیان بافتها. در SEG Technical Program Expanded Abstracts ; انجمن ژئوفیزیکدانان اکتشافی: تولسا، OK، ایالات متحده آمریکا، 2015; جلد 34، ص 1811–1815. [ Google Scholar ]
- هالپرت، ا. Clapp، RG Salt Body Segmentation با ویژگی های شیب و فرکانس، پروژه اکتشاف استانفورد، گزارش SEP134. در دسترس آنلاین: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.483.6634&rep=rep1&type=pdf#page=119 (در 19 نوامبر 2019 قابل دسترسی است).
- شفیق، م. الشاوی، ت. لانگ، ز. Alregib، G. SalSi: یک ویژگی لرزه ای جدید برای تشخیص گنبد نمکی. در مجموعه مقالات ICASSP، کنفرانس بین المللی IEEE در مورد آکوستیک، پردازش گفتار و سیگنال – مجموعه مقالات، شانگهای، چین، 20 تا 25 مارس 2016. موسسه مهندسین برق و الکترونیک: Piscataway، NJ، ایالات متحده آمریکا، 2016; صفحات 1876-1880. [ Google Scholar ]
- عسجد، ع. Mohamed, D. یک رویکرد جدید برای تشخیص گنبد نمکی با استفاده از یک آشکارساز لبه چند جهته سه بعدی. Appl. ژئوفیز. 2015 ، 12 ، 334-342. [ Google Scholar ] [ CrossRef ]
- Wu, X. روشهایی برای محاسبه احتمال نمک و استخراج مرزهای نمک از تصاویر لرزهای سه بعدی. ژئوفیزیک 2016 ، 81 ، IM119–IM126. [ Google Scholar ] [ CrossRef ]
- دی، اچ. شفیق، م. AlRegib، G. چند ویژگی k- به معنی خوشه بندی برای ترسیم مرز نمک از داده های لرزه ای سه بعدی. ژئوفیز. J. Int. 2018 ، 215 ، 1999–2007. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ورونا، تی. پان، آی. Gawthorpe، RL; Fossen, H. تحلیل رخساره های لرزه ای با استفاده از یادگیری ماشین. ژئوفیزیک 2018 ، 83 ، O83–O95. [ Google Scholar ] [ CrossRef ]
- شوگراف، پی. Bittner, K. استخراج خودکار ردپای ساختمان از تصاویر سنجش از دور با وضوح چندگانه با استفاده از یک FCN ترکیبی. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 191. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لیو، اچ. لو، جی. هوانگ، بی. هو، ایکس. سان، ی. یانگ، ی. خو، ن. Zhou، N. DE-Net: شبکه رمزگذاری عمیق برای استخراج ساختمان از تصاویر سنجش از دور با وضوح بالا. Remote Sens. 2019 , 11 , 2380. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- علیدوست، ف. عارفی، ح. Tombari, F. مدل 2D Image-To-3D: بازسازی ساختمان سه بعدی مبتنی بر دانش (3DBR) با استفاده از تصاویر تک هوایی و شبکه های عصبی کانولوشنال (CNN). Remote Sens. 2019 , 11 , 2219. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وو، اس. دو، سی. چن، اچ. خو، ی. گوا، ن. Jing, N. استخراج جاده از تصاویر با وضوح بسیار بالا با استفاده از خط مرکزی OpenStreetMap با برچسب ضعیف. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 478. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Li, L. رمزگذار خودکار باقیمانده عمیق با مقیاس چندگانه برای تقسیم بندی معنایی تصاویر کاربری زمین. Remote Sens. 2019 , 11 , 2142. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- درامش، جی اس؛ Lüthje, M. رخساره های لرزه ای یادگیری عمیق در معماری های پیشرفته CNN. در مجموعه مقالات نمایشگاه بین المللی SEG 2018 و نشست سالانه، SEG 2018، آناهیم، کالیفرنیا، ایالات متحده آمریکا، 14 تا 19 اکتبر 2018؛ انجمن ژئوفیزیکدانان اکتشافی: تولسا، OK، ایالات متحده آمریکا، 2019؛ صفحات 2036–2040. [ Google Scholar ]
- دی، اچ. وانگ، ز. AlRegib، G. تفسیر تصویر لرزه ای در زمان واقعی از طریق شبکه عصبی دکانولوشن. در مجموعه مقالات نمایشگاه بین المللی SEG 2018 و نشست سالانه، SEG 2018، آناهیم، کالیفرنیا، ایالات متحده آمریکا، 14 تا 19 اکتبر 2018؛ انجمن ژئوفیزیکدانان اکتشافی: تولسا، OK، ایالات متحده آمریکا، 2019؛ صفحات 2051–2055. [ Google Scholar ]
- دی، اچ. وانگ، ز. AlRegib، G. شبکه های عصبی پیچیده عمیق برای ترسیم نمک لرزه ای بدن. در مجموعه مقالات کنوانسیون و نمایشگاه سالانه AAPG 2018، یوتا، یوتا، ایالات متحده آمریکا، 20 تا 23 مه 2018. [ Google Scholar ]
- Waldeland، AU; جنسن، AC؛ گلیوس، L.-J. سولبرگ، شبکه های عصبی کانولوشنال AHS برای تفسیر خودکار لرزه ای. رهبری. Edge 2018 , 37 , 529–537. [ Google Scholar ] [ CrossRef ]
- زنگ، ی. جیانگ، ک. چن، جی. تفسیر نمک لرزه ای خودکار با شبکه های عصبی کانولوشنال عمیق. در مجموعه مجموعه مقالات کنفرانس بین المللی ACM، کمبریج، انگلستان، 23 تا 26 مارس 2019؛ انجمن ماشینهای محاسباتی: نیویورک، نیویورک، ایالات متحده آمریکا، 2019؛ ص 16-20. [ Google Scholar ]
- شی، ی. وو، ایکس. Fomel, S. SaltSeg: تقسیم خودکار نمک سه بعدی با استفاده از یک شبکه عصبی پیچیده عمیق. تفسیر 2019 ، 7 ، SE113–SE122. [ Google Scholar ] [ CrossRef ]
- وو، ایکس. لیانگ، ال. شی، ی. Fomel, S. FaultSeg3D: استفاده از مجموعه داده های مصنوعی برای آموزش یک شبکه عصبی کانولوشنال سرتاسر برای تقسیم بندی گسل لرزه ای سه بعدی. ژئوفیزیک 2019 ، 84 ، IM35–IM45. [ Google Scholar ] [ CrossRef ]
- باباخین، ی. ساناکویو، ا. کیتامورا، اچ. تقسیم بندی نیمه نظارت شده اجسام نمک در تصاویر لرزه ای با استفاده از مجموعه ای از شبکه های عصبی کانولوشن. در تشخیص الگو ؛ Springer: Cham، سوئیس، 2019. [ Google Scholar ]
- زی، اس. گیرشیک، آر. دلار، پی. تو، ز. او، ک. سن دیگو، U. تبدیلهای باقیمانده جمعآوری شده برای شبکههای عصبی عمیق. در مجموعه مقالات کنفرانس IEEE در مورد دید رایانه و تشخیص الگو، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ IEEE: Piscataway، نیوجرسی، ایالات متحده آمریکا، 2017؛ صفحات 1492-1500. [ Google Scholar ]
- روی، AG; نواب، ن. Wachinger، C. “فشار و برانگیختگی” فضایی و کانالی همزمان در شبکه های کاملاً کانولوشن. در یادداشت های سخنرانی در علوم کامپیوتر (از جمله زیر مجموعه یادداشت های سخنرانی در هوش مصنوعی و یادداشت های سخنرانی در بیوانفورماتیک) ؛ Springer: Cham, Switzerland, 2018; جلد 11070 LNCS، ص 421–429. [ Google Scholar ]
- لی، اچ. Xiong، P. آن، جی. وانگ، L. شبکه توجه هرم برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس بینایی ماشین بریتانیا 2018، BMVC 2018، نیوکاسل، بریتانیا، 3 تا 6 سپتامبر 2018. [ Google Scholar ]
- Keras: کتابخانه یادگیری عمیق پایتون. در دسترس آنلاین: https://keras.io (در 16 اکتبر 2019 قابل دسترسی است).
- TensorFlow: یک پلتفرم یادگیری ماشین منبع باز سرتاسر. در دسترس آنلاین: https://www.tensorflow.org/ (در 16 اکتبر 2019 قابل دسترسی است).
- Kingma، DP; با، جی. آدام: روشی برای بهینه سازی تصادفی. در مجموعه مقالات سومین کنفرانس بینالمللی برای نمایشهای یادگیری، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 7 تا 9 مه 2015. [ Google Scholar ]
- Yakubovskiy, P. Segmentation Models, Github Library. در دسترس آنلاین: https://github.com/qubvel/segmentation_models (در 19 نوامبر 2019 قابل دسترسی است).
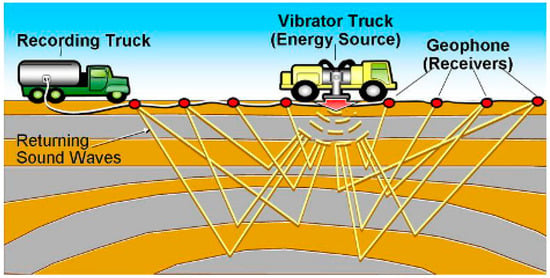
شکل 1. تصویری از فرآیند به دست آوردن تصاویر لرزه ای (منبع: www.petroman.co ).

شکل 2. تصویری از گنبد نمکی که نفت را به دام می اندازد (منبع: geology.com ).

شکل 3. نمونه ای از چندین تکه تصویر لرزه ای با ماسک رسوب نمک و اطلاعات عمق مربوطه.
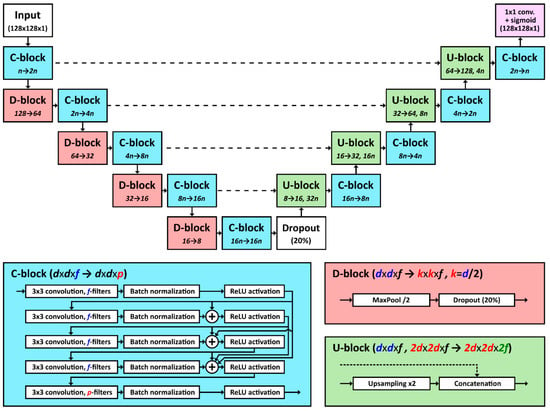
شکل 4. نمای کلی از معماری شبکه عصبی کانولوشنال پیشنهادی (CNN) برای تقسیم بندی معنایی رسوبات نمک. شبکه از سه نوع بلوک (C، D و U) تشکیل شده است که در زیر به تفصیل نشان داده شده است. خروجی نهایی با پیچیدگی 1×1 با 1 فیلتر و تابع فعال سازی سیگموئید به دست می آید. تعداد اولیه فیلترها با n نشان داده می شود .

شکل 5. نمودارهای متریک دقت نمونه ( a ) و تقاطع روی اتحادیه (IoU) ( b ) که مقادیر مجموعه های آموزشی و اعتبار سنجی را نشان می دهد. داده ها از آموزش مدل پنجم با 32 فیلتر اولیه گرفته شده است. فلش قرمز در ( a ) بهترین دوره دقت را هنگام ذخیره مدل نشان می دهد.

شکل 6. تصویری از چارچوب آزمایش بر اساس مدلهای تقسیمبندی Yakubovskiy [ 48 ] و ارتقاء تصویر ورودی. لطفا توجه داشته باشید که در مورد PSPNet، به دلیل محدودیت های شبکه، از اندازه ورودی 120*120 (به 240*240 ارتقا یافته) استفاده شده است.

شکل 7. نمونه ای از چندین تصویر لرزه ای ورودی با ماسک های مربوط به رسوب نمک (حقیقت زمین) به همراه ماسک های پیش بینی شده از همه مدل های درگیر در تحلیل های پس از مسابقه. نمونه ها برای نشان دادن موارد آسان و سخت انتخاب شده اند.
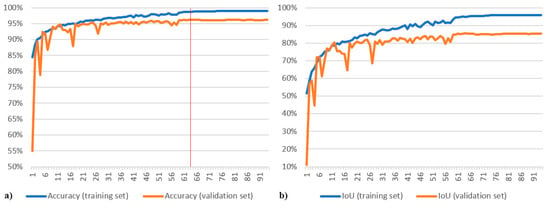
شکل 8. معیارهای دقت ( a ) و IoU ( b ) برای مدل اصلی بدون انصراف ( n = 32).

شکل 9. معیارهای دقت ( a ) و IoU ( b ) برای مدل U-Net ( n = 32).
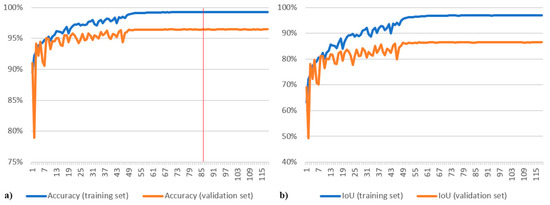
شکل 10. معیارهای دقت ( a ) و IoU ( b ) برای مدل شبکه هرمی ویژگی (FPN).

شکل 11. معیارهای دقت ( a ) و IoU ( b ) برای مدل LinkNet.

شکل 12. معیارهای دقت ( a ) و IoU ( b ) برای مدل PSPNet.


بدون دیدگاه