

کلید واژه ها:
قوانین ترافیکی ؛ مقررات ترافیکی ؛ جمع سپاری ; GPS-trace ; خط سیر ; طبقه بندی ; الگوهای حرکتی ؛ خوشه بندی ; رفتار جمعی ; شهر هوشمند
1. مقدمه
1.1. کار موجود
1.2. شکاف پژوهشی و مشارکت های مقاله
- 1.
-
این روش یک روش جدید تشخیص تنظیم کننده ترافیک را پیشنهاد و آزمایش می کند و آن را در تنظیمات مجموعه داده های مختلف، به عنوان مثال، شهرهای مختلف، تنظیم کننده ها، تراکم مسیر و اندازه مجموعه داده ها ( بخش 2.2.2 ) ارزیابی می کند.
- 2.
-
از آنجایی که بررسی ادبیات مشخص کرد که روشهای ترکیبی به نظر بهتر عمل میکنند، یک روش ترکیبی TRR پیشنهادی این فرضیه را آزمایش میکند (مدل ترکیبی: TRR از دادههای جمعسپاری (ویژگیهای پویا و استاتیک)).
- 3.
-
این اثر نرخ نمونه برداری GPS را در عملکرد طبقه بندی بررسی می کند (اثر نرخ نمونه برداری). این جنبه از مشکل از نرخ های مختلف نمونه برداری از مجموعه داده های مورد استفاده برای آزمایش روش، و همچنین از مشاهده اینکه کیفیت مسیرهای GPS ممکن است بر عملکرد طبقه بندی تأثیر بگذارد، برانگیخته شد.
- 4.
-
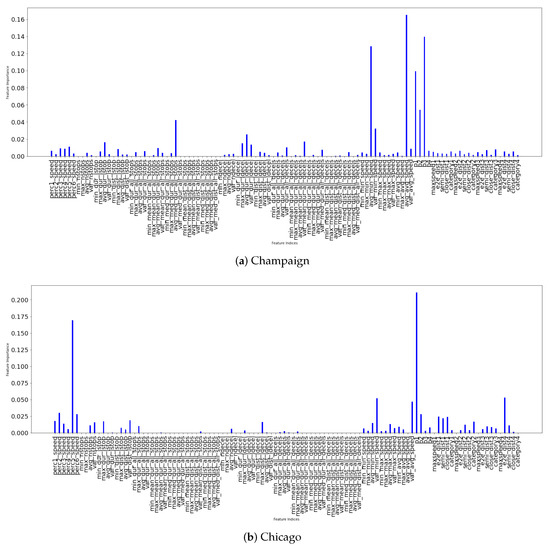
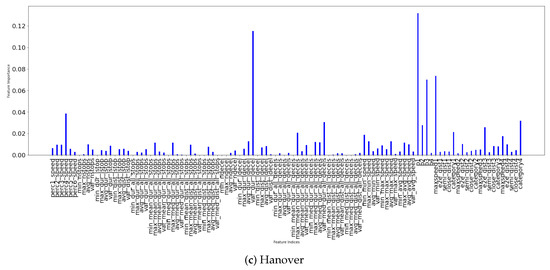
روش پیشنهادی تحت تنظیمات ویژگی های مختلف آزمایش می شود، به عنوان مثال، شامل اطلاعات از بازوهای زمینه و استفاده منحصراً از اطلاعات یک بازو ( بخش 2.2.3 ). تجزیه و تحلیل اهمیت ویژگی ها نیز برای تعیین ویژگی های کلیدی برای کار طبقه بندی انجام می شود.
- 5.
-
روش پیشنهادی اثر (در صورت وجود) مسیرهای چرخشی در عملکرد طبقهبندی را بررسی میکند (اثر مسیرهای چرخشی/بدون چرخش).
- 6.
-
روش پیشنهادی بررسی میکند که آیا تعداد معینی از مسیرها در هر بازوی تقاطع وجود دارد که منجر به عملکرد طبقهبندی بهینه میشود (اثر تعداد مسیرها).
- 7.
-
روش پیشنهادی یک بررسی سازگاری اضافی از برچسبهای پیشبینیشده در سطح تقاطع را پیشنهاد میکند و در صورت امکان، تنظیمکنندههای طبقهبندی اشتباه را اصلاح میکند ( بخش 2.3 ).
- 8.
-
این یک مجموعه داده مسیر جدید همراه با تنظیمکنندههای تقاطع حقیقت پایه که مسیرها از آن عبور میکنند در دسترس قرار میدهد، که میتواند به عنوان معیار روششناسی TRR مورد استفاده قرار گیرد.
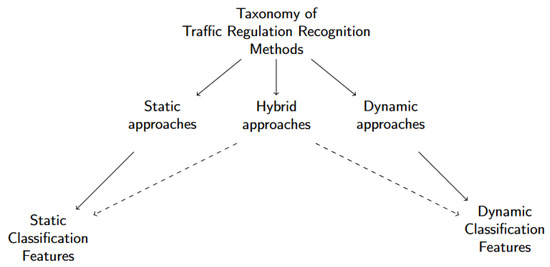
2. مواد و روشها
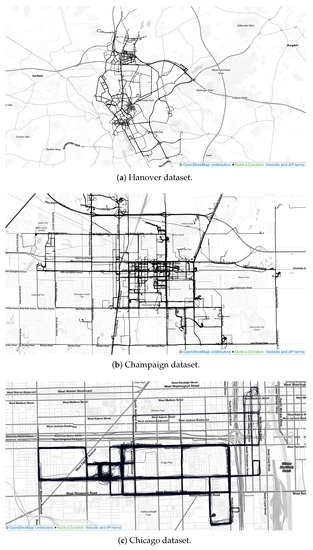
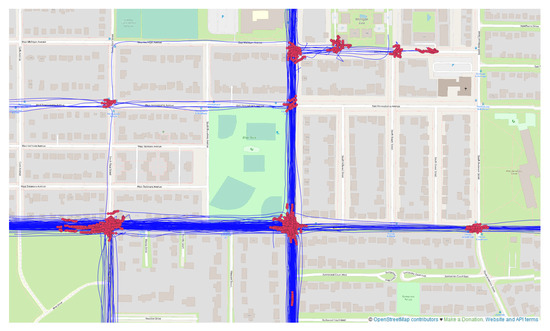
2.1. مجموعه داده ها
2.1.1. الزامات و محدودیت های مجموعه داده
2.1.2. مجموعه داده ها برای آزمایش روش پیشنهادی
2.2. روش شناسی
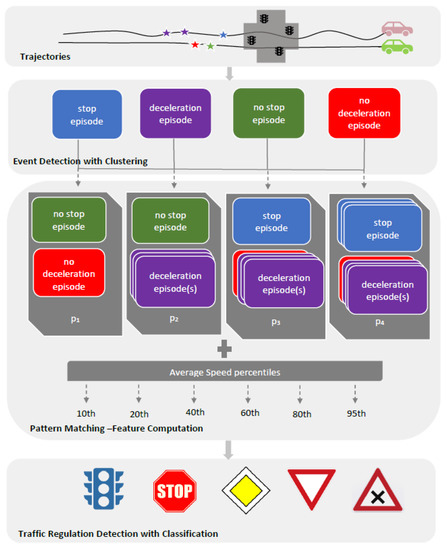
2.2.1. تشخیص رویداد توقف و کاهش سرعت مبتنی بر خوشه در مسیرها (الگوریتم CB-SDot)
2.2.2. یادگیری تنظیم کننده های ترافیک از داده های Crowdsourced
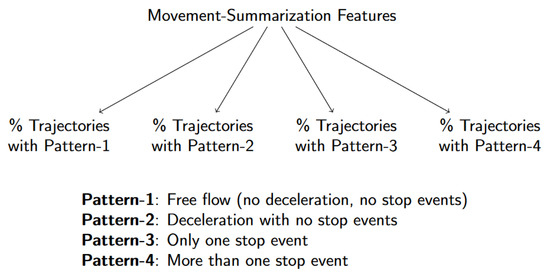
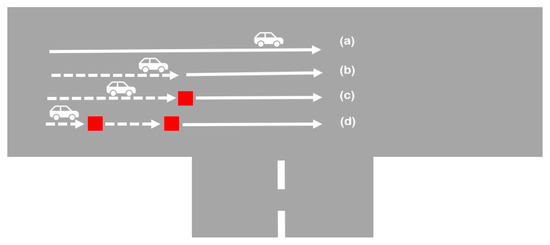
ج-مدل پویا: TRR از طریق خلاصهسازی رفتار حرکت جمعی
برای مثال، فرض کنید مسیرهای N از یک بازوی اتصال عبور کنند من_آrمتر. از مسیرهای N ، مسیرهای M از مسیر عبور می کنند من_آrمترداشتن سرعت ثابت ( پ1: جریان آزاد، یعنی بدون توقف، بدون رویدادهای کاهش سرعت) و ن-ممسیرها یک بار در محل اتصال متوقف می شوند و برای چند ثانیه صبر می کنند ( پ2: یک توقف قبل از عبور از تقاطع). سپس می توانیم آن را توصیف کنیم من_آrمتربا استفاده از نسبت مسیرهای زیر دو الگوی حرکت، پ1و پ2. تعریف کردن پ1به عنوان الگوی حرکت جریان آزاد و پ2به عنوان الگوی حرکت با توقف، سپس من_آrمتررا می توان از نظر کمی به عنوان مکانی توصیف کرد که در آن یک رفتار حرکت مختلط به طور جمعی مشاهده می شود و می توان آن را به صورت زیر خلاصه کرد:
-
پ1: حرکت آزاد (بدون مانع) هنگام عبور از تقاطع. در نتیجه، هیچ رویداد کاهش یا توقف مشاهده نمی شود.
-
پ2: خودرو بدون توقف سرعت خود را کاهش می دهد.
-
پ3: وسیله نقلیه فقط یک بار قبل از عبور از تقاطع توقف می کند. با این حال، ممکن است بیش از یک بار کند شود.
-
پ4: وسیله نقلیه بیش از یک بار قبل از عبور از تقاطع توقف می کند.

مدل دینامیک: TRR از مسیرهای GPS
مدل استاتیک: TRR از ویژگی های استخراج شده OSM
- 1.
-
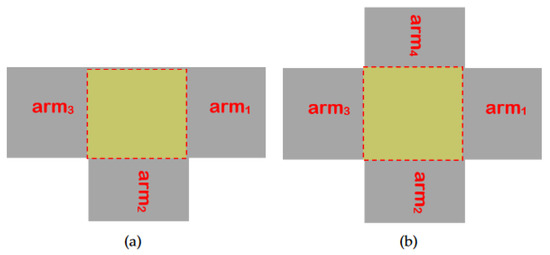
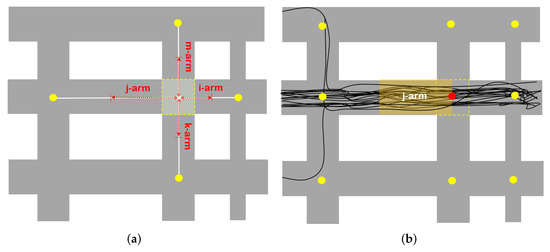
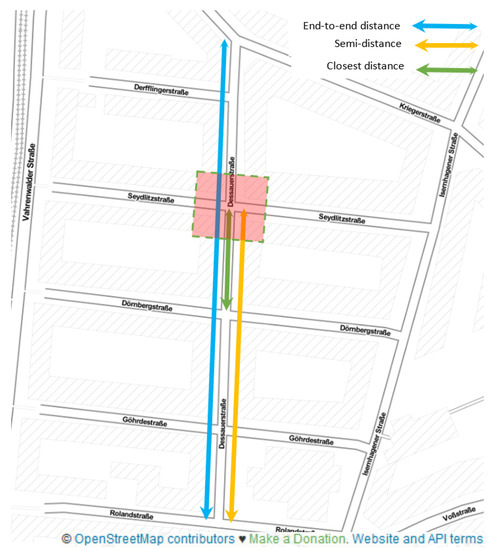
فاصله سرتاسر خیابانی که بازوی تقاطع به آن تعلق دارد (فلش آبی روشن در شکل 9 ). طول یک خیابان نشان دهنده اهمیت آن در شبکه خیابانی است. همین منطق در مورد سایر ویژگی های مبتنی بر فاصله نیز صدق می کند (2، 3).
- 2.
-
نیمه فاصله بازوی تقاطع فاصله از مرکز اتصال تا مرکز دورترین تقاطع است که بازوی تقاطع به آن متصل است (فلش زرد رنگ در شکل 9 ).
- 3.
-
نزدیکترین فاصله یک بازوی تقاطع فاصله از مرکز اتصالی است که بازو به آن تعلق دارد، تا مرکز نزدیکترین اتصالی که بازو به آن متصل است (فلش سبز در شکل 9 ).
- 4.
-
حداکثر سرعت یک تقاطع، حداکثر سرعت مجاز در طول آن است . تقاطع هایی که با علائم راهنمایی و رانندگی کنترل می شوند به طور کلی محدودیت سرعت بالاتری دارند (مثلاً 50 کیلومتر در ساعت) در مقایسه با تقاطع های کنترل شده با علائم ایست (مثلاً 30 کیلومتر در ساعت).
- 5.
-
دسته خیابان به دسته نوع خیابان بازوی تقاطع (به عنوان مثال، اولیه، ثانویه، سوم، مسکونی) اشاره دارد.
مدل ترکیبی: TRR از دادههای جمعسپاری (ویژگیهای پویا و استاتیک)
2.2.3. مدل های تک بازو در مقابل تمام بازوها
- 1.
-
تحت مدل هیبریدی تمام استاتیک ، تمام ویژگیهای استاتیک از تمام بازوهای تقاطع X در بردار ویژگی و همچنین ویژگیهای دینامیکی گنجانده شده است. من_آrمتر.
- 2.
-
در مدل هیبریدی تمام دینامیک ، تمام ویژگیهای دینامیکی از همه بازوهای X به همراه ویژگیهای استاتیک در نظر گرفته میشوند. من_آrمتر.
- 3.
-
در مدل ترکیبی ، تمام ویژگیهای ایستا و پویا از تمام بازوهای تقاطع X در بردار ویژگی گنجانده شده است.
2.2.4. تست عملکرد طبقه بندی تحت تنظیمات مسیرهای مختلف
تأثیر نرخ نمونه گیری
اثر مسیرهای چرخشی/بدون چرخش
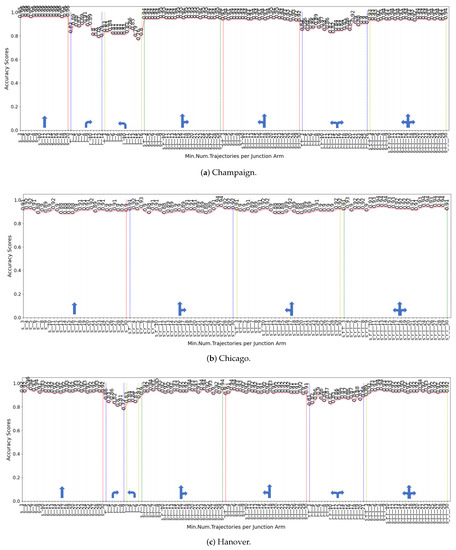
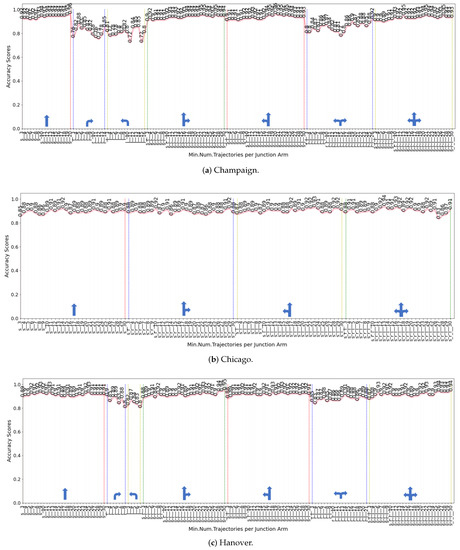
اثر تعداد مسیرها
2.3. قوانین دانش دامنه
2.4. تنظیمات طبقه بندی
3. نتایج
3.1. مدل های تک بازو در مقابل تمام بازوها
3.2. آزمایش اثر نرخ نمونه برداری
3.3. آزمایش اثر مدارهای چرخشی
3.4. آزمایش تأثیر تعداد مسیرها بر عملکرد طبقهبندی
3.5. استفاده از قوانین دانش دامنه
4. بحث
- 1.
-
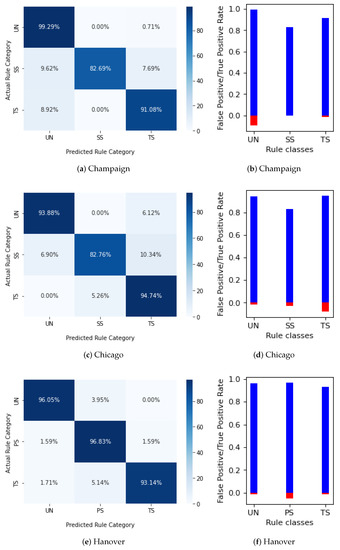
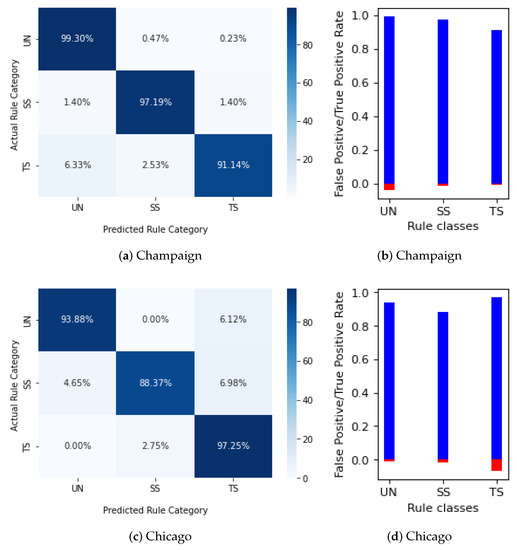
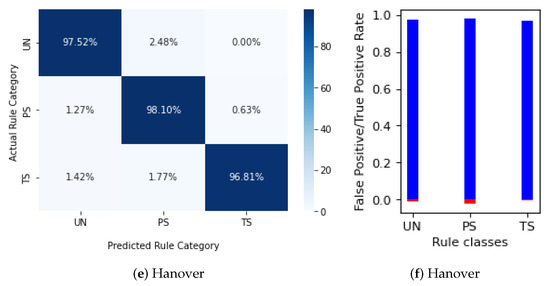
روش تشخیص قوانین ترافیک پیشنهاد شده در این مقاله، که دادههای مسیرها و OSM را ترکیب میکند، میتواند نتایج دقیقی را برای مجموعه قوانین متشکل از تقاطعهای کنترلشده UN، SS، PS و UN ارائه دهد: دقت 97% در Champaign و Hanover و 95% در مجموعه داده های کوچکتر شیکاگو.
- 2.
-
گنجاندن اطلاعات در بردار ویژگی از بازوهای تقاطع زمینه برای طبقهبندی مفید بود: مدلهای همهبازویی بهتر از مدلهای تک بازویی عمل کردند.
- 3.
-
نرخ نمونه برداری می تواند بر عملکرد طبقه بندی تأثیر بگذارد. مقدار کم هم بر مقادیر سرعت محاسبه شده از ردیابی GPS و هم بر قسمت های توقف و کاهش سرعت شناسایی شده تأثیر می گذارد. دقت مدل ترکیبی تمام استاتیک بین 1٪ و 2٪ کاهش یافت که فاصله نمونه برداری از 2 ثانیه به 4 ثانیه دو برابر شد.
- 4.
-
اثر منفی بر دقت، همانطور که توسط دو مجموعه داده بزرگتر تایید شده است، زمانی که از هر دو مسیر مستقیم و منحنی استفاده می شود، بین 1٪ و 3٪ بود. بنابراین، حذف مسیرهای منحنی تأثیر مثبتی بر عملکرد طبقهبندی دارد.
- 5.
-
تعداد بهینه مسیرهای مستقیم پنج است.
- 6.
-
حذف تعداد آهنگ ها به تعداد معینی بر عملکرد طبقه بندی تأثیر منفی می گذارد. با این حال، با تنها سه مسیر مستقیم در هر بازوی اتصال، دقت طبقهبندی در تمام مجموعههای داده برابر یا بیشتر از 85٪ است (85٪ در شیکاگو، 89٪ در هانوفر، و 92٪ در Champaign). تنها با پنج مسیر مستقیم، دقت برابر یا بیشتر از 90٪ است (90٪ در شیکاگو و 92٪ در Champaign و Hanover).
- 7.
-
با اعمال قوانین دانش دامنه، افزایش دقت بین 1% تا 3% وجود دارد، اما مهمتر از آن، پیشبینیهای دقیقی برای سلاحهای بدون داده میتوان انجام داد که مربوط به 27 تا 50% دادههای اصلی است. علاوه بر این، FPR کلاس با بالاترین FPR بین 15.6٪ تا 60٪ کاهش می یابد، بنابراین پیشنهاد ما برای استفاده از قوانین دانش دامنه هم برای بازیابی بازوهای طبقه بندی اشتباه و هم برای پیش بینی تنظیم کننده ها از بازوهای بدون داده، تأیید می شود.
5. نتیجه گیری ها
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| TRR | تشخیص مقررات ترافیکی |
| OSM | نقشه خیابان باز |
| جی پی اس | سیستم موقعیت یاب جهانی |
| SC | جمع سپاری فضایی |
| CC | جمع سپاری |
| DLSTM | حافظه کوتاه مدت توزیع شده |
| ROC | ویژگی عملکرد گیرنده |
| AUC | ناحیه زیر منحنی ROC |
| CVAE | رمزگذار خودکار متغیر مشروط |
| TRR | تشخیص تنظیم کننده ترافیک |
| TS | علائم راهنمایی و رانندگی |
| اس اس | نشانه توقف، ایست |
| PS | علامت اولویت |
| YS | علامت بازده |
| RF | جنگل تصادفی |
| گیگابایت | افزایش گرادیان |
| FPR | نرخ مثبت کاذب |
| TPR | نرخ مثبت واقعی |
پیوست اول


منابع
- Goodchild، M. شهروندان به عنوان حسگرها: دنیای جغرافیای داوطلبانه. ژئوژورنال 2007 ، 69 ، 211-221. [ Google Scholar ] [ CrossRef ]
- گممیدی، SRB; Xie، X. Pedersen, TB A Survey of Spatial Crowdsourcing. ACM Trans. سیستم پایگاه داده 2019 ، 44 ، 8. [ Google Scholar ] [ CrossRef ]
- هیپک، سی. دادههای جغرافیایی جمعسپاری. ISPRS J. Photogramm. Remote Sens. 2010 , 65 , 550-557. [ Google Scholar ] [ CrossRef ]
- تانگ، جی. دنگ، م. هوانگ، جی. لیو، اچ. Chen, X. یک روش خودکار برای تشخیص و به روز رسانی تغییرات افزودنی در شبکه جاده با داده های مسیر GPS. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 411. [ Google Scholar ] [ CrossRef ]
- شان، ز. وو، اچ. سان، دبلیو. ژنگ، بی. COBWEB: یک سیستم به روز رسانی نقشه قوی با استفاده از مسیرهای GPS. در مجموعه مقالات کنفرانس مشترک بین المللی ACM در سال 2015 در محاسبات فراگیر و همه جا ؛ UbiComp’15; انجمن ماشینهای محاسباتی: نیویورک، نیویورک، ایالات متحده آمریکا، 2015. ص 927-937. [ Google Scholar ] [ CrossRef ]
- فاکس، ا. کومار، BV; چن، جی. Bai, F. تشخیص چاله چند لاین از دادههای حسگر خودروی نمونهبرداری نشده جمعآوریشده. IEEE Trans. اوباش محاسبه کنید. 2017 ، 16 ، 3417-3430. [ Google Scholar ] [ CrossRef ]
- دستمزد، او. Sester، M. برآورد مشترک ناهمواری جاده از اندازهگیریهای شتاب دوچرخه با منبع جمعیت. ISPRS Ann. فتوگرام از راه دور. حس اسپات. Inf. علمی 2021 ، V-4-2021 ، 89-96. [ Google Scholar ] [ CrossRef ]
- ویج، دی. Aggarwal، N. تشخیص وضعیت ترافیک مبتنی بر تلفن هوشمند با استفاده از تجزیه و تحلیل صوتی و جمع سپاری. Appl. آکوست. 2018 ، 138 ، 80-91. [ Google Scholar ] [ CrossRef ]
- مینسون، SE; بروکس، کارشناسی; گلنی، CL; موری، جی آر؛ Langbein، JO; اوون، SE; هیتون، TH; ایانوچی، RA; هشدار اولیه زلزله Hauser, DL Crowdsourced. علمی Adv. 2015 ، 1 ، 36. [ Google Scholar ] [ CrossRef ]
- سالپیترو، آر. بدوگنی، ال. دی فلیس، م. بونونی، ال. پارک اینجا! یک سیستم پارک هوشمند مبتنی بر حسگرهای تعبیهشده در گوشیهای هوشمند و فناوریهای ارتباطی کوتاه برد. در مجموعه مقالات دومین انجمن جهانی اینترنت اشیا (WF-IoT) IEEE 2015، میلان، ایتالیا، 14 تا 16 دسامبر 2015؛ ص 18-23. [ Google Scholar ]
- ژو، ایکس. Zhang, L. توابع جمع سپاری شهر زنده از داده های توییتر و Foursquare. کارتوگر. Geogr. Inf. علمی 2016 ، 43 ، 393-404. [ Google Scholar ] [ CrossRef ]
- گائو، آر. سان، اف. زینگ، دبلیو. تائو، دی. نیش، جی. Chai, H. CTTE: تخمین زمان سفر سفارشی از طریق Crowdsensing موبایل. IEEE Trans. هوشمند ترانسپ سیستم 2022 ، 23 ، 19335-19347. [ Google Scholar ] [ CrossRef ]
- لوفور، اس. لوژیر، سی. ایبانز-گوزمن، جی. Bessiere, P. مدلسازی صحنههای پویا در تقاطعهای جادهای بدون علامت. Inria Res. Rep. 2011 , RR-7604 . [ Google Scholar ]
- لفور، اس. لاژیر، سی. Ibanez-Guzmán، J. ارزیابی ریسک در تقاطع های جاده ای: مقایسه قصد و انتظار. در مجموعه مقالات سمپوزیوم وسایل نقلیه هوشمند (IV)، 2012 IEEE، مادرید، اسپانیا، 3 تا 7 ژوئن 2012. صص 165-171. [ Google Scholar ] [ CrossRef ]
- الشائب، س. استوانوویچ، آ. Effinger، JR بررسی اثرات شرایط عملیاتی مختلف بر مصرف سوخت و جریمه توقف در تقاطعهای علامتدار. بین المللی J. Transp. علمی تکنولوژی 2021 ، 11 ، 690-710. [ Google Scholar ] [ CrossRef ]
- گستالدی، م. منگوزر، سی. روسی، آر. لوسیا، LD; Gecchele، G. ارزیابی اثرات آلودگی هوا یک کنترل سیگنال به تبدیل گردشی با استفاده از میکرو شبیهسازی. ترانسپ Res. Procedia 2014 ، 3 ، 1031-1040. [ Google Scholar ] [ CrossRef ]
- مشارکت کنندگان OpenStreetMap. 2020. در دسترس آنلاین: https://www.openstreetmap.org (در 17 اوت 2020 قابل دسترسی است).
- Mapscape. به روز رسانی افزایشی در دسترس آنلاین: https://www.mapscape.eu/telematics/incremental-updating.html (در 14 اوت 2019 قابل دسترسی است).
- زورلیدو، س. Sester, M. Traffic Regulator Detection and Identification from Crowdsourced Data-A Systematic Literature Review. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 491. [ Google Scholar ] [ CrossRef ]
- هوانگ، اس. لین، اچ. چانگ، سی. یک سیستم دوربین داخل خودرو برای تشخیص و تشخیص علائم راهنمایی و رانندگی. در مجموعه مقالات 2017 هفدهمین کنگره جهانی مشترک انجمن بین المللی سیستم های فازی و نهمین کنفرانس بین المللی محاسبات نرم و سیستم های هوشمند (IFSA-SCIS)، اوتسو، ژاپن، 27 تا 30 ژوئن 2017؛ صص 1-6. [ Google Scholar ]
- آردیانتو، اس. چن، سی. Hang, H. تشخیص علائم ترافیکی در زمان واقعی با استفاده از تقسیم بندی رنگ و SVM. در مجموعه مقالات کنفرانس بین المللی 2017 سیستم ها، سیگنال ها و پردازش تصویر (IWSSIP)، پوزنان، لهستان، 22 تا 24 مه 2017؛ صص 1-5. [ Google Scholar ]
- کوسونن، م. هنتونن، کی. جمعیت را تشویق کنید؟ تسهیل مشارکت کاربران در جمع سپاری ایده. بین المللی جی. تکنول. علامت. 2015 ، 10 ، 95-110. [ Google Scholar ] [ CrossRef ]
- بلالی، وی. گلپرور فرد، م. ارزیابی روشهای تشخیص و طبقهبندی علائم ترافیکی چند طبقه برای مدیریت فهرست داراییهای جادهای ایالات متحده. جی. کامپیوتر. مدنی مهندس 2016 , 30 , 04015022. [ Google Scholar ] [ CrossRef ]
- هو، اس. سو، ال. لیو، اچ. وانگ، اچ. عبدالظاهر، TF SmartRoad: سنجش جمعیت مبتنی بر گوشی هوشمند برای تشخیص و شناسایی تنظیم کننده ترافیک. ACM Trans. سناتور Netw. 2015 ، 11 ، 55:1-55:27. [ Google Scholar ] [ CrossRef ]
- مری، ک. Bettinger، P. مطالعه دقت GPS گوشی هوشمند در یک محیط شهری. PLoS ONE 2019 , 14 , e219890. [ Google Scholar ] [ CrossRef ]
- صارمی، ف. عبدالظاهر، TF ترکیب استنتاج مبتنی بر نقشه و سنجش جمعیت برای تشخیص تنظیم کننده های ترافیک. در مجموعه مقالات دوازدهمین کنفرانس بین المللی IEEE 2015 در مورد سیستم های حسگر و Ad Hoc موبایل، دالاس، TX، ایالات متحده، 19 تا 22 اکتبر 2015؛ صص 145-153. [ Google Scholar ]
- گلزه، ج. زورلیدو، س. Sester، M. تشخیص تنظیم کننده ترافیک با استفاده از مسیرهای GPS. جی. کارتوگر. Geogr. Inf. 2020 ، 70 ، 95-105. [ Google Scholar ] [ CrossRef ]
- منروکس، ی. گیلچر، آ. سنت پیر، جی. حامد، م. موستیره، اس. Orfila, O. تشخیص سیگنال ترافیک از پروفایل های سرعت GPS داخل خودرو با استفاده از تجزیه و تحلیل داده های عملکردی و یادگیری ماشین. بین المللی J. Data Sci. مقعدی 2020 ، 10 ، 101-119. [ Google Scholar ] [ CrossRef ]
- چنگ، اچ. زورلیدو، س. Sester, M. Traffic Control Recognition with Speed-Profiles: A Deep Learning Approach. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 652. [ Google Scholar ] [ CrossRef ]
- لیائو، ز. شیائو، اچ. لیو، اس. لیو، ی. یی، الف. ارزیابی تاثیر چراغ های راهنمایی از طریق مسیرهای وسیله نقلیه GPS. ISPRS Int. J. Geo-Inf. 2021 ، 10 ، 769. [ Google Scholar ] [ CrossRef ]
- زورلیدو، س. گلزه، ج. Sester, M. [Dataset] مجموعه داده مسیر GPS منطقه هانوفر، آلمان ; Institut für Kartographie und Geoinformatik: هانوفر، آلمان، 2022. [ Google Scholar ] [ CrossRef ]
- زورلیدو، س. گلزه، ج. Sester, M. [Dataset] Traffic Regulator Ground-truth Information of the City of Hannover, Germany ; Institut für Kartographie und Geoinformatik: هانوفر، آلمان، 2022. [ Google Scholar ] [ CrossRef ]
- احمد، م. کاراگیورگو، اس. Pfoser، D.; Wenk, C. مقایسه و ارزیابی الگوریتمهای ساخت نقشه با استفاده از دادههای ردیابی خودرو. GeoInformatica 2015 ، 19 ، 601-632. [ Google Scholar ] [ CrossRef ]
- زورلیدو، س. گلزه، ج. Sester, M. [Dataset] Traffic Regulator Ground-Truth Information for Chicago Trajectory Dataset ; Institut für Kartographie und Geoinformatik: هانوفر، آلمان، 2022. [ Google Scholar ] [ CrossRef ]
- داده های طبیعی LM ; انتشارات SAGE: Thousand Oaks, CA, USA, 2008; پ. 547. [ Google Scholar ] [ CrossRef ]
- نقشه کشی. Mapillary: یک پلت فرم تصویربرداری در سطح خیابان. 2022. در دسترس آنلاین: https://www.mapillary.com/ (دسترسی در 20 آوریل 2022).
- پالما، AT; بوگورنی، وی. کویجپرز، بی. Alvares, LO رویکردی مبتنی بر خوشه برای کشف مکانهای جالب در مسیرها. در مجموعه مقالات سمپوزیوم ACM در سال 2008 در محاسبات کاربردی . SAC’08; ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2008; صص 863-868. [ Google Scholar ] [ CrossRef ]
- کومیتو، سی. فالکون، دی. تالیا، دی. استخراج الگوهای تحرک انسانی از داده های برچسب گذاری شده جغرافیایی اجتماعی. اوباش فراگیر. محاسبه کنید. 2016 ، 33 ، 91-107. [ Google Scholar ] [ CrossRef ]
- نیو، ایکس. وانگ، اس. Wu، CQ; لی، ی. وو، پی. ژو، جی. روی یک رویکرد کاوی مبتنی بر خوشهبندی با معناشناسی برچسبگذاری شده برای کشف مکان مهم. Inf. علمی 2021 ، 578 ، 37-63. [ Google Scholar ] [ CrossRef ]
- اسپاکاپیترا، اس. پدر و مادر، سی. دامیانی، ام.ال. de Macedo، JA; پورتو، اف. وانگنوت، سی. دیدگاه مفهومی در مسیرها. دانستن داده ها مهندس 2008 ، 65 ، 126-146. [ Google Scholar ] [ CrossRef ]
- کانگ، جی اچ. ولبورن، دبلیو. استوارت، بی. Borriello, G. استخراج مکان ها از ردیابی مکان ها. در مجموعه مقالات دومین کارگاه بین المللی ACM در مورد برنامه ها و خدمات تلفن همراه بی سیم در نقاط اتصال WLAN. WMASH’04. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2004; صص 110-118. [ Google Scholar ] [ CrossRef ]
- فوئرهاک، یو. کونتزش، سی. Sester, M. یافتن مکان های جالب و الگوهای مشخصه در مسیرهای مکانی-زمانی. در مجموعه مقالات هشتمین سمپوزیوم بین المللی خدمات مکان محور ; Forschungsgruppe Kartographie: وین، اتریش، 2011. [ Google Scholar ]
- وو، تی. شن، اچ. کوین، جی. Xiang، L. استخراج توقف ها از مسیرهای مکانی-زمانی در ویژگی های متنی پویا. پایداری 2021 ، 13 ، 690. [ Google Scholar ] [ CrossRef ]
- استر، ام. کریگل، اچ پی؛ ساندر، جی. Xu, X. الگوریتم مبتنی بر چگالی برای کشف خوشهها در پایگاههای داده فضایی بزرگ با نویز. در مجموعه مقالات دومین کنفرانس بین المللی کشف دانش و داده کاوی (KDD ’96)، پورتلند، اورگان، 2 تا 4 اوت 1996. صص 226-231. [ Google Scholar ]
- تانگ، ال. کان، ز. ژانگ، ایکس. یانگ، ایکس. هوانگ، اف. لی، کیو. تخمین زمان سفر در تقاطع ها بر اساس داده های بزرگ مسیر GPS مکانی-زمانی فرکانس پایین. کارتوگر. Geogr. Inf. علمی 2016 ، 43 ، 417-426. [ Google Scholar ] [ CrossRef ]
- کاریسی، ر. جووردانو، ای. پائو، جی. Gerla، M. افزایش در نقشه های دیجیتال خودرو از طریق جمع سپاری GPS. در مجموعه مقالات هشتمین کنفرانس بینالمللی 2011 در مورد سیستمها و خدمات شبکه بیسیم بر اساس تقاضا، باردونکیا، ایتالیا، 26-28 ژانویه 2011. ص 27-34. [ Google Scholar ] [ CrossRef ]
- پایتون XGBoost. کتابخانه پایتون XGBoost. 2022. در دسترس آنلاین: https://xgboost.readthedocs.io/en/stable/python/index.html (در 15 فوریه 2022 قابل دسترسی است).
- کریسپ، جی.ام. کلر، A. مسیرهای محاسباتی ناوبری اتومبیل که از عبور و مرور پیچیده جلوگیری می کنند. بین المللی جی. جئوگر. Inf. علمی 2015 ، 29 ، 1988-2000. [ Google Scholar ] [ CrossRef ]


بدون دیدگاه