

خلاصه
کلید واژه ها:
پهپاد-LS ابرهای نقطه ای ; یادگیری معنایی نقطهای ; بهینه سازی نمودار ; تقسیم بندی درخت ; درختان کنار جاده ; یادگیری تعبیه گراف
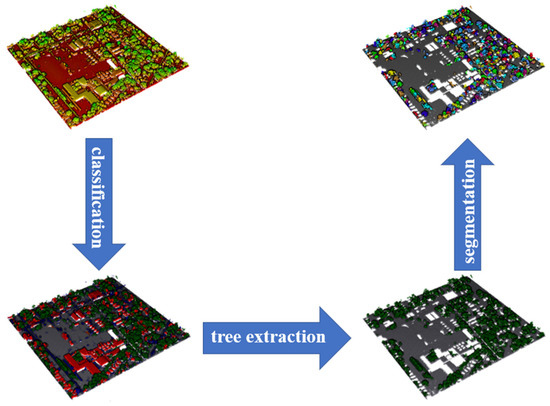
1. معرفی
2. مواد و روشها
2.1. حذف زمین توسط فیلتر تراکم تراکم TIN پیشرفته
2.2. تشخیص سازه های درخت مانند از طریق طبقه بندی نقطه ای در نقاط غیر زمینی
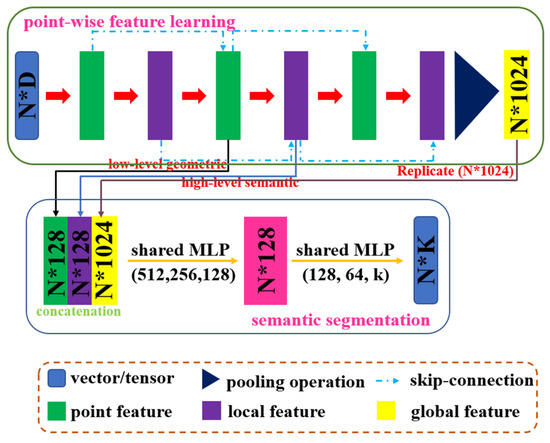
2.2.1. زیر ماژول استخراج ویژگی نقطه
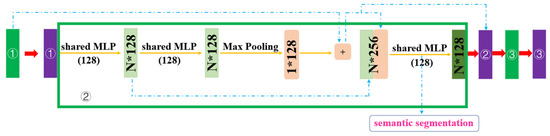
2.2.2. زیر ماژول استخراج ویژگی های محلی
ویژگی های نقاط متعلق به یک دسته معنایی مشابه هستند، هدف این ماژول کاهش فاصله ویژگی بین نقاط مشابه و افزایش تمایز ابر نقاط مختلف است. خروجی ماژول فوق الف را تشکیل می دهد ن×128تانسور با اطلاعات سطح پایین برای به دست آوردن قدرت بیان کافی برای تبدیل هر ویژگی نقطه به یک ویژگی با ابعاد بالاتر، یک لایه کاملاً متصل به ماژول KNN اضافه می شود. ابتدا نقاط اصلی را تغییر می دهیم پبه یک حالت متعارف توسط یک STN (شبکه ترانسفورماتور فضایی) [ 51 ]، و سپس K نزدیکترین همسایه ها را در نقاط غیرمتغیر فضایی جستجو کنید.پ˜برای هر نقطه پرس و جو پ˜n. مجموعه نقطه به نقطه جستجوی KNN به صورت زیر تعریف می شود:
جایی که پ˜n، کنزدیکترین همسایه k- امین نقطه پرس و جو را نشان می دهدپ˜n.
2.2.3. ماژول تقسیم بندی معنایی و تابع ضرر
برای به حداقل رساندن خطاهای مدل در طول آموزش، تابع ضرر ℒشبکه ما شامل از دست دادن بخش بندی معنایی است ℒسهمترو از دست دادن کنتراست ℒپآمنr:
جایی که ℒسهمتربا تابع افت آنتروپی متقاطع softmax کلاسیک و خارج از قفسه تعریف شده است که به صورت زیر فرموله شده است:
جایی که gمننشان دهنده یک برچسب داغ نمونه آموزشی i- امین است، N نشان دهنده اندازه دسته و همن/∑jهjبردار امتیاز پیش بینی softmax است.
در مورد از دست دادن متضاد، با یک تابع تمایز بر اساس این فرض که ویژگی های نقاط متعلق به یک دسته معنایی مشابه هستند بیان می شود. فاصله ویژگی و برچسب نقطه معیارهایی برای اندازه گیری عدم تشابه بین دو نقطه هستند. بنابراین، در فرآیند آموزش، شبکه پیشنهادی تفاوت شباهت ویژگی بین نقاط یک برچسب را به حداقل میرساند و تفاوت ویژگی بین دو نقطه متعلق به برچسبهای شی مختلف در فضای ویژگی را گسترش میدهد. به طور خاص، تابع ضرر کنتراست به صورت زیر تعریف می شود:
که در آن d نشان دهنده فاصله اقلیدسی ویژگی دو نقطه است، N تعداد نقاط است، و حاشیه یک آستانه از پیش تعیین شده است، که یک متریک برای اندازه گیری تمایز بین دو نقطه است. y یک تابع باینری است که نشان می دهد آیا دو نقطه به یک دسته تعلق دارند یا خیر. اگر دو نقطه به یک شی تعلق داشته باشند y برابر است با 1:
در این حالت، اگر فاصله ویژگی بین دو نقطه کم باشد، مدل مناسبتر و از دست دادن است ℒپآمنrکوچکتر است. اگر دو نقطه به یک دسته تعلق ندارند، y = 0:
اگر فاصله ویژگی بین دو نقطه بیشتر از مترآrgمنn، به این معنی است که دو نقطه بر یکدیگر تأثیر نمی گذارد و ضرر ℒپآمنr0 است. اگر فاصله ویژگی دو نقطه کمتر از مترآrgمنn، یعنی ضرر ℒپآمنrبا کاهش فاصله ویژگی افزایش می یابد، پس مدل فعلی مناسب نیست و نیاز به آموزش مجدد دارد.
2.3. بهینه سازی ساختار یافته نمودار برای پالایش طبقه بندی
اولین مرحله ساخت نمودار برای ساختار تابع هدف است، مدل گرافیکی توسط گراف مجاورت غیر جهت دار ساخته می شود. جی={V،E}، جایی که V={vمن}نشان دهنده گره ها و مجموعه ای از لبه ها است E={همنj}رابطه فضایی نقاط مجاور با وزن های w را رمزگذاری می کند . در نمودار G ، برای یک راس مرکزی v ، ده همسایه KNN آن را با توجه به حداقل تعداد یال ها از راس دیگر تعریف می کنیم. vمنبه v _ با توجه به وزن های لبه w∈[0، 1]فاصله مکانی، تفاوت زوایای بردار نرمال و شباهت برای تخمین وزن ها اتخاذ شده است. علاوه بر این، اجازه دهید پ={پ1،…،پن}مجموعه ای از نقاط را نشان دهید، اجازه دهید سی={ج1،…،جمتر}مجموعه ای از برچسب ها (در این مقاله، m با تعداد برچسب ها در مجموعه داده تعیین می شود)، اجازه دهید Ψ={Ψ|من=1،…،ن}مجموعه ای از متغیرهای ویژگی نقاط را نشان می دهد و اجازه دهید L={ل=(ل1،…،لن)|لمن∈سی، من=1،…،ن}تمام تنظیمات برچسب ممکن را نشان می دهد [ 53 ]. برای دستیابی به بهینه سازی جهانی با استفاده از نمودار ساخته شده، پیکربندی برچسب بهینه را به عنوان یک مسئله کمینه سازی تابع انرژی رسمی می کنیم و با معادله زیر تعریف می شود:
که در آن عبارت بالقوه واحد Eدآتیآ(L)به طور کمی اختلاف بین پیکربندی برچسب ممکن L و داده های مشاهده شده را اندازه گیری می کند، در حالی که عبارت پتانسیل صاف Eسمترooتیساعتصافی و سازگاری بین پیش بینی ها را حفظ می کند و λیک ضریب وزنی است که برای متعادل کردن تأثیر بین پتانسیل یکنواخت و صافی محلی استفاده می شود.
با این پیکربندی، فرآیند منظمسازی تقسیمبندی معنایی اولیه برای اطمینان از برچسبها به صورت محلی پیوسته و بهینه جهانی انجام میشود. در چارچوب پیشنهادی، این دو اصطلاح در توابع انرژی فوق، تعاریف متفاوتی دارند. در نتیجه، شکل پتانسیل واحد Eدآتیآ(L)به طور معمول است:
جایی که ϕمن(لمن)میزان خوب برچسب زدن را اندازه می گیرد لمنمتناسب با متغیرهای ویژگی Ψمنداده های مشاهده شده داده شده و تأثیر برچسب ها را اعمال می کند. در مورد منطقه شهری، اشیاء یکسان دارای ویژگی های مشابه هستند، در حالی که اشیاء مختلف دارای ویژگی های متمایز هستند. عبارت ϕمن(لمن)=-ورود به سیستمپ(لمن)از احتمال پیش بینی شده به دست می آید پ(لمن)خروجی از طبقه بندی نقطه ای هر چه احتمال رده پسین بالاتر باشد، پتانسیل یکنواخت کوچکتر است.
عبارت دوم در معادله (7) اثر “نمک و فلفل” را سرکوب می کند و جریمه اختصاص دادن برچسب به چند نقطه سه بعدی را نشان می دهد و بنابراین با قضاوت می شود. Eسمترooتیساعت(L)=∑{من، j}∈Eψمن،j(لمن،لj)=∑{من، j}∈Eμ(لمن،لj)∑پ=1پωپک(fمن،fj)[ 54 ]. به طور خاص، μ(لمن،لj)=1اگر لمن≠لjیا 0 در غیر این صورت، کنشان دهنده هسته گاوسی با تکیه بر ویژگی های استخراج شده f است که توسط مقادیر XYZ و شدت نقاط i و j تعیین می شود ، و ωپضرایب ثابت را نشان می دهد. دو هسته گاوسی [ 55 ، 56 ] به شرح زیر انتخاب می شوند:
جایی که، ωبوزن هسته دو طرفه است، ωسوزن هسته فضایی است، θα، θβو θγسه فراپارامتر از پیش تعریف شده هستند.
در حالی که ضریب منظم شدن λبه شرح زیر برآورد می شود:
جایی که دمنjفاصله بین نقاط i و j و است δانتظار همه فواصل همسایه است.
بر این اساس، پیش بینی برچسب بهینه L*راه حل تابع انرژی کمینه سازی با ساختار زیر است:
اگرچه کمینه سازی دقیق غیرقابل حل است، مشکل کمینه سازی به راحتی و به طور مناسب توسط یک الگوریتم برش نمودار با استفاده از α-گسترش [ 57 ، 58 ]. با چند تکرار برش نمودار، می توانیم به طور موثر و سریع یک راه حل تقریبی برای بهینه سازی انرژی های چند برچسبی پیدا کنیم. هزینه برچسبگذاری در نظر گرفته نمیشود زیرا بهینهسازی مبتنی بر نمودار میتواند به طور موثری از پیشبینی و اطمینان و همچنین تخصیص برچسب معنایی بین دو نقطه مشابه در هر منطقه استفاده کند. نتایج بهینهسازی شده میتواند بهطور خودکار با صحنههای شهری زیربنایی بدون ویژگیهای از پیش تعریفشده برای برخی از اشیاء نامشخص سازگار شود.
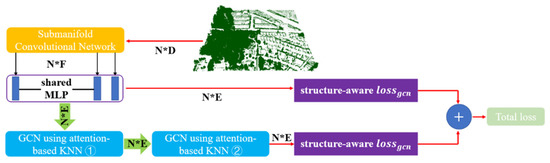
2.4. تقسیم بندی درختان کنار جاده با یادگیری متریک عمیق
به طور خاص، ما مستقیماً از معماری شبکه کانولوشنال زیرمنیفولد (SCN) به عنوان اولین مؤلفه خود با وام گرفتن از [ 63 ] استفاده می کنیم.]. در آزمایش خود، از دو شبکه ستون فقرات، شامل معماری UNet مانند (با ظرفیت کمتر و سرعت بیشتر) و معماری ResNet مانند (با ظرفیت بیشتر و سرعت کمتر) استفاده می کنیم. در این بخش، ما عمدتاً دو مؤلفه آخر روش پیشنهادی خود را برای مثال تقسیمبندی درختان توضیح میدهیم. در یادگیری متریک، نقاط درون یک درخت دارای تعبیههای مشابه هستند در حالی که نقاط درختان مختلف در فضای جاسازی از هم جدا هستند. با در نظر گرفتن نقاط درون هر درخت نه تنها ویژگی های تعبیه شده، بلکه دارای روابط هندسی نیز هستند، امیدواریم با ترکیب اطلاعات ساختار با ویژگی های تعبیه شده، نتایج نهایی متمایزتر باشد. برخی از معیارهای رایج مورد استفاده (به عنوان مثال، فاصله کسینوس) برای اندازهگیری شباهت بین تعبیهها ممکن است فرآیند یادگیری و پس فرآیند را به عنوان نوعی دلیل دشوارتر کند. برای اینکه جاسازی به اندازه کافی متمایز باشد، فاصله اقلیدسی برای اندازهگیری شباهت بین جاسازیها پس از آزمایشهای آزمایشی زیاد انتخاب شد. پس از اندازهگیری شباهت بین تعبیهها، تعبیههای متمایز برای هر درخت را با یک تابع از دست دادن آگاه به ساختار به دست میآوریم. تابع ضرر ما از دو مورد زیر تشکیل شده است:
که در آن N تعداد کل درخت در کل صحنه است. اولین مورد ℒمنمنnتیrآهدف آن به حداقل رساندن فاصله بین جاسازی ها در همان درخت است. همانطور که در رابطه (13) نشان داده شده است، ویژگی کلی یک درخت را می توان با تعبیه متوسط توصیف کرد.
جایی که αنشان دهنده آستانه ای برای جریمه کردن فاصله زیاد جاسازی است، nمنشماره نقطه درخت i است.سدمن،jمختصات نقطه j در درخت i است که فاصله فضایی بین نقطه j و مرکز هندسی را اندازه می گیرد.μسد،مناز درخت منهدمن،jتعبیه نقطه j در درخت i است که فاصله جاسازی بین نقطه j و میانگین جاسازی را اندازه می گیرد. μهد،من. توضیح بیشتر، سدمن،jو هدمن،jسپس به ترتیب معادلات (14) و (15) نشان داده می شوند.
از سوی دیگر، مورد دوم ℒمنjمنnتیهrمعمولاً برای تمایز دادن نقاط از درختان مختلف استفاده می شود. به طور مشخص،
جایی که βنشان دهنده آستانه ای برای فاصله بین جاسازی های متوسط است. پس از آزمایش های مکرر، αو βبه ترتیب 0.7 و 1.5 تنظیم شده است.
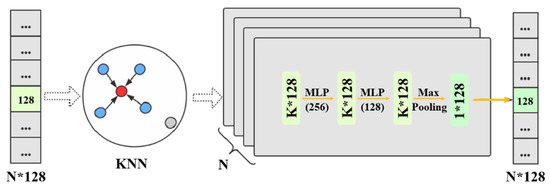
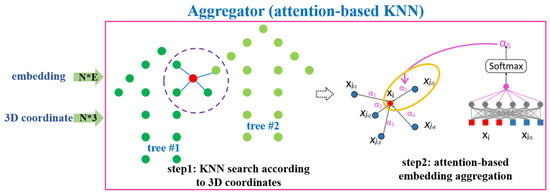
برای دستیابی به هدفی که تولید تعبیههای مشابه در یک درخت و تعبیههای متمایز بین درختان مختلف است، از الگوریتم KNN برای بهبود سازگاری محلی جاسازیها و جمعآوری اطلاعات از نقاط اطراف برای یک نقطه خاص استفاده میشود. با این حال، مایه تاسف است که برخی از اطلاعات نادرست ارائه شده توسط KNN برای جاسازی مضر باشد. واضح تر است که یک نقطه نزدیک به لبه یک درخت خاص ممکن است اطلاعات درخت دیگری را جمع آوری کند. به جای تجمیع استاندارد KNN ( ایکسمنآggrهgآتیه، یک KNN مبتنی بر توجه برای جاسازی تجمع توسعه داده شده است ( ایکسمنآggrهgآتیه”) که می تواند وزن های مختلفی را برای همسایگان مختلف تعیین کند. فرآیند تبدیل را می توان به صورت زیر رسمیت داد:
که در آن جاسازی های ورودی ابرهای نقطه ای با X = نشان داده می شود {ایکس1،…،ایکسn}⊆آراف، {ایکسjمن1،…،ایکسjمنک}k نزدیکترین همسایگان هستندایکسمنبا توجه به موقعیت مکانی آنها، و αمتروزن توجه برای هر همسایه و عادی سازی تابع softmax است.
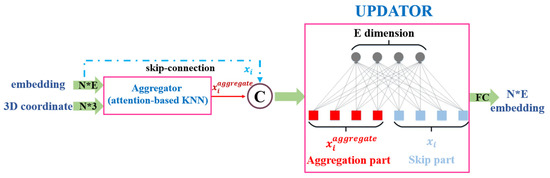
در تحقیق قبلی، GCN معمولاً از دو بخش تشکیل شده است: جمعکننده و بهروزرسانی (نشان داده شده در شکل 8 ). همانطور که در بالا توضیح داده شد، گردآورنده برای جمع آوری اطلاعات از همسایگان با استفاده از KNN مبتنی بر توجه پیشنهادی است . برای بهروزرسانی اطلاعات جمعآوریشده با نگاشت جاسازیها در یک فضای ویژگی جدید، یک لایه کاملاً متصل ساده بدون سوگیری به عنوان بهروزرسانیکننده استفاده میشود. عملیات به شرح زیر رسمیت یافته است:
جایی که W ⊆ آر2اف×افیک پارامتر قابل آموزش از به روز رسانی است.
درختان مستقل فضایی به سرعت و به طور موثر جدا می شوند، اما درختان همپوشانی یا مجاور به سختی جدا می شوند. چندین تحقیق قبلی خطاهای حذف را با یک الگوریتم قطع نمودار کاهش دادند که دقت را افزایش داد اما پیچیدگی محاسباتی را افزایش داد. برای بخش بندی بیشتر آن اشیاء حاوی بیش از یک شی، یک روش تقسیم بندی برش نرمال شده مبتنی بر سوپروکسل توسعه داده شده است. اشیاء مخلوط ابتدا به سوپروکسل های همگن با وضوح تقریباً مساوی با استفاده از الگوریتم تقسیم بیش از حد موجود در [ 64 ] تقسیم می شوند، که می تواند مرز جسم را بسیار بهتر از بقیه حفظ کند. سپس، یک نمودار وزنی کامل G ( V , E ) را در نظر بگیرید) از سوپروکسل های داده شده با توجه به همسایه های فضایی آنها ساخته شده است، که در آن رئوس V با مرکز سوپروکسل ها نشان داده می شوند و یال های E بین هر جفت سوپروکسل مجاور متصل می شوند. وزن معنی دار تخصیص داده شده به لبه برای اندازه گیری شباهت بین یک جفت سوپروکسل که توسط لبه به هم متصل شده اند اتخاذ می شود و با اطلاعات هندسی مرتبط با سوپروکسل ها به صورت زیر محاسبه می شود:
جایی که دیمنjایکسYو دیمنjزبه ترتیب فاصله افقی و عمودی بین سوپروکسل های i و j هستند. σایکسY، σزو σجیانحراف معیار را نشان می دهد دیمنjایکسY، دیمنjزو جیمنjمترآایکس، به ترتیب. rایکسYیک آستانه فاصله برای تعیین حداکثر فاصله معتبر بین دو سوپروکسل در صفحه افقی است. جیمنjمترآایکسبه صورت بیان می شود
جایی که دیایکسY(من، تیrههتیoپ)و دیایکسY(j، تیrههتیoپ)فاصله افقی بین سوپروکسل های i , j و بالای نزدیکترین درخت را نشان می دهد.
به طور خاص، شباهت بین دو سوپروکسل با در نظر گرفتن فاصله آنها در صفحه افقی و توزیع نسبی افقی و عمودی آنها اندازه گیری می شود. با چنین تعریفی، ما نمودار وزنی کامل G را با روش تقسیم بندی برش نرمال شده به دو گروه جدا از هم A و B تقسیم می کنیم، که شباهت را در هر گروه به حداکثر می رساند. آ∩ب=∅) و عدم تشابه بین دو گروه ( آ∪ب=V). با توجه به [ 65 ]، تابع هزینه مربوطه به صورت تعریف شده است
جایی که جتوتی(آ،ب)=∑من∈آ،من∈بωمنjنشان دهنده مجموع وزن های روی لبه های متصل کننده گروه های A و B است. آسسoج(آ،V)=∑من∈آ،من∈Vωمنjو آسسoج(ب،V)=∑من∈ب،من∈Vωمنjمجموع وزنه های روی یال های قرار گرفته در گروه A و B را نشان دهید.
فرآیند تقسیم نمودار وزنی G به دو گروه جداگانه A و B به عنوان کمینه سازی در نظر گرفته می شود نجتوتی(آ،ب). از آنجایی که مشکل کمینهسازی NP-hard است، روش پیشنهادی بر استراتژی تقریب تکیه میکند که نتایج نسبتاً خوبی از نظر کیفیت و سرعت حل به دست میآورد. سپس به حداقل رساندن نجتوتی(آ،ب)با حل مسئله مقدار ویژه تعمیم یافته مربوطه به دست می آید
که در آن W ( i ، j ) = ωمنjو D یک ماتریس مورب است که ردیف i مجموع وزن های لبه های مربوط به سوپروکسل i را ثبت می کند.
ما یک پارامتر z را معرفی می کنیمدی-12yبنابراین، معادله (22) به صورت نمایش داده می شود دی-12(دی-دبلیو)دی-12z=λz. از اصل اولیه ضریب ریلی می توان فهمید که حل مسئله حداقل مقدار از نجتوتی(آ،ب)به حل بردار ویژه دوم سیستم ویژگی تبدیل می شود و بهترین نتیجه تقسیم بندی نرمال شده به دست می آید.
جایی که {λ=0، z0=دی-12من}راه حل کوچک سیستم ویژگی فوق الذکر است، y0=منکوچکترین بردار ویژگی است.
3. نتایج
3.1. توضیحات داده ها
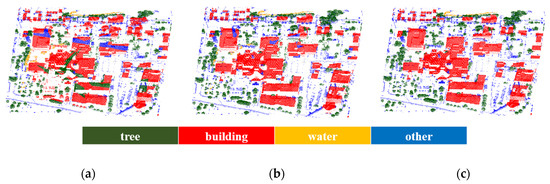
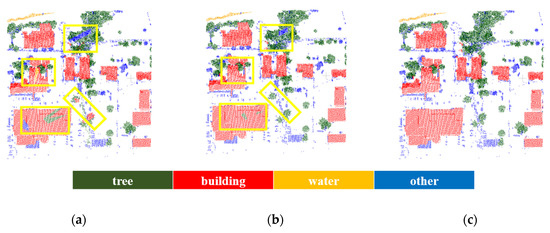
3.2. عملکردهای طبقه بندی
3.2.1. مقایسه بین پوینت نت و روش ما
3.2.2. اثربخشی هموارسازی برچسبگذاری با استفاده از بهینهسازی ساختار یافته نمودار
3.2.3. مقایسه با سایر روش های منتشر شده
برای بررسی بیشتر تطبیق پذیری روش پیشنهادی در مجموعه داده های ALS در مقیاس بزرگ، ما همچنین نتایج طبقه بندی نقطه ای را در مجموعه داده DALES به دست آوردیم. ما معیارهای ارزیابی معیارهای ابر نقطه LiDAR در مقیاس بزرگ را دنبال می کنیم و از میانگین IoU و OA به عنوان معیارهای ارزیابی اصلی خود استفاده می کنیم. هر کلاس IoU ابتدا به عنوان معادله (25) تعریف می شود، میانگین IoU به سادگی میانگین در تمام هشت دسته است، به استثنای دسته مجهول، شکل معادله (26)، و OA را می توان به عنوان معادله (27) محاسبه کرد. . برای ارزیابی بیشتر، روش پیشنهادی با روشهای منتشر شده قبلی مقایسه شد (ما فقط الگوریتمهایی را انتخاب کردیم که نتایج منتشر شده و کدهای موجود را دارند، از جمله PointNet++ [ 30 ]، ShellNet [ 72 ]، و Superpoint Graphs [42 ]). نتایج مقایسه کمی روی مجموعه داده DALES در جدول 6 فهرست شده است ، که نشان میدهد شبکه پیشنهادی نسبت به مدلهای دیگر عملکرد طبقهبندی بهتری از نظر OA و میانگین امتیاز IoU دارد. به طور خاص، مدل پیشنهادی عملکرد استخراج پیشرفتهای را برای درختان به دست میآورد. عملکرد بسیار قوی معماری ما بر روی درختان با IoU 94.1 درصد، بیش از 2 درصد بیشتر از شبکه های دیگر، احتمالاً به دلیل تفاوت بین معماری پیشنهادی و روش های دیگر است، این است که ما بر انتخاب یک عدد ثابت تکیه نکرده ایم. از نقاط در شعاع جستجو این روش انتخاب دسته ای امکان انتخاب یک محله به اندازه کافی وسیع را برای دریافت اطلاعات کافی و همچنین داشتن نقاط کافی برای شناسایی اشیاء کوچک فراهم می کند.
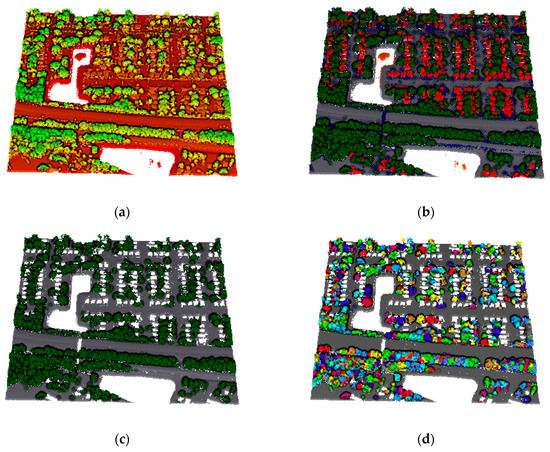
3.3. عملکردهای تقسیم بندی درختان منفرد
3.3.1. تقسیم بندی درختان کنار جاده
3.3.2. ارزیابی روش پیشنهادی
ما الگوریتم تقسیم بندی درخت را در پایتون اجرا کردیم و نتیجه را با درخت های مرجع مقایسه کردیم. در این مطالعه، عملکرد روش تقسیمبندی درختی پیشنهادی روی این دو مجموعه داده ALS با معیارهای زیر [ 6 ] ارزیابی میشود: دقت تقسیمبندی ( AC )، خطای حذف ( OM ) و خطای کمیسیون ( COM ). AC نرخ درختانی است که به درستی شناسایی شده اند. OM نرخ درختان شناسایی نشده است و COM نرخ درختان نادرست شناسایی شده است.
که در آن de تعداد درخت هایی است که به درستی تقسیم شده اند، ude تعداد درخت های بدون بخش، fde تعداد درخت هایی است که به اشتباه تقسیم شده اند و ref تعداد درخت های مرجع است.
3.3.3. مطالعات تطبیقی
4. نتیجه گیری
پیوست اول
| الگوریتم A1: استخراج ویژگی محلی مبتنی بر KNN |
| ورودی: ابر نقطه Pدی={پ1،پ2،…، پn }، بعد هر نقطه d است . |
| خروجی: ابر نقطه Pدی={پ1،پ2،…، پn }، بعد هر نقطه d است . |
| پارامتر: K برای جستجوی KNN |
| مرحله 1: محاسبه فاصله ویژگی بین هر جفت نقطه. |
| مقداردهی اولیه: ماتریس تشابه را تعریف کنید اسn×nبین جفت نقطه |
| برای i = 1، 2، …، n انجام دهید |
| محاسبه فاصله اقلیدسی اسمنj=”ایکسمن-ایکسj”2اففضای ویژگی بین نقطه ایکسمنو امتیازهای فردی ایکسj(1 ≤j ≤n)؛ |
| پایان برای |
| مرحله 2: K نقطه مجاور هر نقطه پرس و جو را انتخاب کنید . |
| مقداردهی اولیه: ماتریس K- نزدیکترین همسایه را تعریف کنیدEن×کماتریس ویژگی هر نقطه و هر محله محلی Eن×د، جایی که d بعد ویژگی است. |
| برای i = 1، 2، …، n انجام دهید |
| بردار فاصله را استخراج کنید اسمن={اسمن1،اسمن2،…، اسمنn }بین نقطه ایکسمنو نکات دیگر؛ |
| بردار را مرتب کنید اسمناز کوچک به بزرگ، و عناصر K بالا را انتخاب کنید، Eمنک=[ه1، ه2،…، هn]; |
| ویژگی های محلی d بعدی را استخراج کنید افمن=مآایکس{ساعت(ایکسمن)،ساعت(ایکسه1)،ساعت(ایکسه2)،…،ساعت(ایکسهک)}(که h MLP است) نقطه ایکسمنو K مناطق مجاور با استفاده از لایه های MLP و max pooling. |
| پایان برای |
| مرحله 3: ویژگی هر نقطه پرس و جو را به روز کنید. |
| برای i = 1، 2، …، n انجام دهید |
| برای نقطه ایکسمن، ویژگی نقطه داده شده را به روز کنید ایکسمن=افمن. |
| پایان برای |
منابع
- روی، اس. بیرن، جی. Pickering، C. بررسی کمی سیستماتیک مزایای درخت شهری، هزینه ها، و روش های ارزیابی در سراسر شهرها در مناطق مختلف آب و هوایی. شهری برای. سبز شهری. 2012 ، 11 ، 351-363. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اسلام، MN; رحمان، ک.س. بهار، م.م. حبیب، م. آندو، ک. هاتوری، N. کاهش آلودگی توسط کمربند سبز کنار جاده در و اطراف مناطق شهری. شهری برای. سبز شهری. 2012 ، 11 ، 460-464. [ Google Scholar ] [ CrossRef ]
- چن، ی. وانگ، اس. لی، جی. ما، ال. وو، آر. لو، ز. وانگ، سی. فهرست درختان کنار جاده شهری سریع با استفاده از سیستم اسکن لیزری سیار. IEEE J. Sel. بالا. Appl. رصد زمین. Remote Sens. 2019 , 12 , 3690–3700. [ Google Scholar ] [ CrossRef ]
- ایان، اس. نیکیل، ن. کارلو، آر. رافائل، پی. خیابان های سبز – کمی سازی و نقشه برداری درختان شهری با تصاویر سطح خیابان و دید کامپیوتری. Landsc. طرح شهری. 2017 ، 165 ، 93-101. [ Google Scholar ]
- خو، ز. شن، ایکس. کائو، ال. نیکلاس، سی. تریستان، جی. ژونگ، تی. ژائو، دبلیو. سان، س. با، اس. ژانگ، ز. و همکاران طبقه بندی گونه های درختی با استفاده از ابرهای نقطه ای فتوگرامتری هوایی دیجیتال مبتنی بر UAS و تصاویر چند طیفی در جنگل های طبیعی نیمه گرمسیری. بین المللی J. Appl. زمین Obs. Geoinf. 2020 , 92 , 102173. [ Google Scholar ] [ CrossRef ]
- یان، دبلیو. گوان، اچ. کائو، ال. یو، ی. لی، سی. Lu, J. A Self-Adaptive Mean Shift Tree-Segmentation Method with Use UAV LiDAR Data. Remote Sens. 2020 , 12 , 515. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یانگ، جی. کانگ، ز. چنگ، اس. یانگ، ز. Akwensi، PH یک روش تقسیمبندی درختان فردی بر اساس الگوریتم حوضه و تحلیل توزیع فضایی سهبعدی از ابرهای نقطهای LiDAR در هوابرد. IEEE J. Sel. بالا. Appl. رصد زمین. Remote Sens. 2020 , 13 , 1055–1067. [ Google Scholar ] [ CrossRef ]
- فالکوفسکی، ام جی. اسمیت، AMS؛ Gessler، PE; Hudak، AT; ویرلینگ، لس آنجلس; Evans، JS تأثیر پوشش تاج جنگلی مخروطیان بر دقت دو الگوریتم اندازهگیری درخت با استفاده از دادههای لیدار. می توان. J. Remote Sens. 2008 , 34 , S338–S350. [ Google Scholar ] [ CrossRef ]
- لاهیوارا، تی. سپانن، آ. کایپیو، جی پی؛ واکونن، جی. کورهونن، ال. توکولا، تی. رویکرد مالتامو، ام بیزی برای تشخیص درخت بر اساس دادههای اسکن لیزری هوابرد. IEEE Trans. Geosci. Remote Sens. 2014 , 52 , 2690–2699. [ Google Scholar ] [ CrossRef ]
- چن، کیو. بالدوکی، دی. گونگ، پی. کلی، ام. جداسازی درختان منفرد در جنگل ساوانا با استفاده از دادههای ردپای کوچک لیدار. فتوگرام مهندس Remote Sens. 2006 , 72 , 923-932. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- واکونن، جی. ان، ال. گوپتا، اس. هاینزل، جی. هولمگرن، جی. پیتکانن، جی. سولبرگ، اس. وانگ، ی. ویناکر، اچ. هاگلین، KM; و همکاران آزمایش مقایسه ای الگوریتم های تشخیص تک درخت در انواع مختلف جنگل. جنگلداری 2011 ، 85 ، 27-40. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پولوسکی، پ. یائو، دبلیو. هیوریچ، ام. کرزیستک، پ. Stilla، U. تشخیص درختان افتاده در ابرهای نقطه ای ALS با استفاده از رویکرد برش عادی آموزش دیده با شبیه سازی. ISPRS J. Photogramm. Remote Sens. 2015 ، 105 ، 252-271. [ Google Scholar ] [ CrossRef ]
- یانگ، بی. دای، دبلیو. دونگ، ز. Liu, Y. نقشه برداری خودکار جنگل در سطوح درختی از ابرهای نقطه اسکن لیزری زمینی با روش حداقل برش سلسله مراتبی. Remote Sens. 2016 , 8 , 372. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فراز، ع. برتار، اف. ژاکمود، اس. گونسالوز، جی. پریرا، ال. تومه، ام. Soares, P. نقشه برداری سه بعدی از یک جنگل مدیترانه ای چند لایه با استفاده از داده های ALS. سنسور از راه دور محیط. 2012 ، 121 ، 210-223. [ Google Scholar ] [ CrossRef ]
- ژن، ز. Quackenbush، LJ; Zhang, L. روندها در تشخیص و ترسیم تاج درخت به طور خودکار – تکامل داده های LiDAR. Remote Sens. 2016 , 8 , 333. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ال. لیم، اس. شن، ایکس. Yebra, M. یک روش ترکیبی برای تقسیم بندی درختان منفرد از داده های لیدار موجود در هوا. محاسبه کنید. الکترون. کشاورزی 2019 ، 163 ، 104871. [ Google Scholar ] [ CrossRef ]
- یان، دبلیو. گوان، اچ. کائو، ال. یو، ی. گائو، اس. Lu, J. یک رویکرد سلسله مراتبی خودکار برای تقسیم بندی سه بعدی تک درختان با استفاده از داده های UAV LiDAR. Remote Sens. 2018 , 10 , 1999. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، اس. ژو، سی. وانگ، اس. گائو، اس. لیو، ز. ناهمگونی فضایی در تعیینکنندههای فرم شهری: تحلیلی از شهرهای چین با رویکرد GWR. پایداری 2019 ، 11 ، 479. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یانگ، بی. دونگ، ز. ژائو، جی. Dai, W. استخراج سلسله مراتبی اشیاء شهری از داده های اسکن لیزری سیار. ISPRS J. Photogramm. Remote Sens. 2015 ، 99 ، 45-57. [ Google Scholar ] [ CrossRef ]
- خو، اس. Xu, SS; بله، ن. Zhu، F. استخراج خودکار اجزای غیرفتوسنتزی درختان خیابان از دادههای MLS. بین المللی J. Appl. رصد زمین. Geoinf. 2018 ، 69 ، 64-77. [ Google Scholar ] [ CrossRef ]
- باباحاجیانی، پ. فن، ال. Kämäräinen، JK; گابوج، م. تقسیم بندی و مدل سازی سه بعدی شهری از تصاویر نمای خیابان و ابرهای نقطه LiDAR. ماخ Vis. Appl. 2017 ، 28 ، 679-694. [ Google Scholar ] [ CrossRef ]
- واینمن، ام. واینمن، ام. مالت، سی. Brédif, M. چارچوب طبقهبندی-بخشبندی برای تشخیص درختان منفرد در دادههای ابر نقطهای MMS متراکم بهدستآمده در مناطق شهری. Remote Sens. 2017 , 9 , 277. [ Google Scholar ] [ CrossRef ][ Green Version ]
- گوا، ی. وانگ، اچ. هو، کیو. لیو، اچ. لیو، ال. بننامون، ام. یادگیری عمیق برای ابرهای نقطه سه بعدی: یک بررسی. IEEE Trans. الگوی مقعدی ماخ هوشمند 2020 . [ Google Scholar ] [ CrossRef ] [ PubMed ]
- یانگ، ز. جیانگ، دبلیو. خو، بی. زو، س. جیانگ، اس. Huang, W. یک روش برچسبگذاری معنایی سه بعدی مبتنی بر شبکه عصبی کانولوشن برای ابرهای نقطه ALS. Remote Sens. 2017 , 9 , 936. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یانگ، ز. تان، بی. پی، اچ. Jiang, W. تقسیم بندی و طبقه بندی شبکه عصبی کانولوشنال چند مقیاسی داده های اسکنر لیزری هوابرد. Sensors 2018 , 10 , 3347. [ Google Scholar ] [ CrossRef ][ Green Version ]
- ژائو، آر. پانگ، ام. Wang, J. طبقهبندی ابرهای نقطهای LiDAR هوابرد از طریق ویژگیهای عمیقی که توسط یک شبکه عصبی کانولوشنال چند مقیاسی آموخته شده است. بین المللی جی. جئوگ. Inf. علمی 2018 ، 32 ، 960-979. [ Google Scholar ] [ CrossRef ]
- ته، جی. هو، دبلیو. گوا، ز. ژنگ، A. RGCNN: نمودار منظم CNN برای تقسیم بندی ابر نقطه ای. در مجموعه مقالات کنفرانس بین المللی ACM در چند رسانه ای (MM)، سئول، کره، 22 تا 26 اکتبر 2018؛ صص 746-754. [ Google Scholar ]
- ماتورانا، دی. Scherer, S. VoxNet: یک شبکه عصبی کانولوشنال سه بعدی برای تشخیص اشیا در زمان واقعی. در مجموعه مقالات کنفرانس بین المللی IEEE/RSJ در مورد ربات ها و سیستم های هوشمند (IROS)، هامبورگ، آلمان، 28 سپتامبر تا 2 اکتبر 2015. ص 922-928. [ Google Scholar ]
- Qi، CR; سو، اچ. مو، ک. Guibas، LJ PointNet: یادگیری عمیق در مجموعه های نقطه برای طبقه بندی و تقسیم بندی سه بعدی. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو (CVPR)، هونولولو، HI، ایالات متحده آمریکا، 25 تا 30 ژوئیه 2017؛ صص 652-660. [ Google Scholar ]
- Qi، CR; یی، ال. سو، اچ. Guibas، LJ PointNet++: یادگیری ویژگی های سلسله مراتبی عمیق در مجموعه های نقطه در یک فضای متریک. در مجموعه مقالات سیستمهای پردازش اطلاعات عصبی (NIPS)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 3 تا 9 دسامبر 2017. [ Google Scholar ]
- ژائو، اچ. جیانگ، ال. فو، CW; Jia, J. PointWeb: بهبود ویژگی های محله محلی برای پردازش ابر نقطه. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 20 ژوئن 2019؛ صص 5565–5573. [ Google Scholar ]
- واسوانی، ع. Shazeer، N. پارمار، ن. Uszkoreit، J. جونز، ال. گومز، AN; قیصر، Ł. Polosukhin، I. توجه شما تمام چیزی است که نیاز دارید. در مجموعه مقالات سیستمهای پردازش اطلاعات عصبی (NIPS)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 3 تا 9 دسامبر 2017. [ Google Scholar ]
- ژائو، سی. ژو، دبلیو. لو، ال. ژائو، کیو. ادغام امتیازات نقاط همسایه برای تقسیم بندی ابر نقطه سه بعدی بهبود یافته. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد پردازش تصویر (ICIP)، تایپه، تایوان، چین، 22 تا 25 سپتامبر 2019؛ ص 1475-1479. [ Google Scholar ]
- وانگ، اس. سو، اس. ما، WC; پوکروفسکی، آ. Urtasun، R. شبکه های عصبی کانولوشن پیوسته پارامتریک عمیق. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ صص 2589-2597. [ Google Scholar ]
- توماس، اچ. Qi، CR; Deschaud، JE; مارکوتگی، بی. گولت، اف. Guibas، LJ KPConv: پیچش انعطاف پذیر و قابل تغییر شکل برای ابرهای نقطه ای. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتری (ICCV)، سئول، کره، 27 اکتبر تا 3 نوامبر 2019؛ صص 6411–6420. [ Google Scholar ]
- Hua، BS; Tran، MK; شبکه های عصبی کانولوشنال یونگ، SK Pointwise. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ ص 984-993. [ Google Scholar ]
- انگلمن، اف. کنتوگیانی، تی. Leibe, B. انبساط نقطه گشاد: در زمینه پذیرنده پیچش نقطه. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد رباتیک و اتوماسیون (ICRA)، پاریس، فرانسه، 31 مه تا 4 ژوئن 2020. [ Google Scholar ]
- هوانگ، Q. وانگ، دبلیو. Neumann، U. شبکه های برش مکرر برای تقسیم بندی سه بعدی ابرهای نقطه ای. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ صص 2626–2635. [ Google Scholar ]
- انگلمن، اف. کنتوگیانی، تی. هرمانز، آ. Leibe, B. کاوش زمینه فضایی برای تقسیم بندی معنایی سه بعدی ابرهای نقطه. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر (ICCV)، ونیز، ایتالیا، 22 تا 27 اکتبر 2017؛ صص 716-724. [ Google Scholar ]
- بله، X. لی، جی. هوانگ، اچ. دو، ال. Zhang، X. شبکه های عصبی بازگشتی سه بعدی با ترکیب زمینه برای تقسیم بندی معنایی ابر نقطه ای. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر (ECCV)، مونیخ، آلمان، 8 تا 14 سپتامبر 2018؛ ص 403-417. [ Google Scholar ]
- لیو، اف. لی، اس. ژانگ، ال. ژو، سی. بله، آر. وانگ، ی. Lu, J. 3DCNN-DQN-RNN: یک چارچوب یادگیری تقویتی عمیق برای تجزیه معنایی ابرهای نقطه سه بعدی در مقیاس بزرگ. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر (ICCV)، ونیز، ایتالیا، 22 تا 27 اکتبر 2017؛ صص 5678–5687. [ Google Scholar ]
- لندریو، ال. Simonovsky، M. تقسیم بندی معنایی ابر نقطه ای در مقیاس بزرگ با نمودارهای ابرنقطه ای. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ صص 4558-4567. [ Google Scholar ]
- لیانگ، ز. یانگ، م. دنگ، ال. وانگ، سی. وانگ، ب. شبکه عصبی کانولوشنال گراف عمقی سلسله مراتبی برای تقسیم بندی معنایی سه بعدی ابرهای نقطه ای. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد رباتیک و اتوماسیون (ICRA)، مونترال، QC، کانادا، 20-24 مه 2019؛ صص 8152–8158. [ Google Scholar ]
- وانگ، ال. هوانگ، ی. هو، ی. ژانگ، اس. شان، جی. پیچیدگی توجه گراف برای تقسیم بندی معنایی ابر نقطه ای. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 20 ژوئن 2019؛ صص 10288-10297. [ Google Scholar ]
- لی، ی. ما، ال. ژونگ، ز. کائو، دی. Li, J. TGNet: نمودار هندسی CNN در تقسیم بندی ابر نقطه ای سه بعدی. IEEE Trans. Geosci. Remote Sens. 2020 , 58 , 3588–3600. [ Google Scholar ] [ CrossRef ]
- وانگ، ایکس. لیو، اس. شن، ایکس. شن، سی. Jia, J. بخشبندی انجمنی نمونهها و معناشناسی در ابرهای نقطه. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 20 ژوئن 2019؛ صص 4096-4105. [ Google Scholar ]
- ژانگ، ک. چن، SC; ویتمن، دی. شیو، ام ال. یان، جی. Zhang, C. یک فیلتر مورفولوژیکی مترقی برای حذف اندازهگیریهای غیرزمینی از دادههای LIDAR در هوا. IEEE Trans. Geosci. Remote Sens. 2003 , 41 , 872-882. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لین، ایکس. ژانگ، جی. فیلتر بر اساس تقسیم بندی ابرهای نقطه ای LiDAR موجود در هوا با متراکم شدن تدریجی بخش های زمین. Remote Sens. 2014 ، 6 ، 1294-1326. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژائو، کیو. گوا، کیو. سو، ی. Xue, B. بهبود الگوریتم فیلتر تراکم TIN پیشرو برای داده های LiDAR موجود در هوا در مناطق جنگلی. ISPRS J. Photogramm. Remote Sens. 2016 ، 117 ، 79–91. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، دبلیو. چی، جی. وان، پی. وانگ، اچ. زی، دی. وانگ، ایکس. Yan, G. یک روش آسان برای استفاده هوابرد LiDAR فیلتر کردن داده ها بر اساس شبیه سازی پارچه. Remote Sens. 2016 , 8 , 501. [ Google Scholar ] [ CrossRef ]
- ژانگ، دی. او، اف. تو، ز. زو، ال. Chen, Y. Pointwise Geometric and Semantic Network Learning on 3D Point Clouds. یکپارچه سازی محاسبه کنید. به کمک مهندس 2020 ، 27 ، 57-75. [ Google Scholar ] [ CrossRef ]
- وانگ، ی. جیانگ، تی. یو، م. تائو، اس. سان، ج. لیو، اس. استخراج ساختمان مبتنی بر معنایی از ابرهای نقطهای LiDAR با استفاده از زمینهها و بهینهسازی در محیط پیچیده. Sensors 2020 , 20 , 3386. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کانگ، ز. یانگ، جی. یک مدل گرافیکی احتمالی برای طبقه بندی ابرهای نقطه LiDAR موبایل. ISPRS J. Photogramm. Remote Sens. 2018 , 143 , 108–123. [ Google Scholar ] [ CrossRef ]
- کین، ن. هو، ایکس. وانگ، پی. شان، جی. Li، Y. برچسبگذاری معنایی ابر نقطهای ALS از طریق آموزش نمایشهای وکسل و پیکسل. IEEE Geosci. سنسور از راه دور Lett. 2020 ، 17 ، 859-863. [ Google Scholar ] [ CrossRef ]
- وانگ، پی. لیو، ی. گوا، ی. سان، سی. Tong, X. O-CNN: شبکه های عصبی کانولوشن مبتنی بر Octree برای تجزیه و تحلیل شکل سه بعدی. ACM Trans. نمودار. 2017 ، 36 ، 72. [ Google Scholar ] [ CrossRef ]
- کراهنبول، پ. کلتون، V. یادگیری پارامتر و استنتاج همگرا برای میدان های تصادفی متراکم. در مجموعه مقالات کنفرانس بین المللی یادگیری ماشین (ICML)، آتلانتا، GA، ایالات متحده آمریکا، 16-21 ژوئن 2013. صص 513-521. [ Google Scholar ]
- کولموگروف، وی. ذبیح، ر. چه توابع انرژی را می توان از طریق برش های نمودار به حداقل رساند؟ IEEE Trans. الگوی مقعدی ماخ هوشمند 2004 ، 26 ، 147-159. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- خو، ی. بله، ز. یائو، دبلیو. هوانگ، آر. تانگ، ایکس. هوگنر، ال. Stilla، U. طبقهبندی ابرهای نقطهای LiDAR با استفاده از ویژگیهای Detrended مبتنی بر Supervoxel و مدل گرافیکی وزندار ادراک. IEEE J. Sel. بالا. Appl. رصد زمین. Remote Sens. 2020 , 13 , 72–88. [ Google Scholar ] [ CrossRef ]
- زنگ، جی. چونگ، جی. نگ، م. پانگ، جی. یانگ، سی. نویز زدایی ابر نقطهای سه بعدی با استفاده از منظمسازی لاپلاسی نمودار یک مدل منیفولد کمبعد. IEEE Trans. فرآیند تصویر 2020 ، 29 ، 3474-3489. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اوشر، اس. شی، ز. Zhu, W. مدل منیفولد کم ابعاد برای پردازش تصویر. SIAM J. Imaging Sci. 2017 ، 10 ، 1669-1690. [ Google Scholar ] [ CrossRef ]
- هوانگ، اچ. وو، اس. گونگ، ام. یا، D. Ascher، U. Edge-aware مجموعه نقطه نمونه برداری مجدد. ACM Trans. نمودار. 2013 ، 32 ، 9-21. [ Google Scholar ] [ CrossRef ]
- لیانگ، ز. یانگ، م. لی، اچ. Wang, C. آموزش تعبیهسازی 3 بعدی با تابع ضایعات آگاه از ساختار برای تقسیمبندی ابر نقطهای. ربات IEEE. خودکار Lett. 2020 ، 5 ، 4915-4922. [ Google Scholar ] [ CrossRef ]
- گراهام، بی. انگلک، م. Maaten، L. تقسیمبندی معنایی سه بعدی با شبکههای کانولوشنال پراکنده زیرمنیفولد. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ ص 9224–9232. [ Google Scholar ]
- لین، ی. وانگ، سی. ژای، دی. لی، دبلیو. لی، جی. به سوی مرزبندی بهتر، تقسیم بندی سوپروکسل برای ابرهای نقطه سه بعدی حفظ شده است. ISPRS J. Photogramm. Remote Sens. 2018 ، 143 ، 39–47. [ Google Scholar ] [ CrossRef ]
- یو، ی. لی، جی. گوان، اچ. وانگ، سی. استخراج خودکار تسهیلات جاده شهری با استفاده از داده های اسکن لیزری سیار. IEEE Trans. هوشمند ترانسپ سیستم 2015 ، 16 ، 2167-2181. [ Google Scholar ] [ CrossRef ]
- رایتبرگر، جی. اشنور، سی. کرزیستک، پ. هنوز، بخشبندی سهبعدی U. تک درختهایی که از دادههای LIDAR شکل موج کامل بهرهبرداری میکنند. ISPRS J. Photogramm. Remote Sens. 2009 ، 64 ، 561-574. [ Google Scholar ] [ CrossRef ]
- لی، دبلیو. وانگ، اف. Xia, G. یک شبکه هندسی توجه برای طبقه بندی ابر نقطه ALS. ISPRS J. Photogramm. Remote Sens. 2020 , 164 , 26–40. [ Google Scholar ] [ CrossRef ]
- LeSaux، B. یوکویا، ن. هانش، آر. براون، M. مسابقه ادغام داده های IEEE GRSS 2019: بازسازی سه بعدی معنایی در مقیاس بزرگ [کمیته های فنی]. IEEE Geosci. سنسور از راه دور Mag. 2019 ، 7 ، 33-36. [ Google Scholar ] [ CrossRef ]
- وارنی، ن. آساری، VK; Graehling، Q. DALES: مجموعه داده های هوایی LiDAR در مقیاس بزرگ برای تقسیم بندی معنایی. در دسترس آنلاین: https://arxiv.org/abs/2004.11985 (در 1 ژوئن 2020 قابل دسترسی است).
- هوانگ، آر. خو، ی. هونگ، دی. یائو، دبلیو. غمیسی، پ. Stilla، U. جاسازی نقطه عمیق برای طبقه بندی شهری با استفاده از ابرهای نقطه ALS: چشم اندازی جدید از محلی به جهانی. ISPRS J. Photogramm. Remote Sens. 2020 , 163 , 62–81. [ Google Scholar ] [ CrossRef ]
- لی، ایکس. وانگ، ال. وانگ، ام. ون، سی. Fang, Y. DANCE-NET: شبکههای پیچشی آگاه از چگالی با رمزگذاری زمینه برای طبقهبندی ابر نقطه LiDAR در هوا. ISPRS J. Photogramm. Remote Sens. 2020 , 166 , 128–139. [ Google Scholar ] [ CrossRef ]
- ژانگ، ز. هوآ، بی. Yeung، SK ShellNet: شبکههای عصبی کانولوشنال ابر نقطه کارآمد با استفاده از آمار پوستههای متحدالمرکز. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتری (ICCV)، سئول، کره، 27 اکتبر تا 3 نوامبر 2019؛ صفحات 1607-1616. [ Google Scholar ]
- لی، دبلیو. گوا، کیو. Jakubowski، MK; کلی، ام. روشی جدید برای تقسیم درختان منفرد از ابر نقطه لیدار. فتوگرام مهندس Remote Sens. 2012 ، 78 ، 75-84. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شندریک، آی. برویچ، م. Tulbure، MG; الکساندروف، SV ترسیم از پایین به بالا درختان منفرد از اسکن لیزری هوابرد شکل موج کامل در یک جنگل اکالیپت ساختاری پیچیده. سنسور از راه دور محیط. 2016 ، 173 ، 69-83. [ Google Scholar ] [ CrossRef ]
- برت، ا. دیزنی، ام. Calders، K. استخراج درختان منفرد از ابرهای نقطه لیدار با استفاده از treeseg. روش ها Ecol. Evolut. 2019 ، 10 ، 438-445. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]






بدون دیدگاه