

دادههای مکانی و فناوریهای مرتبط با نقش برجستهای در فرآیندهای تجزیه و تحلیل دادهها، به یک جنبه مهم فزاینده تبدیل شدهاند. پارادایم بدون سرور به محبوب ترین و پرکاربردترین فناوری در محاسبات ابری تبدیل شده است. این مقاله پارادایم بدون سرور را بررسی میکند و بررسی میکند که چگونه میتوان از آن برای فرآیندهای دادههای مکانی با استفاده از استانداردهای باز در جامعه جغرافیایی استفاده کرد. ما طراحی و معماری سیستمی را برای رسیدگی به کارهای پیچیده پردازش دادههای مکانی با حداقل مداخله انسانی و مصرف منابع با استفاده از فناوریهای بدون سرور پیشنهاد میکنیم. به منظور تعریف و اجرای گردش کار در سیستم، مدلهای جدیدی را برای هر دو مدل گردش کار و تعریف وظایف پیشنهاد میکنیم. علاوه بر این، سیستم پیشنهادی دارای رابط برنامهنویسی کاربردی (API) کنسرسیوم فضایی باز (OGC) است که خدمات وب مبتنی بر مشخصات را پردازش میکند تا قابلیت همکاری با سایر برنامههای مکانی را با پیشبینی اینکه در آینده بیشتر مورد استفاده قرار گیرد، ارائه میکند. ما سیستم پیشنهادی را بر روی یکی از ارائه دهندگان ابر عمومی به عنوان اثبات مفهوم پیادهسازی کردیم و آن را با نمونه گردشهای کاری مکانی و بهترین شیوههای معماری ابر ارزیابی کردیم.
کلید واژه ها:
محاسبات بدون سرور ; گردش کار جغرافیایی ؛ سیستم مدیریت گردش کار
1. مقدمه
در دهه گذشته، دادههای بزرگ مکانی به یک روند حیاتی در صنعت تبدیل شدهاند، زیرا تکنیکهای جمعآوری دادهها آسانتر و در دسترستر شدهاند و گزینههای ذخیرهسازی به طور قابل توجهی در همان زمان افزایش یافتهاند. روشهای جدید فناوریهای جمعآوری دادههای مکانی مانند هواپیماهای بدون سرنشین، رباتها و ماهوارهها نیازمندیهای جدید ذخیرهسازی و پردازش دادهها را به همراه داشته است که پیشبینی میشود پیچیدهتر و سختتر شوند. این الزامات جدید می تواند با فناوری های رایانش ابری برآورده شود. با این حال، این فناوریهای جدید میتوانند یک منحنی یادگیری برای دانشمندان و تحلیلگران دادههای مکانی داشته باشند. کاهش پیچیدگی محاسبات ابری برای جامعه مکانی برای استفاده کارآمد برای تحلیلهای مکانی ضروری است. سیستمهای محاسباتی دادههای مکانی کلاسیک عمدتاً بر روی پلتفرمهای داخلی با ظرفیت محاسباتی یا ذخیرهسازی محدود اجرا میشوند. همچنین حفظ این زیرساخت ها برای ارائه خدمات پایدار چالش برانگیز است. از سوی دیگر، داشتن چنین زیرساخت اختصاصی نیز یک سرمایه گذاری گران برای استفاده تک یا تعداد محدودی از فرآیندها است. پلتفرم های رایانش ابری به عنوان راه حلی برای این مشکلات ارائه شده است. با این حال، استفاده از فناوریهای رایانش ابری به تخصص در این زمینه در سطح معینی نیاز دارد.1 ].
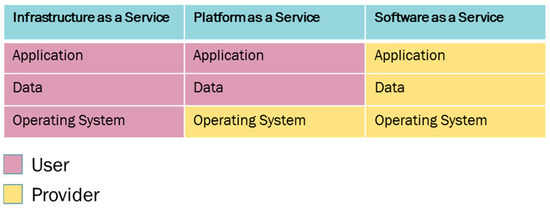
ارائه دهندگان ابر مدل های مختلفی را ارائه می دهند که سطوح مختلف انتزاع و کنترل منابع را ارائه می دهند [ 2 ]. مدل زیرساخت بهعنوان سرویس (IaaS)، که در آن کشش منابع در مرحله ماشین مجازی تحقق مییابد، مقادیر زیادی از منابع ابری را به کاربران ارائه میدهد، که اغلب با افزایش هزینههای میزبانی بیش از حد یا عملکرد ضعیف به دلیل تأمین ناکافی منابع [ 3 ]. مدل دیگری که قابل ذکر است، Platform-as-a-Service (PaaS) است که سطح انتزاعی دیگری را در بالای مدل IaaS فراهم می کند. مدیریت سیستم عامل را حذف می کند. در هر دو مدل، مقیاس پذیری و هماهنگ سازی استقرار برنامه ها همچنان بر عهده کاربر است ( شکل 1)). در مدل Software-as-a-Service (SaaS)، مسئولیت مدیریت در تمام لایه ها از کاربر انتزاع می شود.
پارادایم بدون سرور برای ارائه هماهنگی خودکار از استقرار و پلت فرم مقیاس پذیر که بر اساس تقاضا اجرا می شود، معرفی شده است [ 4 ]. این شبیه به مدل SaaS در انتزاع لایه است، اما به توسعه دهنده اجازه می دهد تا هر کدی را در سرویس بدون سرور اجرا کند. اگرچه به دلیل قابلیتهای کاربری آسان و کارآمدی هزینه، توسعهدهندگان را جذب میکند، اما هنوز یک راهحل پیچیده برای اکثر سناریوهای پردازش دادههای مکانی برای انجام یک گردش کاری متشکل از چند مرحله است. هر مرحله در یک گردش کار فرآیند داده های مکانی ممکن است به قدرت محاسباتی و مقدار داده متفاوتی نیاز داشته باشد [ 5 ]. مزیت قابل توجه برنامه بدون سرور از هیچ منبعی در حالت بیکار استفاده نمی کند.
مدل بدون سرور را می توان با چند مفهوم متفاوت توصیف کرد. یک مفهوم متداول به نام Function-as-a-A-Service (FaaS) بستری را برای اجرای یک کد سفارشی که توسط یک توسعه دهنده بر روی یک پلتفرم ابری ایجاد شده است، بدون پرداختن به مدیریت زیرساخت فراهم می کند. برنامه های FaaS نیز مبتنی بر رویداد اجرا می شوند. آنها می توانند کد را در پاسخ به هر رویدادی، مانند داده های حسگر هوشمند یا رویدادی از سرویس ابری دیگر، اجرا کنند.
مفهوم نسبتاً جدید دیگر بدون سرور، Container-as-a-Service (CaaS) نام دارد که کانتینرها را در یک پلت فرم مجازی سازی اجرا می کند. یک کانتینر از یک برنامه کاربردی و سیستم عامل با وابستگی های نصب شده برای اطمینان از اجرای یک برنامه همراه بر روی هر پلت فرمی که در ابتدا توسعه یافته است، تشکیل شده است. یک سرویس CaaS اجازه اجرای کانتینرها را بدون نیاز به مدیریت پلتفرم مجازی سازی می دهد [ 6 ]. این مدل سرویس نسبت به مدل FaaS قدرت محاسباتی بیشتر و زمان اجرای طولانی تری ارائه می دهد.
این مقاله یک طراحی سیستم پردازش داده را پیشنهاد میکند که به صراحت برای گردشهای کاری مکانی برای اجرای سناریوهای دنیای واقعی بر روی پلتفرمهای بدون سرور با استفاده از هر دو مدل CaaS و FaaS ایجاد شده است. ما راه حلی را پیشنهاد می کنیم که به حداقل مدیریت زیرساخت نیاز دارد و با استفاده از فناوری های بدون سرور، مقیاس پذیری آسانی را فراهم می کند. ما مشاهده کردیم که مدل CaaS میتواند وظایف پیچیده جغرافیایی مانند محاسبات شطرنجی را با ارائه قدرت محاسباتی بیشتر و زمان اجرا طولانیتر انجام دهد. طراحی سیستم پیشنهادی ما دارای یک جزء ارکستراسیون کانتینر برای اجرای کانتینرهای سفارشی ساخته شده است که حاوی کدهای تحلیل جغرافیایی در مدل CaaS است. این مشارکت منحصربهفرد باعث میشود که سیستم پردازش داده ما به طور کامل در سرویسهای بدون سرور، حتی برای کارهای چالش برانگیز جغرافیایی قابل استقرار باشد. علاوه بر این، یکی دیگر از کمک های قابل توجه، پیشنهاد مدل های تعریف گردش کار برای اعلام جریان های پردازش داده به راحتی برای افزایش قابلیت استفاده از سیستم برای کاربران غیر فنی است. این مدلهای تعریف میتوانند کاربران غیر فنی را برای طراحی و اجرای گردشهای کاری مکانی درگیر کنند. کمک مهم دیگر نشان دادن نحوه استفاده از مشخصات جدید OGC API Processes با چنین سیستمی برای افزایش قابلیت همکاری است.
در این مقاله، ما یک اثبات مفهوم را برای بررسی قابلیت کاربرد سیستم پیشنهادی در یک ارائهدهنده ابر عمومی پیادهسازی کردیم. علاوه بر این، ما نمونه گردش کار را طراحی کردیم تا سیستم را با پرکاربردترین فرآیندهای پیچیده و طولانی مدت در زمینه جغرافیایی به چالش بکشیم. توجه داشته باشید که این یک مثال چالش برانگیز اما ارزشمند برای اثبات این است که طراحی سیستم می تواند برای گردش کار ساده و پیچیده استفاده شود.
2. آثار مرتبط
بالدینی و همکاران [ 7 ] پارادایم بدون سرور را با ارائه ویژگیهای آن و مقایسه پلتفرمهای ابری مختلف بررسی کرد. آنها اشاره کردند که یکی از اشکالات رویکرد بدون سرور، خطر قفل شدن فروشنده است که سیستم را به شدت به خدمات ارائه دهنده ابر وابسته می کند. آنها همچنین مشاهده کردند که اهمیت فناوری های بدون سرور به اندازه کافی توسط جامعه تحقیقاتی تشخیص داده نشده است.
کیم و همکاران [ 8 ] چارچوبی به نام Flint برای اجرای کارهای پردازش داده مبتنی بر PySpark در سرویس لامبدا خدمات وب آمازون (AWS) بدون ارائه یک خوشه پیشنهاد کرد. آنها با استفاده از زبان برنامه نویسی پایتون، که برای اجرا به زمان اجرا وابسته نیست، بر مشکلات طولانی راه اندازی سرد غلبه می کنند. آنها همچنین محدودیت های حافظه و مدت زمان اجرا را در سرویس AWS Lambda نشان دادند.
مالاوسکی و همکاران [ 9 ] یک معماری بدون سرور را مورد مطالعه قرار داد که در جریان کار علمی اعمال می شود. آنها دارای نرم افزار منبع باز HyperFlow برای اجرا بر روی پلتفرم های ابری هستند که خدمات بدون سرور ارائه می دهند. آنها ثابت کرده اند که جریان های کاری علمی را می توان بر روی معماری های بدون سرور اجرا کرد. علاوه بر این، آنها اظهار داشتند که به دلیل برخی مشاهدات، مانند مدیریت منابع سرویس های ابری آزمایش شده مانند AWS Lambda، تمام گردش های کاری علمی برای پلتفرم های بدون سرور امکان پذیر نیست.
لی و همکاران [ 10 ] سیستمهای بدون سرور را در ارائهدهندگان ابری بررسی کرد و مبادلات آنها را با ماشینهای مجازی مقایسه کرد. آنها همچنین رفتار پویا محاسبات بدون سرور را برای اجرای موازی وظایف پارتیشن بندی شده در نمونه های تابع کوچک مورد مطالعه قرار دادند. آنها نشان دادند که برنامه های کاربردی داده های بزرگ را می توان برای محاسبات بدون سرور اعمال کرد.
جی و همکاران [ 11 ] استفاده از رایانش ابری را برای گردشهای کاری مکانی ارزیابی کرد. آنها کاربرد معماری پیشنهادی خود را در محاسبات شبکه ای با مطالعه موردی مورد بحث قرار دادند. آنها به این نتیجه رسیدند که برنامههای بزرگ گردش کار مکانی میتوانند از محاسبات ابری با زمان اجرا کوتاهتر و تأمین منابع بر اساس تقاضا بهره ببرند.
کرامر و همکاران [ 12 ] یک سیستم مدیریت گردش کار را توسعه داد که مدلهای تعریف گردش کار جدید مشابه مدلهای تعریف گردش کار پیشنهادی ما را ارائه میدهد. آنها مدل های تعریف خود را با دو سیستم مدیریت گردش کار شناخته شده دیگر مقایسه کردند. مطالعه آنها همچنین نشان می دهد که مدل های تعریف گردش کار ساده شده ما می توانند قابلیت استفاده و خوانایی را افزایش دهند. آنها سیستم را در ماشین های مجازی در یک ارائه دهنده ابری بررسی کرده اند. ما در ارزیابی فقط از خدمات بدون سرور استفاده کردیم و سیستم خود را برای هر ارائه دهنده ابری که فناوری های بدون سرور ارائه می دهد قابل استقرار طراحی کردیم.
گردش کار بدون سرور [ 13 ] یک پروژه منبع باز است که چارچوبی برای اجرا و طراحی گردش کار برای اجرای توابع فراهم می کند. توابع مورد استفاده در گردش کار، نقطه پایانی API پروتکل انتقال ابرمتن (HTTP) را برای دریافت درخواستها با آرگومانها نشان میدهد. این چارچوب همچنین دارای زبان گردش کار اعلامی خود است.
2.1. خدمات گردش کار ابری
ارائهدهندگان بزرگ ابر (Google Cloud، Microsoft Azure، Amazon Web Services) راهحلهای گردش کار را ارائه میدهند که عملکردها و کانتینرهای بدون سرور را قادر میسازد تا وظایف را روی آنها اجرا کنند.
خدمات وب آمازون توابع مرحله آمازون (ASF) را ارائه می دهد [ 14 ]. اجرای گردش کار به زبان ایالات آمازون بر اساس JSON (نشانگذاری شی جاوا اسکریپت) برنامه ریزی می شود. این کنترلرهای توالی، موازی و تصمیم را برای طراحی گردش کار فراهم می کند. علاوه بر این، می تواند توابع بدون سرور (AWS Lambda) و کانتینرها (AWS Fargate) را برای اجرای کدهای از پیش مستقر شده بر روی پلتفرم های بدون سرور فراخوانی کند. می تواند داده های JSON را بین مراحل انتقال دهد. همچنین از فرآیندهای طولانی مدت پشتیبانی می کند و ویژگی های رسیدگی به خطا را فراهم می کند.
Microsoft Azure سرویس Logic App را برای اجرای گردش کار به روشی بدون سرور ارائه می دهد [ 15 ]. از فراخوانی توابع Azure برای اجرای کدهای از پیش مستقر شده در پلتفرم FaaS مایکروسافت Azure پشتیبانی می کند. علاوه بر این، اقدامات کنترل کننده ای مانند “سوئیچ”، “شرایط” و “برای هر” را دارد. این اقدامات اجازه می دهد تا بر اساس شرایط، اجرای گردش کار به مسیرهای مختلف هدایت شود.
Google Cloud خدمات Google Cloud Workflows را ارائه می دهد [ 16 ]. Google Cloud Workflow ها به صورت مراحلی با کنترل جریان منطقی ضروری مانند شرایط یا حلقه ها نشان داده می شوند. هر مرحله یک درخواست HTTP ایجاد می کند که می تواند به عنوان مثال برای راه اندازی یک عملکرد Google Cloud استفاده شود. این برای کارهای موازی گسترده طراحی نشده است زیرا فاقد نقشه اولیه موجود در سیستم های دیگر مانند ASF است.
2.2. موتورهای گردش کار کانتینری
موتورهای گردش کار منبع باز وجود دارند که می توانند در هر پلتفرم کانتینری سازی نیز مستقر شوند. موتور بومی کانتینر راه اندازی یک پلت فرم اجرای گردش کار را امکان پذیر می کند که می تواند بر اساس تقاضا و حجم داده های مورد پردازش مقیاس شود. این موتورها از سیستم های کانتینری بهره می برند. کانتینرها سبک و قابل بسته بندی هستند و بنابراین می توانند قابلیت حمل و کارایی را در یک سیستم گردش کار افزایش دهند [ 17 ].
Argo Workflows یک موتور گردش کار برای سازماندهی مشاغل موازی در Kubernetes است [ 18 ]. به عنوان یک پروژه منبع باز توسعه یافته و نگهداری می شود. اساساً، تعریف گردش کار اعلامی سفارشی خود را که قوانین و ساختار خاص خود را دارد، تجزیه و اجرا می کند. هر مرحله در گردش کار مربوط به یک تصویر ظرف اجرا شده با ورودی است.
Kubeflow پروژه منبع باز دیگری است که گردش کار یادگیری ماشین را روی Kubernetes با کانتینر اجرا می کند [ 19 ]. Kubeflow Pipelines یک افزونه برای Kubeflow است که گردشهای کار یادگیری ماشینی مقیاسپذیر را اجرا میکند. می توان آن را برای ارائه دهندگان ابر و همچنین در وعده ها مستقر کرد. برای اجرای ارکستراسیون گردش کار به ابزارهای اضافی مانند Argo نیاز دارد.
2.3. مرور
اگرچه پارادایم محاسبات بدون سرور هنوز یک مفهوم جدید است و محبوب شده است، کارهای بدون سرور قبلی عمدتاً بر روی محدودیتهای مسائل محاسباتی بیش از مدل استقرار FaaS متمرکز شدهاند. سیستم پیشنهادی ما امکان غلبه بر این مسائل را با استفاده از مدل CaaS بررسی میکند.
همانطور که بررسی کردیم که ارائه دهندگان ابر راه حل هایی برای مدیریت گردش کار دارند، نباید از مبادلاتی مانند قفل فروشنده، سهمیه ها، فناوری های محدود پشتیبانی شده و هزینه اجرا غافل شد.
ما برخی از موتورهای گردش کار کانتینری شناخته شده را که می توانند با مدل CaaS مستقر شوند، بررسی کردیم. با این حال، آنها هنوز راه حل های پیچیده ای برای ایجاد گردش کار برای کاربران غیر فنی هستند. راهحل پیشنهادی ما همچنین مدلهای تعریف گردش کار ساده را برای سادهسازی طراحی گردش کار ارائه میکند.
3. مواد و روشها
این بخش ابتدا تعریف گردش کار پیشنهادی ما و مدلهای تعریف کار را که برای تعریف گردش کار و یک کار بهصورت توضیحی استفاده میشود، توضیح میدهد. در مرحله بعد، ما یک نمودار جزء سطح بالا از سیستم پیشنهادی خود را ارائه می کنیم و جزئیات هر جزء را در نمودار سطح بالا توضیح می دهیم. ما استفاده از اجزای ضروری را برای کاهش پیچیدگی معماری و استقرار در نظر گرفتیم. ما قصد داشتیم سیستم را با هر نرمافزار یا فروشنده خاصی طراحی کنیم، و بنابراین، فناوریهای معمولی و معمولی را در پلتفرمهای بدون سرور در نظر گرفتیم.
3.1. مدل های گردش کار و تعریف کار
مدلهای تعریف گردش کار معمولاً برای تعریف گردشهای کاری پردازش داده با قوانین استفاده میشوند. آنها توضیح می دهند که چگونه یک موتور گردش کار وظایف را با قوانین قابل تایید و تفسیر [ 20 ] اجرا می کند. به منظور ایجاد یک سیستم گردش کار، ما همچنین نیاز به طراحی مدل های تعریف جدید برای رسیدگی به درخواست های گردش کار به روشی استاندارد داشتیم. ما به دلیل سادگی و خوانایی آن، از قالب Yet Another Markup Language (YAML) برای تعاریف پیشنهادی خود استفاده کردیم. YAML به دلیل نحو ساده و پشتیبانی گسترده توسط زبان های برنامه نویسی بسیار محبوب شده است [ 21 ]. YAML به عنوان زبانی قابل خواندن برای انسان در مقایسه با سایر نحوها مانند JSON (JavaScript Object Notation) و XML (Extensible Markup Language) در نظر گرفته می شود.
طرح پیشنهادی ما دو نوع مدل تعریف را معرفی کرد: مدلهای تعریف وظیفه و گردش کار. هر مدل تعریفی نقش و تفسیر متفاوتی در سیستم دارد. در بخشهای فرعی زیر، مدلهای تعریف پیشنهادی ما به تفصیل توضیح داده میشوند.
3.1.1. تعریف وظیفه
تعریف وظیفه یک کار جدید را توصیف می کند که می تواند به عنوان مرحله ای در یک گردش کار برای اجرای کد برنامه کاربردی مستقر در تصویر ظرف مورد استفاده قرار گیرد ( شکل 2 ). از آنجایی که گردش کار از وظایف مختلفی تشکیل شده است، تعریف وظیفه نقشی حیاتی برای افزودن قابلیت های جدید به سیستم ایفا می کند.
تعریف وظیفه دارای مجموعهای از قوانین برای هر ویژگی است تا تعاریف کار را ثابت نگه دارد. همچنین حذف خطاها در تعریف وظایف قبل از اجرای آنها مهم است.
جدول 1 قوانین اعتبارسنجی را برای هر ویژگی در تعریف نشان می دهد. این قوانین در سیستم گردش کار تعبیه شده و قبل از ذخیره در پایگاه داده و همچنین اجرای آنها اجرا می شوند.
اگر خروجی یا ورودی برای کار وجود نداشته باشد، ورودی ها یا خروجی ها می توانند خالی باشند.
مقادیر پارامتر در زمان اجرا به عنوان یک رشته به کانتینر مرتبط ارسال می شود. مسئولیت برنامه کانتینری رسیدگی و ارسال مقدار به نوع دیگری است. مصنوع به یک فرمت داده باینری اشاره دارد و آنها به عنوان یک فایل ارسال می شوند که در سیستم فایل کانتینر در زمان اجرا ذخیره می شوند.
شکل 3 نمونه ای از تعریف کار را نشان می دهد که از یک تصویر ظرف برچسب گذاری شده “process-dem” برای اعمال فیلترهای مختلف بر روی فایل های مدل ارتفاعی دیجیتال رستری (DEM) استفاده می کند. ما از این مثال در بخش پیاده سازی به عنوان بخشی از نمونه گردش کار استفاده خواهیم کرد.
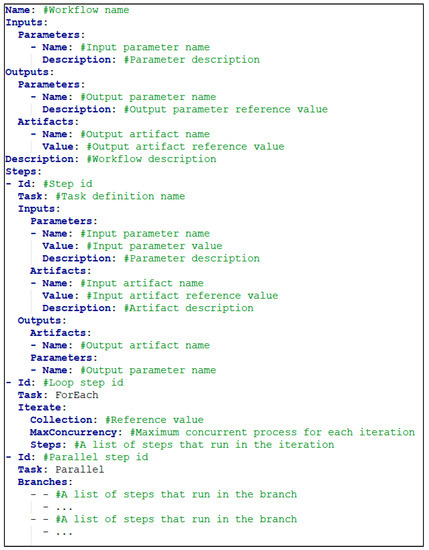
3.1.2. تعریف گردش کار
تعریف گردش کار ترکیبی از وظایف مختلف است که به ترتیب اعلام شده اجرا می شوند ( شکل 4 ). هنگامی که یک گردش کار اعتبارسنجی و ذخیره شد، می توان آن را به تعداد دفعات مورد نظر برای اجرا فراخوانی کرد.
سیستم پیشنهادی از جریان های اجرای متوالی، موازی و حلقه پشتیبانی می کند. برای انجام این نوع جریانها، تعریف گردش کار میتواند دارای مراحل انتزاعی به نامهای «ForEach» و «Parallel» باشد که به تعاریف کار سفارشیسازی شده مرتبط نیستند. این تعریف از تکرارهای تو در تو و جریان های موازی پشتیبانی می کند و به عنوان مثال، یک مرحله موازی می تواند شامل یک مرحله تکرار باشد یا یک شاخه تکرار می تواند شامل یک مرحله موازی باشد.
مقادیر مرجع برای انتقال داده های موقت تولید شده توسط مرحله دیگری در اجرای گردش کار استفاده می شود. مقادیر مرجع برای انتقال داده ها بین مراحل مفید هستند.
اینها مقادیر مرجع ممکن هستند:
{{step.[StepId].[OutputName]}}
{{input.[InputName]}}
مقدار مرجع با یک خروجی مرحله یا نام ورودی رسمیت می یابد و شناسه مرحله باید در همان تعریف گردش کار وجود داشته باشد. مراحل داخل یک مرحله تکرار همچنین می توانند یک مقدار مرجع “{{item}}” به عنوان ورودی داشته باشند. با این حال، این مقدار نمی تواند دامنه های تکرار بالایی را نشان دهد. مقادیر ارجاع شده فقط می توانند به مراحل قبلی اشاره کنند.
مشابه مدل تعریف وظیفه، مدل تعریف گردش کار پیشنهادی ما نیز دارای مجموعهای از قوانین اعتبارسنجی است ( جدول 2 ). هنگامی که یک گردش کار اعتبارسنجی و ذخیره شد، می توان آن را به تعداد دفعات مورد نظر برای اجرا فراخوانی کرد.
همه ویژگی های توضیحات اختیاری هستند و می توانند متن آزاد باشند. حتی اگر آنها اختیاری هستند، توصیه می شود برای ایجاد مستندات کاربر و اطلاعات فوق داده مفید، فیلدهای توضیحات را پر کنید.
هیچ محدودیتی برای تعداد شاخه های موازی و حداکثر محدودیت همزمانی در قوانین اعتبارسنجی وجود ندارد. از سوی دیگر، مدیران سیستم می توانند حداکثر محدودیت ها را بر اساس محدودیت های محاسباتی توصیه کنند.
3.2. معماری سیستم
هدف ما حفظ معماری سیستم با حداقل اجزا برای کاهش پیچیدگی در استقرار و مدیریت بود. این معماری ساده را می توان به راحتی در هر ارائه دهنده ابر یا در محل مستقر کرد. از سوی دیگر، نظارت و سازماندهی یک معماری ساده برای یک مدیر سیستم آسان است. مزیت دیگر این است که به توسعه دهندگان این امکان را می دهد تا به سرعت عیب یابی کنند و در صورت نیاز با قابلیت های جدید همراه شوند. علاوه بر این، ما فرض میکنیم که یک توسعهدهنده با دانش اولیه فناوریهای ابری میتواند طراحی سیستم پیشنهادی ما را بر روی یک ارائهدهنده ابر عمومی یا زیرساخت داخلی راهاندازی کند.
اجزای معماری سیستم باید بر اساس تقاضا کار کنند و برای دستیابی به هدف استقرار بدون سرور، هیچ منبعی به جز ذخیره سازی در فاز بیکار مصرف نکنند. ارتباطات بین هر جزء سیستم باید از طریق کانال های ایمن کامل شود.
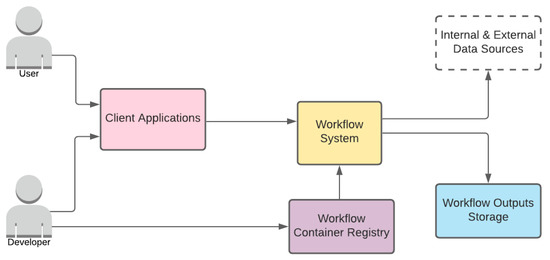
شکل 5 معماری سیستم سطح بالایی را که با چهار جزء مختلف و دو نقش بررسی کردیم را نشان می دهد. این اجزا عبارتند از:
-
سیستم گردش کار
-
رجیستری کانتینر گردش کار
-
ذخیره سازی خروجی های گردش کار
-
برنامه های کاربردی مشتری
هر جزء را با نمودارهای پشتیبانی به تفصیل توضیح خواهیم داد. علاوه بر این، نقش ها عبارتند از؛
-
کاربر
-
توسعه دهنده
در قسمت بعدی به بیان جزئیات این نقش ها و توضیح وظایف آنها می پردازیم. سپس، در بخشهای زیر جزئیاتی در مورد کامپوننتها ارائه میشود.
3.2.1. نقش ها
سیستم پیشنهادی دو نقش متفاوت دارد: توسعه دهنده و کاربر.
توسعه دهنده.توسعه دهنده مسئول نظارت، گسترش و نگهداری سیستم است. این نقش باید به سیستم های نظارت و مدیریت دسترسی داشته باشد. در برخی موارد، یک مدیر سیستم میتواند مسئولیتهای نظارت و مدیریت را به اشتراک بگذارد. توسعه دهنده وظایف گردش کار را توسعه می دهد. بنابراین توسعهدهنده باید در زمینه توسعه وظایف گردش کار به خوبی آموزش دیده باشد و ابزارها و مهارتهای لازم را برای معرفی یک وظیفه گردش کار جدید به سیستم داشته باشد. از آنجایی که سیستم به کانتینرها متکی است و وظایف گردش کار با تصاویر کانتینر همراه است، توسعه دهنده باید به ارسال تصاویر کانتینر جدید به سیستم رجیستری کانتینر دسترسی داشته باشد. توسعه دهنده همچنین مسئول ایجاد اسناد برای هر وظیفه گردش کار جدید ایجاد شده است. باید در نظر گرفت که مستندات وظیفه گردش کار باید تمام اطلاعات لازم را در مورد وظیفه گردش کار ارائه دهد تا کاربر بتواند بدون هیچ مشکلی از آن در یک گردش کار استفاده کند. از آنجایی که سیستم نیازی به مدیریت زیرساخت ابری ندارد زیرا میتواند از APIهای ارائهدهنده ابر برای کنترل سیستم اجرای کانتینر خود استفاده کند، توسعهدهنده نیازی به درک جامعی از زیرساخت ابری ندارد.
کاربر. کاربر مسئول طراحی یک گردش کار با وظایف گردش کار موجود در مخزن وظیفه است. کاربر باید تصمیم بگیرد که از کدام منابع داده در گردش کار استفاده شود و ارزیابی کند که آیا می توان از آنها برای کار گردش کار انتخابی استفاده کرد یا خیر. نقش کاربر و نقش توسعهدهنده ممکن است نیاز به همکاری داشته باشند. به عنوان مثال، فرض کنید یک منبع داده با وظیفه گردش کار ناسازگار است. در آن صورت، کاربر و توسعهدهنده ممکن است برای اصلاح وظیفه ناسازگار یا معرفی یک کار جدید، به یکدیگر بپیوندند. کاربر باید به اسناد منتشر شده دسترسی داشته باشد تا نحوه استفاده از سیستم و وظایف گردش کار موجود را بیاموزد.
کاربر باید بینش کافی برای تشخیص مشکل در اجرای ناموفق گردش کار داشته باشد. اگر مشکل ریشه در اجزای سیستم گردش کار دارد، کاربر باید آن را به توسعه دهندگان گزارش کند. اگر یک رابط کاربری گرافیکی برای استفاده از سیستم گردش کار در اختیار کاربران قرار گیرد، کاربر نیز باید در این رابط به خوبی آموزش دیده باشد.
3.2.2. سیستم گردش کار
جزء اصلی معماری سطح بالا، سیستم گردش کار است که تمام درخواستهای کاربر و کانتینر را مدیریت میکند و یک پاسخ یا رویداد ایجاد میکند.
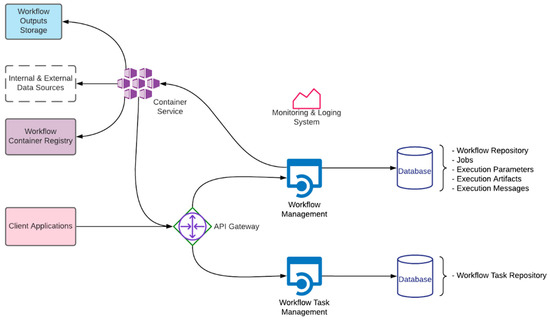
شکل 6 نشان می دهد که سیستم گردش کار از شش مؤلفه فرزند زیر تشکیل شده است که به طور متوالی در این بخش توضیح داده خواهد شد:
-
مدیریت گردش کار
-
دروازه API
-
سرویس کانتینر
-
مدیریت وظایف گردش کار
-
پایگاه داده
-
سیستم مانیتورینگ و ثبت گزارش
ما این سیستم را با قطعات و فناوری هایی طراحی کردیم که می توانند بر روی فناوری های بدون سرور اجرا شوند. در سناریوهای ترکیبی، برخی از مؤلفهها مانند سرویسهای کانتینری را میتوان یا از خدمات ارائهدهنده ابر انتخاب کرد یا در محل مستقر شد.
مدیریت گردش کار مؤلفه مدیریت گردش کار یک سرویس پشتیبان است که API Representational State Transfer (RESTful) را برای اجرا و پیگیری اجرای گردش کار ارائه می دهد. سرویس مدیریت گردش کار مسئول انجام عملیات زیر است:
-
اعتبارسنجی و ذخیره تعاریف گردش کار
-
اجرا، توقف و نظارت بر اجرای گردش کار
-
ارائه اقلام تحویلی اجرای گردش کار مانند خروجی های تحت اللفظی و باینری
در طراحی ما، تمام اجرای گردش کار به عنوان فرآیندهای طولانی مدت در نظر گرفته می شوند، زیرا آنها به شدت با سایر فرآیندهای طولانی مدت مانند اجرای کانتینر و استخراج داده ها از منبع داده دیگر همراه هستند. تمام درخواستهای اجرای گردش کار با الگوی درخواست-پاسخ ناهمزمان مدیریت میشوند. این الگو امکان استقرار سرویس مدیریت گردش کار را در یک سرویس FaaS بدون حالت با زمانهای کوتاه اجرا میکند.
شکل 7 نشان می دهد که چگونه درخواست های مشتری به چه ترتیبی از طریق یک جریان توالی اجرا می شوند. اقدامات منطبق بر OGC API Processes در یک ناحیه سایهدار بنفش نشان داده میشوند.
سرویس مدیریت گردش کار همچنین مسئول اعتبار سنجی تعاریف گردش کار قبل از اجرا و ذخیره آنها است.
علاوه بر نقاط پایانی RESTful API سفارشی، سرویس مدیریت گردش کار، نقاط پایانی سازگار با OGC API Processes را برای افزایش قابلیت همکاری با سایر برنامههای دسکتاپ و تلفن همراه جغرافیایی فراهم میکند. OGC API Processes نسخه جدید مشخصات OGC Web Processing Service (WPS) است و استانداردهای خدمات geoprocessing را تعریف می کند [ 22 ]. نسخه مشخصات جدید مربوط به شیوه های توسعه وب مدرن است که ادغام با معماری های سیستم جدید را آسان می کند. هر تعریف گردش کار ذخیره شده را می توان به عنوان یک فرآیند OGC بازیابی کرد و نام گردش کار به عنوان “شناسه فرآیند” در پاسخ های OGC نشان داده می شود. تمام گردشهای کاری ذخیرهشده فقط میتوانند به صورت ناهمزمان اجرا شوند، بنابراین گزینه اجرای همزمان نباید ارائه شود.
نتایج اجرا با استفاده از خروجی های پارامتر و مصنوع از اجرای کامل تولید می شود. سرویس مدیر گردش کار API ذخیره خروجیهای گردش کار را فراخوانی میکند تا در صورت تولید خروجیهای مصنوع، مکانیابهای منبع یکسان دانلود امضاشده موقت (URL) را ایجاد کند. بنابراین، برنامه مشتری می تواند آنها را بدون مشغول نگه داشتن نمونه سرویس مدیریت گردش کار دانلود کند.
سرویس مدیریت گردش کار نیز مسئولیت اجرای گردش کار را با تعامل با سایر اجزاء بر عهده دارد ( شکل 8 ). ما آن را طوری طراحی کردیم که با مدل FaaS مستقر شود. بنابراین، این یک سرویس بدون حالت است و از پایگاه داده برای ذخیره تمام وضعیت های اجرای گردش کار استفاده می کند. APIهای RESTful را برای رسیدگی به درخواستهای HTTP از کانتینرها برای بهروزرسانی وضعیت اجرا و کار و ادامه مرحله بعدی در گردش کار فراهم میکند. API Gateway تمام درخواست های HTTP را از کانتینرها به سرویس مدیریت گردش کار هدایت می کند.
سرویس مدیریت گردش کار باید بداند که چگونه با سرویس کانتینر برای ایجاد، اجرا و کشتن کانتینرها بر اساس الزامات مرحله اجرا تعامل داشته باشد. بنابراین، سرویس کانتینر باید از طریق API ها برای هماهنگ کننده جریان کار قابل دسترسی باشد.
در طول اجرای کار، سرویس باید URL های موقت آپلود و دانلود امضا شده را از ذخیره سازی خروجی گردش کار برای مصنوعات ورودی و خروجی ایجاد کند و این URL ها را به محفظه تماس گیرنده به طور ایمن آپلود یا دانلود کند. ایجاد URL های موقت با زمان کافی برای آپلود و دانلود فایل های بزرگ بدون وقفه بسیار مهم است.
سرویس مدیریت گردش کار باید متغیرهای محیطی مورد نیاز را برای اجرای کانتینرها تنظیم کند. به عنوان مثال، کلید API باید به عنوان یک پارامتر محیطی به کانتینر تزریق شود تا به طور ایمن با ارکستراتور گردش کار ارتباط برقرار کند.
دروازه API. دروازه API بین برنامه های کاربردی کلاینت و دو سرویس مدیریت قرار می گیرد و ترافیک HTTP را بر اساس پیکربندی مسیریابی به یک سرویس Backend مربوطه هدایت می کند ( جدول 3 ). دروازه API همچنین باید درخواست های HTTP را به رویدادهای FaaS برای فراخوانی خدمات باطن FaaS ترجمه کند [ 23 ]. ضروری است زیرا تمام خدمات مدیریتی طراحی شده اند تا در صورت امکان به صورت FaaS مستقر شوند.
API Gateway باید به عنوان یک سرویس مدیریت شده و بدون سرور در ارائه دهندگان ابر عمومی برای کاهش مدیریت و افزایش مقیاس پذیری انتخاب شود.
دروازه API باید از ایجاد RESTful API و پشتیبانی بار JSON در درخواستها و پاسخهای HTTP پشتیبانی کند.
نقش دیگر API Gateway محافظت از خدمات مدیریت در برابر درخواست های غیرمجاز است [ 24 ]. باید از احراز هویت مبتنی بر توکن پشتیبانی کند ( شکل 9 ). در طراحی پیشنهادی ما، سرویسهای پشتیبان احراز هویت و مجوز را به دروازه API واگذار میکنند. بنابراین، دروازه API باید پشتیبانی از یکپارچه سازی ارائه دهنده هویت برای استفاده از فروشگاه کاربر و مجوز درخواست ها با لیست کنترل دسترسی (ACL) داشته باشد. به این ترتیب، خدمات باطن از لایههای امنیتی اضافی سادهسازی میشوند. علاوه بر این، دروازه API باید از ارتباط ماشین به ماشینی که برای ایمن سازی تماس های HTTP بین مدیریت گردش کار و سرویس کانتینر مورد نیاز است، پشتیبانی کند یا اجازه دهد.
سرویس کانتینر. سرویس Container عنصر محاسباتی اصلی سیستم گردش کار است و مسئول اجرای تصاویر کانتینر درخواستی برای اجرای کد سفارشی ساخته شده با ورودی ها است. در طراحی خود، ما پیشنهاد کردیم از یک پلت فرم مبتنی بر CaaS به عنوان یک سرویس کانتینری در یک ارائه دهنده ابر عمومی استفاده کنیم. این پلتفرمها الزامات عملیاتی پیچیده را انتزاع میکنند و کاربران را قادر میسازند تا سیستم را به سرعت مقیاس و مدیریت کنند [ 25 ].
در پیاده سازی، کانتینرها ممکن است نیاز به دسترسی به منابع داده خارجی یا داخلی برای پردازش داشته باشند. علاوه بر این، کانتینرها باید تماسهای HTTP را با مدیر گردش کار برقرار کنند تا وضعیت خود را گزارش کند و اطلاعات مورد نیاز را برای اجرا بکشد. در چنین شرایطی، سرویس کانتینر باید به کانتینرها امکان دسترسی به منابع اینترنتی خارجی و مدیر گردش کار را از طریق مؤلفه API Gateway بدهد.
سرویس کانتینر همچنین باید یک API داشته باشد که سرویس مدیریت گردش کار را برای مدیریت چرخه حیات کانتینر یکپارچه کند. به عنوان مثال، سرویس مدیریت گردش کار نیاز به چرخش یا خاتمه کانتینرها بر اساس وضعیت اجرای وظیفه دارد، بنابراین یک API باید این رویه ها را ارائه دهد.
مدیر وظیفه گردش کار. مؤلفه مدیریت وظایف گردش کار یکی دیگر از سرویس های پشتیبان است که یک API RESTful برای مدیریت وظایف گردش کار ارائه می دهد و به گونه ای طراحی شده است که عمدتاً توسط نقش توسعه دهنده استفاده شود. سرویس مدیریت وظایف گردش کار مسئول اعتبارسنجی و ذخیره تعاریف وظایف گردش کار است. این سرویس ممکن است نیاز به تماس با رجیستری کانتینر داشته باشد تا بررسی کند که آیا تگ تصویر کانتینر مرتبط در محدوده فرآیند اعتبارسنجی وجود دارد یا خیر.
سرویس مدیر وظیفه گردش کار همچنین باید مستندات API را بر اساس مشخصات Open API (OAS) که به طور گسترده پشتیبانی میشود تا به توسعهدهنده اجازه دهد نقاط پایانی را بیاموزد یا ایجاد یک کیت توسعه نرمافزار (SDK) یا رابط خط فرمان را ممکن کند، در معرض دید قرار دهد. CLI) ابزاری برای تعامل با API [ 26 ].
این سرویس از پایگاه داده برای ذخیره تعاریف وظایف در مدل های تعریف کار پیشنهادی استفاده می کند.
پایگاه داده. طرح پیشنهادی هیچ معیار اجباری برای انتخاب پایگاه داده ندارد. با این وجود، پایگاه داده باید به عنوان سرویس مدیریت شده و بدون سرور در ارائه دهندگان ابر عمومی برای کاهش مدیریت و افزایش بهینه سازی منابع انتخاب شود. فناوری پایگاه داده تعیین شده باید دارای ویژگی های نمایه سازی برای بهبود عملکرد پرس و جو باشد. علاوه بر این، باید از زبان های برنامه نویسی مورد استفاده در توسعه خدمات باطن پشتیبانی کافی داشته باشد.
مدلهای موجودیت پایگاه داده باید با توجه به مشخصات OGC Processing API طراحی شوند تا پاسخهای سازگار با API پردازش را از طریق سرویس مدیریت گردش کار برگردانند.
نکته ضروری دیگر این است که در نظر بگیریم که هر سرویس باطن باید پایگاه داده یا جدول پایگاه داده خصوصی خود را داشته باشد [ 27 ].
سیستم مانیتورینگ و ثبت گزارش ردیابی معیارهای سیستم و گزارش های منتشر شده از اجزای سیستم برای مدیریت و نظارت بسیار مهم است [ 28 ]. نقشهای توسعهدهنده و کاربر باید به مؤلفه نظارت و گزارش دسترسی داشته باشند. کاربر فقط باید دسترسی فقط خواندنی داشته باشد و بر اساس معیارها یا گزارشها هشدار ایجاد کند. توسعهدهنده میتواند معیارها را پیکربندی کند و یک داشبورد نظارتی برای دیدن تصویر بزرگ طراحی کند. توسعهدهنده همچنین میتواند منابع داده جدیدی را برای دریافت گزارشها و معیارهای بیشتر از سایر اجزای زیرساخت اضافه کند.
این سیستم باید APIها و SDK های لازم برای زبان های برنامه نویسی مورد استفاده توسط سرویس های پشتیبان را داشته باشد. علاوه بر این، باید از یکپارچه سازی خدمات انتخاب شده برای جمع آوری معیارها و گزارش های کافی پشتیبانی کند.
3.2.3. رجیستری کانتینر گردش کار
در این کامپوننت، تصاویر ظرف ساخته شده توسط توسعه دهنده ذخیره می شود. هنگامی که مرحله گردش کار برای اجرا مورد نیاز است، سرویس کانتینر تصویر ظرف ذخیره شده را از رجیستری ظرف گردش کار بر اساس نام تصویر کانتینر بیرون می کشد ( شکل 8 ). مقدار نام تصویر ظرف از تعریف وظیفه گردش کار مرتبط به دست می آید.
این تصاویر ظرف باید با یک عامل تماس گیرنده ساخته شوند. این نماینده تماس گیرنده مسئول تماس با سرویس مدیریت گردش کار از طریق درخواست های HTTP است. هنگامی که یک فرآیند شروع یا تکمیل می شود، عامل باید ورودی ها و خروجی ها را دانلود و آپلود کند. اساساً، این عامل تماس گیرنده دستور داده شده را در یک پردازش فرزند اجرا می کند و خروجی ها و خطاهای کنسول آن را جمع آوری می کند. میتواند تمام این گزارشها و خطاهای کنسول را برای ثبتنام به ارکستراتور گردش کار گزارش کند. همچنین می تواند کد بازگشتی را از فرآیند فرزند دریافت کند. بنابراین می تواند زمانی که فرآیند با موفقیت یا خطا تکمیل می شود گزارش دهد.
عامل تماس گیرنده را می توان در یک تصویر ظرف پایه در راه حل پیشنهادی ما برای افزایش قابلیت استفاده مجدد جاسازی کرد. یک تصویر ظرف را می توان از یک تصویر ظرف دیگر به ارث برد تا عملکرد آن را گسترش دهد. بنابراین، همانطور که در شکل 10 نشان داده شده است، تصاویر کانتینر برای اجرای وظایف را می توان از این تصویر کانتینر پایه به ارث برد . نکته مهم دیگر این است که برنامه تماس گیرنده باید مکانیزمی برای امتحان مجدد داشته باشد تا در صورت بروز قطعی کوتاه در سیستم مدیریت گردش کار یا دروازه API، کانتینر را زنده نگه دارد [ 29 ].
3.2.4. ذخیره سازی خروجی گردش کار
اجرای مرحله گردش کار به یک جزء ذخیره سازی برای ذخیره اشیاء مصنوع خروجی نیاز دارد. در ارائهدهندگان ابر عمومی، سیستمهای ذخیرهسازی، ذخیرهسازی شی نامیده میشوند، و ذخیرهسازیهای شی، بر خلاف سیستمهای فایل، باینریها را بهعنوان شی مدیریت میکنند [ 30 ]. همچنین فنآوریهای ذخیرهسازی اشیاء منبع باز وجود دارند که میتوانند در استقرار در محل استفاده شوند [ 31 ]. توصیه می کنیم از سرویس ذخیره سازی اشیاء در هر دو سناریو استقرار استفاده کنید تا مدیریت شی ایمن، مقیاس پذیر و قابل دسترسی را از طریق درخواست های HTTP فعال کنید.
ذخیره سازی خروجی گردش کار باید به عنوان یک سرویس ذخیره سازی شی انتخاب شود. این نوع سرویس ذخیره سازی مدیریت شی و دسترسی از طریق API ها را امکان پذیر می کند. همانطور که در بخش های قبلی توضیح دادیم، سیستم گردش کار باید توسط عوامل تماس گیرنده در کانتینرها و سرویس مدیریت گردش کار قابل دسترسی باشد. آنها باید با APIهای ذخیره سازی خروجی گردش کار سازگار باشند.
این ذخیره سازی باید امکان ذخیره این اشیاء مصنوع را در یک ساختار فراهم کند. اشیاء به صورت پارتیشن بندی شده توسط job id و step id به صورت زیر ذخیره می شوند. «{job-id}/{step-id}/{iteration- id}/output -name». در این ساختار، “{iteration-id}” به طور پیشفرض صفر است، در حالی که خروجیهای مرحله تکرار با یک عدد شاخص تکرار افزایشی ذخیره میشوند.
API ذخیره سازی خروجی گردش کار باید دارای نقاط پایانی برای ایجاد URL های موقت برای اشیاء ذخیره شده، دسترسی ایمن به اشیاء از طریق مؤلفه ها یا نقش های مختلف باشد.
3.2.5. برنامه های کاربردی مشتری
برنامه های مشتری را می توان به دو دسته دسته بندی کرد. دسته اول را می توان “واسط کاربری” نامید که انواع مختلفی از برنامه ها هستند که نقش کاربر را هدف قرار می دهند. دسته دوم را می توان “ابزارهای توسعه دهنده” نامید که برنامه ها و SDK هایی هستند که توسط نقش توسعه دهنده استفاده می شوند ( شکل 11 ). همه برنامه های سرویس گیرنده تماس های API را با احراز هویت مبتنی بر توکن در برابر سیستم گردش کار انجام می دهند.
رابط های کاربری برنامه هایی با رابط کاربری گرافیکی هستند که راه آسان و شهودی برای تعامل با API های ارائه شده توسط معماری سیستم پیشنهادی را ارائه می دهند. آنها را می توان بر روی پلتفرم های دسکتاپ، موبایل و وب اجرا کرد. برنامه های کاربردی رابط کاربری همچنین برای دانلود خروجی های تولید شده با URL های موقت نیاز به دسترسی به ذخیره سازی خروجی گردش کار دارند.
ابزارهای توسعهدهنده میتوانند به ساخت رابطهای کاربری، ثبت تعاریف جدید وظایف گردش کار و انتشار تصاویر کانتینر جدید کمک کنند. هنگامی که فناوریهای کانتینریسازی انتخابشده ابزارهایی را ارائه میکنند، میتوان از آنها برای ساخت و انتشار تصاویر کانتینر توسط توسعهدهنده استفاده کرد [ 32 ].
4. اجرا
برای ارزیابی معماری سیستم پیشنهادی، ابتدا آن را در یکی از ارائه دهندگان ابر عمومی معمولی و بالغ به عنوان اثبات مفهوم پیاده سازی کردیم. ارائهدهنده ابر AWS انتخاب شد زیرا دارای سرویسهای مختلف بدون سرور است که میتوانیم از آنها برای استقرار یک سیستم کامل بدون سرور استفاده کنیم. سایر ارائه دهندگان ابر عمومی خدمات مشابهی دارند که می توانند برای استقرار نیز استفاده شوند. دلیل دیگری برای انتخاب AWS این است که یک چارچوب Well-Architected برای بررسی اینکه آیا معماری ابر از بهترین شیوههای معماری پیروی میکند ارائه میکند [ 33 ]. بنابراین، معماری سیستم پیشنهادی را بر اثبات مفهوم در بخش ارزیابی با ارکان این چارچوب بررسی کردیم.
4.1. پیاده سازی ابر
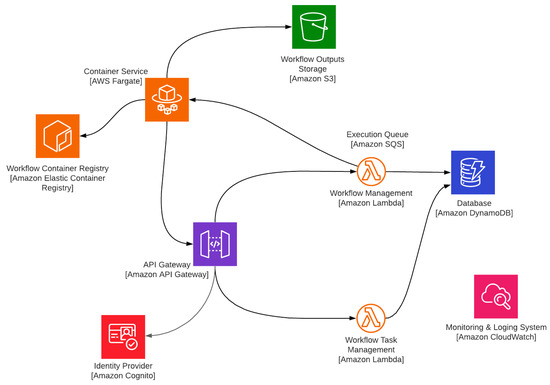
این بخش به بررسی استقرار معماری سیستم پیشنهادی با AWS به عنوان یک ارائه دهنده ابر عمومی می پردازد. ما معماری سیستم خود را طراحی کردهایم که میتواند بهعنوان بدون سرور اجرا شود، بنابراین تنها خدمات بدون سرور ارائهدهنده ابر را برای هر مؤلفه ترجیح میدهیم تا کاربرد آن را با استقرار بدون سرور نشان دهیم. شکل 12 نمودار پیاده سازی سیستم را با نام سرویس AWS و نام اجزا در بخش معماری سیستم نشان می دهد. ما استقرار و پیاده سازی هر جزء را با ارائه جزئیات سرویس انتخابی و زبان برنامه نویسی توضیح می دهیم.
4.1.1. خدمات مورد استفاده در وب سرویس آمازون
همه سرویسهای AWS APIهایی را ارائه میکنند که امکان ادغام با سایر سرویسها و برنامههای کاربردی را فراهم میکنند. ارتباط بین سرویس های AWS به طور یکپارچه و ایمن برقرار می شود. علاوه بر این، AWS از مدلهای مختلف استقرار Infrastructure-as-a-Code (IaaC) پشتیبانی میکند که مدیریت زیرساخت را با مدلهای توصیفی قابل خواندن توسط ماشین ممکن میسازد [ 34 ]. این مدل استقرار، حفظ زیرساخت را در یک سیستم نسخهسازی آسانتر میکند. یکی دیگر از نقاط مشترک همه سرویس های انتخاب شده، ادغام با یک سرویس نظارت و گزارش مرکزی به نام Amazon CloudWatch است. این سرویس بینش ارزشمندی در مورد مشکلات و استفاده از منابع می دهد [ 35 ].
سرویس آمازون S3 برای استفاده به عنوان ذخیره خروجی گردش کار انتخاب شد. ذخیره سازی اشیاء را مدیریت می کند و از سازماندهی اشیا با استفاده از پیشوندها پشتیبانی می کند. علاوه بر این، ایجاد URL های موقت برای بارگیری و آپلود اشیاء نیز امکان پذیر است [ 36 ].
Amazon API Gateway تنها راهحل دروازه API در مجموعه خدمات AWS است، بنابراین ما آن را برای مولفه دروازه API قرار دادیم. ما آن را به گونه ای پیکربندی کردیم که ترافیک را بر اساس نگاشت مسیر به سرویس های پشتیبان هدایت کند. هنگامی که با آمازون لامبدا استفاده می شود، می تواند درخواست های HTTP را به تابع آمازون لامبدا به عنوان رویداد هدایت کند [ 37 ]. همچنین از مجوز مبتنی بر توکن برای محافظت از API ها در برابر دسترسی غیرمجاز پشتیبانی می کند.
ما از Amazon Cognito به عنوان ارائهدهنده هویت برای تأیید درخواستها بر اساس فهرست کنترل دسترسی با نقشهای پیشنهادی کاربر و توسعهدهنده استفاده کردیم. Amazon Cognito همچنین یک ارائه دهنده احراز هویت است که می تواند ورود کاربر را مدیریت کند.
آمازون لامبدا برای استقرار تمام خدمات پشتیبان در طراحی ما استفاده شد. این یک سرویس مبتنی بر FaaS مبتنی بر رویداد است و از طیف گستردهای از زبانهای برنامهنویسی پشتیبانی میکند و توسط رویدادهایی که از سایر سرویسهای AWS سرچشمه میگیرند، راهاندازی میشود [ 38 ]. این به صراحت با آمازون API Gateway ادغام شده است.
Amazon DynamoDB یک پایگاه داده با ارزش کلیدی مبتنی بر سند است، بنابراین رویکردی را برای مدلسازی پایگاه داده متفاوت از پایگاههای داده رابطهای سنتی ارائه میکند [ 39 ]. Amazon DynamoDB به عنوان یک مؤلفه پایگاه داده برای ذخیره همه موجودیت ها استفاده شد. ما از نوع تامین بر اساس تقاضا استفاده کردیم. طراحی ما از فرآیندهای OGC API پشتیبانی می کند، بنابراین ما مشخصات را در مدل سازی داده ها رعایت کردیم. یک گزینه جایگزین سرویس پایگاه داده بدون سرور می تواند Amazon Aurora Serverless باشد. هنگامی که نیاز به ساخت یک پایگاه داده پیچیده و رابطهای وجود دارد، میتوان آن را ترجیح داد زیرا مبتنی بر سرور پایگاه داده رابطهای PostgreSQL با پشتیبانی از دادههای مکانی است [ 40 ].
Amazon Container Registry یکی دیگر از خدمات کاملاً مدیریت شده است که از ذخیره، مدیریت و استقرار تصاویر کانتینر Docker پشتیبانی می کند. به عنوان جزء رجیستری کانتینر برای ذخیره تصاویر کانتینر مرتبط با وظایف گردش کار استفاده می شود.
Amazon Fargate یک سرویس نسبتاً جدید AWS است که به تدریج جایگزین سرویس قدیمی EC2 Container Service (ECS) برای تولید و حجم کاری سندباکس می شود [ 41 ]. این با یک مدل CaaS بدون سرور ارائه می شود و از اجرای کانتینرهای Docker بر اساس تقاضا یا طبق برنامه پشتیبانی می کند. ما Amazon Fargate را برای اجرای ظروف وظیفه گردش کار با دسترسی به اینترنت و حساب ذخیره سازی گردش کار پیکربندی کردیم. بنابراین، کانتینرها می توانند در طول زمان اجرا به منابع داده داخلی و خارجی دسترسی داشته باشند.
4.1.2. توسعه Backend
ما دو سرویس پشتیبان را توسعه دادیم که به عنوان میکروسرویس طراحی شده بودند. هر سرویس می تواند به طور جداگانه مستقر و مقیاس شود. همانطور که ما آنها را در آمازون لامبدا مستقر کردیم، مقیاس بندی و در دسترس بودن توسط AWS مدیریت می شود. ما از .Net Core Framework نسخه 3.1 با زبان برنامه نویسی سی شارپ برای توسعه همه کامپوننت ها استفاده کردیم. ما متدولوژی برنامه دوازده عاملی آدام ویگینز را در توسعه دنبال کردیم و به کار بردیم [ 42 ].
خدمات Backend با چارچوب .Net Core Web API ایجاد شدند که امکان ایجاد API های RESTful با پشتیبانی داخلی از فرمت JSON را فراهم می کند. از آنجایی که ما مدلهای گردش کار و تعریف وظایف خود را در قالب YAML طراحی کردیم، یک کتابخانه برای تجزیه درخواستهای YAML برای پذیرش گردش کار و تعاریف کار اضافه کردیم. علاوه بر این، ما از کتابخانه های منبع باز دیگر برای پیاده سازی الزامات اضافی استفاده کردیم. به عنوان مثال، ما از کتابخانه MediatR برای پیاده سازی Command Query Responsibility Segregation (CQRS)، یک الگوی معماری که دستورات و پرس و جوها را با دو روش مختلف ارتباطی جدا می کند، استفاده کردیم [ 43 ].]. CQRS معمولاً برای سیستمهایی استفاده میشود که تعاملات پیچیده را با چندین منبع داده در حال تغییر در سراسر مرزهای فرآیند مدیریت میکنند. علاوه بر این کتابخانهها، کتابخانههای AWS.Net نیز برای تعامل امن با آمازون Fargate، Amazon S3 و Amazon DynamoDB APIها استفاده میشوند [ 44 ].
عامل ظرف به عنوان قابل اجرا برای محیط های لینوکس کامپایل شده است. چارچوب .Net Core از کامپایل فایل های خود اجرایی برای سیستم عامل لینوکس پشتیبانی می کند. این بسیار مهم است زیرا تصاویر Docker که ما در ارزیابی استفاده کردیم مبتنی بر لینوکس هستند.
4.2. ارزیابی
برای اختصار، سیستم را با دو نمونه گردش کار فراگیر ارزیابی کردیم که از تمام ویژگیهای ارائه شده در مدلهای تعریف گردش کار استفاده میکردند و طراحی سیستم را نسبت به مدلهای اجرایی مانند پردازش موازی و تکراری به چالش میکشیدند. بنابراین، ما نشان دادیم که چگونه مدل تعریف گردش کار ما می تواند فرآیندهای پیچیده جغرافیایی را با سیستم بدون سرور پیشنهادی تعریف کند. علاوه بر این، معماری پیشنهادی را با ابزار AWS Well-Architected که مفاهیم کلیدی، اصول طراحی و بهترین شیوههای معماری را برای طراحی و اجرای بارهای کاری در فضای ابری توصیف میکند، بررسی کردیم [ 33 ].
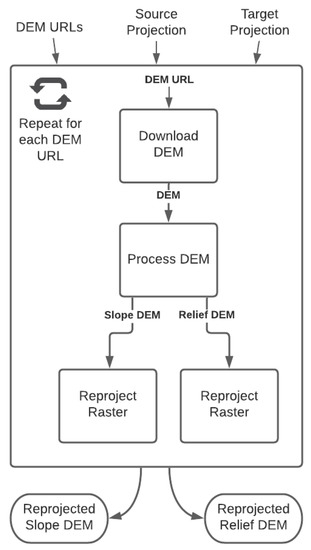
به عنوان مثال اول، یک گردش کار نمونه برای پردازش مدلهای ارتفاعی دیجیتال (DEM) دانلود شده از یک منبع عمومی و انجام محاسبات شطرنجی شیب و برجستگی بر روی هر فایل همراه با بازپرداخت مجدد سیستم مختصات تعریف کردیم. نمونه نشاندادهشده برای جریانهای پردازش دادههای بدون سرور چالشبرانگیز است، زیرا نیازهای محاسباتی در مدل FaaS قابل رسیدگی نیستند. ما به طور خاص پردازش شطرنجی را ترجیح میدهیم تا نشان دهیم که سیستم پیشنهادی برای اجرای طولانیمدت که نیاز به قدرت محاسباتی و حافظه بیشتری دارند، قابل اجرا است. علاوه بر این، گردش کار نمونه شامل وظایف اجرای موازی و تکراری پیشنهادی ما برای نشان دادن استفاده از وظایف “ForEach” و “Parallel” است. شکل 13نمونه گردش کار را نشان دهید که از کار “ForEach” برای تکرار مجموعه ای از وظایف برای دانلود فایل های DEM استفاده می کند و توابع شطرنجی را به صورت تکراری اعمال می کند. هنگامی که تمام تکرارها کامل شد، مرحله بعدی فایلهای DEM را به صورت موازی به سیستم مختصات دیگری بازپخش میکند تا وظیفه «موازی» را نشان دهد و خروجیها را تولید کند.
برای مدیریت این گردش کار، ما سه تعریف مختلف کار و تصاویر محفظه docker را برای استفاده در گردش کار ایجاد کردیم ( شکل 14 ). ما برای این کارها از کتابخانه های زمین فضایی پایتون منبع باز استفاده کردیم.
شکل 15 نمونه پارامترهای ورودی برای اجرا و بازیابی پارامترهای خروجی را در پایان اجرای گردش کار نمونه تعریف شده در بالا نشان می دهد. بار درخواست و بدنه پاسخ در قالب JSON است که با مشخصات OGC API Processes مطابقت دارد.
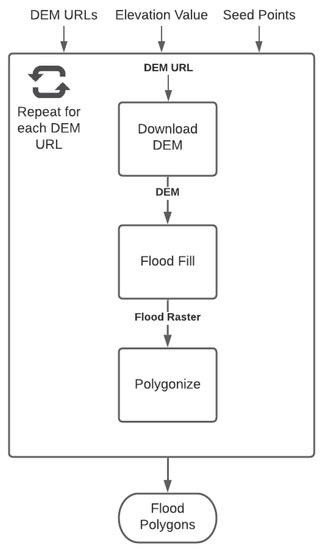
برای مثال در دنیای واقعی، مدل طغیان سیل را در نظر گرفتیم. این یکی از رایجترین تحلیلهای جغرافیایی است که تأثیر سیل را بر زیرساختهای عمومی، تأسیسات حیاتی و جمعیتهای آسیبپذیر تجسم میکند. ما از جریان کار غرقاب سیل که توسط جوئل لاهد [ 45 ] توسعه یافته است استفاده کردیم. به طور خلاصه، این مدل با یک نقطه بذر شروع می شود و منطقه ای با سطح آبگرفتگی را سیل می کند. منطقه سیل زده به عنوان یک چند ضلعی برداری برای هر منطقه زمین تولید می شود. شکل 16 تعریف گردش کار تعریف شده در مدل تعریف گردش کار پیشنهادی را نشان می دهد.
ما گردش کار را با ترکیبی از سه مرحله تعریف کردیم ( شکل 17 ). مرحله اول از کار تکرار ForEach استفاده می کند که URL های DEM را حلقه می کند و مراحلی را که تجزیه و تحلیل سیل را برای هر فایل DEM دانلود شده انجام می دهد، اجرا می کند.
به طور مشابه، کد پیشبینی سیل را نیز داکر کردیم و وظایف گردش کار را از طریق Workflow Task Management API تعریف و ثبت کردیم. ما از کار «دانلود DEM» از نمونه قبلی برای دانلود مدلهای زمین استفاده مجدد کردیم
شکل 18 نمونه بار درخواستی حاوی پارامترهای ورودی برای اجرای گردش کار سیل را نشان می دهد. علاوه بر این، یک بدنه نمونه پاسخ، نشانیهای اینترنتی را برای نشان دادن نشانیهای اینترنتی دانلود امضاشده مناطق سیل در قالب برداری کسر کرده است. نقاط بذر در قالب متن شناخته شده (WKT) MultiPoint ارسال می شوند و محاسبه تحلیل سیل برای هر نقطه متقاطع در منطقه زمین اجرا می شود.
ما معماری ابری بدون سرور پیاده سازی شده را با ابزارهای AWS Well-Architectured با پنج ستون آن بررسی کردیم و آنها برای تولید سیستم های پایدار و کارآمد مفید هستند. AWS ادعا میکند که این ستونها به معماران کمک میکنند تا زیرساختهای امن، با کارایی بالا، انعطافپذیر و کارآمد بسازند.
رکن 1: تعالی عملیاتی – ما اصول این ستون را پذیرفتیم. زیرساخت و استقرار کد را می توان در طراحی ما خودکار کرد. در پیاده سازی، ما همچنین استقرار کد و زیرساخت را با ابزارهای یکپارچه سازی و استقرار مداوم و کیت توسعه ابری AWS خودکار کردیم. استقرار API، گردش کار، و استقرار وظایف را میتوان بهطور تاریخی نسخهبندی کرد و در صورت بروز هر گونه شکست در استقرار، قابل برگشت است. همچنین نقشهای کاربر و مسئولیتهای رویهای را در بخش معماری سیستم اصلاح کردیم. ما سیستم پیشنهادی را با سناریوهای مختلف آزمایش کردیم تا پایداری آن را افزایش دهیم و خرابی ها را کاهش دهیم. به عنوان مثال، ما دو مثال جامع برای به چالش کشیدن طراحی سیستم در این مقاله ارائه کردیم.
ستون 2: امنیت – این ستون بر محافظت از داده ها و سیستم ها تمرکز دارد. همانطور که نشان می دهد، ما نقش ها را با امتیازات مختلف تعریف کردیم و در طراحی سیستم، امنیت را در اولویت قرار دادیم. مؤلفه دروازه API از تمام نقاط پایانی با مدیریت هویت متمرکز محافظت می کند و تمام انتقال داده ها بین مؤلفه ها از کانال های امن استفاده می کند. خروجیهای گردش کار در فضای ذخیرهسازی خصوصی ذخیره میشوند و تنها توسط مدیر گردش کار قابل دسترسی هستند. URL های عمومی فایل های درخواستی با طول عمر کوتاه و پارامترهای منحصر به فرد تولید می شوند.
ستون 3: قابلیت اطمینان – ستون قابلیت اطمینان تضمین می کند که سیستم در صورت نیاز عملکرد مورد نظر را به درستی و به طور مداوم انجام می دهد. ما سیستم را با فناوریهای بدون سرور طراحی کردیم و این رویکرد قابلیت اطمینان را به حداکثر میرساند زیرا مقیاسپذیری و در دسترس بودن را به ارمغان میآورد. بنابراین، سیستم نیازی به ارزیابی حجم کاری ندارد زیرا ما از خدمات کاملاً مدیریت شده استفاده کردیم. تست های واحد و پایان به انتها در پیاده سازی های سطح تولید برای شناسایی خرابی ها پس از هر تغییر کد در مرحله ارزیابی مورد نیاز است.
ستون 4: بهره وری عملکرد – ستون کارایی عملکرد استفاده از منابع محاسباتی را به طور کارآمد برای برآورده کردن نیازها و حفظ کارایی با تغییر تقاضا توصیه می کند. ما یک طراحی بدون سرور پیشنهاد کردیم و از استفاده از هر سرویسی که به طور مداوم در حال اجرا است اجتناب کردیم. معماریهای بدون سرور، بهطور پیشفرض، با استفاده از منابع زیرساختی به روشی بهینه، کارایی عملکرد را تا حد امکان افزایش میدهند. عملکرد طراحی سیستم پیشنهادی به اجرا و عملکرد زیرساخت ابری بستگی دارد. به عنوان مثال، مقداردهی اولیه کانتینر، تأخیر را برای اجرای هر مرحله اضافه می کند. این مدت زمان تأخیر می تواند بین سرویس های کانتینر مختلف برای مدل CaaS متفاوت باشد.
رکن 5: بهینه سازی هزینه– ستون بهینه سازی هزینه بر حذف هزینه های غیر ضروری تمرکز دارد. حتی اگر تمرکز اصلی ما روی این مقاله ارائه یک سیستم بهینه سازی هزینه نیست، معماری های بدون سرور نیز به طور پیش فرض مقرون به صرفه هستند. آنها از منابع بر حسب تقاضا استفاده می کنند و معمولاً هنگام بیکاری در ارائه دهندگان ابر عمومی هزینه ای ندارند. هنگامی که سیستم مستقر شد، باید به طور مداوم نظارت شود و ممکن است نیاز به محدود کردن مصرف منابع برای تحت کنترل نگه داشتن هزینه ها داشته باشد. از سوی دیگر، خدمات بدون سرور، مدیریت زیرساخت و اتوماسیون مقیاس پذیری را از کاربر انتزاع کردند. بنابراین، طراحی سیستم پیشنهادی به یک مدیر سیستم اختصاص داده شده که دانش عمیق در مدیریت زیرساخت ابری را میداند، نیاز ندارد. نقش توسعهدهنده پیشنهادی میتواند وظایف لازم برای مدیریت سیستم را انجام دهد.
5. بحث و نتیجه گیری
طراحی یک سیستم مدیریت گردش کار جغرافیایی با حداقل مداخله انسانی هنوز یک موضوع در جامعه جغرافیایی است. ما مطالعه ای ارائه کردیم که می تواند راه حلی برای این پدیده ارائه دهد. هدف ما ارائه طراحی سیستمی بود که میتواند در سناریوهای دنیای واقعی در هر ارائهدهنده ابر بزرگ یا در محل که فناوریهای بدون سرور را ارائه میدهد، اعمال شود. فنآوریهای بدون سرور راهحلهای ممکن جدید بسیاری را برای مشکلات بحث موجود در پردازش داده و استقرار برنامهها به ارمغان میآورند.
جامعه جغرافیایی در حال کار بر روی این منطقه با انواع تحقیقات مختلف است که برای اجرای الگوریتم های پیشرفته نیاز به گردش کار دارد. آنها به طور فعال در حال توسعه مشخصات جدید برای استانداردسازی و افزایش قابلیت همکاری هستند و OGC یکی از شناخته شده ترین سازمان هایی است که روی این مشخصات کار می کند. آنها روی مشخصات WPS کار کرده اند و آخرین نسخه 2.0 [ 46]. از سوی دیگر، آنها همچنین مجموعه جدیدی از مشخصات را برای جایگزینی استانداردهای موجود با رویکردهای توسعه وب مدرن آغاز کرده اند. WPS قرار است با نام جدید OGC API Processes جایگزین شود. حتی با وجود اینکه OGC API Processes هنوز در پیش نویس است و برای تغییرات اساسی باز است، ما ترجیح دادیم از این استاندارد برای بررسی و بررسی آن با فناوری های بدون سرور استفاده کنیم. ما دریافتیم که استاندارد جدید نسبت به نسخه قبلی منحنی یادگیری تند دارد و به راحتی میتوانیم نقاط پایانی را اضافه کنیم که در قالب و قوانین استاندارد پاسخ میدهند. هدف ما افزایش آگاهی از فناوریهای بدون سرور در جامعه مکانی با کاوش در یک گردش کار پردازش دادههای مکانی در مدل بدون سرور با فرآیندهای OGC API بود.
ما مشاهده کردیم که سرویس Amazon Fargate برای اجرای کانتینرهای یکباره نسبت به سایر ارائه دهندگان کمی پیچیده است. برای مثال، Microsoft Azure سرویس Container Instances را با نیازهای پیکربندی بسیار کمتری ارائه میکند. از سوی دیگر، Amazon Cloud Deployment Kit (CDK) استقرار زیرساختهای ابری را در همان زبان برنامهنویسی که برای توسعه استفاده میکردیم، آسانتر کرد. ما مشاهده کردیم که سیستم همچنین مطابق با سناریوهای ترکیبی کار می کند. ما سیستم را با یک سرویس کانتینر محلی اجرا کردیم. تنها مشکل سیستم ترکیبی این است که سرعت شبکه سرعت اجراها را کاهش می دهد زیرا کانتینرها داده ها را از طریق اینترنت دانلود و آپلود می کنند.
در پیاده سازی، ما از سرویس CaaS برای اجرای وظایف استفاده کردیم، زیرا آنها توانایی بیشتری برای اجرای وظایف پردازش داده های طولانی مدت دارند. ما فکر می کنیم که FaaS می تواند برای اجرای این نوع وظایف در آینده نیز مورد استفاده قرار گیرد. همانطور که ما شاهد پشتیبانی از استقرار تصویر کانتینر در برخی از سرویسهای FaaS ارائهدهندگان ابر عمومی بودیم، فکر میکنیم به زودی امکان پذیر است.
در طراحی ما، ارتباط از مدیر گردش کار به مدیر وظیفه همزمان است و فکر میکنیم افزودن صف پیام میتواند قابلیت اطمینان و تحمل خطا را در طراحی افزایش دهد. با این حال، ما فکر کردیم که می تواند پیچیدگی را نیز افزایش دهد، و خرابی ها را می توان با الگوهای طراحی دیگر مانند قطع کننده مدار یا تلاش مجدد کاهش داد.
این مطالعه همچنین یک مدل گردش کار و تعریف کار جدید ارائه کرد. علاوه بر این، مدل گردش کار دارای دو وظیفه سفارشی ساخته شده است: “ForEach” و “Parallel”. اینها به اجرای عملیات تکراری و همزمان کمک می کنند. ما همچنین در حال برنامه ریزی برای اضافه کردن دستورات کنترل برای تغییر جهت جریان در طول زمان اجرا هستیم.
ما این سیستم را در زمینه جغرافیایی طراحی کردیم، اما میتوان آن را برای سایر گردشهای کاری پردازش داده اعمال کرد. ما قصد داریم پس از تکمیل مستندات کد، کد منبع اثبات مفهوم را به عنوان یک پروژه منبع باز منتشر کنیم.
منابع
- دی اولیویرا، دی. اوگاساوارا، ای. بایائو، اف. Mattoso، M. SciCumulus: یک میان افزار ابری سبک برای کاوش در بسیاری از الگوهای محاسباتی وظایف در جریان های کاری علمی. در مجموعه مقالات سومین کنفرانس بین المللی IEEE در سال 2010 در رایانش ابری، میامی، FL، ایالات متحده آمریکا، 5 تا 10 ژوئیه 2010. صص 378-385. [ Google Scholar ]
- مل، PM; گرنس، تی. تعریف NIST از رایانش ابری. NIST 2011 ، SP 800-145 ، 2-3. [ Google Scholar ]
- لوید، دبلیو. رامش، س. چینتالاپاتی، س. لی، ال. Pallickara، S. محاسبات بدون سرور: بررسی عوامل مؤثر بر عملکرد میکروسرویس. در مجموعه مقالات کنفرانس بین المللی IEEE 2018 در مهندسی ابر، اورلاندو، FL، ایالات متحده آمریکا، 17 تا 20 آوریل 2018؛ صص 159-169. [ Google Scholar ]
- رحمان، م.م. حسن، معماری بدون سرور MH برای تجزیه و تحلیل داده های بزرگ. در مجموعه مقالات کنفرانس جهانی 2019 برای پیشرفت در فناوری، بنگالورو، هند، 18 تا 20 اکتبر 2019؛ صص 1-5. [ Google Scholar ]
- Krämer, M. A Microservice Architecture for the Large Geospatial Data in the Cloud. Ph.D. پایان نامه، Technische Universität Darmstadt, Darmstadt, Germany, 2018. [ Google Scholar ]
- Agarwal, G. Modern DevOps Practices ; بسته: بیرمنگام، بریتانیا، 2021. [ Google Scholar ]
- بالدینی، آی. کاسترو، پی. چانگ، ک. چنگ، پی. فینک، اس. اساکیان، وی. میچل، ن. موثامی، وی. رباح، ر. اسلومینسکی، آ. و همکاران محاسبات بدون سرور: روندهای فعلی و مشکلات باز در پیشرفت های تحقیقاتی در رایانش ابری ؛ Chaudhary, S., Somani, G., Buyya, R., Eds.; Springer: سنگاپور، 2017; ص 1-20. [ Google Scholar ]
- کیم، ی. Lin, J. تجزیه و تحلیل داده های بدون سرور با Flint. در مجموعه مقالات یازدهمین کنفرانس بین المللی IEEE 2018 در محاسبات ابری، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 2 تا 7 ژوئیه 2018؛ ص 451-455. [ Google Scholar ]
- مالاوسکی، م. گاجک، ع. زیما، ع. بالیس، بی. Figiela، K. اجرای بدون سرور جریانهای کاری علمی: آزمایشهایی با HyperFlow، AWS Lambda و Google Cloud Functions. محاسبات ژنرال آینده. Sys 2020 ، 110 ، 502-514. [ Google Scholar ] [ CrossRef ]
- لی، اچ. ساتیام، ک. فاکس، جی. ارزیابی محیطهای محاسباتی بدون سرور تولید. در مجموعه مقالات یازدهمین کنفرانس بین المللی IEEE در محاسبات ابری، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 2 تا 7 ژوئیه 2018؛ صص 442-450. [ Google Scholar ]
- جی، ایکس. چن، بی. هوانگ، ز. سویی، ز. Fang, Y. در مورد استفاده از رایانش ابری برای کاربردهای گردش کار مکانی. در مجموعه مقالات بیستمین کنفرانس بین المللی IEEE در زمینه ژئوانفورماتیک، هنگ کنگ، چین، 15-17 ژوئن 2012. صص 1-6. [ Google Scholar ]
- کرامر، ام. Würz، HM; Altenhofen، C. اجرای گردش های علمی چرخه ای در ابر. J. Cloud Comp. 2021 ، 10 ، 25. [ Google Scholar ] [ CrossRef ]
- گردش کار بدون سرور در دسترس آنلاین: https://serverlessworkflow.io/ (در 23 اکتبر 2021 قابل دسترسی است).
- توابع مرحله AWS. در دسترس آنلاین: https://aws.amazon.com/step-functions (در 23 اکتبر 2021 قابل دسترسی است).
- مستندات Azure Logic Apps. در دسترس آنلاین: https://docs.microsoft.com/en-us/azure/logic-apps/ (در 23 اکتبر 2021 قابل دسترسی است).
- Google Cloud Workflows. در دسترس آنلاین: https://cloud.google.com/workflows (در 23 اکتبر 2021 قابل دسترسی است).
- هوانگ، دبلیو. ژانگ، دبلیو. ژانگ، دی. Meng, L. Elastic Spatial Query Processing در OpenStack Cloud Computing Environment برای تحلیل داده با محدودیت زمانی. ISPRS Int. J. Geo-Inf. 2017 ، 6 ، 84. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Argo Workflows. در دسترس آنلاین: https://argoproj.github.io/argo-workflows/ (در 23 اکتبر 2021 قابل دسترسی است).
- Kubeflow. در دسترس آنلاین: https://www.kubeflow.org/ (در 23 اکتبر 2021 قابل دسترسی است).
- ون در آلست، WMP; تر هافستد، AHM YAWL: زبان گردش کار دیگر. اطلاعات Sys 2005 ، 30 ، 245-275. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- YAML زبان نشانه گذاری نیست. در دسترس آنلاین: https://yaml.org/ (دسترسی در 23 اکتبر 2021).
- پروس، بی. Vretanos، PA OGC API—Processes—Part 1: Core, 1.0-Draft.7 ; کنسرسیوم فضایی باز: آرلینگتون، ویرجینیا، ایالات متحده آمریکا، 2021؛ در دسترس آنلاین: https://docs.ogc.org/is/18-062r2/18-062r2.html (در 23 اکتبر 2021 قابل دسترسی است).
- طیبی، د. اسپیلنر، جی. Wawruch، K. محاسبات بدون سرور – اکنون کجا هستیم و به کجا می رویم؟ IEEE Softw. 2021 ، 38 ، 25-31. [ Google Scholar ] [ CrossRef ]
- طیبی، د. Lenarduzzi, V. On the Definition of Microservice Bad Smels. IEEE Softw. 2018 ، 35 ، 56-62. [ Google Scholar ] [ CrossRef ]
- Ingeno, J. Software Architect’s Handbook ; بسته: بیرمنگام، بریتانیا، 2018. [ Google Scholar ]
- کاراویسیلیو، ا. مایناس، ن. پتراکیس، هستی شناسی EGM برای توضیحات خدمات OpenAPI REST. در مجموعه مقالات سی و دومین کنفرانس بین المللی IEEE در مورد ابزارهای با هوش مصنوعی، بالتیمور، MD، ایالات متحده، 9 تا 11 نوامبر 2020؛ صص 35-40. [ Google Scholar ]
- مسینا، ا. ریزو، آر. استورنیولو، پی. Urso, A. یک الگوی پایگاه داده ساده شده برای معماری میکروسرویس. در مجموعه مقالات هشتمین کنفرانس بین المللی پیشرفت در پایگاه های داده، دانش و کاربردهای داده، لیسبون، پرتغال، 2 تا 4 ژوئن 2016. صص 35-40. [ Google Scholar ]
- سینک، ام. Corte، RD; Pecchia، A. مانیتورینگ میکروسرویس ها با گزارش رویداد و ردیابی اجرای جعبه سیاه. در IEEE Transactions on Services Computing ; IEEE: Greenvile, SC, USA, 2019. [ Google Scholar ]
- راج، پ. رامان، ا. سوبرامانیان، اچ . الگوهای معماری ; بسته: بیرمنگام، بریتانیا، 2017. [ Google Scholar ]
- کلیموویچ، آ. وانگ، ی. کوزیراکیس، سی. استودی، پ. فافرل، جی. Trivedi، A. درک ذخیره سازی زودگذر برای تجزیه و تحلیل بدون سرور. در مجموعه مقالات کنفرانس USENIX 2018 در کنفرانس فنی سالانه Usenix، بوستون، MA، ایالات متحده، 9 تا 13 ژوئیه 2018؛ صص 789-794. [ Google Scholar ]
- مککندریک، R. Kubernetes برای برنامههای بدون سرور ؛ بسته: بیرمنگام، بریتانیا، 2018. [ Google Scholar ]
- نیکولوف، جی. کوئنزلی، اس. Fisher, B. Docker in Action , 2nd ed.; Manning Publications Co.: Shelter Island، NY، ایالات متحده آمریکا، 2019. [ Google Scholar ]
- AWS به خوبی معماری شده است. در دسترس آنلاین: https://aws.amazon.com/architecture/well-architected (در 23 اکتبر 2021 قابل دسترسی است).
- Sisák، M. پیکربندی استقرار AWS بهینه برای سیستمهای رویداد محور کانتینری. پایان نامه کارشناسی ارشد، دانشگاه ماساریک، برنو، چک، 2021. [ Google Scholar ]
- Diagboya، E. نظارت بر زیرساخت با آمازون CloudWatch . بسته: بیرمنگام، بریتانیا، 2021. [ Google Scholar ]
- ساحل، بی. آرمنتروت، اس. بوزو، آر. Tsouris، E. سرویس ذخیره سازی ساده. در Pro PowerShell برای خدمات وب آمازون ؛ Apress: برکلی، کالیفرنیا، ایالات متحده آمریکا، 2019؛ ص 275-299. [ Google Scholar ]
- Vijayakumar، T. API Gateways. در معماری و توسعه API عملی با Azure و AWS . Apress: برکلی، کالیفرنیا، ایالات متحده آمریکا، 2018; صص 51-96. [ Google Scholar ]
- Poccia، D. AWS Lambda در عمل: برنامههای بدون سرور رویداد محور ؛ انتشارات منینگ: جزیره پناهگاه، نیویورک، ایالات متحده آمریکا، 2017. [ Google Scholar ]
- گوو، دی. Onstein، E. پردازش اطلاعات مکانی پیشرفته در پایگاه های داده NoSQL. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 331. [ Google Scholar ] [ CrossRef ]
- Mete، MO; Yomralioglu, T. پیادهسازی بستر GIS ابری بدون سرور برای ارزیابی زمین. بین المللی جی. دیگ. زمین 2021 ، 14 ، 836-850. [ Google Scholar ] [ CrossRef ]
- سرویس آمازون Fargate. در دسترس آنلاین: https://aws.amazon.com/fargate/ (دسترسی در 24 اکتبر 2021).
- برنامه دوازده عاملی. در دسترس آنلاین: https://12factor.net/ (دسترسی در 24 اکتبر 2021).
- مارکوت، سی.-اچ. Zebdi, A. الگوهای طراحی غیر معمول ASP.NET Core 5 ; بسته: بیرمنگام، بریتانیا، 2020. [ Google Scholar ]
- اسناد AWS. در دسترس آنلاین: https://docs.aws.amazon.com/index.html (در 6 دسامبر 2021 قابل دسترسی است).
- Lawhead, J. Learning Geospatial Analysis with Python , 3rd ed.; بسته: بیرمنگام، بریتانیا، 2019. [ Google Scholar ]
- Mueller, M. OGC WPS 2.0.2 Interface Standard Corrigendum 2, 2.0.2 ; کنسرسیوم فضایی باز: آرلینگتون، ویرجینیا، ایالات متحده آمریکا، 2015. در دسترس آنلاین: https://docs.opengeospatial.org/is/14-065/14-065.html (در 1 دسامبر 2021 قابل دسترسی است).
شکل 1. لایه های انتزاعی برای هر مدل خدمات.

شکل 2. ساختار تعریف وظیفه.

شکل 3. یک مثال تعریف کار.
شکل 4. ساختار تعریف گردش کار.
شکل 5. اجزاء و نقش های سیستم سطح بالا.
شکل 6. سیستم گردش کار و اجزای آن.
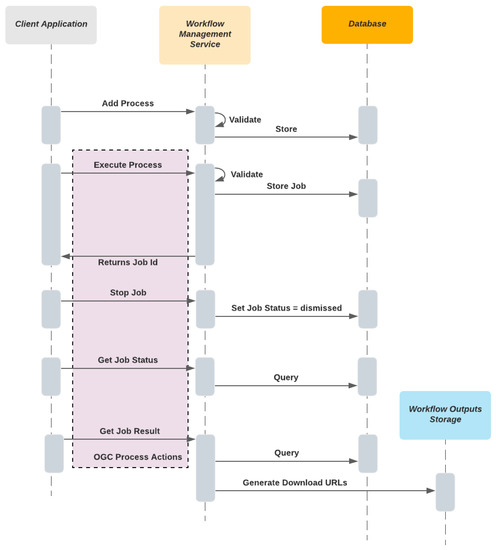
شکل 7. توالی خدمات مدیریت گردش کار برای هر نوع درخواست جریان دارد.
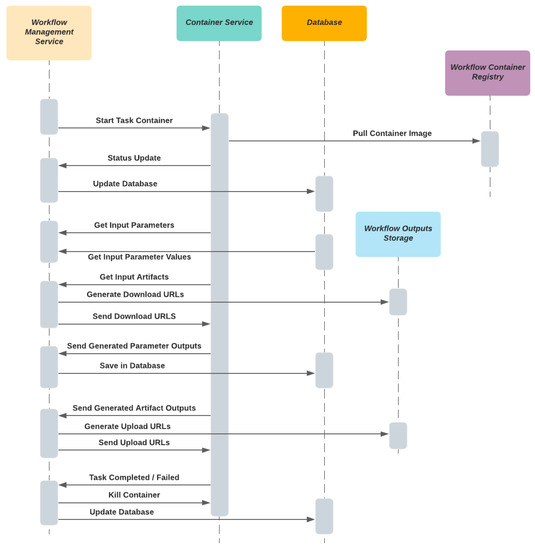
شکل 8. جریان های ترتیب ارکستراسیون گردش کار.
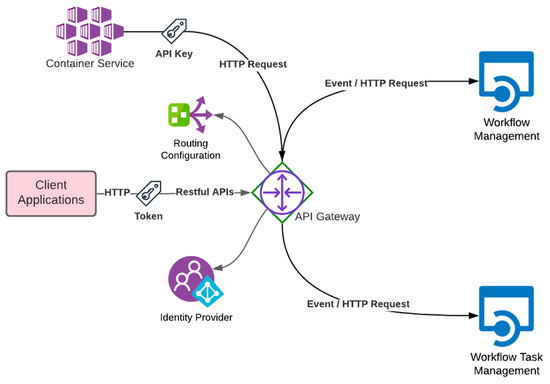
شکل 9. تعاملات API Gateway با اجزای دیگر.

شکل 10. نمونه فایل docker که از تصویر پایه استفاده می کند حاوی عامل است.
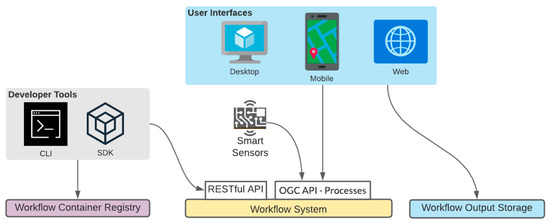
شکل 11. انواع برنامه های مشتری و روابط آنها با اجزای سیستم.
شکل 12. استقرار ابر عمومی معماری سیستم پیشنهادی با خدمات بدون سرور در AWS.

شکل 13. یک نمونه تعریف گردش کار در مدل تعریف گردش کار پیشنهادی.
شکل 14. نمایش بصری گردش کار نمونه.

شکل 15. بارگیری درخواست HTTP برای اجرای نمونه گردش کار ( a ) بدنه پاسخ اجرای گردش کار که URL های امضا شده برای دانلود فایل های شطرنجی خروجی ( b ) تولید کرده است.

شکل 16. یک مثال در دنیای واقعی، تعریف گردش کار از پیش بینی طغیان سیل در مدل تعریف گردش کار پیشنهادی.
شکل 17. نمایش بصری گردش کار پیش بینی طغیان سیل.

شکل 18. بار درخواست HTTP برای اجرای گردش کار پیشبینی سیل ( a ) بدنه پاسخ اجرای گردش کار که URLهای امضا شده برای دانلود فایلهای برداری خروجی ( b ) تولید کرده است.


بدون دیدگاه