

کلید واژه ها:
عادی سازی صفت ; نمودار دانش جغرافیایی ; تجزیه و تحلیل همزمانی ؛ دانه بندی خوشه بندی بهینه
1. مقدمه
2. کارهای مرتبط
عادی سازی ویژگی های سنتی مترادف ها را فقط از نظر شباهت استخراج می کند. شباهت معمولاً با استفاده از روش بردار کلمه محاسبه می شود. بردارهای کلمه با استفاده از word2vector [ 33 ] آموزش داده می شوند. بردارهای کلمه به دست آمده با استفاده از شباهت کسینوس محاسبه می شوند.
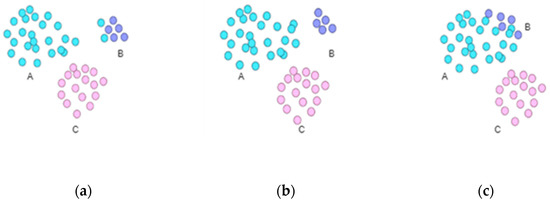
در این مقاله، ما از این روش برای مدولار کردن نام ویژگیها، یعنی خوشهبندی ویژگیها استفاده میکنیم تا راهی برای داشتن یک مدولاریت متوسط برای دستیابی به بهترین اثر خوشهبندی پیدا کنیم. این روش بر مدل زیر متکی است. این به معنای نسبت تعداد کل یالهای داخل جامعه به تعداد کل یالهای شبکه منهای مقدار انتظاری است که اندازه نسبت تعداد کل یالهای داخل جامعه به تعداد کل یالها در شبکه است. هنگامی که شبکه به عنوان یک شبکه تصادفی تنظیم می شود، شبکه ای توسط همان تخصیص جامعه تشکیل می شود.
جایی که Avw���وزن لبه بین v و w را نشان می دهد ، kv=∑wAvw��=∑����مجموع وزن یال های متصل به راس v است، Cv��جامعه ای است که راس v به آن اختصاص داده شده است δ�عملکرد δ(i,j)�(�,�)1 است اگر i=j�=�و 0 در غیر این صورت و m=12∑vwAvw�=12∑�����[ 32 ].
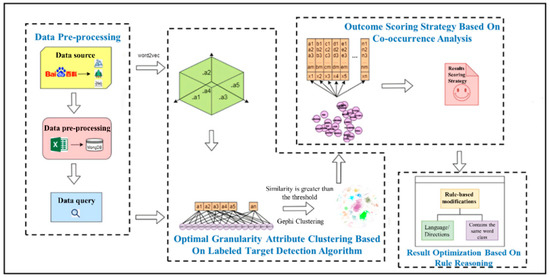
3. روش ها و مدل ها
3.1. بررسی اجمالی
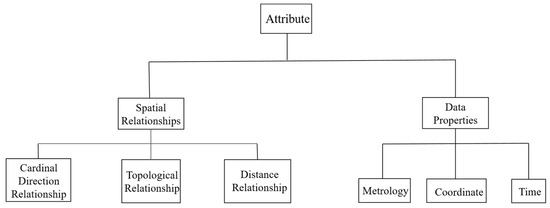
3.2. مدلسازی روش: خوشهبندی مشخصه دانهبندی بهینه بر اساس الگوریتم تشخیص هدف برچسبدار
فرمول الگوریتم به صورت زیر خلاصه می شود:
3.3. مدلسازی روش: شناسایی دقیق ویژگیهای مترادف بر اساس تحلیل همرویداد و استدلال قاعده
3.3.1. استراتژی امتیازدهی به نتیجه بر اساس تحلیل همزمانی
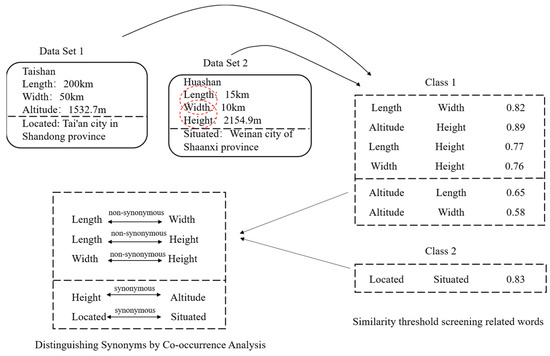
در این مقاله، ما نیاز به تجزیه و تحلیل نام های ویژگی های همزمان داریم تا پدیده های خطا در هر کلاس را که شبیه تر هستند و معانی متفاوتی دارند، پیدا کنیم. ایده استفاده شده این است که اگر دو یا چند نام ویژگی به طور همزمان برای توصیف یک موجودیت استفاده شود، این نام های ویژگی معانی متفاوتی را بیان می کنند و مترادف نیستند. یعنی متوجه می شویم که آیا جفت صفت در مجموعه ویژگی های یک موجودیت به طور همزمان ظاهر می شود یا خیر. مدل خاص در فرمول (5) نشان داده شده است.
در این مقاله، مقدار داده برای موجودیت ها ثابت است، بنابراین فراوانی وقوع نام ویژگی است که مهمترین تأثیر را دارد. اگر فراوانی نام صفت برای هر دو کلمه کم باشد، عدم وقوع همزمان آن ممکن است به دلیل فراوانی کم باشد. هنگامی که بسامد نام ویژگی برای هر دو کلمه زیاد است، اما هنوز همزمان وجود ندارد، بعید است که برای توصیف یک موجودیت استفاده شود. یعنی به همین معناست و مترادف است. بنابراین، معیارهای امتیازدهی زیر آورده شده است. ابتدا تفاوت بین فراوانی کلمه برای اولین کلمه در جفت کلمه فعلی و میانگین فراوانی کلمه محاسبه می شود. مجموع نهایی نمرات دو کلمه با دادن امتیازهای مختلف با توجه به مقدار تفاوت به دست می آید. به عنوان معیاری برای تعداد تکرار صفت، میانگین فراوانی کلمه به عنوان نسبت تعداد تکرار صفت به ویژگی غیر تکراری تعریف می شود. این بدان معنی است که تعداد دفعاتی که ویژگی ها یکسان ظاهر می شوند، همانطور که در فرمول های زیر (6) – (8) نشان داده شده است:
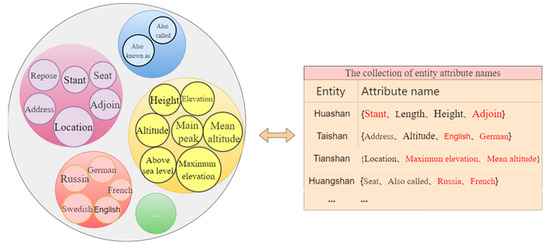
جایی که fمن��فراوانی نام ویژگی را در هر جفت نام ویژگی نشان می دهد، fj��نشان دهنده فراوانی نام ویژگی در همه نام های ویژگی است، n نشان دهنده تعداد کل ویژگی های غیر تکراری است، subمن����نشان دهنده تفاوت فراوانی هر جفت نام ویژگی و scorei������امتیاز نام ویژگی را در هر جفت نام ویژگی نشان می دهد. ما نام ویژگی های هر موجودیت را به عنوان یک مجموعه در نظر می گیریم و همه نام های ویژگی در این مجموعه غیر مترادف هستند. پس از تکمیل خوشه بندی، کلمات هر کلاس در هر یک از مجموعه های بالا دو به دو مورد استعلام قرار می گیرند تا ببینند که آیا همزمان هستند یا خیر، و اگر همزمان هستند، این دو کلمه در یک رابطه مترادف نیستند. بنابراین، می توان به طور موثر کلماتی را که همبستگی بالایی دارند اما مترادف با ویژگی های خود ساختار داده نیستند، حذف کرد. یک مثال ملموس در نشان داده شده است شکل 5 نشان داده شده است، جایی که شکل سمت چپ مجموعه ای را که پس از خوشه بندی به دست می آید و شکل سمت راست مجموعه ای از نام های ویژگی مربوط به موجودیت ها را نشان می دهد. در شکل سمت راست، کلماتی که با رنگ قرمز مشخص شدهاند در یک مجموعه خوشهبندی ظاهر میشوند، بنابراین آنها تقریباً مترادف هستند تا مترادف.
3.3.2. بهینه سازی نتایج بر اساس استدلال قاعده
4. آزمایش و بحث
4.1. مقدمه ای بر DataSets
4.2. شرایط آزمایشی
4.2.1. پارامترهای تجربی
- (1)
-
تنظیم پارامتر Word2vec
- (2)
-
تنظیم پارامتر آستانه تشابه
4.2.2. شاخص ارزیابی تجربی
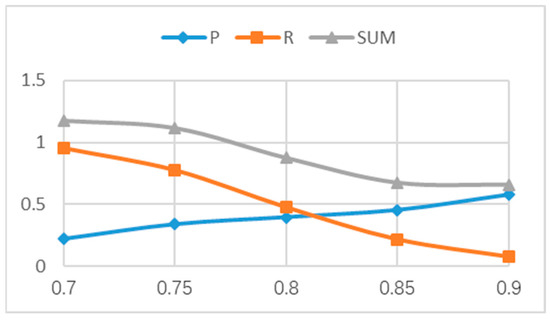
اثربخشی شناسایی مترادف با مقادیر Precision، Recall و F 1 اندازه گیری می شود. TP ها (مثبت های واقعی) نشان می دهد که مترادف به درستی پیش بینی شده است، در حالی که FP ها (مثبت های کاذب) نشان می دهد که مترادف تقریباً به عنوان مترادف اشتباه ارزیابی شده است. FNs (False Negatives) نشان می دهد که مترادف تقریباً مترادف است. TNs (True Negatives) نشان می دهد که تقریباً مترادف به درستی پیش بینی شده است. سپس P ، R و F 1 توسط:
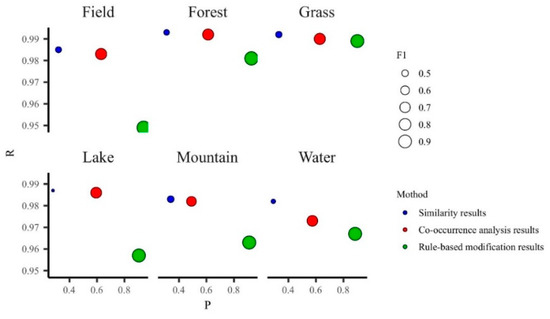
4.3. نتایج تجربی و تجزیه و تحلیل
4.3.1. خوشه بندی آزمایش های دانه بندی
4.3.2. نتایج تجربی شناسایی دقیق صفات مترادف
5. نتیجه گیری ها
منابع
- Deren، LI از Geomatics تا Geospatial Intelligent Service Science. Acta Geod. کارتوگر. گناه 2017 ، 46 ، 1207-1212. [ Google Scholar ] [ CrossRef ]
- رولی، جی. سلسله مراتب خرد: بازنمایی های سلسله مراتب DIKW. J. Inf. علمی 2007 ، 33 ، 163-180. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گولج، RG ماهیت اندیشه جغرافیایی. ان دانشیار صبح. Geogr. 2002 ، 92 ، 1-14. [ Google Scholar ] [ CrossRef ]
- استولتمن، جی. لیدستون، جی. کیدمن، جی. منشور بین المللی آموزش جغرافیایی 2016. بین المللی Res. Geogr. محیط زیست آموزش. 2017 ، 26 ، 1-2. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دونگ، ایکس. گابریلوویچ، ای. هایتس، جی. هورن، دبلیو. لائو، ن. مورفی، ک. استرومن، تی. سان، اس. ژانگ، دبلیو. خزانه دانش: رویکرد مقیاس وب به آمیختگی دانش احتمالی. در مجموعه مقالات بیستمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، نیویورک، نیویورک، ایالات متحده آمریکا، 24 تا 27 اوت 2014. ص 601-610. [ Google Scholar ] [ CrossRef ]
- جی، اس. پان، اس. کامبریا، ای. مارتینن، پی. فیلیپ، SY بررسی نمودارهای دانش: بازنمایی، اکتساب و کاربردها. IEEE Trans. شبکه عصبی فرا گرفتن. سیستم 2021 ، 33 ، 494-514. [ Google Scholar ] [ CrossRef ]
- ژانگ، ن. دنگ، س. چن، اچ. چن، ایکس. چن، جی. لی، ایکس. Zhang، Y. پایگاه دانش ساختاریافته به عنوان دانش قبلی برای بهبود تجزیه و تحلیل داده های شهری. ISPRS Int. J. Geo-Inf. 2018 ، 7 ، 264. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژانگ، ی. ژو، جی. زو، س. زی، ی. لی، دبلیو. فو، ال. ژانگ، جی. Tan, J. ساخت محیط های فاجعه زمین لغزش مجازی شخصی سازی شده بر اساس نمودارهای دانش و شبکه های عصبی عمیق. بین المللی جی دیجیت. زمین 2020 ، 13 ، 1637-1655. [ Google Scholar ] [ CrossRef ]
- سان، ک. هو، ی. آهنگ، جی. Zhu, Y. تراز کردن موجودیت های جغرافیایی از نقشه های تاریخی برای ساختن نمودارهای دانش. بین المللی جی. جئوگر. Inf. علمی 2021 ، 35 ، 2078-2107. [ Google Scholar ] [ CrossRef ]
- شن، ی. چن، ز. چنگ، جی. Qu, Y. CKGG: نمودار دانش چینی برای آموزش جغرافیا در دبیرستان و فراتر از آن. در مجموعه مقالات کنفرانس بین المللی وب معنایی، TBA، رویداد مجازی، 24 تا 28 اکتبر 2021؛ Springer: برلین/هایدلبرگ، آلمان، 2021؛ صص 429-445. [ Google Scholar ]
- اور، اس. لمان، جی. Hellmann, S. LinkedGeoData: افزودن یک بعد فضایی به وب داده ها. در مجموعه مقالات هشتمین کنفرانس بین المللی وب معنایی (ISWC ’09)، مرکز کنفرانس Westfields، واشنگتن، دی سی، ایالات متحده آمریکا، 25-29 اکتبر 2009. Springer: برلین/هایدلبرگ، آلمان، 2009; صص 731-746. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مالتیز، وی. Farazi, F. A Semantic Schema for GeoNames ; Università Di Trento: ترنتو، ایتالیا، 2013. [ Google Scholar ]
- بالاتوره، آ. ویلسون، دی سی؛ برتولتو، ام. بررسی پایگاههای دانش جغرافیایی باز داوطلبانه در وب معنایی. در مسائل کیفیت در مدیریت اطلاعات وب ; Springer: برلین/هایدلبرگ، آلمان، 2013; صص 93-120. [ Google Scholar ]
- سوشانک، اف.ام. کسنسی، جی. ویکوم، جی. یاگو: هسته ای از دانش معنایی. در مجموعه مقالات شانزدهمین کنفرانس بین المللی وب جهانی، Banff، AB، کانادا، 8 تا 12 مه 2007. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Deng, S. CrowdGeoKG: Crowdsourced Geo-Knowledge Graph. در مجموعه مقالات کنفرانس چین درباره نمودار دانش و محاسبات معنایی، چنگدو، چین، 26 تا 29 اوت 2017. [ Google Scholar ] [ CrossRef ]
- اسپیر، آر. حواسی، سی. ConceptNet 5: یک شبکه معنایی بزرگ برای دانش رابطه ای. در The People’s Web Meets NLP ; Springer: برلین/هایدلبرگ، آلمان، 2013; صص 161-176. [ Google Scholar ] [ CrossRef ]
- چن، ج. لیو، دبلیو. وو، اچ. مسائل اساسی و دستور کار تحقیقاتی خدمات دانش مکانی. ژئوماتیک و علم اطلاعات دانشگاه ووهان. Geomat. Inf. علمی دانشگاه ووهان 2019 ، 44 ، 38-47. [ Google Scholar ]
- دو، سی. سی، دبلیو. Xu, J. Querying and Reasoning of Spatial Relations based on Geographic Semantics. J. Geo-Inf. علمی 2010 ، 12 ، 48-55. [ Google Scholar ] [ CrossRef ]
- یانگ، سی. وو، اچ. هوانگ، Q. لی، ز. Jing, L. استفاده از اصول فضایی برای بهینه سازی محاسبات توزیع شده برای فعال کردن اکتشافات علوم فیزیکی. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2011 ، 108 ، 5498-5503. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چن، ایکس. جیا، اس. Xiang، Y. بررسی: استدلال دانش بر نمودار دانش. سیستم خبره Appl. 2020 , 141 , 112948. [ Google Scholar ] [ CrossRef ]
- هایهونگ، ای. چنگ، آر. آهنگ، م. زو، پی. وانگ، زی. روش تعبیه مشترک روابط و صفات برای همسویی موجودیت. بین المللی جی. ماخ. فرا گرفتن. محاسبه کنید. 2020 ، 10 ، 605-611. [ Google Scholar ]
- گوناراتنا، ک. تیرونارایان، ک. جین، پی. شث، ا. Wijeratne، S. یک رویکرد مستقل آماری و طرحواره ای برای شناسایی ویژگی های معادل در داده های پیوندی. در مجموعه مقالات نهمین کنفرانس بین المللی سیستم های معنایی، گراتس، اتریش، 4 تا 6 سپتامبر. 2013; صص 33-40. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، ز. Gentile, AL; بلومکویست، ای. آگنشتاین، آی. Ciravegna، F. روشی مبتنی بر داده بدون نظارت برای کشف روابط معادل در مجموعه دادههای مرتبط بزرگ. سمنت. وب 2017 ، 8 ، 197-223. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بائر، اف. Kaltenböck, M. داده های باز پیوندی: ملزومات ; تک رنگ / تک رنگ: وین، اتریش، 2011; جلد 710. [ Google Scholar ]
- ریستاد، ES; Yianilos، PN آموزش فاصله ویرایش رشته. IEEE Trans. الگوی مقعدی Mach.-Intell. 1998 ، 20 ، 522-532. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تسوروکا، ی. مکنات، جی. تسوجی، جی. Ananiadou، S. سنجش تشابه رشته یادگیری برای جستجوی فرهنگ لغت نام ژن/پروتئین با استفاده از رگرسیون لجستیک. بیوانفورماتیک 2007 ، 23 ، 2768-2774. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ی. چن، S.-H.; چن، J.-GG ویژگی همراستایی داده های پیوندی بر اساس شباهت بین توابع. بین المللی J. Database Theory Appl. 2015 ، 8 ، 191-206. [ Google Scholar ] [ CrossRef ]
- هوانگ، تی. ژانگ، دبلیو. لیانگ، ایکس. Fu، K. روش مبتنی بر داده برای هم ترازی ویژگی های ریز دانه بین مجموعه داده های باز چینی. J. دانشگاه جنوب شرقی (Nat. Sci. Ed.) 2017 ، 47 ، 660-666. [ Google Scholar ] [ CrossRef ]
- اسمید، جی. نرودا، آر. مقایسه مجموعه داده ها بر اساس تراز صفات. در مجموعه مقالات سمپوزیوم IEEE 2014 در زمینه هوش محاسباتی و داده کاوی (CIDM)، اورلاندو، فلوریدا، ایالات متحده آمریکا، 9 تا 12 دسامبر 2014؛ صص 56-62. [ Google Scholar ] [ CrossRef ]
- هینتون، GE Learning بازنمایی مفاهیم را توزیع کردند. در مجموعه مقالات هشتمین کنفرانس انجمن علوم شناختی، Amherst، MA، ایالات متحده، 15-17 اوت 1986. [ Google Scholar ]
- نیومن، من؛ گیروان، م. یافتن و ارزیابی ساختار جامعه در شبکه ها. فیزیک Rev. E 2004 , 69 , 026113. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- بلوندل، وی دی. گیوم، جی. لامبیوت، آر. لوفور، ای. آشکار شدن سریع جوامع در شبکه های بزرگ. J. Stat. مکانیک. تئوری Exp. 2008 ، 2008 ، P10008. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- میکولوف، تی. چن، ک. کورادو، جی. Dean, J. برآورد کارآمد نمایش کلمات در فضای برداری. arXiv 2013 , arXiv:1301.3781. [ Google Scholar ]
- Chen, Z. رویکردی به اندازه گیری ارتباط معنایی اصطلاحات جغرافیایی با استفاده از اصطلاحنامه و منابع پایگاه داده واژگانی. ISPRS Int. J. Geo-Inf. 2018 ، 7 ، 98. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژانگ، اس. هو، ی. Bian, G. تحقیق در مورد الگوریتم تشابه رشته ها بر اساس فاصله لونشتاین. در مجموعه مقالات دومین کنفرانس فناوری اطلاعات پیشرفته، کنترل الکترونیک و اتوماسیون IEEE 2017 (IAEAC)، چونگ کینگ، چین، 25 تا 26 مارس 2017؛ IEEE: نیویورک، نیویورک، ایالات متحده آمریکا، 2017؛ ص 2247–2251. [ Google Scholar ]
- رن، ایکس. Han, J. کشف مترادف خودکار با پایگاه های دانش. در مجموعه مقالات بیست و سومین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، هالیفاکس، NS، کانادا، 13 تا 17 اوت 2017. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، کیو. میکولوف، تی. Com، TG بازنمایی جملات و اسناد را توزیع کرد. در مجموعه مقالات کنفرانس بین المللی یادگیری ماشین، دیترویت، MI، ایالات متحده آمریکا، 3 تا 6 دسامبر 2014. جلد 32، ص 1188–1196. [ Google Scholar ]


بدون دیدگاه