

کلید واژه ها:
مناطق عملکردی شهری ; شناسایی ؛ فاکتورسازی ماتریسی ; داده های POI ؛ داده های مسیر OD
1. مقدمه
- (1)
-
روش CCMF برای ترکیب داده ها برای دستیابی به دقت شناسایی بالاتر پیشنهاد شد. روابط متنی بین منابع داده به منظور استخراج اطلاعات مشترک برای ادغام داده ها در نظر گرفته شد.
- (2)
-
کار تجربی برای تایید قابلیت استفاده از روش پیشنهادی در منطقه مورد مطالعه انجام شد. داده های مسیر POI و OD تاکسی برای استفاده در شناسایی UFR ترکیب شدند. با مقایسه دقت بین داده های ذوب شده و داده های منفرد، نتایج نشان می دهد که روش پیشنهادی به دقت بالاتری در شناسایی UFR ها دست یافته است.
2. کارهای مرتبط
2.1. رویکرد شناسایی منطقه عملکردی شهری
2.2. روش های ترکیب داده ها برای شناسایی منطقه عملکردی شهری
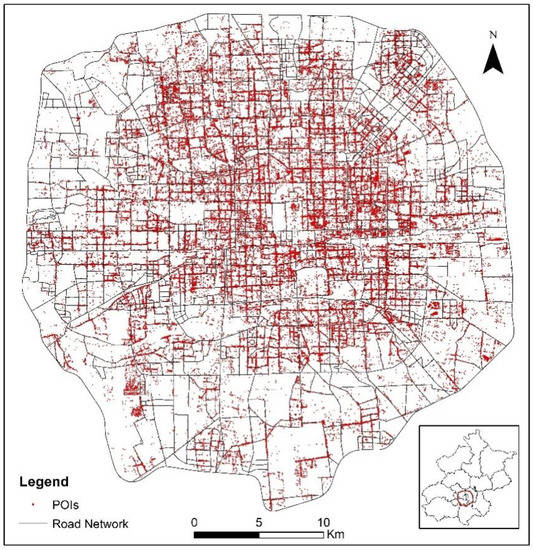
3. منطقه مطالعه و مجموعه داده ها
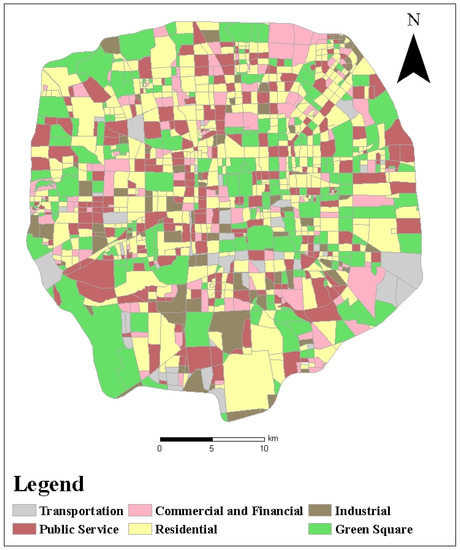
3.1. منطقه مطالعه
3.2. مجموعه داده ها و پردازش
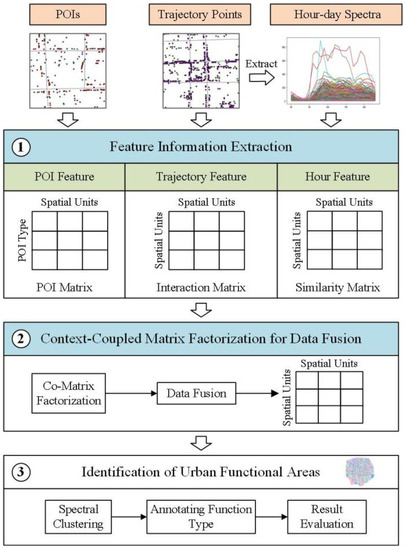
4. روش شناسی
4.1. گردش کار استخراج اطلاعات ویژگی
- (1)
-
تعداد یک نوع خاص از POI در یک واحد فضایی تا حدی می تواند نوع عملکردی را تا حدی منعکس کند. عملیات فضایی همپوشانی بر روی دادههای POI و واحدهای فضایی به منظور تولید یک ماتریس واحد فضایی POI، P انجام شد. ردیفهای ماتریس P نشاندهنده یک نوع POI در این منطقه هستند و ستونها مکان واحد را نشان میدهند. در نهایت، اطلاعات معنایی قدرتمندی به نوع تابع حاشیه نویسی ارائه می شود.
- (2)
-
اطلاعات مکان داده های OD منعکس کننده تقاطعات بین مناطق است. یعنی نقاط مبدأ و مقصد که در یک واحد فضایی قرار میگیرند، برهمکنش آنها را نشان میدهند. با محاسبه مجموع نقاط OD در هر واحد فضایی، یک ماتریس تعامل OD، Q ، به دست می آید. ردیفهای ماتریس Q نشاندهنده نقاط مبدا سوار شدن مسافران هستند و ستونها نشاندهنده نقاط مقصد خروج هستند. مقدار عنصر ماتریس نشان دهنده بسامد سفر از مبدا تا نقطه مقصد است. از آن به عنوان داده اصلی استفاده می شود که عمدتاً از فراوانی تعاملات سفر ساکنان در هر واحد برای کشف عملکردهای بالقوه منطقه استفاده می کند.
- (3)
-
توالیهای فرکانس زمانی استخراجشده از دادههای OD تاکسی، جریانهای تاکسی یا الگوهای سفر ساکنان را برای دوره زمانی در این منطقه نشان میدهند. برای محاسبه توالی زمان-فرکانس از روش آماری معمولی استفاده شد. شباهت واحدهای فضایی برای شناسایی UFR بسیار مهم است. الگوریتم تاب خوردگی زمانی پویا (DTW) یک روش منظم سازی زمانی پرکاربرد برای اندازه گیری شباهت دو مجموعه داده سری زمانی است [ 49 ]]، و این الگوریتم نیز در کار ما برای به دست آوردن ماتریس شباهت زمان-فرکانس، R به کار گرفته شد. در همان زمان، ممکن است موقعیتی وجود داشته باشد که در آن تعداد برهمکنش های OD یکسان باشد اما توابع متفاوت باشند. به عنوان مثال، اگر منطقه اوج ساعت 6 تا 8 صبح و 6 تا 8 بعد از ظهر در روزهای هفته باشد، احتمالاً یک منطقه صنعتی یا مسکونی است، در حالی که در آخر هفته ها احتمالاً یک منطقه تجاری یا سبز است. بنابراین ویژگی های ساعتی به منظور جبران آن کمبود استخراج می شود.
4.2. فاکتورسازی ماتریس همراه با زمینه برای ترکیب داده ها
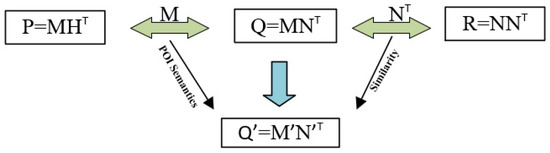
همبستگی بین دو شیء از نظر مکانی نزدیک قویتر از همبستگی بین دو شیء دور است. تعامل OD، POI، و ماتریس های زمان فرکانس OD به طور همزمان تجزیه می شوند. سپس، ماتریس برهمکنش مشترک M برای معناشناسی ویژگی و ماتریس تعامل N برای تشابه ویژگی تشکیل میشوند. اطلاعات مشترک M بین ماتریس تعامل OD Q و ماتریس POI P شباهت نوع POI بین مناطق مختلف است. انواع POI می توانند به تعیین عملکرد شهری کمک کنند. ردیف های ماتریس Pنشان دهنده نوع POI در این منطقه، و ستون ها نشان دهنده مکان واحد هستند. سپس، دو ستون نشان دهنده شباهت نوع POI در مناطق مختلف است. از طریق ادغام، انواع POI به منظور جبران کمبود معنایی به اشتراک گذاشته می شوند. اطلاعات مشترک N توسط ماتریس برهمکنش OD Q و ماتریس زمان-فرکانس OD R شباهت زمان برهمکنش بین سلول ها است. یک ردیف از ماتریس R نشان دهنده یک واحد و یک ستون نشان دهنده تغییر فرکانس OD این واحد در طول زمان است. دو ستون در ماتریس Rنشان دهنده شباهت زمان فعالیت افراد بین واحدها است و شباهت زمان های تعامل بین واحدها را می توان پس از ادغام به اشتراک گذاشت. از طریق همجوشی، شباهت زمانهای تعامل بین واحدها به اشتراک گذاشته میشود تا تفاوت زمانهای فعالیت ساکنان جبران شود. فرمول به شرح زیر است [ 50 ]:
که در آن L نشان دهنده روش همجوشی داده ها است، W نشان دهنده ماتریس وزن در محدوده [0، 1]، αبرای تنظیم تأثیر اطلاعات برهمکنش OD و دسته POI در تشخیص استفاده می شود و M ماتریس مشترک پس از فاکتورسازی Q و P است (یعنی Q و P از طریق M برهم کنش می کنند) . به همین ترتیب، βبرای تنظیم تأثیر برهمکنش OD و اطلاعات زمان-فرکانس در تشخیص استفاده می شود، و N ماتریس مشترک پس از تجزیه Q و R است (یعنی Q و R از طریق N برهم کنش می کنند ). سه عبارت اول فرمول (1) برای کنترل فاکتورسازی ماتریس و آخرین عبارت برای جلوگیری از برازش بیش از حد استفاده می شود. با الهام از ادبیات [ 51 ]، روش نزولی گرادیان تصادفی (SGD) به منظور بهینهسازی فرمول (1) برای دقت بالاتر بر اساس اطلاعات زمینهای در شباهت بین زمان-فرکانس و اطلاعات POI درگیر شد. الگوریتم فاکتورسازی ماتریس پیشنهادی در الگوریتم 1 نشان داده شده است.
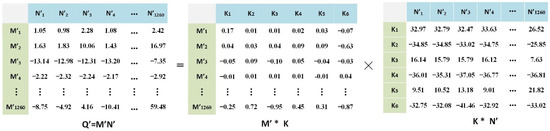
| الگوریتم 1: الگوریتم فاکتورسازی ماتریس جفت شده با زمینه. | |
| ورودی: ماتریس برهمکنش OD Q ، ماتریس POI P ، ماتریس زمان-فرکانس OD، R ، آستانه خطا ε ، شماره تکرار T | |
| خروجی: Q’= MNT، قدرت ارتباط بین سفر کاربر و POI | |
| 1 | مقدار دهی اولیه تصادفی H ،م،ن، نرخ نزول گرادیان γ |
| 2 | t = 1 را تنظیم کنید |
| 3 | اگر (t <T و Lt – Lt + 1 > ε) |
| 4 | برای محاسبه از روش SGD استفاده کنید ∂L∂اچ،∂L∂م،∂L∂ن |
| 5 | تنظیم γ= 1 |
| 6 | در حالی که (( L ( Mt -γ∂L∂اچ, Ut -γ∂L∂م ،Vt -γ∂L∂ن) > L ( H , M , N )) انجام دهید |
| 7 | تنظیم γ= γ/2 |
| 8 | Mt + 1 = Mt -γ∂L∂اچ، Ut + 1 = Ut -γ∂L∂م، Vt + 1 = Vt -γ∂L∂ن |
| 9 | t = t + 1 را تنظیم کنید |
| 10 | حلقه پایانی |
| 11 | پایان اگر |
| 12 | بازگشت Q’ = MN T |
4.3. خوشه بندی طیفی برای شناسایی مناطق عملکردی شهری
- (1)
-
ماتریس مورب T را محاسبه کنید. مقادیر ماتریس T در مورب، مجموع سطرها یا ستون های مربوطه ماتریس W است.
- (2)
-
ماتریس لاپلاسی L را محاسبه کنید . این یک ماتریس متقارن است که با تفریق ماتریس شباهت W از ماتریس مورب T تشکیل شده است.
- (3)
-
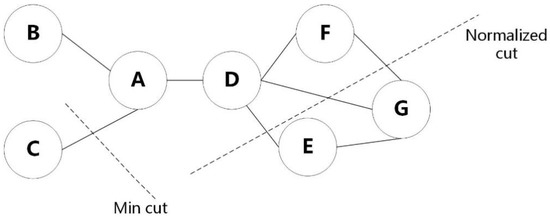
تقسیم گراف بدون جهت را انجام دهید. ماتریس ابتدا با در نظر گرفتن مناطق به عنوان اشیاء نمودار و در نظر گرفتن شباهت به عنوان وزن برای اتصال آنها به شکل نمودار تبدیل می شود ( شکل 4 ). در شکل، «Min cut» نشاندهنده تقسیمبندی با کوچکترین لبه برش، و «برش عادی» نشاندهنده تقسیمبندی تقریباً به همان اندازه با کوچکترین لبه برش است. با توجه به ایده برش نمودار، اولین مقادیر ویژه K ماتریس شباهت پیدا میشود و سپس بردارهای ویژه مربوطه پیدا میشوند.
- (4)
-
روش خوشه بندی k-means را برای بردارهای ویژگی خوشه ای اعمال کنید. بسیاری از مطالعات از روشهای خوشهبندی مبتنی بر فضایی برای تعیین مناطق مانند k-means و DBSCAN استفاده کردهاند. این روش ها بر مجاورت فضایی موجودیت ها تمرکز می کنند و شباهت ها و اطلاعات معنایی موجودات را نادیده می گیرند. با این حال، روش خوشه بندی طیفی می تواند این شکاف را برطرف کند. علاوه بر این، خوشه بندی طیفی برای داده های پراکنده بهتر است زیرا فقط بر روی یک ماتریس شباهت تمرکز می کند.
در خوشه بندی طیفی، ماتریس Q’ از روش CCMF به عنوان داده ورودی استفاده می شود. توزیع فضایی مناطق عملکردی شهری شناسایی شده است. با این حال، ویژگی معنایی هر منطقه کاربردی هنوز ناشناخته است. در کار ما، روشهای پرکاربرد چگالی فرکانس ( FD ) و نسبت طبقهبندی ( CP ) [ 5 ] به کار گرفته شد. فرمول FD به شرح زیر است:
جایی که منبه نوع POI اشاره دارد، nمنبه تعداد POI از انواع اشاره دارد مندر واحد، نمنبه تعداد کل POI از نوع، و افDمنبه چگالی فرکانس نوع اشاره دارد منPOI در تعداد کل POI های آن نوع.
فرمول محاسبه نسبت انواع مختلف در رابطه (3) نشان داده شده است:
جایی که سیپمنبه چگالی فرکانس نوع POI اشاره دارد مندر این منطقه، و k به نوع خوشه اشاره دارد.
4.4. معیارهای ارزیابی
5. نتایج
5.1. ترکیب داده ها با روش پیشنهادی CCMF
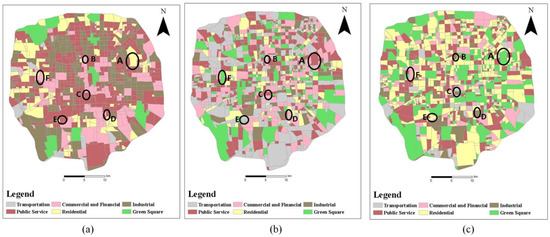
5.2. نتایج شناسایی UFR
5.3. نتایج تجزیه و تحلیل مقایسه دقت
5.3.1. تجزیه و تحلیل دقت با روش پیشنهادی CCMF
- (1)
-
یکی از دلایل چند کارکردی بودن منطقه است. اولا، معمولاً داده های POI بسیار غنی از مناطق تجاری و مالی نزدیک به مسکونی وجود دارد. به همین ترتیب، معمولاً پارک ها یا میدان هایی در نزدیکی محله های مرتفع وجود دارد که ممکن است به اشتباه طبقه بندی شوند و در نتیجه تعداد مناطق مسکونی بسیار کمتر از داده های واقعی باشد. دوم، بر اساس وضعیت فعلی پکن، مراکز خرید بزرگی در بسیاری از ایستگاههای مترو وجود دارد، به طوری که هدف افراد با دادههای POI و دادههای OD به خوبی مشخص نمیشود.
- (2)
-
دلیل دیگر این است که این منطقه قابل تملک نیست. دادههای POI تمایل به انتزاع موجودیتهای فضایی بهعنوان نقاط بدون منطقه دارند، در حالی که در زندگی واقعی، مساحت موجودیتها نیز یکی از عوامل مهم شناسایی مناطق عملکردی شهری است.
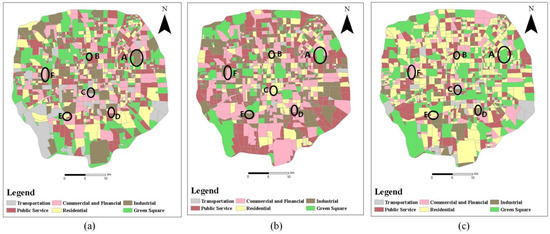
5.3.2. تجزیه و تحلیل دقیق داده های منفرد بدون فیوزینگ
5.3.3. تجزیه و تحلیل دقت روش های مختلف خوشه بندی
6. بحث
6.1. مقایسه دقت شناسایی
6.2. مقایسه با سایر روش های فیوژن
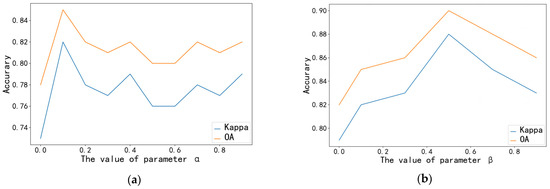
6.3. تاثیر پارامترها بر دقت
7. نتیجه گیری
منابع
- لیو، ی. وانگ، اف. شیائو، ی. گائو، جنوب. استفاده از زمین شهری و ترافیک “مناطق منبع غرق”: شواهد از داده های تاکسی مجهز به GPS در شانگهای. Landsc. طرح شهری. 2012 ، 106 ، 73-87. [ Google Scholar ] [ CrossRef ]
- هو، ی. Han, Y. شناسایی مناطق عملکردی شهری بر اساس داده های POI: مطالعه موردی منطقه توسعه اقتصادی و فناوری گوانگژو. پایداری 2019 ، 11 ، 1385. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- فریاس مارتینز، وی. فریاس مارتینز، E. خوشه بندی طیفی برای سنجش کاربری زمین شهری با استفاده از فعالیت توییتر. مهندس Appl. آرتیف. هوشمند 2014 ، 35 ، 237-245. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- جنرال الکتریک، پی. او، جی. ژانگ، اس. ژانگ، ال. She, J. یک چارچوب یکپارچه ترکیبی از ویژگی های چندگانه فعالیت انسانی برای طبقه بندی کاربری زمین. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 90. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- گائو، کیو. فو، جی. یو، ی. تانگ، X. شناسایی عملکردهای مناطق شهری در چنگدو، چین، بر اساس داده های مسیر خودرو. PLoS ONE 2019 , 14 , e0215656. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شیائو، دی. ژانگ، ایکس. Hu, Y. روش شناسایی منطقه عملکردی شهری بر اساس داده های بزرگ موبایل. Xitong Fangzhen Xuebao/J. سیستم شبیه سازی 2019 ، 31 ، 2281-2288. [ Google Scholar ] [ CrossRef ]
- بله، سی. ژانگ، اف. مو، ال. گائو، ی. لیو، ی. تشخیص عملکرد شهری با ادغام رسانه های اجتماعی و تصاویر در سطح خیابان. محیط زیست طرح. ب مقعد شهری. علوم شهر 2021 ، 48 ، 1430-1444. [ Google Scholar ] [ CrossRef ]
- یوان، جی. ژنگ، ی. Xie, X. کشف مناطق با عملکردهای مختلف در یک شهر با استفاده از تحرک انسان و POI. در مجموعه مقالات هجدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، پکن، چین، 12 تا 16 اوت 2012. ص 186-194. [ Google Scholar ] [ CrossRef ]
- یو، م. لی، جی. Lv، Y.; زینگ، اچ. وانگ، اچ. تشخیص ناحیه عملکردی و تجزیه و تحلیل شدت استفاده بر اساس دادههای چند منبع: مطالعه موردی جینان، چین. ISPRS Int. J. Geo-Inf. 2021 ، 10 ، 640. [ Google Scholar ] [ CrossRef ]
- دای، پی. جینگ، سی. دو، م. Zhou، W. روشی مبتنی بر تحلیلگر فضایی برای تشخیص نقطه داغ رویدادهای مدیریت اجزای شهری. در مجموعه مقالات دومین کنفرانس بین المللی IEEE در سال 2015 در مورد داده کاوی مکانی و خدمات دانش جغرافیایی (ICSDM)، فوژو، چین، 8 تا 10 ژوئیه 2015؛ صص 55-59. [ Google Scholar ] [ CrossRef ]
- کیان، ز. لیو، ایکس. تائو، اف. ژو، تی. شناسایی مناطق عملکردی شهری با جفت کردن تصاویر ماهواره ای و مسیرهای GPS تاکسی. Remote Sens. 2020 , 12 , 2449. [ Google Scholar ] [ CrossRef ]
- منگ، تی. جینگ، ایکس. یان، ز. Pedrycz, W. نظرسنجی در مورد یادگیری ماشین برای ترکیب داده ها. Inf. فیوژن 2020 ، 57 ، 115-129. [ Google Scholar ] [ CrossRef ]
- جیا، ی. Ge، Y. لینگ، اف. گوا، ایکس. وانگ، جی. وانگ، ال. چن، ی. Li, X. نقشهبرداری کاربری زمین شهری با ترکیب تصاویر سنجش از دور و دادههای موقعیتیابی تلفن همراه. Remote Sens. 2018 , 10 , 446. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- زینگ، اچ. Meng, Y. ادغام معیارهای چشم انداز و ویژگی های اجتماعی-اقتصادی برای طبقه بندی منطقه عملکردی شهری. محاسبه کنید. محیط زیست سیستم شهری 2018 ، 72 ، 134-145. [ Google Scholar ] [ CrossRef ]
- ژو، جی. تائو، سی. لین، ایکس. پنگ، جی. هوانگ، اچ. چن، ال. وانگ، کیو. یک مدل مبتنی بر زیرفضاهای چندگانه: تفسیر مناطق عملکردی شهری با دادههای بزرگ مکانی. ISPRS Int. J. Geo-Inf. 2021 ، 10 ، 66. [ Google Scholar ] [ CrossRef ]
- جینگ، سی. دونگ، ام. دو، م. زو، ی. Fu, J. دینامیک فضایی و زمانی گردشگران ورودی بر اساس عکس های دارای برچسب جغرافیایی: مطالعه موردی در پکن، چین. دسترسی IEEE 2020 ، 8 ، 28735–28745. [ Google Scholar ] [ CrossRef ]
- هرولد، ام. لیو، XH; Clarke، KC معیارهای فضایی و بافت تصویر برای نقشه برداری کاربری زمین شهری. فتوگرام مهندس Remote Sens. 2003 , 69 , 991-1001. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وانگ، ی. وانگ، تی. Tsou، MH; لی، اچ. جیانگ، دبلیو. Guo, F. نقشهبرداری از الگوهای پویای کاربری زمین شهری با رسانههای اجتماعی برچسبگذاری شده جغرافیایی جمعسپاری شده (Sina-Weibo) و مجموعههای تجاری در پکن، چین. Sustainability 2016 , 8 , 1202. [ Google Scholar ] [ CrossRef ][ Green Version ]
- پاپاداکیس، ای. گائو، اس. Baryannis، G. ترکیب الگوهای طراحی و مدلسازی موضوع برای کشف مناطقی که از عملکرد خاصی پشتیبانی میکنند. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 385. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژانگ، ایکس. دو، اس. وانگ، Q. شناخت معنایی سلسله مراتبی برای مناطق عملکردی شهری با تصاویر ماهواره ای VHR و داده های POI. ISPRS J. Photogramm. Remote Sens. 2017 ، 132 ، 170-184. [ Google Scholar ] [ CrossRef ]
- کائو، آر. تو، دبلیو. یانگ، سی. لی، کیو. لیو، جی. ژو، جی. ژانگ، Q. لی، کیو. کیو، جی. ادغام داده های سنجش از راه دور و اجتماعی مبتنی بر یادگیری عمیق برای تشخیص عملکرد منطقه شهری. ISPRS J. Photogramm. Remote Sens. 2020 , 163 , 82–97. [ Google Scholar ] [ CrossRef ]
- بائو، اچ. مینگ، دی. گوا، ی. ژانگ، ک. ژو، ک. تشخیص معنایی مبتنی بر DFCNN Du، S. از مناطق عملکردی شهری با ادغام دادههای سنجش از دور و دادههای POI. Remote Sens. 2020 , 12 , 1088. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، سی. سارجنت، آی. پان، X. لی، اچ. گاردینر، آ. هار، جی. اتکینسون، PM یک شبکه عصبی کانولوشن مبتنی بر شی (OCNN) برای طبقهبندی کاربری زمین شهری. سنسور از راه دور محیط. 2018 ، 216 ، 57-70. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پی، تی. سوبولفسکی، اس. راتی، سی. شاو، اس ال. لی، تی. ژو، سی. بینشی جدید در طبقه بندی کاربری زمین بر اساس داده های تلفن همراه جمع آوری شده است. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 1988-2007. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Toole، JL; اولم، ام. گونزالس، ام سی؛ بائر، دی. استنباط کاربری زمین از فعالیت تلفن همراه. در مجموعه مقالات کارگاه بین المللی ACM SIGKDD در محاسبات شهری، پکن، چین، 12 اوت 2012. صص 1-8. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کانگ، سی. شی، ال. وانگ، اف. لیو، ی. گروههای اجتماعی چگونه از مکانهای شهری بازدید میکنند؟ شواهدی از فاکتورسازی ماتریس روی داده های تلفن همراه ترانس. GIS 2020 ، 24 ، 1504-1525. [ Google Scholar ] [ CrossRef ]
- کانگ، سی. Qin، K. درک رفتارهای عملیاتی تاکسی ها در شهرها با فاکتورسازی ماتریسی. محاسبه کنید. محیط زیست سیستم شهری 2016 ، 60 ، 79-88. [ Google Scholar ] [ CrossRef ]
- ژانگ، پی. لی، تی. وانگ، جی. لو، سی. چن، اچ. ژانگ، جی. وانگ، دی. یو، زی. تلفیق اطلاعات چند منبعی بر اساس نظریه مجموعههای خشن: یک بررسی. Inf. فیوژن 2021 ، 68 ، 85-117. [ Google Scholar ] [ CrossRef ]
- بایوض، ک. کنانی، ر. حمدایی، ف. Mtibaa، A. نظرسنجی در مورد یادگیری عمیق چندوجهی برای بینایی کامپیوتر: پیشرفتها، گرایشها، برنامهها و مجموعه دادهها. Vis. محاسبه کنید. 2021 ، 1-32. [ Google Scholar ] [ CrossRef ]
- استبان، ج. استار، ا. ویلتز، آر. هانا، پی. Bryanston-Cross, P. مروری بر مدلها و معماریهای ترکیب دادهها: به سوی دستورالعملهای مهندسی. محاسبات عصبی Appl. 2005 ، 14 ، 273-281. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شیائو، جی. شن، ی. جی، جی. تطیشی، ر. تانگ، سی. لیانگ، ی. Huang، Z. ارزیابی گسترش شهری و تغییر کاربری زمین در شیجیاژوانگ، چین، با استفاده از GIS و سنجش از دور. Landsc. طرح شهری. 2006 ، 75 ، 69-80. [ Google Scholar ] [ CrossRef ]
- عاصم، اچ. خو، ال. بودا، تی اس؛ O’Sullivan، D. رویکرد خوشه بندی فضایی-زمانی برای تشخیص مناطق عملکردی در شهرها. در مجموعه مقالات بیست و هشتمین کنفرانس بین المللی IEEE 2016 در مورد ابزارهای با هوش مصنوعی (ICTAI)، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 6 تا 8 نوامبر 2016؛ صص 370-377. [ Google Scholar ] [ CrossRef ]
- آهنگ، جی. لین، تی. لی، ایکس. پریشچپوف، نقشه برداری AV مناطق عملکردی شهری با ادغام تصاویر سنجش از دور با وضوح بسیار بالا و نقاط مورد علاقه: مطالعه موردی Xiamen، چین. Remote Sens. 2018 ، 10 ، 1737. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژنگ، ی. روششناسی برای تلفیق دادههای متقابل دامنه: یک مرور کلی. IEEE Trans. کلان داده 2015 ، 1 ، 16-34. [ Google Scholar ] [ CrossRef ]
- تو، دبلیو. هو، ز. لی، ال. کائو، جی. جیانگ، جی. لی، کیو. لی، کیو. به تصویر کشیدن مناطق عملکردی شهری با جفت کردن تصاویر سنجش از دور و دادههای سنجش انسان. Remote Sens. 2018 , 10 , 141. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژو، دبلیو. مینگ، دی. Lv، X.; ژو، ک. بائو، اچ. Hong, Z. SO-CNN بر اساس تقسیم بندی دقیق منطقه عملکردی شهری با تصویر سنجش از دور VHR. سنسور از راه دور محیط. 2020 ، 236 ، 111458. [ Google Scholar ] [ CrossRef ]
- ژای، ی. یائو، ی. گوان، کیو. لیانگ، ایکس. لی، ایکس. پان، ی. یو، اچ. یوان، ز. ژو، جی. شبیه سازی تغییر کاربری زمین شهری با ادغام یک شبکه عصبی کانولوشنال با اتوماتای سلولی مبتنی بر برداری. بین المللی جی. جئوگر. Inf. علمی 2020 ، 34 ، 1475-1499. [ Google Scholar ] [ CrossRef ]
- کائو، ک. گوا، اچ. ژانگ، ی. مقایسه رویکردهای طبقهبندی مناطق عملکردی شهری بر اساس دادههای چندمنبعی جغرافیایی: مطالعه موردی در منطقه یوژونگ، چونگ کینگ، چین. پایداری 2019 ، 11 ، 660. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یو، بی. وانگ، ز. مو، اچ. سان، ال. هو، اف. شناسایی مناطق عملکردی شهری بر اساس دادههای مسیر خودروی شناور و دادههای POI. پایداری 2019 ، 11 ، 6541. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- فنگ، ی. هوانگ، ز. وانگ، ی. وان، ال. لیو، ی. ژانگ، ی. شان، ایکس. یک چارچوب آموزشی مبتنی بر SOE با استفاده از داده های بزرگ چند منبعی برای شناسایی مناطق عملکردی شهری. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2021 , 14 , 7336–7348. [ Google Scholar ] [ CrossRef ]
- سریواستاوا، اس. بارگاس-مونوز، جی. Tuia، D. درک استفاده از زمین شهری از دیدگاه های بالا و زمین: یک یادگیری عمیق، راه حل چندوجهی. سنسور از راه دور محیط. 2019 ، 228 ، 129-143. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گووین، ال. پانیسون، آ. کاتتوتو، سی. تشخیص ساختار جامعه و الگوهای فعالیت شبکه های زمانی: یک رویکرد فاکتورسازی تانسور غیر منفی. PLoS ONE 2014 ، 9 ، e86028. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، دبلیو. جی، سی. یو، اچ. ژائو، ی. Chai، Y. تغییرات بین فردی و درون فردی در الگوهای فعالیت روزانه سفر: تحلیل فضایی و زمانی شبکه ای. ISPRS Int. J. Geo-Inf. 2021 ، 10 ، 148. [ Google Scholar ] [ CrossRef ]
- ژانگ، ی. لی، کیو. تو، دبلیو. مای، ک. یائو، ی. چن، ی. تشخیص کاربری زمین شهری کاربردی با ادغام دادههای مکانی چند منبعی و همبستگیهای متقابل. محاسبه کنید. محیط زیست سیستم شهری 2019 ، 78 ، 101374. [ Google Scholar ] [ CrossRef ]
- وانگ، جی. بله، ی. Fang, F. مطالعه منطقهبندی عملکردی شهری بر اساس دادههای چگالی و همجوشی هستهای. Geogr. Geo-Inf. علمی 2019 ، 35 ، 66-71. [ Google Scholar ] [ CrossRef ]
- ژو، بی. ژائو، بی. شیائو، ایکس. لی، جی. Xie، X. رن، دبلیو. یک مطالعه مبتنی بر دادههای پوی در مناطق عملکردی شهری شهر مبتنی بر منابع: مطالعه موردی بنشی، لیائونینگ. هوم Geogr. 2020 ، 35 ، 81-90. [ Google Scholar ] [ CrossRef ]
- کیم، ک. لی، ک. رسیدگی به نقاط مورد علاقه (POIs) در یک سرویس نقشه وب تلفن همراه مرتبط با اشیاء فضایی داخلی: مطالعه موردی. ISPRS Int. J. Geo-Inf. 2018 ، 7 ، 216. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یی، بی. شن، ایکس. لیو، اچ. ژانگ، ز. ژانگ، دبلیو. لیو، اس. Xiong، N. فاکتورسازی ماتریس عمیق با تعبیه بازخورد ضمنی برای سیستم توصیه. IEEE Trans. Ind. اطلاع رسانی. 2019 ، 15 ، 4591-4601. [ Google Scholar ] [ CrossRef ]
- شکوهی یکتا، م. هو، بی. جین، اچ. وانگ، جی. Keogh, E. تعمیم DTW به حالت چند بعدی نیاز به یک رویکرد تطبیقی دارد. حداقل داده بدانید. کشف کنید. 2016 ، 31 ، 1-31. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ما، اچ. یانگ، اچ. لیو، ام آر؛ King, I. SoRec: توصیه اجتماعی با استفاده از فاکتورسازی ماتریس احتمالی. در مجموعه مقالات هفدهمین کنفرانس ACM در مدیریت اطلاعات و دانش، دره ناپا، کالیفرنیا، ایالات متحده آمریکا، 26 تا 30 اکتبر 2008. ص 931-940. [ Google Scholar ] [ CrossRef ]
- دو، آر. لو، جی. Cai, H. الگوریتم پیشنهاد فاکتورسازی ماتریس منظم سازی دوگانه. IEEE Access 2019 ، 7 ، 139668–139677. [ Google Scholar ] [ CrossRef ]
- فیدلر، ام. اتصال جبری نمودارها. چکسلوف ریاضی. J. 1973 , 23 , 298-305. [ Google Scholar ] [ CrossRef ]
- شی، ج. Malik, J. برش های عادی و تقسیم بندی تصویر. IEEE Trans. الگوی مقعدی ماخ هوشمند 2000 ، 22 ، 888-905. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژو، ام. لو، ال. گوا، اچ. ونگ، کیو. کائو، اس. ژانگ، اس. لی، کیو. پراکندگی شهری و تغییرات در بهره وری استفاده از زمین در منطقه پکن-تیانجین-هبی، چین از سال 2000 تا 2020: تجزیه و تحلیل مکانی-زمانی با استفاده از داده های مشاهده زمین. Remote Sens. 2021 , 13 , 2850. [ Google Scholar ] [ CrossRef ]
- سان، ز. جیائو، اچ. وو، اچ. پنگ، ز. Liu, L. Block2vec: رویکردی برای شناسایی مناطق عملکردی شهری با ادغام مدل جاسازی جمله و نقاط مورد علاقه. ISPRS Int. J. Geo-Inf. 2021 ، 10 ، 339. [ Google Scholar ] [ CrossRef ]
- او، X. یوان، ایکس. ژانگ، دی. ژانگ، آر. لی، ام. ژو، سی. تعیین مرز تراکم شهری بر اساس ترکیب داده های بزرگ چند منبعی – مطالعه موردی منطقه خلیج بزرگ گوانگدونگ-هنگ کنگ-ماکائو (GBA). Remote Sens. 2021 , 13 , 1801. [ Google Scholar ] [ CrossRef ]
- لیو، ایکس. تیان، ی. ژانگ، ایکس. Wan, Z. شناسایی مناطق عملکردی شهری در چنگدو بر اساس دادههای سری زمانی مسیر تاکسی. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 158. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- دو، اس. دو، اس. لیو، بی. ژانگ، ایکس. Zheng, Z. نقشهبرداری منطقه عملکردی شهری در مقیاس بزرگ با ادغام تصاویر سنجش از دور و دادههای اجتماعی باز. GIScience Remote Sens. 2020 ، 57 ، 411-430. [ Google Scholar ] [ CrossRef ]
- ژونگ، ی. سو، ی. وو، اس. ژنگ، ز. ژائو، جی. ما، ا. زو، س. بله، آر. لی، ایکس. پلیککا، پ. و همکاران نقشهبرداری کاربری زمین شهری مبتنی بر دادههای منبع باز با ادغام اشیاء معنایی نقطه-خط-چند ضلعی: مطالعه موردی شهرهای چین. سنسور از راه دور محیط. 2020 , 247 , 111838. [ Google Scholar ] [ CrossRef ]


بدون دیدگاه