

قابلیتهای پیشبینی و عدم قطعیت جنگلهای رگرسیون کوانتیل در تخمین پراکندگی فضایی مواد آلی خاک
چکیده
یکی از وظایف اصلی در مطالعات نقشه برداری دیجیتالی خاک (DSM) تخمین توزیع مکانی متغیرهای مختلف خاک است. علاوه بر این، با این حال، ارزیابی عدم قطعیت این برآوردها به همان اندازه مهم است، چیزی که بسیاری از مطالعات DSM فعلی فاقد آن هستند. روشهای یادگیری ماشینی (ML) به طور فزایندهای در این زمینه علمی استفاده میشوند، که اکثر آنها قابلیتهای تخمین عدم قطعیت ذاتی را ندارند. یک راه حل برای این، استفاده از روشهای خاص ML است که قابلیتهای پیشبینی پیشرفته را همراه با معیارهای تخمین عدم قطعیت ذاتی، مانند جنگلهای رگرسیون چندکی (QRF) ارائه میکند.

در مقاله حاضر، قابلیت های پیش بینی و عدم قطعیت روش های QRF، جنگل های تصادفی (RF) و زمین آماری مورد ارزیابی قرار گرفت. تایید شد که QRF نتایج برجسته ای را در پیش بینی ماده آلی خاک (OM) در منطقه مورد مطالعه به نمایش گذاشته است. به ویژه، R2 بسیار بالاتر از روش های زمین آماری بود، به این معنی که تنوع بیشتر توسط مدل خاص توضیح داده می شود. علاوه بر این، قابلیتهای عدم قطعیت آن همانطور که در نقشههای عدم قطعیت ارائه شده است، نشان میدهد که میتواند تخمین خوبی از عدم قطعیت با نمایش متمایز از تغییرات محلی در بخشهای خاص منطقه ارائه دهد، چیزی که مزیت قابل توجهی بهویژه برای پشتیبانی تصمیمگیری در نظر گرفته میشود.
کلید واژه ها:
جنگل های رگرسیون چندکی ; جنگل های تصادفی ; زمین آمار ; یادگیری ماشینی ؛ مواد آلی خاک ; عدم قطعیت پیش بینی
1. مقدمه
نقشه برداری دیجیتالی خاک (DSM)، همچنین به عنوان نقشه پیش بینی خاک یا نقشه برداری پدومتریک شناخته می شود، به ایجاد نقشه های دیجیتالی اشاره دارد که شامل اطلاعات فضایی خاک، مانند نوع خاک یا ویژگی های خاک است. این نقشه ها از ترکیب پارامترهای متعدد (خاک، آب و هوا، امداد و غیره) ایجاد می شوند و معمولاً توزیع مکانی پدیده های خاک را همراه با اطلاعات نسبی (مثلا عدم قطعیت برآورد) به تصویر می کشند.
DSM از سیستمهای اطلاعات جغرافیایی (GIS)، سیستمهای موقعیتیابی جهانی (GPS)، دادههای طیفی سنجش از راه دور، دادههای توپوگرافی حاصل از مدلهای ارتفاعی دیجیتال (DEMs)، مدلهای پیشبینی یا استنتاج و نرمافزار برای تجزیه و تحلیل دادهها استفاده گسترده میکند. برای مقابله با حجم زیادی از داده های مورد استفاده در DSM، از تکنیک ها و فناوری های نیمه خودکار برای به دست آوردن، پردازش و تجسم این داده ها استفاده می شود. یادگیری ماشینی (ML) و هوش مصنوعی (AI) برخی از فنآوریهای نوآورانه هستند که به طور فزایندهای در نقشهبرداری خاک مورد استفاده قرار میگیرند و جذب آنها در حال تغییر روشی است که دانشمندان خاک نقشههای خود را تولید میکنند [ 1 ]. ML که در دهه 1990 به عنوان ابزاری برای DSM ظهور کرد [ 2] به عنوان تمرین کامپیوتری برای استفاده از مدلهای آماری مبتنی بر داده (و عمدتاً غیر خطی) تعریف میشود که برای یادگیری یک الگو و پیشبینی به مقدار زیادی از دادههای ورودی متوسل میشود [ 1 ].
بر اساس لئو بریمن [ 3 ] دو پارادایم مدل سازی آماری متمایز شد: یک مدل داده و یک مدل الگوریتمی. مدل داده یک مدل انتزاعی است که عناصر داده را سازماندهی می کند و نحوه ارتباط آنها با یکدیگر و ویژگی های موجودات واقعی را استاندارد می کند، در حالی که مدل الگوریتمی مدلی است که از الگوریتم های ریاضی بر اساس عناصر داده استفاده می کند و تخمین می زند. مولفه های. یکی از الگوریتمهای پرکاربرد برای این نوع مدل، جنگلهای تصادفی (RF) است. RF یک روش یادگیری مجموعه ای برای طبقه بندی، رگرسیون و سایر وظایف است که با ساختن تعداد زیادی درخت تصمیم در زمان آموزش عمل می کند و به طور گسترده در DSM استفاده می شود [ 4 ]. به عنوان مثال، بهترین نتایج را در تخمین OM خاک ارائه کرد [ 5]، زمان آموزش را در طول فرآیند مدل سازی OM خاک کوتاه کرد و دقت مدل و توانایی پیش بینی آن را بهبود بخشید [ 6 ]. در نهایت، با توجه به جان و همکاران. [ 7 ]، RF بهترین مدل در بین سایر الگوریتمهای ML مانند شبکه عصبی مصنوعی (ANN)، ماشین بردار پشتیبان (SVM) و رگرسیون مکعبی بود.
اغلب اوقات، محصولات DSM تخمینی از ویژگی های خاک توزیع شده در فضایی را نشان می دهند. این برآوردها شامل یک عنصر عدم قطعیت است که به طور مساوی در منطقه تحت پوشش DSM توزیع نشده است. اگر عدم قطعیت را به طور صریح به صورت مکانی تعیین کنیم، این اطلاعات می تواند برای بهبود کیفیت DSM با بهینه سازی طرح نمونه برداری [ 8 ] استفاده شود. وادوکس و همکاران [ 1] بیان کرد که در حالی که نتایج اعتبارسنجی متقابل (فضایی) ممکن است توافق قوی بین ویژگی یا طبقه خاک پیشبینیشده و اندازهگیری شده را نشان دهد و بنابراین یک مدل ML با تواناییهای پیشبینی بسیار بالا را تأیید میکند، یک کمیسازی عدم قطعیت پیشبینیهای غیرواقعی را نشان میدهد که با عدم قطعیت بزرگ مشخص میشود. با این حال، اکثر روشهای ML شامل RF بهطور پیشفرض تخمینهای عدم قطعیت را ارائه نمیکنند و تنها 30 درصد از مطالعات اخیر خاک در بررسی متون خود، عدم قطعیت مرتبط با پیشبینی را کمیسازی کردند.
یکی از روشهای ML که به طور ذاتی به کمبود تخمینهای عدم قطعیت میپردازد، جنگلهای رگرسیون چندکی (QRF) است. QRF توسعه یافته RF است که توسط Nicolai Meinshausen [ 9 ] توسعه یافته است که تخمین های غیر پارامتریکی از مقدار متوسط پیش بینی شده و همچنین چندک های پیش بینی را ارائه می دهد. بنابراین تخمینهای غیر پارامتری صریح فضایی عدم قطعیت مدل را با ارائه اطلاعات برای توزیع شرطی کامل متغیر پاسخ، و نه تنها در مورد میانگین شرطی [ 10 ] امکان پذیر میسازد. در نتیجه، QRF به طور بالقوه می تواند دقت بالای RF را با تخمین های عدم قطعیت داخلی ترکیب کند. با این حال، QRF علیرغم مزایایی که دارد به طور گسترده در مطالعات خاک مورد استفاده قرار نمی گیرد.
برای مثال Vaysse و Lagacherie [ 11 ] آزمایشی را انجام دادند که در آن از QRF در یک منطقه معتدل مدیترانه با مجموعه داده کربن آلی خاک (SOC) قابل مقایسه از نظر وسعت منطقه، تراکم مشاهده و همگنی توزیع استفاده کردند. آنها ادعا می کنند که QRF در تفسیر الگوهای عدم قطعیت بهتر از RK عمل می کند و زمانی که نمونه برداری فضایی پراکنده است نسبت به سایر روش های مدل سازی مناسب تر است. در مطالعه Dharumarajan [ 12] مدل QRF برای تخمین چند کیفیت مهم خاک کارناتاکای شمالی با توجه به معیارهای GlobalSoilMap استفاده شد. مدل QRF حداکثر تنوع را برای بسیاری از پارامترهای خاک گرفت و مقادیر خاک پیشبینیشده با حداقل خطا قابل اعتماد بود. QRF همچنین برای تولید نقشههای جهانی از ویژگیهای خاک استفاده شد که به صراحت اهمیت ارزیابی کمی و کیفی و ارتباطات عدم قطعیت را برجسته میکند [ 13 ]. در نهایت، در مطالعه ورونزی در سال 2019 [ 14 ]، RF و QRF معتبرترین فواصل اطمینان را برای پیشبینی SOC ایجاد کردند. حتی اگر این به طور بالقوه برای استفاده های عملی مهم است، فواصل اطمینان نیز بسیار گسترده بود، بنابراین آنها پیشنهاد می کنند که این فواصل باید با دقت انجام شود.
در مطالعه حاضر، قابلیت پیشبینی به همراه ظرفیت ارزیابی عدم قطعیت QRF مورد بررسی قرار میگیرد. روشهای زمین آماری رایج کریجینگ معمولی (OK) و کریجینگ با رانش خارجی (KED) با روشهای ML RF و QRF در مورد OM خاک مقایسه شدند. نقشه های پیش بینی OM خاک به همراه نقشه عدم قطعیت ها نیز تهیه و ارائه شد. منطقه مورد مطالعه انتخاب شده در شمال یونان، در واحد منطقه ای کاستوریا و در کنار ساحل دریاچه اورستیادا است. تعداد کل 414 نمونه خاک در یک دوره شش ساله در مکان های منحصر به فرد نمونه برداری تصادفی در پاییز جمع آوری شد. برای شناسایی موقعیت های نمونه گیری از گیرنده های GPS استفاده شد. یک مدل ارتفاع دیجیتال با وضوح بالا (DEM) برای استخراج محصولات توپوگرافی مانند جنبه، شیب، ارتفاع و غیره استفاده شد. همراه با تصاویر Sentinel-2، برای هر سال از دوره مطالعه ما، برای تولید شاخص تفاوت عادی شده گیاهی (NDVI) و شاخص تفاوت عادی آب (NDWI) که به عنوان داده های ورودی استفاده شد. در نهایت، تأثیر متغیرهای کمکی فوق در پیشبینی OM خاک بر اساس امتیاز اهمیت روشهای یادگیری ماشینی کاربردی مورد ارزیابی قرار گرفت.
2. مواد و روشها
2.1. منطقه مطالعه و نمونه برداری از خاک
منطقه مورد مطالعه در شمال یونان، در نزدیکی ساحل دریاچه Orestiada، در واحد منطقه ای Kastoria انتخاب شد ( شکل 1 ). مختصات آن در سیستم ژئودتیک جهانی 1984 (WGS84) شامل ناحیه بین 40°28’42.41″ شمالی و 40°32’35.61″ عرض جغرافیایی شمالی و طول جغرافیایی 21°19’4.01″ شرقی و 21°23’8 E11 است. طول جغرافیایی
در حالی که منطقه مورد نظر مسطح است، میانگین ارتفاع از سطح دریا در حدود 640 متر است که از 620 متر در نزدیکی دریاچه تا 700 متر شمالی تر است. آب و هوا معتدل و اغلب گرم است و زمستان های سختی دارد که اغلب در طول روز دما را زیر صفر نگه می دارد. میانگین سالانه دما 11.5 درجه سانتی گراد است که میزان بارش به 636 میلی متر می رسد. تابستان ها گرم و خشک و با رطوبت نسبی 50 تا 55 درصد است. درختان سیب و لوبیا محصولات کشاورزی اولیه هستند.
در طی یک دوره شش ساله، در مجموع 414 نمونه خاک در مکانهای مجزای نمونهبرداری تصادفی در اطراف منطقه مورد مطالعه (2012 تا 2019) جمعآوری شد. در مجموع 30 سانتی متر از خاک بالا در اواخر فصل پاییز (حدود اواخر نوامبر) جمع آوری شد. موقعیت های نمونه گیری با استفاده از دستگاه های سیستم موقعیت یاب جهانی (GPS) تعیین شد. حداقل فاصله بین دو محل نمونه برداری بین 60 تا 480 متر با میانگین 90 متر متغیر است.
2.2. متغیرهای کمکی خاک، محیطی و ماهواره ای
در این مطالعه، متغیرهای خاک، متغیرهای محیطی و تصاویر ماهواره ای ( جدول 1 ) به عنوان ورودی های بالقوه در مدل ها انتخاب شدند. با توجه به متغیرهای کمکی خاک، 414 نمونه خاک که از منطقه جمع آوری شد، از نظر خاک رس (C) با روش هیدرومتر خاک (Bouyoucos) [ 15 ]، منیزیم (Mg) با روش استات آمونیوم و روی (روی) با روش DTPA [ 16 ] تجزیه و تحلیل شدند.]. علاوه بر این، تجزیه و تحلیل ماده آلی (OM) (روش اکسیداسیون مرطوب) از همان مکانها برای کالیبره کردن مدلها و ارزیابی نتایج پیشبینی انجام شد. به طور دقیق تر، در طی مراحل نمونه برداری از خاک، از هر قطعه زراعی یک نمونه خاک مرکب شامل چند نمونه فرعی تا عمق 30 سانتی متری تهیه و نمونه های خاک خشک شده و در آزمایشگاه منابع آب و خاک مورد تجزیه و تحلیل قرار گرفت. موسسه در تسالونیکی، یونان.
متغیرهای محیطی از نسخه دوم رادیومتر انتشار حرارتی پیشرفته فضایی- مدل ارتفاع دیجیتال جهانی نسخه 2 (ASTER GDEM2) مشتق شدهاند. انتشار ASTER GDEM2 در دسترس بودن منابع DEM رایگان را که به ویژه برای کشورهای در حال توسعه مفید است، غنی کرده است و کاربران را بر آن داشت تا کیفیت و دقت آن را ارزیابی کنند [ 17 ]. ASTER GDEM2 از کاشی های 1°×1° (رزولوشن 30 متر) در سیستم ژئودتیک جهانی 1984 (WGS84) تشکیل شده است، که برای این مطالعه به سیستم مرجع ژئودتیک یونان 1987 (GGRS87) بازپخش شد [ 18 ].
علاوه بر این، شاخصهای ماهوارهای از تصاویر Sentinel-2 استخراج شدند. به طور خاص، شاخص تفاوت نرمال شده گیاهی (NDVI) و شاخص تفاوت نرمال شده آب (NDWI) از سال 2016 تا 2019 تقریباً در همان دوره زمانی جمعآوری شد که دادههای خاک (پایان نوامبر) جمعآوری شد. NDVI شناخته شده و پرکاربرد یک شاخص ساده اما موثر برای تعیین کمیت پوشش گیاهی سبز است. نور قرمز به طور فعال توسط گیاهان سالم جذب می شود، در حالی که مادون قرمز نزدیک منعکس می شود. برای تعیین وضعیت سلامت گیاه، باید مقادیر جذب و بازتاب نور قرمز و مادون قرمز را با هم مقایسه کنیم [ 7 ، 19 ]]. NDWI یک شاخص گیاهی حساس به محتوای آب پوشش گیاهی است و مکمل NDVI است. مقادیر بالای NDWI نشان دهنده محتوای بالای آب گیاه و پوشش با کسر گیاهی بالا است. محتوای کم پوشش گیاهی و پوشش گیاهی کم با مقادیر کم NDWI مطابقت دارد. نرخ NDWI در زمان تنش آب کاهش می یابد [ 20 ].
2.3. آماده سازی و ارزیابی داده ها
ابتدا دادههای توپوگرافی و شاخصهای ماهوارهای به همراه دادههای آنالیز خاک با هم ترکیب شدند و به صورت مکانی در محلهای نمونهبرداری قرار گرفتند. مجموعه داده کلی برای مقادیر پرت و از دست رفته ارزیابی شد. از 414 نقطه اولیه، 403 نقطه در پایان باقی مانده است که به عنوان ورودی برای مدل های مورد مطالعه استفاده شده است.
از مجموعه کامل متغیرها، تنها یک زیرمجموعه در مطالعه استفاده شد. متغیرها با استفاده از تکنیک Akaike Information Criteria (stepAIC) و تجزیه و تحلیل مؤلفه اصلی (PCA) حذف شدند و همچنین برای چند خطی بودن ارزیابی شدند. متغیرهای باقیمانده C، OM، ZN، MG، Vdepth، Altitude، NDVI_2016، NDVI_2017، و NDWI_2019 بودند ( جدول 2 ).
نقشههای توزیع فضایی متغیرهای کمکی محیطی که از ASTER GDEM2 مشتق شدهاند و در مطالعه مورد استفاده قرار گرفتهاند (عمق و ارتفاع)، در ادامه ارائه شدهاند ( شکل 2 ).
نقشههای متغیرهای ماهوارهای که در مطالعه مورد استفاده قرار گرفتند (NDVI_2016، NDVI_2017 و NDWI_2019) به شرح زیر است ( شکل 3 ).
در نهایت، متغیرهای کمکی خاک (C، MG، ZN) از مکانهای نقطهای شناخته شده مجموعه داده کامل با استفاده از OK درون یابی شدند و توزیع فضایی آنها برای کل منطقه مورد مطالعه برآورد شد ( شکل 4 ).
برای تمامی پارامترهای خاک، مدل نیم متغیره ماترن با پارامترسازی M. Stein (Ste) به عنوان مدل برازش با استفاده از پارامترهای پیشفرض gstat اعمال شد. با توجه به C، برد آن 660 متر بود و یک وابستگی مکانی قوی با نسبت قطعه به آستانه 0.8٪ نشان داد [ 21 ]. منیزیم دارای برد 1955 متر با وابستگی فضایی قوی (قطعه به آستانه 3.5٪) بود در حالی که روی دارای محدوده 279 متر با وابستگی مکانی متوسط با قطعه به آستانه نزدیک به 65٪ بود.
نقشههای کریجینگ تولید شده از متغیرهای کمکی خاک برای تخمین OM خاک در منطقه توسط مدلهای مطالعه حاضر (KED، RF، QRF) استفاده شد ( شکل 5 ).
2.4. کریجینگ معمولی (OK) و کریجینگ با رانش خارجی (KED)
کریجینگ معمولی نوعی کریجینگ است که در آن وزن مقادیر برابر یک جمع می شود. خطی است زیرا تخمین های آن ترکیبی خطی از داده های موجود است. همچنین بی طرف است زیرا سعی می کند میانگین باقیمانده را صفر نگه دارد و سعی می کند واریانس باقیمانده را به حداقل برساند [ 22 ]. OK به طور ضمنی میانگین را در یک محله متحرک با ایستایی مرتبه دوم محلی ارزیابی می کند و واریانس آن برابر با مجموع واریانس کریجینگ ساده (با فرض میانگین شناخته شده) به اضافه واریانس ناشی از عدم اطمینان در مورد مقدار میانگین واقعی است [ 23 ].
کریجینگ جهانی (بریتانیا)، کریجینگ با رانش خارجی و رگرسیون-کریجینگ (RK) به گروهی از به اصطلاح «هیبرید» [ 24 ]، یعنی روشهای زمین آماری غیر ثابت [ 23 ] تعلق دارند. در زمینآمار کلاسیک، پیشبینی فضایی برای فرآیندهای غیر ثابت با در نظر گرفتن یک روند فضایی (همچنین به عنوان “رانش” شناخته میشود) انجام میشود که یا صرفاً به عنوان تابعی از مختصات (در انگلستان) مدلسازی میشود یا به صورت “خارجی” از طریق برخی تعریف میشود. متغیرهای کمکی (در KED) [ 25 ].
KED وزنهای کریجینگ را با گسترش ماتریس کوواریانس با متغیرهای کمکی حل میکند تا شرایط جهانشمولی در سیستم کریجینگ یکپارچه شود. در اینجا، مشکل به دست آوردن واریوگرام باقیمانده رضایت بخش در حضور رانش است [ 26 ].
اجرای هر دو OK و KED در مطالعه حاضر با بسته gstat در R انجام شد.
2.5. جنگلهای تصادفی (RF) و جنگلهای رگرسیون کمی (QRF)
ایده توسعه روش RF بر اساس ترکیبی از روش کیسهای و زیرفضای تصادفی، استفاده از مزایا و جبران معایب آنها، با نتایج چشمگیر است [ 3 ، 27 ].
طبق نظر بریمن (2001) [ 3 ]، در مورد طبقه بندی، “جنگل تصادفی طبقه بندی کننده ای است متشکل از مجموعه ای از طبقه بندی کننده های ساختار درختی {h(x، Θk)، k = 1، …} که در آن {Θk } بردارهای تصادفی مستقلی هستند که به طور یکسان توزیع شده اند و هر درخت یک رای واحد برای محبوب ترین کلاس در ورودی x می دهد. در صورت رگرسیون، بریمن بیان میکند که «…جنگلهای تصادفی برای رگرسیون با رشد درختان بسته به بردار تصادفی Θ تشکیل میشوند، به طوری که پیشبینیکننده درخت h(x، Θ) مقادیر عددی را بر خلاف برچسبهای کلاس میگیرد. مقادیر خروجی عددی هستند و ما فرض می کنیم که مجموعه آموزشی به طور مستقل از توزیع بردار تصادفی Y, X گرفته شده است.
RF برای رگرسیون به طور گسترده در DSM استفاده می شود (به عنوان مثال، [ 28 ، 29 ، 30 ، 31 ، 32 ، 33]) با نتایج بسیار مثبت در پیش بینی پارامترهای مختلف خاک. مهمتر از آن، با متغیرهای اریب و معمولی توزیع شده، بدون نیاز به فرضیات آماری یا محدودیتهایی که روشهای دیگر اقتضا میکنند، به خوبی کار میکند. بنابراین، استفاده از آن آسان تر و ساده تر است. فقط نیاز به توجه ویژه در بهینه سازی هایپرپارامترها برای گرفتن بهترین نتایج دارد. یکی از اشکالات عمده برخی از روشهای شناخته شده ML (RF، ANN و غیره) فقدان قابلیتهای تخمین عدم قطعیت ذاتی است. بنابراین، به غیر از نقشههای پیشبینی، برخلاف روشهای کلاسیک زمینآمار، واریانس خطای پیشبینی را نمیتوان تخمین زد. دلیل اصلی این امر این است که اکثر روشهای ML، از جمله RF، تنها پیشبینیهای مقدار میانگین را ارائه میدهند.
یک راه حل ممکن برای این کمبود از Nicolai Meinshausen [ 9 ] آمد، که RF استاندارد را تعمیم داد تا اطلاعاتی را برای توزیع شرطی کامل متغیر پاسخ و نه تنها در مورد میانگین شرطی ارائه کند. این الگوریتم ML جنگلهای رگرسیون چندکی (QRF) نامیده میشود و روشی غیر پارامتریک و دقیق برای تخمین چندکهای شرطی برای متغیرهای پیشبینیکننده با ابعاد بالا ارائه میدهد. تفاوت اصلی بین QRF و RF به شرح زیر است: برای هر گره در هر درخت، RF تنها میانگین مشاهداتی را که در این گره قرار می گیرند و از تمام اطلاعات دیگر غفلت می کنند، نگه می دارد. در مقابل، QRF مقادیر تمام مشاهدات را در این گره نگه می دارد، نه فقط میانگین آنها را، و توزیع شرطی را بر اساس این اطلاعات ارزیابی می کند.
در مطالعه حاضر از بسته رنجر به زبان R برای پیاده سازی مدل های ML استفاده شد. Ranger پیاده سازی سریع RF یا پارتیشن بندی بازگشتی است که به ویژه برای داده های با ابعاد بالا مناسب است.
ارزیابی فراپارامترهای بهینه یک مدل ML یک گام مهم برای تخمین بهترین مدلهای ML برای هر مورد استفاده خاص است. تنظیمات فراپارامتر ایده آل تأثیر مستقیمی بر عملکرد مدل دارد. اگرچه روشهای بهینهسازی خودکار مختلفی وجود دارد، اما نقاط قوت و معایب آنها هنگام اعمال در انواع موقعیتها تغییر میکنند [ 34 ]]. در مطالعه حاضر، روش جستجوی تصادفی (10 کیلو برابری با 3 تکرار) انجام شد که در آن از ترکیبات تصادفی پارامترها از طیفی از مقادیر استفاده شد و به عنوان فراپارامتر استفاده شد. مدل ML با مجموعه ای از پارامترها که بالاترین دقت را داشت بهترین در نظر گرفته شد و برای پیش بینی استفاده شد. مجموعه داده کلی (403 نمونه) به دو مجموعه داده مجزا تقسیم شد: مجموعه داده آموزشی (70٪ از داده ها) که برای تخمین فراپارامترهای مدل استفاده شد و مجموعه داده آزمایشی (30٪ از داده ها) که برای ارزیابی موارد مختلف استفاده شد. مدل ها. هایپرپارامترهای خاص برای RF که بهینه شده بودند در جدول 3 ارائه شده است.
2.6. عدم قطعیت
محصولات DSM تخمینی از خواص خاک توزیع شده در فضایی را نشان می دهد. این برآوردها شامل یک عنصر عدم قطعیت است که به طور مساوی در منطقه تحت پوشش DSM توزیع نشده است [ 8 ]. این نقص ها با ترکیب داده های خاک در سایت ها با عوامل محیطی جامع فضایی با استفاده از مدل های کمی برطرف می شوند (به عنوان مثال، [ 35 ، 36 ، 37 ]). مدل ها همچنین می توانند به دلایل متعدد به روز شوند و عدم قطعیت را می توان اندازه گیری کرد [ 38 ، 39 ].
اندازهگیریها، رقومیسازی، ورودی دادهها، تفسیر، طبقهبندی، تعمیم و درونیابی همگی منابع رایج اشتباه هستند [ 40 ]. تعصب مدلسازی، پارامترسازی یا حتی اشتباهات اندازهگیری مرتبط با دادههای ورودی، همگی میتوانند باعث عدم قطعیت در نقشههای خاک دیجیتال شوند [ 41 ]. نلسون و همکاران [ 42 ] توصیه میکند بودجه خطا را برای ارزیابی سهم هر خطا با استفاده از ترکیبی از شبیهسازیهای زمین آماری و مونت کارلو انجام دهید تا درک بهتری از عدم قطعیت به دست آورید. تمایز بین خطای مدل و عدم قطعیت صریح فضایی نیز باید در نظر گرفته شود [ 43]. میانگین مجذور اختلاف بین مقدار برآورد شده و مقدار واقعی به عنوان خطای مدل شناخته می شود، که اغلب به عنوان میانگین مربع خطا (MSE) ارزیابی می شود [ 44 ، 45 ]. با این حال، عدم قطعیت صریح فضایی، که اغلب به عنوان “خطای محلی” شناخته می شود، به کمی سازی فواصل پیش بینی خروجی مدل اشاره دارد (به عنوان مثال، [ 11 ، 44 ، 46 ]).
این پیشبینی با معیار صریح عدم قطعیت مرتبط است. در بسیاری از شرایط، مانند فرآیند تصمیمگیری، تعیین کمیت عدم قطعیت پیشبینی به همان اندازه مهم است که خود پیشبینی را انجام دهیم، بنابراین نقشههای عدم قطعیت ضروری هستند (به عنوان مثال، [ 47 ، 48 ]). در DSM، تجزیه و تحلیل عدم قطعیت برای تصمیم گیری در مورد اینکه آیا نقشه خاک پیش بینی شده به اندازه کافی قابل اعتماد است که در سیستم های تولید کشاورزی یا تصمیم گیری اعمال شود، بسیار مهم است. تجزیه و تحلیل عدم قطعیت همچنین شامل تصدیق محدودیت های مدل است که گامی به سوی تفسیرپذیری مدل است [ 1 ]. همانطور که Heuvelink [ 49] بیان می کند، ما علاقه زیادی به فواصل پیش بینی در نقشه برداری خاک داریم، یعنی محدوده ای که احتمالاً حاوی مقداری است که هنوز اندازه گیری نشده است. با این حال، تعداد بسیار کمی از مطالعات DSM عدم قطعیت را تخمین می زنند. با توجه به Wadoux [ 1 ]، تنها حدود 30٪ از مطالعات ارائه شده در مقاله خود، عدم قطعیت پیش بینی را کمی کردند.
در مطالعه حاضر عدم قطعیت تنها برای سه روش از چهار روش OK، KED، QRF برآورد شد. RF به خودی خود قابلیت های تخمین عدم قطعیت را ارائه نمی دهد. روش های زمین آماری OK و KED به طور پیش فرض واریانس مورد استفاده برای ارزیابی عدم قطعیت را ارائه می دهند. عمدتاً انحراف معیار محاسبه و محدوده آن در نقشه ها نشان داده شد. برای QRF محدوده به عنوان یک انحراف استاندارد بالاتر و پایین تر از مقدار میانه تعریف شد. این محدوده برای ایجاد نقشه عدم قطعیت منطقه مورد مطالعه استفاده شد
2.7. ارزیابی خطا
معیارهای مختلف ( جدول 4 ) برای تخمین عملکرد مدل بر اساس تفاوت بین مشاهدات و پیشبینیها در مجموعه دادههای آزمایش استفاده شد.
ریشه میانگین مربعات خطا (RMSE) و میانگین خطای مطلق (MAE) بر اساس مقدار اندازه گیری شده برآورد شد. و پیش بینی آن که در مکان نمونه ها (معادلات (1) و (2)). MAE میانگین مقادیر مطلق تفاوت بین پیش بینی و مشاهده مربوطه در نمونه تأیید است. از آنجایی که MAE یک امتیاز خطی است، همه تفاوت های فردی به طور مساوی در میانگین وزن می شوند. RMSE یک قانون امتیازدهی درجه دوم است که میانگین بزرگی خطا را محاسبه می کند. از آنجایی که خطاها قبل از میانگین گیری مجذور می شوند، RMSE به خطاهای بزرگ وزن نسبتاً بالایی می دهد. در نتیجه، RMSE زمانی بسیار مفید است که خطاهای بزرگ به ویژه نامطلوب باشند. MAE و RMSE هر دو دارای محدوده ای از 0 تا ∞ هستند. آنها نمرات منفی هستند، بنابراین هرچه این تعداد کمتر باشد، بهتر است. ضریب تعیین (R 2 ) (معادله (3)) نشان دهنده توانایی یک مدل برای پیش بینی یا توضیح یک نتیجه است. R 2درصد واریانس متغیر پیشبینیشده و متغیر اندازهگیری شده را نشان میدهد که در آن SSE مجموع مجذور خطاها و SSTO مجموع مجذورات است. ضریب تعیین از 0 تا 1 متغیر است که در 0 (صفر) هیچ تغییری توسط مدل توضیح داده نمی شود و در 1 (یک) همه تغییرات توسط مدل توضیح داده می شود. یک مقدار R2 بالا ، به طور کلی، نشان میدهد که مدل مناسب برای دادهها است، اگرچه تفاسیر مناسب بسته به زمینه تحلیل متفاوت است. در نهایت، میانگین خطای سوگیری (MBE) به عنوان اندازه گیری برآورد سوگیری مدل ها استفاده شد (معادله (4)).
2.8. نرم افزار
برای تجزیه و تحلیل آماری مطالعه حاضر، از نرم افزار آماری R (نسخه 4.0.3) و بسته کارت [ 50 ] استفاده شد. همچنین، بسته رنجر [ 51 ] برای RF و QRF استفاده شد. زمین آمار با بسته gstat [ 52 ] اجرا شد. در نهایت از نرم افزار Saga-GIS ( https://saga-gis.sourceforge.io/en/index.html (دسترسی در 18 نوامبر 2021)) برای شاخص های زیست محیطی استفاده شد.
3. نتایج
3.1. Semivariograms و Fitting Parameters OK و KED
در ابتدا، OK و KED با استفاده از مجموعه داده آموزشی برای پیشبینی OM خاک در منطقه مورد مطالعه پیادهسازی شدند. در مورد OK، بر اساس نیمواریوگرام تجربی، مدل نیمواریوگرام مادر با پارامترسازی M. Stein (Ste) با استفاده از برازش حداقل مربعات وزنی بسته gstat برازش شد ( شکل 6 ). برد 207 متر با یک قطعه در 0.35 و آستانه در 0.49 بود. یک وابستگی فضایی متوسط بر اساس نسبت قطعه به آستانه (71٪) وجود داشت.
در مورد KED، مدل کروی برای برازش با روش پیشفرض gstat بر اساس برازش حداقل مربعات وزنی استفاده شد. برد در 414 متر، دو برابر از برد OK بود. در این مورد یک وابستگی فضایی ضعیف با نسبت قطعه به آستانه کل 83٪ وجود داشت.
3.2. نتایج بهینه سازی فراپارامترهای RF و QRF
همانطور که قبلاً بیان شد ( بخش 2.5 )، مدلهای ML به ارزیابی فراپارامترهای بهینه خود نیاز دارند تا بهترین نتایج پیشبینی را ارائه کنند. در مورد RF و QRF همانطور که توسط کتابخانه رنجر تعریف شده است، چهار فراپارامتر باید تخمین زده شود ( جدول 3 ). یک فرآیند تکراری (آزمایش و خطا) با روش بهینهسازی جستجوی تصادفی مورد استفاده قرار گرفت، که در آن مقادیر تصادفی مختلف این پارامترها از طیف وسیعی از مقادیر معرفی شدند. R2 مدلهای ML با استفاده از روش اعتبارسنجی متقاطع 10 برابری که 3 بار در مجموعه دادههای آموزشی تکرار شد، ارزیابی شد ( شکل 7 ). ابرپارامترهایی که بالاترین R 2 را برگرداندند در نهایت انتخاب شدند ( جدول 5).
برای ابرپارامتر splitrule، تنها از روشهای “واریانس” و “extratrees” به دلیل خطاهای غیرقابل جبران از مقادیر “maxstat” و “beta” استفاده شد.
فراپارامترهای بهینه خاص در مدلهای RF و QRF معرفی شدند و برای تخمین قابلیتهای پیشبینی آنها بر روی مجموعه داده آزمایشی استفاده شدند.
3.3. اهمیت ویژگی های مدل های ML
اهمیت ویژگی RF و QRF برآورد شد ( شکل 8 ) با تکنیک جایگشت [ 3 ]، که به عنوان کاهش در امتیاز مدل زمانی که یک مقدار مشخصه به طور تصادفی مخلوط میشود، تعریف میشود. یک ویژگی اگر به هم زدن مقادیر آن خطای مدل را افزایش دهد (اثر قوی بر پیشبینی) «مهم» است و اگر به هم زدن مقادیر آن خطای مدل را بدون تغییر باقی بگذارد (تاثیر کم یا بدون تأثیر بر پیشبینی) «بیاهمیت» است.
با توجه به نمرات اهمیت، RF و QRF هر دو تصدیق می کنند که متغیرهای کمکی خاک بالاترین اهمیت را نشان می دهند، چیزی که به دلیل یافته های قابل مقایسه مطالعه قبلی [ 28 ] در یک منطقه مجاور انتظار می رفت. در مطالعه حاضر به طور خاص، روی با C دوم و منیزیم سوم بالاترین امتیاز را داشت. ارتفاع از شاخص های توپوگرافی به همراه NDVI 2016 و Vdepth در رتبه بعدی قرار گرفت. آخرین موقعیت ها توسط NDVI سال 2017 و NDWI در سال 2019 اشغال شد.
3.4. نتایج پیش بینی
مجموعه داده به دو مجموعه تصادفی اما متوازن فضایی 70 درصد برای آموزش مدل ها و 30 درصد برای آزمایش تقسیم شد. تفاوت بین مشاهدات OM خاک و پیشبینیهای آنها در مجموعه دادههای آزمایش برای ارزیابی دقت پیشبینی مدلهای مختلف استفاده شد و آنها در جدول 6 و شکل 9 ارائه شدهاند .
همانطور که در نتایج نشان داده شده است ( جدول 6 )، OK کم دقت ترین مدل با R 2 بسیار کم (0.127) و RMSE و MAE بالا بود، چیزی که به دلیل عدم ظرفیت آن برای ترکیب اطلاعات کمکی انتظار می رفت. قابلیت پیشبینی OK فقط بر اساس خودهمبستگی فضایی متغیر (OM) است، از این رو نتایج فعلی ضعیف است. گرچه بر اساس MBE (0.002-) تعصب کوچکتر را ارائه کرد.
KED قابلیت های پیش بینی روند را که بر اساس متغیرهای کمکی است، همراه با درون یابی کریجینگ ترکیب می کند. بنابراین، نتایج مناسب هستند، با RMSE پایین (0.618) و MAE (0.455) که بسیار نزدیک به RF و حتی کمی بهتر از QRF هستند. با این حال، ضریب تعیین (0.452) بسیار بدتر از روش های ML است. بایاس نیز نزدیک به صفر (0.022-) کوچک بود، اما بالاتر از OK بود.
مدلهای ML قابلیت پیشبینی بالاتری نسبت به مدلهای زمینآماری نشان دادند. به طور خاص، بهترین نتایج توسط RF به دست آمد. به خصوص R 2 آن بالاترین (0.538) در بین مدل ها با بهبود حدود 20٪ از KED بود. با توجه به RMSE و MAE، نتایج RF با کمترین مقادیر کلی بهترین بود. سوگیری مدل کم (0.020-) نزدیک به مقدار KED بود.
مدل QRF همچنین قابلیتهای پیشبینی بسیار خوبی را با R2 بالا ( 0.532 ) بسیار نزدیک به RF و RMSE و MAE بسیار پایین، نزدیک به RF و KED نشان داد. MBE بالاتر از مدل های دیگر بود (-0.046)، اما همچنان پایین و نزدیک به صفر بود. بنابراین، RF و QRF هر دو می توانند به جای یکدیگر برای پیش بینی OM خاک با نتایج مشابه در مطالعه حاضر استفاده شوند.
3.5. نقشه های پیش بینی و عدم قطعیت
در ادامه، دو مجموعه نقشه از مدلهای مختلف مطالعه حاضر تولید شد. مجموعه اول شامل چهار نقشه پیشبینی است که توزیع فضایی OM خاک در منطقه را ارائه میکند، یکی برای هر روش: OK، KED، RF و QRF ( شکل 10 ). مجموعه دوم نقشه ها شامل سه نقشه با روش های OK، KED و QRF است که توزیع فضایی عدم قطعیت پیش بینی را در منطقه نشان می دهد ( شکل 11 ). در این مورد از RF به دلیل عدم وجود قابلیت عدم قطعیت استفاده نشد.
نقشه پیشبینی OK نتایج درونیابی را با الگوهای پیشبینی نسبتاً یکنواخت در سراسر منطقه مورد مطالعه نشان داد. دلیل اصلی این امر این است که OK تنها بر اساس همبستگی خودکار فضایی OM با استفاده از پارامترهای مدل جهانی است که نتایج را هموار می کند. مدل KED نقشهای را تولید میکند که به دلیل تأثیر متغیرهای کمکی آن به طور ناگهانی تغییر میکند و منجر به ایجاد مناطق متعدد با مقادیر محلی بالاتر و پایینتر از OK میشود. با توجه به روشهای ML (RF، QRF) نقشههای آنها حتی کنتراست بیشتری نسبت به OK و KED داشتند، به دلیل توانایی آنها در تولید الگوهایی که با برازش بهتر با مجموعه دادهها تا حد امکان مطابقت دارند. در میان آنها، به نظر می رسد QRF الگوهای کمی ناگهانی تر از RF با مناطق با مقادیر کمی پایین تر و بالاتر ارائه می کند.
همانطور که قبلاً ذکر شد، جدای از نتایج پیشبینی، عدم قطعیت پیشبینی پارامتری حیاتی است که باید در مکانهای مختلف منطقه مورد مطالعه برآورد شود. در مطالعه حاضر نقشه های عدم قطعیت تنها برای 3 روش از 4 روش محاسبه شد. RF از برآورد عدم قطعیت پشتیبانی نمی کند. OK و KED ذاتاً واریانس خطا را ارائه می دهند که توسط آن انحراف استاندارد محاسبه شده و محدوده آن در نقشه ها ارائه شده است. برای QRF محدوده به عنوان یک انحراف استاندارد بالا و پایین میانه تعریف شد و برای ایجاد نقشه عدم قطعیت منطقه مورد مطالعه استفاده شد ( شکل 11 ).
بر اساس نقشه های عدم قطعیت، بدیهی است که OK دارای یک محدوده عدم قطعیت صاف و یکسان در منطقه با مقدار میانگین تقریباً 0.8٪ است. بنابراین، در هر مکان، مقدار OM واقعی تقریباً 0.4% بالاتر یا کمتر از مقدار پیشبینیشده است.
نقشه عدم قطعیت KED دارای محدوده عدم قطعیت کلی کمتری نسبت به OK (حدود 0.6٪) است، که تقریباً به طور مساوی در منطقه مورد مطالعه کلی توزیع شده است، مشابه با OK. برخی مقادیر دامنه کمی افزایش یافته در ناحیه شمال غربی همراه با برخی تکه های کوچک در بین (مناطق آبی روشن تر) به دلیل تأثیر جزئی متغیرهای کمکی بر نتایج عدم قطعیت وجود دارد.
در مورد QRF، نقشه عدم قطعیت متنوعتر از نقشههای قبلی است. مناطق متمایز با عدم قطعیت بسیار کم مانند آن در شمال یا در مرکز منطقه (با رنگ آبی تیره) و مناطق با عدم قطعیت بالاتر مانند مناطق جنوب یا نزدیک به دریاچه (با رنگ زرد) وجود دارد. این تصویر واضح از عدم قطعیت در مقیاس محلی و تعریف ساده مناطق عدم قطعیت ممکن، یک مزیت عمده نسبت به روشهای زمینآماری بهویژه برای اهداف پشتیبانی تصمیم است.

4. بحث
یکی از وظایف اصلی در مطالعات DSM، برآورد و ارائه توزیع مکانی متغیرهای مختلف خاک در منطقه مورد مطالعه با استفاده از روشهای درونیابی مختلف است. جدای از آن، تخمین و ارائه عدم قطعیت این روشهای درونیابی به همان اندازه برای ارزیابی کار کلی مهم است، چیزی که در برخی از مطالعات اخیر DSM، بهویژه مطالعات مبتنی بر ML، فاقد آن است.
روشهای ML به طور فزایندهای در DSM استفاده میشوند، بر اساس قابلیتهای پیشبینی برجستهشان که از روشهای زمین آماری کلاسیک، بدون اشکالات مفروضات آماری و محدودیتهای روشهای دیگر، بهتر عمل میکنند. با این حال، اکثر آنها قابلیت تخمین عدم قطعیت ذاتی را ندارند. RF یک روش ML بسیار امیدوارکننده است که در مطالعات متعدد DSM استفاده میشود که با این وجود فاقد ظرفیت تخمین عدم قطعیت داخلی است. یک جایگزین جالب QRF است که به نظر میرسد قابلیتهای پیشبینی پیشرفته مشابه RF را همراه با معیارهای تخمین عدم قطعیت ذاتی ارائه میدهد.
در مقاله حاضر، تایید شد که QRF نتایج برجستهای را در پیشبینی OM خاک در منطقه مورد مطالعه، بسیار نزدیک به روش RF نشان میدهد. مخصوصا R2بسیار بالاتر از روش های زمین آماری بود، چیزی که نشان می دهد تنوع بیشتر توسط مدل خاص توضیح داده می شود. علاوه بر این، قابلیتهای عدم قطعیت آن همانطور که در نقشههای عدم قطعیت ارائه شده است، نشان میدهد که میتواند تخمین بسیار کارآمدی از عدم قطعیت در منطقه مورد مطالعه ارائه دهد. نقشه عدم قطعیت با QRF کنتراست قویتری را در مقایسه با نقشههای عدم قطعیت OK، و KED با نمایش متمایز از تغییرات محلی عدم قطعیت مانند مناطق کوچک با عدم قطعیت بالاتر یا پایینتر نشان میدهد. بر اساس این نقشه، برای کاربر بسیار آسان است که خوشه هایی از مناطق عدم قطعیت را تعریف کرده و اثر آن را به صورت محلی طبقه بندی کند.
منابع
- Wadoux، AMJC; میناسنی، بی. مک براتنی، AB یادگیری ماشینی برای نقشه برداری دیجیتال خاک: کاربردها، چالش ها و راه حل های پیشنهادی Earth-Sci. Rev. 2020 , 210 , 103359. [ Google Scholar ] [ CrossRef ]
- Lagacherie, P. نقشه برداری دیجیتال خاک: وضعیتی از هنر . نقشه برداری دیجیتال خاک با داده های محدود. Springer: برلین، آلمان، 2008; صص 3-14. [ Google Scholar ] [ CrossRef ]
- بریمن، ال. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آموزش پرسپترون کام، TH جنگل های تصمیم تصادفی تین کام هو. Proc. بین المللی 3 Conf. Doc. مقعدی تشخیص دهد. 1995 ، 1 ، 278-282. [ Google Scholar ]
- ویزمایر، ام. بارتولد، اف. خالی، بی. Kögel-Knabner, I. نقشه برداری دیجیتالی ذخایر مواد آلی خاک با استفاده از مدل سازی تصادفی جنگل در یک اکوسیستم استپی نیمه خشک. خاک گیاهی 2011 ، 340 ، 7-24. [ Google Scholar ] [ CrossRef ]
- لیو، جی. دونگ، ز. شیا، جی. وانگ، اچ. منگ، تی. ژانگ، آر. هان، جی. وانگ، ن. Xie, J. برآورد محتوای مواد آلی خاک بر اساس الگوریتم CARS همراه با جنگل تصادفی. اسپکتروشیم. Acta-Part A Mol. Biomol. Spectrosc. 2021 ، 258 ، 119823. [ Google Scholar ] [ CrossRef ]
- جان، ک. ایسونگ، IA; Kebonye، NM; آیتو، EO; Agyeman، PC; Afu، SM با استفاده از الگوریتم های یادگیری ماشین برای تخمین تنوع کربن آلی خاک با متغیرهای محیطی و شاخص های مواد مغذی خاک در یک خاک آبرفتی. Land 2020 , 9 , 487. [ Google Scholar ] [ CrossRef ]
- استامف، اف. اشمیت، ک. گوبس، پی. بهرنز، تی. شونبرودت-استیت، اس. وادوکس، ا. شیانگ، دبلیو. شولتن، تی. نمونه برداری با هدایت عدم قطعیت برای بهبود نقشه های خاک دیجیتال. Catena 2017 ، 153 ، 30-38. [ Google Scholar ] [ CrossRef ]
- ماینشاوزن، ن. ریج وی، جی. جنگل های رگرسیون کوانتیل. جی. ماخ. فرا گرفتن. Res. 2006 ، 7 ، 983-999. [ Google Scholar ]
- فریمن، EA؛ Moisen، GG کاربرد جنگلهای تصادفی چندگانه برای نقشهبرداری پیشبینیکننده ویژگیهای جنگل. برای. اختراع کردن. مقعدی علائم 2015 ، 931 ، 362. [ Google Scholar ]
- وایسه، ک. Lagacherie, P. استفاده از جنگل رگرسیون چندک برای تخمین عدم قطعیت محصولات رقومی نقشه برداری خاک. Geoderma 2017 ، 291 ، 55-64. [ Google Scholar ] [ CrossRef ]
- دارومراجان، س. واسونهارا، ر. سوپوترا، ا. لالیتا، م. Hegde, R. پیشبینی عمق خاک در کارناتاکا با استفاده از رویکرد نقشهبرداری دیجیتالی خاک. J. شرکت هندی Remote Sens. 2020 , 48 , 1593–1600. [ Google Scholar ] [ CrossRef ]
- پوجیو، ال. دی سوزا، ال.ام. Batjes، NH; Heuvelink، GBM؛ کمپن، بی. ریبیرو، ای. Rossiter, D. SoilGrids 2.0: تولید اطلاعات خاک برای کره زمین با عدم قطعیت فضایی کمی. خاک 2021 ، 7 ، 217-240. [ Google Scholar ] [ CrossRef ]
- ورونزی، اف. Schillaci، C. مقایسه بین مدلهای زمینآماری و یادگیری ماشینی به عنوان پیشبینیکننده کربن آلی خاک سطحی با تمرکز بر تخمین عدم قطعیت محلی. Ecol. اندیک. 2019 ، 101 ، 1032-1044. [ Google Scholar ] [ CrossRef ]
- Bouyoucos, GJ دستورالعمل برای ساخت آنالیزهای مکانیکی خاک با روش هیدرومتر. علم خاک 1936 ، 42 ، 225-230. [ Google Scholar ] [ CrossRef ]
- لیندسی، WL; Norvell، WA توسعه آزمایش خاک DTPA برای روی، آهن، منگنز و مس. علم خاک Soc. صبح. J. 1978 , 42 , 421-428. [ Google Scholar ] [ CrossRef ]
- سوواندانا، ای. کاوامورا، ک. ساکونو، ی. کوستیانتو، ای. Raharjo, B. ارزیابی aster GDEM2 در مقایسه با GDEM1، SRTM DEM و DEM مشتق شده از نقشه توپوگرافی با استفاده از تجزیه و تحلیل منطقه غرقاب و داده های RTK-DGPS. Remote Sens. 2012 , 4 , 2419–2431. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دل روزاریو گونزالس موراداس، م. Viveen، W. ارزیابی ASTER GDEM2، SRTMv3.0، ALOS AW3D30 و TanDEM-X DEMs برای آندهای پرو در برابر نقاط کنترل زمینی GNSS بسیار دقیق و معیارهای ژئومورفولوژیکی-هیدرولوژیکی. سنسور از راه دور محیط. 2020 , 237 , 111509. [ Google Scholar ] [ CrossRef ]
- روی، DP; لی، ز. Zhang، HK تنظیم بازتاب باند لبه قرمز Sentinel-2 (MSI) به بازتاب تنظیم شده BRDF (NBAR) و تعیین کمیت اثرات BRDF باند لبه قرمز. Remote Sens. 2017 , 9 , 1325. [ Google Scholar ] [ CrossRef ][ Green Version ]
- مجموعههای شاخص گیاهی Hill، MJ به عنوان شاخصهای وضعیت پوشش گیاهی در علفزار و ساوانا: تجزیه و تحلیل با دادههای SENTINEL 2 شبیهسازی شده برای یک ترانسکت آمریکای شمالی. سنسور از راه دور محیط. 2013 ، 137 ، 94-111. [ Google Scholar ] [ CrossRef ]
- کامباردلا، کالیفرنیا؛ مورمن، سل؛ نواک، جی.ام. پارکین، سل؛ کارلن، دی.ال. تورکو، RF؛ Konopka، تغییرپذیری در مقیاس میدانی ویژگیهای خاک در خاکهای مرکزی آیووا. علم خاک Soc. صبح. J. 1994 , 58 , 1501-1511. [ Google Scholar ] [ CrossRef ]
- پنگ، ایکس. وانگ، ک. Li, Q. یک روش جدید نقشه برداری توان مبتنی بر کریجینگ معمولی و تعیین استراتژی مکان آشکارساز بهینه. ان هسته انرژی 2014 ، 68 ، 118-123. [ Google Scholar ] [ CrossRef ]
- Wackernagel, H. Geostatistics چند متغیره ; Springer: برلین، آلمان، 1998; ISBN 9783662035528. [ Google Scholar ]
- مک براتنی، AB; عوده، IOA; اسقف، TFA; دانبار، ام اس; Shatar, TM مروری بر تکنیک های پدومتریک برای استفاده در بررسی خاک. ژئودرما 2000 ، 97 ، 293-327. [ Google Scholar ] [ CrossRef ]
- ایگناکولو، آر. ماتو، جی. Giraldo, R. Kriging با رانش خارجی برای داده های عملکردی برای نظارت بر کیفیت هوا. استوک. محیط زیست Res. ارزیابی ریسک 2014 ، 28 ، 1171-1186. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وبستر، آر. الیور، کارشناسی ارشد زمین آمار برای دانشمندان محیط زیست . وایلی: چیچستر، انگلستان، 2001; ISBN 0471965537. [ Google Scholar ]
- دیتریکل، آموزش گروه TG. در کتاب راهنمای نظریه مغز و شبکه های عصبی ; اربیب، م.، ویرایش. مطبوعات MIT: کمبریج، MA، ایالات متحده آمریکا، 2002; ص 405-408. [ Google Scholar ]
- تزیاکریس، پی. آستونیت، V. Chatzistathis، T. Papadopoulou, M. ارزیابی روشهای ترکیبی فضایی برای پیشبینی مواد آلی خاک با استفاده از مشتقات DEM و پارامترهای خاک. Catena 2019 ، 174 ، 206–216. [ Google Scholar ] [ CrossRef ]
- دارومراجان، س. هگده، ر. سینگ، SK پیشبینی فضایی ویژگیهای اصلی خاک با استفاده از تکنیکهای جنگل تصادفی – مطالعه موردی در مناطق استوایی نیمهخشک جنوب هند. ژئودرما Reg. 2017 ، 10 ، 154-162. [ Google Scholar ] [ CrossRef ]
- وانگ، دی. زو، AX نقشه برداری خاک بر اساس ادغام رویکرد مبتنی بر شباهت و جنگل های تصادفی. Land 2020 , 9 , 174. [ Google Scholar ] [ CrossRef ]
- استام، AK; بوتینگر، جی ال. White, MA; رمزی، جنگلهای تصادفی RD به عنوان یک مدل پیشبینی فضایی خاک در آرید یوتا استفاده شد. رقم. نقشه خاک 2010 ، 179-190. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فرناندز، دی. ماچادو، تی. سیلوا، HG; کوری، ن. Duarte De Menezes، M. پیش بینی فضایی نوع خاک از جنگل تصادفی: مجموعه داده های آموزشی مختلف. علمی کشاورزی 2019 ، 76 ، 243-254. [ Google Scholar ]
- شوکلا، جی. Garg، RD; سریواستاوا، اچ اس. Garg، PK پیاده سازی و ارزیابی موثر طبقه بندی کننده جنگل تصادفی به عنوان یک مدل پیش بینی فضایی خاک. بین المللی J. Remote Sens. 2018 , 39 , 2637–2669. [ Google Scholar ] [ CrossRef ]
- یانگ، ال. Shami، A. در بهینه سازی فراپارامتر الگوریتم های یادگیری ماشین: تئوری و عمل. محاسبات عصبی 2020 ، 415 ، 295-316 . [ Google Scholar ] [ CrossRef ]
- مک براتنی، AB; مندونسا سانتوس، ام ال. Minasny, B. در مورد نقشه برداری خاک دیجیتال. ژئودرما 2003 ، 117 ، 3-52. [ Google Scholar ] [ CrossRef ]
- مک میلان، RA تجربیات با DSM کاربردی: پروتکل، در دسترس بودن، کیفیت و ظرفیت سازی BT- نقشه برداری خاک دیجیتال با داده های محدود. در نقشه برداری خاک دیجیتال با داده های محدود . Hartemink، AE، McBratney، A.، Mendonça-Santos، M.، Eds. Springer: Dordrecht، هلند، 2008; صص 113-135. شابک 978-1-4020-8592-5. [ Google Scholar ]
- اسکال، پی. فرانکلین، جی. چادویک، OA; مک آرتور، دی. نقشه برداری خاک پیش بینی: یک بررسی. Prog. فیزیک Geogr. 2003 ، 27 ، 171-197. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Heuvelink، GBM شناسایی خطای صفت میدان تحت مدلهای مختلف تغییرات فضایی. بین المللی جی. جئوگر. Inf. سیستم 1996 ، 10 ، 921-935. [ Google Scholar ] [ CrossRef ]
- کمپن، بی. بروس، دی جی; استورووگل، جی جی. Heuvelink، GBM؛ de Vries, F. مقایسه کارایی نقشه برداری خاک معمولی و دیجیتال برای به روز رسانی نقشه های خاک. علم خاک Soc. صبح. J. 2012 ، 76 ، 2097-2115. [ Google Scholar ] [ CrossRef ]
- Arrouays، D.; مک کنزی، ن. همپل، جی. د فورجس، آر. مک براتنی ، AB GlobalSoilMap: اساس سیستم اطلاعاتی فضایی جهانی خاک . CRC Press: Boca Raton، FL، USA، 2014. [ Google Scholar ]
- میناسنی، بی. مک براتنی، AB تجزیه و تحلیل عدم قطعیت برای توابع انتقال pedotransfer. یورو J. Soil Sci. 2002 ، 53 ، 417-429. [ Google Scholar ] [ CrossRef ]
- نلسون، MA; اسقف، TFA; تریانتافلیس، جی. Odeh, IOA بودجه خطا برای منابع مختلف خطا در نقشه برداری دیجیتالی خاک. یورو J. Soil Sci. 2011 ، 62 ، 417-430. [ Google Scholar ] [ CrossRef ]
- کسرایی، ب. هیونگ، بی. Saurette، DD; اشمیت، ام جی; Bulmer، CE; Bethel، W. رگرسیون کوانتیل به عنوان یک رویکرد عمومی برای تخمین عدم قطعیت نقشه های خاک دیجیتال تولید شده از یادگیری ماشینی. محیط زیست مدل. نرم افزار 2021 , 144 , 105139. [ Google Scholar ] [ CrossRef ]
- مالون، BP; مک براتنی، AB; میناسنی، ب. برآوردهای تجربی عدم قطعیت برای نقشه برداری توابع عمق پیوسته ویژگی های خاک. ژئودرما 2011 ، 160 ، 614-626. [ Google Scholar ] [ CrossRef ]
- وانگ، ز. Bovik، AC میانگین مربعات خطا: آن را دوست دارم یا ترک می کنم؟ فرآیند سیگنال IEEE Mag. 2009 ، 26 ، 98-117. [ Google Scholar ] [ CrossRef ]
- فیضی زاده، ب. یانکوفسکی، پ. Blaschke، T. رویکرد تحلیل عدم قطعیت و حساسیت صریح فضایی مبتنی بر GIS برای تجزیه و تحلیل تصمیم چند معیاره. محاسبه کنید. Geosci. 2014 ، 64 ، 81-95. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هنگل، تی. Toomanian, N. نقشه ها آنطور که به نظر می رسند نیستند: نشان دهنده عدم قطعیت در نقشه های خاک. در مجموعه مقالات دقت 2006: هفتمین سمپوزیوم بین المللی ارزیابی دقت فضایی در منابع طبیعی و علوم محیطی، لیسبون، پرتغال، 5-7 ژوئیه 2006. ص 805-813. [ Google Scholar ]
- Goovaerts, P. مدلسازی زمین آماری عدم قطعیت در علم خاک. ژئودرما 2001 ، 103 ، 3-26. [ Google Scholar ] [ CrossRef ]
- Heuvelink، GBM تعیین کمیت عدم قطعیت محصولات نقشه جهانی خاک. اساس اطلاعات فضایی جهانی خاک، سیستم. در مجموعه مقالات اولین کنفرانس نقشه جهانی خاک، اورلئان، فرانسه، 7 تا 9 ژانویه 2014. صص 335-340. [ Google Scholar ] [ CrossRef ]
- کوهن، ام. ساخت مدل های پیش بینی در R با استفاده از بسته کارت. J. Stat. نرم افزار 2008 ، 28 ، 1-26. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رایت، MN; Ziegler, A. Ranger: پیادهسازی سریع جنگلهای تصادفی برای دادههای با ابعاد بالا در C++ و R. J. Stat. نرم افزار 2017 ، 77 ، 1-17. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Pebesma، EJ زمین آمار چند متغیره در S: بسته gstat. محاسبه کنید. Geosci. 2004 ، 30 ، 683-691. [ Google Scholar ] [ CrossRef ]
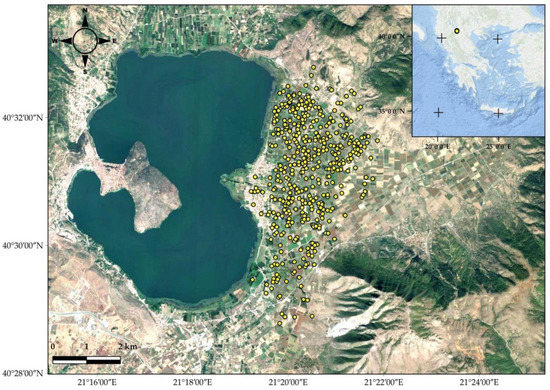
شکل 1. منطقه مورد مطالعه در ساحل دریاچه Orestiada، در واحد منطقه ای Kastoria، یونان.
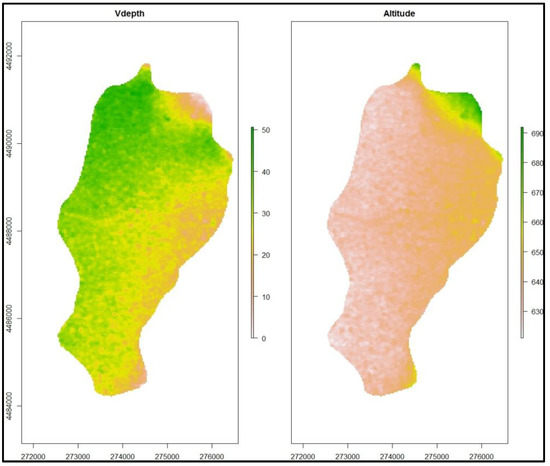
شکل 2. متغیرهای توپوگرافیک منطقه مورد مطالعه.
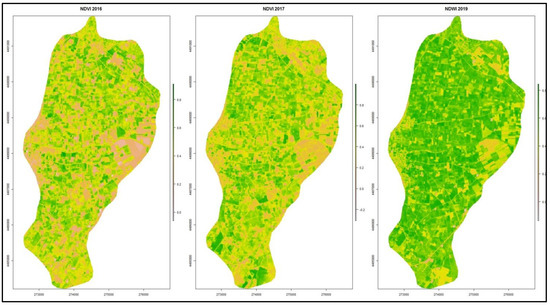
شکل 3. متغیرهای کمکی ماهواره ای منطقه مورد مطالعه.
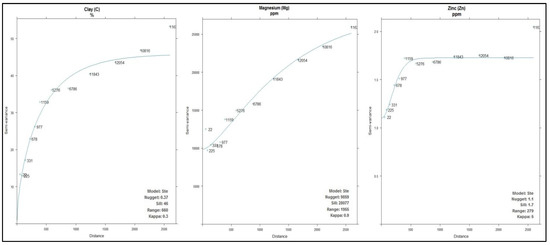
شکل 4. نیم واریوگرام ها و مدل برازش متغیرهای کمکی خاک منطقه مورد مطالعه.
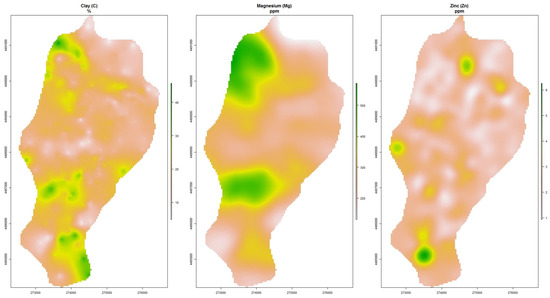
شکل 5. توزیع فضایی متغیرهای کمکی خاک منطقه مورد مطالعه.
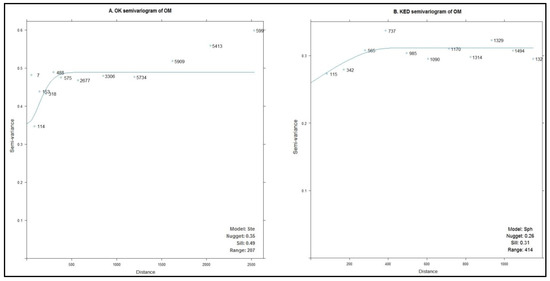
شکل 6. نیمه متغیریگرام تجربی و مدل برازش OK و KED.
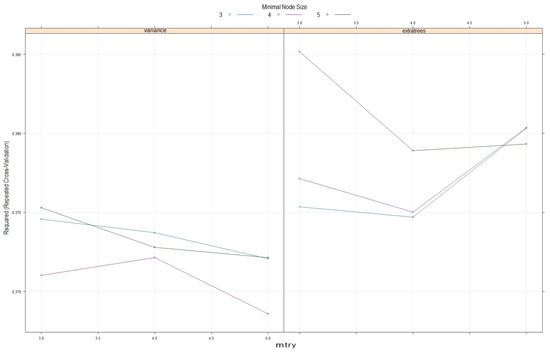
شکل 7. نتایج ارزیابی فراپارامترها بر اساس R 2 در مجموعه داده آموزشی.
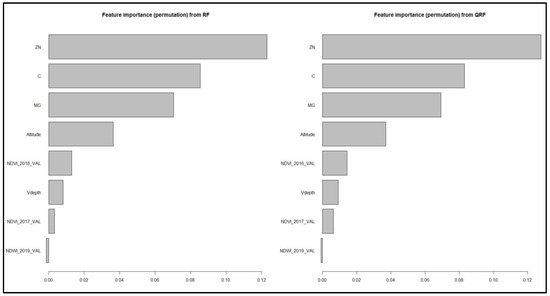
شکل 8. نتایج ارزیابی فراپارامترها بر اساس R 2 در مجموعه داده آموزشی.
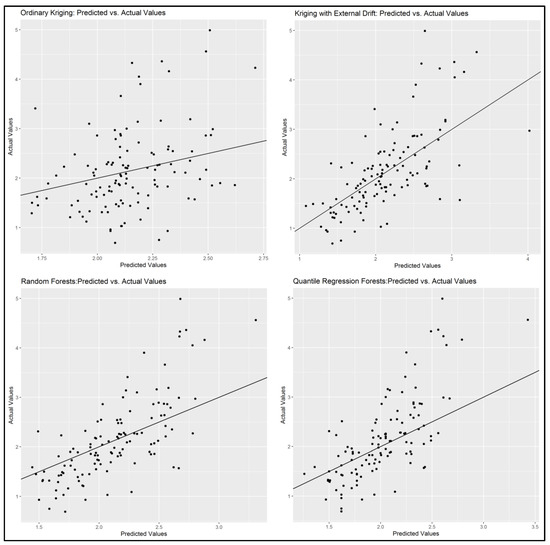
شکل 9. نمودارهای پراکندگی پیش بینی شده در مقابل مشاهده شده.
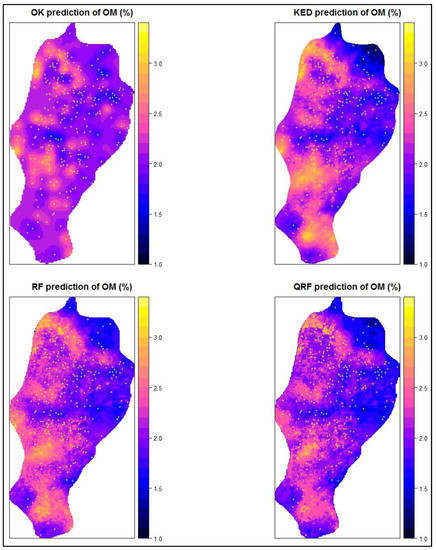
شکل 10. نقشه های پیش بینی OM خاک.
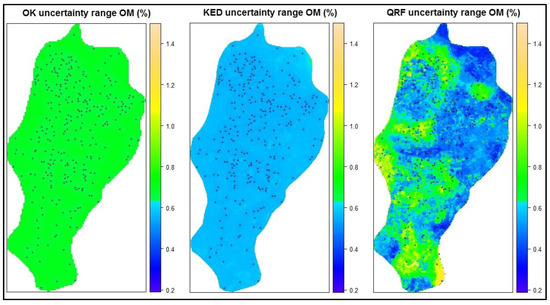
شکل 11. نقشه های عدم قطعیت OM خاک.


بدون دیدگاه