

Kadaster، آژانس ملی ثبت زمین و نقشه برداری هلند، چندین سال است که به طور فعال ثبت پایگاه خود را به عنوان داده های مکانی مرتبط (باز) منتشر کرده است. تا به امروز، تعدادی از این رجیسترهای پایه و همچنین تعدادی از مجموعه داده های خارجی با موفقیت به عنوان داده های پیوندی منتشر شده اند و در دسترس عموم هستند. افزایش تقاضا برای محصولات دادههای پیوندی و در دسترس بودن فناوریهای دادههای پیوندی جدید، نیاز به یک رویکرد جدید و نوآورانه برای انتشار دادههای مرتبط در سازمان را به منظور کاهش زمان و هزینههای مرتبط با انتشار مذکور برجسته کرده است. رویکرد جدید برای انتشار دادههای پیوندی هم در رویکردش به مدلسازی دادهها، تبدیل و معماری انتشار جدید است. در مدل سازی کل مجموعه داده ها، تمایز واضحی بین مدل اطلاعات و مدل دانش ایجاد میشود تا هم الزامات خاص سازمان را در بر بگیرد و هم استانداردهای خارجی جامعه را در فرآیند انتشار پشتیبانی کند. معماری انتشار شامل چندین مرحله است که در آن دادههای نمونه از منبع خود به عنوان GML بارگیری میشوند و با استفاده از یک Enhancer تبدیل میشوند و در فروشگاه سهگانه منتشر میشوند. هر دو معماری مدلسازی و انتشار بخشی از دیدگاه بزرگتر Kadaster برای توسعه نمودار دانش Kadaster از طریق ادغام مجموعههای داده مرتبط مختلف را تشکیل میدهند. معماری انتشار شامل چندین مرحله است که در آن دادههای نمونه از منبع خود به عنوان GML بارگیری میشوند و با استفاده از یک Enhancer تبدیل میشوند و در فروشگاه سهگانه منتشر میشوند. هر دو معماری مدلسازی و انتشار بخشی از دیدگاه بزرگتر Kadaster برای توسعه نمودار دانش Kadaster از طریق ادغام مجموعههای داده مرتبط مختلف را تشکیل میدهند. معماری انتشار شامل چندین مرحله است که در آن دادههای نمونه از منبع خود به عنوان GML بارگیری میشوند و با استفاده از یک Enhancer تبدیل میشوند و در فروشگاه سهگانه منتشر میشوند. هر دو معماری مدلسازی و انتشار بخشی از دیدگاه بزرگتر Kadaster برای توسعه نمودار دانش Kadaster از طریق ادغام مجموعههای داده مرتبط مختلف را تشکیل میدهند.
کلید واژه ها:
داده های مکانی مرتبط ؛ نمودار دانش ; فن آوری های معنایی ; قابلیت همکاری مدلسازی معنایی
1. مقدمه
آژانس کاداستر، ثبت زمین و نقشه برداری هلند، Kadaster ( www.kadaster.nl)، منبع معتبر اطلاعات مربوط به داده های اداری و مکانی پیرامون اموال و حقوق مالکیت در هلند است. Kadaster چندین ثبت بزرگ کلیدی دولت هلند را نگهداری می کند، از جمله ثبت پایه برای آدرس ها و ساختمان ها (مخفف هلندی: BAG)، ثبت پایه برای توپوگرافی (مخفف هلندی: BRT)، و ثبت پایه برای توپوگرافی در مقیاس بزرگ (مخفف هلندی). : BGT)؛ که همه آنها به عنوان داده باز در دسترس هستند. علاوه بر این، سازمان فعالانه این و سایر داراییهای جغرافیایی را به عنوان دادههای مرتبط (باز) منتشر و نگهداری میکند و به عنوان بخشی از این تلاش، و با روحیه نوآوری مستمر، اکنون چندین مورد از این داراییهای مکانی بهعنوان دادههای باز مرتبط زیر منتشر شده است. یک رویکرد جدید همانطور که در این مقاله مورد بحث قرار گرفته است.1]، دو مورد از این دارایی های مکانی به عنوان داده های مرتبط منتشر شده بود. از اکتبر 2021، چهار رجیستر پایه و تعدادی از مجموعه داده های خارجی مرتبط با این ثبات ها در حین استفاده از این رویکرد جدید منتشر شده است: برجسته کردن کارایی و تکرارپذیری این رویکرد. فرمولبندی و اجرای این رویکرد جدید در Kadaster با انگیزه افزایش تقاضا برای محصولات دادههای مرتبط، هم در داخل و هم در خارج، به روشی مقرونبهصرفه ارائه میشود. در دسترس بودن و توسعه مداوم فنآوریها و استانداردهای دادههای پیوندی، ارائه یک رویکرد به روز و مقیاسپذیر برای انتشار دادههای پیوندی برای پاسخگویی به این تقاضا را ممکن کرده است.بخش 6 این مقاله همچنین چشم انداز بزرگتر اجرای این رویکرد را در سازمان مورد بحث قرار خواهد داد. با در دسترس قرار دادن چندین مجموعه داده از طریق این رویکرد و با اولین اجرای نمودار دانش موجود در Kadaster، این مقاله همچنین ارزیابی و دیدگاهی از درس های آموخته شده را در مورد رویکرد ارائه شده در این مقاله ارائه می دهد.
2. زمینه مشکل
مجموعه دادههای جغرافیایی دولتی هلند، که در بخش زیر به طور گستردهتر مورد بحث قرار میگیرند، بهعنوان سیلوهای داده به نام ثبتهای کلیدی سازماندهی شدهاند. که ادغام آن نیز به طور کلی ضعیف است. کاربرانی که به دنبال ترکیب این سیلوها برای یک هدف معین هستند، اغلب باید به استفاده از ابزار خاصی متوسل شوند که از این ادغام پشتیبانی می کند یا دانلود مجموعه داده های کامل و انجام یکپارچه سازی کل مجموعه داده ها. به عنوان مثال، تلاش برای پاسخ به سوال نسبتاً ساده جغرافیایی “کدام کلیساها قبل از سال 1800 در شهر آمستردام ساخته شده اند؟” نیاز به ادغام ثبت کلید برای توپوگرافی (مخفف هلندی: BRT) که شامل انواع ساختمان ها و ثبت کلید آدرس ها و ساختمان ها است که شامل سال ساخت هر ساختمان است. برای انجام این ادغام، کاربر یا باید از ابزار خاص GIS (مثلا QGIS یا ArcGIS) استفاده کند یا کل ثبت کلید را دانلود کند و سپس این یکپارچه سازی را انجام دهد. این مشکل ادغام آسانتر کاربر از رجیسترهای پایه همان چیزی است که یکی از جدیدترین پروژههای انجامشده توسط Kadaster، پروژه راهحل کاربر یکپارچه (هلندی: Integrale Gebruiksoplossing (IGO)) را هدایت کرد.https://www.geobasisregistraties.nl/basisregistraties/doorontwikkeling-in-samenhang/inspirerend-gebruik ). یکی از راهحلهای این مشکل یکپارچهسازی، و راهحلی که چندین سال در Kadaster پیادهسازی شده است، ارائه این سیلوهای داده بهعنوان دادههای باز مرتبط و انجام این یکپارچهسازی با استفاده از فناوریهای مرتبط است.
اگرچه چندین مورد از دارایی های مکانی Kadaster به عنوان داده های مرتبط برای چندین سال در دسترس بوده اند و معماری پیرامون این نشریه در واقع به خوبی اجرا شده است [ 2 ]]، اثرات شبکه افزایش جذب در فناوریهای دادههای پیوندی، ایجاب کرده است که یک رویکرد به روز و مقیاسپذیر برای انتشار برای انتشار این مجموعه دادههای مرتبط طراحی و اجرا شود. در واقع، تقاضای فزاینده ای برای خدمات داده های پیوندی هم در خود Kadaster و هم در خارج وجود دارد، و این تقاضا را برای در دسترس قرار دادن داده های پیوندی سریعتر و به بهترین شکل ممکن (به صرفه) به همراه دارد. این تقاضا، همراه با افزایش در دسترس بودن و توسعه مداوم فناوریها و استانداردهای دادههای مرتبط، نیروی محرکه پشت نوآوری انتشار دادههای مرتبط در سازمان بوده است و با شروع پروژههایی مانند راهحل کاربر یکپارچه تحریک شده است. رویکردی که در این مقاله بیان شده است این تقاضا را از طرق مختلف برآورده می کند.
اولاً، این رویکرد، در راستای اصول کلی معماری، از کتابخانههای موجود جامعه (به عنوان مثال، rdf-validate-shacl ( https://github.com/zazuko/rdf-validate-shacl ) و (hdt-cpp ( https ) استفاده میکند. ://github.com/rdfhdt/hdt-cpp ))، بر روی پروژه های منبع باز (به عنوان مثال، Comunica ( https://comunica.dev ) و ClioPatria ( https://cliopatria.swi-prolog.org ))) و بنابراین دور زدن نیاز به توسعه راه حل های سفارشی داخلی برای پاسخگویی به این تقاضا. به طور مشابه، این رویکرد از محصولات تجاری موجود در جایی که در دسترس هستند به نفع کاهش هزینه های نگهداری استفاده می کند. ثانیاً، این رویکرد یک اصل پیکربندی بیش از کد را اعمال میکند که تضمین میکند که خط لوله یکسان برای همه پروژههای انتشار دادههای مرتبط اعمال میشود، تنها در صورت لزوم اجزا را پیکربندی میکند و این جنبه از معماری است که اجازه میدهد این رویکرد در چندین مورد تکرار شود. مجموعه های داده، انتقال آنها از منبع به انتشار در یک بازه زمانی کوتاه. در نهایت، اجرای تمامی اجزای مرتبط در این طرح با رویکرد جریان سازی انجام می شود. در عمل، این بدان معناست که همه مدلهای داده پیوندی تا حد امکان به مدل منبع نزدیک هستند و منابع انتخاب شده قادر به پشتیبانی از عملکرد جریان به نفع تحویل بلادرنگ داده هستند. اگرچه این قابلیت جریان هنوز یک ویژگی کار در معماری توصیف شده نیست، این گنجاندن طراحی در چشم انداز تصویر بزرگتر برای این رویکرد مهم است همانطور که در مورد بحث قرار گرفت.بخش 6 .
به منظور تشریح دقیق محل اجرای این رویکرد نسبت به روشهای موجود یا قبلی که برای انتشار دادههای مرتبط در Kadaster استفاده میشد، پیشرفتهای قابلاندازهگیری را شاهد بود، توجه به این نکته مهم است که ثبتهای BAG و BGT با استفاده از این رویکرد جدید توسط یک تیم داخلی کوچک ارائه شدند. در Kadaster به ترتیب در 9 و 5 هفته. اینها مجموعه دادههای پیوندی نسبتاً پیچیدهای هستند که هر کدام دارای یک مدل داده پیچیده هستند و از نظر اندازه بزرگ هستند. در واقع، هر مجموعه داده شامل 800 میلیون تا 1 میلیارد سه گانه است. در جایی که رویکردهای قبلی می توانست طولانی باشد، این رویکرد بهبود هزینه و اثربخشی منابع را برجسته می کند، و پرونده تجاری برای داده های مرتبط در سازمانی مانند Kadaster را تقویت می کند [ 3 ]]. بخشهایی که در ادامه میآیند، مفاهیم و معماریهایی را که از این رویکرد بهروز شده برای انتشار دادههای مرتبط در Kadaster پشتیبانی میکنند، شامل استانداردها، فنآوریها و انتخابهای مرتبط با این موارد در طول انتشار مجموعه دادههای جغرافیایی توسط Kadaster، نشان میدهند.
3. منابع داده های مکانی بومی
اولین مورد، ثبت کلید برای توپوگرافی در مقیاس بزرگ (مخفف هلندی: BGT) بود که در نوامبر 2020 تغییر شکل داده و منتشر شد و در هر سه ماهه سال 2021 به روز شده است. این دارایی یک نقشه دیجیتالی از هلند با اشیاء است. مانند ساختمانها، جادهها، آبها و راهآهنها. مدلسازی، بهروزرسانی و نگهداری این مجموعه داده توسط قانون هلند تنظیم میشود. ثبت کلید برای آدرسها و ساختمانها (BAG) در فوریه 2021 تغییر شکل داد و منتشر شد. همانطور که از نام مجموعه داده پیداست، مجموعه داده شامل تمام ساختمانها و آدرسها در هلند و همچنین ویژگیهای مرتبط با آنها، از جمله شماره خانه، نامگذاری، و آدرس های اصلی و جانبی این مجموعه داده یک مجموعه داده مشابه دارد، یعنی آدرس های INSPIRE ( که در نوامبر 2020 تغییر شکل یافته و منتشر شده است و در هر سه ماهه سال 2021 به روز شده است. این دارایی نقشه دیجیتال هلند با اشیایی مانند ساختمان ها، جاده ها، بدنه های آبی و راه آهن است. مدلسازی، بهروزرسانی و نگهداری این مجموعه داده توسط قانون هلند تنظیم میشود. ثبت کلید برای آدرسها و ساختمانها (BAG) در فوریه 2021 تغییر شکل داد و منتشر شد. همانطور که از نام مجموعه داده پیداست، مجموعه داده شامل تمام ساختمانها و آدرسها در هلند و همچنین ویژگیهای مرتبط با آنها، از جمله شماره خانه، نامگذاری، و آدرس های اصلی و جانبی این مجموعه داده یک مجموعه داده مشابه دارد، یعنی آدرس های INSPIRE ( که در نوامبر 2020 تغییر شکل یافته و منتشر شده است و در هر سه ماهه سال 2021 به روز شده است. این دارایی نقشه دیجیتال هلند با اشیایی مانند ساختمان ها، جاده ها، بدنه های آبی و راه آهن است. مدلسازی، بهروزرسانی و نگهداری این مجموعه داده توسط قانون هلند تنظیم میشود. ثبت کلید برای آدرسها و ساختمانها (BAG) در فوریه 2021 تغییر شکل داد و منتشر شد. همانطور که از نام مجموعه داده پیداست، مجموعه داده شامل تمام ساختمانها و آدرسها در هلند و همچنین ویژگیهای مرتبط با آنها، از جمله شماره خانه، نامگذاری، و آدرس های اصلی و جانبی این مجموعه داده یک مجموعه داده مشابه دارد، یعنی آدرس های INSPIRE ( بدنه های آبی و راه آهن. مدلسازی، بهروزرسانی و نگهداری این مجموعه داده توسط قانون هلند تنظیم میشود. ثبت کلید برای آدرسها و ساختمانها (BAG) در فوریه 2021 تغییر شکل داد و منتشر شد. همانطور که از نام مجموعه داده پیداست، مجموعه داده شامل تمام ساختمانها و آدرسها در هلند و همچنین ویژگیهای مرتبط با آنها، از جمله شماره خانه، نامگذاری، و آدرس های اصلی و جانبی این مجموعه داده یک مجموعه داده مشابه دارد، یعنی آدرس های INSPIRE ( بدنه های آبی و راه آهن. مدلسازی، بهروزرسانی و نگهداری این مجموعه داده توسط قانون هلند تنظیم میشود. ثبت کلید برای آدرسها و ساختمانها (BAG) در فوریه 2021 تغییر شکل داد و منتشر شد. همانطور که از نام مجموعه داده پیداست، مجموعه داده شامل تمام ساختمانها و آدرسها در هلند و همچنین ویژگیهای مرتبط با آنها، از جمله شماره خانه، نامگذاری، و آدرس های اصلی و جانبی این مجموعه داده یک مجموعه داده مشابه دارد، یعنی آدرس های INSPIRE ( از جمله شماره خانه، نامگذاری، و آدرس اصلی و جانبی. این مجموعه داده یک مجموعه داده مشابه دارد، یعنی آدرس های INSPIRE ( از جمله شماره خانه، نامگذاری، و آدرس اصلی و جانبی. این مجموعه داده یک مجموعه داده مشابه دارد، یعنی آدرس های INSPIRE (https://www.pdok.nl/introductie/-/article/adressen-inspire-geharmoniseerd-) که بر اساس الزامات انطباق INSPIRE منتشر شده است. در میان مجموعه دادههای دیگری که با استفاده از این رویکرد منتشر شدهاند، دفتر مرکزی آمار در هلند (مخفف هلندی: CBS) ارقام کلیدی مجموعه دادههای ناحیه و محله (مخفف هلندی: KWB) است. این نقشه از مرزهای شهرداری تعریف شده در ثبت کلید برای ثبت زمین (مخفف هلندی: BRK) استفاده می کند و آمار کلیدی کل محله ها و مناطق در هلند را به همراه آماری در مورد نزدیک بودن آمار در هر منطقه ارائه می دهد. چهارمین ثبت کلیدی که تا به امروز تبدیل شده است، ثبت کلید برای توپوگرافی (مخفف هلندی: BRT) است. همه مجموعه داده ها، از جمله اطلاعات مربوط به در دسترس بودن API و احتمالات جستجو، در فروشگاه سه گانه مدیریت شده توسط تیم علم داده Kadaster در دسترس هستند (https://data.labs.kadaster.nl ).
4. مدل دانش در مقابل مدل اطلاعات
اولین مورد اضافه شده جدید به انتشار داده های مرتبط توسط Kadaster، تمایز صریح بین مدل دانش و مدل اطلاعات است، که هر دو مدل داده های مرتبط بزرگتر را برای هر مجموعه داده تشکیل می دهند. این جداسازی نشاندهنده این واقعیت است که یک مدل داده پیوندی باید بتواند با استفاده از مدل دانش، معنای دادهها را برای دنیای خارج توصیف کند، در حالی که جنبههای خاص سازمان را در مدل اطلاعاتی نیز توصیف میکند. این جداسازی به مدل اطلاعاتی اجازه میدهد تا در جهت نیازهای داخلی سازمان، از جمله مدلها و فرآیندهای خاص مربوط به یک دارایی، بهینهسازی شود، در حالی که همچنان به مدل دانش مرتبط اجازه میدهد تا بهمنظور پشتیبانی مؤثر خارجی، بهینه شود.4 ]. از آنجایی که هر دو جنبه داخلی و خارجی برای تلاشهای Kadaster در انتشار دادهها مهم هستند، این رویکرد جدید برای انتشار دادههای پیوندی بهتر میتواند الزامات سازمانی را برای مجموعه دادههای پیوندی پیادهسازی کند. در واقع، تعدادی از دلایل خاص در زمینه Kadaster وجود دارد که این انشعاب در طراحی رویکرد جدیدی برای انتشار ضروری بود.
اولاً، یک مدل اطلاعاتی برای یک دارایی معین حاوی اطلاعات خاص و داخلی مربوط به یک دارایی معین است. این اطلاعات شامل ویژگیهای سیستمهای اطلاعاتی فعلی است که در یک دارایی خاص و در مجاورت آن استفاده میشوند، قوانین خاص سازمان مربوط به یک دارایی و همچنین جزئیات فنی دارایی. به عنوان مثال، این واقعیت که نام شهرداری ها در هلند مجاز نیست بیش از 80 کاراکتر باشد در قوانین هلند به صراحت رمزگذاری نشده است، بلکه محدودیتی است که توسط سیستم های داخلی اعمال می شود که Kadaster برای ثبت این اطلاعات هنگام ثبت در یک کلید استفاده می کند. ثبت نام. گنجاندن این اطلاعات در مدل دانش نادرست است: این طول حداکثر بخشی از معنایی نام شهرداری ها نیست. با این حال، کنار گذاشتن این اطلاعات نیز نادرست است زیرا مدل داده های پیوندی قادر به حذف مقادیری که توسط سیستم های ثبت داخلی Kadaster پذیرفته نشده اند، نخواهد بود. به این ترتیب، این اطلاعات در مدل اطلاعاتی یک دارایی مشخص مدلسازی میشود و با استفاده از زبان محدودیت اشکال (SHACL) [5 ] که در خدمت محدود کردن یک مدل معین بر اساس قوانین و روابط تعریف شده داخلی برای یک دارایی است. چندین رویکرد فنی وجود دارد که میتواند برای رسمی کردن چنین محدودیتهایی در مدل اطلاعات استفاده شود، برای مثال طرحواره XML یا طرحواره JSON، اما SHACL برای دادههای شکل گراف و دادههای پیوندی بهینهسازی شده است. بنابراین SHACL به عنوان زبان نمایندگی در این پروژه انتخاب شد.
ثانیاً، یک مدل دانش برای همان دارایی، هر دانش عمومی و قابل تعویضی را تعریف میکند که حفظ آن در سازمان مهم است، اما باید با دیگران نیز به اشتراک گذاشته شود. این مدل دانش همچنین استفاده مجدد از مدلهای دادههای مرتبط خارجی را با زمینههای خاص سازمان آسانتر میکند. به عنوان مثال، ویژگی برچسب ترجیحی SKOS خارجی (skos:prefLabel) را می توان برای نشان دادن نام فضاهای عمومی (مدل دانش) استفاده کرد، در حالی که محدودیت کاراکترهای ذکر شده در بالا (مدل اطلاعات) را نیز رمزگذاری می کند. در پیادهسازی مدل دانش توسط Kadaster، همه مدلهای داده پیوندی از RDF(S) [ 6 ]، OWL [ 7 ] و/یا SKOS [ 8 ] استفاده میکنند.] واژگان و هستی شناسی ها، در میان دیگران، که همواره به نفع قابلیت استفاده مجدد و قابلیت متقابل بودن مدل را با دنیای خارج مرتبط می کنند.
همانطور که در شکل 1 الف، ب نشان داده شده است، مدل های اطلاعات و دانش کاملاً مستقل از یکدیگر نیستند و در واقع هنگام تعریف و تبدیل مدل به یکدیگر نگاشت می شوند. به عنوان مثال، این فرآیند اشکال SHACL تعریف شده در مدل اطلاعات را به کلاس های OWL مربوطه یا RDF literals تعریف شده در مدل دانش نگاشت می کند. دو نوع برای این فرآیند نگاشت وجود دارد، یکی نگاشت ویژگی های شی در دو مدل ( شکل 1 الف) و دیگری نگاشت ویژگی های نوع داده در بین مدل ها ( شکل 1 ب). هر دو نوع باید در طول تبدیل مدل داده به داده های پیوندی تکمیل شوند.
در نوع اول ( شکل 1 الف)، فرآیند تقریباً یکسان است، به جز این واقعیت که گرههای SHACL و شکلهای ویژگی که برای ویژگیهای شی در یک مدل داده معین تعریف شدهاند، به کلاسهای OWL مربوطه و ویژگیهای شی تعریف شده در مدل دانش نگاشت میشوند. در نوع دوم ( شکل 1 B)، ویژگیهای نوع داده در مدل داده با نگاشت گره SHACL و شکلهای ویژگی مربوطه برای هر نوع داده به کلاس OWL مربوطه، ویژگی نوع داده و واژه RDFS تعریف شده در مدل دانش تعریف میشوند.
در تلاش برای حمایت از اعتبارسنجی بهتر مدل حاصل، یک مرحله اعتبار سنجی SHACL نیز در فرآیند مدلسازی اعمال شده است. این مرحله تضمین میکند که اشکال برای هر شی و ویژگی نوع داده در مدل داده کاملاً در برابر دادههای نمونه اعتبارسنجی میشوند. این مرحله اعتبارسنجی شامل تعدادی از بهترین شیوهها در رابطه با مدلسازی مدل اطلاعاتی با تمرکز بر استفاده از اشکال گره بسته است [ 9 ، 10 ]. این تضمین میکند که مدل به همان اندازه که لازم است برای اطمینان از اعتبار معنادار مدل وجود دارد و در عین حال اجازه میدهد نمونههای داده صحیح، اما نادر، اعتبارسنجی شوند، خاص است. میز 1مثال هایی از نحوه استفاده از مدل اطلاعات علاوه بر مدل دانش برای اجرای بهترین شیوه های خاص برای مدل داده و برای مثال داده ها ارائه می دهد. توجه داشته باشید که مدل دانش (ستون 3) معنای/معنای صحیح داده ها را مشخص می کند. مدل اطلاعات (ستون 2) معیارهای ساختاری اضافی را مشخص می کند که – به بیان دقیق – بخشی از معنای داده ها نیستند.
5. طراحی و توسعه معماری های پشتیبان
فرآیند تبدیل دادههای رابطهای برای یک دارایی مکانی دادهشده به دادههای مرتبط در چندین مرحله طی فرآیند استخراج، تبدیل و بارگذاری (ETL) تکمیل میشود. این فرآیند در طرح کلی معماری در شکل زیر ( شکل 2 ) نشان داده شده است و به شرح زیر توضیح داده شده است. در جزئیات معماری مورد استفاده در این رویکرد، بحثهای کوتاه پیرامون اجرای فعلی و زمینههای بهبود به طور متناوب با دیدگاه ارائه دیدگاهی در مورد توسعه بیشتر این معماری گنجانده خواهد شد.
مرحله اول دادههای رابطهای را از منبع بارگیری میکند، در این مورد از پلتفرم هلندی برای دسترسی به خدمات زمین (PDOK)، به پایگاه داده PostgreSQL پس از مرحله نمایهسازی زبان نشانهگذاری جغرافیا (GML) [ 11 ]. یک GraphQL ( https://graphql.org/) سپس نقطه پایانی برای دسترسی به داده های تحویل داده شده از طریق یک API از پایگاه داده PostgreSQL پس از تحویل و اعتبارسنجی مدل داده از کاربر نهایی استفاده می شود. در عمل، این مرحله با گسترش typedefs به گونهای انجام میشود که اشیاء در یک مدل داده به درستی در GraphQL توصیف شوند، حلکنندهها را گسترش میدهد تا به اشیاء اجازه داده شود با پارامترهای مناسب پرس و جو شوند و در نهایت، کوئریهای SQL مورد نیاز را به حلکنندههای مربوطه اضافه میکنند. . توجه داشته باشید که این رویکرد ذاتاً به منابع داده رابطهای محدود نمیشود، زیرا یک نقطه پایانی GraphQL ممکن است بتواند از انواع دیگر منابع نیز ارائه کند. علاوه بر این، تمام نقاط پایانی GraphQL که برای هر سیلو داده در دسترس هستند، با استاندارد Apollo GraphQL مطابقت دارند. انطباق با این استاندارد، فدراسیون نقاط پایانی را آسان تر می کند و بنابراین در عمل،
در فرآیند بازیابی دادهها از منبع، دادهها تا حد امکان نزدیک به منبع در دسترس این خط لوله قرار میگیرند تا از هرگونه کپی غیرضروری از دادهها جلوگیری شود و اطمینان حاصل شود که موضوعیت دادهها تا حد امکان به دادههای زمان واقعی نزدیک است. این رویکرد «نزدیک به منبع» تضمین میکند که در مدلسازی مدلهای داده پیوندی برای هر مجموعه دادهای که باید تبدیل شود، هیچ تغییر غیرضروری یا مبهم برای مدل داده انجام نمیشود و به این ترتیب، مدل داده پیوندی کاملاً برای متخصصان دامنه قابل تشخیص است. . در پیادهسازی فعلی معماری برای هر مجموعه داده، Kadaster دادهها را برای تبدیل در درجات مختلف فاصله تا منبع صرفاً بر اساس روش فعلی تحویل که توسط خود منبع پیادهسازی شده است، بازیابی میکند. در واقع، این روشهای تحویل از انتشارات GitHub در یک بازه زمانی خاص (BAG) تا دانلود یک نسخه از دادههای تحویلشده در هر سه ماهه (BGT) و تا امکان دسترسی مستقیم به دادهها از خود مرکز (BRT) متغیر است. در کوتاه مدت، این احتمال وجود دارد که تحویل این منابع در یک مرکز اطلاعاتی متمرکز شود که از طریق آن این خط لوله بتواند به منبع دسترسی داشته باشد.
هنگامی که مدل به عنوان یک نقطه پایانی GraphQL در دسترس است، می توان آن را توسط Enhancer که یک مؤلفه داخلی توسعه یافته است که امکان جست و جوی JSON-LD بر اساس نقطه پایانی GraphQL را فراهم می کند، جستجو کرد. برای انجام این کار، مراحل زیر مورد نیاز است. اولاً، Enhancer دارای مجموعه ای از پرس و جوهای از پیش تعریف شده با پارامترهای زمان و/یا صفحه بندی خاص برای هر شی است، به طوری که شی به عنوان نقطه پایانی تحویل داده می شود که میکروسرویس می تواند برای تحویل JSON-LD به آن دسترسی داشته باشد [ 12 ].] نتایج. پیکربندی پرس و جوهای از پیش تعریف شده مورد استفاده در Enhancer در حال حاضر با افزودن یک پرس و جو GraphQL در زیر پوشه/query در Enhancer کار می کند. این پرس و جو داده های نمونه را بر اساس اشیاء تعریف شده در مدل داده برای یک مجموعه داده خاص برمی گرداند و می تواند در بارگذاری کامل یک مجموعه داده مانند داده های پیوندی استفاده شود. فرمت خاص این نقطه پایانی بر اساس یک هدر پذیرش از application/n-quads یا application/ld+json است. توجه داشته باشید که دسترسی به نقطه پایانی Enhancer با یک درخواست POST حاوی یک کوئری GraphQL نیز امکان پذیر است. ثانیاً، یک ارجاع به مکان مربوطه زمینه JSON-LD برای یک مجموعه داده خاص باید تعریف شود و این برای هر مجموعه داده جدیدی که از طریق فرآیند ETL می گذرد، انجام می شود. هر کلید در زمینه JSON-LD به ویژگیها و/یا اشیاء در تایپدفهای GraphQL اشاره دارد که از Enhancer با تبدیل این ویژگیها به قالب دادههای پیوندی پشتیبانی میکنند. همانطور که از بخش قبل مشهود است، SHACL را می توان هم برای اعتبارسنجی مدل داده با استفاده از داده های مثال و هم برای اعتبار سنجی داده های نمونه تبدیل شده با استفاده از مدل داده استفاده کرد. در واقع، در این معماری، یک مرحله اعتبار سنجی SHACL مورد نیاز است تا اطمینان حاصل شود که داده های تحویل شده از Enhancer معتبر هستند. در نهایت، در خط لوله تبدیل یک تحویل GraphQL به داده های پیوندی، لازم است مجموعه ای از اشیاء را با استفاده از پرس و جوهای از پیش تعریف شده پرس و جو دسته ای کرد. این پرس و جوهای دسته ای در یک قطعه کد حداقلی به نام میکروسرویس همانطور که در نشان داده شده است قرار دارند همانطور که از بخش قبل مشهود است، SHACL را می توان هم برای اعتبارسنجی مدل داده با استفاده از داده های مثال و هم برای اعتبار سنجی داده های نمونه تبدیل شده با استفاده از مدل داده استفاده کرد. در واقع، در این معماری، یک مرحله اعتبار سنجی SHACL مورد نیاز است تا اطمینان حاصل شود که داده های تحویل شده از Enhancer معتبر هستند. در نهایت، در خط لوله تبدیل یک تحویل GraphQL به داده های پیوندی، لازم است مجموعه ای از اشیاء را با استفاده از پرس و جوهای از پیش تعریف شده پرس و جو دسته ای کرد. این پرس و جوهای دسته ای در یک قطعه کد حداقلی به نام میکروسرویس همانطور که در نشان داده شده است قرار دارند همانطور که از بخش قبل مشهود است، SHACL را می توان هم برای اعتبارسنجی مدل داده با استفاده از داده های مثال و هم برای اعتبار سنجی داده های نمونه تبدیل شده با استفاده از مدل داده استفاده کرد. در واقع، در این معماری، یک مرحله اعتبار سنجی SHACL مورد نیاز است تا اطمینان حاصل شود که داده های تحویل شده از Enhancer معتبر هستند. در نهایت، در خط لوله تبدیل یک تحویل GraphQL به داده های پیوندی، لازم است مجموعه ای از اشیاء را با استفاده از پرس و جوهای از پیش تعریف شده پرس و جو دسته ای کرد. این پرس و جوهای دسته ای در یک قطعه کد حداقلی به نام میکروسرویس همانطور که در نشان داده شده است قرار دارند یک مرحله اعتبار سنجی SHACL مورد نیاز است تا اطمینان حاصل شود که داده های تحویل داده شده از Enhancer معتبر هستند. در نهایت، در خط لوله تبدیل یک تحویل GraphQL به داده های پیوندی، لازم است مجموعه ای از اشیاء را با استفاده از پرس و جوهای از پیش تعریف شده پرس و جو دسته ای کرد. این پرس و جوهای دسته ای در یک قطعه کد حداقلی به نام میکروسرویس همانطور که در نشان داده شده است قرار دارند یک مرحله اعتبار سنجی SHACL مورد نیاز است تا اطمینان حاصل شود که داده های تحویل داده شده از Enhancer معتبر هستند. در نهایت، در خط لوله تبدیل یک تحویل GraphQL به داده های پیوندی، لازم است مجموعه ای از اشیاء را با استفاده از پرس و جوهای از پیش تعریف شده پرس و جو دسته ای کرد. این پرس و جوهای دسته ای در یک قطعه کد حداقلی به نام میکروسرویس همانطور که در نشان داده شده است قرار دارندشکل 2 .
کل فرآیند ETL از کمترین کد سفارشی استفاده میکند و بنابراین، این فرآیند از نرمافزار Apache Airflow ( https://airflow.apache.org/ ) بهعنوان یک «هندلر» استفاده میکند که دادهها را از طریق کل فرآیند ETL همانطور که در شکل 2 نشان داده شده است، میکروسرویس داده ها را از تقویت کننده واکشی می کند و این فرآیند را تا زمانی که همه داده ها به صورت JSON-LD از نقطه پایانی اصلی GraphQL بازیابی شوند، تکرار می کند. در عمل، این میکروسرویس یک وظیفه در جریان هوا است که در آن Enhancer به صورت سریال با کد محدود آدرسدهی میشود و نتایج بهعنوان دادههای مرتبط جمعآوری میشوند. هنگامی که تمام داده ها اعتبارسنجی و در فروشگاه سه گانه بارگذاری می شوند، که در این مورد نمونه ای از TriplyDB است ( https://triplydb.com، خدمات مختلفی را می توان نمونه سازی کرد، از جمله ElasticSearch، یک مرورگر داده، یک نقطه پایانی SPARQL [ 13 ] برای استفاده در داستان های داده. اینها را می توان در رابط خود فروشگاه سه گانه مثال زد. به منظور دسترسی بهتر به مدلهای داده پیوندی، مدلهای داده برای هر ثبت کلید نیز با استفاده از ابزار Weaver ( https://kadaster.wvr.io/bag2-0/home ) تجسم میشوند.
اگرچه معماری فعلی هنوز شامل یک رویکرد جریانی برای انتشار داده های پیوندی نمی شود، خود معماری به گونه ای طراحی شده است که این رویکرد با گذشت زمان ممکن می شود. عامل مهم در ارائه این قابلیت جریان برای داده های پیوندی در Kadaster، افزایش در دسترس بودن این مجموعه داده ها در Datahub در ثبت زمین است. در واقع، از آنجایی که چشم انداز این است که این Datahub منبع مرکزی همه مجموعه داده های کاداستر باشد، Datahub باید با تعدادی از اصول از جمله ارائه داده ها در زمان واقعی مطابقت داشته باشد. به منظور ارائه این اصول در طراحی آن، احتمالاً یک API جریان برای هر مجموعه داده گنجانده شده است، که هم پرس و جوهای کششی و هم مبتنی بر اشتراک را امکان پذیر می کند.
6. چشم انداز یکپارچه سازی داده های مکانی
در حالی که پیشرفتها در فنآوریها و استانداردهای دادههای مرتبط، و همچنین افزایش تقاضا برای این خدمات، نیاز به رویکردی بهروز برای تحویل دادههای مکانی مرتبط توسط Kadaster را آغاز کرد، این رویکرد اکنون در مرکز جاهطلبی Kadaster برای ارائه یک نمودار دانش قرار دارد. 14]. در معماری راه حل ارائه شده در بخش قبل، اولین گام به سمت این نمودار دانش در در دسترس قرار دادن رجیسترهای کلیدی مختلف به عنوان داده های مرتبط برداشته شده است. این مجموعه داده ها، در تلاش برای نگه داشتن مدل داده های پیوندی تا حد امکان به مدل داده منبع، هنوز مختص دامنه هستند. این مزیتی برای مجموعه دادههای پیوندی siled دارد، زیرا مدلهای داده برای متخصصان دامنه قابل تشخیص و در دسترس هستند و تکنیک حاکمیت در مدیریت این دادهها توسط مالک مجموعه مشخص است. عواملی که برای حاکمیت داخلی و مالکیت داده ها در قالب های مختلف در Kadaster مهم هستند.
با این حال، این رویکرد «نزدیک به منبع» برای انتشار دادههای مرتبط هنگام تلاش برای دسترسی بیشتر به دادههای موجود در ثبتهای کلیدی برای کاربر غیرمتخصص مفید نیست، زیرا استفاده از این دادهها به دانش دامنه نیاز دارد. در عمل، کاربران غیرمتخصص چنین منابع داده ای بیشتر به اطلاعات مربوط به خانه یا محیط زندگی خود علاقه مند هستند و به دنبال تعامل با داده ها با عباراتی هستند که برای آنها بر اساس محیط اطرافشان آشنا است. به این ترتیب، در ارائه نمودار دانش در نتیجه ترکیب رجیسترهای کلیدی و سایر مجموعه دادههای تبدیل شده با استفاده از معماری راهحل بالا، یک مدل داده کاربرپسند جدید برای نمودار دانش Kadaster استفاده میشود. محتویات نمودار دانش مجموعه داده های مرتبط برای هر ثبت کلید است، نقشه کاداستر دیجیتال و همچنین سایر مجموعه داده های مرتبط که حول موضوع یک ساختمان متمرکز شده اند. فرآیند فنی ترکیب مجموعه دادههای سیلو شده برای تشکیل نمودار دانش در نشان داده شده استشکل 3 .
همانطور که در شکل 3نشان میدهد، نمودار دانش Kadaster با ایجاد یک لایه در بالای ثبتهای کلیدی در فرم دادههای پیوندی آنها ارائه میشود. ترکیبی از این رجیستری های داده مرتبط در حال حاضر با تعریف یک مدل داده با استفاده از مشخصات schema.org مربوط به ساختمان ها انجام می شود. استفاده از schema.org در اولین انتشار نمودار دانش Kadaster به سه دلیل انجام شده است. اولاً، با معماری نمودار دانش به عنوان یک لایه در بالای مجموعه دادههای پیوندی siled که نمودار را تشکیل میدهند، منشأ مجموعه دادههای اصلی همچنان در صورت لزوم در دسترس کاربر نهایی نمودار دانش است. ثانیاً، استفاده از مشخصات schema.org به نفع استفاده مجدد از استانداردهای موجود جامعه و همچنین به نفع پشتیبانی از قابلیت کشف خارجی و قابلیت همکاری است. علاوه بر این، طرح واره مشخصات org مربوط به یک ساختمان به طور کلی به نحوه درک کاربران غیر متخصص از محیط خود بسیار نزدیکتر است. در واقع، زمانی که کاربر به دنبال اطلاعاتی درباره یک خانه است، ممکن است به کدپستی و شماره خانه فکر کند و نه تعیین شماره. به این ترتیب، مدل داده بسیار کاربرپسندتر از مدل های داده پیچیده است که ثبت های کلید را تعریف می کنند. دسترسی به نمودار دانش فعلی از طریق REST، GraphQL، GeoSPARQL [15 ]، و خدمات ElasticSearch که در آنها برنامه های شخص ثالث از آنها برای ارائه اطلاعات جغرافیایی به کاربر نهایی استفاده می کنند [ 16 ].
در حالی که استفاده از مشخصات schema.org در توسعه یک اثبات مفهوم برای نمودار دانش Kadaster مفید بوده است، بعید است که این مشخصات مشخصات نهایی مورد استفاده برای مدل داده باشد. این بیشتر به دلیل این واقعیت است که تکرار آتی نمودار دانش به احتمال زیاد فقط حاوی اطلاعاتی در مورد ساختمان ها نیست و مشخصات schema.org (هنوز) به اندازه کافی گسترده نیست که به طور مداوم همه اشیاء اطلاعات جغرافیایی مربوطه را مدل کند (مانند جاده ها، زیرساخت، ویژگی های توپوگرافی). در تکرارهای بعدی نمودار دانش،
7. ارزشیابی و درس های آموخته شده
در اجرای رویکرد مشخص شده در این مقاله، چالشهای مختلفی در رابطه با انتشار دادههای مرتبط در Kadaster مورد توجه قرار گرفت. در واقع، از آنجایی که رویکرد اولیه در زمینه کتابخانهها و محصولات دادههای پیوندی بسیار کمتر توسعه داده شد، اغلب لازم بود زیرساخت مورد نیاز برای انتشار دادههای مرتبط در داخل توسعه داده شود. این مقدار قابلتوجهی از زیرساختهای قدیمی را بهوجود آورد که برای نگهداری آن نیاز به منابع زیادی داشت. با گذشت زمان، این زیرساخت همچنین تحولاتی را که در جامعه دادههای مرتبط گستردهتر با توجه به کتابخانهها و فنآوریها اتخاذ شده بود، منعکس نکرد. همانطور که در سراسر مقاله اشاره شد، تقاضا برای یک رویکرد مقیاس پذیرتر به عنوان یک نتیجه از اثرات شبکه مربوط به در دسترس بودن بیشتر داده های پیوندی مستلزم این بود که فرآیند انتشار داده های مرتبط در Kadaster نوآوری شود. برای اطمینان از این مقیاسپذیری و کارایی منابع، رویکرد جدید به استانداردهای موجود جامعه و راهحلهای فناوری تجاری برای توسعه جدول زمانی انتشار در راستای اصول کلی معماری که بر نیاز به ترکیب فناوریهای موجود در هر جایی که ممکن است تأکید میکند، روی آورد.
همانطور که در زمینه مشکل اشاره شد، بازنگری رویکرد موجود به نفع رویکردی که در این مقاله مشخص شده است منجر به انتشار و نگهداری چندین مجموعه داده بزرگ و پیچیده توسط یک تیم داخلی نسبتاً کوچک در Kadaster شده است. این امر از طریق تأکید بیشتر بر استفاده مجدد اجتماعی و تجاری از استانداردها و محصولات حاصل می شود که میزان منابع صرف شده برای توسعه و نگهداری زیرساخت انتشار داده های مرتبط را کاهش می دهد. علاوه بر این، با افزودن اصولی مانند پیکربندی بیش از کد و همچنین انتشار مجموعه داده “نزدیکتر به منبع” با در نظر گرفتن رویکرد جریان، رویکرد جدید به طور قابل توجهی پیچیدگی و شدت منابع رویکردهای قبلی را کاهش می دهد. در واقع،
انتشار موفقیتآمیز ثبتهای کلیدی مختلف و مجموعه دادههای خارجی فرصتی برای تأمل در رویکرد اتخاذ شده توسط Kadaster همانطور که در این مقاله ذکر شده است، فراهم میکند. در اینجا، تعدادی از «درس های آموخته شده» را می توان شناسایی کرد، که هر یک را می توان به طور تقریبی در دو موضوع دسته بندی کرد. موضوع اول را می توان به عنوان نیاز به تناسب بهتر بین دیدگاه های تجاری و فنی در مورد داده های مرتبط خلاصه کرد و شامل دو درس آموخته شده است. در مرحله اول، رویکرد ارائه شده در این مقاله یک پیاده سازی فنی سبک، کم هزینه و کم کد (با استفاده از راه حل های نرم افزاری موجود) برای انتشار داده های مرتبط است. این با دیدگاه کسب و کار و اصول معماری که به طور کلی در سازمان ها دنبال می شود، تناسب بسیار بهتری دارد. مثلا، هزینه پایین پیاده سازی این واقعیت را تکمیل می کند که در حال حاضر استفاده نسبتاً محدودی از این خدمات توسط کاربران نهایی وجود دارد. علاوه بر این، استفاده از ابزارهای موجود در خط لوله انتشار، مکمل استفاده مجدد از راهحلهای نرمافزاری موجود در سازمانها بر اساس اصول کلی معماری «عمل خوب» است.
دومین درسی که باید در این موضوع آموخته شود به فقدان عمومی حاکمیتی مربوط می شود که رویکردهای موجود برای انتشار داده های مرتبط در سازمان ها را احاطه می کند. رویکرد ارائهشده در این مقاله تمایز واضحی بین انتشار مجموعههای دادههای پیوندی siled، مجموعههای دادهای که تا حد امکان به مدل داده منبع مدلسازی و پیادهسازی شدهاند، و چشمانداز اجرای نمودار دانش بهعنوان یک لایه در بالا، ایجاد میکند. از این مجموعه داده ها این تمایز از منظر حاکمیتی به مالک مجموعه دادههای سیلو شده اجازه میدهد تا مسئول نسخه دادههای مرتبط سیلو خود باقی بماند، زیرا هیچ تغییر قابل توجهی در خود داده (مدل) ایجاد نشده است و این به نمودار دانش اجازه میدهد تحت یک مدل حاکمیتی متفاوت قرار گیرد.
موضوع دوم به موضوع مدلسازی دادههای نمودارهای دانش در یک زمینه دولتی مربوط میشود. اولین پیاده سازی نمودار دانش در Kadaster با توسعه یک مدل داده بر اساس schema.org انجام شد. همانطور که در بخش قبل اشاره شد، این مدل داده دارای کاستی های مختلفی است و این امر منجر به اذعان به این امر شده است که این مدل داده یکپارچه ضروری است و باید توسط یک منبع معتبرتر مانند مرجع استاندارد مربوطه یا توسط Kadaster توسعه و نگهداری شود. خود مدلسازی دادهها در بافت دولتی به دلیل الزامات قانونی و حاکمیتی مختلف که یک مدل داده را احاطه میکند، میتواند تا حدودی پیچیده باشد. توسعه یک مدل داده جدید و یکپارچه برای نمودار دانش می تواند زمان بر باشد و این سوال که چه کسی باید مسئول توسعه، تحویل، و نگهداری مدل همچنان یک سوال باز است. به این ترتیب، بزرگترین مانع برای ارائه یک مدل داده یکپارچه در زمینه دولت ممکن است پیچیدگی فعالیت های مدل سازی داده باشد. مانعی که پتانسیل آن را دارد که کاربرد گسترده این نمودارها را برای سال های آینده به تاخیر بیندازد.
8. نتیجه گیری
Kadaster، ثبت ملی زمین هلند، اخیراً یک رویکرد به روز را برای انتشار داده های مرتبط دارایی های مکانی خود در پاسخ به تقاضای فزاینده برای خدمات داده های مرتبط و نیاز مبرم به نوآوری رویکردهای موجود برای برآورده کردن الزامات مقیاس پذیری، اجرا کرده است. Kadaster با تکیه بر تجربیات موجود در انتشار رجیستری های پایه خود به عنوان داده های مرتبط، از فناوری ها و استانداردهای موجود جامعه و همچنین محصولات تجاری موجود برای تعریف رویکردی استفاده کرده است که دارایی های داده مرتبط را به موقع، مقرون به صرفه و با افزایش قابلیت استفاده مجدد در پروژه ها این رویکرد بخشی از یک چشم انداز بزرگتر برای ارائه یک نمودار دانش متمرکز بر موضوع “ساختمان” است که در آن هم این چشم انداز بزرگتر و هم اصول اعمال شده در این رویکرد مرکزی برای تبدیل ثبت های پایه به نفع یکپارچه سازی داده های مکانی بهتر اجرا می شوند. قابلیت همکاری و کشف اگرچه نوآورانه است، اما تلاش Kadaster برای بهبود یافتن و پیوندپذیری مکانی به صورت مجزا انجام نشده است و نیاز کلی به قابلیت همکاری فضایی بهتر در سطح ملی را برجسته میکند.17 ، 18 ] و بین کشورهای (اروپایی) [ 19 ] و قابلیت استفاده مجدد از این داده ها در زمینه های مختلف [ 20 ].
منابع
- رولند، ا. فولمر، ای. بیک، دبلیو. Wenneker, R. قابلیت همکاری و یکپارچگی: یک رویکرد به روز شده برای انتشار داده های مرتبط در اداره ثبت زمین هلند. در مجموعه مقالات چهارمین کارگاه بین المللی در مورد داده های پیوندی جغرافیایی در EWSC، هرسونیسوس، یونان، 6 تا 10 ژوئن 2021. [ Google Scholar ]
- فولمر، ای. Beek، W. Kadaster Data Platform—Overview Architecture. در مجموعه مقالات کنفرانس نرم افزار رایگان و منبع باز برای زمین فضایی (FOSS4G)، بوستون، MA، ایالات متحده آمریکا، 14 تا 19 اوت 2017. جلد 17. [ Google Scholar ]
- فولمر، ای. رونژین، اس. ون هیلگرسبرگ، جی. بیک، دبلیو. Lemmens، R. منطق تجاری برای داده های مرتبط در دولت ها: مطالعه موردی در پلت فرم داده Kadaster هلند. IEEE 2020 ، 8 ، 70822–70835. [ Google Scholar ] [ CrossRef ]
- کنسرسیوم وب جهانی بهترین روش ها برای انتشار داده های پیوندی یادداشت گروه کاری W3C. 2014. در دسترس آنلاین: https://www.w3.org/TR/ld-bp/ (در 2 مارس 2021 قابل دسترسی است).
- کنسرسیوم وب جهانی زبان محدودیت اشکال (SHACL). توصیه W3C 2017. در دسترس آنلاین: https://www.w3.org/TR/shacl/ (در 3 مارس 2021 قابل دسترسی است).
- کنسرسیوم وب جهانی طرحواره RDF 1.1. توصیه W3C 2014. در دسترس آنلاین: https://www.w3.org/TR/rdf-schema/ (در 3 مارس 2021 قابل دسترسی است).
- کنسرسیوم وب جهانی OWL 2 Web Ontology Language Primer (نسخه دوم). توصیه W3C 2012. در دسترس آنلاین: https://www.w3.org/TR/owl2-primer/ (در 3 مارس 2021 قابل دسترسی است).
- کنسرسیوم وب جهانی پرایمر سیستم سازماندهی دانش ساده SKOS. یادداشت گروه کاری W3C. 2009. در دسترس آنلاین: https://www.w3.org/TR/skos-primer/ (در 3 مارس 2021 قابل دسترسی است).
- ون دن برینک، ال. برنقی، پ. تندی، جی. اتمزینگ، جی. اتکینسون، آر. کاکرین، بی. فتحی، ی. گارسیا کاسترو، آر. هالر، ا. هارث، آ. و همکاران بهترین روش ها برای انتشار، بازیابی و استفاده از داده های مکانی در وب. سمنت. وب 2018 ، 10 ، 95-114. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تندی، جی. ون دن برینک، ال. برنقی، ص. داده های فضایی در وب بهترین شیوه ها. یادداشت گروه کاری W3C. 2017. در دسترس آنلاین: https://www.w3.org/TR/2017/NOTE-sdw-bp-20170928/ (دسترسی در 11 نوامبر 2021).
- ون دن برینک، ال. یانسن، پی. کواک، دبلیو. Stoter, J. پیوند داده های فضایی: تبدیل خودکار مدل های اطلاعات جغرافیایی و داده های GML به RDF. بین المللی جی. اسپات. زیرساخت داده Res. 2014 ، 9 ، 59-85. [ Google Scholar ]
- کنسرسیوم وب جهانی JSON-LD 1.1. توصیه W3C 2020. در دسترس آنلاین: https://www.w3.org/TR/json-ld11/ (در 3 مارس 2021 قابل دسترسی است).
- کنسرسیوم وب جهانی بررسی اجمالی SPARQL 1.1. توصیه W3C 2013. در دسترس آنلاین: https://www.w3.org/TR/sparql11-overview/ (در 3 مارس 2021 قابل دسترسی است).
- رونژین، اس. فولمر، ای. ماریا، پی. براتینگا، ام. بیک، دبلیو. لمنز، آر. van’t Heer, R. Kadaster Graph Knowledge: Beyond the Fifth Star of Open Data. اطلاعات 2019 ، 10 ، 310. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کنسرسیوم فضایی باز GeoSPARQL – یک زبان پرس و جوی جغرافیایی برای داده های RDF. در دسترس آنلاین: https://www.ogc.org/standards/geosparql (در 3 مارس 2021 قابل دسترسی است).
- رولند، ا. فولمر، ای. Beek, W. Towards Self-Service GIS-ترکیب بهترین وب معنایی و GIS. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 753. [ Google Scholar ] [ CrossRef ]
- گودوین، جی. دولبر، سی. هارت، جی. داده های مرتبط جغرافیایی: جغرافیای اداری بریتانیای کبیر در وب معنایی. ترانس. GIS 2008 ، 12 ، 19-30. [ Google Scholar ] [ CrossRef ]
- دبروین، سی. میهن، ع. کلینتون، ای. مک نرنی، ال. ناوتیال، ا. لاوین، پ. O’Sullivan، D. داده های مرتبط جغرافیایی معتبر ایرلند. در وب معنایی-ISWC ; D’Amato, C., Fernandez, M., Tamma, V., Lecue, F., Cudré-Mauroux, P., Sequeda, J., Lange, C., Heflin, J., Eds. انتشارات بین المللی Springer: برلین/هایدلبرگ، آلمان، 2017; جلد 10588، ص 66–74. در دسترس آنلاین: https://link.springer.com/10.1007/978-3-319-68204-4_6 (در 12 مارس 2021 قابل دسترسی است).
- رونژین، اس. فولمر، ای. لمنز، آر. ملوم، آر. فون براش، TE; مارتین، ای. رومرو، EL; کیتو، اس. هیتانن، ای. Latvala، P. نسل بعدی زیرساخت داده های مکانی: درس هایی از پیاده سازی داده های مرتبط در سراسر اروپا. بین المللی جی. اسپات. زیرساخت داده Res. 2019 ، 14 ، 83-107. [ Google Scholar ]
- بوچر، بی. فولمر، ای. برنان، آر. بیک، دبلیو. هبیچ، ای. Würriehausen، F. رولند، ال. ماتورانا، RA; آلوارادو، ای. بویل، R. داده های پیوندی فضایی در اروپا: گزارش از جلسه داده های پیوندی فضایی در نمودار دانش در عمل. 2021. در دسترس به صورت آنلاین: https://www.eurosdr.net/sites/default/files/uploaded_files/eurosdr_publication_ndeg_73.pdf (دسترسی در 10 مارس 2021).
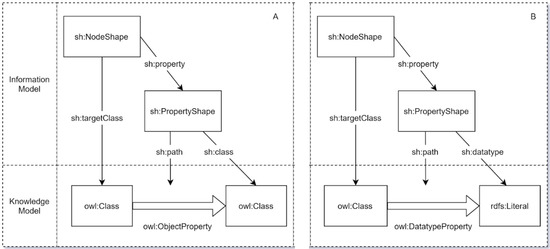
شکل 1. مدل نگاشت خصوصیات شی/نوع داده. طرح ها از قالب دیگری پیروی می کنند. ( الف ) این شکل نشان می دهد که چگونه نگاشت بین مدل اطلاعات و مدل دانش در عمل با توجه به جغد:ObjectProperty انجام می شود. ( B ) این شکل نشان می دهد که چگونه نگاشت بین مدل اطلاعات و مدل دانش در عمل با توجه به جغد:DatatypeProperty انجام می شود.
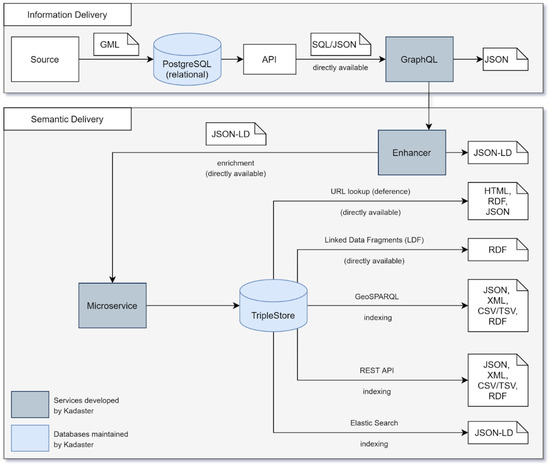
شکل 2. معماری که از فرآیند ETL پشتیبانی می کند که داده های مرتبط را ارائه می دهد.
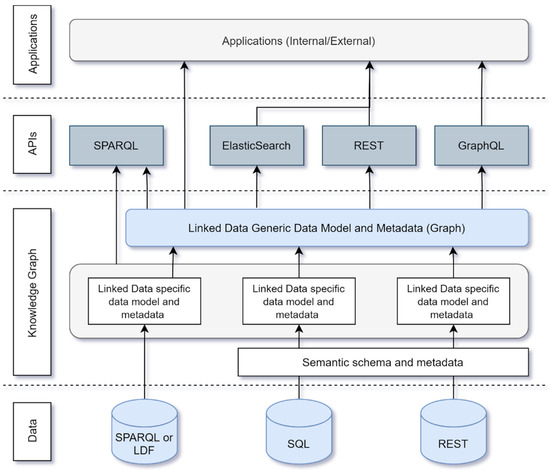
شکل 3. چشم انداز Kadaster برای اجرای نمودار دانش.


بدون دیدگاه