

محدود کردن مجموعه داده های حقیقت زمین برای استفاده از زمین و نقشه های پوشش زمین با الگوریتم های یادگیری ماشین

کلید واژه ها:
شاخص های سنجش از دور ; یادگیری ماشینی ؛ داده های حقیقت پایه ؛ نقشه برداری LULC ; تصویربرداری ماهواره ای
1. مقدمه
2. مواد و روشها
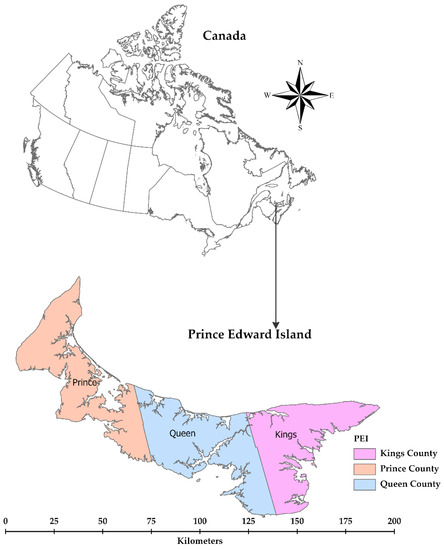
2.1. منطقه مطالعه
2.2. اکتساب داده ها
2.3. آماده سازی داده ها
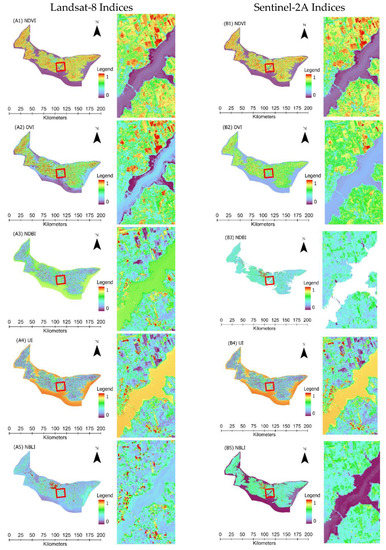
2.4. شاخص های سنجش از راه دور و کلاس های LULC
2.5. الگوریتم یادگیری ماشین
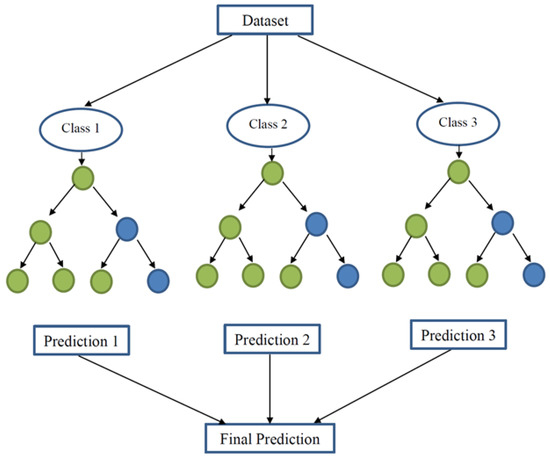
2.5.1. طبقه بندی جنگل تصادفی
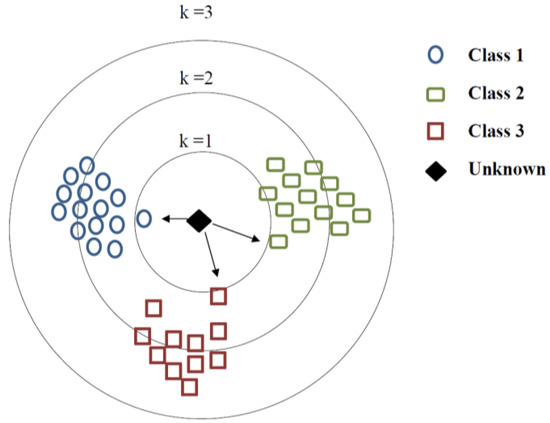
2.5.2. K-نزدیکترین همسایه
2.5.3. K بعدی-درخت
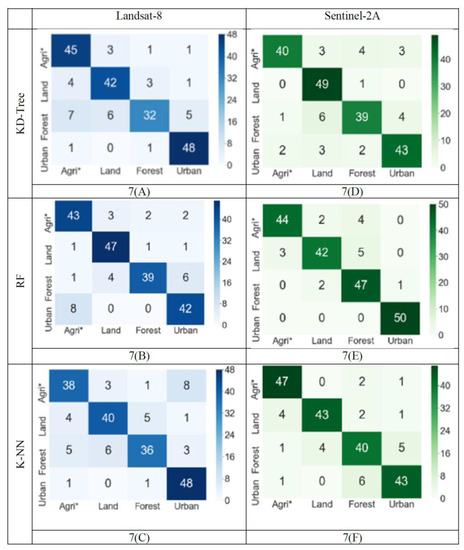
2.6. داده های حقیقت پایه برای اعتبارسنجی و معیارهای ارزیابی مدل
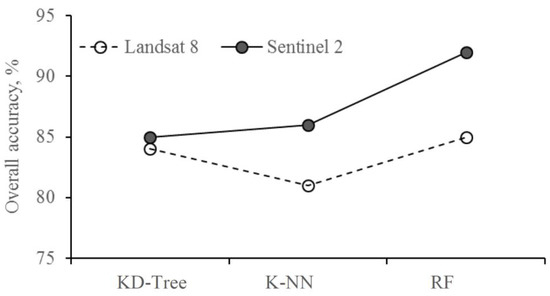
برای ارزیابی دقت مدل ها از چندین شاخص آماری استفاده شد. دقت کلی مدل ها برای توصیف نسبت صحیح پیکسل های نقشه برداری شده استفاده شد. دقت کلی در نظر می گیرد که 100٪ از تمام سایت های مرجع طبقه بندی شده به طور دقیق نقشه برداری شده اند [ 47 ]. دقت کلی با استفاده از فرمول زیر محاسبه شد:
به طور مشابه، دقت هر کلاس LULC با استفاده از دقت سازنده/کاربر تعیین شد. دقت تولیدکننده/کاربر ویژگی واقعی روی سطح زمین را که به درستی در نقشه طبقه بندی شده نشان داده شده است، تعیین می کند [ 47 ]. دقت تولید کننده و کاربر با استفاده از فرمول زیر محاسبه شد:
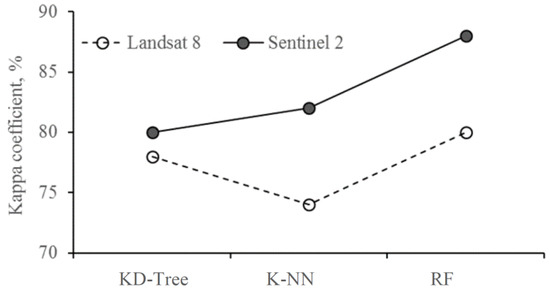
ضریب کاپا یکی دیگر از شاخص های آماری برای ارزیابی دقت طبقه بندی است. کاپا ارزیابی می کند که طبقه بندی در مقایسه با مقدار تخصیص تصادفی چقدر خوب عمل کرده است. مقادیر آن از 1- تا 1 متغیر است، با کمترین مقدار نشان می دهد که طبقه بندی بهتر از یک طبقه بندی تصادفی نیست، در حالی که مقدار نزدیک به مثبت نشان می دهد که طبقه بندی به طور قابل توجهی بهتر از طبقه بندی تصادفی است [ 48 ]. ضریب کاپا با استفاده از فرمول زیر محاسبه شد:
که در آن TS تعداد کل نمونه ها، TCS تعداد کل نمونه های طبقه بندی شده است، و مجموع ستون ها و مجموع ردیف ها به ترتیب تعداد کل پیکسل های طبقه بندی شده برای هر کلاس در هر ستون و ردیف را نشان می دهند.
3. نتایج
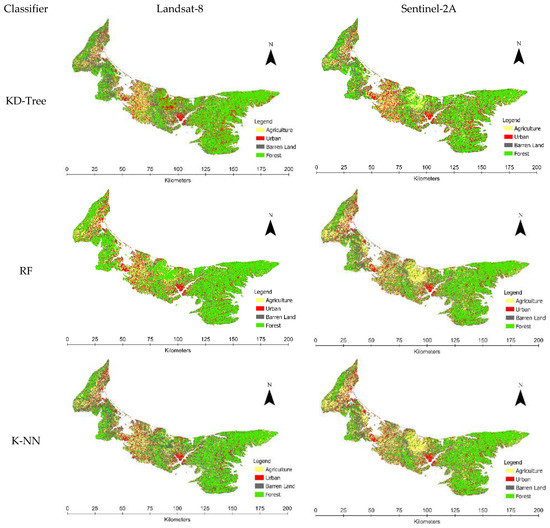
3.1. نتایج نقشه برداری کاربری و پوشش زمین
3.2. مقایسه دقت ماهواره
4. بحث
5. نتیجه گیری ها
منابع
- نگوین، HTT؛ Doan، TM; Radeloff, V. اعمال طبقهبندی تصادفی جنگل برای نقشه کاربری زمین/پوشش زمین با استفاده از Landsat 8 OLI. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2018 ، 42 ، 363-367. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بورکهارد، بی. کرول، اف. ندکوف، اس. مولر، اف. نقشه عرضه، تقاضا و بودجه خدمات اکوسیستم. Ecol. اندیک. 2012 ، 21 ، 17-29. [ Google Scholar ] [ CrossRef ]
- فیری، دی. مورگنروث، جی. تحولات در روش های طبقه بندی پوشش زمین لندست: مروری. Remote Sens. 2017 , 9 , 967. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- عملکرد عبدی، AM پوشش زمین و طبقهبندی کاربری اراضی الگوریتمهای یادگیری ماشین در یک منظره شمالی با استفاده از دادههای Sentinel-2. GISci. Remote Sens. 2020 , 57 , 1-20. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شوقی، آی. رشید، من. رومشو، SA دینامیک پوشش زمین کاربری اراضی به عنوان تابعی از تغییر جمعیت شناسی و هیدرولوژی. ژئوژورنال 2014 ، 79 ، 297-307. [ Google Scholar ] [ CrossRef ]
- وزارت امور اقتصادی و اجتماعی سازمان ملل متحد – بخش جمعیت. رشد جمعیت جهانی و توسعه پایدار ; وزارت امور اقتصادی و اجتماعی سازمان ملل متحد – بخش جمعیت: نیویورک، نیویورک، ایالات متحده آمریکا، 2021؛ ISBN 9789211483505. [ Google Scholar ]
- لی، پی. ماه، WM طبقهبندی پوشش زمین با استفاده از دادههای شبیهساز هوابرد MODIS–ASTER (MASTER) و NDVI: مطالعه موردی منطقه کوچانگ، کره. می توان. J. Remote Sens. 2004 ، 30 ، 123-136. [ Google Scholar ] [ CrossRef ]
- وجدا، س. Santosh، KC طبقهبندیکننده سریع K-نزدیکترین همسایه با استفاده از خوشهبندی بدون نظارت. در مجموعه مقالات ارتباطات در علوم کامپیوتر و اطلاعات، استانبول، ترکیه، 17-18 دسامبر 2017. جلد 709، ص 185–193. [ Google Scholar ]
- موهان، م. Pathan, SK; نارندراردی، ک. کاندیا، ا. پاندی، اس. پویایی شهرسازی و تأثیر آن بر کاربری زمین/پوشش زمین: مطالعه موردی کلان شهر دهلی. جی. محیط زیست. Prot. 2011 ، 2 ، 1274-1283. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سرا، پ. بیشتر، G. Pons, X. پیامدهای دقت موضوعی در غنیسازی پوشش زمین کاداستر از یک پیکسل و از منظر چندضلعی. فتوگرام مهندس Remote Sens. 2009 ، 75 ، 1441-1449. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، اچ. وانگ، سی. ژونگ، سی. ژانگ، ز. لیو، کیو. نقشه برداری LULC شهری معمولی از تصاویر Landsat بدون نمونه های آموزشی یا پارامترهای خود تعریف شده. Remote Sens. 2017 , 9 , 700. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فیست، تی. دیویدسون، ا. دانشفر، ب. رولین، پی. علی، ز. کمپبل، L. فهرست سالانه محصولات مبتنی بر فضا برای کانادا: 2009-2014. در مجموعه مقالات سمپوزیوم IEEE Geoscience and Remote Sensing 2014، شهر کبک، QC، کانادا، 13 تا 18 ژوئیه 2014. ص 5095–5098. [ Google Scholar ] [ CrossRef ]
- فودی، جنرال موتورز; ماتور، ا. سانچز-هرناندز، سی. الزامات اندازه مجموعه آموزشی Boyd، DS برای طبقه بندی یک کلاس خاص. سنسور از راه دور محیط. 2006 ، 104 ، 1-14. [ Google Scholar ] [ CrossRef ]
- لو، دی. Weng, Q. بررسی روشها و تکنیکهای طبقهبندی تصویر برای بهبود عملکرد طبقهبندی. بین المللی J. Remote Sens. 2007 , 28 , 823-870. [ Google Scholar ] [ CrossRef ]
- پایپر، جی. تغییرپذیری و تعصب در میزان خطای طبقهبندیکننده تجربی اندازهگیری شده. تشخیص الگو Lett. 1992 ، 13 ، 685-692. [ Google Scholar ] [ CrossRef ]
- حیدری، س.س. Mountrakis، G. اثر انتخاب طبقهبندیکننده، حجم نمونه مرجع، توزیع کلاس مرجع و ناهمگونی صحنه در دقت طبقهبندی در هر پیکسل با استفاده از ۲۶ سایت Landsat. سنسور از راه دور محیط. 2018 ، 204 ، 648-658. [ Google Scholar ] [ CrossRef ]
- هوانگ، سی. دیویس، LS; Townshend، JRG ارزیابی ماشینهای بردار پشتیبان برای طبقهبندی پوشش زمین. بین المللی J. Remote Sens. 2002 ، 23 ، 725-749. [ Google Scholar ] [ CrossRef ]
- رمضان، کالیفرنیا; وارنر، TA; ماکسول، AE; قیمت، تأثیرات BS اندازه مجموعه آموزشی بر طبقهبندی پوشش زمینی یادگیری ماشینی نظارت شده از دادههای سنجش از راه دور با وضوح بالا. Remote Sens. 2021 , 13 , 368. [ Google Scholar ] [ CrossRef ]
- ماکسول، AE; وارنر، TA; Fang, F. پیادهسازی طبقهبندی یادگیری ماشینی در سنجش از دور: یک بررسی کاربردی. بین المللی J. Remote Sens. 2018 , 39 , 2784–2817. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- جمالی، ع. ارزیابی و مقایسه هشت مدل یادگیری ماشین در نقشهبرداری کاربری زمین/پوشش زمین با استفاده از Landsat 8 OLI: مطالعه موردی منطقه شمال ایران. SN Appl. علمی 2019 ، 1 ، 1448. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ویشوانات، ن. رامش، ب. Sreenivasa Rao, P. طبقه بندی بدون نظارت تصاویر سنجش از دور با استفاده از الگوریتم K-Means. بین المللی J. آخرین روندها Eng. تکنولوژی 2016 ، 7 ، 548-552. [ Google Scholar ] [ CrossRef ]
- شیواکومار، BR; Rajashekararadhya، SV بررسی قابلیت نقشهبرداری پوشش زمین طبقهبندیکننده حداکثر احتمال: مطالعه موردی در کانارای شمالی، هند. Procedia Comput. علمی 2018 ، 143 ، 579-586. [ Google Scholar ] [ CrossRef ]
- مادر، پ. Tso، B. روشهای طبقهبندی برای دادههای سنجش از راه دور . CRC Press: Boca Raton، FL، USA، 2016; ISBN 9780429192029. [ Google Scholar ]
- عباس، ز. جابر، ارزیابی دقت HS روشهای طبقهبندی نظارت شده برای استخراج نقشههای کاربری اراضی با استفاده از تکنیکهای سنجش از دور و GIS. IOP Conf. سر. ماتر علمی مهندس 2020 , 745 , 012166. [ Google Scholar ] [ CrossRef ]
- دسای، سی. Umrikar، B. ابزار طبقهبندی تصویر برای تحلیل پوشش زمین کاربری: مطالعه مقایسهای روش حداکثر احتمال و حداقل فاصله. بین المللی جی. جئول. محیط زمین. علمی 2012 ، 2 ، 189-196. [ Google Scholar ]
- نگوین، کلاه؛ سوفیا، تی. Gheewala، SH; راتاناکوم، آر. آریروب، تی. Prueksakorn، K. ادغام سنجش از دور و یادگیری ماشین در پایش محیطی و ارزیابی تغییر کاربری زمین. حفظ کنید. تولید مصرف کنید. 2021 ، 27 ، 1239-1254. [ Google Scholar ] [ CrossRef ]
- جیا، ک. وی، ایکس. گو، ایکس. یائو، ی. Xie، X. Li، B. طبقهبندی پوشش زمین با استفاده از دادههای تصویرگر زمین عملیاتی Landsat 8 در پکن، چین. Geocarto Int. 2014 ، 29 ، 941-951. [ Google Scholar ] [ CrossRef ]
- Thanh Noi، P. کاپاس، ام. مقایسه طبقهبندیکنندههای جنگل تصادفی، k-نزدیکترین همسایه و ماشین بردار پشتیبان برای طبقهبندی پوشش زمین با استفاده از تصاویر Sentinel-2. سنسورها 2017 ، 18 ، 18. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- علی، م.ز. قاضی، و. Aslam, N. A مطالعه مقایسه ای تصاویر ALOS-2 PALSAR و Landsat-8 برای طبقه بندی پوشش زمین با استفاده از طبقه بندی کننده حداکثر احتمال. مصر. J. Remote Sens. Space Sci. 2018 ، 21 ، 29-35. [ Google Scholar ] [ CrossRef ]
- کلریسی، ن. والبوئنا کالدرون، کالیفرنیا؛ Posada، JM Fusion داده های Sentinel-1a و Sentinel-2A برای نقشه برداری پوشش زمین: مطالعه موردی در منطقه ماگدالنا پایین، کلمبیا. J. Maps 2017 ، 13 , 718–726. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دولت جزیره پرنس ادوارد گزارش جمعیت جزیره پرنس ادوارد 2020 ; دولت جزیره پرنس ادوارد: شارلوت تاون، PE، کانادا، 2020.
- اداره محیط زیست، E. و CA ما در حال تغییر اقلیم. در دسترس آنلاین: https://www.princeedwardisland.ca/en/information/environment-energy-and-climate-action/our-changing-climate (در 27 ژوئیه 2021 قابل دسترسی است).
- آسوکان، ع. آنیتا، جی. چیوبانو، ام. گابور، ا. نااجی، ع. Hemanth، DJ Image Processing Techniques for Analysis of Satellite Images for Historical Maps Classification-An Overview. Appl. علمی 2020 ، 10 ، 4207. [ Google Scholar ] [ CrossRef ]
- دروش، ام. دل بلو، U. کارلیر، اس. کالین، او. فرناندز، وی. گاسکون، اف. هورش، بی. ایزولا، سی. لابرینتی، پ. مارتیمورت، پی. و همکاران Sentinel-2: ماموریت نوری با وضوح بالا ESA برای خدمات عملیاتی GMES. سنسور از راه دور محیط. 2012 ، 120 ، 25-36. [ Google Scholar ] [ CrossRef ]
- روی، DP; Wulder، MA; لاولند، TR; Woodcock، CE; آلن، آر جی. اندرسون، ام سی؛ هلدر، دی. آیرونز، جی آر. جانسون، دی.م. کندی، آر. و همکاران Landsat-8: علم و چشم انداز محصول برای تحقیقات تغییرات جهانی زمینی. سنسور از راه دور محیط. 2014 ، 145 ، 154-172. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ریچاردسون، ای جی; Everitt, JH با استفاده از شاخصهای پوشش گیاهی طیفی برای تخمین بهرهوری مرتع. Geocarto Int. 1992 ، 7 ، 63-69. [ Google Scholar ] [ CrossRef ]
- Tucker، CJ Red و ترکیبات خطی مادون قرمز عکاسی برای نظارت بر پوشش گیاهی. سنسور از راه دور محیط. 1979 ، 8 ، 127-150. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژا، ی. گائو، جی. Ni, S. استفاده از شاخص ایجاد شده با تفاوت عادی در نقشه برداری خودکار مناطق شهری از تصاویر TM. بین المللی J. Remote Sens. 2003 , 24 , 583-594. [ Google Scholar ] [ CrossRef ]
- لی، اچ. وانگ، سی. ژونگ، سی. سو، آ. شیونگ، سی. وانگ، جی. لیو، جی. نقشه برداری زمین برهنه شهری به صورت خودکار از تصاویر Landsat با یک شاخص ساده. Remote Sens. 2017 , 9 , 249. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بریمن، ال. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیاو، ا. وینر، ام. طبقه بندی و رگرسیون توسط RandomForest. R News 2002 , 2 , 18-22. [ Google Scholar ]
- فیکس، ای. تجزیه و تحلیل تبعیض آمیز: تبعیض ناپارامتری، ویژگی های سازگاری . موسسه بین المللی آمار: Voorburg، هلند، 1951. [ Google Scholar ]
- پوشش، TM; هارت، PE طبقه بندی الگوی نزدیکترین همسایه. IEEE Trans. Inf. نظریه 1967 ، 13 ، 21-27. [ Google Scholar ] [ CrossRef ]
- Karegowda، AG; Jayaram، MA; Manjunath، AS Cascading K-Means Clustering و K-Nearest Neighbor Classifier برای طبقه بندی بیماران دیابتی. بین المللی J. Eng. Adv. تکنولوژی 2012 ، 1 ، 147-151. [ Google Scholar ]
- ناراسیمهلو، ی. سوتر، ا. پاسونوری، ر. China Venkaiah، V. Ckd-Tree: An Improved Kd-Tree Construction الگوریتم. CEUR Workshop Proc. 2021 ، 2786 ، 211-218. [ Google Scholar ]
- دولتشاه، م. هادیان، ع. مینایی-بیدگلی، ب. توپ*-درخت: نمایه سازی فضایی کارآمد برای جستجوی محدود نزدیکترین همسایه در فضاهای متریک. arXiv 2015 ، arXiv:1511.00628. [ Google Scholar ]
- داستان، م. کنگالتون، سنجش از دور RG ارزیابی مختصر دقت: دیدگاه کاربر. فتوگرام مهندس Remote Sens. 1986 ، 52 , 397-399. [ Google Scholar ]
- مکهو، درسهای امال در آمار زیستی قابلیت اعتماد بینسنجی: آمار کاپا. بیوشیمی. پزشکی 2012 ، 22 ، 276-282. [ Google Scholar ] [ CrossRef ]
- چن، دی. استو، دی. گونگ، پی. بررسی اثر تفکیک فضایی و اندازه پنجره بافت بر دقت طبقهبندی: یک مورد محیط شهری. بین المللی J. Remote Sens. 2004 ، 25 ، 2177-2192. [ Google Scholar ] [ CrossRef ]
- رائو، پی. ژو، دبلیو. بهاتارای، ن. سریواستاوا، AK; سینگ، بی. پونیا، اس. لوبل، دی بی؛ Jain، M. استفاده از Sentinel-1، Sentinel-2، و تصاویر سیاره برای نقشه برداری از نوع محصول مزارع کوچک. Remote Sens. 2021 ، 13 ، 1870. [ Google Scholar ] [ CrossRef ]
- نگوین، HTT؛ Doan، TM; تومپو، ای. McRoberts، RE استفاده از زمین/نقشهبرداری پوشش زمین با استفاده از تصاویر چندزمانی Sentinel-2 و چهار روش طبقهبندی – مطالعه موردی از Dak Nong، ویتنام. Remote Sens. 2020 , 12 , 1367. [ Google Scholar ] [ CrossRef ]
- لو، بی. Kulkarni، A. تجزیه و تحلیل تصویر چندطیفی با استفاده از جنگل تصادفی. بین المللی J. Soft Comput. 2015 ، 6 ، 1-14. [ Google Scholar ] [ CrossRef ]
- فرانکو لوپز، اچ. Ek، AR; تخمین بائر، ME و نقشه برداری از تراکم، حجم و نوع پوشش جنگلی با استفاده از روش k-نزدیکترین همسایگان. سنسور از راه دور محیط. 2001 ، 77 ، 251-274. [ Google Scholar ] [ CrossRef ]
- سالوآرا، کی جی. تسلر، اس. مالک، RN; Tuomisto، H. طبقهبندی پوشش گیاهی جنگلهای بارانی اولیه آمازون با استفاده از تصاویر ماهوارهای Landsat ETM+. سنسور از راه دور محیط. 2005 ، 97 ، 39-51. [ Google Scholar ] [ CrossRef ]
- اولوفسون، پی. فودی، جنرال موتورز; هرولد، ام. Stehman، SV; Woodcock، CE; Wulder، MA اقدامات خوب برای تخمین مساحت و ارزیابی دقت تغییر زمین. سنسور از راه دور محیط. 2014 ، 148 ، 42-57. [ Google Scholar ] [ CrossRef ]
- Chaves، MED; پیکولی، MCA؛ Sanches، ID آخرین کاربردهای Landsat 8/OLI و Sentinel-2/MSI برای استفاده از زمین و نقشه برداری پوشش زمین: یک بررسی سیستماتیک. Remote Sens. 2020 , 12 , 3062. [ Google Scholar ] [ CrossRef ]



بدون دیدگاه