

کلید واژه ها:
توصیه POI بعدی ؛ شبکه عصبی مکرر ؛ LSTM ; مکانیسم توجه ؛ شبکه های اجتماعی مبتنی بر مکان
1. مقدمه
-
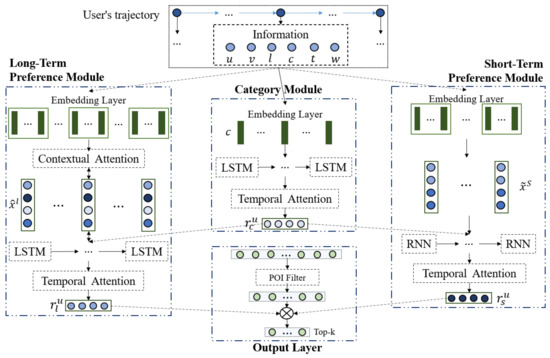
ما به ترتیب ترجیحات بلندمدت و کوتاه مدت کاربر را تجزیه و تحلیل می کنیم و آنها را ترکیب می کنیم تا اولویت کاربر نهایی را تشکیل دهیم. یک لیست پیشنهادی POIهای k بالا بر اساس احتمال دسترسی به POI بعدی محاسبه شده توسط تنظیمات برگزیده کاربر و همه POIهای نامزد از طریق فیلتر POI که ما طراحی کرده ایم، ایجاد می شود.
-
ما از یک مکانیسم توجه چند سطحی برای مطالعه نمایش دینامیک چند عاملی رفتار ورود کاربر و وابستگی غیرخطی بین ورودها در مسیر ورود آنها استفاده میکنیم. این میتواند وزن ویژگیهای مختلف را در هر ورود کاربر و تأثیر ورود در مراحل زمانی مختلف در بررسی POI بعدی را بیاموزد.
-
ما ترجیحات انتقال دسته کاربر را در سطح معنایی مطالعه میکنیم تا با استفاده از ماژول دستهبندی که ساختیم، نمایش ورود کاربر را ایجاد کنیم. علاوه بر این، تناوب ورود کاربر را در نظر می گیریم و الگوی ترتیبی کاربر را بر اساس اطلاعات زمینه مکانی-زمانی استخراج می کنیم. هر دوی اینها شکل گیری ترجیحات کاربر را تا حد زیادی ترویج می کنند و توصیه عملکرد را افزایش می دهند.
2. کارهای مرتبط
2.1. توصیه POI
2.2. توصیه POI بعدی
3. مقدمات
3.1. مشاهدات مسیر کاربر
-
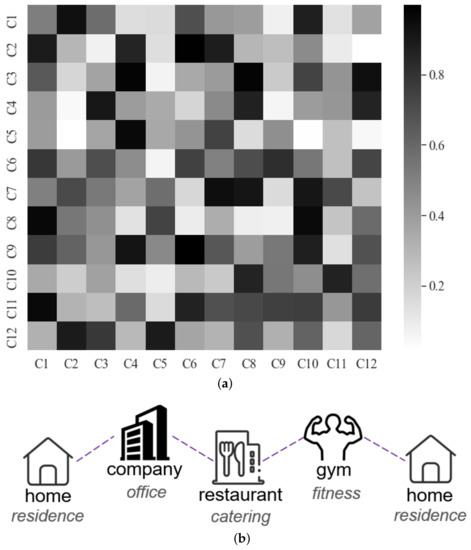
Obs.1: (ترجیح انتقال دسته.) در سطح معنایی، رفتار ورود کاربر دارای یک همبستگی طبقه بندی است. شکل 2a احتمال انتقال دسته بندی ورود کاربران در مجموعه داده شارلوت را نشان می دهد. ارتباط بین اعلام حضورهای کاربر در طول زمان تغییر می کند و متوالی است. متفاوت از سایر مطالعات با استفاده از یک دسته به عنوان یکی از ویژگی های ورود به یک توصیه POI، ما یک ماژول دسته بندی از مدل پیشنهادی ایجاد می کنیم تا مسیر دسته بندی کاربر را در نظر بگیریم و ترجیحات انتقال دسته کاربر را در سطح دسته بندی درشت مطالعه کنیم. . ماژول بر ترجیح کاربر برای یک POI خاص تأثیر می گذارد. علاوه بر این، صدها برچسب دستهبندی POI در مجموعه دادهها وجود دارد که فضای پیشبینی را بسیار بزرگ میکند و برای کمک به پیشبینی POI خاص بررسی ورود مناسب نیست. بنابراین، با الهام از [ 27]، دوازده دسته درشت دانه را بر اساس دسته بندی های موجود خلاصه می کنیم. توجه داشته باشید که وابستگی هر کاربر به اولویت انتقال دسته متفاوت است. به عنوان مثال، کاربر در شکل 2 b از “محل اقامت” به “دفتر” می رود و بالعکس.
-
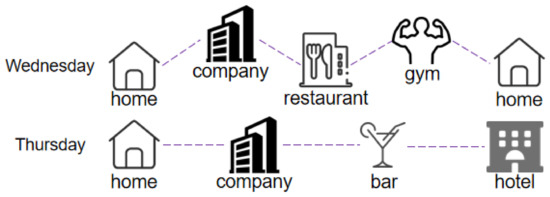
Obs.2: (ترجیح دورهای.) کاربر ممکن است یک الگوی ثابت تلفن همراه در روزهای هفته و یک الگوی دیگر ورود به آخر هفته (شنبه و یکشنبه) داشته باشد. با این حال، به جز تمایز الگوی ورود کاربر تقریباً در روزهای کاری و آخر هفته برای تجزیه و تحلیل ترجیحات دورهای کاربر، رفتار ورود کاربر یک الگوی تغییر نسبتاً واضح در هر روز از هفته در زندگی واقعی خواهد داشت. همانطور که در شکل 3 نشان داده شده استبه عنوان مثال، یک کاربر دوست دارد چهارشنبه بعد از رستوران از سالن بدنسازی بازدید کند و پنجشنبه قبل از بار از شرکت بازدید کند. مطالعه تناوب حرکت ورود کاربر در روزهای هفته و آخر هفته مناسب نیست، بنابراین اطلاعات مکانی-زمانی ورود را تجزیه و تحلیل می کنیم و الگوی ورود دوره ای کاربران را برای هر روز هفته مطالعه می کنیم.
3.2. بیان مسأله
4. روش پیشنهادی
4.1. ماژول دسته
ما ترجیحات انتقال دسته کاربر را یاد می گیریم rcuاز دنباله دسته Cu=Ct1u,Ct2u,⋯,CtNu، جایی که هر عنصر از Cuبه عنوان مشخص می شود Ctku=u,cv. این نشان می دهد که کاربر u یک POI v از دسته بازدید می کندcvدر زمان tk. بردار نهفته ماژول دسته به صورت زیر تعریف می شود.
جایی که WC∈Rd×dماتریس وزن است، d بعد بردار پنهان است، bC∈Rdتعصب است و cv∈RDcبردار تعبیه شده از دسته POI را نشان می دهد cv. سپس، xtkcبرای پی بردن به حالت پنهان به شبکه LSTM وارد می شود htkcکاربر u در زمان tk.
جایی که LSTM·ارتباط متوالی مقوله ها را به تصویر می کشد و htk−1cدسته ورود تا را نشان می دهد tk−1. توجه داشته باشید که ما آخرین بردار پنهان را درمان می کنیم htNجبه عنوان نمایش اولویت انتقال دسته کاربر u .
4.2. ماژول اولویت بلند مدت
4.2.1. ورودی شبکه
توالی ورود به تاریخ کاربر u شامل تمام اعلام حضورهای آنها است. هر ورود شش تایی است Atku=u،vتیکتو،لv،جv،تیک،wتیک، که نشان دهنده ترجیح طولانی مدت کاربر برای دسترسی به POI است، بنابراین ما از آن برای یادگیری ترجیحات کاربر در سطح POI استفاده می کنیم. از آنجا که ورود کاربر معمولاً تحت تأثیر فاصله بین مکان فعلی و مکان بعدی و همچنین تفاوت زمانی بین آخرین ورود و ورود فعلی، لایه جاسازی ماژول ترجیحی طولانی مدت است. باید بر اساس مکان و زمان ورود، تأثیر اطلاعات زمینهای مکانی-زمانی را بر ورود بررسی کند. مدلسازی فعالیتهای ورود مداوم همراه با روز هفته، برای مطالعه منظم بودن ورود کاربر مفیدتر است. در نتیجه، بردار نهفته لایه جاسازی ماژول ترجیح بلند مدت به صورت زیر تعریف می شود:
جایی که دبلیوماتریس وزن است، باصطلاح تعصب است، vتیکتو∈آرDvتعبیه شماره POI است، لv∈آرDلجاسازی مکان POI است، تیک∈آرDتیتعبیه مُهر زمان دسترسی است، wتیک∈آرDwتعبیه شدن است wتیک، دتیک∈آرDدبر اساس فاصله تعبیه می شود دتیکبین لتیکتوو لتیک-1تواز vتیکتوو vتیک-1تو، و tdتیک∈آرDتیدبر اساس اختلاف زمانی تعبیه می شود تیدتیکبین تیکو تیک-1از vتیکتوو vتیک-1تو.
ما استفاده می کنیم ایکس˜من،تیکبرای نشان دادن ویژگی i -امین تاریخچه ورود به سیستم. مثلا، ایکس˜1،تی2نشان دهنده اطلاعات شماره POI کاربر u در دومین ورود و ρمن،تیکوزن صفت i- th را در k -th check-in نشان می دهد و تابع softmax برای عادی سازی استفاده می شود.
جایی که من تعداد صفات است، دبلیومن∈آرد×2د، دبلیومنایکس˜∈آرد×د، بمن∈آردپارامترهایی هستند که باید یاد بگیرند، و جتیک-1لوضعیت سلولی شبکه LSTM در آن زمان است تیک-1. سپس، ایکس˜من،تیکضرب می شود ρمن،تیکبرای به دست آوردن نمایش دینامیکی چند عاملی ورود به زمان تیکتحت مکانیسم توجه متنی، و سپس بردار تعبیه ویژگی به روز شده برای به دست آوردن تجمع متصل می شود ایکس^تیکللایه جاسازی بر اساس مکانیسم توجه متنی.
جایی که دبلیومن∈آرد×دپارامتر وزنی است که باید یاد بگیریم مربوط به صفت i -ام و ب∈آردبردار سوگیری برای یادگیری است.
برای در نظر گرفتن اولویت انتقال کاربر در سطح معنایی، ترجیح دسته کاربر را بر اساس لایه تعبیه شده بر اساس توجه زمینه اضافه می کنیم و بیان رفتار ورود طولانی مدت کاربر نهایی را همانطور که در زیر نشان داده شده است به دست می آوریم.
جایی که λجل∈آرد×دوزن اولویت انتقال دسته کاربر u در نمایش ورود فعلی ماژول ترجیحی طولانی مدت است، و ایکستیکلبردار پتانسیل نهایی ارسال شده به شبکه LSTM برای استنتاج وضعیت پنهان در آن است تیک.
4.2.2. توجه زمانی
اجازه دهید اچل∈آرد×نماتریسی متشکل از تمام بردارهای پنهان باشد ساعتتی1ل،ساعتتی2ل،⋯،ساعتتینلاز ماژول اولویت بلند مدت، که در آن N طول توالی ثبت ورود تاریخی است. بردار وزن μلورود تاریخی از طریق مکانیسم توجه زمانی ایجاد میشود و درجه تأثیر k -امین ورود تاریخی در ورود بعدی با وزن اندازهگیری میشود. μکلمربوط به هر کدام ساعتتیکل.
تابع توجه gساعتتیکل،qتولبه شرح زیر است.
جایی که qulاطلاعات پرس و جو از توالی ورود طولانی مدت در مکانیسم توجه زمانی است، یعنی POI که کاربر بعداً آن را بررسی می کند. توجه محصول نقطه ای به عنوان تابع توجه استفاده می شود، زیرا d کوچک است و توجه محصول نقطه ای برتر از توجه افزودنی است. نمایش تعبیهشده پرس و جو «بررسی POI بعدی» برای همه ورودهای تاریخی به دست میآید. سپس بردار وزن حاصل را ضرب کنید μlتوسط Hlبرای به دست آوردن نمایش ترجیحی کاربر در دراز مدت.
4.3. ماژول اولویت کوتاه مدت
همانند مدل بلندمدت، هفت ویژگی چک-این از تاپل فعالیت چک کردن استخراج میشوند Atmu=u,vtmu,lv,fv,tm,wtmویژگیهای کوتاهمدت بهعنوان ویژگیهای ورود کاربر که باید در ماژول اولویت کوتاهمدت یاد بگیرند. بردار پنهان لایه جاسازی ماژول اولویت کوتاه مدت به صورت زیر تعریف می شود:
جایی که WSماتریس وزن است و bSاصطلاح تعصب است.
به طور مشابه، اولویت انتقال دسته کاربران نیز در ماژول اولویت کوتاهمدت این مطالعه در نظر گرفته میشود، بنابراین تجمع یادگیری ترجیحی کوتاهمدت به صورت زیر تعریف میشود:
جایی که λجس∈آرد×دوزن اولویت انتقال دسته کاربر u در نمایش ورود فعلی ماژول اولویت کوتاه مدت است. ایکستیمترسRNN را به عنوان یک بردار بالقوه برای ورود کاربر برای کوتاه مدت وارد می کند.
اجازه دهید اچس∈آرد×نماتریسی متشکل از تمام بردارهای پنهان باشد ساعتتی1س،⋯،ساعتتیمترس،⋯،ساعتتیاسساز ماژول اولویت کوتاه مدت، که در آن S طول توالی ورود کوتاه مدت است. بردار وزن μسورود کوتاهمدت از طریق مکانیسم توجه زمانی ماژول اولویت کوتاهمدت ایجاد میشود، و درجه تأثیر m- امین ورود کوتاهمدت در ورود بعدی با وزن اندازهگیری میشود. μمترسمربوط به هر کدام ساعتتیمترس.
جایی که qتوساطلاعات پرس و جو مکانیسم توجه زمانی است، یعنی نمایش تعبیه شده پرس و جو “بررسی POI بعدی” برای همه بررسی های کوتاه مدت. سپس آن بردار وزن را ضرب می کنیم μسبار اچسبرای به دست آوردن نمایش اولویت کوتاه مدت برای کاربر u .
4.4. لایه خروجی
4.4.1. فیلتر POI
4.4.2. Top-k POIs را توصیه کنید
به منظور مطالعه جامع و پویا ترجیحات کاربر، از ترکیب وزنی ترجیحات بلندمدت کاربر به دست آمده توسط ماژول اولویت بلند مدت و اولویت کوتاه مدت آنها به دست آمده توسط ماژول اولویت کوتاه مدت برای محاسبه ترجیح کاربر نهایی استفاده می کنیم. .
جایی که αو βوزنه هایی برای یادگیری هستند احتمال دسترسی به POI بعدی که توسط تابع softmax عادی شده است به صورت زیر تعریف می شود:
جایی که vکیک نمایش تعبیه شده از POI نامزد است vکو P تعداد کل POIهای نامزد عبور از یک فیلتر است. سپس، میتوانیم احتمال بازدید بعدی همه POIهای نامزد در لایه خروجی و فهرست POI رتبهبندی شده را بدست آوریم و POIهای k بالا را برای کاربر u توصیه کنیم (الگوریتم 1).
| الگوریتم 1 آموزش LSMA |
| ورودی: مجموعه کاربر U ، توالیهای ورود تاریخی تنظیم شده است آU، منتیهr-مترآایکس، مجموعه پارامترها Θ خروجی: مدل LSMA آرتو
|
4.5. آموزش شبکه
تابع از دست دادن ماژول دسته عبارت است از:
جایی که ج”دسته منفی c است، Ωجمثال آموزشی متشکل از u , c , ج”در ماژول دسته، oتیجاحتمال پیش بینی شده بازدید کاربر از POI دسته c در زمان t و oتیج”احتمال پیش بینی شده بازدید کاربر از POI دسته است ج”در زمان t .
تابع ضرر ماژول ترجیحی بلند مدت به صورت زیر است:
جایی که v”یک نمونه منفی از v در ماژول ترجیح بلند مدت است و Ωلمثال آموزشی متشکل از u , v , v”.
تابع ضرر ماژول اولویت کوتاه مدت:
جایی که vس”نمونه منفی است vسدر ماژول اولویت کوتاه مدت، و Ωسنمونه آموزشی متشکل از شما است، vس، vس”.
به طور خلاصه، ما تابع ضرر کل را با ادغام توابع ضرر و شرایط تنظیم سه ماژول طراحی می کنیم که به صورت زیر نشان داده شده است:
جایی که εضریب منظم شدن است و Θ=دبلیوسی،بسی،دبلیو،ب،دبلیواس،باس،μمجموعه ای از پارامترهای مدل برای یادگیری است. AdaGrad در وظایف یادگیری در مقیاس بزرگ استفاده شده است. بنابراین، AdaGrad برای بهینه سازی پارامترهای شبکه به کار گرفته شد.
4.6. تحلیل پیچیدگی
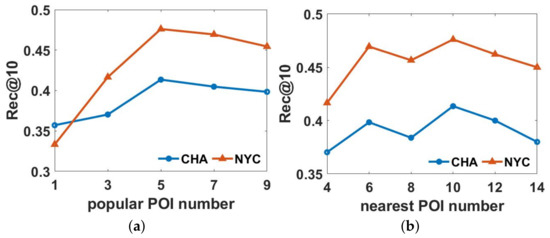
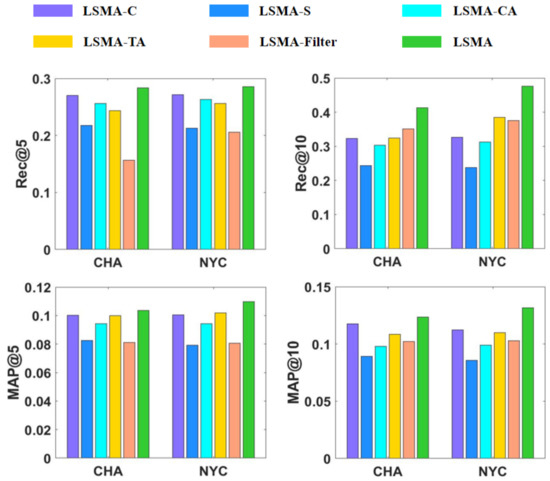
5. آزمایشات
5.1. مجموعه داده ها
5.2. روش های مقایسه
-
PMF [ 12 ]: یک الگوریتم توصیه طراحی شده بر اساس تجزیه ماتریس احتمال مرسوم در ماتریس کاربر-POI.
-
ST-RNN [ 7 ]: الگوریتم پیشنهادی POI بعدی مبتنی بر RNN، که اطلاعات مکانی-زمانی را در بردار پنهان ادغام می کند.
-
Time-LSTM [ 16 ]: LSTM را به یک گیت زمانی مجهز می کند تا اقدامات مستمر کاربر را مدل سازی کند تا POI ورود بعدی را پیش بینی کند.
-
ATST-LSTM [ 19 ]: مکانیزم توجه را بر اساس شبکه LSTM اضافه می کند و به طور جامع اطلاعات زمینه ای مکانی-زمانی را برای بهبود اثربخشی پیش بینی POI بعدی در نظر می گیرد.
-
LSPL [ 25 ]: ترجیحات بلند مدت و کوتاه مدت کاربران را با در نظر گرفتن اطلاعات متوالی و موقعیت جغرافیایی و دسته بندی POI یاد می گیرد.
-
iMTL [ 17 ]: یک چارچوب یادگیری چند وظیفه ای تعاملی جدید متشکل از یک رمزگذار فعالیت آگاه از زمان، رمزگذار اولویت موقعیت آگاه از فضای و رمزگشای ویژه کار، که عمدتاً توصیه POI بعدی را در شرایط نامشخص بررسی می کند.
-
RTPM [ 26 ]: ترجیحات بلند مدت و کوتاه مدت را ترکیب می کند و منافع عمومی را به اولویت کوتاه مدت معرفی می کند تا علاقه زمان واقعی کاربر را مطالعه کند.
5.3. معیارهای ارزیابی
تمام روشهای مورد بحث در این مطالعه، حاصل ضرب نقطهای بین نمایش کاربر و نمایش POI را محاسبه میکنند تا احتمال دسترسی کاربر به POI در دفعات بعدی را به دست آورند. در واقع، تفاوت هر روش در مدلسازی متفاوت بازنمایی کاربر نهفته است. برای نشان دادن اثربخشی روش ها، نرخ فراخوان ( آرهج@ک) و میانگین دقت متوسط ( مآپ@ک) به شرح زیر تعریف شد:
جایی که Pukمجموعه ای از k POI های توصیه شده به کاربر u را نشان می دهد . Vuمجموعه POI را نشان می دهد که کاربر در دفعه بعد در مجموعه آزمایشی واقعاً به آن دسترسی پیدا می کند mapنشان دهنده رتبه بندی است Puk∩Vuکه در Puk. توجه داشته باشید که برای جلوگیری از خطای تقسیم، مشخص می کنیم 1map=0چه زمانی Puk∩Vu=ϕ.
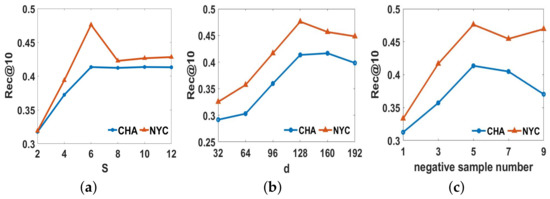
5.4. تنظیم پارامتر
5.5. نتایج و تجزیه و تحلیل
6. نتیجه گیری
منابع
- شی، م. شن، دی. کو، ی. نی، تی. Yu, G. توصیه بعدی مورد علاقه توسط استخراج متوالی ویژگی و آگاهی از ترجیحات عمومی. جی. اینتل. سیستم فازی 2021 ، 40 ، 4075-4090. [ Google Scholar ] [ CrossRef ]
- جیائو، دبلیو. فن، اچ. Midtbø، T. یک رویکرد مبتنی بر شبکه برای اندازهگیری شباهتهای مسیرهای تاکسی. Sensors 2020 , 20 , 3118. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- سرکار، جی ال. ماجومدر، ا. پانی گراهی، CR; Roy, S. MULTITOUR: موتور توصیه گردشگران چندگانه. الکترون. بازرگانی Res. Appl. 2020 , 40 , 100943. [ Google Scholar ] [ CrossRef ]
- رندل، اس. فرودنتالر، سی. Schmidt-Thieme، L. فاکتورسازی زنجیره های مارکوف شخصی شده برای توصیه سبد بعدی. در مجموعه مقالات نوزدهمین کنفرانس بین المللی وب جهانی، WWW 2010، رالی، NC، ایالات متحده، 26-30 آوریل 2010; صص 811-820. [ Google Scholar ]
- ژان، جی. خو، جی. هوانگ، ز. ژانگ، Q. خو، ام. ژنگ، ن. یک مدل LSTM مبتنی بر همبستگی ترتیبی معنایی برای توصیه POI بعدی. در مجموعه مقالات بیستمین کنفرانس بین المللی IEEE در مورد مدیریت داده های تلفن همراه، MDM 2019، هنگ کنگ، چین، 10 تا 13 ژوئن 2019؛ صص 128-137. [ Google Scholar ]
- چانگ، بی. جانگ، جی. کیم، اس. کانگ، جی. نمایش نهفته جغرافیایی مبتنی بر نمودار یادگیری برای توصیه نقطه مورد علاقه. در مجموعه مقالات CIKM ’20: بیست و نهمین کنفرانس بین المللی ACM در مدیریت اطلاعات و دانش، رویداد مجازی، ایرلند، 19 تا 23 اکتبر 2020؛ صص 135-144. [ Google Scholar ]
- لیو، کیو. وو، اس. وانگ، ال. Tan, T. پیشبینی مکان بعدی: یک مدل تکرارشونده با زمینههای مکانی و زمانی. در مجموعه مقالات سی امین کنفرانس AAAI در مورد هوش مصنوعی، فینیکس، AZ، ایالات متحده آمریکا، 12 تا 17 فوریه 2016; صص 194–200. [ Google Scholar ]
- سان، ک. کیان، تی. چن، تی. لیانگ، ی. نگوین، QVH؛ یین، اچ. کجا برویم بعدی: مدلسازی ترجیحات بلندمدت و کوتاهمدت کاربر برای توصیههای نقطهنظر. در مجموعه مقالات سی و چهارمین کنفرانس AAAI در مورد هوش مصنوعی، AAAI 2020، نیویورک، نیویورک، ایالات متحده آمریکا، 7 تا 12 فوریه 2020؛ صص 214-221. [ Google Scholar ]
- وانگ، ک. وانگ، ایکس. روش توصیه Lu, X. POI با استفاده از LSTM-attention در LBSN با در نظر گرفتن حفاظت از حریم خصوصی. هوش پیچیده سیستم 2021 ، 1-12. [ Google Scholar ] [ CrossRef ]
- ژانگ، دبلیو. وانگ، جی. بازیابی مشارکتی اجتماعی آگاه از مکان و زمان برای توصیههای جدید پی در پی نقطهای از علاقه. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی ACM در مورد مدیریت اطلاعات و دانش، ملبورن، استرالیا، 18 تا 23 اکتبر 2015. ص 1221-1230. [ Google Scholar ]
- Xu، YN; خو، ال. هوانگ، ال. وانگ، سی دی اجتماعی و فیلتر مشارکتی مبتنی بر محتوا برای توصیههای مورد علاقه. در مجموعه مقالات کنفرانس بین المللی پردازش اطلاعات عصبی، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 دسامبر 2017. صص 46-56. [ Google Scholar ]
- واسوانی، ع. Shazeer, N. پارمار، ن. Uszkoreit، J. جونز، ال. گومز، AN; قیصر، ال. Polosukhin، I. توجه شما تمام چیزی است که نیاز دارید. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی 30: کنفرانس سالانه سیستمهای پردازش اطلاعات عصبی 2017، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 دسامبر 2017. صفحات 5998-6008. [ Google Scholar ]
- دوطلب، م. Alesheikh, AA یک رویکرد توصیه POI که اطلاعات مکانی-زمانی اجتماعی را در فاکتورسازی ماتریس احتمالی ادغام می کند. بدانید. Inf. سیستم 2021 ، 63 ، 65-85. [ Google Scholar ] [ CrossRef ]
- Lv، Q. کیائو، ی. انصاری، ن. لیو، جی. یانگ، جی. مدل مارکوف پنهان مبتنی بر داده های بزرگ بر اساس پیش بینی تحرک فردی در نقاط مورد علاقه. IEEE Trans. وه تکنولوژی 2017 ، 66 ، 5204-5216. [ Google Scholar ] [ CrossRef ]
- چنگ، سی. یانگ، اچ. لیو، ام آر؛ King, I. جایی که دوست دارید در مرحله بعد بروید: توصیه نقطه مورد علاقه پی در پی. در مجموعه مقالات بیست و سومین کنفرانس مشترک بین المللی هوش مصنوعی، پکن، چین، 3 تا 9 اوت 2013. صص 2605-2611. [ Google Scholar ]
- زو، ی. لی، اچ. لیائو، ی. وانگ، بی. گوان، ز. لیو، اچ. Cai, D. بعدی چه باید کرد: مدلسازی رفتارهای کاربر توسط Time-LSTM. در مجموعه مقالات بیست و ششمین کنفرانس مشترک بین المللی هوش مصنوعی، IJCAI 2017، ملبورن، استرالیا، 19 تا 25 اوت 2017؛ صص 3602–3608. [ Google Scholar ]
- ژانگ، ال. سان، ز. ژانگ، جی. لی، ی. لی، سی. وو، زی. کلودن، اچ. Klanner، F. یک چارچوب یادگیری چند وظیفه ای تعاملی برای توصیه های بعدی POI با ورود نامشخص. در مجموعه مقالات بیست و نهمین کنفرانس مشترک بین المللی هوش مصنوعی، یوکوهاما، ژاپن، 7 تا 15 ژانویه 2020؛ صص 3551–3557. [ Google Scholar ]
- ژانگ، ی. دای، اچ. خو، سی. فنگ، جی. وانگ، تی. بیان، جی. وانگ، بی. لیو، تی. پیشبینی کلیک متوالی برای جستجوی حمایت شده با شبکههای عصبی مکرر. در مجموعه مقالات بیست و هشتمین کنفرانس AAAI در مورد هوش مصنوعی، شهر کبک، QC، کانادا، 27-31 ژوئیه 2014. صص 1369–1375. [ Google Scholar ]
- هوانگ، ال. ممکن است.؛ وانگ، اس. Liu, Y. یک شبکه LSTM فضایی-زمانی مبتنی بر توجه برای توصیه POI بعدی. IEEE Trans. خدمت محاسبه کنید. 2019 ، 14 ، 1585-1597. [ Google Scholar ] [ CrossRef ]
- ژنگ، سی. تائو، دی. وانگ، جی. کوی، ال. روآن، دبلیو. یو، اس. حافظه شبکه توجه سلسله مراتبی را برای توصیه های بعدی مورد توجه قرار داد. IEEE Trans. محاسبه کنید. Soc. سیستم 2021 ، 8 ، 489-499. [ Google Scholar ] [ CrossRef ]
- لیو، ی. پی، ا. وانگ، اف. یانگ، ی. ژانگ، ایکس. وانگ، اچ. دای، اچ. چی، ال. Ma, R. یک مدل GRU مبتنی بر طبقه بندی آگاه برای توصیه POI بعدی. بین المللی جی. اینتل. سیستم 2021 ، 36 ، 3174-3189. [ Google Scholar ] [ CrossRef ]
- شیا، تی. چی، ی. فنگ، جی. خو، اف. سان، اف. گوو، دی. Li, Y. AttnMove: تاریخ بهبود مسیر از طریق شبکه توجه. در مجموعه مقالات سی و پنجمین کنفرانس AAAI در مورد هوش مصنوعی، پالو آلتو، کالیفرنیا، ایالات متحده آمریکا، 2 تا 9 فوریه 2021؛ صفحات 4494-4502. [ Google Scholar ]
- فنگ، جی. لی، ی. ژانگ، سی. سان، اف. منگ، اف. گوا، ا. Jin, D. DeepMove: پیش بینی تحرک انسان با شبکه های تکراری توجه. در مجموعه مقالات کنفرانس وب جهانی 2018 در وب جهانی، WWW 2018، لیون، فرانسه، 23 تا 27 آوریل 2018؛ ص 1459–1468. [ Google Scholar ]
- جاناخ، دی. لرچه، ال. Jugovac, M. انطباق و ارزیابی توصیه ها برای اهداف خرید کوتاه مدت. در مجموعه مقالات نهمین کنفرانس ACM در مورد سیستم های توصیه کننده، RecSys 2015، وین، اتریش، 16-20 سپتامبر 2015. ص 211-218. [ Google Scholar ]
- وو، ی. لی، ک. ژائو، جی. Qian، X. یادگیری ترجیحی بلند مدت و کوتاه مدت برای توصیه POI بعدی. در مجموعه مقالات بیست و هشتمین کنفرانس بین المللی ACM در مدیریت اطلاعات و دانش، پکن، چین، 3 تا 7 نوامبر 2019؛ صص 2301–2304. [ Google Scholar ]
- لیو، ایکس. یانگ، ی. خو، ی. یانگ، اف. هوانگ، Q. Wang, H. توصیه POI در زمان واقعی از طریق مدلسازی اولویتهای کاربر درازمدت و کوتاهمدت. محاسبات عصبی 2022 ، 467 ، 454-464 . [ Google Scholar ] [ CrossRef ]
- بله، جی. زو، ز. چنگ، اچ. حرکت بعدی شما چیست: پیشبینی فعالیت کاربر در شبکههای اجتماعی مبتنی بر مکان. در مجموعه مقالات کنفرانس بین المللی SIAM 2013 در مورد داده کاوی، فیلادلفیا، PA، ایالات متحده، 6 تا 13 اکتبر 2013. صص 171-179. [ Google Scholar ]
- رندل، اس. فرودنتالر، سی. گانتنر، ز. اشمیت-تیمه، L. BPR: رتبه بندی شخصی بیزی از بازخورد ضمنی. arXiv 2012 ، arXiv:1205.2618. [ Google Scholar ]
- یانگ، دی. ژانگ، دی. ژنگ، فولکس واگن؛ Yu, Z. مدلسازی اولویت فعالیت کاربر با اعمال نفوذ ویژگیهای زمانی مکانی کاربر در LBSN. IEEE Trans. سیستم مرد، سایبرن. سیستم 2015 ، 45 ، 129-142. [ Google Scholar ] [ CrossRef ]



بدون دیدگاه