

چکیده
زیرساخت ها نقش مهمی در شهرنشینی و فعالیت های اقتصادی دارند اما آسیب پذیر هستند. به دلیل در دسترس نبودن نقشههای زیرساخت زیرسطحی دقیق، اطمینان از پایداری و انعطافپذیری اغلب ضعیف تشخیص داده میشود. در مقاله حاضر یک مدل پیشبینی توپوگرافی سهبعدی با استفاده از دادههای جغرافیایی توزیعشده همراه با برنامهریزی بیان ژن تکاملی ( GEP ) توسعه داده شد و بر روی یک سد سنگی سطحی بتنی ( CFRD ) در استان گیلان-شمال برای ایجاد تنوع فضایی توپوگرافی سنگ بستر زیرسطحی استفاده شد. . مقایسه مهارت مدل GEP با کریجینگ معمولی زمین آماری ( OK) با استفاده از شاخص های تحلیلی مختلف، عملکرد دقت 82.53 درصد و بهبود 9.61 درصد در داده های دقیقاً برچسب گذاری شده را نشان داد. دستاوردها حاکی از آن است که مدل GEP بازیابی شده به طور موثر می تواند پیش بینی دقیق کافی را ارائه دهد و در نتیجه بینش تجسم مرتبط با نگرانی های طبیعی و مهندسی را بهبود بخشد. بر این اساس، مدل سنگ بستر زیرسطحی تولید شده اطلاعات زیادی را در مورد پایداری سازهها و ویژگیهای هیدروژئولوژیکی اختصاص میدهد، بنابراین پایههای مناسب را اتخاذ میکند.
کلید واژه ها:
GEP _ مدل پیش بینی ; جغرافیایی ; زمین آماری ; زیر سطحی ; توپوگرافی ; سنگ بستر ; ایران
1. مقدمه
افزایش دسترسی به دادههای مکانی بهموقع و مستند منجر به استفاده از روشهای داده کاوی پیشبینیکننده متنوع [ 1 ] برای رسیدگی به مشکلات استخراجشده دانش از طریق پارادایمهای پردازش اطلاعات معقولتر میشود [ 2 ، 3 ، 4 ]. در سالهای اخیر، مدلهای مبتنی بر سنجش از دور زمینفضایی پیشبینیکننده در ترکیب با دادههای بررسیشده میدانی از طریق پلتفرم GIS برای تفسیر انواع مختلف ژئواشیاء علاقهمند استفاده شده است [ 5 ، 6 ، 7 ، 8 ، 9 ]. علیرغم ایرادات GIS در ابزارهای مدلسازی پارامتریک [10 ، 11 ]، ادغام آن با رویکردهای هوشی نوآورانه، میزان موفقیت قابل توجهی را در یک سری از پدیده های محیطی نوظهور در سطح زمین نشان داده است [ 12 ، 13 ، 14 ، 15 ، 16 ]. با این حال، توسعه چنین مدلهایی از طریق منابع جغرافیایی برای تحقیقات زیرسطحی به دلیل دادههای محدود، نیازمند ابزارهای درونیابی اکتشافی است و پیچیدگی اشیاء جغرافیایی پیشبینیشده یک کار دشوار و دستوپاگیر است [ 17 ، 18 ].
در فرآیند نقشه برداری زیرسطحی زیرساخت هایی مانند سدها، تحلیل داده های مکانی موضوعی و بررسی شده به دلیل پیچیدگی در هر دو فاز طراحی و ساخت نقش اساسی دارد. دادههای زمینفضایی سطحی منجر به یافتن بهترین مکانهای سایت با حداقل تأثیرات بر مناطق مجاور میشود [ 19 ، 20 ]، در حالی که زمینفضایی زیرسطحی بینش بیشتری در مورد فرآیند ساخت و ساز و عناصر ساختاری مورد نیاز برای ایمنی بیشتر ارائه میدهد. این امر حاکی از اهمیت زیادی از تجزیه و تحلیل های مکانی در هر دو روی / زیر سطح زمین است. بنابراین، علاوه بر پیاده سازی روش های سنتی تصمیم گیری [ 21]، یکپارچه سازی سیستم های اطلاعاتی مختلف با هدف بهبود تجزیه و تحلیل داده های مکانی در انتخاب مکان های سایت سد پدیدار شده است [ 22 ، 23 ]. برای چنین مطالعاتی، انواع لایههای مکانی مانند سازند زمینشناسی، نوع خاک و فرسایش، خط گسل، مدل رقومی ارتفاعی ( DEM )، شیب، آبهای زیرزمینی، بارندگی، دبی آب، کاربری/پوشش زمین، شبکه جادهای، غالبهای شهری مناطق، الگوهای لرزه خیزی، اسکارهای زمین لغزش، و جامدات محلول استفاده می شود. با این حال، در ساخت و ساز، داده های فضایی زیرسطحی که شرایط توپوگرافی، نگرانی های پی، سطح آب زیرزمینی و در دسترس بودن مواد را توصیف می کند جالب تر است [ 24 ، 25 ].]. این امر مستلزم لزوم استفاده از پایگاه دادههای بهروز یکپارچه بررسیشده مکانی در تجزیه و تحلیل مشکلات مرتبط برای سرعت بخشیدن به مراحل گردش کار در مقیاس زیرساخت است [ 26 ]. با این حال، ارائه مخزن داده های مکانی به دلیل مجموعه های سنتی معمولاً یک فرآیند زمان بر است [ 27 ، 28 ].
شکل 1 مراحل معمول در ارائه پایگاه داده های مکانی مناسب برای اختصاص یک مدل پیش بینی مبتنی بر دانش را نشان می دهد. چنین پایگاه داده مکانی شامل طیف گسترده ای از اطلاعات جغرافیایی، محصولات/تصاویر سنجش از راه دور و بررسی های سایت است. بسته به ویژگی مورد نیاز، پایگاه داده مکانی میتواند DEM ، کاربری زمین، توزیع نوع خاک، شاخصهای توپوگرافی، دادههای جغرافیایی سطح، الگوی زهکشی حوضه آبریز، و پایداری شیب و همچنین خطرات احتمالی خطر طبیعی را پوشش دهد. بر این اساس، این ادغام ها مزایای اقتصادی، اجتماعی و زیست محیطی قابل توجهی را برای توسعه شهری و صنعتی آینده در هر دو مقیاس محلی و منطقه ای اختصاص می دهند [ 27 ].
عمق به سنگ بستر ( DTB ) یکی از ویژگی های زیرسطحی جالب در برنامه ریزی و ساخت سدها به دلیل تأثیر قابل توجه بر عملکرد پایداری و فرآیندهای سطح زمین است [ 22 ، 23 ، 26 ]. این ویژگی ( شکل 2 ) دانشی را در مورد تغییرات فضایی و رابط توپوگرافی بین رسوبات تثبیت نشده و لایه سفت، و همچنین بینش زیست محیطی بیشتری در مورد مهاجرت آلاینده ها به دنبال گرادیان سنگ بستر ارائه می دهد [ 29 ، 30 ، 31 ]. از دیدگاه اقتصادی، DTBمی تواند به طور قابل توجهی بر هزینه های اولیه پروژه بر اساس آسیب، شکاف پذیری و حجم حفاری و همچنین اقدامات کاهش غیر ضروری تأثیر بگذارد. در طراحی فونداسیون، سنگ بستر کم عمق نیاز به برداشتن پوشش کمتری برای پایه گذاری دارد، در حالی که توزیع های عمیق تر می تواند مسئولیت تغییرات جانبی در ویژگی های خاک [ 32 ] و در نتیجه شکست پایه و دال در صورت عدم تطبیق باشد.
با مراجعه به ادبیات، خطر پروژه سد را می توان از طریق مدل DTB فضایی سه بعدی زیرسطحی کارآمد اما دقیق [ 33 ، 34 ، 35 ] کاهش داد. با این حال، ایجاد مدل DTB فضایی پیشبینیکننده دقیق ادامهدار به دلیل چگالی نقاط بررسیشده پراکنده و دادههای فیزیکی نادقیق از سازندهای مواد و همچنین عدم قطعیتهای مرتبط [ 17 ، 18 ، 36 ] معمولاً فراتر از توانایی روشهای کاربردی سنتی است. علاوه بر این، تضادهای مشاهده شده نتیجه در DTB پیشبینیشده تحت هر الگوریتم درونیابی فردی [ 17 ]] به وضوح توضیح می دهد که چرا همیشه مشخص نیست که کدام روش می تواند مناسب ترین مدل را ارائه دهد.
برنامه نویسی بیان ژن ( GEP ) یک الگوریتم محاسباتی تکاملی برای مسائل بهینه سازی است که ارتباط نزدیکی با الگوریتم های ژنتیک و برنامه ریزی ژنتیک دارد [ 37 ]. علیرغم موفقیت بهدستآمده تکنیکهای محاسباتی هوشمند در حل معایب مدلهای DTB [ 17 ، 38 ، 39 ]، هیچ کار متمایز با استفاده از GEP برای مدلسازی زیرسطحی DTB گزارش نشده است. علاوه بر این، تغییرپذیری DTB به دلیل تأثیر زیاد بر پایداری سد در ناحیه لرزهخیز بالا مانند شمال ایران ترجیح داده میشود تا حد امکان دقیق برآورد شود [ 40 ,41 ، 42 ، 43 ]. این شکاف با معرفی یک DTB فضایی سه بعدی پیش بینی کننده با استفاده از GEP ، یک جایگزین مناسب با سطوح قابل پیش بینی عالی را اختصاص می دهد . علاوه بر این، این در سایت سدی در استان گیلان-شمال ایران، که در آن مدل کمی با دقت بالا بسیار مورد توجه است، اعمال شد.
در مطالعه حاضر، پایگاه داده جغرافیایی با استفاده از سه مرحله اول ارائه شده در شکل 1 از طریق اطلاعات بازیابی شده از 63 گمانه گردآوری شده، DEM ، نقشه زمین شناسی و مختصات جغرافیایی مکانی ارائه شد. ساختار مدل GEP بهینه از طریق برنامهنویسی در C++ با قابلیت بررسی طیف گستردهای از ویژگیهای داخلی به دست آمد. سپس با تکنیک کریجینگ معمولی ( OK ) مقایسه شد و با استفاده از معیارهای مختلف عملکرد و تجزیه و تحلیل عدم قطعیت ارزیابی شد. سپس دقت 82.53% با R2 = 0.97 در GEP در مقایسه با R2 مشاهده شد .0.92 = و 74.6% برای OK عملکرد برتر را در پیش بینی DTB نشان داد . این پیش بینی ها می توانند به کاهش احتمالی تعداد گمانه ها و هزینه های مربوطه کمک کنند.
2. اصل GEP
GEP [ 37 ] مانند برنامه ریزی ژنتیکی ( GP ) [ 44 ] یک الگوی هوشمند تکاملی است که از الگوریتم های ژنتیک ( GAs ) نشات گرفته است [ 45 ]. تفاوتهای اساسی اصلی بین GA ، GP و GEP به دلیل افراد شاغل مطرح میشوند، جایی که GA از رشتههای خطی با طول ثابت (کروموزومها) استفاده میکند و GP با موجودیتهای غیرخطی با اندازهها و اشکال مختلف (درخت تجزیه) کار میکند. این مشخصه در GEPبه رشتههای خطی رمزگذاریشده با طول ثابت (ژنوم یا کروموزومها) تبدیل میشود تا موجودیتهای غیرخطی با اندازهها و شکلهای مختلف، به عنوان مثال، نمایشهای نمودار ساده یا درختهای بیان ( ET ) را بیان کند.
با اشاره به شکل 3 ، GEP با جمعیت های تولید شده تصادفی اولیه (کروموزوم ها) شروع می شود و هدف آن انتخاب و بازتولید افراد با استفاده از عملگرهای ژنتیکی و تابع تناسب محاسبه شده ( FT ) است. سپس راه حل مناسب از طریق یک روش تکراری شامل سه عملگر اصلی ژنتیکی شامل جهش، جابجایی و نوترکیب یافت می شود. اگر معیار خاتمه (تعداد نسل) به دست نیاید، آنگاه این فرآیند با استفاده از چرخ رولت ژنهای جدیدی را تولید میکند [ 46 ]]. بنابراین، در فرآیند تکرار، هر کروموزوم ممکن است توسط هیچ یک یا چند عملگر که به طور تصادفی افراد را انتخاب می کند، اصلاح شود. در فرآیند اصلاح، عملگر جهش اساساً بسیار مؤثرتر از سایرین است زیرا می تواند در هر سطحی از کروموزوم رخ دهد. مقدار مناسب برای این عملگر را می توان در بازه [0.01-0.1] [ 37 ، 46 ] انتخاب کرد. عملگر جابجایی به صورت داخلی برخی از عناصر متوالی کروموزوم را جایگزین می کند. می توان آن را با استفاده از روش های ژن، توالی درج ( IS ) یا ریشه IS ( RIS ) انجام داد. IS یک کپی از بخش انتخاب شده تصادفی از عناصر متوالی در دم در حالی که در RIS است ارائه می دهددر سر (ریشه) ژن ها جایگزین می شود. هدف جابجایی ژن جایگزینی بخش انتخابی هر ژن به جز قسمت اول در ابتدای کروموزوم است. برای جابجایی، انتخاب یک مقدار در دامنه [0.01-0.1] توصیه می شود [ 46 ]. پس از آن، اطلاعات دو کروموزوم والد با استفاده از روش نوترکیبی مبادله می شود تا دو فرزند تولید شود. بنابراین، جمعیتهای جدیدی با اندازه یکسان والدین اما به شکل زیرشاخههای مختلف تولید میشوند که بیشتر باید با استفاده از FT ارزیابی شوند .
هر ژن از موجودات تکامل یافته یک رشته با طول ثابت از الفبای مختلف است که شامل سر (عملکرد و پایانه) و دم (ترمینال) است. با در نظر گرفتن سر ( h ) به عنوان یک پارامتر تعریف شده استفاده شده، طول دم ( t ) با روش خطای آزمایشی به صورت زیر تعیین می شود:
تی=ساعت(n–1)+1
جایی که؛ n تعداد آرگومان های توابع را نشان می دهد.
بنابراین، ریشه ET (موقعیت 0) همیشه توسط عملگر تابعی پر می شود و متعاقباً توابع مناسب بسته به ماهیت مشکل به عنوان شاخه ها متصل می شوند. ورودی های مدل در پایانه ها به صورت متغیرهای شامل و ثابت های عددی ارائه می شوند. توابع مناسب برای ریشه را می توان از بین فاکتورهای استاندارد ریاضی (به عنوان مثال، +، −، *، /، sqrt، exp، log، ln، sin، cos، و غیره) و عملگرهای منطقی (مانند، و، یا، نه) انتخاب کرد. ، نه، و غیره)، و همچنین روابط بولین یا تعریف شده توسط کاربر. سپس ET مربوطه با استفاده از زبان Kavra [ 37 ] همانطور که در شکل 4 نشان داده شده است ترجمه می شود.
3. منطقه مطالعاتی و پایگاه داده های جغرافیایی
استان گیلان در امتداد دریای خزر در شمال ایران قرار دارد که با استفاده از طبیعت و آب و هوای نیمه گرمسیری مرطوب با بارش های زیاد می توان آن را مشخص کرد. همچنین بخشی از این قلمرو در استان لرزهساخت البرلز فعال کوهستانی قرار دارد که چندین زلزله مخرب مانند منجی رودبار 1990 (Ms7.3) را متحمل شده است. همانطور که در شکل 5 ارائه شده است، CFRD بیجار بین شهرهای رودبار و رشت در استان گیلان با ظرفیت مخزن اسمی 105 میلی متر مکعب ، ابعاد تاج 430 × 10 متر و ارتفاع 59.4 متر از زیرزمین مناسب است.
برای ارائه پایگاه داده های جغرافیایی، DEM با وضوح 10 × 10 متر برای منطقه مورد مطالعه ( شکل 5 ) و شیب مربوطه ایجاد شد. اطلاعات زمین شناسی و بارش باران از سازمان زمین شناسی و هواشناسی کشور به پایگاه داده اضافه شد. سطح رسوبات، عمق و مختصات جغرافیایی 63 گمانه حفر شده پراکنده و شبه مشاهدات مبتنی بر دانش نیز پردازش و در پایگاه داده ذخیره شد. سپس این دادههای مکانی مستند شده برای ارائه مدل توپوگرافی پیشبینیکننده DTB اعمال شد. با مراجعه به شکل 5 ، ارتفاع منطقه بین 130 تا بیش از 430 متر متغیر است.
4. مدل سازی DTB با استفاده از GEP
مانند همه الگوریتمهای هوشمند، دادههای بهدستآمده باید در جایی تصادفی شوند که درصد اختصاص داده شده توسط کاربر تعریف شده باشد. تصادفی سازی متغیر کمین را کنترل می کند و سوگیری های احتمالی را که ممکن است در آزمایش ایجاد شود حذف می کند. در این مقاله مقادیر 65%، 20% و 15% برای ساخت مجموعه آموزش، تست و اعتبار سنجی در نظر گرفته شده است. برای افزایش دقت فرآیند مدلسازی و دریافت بینش بیشتر در مورد منطقه با کمبود داده، از رویکرد مبتنی بر دانش هوشمند متخصص ارائه شده در [ 17 ] استفاده شد. مناسبترین تعداد کروموزومها و ژنها برای مدل GEP پیشبینیکننده در معرض خطای میانگین مربعات ریشه ( RMSE ) به عنوان FT ثبت شد.از طریق ترکیب آزمون-خطا و تکنیک سازنده [ 32 ، 47 ]. بر این اساس، تغییر RMSE در برابر R2 به دست آمده منجر به تعداد بهینه کروموزوم ها می شود، جایی که ساختار GEP پیش بینی کننده به عنوان نتیجه حلقه های بازخورد سیستمیک از طریق تغییر ویژگی های داخلی انتخاب شد. هر مدل تولید شده برای پاسخگویی به نیازهای مورد نیاز بررسی و کنترل شد. روش توضیح داده شده در C++ برنامه ریزی شد . جدول 1 محدوده پارامترهای اعمال شده در تنظیم مدل را نشان می دهد.
شکل 6 نمونه ای از مدل های اجرا شده و عملکردهای مقایسه شده مربوطه را به عنوان تابعی از تعداد کروموزوم ها و اندازه سر نشان می دهد. چنین بررسی های پارامتری نشان داد که توپولوژی 35-8-3 بیانگر تعداد کروموزوم ها است. اندازه سر و ژن ها و در نتیجه ET های اختصاص داده شده ( شکل 7 ) را می توان به عنوان بهینه انتخاب کرد. بر این اساس، ET های مدل GEP سپس رابطه ریاضی را به صورت زیر اختصاص می دهند:
Dتیب=Log((سیoسد2+د0د2 د1+5.682)2)2+(11–آتیآn(10سمنnد2)+د2)+Log((1–د23)(اسمنn10د1))2
قابل پیش بینی بودن مدل GEP با استفاده از داده های به کار گرفته شده در شکل 8 ارائه شده است . متعاقباً، مدل فضایی DTB منطقه با استفاده از پیکسل های DEM ( شکل 5 ) شامل عرض جغرافیایی ( d0 )، طول جغرافیایی ( d1 ) و ارتفاع ( d3 ) ایجاد و در شکل 9 ارائه شد .
5. مقایسه، اعتبارسنجی و بحث
در فرآیند نقشه برداری زیرسطحی زیرساخت ها، تجزیه و تحلیل داده های مکانی موضوعی و بررسی شده به دلیل پیچیدگی در هر دو فاز طراحی و ساخت نقش اساسی دارد. چنین مدلسازی یک کار پیچیده برای فناوری GIS است. با این حال، ماهیت فضایی اشیاء جغرافیایی همیشه GIS را به سمت بخشی از سیستمهای مدلسازی سوق میدهد.
پروژههای سد به دلیل آسیبپذیریها و آسیبپذیریهای بیشتر نیازمند اطلاعات تا حد امکان دقیق در مورد شرایط زیرسطحی هستند. بر این اساس، در دسترس نبودن نقشههای زیرسطحی دقیق و کافی میتواند شرایط چالشبرانگیزی ایجاد کند و مواجهه با مشکلات سنجیده و غیرمنتظره در فرآیند برنامهریزی و ساخت را تشدید کند. علاوه بر این، خودهمبستگی، ناهمگنی، حقیقت زمینی محدود، و مقیاسها و تفکیکهای چندگانه نیز چالشهای منحصربهفردی را ایجاد میکنند [ 48 ] که فرض رایج استفاده از بسیاری از مدلهای پیشبینی سنتی [ 49 ] را نقض میکند.]. از آنجایی که اکثر گمانه های اکتشافی به صورت تصادفی توزیع می شوند و ممکن است در منطقه مورد مطالعه نماینده نباشند، انتخاب بهترین روش درونیابی که نزدیک ترین تقریب را به پارامترهای شناخته شده ارائه می دهد معمولا دشوار اما ضروری است [ 50 ]. بنابراین، مدلهای فضایی پیشبینیکننده برای افزایش وضوح متغیر پاسخ بر اساس ویژگیهای توضیحی توسعه داده میشوند. از آنجایی که بررسیهای سیستماتیک زیرزمینی حیاتی است، نقشهبرداری و مدلسازی زیرسطحی به کاهش خطر از یک سناریوی متراکم شهری کمک میکند. ترکیب فناوری های نوآورانه مانند BIM نیز در کاهش خطرات مهندسی مرتبط با سایت ساخت و ساز زیرسطحی حیاتی است [ 10 ، 11 ].
از منظر مهندسی، مدل های تولید شده باید برای اعتبارسنجی و بررسی انطباق و تحقق سیستم دنبال شوند. چنین فرآیندی با هدف اطمینان از مطابقت مدل تولید شده با دقت و معیارهای عملیاتی انجام می شود. در این مقاله، مقایسه نتایج با تکنیک زمین آماری OK ، عملکرد دقت با استفاده از ماتریس سردرگمی و معیارهای خطای آماری و همچنین تحلیل عدم قطعیت از طریق فواصل اطمینان و پیشبینی ( CI و PI ) انجام شد.
کریجینگ [ 51 ] یک تکنیک درونیابی زمین آماری قابل استفاده برای مقادیر ناشناخته متغیرهای مکانی و زمانی است. این الگوریتم با حاکمیت کوواریانسهای قبلی از طریق رگرسیون فرآیند گاوسی، بهترین پیشبینی بیطرفانه عملی را برای مقادیر میانی اختصاص میدهد [ 52 ]. در میان انواع مختلف کریجینگ، OK می تواند به طور ضمنی میانگین را در یک محله متحرک ارزیابی کند و همچنین یک مقدار بلوک را تخمین بزند [ 53 ]. این روش یک برآورد حداقلی از واریانس را از طریق وزنهای بهینه برای کاهش خطا [ 45 ] ارائه میکند:
[γ(z1–z1)γ(z2–z1)⋯γ(z1–z2)γ(z2–z2)…⋯γ(z1–zn)1γ(z2–zn)1…1⋮⋱⋮γ(zn–z1)1γ(zn–z2)1⋯γ(zn–zn)110]×[λ1λ2⋮λnμ]=[γ(ایکس1–ایکس)γ(ایکس2–ایکس)⋮γ(ایکسn–ایکس)1]
جایی که؛ γ مقدار واریوگرام است. z i و X i به ترتیب مقادیر واقعی و تخمینی را در مکان i نشان می دهند. λ i ضریب وزنی اختصاص داده شده را نشان می دهد و μ عامل لاگرانژ است.
عملکرد و مقایسه بین مدل OK و GEP تحت مجموعه داده های تصادفی در شکل 10 الف نشان داده شده است. سطح CI نشان دهنده حس بصری موفقیت طولانی مدت روش در گرفتن DTB است، در حالی که PI احتمال قطعی آینده را نشان می دهد. برآورد کردن. ثبات و ظرفیت مدلهای پیشبینی GEP و OK با استفاده از دادههای بکار گرفته شده در شکل 10 ب منعکس شده است. از نظر آماری، اگر خروجیها در محدودههای خاصی قرار گیرند که CI وسیعتر باشد، مدل پیشبینیکننده کنترل میشود.، رابطه ناپایدارتر است. باقیمانده به عنوان تفاوت بین مشاهده شده و پیش بینی شده نشان دهنده انحراف برازش است و در شکل 10 C ارائه شده است.
مقایسه بصری که سطح قابل پیش بینی OK و GEP را با استفاده از ماتریس سردرگمی [ 54 ] توصیف می کند در جدول 2 آورده شده است ، جایی که هر آرایه تعداد خروجی های برچسب گذاری شده واقعی را اختصاص می دهد. نتایج نشاندهنده عملکرد 82.53 درصدی در برچسبگذاری دقیق دادهها در GEP و 9.61 درصد بهبود نسبت به OK بود. سپس چشم اندازهای مدل های تولید شده سه بعدی در شکل 11 ارائه شده است.
عملکرد مدل پیشبینی شامل مقادیر عددی کمی را میتوان با استفاده از معیارهای خطای آماری مانند میانگین درصد مطلق خطا ( MAPE ) ، RMSE ، R2 و باقیماندهها مقیاس و مقایسه کرد. MAPE یکی از محبوب ترین شاخص ها برای توصیف دقت و اندازه خطای پیش بینی است، در حالی که باقیمانده نشان دهنده انحراف مناسب مقدار پیش بینی شده از اندازه گیری است. RMSE دقت پیشبینی یک مدل را بیان میکند و یک برآوردگر مناسب برای انحراف استاندارد توزیع خطا است. R2 منعکس کننده خوبی تناسب در مسئله پیش بینی است . همانطور که در شکل 12 ارائه شده است، مقادیر بالاتر R2 و همچنین MAPE کوچکتر ، باقیمانده و RMSE به عنوان سطوح دقیق تر تفسیر می شوند ( شکل 11 ) .
6. نکات پایانی
توسعه مدلهای پیشبینی توپوگرافی زیرسطحی به اندازه کافی دقیق میتواند چالشهای جدیدی را هم در مقیاس زیرساخت و هم در مقیاس شهری برطرف کند. در مقیاس منطقهای، مدلهای سهبعدی میتوانند به طور کامل پایگاههای دادههای مکانی را به مدلهای زیرسطحی پیوند دهند. بر این اساس، شرایط پیش بینی نشده زیرسطحی به دلیل اطلاعات ناقص می تواند هزینه های غیرمستقیم زیادی را ایجاد کند. این منجر به یک پایگاه داده با کیفیت بالاتر، دانش برتر، و در نتیجه بینش تجسمی بیشتر در مورد فرصت های جدید می شود. سپس منجر به برنامه ریزی و مدیریت مناسب تر استفاده های زیرسطحی و در نتیجه مزایای گسترده تر و بلند مدت می شود.
این نگرانیها باعث تحریک عملکرد بررسی الگوریتمهای تکاملی GEP در تحلیلهای زیرسطحی میشوند که در آن مدلهای DTB پیشبینی با وضوح بالا و دقیقتر به طور قابلتوجهی مورد نیاز هستند. سپس قابلیت های GEP برنامه ریزی شده در C++ در سد CFRD بیجار در شمال ایران پیگیری و با OK مقایسه شد. با توجه به نتایج بهدستآمده، مدل GEP در سطوح پیشبینیپذیری DTB ، 81/9 درصد پیشرفت بیشتر از OK را نشان داد . عملکرد کنترل را بر حسب MAPE ، RMSE ، باقیمانده و R2 تجزیه و تحلیل کردمنعکس کننده عملکرد عالی در GEP نسبت به OK است. با اشاره به ایجاد CI و PI پایداری بیشتر در مدل و در نتیجه پیشبینی آینده در GEP به جای OK انتظار میرود. نتایج مقایسه نشان داد که OK نتایج بیشتری نسبت به GEP ارائه می دهد و بنابراین می تواند درون یابی غیرنماینده ای را برای کل منطقه مورد مطالعه ایجاد کند. این نشان می دهد که GEP به طور کارآمد پیش بینی مقرون به صرفه تر و دقیق تری را برای DTB اختصاص می دهد.
از منظر عملی، نقشه برداری DTB می تواند در تشخیص رسوبات پرکننده کمک کند. میتوان آن را برای مدلسازی تکامل چشمانداز، ارزیابی خطرات طبیعی و ارزیابی آبهای زیرزمینی برای کمک به تصمیمگیرندگان در ارزیابی الگوهای خطر و ترویج پاسخهای جدید برای تشخیص رفتار غیرعادی قبل از وارد شدن آسیبهای جدی به کار برد.
منابع
- کوتسف، آ. مینگینی، ام. توماس، آر. سیتل، وی. Lutz, M. From Spatial Data Infrastructures to Data Spaces- A Technological Perspective on Evolution of European SDIs. ISPRS Int. J. Geo Inf. 2020 ، 9 ، 176. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لی، دی. وانگ، اس. یوان، اچ. لی، دی. نرم افزار و کاربردهای داده کاوی فضایی. وایلی اینتردیسیپ. Rev. Data Min. بدانید. کشف کنید. 2016 ، 6 ، 84-114. [ Google Scholar ] [ CrossRef ]
- ریستوسکی، پ. Paulheim, H. Semantic Web in Data Mining and Knowledge Discovery: A Comprehensive Survey. J. وب سمنت. 2016 ، 36 ، 1-22. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گروون، جی. لین، جی. Waters, N. Data Mining for Geoinformatics: Methods and Applications ; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2014. [ Google Scholar ]
- امیدی پور، م. تومانیان، ع. سامانی، NN; منصوریان، ع. سرویس وب کشف دانش برای زیرساختهای دادههای مکانی. ISPRS Int. J. Geo Inf. 2021 ، 10 ، 12. [ Google Scholar ] [ CrossRef ]
- Sikder، SK; بهنیش، م. هرولد، اچ. Koetter، T. تحلیل جغرافیایی سازههای ساختمانی در کلان شهر داکا: استفاده از آمار فضایی برای ارتقای تصمیمگیری مبتنی بر دادهها. جی. جوویس. تف کردن مقعدی 2019 ، 3 ، 7. [ Google Scholar ] [ CrossRef ]
- رایششتاین، ام. کمپز-والز، جی. استیونز، بی. یونگ، ام. دنزلر، جی. Carvalhais، N. Prabhat. یادگیری عمیق و درک فرآیند برای علم سیستم زمین مبتنی بر داده. Nature 2019 ، 566 ، 195-204. [ Google Scholar ] [ CrossRef ]
- دارابی، ح. حقیقی، AT; محمدی، م. رشیدپور، م. زیگلر، AD; حکمت زاده، ع.ا. Kløve, B. نقشهبرداری خطر سیل شهری با استفاده از تکنیکهای جغرافیایی مبتنی بر داده برای یک منطقه موردی مستعد سیل در ایران. هیدرول. Res. 2020 ، 51 ، 127-142. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سنانایاک، اس. پرادان، بی. هیوت، ا. برنان، جی. مروری بر ارزیابی و نقشه برداری خطر فرسایش خاک با استفاده از فناوری ژئو انفورماتیک برای مدیریت سیستم کشاورزی. Remote Sens. 2020 , 12 , 4063. [ Google Scholar ] [ CrossRef ]
- ما، ز. Ren, Y. کاربرد یکپارچه BIM و GIS: مروری. Procedia Eng. 2017 ، 96 ، 1072-1079. [ Google Scholar ] [ CrossRef ]
- آهنگ، ی. وانگ، ایکس. تان، ی. وو، پی. سوتریسنا، م. چنگ، JCP; Hampson، K. روندها و فرصت های یکپارچه سازی BIM-GIS در معماری، مهندسی و صنعت ساخت و ساز: مروری از دیدگاه آماری مکانی-زمانی. ISPRS Int. J. Geo Inf. 2017 ، 6 ، 397. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- عباس زاده شهری، ع. اسپروس، جی. یوهانسون، اف. لارسون، S. نقشه خطر حساسیت زمین لغزش در جنوب غربی سوئد با استفاده از یک شبکه عصبی مصنوعی. Catena 2019 , 183 , 104225. [ Google Scholar ] [ CrossRef ]
- دی رو، APJ ارزیابی فرسایش خاک با استفاده از GIS در سیستم های اطلاعات جغرافیایی در هیدرولوژی . سینگ، معاون، فیورنتینو، ام.، ویرایش. Springer: Dordrecht، هلند، 1996; صص 339-356. [ Google Scholar ]
- ژو، ک. زی، ی. گائو، ز. میائو، اف. Zhang, L. FuNet: یک شبکه جدید استخراج جاده با ادغام داده های مکان و تصاویر سنجش از دور. ISPRS Int. J. Geo Inf. 2021 ، 10 ، 39. [ Google Scholar ] [ CrossRef ]
- بای، جی. ژو، ز. زو، ی. پولاتوف، بی. Siddique، KHM حوضه خشکسالی و خدمات اکوسیستم: ویژگی های فضایی و زمانی و تجزیه و تحلیل رابطه خاکستری. ISPRS Int. J. Geo Inf. 2021 ، 10 ، 43. [ Google Scholar ] [ CrossRef ]
- عباس زاده شهری، ع. مقصودی مود، ف. نگاشت حساسیت به زمین لغزش با استفاده از مدل هوش مدولار بلوک ترکیبی. گاو نر مهندس جئول محیط زیست 2021 ، 80 ، 267-284. [ Google Scholar ] [ CrossRef ]
- عباس زاده شهری، ع. لارسون، اس. Renkel، C. مدلهای هوش مصنوعی برای ایجاد سطح بستر تجسمشده: مطالعه موردی در سوئد. مدل. سیستم زمین محیط زیست 2020 ، 6 ، 1509-1528. [ Google Scholar ] [ CrossRef ]
- Nath، RR; کومار، جی. شارما، ام ال. گوپتا، SC برآورد عمق سنگ بستر برای بخشی از هیمالیا گرهوال با استفاده از دو تکنیک مختلف ژئوفیزیک. Geosci. Lett. 2018 ، 5 ، 9. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لی، ز. لی، دبلیو. جنرال الکتریک، W. تجزیه و تحلیل وزن عوامل موثر بر پیامدهای خطر شکست سد. نات. سیستم خطرات زمین. علمی 2018 ، 18 ، 3355-3362. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Ge، W. لی، ز. لیانگ، RY؛ لی، دبلیو. Cai, Y. روش شناسی برای ایجاد معیارهای ریسک برای سدها در کشورهای در حال توسعه، مطالعه موردی چین. منبع آب مدیریت 2017 ، 31 ، 4063-4074. [ Google Scholar ] [ CrossRef ]
- جوزاقی، ع. علیزاده، ب. حاتمی، م. سیل، I. خرمی، م. خدایی، ن. قاسمی طوسی، ا.. مطالعه تطبیقی تکنیکهای AHP و TOPSIS برای انتخاب محل سد با استفاده از GIS: مطالعه موردی استان سیستان و بلوچستان، ایران. Geosciences 2018 , 8 , 494. [ Google Scholar ] [ CrossRef ][ Green Version ]
- پورقاسمی، HR; یوسفی، س. نیتهشنیرمال، س. اسکندری، س. ارزیابی، نقشهبرداری و بهینهسازی مکانهای بررسی کنترل رسوب در ساخت سدها. علمی کل محیط. 2020 , 739 , 139954. [ Google Scholar ] [ CrossRef ]
- الروزوق، ر. شانبله، ع. یلماز، AG; ادریس، ع. موکرجی، اس. خلیل، م. نقشه برداری و تجزیه و تحلیل مناسب بودن سایت سد جیبریل، MBA با استفاده از یک رویکرد یکپارچه GIS و یادگیری ماشین. Water 2019 ، 11 ، 1880. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کیم، اچ اس. چانگ، CK; کیم، هنگ کنگ ادغام دادههای ژئو فضایی برای چینهبندی زیرسطحی محل سد با تحلیلهای پرت. محیط زیست علوم زمین 2016 ، 75 ، 168. [ Google Scholar ] [ CrossRef ]
- سیساکیان، VK; آدامو، ن. الانصاری، ن. نقش تحقیقات زمین شناسی برای مکان یابی سد: مطالعه موردی سد موصل. ژئوتک. جئول مهندس 2020 ، 38 ، 2085–2096. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Malczewski، J. تجزیه و تحلیل مناسب کاربری زمین مبتنی بر GIS: مروری انتقادی. Prog. طرح. 2004 ، 62 ، 3-65. [ Google Scholar ] [ CrossRef ]
- لی، اس. دراگیسویچ، اس. کاستروک، FA; سستر، ام. زمستان، اس. کولتکین، ا. پتیتگ، سی. جیانگ، بی. هاورث، جی. استین، ا. و همکاران نظریه و روشهای مدیریت دادههای بزرگ جغرافیایی: بررسی و چالشهای پژوهشی. ISPRS J. Photogramm. Remote Sens. 2016 ، 115 ، 119-133. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ترنر، مدلسازی زمینشناسی AK: گذشته، حال و آینده. در کاربرد کامپیوتری AAPG در زمین شناسی، شماره 4: سیستم های اطلاعات جغرافیایی در اکتشاف و توسعه نفت . Coburn, TC, Yarus, JM, Eds. انجمن زمین شناسان نفت آمریکا: تولسا، OK، ایالات متحده آمریکا، 2000; ص 27-36. [ Google Scholar ]
- ژانگ، سی. چای، جی. کائو، جی. خو، ز. Qin، Y. Lv، Z. شبیه سازی عددی نشت و پایداری سدهای باطله: مطالعه موردی در لیکسی، چین. Water 2020 , 12 , 742. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Jardine، PM; سنفورد، ما؛ Gwo، JP; ریدی، سی. هیکس، دی اس; ریگز، جی اس؛ بیلی، WB کمی انتقال جرم انتشاری در سنگ بستر شیل شکسته شده. منبع آب Res. 1999 ، 35 ، 2015-2030. [ Google Scholar ] [ CrossRef ]
- بوندو، آر. کلوتیر، وی. رزا، E. وقوع آلایندههای زمینزا در چاههای خصوصی از یک سفره زیرزمینی کریستالی در غرب کبک، کانادا: منابع ژئوشیمیایی و خطرات بهداشتی. جی هیدرول. 2018 ، 559 ، 627-637. [ Google Scholar ] [ CrossRef ]
- قادری، ع. عباس زاده شهری، ع. لارسون، اس. یک مدل مبتنی بر شبکه عصبی مصنوعی برای پیشبینی توزیع نوع خاک فضایی با استفاده از دادههای تست نفوذ پیزوکون (CPTu). گاو نر مهندس جئول محیط زیست 2019 ، 78 ، 4579-4588. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- صالح، SA; الطریف، AM با استفاده از تحلیل های فضایی GIS برای مطالعه مکان انتخابی برای مخزن سد در وادی الجرناف، غرب منطقه شرقات، عراق. جی. جئوگر. Inf. سیستم 2012 ، 4 ، 117-127. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کاوورا، ک. کنستانتوپلو، م. کیریو، ا. نیکولاکوپولوس، KG; ساباتاکیس، ن. Depountis، N. مدلسازی زمینشناسی زیرسطحی سهبعدی با استفاده از GIS، سنجش از دور، و دادههای گمانه. در مجموعه مقالات چهارمین کنفرانس بین المللی سنجش از دور و اطلاعات جغرافیایی محیط، پافوس، قبرس، 4 تا 8 آوریل 2016. [ Google Scholar ] [ CrossRef ]
- بالاسوبرمانی، DP; Dodagoudar، GR یک پایگاه داده ژئوتکنیکی یکپارچه و GIS برای مدلسازی زیرسطحی سه بعدی: کاربرد در شهر چنای، هند. Appl. Geomat. 2018 ، 10 ، 47-64. [ Google Scholar ] [ CrossRef ]
- یان، اف. شانگگوان، دبلیو. ژانگ، جی. Hu, B. نقشه چین از عمق تا بستر با وضوح فضایی 100 متر. علمی داده 2020 ، 7 ، 2. [ Google Scholar ] [ CrossRef ] [ PubMed ] [ نسخه سبز ]
- فریرا، سی. برنامه ریزی بیان ژن: الگوریتم تطبیقی جدید برای حل مسائل. سیستم پیچیده 2001 ، 13 ، 87-129. [ Google Scholar ]
- سامویی، پی. کوماری، س. ماکاروف، وی. Kurup, P. مدلسازی در مهندسی ژئوتکنیک ; الزویر: کمبریج، MA، ایالات متحده آمریکا، 2020. [ Google Scholar ]
- چانگ، جی آر. Chao، SJ استفاده از روش گروهی مدیریت داده (GMDH) برای پیشبینی عمق بستر. محاسبه کنید. مدنی مهندس 2009 . [ Google Scholar ] [ CrossRef ]
- تمپا، ک. سرکار، ر. دیکشیت، ا. پرادان، بی. سیمونلی، آل. آچاریا، اس. Alamri، AM مطالعه پارامتری پاسخ سایت محلی برای حرکت زمین بستر به زلزله در Phuentsholing، بوتان. پایداری 2020 ، 12 ، 5273. [ Google Scholar ] [ CrossRef ]
- مناندار، س. چو، سلام؛ کیم، DS اثر سختی و ضخامت سنگ بستر بر روی طیف پاسخ در کره. KSCE J. Civ. مهندس 2016 ، 20 ، 2677-2691. [ Google Scholar ] [ CrossRef ]
- گومز، GJC; Vrugt، JA; وارگاس، EA، جونیور؛ Camargo، JT; Velloso، RQ; van Genuchten، MT نقش عدم قطعیت در عمق سنگ بستر و خواص هیدرولیک در پایداری یک شیب متغیر اشباع شده. محاسبه کنید. ژئوتک. 2017 ، 88 ، 222-241. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Boore، DM تخمین Vs(30) (یا کلاس های سایت NEHRP) از مدل های سرعت کم عمق (عمق <30 متر). گاو نر سیسمول. Soc. صبح. 2004 ، 94 ، 591-597. [ Google Scholar ] [ CrossRef ]
- Koza, JR برنامه نویسی ژنتیکی: در مورد برنامه ریزی کامپیوترها با استفاده از انتخاب طبیعی . مطبوعات MIT: Camridge، MA، ایالات متحده آمریکا، 1992. [ Google Scholar ]
- گلدبرگ، دی. هلند، الگوریتم های ژنتیک JH و یادگیری ماشینی. ماخ فرا گرفتن. 1988 ، 3 ، 95-99. [ Google Scholar ] [ CrossRef ]
- Ferreira, C. Gene Expression Programming: Mathematical Modeling by an Artificial Intelligence , 2nd ed.; Springer: برلین، آلمان، 2006. [ Google Scholar ]
- عاشقی، ر. عباس زاده شهری، ع. خرسند زک، م. پیشبینی پارامترهای شاخص مقاومت انواع سنگهای مختلف با استفاده از مدل هوش چند خروجی ترکیبی. عرب J. Sci. مهندس 2019 ، 44 ، 8645–8659. [ Google Scholar ] [ CrossRef ]
- جیانگ، ز. بررسی روشهای پیشبینی فضایی. IEEE Trans. بدانید. مهندسی داده 2019 ، 31 ، 1645-1664. [ Google Scholar ] [ CrossRef ]
- فرانک، آر. استر، ام. Knobbe، A. رویکرد چند عقلانی به طبقه بندی فضایی. در مجموعه مقالات KDD09: پانزدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، پاریس، فرانسه، 28 ژوئن تا 1 ژوئیه 2009. صص 309-318. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بامیسایه، نقشه برداری زیرسطحی OA: انتخاب بهترین روش درونیابی برای تجزیه و تحلیل داده های گمانه. تف کردن Inf. Res. 2018 ، 26 ، 261-269. [ Google Scholar ] [ CrossRef ]
- Krige، DG یک رویکرد آماری به برخی از مشکلات اساسی ارزیابی معدن در Witwatersrand. جی. شیمی. فلز. شرکت معدن اس افر. 1951 ، 52 ، 119-139. [ Google Scholar ]
- واکرناگل، اچ. کریجینگ معمولی. در زمین آمار چند متغیره ; Springer: برلین/هایدلبرگ، آلمان، 1999; صص 74-81. [ Google Scholar ]
- ساولیف، AA; موخاراموا، اس.اس. چیژیکووا، NA; باجی، آر. Zuur، تحلیل و مدلسازی داده های پیوسته فضایی AF. در تجزیه و تحلیل داده های اکولوژیکی. آمار زیست شناسی و سلامت ; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2007. [ Google Scholar ]
- Stehman، SV انتخاب و تفسیر معیارهای دقت طبقه بندی موضوعی. سنسور از راه دور محیط. 1999 ، 62 ، 77-89. [ Google Scholar ] [ CrossRef ]
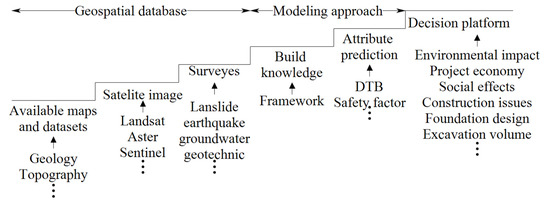
شکل 1. به سمت پلت فرم تصمیم گیری با استفاده از پایگاه داده جغرافیایی.
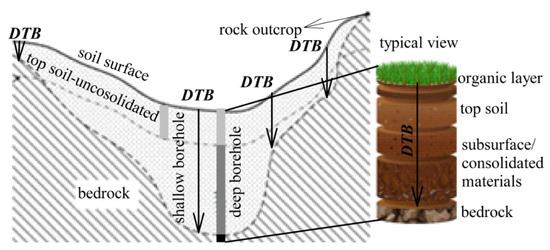
شکل 2. اصطلاحات کاربردی در تعریف DTB .
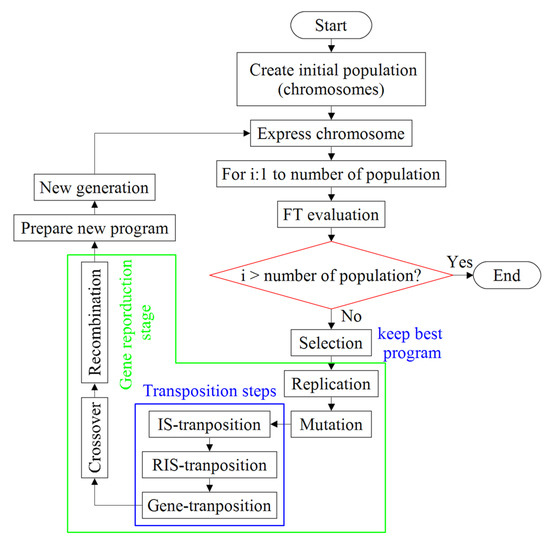
شکل 3. نمودار جریان الگوریتم GEP .
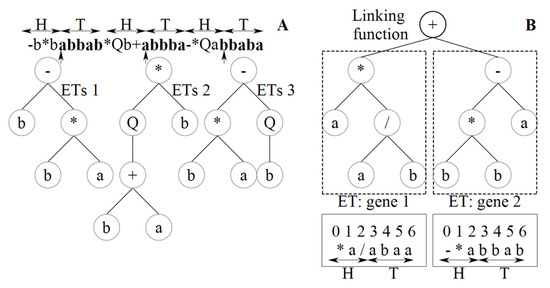
شکل 4. بیان ETs و کروموزوم کد شده برای ( A ) سه و ( B ) دو ژن که سر ( H ) و دم ( T ) را نشان می دهند. فلش عمودی مربوط به کاراکترهای پررنگ، نقطه پایان هر ژن ( A ) را نشان می دهد.
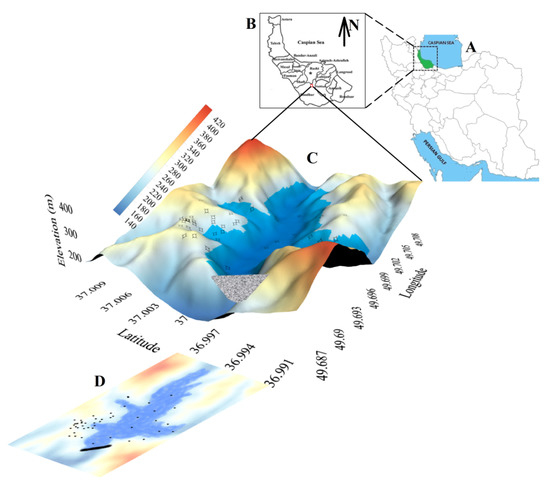
شکل 5. موقعیت منطقه مورد مطالعه در ایران ( A ) و استان گیلان ( B )، DEM تولید شده و داده های فضایی پوشش داده شده ( C )، و توزیع گمانه های حفر شده بررسی شده جغرافیایی ( D ).
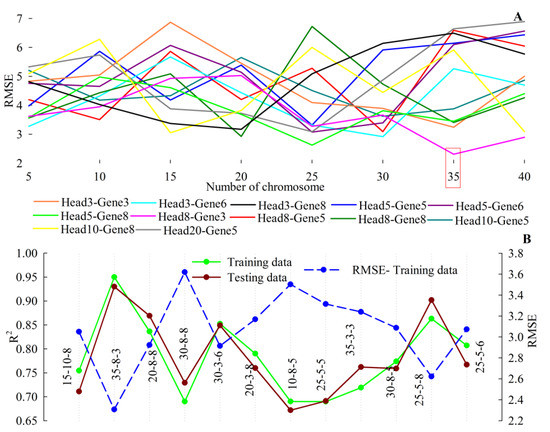
شکل 6. ( A ) تنوع RMSE برای آنالیزهای پارامتریک سری با استفاده از اندازه سر و ژن های مختلف بر اساس تعداد کروموزوم ها، ( B ) مدل های کاندید را با استفاده از RMSE و R2 ارزیابی کرد .
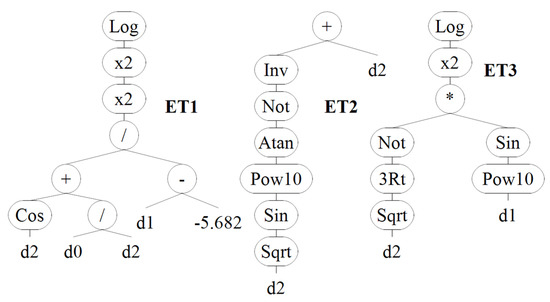
شکل 7. بیان ETs مدل GEP بهینه انتخاب شده.
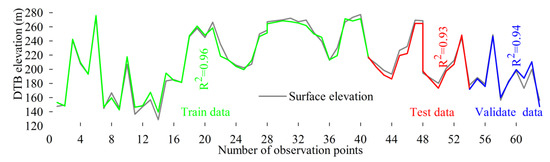
شکل 8. قابل پیش بینی بودن مدل GEP توسعه یافته با استفاده از مجموعه داده های به کار گرفته شده.
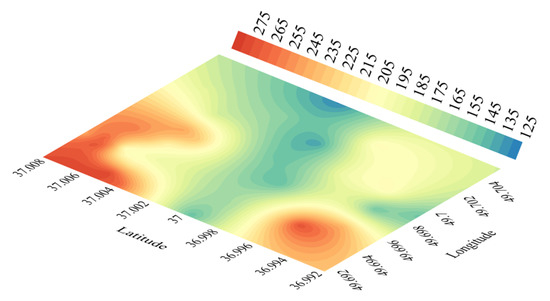
شکل 9. DTB فضایی پیش بینی شده با استفاده از توپولوژی GEP بهینه .
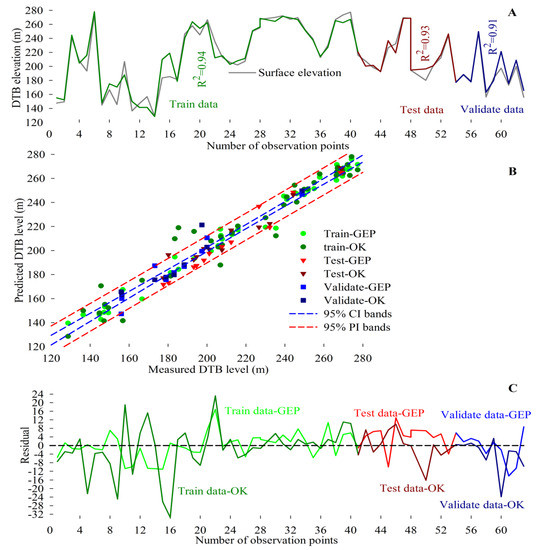
شکل 10. نتایج OK ( A )، قابل پیش بینی بودن OK و GEP با استفاده از CI و PI ( B ) و مقایسه باقیمانده ها ( C ).
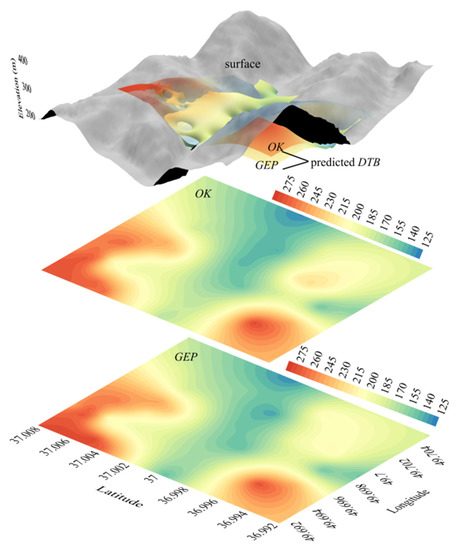
شکل 11. بینش های تصویری در مورد مدل های پیش بینی شده فضایی DTB با استفاده از GEP و OK بهینه .
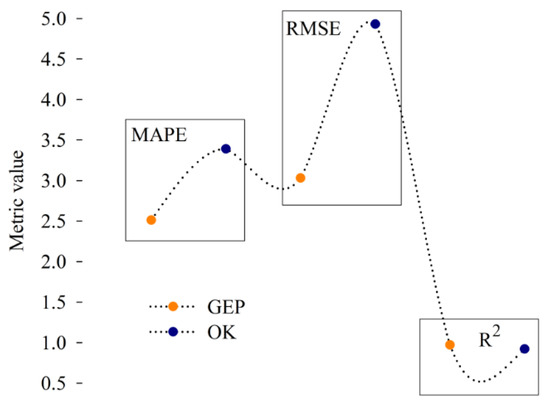
شکل 12. مقایسه عملکرد مدل ها با استفاده از معیارهای خطای آماری برای کل مجموعه داده ها (حذف خط نقطه).


بدون دیدگاه