

چکیده
کلید واژه ها:
ناهمگونی فضایی ; مدل دوجمله ای منفی پارامتر تصادفی ; رگرسیون وزنی جغرافیایی ; حمل و نقل ; تصادف وسیله نقلیه
1. مقدمه
2. آثار مرتبط
3. روش شناسی
3.1. مدل های غیر فضایی
برای دادههای شمارش تصادف اعداد صحیح غیرمنفی، رگرسیون پواسون اساسیترین مورد است [ 47 ]. با این حال، ویژگی توزیع پواسون که واریانس با میانگین یکسان است، اغلب در دادههای شمارش خرابی نقض میشود [ 48 ]. مدل رگرسیون NB به طور کلی برای توضیح مسئله پراکندگی بیش از حد استفاده شده است. مدل رگرسیون NB را می توان با استفاده از تابع log-linear ارائه کرد در حالی که پارامتر پواسون ( λمن) از اصطلاحات سیستماتیک و یک عبارت تصادفی به شرح زیر تشکیل شده است:
جایی که λمنتعداد مورد انتظار تصادف در مشاهده است من، β0، β1، …، βکپارامترهای مدل هستند، ایکسمنکهست کمتغیر توضیحی برای مشاهده من، پتعداد پارامترهای مدل است، هθمنیک عبارت خطای توزیع شده گاما با میانگین 1 و واریانس است α. اضافه کردن عبارت خطای توزیع شده گاما، واریانس متغیر وابسته را امکان پذیر می کند Yمنبا میانگین آن متفاوت باشد λمنبه طوری که varYمن=λمن+αλمن2. وقتی α به صفر نزدیک می شود، رگرسیون دو جمله ای منفی همان رگرسیون پواسون است. رگرسیون دو جمله ای منفی زمانی مناسب است αبه طور قابل توجهی با صفر تفاوت دارد [ 49 ].
مدل NB می تواند شخصیت بیش از حد پراکندگی داده های تصادف ترافیک را به تصویر بکشد. با این حال، وابستگی فضایی احتمالی در میان بخشهای منحنی، همانطور که قبلاً گفته شد، ممکن است نادیده گرفته شود. با ترکیب یک عبارت تصادفی در تابع مدل NB، یعنی معادله (2)، یک مدل RPNB میتواند در پاسخ به متغیرهای توضیحی غیر ثابت در مدلهای شمارش استفاده شود:
جایی که βمنکپارامتر از است کمتغیر توضیحی برای مشاهده من، βکپارامتر میانگین در تمام مشاهدات است و φمنکیک عبارت توزیع شده تصادفی با توزیع تعیین شده توسط تحلیلگر است (مانند توزیع نرمال با میانگین 0 و واریانس σک2) که ناهمگونی مشاهده نشده را توصیف می کند. اگر برخی از واریانسهای توزیع بهعنوان تفاوت معنیداری با صفر برای یک متغیر توضیحی جداگانه آزمایش شوند، پارامتر ثابت مرسوم در همه مشاهدات از نظر آماری مناسب است. اگر عبارت ثابت تنها پارامتر تصادفی باشد، یک مدل پارامتر تصادفی معادل یک مدل اثر تصادفی است.
3.2. مدل های فضایی
برای مقابله با غیر ایستایی فضایی، رویکرد GWR در این مقاله در نظر گرفته شده است. مدل اساسی برای تفسیر مسائل ناهمگونی فضایی، مدل GWPR است که توسط ناکایا و همکاران توسعه یافته است. [ 36 ]، که به پارامترهای رگرسیون تخمینی اجازه می دهد تا در فضا تغییر کنند. چارچوب زیر مدل را تشکیل می دهد:
که در آن ضرایب برآورد شده است βکبر اساس مکان تعیین می شوند تومن= (توایکسمن، توyمن)نشان دهنده مختصات نقطه میانی بخش منحنی، و دلالت بر این دارد که پارامتر βکدر بین بخش های منحنی متفاوت است.
ماتریس پارامترها برای هر واحد فضایی به صورت زیر برآورد می شود:
جایی که β^تومنضرایب رگرسیون محلی برای واحد فضایی است منX ماتریس طراحی متغیرهای توضیحی است ،ایکستیX جابجا شده است ، Y متغیرهای وابسته است و دبلیوتومننشان دهنده یک n×nماتریس وزن دهی فضایی که به صورت زیر تعریف می شود:
جایی که wمنjj=1،2،…، nوزن جغرافیایی است jمشاهده ام در مننقطه رگرسیون در نظریه رویکرد GWR، تخمین پارامترهای هر نقطه رگرسیون بر اساس مشاهدات دیگر در پهنای باند مناسب است. به این مشاهدات نزدیک با توجه به فاصله مشاهدات تا نقطه رگرسیون در فرآیند رگرسیون وزن اختصاص داده می شود. برای هر نقطه رگرسیون، مشاهدات از لبه پهنای باند تا نقطه خروج وزن بیشتری را به همراه خواهد داشت. وزن wمنjمعمولاً توسط دو نوع هسته معمولی محاسبه می شود، یعنی توابع گاوسی و دو مربعی (تطبیقی) که به صورت زیر تعریف می شوند:
جایی که دمنjفاصله بین مشاهدات همسایه است منو j، بپهنای باند ثابت است و بمنکیک اندازه پهنای باند تطبیقی است که با k- امین فاصله نزدیکترین همسایه تعریف شده است [ 50 ]. پهنای باند در تابع گاوسی (هسته ثابت) ثابت است، در حالی که پهنای باند تابع دو مربعی تطبیقی در پاسخ به چگالی مکان نمونه متفاوت است.
مشابه مدلهای شمارش سنتی، نقض توزیع پواسون نیز زمانی اتفاق میافتد که واریانس با میانگین متفاوت باشد. شکل دوجمله ای منفی نیز به رویکرد GWR برای توضیح مشکل پراکندگی بیش از حد اعمال می شود. سیلوا و رودریگز [ 37 ] الگوریتمی را برای مدل سازی داده های بیش از حد پراکنده به روشی غیر ثابت توسط GWNBR توسعه دادند. مدل GWNBR پیشنهادی به صورت زیر تعریف می شود:
که در آن عبارت خطای توزیع شده گاما هθمنبا معادله (1) یکسان است، اما فقط αتومندر واحدهای فضایی متفاوت است. اصطلاحات دیگر همانطور که در رابطه (4) تعریف شده است. برای تخمین پارامترها از روش اصلاح شده حداقل مربعات با وزن مجدد تکراری (IRLS) استفاده می شود. βکو α. با استفاده از الگوریتم نیوتن رافسون (NR)، یک زیربرنامه با روش حداکثر احتمال (ML) میتواند در این روش انجام شود. (سیلوا و رودریگز، 2014).
میانگین پیش بینی شده را به عنوان تنظیم کنید μمن، پارامترسازی این مدل بر حسب μمن/تیمن، تیمنمتغیرهای افست را می دهد. بنابراین، این مدل را می توان به صورت λمن~NBتیمنانقضا∑کβکتومنایکسمنک،αتومنیا λمن~NBμمن،αتومن. بردار پارامتر برای هر واحد فضایی توسط:
جایی که آتومنمتریک n است ×n ماتریس وزنی مورب GLM برای تکرار m و مکان من، zتومنمتغیرهای وابسته تعدیل شده اند. اصطلاحات دیگر همانطور که قبلا در مدل GWPR تعریف شده است. تعداد موثر پارامترهای GWNBR کرا می توان با افزودن اعداد موثر پارامتر در پاسخ به محاسبه کرد βو α.
3.3. معیارهای حسن تناسب
برای ارائه میانگین بزرگی متغیر پیش بینی، انحراف مطلق میانه (MAD) استفاده می شود:
جایی که nتعداد مشاهدات است (یعنی تعداد قطعات منحنی در این مقاله)، و λ^منفرکانس تصادف پیش بینی شده است و yمنفرکانس تصادف مشاهده شده است. کوچکترین مقدار MAD بهترین نتیجه در پیش بینی است.
یکی دیگر از خوبی های سنجش تناسب- آمنسیجهمچنین برای در نظر گرفتن پیچیدگی مدل به صورت زیر اتخاذ شده است:
جایی که Dنشان دهنده انحراف است، کتعداد پارامترهای تخمین زده شده در مدل است، نتعداد مشاهدات است. انحراف مدل رگرسیون پواسون را می توان به صورت زیر بیان کرد:
با توجه به تخمین رگرسیون فضایی، تعداد پارامترها به تعداد موثر پارامترها جایگزین میشود که میتوان آن را به این صورت تعریف کرد (Fotheringham et al. 2002):
که در آن ماتریس S توسط [ 36 ] محاسبه می شود:
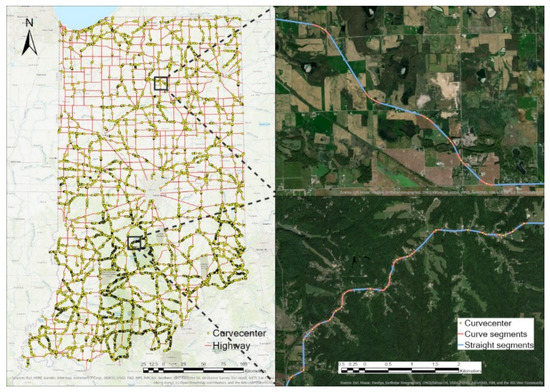
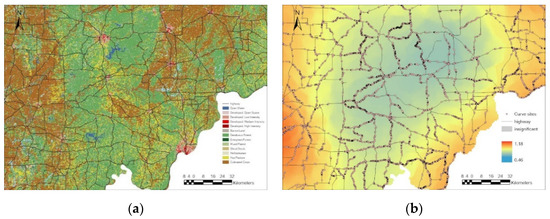
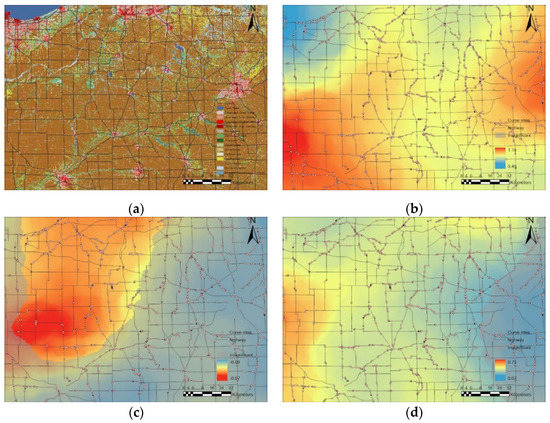
4. شرح داده ها
5. نتایج و بحث
5.1. مقایسه مدل
5.2. آمار پارامترهای تخمینی
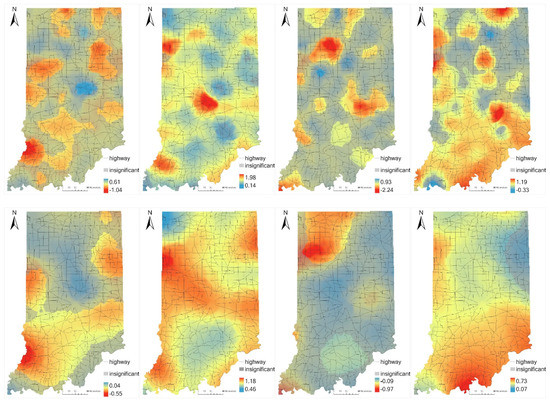
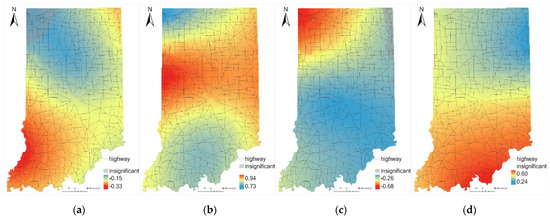
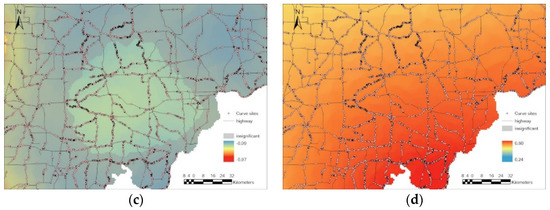
5.3. ناهمگونی مکانی پارامترهای برآورد شده
5.4. تجزیه و تحلیل محلی نتایج GWR
6. نتیجه گیری
منابع
- درمان های کم هزینه برای ایمنی منحنی افقی 2016–ایمنی|اداره بزرگراه فدرال. در دسترس آنلاین: https://safety.fhwa.dot.gov/roadway_dept/countermeasures/horicurves/fhwasa15084/#toc (در 11 مارس 2021 قابل دسترسی است).
- بوداواراپو، پ. بانرجی، ا. تاثیر پروزی، JA از وضعیت روسازی بر ایمنی منحنی افقی. اسید. مقعدی قبلی 2013 ، 52 ، 9-18. [ Google Scholar ] [ CrossRef ]
- اشنایدر، WH; Savolainen، PT; مور، DN اثرات انحنای افقی بر تصادفات موتورسیکلت تک وسیله نقلیه در امتداد بزرگراه های دو خطه روستایی. ترانسپ Res. ضبط 2010 ، 2194 ، 91-98. [ Google Scholar ] [ CrossRef ]
- موسی، ک. پارک، S. شماره لغزنده روسازی و ایمنی منحنی افقی. Procedia Eng. 2016 ، 145 ، 828-835. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گوچ، جی پی؛ Gayah، VV; دانل، ET اثرات ایمنی منحنیهای افقی را در جادههای روستایی دو طرفه و دو بانده تعیین میکند. اسید. مقعدی قبلی 2016 ، 92 ، 71-81. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ونکاتارامان، ن. شانکار، وی. Ulfarsson، GF; Deptuch، D. مدل شمارش ناهمگونی در میانگین برای ارزیابی اثرات نوع تبادل بر تأثیرات ناهمگن هندسه بین ایالتی بر فرکانس های تصادف. مقعدی روش ها اسید. Res. 2014 ، 2 ، 12-20. [ Google Scholar ] [ CrossRef ]
- منرینگ، FL; شانکار، وی. Bhat، CR ناهمگونی مشاهده نشده و تجزیه و تحلیل آماری داده های تصادف بزرگراه. مقعدی روش ها اسید. Res. 2016 ، 11 ، 1-16. [ Google Scholar ] [ CrossRef ]
- کای، س. عبدالعطی، م. لی، جی. هوانگ، اچ. یکپارچهسازی تحلیلهای ایمنی سطح کلان و میکرو: رویکرد بیزی که تعامل فضایی را در بر میگیرد. ترانسپ ترانسپ علمی 2019 ، 15 ، 285–306. [ Google Scholar ] [ CrossRef ]
- Wan, D. تجزیه و تحلیل فضایی فرکانس تصادف و شدت آسیب در شهر نیویورک: کاربردهای روش رگرسیون وزندار جغرافیایی. Ph.D. پایان نامه، کالج شهری نیویورک، نیویورک، نیویورک، ایالات متحده آمریکا، 2018. [ Google Scholar ]
- دودو، VR؛ Pulugurtha، شبکه های عصبی SS برای برآورد تصادفات در سطح منطقه ای برای برنامه ریزی حمل و نقل. در مجموعه مقالات کنفرانس حمل و نقل اروپا 2012، گلاسکو، اسکاتلند، 8 تا 10 اکتبر 2012. [ Google Scholar ]
- لی، جی. عبدالعطی، م. جیانگ، X. توسعه سیستم منطقه برای تجزیه و تحلیل ایمنی ترافیک سطح کلان. J. Transp. Geogr. 2014 ، 38 ، 13-21. [ Google Scholar ] [ CrossRef ]
- Gomes، MJTL؛ کانتو، اف. دا سیلوا، رگرسیون دوجمله ای منفی دارای وزن جغرافیایی AR که برای مدل های عملکرد ایمنی سطح منطقه ای اعمال شد. اسید. مقعدی قبلی 2017 ، 106 ، 254-261. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ثروری، ا. مقدم، ع.م. صالحی، محمد. J. Transp. Saf. امن 2020 ، 1-25. [ Google Scholar ] [ CrossRef ]
- آگوئرو والورده، جی. Jovanis، PP تجزیه و تحلیل فضایی تصادفات مرگبار و جراحات در پنسیلوانیا. اسید. مقعدی قبلی 2006 ، 38 ، 618-625. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- هوانگ، اچ. عبدالعطی، MA; دارویچ، تجزیه و تحلیل ریسک تصادف در سطح شهرستان ایالت AL در فلوریدا: مدلسازی فضایی بیزی. ترانسپ Res. ضبط 2010 ، 2148 ، 27-37. [ Google Scholar ] [ CrossRef ]
- عبدالعطی، م. لی، جی. صدیقی، ج. چوی، ک. تجزیه و تحلیل مبتنی بر واحد جغرافیایی در زمینه برنامه ریزی ایمنی حمل و نقل. ترانسپ Res. بخش A سیاست سیاست. 2013 ، 49 ، 62-75. [ Google Scholar ] [ CrossRef ]
- Quddus، MA مدل سازی نتایج شمارش گسترده منطقه با همبستگی فضایی و ناهمگونی: تجزیه و تحلیل داده های سقوط لندن. اسید. مقعدی قبلی 2008 ، 40 ، 1486-1497. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- وانگ، سی. قدوس، م. ایسون، اس. اثرات سرعت و انحنای جاده در سطح وسیع بر تلفات ترافیکی در انگلستان. J. Transp. Geogr. 2009 ، 17 ، 385-395. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رحمان، MT; جمال، ع. الاحمدی، HM بررسی نقاط داغ برخوردهای ترافیکی و روابط فضایی آنها با کاربری زمین: یک رویکرد رگرسیون وزندار جغرافیایی مبتنی بر GIS برای دمام، عربستان سعودی. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 540. [ Google Scholar ] [ CrossRef ]
- آموه گیمه، ر. صابری، م. سروی، م. مدلسازی ماکروسکوپی تصادفات عابر پیاده و دوچرخه: مقایسه متقابل روشهای برآورد. اسید. مقعدی قبلی 2016 ، 93 ، 147-159. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- آموه گیمه، ر. سروی، م. صابری، م. بررسی اثرات ترافیک، اجتماعی-اقتصادی و ویژگی های کاربری زمین بر تصادفات عابر پیاده و دوچرخه: مطالعه موردی ملبورن، استرالیا. در مجموعه مقالات نود و پنجمین نشست سالانه هیئت تحقیقات حمل و نقل، واشنگتن دی سی، ایالات متحده آمریکا، 10 تا 14 ژانویه 2016. [ Google Scholar ]
- آموه گیمه، ر. صابری، م. سروی، م. تأثیر تغییرات در واحدهای فضایی بر ناهمگونی مشاهده نشده در مدلهای تصادف ماکروسکوپی. مقعدی روش ها اسید. Res. 2017 ، 13 ، 28-51. [ Google Scholar ] [ CrossRef ]
- آناستازوپولوس، کامپیوتر؛ Mannering، FL یک ارزیابی تجربی مدلهای لاجیت پارامترهای ثابت و تصادفی با استفاده از دادههای آسیب تصادفی و غیر اختصاصی تصادف. اسید. مقعدی قبلی 2011 ، 43 ، 1140-1147. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- زیاکوپولوس، ا. یانیس، جی. مروری بر رویکردهای فضایی در ایمنی راه. اسید. مقعدی قبلی 2020 ، 135 ، 105323. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- حدایقی، ع. شلبی، ع. Persaud، BN توسعه ابزارهای ایمنی حمل و نقل در سطح برنامهریزی با استفاده از رگرسیون پواسون وزندار جغرافیایی. اسید. مقعدی قبلی 2010 ، 42 ، 676-688. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Sun، Y. مدلهای خودرگرسیون فضایی تابعی-ضریب با وزنهای فضایی ناپارامتری. جی. اکونوم. 2016 ، 195 ، 134-153. [ Google Scholar ] [ CrossRef ]
- البسیونی، ک. سید، تی. مدل های پیش بینی حوادث شریانی شهری با اثرات فضایی. ترانسپ Res. ضبط 2009 ، 2102 ، 27-33. [ Google Scholar ] [ CrossRef ]
- خو، پی. Huang، H. مدل سازی تصادف ناهمگونی فضایی: پارامتر تصادفی در مقابل وزن جغرافیایی. اسید. مقعدی قبلی 2015 ، 75 ، 16-25. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- مارک، ال. کمپبل، ام. اپتون، ام. کینگهام، اس. استورر، ام. زمستان در راه است: پایش اجتماعی-محیطی و رویکرد مدلسازی مکانی-زمانی برای درک بهتر یک بیماری تنفسی. ISPRS Int. J. Geo-Inf. 2018 ، 7 ، 432. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- چن، جی. لیو، ال. شیائو، ال. خو، سی. Long, D. تحلیل یکپارچه ناهمگونی فضایی و پراکندگی بیش از حد جرم با یک مدل دوجمله ای منفی وزن دار جغرافیایی. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 60. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- وانگ، دی. یانگ، ی. کیو، ا. کانگ، ایکس. هان، جی. Chai, Z. یک رگرسیون موازی موازی جغرافیایی مبتنی بر CUDA برای داده های جغرافیایی در مقیاس بزرگ. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 653. [ Google Scholar ] [ CrossRef ]
- لی، ز. Fotheringham، AS; لی، دبلیو. اوشان، تی. رگرسیون وزندار جغرافیایی سریع (FastGWR): یک الگوریتم مقیاسپذیر برای بررسی ناهمگونی فرآیند فضایی در میلیونها مشاهده. بین المللی جی. جئوگر. Inf. علمی 2019 ، 33 ، 155-175. [ Google Scholar ] [ CrossRef ]
- Fotheringham، AS; کرسپو، آر. یائو، جی. رگرسیون وزنی جغرافیایی و زمانی (GTWR). Geogr. مقعدی 2015 ، 47 ، 431-452. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- حدایقی، ع. شلبی، ع. Persaud، B. مدل های پیش بینی تصادف در سطح کلان برای ارزیابی ایمنی سیستم های حمل و نقل شهری. ترانسپ Res. ضبط 2003 ، 1840 ، 87-95. [ Google Scholar ] [ CrossRef ]
- لی، ز. وانگ، دبلیو. لیو، پی. بیغام، جی.ام. Ragland، DR با استفاده از رگرسیون پواسون وزندار جغرافیایی برای مدلسازی تصادف در سطح شهرستان در کالیفرنیا. Saf. علمی 2013 ، 58 ، 89-97. [ Google Scholar ] [ CrossRef ]
- ناکایا، تی. Fotheringham، AS; براندون، سی. چارلتون، ام. رگرسیون پواسون دارای وزن جغرافیایی برای نقشه برداری انجمن بیماری. آمار پزشکی 2005 ، 24 ، 2695-2717. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- دا سیلوا، آر. رودریگز، TCV رگرسیون دوجملهای منفی وزندار جغرافیایی – شامل پراکندگی بیش از حد. آمار محاسبه کنید. 2013 . [ Google Scholar ] [ CrossRef ]
- Shaon، MRR; Qin، X. شیرازی، م. لرد، دی. Geedipally، SR در حال توسعه یک مدل دوجمله ای-لیندلی منفی با پارامترهای تصادفی برای تجزیه و تحلیل داده های تعداد تصادف بسیار پراکنده. مقعدی روش ها اسید. Res. 2018 ، 18 ، 33-44. [ Google Scholar ] [ CrossRef ]
- Shaon، MRR; اشنایدر، RJ; Qin، X. او، ز. صنعتی زاده، ع. Flanagan، MD کاوش قاطعیت عابر پیاده و ارتباط آن با رفتار تسلیم راننده در گذرگاه های کنترل نشده. ترانسپ Res. ضبط 2018 ، 2672 ، 69-78. [ Google Scholar ] [ CrossRef ]
- چن، اس. سعید، TU; القاضی، اس.د. Labi، S. اثرات ایمنی ناهمواری سطح روسازی در بزرگراه های دو خطه و چند بانده: حسابداری ناهمگونی و همبستگی ظاهراً نامرتبط بین شدت تصادف. ترانسپ ترانسپ علمی 2019 ، 15 ، 18-33. [ Google Scholar ] [ CrossRef ]
- ونکاتارامان، NS; Ulfarsson، GF; شانکار، وی. اوه، جی. پارک، ام. مدل رابطه بین وقوع تصادف بین ایالتی و هندسه: بینش های اکتشافی از رویکرد دو جمله ای منفی پارامتر تصادفی. ترانسپ Res. ضبط 2011 ، 2236 ، 41-48. [ Google Scholar ] [ CrossRef ]
- ونکاتارامان، ن. Ulfarsson، GF; Shankar، مدلهای پارامتر تصادفی VN فرکانسهای تصادف بین ایالتی بر اساس شدت، تعداد وسایل نقلیه درگیر، برخورد و نوع مکان. اسید. مقعدی قبلی 2013 ، 59 ، 309-318. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- چن، ای. Tarko، AP مدلسازی ایمنی مناطق کاری بزرگراه با پارامترهای تصادفی و مدلهای اثرات تصادفی. مقعدی روش ها اسید. Res. 2014 ، 1 ، 86-95. [ Google Scholar ] [ CrossRef ]
- سعید، TU; هال، تی. بارود، ح. Volovski، MJ تحلیل فرکانسهای تصادف جادهای با مدلهای تعداد پارامترهای تصادفی ناهمبسته و همبسته: ارزیابی تجربی بزرگراههای چند خطی. مقعدی روش ها اسید. Res. 2019 ، 23 ، 100101. [ Google Scholar ] [ CrossRef ]
- شین، سی. وانگ، ز. لی، سی. لین، پی.اس. مدلسازی اثرات ایمنی طراحی منحنی افقی بر شدت آسیب تصادفات تک موتورسیکلت با مدل لجستیک اثرات مختلط. ترانسپ Res. ضبط 2017 ، 2637 ، 38-46. [ Google Scholar ] [ CrossRef ]
- شین، سی. وانگ، ز. لین، پی اس. لی، سی. Guo, R. اثرات ایمنی طراحی منحنی افقی بر فرکانس تصادف موتور سیکلت در بزرگراه های روستایی، دو خطه، تقسیم نشده در فلوریدا. ترانسپ Res. ضبط 2017 ، 2637 ، 1-8. [ Google Scholar ] [ CrossRef ]
- منرینگ، FL; بات، روشهای تحلیلی CR در تحقیقات حوادث: مرزهای روششناختی و جهتگیریهای آینده. مقعدی روش ها اسید. Res. 2014 ، 1 ، 1-22. [ Google Scholar ] [ CrossRef ]
- Agresti, A. مبانی مدل های خطی و تعمیم یافته خطی ; جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2015. شابک 978-1-118-73005-8. [ Google Scholar ]
- Hilbe، JM رگرسیون دو جمله ای منفی . انتشارات دانشگاه کمبریج: کمبریج، انگلستان، 2011; شابک 978-0-521-19815-8. [ Google Scholar ]
- Fotheringham، AS; براندون، سی. چارلتون، ام. رگرسیون وزندار جغرافیایی: تحلیل روابط متغیر فضایی . جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2003; شابک 978-0-470-85525-6. [ Google Scholar ]
- امپریالو، ام. Quddus, M. کیفیت داده های تصادف برای تحقیقات ایمنی جاده: وضعیت فعلی و جهت گیری های آینده. اسید. مقعدی قبلی 2019 ، 130 ، 84–90. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- رومرو، ام. آتیسو، ای. وانگ، تی. اسلاشر، ال. Tarko، A. استفاده از GIS برای تعیین مکان برای بهبود ایمنی. در دسترس آنلاین: https://docs.lib.purdue.edu/purduegisday/2017/allevents/1/ (در 26 آوریل 2021 قابل دسترسی است).
- بیل، ام. آندراشیک، آر. سدونیک، جی. Cícha، V. ROCA – جعبه ابزار ArcGIS برای شناسایی تراز جاده و محاسبه شعاع منحنی افقی. PLoS ONE 2018 , 13 , e0208407. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- هایبرگر، RM; هلند، ب. تجزیه و تحلیل آماری و نمایش داده ها . متون Springer در آمار; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2015; شابک 978-1-4939-2121-8. [ Google Scholar ]
- الیوت، ای سی؛ Hynan، LS A SAS® ماکرو پیادهسازی آزمون تعقیبی مقایسه چندگانه برای تحلیل کروسکال-والیس. محاسبه کنید. روش ها برنامه های Biomed. 2011 ، 102 ، 75-80. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- موران، یادداشت های PAP در مورد پدیده های تصادفی پیوسته. Biometrika 1950 ، 37 ، 17-23. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Geedipally، SR; پرت، نماینده مجلس؛ لرد، دی. اثرات هندسه و اصطکاک روسازی بر فرکانس تصادف منحنی افقی. J. Transp. Saf. امن 2019 ، 11 ، 167-188. [ Google Scholar ] [ CrossRef ]
- هیمز، اس. پورتر، RJ; همیلتون، آی. دانل، E. ارزیابی ایمنی معیارهای طراحی هندسی: شعاع منحنی افقی و تقاضای اصطکاک جانبی در بزرگراههای روستایی، دو خطه. ترانسپ Res. ضبط 2019 ، 2673 ، 516-525. [ Google Scholar ] [ CrossRef ]
- Fotheringham، AS; اوشان، TM رگرسیون وزندار جغرافیایی و چند خطی: رد اسطوره. جی. جئوگر. سیستم 2016 ، 18 ، 303-329. [ Google Scholar ] [ CrossRef ]
- ژانگ، ایکس. هوانگ، بی. زو، S. تأثیر فضای زمانی محیط شهری بر تاکسی سواری با استفاده از رگرسیون وزنی جغرافیایی و زمانی. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 23. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]


بدون دیدگاه