

کلید واژه ها:
جاذبه های گردشگری ؛ عکس های دارای برچسب جغرافیایی ؛ فاکتورسازی ماتریسی ; Word2Vec _ محتوای بصری
1. مقدمه
-
با توجه به مشکلات شروع سرد مدلهای مبتنی بر CF و مشکلات دقت پایین مدلهای مبتنی بر محتوا، ما یک مدل توصیه ترکیبی برای جاذبههای توریستی پیشنهاد میکنیم که جاسازیهای مکانی، زمانی و بصری (STVE) را با هم ترکیب میکند.
-
ما تابع هدف Skip-gram را برای مدلسازی عوامل متوالی در STVE تغییر میدهیم، که از ویژگیهای Skip-gram استفاده میکند که دادههای متوالی را به خوبی مدیریت میکند و بیشتر با سناریوی پیشنهادی واقعی جاذبههای توریستی مطابقت دارد.
-
با توجه به مشکلاتی که عکسهای نویزدار و زائد ممکن است تأثیر بدی بر استخراج جاسازیهای بصری داشته باشند و نتایج توصیهها، چارچوبی را پیشنهاد میکنیم که میتواند به طور خودکار عکسهای نویزدار و زائد را حذف کند و تصاویر معرف را برای استخراج جاسازیهای بصری جاذبههای گردشگری انتخاب کند. برای استفاده بیشتر
2. کارهای مرتبط
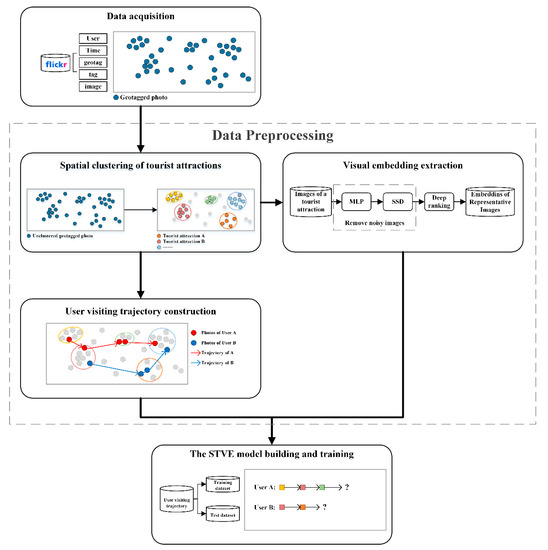
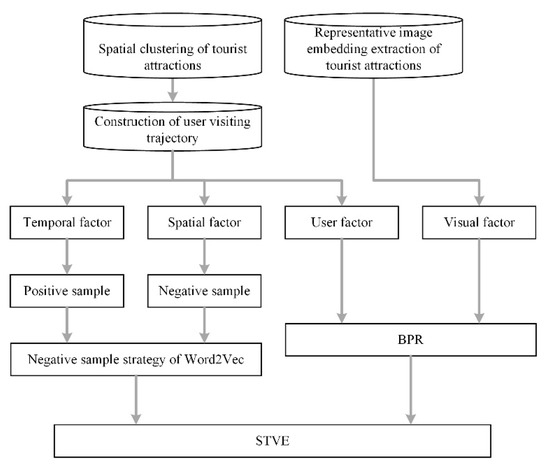
3. روش شناسی
3.1. مقدماتی و چارچوب
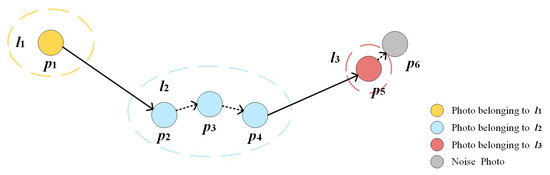
تعریف 1 (عکس دارای برچسب جغرافیایی).
تعریف 2 (مجموعه عکس).
تعریف 3 (مکان معنایی).
تعریف 4 (بازدید).
تعریف 5 (مسیر بازدید کاربر).
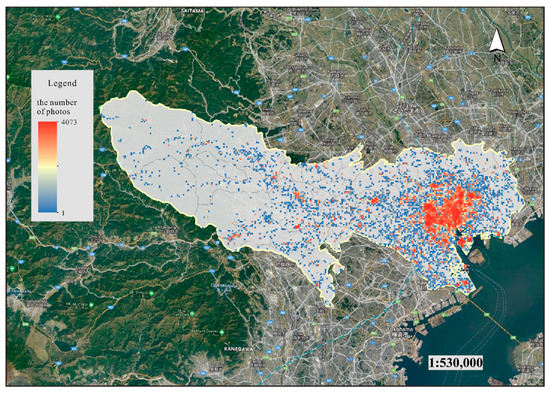
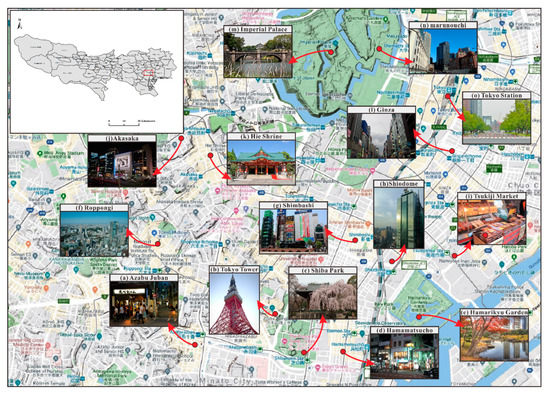
3.2. مجموعه داده ها و حوزه مطالعاتی
3.3. پیش پردازش داده ها
3.3.1. خوشه بندی فضایی جاذبه های گردشگری
3.3.2. استخراج تعبیه بصری
پس از خوشهبندی، ما از یک مدل رتبهبندی عمیق از پیش آموزشدیده برای به دست آوردن بازنمایی بصری جاسازی هر جاذبه گردشگری استفاده کردیم. مدل رتبه بندی عمیق یک مدل مبتنی بر کانولوشن است که هدف آن بازیابی تصویر با شباهت بصری ریز است [ 40 ]]. هر عکس را در مدل رتبه بندی عمیق وارد کنید و یک جاسازی با ابعاد 2048 بدست خواهید آورد. لازم به ذکر است که تعداد عکسهای هر جاذبه گردشگری یکسان نیست و برخی عکسها هستند که محتوای بصری آنها ارتباطی با جاذبه گردشگری ندارد (مثلاً سلفی). بنابراین، محاسبه مقادیر جاسازی همه عکسها و گرفتن میانگین برای نمایش تعبیه هر جاذبه گردشگری مناسب نیست. برای به دست آوردن یک نمایش بصری دقیق تر، دو پیشرفت انجام دادیم. ابتدا، قبل از وارد شدن عکسها به مدل رتبهبندی عمیق، دو نوع عکس پر سر و صدا را فیلتر کردیم: عکسهایی که محتوای آنها عمدتاً توسط افراد اشغال شده است، توسط یک مدل آشکارساز چند جعبه تکشات (SSD) شناسایی و حذف میشوند [ 41 ].]، و عکسهایی که عمدتاً اشیاء را نشان میدهند، توسط پرسپترون چندلایه که توسط مجموعه داده Caltech 101 [ 42 ] و مجموعه داده Places2 از قبل آموزش داده شده است، فیلتر میشوند . دوم، پس از به دست آوردن تعبیههای عکسهای باقیمانده از مدلهای رتبهبندی عمیق، فاصله اقلیدسی هر تعبیه را از همه جاسازیهای دیگر محاسبه کرده و آنها را به ترتیب صعودی مرتب میکنیم. اگر فاصله بین دو جاسازی کم باشد، محتوای بصری دو عکس مربوطه مشابه است. بنابراین، اگر فاصله یک جاسازی بین همه جاسازیهای دیگر کم باشد، محتوای بصری این عکس نسبتاً معمولی و معرف است. برای هر جاذبه توریستی، میانگین بالا را محاسبه کردیم nتعبیههایی با کمترین فاصله از سایر تعبیهها و نتیجه بهعنوان تعبیه بصری این جاذبه گردشگری بهصورت زیر استفاده میشود. ه¯لj:
جایی که هلjکنشان دهنده ک-ام تعبیه در بالا nلیستی از j-ام جاذبه توریستی، و ما مجموعه nبه عنوان 50 در این مطالعه. تعبیه بصری هر جاذبه گردشگری در مدل توصیه ادغام شد.
3.3.3. ساخت مسیر بازدید کاربر
3.4. توصیف و بهینه سازی مدل
3.4.1. جاسازی مکانی – زمانی
ما ابتدا ویژگیهای متوالی مسیرهای بازدید گردشگران را با اصل Skip-gram مدلسازی کردیم، زیرا Skip-gram، به عنوان نوعی روش Word2Vec، به خوبی میتواند دادههای متوالی مانند جملات را مدیریت کند. تابع هدف Skip-gram به حداکثر رساندن احتمال کلمات متنی با توجه به کلمه مرکزی است که به صورت زیر نمایش داده می شود:
جایی که سیکل مجموعه آموزشی را نشان می دهد و wمنبیانگر کلمه متنی از wتیدر اندازه پنجره ک. هر دو wتیو wمنمتعلق به بدنه سی. ما یک کاربر از مسیر را به عنوان یک جمله و هر جاذبه گردشگری در مسیر را به عنوان هر کلمه در نظر می گیریم. با تابع هدف Skip-gram، جاذبه های توریستی متنی را با توجه به جاذبه های مرکز در مسیر استنتاج می کنیم. با این حال، در سناریوی جملات زبان طبیعی، استراتژی انتخاب کلمه متنی Word2Vec بدون جهت است، در حالی که در سناریوی توصیه جاذبه توریستی، پیش بینی جاذبه بعدی با توجه به جاذبه بازدید شده فعلی، بیشتر با وضعیت واقعی مطابقت دارد. به این ترتیب، احتمال شرطی را به عنوان معادله (3) تغییر می دهیم:
جایی که تیکل مسیرهای بازدید همه کاربران را نشان می دهد. لکو لک+1نماینده ک-ام و (ک+1)- بازدید از جاذبه های گردشگری از مسیرهای متعلق به کاربر تومنبه ترتیب و ک=1،2،…،|تیتومن|-1. پ(لک+1|لک)نشان دهنده احتمال شرطی از لکبه لک+1. معادله (3) مشابه هدف آموزش جمله Word2Vec، این احتمالات شرطی را در کل مجموعه داده به حداکثر می رساند. تی.
فرض کنید سناریوی پیشنهادی هدف، استنتاج محتملترین جاذبههای بازدید با توجه به جاذبههای بازدید قبلی و زمان فعلی است، معادله اضافه کردن عامل زمانی بر اساس رابطه (3) را میتوان به صورت زیر فرمولبندی کرد:
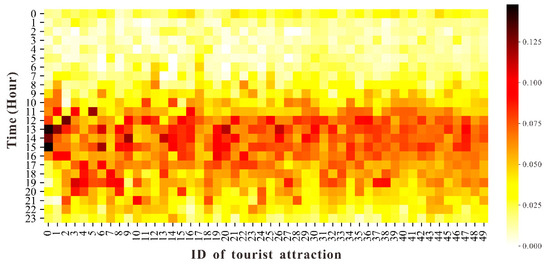
جایی که تیک+1نشان دهنده زمان آن کاربر است تومنبازدید کرد (ک+1)-مین جاذبه گردشگری ما زمان روز را به مقادیر صحیح از 0 تا 23 ترسیم می کنیم تا از مشکلات مربوط به شکاف های زمانی زیاد و پراکندگی داده ها جلوگیری کنیم. به عنوان مثال، اگر کاربر بین ساعت 8 صبح تا 9 صبح از یک جاذبه گردشگری بازدید کند (بدون احتساب ساعت 9 صبح)، زمان بازدید به 8 نشان داده می شود.
تابع SoftMax برای تعریف احتمال شرطی استفاده می شود پ(لک+1|لک،تیک+1)و آموزش عوامل نهفته از لک، لک+1و تیک+1(مشخص می شود vلک، vلک+1و vتیک+1، به ترتیب). دو نماد v^جتیو v^nبرای توضیح بهتر معرفی می شوند و به شرح زیر تعریف می شوند: v^جتی=vلک⊕vتیک+1، v^n=vلک+1⊕vلک+1، جایی که ⊕عملگر الحاق را نشان می دهد. محصول درونی از v^جتیو v^nرا می توان به صورت زیر نشان داد: v^n⋅v^جتی=vلک⋅vلک+1+vتیک+1⋅vلک+1. سپس پ(لک+1|لک،تیک+1)را می توان به صورت زیر فرموله کرد:
با این حال، هزینه محاسبه معادله (5) به دلیل تابع SoftMax غیرعملی بالا است. بنابراین، روش نمونه گیری منفی به عنوان یک الگوریتم تقریبی کارآمد محاسباتی در رابطه (4) به کار گرفته شده است. بنابراین، معادله (4) را می توان به معادله (6) تبدیل کرد:
جایی که σ(ایکس)تابع سیگموئید است. لnهنشان دهنده جاذبه های نمونه منفی و کnهتعداد نمونه های منفی است. به دلیل محدودیت فواصل مکانی، گردشگران ممکن است یک جاذبه گردشگری نزدیک به جاذبه گردشگری فعلی را ترجیح دهند. به عبارت دیگر، گردشگران کمتر یک جاذبه گردشگری دور از جاذبه فعلی را انتخاب می کنند. بنابراین، این ایده محدودیت فاصله فضایی را به فرآیند نمونه گیری منفی معرفی می کنیم، یعنی نمونه های منفی به طور تصادفی انتخاب نمی شوند، بلکه از جاذبه هایی انتخاب می شوند که فاصله آنها با جاذبه بازدیدکننده فعلی بزرگتر از آستانه فاصله از پیش تعریف شده است. مجموعه نمونه های منفی را می توان به صورت معادله (7) فرموله کرد:
جایی که Δدمنسیک آستانه فاصله از پیش تعریف شده است. جایگزین Lnهبا Lnهgدر معادله (6)، و نمایش نهایی تعبیه مکانی-زمانی را می توان به صورت زیر نشان داد:
3.4.2. جاسازی بصری
همانطور که در بالا تحلیل شد، عامل بصری نیز یکی از عوامل اساسی است که بر تصمیم گردشگران برای انتخاب جاذبه های گردشگری تاثیر می گذارد. بنابراین، مدل توصیه باید با اطلاعات بصری ترکیب شود. روشن شده توسط ویژوال بیزی رتبه بندی شخصی (VBPR) پیشنهاد شده توسط او و همکاران. [ 44 ]، ما همچنین سعی میکنیم تعبیههای بصری جاذبههای توریستی را با فاکتورسازی ماتریسی و رتبهبندی شخصی بیزی ترکیب کنیم. فاکتورسازی ماتریسی “کاربران-جاذبه های توریستی” را می توان به صورت زیر ایجاد کرد:
جایی که vتومنتعبیه کاربر است من، و vلjتعبیه جاذبه گردشگری است j. ابعاد آنها هر دو است f2. ما از محصول درونی تعبیه بصری استفاده می کنیم ه¯لjتولید شده در بخش 3.3 و یک ماتریس پارامتر دبلیوتولنشان دادن vلj:
جایی که دبلیوتولهست یک f2×fهماتریس پارامتر و fهتعداد ابعاد برای تعبیه بصری است ه¯لj(2048 همانطور که در بالا ذکر شد). جایگزین vلjبا معادله (10) و اصطلاح سوگیری را بیشتر معرفی کنید βدر معادله (9)، نمایش تعبیه بصری را می توان به صورت زیر فرمول بندی کرد:
بهینه سازی کنید ℒVبا VBPR، که فرض می کند کاربر این جاذبه را بر سایر جاذبه ها ترجیح می دهد. به طور تصادفی نمونه منفی را انتخاب کنید لnه”. فرض کنید تعداد نمونه های منفی است کnه”، سپس ℒVرا می توان به صورت زیر فرموله کرد:
برای کل مجموعه داده آموزشی، ترجیح بصری کاربران برای جاذبه های گردشگری را می توان به صورت معادله (13) مدل کرد:
3.4.3. یادگیری مدل
ما معادله (8) را با معادله (13) با روش جمع وزنی خطی و تابع هدف مدل STVE پیشنهادی که اطلاعات مکانی، زمانی و بصری را ترکیب میکند، ترکیب میکنیم که به صورت زیر فرموله میشود:
جایی که θمجموعه پارامتری است که می تواند مقدار را به حداکثر برساند (α·ℒاستی+(1-α)·ℒV)از طریق آموزش، و θ={VL،Vن،Vتی،VU،دبلیوتول،β}. vلک، vلک+1، vتیک+1، و vتومننشان داده شده در معادله بخش 3.4.1 و بخش 3.4.2 متعلق به جاسازی زیرنویس مربوطه در ماتریس است. VL، Vن، Vتی، و VU، به ترتیب. αپارامتر خطی برای کنترل وزن است ℒاستیو ℒV، و در این آزمایش آن را 0.7 قرار دادیم.
جزئیات فرآیند یادگیری STVE در الگوریتم 1 نشان داده شده است. ورودی آموزش STVE شامل مجموعه داده های آموزشی است. تیو مجموعه پارامترها θ. برای بهروزرسانی پارامترها، از شیب صعود دستهای کوچک استفاده میکنیم و پارامتر نسبت را تنظیم میکنیم. ببه عنوان 0.5. دوران آموزش است مترآایکس_هپoجساعت، و η1و η2میزان یادگیری هستند ℒاستیو ℒV، به ترتیب. Δدمنسپارامتر آستانه فاصله قطع است. ابتدا تمام پارامترها را با توزیع نرمال مقداردهی کنید (خط 1) و فرمول به روز رسانی پارامترها به شرح زیر است:
جایی که ηمیزان یادگیری است. به روز رسانی vتیک+1، vلکو vلک+1برای بالای هر کاربر ( |تیتوj|-1) جاذبه های بازدید شده (خط 6 تا 9)، و انتخاب کنید کnهنمونه های منفی از Lnهgبرای به روز رسانی vتیک+1، vلکو vلمتر(خط 10 تا 14)، که فرآیند به روز رسانی پارامترها در ℒاستیبخش در مورد ℒVبخش، ما تعریف می کنیم ایکس^تومنلکلnمانند:
جایی که ایکس^تومنلکلnو ایکس^تومنلnبا معادله (11) تعریف می شوند. به روز رسانی vتومن، βو دبلیوتولبا VBPR (خط 17 تا 20):
جایی که λθپارامتر منظم سازی است. در اینجا تنظیم کردیم vتومن، βو دبلیوتولبه عنوان همان مقدار λ.
| الگوریتم 1: مدل STVE | |
| ورودی: | تی-مجموعه داده؛ θ={VL،Vن،Vتی،VU،دبلیوتول،β}; مترآایکس_هپoجساعت-تعداد دوره؛ ب-نسبت اندازه دسته η1-نرخ یادگیری از ℒاستی; η2-نرخ یادگیری از ℒV; Δدمنسفاصله برش؛ کnه-تعداد نمونه منفی در ℒاستی; کnه”-تعداد نمونه منفی در ℒV; λ-پارامتر منظم سازی |
| خروجی: | θ |
| 1 | مقدار دهی اولیه کنید θبا توزیع عادی |
| 2 | برای من=0; من<مترآایکس_هپoجساعتانجام دادن |
| 3 | تیتوس ←انتخاب تصادفی ( تیتو، ب) |
| 4 | برای j=0; j<|تیتوس|; تیتوj∈تیتوس انجام دادن |
| 5 | برای ک=0; ک<|تیتوj|; لک∈تیتوj انجام دادن |
| 6 | اگر ک<|تیتوj|-1 انجام دادن |
| 7 | vتیک+1←vتیک+1+αη1(1-σ(v^n⋅v^جتی))vلک+1 |
| 8 | vلک←vلک+αη1(1-σ(v^n⋅v^جتی))vلک+1 |
| 9 | vلک+1←vلک+1+αη1(1-σ(v^n⋅v^جتی))(vتیک+1+vلک) |
| 10 | Lnهg={لnهg∈L\لک+1:دمنس(لک،لnه)≥Δدمنس} |
| 11 | برای متر=0; متر<کnه; لمتر∈Lnهg انجام دادن |
| 12 | vتیک+1←vتیک+1-αη1(1-σ(1-v^n⋅v^جتی))vلمتر |
| 13 | vلک←vلک-αη1(1-σ(1-v^n⋅v^جتی))vلمتر |
| 14 | vلمتر←vلمتر-αη1(1-σ(1-v^n⋅v^جتی))(vتیک+1+vلک) |
| 15 | پایان |
| 16 | پایان |
| 17 | برای n=0; n<کnه”; لn∈Lnه” انجام دادن |
| 18 | vتومن←vتومن+(1-α)η2(1-σ(ایکس^تومنلکلn))دبلیوتول(ه¯لj-ه¯لک)-λvتومن |
| 19 | β←β+(1-α)η2(1-σ(ایکس^تومنلکلn))(ه¯لj-ه¯لک)-λβ |
| 20 | دبلیوتول←دبلیوتول+(1-α)η2(1-σ(ایکس^تومنلکلn))vتومن(ه¯لj-ه¯لک)تی-λدبلیوتول |
| 21 | پایان |
| 22 | پایان |
| 23 | پایان |
| 24 | پایان |
4. نتیجه تجربی
4.1. تنظیمات آزمایش
4.1.1. معیارهای ارزیابی
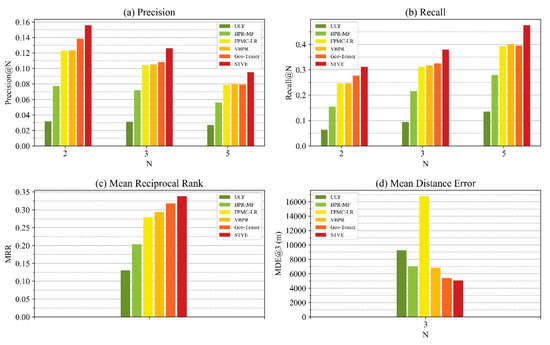
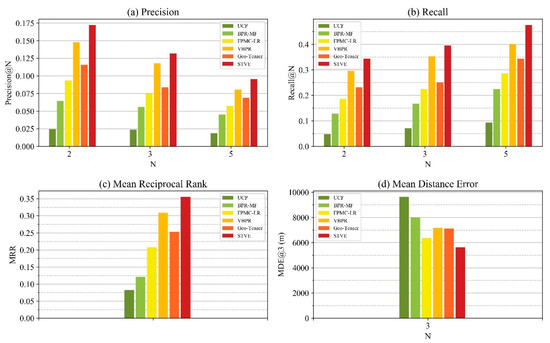
ما از چهار معیار برای ارزیابی مدل STVE خود استفاده می کنیم، از جمله دقت، یادآوری، میانگین رتبه متقابل (MRR) و میانگین خطای فاصله (MDE). Precision@N به نسبت جاذبههای گردشگری با حقیقت زمینی اشاره دارد که در لیست توصیهشده برتر N گنجانده شدهاند، و Recall@N به معنای نسبت بین تعداد جاذبههای واقعی زمین در نتایج توصیهشده top-N و تعداد جاذبه های گردشگری که کاربر بازدید کرده است. این دو معیار رایج برای ارزیابی کیفیت توصیه هستند و میتوانند به ترتیب به صورت معادلات (18) و (19) فرموله شوند:
جایی که آرن(تومن)مجموعه ای از بالا است ننتایج توصیه، و لکنشان دهنده جاذبه گردشگری واقعی است که کاربر از آن بازدید کرده است.
MRR معیارهای رتبه بندی توصیه است که به صورت زیر تعریف می شود:
جایی که rآnکلکشماره رتبه بندی جاذبه زمین-حقیقت در لیست توصیه شده است.
MDE میانگین حداقل فاصله جغرافیایی بین جاذبههای گردشگری واقعی و هر یک از مکانهای برتر را محاسبه میکند. نجاذبه های پیش بینی شده این یک معیار کلی برای ارزیابی سیستم توصیه نیست، اما می توان از آن برای ارزیابی خطای فاصله نتایج توصیه ها استفاده کرد، که در مطالعه یائو و همکاران نیز استفاده شد. [ 45 ] مربوط به پیش بینی مکان. MDE را می توان به صورت زیر فرموله کرد:
جایی که لکnهر جاذبه ای را در بالا نشان می دهد نلیست، و دمنس(ایکس،y)نشان دهنده فاصله بین ایکسو y، با فاصله هاورسین تعریف می شود. مقدار کوچکتر MDE نشان دهنده عملکرد بهتر در خطای فاصله است.
4.1.2. روش های مقایسه
-
فیلتر مشارکتی مبتنی بر کاربر (UCF): UCF یک مدل توصیه مبتنی بر حافظه کلاسیک است که عمدتاً از سایر کاربران با ترجیحات مشابه برای ارائه توصیهها استفاده میکند [ 46 ، 47 ].
-
فاکتورسازی ماتریس رتبهبندی شخصی بیزی (BPR-MF): BPR-MF یک روش فاکتورسازی ماتریس ساده «کاربر آیتم» است که با رتبهبندی شخصی بیزی بهینه شده است.
-
فاکتورسازی زنجیرههای مارکوف شخصی شده با مناطق محلی (FPMC-LR): FPMC-LR [ 15 ] یک روش توصیهای است که با افزودن محدودیت فاصله جغرافیایی به روشهای زنجیره مارکوف شخصیسازی شده (FPMC) [ 14 ] بهبود یافته است.
-
VBPR: VBPR یک مدل فاکتورسازی ماتریسی با اطلاعات بصری با هدف توصیههای خرید آنلاین است [ 44 ].
-
Geo-Teaser: Geo-Teaser روشی بود که اطلاعات زمانی و جغرافیایی را با استراتژی نمونه گیری منفی Word2Vec و رتبه بندی زوجی سلسله مراتبی برای ارائه توصیه ها ادغام می کرد [ 19 ].
4.2. مقایسه عملکرد
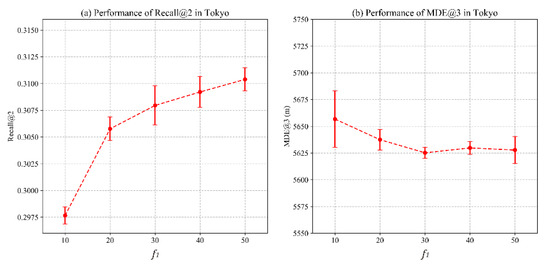
4.3. تجزیه و تحلیل حساسیت پارامتر
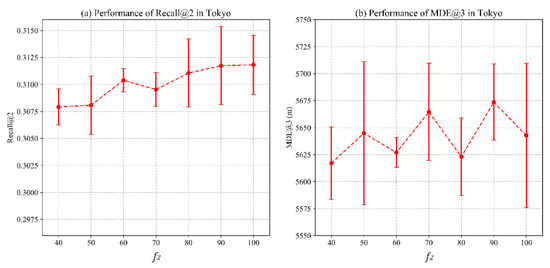
4.3.1. تاثیر ابعاد
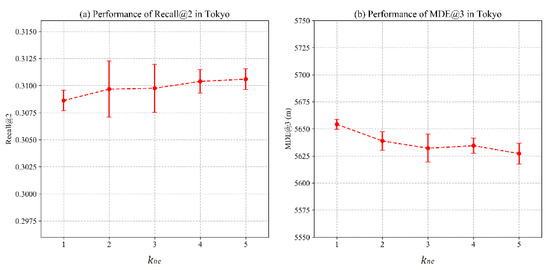
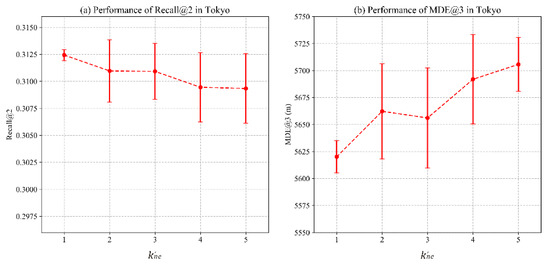
4.3.2. تاثیر نمونه های منفی
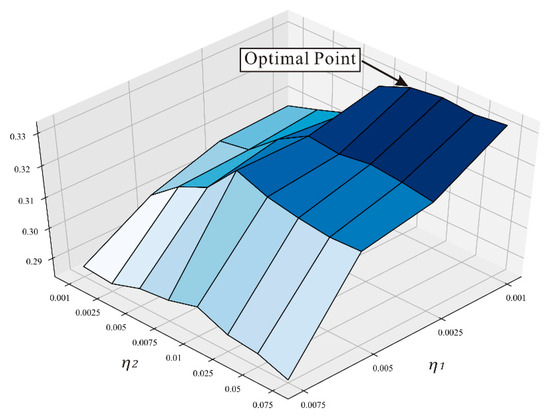
4.3.3. تاثیر نرخ یادگیری
4.4. مطالعه جزء عاقلانه
4.5. نتایج برای کاربر شروع سرد
5. نتیجه گیری ها
منابع
- هندلر، جی. وب 3.0 در حال ظهور. کامپیوتر 2009 ، 42 ، 111-113. [ Google Scholar ] [ CrossRef ]
- رودمن، آر. بروور، آر. تعریف وب 3.0: فرصت ها و چالش ها. الکترون. Libr 2016 ، 34 ، 132-154. [ Google Scholar ] [ CrossRef ]
- شورای جهانی سفر و گردشگری در دسترس آنلاین: https://www.wttc.org (در 25 فوریه 2020 قابل دسترسی است).
- سازمان جهانی گردشگری نکات مهم گردشگری UNWTO ، ویرایش 2019. UNWTO: مادرید، اسپانیا، 2018. [ Google Scholar ]
- گزارش سفر مستقل جهانی. 2017. در دسترس آنلاین: https://www.mafengwo.cn/activity/sales_.report2017/index (در 28 دسامبر 2019 قابل دسترسی است).
- گائو، ی. تانگ، جی. هونگ، آر. دای، Q. چوآ، تی اس؛ جین، R. W2Go: یک سیستم راهنمای سفر با رتبهبندی خودکار. در مجموعه مقالات هجدهمین کنفرانس بین المللی ACM در چند رسانه ای، Firenze، ایتالیا، 25-29 اکتبر 2010. صص 123-132. [ Google Scholar ]
- ژو، ایکس. خو، سی. کیمونز، ب. تشخیص مقاصد گردشگری با استفاده از تجزیه و تحلیل جغرافیایی مقیاس پذیر بر اساس پلت فرم رایانش ابری. محاسبه کنید. محیط زیست سیستم شهری 2015 ، 54 ، 144-153. [ Google Scholar ] [ CrossRef ]
- رفسنجانی، AHN; سلیم، ن. اقدم، ع. فرد، سیستم های توصیه KB: یک بررسی. بین المللی جی. کامپیوتر. مهندس Res. 2013 ، 3 ، 47-52. [ Google Scholar ]
- ون مترن، آر. Van Someren, M. استفاده از فیلترینگ مبتنی بر محتوا برای توصیه. در مجموعه مقالات یادگیری ماشین در عصر اطلاعات جدید کارگاه آموزشی MLnet/ECML2000، بارسلون، اسپانیا، 30 مه 2000. صص 47-56. [ Google Scholar ]
- شافر، جی بی. فرانکوفسکی، دی. هرلوکر، جی. Sen, S. سیستم های توصیه کننده فیلتر مشترک ; Springer: برلین/هایدلبرگ، آلمان، 2007; صص 291-324. [ Google Scholar ]
- بائو، جی. ژنگ، ی. ویلکی، دی. موکبل، توصیه های MF در شبکه های اجتماعی مبتنی بر مکان: یک نظرسنجی. GeoInformatica 2015 ، 19 ، 525-565. [ Google Scholar ] [ CrossRef ]
- آدوماویسیوس، جی. سانکارانارایانان، ر. سن، اس. Tuzhilin، A. ترکیب اطلاعات زمینه ای در سیستم های توصیه گر با استفاده از یک رویکرد چند بعدی. ACM Trans. Inf. سیستم 2005 ، 23 ، 103-145. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رنجیت، اس. سریکومار، ا. Jathavedan, M. یک مطالعه گسترده در مورد تکامل سیستمهای توصیهکننده سفر شخصیشده آگاه از زمینه. به اطلاع رساندن. روند. مدیریت 2020 , 57 , 102078. [ Google Scholar ] [ CrossRef ]
- رندل، اس. فرودنتالر، سی. Schmidt-Thieme، L. فاکتورسازی زنجیره های مارکوف شخصی شده برای توصیه سبد بعدی. در مجموعه مقالات نوزدهمین کنفرانس بین المللی پشتیبانی معماری از زبان های برنامه نویسی و سیستم عامل ها؛ انجمن ماشینهای محاسباتی (ACM)، رالی، NC، ایالات متحده آمریکا، 26 تا 30 آوریل 2010. صص 811-820. [ Google Scholar ]
- چنگ، سی. یانگ، اچ. لیو، ام آر؛ King, I. جایی که دوست دارید در مرحله بعد بروید: توصیه نقطه مورد علاقه پی در پی. در مجموعه مقالات بیست و سومین کنفرانس بین المللی مشترک هوش مصنوعی، پکن، چین، 3 تا 9 اوت 2013. [ Google Scholar ]
- فنگ، اس. لی، ایکس. زنگ، ی. Chee, YM تعبیه متریک رتبه بندی شخصی برای توصیه poi جدید بعدی. در مجموعه مقالات بیست و چهارمین کنفرانس مشترک بین المللی در مورد هوش مصنوعی، بوئنوس آیرس، آرژانتین، 25 تا 31 ژوئیه 2015. ص 2069–2075. [ Google Scholar ]
- تانگ، جی. کو، م. وانگ، ام. ژانگ، ام. یان، جی. Mei, Q. Line: تعبیه شبکه اطلاعات در مقیاس بزرگ. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی وب جهانی، نیویورک، نیویورک، ایالات متحده آمریکا، 18 تا 22 مه 2015; صص 1067–1077. [ Google Scholar ]
- زی، ام. یین، اچ. وانگ، اچ. خو، اف. چن، دبلیو. وانگ، اس. آموزش جاسازی پوی مبتنی بر نمودار برای توصیه مبتنی بر مکان. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی ACM در مورد مدیریت اطلاعات و دانش، ایندیاناپولیس، IN، ایالات متحده، 24-28 اکتبر 2016. صص 15-24. [ Google Scholar ]
- ژائو، اس. ژائو، تی. کینگ، آی. Lyu, MR Geo-teaser: رتبه جاسازی متوالی جغرافیایی-زمانی برای توصیه نقطه مورد علاقه. در مجموعه مجموعه مقالات بیست و ششمین کنفرانس بین المللی در مورد همنشین وب جهانی، ژنو، سوئیس، 3 تا 7 آوریل 2017؛ صص 153-162. [ Google Scholar ]
- بله، م. یین، پی. لی، W.-C. لی، دی.-ال. بهرهبرداری از نفوذ جغرافیایی برای توصیه مشترک نقطهای از علاقه. در مجموعه مقالات سی و چهارمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در اطلاعات – SIGIR ’11، پکن، چین، 25-29 ژوئیه 2011; صص 325-334. [ Google Scholar ]
- ژانگ، ز. زو، سی. دینگ، آر. Chen, Z. VCG: بهرهبرداری از محتوای بصری و نفوذ جغرافیایی برای توصیههای نقطهای از علاقه محاسبات عصبی 2019 ، 357 ، 53-65. [ Google Scholar ] [ CrossRef ]
- چنگ، سی. یانگ، اچ. کینگ، آی. لیو، MR فاکتورسازی ماتریس ذوب شده با نفوذ جغرافیایی و اجتماعی در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات بیست و ششمین کنفرانس AAAI در مورد هوش مصنوعی، تورنتو، ON، کانادا، 22 ژوئیه 2012; صص 17-23. [ Google Scholar ]
- لیان، دی. ژائو، سی. Xie، X. سان، جی. چن، ای. Rui, Y. GeoMF: مدلسازی جغرافیایی مشترک و فاکتورسازی ماتریسی برای توصیه نقطهنظر. در مجموعه مقالات بیستمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، نیویورک، نیویورک، ایالات متحده آمریکا، 24 تا 27 اوت 2014. صص 831-840. [ Google Scholar ]
- او، جی. لی، ایکس. لیائو، ال. آهنگ، دی. Cheung، WK استنباط یک مدل توصیهای شخصیشده نقطهای از علاقه بعدی با الگوهای رفتاری پنهان. در مجموعه مقالات سی امین کنفرانس AAAI در مورد هوش مصنوعی، فینیکس، AZ، ایالات متحده آمریکا، 12 تا 17 فوریه 2016; صص 137-143. [ Google Scholar ]
- گائو، اچ. تانگ، جی. هوان، ال. لیو، اچ. بررسی اثرات زمانی برای توصیه مکان در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات هفتمین کنفرانس ACM در مورد سیستم های توصیه کننده، هنگ کنگ، چین، 12 تا 17 اکتبر 2013. صص 93-100. [ Google Scholar ]
- یوان، Q. کنگ، جی. ما، ز. سان، ا. Thalmann، NM توصیه نقطه مورد علاقه آگاه از زمان. در مجموعه مقالات سی و ششمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات – SIGIR ’13، دوبلین، ایرلند، 28 ژوئیه تا 1 اوت 2013. صص 363-372. [ Google Scholar ]
- شی، ی. سردیوکوف، پ. هانجالیچ، ع. Larson, M. توصیههای شاخص شخصی بر اساس برچسبهای جغرافیایی از سایتهای اشتراکگذاری عکس. در مجموعه مقالات پنجمین کنفرانس بین المللی AAAI در وبلاگ ها و رسانه های اجتماعی، بارسلون، اسپانیا، 17 تا 21 ژوئیه 2011. [ Google Scholar ]
- ممون، آی. چن، ال. مجید، ع. Lv، M. حسین، من. چن، جی. توصیه سفر با استفاده از عکسهای دارای برچسب جغرافیایی در رسانههای اجتماعی برای گردشگران. کلوو اشتراک. 2015 ، 80 ، 1347–1362. [ Google Scholar ] [ CrossRef ]
- چن، Y.-Y.; چنگ، A.-J. Hsu، WH توصیه سفر توسط ویژگیهای افراد معدن و انواع گروههای سفر از عکسهای مشارکتشده در جامعه. IEEE Trans. چندتایی. 2013 ، 15 ، 1283-1295. [ Google Scholar ] [ CrossRef ]
- سوبرامانیاسوامی، وی. ویجایاکومار، وی. لوگش، ر. Indragandhi، V. سیستم توصیه سفر هوشمند با ویژگیهای استخراج از عکسهای ارائهشده توسط جامعه. Procedia Comput. علمی 2015 ، 50 ، 447-455. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آلبانا، بی. ساکر، م. موسی، س. Moawad, I. سیستم توصیهکننده مبتنی بر مکان آگاه از علاقه با استفاده از رسانههای اجتماعی دارای برچسب جغرافیایی. ISPRS Int. J. Geo.-Inf. 2016 ، 5 ، 245. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لیو، ز. ژو، ایکس. شی، دبلیو. Zhang، A. توصیه مناطق موضوعی جذاب با تشخیص جامعه معنایی با داده های VGI چند منبعی. بین المللی جی. جئوگر. Inf. علمی 2019 ، 33 ، 1520-1544. [ Google Scholar ] [ CrossRef ]
- کائو، ال. لو، جی. گالاگر، ا. جین، ایکس. هان، جی. Huang, TS یک سیستم توصیه گردشگری در سراسر جهان بر اساس عکس های وب دارای برچسب جغرافیایی. در مجموعه مقالات کنفرانس بین المللی IEEE در سال 2010 در مورد آکوستیک، گفتار و پردازش سیگنال، دالاس، تگزاس، ایالات متحده آمریکا، 14 تا 19 مارس 2010. ص 2274-2277. [ Google Scholar ]
- جیانگ، ک. وانگ، پی. Yu, N. ContextRank: توصیه گردشگری شخصی شده با بهره برداری از اطلاعات زمینه عکس های وب دارای برچسب جغرافیایی. در مجموعه مقالات ششمین کنفرانس بین المللی تصویر و گرافیک 2011، هفی، چین، 12 تا 15 اوت 2011; ص 931-937. [ Google Scholar ]
- وانگ، اس. وانگ، ی. تانگ، جی. شو، ک. رانگانات، اس. لیو، اچ. تصاویر شما چه چیزی را نشان میدهند: بهرهبرداری از محتوای بصری برای توصیههای مورد علاقه. در مجموعه مقالات بیست و ششمین کنفرانس بین المللی وب جهانی، پرت، استرالیا، 3 تا 7 آوریل 2017؛ صص 391-400. [ Google Scholar ]
- تومی، بی. Shamma، DA; فریدلند، جی. الیزالد، بی. نی، ک. لهستان، دی. Li، LJ YFCC100M: داده های جدید در تحقیقات چند رسانه ای. اشتراک. ACM 2016 ، 59 ، 64-73. [ Google Scholar ] [ CrossRef ]
- منک، ا. سباستیا، ال. فریرا، آر. سیستم های توصیه ای برای گردشگری بر اساس شبکه های اجتماعی: نظرسنجی. arXiv 2019 ، arXiv:1903.12099. [ Google Scholar ]
- نظرسنجی در مورد بازدیدکنندگان از توکیو در سال 2018. در دسترس به صورت آنلاین: https://www.metro.tokyo.jp/english/topics/.2019/0828_01.html (در 20 دسامبر 2019 قابل دسترسی است).
- هان، اس. رن، اف. دو، س. Gui, D. استخراج تصاویر نمایندگی از جاذبه های گردشگری از فلیکر با ترکیب یک روش خوشه ای بهبود یافته و چندین مدل یادگیری عمیق. ISPRS Int. J. Geo.-Inf. 2020 ، 9 ، 81. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- وانگ، جی. آهنگ، ی. لئونگ، تی. روزنبرگ، سی. وانگ، جی. فیلبین، جی. چن، بی. Wu, Y. یادگیری تشابه تصویر ریز دانه با رتبه بندی عمیق. در مجموعه مقالات کنفرانس IEEE 2014 در مورد بینایی کامپیوتری و تشخیص الگو، کلمبوس، OH، ایالات متحده آمریکا، 23 تا 28 ژوئن 2014. صص 1386–1393. [ Google Scholar ]
- لیو، دبلیو. آنگلوف، دی. ایرهان، د. سگدی، سی. رید، اس. Fu، C.-Y.; Berg, AC Ssd: آشکارساز چند جعبه ای تک شات. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر، آمستردام، هلند، 11 تا 14 اکتبر 2016؛ ص 21-37. [ Google Scholar ]
- Li، FL; فرگوس، آر. Perona، P. یادگیری مدلهای بصری مولد از چند نمونه آموزشی: یک رویکرد بیزی افزایشی که بر روی 101 دسته شی آزمایش شده است. محاسبه کنید. Vis. تصویر لغو. 2007 ، 106 ، 59-70. [ Google Scholar ]
- ژو، بی. لاپدریزا، ا. خسلا، ع. اولیوا، ا. Torralba, A. Places: یک پایگاه داده 10 میلیونی تصویر برای تشخیص صحنه. IEEE Trans. الگوی مقعدی ماخ هوشمند 2018 ، 40 ، 1452-1464. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- او، ر. McAuley، J. VBPR: رتبهبندی شخصی بیزی ویژوال از بازخورد ضمنی. در مجموعه مقالات سی امین کنفرانس AAAI در مورد هوش مصنوعی، فینیکس، AZ، ایالات متحده آمریکا، 12 تا 17 فوریه 2016; صص 144-150. [ Google Scholar ]
- یائو، دی. ژانگ، سی. هوانگ، جی. Bi, J. Serm: مدلی تکرارشونده برای پیشبینی مکان بعدی در مسیرهای معنایی. در مجموعه مقالات ACM 2017 در کنفرانس مدیریت اطلاعات و دانش، سنگاپور، 6 تا 10 نوامبر 2017؛ ص 2411-2414. [ Google Scholar ]
- آدوماویسیوس، جی. توژیلین، الف. به سوی نسل بعدی سیستمهای توصیهگر: بررسی پیشرفتهای پیشرفته و احتمالی. IEEE Trans. بدانید. مهندسی داده 2005 ، 17 ، 734-749. [ Google Scholar ] [ CrossRef ]
- مجید، ع. چن، ال. چن، جی. میرزا، ح.ت. حسین، من. Woodward, J. یک سیستم توصیه مسافرتی شخصیشده آگاه از زمینه مبتنی بر دادهکاوی رسانههای اجتماعی دارای برچسب جغرافیایی. بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 662-684. [ Google Scholar ] [ CrossRef ]


بدون دیدگاه