

محتوای انتهای هر پیوندی در معرض دو پدیده است: ممکن است پیوند شکسته شود ( پوسیدگی پیوند ) یا محتوای انتهای پیوند ممکن است دیگر مانند زمان ایجاد آن نباشد ( دریفت محتوا ). Reference Rot ترکیبی از هر دو اثر را نشان می دهد. سوابق فراداده فضایی برای نشان دادن محل منابعی که توصیف می کنند، بر پیوندها متکی هستند. بنابراین، آنها نیز مشمول پوسیدگی مرجع هستند. این مقاله حضور پوسیدگی مرجع و تأثیر آن را بر روی 22738 URI توزیع 18054 رکورد ابرداده از 26 کاتالوگ داده های فضایی اروپایی INSPIRE ارزیابی می کند. پوسیدگی پیوند ماروش بررسی، پیوندهای شکسته را با در نظر گرفتن الزامات خاص خدمات دادههای مکانی شناسایی میکند. روش بررسی دریفت محتوا ما از قالب داده به عنوان نشانگر استفاده می کند. این فرمت های داده اعلام شده در ابرداده را با انواع داده های واقعی بازگردانده شده توسط لینک ها مقایسه می کند. یافته ها نشان می دهد که از URI های توزیع از پوسیدگی لینک و حداقل رنج می برند رکوردها از Content Drift رنج می برند (انواع توزیع آن را به درستی اعلام نکنید). علاوه بر این، رکوردهای ابرداده فقط شامل صفحات وب میانی HTML به عنوان URIهای توزیع و حداقل یک صفحه وب HTML داشته باشد. بنابراین، آنها را نمی توان به طور مستقیم دسترسی یا بررسی کرد.
کلید واژه ها:
فراداده ; زیرساخت های داده های مکانی ; رفرنس پوسیدگی ; پوسیدگی پیوند ; دریفت محتوا
1. مقدمه
زیرساخت های داده های مکانی (SDI) را می توان به عنوان یک رویکرد هماهنگ به فن آوری ها، سیاست ها و ترتیبات سازمانی تعریف کرد که دسترسی و دسترسی به داده های مکانی را تسهیل می کند. SDIها به عنوان یک شبکه سلسله مراتبی از گره ها سازماندهی می شوند که در آن اجزای اصلی فناوری در هر گره داده های مکانی، ابرداده، خدمات میان افزار (برای مکان یابی، تجسم و دانلود داده ها در میان اهداف دیگر) و برنامه های کاربردی کاربر نهایی است. خدمات کاتالوگ ضروری است زیرا مکانیسمی را برای جستجو و کشف داده ها و خدمات جغرافیایی آن فراهم می کند [ 1 ، 2 ].
یک مثال خوب از SDI دستورالعمل INSPIRE است، ابتکاری برای به اشتراک گذاشتن SDI مشترک در سراسر اتحادیه اروپا. هدف آن تسهیل دسترسی و قابلیت همکاری منابع و در عین حال تمرکز بر توسعه پایدار است. این دستورالعمل یک راهنمای فنی (راهنمای پیادهسازی INSPIRE ) را برای اجرای فرادادههای مکانی پیشنهاد میکند [ 3 ]. ISO 19115 را پیشنهاد می کند [ 4] به عنوان استاندارد فراداده و محدودیت هایی را در مورد نحوه پیاده سازی یا اعلام هرگونه اطلاعات مرتبط در مورد آن ارائه می کند. استاندارد خود منبع را همراه با توزیع منابع آنها توصیف می کند. هر توزیع روش متفاوتی را برای دسترسی به اطلاعات مشابه توصیف می کند و ممکن است در قالب (نوع داده)، مکان (URI) و غیره متفاوت باشد.
یک SDI به طور کامل به ابرداده های مکانی [ 5 ] متکی است. دسترسی به یک منبع فضایی به زنجیره ای از الزامات بستگی دارد. اگر تولیدکنندگان داده، فراداده خود را در این کاتالوگ ها منتشر نکنند، کاربران نمی توانند هیچ منبعی را پیدا کنند. با این حال، اگر ابرداده منتشر شده حاوی پیوندهای شکسته در اطلاعات توزیع خود باشد یا به داده های ناخواسته دیگری اشاره کند، کاربران نمی توانند هیچ منبعی را پیدا کنند. از آنجایی که هیچ مکانیزم بررسی خودکار وجود ندارد، سوابق به درستی مدیریت و نگهداری تکیه دارند [ 6 ]. بنابراین، کیفیت فراداده مکانی از دیدگاه ها و چارچوب های مختلف توسط نگهبانان، ذینفعان و محققان مورد مطالعه قرار گرفته است [ 7 ، 8 ].
نحوه ارجاع رکوردهای فراداده به مکان های توزیع خود، از طریق URI های توزیع، شرایطی را که برای مستعد بودن در معرض پوسیدگی مرجع ذکر شده است، برآورده می کند . Reference Rot [ 9 ] ترکیبی از دو مشکل را نشان می دهد: Link Rot و Content Drift . پوسیدگی پیوند (یا پیوند شکسته ) زمانی اتفاق میافتد که یک URI از زمانی که منبع منتقل شده یا حذف شده است، دیگر به نمایشهای منبع دسترسی ندارد. به عنوان مثال، یک رکورد ابرداده که دارای یک URI است که به یک سرویس نقشه وب اشاره می کند که سال ها پیش خاموش شده است، از Link Rot رنج می برد . دریفت محتوازمانی اتفاق میافتد که یک URI بازنماییهایی از منابع را برمیگرداند که منبعی را که قرار بود توسط آن URI ارجاع داده شود، نشان نمیدهند. به عنوان مثال، یک رکورد ابرداده که یک سرویس نقشه وب را توصیف می کند که URI آن اکنون به سایت یا منبع دیگری اشاره یا هدایت می کند. Content Drift از اصلاحات ساده متنی که معنای جمله را تغییر می دهد تا انواع به روز رسانی های منبع را شامل می شود.
این دو پدیده جوامع مختلف دانشگاهی از جمله مدیران کتابخانه های دیجیتال و کارشناسان وب را درگیر کرده است. تخمین های قبلی Link Rot به طور چشمگیری در بین مطالعات متفاوت است (به عنوان مثال، از مقالات STM [ 9 ]، از استنادهای وب در کتابخانه کشاورزی [ 10 ] یا پیوندهای American Political Science Review [ 11 ]).
مطالعات درباره Reference Rot بر حوزه هایی مانند استنادات مجلات دانشگاهی، متون قانونی و کتابخانه های دیجیتال متمرکز شده است. با این حال، میزان پوسیدگی مرجع در ابرداده های مکانی، تا آنجا که ما می دانیم، با جزئیات نشان داده شده در این مقاله تجزیه و تحلیل نشده است.
حوزه جغرافیایی ویژگی های خاص خود را دارد که نیازمند توسعه روش شناسی خاصی برای تحلیل آن است. تمام مطالعات Link Rot که قبلا ذکر شد، دامنه خود را به بررسی اولیه هایپرلینک شکسته بدون تجزیه و تحلیل محتوای پاسخ ها محدود می کنند. این رویکرد ساده لوحانه هنگام استفاده از ابرداده مکانی دو مشکل دارد: (1) بررسی نمی کند که آیا محتوای برگشتی با انتظارات اعلام شده در ابرداده مطابقت دارد یا خیر ( Content Drift ) و (2) هنگام برخورد با سرویس های وب فضایی، که نیاز به درک عمیق تر از پروتکل های جغرافیایی، با موارد مثبت کاذب مواجه می شود (یک پیوند منبع قابل دسترسی وضعیت خطای HTTP را برمی گرداند ) ومنفی های کاذب (یک پیوند منبع غیرقابل دسترسی وضعیت خطای HTTP را نشان نمی دهد، بلکه وضعیت HTTP OK را نشان می دهد).
در این مقاله، ما مشارکت های زیر را انجام دادیم:
-
ما روشی را برای مطالعه حضور پوسیدگی مرجع در رکوردهای فراداده فضایی پیشنهاد میکنیم که محتوای منابع پیوندی را برای بهبود رویکرد بررسی پوسیدگی پیوند ساده در نظر میگیرد و از نوع آن به عنوان شاخصی برای دریفت محتوا استفاده میکند. این روش را می توان برای سایر کاتالوگ ها نیز به کار برد.
-
ما حضور پوسیدگی مرجع را در 18054 رکورد ابرداده و 22738 URI توزیع آن از 26 خدمات کشف INSPIRE ثبت شده رسمی کشورهای اتحادیه اروپا و EFTA شناسایی و اندازه گیری کرده ایم.
-
ما فقدان رویههای خوب را در میان ناشران اجراکننده استاندارد ISO 19115 و راهنمای پیادهسازی INSPIRE بهعنوان یکی از دلایل بالقوه برای دریفت محتوا شناسایی کردهایم .
ما تجزیه و تحلیل را به یک عکس فوری ایستا از فراداده و منابع آن محدود کردهایم که در 1 سپتامبر و 3 سپتامبر 2021 گرفته شده است. از این رو، هدف ما بررسی تکامل رفرنس ریت در یک بازه زمانی مشخص نیست، بلکه حضور آن در یک زمان خاص است. لحظه از آنجایی که کاتالوگ های استفاده شده سرویس های رسمی کشف INSPIRE هستند، انتظار می رود که بهترین کیفیت را در بین همه کاتالوگ های موجود داشته باشند. بنابراین، مشکلات شناسایی شده را می توان به عنوان مسائل کلی موثر بر دسترسی به داده های مکانی در نظر گرفت. ما فقط از انواع داده ها به عنوان Content Drift استفاده می کنیمنشانگر بنابراین، هر گونه عدم تطابق دیگر بین ابرداده و منبع، مانند تاریخ، وسعت داده های مکانی و غیره، قابل تشخیص نیست. ما فقط محتوای جزئی پاسخ های HTTP را واکشی کردیم (دلایل در بخش 4.3 به تفصیل آمده است). این نشان میدهد که ابزاری که ما برای حدس زدن انواع دادهها توسعه دادهایم ممکن است با برخی از فایلهای فشرده خاص که در آن کل بدنه پاسخ برای شناسایی محتوای آن مورد نیاز است، شکست بخورد (جزئیات بیشتر در بخش 4.4 ).
بقیه این مقاله به شرح زیر سازماندهی شده است. ابتدا برخی از آثار مرتبط را در بخش 2 جمع آوری می کنیم . در بخش 3 ، ابعاد چندگانه مسئله و چالش هایی را که با آن مواجه خواهیم شد، تحلیل می کنیم. در بخش 4 ، روشی را که برای تشخیص پوسیدگی مرجع در کاتالوگهای فضایی طراحی کردهایم به همراه جزئیات آزمایش توضیح میدهیم. در بخش 5 ، نتایج اجرای بر روی کاتالوگ های واقعی را با یک تحلیل مختصر ارائه می کنیم. در بخش 6 این نتایج را مورد بحث قرار می دهیم. در نهایت، نتایج و کارهای آتی را در بخش 7 نشان میدهیم .
2. کارهای مرتبط
از همان روزهای اولیه وب، محققان دریافتند که Link Rot یکی از مشکلات بدنام آن است [ 12 ، 13 ]. مطالعات مختلفی در طول زمان بر روی مجموعههای مختلف انجام شده است: وب، ابردادههای کتابخانههای دیجیتال، مجلات الکترونیکی دانشگاهی، اسناد حقوقی، و غیره [ 6 ، 10 ، 14 ، 15 ، 16 ، 17 ، 18 ، 19 ]. آزمایشات اول درجات مختلفی از بروز پوسیدگی پیوند را گزارش کردند که از آنها متفاوت بود برای URI ها در مجلات پوست از سال 1999 تا 2004 [ 18 ]، تا برای مراجع سه ساله در مقالات ترم کارشناسی در سال 2000 [ 16 ]. اتفاق نظر در آن زمان این بود که نیمه عمر یک هایپرلینک به طور مستقیم با سن آن مرتبط است.
مطالعات دیگر بر روی علل ایجاد پوسیدگی پیوند [ 12 ، 20 ] تمرکز کردند و به این نتیجه رسیدند که دلایل این امر عبارتند از: (1) نویسندگان و متصدیان ابرداده از خطرات پوسیدگی پیوند در منابع خود آگاه نیستند. (2) فقدان خط مشی های نگهداری URI. و (3) عدم هماهنگی بین نویسندگان و متصدیان متادیتا.
رجبی فرد و همکاران [ 21 ] در سال 2009 اشاره کرد که ایجاد و ذخیره مجموعه داده های فضایی و ابرداده های آنها به طور جداگانه دو مجموعه مستقل را ایجاد می کند که باید به دقت مدیریت و به روز می شد تا آنها را همگام نگه داشت. در همان زمان، اولفت و همکاران. [ 22 ] نیاز به روشهای خودکار برای مدیریت ابردادهها را به دلیل تلاشهای انجام شده برای مدیریتها برجسته کرد. با این حال، هنگامی که منبع ارجاع شده توسط مالک کاتالوگ مدیریت نمی شود، این سیستم ها عدم همگام سازی را برطرف نمی کنند.
ادبیات مربوط به Content Drift خیلی قبل از اینکه این اصطلاح در هنگام مطالعه تکامل و پویایی محتوای وب ابداع شود شروع شد [ 23 ، 24 ، 25 ، 26 ، 27 ، 28 ]. یکی از یافتههای اصلی این بود که برخی از انواع دادهها بیشتر از انواع دیگر تغییر میکنند. به عنوان مثال، صفحات HTML بیشتر از فایل های PDF تغییر می کنند.
پروژه هایبرلینک [ 29 ] اصطلاح پوسیدگی مرجع را برای جمعآوری این دو پدیده که بر در دسترس بودن منابع مرتبط تأثیر میگذارند، معرفی کرد: پوسیدگی پیوند و دریفت محتوا . محققان مرتبط با این پروژه مطالعات را با اصطلاحات جدید ادامه دادند [ 9 ، 30 ].
نزدیکترین رویکرد برای اندازهگیری پوسیدگی مرجع در فرادادههای باز در مطالعات و سیستمهای ارزیابی کیفیت فراداده غیرمکانی یافت میشود. روشها و چارچوبها، مانند دیدهبان پورتال داده باز (ODPW) توسط Neumaier و همکاران. [ 31 ]، ارزیابی کیفیت فراداده (MQA) توسط پورتال داده اروپایی [ 32 ]، و سرویس پیوند داده مجموعه-سرویس توسط INSPIRE [ 33 ].
هر دو ODPW و MQA با ابرداده های عمومی کار می کنند که از طرح واژگان کاتالوگ داده (DCAT) پیروی می کنند [ 34 ]، واژگان RDF که برای تسهیل همکاری بین کاتالوگ های داده باز منتشر شده در وب طراحی شده است. به این معنی که هیچ یک از آنها به صورت بومی با هیچ استاندارد ابرداده مکانی مانند ISO 19115 کار نمی کنند. ODPW تجزیه و تحلیل خود را به صحت ابرداده و انطباق با استاندارد محدود می کند، بنابراین هیچ تجزیه و تحلیل رفرنس روت را انجام نمی دهد . MQA از یک درخواست ساده ساده HTTP برای بررسی Link Rot از وضعیت پیوندهای توزیع استفاده می کند، بنابراین از محدودیت های توضیح داده شده در بخش 3 رنج می برد.. هدف سرویس INSPIRE فوق الذکر ایجاد رابطه ای بین ابرداده مجموعه داده ها و سرویس هایی است که محتوای یکسانی را ارائه می دهند. برخلاف سیستم های قبلی، این سیستم با فراداده ISO 19115 کار می کند. فرآیند نیاز به دسترسی به مکان های منبع دارد. بنابراین، پیدا می کند که کدام لینک ها خراب شده اند.
Nogueras-Iso و همکاران. [ 35 ] مطالعه ای مشابه این مطالعه انجام دادند که در آن آنها پورتال داده باز با هدف کلی (غیر مکانی) دولت اسپانیا را با 22406 رکورد و 112874 توزیع تجزیه و تحلیل کردند. در این مطالعه، آنها یک تشخیص ساده پیوندهای شکسته و مقایسه اولیه انواع داده های اعلام شده و به دست آمده را، تنها بر اساس پسوند فایل منابع انجام دادند. آنها آن را پیدا کردند از URI های تجزیه و تحلیل شده شکسته و تنها منابع با نوع اعلامی خود مطابقت داشتند.
3. پوسیدگی مرجع در فراداده های مکانی
مدل داده ISO 19115 برای توصیف توزیع های فراداده به یک منبع اجازه می دهد که صفر، یک یا چند URI توزیع داشته باشد. توزیعها حاوی اطلاعاتی درباره توزیعکنندگان، مکانهای آنلاین و قالبهای آن هستند. مکان های آنلاین مکانی هستند که URI های دسترسی اعلام می شوند. فرمت ها انواع داده ها یا پروتکل های مورد انتظار را که در آنها منبع ارائه می شود، تعریف می کنند.
پوسیدگی پیوند توزیع زمانی اتفاق میافتد که URI موجود در یک توزیع خاص نمیتواند محتوایی را بازیابی کند. این به عنوان یک خطای اتصال (یعنی URI نامعتبر یا مهلت زمانی اتصال ) یا کد وضعیت خطای HTTP ( 4XX یا 5XX ) ظاهر می شود و به این معنی است که مصرف کننده نمی تواند منبع را از آن URI توزیع خاص بازیابی کند. نادیده گرفتن لینک پوسیدگی نه تنها منجر به آسیب به سودمندی URI های توزیع می شود، بلکه به خود ابرداده نیز آسیب می رساند. پوسیدگی پیوند ابرداده زمانی اتفاق میافتد که ابرداده فقط حاوی لینکهای شکسته باشد و مصرفکننده به هر طریقی شانس دستیابی به منبع را از دست داده باشد. اینرکورد ابرداده شکسته ممکن است دارای مقداری تاریخی یا بایگانی باشد، اما برای به اشتراک گذاری داده بی فایده است.
یک رویکرد ساده لوحانه استفاده از یک درخواست ساده HTTP برای تشخیص پوسیدگی لینک ممکن است برای بررسی لینک های دانلود مستقیم کافی باشد، اما ممکن است زمانی که منبع پیوند شده یک نقطه پایانی سرویس وب است که به پروتکل خاصی نیاز دارد ، موارد مثبت کاذب را گزارش کند. به عنوان مثال، سرویس های وب OGC همیشه به مجموعه ای از پارامترهای اجباری نیاز دارند که گاهی اوقات در URI های توزیع گنجانده نمی شوند. راهنمای پیادهسازی INSPIRE پیشنهاد میکند که URIهای کامل با تمام پارامترهای مورد نیاز، مانند GetCapabilities را به عنوان یک روش درج کنید. با وجود آن، مواردی را که این مورد را دنبال نمی کنند، اگر به یک نقطه پایانی سرویس کار و در دسترس اشاره کنند، به عنوان پیوندهای شکسته در نظر نمی گیریم. در این موارد، یک ساده لوحرویکرد درخواست HTTP به اشتباه Link Rot را گزارش میکند. دانستن پروتکل به ما امکان می دهد یک URI معتبر ایجاد کنیم تا دوباره در دسترس بودن سرویس را آزمایش کنیم.
علاوه بر این، از آنجایی که مشخصات OGC اجرای کدهای وضعیت پاسخ HTTP مناسب را اعمال نمی کند، برخی از پیاده سازی ها از وضعیت HTTP OK ( 200 ) برای پاسخ های خطا نیز استفاده می کنند (به عنوان مثال، خطای سرویس، در دسترس نیست، آرگومان های مورد نیاز، و غیره). همچنین لینک هایی وجود دارند که یک صفحه خالی را با وضعیت HTTP OK برمی گردانند . ما این سناریو را نامعتبر می دانیم زیرا آنها هیچ محتوایی را ارائه نمی دهند. در هر دو مورد، یک درخواست ساده HTTP فقط بر اساس کد وضعیت HTTP، پوسیدگی پیوند را تشخیص نمیدهد . در این مطالعه، ما این سناریوها را به عنوان یک دسته مورد علاقه به نام وضعیت اشتباه اشتباه در نظر خواهیم گرفت تا بتوانیم حضور آن را به عنوان یک نوع خاص از پوسیدگی لینک مورد تجزیه و تحلیل قرار دهیم..
Content Drift زمانی اتفاق می افتد که منبع بازیابی شده توسط URI با منبع مورد انتظار/اعلام شده مطابقت نداشته باشد. این عدم تطابق ممکن است معنایی (محتوا مورد انتظار نیست، معنی آن را تغییر میدهد) یا نحوی (محتوا به شکل مورد انتظار ارائه نشده است و نحوه مصرف ما را تغییر میدهد). در این مطالعه، با استفاده از قالب داده ها به عنوان شاخصی برای اندازه گیری این پدیده، بر عدم تطابق نحوی تمرکز خواهیم کرد. به این ترتیب، دریفت محتوای توزیع را به عنوان عدم تطابق بین قالب منبع مورد انتظار و قالب واقعی موجود در URI تشخیص می دهیم. دریفت محتوای فراداده زمانی اتفاق می افتد که هیچ یک از قالب های اعلام شده در هیچ یک از توزیع ها یافت نشود.
ISO 19115 یک استاندارد انعطاف پذیر است که درجه بالایی از آزادی را با طراحی اجازه می دهد، اما برای ایجاد انتظارات در مورد قالب های توزیع مشکلاتی دارد. حتی اگر SDI مانند INSPIRE محدودیتهای پیادهسازی را در راهنمای پیادهسازی خود پیشنهاد میکند، ناشران ابرداده همیشه از بهترین شیوهها پیروی نمیکنند که درک خودکار سوابق فراداده را دشوارتر میکند.
اول، استاندارد به خودی خود هیچ واژگان کنترل شده ای مانند انواع MIME [ 36 ] را برای اعلام قالب ها اعمال نمی کند. این به این معنی است که ناشران آزادند که آن اطلاعات را هر طور که میخواهند پر کنند و شناسایی خودکار آن را دشوار میکند. این امر تجزیه و تحلیل دریفت محتوا را سخت می کند، اما همچنین از مفید بودن ابرداده در سناریوهایی که کاربر می خواهد رکوردها را در قالب خاصی جستجو کند، جلوگیری می کند زیرا نمی تواند با هیچ کلمه کلیدی فیلتر شود. راهنمای پیادهسازی INSPIRE استفاده از gmx:Anchor را توصیه میکندبرای اعلام فرمت رمزگذاری با استفاده از واژگان کنترل شده تگ کنید، اما اکثر ناشران ترجیح می دهند از قسمت متن آزاد استفاده کنند. علاوه بر این، رابطه بین توزیع ها و قالب های مورد انتظار آنها به هیچ وجه اعمال نمی شود. این استاندارد هیچ نوع مکانیزم رابطه “URI-to-Format” را پیشنهاد نمی کند. تعداد انواع اعلام شده حتی نباید با تعداد توزیع ها مطابقت داشته باشد. این امر ما را از انتظار هر نوع خاصی از یک توزیع خاص باز می دارد. در نهایت، زمانی که URI به یک رسانه میانی، مانند یک صفحه وب یا یک فید اشاره می کند، ممکن است داده های بازیابی شده از URI با فرمت اعلام شده مطابقت نداشته باشد. این یک رویه رایج در بسیاری از کاتالوگ های عمومی، فضایی یا غیر فضایی است.
4. مواد و روش ها
برای اندازه گیری حضور پوسیدگی مرجع در رکوردهای فراداده فضایی و پیوندهای توزیع آن، رکوردهای به دست آمده از کاتالوگ های مختلف داده های مکانی را بررسی کردیم. به طور خاص، ما بر روی سؤالات زیر تمرکز کردیم:
-
درصد سوابق ابرداده با مسائل مربوط به رفرنس ریت چقدر است ؟
-
درصد منابع مکانی غیرقابل دسترس با استفاده از سوابق ابرداده آنها به دلیل پوسیدگی لینک چقدر است ؟
-
درصد منابع مکانی قابل دسترسی با استفاده از سوابق فراداده با توضیحات فرمت گمراه کننده به دلیل دریفت محتوا چقدر است ؟
-
درصد منابع فضایی با دسترسی غیرمستقیم (قابل دسترسی از طریق وب سایت های شخص ثالث واسطه) چقدر است؟
سوابق فراداده ISO 19115 از کاتالوگ های خدماتی که استاندارد OGC CSW را اجرا می کنند [ 37 ] جمع آوری شد. کل فرآیند شامل مراحل زیر است:
-
استخراج لینک URI هایی را شناسایی کنید که ممکن است به منبع مرجع در رکورد ابرداده دسترسی داشته باشند.
-
استخراج فرمت با توجه به رکورد ابرداده، قالب های توزیع را برای نمایش های برگشتی شناسایی کنید.
-
مرحله درخواست درخواست های HTTP را با استفاده از URI های استخراج شده انجام دهید و تخمین اولیه Link Rot را تهیه کنید.
-
فاز حدس زدن را تایپ کنید. پاسخهای موفق HTTP را تجزیه و تحلیل کنید، قالب نمایشهای برگشتی را حدس بزنید و یک تخمین اولیه از Content Drift تهیه کنید.
-
حذف مثبت کاذب و منفی کاذب . موارد بالقوه Reference Rot مثبت و منفی کاذب را شناسایی کنید و آنها را به درستی مدیریت کنید (به جزئیات در بخش 4.5 مراجعه کنید ).
-
ارزیابی پوسیدگی مرجع فراداده . پوسیدگی مرجع را در سطح فراداده با در نظر گرفتن پوسیدگی پیوند و دریفت محتوا در همه توزیعها ارزیابی کنید.
-
منبع دسترسی غیر مستقیم ارزیابی کنید که چه تعداد از منابع فقط به صورت غیر مستقیم قابل دسترسی هستند.
4.1. برداشت فراداده
مرحله اول فرآیند با به دست آوردن سوابق فراداده ای که مورد تجزیه و تحلیل قرار می گیرند آغاز شد. این رکوردها با استفاده از عملیات GetRecords از کاتالوگ هایی استخراج شده اند که نقطه پایانی OGC CSW را ارائه می دهند . این روش در کاتالوگ های مطابق با OGC CSW اجباری است. این عملیات به ما این امکان را داد که تمام رکوردهای فراداده را در یک طرحواره ابرداده معین جمع آوری کنیم. فرمت خروجی درخواستی ISO 19115 XML بود. رکوردهای فراداده بازیابی شده برای پردازش بیشتر ذخیره شدند.
4.2. استخراج لینک و فرمت
رکوردهای ذخیره شده برای استخراج هر URI توزیع بالقوه، همه فرمت های توزیع اعلام شده و تاریخ ایجاد رکورد ابرداده تجزیه شدند.
فرمت های اعلام شده در گره های gmd:distributionFormat و gmx :Anchor قرار داشتند. gmd:distributionFormat حاوی یک توضیح متن آزاد بود در حالی که gmx :Anchor حاوی یک URI بود که یک نوع داده کنترلشده یا مشخصات مدل داده را توصیف میکرد. تاریخ مورد استفاده برای تأیید جدید بودن و مرتبط بودن اسناد، در gmd:dateStamp یافت شد .
به منظور رفع فقدان واژگان استاندارد برای توصیف قالبهای توزیع، ما فهرستی از مترادفها و نامهای مستعار معروف برای قالبهای محبوب ایجاد کردیم. به این ترتیب، ما آنها را به یک لیست محدود داخلی مشترک از کلمات کلیدی عادی کردیم. برای مثال، ogc wms ، سرویس نقشه وب و ogc:wms همگی به wms نگاشت خواهند شد . این لیست بر اساس رایج ترین کلمات کلیدی موجود در رکوردهای ابرداده است. روند به دست آوردن لیست مورد استفاده در آزمایش زیر در بخش 4.7.3 به تفصیل آمده است .
برخی از رکوردهای فراداده از کلمات کلیدی مانند nd یا ناشناخته به عنوان نوع “اعلام شده” استفاده می کنند. ما این را معادل عدم اعلام چیزی میدانستیم، بنابراین آنها را نادیده میگرفتیم و در مواردی که تنها نوع «اعلام شده» هستند، این ابرداده را طوری در نظر گرفتیم که گویی چیزی را اعلام نکرده است.
4.3. مرحله درخواست
در این مرحله، یک درخواست HTTP برای هر URI توزیع استخراج شده انجام دادیم. پس از تکمیل دسترسی URI، وضعیت درخواست و بدنه پاسخ برای تجزیه و تحلیل بیشتر ذخیره شد. در وضعیت درخواست، یک کد خاص برای هر مشکل نحوی URI شناسایی شده، خرابی شبکه یا کد وضعیت HTTP ذخیره کردیم. بدنه پاسخ حاوی محتوای پاسخ خام HTTP است.
نتایج این مرحله به ما تخمین اولیهای از تعداد توزیعهای تحت تأثیر Link Rot داد زیرا خطاهای اتصال و کدهای وضعیت پاسخ HTTP ناموفق، پوسیدگی پیوند بالقوه را نشان میدهند . با این وجود، برخی از خطاها ممکن است به دلیل خرابی موقت سرویس رخ دهد. به همین دلیل، به URI هایی که به دلیل مشکلات شبکه یا سرور با شکست مواجه می شدند، یک مهلت دو روزه برای بازیابی سرویس خود قبل از تلاش دوم داده شد. این دوره مهلت بر اساس مطالعات Link Rot مشابه ذکر شده در بخش 2 بود.
اندازه منابع مکانی ممکن است از چند کیلوبایت تا صدها مگابایت متفاوت باشد. در این مرحله، ما تصمیم گرفتیم فقط 5000 بایت اول هر پاسخ را واکشی کنیم. این به این دلیل است که ابزار حدس زدن نوع که در فاز بعدی استفاده کردیم بر اساس تشخیص عدد جادویی [ 38 ] است. این تکنیک تنها به کسری از فایل نیاز دارد تا امضای فایل آن را شناسایی کند و ما 5000 بایت برای اکثر موارد کافی پیدا کرده ایم. جزئیات در مورد نحوه عملکرد ابزار حدس زدن نوع و چگونگی تأثیر آن توسط این محدودیت 5000 بایت در بخش 4.4 و بخش 4.5.2 توضیح داده شده است .
4.4. فاز حدس زدن را تایپ کنید
در این مرحله، محتوای پاسخهای HTTP را برای هر URI توزیع با استفاده از ابزار Libmagic برای حدس زدن فرمت فایل آن تحلیل کردیم. سپس قالب فایل استنباط شده را به واژگان کنترل شده خود نگاشت کردیم (به بخش 4.2 مراجعه کنید ) تا بتوانیم آن را با لیست موارد مورد انتظار اعلام شده در فراداده مقایسه کنیم.
Libmagic با بسیاری از انواع داده های پشتیبانی شده (مانند HTML، PDF، PNG) کار می کند. با این حال، برای شناسایی فرمتهای دامنه فضایی خاص (یعنی GML، GeoJSON، OGC WMS قابلیتهای) استراتژیهای مختلفی را اعمال کردیم.
هنگامی که قالب حدس زده XML، HTML یا متن ساده است، ابتدا سعی کردیم آنها را به عنوان XML تجزیه کنیم و در صورت موفقیت، به دنبال گرههای XML و فضاهای نام XML خاصی گشتیم که نوع آن را نشان میدهند. ما همچنین سعی کردیم الگوهای متنی شناخته شده دیگری را شناسایی کنیم که فرمتهای فضایی دیگر مانند GeoJSON را نشان میدهند. در نهایت، ما سعی کردیم برخی از پیامهای خطای رایج OGC را که اکثر پیادهسازیهای سرویس OGC باز میگردانند، شناسایی کنیم. همانطور که در بخش 4.5 بعدی توضیح داده شد، این ضروری و مفید است .
الگوریتمهای فشردهسازی مانند ZIP به ما این امکان را میدهند که اولین بایتهای یک فایل را بدون داشتن کل محتوا از حالت فشرده خارج کنیم (فشردهسازی جریان). این به Libmagic اجازه می دهد تا شماره جادویی یک فایل فشرده را حتی در صورت دانلود جزئی تشخیص دهد. با این حال، اگر آرشیو فشرده حاوی بیش از یک فایل باشد، فقط اولین فایلها قابل شناسایی هستند. به عنوان مثال، اگر محتوای آن را از حالت فشرده خارج کرده و هدر یک .shp را پیدا کنیم، میتوانیم یک فایل شکل فشرده ESRI را تنها با استفاده از 5000 بایت اول در یک فایل ZIP شناسایی کنیم.فایل. با این حال، اگر فایل ZIP حاوی محتویات پیوست دیگری مانند اسناد PDF باشد که قبل از Shape Files اضافه شدهاند، اولین بایتها ممکن است فقط برای شناسایی پیوستها کافی باشد اما نه فایلهای فضایی. علاوه بر این، ما از این واقعیت استفاده کردیم که ZIP شامل نام فایلها به عنوان متن ساده است تا به دنبال پسوند فایل خاص بگردیم تا تشخیص نوع را تقویت کنیم.
در مواردی که این استراتژیها برای تشخیص نوع فایلهای فشرده کافی نبود، ما آنها را بهعنوان «موردهای خاص» علامتگذاری کردیم و در مرحله بعد به آنها پرداختیم (به بخش 4.5.2 مراجعه کنید ).
نتایج این مرحله میتواند تخمین اولیهای از تعداد توزیعهایی که از Content Drift رنج میبرند به ما بدهد، وقتی آنها را با انواع اعلام شده استخراج شده در بخش 4.2 مقایسه میکنیم. ما می توانیم مستقیماً این کلمات کلیدی را با هم مقایسه کنیم زیرا از واژگان کنترل شده یکسانی استفاده می کنیم.
4.5. موارد خاص فضایی
در بخش 3 توضیح دادیم که چگونه یک رویکرد سادهلوحانه برای اندازهگیری پوسیدگی مرجع ممکن است نتایج اشتباهی را برای کاتالوگهای فراداده مکانی گزارش کند. در این مرحله روش های مورد استفاده برای مدیریت این موقعیت ها را توضیح می دهیم.
4.5.1. URI های سرویس ناقص
یک مورد رایج از Link Rot مثبت کاذب ممکن است زمانی اتفاق بیفتد که URI توزیع فقط حاوی یک نقطه پایانی وب سرویس OGC باشد که برخی از پارامترهای اجباری را از دست داده است. از آنجایی که استاندارد OGC حداقل یک تابع GetCapabilities را اجرا می کند ، می توانیم یک درخواست GetCapabities بسازیم تا URI هایی را که قبلاً به عنوان خطاهای OGC در مرحله حدس زدن نوع شناسایی کرده بودیم بررسی کنیم. سپس، URI های جدید دوباره درخواست و حدس زدند.
4.5.2. اعلانات نوع داده های غیر منطبق
موارد مثبت کاذب Content Drift ممکن است زمانی اتفاق بیفتند که ما نتوانیم تضمین کنیم که مشکلی وجود دارد، حتی اگر انواع آنها مطابقت نداشته باشند (زمانی که “محتوای غیرقابل تصمیم گیری” دارند). این موارد باید به صورت جداگانه شناسایی شوند تا بتوانیم آنها را به درستی مدیریت کنیم:
-
پورتال های وب HTML متوسط یا فیدهای Atom. یعنی، متادیتا gml را اعلام کرد و URI توزیع، یک صفحه وب html را که ممکن است حاوی یک پیوند مستقیم به منبع باشد (یا نه) بازگرداند.
-
ترکیبی از خدمات وب و فرمت های داده های مکانی سازگار. یعنی، متادیتا wms را اعلام کرد و URI توزیع یک png برگرداند .
-
URI توزیع یک فایل فشرده را برگرداند که نوع محتوای آن را نمی توانستیم حدس بزنیم. یعنی URI توزیع یک gml فشرده را برگرداند که به جای gml به عنوان zip شناسایی شد .
-
هر توزیعی که نوع آن xml حدس زده شد ، اما ما نمیتوانیم طرح واره را مشخص کنیم. این برخی از نتایج حاشیهای مانند خطاهای OGC شناسایی نشده یا سایر قالبهای پشتیبانینشده را پوشش میدهد که نمیتوانیم اطمینان حاصل کنیم که نتیجه مورد انتظار نبوده است.
ما یک استراتژی برای شناسایی جفت انواع داده های اعلام شده و حدس زده شده طراحی کرده ایم که ممکن است صحیح باشند. این بر اساس لیستی با نوع هدف و انواع مطابق بالقوه مجاز آنها است. جدول 1 موارد موجود و تصمیمات مربوطه را نشان می دهد. این روش اولین مورد تطبیق را با ارزیابی از بالا به پایین میگیرد. فرقی نمی کند که نوع هدف، نوع اعلام شده باشد یا حدس زده. یعنی همان قانون یک gml اعلام شده را با یک سرویس wfs حدس زده و یک سرویس wfs اعلام شده را با یک gml حدس زده مطابقت می دهد ، بنابراین برای هر دو تصمیم یکسان گرفته می شود.
شایان ذکر است که شامل جفت WMS – GML به عنوان یک مورد غیرقابل تصمیم گیری است. حتی اگر WMS در درجه اول یک سرویس تصویر است، می تواند GML را از طریق روش GetFeatureInfo ارائه دهد. ما اعلام یک سرویس WMS با فرمت GML را خوب در نظر نگرفتیم، اما نمیتوانیم بگوییم که این سرویس نادرست است.
4.5.3. وضعیت OK اشتباه است
قبلاً اشاره کردیم که برخی از پیادهسازیهای خدمات OGC به اشتباه یک کد وضعیت HTTP OK را حتی زمانی که محتوا خطایی را نشان میدهد، برمیگرداند. ما موقعیتهایی را که خطای OGC در مرحله حدس زدن نوع شناسایی شده بود، به عنوان وضعیت تأیید اشتباه در نظر گرفتیم. وضعیت HTTP خطا را نشان نمی دهد. و توزیع با GetCapabilities URI جدید نیز در تلاش مجدد ناموفق بود. ما همچنین پاسخهای خالی را که کد وضعیت HTTP OK را برمیگرداند، به عنوان وضعیت تأیید اشتباه در نظر گرفتیم.
4.6. تجزیه و تحلیل پوسیدگی مرجع فراداده
تجزیه و تحلیل قبلی معیارهای پوسیدگی مرجع را در هر URI توزیع ارائه می دهد. با این وجود، هر توزیع نشان دهنده راه متفاوتی برای بدست آوردن همان منبعی است که در ابرداده توضیح داده شده است. این بدان معناست که تجزیه و تحلیل کل رکورد فراداده نه تنها باید وجود مسائل فردی، بلکه تأثیر مشترک آنها را نیز در نظر بگیرد.
با توجه به Link Rot ، یک رکورد ابرداده تخریب شده با حداقل یک URI توزیع معتبر همچنان باید بتواند به نحوی دسترسی به منبع توصیف شده را فراهم کند. بدترین حالت زمانی اتفاق می افتد که منبع به طور کامل از بین برود زیرا همه URI های توزیع آن خراب شده اند.
در مورد دریفت محتوا ، سناریوها بسیار متنوعتر هستند. از دیدگاه قابلیت استفاده و قابلیت همکاری، یک نوع اعلام شده که در هیچ توزیعی ارائه نمی شود بسیار بدتر از توزیعی است که نوع آن به درستی اعلام نشده است. دلیل آن این است که توزیع «اضافی» که نوع آن اعلان نشده است، از قابلیت همکاری سود نمی برد، اما هیچ انتظاری را نیز بر هم نمی زند. از سوی دیگر، زمانی که یک نوع اعلام شد، انتظار داشتیم حداقل یک توزیع را پیدا کنیم که در خدمت آن نوع باشد. به همین دلیل است که میخواهیم انواع اعلامشدهای را که توسط هیچ یک از URIهای توزیع قابل دسترسی ارائه نشدهاند، مورد هدف قرار دهیم.
ما هر رکورد ابرداده را بر اساس ترکیبی از تحلیل پوسیدگی پیوند و دریفت محتوا در سراسر فراداده طبقه بندی کردیم ( شکل 1 را ببینید ). این به ما امکان داد تا وضعیت رکوردها را تجزیه و تحلیل کنیم و یک نمای کلی از هر مجموعه ابرداده به دست آوریم. دسته بندی های اصلی عبارتند از:
-
منبع پیدا شد: رکورد دارای حداقل یک URI مستقیماً قابل دسترسی است و نوع آن به درستی اعلام شده است.
-
بدون دسترسی مستقیم: رکورد دارای حداقل یک URI قابل دسترسی است اما هیچ یک از آنها دسترسی مستقیم به منبع را فراهم نمی کند.
-
داده های بیشتر مورد نیاز: هر یک از سناریوهای توضیح داده شده در بخش 4.5.2 را پوشش می دهد که در آن اطلاعات موجود برای دادن پاسخی قوی در مورد وضعیت فراداده کافی نیست.
-
Content Drift : هیچ یک از انواع اعلام شده با انواع موجود در URIهای قابل دسترسی مطابقت ندارد.
-
بدون انتظار: رکورد هیچ نوع داده ای را اعلام نمی کند.
-
پوسیدگی پیوند : همه URI ها خراب هستند.
-
بدون پیوند: منبع URI ندارد.
برخی از دسته ها برای پوشش سناریوهای خاص به زیر دسته تقسیم می شوند. دسته منبع یافت شده بر اساس تعداد فرمت های اعلام شده در دسترس تقسیم می شود:
-
بدون واپاشی ابرداده: همه فرمت های اعلام شده در توزیع های قابل دسترسی موجود هستند.
-
فروپاشی برخی فراداده ها: برخی، اما نه همه، فرمت های اعلام شده در توزیع های قابل دسترس در دسترس هستند. لازم به ذکر است که این دسته را نمی توان برای رکوردهای ابرداده تنها با یک توزیع اعمال کرد.
دسته بدون دسترسی مستقیم مشخص می کند که آیا رسانه میانی:
-
صفحه وب: یک صفحه HTML که ممکن است حاوی یک URI برای منبع باشد.
-
فید وب: یک Atom یا RSS که ممکن است حاوی یک URI برای منبع باشد.
دسته اطلاعات بیشتر مورد نیاز شامل موارد زیر است:
-
فایل فشرده شناسایی شد: برخی از توزیعها فایل فشردهای را ارائه کردند که محتوای آن شناسایی نشد. این بدان معنی است که ممکن است حاوی منبعی باشد که با نوع اعلام شده مطابقت دارد.
-
سرویس شناسایی یا اعلام شد: برخی از سرویسهای OGC اعلام شدهاند و یک نوع داده سازگار در برخی توزیعها موجود است. همچنین شامل مواردی می شود که یک نوع داده سازگار اعلام شده است و قابلیت های سرویس در یک توزیع موجود است.
-
XML شناسایی شد: برخی از توزیعها یک فایل XML را ارائه کردند که طرحواره آن قابل شناسایی نبود. این سناریو انواع داده ها و طرحواره هایی را پوشش می دهد که در طراحی آزمایش در نظر گرفته نشده اند.
طبقه بندی Content Drift بر اساس علت عدم تطابق تقسیم می شود:
-
فقط اعلامیه های ناشناخته: هیچ یک از قالب های اعلام شده قابل شناسایی نیستند. این زمانی اتفاق میافتد که توضیحات متن ناشناخته یا نامشخص باشد.
-
انتظار ناموفق: هیچ یک از منابع قابل دسترسی با هیچ یک از قالب های اعلام شده شناسایی شده مطابقت ندارد.
دسته Link Rot بر اساس انواع خطا تقسیم می شود:
-
درخواست HTTP شکست: همه URI ها خراب هستند اما برخی از آنها یک پاسخ خطای HTTP را از سرور دریافت کردند.
-
اتصال ناموفق: همه URI ها خراب هستند و هیچ کدام موفق به اتصال به هیچ سروری نمی شوند.
4.7. آزمایش کنید
4.7.1. مجموعه فراداده
برای این آزمایش، ما از 26 مورد از 35 خدمات کشف INSPIRE ثبت شده رسمی کشورهای اتحادیه اروپا و EFTA در INSPIRE Geoportal ( https://inspire-geoportal.ec.europa.eu/harvesting_status.html ، قابل دسترسی در 1 سپتامبر 2021) استفاده کردیم.
ما این کاتالوگ ها را انتخاب کردیم زیرا برای مطابقت با دستورالعمل INSPIRE نگهداری و نگهداری می شوند، بنابراین انتظار می رود کیفیت بالایی داشته باشند. با این وجود، برخی از کاتالوگهای فهرستشده به دلیل مشکلات دسترسی یا تفاوتهای بزرگ در سیاستهای ابرداده که با اندازه کاتالوگ یا برخی روشهای دیگر مشخص میشود، گنجانده نشدند. یکی از نمونههای این موارد مشکلساز، کاتالوگ ایتالیایی است که به اندازه همه کاتالوگهای دیگر با هم، رکوردهای فراداده را منتشر کرد. همچنین برخی از روشها را اعمال کرد که نتایج را بهطور چشمگیری تحریف کرد، مانند فهرست کردن 7717 رکورد ابرداده مختلف که به یک URI سرویس OGC WMS اشاره میکردند و آن را به درستی اعلام نکردند. کاتالوگ های انتخاب شده در جدول A1 فهرست شده اند .
از 26 کاتالوگ جمع آوری شده، تجزیه و تحلیل 18054 رکورد ابرداده از تولیدکنندگان مختلف با مجموع 22738 لینک مختلف پیدا کرد. فرآیند استخراج بین 1 سپتامبر تا 3 سپتامبر 2021 اجرا شد.
4.7.2. تعداد توزیع و چشم انداز زمانی
از آنجایی که هر رکورد ابرداده می تواند صفر، یک یا چند URI توزیع داشته باشد، ما تعداد توزیع های ارائه شده توسط هر رکورد ابرداده را تجزیه و تحلیل کردیم. نتایج را می توان در جدول 2 مشاهده کرد. رایج ترین مورد یک رکورد ابرداده است ( ) با یک URI توزیع. بعد، دومین مورد رایج، یک رکورد ابرداده است ( ) با 7 URI توزیع. این به این دلیل است که کاتالوگ بلژیکی (فلاندرز) دارای بیش از 3500 رکورد ابرداده با این ویژگی است. سپس، ما داریم رکوردهای فراداده ای که بین 2 تا 6 دارند. و که 8 یا بیشتر دارند. موارد پرت نیز وجود دارد. به عنوان مثال، یک رکورد ابرداده در کاتالوگ کاتالوگ لوکزامبورگ شامل 422 URI توزیع است. سرانجام، رکوردهای فراداده دارای توزیع صفر هستند.
با تجزیه و تحلیل تاریخ سوابق می بینیم که اکثر آنها جدید هستند. سابقه کمتر از 4 سال (2018) ), 2019 ( ), 2020 ( ), 2021 ( )). کمتر از رکوردهای فراداده بیش از 10 سال پیش ایجاد شد.
4.7.3. انواع داده های اعلام شده
همانطور که در بخش 4.2 توضیح داده شد ، برای ایجاد مقایسه بین انواع، مجموعه ای از تعاریف نوع زبان طبیعی کنترل نشده را با یک کلمه کلیدی کنترل شده مرتبط کرده ایم. با استفاده از رایج ترین کلمات کلیدی یافت شده، به پوشش عالی همه موارد دست یافتیم: کمتر از موارد کنترل نشده در استنتاج نوع (نگاه کنید به جدول A2 ) و موارد کنترل نشده ( OTHER ) در اظهارنامه های نوع. بسیاری از انواع کنترل نشده، نه تنها به دلیل تنوع کلمات کلیدی برای بیان قالب یکسان، بلکه به دلیل عبارات عمومی یا مبهم مورد استفاده، شناسایی نشدند. اگر ناشران فراداده از مکانیسم پیشنهادی راهنمای پیاده سازی استفاده کنند، این مشکل حل می شود . چند نمونه از اعلامیه های گیج کننده:
-
” vettoriale ” 649 بار در کاتالوگ ایتالیایی استفاده شده است .
-
“aaa” 178 بار در کاتالوگ دانمارکی استفاده شده است .
-
“volgens afspraak ” (طبق قرار ملاقات) 101 بار در کاتالوگ دانمارکی استفاده شده است .
-
“آنلاین ” 79 بار در کاتالوگ اتریش استفاده شده است .
-
در کاتالوگ بریتانیا : «سیستم اطلاعات جغرافیایی» (44 بار)، «کاغذی» (32 بار) و «دیجیتال» (32 بار). در کل، کاتالوگ دارای بیش از 500 اعلان متن مختلف است.
5. نتایج
این بخش نتایج اجرای فرآیند تحلیل را تشریح می کند.
5.1. پوسیدگی پیوند
جدول 3 تعداد کد وضعیت پاسخ دقیق برای هر URI توزیع منحصر به فرد را نشان می دهد. منظور ما از منحصر به فرد این است که یک URI که در دو رکورد ابرداده مختلف ظاهر می شود، دو بار شمارش نمی شود.
این نشان می دهد که تنها از توزیع ها در دسترس هستند، در حالی که بقیه از پوسیدگی لینک رنج می برد . رایج ترین خطاهای HTTP عبارتند از 404 Not Found و 500 Server Error . رایج ترین خطاهای غیر HTTP خطای اتصال و زمان خواندن است. از URI ها یک کد وضعیت HTTP OK را برمی گرداند در حالی که محتوای منبع یک خطای OGC را نشان می دهد (به بخش 4.5.3 مراجعه کنید ).
از آنجایی که رکوردهای ابرداده ممکن است بیش از یک توزیع داشته باشند، باید بررسی کنیم که چگونه رکوردها تحت تأثیر Link Rot قرار می گیرند . نتایج نشان می دهد که تنها از رکوردها همه پیوندهای آن قابل دسترسی است، در حالی که دیگر برخی از آنها شکسته است باقیمانده دسترسی به هیچ منبعی را فراهم نکنید زیرا: (1) آیا تمام URI های آن خراب شده است ( ) یا وضعیت OK اشتباه داشت ( ), (2) هیچ توزیعی ندارند این درصدها حتی بیشتر خواهند شد اگر ما تصمیم به حذف آن بگیریم رکوردهای بدون پیوندهای توزیع از محاسبه.
5.2. انواع منابع
جدول 4 انواع توزیع به دست آمده در فرآیند حدس نوع را نشان می دهد. جدول دقیق تر را می توان در جدول A2 یافت . این فقط منابعی را شمارش میکند که کد وضعیت HTTP OK را دریافت کردهاند ، حتی اگر فرآیند تمام پاسخها را برای تشخیص مثبت کاذب تجزیه و تحلیل کرد (مجموعاً 20687 منبع).
دومین خانواده رایج “صفحه متوسط” است ( ) که نمایانگر صفحات HTML همانطور که در بخش 3 توضیح داده شده است. دسته “تصمیم ناپذیر” شامل منابع فشرده غیرقابل حدس زدن است ( )، فایل های XML با طرحواره کنترل نشده ( ) و سایر فایل های ناشناخته ( ). دسته بندی وضعیت OK اشتباه اضافه می شود از رکوردهای حدس زده شده ترکیبی از خطاهای OGC و چند پاسخ خالی . بقیه انواع داده ها، همانطور که انتظار می رود، مجموعه داده های مکانی و خدمات هستند.
5.3. مرجع پوسیدگی حضور در طول زمان
شکل 2 حضور پوسیدگی پیوند و دریفت محتوا را در طول زمان بر اساس تاریخ های استخراج شده از ابرداده ها نشان می دهد. دسته بندی های شناسایی شده به شرح زیر است:
-
All Link Rot : رکوردها فقط دارای توزیع شکسته هستند (از جمله وضعیت OK اشتباه ).
-
برخی از پوسیدگی پیوندها : رکوردها دارای تعدادی توزیع شکسته هستند (از جمله وضعیت OK اشتباه ).
-
All Content Drift : همه توزیعها قابل دسترسی هستند، اما هیچ یک از انواع اعلام شده آن ارائه نمیشوند.
-
با مسائل: برخی از انواع اعلام شده ارائه نمی شوند، یا رکوردها دارای توزیع های غیرقابل تصمیم گیری هستند.
-
Perfect: همه URI های توزیع قابل دسترسی هستند و همه انواع اعلام شده آنها ارائه می شود.
می بینیم که حتی جدیدترین ها نیز درصد قابل توجهی از مسائل Reference Rot را دارند. اگر شاهد تکامل Link Rot در 4 سال گذشته باشیم، رکوردهایی که فقط لینک های شکسته دارند کاهش یافته است. در سال 2018 به در سال 2021. حضور کلی Link Rot نیز کاهش یافت در سال 2018 به در سال 2021. این با کار مرتبطی که نشان میدهد خطر پیوند پوسیدگی مربوط به سن سند است، موافق است. نتیجه جالب دیگر این است که رکوردهای سال 2021 دسترسی آن را به طور چشمگیری بهبود بخشیده است آنها نه پیوندهای شکسته دارند و نه انواع اشتباه اعلام شده ( رکوردهای کامل )، در مقایسه با بقیه سال هایی که هرگز از آنها پیشی نگرفته اند. . همچنین میتوانیم شاهد روند رو به رشدی در تعداد رکوردهایی باشیم که URIهای توزیع را ارائه میکنند. تعداد رکوردهای بدون توزیع کاهش می یابد در سال 2010 به در سال 2021. در نهایت، شایان ذکر است که در سال 2017، نتایج فوق العاده خوبی وجود دارد. این را می توان توضیح داد زیرا از این سال فقط 330 رکورد از 9 کاتالوگ وجود دارد.
5.4. پوسیدگی مرجع گسترده فراداده
شکل 3 مقولههای پوسیدگی مرجع در سراسر فراداده را نشان میدهد که قبلاً در بخش 4.6 تعریف کردیم .
می توانیم این را بیان کنیم از سوابق فراداده برخی از انواع منابع اعلام شده خود را ارائه می دهند ارائه همه آنها این بدان معنی است که آنها بالاترین درجه همکاری را دارند و حتی یک عامل کاربر مستقل می تواند این منابع را در قالب مورد انتظار فقط از رکورد ابرداده کشف کرده و به آنها دسترسی داشته باشد.
اگر متادیتا را در نظر بگیریم که ممکن است دسترسی غیرمستقیم را فراهم کند ( ( ) که هر دو با هم جمع می شوند ، بهترین سناریو به پتانسیل افزایش می یابد سوابق پیدا کرد این بدان معنی است که فقط در اطراف رکوردهای فراداده ممکن است حداقل یکی از انواع اعلام شده خود را ارائه دهند. دیگری در ادامه تحلیل خواهد شد.
از رکوردها اصلاً هیچ پیوند توزیعی وجود ندارد. این نشان می دهد که هدف ابرداده ها توزیع عمومی منبع نیست. از سوابق هیچ نوع داده ای را اعلام نکردند اما حداقل یک لینک قابل دسترسی را ارائه کردند. این باعث می شود که انتظار چیزی در مورد نوع منابع غیرممکن باشد.
باقیمانده رکوردها متعلق به Link Rot مناسب هستند ( ) و دریفت محتوا ( ) پدیده هایی که به طور گسترده در این مقاله توضیح داده شده است. از رکوردهای ابرداده با تمام URI های شکسته شده: (1) حداقل یک پیوند داشته باشید که موفق به اتصال به یک سرور شود. (2) هیچ پیوندی وجود ندارد که موفق به اتصال به چیزی شود. و (3) حداقل یک پیوند داشته باشید که وضعیت HTTP OK دریافت کرده باشد اما محتوای آن وضعیت تأیید اشتباه را نشان دهد . از آن سوابق فراداده تحت تأثیر Content Drift : (1) انواع متفاوت از موارد ارائه شده را اعلام کرد. و (2) آنها را به گونه ای اعلام کرد که نتوانستیم آنها را شناسایی کنیم.
جدول A3 نتایج را برای هر کاتالوگ جداگانه تجزیه می کند. این نشان میدهد که هر کدام از روشها و سیاستهای فراداده خود را دارند و هر استراتژی به طور متفاوتی بر دسترسی به دادههای آن تأثیر میگذارد.
به عنوان مثال، کاتالوگ Lettish و کاتالوگ بلژیک (والونیا) به سختی هیچ نوع داده ای را اعلام کردند ( و به ترتیب سوابق). این ما را از داشتن هر گونه انتظاری باز می دارد و نشان می دهد که نسبت به دیگران علاقه کمتری به اشتراک گذاری داده های باز داریم . کاتالوگ بلغاری دارد رکوردهای بدون نوع اعلام شده زیرا اکثر رکوردهای فراداده ناشناخته را به عنوان تنها نوع داده توزیع اعلام می کنند.
برخی از کاتالوگ ها مانند کاتالوگ رومانیایی ، کاتالوگ بلژیکی (فدرال) و کاتالوگ سوئیس شامل بین و رکوردهایی با URI های توزیع صفر، که نشان دهنده علاقه کمتر به اشتراک گذاری داده ها نیز می باشد.
کاتالوگ هایی با رکوردهای شکسته بیشتر عبارتند از کاتالوگ بلژیک (بروکسل) و کاتالوگ لهستانی با و ، به ترتیب.
کاتالوگ لیختن اشتاینر بالاترین درصد سوابق دسترسی غیرمستقیم را دارد ( ). این به این دلیل است که فقط شامل 20 رکورد و 14 مورد از 20 صفحه HTML مرجع موجود است. با این حال، کاتالوگ های دیگر مانند کاتالوگ ایرلندی ، کاتالوگ بریتانیا یا کاتالوگ سوئیس نیز دارای درصد بالایی از منابع غیر مستقیم در دسترس هستند (بین و ).
کاتالوگ هایی که دارای بالاترین درصد منابع به خوبی اعلام شده و در دسترس هستند، معمولاً در اکثر رکوردهای خود از الگوهای یکسانی پیروی می کنند.
-
کاتالوگ بلژیکی (فلاندرز) که بزرگترین مجموعه است، دارای حدود 4300 (از 6648) رکورد است که منجر به خدمات wfs می شود که به عنوان gml اعلام شده است .
-
کاتالوگ لیتوانیایی بیشتر از سه نوع منبع استفاده می کند : wms ، shp و gml .
-
کاتالوگ یونانی فقط شامل 80 رکورد است: همه موارد قابل دسترس خدمات wfs بودند که gml را ارائه میکردند .
5.5. دسترسی غیر مستقیم
بخش 5.4 نشان داد که حداقل سوابق ابرداده ممکن است فقط دسترسی غیرمستقیم به منابع خود را به عنوان یک صفحه وب HTML فراهم کند. از آنجایی که هر رکورد ابرداده فقط می تواند یک دسته را دریافت کند، درصد ممکن است حتی بیشتر باشد.
ما به طور خاص حضور صفحات وب HTML را به عنوان توزیع در ابرداده مطالعه کرده ایم. نتایج نشان می دهد که (1) فقط به منابع HTML اشاره کنید. (2) به یک یا چند منبع HTML اشاره می کند، اما به منابعی از نوع متفاوت نیز اشاره می کند. (3) به هیچ منبع HTML اشاره نکنید (این شامل 6.30٪ با ابرداده Rot پیوند از بخش 5.1 است)، و (4) هیچ توزیعی ندارند
ما می توانیم آن را ببینیم از رکوردهای فراداده حداقل یک منبع HTML مرتبط است. این وضعیت ممکن است برای یک انسان کافی باشد، اما یک عامل کاربر مستقل نیاز به منطق پیچیده تری برای مرور آن صفحات HTML و یافتن منبع فضایی مورد نظر (در صورت وجود) دارد.
6. بحث
ادبیات SDI همیشه تاکید می کند که کاتالوگ فضایی یک جزء ضروری برای کشف و اشتراک مجموعه داده ها و خدمات است. در این مطالعه ما به مواردی اشاره کردهایم که سودمندی وضعیت فعلی کاتالوگها را برای کشف و دسترسی به منابع فضایی توصیفشده زیر سوال میبرد.
ما دریافتیم که ابرداده تحت تأثیر Link Rot نمی تواند به منبع آن دسترسی داشته باشد. این بدان معناست که کاتالوگ ها منابع تبلیغاتی هستند که نمی توانند ارائه کنند. حتی در کاتالوگهایی که به خوبی مدیریت شدهاند با سوابق اخیر، مانند مواردی که در این مقاله تحلیل شدهاند، بیش از از URI های توزیع شکسته شد و در نتیجه بیش از سوابق فراداده ای که دسترسی کامل به منبع خود را از دست داده اند. میزان حضور Link Rot در سوابق سالهای گذشته (2020-2021) نشان میدهد که میانگین عمر برخی منابع کوتاهتر از آن چیزی است که ما انتظار داشتیم. ما همچنین از روند رو به رشد Link Rot با قدیمی شدن ابرداده ها قدردانی می کنیم. با این حال، نمیتوانیم آن را با یک تحلیل زمانی تأیید کنیم ( برای جزئیات بیشتر به بخش 7 مراجعه کنید).
نتایج نشان میدهد که بررسی پوسیدگی پیوند ساده به دلیل ماهیت سرویسهای فضایی که موارد مثبت کاذب و منفی کاذب را گزارش میکنند ، زمانی که محتوا در نظر گرفته نمیشود، کافی نیست. موارد مثبت کاذب را می توان با استفاده از URI کامل GetCapabilities به جای نقطه پایانی که در راهنمای پیاده سازی پیشنهاد شده است، برطرف کرد . برای رفع علت اصلی منفیهای کاذب ، پیادهسازیهای سرویس OGC تحت تأثیر باید از کدهای وضعیت پاسخ HTTP مناسب استفاده کنند. حتی زمانی که آنها مشخصات OGC را نقض نمی کنند، از نظر ترکیب استاندارد نادرست هستندهمانطور که آنها روی پروتکل HTTP نیز کار می کنند.
همچنین نکته جالب توجه این است که از رکوردها هیچ نوع منبعی را اعلام نکرده است. این نشان می دهد که ناشران از مفید بودن آن برای اهداف کشف آگاه نیستند. حتی اگر فرض کنیم که از عدم دسترسی مستقیم و اطلاعات بیشتر مورد نیاز سوابق به درستی اعلام شد، آن را به ما می گذارد رکوردهای بدون تطابق یا انواع اشتباه اعلام شده. چنین مسائلی مانع دسترسی به منابع نمی شود، اما ممکن است بر نحوه مصرف آنها تأثیر بگذارد. زمانی که عامل کاربری که سعی در دسترسی به منبع دارد، یک انسان نیست، بلکه یک سیستم مستقل مانند خزنده باشد، این اثر بدنامتر است.
حدود یک سوم از رکوردهای فراداده حداقل یک صفحه HTML را به عنوان رسانه توزیع غیرمستقیم در خود داشت آنها را منحصراً داشته باشید. این لایه اضافی غیرمستقیم نشان میدهد که مصرفکننده باید URI توزیع مؤثر را مرور کرده و کشف کند (گاهی اوقات این کار زمانی که کمبود زمینه وجود دارد دشوار است). همچنین وضعیت URI توزیع نهایی را مخفی می کند، بنابراین ممکن است وقتی منبع خاموش است اما صفحه بالا است، منفی های غلط Link Rot را گزارش کند. چه پیوند موجود در پیوند فراداده یا پیوند در رسانه میانی از کار بیفتد، پیوند خراب خواهد شد. همچنین یک مانع دسترسی برای انسان های غیرمتخصصی که به کاتالوگ و عوامل کاربر خودکار دسترسی دارند، فرض می کند.
در بخش 3 روشی را که ISO 19115 توزیع های خود را اعلام می کند توضیح دادیم. ما اشاره کردیم که آزادی در مدل داده آن همراه با فقدان شیوه های خوب در میان ناشران ابرداده منجر به تجربه ناخوشایندی در هنگام تلاش برای کشف، یافتن و دسترسی به منابع مکانی می شود. در بخش 4.7.3 ، شاهد عدم وجود اعلانهای نوع سازگار در میان برخی از دادههای منتشر شده بودیم. اعلان انواع داده های منبع بدون واژگان استاندارد، جستجو یا فیلتر کردن منابع را در یک قالب خاص دشوار می کند. علاوه بر این، عدم اعلام فرمت هر توزیع منفرد، تعیین اینکه کدام یک از توزیعها را میخواهیم غیرممکن میکند یا ادعا میکنیم که محتوا مطابق انتظارات است.
اصل Go FAIR A1 [ 39 ] “اجزای شامل مداخله دستی انسان” را به عنوان یکی از موانع دسترسی که یک سرویس باز باید از آن اجتناب کند، مگر اینکه به شدت ضروری باشد (در موارد مربوط به اطلاعات محرمانه) توصیف می کند. رسانه های متوسط با این توصیف مطابقت دارند. آنها همچنین تاکید می کنند که حتی زمانی که منبعی آزادانه در دسترس نیست، مطلوب است که “یک ماشین بتواند به طور خودکار الزامات را درک کند و سپس یا به طور خودکار الزامات را اجرا کند یا به کاربر در مورد نیازها هشدار دهد”.
نتایج تفکیک نشان داد که هر سازمان قوانین خود را تفسیر می کند و سیاست های خود را اعمال می کند. حداقل درجه تنوع مثبت است زیرا به هر موسسه اجازه می دهد تا گردش کار خود را تطبیق دهد، اما مازاد آن به طور چشمگیری بر قابلیت همکاری داده ها تأثیر می گذارد. وقتی استاندارد ISO 19115 را با سایر استانداردهای ابرداده مانند واژگان DCAT مقایسه می کنیم، می بینیم که چگونه آنها این اطلاعات را واضح تر می کنند. DCAT از فیلدهای توزیع مختلف برای تشخیص اینکه آیا URI به یک سرویس ( dcat:accessService )، یک پیوند مستقیم به یک مجموعه داده ( dcat:downloadURL )، یا یک پیوند به یک پورتال میانی یا فرم وب که به منبع دسترسی می دهد ( dcat ) اشاره می کند استفاده می کند. :accessURL). این به ایجاد یک انتظار قوی در مورد نتیجه URI توزیع و نحوه دسترسی به آنها کمک می کند. با این حال، حتی با استفاده از مدل DCAT، ناشران همچنان شیوه های خود را با نادیده گرفتن دستورالعمل ها اعمال می کنند [ 35 ]. ما این تلاش را ارزشمند می دانیم زیرا به طور چشمگیری دسترسی به منابع را افزایش می دهد و در عین حال تأیید پوسیدگی مرجع را تسهیل می کند.
واقعیت وب نشان می دهد که هایپرلینک ها هرگز پایدار نیستند. کاتالوگ های فضایی، به عنوان سیستم های سند محور ، از همین مسائل رنج می برند. هنگامی که یک منبع منتشر یا به روز می شود، هیچ مکانیزمی وجود ندارد که کسی را مجبور به ثبت نام یا اطلاع رسانی به روز رسانی در کاتالوگ کند. آرمانشهری است که فرض کنیم نویسندگان ابرداده همیشه مایلند (یا خواهند توانست) ابردادههای خود را در طول زمان حفظ کنند. برای تضمین در دسترس بودن آینده، باید از آن خطر آگاه باشیم و برخی از اندازهگیریها را اتخاذ کنیم.
یکی از سادهترین اما مؤثرترین راهحلهای پیشنهادی برای جلوگیری از پوسیدگی پیوند ، انجام بررسی دورهای پیوند [ 6 ] است. این رویکرد زمانی جالب است که فرآیند بررسی توسط مالک ابرداده انجام شود تا آنها بتوانند هر مشکلی را در لحظه شناسایی برطرف کنند. همچنین از سوابق فراداده که بررسی خودکار را تسهیل می کند، سود می برد.
از نظر تاریخی، سایر نویسندگان معماری هایی را برای جلوگیری از پوسیدگی پیوند در وب پیشنهاد کردند، مانند W3Objects [ 12 ] یا Hyper-G [ 40 ]، که سعی در حفظ یکپارچگی ارجاعی در سیستم های مبتنی بر وب در مقیاس بزرگ داشتند.
سیستم هایی مانند Handle [ 41 ] و زیرسیستم آن DOI [ 42 ] رویکرد ارائه شناسه های پایدار (PID) به منابع و ارائه سیستم های حل برای مکان یابی آنها را در پیش گرفته اند. نویسندگان دیگری مانند کلمپ و همکاران. [ 43 ] در مورد ارتباط دادن شناسه های DOI به داده های علوم زمین بحث کرد. مزیت PID ها این است که با معماری و ساختار شبکه جهانی وب سازگار هستند و می توانند به حل مشکل Link Rot کمک کنند. تنها شرط در دسترس بودن یک سیستم تفکیک پذیری است.
تمام روش های ذکر شده در بالا با هدف حل رفرنس ریت برای منابع تغییرناپذیر است. چندین سیستم بایگانی وب برای جلوگیری از پوسیدگی پیوند در هنگام حذف منابع وب و از جابجایی محتوا هنگام تکامل منابع وب پدید آمده اند. نمونههای خوبی را در پروژههایی مانند Wayback Machine of The Internet Archive [ 44 ] (امروزه، بزرگترین آرشیو عکس فوری صفحات وب)، The Memento Protocol [ 45 ] (پروتکلی برای دسترسی به عکسهای فوری صفحه وب سازگار با Wayback Machine، از جمله مییابیم. دیگران) و WebCite [ 46] (متمرکز بر بایگانی مطالب مرتبط دانشگاهی). برخی از این سیستم ها مبتنی بر خزنده های وب هستند در حالی که برخی دیگر کاملاً به درخواست کاربر متکی هستند. با این حال، بسیاری از این سیستم ها به طور گسترده مورد استفاده قرار نمی گیرند، بنابراین اتکا به آنها، به عنوان سیستم های شخص ثالث، ممکن است بهترین راه حل نباشد.
7. نتیجه گیری
در این مطالعه، ما یک روش برای تشخیص پوسیدگی مرجع در کاتالوگهای فراداده فضایی ایجاد کردهایم که محتوای منابع پیوندی را برای بهبود رویکرد بررسی پوسیدگی پیوند ساده در نظر میگیرد و از نوع آن به عنوان شاخصی برای دریفت محتوا استفاده میکند. ما این روش را در بیش از 26 سرویس INSPIRE Discovery ثبت شده رسمی به کار برده ایم. ما نشان دادهایم که URIهای توزیع رکوردهای فراداده مکانی، حتی در مجموعههای ابرداده به خوبی تنظیم شده، تحتتاثیر Reference Rot قرار میگیرند.
وجود پوسیدگی مرجع در پیکره تجزیه و تحلیل شده نشان می دهد که برای جلوگیری از پوسیدگی پیوند، پیاده سازی سیستم های کیفیت ضروری است. سیستمهای خودکار مانند آنچه در پرتال داده اروپایی پیادهسازی شده است، که از متدولوژی MQA استفاده میکند، ممکن است مرجع خوبی باشد. با این حال، ما باید آنها را به حوزه ابرداده های مکانی و ویژگی های آن بسط دهیم. همچنین میتوانیم از ابزارهای جستجو برای یافتن منابع گمشده که جابهجا شدهاند استفاده کنیم. با این وجود، این کار بیشتر بر شناسایی و اطلاع رسانی هر مشکلی به صاحبان ابرداده متمرکز است تا بازیابی خودکار مشکلات موجود.
این منجر به نتیجه دوم می شود. ناشران باید تلاش بیشتری برای پیروی از بهترین شیوه ها و دستورالعمل ها انجام دهند. این آزمایش با چالش های متعددی مانند شناسایی و تفسیر انواع اعلام شده یا شناسایی URI های ناقص سرویس OWS مواجه شده است. این شکافهایی را در سودمندی ابردادههای فعلی برای وظایفی فراتر از توصیف و مدیریت، مانند کشف و دسترسی به منابع، آشکار میکند.
مطالعات بیشتر ممکن است این تجزیه و تحلیل را بر روی کاتالوگ های بزرگتر و کمتر مدیریت شده برای مقایسه نتایج انجام دهند و انتظار کیفیت پایین تری را داشته باشند. آنها همچنین ممکن است دیدگاه زمانی رانش محتوا و تکامل Link Rot در طول زمان را در نظر بگیرند. دریفت محتوا با استفاده از نوع داده به عنوان تنها شاخص ارزیابی شده است. کارهای آینده ممکن است ویژگیهای خاصتری را بررسی کنند، مانند: (1) اگر دادهها در جعبه محدود اعلام شده باشد. یا (2) اگر همه توزیع ها مجموعه داده فضایی یکسانی را نشان دهند. تکرار آزمایش برای واکشی کل محتویات پاسخ، ذخیره سازی و زمان مورد نیاز و همچنین کیفیت حدس زدن نوع را افزایش می دهد. حدس زدن نوع داده های مکانی بالغ تر و قوی ترابزار نیز می تواند پیاده سازی شود.
ما می خواهیم جامعه داده های مکانی و به ویژه ذینفعان درگیر در مدیریت کاتالوگ داده های مکانی از این مسائل آگاه شوند. ما به دنبال کاتالوگهای فضایی بهتری هستیم که به انسانها و عوامل کاربر خودکار اجازه میدهد منابع فضایی را کشف، دسترسی و استفاده مجدد کنند. ما معتقدیم که اینها بلوک های سازنده سیستم های اطلاعات مکانی آینده هستند.
منابع
- Nebert, D. کاتالوگ های داده های فضایی تعاملی. فتوگرام مهندس Remote Sens. 1999 , 65 , 3. [ Google Scholar ]
- نوگراس-ایسو، جی. Zarazaga-Soria، FJ; بیجار، ر. آلوارز، پی جی؛ Muro-Medrano، خدمات کاتالوگ PR OGC: یک عنصر کلیدی برای توسعه زیرساخت های داده های مکانی. محاسبه کنید. Geosci. 2005 ، 31 ، 199-209. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- INSPIR MIG. دستورالعمل های فنی برای پیاده سازی مجموعه داده و فراداده خدمات بر اساس ISO/TS 19139:2007. INSPIRE Maintenance and Implementation Group (MIG)، نسخه 2.0.1 . گزارش فنی؛ INSPIRE MIG: بروکسل، بلژیک، 2017.
- ISO 19115-1:2014 ; اطلاعات جغرافیایی – فراداده – قسمت 1: مبانی. سازمان بین المللی استاندارد: ژنو، سوئیس، 2014.
- Nebert، DD کتاب آشپزی SDI. 2001. در دسترس آنلاین: https://www.gsdi.org/pubs.html (در 2 فوریه 2021 قابل دسترسی است).
- تایلر، دی سی؛ مک نیل، کتابداران DCB و پوسیدگی پیوند: تحلیل مقایسه ای با برخی ملاحظات روش شناختی. پورتال Libr. آکادمی 2003 ، 3 ، 309-314. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Ureña-Cámara، MA; نوگراس-ایسو، جی. لاکاستا، جی. Ariza-López, FJ روشی برای بررسی کیفیت فراداده های جغرافیایی بر اساس ISO 19157. Int. جی. جئوگر. Inf. علمی 2019 ، 33 ، 1-27. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کواراتی، ع. دی مارتینو، ام. Rosim, S. استفاده از داده های باز جغرافیایی و کیفیت فراداده. ISPRS Int. J. Geo-Inf. 2021 ، 10 ، 30. [ Google Scholar ] [ CrossRef ]
- کلاین، ام. ون دی سامپل، اچ. ساندرسون، آر. شانکار، اچ. بالاکیروا، ال. ژو، ک. Tobin, R. زمینه پژوهشی یافت نشد: از هر پنج مقاله یک مقاله از پوسیدگی مرجع رنج می برد. PLoS ONE 2014 ، 9 ، e115253. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- Sife, AS; برنارد، آر. تداوم و زوال استنادهای وب مورد استفاده در پایان نامه ها و پایان نامه های موجود در کتابخانه ملی کشاورزی سوکوئین، تانزانیا. بین المللی جی. آموزش. توسعه دهنده با استفاده از Inf. اشتراک. تکنولوژی (IJEDICT) 2013 ، 9 ، 85-94. [ Google Scholar ]
- Gertler، AL; بولاک، JG Reference Rot: تهدیدی نوظهور برای شفافیت در علوم سیاسی. PS-Polit. علمی سیاسی. 2017 ، 50 ، 166-171. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اینگام، دی. کوی، اس. لیتل، ام. رفع مشکل “لینک شکسته”: رویکرد W3 Objects. محاسبه کنید. شبکه سیستم ISDN 1996 ، 28 ، 1255-1268. [ Google Scholar ] [ CrossRef ]
- نیلسن، جی. فایتینگ لینکروت. 1998. در دسترس آنلاین: https://www.nngroup.com/articles/fighting-linkrot/ (در 13 ژانویه 2021 قابل دسترسی است).
- هارتر، آرشیو SPK: مجلات الکترونیکی و ارتباطات علمی: مطالعه استنادی و مرجع. جی. الکترون. انتشار 1997 ، 3 ، 299-315. [ Google Scholar ] [ CrossRef ]
- Koehler, W. تحلیلی از پایداری و ماندگاری صفحه وب و وب سایت. مربا. Soc. Inf. علمی 1999 ، 50 ، 162-180. [ Google Scholar ] [ CrossRef ]
- دیویس، پی. کوهن، اس. تأثیر وب بر رفتار استنادی در مقطع کارشناسی 1996-1999. مربا. Soc. Inf. علمی تکنولوژی 2001 ، 52 ، 309-314. [ Google Scholar ] [ CrossRef ]
- Casserly، MF; Bird, JE Web Citation Availability: Analysis and Implications for Scholarship | کاسرلی | کالج و کتابخانه های تحقیقاتی صبح. اشتراک. J. 2003 ، 9 ، 300-317. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رن، جی دی. جانسون، KR; Crockett، DM; Heilig، LF; شیلینگ، LM; Dellavalle، پوسیدگی منبع یکنواخت RP در مجلات پوستی: نگرش های نویسنده و شیوه های حفظ. قوس. درماتول. 2006 ، 142 ، 1147-1152. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- دیمیتروا، دی.وی. Bugeja, M. Raising the Dead: Recovery of Decayed Online Citations. صبح. اشتراک. J. 2007 , 9 , 2. [ Google Scholar ]
- رودز، وب سایت های JS که بهبود می یابند. 2002. در دسترس آنلاین: https://web.archive.org/web/20160315090512/https://www.webword.com/moving/healing.html (در 15 مارس 2016 قابل دسترسی است).
- رجبی فرد، ع. کلانتری سلطانیه، س. Binns، A. SDI و ابزارهای ورود و به روز رسانی فراداده. در مجموعه مقالات کنفرانس جهانی GSDI 11، روتردام، هلند، 15-19 ژوئن 2009. انجمن GSDI: منوبا، تونس. [ Google Scholar ]
- الفت، ح. کلانتری، م. رجبی فرد، ع. ویلیامسون، IP; پتیت، سی. ویلیامز، اس. کاوش در زمینه های کلیدی تحقیقات اتوماسیون فراداده فضایی در استرالیا. در مجموعه مقالات کنفرانس جهانی GSDI 12: تحقق جوامع توانمند فضایی، سنگاپور، 19 تا 22 اکتبر 2010. انتشارات دانشگاه لوون: لوون، بلژیک. [ Google Scholar ]
- بروینگتون، BE; Cybenko، G. همگام با وب در حال تغییر. کامپیوتر 2000 ، 33 ، 52-58. [ Google Scholar ] [ CrossRef ]
- چو، جی. گارسیا-مولینا، اچ. تکامل وب و مفاهیم برای یک خزنده افزایشی. در مجموعه مقالات کنفرانس در مورد پایگاه های داده بسیار بزرگ، قاهره، مصر، 10-14 سپتامبر 2000. پ. 18. [ Google Scholar ]
- کوهلر، دبلیو. تغییر و تداوم صفحه وب – یک مطالعه چهار ساله طولی. مربا. Soc. Inf. علمی تکنولوژی 2002 ، 53 ، 162-171. [ Google Scholar ] [ CrossRef ]
- Fetterly، D.; ماناس، م. ناجورک، م. وینر، JL مطالعه ای در مقیاس بزرگ در مورد تکامل صفحات وب. نرم افزار تمرین کنید. انقضا 2004 ، 34 ، 213-237. [ Google Scholar ] [ CrossRef ]
- نتولاس، ا. چو، جی. اولستون، سی. در وب چه خبر؟ تکامل وب از دیدگاه موتورهای جستجو در مجموعه مقالات سیزدهمین کنفرانس بین المللی وب جهانی (WWW’04)، نیویورک، نیویورک، ایالات متحده آمریکا، 17-20 می 2004. صص 1-12. [ Google Scholar ] [ CrossRef ]
- شهامت.؛ تیوان، جی. دومایس، ST; الزاس، جی ال وب همه چیز را تغییر می دهد: درک پویایی محتوای وب. در مجموعه مقالات دومین کنفرانس بین المللی ACM در جستجوی وب و داده کاوی (WSDM’09)، بارسلون، اسپانیا، 9 تا 12 فوریه 2009. ص 282-291. [ Google Scholar ] [ CrossRef ]
- ساندرسون، آر. ون دو سامپل، اچ. برن هیل، پی. گروور، سی هیبرلینک: به سوی سفر در زمان برای وب علمی. در مجموعه مقالات اولین کارگاه بین المللی در زمینه حفظ دیجیتال روش های تحقیق و مصنوعات (DPRMA’13)، ایندیاناپولیس، IN، ایالات متحده آمریکا، 25 ژوئیه 2013; پ. 21. [ Google Scholar ] [ CrossRef ]
- برن هیل، پی. میویسن، م. Wincewicz, R. Reference Rot in Scholarly Statement: Threat and Remedy. بینش UKSG J. 2015 ، 28 ، 55-61. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- نویمایر، اس. آمبریچ، جی. Polleres، A. ارزیابی خودکار کیفیت فراداده در سراسر پورتال های داده باز. J. Data Inf. کیفیت 2016 ، 8 ، 2:1-2:29. [ Google Scholar ] [ CrossRef ]
- پورتال داده اروپا داشبورد کیفیت فراداده-روش شناسی. 2020. در دسترس آنلاین: https://www.europeandataportal.eu/mqa/methodology?locale=en# (در 29 مارس 2021 قابل دسترسی است).
- مرکز تحقیقات مشترک INSPIRE گردش کار ژئوپورتال برای ایجاد پیوند بین مجموعه داده ها و خدمات شبکه . گزارش فنی؛ مرکز تحقیقات مشترک INSPIRE: بروکسل، بلژیک، 2020. [ Google Scholar ]
- W3C. واژگان کاتالوگ داده (DCAT)—نسخه 2 ; گزارش فنی؛ کنسرسیوم وب جهانی: کمبریج، MA، ایالات متحده آمریکا، 2020. [ Google Scholar ]
- نوگراس-ایسو، جی. لاکاستا، جی. Ureña-Cámara، MA; Ariza-López، FJ کیفیت فراداده در پورتال های داده باز. دسترسی IEEE 2021 ، 9 ، 60364–60382. [ Google Scholar ] [ CrossRef ]
- آزاد شده، ن. Borenstein, N. برنامه های افزودنی ایمیل چند منظوره اینترنتی (MIME) قسمت اول: قالب بدنه های پیام اینترنتی ; RFC 2045; ویرایشگر RFC: مارینا دل ری، کالیفرنیا، ایالات متحده آمریکا، 1996. [ Google Scholar ]
- نبرت، دی. وایتساید، ا. Vretanos, P. Open GIS Catalog Services Specification (نسخه: 2.0.2) ; گزارش فنی؛ کنسرسیوم فضایی باز: Rockville، MD، ایالات متحده، 2007. [ Google Scholar ]
- Kessler, G. امضاهای فایل. 2002. در دسترس آنلاین: https://www.garykessler.net/library/file_sigs.html (دسترسی در 4 فوریه 2021).
- منصفانه برو. اصول عادلانه 2016. در دسترس آنلاین: https://www.go-fair.org/fair-principles/ (در 22 سپتامبر 2021 قابل دسترسی است).
- اندروز، ک. کاپ، اف. Maurer, H. سیستم اطلاعات شبکه Hyper-G. J. Univers. محاسبه کنید. علمی 1995 ، 1 ، 206-220. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سان، اس. ریلی، اس. لانوم، ال. مشخصات پروتکل سیستم پترون، J. Handle (نسخه 2.1) . RFC 3652; ویرایشگر RFC: Marina del Rey، CA، USA، 2003. [ Google Scholar ]
- ISO 26324:2012 ; اطلاعات و اسناد – سیستم شناسایی شیء دیجیتال. سازمان بین المللی استاندارد: ژنو، سوئیس، 2012.
- کلمپ، جی. هوبر، آر. Diepenbroek، M. DOI برای دادههای علوم زمین – چگونه تمرینهای اولیه ادراکات حال را شکل میدهند. علوم زمین آگاه کردن. 2016 ، 9 ، 123-136. [ Google Scholar ] [ CrossRef ]
- آرشیو اینترنت ماشین راه برگشت. 2001. در دسترس آنلاین: https://web.archive.org/ (در 13 ژانویه 2021 قابل دسترسی است).
- ون دو سامپل، اچ. نلسون، ام. Sanderson, R. HTTP Framework for Time-based Access to Resource States—Memento ; RFC 7089; ویرایشگر RFC: مارینا دل ری، کالیفرنیا، ایالات متحده آمریکا، 2013. [ Google Scholar ]
- کنسرسیوم وب سایت. وب سایت. 1998. در دسترس آنلاین: https://www.webcitation.org/ (دسترسی در 28 دسامبر 2020).
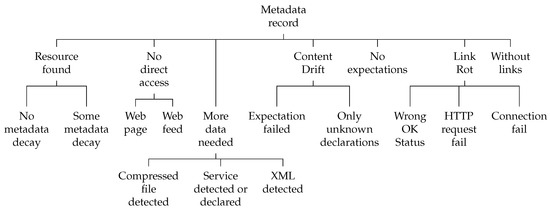
شکل 1. مقوله های پوسیدگی مرجع فراداده .
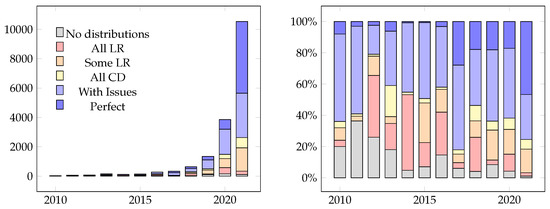
شکل 2. وجود پوسیدگی مرجع در طول زمان.
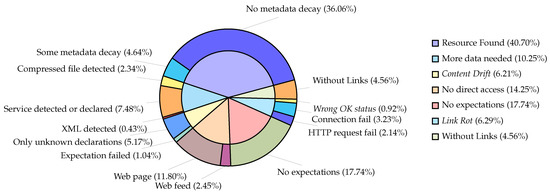
شکل 3. پوسیدگی مرجع در سطح فراداده .


بدون دیدگاه