

چکیده
کلید واژه ها:
داده های چند منبعی ؛ رانش زمین ; خطرات احتمالی زمین شناسی ; فراگیری ماشین
1. مقدمه
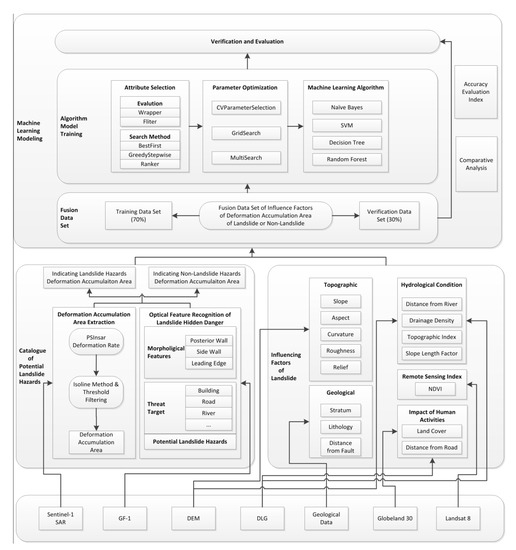
2. مواد و روشها
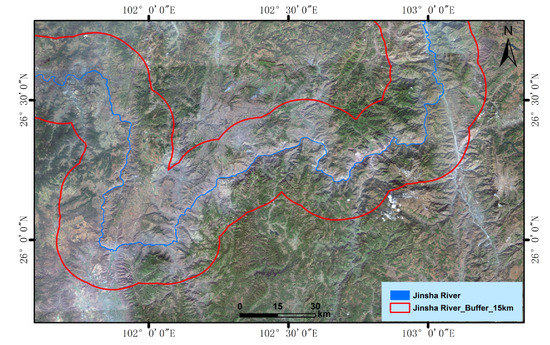
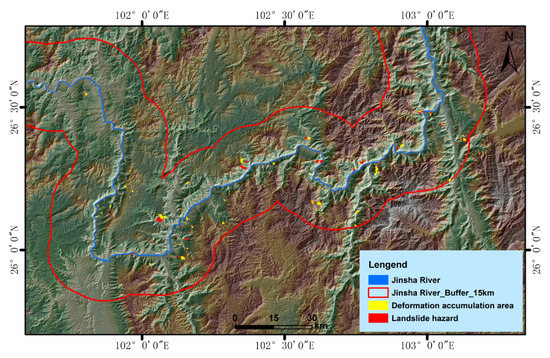
2.1. منطقه مطالعه
2.2. داده ها
2.3. مواد و روش ها
2.3.1. کاتالوگ خطرات احتمالی زمین لغزش
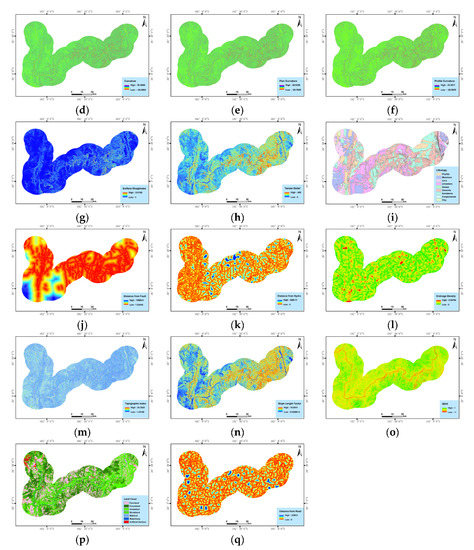
2.3.2. عوامل موثر بر زمین لغزش
2.3.3. الگوریتم های یادگیری ماشین
-
بیز ساده لوح
فرض کنید یک مورد به صورت X = f 1، f 2، ⋯، fn طبقه بندی شود ، که در آن هر f یک ویژگی مشخصه X است و مجموعه دسته C 1، C 2، ⋯، Cm است، احتمال شرطی را جداگانه محاسبه کنید P ( fn | سانتی متر ). اگر P ( Ck | X ) = MAX ( P ( C 1 | X ), P ( C 2 | X ),…, P( Cm | X ))، سپس X ∊ Ck ، که بیشترین احتمال را دارد، نتیجه طبقه بندی بیزی است. بیز ساده فرض می کند که هر ویژگی مستقل است، طبق قضیه بیز، می توان آن را استخراج کرد: P ( Ci | X ) = P ( X | Ci ) P ( Ci ) / P ( X ) [ 30 ]. در نهایت، فرمول طبقهبندیکننده مربوط به الگوریتم Naive Bayes به صورت زیر تعریف میشود:
- 2.
-
درخت تصمیم
این تحقیق از الگوریتم درخت تصمیم C4.5 استفاده می کند. اطلاعات تقسیم شده توسط الگوریتم به شرح زیر است که تعریف آنتروپی است:
با توجه به فرمول فوق، فرمول نرخ بهره اطلاعات تعریف شده توسط الگوریتم C4.5 به شرح زیر است:
- 3.
-
ماشین بردار پشتیبانی
ایده اصلی SVM محاسبه ابر صفحه جداکننده است: w × x + b = 0، که در آن w بردار نرمال و b است.رهگیری است. برای یک مجموعه داده خطی قابل جداسازی، بینهایت چنین ابرصفحههایی وجود دارد که پرسپترون هستند، اما ابرصفحه جداکننده با بزرگترین بازه هندسی منحصربهفرد است. برای مسائل طبقهبندی غیرخطی، میتوان آن را با تبدیل غیرخطی به یک مسئله طبقهبندی خطی در فضای مشخصه ابعادی خاص تبدیل کرد و ماشینهای بردار پشتیبان خطی را میتوان در فضای ویژگیهای با ابعاد بالا آموخت. به دلیل مشکل دوگانه SVM خطی، تابع هدف و تابع تصمیم طبقهبندی فقط حاصلضرب داخلی بین نمونه و نمونه را دربرمیگیرد، بنابراین نیازی به مشخص کردن صریح تبدیل غیرخطی نیست، بلکه حاصلضرب داخلی با هسته جایگزین میشود. تابع [ 32 ، 33 ، 34]. به طور خاص، K ( x ، z ) یک تابع است، به این معنی که یک نقشه برداری ɸ ( x ) از فضای ورودی به فضای ویژگی وجود دارد. برای x ، z در هر فضای ورودی،
در مسئله دوگانه یادگیری SVM خطی، جایگزینی حاصلضرب داخلی با تابع هسته K ( x , z )، نتیجه SVM غیرخطی است:
- 4.
-
جنگل تصادفی
به طور خاص، Random Forest بر اساس Bagging اصلاح شده است. ابتدا از روش Bootstrap برای نمونه برداری از n نمونه از مجموعه داده استفاده کنید، سپس به صورت تصادفی k مشخصه را از همه ویژگی ها انتخاب کنید تا یک درخت CART بسازید و در نهایت مراحل فوق را m بار تکرار کنید تا m درختان CART بسازید. این مدرختان CART یک جنگل تصادفی را تشکیل می دهند و نتیجه رای گیری مشخص می کند که داده ها به کدام دسته تعلق دارند. CART اساساً شبیه به روش های درخت تصمیم مانند ID3.5 و C4.5 است. تفاوت این است که CART از ضریب جینی به عنوان معیار انتخاب ویژگی استفاده می کند. ضریب جینی اساساً تقریبی از به دست آوردن اطلاعات است. هر چه ضریب جینی یک ویژگی بزرگتر باشد، توانایی آن ویژگی برای کاهش آنتروپی نمونه قوی تر است. این ویژگی داده ها را از عدم قطعیت به قطعیت قوی تر می کند. فرمول به شرح زیر است:
2.3.4. ارزیابی دقت
دقت نرخ دقت است که برای اندازه گیری توانایی الگوریتم طبقه بندی در رد اطلاعات نامربوط استفاده می شود، دقت به صورت زیر محاسبه می شود:
Recall نسبت Recall است که برای اندازهگیری توانایی الگوریتم طبقهبندی برای تشخیص اطلاعات مربوطه استفاده میشود و به صورت زیر محاسبه میشود:
F-Measure (F1) میانگین هارمونیک دقت و فراخوان است و به صورت زیر محاسبه می شود:
3. نتایج
3.1. نتایج شاخص مرجع انتخاب ویژگی
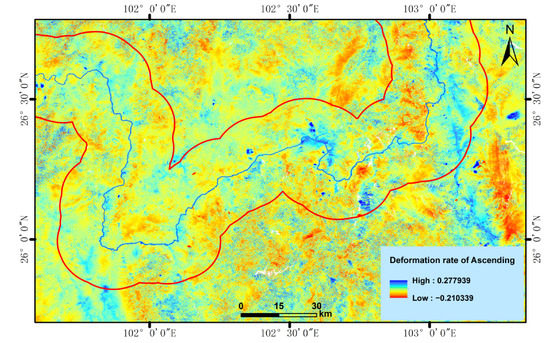
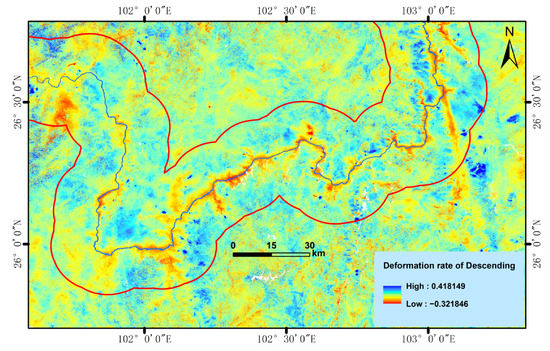
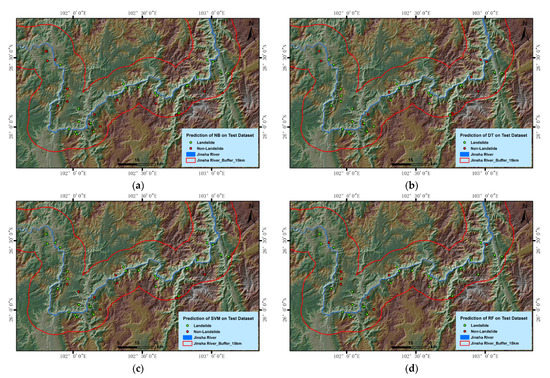
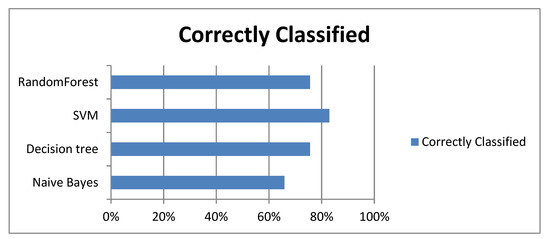
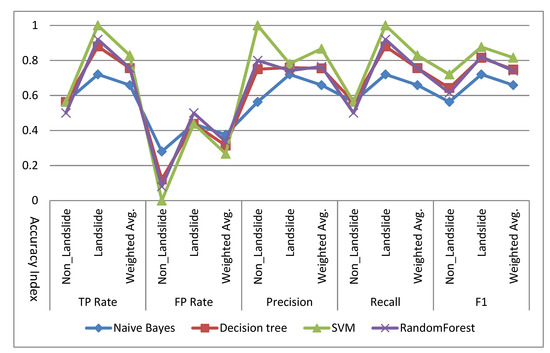
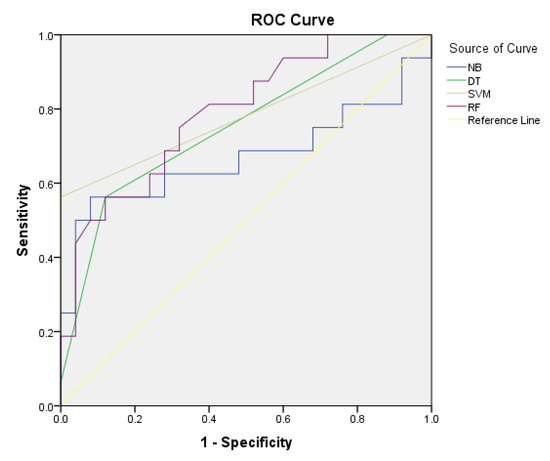
3.2. نتایج و دقت شناسایی خطرات احتمالی زمین لغزش
4. بحث
5. نتیجه گیری ها
منابع
- خو، Q. دونگ، XJ; Li, WL سیستم یکپارچه تشخیص زودهنگام، نظارت و هشدار فضا-هوا-زمین برای مخاطرات زمینی فاجعه آمیز بالقوه. Geomat. Inf. علمی دانشگاه ووهان 2019 ، 44 ، 957–966. [ Google Scholar ]
- جنرال الکتریک، DQ؛ دای، KR؛ Guo، ZC; Li, ZH شناسایی اولیه خطرات زمینشناسی جدی با فناوریهای سنجش از دور یکپارچه: افکار و توصیهها. Geomat. Inf. علمی دانشگاه ووهان 2019 ، 44 ، 949–956. [ Google Scholar ] [ CrossRef ]
- مارکو، اس. لورا، ال. والنتینا، م. مونیکا، پی. سنجش از دور برای تحقیقات زمین لغزش: مروری بر دستاوردها و چشم اندازهای اخیر. Remote Sens. 2014 , 6 , 9600–9652. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژائو، سی. Lu, Z. سنجش از دور زمین لغزش – بررسی. Remote Sens. 2018 , 10 , 279. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Kirschbaum، DB; فوکوکا، اچ. سنجش از دور و مدلسازی زمین لغزشها: تشخیص، پایش و ارزیابی ریسک. محیط زیست علوم زمین 2012 ، 66 ، 1583. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- تازیو، اس. کریستین، آ. Hugo, R. تفسیر عکس های هوایی و تداخل سنجی SAR ماهواره ای برای فهرست زمین لغزش ها. Remote Sens. 2013 , 5 , 2554–2570. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کیرشباوم، دی. استنلی، تی. ژو، ی. تجزیه و تحلیل مکانی و زمانی کاتالوگ جهانی زمین لغزش. ژئومورفولوژی 2015 ، 249 ، 4-15. [ Google Scholar ] [ CrossRef ]
- جوانگ، CS; استانلی، TA; Kirschbaum، DB استفاده از علم شهروندی برای گسترش نقشه جهانی زمین لغزش: معرفی مخزن زمین لغزش آنلاین باز تعاونی. PLoS ONE 2019 , 14 , e0218657. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- حمید، ع. جیسون، KL; Wang, X. فجایع زمین لغزش و کاهش خطر بلایا: یک چارچوب GIS برای پیشگیری و مدیریت زمین لغزش. Remote Sens. 2010 , 2 , 2259–2273. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کیرشباوم، دی. استنلی، تی. Yatheendradas، S. مدلسازی حساسیت زمین لغزش در مناطق بزرگ با پوشش فازی. زمین لغزش 2016 ، 13 ، 485-496. [ Google Scholar ] [ CrossRef ]
- استنلی، تی. Kirschbaum، DB یک رویکرد اکتشافی به نقشه برداری جهانی حساسیت زمین لغزش. نات. خطرات 2017 ، 87 ، 145-164. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پیرالیلو، ST; شهابی، ح. جاریانی، ب. قربانزاده، ا. بلاشکه، تی. غلام نیا، ک. مینا، اس آر. Aryal, J. تشخیص زمین لغزش با استفاده از تقسیمبندی تصویر در مقیاس چندگانه و مدلهای مختلف یادگیری ماشین در هیمالیاهای عالی. Remote Sens. 2019 , 11 , 2575. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژائو، سی. کانگ، ی. ژانگ، Q. لو، ز. Li، B. شناسایی و پایش زمین لغزش در امتداد حوضه آبریز رودخانه جینشا (منطقه مخزن Wudongde)، چین، با استفاده از روش InSAR. Remote Sens. 2018 , 10 , 993. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تانگ، پی. چن، اف. گوا، اچ. تیان، بی. وانگ، ایکس. Ishwaran، N. نظارت بر زمین لغزش در منطقه بزرگ با استفاده از تکنیک پیشرفته InSAR چند زمانی بر روی زیستگاه پانداهای غول پیکر، سیچوان، چین. Remote Sens. 2015 ، 7 ، 8925–8949. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ی. لو، ز. ژائو، سی. کیم، جی. ژانگ، کیو. De La Fuente، J. خصوصیات سینماتیک زمین لغزش سه خرس در شمال کالیفرنیا با استفاده از مشاهدات InSAR باند L. Remote Sens. 2019 , 11 , 2726. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Tien Bui، DT; شهابی، ح. شیرزادی، ع. چاپی، ک. علیزاده، م. چن، دبلیو. محمدی، ع. بن احمد، بی. پناهی، م. هونگ، اچ. و همکاران شناسایی زمین لغزش و نگاشت حساسیت توسط داده های AIRSAR با استفاده از ماشین پشتیبان Vevtor و شاخص مدل های آنتروپی در کامرون هایلندز، مالزی. Remote Sens. 2018 , 10 , 1527. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آچور، ی. پورقاسمی، منابع انسانی چگونه تکنیکهای یادگیری ماشینی به افزایش دقت نقشههای حساسیت زمین لغزش کمک میکنند؟ Geosci. جلو. 2019 ، 11 ، 871-883. [ Google Scholar ] [ CrossRef ]
- کدوی، روابط عمومی; لی، سی دبلیو; لی، اس. کاربرد مدلهای یادگیری ماشینی مبتنی بر مجموعه برای نقشهبرداری حساسیت زمین لغزش. Remote Sens. 2018 , 10 , 1252. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ولی، وی. حمید، ر.پ. محمد، ز. توماس، بی. نقشهبرداری حساسیت زمین لغزش با استفاده از الگوریتمهای داده کاوی مبتنی بر GIS. Water 2019 , 11 , 2292. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کلانتر، بی. پرادان، بی. نقیبی، س. متولی، ع. منصور، اس. ارزیابی اثرات انتخاب دادههای آموزشی بر روی نقشهبرداری حساسیت زمین لغزش: مقایسه بین ماشین بردار پشتیبان (SVM)، رگرسیون لجستیک (LR) و شبکههای عصبی مصنوعی (ANN). Geomat. نات. خطر خطرات 2018 ، 9 ، 49-69. [ Google Scholar ] [ CrossRef ]
- فام، بی تی؛ شیرزادی، ع. Bui، DT; پراکاش، آی. رویکرد گروه یادگیری ماشین Ahybrid Dholakia، MB مبتنی بر شبکه عصبی تابع پایه شعاعی و جنگل چرخشی برای مدلسازی حساسیت زمین لغزش: مطالعه موردی در منطقه هیمالیا، هند. بین المللی J. Sediment Res. 2018 ، 33 ، 157-170. [ Google Scholar ] [ CrossRef ]
- عربامری، ع. پرادان، بی. رضایی، ک. لی، CW ارزیابی حساسیت زمین لغزش با استفاده از مدل یکپارچه FR-RF مبتنی بر هوش مصنوعی و آماری و DEM های چند وضوحی. Remote Sens. 2019 , 11 , 999. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گوتز، JN; برنینگ، آ. پتچکو، اچ. لئوپولد، پی. ارزیابی تکنیکهای یادگیری ماشین و پیشبینی آماری برای مدلسازی حساسیت زمین لغزش. محاسبه کنید. Geosci. 2015 ، 81. [ Google Scholar ] [ CrossRef ]
- گلوفکو، دی. روسنر، اس. بهلینگ، ر. وتزل، H.-U.; Kleinschmit، B. ارزیابی موجودی زمین لغزش مبتنی بر سنجش از دور برای ارزیابی خطر در جنوب کورگیزستان. Remote Sens. 2017 , 9 , 943. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پارک، اس جی. لی، سی.- دبلیو. لی، اس. لی، ام.-جی. نقشهبرداری و مقایسه حساسیت زمین لغزش با استفاده از مدلهای درخت تصمیم: مطالعه موردی منطقه جومونجین، کره. Remote Sens. 2018 , 10 , 1545. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چن، دبلیو. پنگ، جی. هونگ، اچ. شهابی، ح. پرادان، بی. لیو، جی. زو، A.-X. پی، ایکس. Duan، Z. مدلسازی حساسیت زمین لغزش با استفاده از تکنیکهای یادگیری ماشین مبتنی بر GIS برای شهرستان Chongren، استان جیانگشی، چین. علمی کل محیط. 2018 ، 626 ، 1121-1135. [ Google Scholar ] [ CrossRef ]
- عدنان، م. رحمان، س. احمد، ن. احمد، بی. خاخام، اف. رحمان، ر. بهبود توافق فضایی در نگاشت حساسیت زمین لغزش مبتنی بر یادگیری ماشین. Remote Sens. 2020 , 12 , 3347. [ Google Scholar ] [ CrossRef ]
- کلانتر، بی. اوئدا، ن. سعیدی، و. احمدی، ک. هالین، AA; شعبانی، ف. نقشهبرداری حساسیت زمین لغزش: یادگیری ماشینی و مجموعهای بر اساس دادههای بزرگ سنجش از دور. Remote Sens. 2020 ، 12 ، 1737. [ Google Scholar ] [ CrossRef ]
- چن، دبلیو. Li.، Y. ارزیابی مبتنی بر GIS حساسیت زمین لغزش با استفاده از مدلهای هوش محاسباتی ترکیبی. Catena 2020 , 195 , 104777. [ Google Scholar ] [ CrossRef ]
- جورج، اچ. جان، PL تخمین توزیع مداوم در طبقهبندیکنندههای بیزی. در یازدهمین کنفرانس عدم قطعیت در هوش مصنوعی ; Morgan Kaufmann ناشران: San Mateo، CA، USA، 1995; صص 338-345. [ Google Scholar ]
- Ross, Q. C4.5: Programs for Machine Learning ; مورگان کافمن ناشران: سن متئو، کالیفرنیا، ایالات متحده آمریکا، 1993. [ Google Scholar ]
- Platt, J. آموزش سریع ماشینهای بردار پشتیبان با استفاده از بهینهسازی حداقل متوالی. In Advances in Kernel Methods Support Vector Learning ; Schoelkopf, B., Burges, C., Smola, A., Eds.; انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، 1998. [ Google Scholar ]
- چانگ، سی سی; Lin, CJ LIBSVM: کتابخانه ای برای ماشین های بردار پشتیبانی. در دسترس آنلاین: https://www.csie.ntu.edu.tw/~cjlin/libsvm/ (در 11 سپتامبر 2019 قابل دسترسی است).
- Keerthi، SS; شواد، SK; باتاچاریا، سی. مورتی، KRK بهبود الگوریتم SMO Platt برای طراحی طبقهبندی کننده SVM. محاسبات عصبی 2001 ، 13 ، 637-649. [ Google Scholar ] [ CrossRef ]
- لئو، بی. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ]
- ترور، اچ. رابرت، تی. طبقه بندی توسط جفت زوجی. در پیشرفت در سیستم های پردازش اطلاعات عصبی ; انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، 1998. [ Google Scholar ]
- کهوی، ر. جان، GH Wrappers برای انتخاب زیر مجموعه ویژگی. آرتیف. هوشمند 1997 ، 97 ، 273-324. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Kohavi, R. Wrappers for Performance Enhancement and Oblivious Decision Graphs ; دانشگاه استنفورد: استانفورد، کالیفرنیا، ایالات متحده آمریکا، 1995. [ Google Scholar ]
- هال، انتخاب زیرمجموعه ویژگی مبتنی بر همبستگی MA برای یادگیری ماشینی ؛ دانشگاه وایکاتو: همیلتون، نیوجرسی، ایالات متحده آمریکا، 1998. [ Google Scholar ]
- مارک، اچ. جفری، اچ. تکنیکهای انتخاب ویژگی معیار برای دادهکاوی کلاس گسسته. IEEE Trans. بدانید. مهندسی داده 2003 ، 15 ، 1437-1447. [ Google Scholar ]




بدون دیدگاه