1. مقدمه
فرسایش خاک یک مسئله جهانی شدید است که بر کشاورزی و محیط زیست در مناطق گرمسیری و نیمه گرمسیری تأثیر می گذارد. به طور خاص، فرسایش خاک منجر به آسیب های زیست محیطی مانند از دست دادن مواد مغذی خاک، آلودگی توسط رسوب و افزایش احتمال سیل می شود. میزان فرسایش خاک به ویژگی های خاک، آب و هوا، شیب شیب [ 1 ]، کاربری زمین و پوشش گیاهی محافظ [ 2 ] بستگی دارد. علاوه بر این، خاک های فرسایش یافته 75 تا 80 درصد محتوای کربن را از دست می دهند [ 3 ] که منجر به کسری بودجه کربن زمینی می شود. فعالیت انسانی عامل اصلی فرسایش خاک است [ 4 ]. تخریب خاک با افزایش جمعیت در قرن بیستم به سرعت تشدید شده است [ 5 ]] و فراتر.
بسیاری از مدل های نظری/تجربی را می توان برای مطالعه فرسایش خاک استفاده کرد. به گفته بورلی و همکاران. [ 6 ]، 435 مدل متمایز و انواع مدل برای تجزیه و تحلیل فرسایش خاک از سال 1994 تا 2017 در 1697 مقاله علمی در پایگاه داده اسکوپوس استفاده شد. پنج مدل برتر پرکاربرد عبارتند از: RUSLE (معادله جهانی تلفات خاک)، USLE (معادله جهانی تلفات خاک)، WEPP (پروژه پیشبینی فرسایش آب)، SWAT (ابزار ارزیابی خاک و آب)، و WATEM/SEDEM (فرسایش آب و خاکورزی). مدل و مدل تحویل رسوب). بیش از نیمی از این مطالعات (58٪ از 1697 مقاله) شامل اعتبار سنجی نتایج تحقیق در قالب دانش تخصصی، رسوب اندازه گیری شده، نرخ فرسایش اندازه گیری شده، یا مقایسه با مدل های دیگر بود.
تایوان دارای مخاطرات طبیعی متعددی است و طوفان و زلزله هر ساله رخ می دهد. میانگین بارندگی سالانه 2500 میلی متر است که از ماه می تا سپتامبر متمرکز است [ 7 ]. به همین دلیل مقدار زیادی خاک با جریان آب فرسایش یافته و به دور منتقل می شود. در سال های اخیر، مطالعات زیادی برای مدل سازی فرسایش خاک در تایوان انجام شده است. به طور سنتی، یک مدل فرسایش خاک مبتنی بر فیزیکی یا تجربی برای چنین مطالعاتی مورد نیاز است. به عنوان مثال، فن و وو [ 8 ] معادلاتی را برای ارزیابی رابطه بین شیب شیب، ویژگیهای خاک، شدت بارندگی و نرخ فرسایش خاک بینشیاری در تایوان توسعه دادند. لو [ 9] از مدل آلودگی منبع غیرنقطه ای کشاورزی (AGNPS) برای تعیین کمیت فرسایش خاک در حوضه رودخانه باجون و حوضه آبخیز مخزن Tsengwen استفاده کرد. از طرف دیگر، Chiu و همکاران. [ 10 ] غلظت 137Cs را در 60 محل نمونه برداری در حوضه آبخیز مخزن Shihmen برای برآورد فرسایش خاک اندازه گیری کرد. چن و همکاران [ 11 ] مدل USLE را برای مطالعه اثر مدل رقومی ارتفاع (DEM) بر فرسایش خاک در همان حوضه اعمال کرد. در نهایت لیو و همکاران [ 12 ] با اعمال واحدهای شیب برای مدلسازی فرسایش خاک در همان حوضه دنبال شد.
برخلاف رویکرد سنتی مدلسازی فرسایش خاک، که در آن به یک مدل مبتنی بر فیزیکی یا تجربی برای پیشبینی نیاز است و دادههای میدانی برای تأیید صحت مدل جمعآوری میشوند، رویکرد مبتنی بر یادگیری ماشین (ML) به مدل پیشینی نیاز ندارد. . اندازهگیریهای میدانی (مانند پینهای فرسایش) مستقیماً برای تدوین قوانین و تعمیم دادهها (یعنی پیشبینیها) استفاده میشوند. اگرچه رویکردهای مبتنی بر ML به طور گسترده در زمینه های مرتبط مانند نقشه برداری حساسیت زمین لغزش [ 13 ، 14 ]، پیش بینی ضخامت خاک [ 15 ]، نقشه برداری دیجیتالی خاک [ 16 ] و بازیابی زیست توده [ 17 ] استفاده شده است.]، اخیراً برای مطالعه پین فرسایش خاک [ 18 و 19 ] استفاده شده است. برای بهبود روشهای قبلی برای کمیسازی فرسایش خاک، این مطالعه کاربرد احتمالی الگوریتمهای یادگیری ماشینی مجموعهای را در حوزه آبخیز مخزن Shihmen در شمال تایوان بررسی کرد. سه دسته از روشهای مجموعه در این مطالعه در نظر گرفته شد: (الف) کیسهبندی، (ب) تقویت، و (ج) انباشته کردن. نتایج در بین روشهای مجموعه از نظر سه شاخص آماری مقایسه شد: (1) ریشه میانگین مربع خطا (RMSE)، (2) کارایی نش – ساتکلیف (NSE) و (3) شاخص توافق (d).
2. روش ها
پین فرسایشی یک میله چوبی یا فلزی است که برای اندازه گیری تغییر سطح زمین در زمین قرار می گیرد. پین مورد اشاره در این تحقیق از فلز با قطر 15.9 میلی متر و طول 300 میلی متر ساخته شده است. حدود 270 میلی متر از پین با رنگ قرمز رنگ آمیزی قسمت در معرض آن در زمین جاسازی شده است. پین فرسایشی یکی از سادهترین و مؤثرترین روشها برای پایش تغییرات سطح زمین به دلیل فرسایش خاک و رسوبگذاری است [ 20 ]. برای نظارت بر فرسایش ورق، فرسایش خندقی، زمین لغزش و فرسایش حاشیه رودخانه استفاده شده است [ 21 ، 22 ، 23 ]. لین و همکاران [ 24] مراحل نصب پین های فرسایشی در تایوان را مستند کرده است. اندازه گیری پین های فرسایش از حوضه های مختلف جمع آوری شده است. داده های حوزه آبخیز مخزن شیمن نشان می دهد که متوسط فرسایش خاک 90.6 تن در هکتار در سال است [ 12 ].
یادگیری ماشین گروهی تکنیکی است که چندین مدل پایه ML (همگن یا ناهمگن) را برای پیشبینی بهتر ترکیب میکند. توجه داشته باشید که کلمه “مدل” در یادگیری ماشین معنای متفاوتی نسبت به فرسایش خاک دارد. همانطور که قبلا توضیح داده شد، یک رویکرد مبتنی بر یادگیری ماشین (ML) برای کار کردن به یک مدل پیشینی (فرسایش خاک) نیاز ندارد. علاوه بر این، روشهای مجموعه عملکردی را نسبت به مدلهای ML فردی کسب میکنند [ 25 ]. روشهای مجموعه در بسیاری از زمینههای متنوع مانند بانکداری [ 26 ]، امنیت کلان داده [ 27 ] و تشخیص سرطان پستان [ 28 ] اعمال شدهاند. در محیط زیست و زمینه های مرتبط، فام و همکاران. [ 29] چندین روش مجموعه (AdaBoost، Bagging، Dagging، MultiBoost، Rotation Forest، و Random Subspace) را برای ارزیابی حساسیت زمین لغزش در هیمالیا هند به کار برد. نتایج نشان داد که سطح زیر منحنی (AUC) منحنی مشخصه عملکرد گیرنده (ROC) همگی بالاتر از 0.876 بود. به همین ترتیب تهرانی و همکاران. [ 30 ] از یک ماشین بردار پشتیبان مجموعه (SVM) و روش وزن شواهد برای انجام نقشهبرداری حساسیت سیل در ترنگانو مالزی استفاده کرد. نتایج آنها مدل سازی سیل را تا 29 درصد بهبود بخشید.
یک روش مجموعه ای به عنوان یک مدل ترکیبی در نظر گرفته می شود. هدف از چنین مدلی دستیابی به عملکرد پیش بینی بهتر با کاهش نویز یا خطا بین داده های مشاهده شده و پیش بینی شده است. روشهای گروهی معمولاً به روشهای بوت استرپ جمعآوری (کیسهبندی)، تقویت و انباشتگی گروهبندی میشوند. هر سه دسته تلاش میکنند تا پیشبینیهای خود را با کاهش واریانس مدل، سوگیری یا هر دو به طور همزمان با مشاهدات هماهنگ کنند. تفاوت اصلی این است که بسته بندی و تقویت معمولاً با مدلهای همگن کار میکند، در حالی که پشتهسازی در ترکیب مدلهای ناهمگن برتری دارد. رویکردهای مربوط به آنها در زیر بخش های زیر توضیح داده شده است. در این تحقیق از هر دسته دو روش را برای تحلیل و مقایسه انتخاب خواهیم کرد.
2.1. کوله بری
Bagging تکنیکی است که چندین مدل همگن را از زیر نمونههای مختلف از مجموعه دادههای آموزشی مشابه ایجاد میکند تا پیشبینیهای دقیقتری نسبت به مدلهای فردی آن به دست آورد. این یک کاربرد از روش بوت استرپ برای مشکلات یادگیری ماشین با واریانس بالا است. به عنوان مثال، جنگل تصادفی (RF) بسته بندی درختان تصمیم (DT) است. با استفاده از CART (درخت طبقه بندی و رگرسیون) به عنوان مثال، RF به طور تصادفی از مجموعه داده آموزشی چندین بار (با جایگزینی) نمونه برداری می کند تا نمونه های فرعی زیادی به دست آورد. سپس، یک درخت تصمیم برای هر نمونه فرعی با استفاده از CART ساخته می شود. در نهایت، RF پیشبینی خود را با ترکیب کردن نتایج همه درختهای تصمیم یا با رای دادن (طبقهبندی) یا میانگینگیری (رگرسیون) صادر میکند. RF یک ابزار یادگیری ماشینی بسیار موثر است و برای مشکلات تحقیقاتی مختلف از جمله فرسایش خاک استفاده شده است.18 ]. بنابراین، ما RF و MARS کیسهای (خطهای رگرسیون تطبیقی چند متغیره) را در این مطالعه برای مقایسه با سایر الگوریتمهای مجموعه انتخاب کردیم.
مریخ اولین بار توسط فریدمن و روزن [ 31 ] معرفی شد. این رابطه بین متغیرهای وابسته و مستقل را به روشی بسیار شبیه به رگرسیون حداقل مربعات بررسی می کند [ 32 ]. مزایای MARS شامل کارایی محاسباتی آن، توانایی آن در ارائه مدل های آسان برای تفسیر، و عملکرد آن برای تعیین کمیت سهم متغیرهای پیش بینی کننده است. با این حال، عدم پیش بینی دقیق آن یکی از مهم ترین اشکالات است [ 32 ]. برای رفع این مشکل، کیسهبندی به MARS معرفی شد تا تبدیل به MARS کیسهای شود تا دقت طبقهبندی بهبود یابد. مدل MARS کیسهای توسط بسته «زمین» در R و مدل RF توسط بسته «randomForest» پیادهسازی شد.
2.2. افزایش
تقویت به گروهی از الگوریتمها اشاره دارد که از میانگینهای وزنی استفاده میکنند تا الگوریتمهای یادگیری ضعیف را الگوریتمهای یادگیری قویتر کنند. برخلاف bagging که به هر مدلی که به طور مستقل اجرا می شود و سپس در پایان جمع می شود، متکی است، بوستینگ به صورت متوالی با استفاده از مدل های بعدی برای رفع خطاهای پیش بینی مدل های قبلی در دنباله اجرا می شود. برای این مطالعه، ما دستگاه تقویت کننده کوبیست و گرادیان (GBM) را برای مقایسه با سایر روشهای مجموعه انتخاب کردهایم.
کوبیست یک مدل رگرسیون پیش بینی گرا است که توسط کوینلان [ 33 ، 34 ] ارائه شده است. ایده کلی مدل رگرسیون کوبیست در اینجا به اختصار توضیح داده شده است. در مرحله رشد درخت، شاخه ها و برگ های زیادی رشد می کنند. مدل های رگرسیون خطی به برگ درخت اضافه می شود. روش کوبیستی مجموعه ای از قوانین «اگر-آنگاه» را ایجاد می کند. هر قانون دارای یک مدل خطی چند متغیره مرتبط است [ 35]. اگر مجموعه ای از متغیرها شرایط قاعده را برآورده کنند، از مدل مربوطه برای محاسبه مقدار پیش بینی شده استفاده می شود. قوانین از طریق هرس حذف می شوند و/یا برای ساده سازی ترکیب می شوند. مزیت اصلی روش کوبیست، اضافه شدن چند کمیته آموزشی برای متعادل کردن وزن پرونده است. در این تحقیق، مدل کوبیست توسط بستههای «کارت» و «کوبیست» در R پیادهسازی شد.
GBM توسط فریدمن [ 36 ، 37 ] به عنوان یک روش ساده و بسیار سازگار برای یادگیری ماشین پیشنهاد شد [ 38 ]. این یک الگوریتم تقویت بهبود یافته برای مشکلات رگرسیون و طبقه بندی است. تئوری اصلی GBM تولید یک مدل پیشبینی است که توسط گروهی از الگوریتمهای یادگیری ضعیف، معمولا درختهای تصمیمگیری ساخته شده است. هر درخت به صورت متوالی با استفاده از اطلاعات درختان رشد کرده قبلی رشد می کند [ 39 ]. در این مطالعه، مدل GBM توسط بسته “gbm” در R پیادهسازی شد.
2.3. پشته سازی
پشتهبندی، که گاهی اوقات تعمیم انباشته نامیده میشود، یک روش یادگیری ماشینی مجموعهای است که چندین مدل پایه یا مؤلفه ناهمگن را از طریق یک متا مدل ترکیب میکند. مدل پایه بر روی داده های آموزشی کامل آموزش داده می شود و سپس فرامدل بر روی پیش بینی های مدل های پایه آموزش داده می شود. مزیت انباشته شدن توانایی کشف فضای راه حل با مدل های مختلف در یک مسئله است. در این مطالعه، دو گروه انباشته انتخاب شدند. آنها (1) RF + DT + LM + شبکه های عصبی مصنوعی (ANN) + SVM و (2) GBM + DT + LM + ANN + SVM هستند. برای پیاده سازی، از بسته “caretEnsemble” در R استفاده شد.
2.4. ارزیابی مدل
به منظور ارزیابی عملکرد مدلهای مجموعه، از سه شاخص آماری به عنوان معیار ارزیابی استفاده شد: (1) ریشه میانگین مربع خطا (RMSE)، (2) کارایی نش – ساتکلیف (NSE) و (3) شاخص توافق (د). این شاخص های آماری به طور مکرر در بسیاری از مطالعات استفاده شده است [ 40 ، 41 ].
RMSE شاخص خوبی برای ارزیابی عملکرد مدل برای متغیرهای پیوسته است. در این مطالعه، RMSE تفاوت بین اندازهگیریهای پین فرسایش و پیشبینیهای مدل مجموعه را نشان میدهد. می توان آن را به صورت زیر نوشت:
که در آن P و O به ترتیب مقادیر پیش بینی شده و مشاهده شده هستند.
NSE مقدار نسبی بین “نویز” و “اطلاعات” را تعریف می کند [ 42 ]. مقدار آن از -∞ تا 1 متغیر است. هر چه مقدار NSE به 1 نزدیکتر باشد، مدل کارآمدتر است. در صورتی که NSE منفی باشد، مدل ضعیف در نظر گرفته می شود زیرا میانگین مشاهده شده به عنوان پیش بینی بهتری نسبت به مدل عمل می کند. NSE به صورت زیر تعریف می شود:
جایی که O¯میانگین مقدار مشاهده شده است.
در نهایت، شاخص توافق (d) اغلب برای نشان دادن عملکرد مدل استفاده می شود [ 43 ]. مقدار آن از 0 تا 1 متغیر است و مقادیر بالاتر نشان دهنده تطابق بهتر بین پیش بینی ها و مشاهدات است. شاخص d به صورت زیر تعریف می شود:
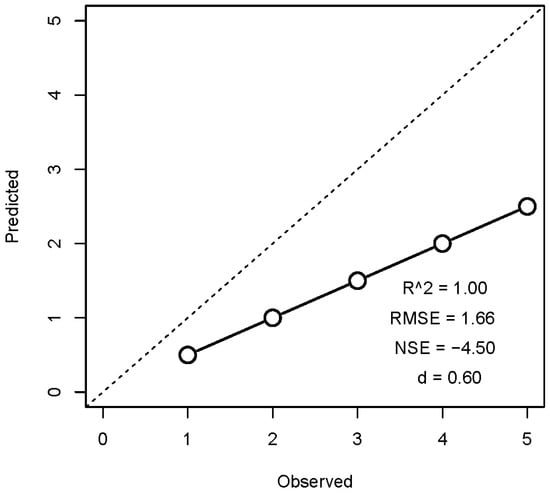
توجه داشته باشید که در ارزیابی مدل از R2 ( ضریب تعیین) به عنوان شاخص آماری استفاده نمی کنیم. همانطور که نگوین و همکاران اشاره کردند. [ 18 ، 19 ]، R2 تناسب را فقط با خط رگرسیون ارزیابی می کند. R 2 بالا به معنای تفاوت های کوچک بین پیش بینی ها و مشاهدات نیست. این نکته در شکل 1 نشان داده شده است که در آن یک مدل ضعیف دارای R2 کامل است اما فقط مقادیر متوسط (حتی ضعیف) سایر شاخص های آماری را دارد. پیشبینیهای خوب باید روی خط 45 درجه قرار بگیرند.
2.5. منطقه مطالعه
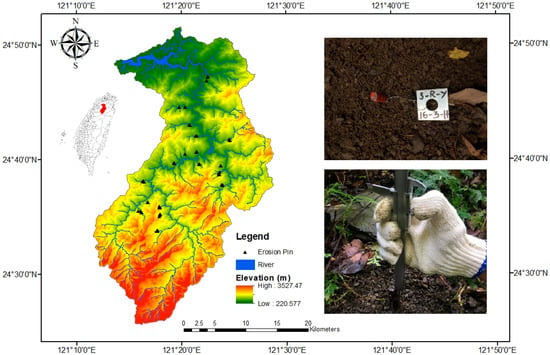
در این مطالعه، حوزه آبخیز مخزن شیهمن در شمال تایوان به عنوان منطقه تحقیقاتی انتخاب شد ( شکل 2 ). حوضه آبخیز مخزن شیمن 76340 هکتار مساحت با حداکثر ارتفاع 3527 متر را پوشش می دهد. فصل بارانی این حوزه مصادف با ماه های توفان است. بنابراین، بارندگی های شدید رایج است [ 44 ]. در شمال تایوان، مخزن شیهمن نقش اساسی در تامین آب آشامیدنی برای مصارف خانگی، آبیاری برای کشاورزی، و کنترل سیل برای بلایای مربوط به طوفان دارد [ 45 ]. شکل 2 همچنین عکسی از یک پین فرسایش فلزی را نشان می دهد که قسمت در معرض آن قرمز رنگ شده است و تصویر اندازه گیری توسط میکرومتر گرفته شده است.
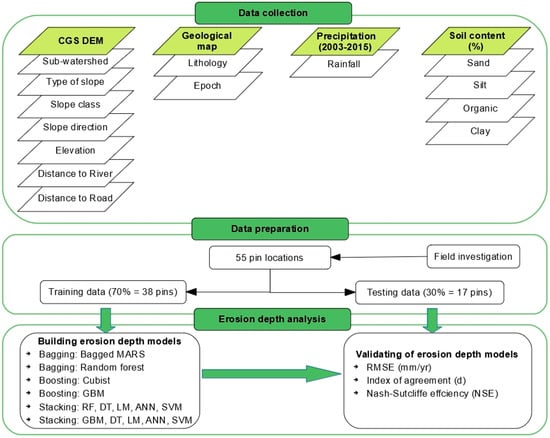
گردش کار این تحقیق در شکل 3 نشان داده شده است و شامل سه بخش است: (1) جمع آوری داده ها، (2) آماده سازی داده ها، و (3) تجزیه و تحلیل پین فرسایش خاک. در مرحله اول، متغیر هدف و متغیرهای پیش بینی در یک مجموعه داده گردآوری شدند. سپس مجموعه داده ها با استفاده از روش نمونه گیری تصادفی طبقه ای به داده های آموزشی و آزمون تقسیم شدند. در نهایت، دادههای آموزشی برای ایجاد مدلهای پیشبینی به روشهای مجموعه داده شد. مدل ها با استفاده از داده های آزمون مورد آزمایش قرار گرفتند و شاخص های آماری محاسبه شدند.
همانطور که در شکل 3 نشان داده شده است، چهارده ویژگی در چهار دسته به عنوان متغیرهای پیش بینی کننده استفاده شد . پنج مورد از ویژگیها دادههای نقطهای بودند که در سراسر حوزه آبخیز در دسترس نبودند، اما فقط در مکانهای پینهای فرسایش در دسترس بودند. مجموعه داده با استفاده از یک تقسیم 70/30 به دو گروه تقسیم شد، که نسبت رایج مورد استفاده در بسیاری از مطالعات [ 46 ، 47 ، 48 ] است. کل فرآیند سه بار تکرار شد تا میانگین نتیجه مشخص شود.
متغیر هدف اندازه گیری پین فرسایش است. در مجموع 550 پین در 55 شیب (10 پین در هر شیب) در حوضه آبخیز مخزن شیهمن نصب شد ( شکل 2 ). لین و همکاران [ 24 ] مراحل نصب را مستند کرد. اندازهگیریهای عمق فرسایش از 8 سپتامبر 2008 تا 10 اکتبر 2011 جمعآوری شد.
برای استخراج ویژگیهای مرتبط با توپوگرافی، مانند ارتفاع، زیرحوضه، کلاس شیب، جهت شیب، فاصله تا رودخانه، و فاصله تا جاده، از مرکز زمینشناسی مرکز (CGS) DEM ایجاد شده از یک LiDAR در هوا (تشخیص نور و محدوده استفاده کردیم. ) بررسی که دارای تفکیک مکانی 10 متر است ( جدول 1 ). داده های DEM در سال 2013 [ 11 ] ایجاد شد.
میانگین بارندگی سالانه منطقه مورد مطالعه از 22 ایستگاه بارندگی از سال 2003 تا 2015 محاسبه شد. شیب ها به هفت کلاس طبقه بندی شدند: (1) <5٪، (2) 5-15٪، (3) 15-30٪، (3) 15-30٪. (4) 30-40٪، (5) 40-55٪، (6) 55-100٪، و (7) > 100٪ بر اساس سیستم طبقه بندی اداره حفاظت از خاک و آب. جهت شیب جنبه ای از شیب است که می تواند صاف یا رو به شمال، شمال شرق، شرق، جنوب شرق، جنوب، جنوب غرب، غرب یا شمال غرب باشد. فاصله تا رودخانه بر اساس نقشه شبکه رودخانه محاسبه شد. به همین ترتیب فاصله تا جاده توسط نقشه شبکه راه با مقیاس 1:5000 پیدا شد. هر دو فاصله به عنوان کوتاه ترین فاصله بین پین فرسایشی فردی و شبکه رودخانه یا جاده با استفاده از نرم افزار ArcGIS 10.2 محاسبه شد.
در نهایت سنگ شناسی و دوران از نقشه های زمین شناسی سازمان زمین شناسی مرکزی بود. مقیاس هر دو 1:50000 بود. محتوای خاک شامل درصد ماسه، سیلت، آلی و رس بود. داده ها توسط لین و همکاران ارائه شده است. [ 49 ].
3. نتایج و بحث
نتایج سه نوع یادگیری گروهی (یعنی بسته بندی، تقویت و انباشتگی) و مقایسه آنها در زیر ارائه شده است.
3.1. کوله بری
در دسته کیسهبندی، ما MARS کیسهای و جنگل تصادفی (همچنین توسط [ 18 ] استفاده میشود) را بهعنوان روشهای یادگیری گروهی انتخاب کردیم. سه نمونهگیری مکرر (گروهبندی) از یک مجموعه داده برای ایجاد سه تقسیم 70/30 مختلف با استفاده از روش نمونهگیری تصادفی طبقهای انجام شد. پس از برازش مدل، معیارهای آماری حاصل از جمله مقادیر RMSE، NSE و d محاسبه شد که در جدول 2 آمده است.. در بین سه شاخص MARS کیسهای، RMSE از 0.92 تا 1.83 میلیمتر در سال برای دادههای آموزشی و از 1.70 تا 2.18 میلیمتر در سال برای دادههای آزمایشی متغیر است. علاوه بر این، NSE (-∞ تا 1) از 0.38 تا 0.83 برای داده های آموزشی و از 0.19 تا 0.60 برای داده های آزمون متغیر است. در نهایت، d (0 تا 1) از 0.64 به 0.94 برای داده های آموزشی و از 0.60 تا 0.85 برای داده های آزمون می رود. همانطور که انتظار می رفت، هر سه شاخص برای داده های آموزشی بهتر از داده های آزمون بدون استثنا هستند. همین مشاهدات را می توان در معیارهای RF نیز انجام داد.
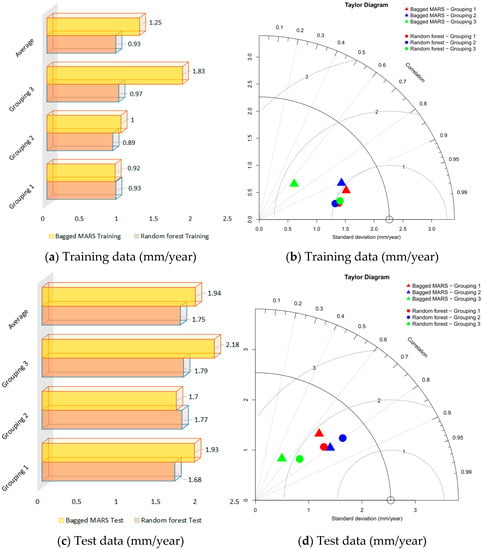
برای ارزیابی تناسب نسبی MARS کیسهای و RF به عنوان ابزارهایی برای یادگیری گروهی، مقادیر RMSE دو روش مجموعه را مقایسه کردیم. نتایج مخلوط شدند، همانطور که در شکل 4 نشان داده شده است. همانطور که در شکل 4 a,c نشان داده شده است، RF دو از سه بار در دادههای آموزشی و دادههای آزمایشی MARS کیسهای را بهتر انجام داد و در کل برتر بود. همین نتیجه نیز با میانگین پایینتر مقادیر RMSE RF نسبت به MARS کیسهای تأیید شد.
اگر نتایج را بر روی نمودار تیلور رسم کنیم، میتوانیم تفاوتهای بیشتری را بین RF و MARS کیسهای مشاهده کنیم. همانطور که از شکل 4 ب مشاهده می شود، هر سه نتیجه نمونه گیری (گروه بندی) از خوشه RF همراه با RMSE، همبستگی و انحراف معیار بسیار مشابه هستند. این نشان دهنده نتایج آموزشی ثابت در نمونه های مختلف است. در مقابل، تنها دو مورد از نتایج نمونه برداری از خوشه MARS کیسه ای با هم جمع می شوند. سومی با همبستگی و انحراف معیار بسیار کوچکتر و RMSE بسیار بزرگتر از دو مورد دیگر بسیار دور است. این نشان می دهد که MARS کیسه ای با داده های آموزشی مختلف به همان اندازه خوب کار نمی کند. در این مورد، در برازش یک مدل برای گروه بندی (نمونه گیری) شماره 3 با مشکل مواجه شد. از این رو، به RF باخت و در مقایسه آماری کوتاه آمد. شکل 4d یک مقایسه نمودار تیلور بین مجموعه داده های آزمایشی را نشان می دهد. گسترش بزرگتر در داده ها برای MARS کیسه ای و RF مشاهده شده است. با این حال، به نزدیکی نقاط داده همرنگ توجه کنید. این نشان میدهد که MARS کیسهای و RF پیشبینیهای مشابهی را در مجموعه دادههای آزمایشی مشابه ایجاد کردند. به عنوان مثال، اگرچه مثلث سبز و دایره سبز در شکل 4 ب بسیار دور از هم هستند، اما در شکل 4 d نسبتاً به یکدیگر نزدیک هستند .
3.2. افزایش
دو روش گروه تقویتی در این مطالعه مورد بررسی قرار گرفت. آنها مدل های GBM و کوبیست بودند. جدول 3معیارهای عملکرد (RMSE، NSE، و d) را در سه نمونه (گروهبندی) مختلف از دادههای پین فرسایش نشان میدهد. برای گروههای شماره 1 و 2، GBM در هر رده در برابر کوبیست پیروز شد (RMSE پایین، NSE بالاتر، و مقادیر d بالاتر). با این حال، برای گروه شماره 3، نتیجه مخلوط است. از یک طرف، GBM در هر سه شاخص مربوط به داده های آموزشی، به Cubist باخت. از سوی دیگر، GBM در داده های آزمایشی با برنده شدن دو شاخص از سه شاخص، کوبیست را شکست داد. RMSE GBM کمتر از کوبیست است (1.71 در مقابل 1.98). به طور مشابه، NSE GBM بالاتر از Cubist است (0.50 در مقابل 0.33). با این حال، مقدار d GBM کمتر از Cubist است (0.75 در مقابل 0.78). این یکی از موارد نادری است که NSE و d با یکدیگر موافق نیستند. با کنار هم گذاشتن همه چیز، میتوان نتیجه گرفت که GBM همچنان برتر از کوبیست است.
شکل 5 به صورت بصری مقادیر میانگین RMSE (mm/year) را بین GBM و Cubist مقایسه می کند. برای داده های آموزشی، RMSE کوبیست 0.84 میلی متر در سال است، که کمتر از 0.61 میلی متر در سال GBM است. برای داده های آزمون، نتیجه مشابهی به دست می آید. RMSE کوبیست 1.95 میلی متر در سال است که به خوبی 1.72 میلی متر در سال GBM نیست. در نتیجه، میتوان تأیید کرد که GBM مدل با عملکرد بهتر در دسته روشهای گروه تقویتی است.
3.3. پشته سازی
دسته بندی سومین و آخرین دسته از روش های مجموعه ای است که در این مطالعه مورد بررسی قرار گرفته است. ایده اصلی انباشته کردن این است که چندین مدل ضعیف را با هم ترکیب کنیم تا از پیشبینیهای آنها به عنوان ویژگیها در یک فرامدل کلی استفاده کنیم. متا مدل آموزش داده شده است تا پیش بینی های بهتری نسبت به مدل های پایه (مدل های مولفه) ارائه دهد. با استفاده از همان شش مدل ML مطالعه شده توسط نگوین و همکاران. [ 18 ، 19 ]، جدول 4 را ایجاد کردیم و مدلهای ML را به چهار دسته طبقهبندی کردیم: مدل درختی، مدل شبکه عصبی، مدل ابرصفحه و مدل رگرسیون خطی. میانگین مقادیر RMSE این مدل ها نیز در جدول 4 نشان داده شده است. بر اساس جدول 4، ما چهار مدل ضعیف را انتخاب کردیم (یکی از هر دسته) و از آنها به عنوان مدل های پایه در یادگیری گروه انباشته استفاده کردیم. آنها DT، ANN، SVM و LM هستند. علاوه بر این، RF و GBM، یکی از بستهبندی و دیگری از تقویت، بهعنوان متا مدلها برای تشکیل دو مجموعه از مدلهای انباشته انتخاب شدند: (1) RF + DT + LM + ANN + SVM و (2) GBM + DT + LM + ANN + SVM. در این مطالعه تمامی شاخص های آماری در R محاسبه شد.
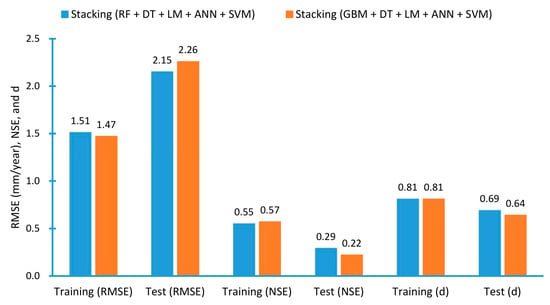
نتایج RF-stacking (RF + DT + LM + ANN + SVM) و GBM-stacking (GBM + DT + LM + ANN + SVM) در جدول 5 نشان داده شده است. برای مجموعه داده های آموزشی، GBM-stacking در هر سه شاخص آماری (RMSE، NSE، و d) از RF-stacking در گروه های #1 و #3 بهتر عمل کرد. در گروه شماره 2، GBM-stacking نیز در برابر RF-stacking بر حسب RMSE (1.45 در مقابل 1.46) پیروز شد، اما در برابر RF-stacking از نظر مقادیر d (0.79 در مقابل 0.83) شکست خورد. این یک مورد نادر است که ناسازگاری بین RMSE و d مشاهده شود.
در مورد مجموعه داده های آزمایشی، مدل با بهترین عملکرد معکوس است. در هر سه گروهبندی مختلف (نمونهگیری)، انباشتن RF در همه شاخصهای آماری بدون استثنا، GBM-stacking را انجام داد. به طور خلاصه، اگرچه GBM-stacking بهترین عملکرد را با داده های آموزشی داشت، اما داده های تست را از دست داد. از آنجایی که عملکرد پیشبینی یک مدل بر اساس دادههای آزمایشی دیده نشده است، نتیجه میگیریم که انباشتن RF مدل انباشتگی بهتری از این دو است. مقایسه بصری بین RF-stacking و GBM-stacking در شکل 6 نشان داده شده است ، جایی که هر سه شاخص ترسیم شده اند (RMSE، NSE، و d). اعداد در شکل نشان دهنده مقادیر متوسط سه گروه بندی مختلف (پارتیشن بندی) هستند.
3.4. مقایسه مدل های گروه
تاکنون شش روش گروهی را در سه دسته مقایسه کرده ایم و بهترین مدل را برای هر دسته تعیین کرده ایم. سوال بعدی این است که چگونه آنها در یک مقایسه شش جانبه با یکدیگر مقایسه می کنند. نتایج در شکل 7 گردآوری شده استبا استفاده از مقادیر RMSE در میان شش مدل گروه مورد بررسی در این مطالعه، اگر فقط داده های آموزشی را در نظر بگیریم، بهترین مدل کلی GBM (0.61 میلی متر در سال) و پس از آن Cubist (0.84 میلی متر در سال) است. هر دوی آنها به دسته تقویت کننده تعلق دارند. میانگین مقادیر d آنها به ترتیب 0.96 و 0.95 است. با این حال، اگر فقط بر روی دادههای آزمایش تمرکز کنیم، اگرچه مدل برنده کلی هنوز GBM (1.72 میلیمتر در سال) است، RF (1.75 میلیمتر در سال) جایگزین Cubist (1.95 میلیمتر در سال) به عنوان دومین مدل با بهترین عملکرد خواهد شد. اگر NSE و d به جای RMSE در نظر گرفته شوند، نتیجه تغییر نمی کند. در این موارد، GBM و RF دو مدل بهترین مجموعه باقی می مانند. بر اساس شکل 7 ، مدل ها را از بهترین تا بدترین رتبه بندی می کنیم:
برای یادگیری ماشین، قضاوت در مورد عملکرد مدلهای ML بر اساس دادههای آزمایشی دیده نشده مناسبتر است. بنابراین، برای دادههای تست، GBM (تقویت) برنده کلی است و پس از آن RF (کیسهبندی) قرار دارد. مدل های بعدی که بهترین عملکرد را دارند MARS کیسه ای (کیسه زنی) و کوبیست (تقویت کننده) هستند. واضح است که چهار مکان برتر به طور مساوی بین روش بسته بندی و روش تقویت تقسیم شده است. از این رو، این دو نوع مدل مجموعه، کیسهبندی و تقویت، از نظر عملکرد با یکدیگر رقابت میکنند و به همان اندازه در پیشبینی عمق فرسایش خاک اندازهگیری شده توسط پینهای فرسایش خوب هستند. در مقابل، به نظر میرسد که روشهای مجموعه انباشته (RF + DT + LM + ANN + SVM و GBM + DT + LM + ANN + SVM) از هر دو روش بستهبندی و تقویت عقبتر هستند. ما این نتیجه را بسیار جذاب یافتیم. با وجود اینکه GBM و RF دو مدل برتر هستند، زمانی که در رویکرد انباشتگی برای ترکیب سایر مدلهای ضعیفتر استفاده میشوند، عملکرد خوبی ندارند. شاید این به این دلیل است که GBM و RF زمانی که بهصورت جداگانه بهعنوان مدلهای منفرد استفاده میشوند، مستقیماً با ۱۴ ویژگی کار میکنند. هنگامی که GBM و RF به عنوان متا مدلها در رویکرد انباشتگی مورد استفاده قرار گرفتند، آنها فقط بر اساس پیشبینیهای مدلهای پایه (DT، LM، ANN و SVM) آموزش دیدند. به نظر می رسد ناتوانی مستقیماً با 14 ویژگی اساسی، توانایی GBM و RF را برای پیش بینی بهتر تضعیف کرده است. و SVM). به نظر می رسد ناتوانی مستقیماً با 14 ویژگی اساسی، توانایی GBM و RF را برای پیش بینی بهتر تضعیف کرده است. و SVM). به نظر می رسد ناتوانی مستقیماً با 14 ویژگی اساسی، توانایی GBM و RF را برای پیش بینی بهتر تضعیف کرده است.
3.5. پیش بینی های مدل و اهمیت عوامل
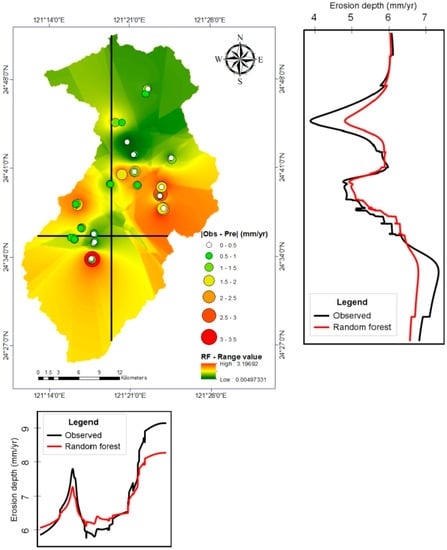
از آنجایی که GBM و RF دو مدل بهترین گروه در کلاس خود هستند (به ترتیب RMSE = 1.72 و 1.75 میلی متر در سال)، ما فقط نتایج یادگیری گروه مربوطه آنها را در شکل 8 و شکل 9 نشان می دهیم . همانطور که در شکل ها نشان داده شده است، اندازه و رنگ دایره ها نشان دهنده تفاوت مطلق (خطا) بین پیش بینی ها و مشاهدات مدل است. |Oبس-پrه|). از نمادهای متناسب استفاده شد. بنابراین، هرچه دایره بزرگتر باشد، تفاوت بزرگتر است. به طور مشابه، هر چه رنگ نقطه قرمزتر باشد، خطا بیشتر است. نتایج متضاد تولید شده توسط GBM و RF مشهود است. برای GBM، از شکل 8 مشخص است که اکثر نقاط به جز نقاطی که در قسمت شرقی منطقه مورد مطالعه قرار دارند، خطای کمی دارند. در مقابل، شکل 9 نشان می دهد که RF دارای خطاهای بزرگی در هر دو بخش شرقی و جنوبی منطقه مورد مطالعه است. برای تجسم بهتر توزیع خطا، ما بیشتر مقادیر درونیابی فضایی (خطاهای مطلق) را در سراسر منطقه مورد مطالعه نگاشت کردیم. همانطور که در شکل 8 نشان داده شده استحوضه حاصله عمدتاً سبز (همراه با خطای کم) برای GBM است، به جز در قسمت شرقی که خطاهای بزرگ به دلیل توپوگرافی تند و جهت های شیب نامطلوب، بازگشت به رنگ های قرمز را به همراه دارد. با این حال، طبق شکل 9 ، حوضه آبخیز فقط در منطقه شمالی برای RF سبز است. بقیه حوضه به رنگ قرمز یا زرد است.
علاوه بر این، ما دو نمایه عمودی روی نقشه ایجاد کردیم، یکی در جهت شرق به غرب و دیگری در جهت شمال به جنوب، تا پیشبینیها و مشاهدات مدل را برای هر دو GBM و RF مقایسه کنیم. همانطور که در شکل 8 نشان داده شده است، خط سیاه مشاهدات است و خط آبی پیش بینی GBM است. هر دو خط روند مشابهی را نشان میدهند و در یک جهت حرکت میکنند: اگر مشاهده افزایش یابد، پیشبینی نیز افزایش مییابد، و اگر مشاهده کاهش یابد، پیشبینی نیز افزایش مییابد. با این حال، به نظر بدیهی است که GBM تمایل دارد مقادیر بالای مشاهده را دست کم برآورد و مقادیر پایین مشاهده را در هر دو نمای شمالی-جنوبی و شرقی-غربی بیش از حد برآورد کند. علاوه بر این، اگر نمایه های مشابه را در شکل 9 ترسیم کنیمو از یک خط قرمز برای نشان دادن پیش بینی RF استفاده کنید، می توانیم نتیجه مشابهی را مشاهده کنیم. پیش بینی RF نیز در همان جهت مشاهده حرکت می کند. مدل RF همچنین مقادیر بالای مشاهدات را دست کم می گیرد و مقادیر پایین مشاهده را در پروفایل های شمال-جنوب و شرق-غرب بیش از حد برآورد می کند. با این حال، تفاوت این است که خطاهای RF در مقایسه با GBM بیشتر است.
به طور خلاصه، هر دو GBM و RF در منطقه شمالی حوضه، جایی که مخزن در آن قرار دارد، عملکرد بهتری دارند. از آنجایی که شیب حوضه از جنوب به شمال است (همانطور که قبلا در شکل 2 نشان داده شده است )، این نشان می دهد که مدل ها رفتار فرسایش (اندازه گیری شده توسط پین های فرسایش) را در ارتفاعات پایین تر به اندازه کافی نسبت به ارتفاعات بالاتر نشان می دهند. قسمت شرقی مشکل دارد. هیچ یک از این دو مدل در اینجا خوب کار نمی کند. به طور کلی، GBM بهتر از RF عمل می کند زیرا GBM با اندازه گیری های موجود بهتر از RF در غرب و جنوب مطابقت دارد. این باعث می شود GBM به طور کلی بهترین مدل باشد که با نتایج مبتنی بر RMSE سازگار است.
هر دو GBM و RF رتبه ای از اهمیت را برای 14 ویژگی مورد استفاده در این مطالعه ایجاد می کنند. شش شبیهسازی (سه شبیهسازی GBM و سه شبیهسازی RF) در یک باکس پلات برای نشان دادن محدوده رتبهها (اهمیت عامل) همانطور که در شکل 10 نشان داده شده است، ترکیب شدهاند . چندین نکته در این شکل قابل بررسی است. ابتدا، کادر خاکستری در شکل، محدوده رتبه های بین ربع اول و سوم نتایج را نشان می دهد. بدیهی است که هر ویژگی دارای یک محدوده متغیر از رتبه ها است. دوم، خط سیاه در کادر نشان می دهد که رتبه میانه (1 مهم ترین و 14 کمترین اهمیت است). رتبه متوسط و کادر خاکستری را می توان برای مقایسه اهمیت نسبی ویژگی ها استفاده کرد. بنابراین، از شکل 10 قابل مشاهده استکه A (جهت شیب) و B (نوع شیب) دو ویژگی کلی مهم در مدلهای GBM و RF هستند. آنها مرتباً بالاتر از 12 ویژگی دیگر قرار می گیرند. ویژگی D (ارتفاع) جالب است. رتبه چهارم پایین ترین میانه در مقایسه را دارد. در عین حال، همچنین دارای طولانی ترین جعبه خاکستری و وسیع ترین محدوده نسبت به سایر ویژگی ها است. این بدان معنی است که ارتفاع بسته به مدل و مجموعه داده دارای اهمیت متغیر است. در برخی موارد، ارتفاع بسیار مهم است، در حالی که در برخی دیگر اینطور نیست.
4. نتیجه گیری
فرسایش خاک یک تهدید مهم برای محیط زیست و معیشت منطقه است و باید برای کاهش پیامدهای فاجعهبار آن جدی گرفته شود. از این رو، پیش بینی مکانی دقیق فرسایش خاک یک نیاز حیاتی است. در این مطالعه، ما از شش روش یادگیری گروهی (کیسهای MARS، RF، GBM، Cubist، RF-stacking و GBM-stacking) در سه دسته (کیسهبندی، تقویت، و انباشته) برای مدلسازی اندازهگیریهای پینهای فرسایش در Shihmen استفاده کردیم. حوضه آبخیز مخزن تایوان. هدف بهبود دقت مدلسازی و قابلیت پیشبینی مرتبط با فرسایش خاک بود. در فرآیند ارزیابی عملکرد سه نوع رویکرد گروهی، آموختهایم که روشهای گروهی با دادههای آزمایشی دیده نشده چقدر مؤثر هستند.
نتایج مطالعه نشان میدهد که روشهای مجموعه، دقت پیشبینی را با سه شاخص آماری RMSE، NSE و d اندازهگیری میکنند. در میان سه دسته از روشهای گروهی، کیسهسازی و تقویت به همان اندازه روی دادههای آزمایشی دیده نشده کار میکنند. انباشته کردن کمترین مطلوب ترین رویکرد است، با RMSE آن پس از سایر انواع الگوریتم های گروه. به طور جداگانه، ما دریافتیم که GBM بهترین مدل مناسب است. مقادیر RMSE، NSE و d آن به ترتیب 1.72 میلی متر در سال، 0.54 و 0.81 است. دومین مدل برتر RF است. ما از GBM و RF برای ترسیم تفاوت های مطلق (خطاها) بین پیش بینی ها و مشاهدات مدل استفاده کردیم. |Oبس-پrه|) در منطقه مورد مطالعه. نتایج نشان میدهد که هر دو مدل در ناحیه شمالی حوضه (محل قرارگیری مخزن) عملکرد خوبی دارند و در قسمت شرقی حوضه به دلیل توپوگرافی تند و جهتهای شیب نامطلوب عملکرد نسبتاً ضعیفی دارند. آنچه GBM را نسبت به RF برتری می دهد این است که GBM در قسمت های غربی و جنوبی منطقه مورد مطالعه نیز به خوبی کار می کند در حالی که RF اینطور نیست. این نتیجه گیری با نتایج مبتنی بر RMSE مطابقت دارد.
در نهایت، به عنوان یک کشف اضافی در مطالعه، ما متوجه دو مورد از شاخص های آماری ناسازگار در طول مقایسه مدل شدیم. یکی از آنها زمانی اتفاق افتاد که ما GBM را با Cubist مقایسه کردیم (داده های آزمون گروه شماره 3). مورد دیگر زمانی رخ داد که ما عملکرد دو مدل انباشتگی (داده های آموزشی گروه شماره 2) را بررسی کردیم. در هر دوی این موارد، RMSE و NSE یک مدل را ترجیح دادند، اما d دیگری را ترجیح دادند. بنابراین، اگر تنها بر یک شاخص تکیه کنیم، میتوان نتیجهگیریهای بالقوه متناقضی داشت. این خطر نیاز به ارائه شاخص های متعدد در چنین مطالعاتی را نشان می دهد.








بدون دیدگاه