1. معرفی
رهاسازی زمین های کشاورزی (FLA) را می توان به عنوان توقف فعالیت های کشاورزی در سطح معینی از زمین تعریف کرد [ 1 ]. FLA پیامدهای زیست محیطی قابل توجهی دارد و اغلب با مشکلات اجتماعی و اقتصادی در مناطق روستایی همراه است. FLA در مناطقی رخ می دهد که فعالیت های کشاورزی دیگر قابل دوام نیستند، اما همچنین در مناطقی که به خوبی به شبکه های حمل و نقل متصل هستند و دارای فعالیت اقتصادی شدید هستند، رخ می دهد [ 2 ]. به گفته گرادینارو و همکاران. [ 2]، این نوع دوم رهاسازی با فرآیندهای سریع شهرنشینی در ارتباط است. بنابراین، فرصت های اقتصادی جدید، شهرنشینی، ترجیحات املاک و مستغلات، و تغییرات در ساختار جمعیتی مهم ترین محرک های این از دست دادن علاقه به فعالیت های کشاورزی در نظر گرفته می شوند [ 3 ].]. در نتیجه زمین کم استفاده می شود که متروکه واقعی محسوب می شود. اصطلاح شهرنشینی سریع به گسترش شهری پراکنده، مصرفکننده و سازمانیافته شهری اشاره دارد که به دلیل قوانین مجاز یا حتی عدم رعایت مقررات برنامهریزی توسعه یافته است. در چند دهه اخیر، ساختوساز نیروی محرکه اصلی برای اقتصاد بسیاری از کشورهای اروپایی بوده است، بنابراین زمینهای کشاورزی پیرامون شهری بهویژه تحت فشار، رنج فرآیندهای تخریب و رها شدن در انتظار توسعه شهری بودهاند [ 4 ].
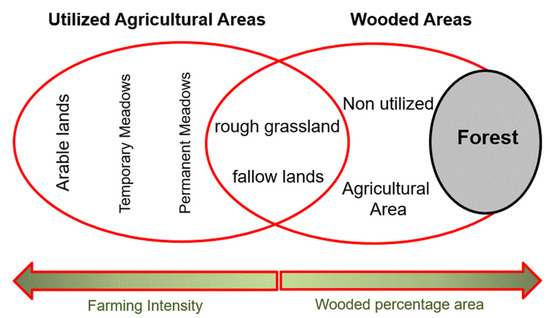
مکان یابی اراضی متروکه و ثبت اطلاعات مکانی مربوط به آن نقش مهمی در مدیریت اراضی شهری دارد. بنابراین، نقشه برداری از زمین های متروکه ممکن است مسیرهای آینده تغییر زمین را آشکار کند. این می تواند مقامات محلی را قادر سازد تا اثربخشی مقررات کاربری زمین را ارزیابی کنند و برنامه ریزی شهری را برای استفاده پایدارتر از زمین تطبیق دهند [ 2 ]. مکان یابی زمین یا زمین متروکه در فرآیند رهاسازی دشوار است زیرا محدودیت بین کاربری های مختلف مشخص و دقیق نیست. با توجه به Pointereau و همکاران. [ 1 ]، مرز بین زمین کشاورزی استفاده شده، زمین کشاورزی استفاده نشده و جنگل ممکن است همانطور که در شکل 1 نشان داده شده است ایجاد شود.. بنابراین، مناطق کشاورزی استفاده نشده را می توان به عنوان مناطق جنگلی تعریف کرد که به عنوان جنگل، علفزار ناهموار، یا زمین های آیش قابل شناسایی نیستند. مناطق کشاورزی مورد استفاده (UAA) شامل زمین های زراعی، علفزارهای موقت و علفزارهای دائمی است.
بر اساس موارد فوق، لازم است روش هایی ایجاد شود که به ما امکان می دهد FLA را تا حد امکان دقیق برآورد و نقشه برداری کنیم. بنابراین، به عنوان یک جایگزین موثر برای روشهای سنتی مبتنی بر مشاهدات مستقیم که میتواند زمانبر، پرهزینه و نیازمند کار میدانی گسترده باشد، اشکال جدیدی از تخمین در نتیجه توسعه مداوم و سریع فناوریهای ژئوماتیک در حال ظهور هستند. یکی از این فناوریهای ژئوماتیک که برای مطالعه مناظر و نقشهبرداری استفاده از زمین در مناطق وسیع به کار میرود، سنجش از دور ماهوارهای (SRS) است [ 5 ، 6 ، 7 ، 8 ].]. مطالعات متعددی در رابطه با کاربرد SRS در نقشه برداری FLA وجود دارد و در همه آنها ثابت شده است که SRS یک ابزار موثر و ارزشمند است. در میان این مطالعات، ما آثار استل و همکاران، لیو و همکاران، گرادینارو و همکاران، و استریاکیویکز و همکاران را برجسته میکنیم. [ 2 ، 9 ، 10 ، 11 ]. لیو و همکاران [ 10 ] کاربرد تصاویر هوابرد با وضوح بالا (تصاویر چند طیفی دیجیتال (DMSI)) که در طی دو فصل به دست آمد برای تخمین کاهش کربن در پوشش گیاهی مجدد زمینهای کشاورزی رها شده را بررسی کرد. نتایج آنها نشان داد که روش پیشنهادی به طور بالقوه می تواند برای نقشه برداری در مقیاس بزرگ زمین های متروکه در مناطق کوهستانی به کار رود. در مقاله خود، Grădinaru و همکاران. [ 2] تحلیل کرد که چگونه سری های زمانی تصاویر فصلی بر دقت طبقه بندی در مناظر شهری ناهمگن که با تکه تکه شدن بالا و تنوع محصول بالا مشخص می شود، تأثیر می گذارد. برای انجام این کار، آنها روشی را برای ارزیابی سریع FLA با استفاده از سریهای زمانی فصلی دادههای Landsat پیشنهاد کردند. به طور خاص، آنها از تصاویر لندست با وضوح بالا (30 متر) استفاده کردند که به آنها اجازه می داد تا نرخ رهاسازی را در مقیاس دقیق نقشه برداری کنند و الگوهای فضایی را شناسایی کنند. با این حال، دادههای Landsat در بسیاری از موارد قبلی به منظور: (1) تعیین نیروهای محرک و نرخ رهاسازی در مناطق کشاورزی استفاده شده است [ 12 ، 13 ]]، (ii) تأثیر در دسترس بودن Landsat ETM/ETM+ و تاریخهای کسب تصویر را در تشخیص زمینهای متروکه تجزیه و تحلیل میکند، و (iii) اهمیت مجموعه دادههای چند فصلی را در دستیابی به دقت طبقهبندی بالا نشان میدهد [ 14 ]. از سوی دیگر، Stryjakiewicz و همکاران. [ 11 ] میزان رها شدن زمین کشاورزی را با استفاده از تصاویر سنتینل ارزیابی کرد. اگرچه این نوع تصاویر با وضوح بسیار بالا (10 متر) قبلاً ثابت شده بود که منبع قابل اعتمادی برای ارزیابی تغییرات کاربری اراضی در مقیاس های محلی یا منطقه ای است [ 15 ، 16 ]، اما تا زمانی که مطالعه توسعه یافته توسط Stryjakiewicz برای شناسایی FLA آزمایش نشده بود. و همکاران [ 11]. نتایج آنها نه تنها نشان داد که Sentinel خود را به عنوان یک ابزار کارآمد برای مکان یابی زمین های زراعی متروکه در مناظر شهری نشان داد، بلکه اطلاعاتی در مورد مساحت و درصد این نوع زمین ارائه کرد.
علیرغم موارد فوق و همانطور که توسط اکثر مطالعات ذکر شده در بالا بیان شد، SRS نتایج دقیق کمتری نسبت به نقشه های بدست آمده از تصاویر هوایی و کار میدانی گسترده ارائه می دهد. دلیل این امر این است که دقت نقشههای زمین رها شده به دست آمده از دادههای SRS به موارد زیر بستگی دارد: (1) وضوح فضایی ارائه شده توسط سکوی ماهوارهای به کار گرفته شده و (ب) دقت حاصل از مجموعه فرآیندهایی که توسط آن یک تصویر ماهوارهای تولید میشود. از این نظر، باید توجه داشته باشیم که برخلاف تصاویری که توسط سکوهای هوایی ارائه میشوند، استفاده از تصاویر ماهوارهای شامل توسعه چندین فرآیند ذاتی سکوهای ماهوارهای است، مانند طبقهبندی اولیه (که برای تجزیه و تحلیل رفتار منطقه کار استفاده میشود. با توجه به فنولوژی فصلی کاربری های مختلف زمین) یا طبقه بندی (تحلیل اجزای اصلی، تجزیه و تحلیل کلاس ها با استفاده از دندروگرام و غیره). بر اساس شواهد فوق، رویکرد ما چارچوبی را برای مکان یابی و نقشه برداری خودکار FLA در مناظر شهری با استفاده از خصوصیات بافتی و تقسیم بندی تصاویر هوایی پیشنهاد می کند.
2. داده ها و روش
2.1. رویکرد تحقیق
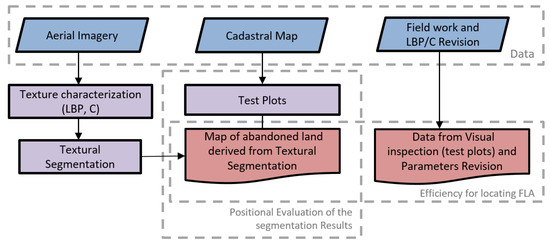
بر اساس روشی که در ابتدا توسط Ojala و Pietikäinen [ 17 ] توسعه داده شد، ما الگوریتمی را برای شناسایی و استخراج پیکسل هایی که به زمین های متروکه تعلق دارند بر اساس یک رویکرد ناپارامتریک برای توصیف بافت ایجاد کردیم. گردش کار رویکرد ما در شکل 2 نشان داده شده است . توصیف بافت با استفاده از دو توصیفگر بافتی انجام شد: الگوی باینری محلی (LBP) و کنتراست (C). LBP به یک معیار واقعاً قدرتمند برای بافت تصویر تبدیل شده است که نتایج عالی را از نظر دقت و پیچیدگی محاسباتی در بسیاری از مطالعات تجربی نشان می دهد [ 18 ]]. این رویکرد برای توصیف بافت قبلاً با موفقیت در بسیاری از فرآیندهای ترکیبی بین داده های برداری و تصاویر آزمایش شده است که در آن تقاطع های جاده به طور خودکار از تصاویر استخراج می شوند و سپس به عنوان نقاط کنترل به منظور انجام روش تطبیق استفاده می شوند [ 19 , 20 ]]. پس از به دست آوردن نقشه زمین متروکه، اثربخشی روش پیشنهادی را از دو محور مختلف ارزیابی کردیم: (1) دقت نتایج تقسیمبندی (از نقطه نظر موقعیت) و (2) کارایی برای مکانیابی زمینهای متروکه (به عنوان نوع خاصی از کاربری زمین) در مناطق شهری به ویژه تحت تأثیر شهرنشینی سریع. برای هر دو مورد، از نمونه یکسانی از نمودارهای آزمایشی استفاده کردیم. به طور خاص برای ارزیابی نتایج تقسیمبندی، مرزهای این قطعات از پایگاههای اطلاعاتی کاداستر استخراج شد، در حالی که برای بررسی کاربری زمین، دو روش بازرسی انجام شد: (1) اعتبار سنجی خارجی بر اساس روش بازرسی بصری از طریق بازدیدهای میدانی و (ب) تجدید نظر در پارامترهای LBP/C متعلق به نمونه نمودارهای آزمایشی.
2.2. حوزه و داده های مطالعه
در کشورهای سوسیالیستی سابق، گذار از اقتصادهای دستوری به اقتصادهای مبتنی بر بازار با واگذاری های گسترده مالکیت زمین [ 21 ] دنبال شد که منجر به استفاده از زمین بسیار پراکنده و کاهش سودآوری کشاورزی و در نتیجه رها شدن زمین شد. از این نظر، لهستان نیز از این قاعده مستثنی نبود.
در لهستان، FLA قابل توجهی در طول دوره 1996-2002 رخ داد و عمدتاً مربوط به علفزارها بود. به نظر می رسد FLA عمدتاً در شرق کشور واقع شده است، جایی که دارایی های کوچک و متنوع وجود دارد، برخلاف غرب، جایی که در دوره کمونیستی، بسیاری از مزارع بزرگ مزارع دولتی بودند [ 1 ]. با توجه به مناطق شهری و برای همین مدت، تلفات UAA معادل 764032 هکتار برآورد شد که معادل 36 درصد کاهش کل (شهری و روستایی) (30 درصد) است. در شهرداریهایی با تراکم بیش از 200 اینچ بر کیلومتر مربع ، 35 درصد از UAA (633193 هکتار) در طول دوره از بین رفت.
به طور خاص، پوزنان به عنوان منطقه مورد مطالعه انتخاب شد ( شکل 3 ). طبق طبقه بندی ایجاد شده توسط CORINE Land Cover، زمین های کشاورزی 33٪ از مساحت پوزنان را پوشش می دهد و زمین های قابل کشت به وضوح (82٪) بر ساختار این زمین کشاورزی غالب است. دلیل اصلی انتخاب پوزنان این بود که در دهه گذشته به شدت تحت تأثیر تکه تکه شدن چشم انداز و FLA قرار گرفته است. همانطور که در بخش 1 ذکر شد، این رها عمدتاً ناشی از قوانین مجاز یا حتی عدم رعایت مقررات برنامه ریزی بوده است. با این حال، یک عامل کلیدی دیگر در FLA وجود داشته است: تکامل جمعیتی. پوزنان دارای یک تحول جمعیتی خاص است که با جریانهای مختلفی که همزمان اتفاق میافتد مشخص میشود: (1) مهاجرت از برخی مناطق روستایی به مناطق شهری، (2) مهاجرت از مراکز شهر به مناطق حاشیهشهری، و (iii) گسترش مسکن. مطابقت با استانداردهای جدید سبک زندگی). این جریانهای جمعیتی با فشار توسعه اقتصاد، نیازهای مسکن و زیرساختها را ایجاد میکنند. بنابراین نیاز به زمین در این مناطق شهری اهمیت پیدا می کند.
در نهایت، و با توجه به داده ها، از تصاویر هوایی با وضوح بالا که توسط World_Imagery (MapServer) [ 22 ] ارائه شده است، استفاده کردیم. World_Imagery تصاویر ماهواره ای و هوایی (با وضوح 0.5 متر بر پیکسل تا 1 متر بر پیکسل) را از بسیاری از نقاط جهان ارائه می دهد. برای اطلاعات بیشتر در مورد این منبع داده، از جمله شرایط استفاده، به صورت آنلاین در [ 22 ] مراجعه کنید. در مورد ما، وضوح تصویر انتخاب شده 1 m/pixel بود.
2.3. الگوریتم استخراج زمین های کشاورزی رها شده
تکنیکهای تقسیمبندی اصلی بر اساس مشاهدات تن پیکسل، شکل هیستوگرام مقیاس خاکستری را تجزیه و تحلیل میکنند و خوشههای هیستوگرام را بر اساس اندازههایشان طبقهبندی میکنند و تصویر اصلی را تقسیم میکنند. اگرچه مناطق حاصل از نظر بصری متفاوت هستند، اما با توجه به ویژگیهای آماری خاصی شباهت دارند. با این حال، این رفتار آماری یکنواخت در اکثر مناطق تصویر واقعی معمول نیست. در نتیجه، به نظر نمیرسد استفاده از رنگ پیکسل برای بخشبندی تصاویر بهترین گزینه باشد [ 20 ]]. برای غلبه بر این چالش، الگوریتمی را برای استخراج پیکسل ها از تصاویر بر اساس یک رویکرد محلی-ناپارامتریک برای تحلیل بافت ایجاد کردیم. تقسیم بندی بافتی را می توان به عنوان فرآیند پارتیشن بندی یک تصویر به قسمت های مختلف با هم، که متعلق به یک کلاس شیء هستند، تعریف کرد. برای این منظور، اطلاعات بافتی از تصویر استخراج می شود و برای توسعه وظایفی مانند تشخیص، طبقه بندی و تجزیه و تحلیل استفاده می شود [ 23 ]. در سالهای اخیر، توصیفکنندههای بافت محلی بسیار متمایز و کارآمد محاسباتی توسعه یافتهاند [ 23 ]. در میان همه اینها، الگوریتم ما از دو معیار بافتی اصلی استفاده می کند:
-
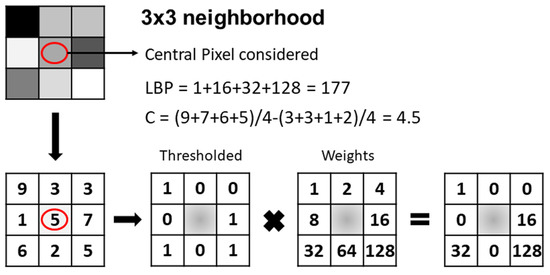
الگوی باینری محلی (LBP): LBP یک توصیفگر بافت محلی است که قادر به مشخص کردن مناطق بافت کوچک است [ 23 ]. LBP یک عملگر بافت ساده و در عین حال بسیار کارآمد است که پیکسل های همسایه را بر اساس مقدار پیکسل فعلی آستانه گذاری می کند [ 24 ]. با توجه به قدرت تمایز خود، عملگر بافت LBP به یک رویکرد محبوب در چندین برنامه تبدیل شده است، که رویه های تحلیل بافت را برجسته می کند [ 25 ]. شکل 4روش محاسبه مقادیر LBP را نشان می دهد. ابتدا هر پیکسل مرکزی با هشت همسایه خود مقایسه می شود. این همسایگی 3 × 3 باید با مقدار پیکسل مرکزی در آستانه باشد. همسایههایی که مقدار کمتری نسبت به پیکسل مرکزی دارند، بیت 0 خواهند داشت و سایر همسایههایی که مقداری برابر یا بزرگتر از پیکسل مرکزی دارند، بیت 1 خواهند داشت. سپس این مقادیر باینری پیکسلها در همسایگی آستانهای باید در وزن های داده شده به پیکسل های مربوطه ضرب شود. در نهایت، مقادیر هشت پیکسل اضافه می شود تا عددی برای این محله به دست آید. اگر هیستوگرام LBP را در کل یک منطقه محاسبه کنیم، ممکن است برای توصیف بافت آن استفاده شود. علاوه بر این، LBP به سطوح بالایی از دقت در فرآیندهای توصیف بافت در مقایسه با سایر اپراتورهای بافت دست می یابد.
-
معیار کنتراست (C): توصیفگرهای LBP به طور موثر الگوهای فضایی محلی را ضبط می کنند. با این حال، در حالی که LBP در برابر هر تبدیل مقیاس خاکستری یکنواخت ثابت است، ما باید آن را با یک کنتراست ساده C ترکیب کنیم تا حتی قدرتمندتر شود. محاسبه C نیز در شکل 4 نشان داده شده است.
شش مرحله اصلی روش استخراج FLA ما را تعریف می کند:
همانطور که در پاراگراف های قبلی ذکر شد، بافت یک ویژگی تصویر نیست که ممکن است با یک پیکسل مرتبط باشد. به همین دلیل است که تصویر به شبکه ای تجزیه می شود که هر سلول آن شامل تعداد ثابتی پیکسل است. توزیع LBP/C آن توسط یک هیستوگرام دو بعدی گسسته (آرایه) 256 × b پیکسل، که در آن b تعداد bin ها برای اندازه گیری کنتراست C است ( شکل 5 ) تقریب زده شد. این تعداد سطل به عنوان یک مبادله بین قدرت تمایز و ثبات توصیف بافت انتخاب شده است [ 17 ].
هنگامی که این هیستوگرام ها به دست آمد، هدف اساسی مقایسه توزیع های LBP/C بود که دو بافت را برابر یا متفاوت تشخیص می داد. ابزاری که به ما اجازه داد تا این شناسایی را انجام دهیم، آماره G [ 26 ] بود. در مقایسه با سایر معیارهای آماری شباهت، مانند فاصله log- تجمعی یا واگرایی جفری [ 17 ، 23 ]، که دارای قابلیت تمایز پایینی هستند، مقدار G (معادله (1)) یک آماره لگاریتم-احتمالی غیر پارامتری است که معمولاً برای ارزیابی استفاده میشود. شباهت بین دو هیستوگرام ( A و B) زمانی که سطح بالایی از تبعیض مورد نیاز است. بنابراین، هر چه مقدار بیشتر باشد، شباهت بین آنها کمتر است. علاوه بر این، در رابطه (1)، N نشان دهنده تعداد bin ها و fi نشان دهنده فرکانس در bin i است.
- (2)
-
تولید ساختار سلسله مراتبی
با هدف اصلی بهینهسازی ظرفیت ذخیرهسازی و در نتیجه بهبود زمان محاسبات، رویکردی مبتنی بر یک نمایش هرمی برای تقسیمبندی بافت اقتباس شد. به جای انجام تقسیمبندی تصویر بر اساس یک نمایش واحد از تصویر ورودی، یک الگوریتم تقسیمبندی هرمی محتویات تصویر را با استفاده از نمایشهای متعدد با وضوح کاهش توصیف میکند [ 27 ]. به گفته مارفیل و همکاران. [ 27 ]، این نوع الگوریتم ویژگی های جالبی را با توجه به الگوریتم های تقسیم بندی مبتنی بر یک نمایش واحد نشان می دهد: (1) تشخیص ویژگی های جهانی مورد علاقه و نمایش آنها در سطوح وضوح پایین [ 28 ، 29 ]]، (ii) کاهش نویز و پردازش ویژگیهای محلی و جهانی در چارچوب یکسان [ 30 ]، و (iii) کاهش پیچیدگی وظیفه تقسیمبندی تصویر [ 28 ، 29 ]. به طور خاص، ما از یک الگوریتم تقسیم بندی بر اساس اهرام منظم استفاده کردیم.
اصل کلی رویکرد هرمی ما به طور خلاصه توسط Jolion و Montanvert [ 31 ] توضیح داده شد. بر اساس آن اصل، اگر مشخص کنیم که چگونه یک سطح جدید ساخته شده است ( شکل 6 الف) و چگونه یک والدین با فرزندان خود ارتباط دارند، یک معماری هرمی کاملاً تعریف می شود ( شکل 6 ب). این رابطه والد-فرزند توسط پنجره کاهش تعریف می شود و ممکن است با گذر به سطح پایه گسترش یابد ( شکل 6 a). مجموعه فرزندان یک سلول در سطح پایه، میدان پذیرنده آن نامیده می شود [ 27]، و تعبیه این راس را در تصویر اصلی تعریف می کند. با توجه به کارایی یک نمایش هرمی برای حل یک روش تقسیم بندی، باید توجه داشته باشیم که به شدت تحت تأثیر ساختار داده مورد استفاده در هرم است، اطلاعاتی را که ممکن است در هر سطح رمزگذاری شود، و طرح کاهش مورد استفاده را محدود می کند. پویایی آن را از نظر ارتفاع و حفظ جزئیات تعریف می کند [ 29 ].
در ساختار هرمی ما، یک سلول در سطح l نشان دهنده a است 2ل×2ل2�×2�مربع در تصویر ورودی، و پایه ساختار توسط توزیع های LBP/C تشکیل شده است. هر سلول هرمی که با (x, y, l) مشخص می شود دارای پارامترهای زیر است:
-
همگنی که با H(x, y, l) نشان داده می شود . همگنی از 1 (اگر چهار سلول بلافاصله زیر آن بافت یکسانی داشته باشند) تا 0 (در هر مورد دیگری) متغیر بود. تنظیم H بر اساس آزمون یکنواختی بود. بنابراین، اگر اندازهگیری عدم تشابه نسبی در آن ناحیه از یک آستانه خاص U کمتر باشد، چهار سلول دارای بافت یکسانی بودند. جیm a x����/ جیm i n����< U). U باید به گونه ای تنظیم شود که از تشخیص و تمایز بافت ها اطمینان حاصل کند و تا حد امکان از گنجاندن دو منطقه با بافت های متفاوت در یک کلاس جلوگیری شود. به همین دلیل، توصیه می شود مقداری برای U تا حد امکان کوچک انتخاب کنید.
-
بافت، با T(x، y، l) نشان داده می شود . بافت یک سلول بهعنوان مجموع توزیعهای LBP/C چهار سلولی که بلافاصله زیر آنها قرار دارند، اگر و تنها در صورتی که سلول همگن بود، محاسبه شد. در غیر این صورت، مقدار T(x, y, l) روی یک مقدار ثابت تنظیم شد (تیناچ)(���).
-
پیوند والد، نشان داده شده با ( X، ی)( x ، y، ل )(�,�)(�,�,�). اگر اچ( x ، y، ل )�(�,�,�)برابر 1 بود، مقادیر پیوندهای والد چهار سلول بلافاصله در زیر (x, y) تنظیم شد. در غیر این صورت، این چهار پیوند والد روی یک مقدار تهی تنظیم شدند.
-
مرکز، نشان داده شده با سی( x ، y، ل )�(�,�,�). سی( x ، y، ل )�(�,�,�)، مرکز جرم ناحیه پایه مرتبط با (x,y,l) را نشان می دهد.
-
هیستوگرام. هر پیوند والد، هیستوگرام دو بعدی را ذخیره میکرد که بافت ناحیه تصویر نشاندادهشده توسط این گره را مشخص میکرد. به منظور بهینه سازی ظرفیت ذخیره سازی و بهبود زمان محاسبات، اگر یک گره (واقع در سطح l ) ناحیه ای از بافت همگن را نشان دهد، تمام گره های واقع در سطوح پایین تر (تا انتهای هرم) خود را ذخیره نمی کنند. هیستوگرام های مربوطه، بافت آنها با هیستوگرام ذخیره شده در پیوند والد مشخص می شود.
پس از تکمیل ساخت ساختار سلسله مراتبی (مرحله شماره 2)، تمام سلول های متعلق به این ساختار با مقدار همگنی برابر با 1 و بدون والد به مناطق همگن در پایه مرتبط شدند و تقسیم بندی اولیه تصویر را مشخص می کنند.
- (3)
-
رشد سلول های همگن
در این مرحله، الگوریتم سلول هایی را که مقادیر پیوند والد آنها تهی بود، پیوند داد. اساساً، یک سلول (x، y، l) به والد همسایگان خود (xp، yp، l+1) پیوند داده میشود که دو سلول دارای بافت یکسانی باشند.
- (4)
-
ترکیب سلول های همگن
سلول های همسایه، (x1، y1، l) و (x2، y2، l) ادغام می شوند اگر چهار شرط زیر درست باشد:
-
( X، ی)( x 1 , y1 ، l )(�,�)(�1,�1,�)= پوچ بنابراین سلول پدر و مادری نداشت.
-
( X، ی)( x 2 , y2 ، ل )(ایکس،�)(ایکس2،�2،ل)= پوچ بنابراین سلول پدر و مادری نداشت.
-
سلول ها دارای بافت همگن بودند. اچ( x 1 , y1 ، l )اچ(ایکس1،�1،ل)= 1 و اچ( x 2 , y2 ، ل )اچ(ایکس2،�2،ل)= 1.
-
سلول ها همان بافت را داشتند.
- (5)
-
از نظر پیکسلی
از آنجایی که پیکسل ها در سطح پایه هرم به عنوان بلوک در نظر گرفته می شدند، وضوح تصویر قطعه بندی شده R با معادله (2) نشان داده شد، که در آن S وضوح تصویر اولیه و A مساحت پیکسل ها به طور میانگین برای ایجاد یک تصویر است. سلول.
به منظور بهبود وضوح تصویر خروجی و در نتیجه کاهش خطای بخشبندی، یک مرحله پس پردازش توسعه داده شد. این پس پردازش بر اساس یک نوع روش تقسیمبندی به نام بخشبندی نرم [ 32 ] بود که در آن هر پیکسل میتواند به بیش از یک منطقه تعلق داشته باشد، بنابراین از اشتباهات در مرزهای منطقه جلوگیری میشود. هنگامی که یک تصویر قطعهبندی میشود، پیکسلهای نزدیک به مرزهای ناحیه معمولاً از نظر مقدار متوسط بین مناطق هستند و میتوانند در طی همجوشی سلولی در هر یک از آنها قرار گیرند [ 27 ].]. با در نظر گرفتن این، ابتدا الگوریتم ما به صورت بازگشتی وضوح تمام بلوک ها را در مرزهای ناحیه بافت افزایش داد تا زمانی که این مرزها یک پیکسل عرض داشته باشند و سپس نقشه احتمال تقسیم بندی را ساخت. این نقشه احتمال، احتمال هر پیکسل را نشان می دهد که متعلق به یکی از کلاس های از پیش تعریف شده است و بر اساس پارامتر بافت ساخته شده است. ( L B P، سی)افL A(�بپ،سی)اف�آارزش های آموخته شده از روش آموزشی که در پاراگراف بعدی توضیح داده شده است. از این داده ها، چندین کانتور تقسیم بندی بسته تولید شد و بخش بندی بافتی نهایی به دست آمد.
- (6)
-
استخراج مناطق FLA
پس از حل مشکل تقسیم بندی، باید مناطق FLA را از بقیه شناسایی و جدا می کردیم. ما تصویری داشتیم که شامل چندین زون مانند پوشش گیاهی، ساخت و ساز و غیره بود. در این مرحله، مناطق FLA را از تصویر استخراج و بازسازی کردیم. برای استخراج مناطق FLA، ما نیاز به حذف اشیایی داریم که دارای ویژگی های بافتی FLA نیستند. بدون از دست دادن کلیت، فرض اصلی ما در مورد FLA بر روی تصاویر این بود: بر خلاف سایر مناطق پوشش گیاهی یا مناطق ساخت و ساز، که میتوانند مدلهای بافت متفاوتی داشته باشند، مناطق FLA معمولاً به دلیل ویژگیهای معرف زمین و پوشش گیاهی دارای مدل بافت مشابهی هستند. آنها را مشخص کرد. بر اساس این فرض، ما سیستم را در مناطق مختلف تصویر آموزش دادیم تا پارامترهای بافت مناطق FLA را یاد بگیریم. ( L B P، سی)افL A(�بپ،سی)اف�آ; بدین ترتیب مجموعه ای از آستانه ها برای این پارامترهای بافت ایجاد می شود. در این رابطه، یادآوری این نکته بسیار مهم است که اگرچه LBP در مقایسه با سایر اپراتورهای بافت به سطوح بالایی از دقت در فرآیندهای توصیف بافت دست مییابد، این آستانهها (مرتبط با روش آموزش) در طول فرآیند طبقهبندی عدم قطعیت ایجاد میکنند. علاوه بر این، و به منظور افزایش تا حد ممکن استحکام نتایج، این مناطق آموزشی نباید شامل قطعات کاداستری مورد استفاده برای ارزیابی نتایج تقسیمبندی (نقاط آزمایشی) (شرح شده در بخش فرعی بعدی) باشد.
2.4. ارزیابی نتایج تقسیم بندی
همانطور که چندین نویسنده و مطالعات اشاره کرده اند [ 17 ، 18 ، 23 ]، اطمینان از اینکه یک الگوریتم یک بخش بندی “خوب” نهایی تصویر را ارائه می دهد آسان نیست. به طور کلی، “مشخص نیست که یک تقسیم بندی “خوب” چیست” [ 29 ]، و لازم است نظر یک متخصص انسانی داشته باشیم که در مورد دقت نهایی الگوریتم مورد مطالعه تصمیم گیری می کند. بنابراین، اندازه گیری کیفیت تقسیم بندی به شهود انسان بستگی دارد و می تواند برای ناظران متمایز متفاوت باشد. برای غلبه بر این ناراحتی، روشی را توسعه دادیم که به دنبال جلوگیری از تحریف ها و سوگیری های ناشی از مداخله انسان در فرآیند بود.
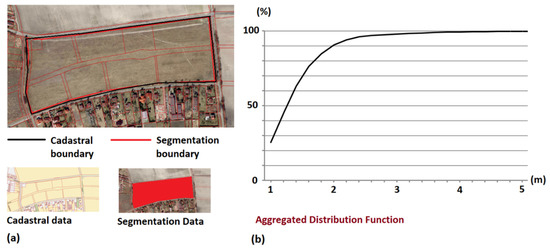
با توجه به طبقه بندی ایجاد شده توسط Marfil و همکاران. [ 27 ]، روش ما می تواند به عنوان یک روش اختلاف طبقه بندی شود. روشهای اختلاف روشهای کمی و تجربی هستند که از تقسیمبندی ایدهآل (دادههای مرجع) برای ارزیابی کیفیت بخشبندی بهدستآمده با یک الگوریتم (دادههای آزمایششده یا ارزیابیشده) با شمارش تفاوتهای بین هر دو مجموعه داده استفاده میکنند. اگر این تفاوتها بر حسب موقعیت یا موقعیت مکانی بیان شوند، روشهای مغایرت دارای چارچوب مفهومی یکسانی هستند که رویه خودکار بکار گرفته شده برای ارزیابی دقت موقعیتی پایگاههای اطلاعاتی جغرافیایی (با استفاده از عناصر خطی) توسعهیافته توسط Ruiz-Lendínez و همکاران. [ 33 ]. به طور خاص، این نویسندگان از روش پوشش تک بافر (SBOM) استفاده کردند (شکل 7 ). بر اساس تولید بافر بر روی خط منبع دقت بیشتر (Q) (داده های مرجع)، این روش درصد خط کنترل شده (X) (داده های آزمایش شده یا ارزیابی شده) را که در این بافر قرار دارد تعیین می کند ( شکل 7 a). با افزایش عرض بافر، توزیع احتمال درج خط کنترل شده در داخل بافر منبع با دقت بیشتری به دست می آید ( شکل 7 ج). در نهایت، شکل 7 ب انطباق این متریک را با مورد خط بسته انجام شده توسط Ruiz-Lendínez و همکاران نشان می دهد. [ 33 ].
با توجه به موارد فوق، روش های مغایرت به شهود انسان بستگی ندارد، اما در جبران، این مشکل را مطرح می کند که داشتن یک تقسیم بندی ایده آل قبلی ضروری است. در بسیاری از زمینه ها، تحقیقات مبتنی بر تشخیص الگو ممکن است مشکل ساز باشد. با این حال، در مورد داده های جغرافیایی، یافتن منبعی با دقت بیشتر (داده های مرجع) نسبتاً ساده است. در مورد خاص ما، بخشبندی ایدهآل (دادههای مرجع) با نمونهای از قطعههای کاداستر (نقاط آزمایشی) که هندسه آنها (پیشینی) با دقت بالا مشخص است، نشان داده میشود، و به عنوان دادههای آزمایشی، از همین نمودارهای بهدستآمده با اعمال ما استفاده کردیم. الگوریتم استخراج زمین های کشاورزی رها شده در این مورد دوم (دادههای آزمون)، مرزهای نمودارهای آزمایشی با استفاده از روش برداری به دست آمد.
در نهایت، برای پیادهسازی روششناسی خود، از تمام بستههای موجود در نمونه کنترل استفاده کردیم و یک منحنی توزیع انبوه را بهدست آوردیم. تعداد و خصوصیات این مجموعه کرت ها در زیربخش بعدی مشخص شده است.
2.5. ارزیابی کارایی رویکرد ما برای مکان یابی زمین های متروکه
همانطور که در بخش مقدمه ذکر شد، اثربخشی روش پیشنهادی نه تنها از منظر نتایج تقسیمبندی، بلکه با در نظر گرفتن کارایی رویکرد ما برای مکانیابی زمینهای متروکه ارزیابی شد. در این مورد دوم، دقت در آموزش الگوریتم برای یادگیری پارامترهای بافت ناحیه FLA ( L B P، سی)افL A(�بپ،سی)اف�آبرای دستیابی به طبقهبندی دقیق کاربری زمین، با مقادیر LBP که خارج از محدوده مشخصه مناطق FLA ظاهر میشوند، عدم اطمینان را در طول فرآیند طبقهبندی افزایش میدهد، کلیدی بود. به همین دلیل، و به منظور بررسی کاربری زمین، دو روش بازرسی انجام شد: (1) اعتبار سنجی خارجی بر اساس یک روش بازرسی بصری از طریق بازدیدهای میدانی و (ب) تجدید نظر در پارامترهای LBP/C متعلق به نمونه طرح های آزمایشی از آنجایی که ما دو مشاهده متفاوت از دو روش بازرسی متفاوت داشتیم، ضریب کاپا کوهن [ 34 ] را به منظور تعیین کاربری زمین اعمال کردیم. ضریب کاپا کوهن (k) (معادله (3)) تطابق بین دو مشاهدات مختلف را در طبقه بندی متناظر آنها از N اندازه گیری می کند.عناصر در دسته های C متقابل منحصر به فرد. K اندازه گیری قوی تر از محاسبه ساده درصد تطابق است، زیرا توافقی را که به طور تصادفی رخ می دهد در نظر می گیرد.
جایی که پr( الف )پ�(آ)توافق نسبی مشاهده شده بین هر دو مشاهدات و پr( ه )پ�(ه)احتمال فرضی توافق تصادفی با استفاده از داده های مشاهده شده برای محاسبه احتمالات هر ناظر (رویه بازرسی) با طبقه بندی تصادفی هر دسته است. با توجه به تفسیر مقدار k : (i) اگر هر دو مشاهدات کاملاً موافق باشند، آنگاه k = 1، و (ii) اگر توافقی بین مشاهدات غیر از آنچه که به طور تصادفی انتظار می رود وجود نداشته باشد (همانطور که توسط پr( ه )پ�(ه)سپس k = 0 [ 34 ].
در نهایت و با توجه به تعداد و ویژگیهای قطعههای آزمایشی، 40 قطعه را انتخاب کردیم که به طور یکنواخت در منطقه مورد مطالعه توزیع شده بودند. بنابراین، N = 40 عنصر (نمونه قطعات)، و C = 2 دسته (زمین طبقه بندی شده به عنوان متروک یا زمین طبقه بندی شده به عنوان کاربری دیگر). بدیهی است که به منظور افزایش هرچه بیشتر استحکام نتایج و اجتناب از سوگیری های احتمالی، این نمودارها با مناطق آموزشی استفاده شده برای یادگیری پارامترهای بافت FLA همپوشانی ندارند.
3. نتایج
3.1. نقشه برداری زمین های کشاورزی رها شده برگرفته از تقسیم بندی بافتی تصویر هوایی
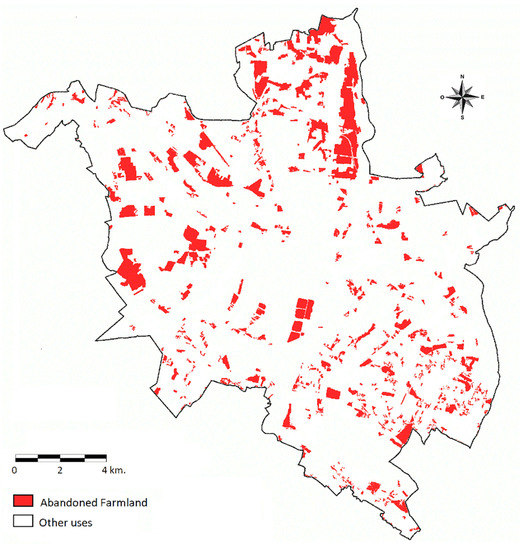
بر اساس یک تفسیر بصری از نقشه مشتق شده، این مدل توانست الگوی زمین های رها شده در مناطق تحت تاثیر شهرنشینی سریع را به تصویر بکشد. شکل 8 نشان می دهد که: (1) زمین های قابل کشت متروکه عمدتاً در قسمت های شمالی و غربی شهر قرار داشت که با جهت اصلی روند شهرنشینی پوزنان مطابقت داشت. (ii) با مقایسه نتایج بهدستآمده با دادههای ارائهشده توسط CORINE Land Cover، 2275 هکتار (40.3٪) از زمینهای قابل کشت در محدوده شهر رها شد. و (iii) مساحت زمین های قابل کشت متروکه تقریباً 9.2 درصد از مساحت شهر بود.
3.2. ارزیابی نتایج تقسیم بندی
همانطور که در بخش 2.3 ذکر شد ، ما از SBOM (به طور خاص، انطباق متریک آن با حالت بسته شده) برای ارزیابی کیفیت تقسیم بندی به دست آمده با الگوریتم خود استفاده کردیم ( شکل 9 a). شکل 9 ب تابع توزیع انبوه حاصل را با اعمال SBOM بر روی دو مجموعه داده ما نشان می دهد، به این معنی که خطوط مرزی را از داده های کاداستر و خطوط مرزی نمودار را از نتایج ارائه شده توسط الگوریتم استخراج زمین های کشاورزی رها شده (مرزهای قطعه بندی) با استفاده از بافرهایی با عرض از 1 تا 5 متر توجه به این نکته ضروری است که در این مورد دوم، مرزهای این نمودارهای آزمایشی با استفاده از یک روش برداری به دست آمد.
منحنی انبوه بهدستآمده با روش ما یک تابع توزیع عدم قطعیت را برای چندین سطح اطمینان نشان داد. شکل 9 b مقداری در حدود 2.4 متر را برای سطح اطمینان 95 درصد نشان می دهد. با در نظر گرفتن وضوح تصویر و عدم قطعیت مرتبط با روش برداری، به نظر می رسید که این مقدار پیشینی قابل قبول باشد.
در هر صورت و به منظور بررسی خوب بودن این معیار، با استفاده از روش ارزیابی تجربی پیشنهاد شده توسط لیو و یانگ [ 35 ] آزمایش شد که بر اساس محاسبه تفاوت بین تصویر اصلی و تصویر قطعهبندی شده با استفاده از آن بود. مساحت مناطق تقسیم شده به عنوان پارامتر مرجع. مطابق با این و با در نظر گرفتن مقدار میانگین سطح قطعه آزمایشی، تغییر در عرض بافر 2.4 متر (1.2 ± متر) در محیط کرت ها کمتر از 0.35٪ از سطح قطعه بندی را نشان می دهد.
3.3. ارزیابی کارایی رویکرد ما برای مکان یابی زمین های متروکه
همانطور که در بخش 2.4 ذکر شد ، به منظور تعیین کاربری زمین به دست آمده از نقشه مشتق شده ما ( شکل 8 )، ضریب کاپا کوهن را در دو روش بازرسی مختلف اعمال کردیم: (1) یک روش بازرسی بصری از طریق بازدیدهای میدانی و (2) یک تجدید نظر. از پارامترهای LBP/C متعلق به نمونه نمودارهای آزمایشی. جدول 1 نتایج تجزیه و تحلیل هر روش بازرسی را نشان می دهد.
مقادیر واقع در مورب اول (36،1) نشان دهنده تعداد کل قطعاتی است که در آنها بین هر دو روش بازرسی توافق وجود داشت. مورب دوم که از مقادیر یک و دو تشکیل شده است، نمودارهایی را نشان می دهد که در آنها اختلاف نظر بین آنها وجود دارد. با احتساب این نتایج، درصد توافق 92.5 درصد بود. برای محاسبه احتمال اینکه توافق بین هر دو روش بازرسی به دلیل تصادفی بوده است، باید این موارد را در نظر بگیریم:
-
تعداد قطعات طبقهبندی شده بهعنوان زمینهای متروکه با روش بازدید میدانی 37 قطعه و تعداد قطعات طبقهبندی شده به عنوان «سایر کاربریها» سه قطعه بود. در نتیجه با استفاده از این رویه 5/92 درصد از قطعات به عنوان اراضی متروکه طبقه بندی شدند.
-
تعداد قطعات طبقهبندیشده بهعنوان زمینهای متروکه با استفاده از بازنگری در پارامترهای LBP/C، 38 قطعه و تعداد قطعههایی که بهعنوان «سایر کاربریها» طبقهبندی شدند، دو قطعه بود. در نتیجه، با استفاده از این رویه، 95 درصد از قطعات به عنوان زمین های متروکه طبقه بندی شدند.
بنابراین، احتمال اینکه هر دو رویه قطعهها را بهعنوان زمینهای متروکه بهطور تصادفی طبقهبندی کنند، 87.8 درصد بود، در حالی که احتمال اینکه هر دو رویه، قطعهها را بهعنوان «سایر کاربریها» بهطور تصادفی طبقهبندی کردند، 0.37 درصد بود. از این، ما نتیجه گرفتیم که احتمال اینکه توافق بین هر دو روش بازرسی به دلیل تصادفی باشد 88.2٪ است. در نهایت با استفاده از رابطه (3)، مقدار K برابر با 0.82 به دست آوردیم. این مقدار نشان دهنده سطح بالایی از تطابق بین هر دو مشاهدات (روش های بازرسی) است.
4. بحث
این مقاله با استفاده از توصیف بافتی تصاویر هوایی با وضوح بالا، روشی سریع و آسان برای نقشهبرداری از زمینهای متروکه در شهرهای تحت تأثیر شهرنشینی سریع ارائه میکند. روش ما، که از دادههای رایگان ارائه شده توسط World_Imagery (MapServer) [ 22 ] استفاده میکرد، مرتبط بود زیرا: (1) نقشههای کاربری زمین را در شرایطی که زمان و منابع انسانی کمیاب بود تولید میکرد. و (ب) تأثیر اجتماعی و اقتصادی قابل توجهی داشت.
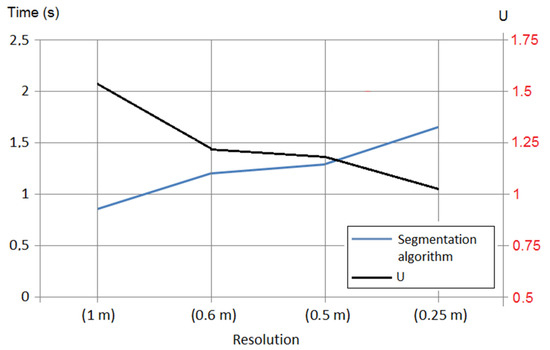
با توجه به جنبه اول (زمان)، رویکرد ما به ویژه در مقایسه با گزینه های دیگر مانند SRS کارآمد بود. نقشه برداری از زمین های متروکه با استفاده از تصاویر هوایی با وضوح بالا نیازی به مراحل پیش پردازش یا روش های طبقه بندی ذاتی سکوهای ماهواره ای نداشت. چنین رویههایی با یک مرحله آموزشی در مناطق مختلف تصویر برای یادگیری پارامترهای بافت مناطق FLA جایگزین شدند. ( L B P، سی)افL A(�بپ،سی)اف�آ، زمان محاسباتی لازم برای به دست آوردن نقشه نهایی را به میزان قابل توجهی کاهش می دهد. با توجه به خود فرآیند محاسباتی، کارایی محاسباتی الگوریتم ما به (i) آستانه U (به بخش “تولید ساختار سلسله مراتبی” مراجعه کنید) و (ii) تعداد مناطق بافتی در تصویر بستگی دارد. برای دستیابی به تقسیم بندی تصاویر با وضوح بالاتر، الگوریتم به زمان محاسبات بیشتری نیاز داشت زیرا در این مورد، مقداری برای U تا حد امکان کوچک مورد نیاز بود.
همانطور که در بخش مقدمه ذکر شد، رویکرد ما به خصوصیات بافت قبلاً با موفقیت در مطالعات دیگر آزمایش شده بود [ 19 ، 20 ]. اگرچه هم هدف و هم ویژگی های استفاده شده با مواردی که در اینجا به آنها اشاره شد متفاوت بود، این مطالعات زمانی که رابطه بین زمان محاسبات، وضوح تصویر و آستانه “U” تحلیل شد بسیار مفید بودند زیرا نتایج به دست آمده را می توان به انواع دیگر فرآیندهای تقسیم بندی تعمیم داد. در مورد ما، این به ویژه برای تنظیم U مفید بود.
شکل 10 رابطه به دست آمده برای پارامترهای ذکر شده در بالا را نشان می دهد: زمان، U و وضوح. با توجه به مقادیر نشان داده شده در شکل 10 و با در نظر گرفتن وضوح تصویر ما (1 متر)، مقدار آستانه U بر روی 1.5 تنظیم شد. در نهایت، زمان محاسبه به دست آمده برای مورد مطالعه ما 15.3 ثانیه بود. این مقدار بالاتر از حد انتظار بود. این به این دلیل بود: (1) اندازه بزرگ منطقه مطالعه ما و (2) نیاز به پردازش کل تصویر زیرا در مورد ما، اعمال فیلترهای فضایی محلی، مانند تطبیق قالب محلی (LTM) ممکن نبود [ 36 ]. در همین راستا، باید به این نکته اشاره کنیم که پلتفرم آزمایشی ما یک Intel Core i5 3.8 گیگاهرتز با 16 گیگابایت حافظه بود.
با توجه به تأثیرات اجتماعی-اقتصادی، مکان یابی روندها و الگوهای FLA می تواند به مقامات در توسعه سیاست های شهری، ارائه اطلاعات عینی به شهرداری ها در جایی که آمار رسمی در مورد رها شدن زمین غیر قابل اعتماد یا با کیفیت پایین است، کمک کند. رویکرد ما می تواند توسط مقامات محلی استفاده شود که نمی توانند منابع قابل توجهی را برای نظارت بر تغییر زمین اختصاص دهند. علاوه بر این، ابزار مفیدی برای مدیریت فضایی و همچنین برای اهداف مالیاتی کاداستر ارائه کرد و میتوان آن را برای هر شهر، منطقه شهری، یا منطقه فضایی اعمال کرد.
5. نتیجه گیری ها
این مطالعه به درک چگونگی استفاده از خصوصیات بافتی تصاویر هوایی با وضوح بالا برای مکان یابی و نقشه برداری FLA کمک کرد. ما از یک الگوریتم تقسیمبندی بافتی استفاده کردیم که قبلاً با موفقیت در انواع دیگر فرآیندها بر اساس استخراج خودکار موجودیتهای جغرافیایی از تصاویر آزمایش شده بود. همانطور که در آن فرآیندها، الگوریتم ما ثابت کرد که یک ابزار موثر و ارزشمند برای مکان یابی و استخراج زمین های کشاورزی متروکه از تصاویر در مناطق تحت تاثیر شهرنشینی سریع است. در میان تمام توصیفگرهای بافت محلی، ما از توصیفکنندههای بافت مبتنی بر LBP همراه با یک کنتراست ساده استفاده کردیم تا روش خود را قویتر کنیم. LBP اطلاعاتی در مورد ساختار فضایی بافت تصویر محلی در اختیار ما قرار داد و از نقطه نظر محاسباتی بسیار کارآمد بود. علاوه بر این، LBP در مقایسه با سایر اپراتورهای بافت به سطوح بالایی از دقت در فرآیندهای توصیف بافت دست یافت. با توجه به ساختار، الگوریتم ما بر روی یک نمایش هرمی اجرا شد که به طور قابل توجهی زمان محاسبات را کاهش داد و استحکام را تضمین کرد.
اثربخشی روش پیشنهادی از دو دیدگاه مختلف مورد ارزیابی قرار گرفت: (1) دقت نتایج تقسیمبندی و (ب) کارایی برای مکانیابی FLA. در مورد اول، ما یک روش ابتکاری را بر اساس روشهای به کار گرفته شده برای ارزیابی دقت موقعیت پایگاههای اطلاعاتی جغرافیایی توسعه دادیم. این روش با توجه به منبع دقت بیشتر به کار گرفته شده (داده های کاداستر) مقدار عدم قطعیت (از قطعه های قطعه بندی شده) در حدود 2.4 متر را به ما ارائه داد. در مورد دوم، ما دو روش بازرسی تجربی مختلف را به کار بردیم و تطابق بین آنها را اندازهگیری کردیم (و تأیید کردیم).
با توجه به نتایج، مدل بهدستآمده به ما امکان میدهد تا الگوهای زمینهای متروکه شهر را شناسایی کنیم. این الگوها با جهت اصلی فرآیند شهرنشینی پوزنان، یعنی مناطقی که تحت تأثیر شهرنشینی سریع در شهر قرار دارند، مطابقت داشت. مساحت زمین های زراعی متروکه تقریباً 2/9 درصد مساحت شهر بود. در نهایت، با مقایسه نتایج بهدستآمده با دادههای ارائهشده توسط CORINE Land Cover، 2275 هکتار (40.3 درصد) از زمینهای قابل کشت در محدوده شهر رها شد.
در نهایت، باید توجه داشته باشیم که مطالعه ما میتواند از مقامات محلی در تطبیق برنامهریزی شهری برای استفاده کارآمدتر از زمین حمایت کند.
در نهایت، این مطالعه تنها یک گام بیشتر به سمت بهبود مکان یابی و مدیریت زمین های متروکه را نشان می دهد. بنابراین، اگرچه الگوریتم ما مشکل را به روشی موثر حل کرد، روشهای بازرسی انجامشده برخی ناسازگاریها را در طول فرآیند طبقهبندی نشان داد که احتمالاً از مرحله آموزش (برای یادگیری پارامترهای بافت مناطق FLA ایجاد شده است. ( L B P، سی)افL A(�بپ،سی)اف�آ). از این نظر، استفاده از مکانیسمهای هوش مصنوعی میتواند به طبقهبندی مناطق FLA بسیار کارآمدتر کمک کند. این به معنای گنجاندن سایر توصیفگرهای بافت در فرآیند است که سطوح تبعیض را افزایش می دهد. از سوی دیگر، اگرچه رویکرد ما مناطق FLA را شناسایی کرد، اما قادر به تعیین کیفیت خاکی که آنها اشغال کردند، نبود، که ارزیابی دامنه واقعی مشکل را غیرممکن کرد.
همه این چالش ها باید در کارهای آینده مورد توجه قرار گیرد. بنابراین، ما ادغام الگوریتمهای ژنتیک (GA) را در فرآیند یادگیری ذکر شده در بالا برنامهریزی میکنیم و توصیفگرهای بافت جدید (و قدرتمندتر) را اضافه میکنیم. در این رابطه، برخی از مطالعات قبلی [ 37 ] قبلاً نشان دادند که GA یک روش یادگیری مناسب و کارآمد برای مسائلی است که در آن متغیرهای فضایی ضمنی است. با توجه به کیفیت خاک اشغال شده توسط مناطق FLA، ما قصد داریم نقشه خود را از زمین های متروکه با نقشه های کیفیت خاک ارائه شده توسط مقامات محلی و منطقه ای مقایسه کنیم. این به ما امکان می دهد تا بررسی کنیم که آیا بخش قابل توجهی از زمین های قابل کشت که بیشترین اهمیت را برای کشاورزی دارد هنوز در شهر کشت می شود یا برعکس، این خاک ها باید فوراً محافظت شوند.







بدون دیدگاه