

کلید واژه ها:
مدل های جمعیت جهانی ; عدم قطعیت ها ؛ دقت ها GHS-POP ; مدل های شهری
چکیده گرافیکی
1. مقدمه
-
ارتباط GHS-POP و داده های جمعیت محلی در پایین ترین سطح اداری موجود چیست؟
-
چه رابطه ای بین الگوی فضایی مناطق بیش از حد و کم برآورد شده و انواع کاربری اراضی وجود دارد؟
-
پیامدهای استفاده از داده های جمعیتی موجود در مدل های رشد شهری چیست؟
2. مدل های جمعیت شبکه ای – نقاط قوت و محدودیت های آنها
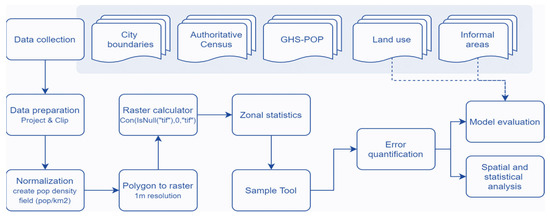
3. مواد و روشها
3.1. رویکرد ارزیابی دقت
3.2. انتخاب مطالعات موردی
برای پشتیبانی از یک ارزیابی جهانی برای هر یک از مناطق جهانی بانک جهانی، از یک شهر نمونه استفاده شده است ( جدول 5). این انتخاب به دلیل در دسترس بودن دادههای جمعیت محلی نسبتاً تفکیکشده که نزدیک به یکی از سالهای مرجع لایه GHS هستند (یعنی 1975، 1990، 2000 و 2015) انجام شد. شهرهای انتخاب شده شامل انواع مختلف (مورفولوژی های مختلف شهری)، به عنوان مثال، شهرهای ساحلی (به عنوان مثال، جاکارتا) و داخلی (به عنوان مثال، Enschede)، کلان شهرها (به عنوان مثال، سائوپائولو) و شهرهای ثانویه (کوماسی)، قطب های اقتصادی (به عنوان مثال، نیویورک). ) و شهرهای دارای تحولات غیررسمی (مانند کابل). در مواردی که دادههای جمعیت محلی با سال مرجع دقیق GHS-POP مطابقت نداشت، دادههای جمعیت محلی برای مقایسه با GHS-POP با استفاده از معادلات زیر پیشبینی شد: معادله (1) – نرخ رشد و معادله (2) – پیش بینی جمعیت
که در آن P t = مقدار در زمان GHS-POP، P 0 مقدار در شروع، r نرخ رشد و t تعداد سال است.
3.3. مقایسه مطالعات موردی: الگوهای فضایی عدم قطعیت
4. نتایج
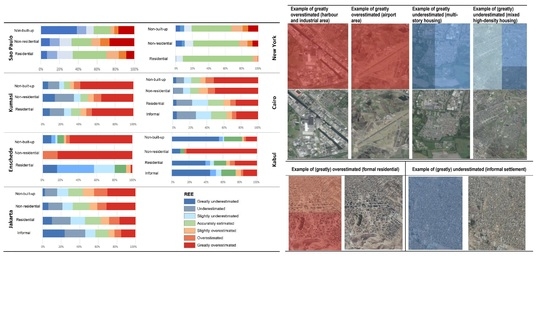
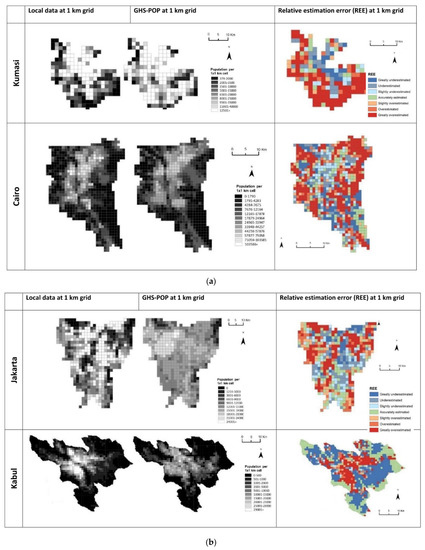
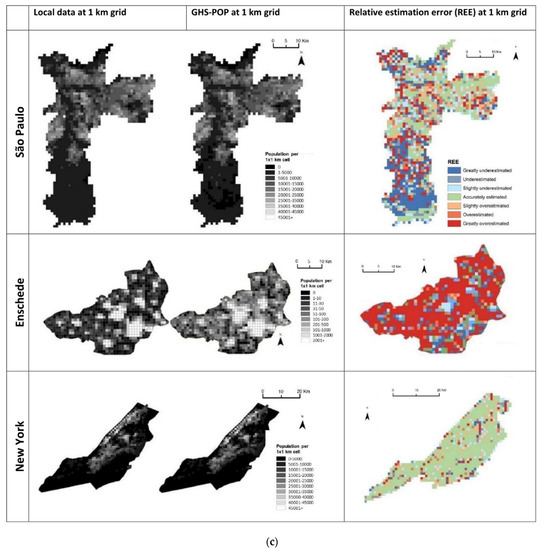
4.1. برآورد خطای کلی در هر مطالعه موردی
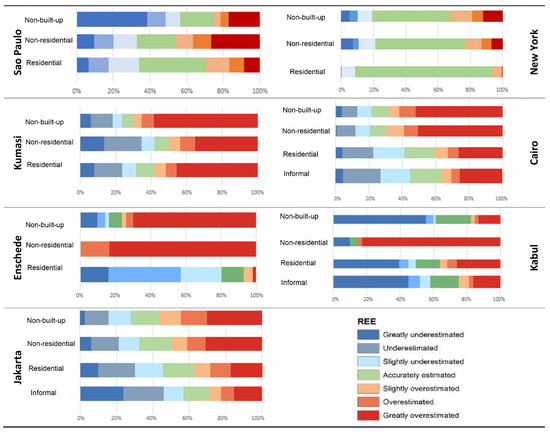
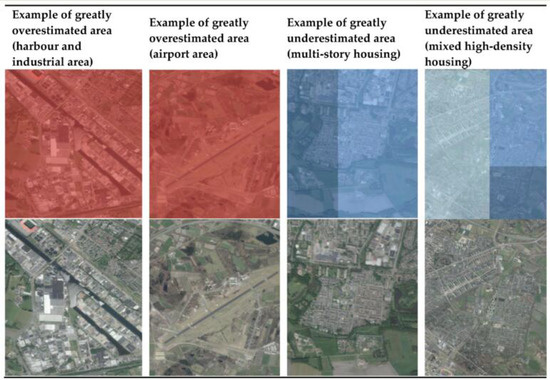
4.2. الگوهای فضایی خطاها
4.3. استفاده از زمین و روابط توزیع جمعیت
5. بحث
5.1. مسائل رایج در همه مطالعات موردی چیست؟
5.2. توصیه هایی برای مدل سازان داخلی در هنگام استفاده از داده ها چیست؟
5.3. توصیه هایی برای مدل سازان جمعیت برای بهبود مدل های خود چیست؟
6. نتیجه گیری
پیوست اول
| نام مجموعه داده | مفهوم جمعیت | مواد و روش ها | وضوح | منبع | سال ها | پوشش | داده های جانبی | خط مشی توزیع |
| Gridded of the World V4 | شبانه | وزنی مساحتی | 1 کیلومتر | دانشگاه کلمبیا – مرکز بینالمللی شبکه اطلاعات علوم زمین (CIESIN) https://sedac.ciesin.columbia.edu/data/collection/gpw-v4 (دسترسی در 15 ژوئن 2022) | 2000، 2005، 2010، 2015، 2020 | جهانی | ☑ *7،8 | دسترسی آزاد |
| جمعیت جهانی سکونتگاه انسانی (GHS-POP) | شبانه | مدل داسیمتری باینری (با استفاده از GHSL ساخته شده و جمعیت سرشماری) | 250 متر 1 کیلومتر |
مرکز تحقیقات مشترک کمیسیون اروپا (JRC) و CIESIN-دانشگاه کلمبیا https://ghsl.jrc.ec.europa.eu/ghs_pop.php (دسترسی در 15 ژوئن 2022) |
1975، 1990، 2000، 2015 | جهانی | ☑ *2 | دسترسی آزاد |
| پروژه جهانی نقشه برداری شهری روستایی (GRUMP) | شبانه | مدل داسیمتری باینری (با استفاده از چراغهای شبانه DMSP-OLS و دادههای جمعیت سرشماری) | 1 کیلومتر | CIESIN; موسسه تحقیقات بینالمللی سیاست غذایی (IFPRI)، بانک جهانی، مرکز بینالمللی کشاورزی گرمسیری (CIAT) https://sedac.ciesin.columbia.edu/data/collection/grump-v1 (دسترسی در 15 ژوئن 2022) | 1990، 1995، 2000 | جهانی | ☑ *4،7،8،9 | دسترسی آزاد |
| پایگاه داده تاریخچه شبکه های جمعیتی محیط جهانی (HYDE)، نسخه 3.1 | شبانه | مدل داسیمتری صریح فضایی (با استفاده از آمار جمعیت تاریخی، اراضی زراعی و مرتع، اطلاعات ماهواره ای و الگوریتم تخصیص خاص) | 10 کیلومتر | آژانس ارزیابی زیستمحیطی هلند (PBL) https://themasites.pbl.nl/tridion/en/themasites/hyde/download/index-2.html (دسترسی در 15 ژوئن 2022) | 10000 قبل از میلاد تا 2015 | جهانی | ☑ *1 | دسترسی آزاد |
| پایگاه داده جمعیت جهانی LandScan | محیط | مدل داسیمتری چند متغیره (با استفاده از داده های مکانی و تصاویر برای تخصیص جمعیت به هر کشور و منطقه) | 1 کیلومتر | آزمایشگاه ملی اوک ریج (ORNL) https://landscan.ornl.gov/ (دسترسی در 15 ژوئن 2022) | 2000–2017 (انتشار سالانه) | جهانی (100 متر برای 23 کشور موجود است) | ☑ *1–9 | پولی / رایگان برای هدف تحقیق |
| لایه حل با وضوح بالا (HRSL) | شبانه | داسیمتری باینری | 30 متر | فیس بوک، CIESIN، و بانک جهانی https://ciesin.columbia.edu/data/hrsl/ (دسترسی در 15 ژوئن 2022) | 2015–2019 | 140 کشور | ☑ *1،2،3،5،7،8 | دسترسی آزاد |
| برآورد جمعیت جهان (WPE) | شبانه | توزیع مجدد داسیمتری (هوشمند) | 150 متر 250 متر |
موسسه تحقیقات سیستم محیطی (ESRI) https://sites.google.com/ciesin.columbia.edu/popgrid/find-data/esri (دسترسی در 15 ژوئن 2022) | 2013، 2015 و 2016 (150 متر) | جهانی | ☑ *1،3،8،9 | پرداخت شده |
| ورلد پاپ | شبانه | داسیمتریک جنگل تصادفی | 100 متر | WorldPop، دانشگاه ساوتهمپتون https://www.worldpop.org/ (دسترسی در 15 ژوئن 2022) | 2000–2020 | سالهای جهانی و خاص کشور | ☑ *1–9 | دسترسی آزاد |
| LandScan HD | محیط | 100 متر | آزمایشگاه ملی اوک ریج https://landscan.ornl.gov/ (دسترسی در 15 ژوئن 2022) | مشخص نیست (متغیر) | 23 کشور | ☑ *1–9 | پولی / رایگان برای اهداف تحقیقاتی | |
| *1 پوشش/کاربری زمین، *2 ساخته شده، *3 جاده، *4 چراغ شبانه، *5 زیرساخت، *6 داده محیطی/توپوگرافی، *7 منطقه حفاظت شده، *8 آب، *9 شهر یا منطقه شهری . | ||||||||
منابع
- سازمان ملل. آمار جمعیتی و اجتماعی. در دسترس آنلاین: https://unstats.un.org/unsd/demographic-social/census/document-resources/ (دسترسی در 14 دسامبر 2020).
- بو، جی. دارین، ای. Leasure, DR; دولی، کالیفرنیا؛ چمبرلین، منابع انسانی؛ Lázár، AN; تشیرهارت، ک. سینا، سی. هاف، NA; فولر، تی. و همکاران برآورد جمعیت با وضوح بالا با استفاده از دادههای نظرسنجی خانوار و ردپای ساختمان. نات. اشتراک. 2022 ، 13 ، 1330. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- وبر، EM; سیمن، وی. استوارت، RN; پرنده، تی جی; تاتم، ای جی; مک کی، جی جی؛ بهادوری، BL; موهل، جی جی. Reith، نقشه برداری جمعیت مستقل از سرشماری AE در شمال نیجریه. سنسور از راه دور محیط. 2018 ، 204 ، 786-798. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لیک، اس. Uhl، JH; بالک، دی. جونز، ب. ارزیابی دقت لایههای زمین ساختهشده چند زمانی در مسیرهای روستایی-شهری در ایالات متحده. سنسور از راه دور محیط. 2018 ، 204 ، 898-917. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کاوادا، ا. مترنیخت، جی. کربلات، اف. موداو، ن. هالدورسون، ام. للداپارساد، س. فریدل، ال. برگزار شد، ا. Chuvieco، E. به سوی تحقق اهداف توسعه پایدار با استفاده از مشاهدات زمین. سنسور از راه دور محیط. 2020 , 247 , 111930. [ Google Scholar ] [ CrossRef ]
- بخش آمار سازمان ملل متحد گزارش اهداف توسعه پایدار 2018. در دسترس آنلاین: https://unstats.un.org/sdgs/report/2018/overview/ (دسترسی در 9 دسامبر 2019).
- انگستروم، آر. نیوهاوس، دی. Soundararajan, V. تخمین تراکم جمعیت منطقه کوچک با استفاده از داده های پیمایشی و تصاویر ماهواره ای: یک کاربرد در سریلانکا . بانک جهانی: واشنگتن، دی سی، ایالات متحده آمریکا، 2019. [ Google Scholar ]
- لوید، سی تی. چمبرلین، اچ. کر، دی. یتمن، جی. پیستولسی، ال. استیونز، FR; Gaughan، AE; نیوز، جی جی; هورنبی، جی. مک مانوس، ک. و همکاران مجموعه دادههای جهانی هماهنگ مکانی-زمانی برای تولید مجموعه دادههای توزیع جمعیت شبکهای با وضوح بالا. داده های بزرگ زمین 2019 ، 3 ، 108-139. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کیو، جی. بائو، ی. یانگ، ایکس. وانگ، سی. هنوز.؛ استین، ا. جیا، ص. نقشه برداری جمعیت محلی با استفاده از مدل جنگل تصادفی بر اساس داده های سنجش از راه دور و اجتماعی: مطالعه موردی در ژنگژو، چین. Remote Sens. 2020 , 12 , 1618. [ Google Scholar ] [ CrossRef ]
- تامسون، DR; استیونز، FR; Ruktanonchai، NW; تاتم، ای جی; Castro، MC GridSample: یک بسته R برای تولید واحدهای نمونه گیری اولیه نظرسنجی خانگی (PSUs) از داده های جمعیت شبکه ای. بین المللی J. Health Geogr. 2017 ، 16 ، 25. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- تامسون، DR; رودا، دی. تاتم، ای جی; کاسترو، MC نمونهگیری از نظر جمعیتی گریدد: بررسی محدوده سیستماتیک دستور کار تحقیقاتی میدانی و استراتژیک. بین المللی J. Health Geogr. 2020 ، 19 ، 34. [ Google Scholar ] [ CrossRef ]
- شیاوینا، م. فریره، اس. MacManus، K. GHS Population Grid Multitemporal (1975، 1990، 2000، 2015) R2019A ; کمیسیون اروپا، مرکز تحقیقات مشترک (JRC)، ویرایش. کمیسیون اروپا: بروکسل، بلژیک، 2019. [ Google Scholar ]
- Badmos, OS; رینو، ا. Callo-Concha، D. گریو، ک. یورگنز، سی. شبیه سازی رشد محله فقیر نشین در لاگوس: ادغام مدل مبتنی بر قانون و مبتنی بر تجربی. محاسبه کنید. محیط زیست سیستم شهری 2019 ، 77 ، 101369. [ Google Scholar ] [ CrossRef ]
- پرز-مولینا، ای. اسلیوزاس، آر. فلاک، جی. Jetten، V. توسعه یک مدل اتوماتای سلولی رشد شهری برای اطلاع از سیاست فضایی برای کاهش سیل: مطالعه موردی در کامپالا، اوگاندا. محاسبه کنید. محیط زیست سیستم شهری 2017 ، 65 ، 53-65. [ Google Scholar ] [ CrossRef ]
- ندوویزو، جی. اسلیوزاس، آر. کوفر، ام. مدلسازی رشد شهری در شهر کیگالی رواندا. رواندا J. 2016 ، 1 ، 82-87. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Wardrop، NA; Jochem، WC; پرنده، تی جی; چمبرلین، منابع انسانی؛ کلارک، دی. کر، دی. بنگتسسون، ال. جوران، اس. سیمن، وی. Tatem، AJ برآوردهای جمعیتی تفکیک مکانی در غیاب دادههای سرشماری ملی نفوس و مسکن. Proc. Natl. آکادمی علمی USA 2018 , 115 , 3529. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- Carr-Hill، R. میلیون ها نفر از دست رفته و اندازه گیری پیشرفت توسعه. توسعه دهنده جهانی 2013 ، 46 ، 30-44. [ Google Scholar ] [ CrossRef ]
- روی، دی. لیز، MH; پففر، ک. Sloot، P. مدلسازی تأثیر چرخه زندگی خانوار بر محلههای فقیر نشین در بنگلور. محاسبه کنید. محیط زیست سیستم شهری 2017 ، 64 ، 275-287. [ Google Scholar ] [ CrossRef ]
- Openshaw, S. مسئله واحد مساحتی قابل تغییر . Geobooks: Norwich، UK، 1984. [ Google Scholar ]
- Balk، DL; دایچمن، یو. یتمن، جی. پوزی، اف. هی، SI; نلسون، الف. تعیین توزیع جهانی جمعیت: روش ها، کاربردها و داده ها. در پیشرفت در انگل شناسی ; Hay, SI, Graham, A., Rogers, DJ, Eds. مطبوعات دانشگاهی: کمبریج، MA، ایالات متحده آمریکا، 2006; جلد 62، ص 119–156. [ Google Scholar ]
- داکسی ویتفیلد، ای. مک مانوس، ک. آدامو، اس بی؛ پیستولسی، ال. اسکوایرز، جی. بورکوفسکا، او. باپتیستا، اس آر با بهره گیری از دسترسی بهبودیافته داده های سرشماری: اولین نگاه به جمعیت شبکه بندی شده جهان، نسخه 4. پاپ. Appl. Geogr. 2015 ، 1 ، 226-234. [ Google Scholar ] [ CrossRef ]
- فریره، اس. مکمانوس، ک. پسری، م. داکسی ویتفیلد، ای. میلز، جی. توسعه شبکههای جمعیت جهانی چندزمانی باز و رایگان جدید با وضوح 250 متر . داده های جغرافیایی در جهان در حال تغییر. انجمن آزمایشگاه های اطلاعات جغرافیایی در اروپا (AGILE) (سازمان دهنده); AGILE: هلسینکی، فنلاند، 2016. [ Google Scholar ]
- چن، آر. یان، اچ. لیو، اف. دو، دبلیو. یانگ، ی. مجموعه داده های چندگانه جمعیت جهانی: تفاوت ها و ویژگی های توزیع فضایی. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 637. [ Google Scholar ] [ CrossRef ]
- مک اودی، سی. جونز، R. اطلس تاریخ جمعیت جهان . Pengium Books Ltd.: New York, NY, USA; آلن لین: نیویورک، نیویورک، ایالات متحده آمریکا، 1979. [ Google Scholar ]
- هنوز.؛ ژائو، ن. یانگ، ایکس. اویانگ، ز. لیو، ایکس. چن، کیو. هو، ک. یو، دبلیو. چی، جی. لی، ز. و همکاران بهبود نقشهبرداری جمعیت برای چین با استفاده از دادههای سنجش از راه دور و نقاط مورد علاقه در یک مدل جنگلهای تصادفی. علمی کل محیط. 2019 ، 658 ، 936–946. [ Google Scholar ] [ CrossRef ]
- استیونز، FR; Gaughan، AE; نیوز، جی جی; کینگ، آ. سوریچتا، ا. لینارد، سی. Tatem، AJ مقایسه دو مجموعه داده پوشش زمین منطقه ساخته شده جهانی در روش هایی برای تفکیک جمعیت انسانی در یازده کشور از جنوب جهانی. بین المللی جی دیجیت. زمین 2020 ، 13 ، 78-100. [ Google Scholar ] [ CrossRef ]
- کیت، او. لودکه، م. Reckien، D. تعریف چشم گاو: ارزیابی جمعیت زاغهنشینی به کمک تصاویر ماهوارهای در حیدرآباد، هند. جئوگر شهری. 2013 ، 34 ، 413-424. [ Google Scholar ] [ CrossRef ]
- شوارتز، ن. فلاک، جی. Sliuzas، RV مدل سازی اثرات ارتقاء شهری بر پویایی جمعیت. محیط زیست مدل. نرم افزار 2016 ، 78 ، 150-162. [ Google Scholar ] [ CrossRef ]
- وو، سی. موری، AT برآورد جمعیت با استفاده از تصاویر نقشهبردار موضوعی پیشرفته Landsat. Geogr. مقعدی 2007 ، 39 ، 26-43. [ Google Scholar ] [ CrossRef ]
- رونی، ر. Jia, P. یک رویکرد مدلسازی جمعیت بهینه با استفاده از رگرسیون وزندار جغرافیایی بر اساس دادههای سنجش از دور با وضوح بالا: مطالعه موردی در شهر داکا، بنگلادش. Remote Sens. 2020 , 12 , 1184. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بریمن، ال. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Gaughan، AE; استیونز، FR; هوانگ، ز. نیوز، جی جی; سوریچتا، ا. لای، اس. بله، X. لینارد، سی. هورنبی، جنرال موتورز؛ هی، SI; و همکاران الگوهای فضایی و زمانی جمعیت در سرزمین اصلی چین، 1990 تا 2010. علم. داده 2016 ، 3 ، 160005. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لیک، اس. Gaughan، AE; آدامو، اس بی؛ د شربینین، ا. بالک، دی. فریره، اس. رز، ا. استیونز، FR; بلانکسپور، بی. فرای، سی. و همکاران تخصیص فضایی جمعیت: مروری بر محصولات دادههای جمعیت شبکهای در مقیاس بزرگ و تناسب آنها برای استفاده. سیستم زمین علمی داده 2019 ، 11 ، 1385-1409. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تامسون، DR; Gaughan، AE; استیونز، FR; یتمن، جی. الیاس، پ. چن، آر. ارزیابی دقت برآوردهای جمعیت شبکهای در زاغهها: مطالعه موردی در نیجریه و کنیا. علوم شهری 2021 ، 5 ، 48. [ Google Scholar ] [ CrossRef ]
- کوفر، م. پرسلو، سی. پففر، ک. اسلیوزاس، آر. رائو، وی. آیا ما جمعیت جهان زاغه را دست کم می گیریم؟ در مجموعه مقالات رویداد مشترک سنجش از دور شهری 2019 (JURSE)، وان، فرانسه، 22 تا 24 مه 2019؛ صص 1-4. [ Google Scholar ]
- اسلیوزاس، آر. کوفر، م. کمپر، تی. ارزیابی کیفیت محصولات لایه سکونت انسانی جهانی برای کامپالا، اوگاندا. در مجموعه مقالات رویداد مشترک سنجش از دور شهری 2017 (JURSE)، دبی، امارات متحده عربی، 6 تا 8 مارس 2017؛ صص 1-4. [ Google Scholar ]
- اوبرشت، سی. گوناسکرا، ر. اونگار، ج. Ishizawa، O. شناسایی جغرافیایی جهانی سازگار و در عین حال سازگار الگوهای شهری-روستایی: مدل iURBAN. سنسور از راه دور محیط. 2016 ، 187 ، 230-240. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گوناسکرا، ر. ایشیزاوا، او. اوبرشت، سی. بلانکسپور، بی. موری، اس. پومونیس، ا. دانیل، جی. توسعه یک مدل مواجهه جهانی تطبیقی برای پشتیبانی از تولید پروفایلهای خطر بلایای کشور. Earth-Sci. Rev. 2015 , 150 , 594-608. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کالکا، بی. Bielecka، E. ارزیابی دقت GHS-POP: مطالعه موردی لهستان و پرتغال. Remote Sens. 2020 , 12 , 1105. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آذر، د. انگستروم، آر. گریسر، جی. Comenetz, J. تولید لایههای جمعیتی در مقیاس ریز با استفاده از تصاویر ماهوارهای با وضوح چندگانه و دادههای مکانی. سنسور از راه دور محیط. 2013 ، 130 ، 219-232. [ Google Scholar ] [ CrossRef ]
- فریره، اس. شیاوینا، م. فلورچیک، ای جی؛ مک مانوس، ک. پسری، م. کوربن، سی. بورکوفسکا، او. میلز، جی. پیستولسی، ال. اسکوایرز، جی. و همکاران دادهها و روشهای پیشرفته برای بهبود شبکههای جمعیتی آزاد و باز جهانی: عملی کردن «هیچکس را پشت سر نگذارید». بین المللی جی دیجیت. زمین 2020 ، 13 ، 61-77. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Uhl، JH; زورقین، ح. لیک، اس. بالک، دی. کوربن، سی. سیریس، وی. Florczyk، AJ افشای پیوستار شهری: مفاهیم و مقایسه متقابل از دیدگاه بین رشتهای. بین المللی جی دیجیت. زمین 2020 ، 13 ، 22-44. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ون هویجیستی، جی. ون بمل، بی. بومن، ا. Van Rijn، F. Towards an Urban Preview: Modeling Future Urban Growth with 2UP ; آژانس ارزیابی زیست محیطی PBL هلند: لاهه، هلند، 2018. [ Google Scholar ]
- آگیلار، آر. Kuffer، M. محاسبات ابری با استفاده از تصاویر با وضوح بالا برای بهبود شاخص SDG در فضاهای باز. Remote Sens. 2020 , 12 , 1144. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پسری، م. کوربن، سی. رن، سی. ادوارد، N. مولفه های عمودی تعمیم یافته مناطق ساخته شده از مدل های دیجیتال ارتفاعی جهانی با مدل سازی رگرسیون خطی چند مقیاسی. PLoS ONE 2021 , 16 , e0244478. [ Google Scholar ] [ CrossRef ]
- لی، ام. کوکس، ای. تاوبنبوک، اچ. van Vliet، J. نقشه برداری در مقیاس قاره و تجزیه و تحلیل ساختار سه بعدی ساختمان. سنسور از راه دور محیط. 2020 , 245 , 111859. [ Google Scholar ] [ CrossRef ]
- شیاوینا، م. فریره، اس. MacManus، K. GHS-POP R2022A-GHS Population Grid Multitemporal (1975-2030) ; کمیسیون اروپا، مرکز تحقیقات مشترک (JRC)، ویرایش. کمیسیون اروپا: بروکسل، بلژیک، 2022. [ Google Scholar ]




بدون دیدگاه