

خلاصه
داده های مسیر امکان مطالعه رفتار اجسام متحرک، از انسان تا حیوانات را فراهم می کند. ارتباطات بیسیم، دستگاههای تلفن همراه و فناوریهایی مانند سیستم موقعیتیابی جهانی (GPS) به رشد زمینه تحقیقات مسیر کمک کردهاند. با رشد قابل توجهی در حجم داده های مسیر، ذخیره چنین داده هایی در سیستم های مدیریت پایگاه داده مکانی (SDBMS) چالش برانگیز شده است. از این رو، داده های بزرگ مکانی به عنوان یک فناوری مدیریت داده برای نمایه سازی، ذخیره سازی و بازیابی حجم زیادی از داده های مکانی-زمانی پدیدار می شود. انبار داده (DW) یکی از برترین زیرساخت های تجزیه و تحلیل کلان داده و پردازش پرس و جو پیچیده است. انبارهای داده مسیر (TDW) به عنوان یک DW که به تجزیه و تحلیل داده های مسیر اختصاص داده شده است ظاهر می شود. فهرست و بحث در مورد مشکلاتی که از TDW و جهتهای رو به جلو برای کارهای در این زمینه استفاده میکنند، اهداف اولیه این نظرسنجی است. این مقاله پیشرفتهترین روشهای تحلیل مسیر دادههای بزرگ را جمعآوری میکند. درک اینکه چگونه تحقیق در داده های مسیر انجام می شود، چه تکنیک های اصلی استفاده شده است، و چگونه می توان آنها را در معماری پردازش تحلیلی آنلاین (OLAP) جاسازی کرد، می تواند کارایی و توسعه سیستم های تصمیم گیری را که با داده های مسیر سر و کار دارند، افزایش دهد.
کلید واژه ها:
انبار داده ; داده های تحرک سیر معنایی ; کلان داده ؛ تجزیه و تحلیل
1. معرفی
توسعه سریع ارتباطات بیسیم و فنآوریهای جمعآوری داده، همراه با تکامل فناوریهایی که ذخیره و پردازش حجمهای بزرگ داده را امکانپذیر میسازد، به رشد قابلتوجه برنامههایی که با دادههای مسیر سر و کار دارند، کمک کرده است. داده های مسیر، موقعیت جسم را در فضا در یک لحظه خاص ثبت می کنند. به گفته ژنگ، چهار دسته از داده های مسیر وجود دارد: تحرک افراد، تحرک وسایل نقلیه حمل و نقل، تحرک حیوانات، و تحرک پدیده های طبیعی [ 1 ].
اجسامی که توسط مسیرها توصیف می شوند معمولاً اجسام متحرک نامیده می شوند زیرا مکان مکانی آنها در طول زمان تغییر می کند و اغلب این تغییرات در زمان پیوسته هستند. با این حال، برای ذخیره در یک سیستم پایگاه داده، آنها به عنوان مکان های مجزا نشان داده می شوند [ 2 ].
به طور کلی، کارهای تحقیقاتی موجود، مسیرها را به عنوان دنباله ای از نقاط جغرافیایی که در رابطه با زمان مرتب شده اند نشان می دهند [ 3 ]. داده های مسیر را می توان در هر دو سیستم پایگاه داده مکانی یا غیر مکانی ذخیره کرد. مزیت مدیریت داده های مسیر در یک پایگاه داده فضایی (به عنوان مثال، Oracle Spatial و PostgreSQL + Postgis) یکپارچگی ایجاد شده بین اجزای فضایی و الفبایی است. علاوه بر این، سیستمهای مدیریت پایگاه داده مکانی (SDBMS) دارای مجموعهای از انواع دادهها و عملکردهایی هستند که به ذخیره و نمایهسازی اشیاء جغرافیایی کمک میکنند، به طوری که جستجوی این دادهها سریعتر از معماری دوگانه با استفاده از یک سیستم پایگاه داده غیرمکانی است. 4 ].]. سایر سیستم های مدیریت پایگاه داده (DBMS) فراتر رفته و همچنین دارای ساختارها و انواع داده هایی هستند که داده های زمانی را دستکاری می کنند. این مورد پسوند زمانی SECONDO [ 5 ] و PostgreSQL ( https://wiki.postgresql.org/wiki/Temporal_Extensions ) است که دادههای مسیر را از طریق انواع دادههای مکانی-زمانی مدیریت میکند.
در برخی از برنامهها، حجم دادههای مسیر آنقدر زیاد است که ذخیرهسازی فضایی یا غیرمکانی DBMS با چنین نیازهایی مقابله نمیکند. برنامههایی که حجم عظیمی از دادههای مسیر را مدیریت میکنند باید با مسائل مهمی مانند افزایش اندازه، تنوع و نرخ بهروزرسانی مجموعههای داده سروکار داشته باشند. فراتر از تمام اطلاعات تولید شده توسط صنعت علمی، تحقیقاتی و دولت ها، افزایش سریع داده های مسیر به موضوع مورد علاقه در داده های بزرگ تبدیل شد [ 6 ].
جین و همکاران Big Data را به عنوان یک اصطلاح جامع برای هر مجموعه داده به قدری بزرگ و پیچیده معرفی می کند که پردازش آن با استفاده از برنامه های کاربردی پردازش داده سنتی دشوار است [ 6 ]. علاوه بر حجم زیاد داده، داده های بزرگ را می توان با سرعت بالا (سرعت)، تنوع بالا، صحت کم و ارزش بالا مشخص کرد [ 7 ]]. این ویژگی های Big Data به عنوان 5V شناخته می شوند. به طور کلی، DBMS های سنتی با داده های ساخت یافته سر و کار دارند و فناوری های Big Data با داده های ساختاریافته، بدون ساختار و نیمه ساختار یافته، مانند ایمیل، اخبار، تراکنش های بانکی، جریان های سمعی و بصری (صدا، تصویر، و ویدئو) از جمله موارد دیگر سروکار دارند. اگرچه مسیرهای خام ممکن است به عنوان داده های ساخت یافته نشان داده شوند، مسیرهای معنایی به ساختارهای داده پیچیده تری نیاز دارند. بنابراین، نسل جدیدی از فناوری های پایگاه داده برای رفع چالش های جدید مورد نیاز است.
تجزیه و تحلیل مسیر به عنوان یک شاخه ضروری از این موضوع مطرح شده است، زیرا حجم داده های مسیر به دلیل در دسترس بودن زیاد دستگاه های تلفن همراه و برنامه های کاربردی با استفاده از GPS به طور مداوم در حال افزایش است. پرداختن به داده های فضایی در مقیاس بزرگ یک موضوع تحقیقاتی است به نام داده های بزرگ فضایی [ 8] که در آن مسائل مربوط به برنامه های کاربردی داده های بزرگ برای ایجاد امکان توسعه سیستم های اطلاعات جغرافیایی رسیدگی می شود. از آنجایی که حجم داده های مسیر معمولاً بسیار زیاد است، لازم است زیرساختی مستقر شود که بتواند این داده های عظیم را به درستی تجزیه و تحلیل کند، پرس و جوهای پیچیده را حل کند، بینش های مرتبط را استخراج کند و از فرآیند تصمیم گیری پشتیبانی کند. معمولاً، این مشکل با استفاده از یک انبار داده حل می شود، که زیرساختی است که داده های موجود در سطح عملیاتی DBMS را برای تولید تجزیه و تحلیل و گزارش هایی که به فرآیند پشتیبانی تصمیم گیری در سازمان ها کمک می کند، خلاصه می کند. انبارهای داده ای که برای مدیریت داده های مسیر ساخته شده اند، انبار داده های مسیری نامیده می شوند. فرآیند تبدیل از سطح داده های عملیاتی به انبار داده ETL (Extraction, Transformation, and Loading) نامیده می شود.9 ].
در سال های اخیر، برخی از نظرسنجی ها برای بحث در مورد استفاده از داده های مسیر توسعه یافته اند. این نظرسنجی ها بر جنبه های مختلف داده های مسیر تمرکز دارند. به عنوان مثال، نظرسنجی والدین و همکاران. [ 10 ] تجزیه و تحلیلی از مدیریت دادههای تحرک، فهرستبندی و بحث درباره تکنیکهای اصلی برای ساخت، غنیسازی، استخراج و استخراج دانش از دادههای مسیر ارائه میکند. نظرسنجی کنگ و همکاران [ 11 ] کاربردهای مسیر و دادههای مربوط به رفتار سفر، الگوهای سفر، شرح خدمات داده مسیر را از نظر مدیریت حملونقل و سایر جنبهها ارائه میکند. از سوی دیگر، نظرسنجی بیان و همکاران [ 12] مجموعه ای از تکنیک های خوشه بندی مسیر را ارائه می دهد و آنها را به سه دسته طبقه بندی می کند: نظارت نشده، نظارت شده و نیمه نظارت. نظرسنجی فنگ و ژو [ 13 ] برخی از کاربردهای استخراج مسیر، مانند مسیریابی، پیشبینی مکان، تحلیل رفتار شی موبایل و غیره را ارائه میکند. با بهترین دانش ما، تنها یک نظرسنجی [ 14 ] پیدا شد که تحقیقات متمرکز بر معماری سنتی سیستمهای OLAP اعمال شده در تحلیل مسیر را خلاصه میکند، اما هنوز در مورد جنبههای مختلف مربوط به انواع TDW، مسیرهای معنایی، و اطلاعات بزرگ.
علاوه بر این، سایر مشارکتهای ارائه شده توسط این تحقیق دادههای مسیر، روشن کردن چگونگی انجام تحقیقات دادههای مسیر، تکنیکهای اصلی مورد استفاده، و نحوه تعبیه آنها در معماری OLAP است. این مطالعه همچنین می تواند به بهبود کارایی و توسعه تصمیم گیری های مربوط به مسیرها مانند سیستم های برنامه ریزی شهری، کنترل ترافیک، نظارت بر شناورها، پیش بینی حرکت، نظارت و مطالعه حرکت برخی از گونه های جانوری کمک کند.
بقیه این نظرسنجی به شرح زیر سازماندهی شده است. بخش 2 مفاهیم اساسی مسیر را توضیح می دهد. بخش 3 بر فرآیند یکپارچه سازی داده های مسیر متمرکز است. بخش 4 طراحی انبار داده مسیر را مورد بحث قرار می دهد. بخش 5 به نحوه انجام عملیات تجزیه و تحلیل داده ها می پردازد. بخش 6 مسائل باز در تجزیه و تحلیل مسیر را برجسته می کند. در نهایت، بخش 7 نظرسنجی را به پایان میرساند.
2. مفاهیم اساسی
یک مسیر را می توان به عنوان دنباله ای از موقعیت ها که به صورت زمانی مرتب شده اند توصیف کرد. به گفته بوگرنی و همکاران. [ 3 ]، یک مسیر T را می توان به طور رسمی به صورت T = < تعریف کردپ1،پ2،پ3،…،پn> ، جایی که هر موقعیت پمننشان دهنده یک نقطه از T. علاوه بر این، هر پمنرا می توان به صورت p=< سه گانه تعریف کردایکسمن،yمن،تیمن> ، جایی که:
-
ایکسمنو yمننشان دهنده مختصات جغرافیایی
-
تیمنلحظه زمان مکان شی را نشان می دهد. و
-
تی1< تی2< تی3… تیn.
داده های مسیر اصلی، که فقط از اطلاعات مکانی-زمانی یک جسم متحرک تشکیل شده است، به عنوان مسیرهای خام شناخته می شوند [ 10 ، 15 ، 16 ]. گاهی اوقات، این تعریف بسط مییابد و هر موقعیت p شامل یک شناسه نیز میشود. در این موارد، هر نقطه به عنوان یک < چهارگانه تعریف می شودمند،ایکسمن،yمن،تیمن> _ این تعریف توسعهیافته برای پیادهسازی برنامههایی که نیاز به نظارت بر چندین شی تلفن همراه دارند، مفید است مندویژگی برنامهها را قادر میسازد تا هر یک از این اشیاء را به طور منحصربهفرد شناسایی کنند.
به طور کلی، در داده های مسیر، واحدی که باید پردازش شود، قسمت (همچنین به عنوان بخش یا مسیر فرعی شناخته می شود) است نه کل حرکت. معیارهای مورد استفاده برای تقسیم مسیر به اپیزود، فاصله زمانی، شکل فضایی یا معانی معنایی [ 1 ] است. به عنوان مثال، در یک مطالعه در مورد مسیر حیوانات، یک بخش می تواند با یک مسیر روزانه مطابقت داشته باشد. برای کارمندان شرکت، این بخش می تواند ساعات کاری باشد، از ساعت 8 صبح تا 6 بعد از ظهر. این بخش می تواند دوره توقف یا حرکت یک فرد در منطقه ای از شهر باشد که بر اساس فعالیت منطقه ای مانند اقامت، گردشگری، تجاری، تفریحی یا وسایل حمل و نقل طبقه بندی می شود [ 13 ، 17 ]]. فرآیند تقسیمبندی ممکن است با استراتژیهای مبتنی بر درونیابی [18 ]، یا فقط بر روی همگنی در داده های مسیر، مانند GRASP-UTS [ 19 ] و GRASP-SemTS [ 20 ].
تعریف 1.
به طور رسمی، اپیزود با چهارگانه نمایش داده می شود (traj_id، ep_id، type، subseq: LISTOF position < پمن،…،پj>)، جایی که:
- 1 .
-
traj_id شناسه مسیر است.
- 2 .
-
ep_id شناسه قسمت است.
- 3 .
-
نوع، نوع اپیزود است، یعنی معیار فرآیند تقسیم بندی (به عنوان مثال، نوع وسیله حمل و نقل، نوع فعالیت، توقف، حرکت).
- 4 .
-
subseq یک زیر دنباله حداکثر از نقاط مکانی-زمانی < است پمن،…،پj> از مسیر خام که نوع معیار قسمت را برآورده می کند (مثلاً وسیله حمل و نقل) و 1 ≤ i ≤ j ≤ n، که در آن n تعداد نقاط مسیر است.
داده های مسیر را می توان از منابع مختلف جمع آوری کرد [ 11 ]:
-
به روشی صریح ، یعنی استفاده از حسگرهایی مانند GPS که مختصات جغرافیایی را با سرعت فاصله زمانی و مکانی تقریبا استاندارد شده به گیرنده منتقل می کند.
-
به طور ضمنی ، زمانی که مسیر از طریق اطلاعات بهدستآمده از دستگاههایی استنباط میشود که استانداردسازی زمانی و مکانی را تضمین نمیکنند، به عنوان مثال، دانهبندی زمانی نسبتاً زیاد است و توزیع نقاط زمانی ثبتشده نسبتاً تصادفی است [ 11 ]، مانند سنسورهای دوربین هوشیاری، کارت های مغناطیسی، RFID (شناسایی فرکانس رادیویی) و GSM (سیستم جهانی برای ارتباطات سیار). راه دیگر برای به دست آوردن داده های مسیر به طور ضمنی از طریق VGI (اطلاعات جغرافیایی داوطلبانه) است [ 21 ، 22 ]، که شامل اطلاعات جغرافیایی ارائه شده توسط شهروندان با استفاده از ابزارهای رسانه های جغرافیایی اجتماعی است.
مسیرهای خام فقط دارای موقعیت های مکانی-زمانی هستند و گاهی اوقات برای ساخت برنامه های مسیر معنی دار کافی نیستند [ 23 ]. پس از چندین سال تحقیق در داده های مسیر، تأیید شد که اطلاعات زمینه ای برای چندین کاربرد ارزشمند است. اگرچه دانستن مکان یک شی در یک لحظه معین، بخشی از اطلاعات مرتبط است، اما بسیاری از برنامه ها نیاز به ادامه کار دارند. به عنوان مثال، در برخی موارد، دانستن اینکه جسم متحرک چیست و هدف آن چیست، ضروری است.
2.1. سیر معنایی
برخی از برنامه ها بیشتر به جنبه رفتاری علاقه مند هستند تا صرفاً به داده های موقعیتی، به عنوان مثال، تفسیر مسیرهای کاربران در داخل یک شهر با توجه به دانش قبلی در مورد شهر. سیستمی که با دادههای مسیر سر و کار دارد، میتواند با دادههای معنایی غنی شود که نه تنها خود مسیر، بلکه جنبههایی را که فراتر از مکان هستند، مانند نقاط مورد نظر، هدف جسم متحرک، و نوع انتقال، تجزیه و تحلیل میکند. به عنوان مثال، بسیاری از برنامه های کاربردی [ 24 ، 25]، به جای تجزیه و تحلیل داده های خام GPS، ترجیح می دهید مسیر را به عنوان دنباله ای از حاشیه نویسی های معنایی ارزیابی کنید، مانند: (خانه، -9:00 ساعت، -) → (جاده، 9-10 ساعت، اتوبوس) → (دفتر ، ساعت 10 تا 17، کار) → (جاده، ساعت 17 تا 15:30، مترو) → (سوپرمارکت، ساعت 17:30 تا 18، مرکز خرید) → (جاده، ساعت 18 تا 18:20، پیاده روی) → (در خانه ، 18:20-، -). در این مثال، هر سه گانه نشان دهنده مکان، فاصله زمانی و حاشیه نویسی معنایی است که نوع فعالیت یا نحوه حمل و نقل در آن مسیر را توصیف می کند [ 26 ].
Spaccapietra ایده شناسایی معناشناسی در داده های مسیر را در سال 2008 معرفی کرد [ 27 ]. از آن زمان، بسیاری از نویسندگان آثاری را توسعه دادهاند که تلاش میکنند مسیرهای معنایی غنیشده را تولید کنند. غنیسازی معنایی میتواند در نقطه مسیر، در قسمت یا در کل مسیر رخ دهد و شامل پیوستن به دادههای خط سیر خام و اطلاعات زمینه برای تولید مسیرهای غنیشده معنایی است [ 10 ]. Spaccapietra و Parent [ 28 ] مسیر معنایی را به عنوان یک مسیر خام که از نظر معنایی با حاشیه نویسی و/یا یک یا چند تفسیر غنی شده است تعریف می کنند. اپیزودها را می توان با همان تفسیر گروه بندی کرد، به عنوان مثال، قسمت های فعالیت، قسمت های توقف یا حرکت و غیره.
تعریف 2.
به طور رسمی، مسیر معنایی به صورت یک تاپل [ 28 ] تعریف میشود: (TrajectoryID، ObjectID، TrajectoryAnnotations، مسیر: موقعیت LISTOF (ti، p، posAnnotations)، تفاسیر: تفسیر SETOF (interpretationID، SemanticGaps: شکاف LISTOF ( تیمتر، تیn), قسمت ها: قسمت LISTOF)) که در آن:
- 1 .
-
trajectoryID شناسه مسیر است.
- 2 .
-
objectID شناسه شی موبایل است.
- 3 .
-
trajectoryAnnotations مجموعه ای از حاشیه نویسی های مرتبط با مسیر به عنوان یک کل است، به عنوان مثال: مدت زمان، اندازه، هدف.
- 4 .
-
آهنگ فهرستی از موقعیت های مکانی-زمانی جسم متحرک است. لیست به طور موقت مرتب شده است.
- 5 .
-
معمولاً لحظههایی از زمان هستند. همه تی ناهمگون هستند.
- 6 .
-
p یک عنصر فضایی را مشخص می کند. به طور کلی با یک نقطه (x، y) برای مختصات دو بعدی و (x، y، z) برای مختصات سه بعدی نشان داده می شود.
- 7 .
-
posAnnotations یک مجموعه حاشیه نویسی مرتبط با موقعیت p است.
- 8 .
-
semanticGaps فهرستی از شکاف های معنایی در مسیری است که با یک دوره زمانی مشخص شده است. تیمترو تیn، جایی که تیمتر≤ تیn;
- 9 .
-
تفاسیر مجموعه تفاسیری است که به مجموعهای از قسمتهای مسیر اشاره دارد، به عنوان مثال، قسمتهای فعالیت، قسمتهای توقف/حرکت، و غیره.
- 10 .
-
interpretationID شناسه تفسیر است.
- 11 .
-
قسمت ها لیست اپیزودهای مربوط به یک تفسیر خاص است.
برخی از برنامه ها از اطلاعاتی مانند وسایل حمل و نقل و فعالیت های جسم متحرک برای برچسب گذاری داده های خط سیر خام استفاده می کنند. SeMiTri [ 26 ] علاوه بر تقسیمبندی مسیرها با استفاده از ویژگیهای هندسی (مثلاً سرعت، شتاب)، از الگوریتم تطبیق نقشه در نقشه راه جغرافیایی برای استنباط نوع حمل و نقل کاربر استفاده میکند. استنباط سایر اطلاعات، مانند هدف جابجایی، دشوارتر است. در این موارد، معمولاً لازم است تکنیکهای یادگیری ماشینی بر مبنای تاریخی برای به دست آوردن چنین اطلاعاتی اعمال شوند [ 3 ]. با این حال، این اطلاعات چندان دقیق نیست.
از طریق طرح های مفهومی سطح بالا، انسان ها داده ها را تفسیر، درک و استفاده می کنند. بین داده های مشاهده شده سطح پایین و سطح مفهومی، شکاف معنایی وجود دارد [ 29 ]. این شکاف معنایی را می توان با فرو بردن تفسیر داده ها در زمینه حرکت مسیر کاهش داد. اغلب، داده های زمینه از رسانه های اجتماعی مانند توییتر و فیس بوک به دست می آیند. در این نوع رسانه، کاربران معمولاً اطلاعات تکمیلی (مانند هشتگ ها و نظرات) را در مورد جابجایی خود می گذارند. چنین اطلاعاتی می تواند در فرآیند غنی سازی معنایی داده های خط سیر خام [ 30 ] پشتیبانی کند. مکمل رسانه های اجتماعی، LinkedGeoData یک پایگاه داده فضایی بزرگ از داده های وب است که در فرآیند مسیرهای معنایی نیز استفاده می شود [ 15 ]].
مدل دیگری که برای نشان دادن مسیرهای معنایی استفاده می شود 5W1H [ 31 ] است. این مدل مخفف شش سؤال روایی است که هدف آنها درک زمینه یک شرایط است و در حال حاضر، تحقیقات متعددی از 5W1H برای مدلسازی بافت جسم متحرک استفاده میکند [ 16 ، 32 ]. 5W1H توسط روزنامه نگاران به عنوان راهنمای توصیف یک واقعیت استفاده شده است و از سؤالات زیر تشکیل شده است:
-
چه کسی: شناسایی شی متحرک.
-
کجا: جایی که نقطه مسیر در آن قرار دارد.
-
زمان : زمان مربوط به نقاط مسیر.
-
چه چیزی: شیء متحرک چه کاری انجام میداد، یا داشت انجام میداد.
-
چرا: نشان دهنده انگیزه سفر است.
-
How: نشان دهنده نحوه حرکت جسم، مانند وسیله حمل و نقل است.
پروژه MASTER [ 33 ] یک رویکرد جدید برای غنی سازی معنایی مسیرها با جنبه های مختلف ارائه می دهد که فراتر از مدل 5W1H است. جنبه یک واقعیت از دنیای واقعی مربوط به تجزیه و تحلیل داده های مسیر است. از فناوریهایی مانند ساعت هوشمند، تجزیه و تحلیل صدای صدا، حسگرهای نور، از جمله، میتواند انواع اطلاعات جدید را جمعآوری کند و مسیر را با جنبههای معنایی مختلف غنی کند. به این ترتیب، می توان بخش های مسیر را با اطلاعاتی مانند فشار خون کاربر، وضعیت احساسی، ضربان قلب، سطح درخشندگی محیط، دما و سطح سر و صدا مرتبط کرد. هر چه ما جنبه های بیشتری داشته باشیم، حرکت واقعی یک جسم کامل تر است و اطلاعات بیشتری در مورد اشیا و مکان ها می توانیم استنباط کنیم.
شکل 1 سطوح غنی سازی معنایی را نشان می دهد که ممکن است در داده های مسیر وجود داشته باشد. پایین ترین سطح، مسیر خام با اطلاعات اولیه (مکان و زمان) است. سطح 5W1H مسیرهایی است که طبق مدل 5W1H به سوالات پاسخ می دهد. سطح جنبه های چندگانه زمانی است که مسیر با هر گونه اطلاعات زمینه ای فراتر از آنچه در مدل 5W1H مشخص شده است غنی می شود.
بر اساس چشم انداز فرآیند تجزیه و تحلیل داده ها، که از جمع آوری داده ها تا ساخت و اکتشاف DW و مکعب چند بعدی می رود، این مقاله بررسی برنامه هایی را ارائه می دهد که شامل تجزیه و تحلیل مسیرها از ذخیره سازی، پردازش، خلاصه سازی و تجزیه و تحلیل است. دیدگاه ها بر اساس معماری انبار داده معمولی [ 34 ]، این بررسی سیستم های مسیر را در سه مرحله متمایز، همانطور که در شکل 2 مشخص شده است، تجزیه و تحلیل می کند :
-
یکپارچه سازی: شامل جمع آوری و ادغام داده های خط سیر خام، مانند مختصات جغرافیایی و زمان، و ذخیره سازی متعاقب آن در یک پایگاه داده است. این مرحله شامل منبع داده و لایه های پشتیبان معماری انبار داده است که توسط Vaisman و Zimányi [ 2 ] توضیح داده شده است. در طول این فرآیند، داده های جمع آوری شده را می توان با سایر داده های به دست آمده از منابع خارجی مورد علاقه برنامه، مانند Geonames ( https://www.geonames.org/ )، OpenStreetMaps و Twitter غنی کرد. برای غنی سازی معنایی داده های خام جمع آوری شده، می توان اطلاعات بیشتری را به دست آورد. فرآیند غنیسازی معنایی میتواند هم در مراحل ادغام و هم در مراحل طراحی رخ دهد.
-
طراحی: این مرحله مربوط به مرحله ای است که داده های مسیر را می توان در یک انبار داده از طریق فرآیند ETL خلاصه کرد.
-
تجزیه و تحلیل: این مرحله اکتشافی معماری است که از انبار داده و سایر منابع داده در صورت لزوم برای تولید گزارش ها و سایر اطلاعات تصمیم گیری پرس و جو می کند. در صورت لزوم، ابزار تجزیه و تحلیل می تواند مستقیماً منبع داده را از طریق فرآیندی به نام ETQ (Extract, Transform, Query) جستجو کند [ 35 ]. فرآیند ETQ تبدیل داده ها را تا آخرین لحظه به تاخیر می اندازد و در صورت درخواست به کاربر ارائه می شود [ 35 ]. جزئیات بیشتر در مورد ETQ در بخش Analytics توضیح داده شده است.
ما چندین کار تحقیقاتی را بر اساس این طبقه بندی تحلیل کردیم. جدول 1 خلاصه ای از این آثار را ارائه می دهد که در این بررسی به تفصیل آمده است. در بخشهای بعدی، مراحل فوقالذکر را با تمرکز بر دادههای مسیر به تفصیل و بیشتر مورد بحث قرار میدهیم.
3. یکپارچه سازی داده های مسیر
حجم زیادی از داده های تحرک از طریق دستگاه های دارای سیستم موقعیت یابی جهانی (GPS) تولید و در مخازن داده ها ذخیره می شود. انواع مختلفی از موجودات متحرک را می توان ردیابی کرد، مانند عابران پیاده، اتومبیل ها، کشتی ها، هواپیماها و حیوانات. این مجموعه داده ها منبع غنی از اطلاعات را برای تحلیل و استنتاج الگوهای تحرک فراهم می کنند. در چند سال اخیر، این نوع اطلاعات توجه محققان صنعت و آکادمی را به خود جلب کرده است که می توانند از داده های تحرک برای استخراج اطلاعات و دانشی که برای کاربردهایشان ضروری است استفاده کنند. به عنوان مثال، چه چیزی، چگونه و چه مدت یک واحد در حال انجام یک فعالیت خاص است. این روزها،51 ]. بخشهای فرعی زیر نحوه جمعآوری، مرتبسازی و ذخیره دادههای مسیر را توضیح میدهند.
3.1. گردآوری و ذخیره سازی داده های مسیر
مرحله جمعآوری دادهها میتواند شامل چندین کار پردازشی برای بهبود کیفیت دادههای مسیر قبل از شروع فعالیتهای استخراج و تحلیل باشد. به عنوان مثال، سیستم می تواند یک فرآیند تمیز کردن را برای حذف نقاط پرت انجام دهد. نظرسنجی ژن [ 1] راه حل های مشکل پرت را به سه دسته تقسیم می کند: فیلتر میانگین (یا میانه). فیلتر کالمن و ذرات؛ و تشخیص بیرونی مبتنی بر اکتشاف. فیلتر میانگین (یا میانه) میانگین (میانگین) را در یک پنجره کشویی برای تخمین مقدار واقعی یک نقطه تعیین شده در مسیر محاسبه می کند. این فیلتر زمانی بهتر نشان داده می شود که نرخ نمونه برداری مسیر بالا باشد. فیلترهای کالمن و ذرات الگوریتمهایی هستند که برای تخمین اندازهگیریهای واقعی از دادههای آلوده به نویز استفاده میشوند. کالمن و ذرات مدلهایی را پیشنهاد میکنند که به اندازهگیریهای اولیه بستگی دارند، به عنوان مثال، اگر اولین نقاط مسیر نویز باشد، اثربخشی مدل به طور قابلتوجهی کاهش مییابد. روش تشخیص دورافتاده مبتنی بر اکتشاف، نقاط نویز را از مسیر حذف میکند و فقط نقاطی را در محدودههای محاسبهشده نگه میدارد، یعنی: این روش سرعت و فاصله بین هر نقطه و جانشین آن را محاسبه می کند. اگر این پارامترها از حدود اعلام شده فراتر رود، نقطه در مسیر قرار نمی گیرد.
حجم وسیعی از داده ها بر ذخیره، انتقال، پردازش و نمایش داده ها تأثیر می گذارد. هدف از فشرده سازی داده های مسیر، کاهش اندازه مجموعه داده ها بدون تحریف روند مسیر است [ 23 ]. دو دسته از الگوریتم های فشرده سازی داده های مسیر [ 52 ] وجود دارد:
-
فشرده سازی آفلاین: این دسته بعد از ایجاد کامل مسیر، اندازه مسیر را کاهش می دهد. الگوریتم کلاسیک داگلاس-پیکر (DP) است که بر اساس اکتشافی است که به صورت بازگشتی دنباله موقعیت ها را تقسیم می کند و تنها موقعیت نماینده هر زیر دنباله را ذخیره می کند. امروزه، اصلاحات و بهبودهایی در DP مانند نسبت زمانی بالا به پایین (TD-TR) [ 53 ] وجود دارد.
-
فشرده سازی آنلاین: فشرده سازی مسیر به دنبال حرکت جسم در طول مسیر رخ می دهد. ایده آل برای محیط های بلادرنگ، مانند نظارت بر ترافیک. الگوریتم های اصلی عبارتند از Sliding Window، Open Window [ 53 ] و STTrace [ 54]. Sliding Window و Open Window الگوریتم های مشابهی هستند که در انتخاب مکان نقطه پنجره کشویی متفاوت هستند. الگوریتم باعث می شود که یک پنجره کشویی همراه با نقاط مسیر رشد کند. در مقابل، خطای قطعات خط تنظیم (خط که از اولین و آخرین نقطه پنجره می رود) و مسیر اصلی از حد خطای مشخص شده بیشتر نیست. الگوریتم STTrace از مختصات، سرعت و جهت گیری نقطه مسیر فعلی برای محاسبه یک منطقه امن که موقعیت بعدی را می توان در آن قرار داد استفاده می کند. اگر نقطه بعدی در این منطقه باشد، می توان آن را نادیده گرفت.
پس از جمعآوری، سازماندهی، تمیز کردن و فشردهسازی، دادههای مسیر میتوانند قبل از ذخیرهسازی در پایگاه داده به یک نمایش جغرافیایی تبدیل شوند. دو فرمت متداول از انواع داده های مکانی وجود دارد: شطرنجی و برداری. قالب گراف زیر مجموعه ای از مدل برداری [ 55 ] است. در میان تحقیقات تجزیه و تحلیل شده مشاهده شد که فرمت شطرنجی بیشتر در انبارهای داده استفاده می شود که با اطلاعات خلاصه در سطح سلول کار می کنند. در قالب شطرنجی، نقشه به چندین سلول از یک شکل (مربع، مثلث یا چند ضلعی) تقسیم می شود و هر سلول می تواند حاوی اطلاعاتی در مورد یک متغیر خاص باشد، به عنوان مثال، بارندگی، دما، رطوبت، نوع خاک و غیره [ 56 ].]. از سوی دیگر، در قالب برداری، نقشه با استفاده از نقاط، خطوط و چندضلعی ها ساخته می شود و اغلب برای نشان دادن حرکت مسیرها به صورت جغرافیایی استفاده می شود. در زمینه مسیر، واحد منطقی پایه در یک مدل برداری، خط است که برای رمزگذاری مکان شی مورد استفاده قرار می گیرد و به صورت رشته ای از مختصات نقاط در امتداد خط نشان داده می شود [ 57 ].]. در نهایت، نمودار جغرافیایی نشان دهنده ویژگی های جغرافیایی داده ها در یک نقشه است. این نمایش عموماً برای توصیف شبکه شهری استفاده می شود که در آن جاده ها به عنوان لبه ها و نقاط مرجع (یا تقاطع خیابان ها) به عنوان رئوس نشان داده می شوند. این نوع نمایشی است که می تواند برای اجرای فرآیند تطبیق نقشه استفاده شود، که در آن نمایش جغرافیایی نقاط مسیر به گونه ای تبدیل می شود که مختصات با نمایش مش شهری مطابقت داشته باشد. از طریق نمودار، می توان یک نمایش مسیر دیگر را بدست آورد: مسیرها. در اینجا، مسیر با دنباله ای از قطعات نشان داده می شود، و هر بخش از دو راس نمودار تشکیل شده است به طوری که دو بخش متوالی دارای یک راس مشترک هستند [ 13 ].
داده های مسیر در قالب های مختلف با توجه به نوع دستگاه، اشیاء نظارت شده و هدف برنامه ذخیره می شوند. علاوه بر داده های خط سیر خام، سایر خصوصیات مرتبط مانند سرعت، جهت و شتاب را می توان به دست آورد و ذخیره کرد [ 12 ]. به طور معمول، داده های مسیر در زمان واقعی ضبط می شوند و یک جریان داده را تشکیل می دهند که یک نوع پایگاه داده مکانی-زمانی به نام MOD (پایگاه داده شی متحرک) را تغذیه می کند [ 39 ]. یک ساختار بزرگ برای ذخیره سازی برای صرفه جویی در جریان داده های عظیم و در حال افزایش نیاز است [ 58]. سیستمهای فعلی میتوانند از فناوریهای فضای داده و پلتفرمهای Big Data مانند Apache Spark و Hadoop استفاده کنند. هدف از پشتیبانی فضای داده، ارائه عملکردهای اساسی بر روی چندین منبع داده است، صرف نظر از اینکه چقدر یکپارچه هستند [ 59 ]. سیستمهای فضای داده خدماتی را بر روی دادهها بدون نیاز به یکپارچهسازی معنایی اولیه و خدماتی مانند pay-as-you-go ارائه میکنند، یعنی قبل از استفاده از سرویس، هزینه آن را پرداخت کنید و از چیزی که برای آن پرداخت کردهاید فراتر نروید [ 60 ]. با این حال، اگر عملیات پیچیدهتری مورد نیاز باشد، مانند عملیات به سبک DB رابطهای یا دادهکاوی، تلاشهای بیشتری میتواند برای ادغام منابع داده ناهمگن موجود در بستر پشتیبانی از فضای داده (DSSP) [ 61 ] به کار گرفته شود.
ما متوجه دو نوع دستکاری دادههای مسیر شدهایم: دادههای مسیر را میتوان در زمان واقعی، مانند سیستمهای ناوبری، به عنوان مثال، Waze ( https://www.waze.com )، یا از طریق یک مبنای تاریخی تجزیه و تحلیل کرد. برنامه مسیر بیدرنگ مکان فعلی اشیاء را حفظ می کند، یعنی پرس و جوهای آنها در مکان فعلی و موقعیت های آینده مورد انتظار شی مطرح می شود. سیستم بحران [ 48] نمونهای از برنامهای است که با جریانهای داده مسیر سر و کار دارد و از Apache Jena برای نگهداشتن یک نمودار RDF (چارچوب توصیف منابع) حاوی نمایش معنایی دادههای دریافتشده از حسگرهای مختلف در حافظه استفاده میکند. در آن سیستم، دادههای چندین حسگر ناهمگن در ساختاری ادغام میشوند که از وب معنایی برای جاسازی دادهها در یک زمینه (در این مورد، ناوبری دریایی) استفاده میکند، که قابلیت همکاری و کشف دانش جدید در مورد محیط مورد نظارت را تسهیل میکند. 48 ]. جریان داده توسط حسگرهای AIS (سیستم شناسایی خودکار) و ایستگاه های نظارت بر آب و هوا و یخچال های طبیعی تولید می شود. داده های جریان پردازش شده و به عنوان یک نمودار RDF نشان داده می شود که می تواند به صورت محلی یا در ابر LOD (داده های باز پیوند داده شده) ذخیره شود. سیستم موبی دیک [ 43] یک چارچوب اولیه برای مدیریت و نظارت بر اشیاء موبایل ارائه می دهد. این تحقیق هیچ اطلاعاتی را در پایگاه داده ذخیره نمی کند. فقط با اطلاعات موجود در حافظه اصلی کار می کند. MobyDick یک مدل داده را بر اساس مشخصات ISO زمانی و مکانی پیادهسازی میکند: ISO 19108:2002 [ 62 ] و ISO 19107: 2003 [ 63 ]. MobyDick به عنوان یک لایه در بالای پلت فرم Apache Flink [ 64 ] عمل می کند که پردازش موازی توزیع شده داده ها را پیاده سازی می کند.
برخلاف برنامههایی که از جریانهای داده استفاده میکنند، پایگاه داده مسیر تاریخچه حرکت را حفظ میکند. تمایل جدید برای حفظ پایگاه داده مسیر تاریخی که به طور مداوم توسط جریان داده های شی متحرک تغذیه می شود، به ساختاری قوی با ظرفیت ذخیره سازی بزرگ نیاز دارد. خوشه های محاسباتی با پردازش موازی و مقیاس پذیری افقی زیرساخت هایی هستند که از ذخیره سازی و تجزیه و تحلیل داده های بزرگ پشتیبانی می کنند [ 65 ]. بائو و همکاران تحقیق [ 42 ] سیستمی را ارائه می دهد که بر مسیرهای شهری تمرکز دارد. سیستم آنها از Microsoft Azure برای ذخیره حجم زیادی از داده ها استفاده می کند. این سیستم از سه ماژول تشکیل شده است: ذخیره مسیر، نمایه سازی فضا-زمان و تطبیق نقشه. جدیدترین داده ها در پایگاه داده Redis و Azure برای داده های تاریخی ذخیره می شوند. ST-Hadoop [47 ] اولین چارچوب MapReduce منبع باز با پشتیبانی از داده های مکانی-زمانی بومی بود. با ذخیره سازی داده ها در سطح روز، ماه و سال، فضای ذخیره سازی را فدای عملکرد بهتر می کند. داده ها در فایل ها در HDFS (سیستم فایل توزیع شده Hadoop) با نمایه سازی مکانی-زمانی که فرآیند پرس و جو را سرعت می بخشد ذخیره می شود.
سیستمهای مدیریت مسیر سنتی، مانند PostgreSQL، Oracle، HDFS و Azure، دیسکگرا هستند که میتواند مشکلات مقیاسپذیری و پردازش کند پرس و جو را ایجاد کند. از این رو، استفاده از پلتفرم های Big Data مانند Apache Spark به طور فزاینده ای در مدیریت داده های مسیر رایج شده است. پلتفرم Spark یک سیستم توزیعشده است که انتزاعی به نام RDD (مجموعه دادههای توزیعشده انعطافپذیر) ارائه میدهد ( https://spark.apache.org/docs/latest/rdd-programming-guide.html,ApacheSpark-RDDProgrammingGuide ). این RDD ها مجموعه ای از اشیا را در حافظه نگه می دارند که می تواند به راحتی توسط Spark مدیریت شود. سیستم TrajSpark [ 46] Apache Spark را با ساختن یک ساختار نمایه سازی جهانی و محلی برای سرعت بخشیدن به فرآیند جستجو گسترش می دهد. علاوه بر این، TrajSpark به یک مانیتور متعادل کننده بار متکی است که استفاده از پارتیشن های داده را بهبود می بخشد. در برخی از برنامه ها، تعادل با افزودن داده های جدید در پایگاه داده ساعتی یا روزانه انجام می شود و توزیع داده ها در طول زمان تغییر می کند. اگر هنگام بارگیری داده های جدید، کل مجموعه داده مجدداً پارتیشن بندی شود، این می تواند هزینه های سربار ایجاد کند. برای پارتیشن بندی مجدد، داده های قدیمی ارزشش را ندارند زیرا داده های جدید ارزشمندتر هستند. بنابراین، TrajSpark فقط سعی می کند گروه های داده جدید را بدون دست زدن به داده های موجود پارتیشن بندی کند.
سیستم دیگری که از معماری Spark استفاده می کند DiStRDF (سیستم فضایی-زمانی RDF توزیع شده) است [ 49 ]. DiStRDF یک سیستم توزیع شده است که از RDF برای پردازش پرس و جوهای مکانی-زمانی در شبکه ای از پایگاه های داده ناهمگن استفاده می کند. در آزمایشهای نیکیتوپولوس و همکاران، دادهها در یک سیستم HDFS که توسط یک محیط آپاچی اسپارک مدیریت میشد، ذخیره میشد. داده های RDF به عنوان یک فرهنگ لغت بزرگ شامل خلاصه مکان تقریبی شی و زمان رویداد عمل می کند. این فرهنگ لغت در پایگاه داده Redis ذخیره می شود تا پردازش پرس و جو را سرعت بخشد.
بر اساس سیستم ذخیره سازی و نمایش هندسی، برخی از سیستم ها مطابق جدول 2 تجزیه و تحلیل و مرتب شدند . این جدول پلت فرم های مورد استفاده برای مدیریت داده های مسیر مورد استفاده در برخی از آثار و نوع نمایش هندسی استفاده شده را ارائه می دهد. ستون نمایش هندسی نوع نمایش هندسی مورد استفاده در تحقیق مورد تجزیه و تحلیل را نشان می دهد . در مرحله یکپارچه سازی، مشاهده می شود که هیچ یک از معماری های پیشنهادی با داده ها در قالب شطرنجی سروکار ندارند. تمام تحقیقات تحلیل شده داده های مسیر را در قالب برداری ذخیره می کنند و یکی از آنها نیز اطلاعات را به صورت نمودار نشان می دهد. هر مدیر داده برای مطابقت با مدل داده مسیر مورد استفاده در هر کار تحقیقاتی انتخاب شد.
جدول 2 برخی از سیستم هایی را نشان می دهد که از پایگاه داده های فضایی مانند PostgreSQL، همراه با گسترش فضایی Postgis و Oracle استفاده می کنند. کارهای جدیدتر فناوریهای Big Data را پذیرفتهاند، زیرا این روند جدید به دلیل حجم زیادی از دادههای مسیری است که توسط حسگرها و رسانههای اجتماعی تولید میشود. تخمین زده میشود که حجم دادههای دیجیتال هر دو سال دو برابر میشود و دادههای مکانی سهم عمدهای در سناریوی Big Data دارند [ 66 ]. فنآوریهای ذخیرهسازی سنتی، مانند آنهایی که در [ 26 ، 40 ] استفاده میشوند، نمیتوانند این حجم بزرگ از دادهها را سازماندهی و پرس و جو کنند. خوشه های محاسباتی با پردازش موازی و مقیاس پذیری افقی زیرساخت هایی هستند که از ذخیره سازی و تجزیه و تحلیل داده های بزرگ پشتیبانی می کنند [ 65 ]]. فناوریهای کلان داده مانند Hadoop، MongoDB، Flink و Spark به طور فزایندهای در سیستمهای مدیریت پایگاه داده بزرگ رایج میشوند [ 65 ، 67 ]. میتوان نتیجه گرفت که سیستمهای مسیری جدیدتر تمایل دارند از فناوریهای Big Data (Azure، Spark، ST-Hadoop، MongoDB) برای مقابله با دادههای مسیر استفاده کنند. علاوه بر این، پلتفرمهای رایانش ابری، مانند آنهایی که از Azure، HDFS و Spark استفاده میکنند، برای مقابله با دادههای مکانی-زمانی بهینهسازی نشدهاند.
سیستم های مسیر نشان داده شده در جدول 2 را نیز می توان بر اساس ساختار داده اتخاذ شده گروه بندی کرد: داده های ساختاریافته یا داده های نیمه ساختار یافته. سیستم T-Warehouse [ 39 ] معماری کامل یک سیستم مسیر را با ماژول های MOD و TDW ارائه می دهد. ماژول MOD از چارچوب هرمس [ 68 ] برای ارائه یک DBMS شی – رابطه ای (ORDBMS) برای داده های مسیر استفاده می کند. Oracle DBMS برای ساخت TDW استفاده می شود. مشاهده می شود که آثار قدیمی تر، مانند SeMiTri [ 26]، از یک پایگاه داده رابطه ای ساده با پسوند فضایی، مانند مورد PostgreSQL + postgis استفاده کنید. کارهای دیگر از یک مدل داده نیمه ساختاریافته استفاده می کنند، به ویژه زمانی که باید اطلاعات معنایی مسیر را نشان دهد. مدلسازی دادههای مسیر با استفاده از نمودارها یا هستیشناسیهای RDF با ظهور کارهای جدید در مورد غنیسازی مسیرهای معنایی، قدرت بیشتری به دست آورده است [ 33 ، 49 ]. نمایش دادههای مسیر معنایی با استفاده از RDF نه تنها استنباط دانش جدید را امکانپذیر میکند، بلکه انتشار دادهها را بهعنوان دادههای باز پیوندی (LOD) نیز امکانپذیر میکند و آن را در وب معنایی قابل دسترسی میسازد. برای مثال، پروژه MASTER [ 33 ] از پایگاه داده ای به نام Rendezvous [ 69 ] استفاده می کند] که نمودارها را در قالب RDF ذخیره می کند و قصد دارد داده های خود را در وب معنایی در دسترس قرار دهد. Rendezvous یک فروشگاه سه گانه [ 70 ] است که بر اساس یک پایگاه داده توزیع شده NoSQL است که داده ها را در قالب RDF ذخیره می کند. طبق [ 29 ]، فناوریهای ذخیرهسازی دادههای مسیر به خوبی ارائه میشوند، و چالش جدید در حال حاضر غنیسازی معنایی دادههای مسیر است، که موضوعی است که در بخش فرعی بعدی به آن پرداخته میشود.
3.2. مسیرهای معنایی
این بخش MOD های غنی شده از نظر معنایی ( جدول 2 ) را با نوع اطلاعات معنایی مربوطه توصیف می کند.
سیستم SeMiTri [ 26 ] یک مثال کاربردی است که داده های هندسی و داده های زمینه را برای تولید مسیرهای معنایی غنی شده پردازش می کند. این سیستم سه نوع حاشیه نویسی معنایی را انجام می دهد: بر اساس منطقه، خط و نقطه. حاشیه نویسی بر اساس منطقه از طریق نقشه های آنلاین مانند OpenStreetMap محاسبه می شود و می تواند مناطقی مانند مسکونی، صنعتی و تجاری را شناسایی کند. برای حاشیه نویسی خط، سیستم عملیات تطبیق نقشه را انجام می دهد و سپس، بر اساس زمینه، سیستم نوع حمل و نقل کاربر (اتوبوس، مترو، پیاده روی و غیره) را استنباط می کند. حاشیه نویسی نوع نقطه با آن بخش های مسیری مرتبط است که جسم متحرک در آن ساکن است. در این نوع بخش، سیستم با استفاده از الگوریتم زنجیره مارکوف [ 71 ] PoI را شناسایی می کند.] که برای این نوع سگمنت (خانه، محل کار، بازار و …) مناسب تر است.
سیستمی به نام VISTA [ 50 ] ابزاری با قابلیت های تحلیل بصری ارائه می دهد که از کاربران پشتیبانی می کند: (i) در کاوش و پردازش داده های مسیر. و (ii) در ایجاد ویژگی ها و اطلاعات معنایی، برای راهنمایی کاربر برای درک نحوه برچسب گذاری صحیح مسیرها. سیستم دیگری که حاشیه نویسی مسیر را نیز اختصاص می دهد ANALYTiC [ 45 ] است]، که از الگوریتم های یادگیری ماشینی برای استنباط حاشیه نویسی های معنایی در مورد داده های مسیر استفاده می کند. در آن مقاله، یک حاشیه نویسی معنایی یا برچسب، هر گونه اطلاعات متنی مربوط به مسیر است، به عنوان مثال: اطلاعات فعالیت مانند راه رفتن، مطالعه، رانندگی یا ماهیگیری. ANALYTiC از استراتژی یادگیری فعال برای حفظ عملکرد خوب طبقه بندی کننده ها در حالی که از تعداد کمتری نمونه آموزشی استفاده می کند، استفاده می کند.
مدل CONSTAnT [ 3 ] تنها یک مدل داده مفهومی است که جنبه های مهم برای پیاده سازی یک سیستم مسیر معنایی را تعریف می کند. این مدل اساساً به دو بخش تقسیم می شود. بخش اول به سادهترین موجودیتها اشاره دارد که حاوی اطلاعاتی درباره شی، مسیر، ردیابیهای فرعی، نقاط معنایی، محیط، مکان و رویدادها است. بخش دوم به اشیاء پیچیده تری اشاره دارد که در آنها تکنیک های داده کاوی برای نمونه سازی اشیاء مورد نیاز است، مانند هدف، وسایل حمل و نقل و رفتار.
سیستم MASTER نه تنها مدل مفهومی بلکه مدل منطقی و نمونه ای از ذخیره سازی داده ها و پرس و جوی اطلاعات را نیز ارائه می دهد. تمرکز پروژه MASTER نحوه به دست آوردن اطلاعات معنایی نیست، بلکه نحوه نمایش اطلاعات معنایی توسط مدل های مفهومی و منطقی است. مدل منطقی با یک گراف RDF نشان داده می شود زیرا به اندازه کافی عمومی است تا مسیرها و جنبه های استخراج شده از منابع داده ناهمگن را مدل کند [ 33 ]. سیستم MASTER از پایگاه داده Rendezvous [ 69 ] به منظور مدیریت حجم زیاد داده استفاده می کند.
جدول 3 پروژه هایی را نشان می دهد که از برخی نمادهای معنایی برای مسیرها استفاده کرده اند. جدول همچنین نوع اطلاعات معنایی را، با توجه به مدل 5W1H، در هر سیستمی که دارای برخی اطلاعات معنایی مرتبط با مسیر است، نشان میدهد. در میان برنامههای مورد بحث در این بخش، پروژه MASTER [ 33 ] میتواند با مدل 5W1H مطابقت داشته باشد، علاوه بر اینکه اجازه میدهد اطلاعات زمینهای دیگر را وارد کند.
برخی از سیستم ها فقط یک برچسب برای مسیر [ 45 ] اتخاذ می کنند و برخی دیگر اجازه حاشیه نویسی را برای هر بخش از مسیر می دهند: نقطه، بخش و کل مسیر. ستون Semantic Annotation از جدول 3 ، حاشیه نویسی معنایی مجاز برای هر بخش از مسیر را برجسته می کند. SeMiTri [ 26 ] و MASTER [ 33 ] اجازه می دهند اطلاعات معنایی مرتبط با نقطه، قطعه، و/یا کل مسیر را به هم مرتبط کنند. سیستم ANALYTiC [ 45 ] اطلاعات معنایی را به کل مسیر و سیستم های VISTA [ 50 ] اطلاعات معنایی را به بخش مسیر مرتبط می کند.
4. طراحی انبار داده مسیر
فناوریهای جدید توسعهیافته برای دستگاههای تلفن همراه و حسگرهای کمهزینه منجر به رشد حجم دادههای مسیر شدهاند. این حجم داده را می توان در یک مدل چند بعدی، که توسط یک انبار داده مسیر (TDW) تعریف شده است، ذخیره کرد و تجزیه و تحلیل دقیق تری را ممکن می سازد. هدف این انبارهای داده ذخیره، مدیریت و تجزیه و تحلیل داده های مسیرها به روشی چند بعدی است [ 36 ].
انگیزه پشت Trajectory Data Warehouses (TDWs) تبدیل مسیرهای خام به اطلاعات ارزشمندی است که می تواند به تصمیم گیری در برنامه های کاربردی همه جا حاضر مانند خدمات مبتنی بر مکان، کنترل ترافیک و مهاجرت گونه ها کمک کند [ 72 ، 73 ]. سوالاتی مانند اینکه کدام خیابان در شعاع 1 کیلومتری هر بیمارستان بیشترین ترافیک را دارد؟ یا “چند کاربر در یک محدوده زمانی در یک منطقه حرکت می کنند؟” می توان با استفاده از سیستم های قدیمی پاسخ داد. با این حال، هزینه محاسباتی و زمان پاسخ برای خدمات بلادرنگ ناکافی به نظر می رسد [ 72 ].
بخشهای فرعی زیر انبار دادههای مسیر فعلی موجود را توصیف میکنند که TDWهای مبتنی بر سلول و TDWهای مبتنی بر بخش هستند. در نهایت، کارهای مربوط به TDW معنایی شرح داده شده است.
4.1. انبار داده مسیر
انبار داده یکی از اجزای اصلی در هوش تجاری (BI) است. در محیط BI، چرخه حیات یک رکورد داده با وقوع یک رویداد آغاز می شود. سپس، فرآیند ETL رکورد رویداد را به یک مخزن مشترک به نام Data Warehouse تحویل می دهد. در نهایت، پردازش تحلیلی دادهها را به اطلاعاتی برای فرآیند تصمیمگیری تبدیل میکند و یک تصمیم تجاری منجر به اقدام مربوطه میشود. هوش تجاری مجموعهای از روشها، فرآیندها، معماریها و فناوریهایی است که دادههای خام را به اطلاعات مفید و معنادار برای تصمیمگیری تبدیل میکند [ 2 ].]. این سیستم ها حجم زیادی از داده ها را جمع آوری و خلاصه می کنند تا بتوان از آنها در تحلیل رفتار سازمانی استفاده کرد. این تبدیل داده شامل مجموعهای از وظایف است که دادهها را از منابع داده جمعآوری میکند و پس از فرآیندهای استخراج، تبدیل، یکپارچهسازی و تمیز کردن، دادههای پردازش شده را در یک انبار داده ذخیره میکند [ 74 ].
مشاهده شده است که دو رویکرد برای برخورد با داده های مسیر در انبارهای داده وجود دارد. در مورد اول، منطقه مورد نظر به چندین سلول تقسیم می شود و هر سلول حاوی خلاصه ای از اطلاعات در مورد محل عبور مسیرها است. از طرف دیگر، مسیرها در چندین بخش گروه بندی می شوند که به آنها اپیزود نیز می گویند.
در رویکرد طراحی انبار داده مبتنی بر سلول، فضا و زمان به سلولهای مکانی-زمانی (یا شبکهها) تقسیم میشوند و هر سلول حاوی معیارهای تجمعی است که از پیش محاسبه شده از مسیرهایی که از سلول عبور میکنند [ 39 ، 75 ]. مزیت یک DW مبتنی بر سلول این است که می توان آن را در یک انبار داده سنتی با استفاده از یک DBMS رابطه ای مانند SQL Server پیاده سازی کرد [ 75 ]]. فضای جغرافیایی به مناطق تقسیم می شود و داده های مسیر برای هر پارتیشن نقشه از پیش محاسبه می شوند. هندسه مسیر در TDW ذخیره نمی شود، فقط اطلاعات جمع آوری شده مانند سرعت متوسط و کل مسافت طی شده در سلول و تعداد دفعاتی که لبه سلول طی شده است. اطلاعات انبوه ذخیره شده در هر سلول مدل DW می تواند برای آشکار کردن دانش در مورد یک منطقه جغرافیایی خاص استفاده شود [ 36 ].
شکل 3 یک طرح برف ریزه [ 34 ] از یک TDW مبتنی بر سلول را نشان می دهد. این مثال حاوی اطلاعات اولیه یک TDW، یک جدول واقعی با برخی اندازهگیریها و ابعاد است که به مشخصات جسم متحرک، و ابعاد مکانی و زمانی مسیر اشاره دارد. در مثال شکل 3 ، اشیاء متحرک با موجودیت OBJECT_PROFILE_DIM نشان داده می شوند.که حاوی ویژگی برای نوع شیء است و ممکن است شامل ویژگی های دیگری باشد، به عنوان مثال، مارک و مدل خودرو، نوع کشتی، حرفه کاربر، و غیره. بعد سلول شامل یک ستون فضایی برای نشان دادن سلول از نظر جغرافیایی و همچنین شهر، ایالت و کشور است. جدول حقایق شامل اندازه گیری هایی است که در طی فرآیند ETL محاسبه می شوند. استفاده از عملگرهای فضایی مانند INSIDE، CONTAINS، COVERS و OVERLAPS [ 76]، میتوانیم بفهمیم که مسیر کدام سلولها را طی میکند. نمونههایی از اندازهگیریهایی که میتوانند در جدول واقعی محاسبه و ذخیره شوند عبارتند از: تعداد مشخص مسیرها (مقدار)، سرعت متوسط اجسام (سرعت)، میانگین مسافت طی شده (فاصله) و اندازهگیریهای کمکی (به عنوان مثال cross_x، cross_y، cross_t) . اندازهگیریهای کمکی تعداد اجسامی را گزارش میکنند که از لبههای فضایی سلول (به عنوان مثال cross_x و cross_y) و زمانی (cross_t) عبور کردهاند.
در Data Warehouse و OLAP مکعب، امکان جمعآوری معیارها در امتداد سلسله مراتب ابعادی (با استفاده از یک تابع تجمعی) برای به دست آوردن اندازهها در دانهبندی درشتتر وجود دارد. این عملیات جمع آوری [ 77 ] نامیده می شود. رویکرد TDW سلولی دارای دو مسئله شناخته شده مربوط به عملیات جمعآوری است. یکی مشکل double_counting است زیرا سلول ممکن است در بیش از یک شهر وجود داشته باشد. این به این دلیل است که بعد سلول یک سلسله مراتب غیرمستقیم [ 34 ] را با موجودیت city_dim تشکیل می دهد . یک راه حل برای این مشکل استفاده از یک ویژگی توزیع در رابطه است که نشان دهنده درصد مقدار تجمیع شده است که به عضو اصلی تخصیص داده می شود (در مثال شکل 3 ، شهر_dim است.موجودیت) [ 2 ]. مشکل دیگر، مسئله شمارش متمایز [ 78 ] نامیده می شود که در مجموع مقداری اندازه گیری در جدول واقعیت در حین عملیات جمع آوری رخ می دهد. اگر با یک Data Warehouse سنتی سر و کار داشتیم، برای بدست آوردن تعداد اجسام متحرک در داخل یک شهر در یک بازه زمانی معین، کافی است تعداد اشیاء درون هر سلول را اضافه کنیم، اما این عملیات در سلولی بی معنی است. TDW، از آنجایی که یک شی ممکن است در طول بازه زمانی از چند سلول عبور کرده باشد. مارکتوس و همکاران [ 38 ] راه حلی برای این مشکل با استفاده از معیارهای کمکی (cross_x، cross_y و cross_t) برای محاسبه تعداد شیء از لبه سلول و در نتیجه تصحیح خطای محاسبه در تجمع اندازه گیری پیشنهاد کرد.مقدار دارایی
Vaisman and Zimányi [ 2 ] و Renso et al. [ 23 ] یک طرح مفهومی از یک TDW مبتنی بر بخش ارائه میکند، که در آن جدول واقعیت شامل بخشهای مسیر و ویژگیهای آنها از جمله: هندسه مسیر قطعه، مسافت طی شده، سرعت و مدت زمان است. شکل 4 نمونه ای از TDW مبتنی بر بخش را نشان می دهد. ابعاد عبارتند از: زمان شروع قطعه، زمان پایان بخش، جسم متحرک و مسیر. در این نوع TDW، Data Warehouse باید از داده های مکانی پشتیبانی کند. علاوه بر این، جدول واقعیت حاوی یک ویژگی فضایی است که به یک بخش (مسیر) اشاره دارد، و موجودیت Trajectory نقطه عزیمت و رسیدن مسیر جغرافیایی را دارد.
یک مسیر را می توان در قسمت هایی با فرمت های مختلف [ 23 ] ساختار داد. به عنوان مثال، برای یک گردشگر، مسیر را می توان به قسمت هایی بر اساس موارد زیر تقسیم کرد:
-
توقف و حرکت؛
-
دوره زمانی مربوط به لحظه موقعیت مکانی-زمانی. مثال: صبح، ظهر، بعد از ظهر، عصر; و
-
دسته بندی منطقه شهر مربوط به موقعیت مکانی-زمانی. مثال: اقامت، گردشگری، تجاری، تفریحی.
جدول 4 TDW تجزیه و تحلیل شده و نحوه گروه بندی آنها را بر اساس نوع طراحی آنها نشان می دهد. لئوناردی و همکاران [ 40 ] تنها موردی است که از دو نوع طراحی استفاده می کند. فراتر از شبکه فضایی منظم، آنها می توانند مسیر را با استفاده از تقسیم سیاسی به عنوان مناطق شهری خلاصه کنند. در [ 40 ]، مسیر را می توان با بخش خیابان نیز خلاصه کرد. قبل از خلاصه کردن مسیر به بخش، یک کار نقشه برداری [ 79 ] ضروری است. بنابراین، می توان اطلاعاتی مانند میانگین سرعت، زمان سفر و بازدید از بخش خیابان را دانست.
4.2. انبار داده مسیر معنایی
به گفته واگنر و همکاران. [ 31 ]، محدودیت اصلی یک سیستم خط سیر استاندارد این واقعیت است که آنها با مسیرهای معنایی سروکار ندارند، بلکه صرفاً با توالی نقاط مکانی-زمانی سروکار دارند. برخی تحقیقات مربوط به مدل STrDW (Semantic Trajectory Data Warehouse) قبلاً پیشنهاد شده است. به عنوان مثال، Manaa و Akaichi [ 44 ] مدلی را توصیف می کنند که به مراحل مهم در فرآیند طراحی DW نزدیک می شود: یکپارچه سازی، طراحی و تجزیه و تحلیل، اما با تأکید بیشتر بر طراحی. چارچوب پیشنهادی در [ 44] داده ها را از منابع ناهمگن در یک هستی شناسی جهانی که قبلا توسط یک متخصص ایجاد شده بود، گروه بندی می کند. هستی شناسی جهانی برای ایجاد یک هستی شناسی چند بعدی با ابعاد، حقایق و معیارها استفاده می شود. این مدل فرعی هستی شناسی، هستی شناسی انبار داده مسیر معنایی نامیده می شود.
سروکار داشتن با داده ها در هستی شناسی ها یا نمودارهای RDF، هنوز دارای برخی مشکلات عملکردی است که زمان قابل توجهی برای اجرا صرف می کند یا باعث وقفه می شود. برای اطمینان از قابلیت استفاده از LOD ها در سیستم های BI، یک فرآیند بهینه سازی برای پشتیبانی از چنین پرسش هایی لازم است. ابراگیموف و همکاران ارائه یک مدل مفهومی از یک مکعب داده مجازی با استفاده از واژگان QB4OLAP [ 80 ]. QB4OLAP یک واژگان RDF است که انتشار داده های چند بعدی را در وب معنایی امکان پذیر می کند [ 81 ]. مکعب داده مجازی در نظر گرفته می شود زیرا داده ها در سیستم محلی ذخیره نمی شوند. هنگام بیان پرس و جو چند بعدی در MDX، سیستم پرس و جوهای SPARQL را مانند یک سیستم فدرال تبدیل و به منابع داده از راه دور ارسال می کند [ 75 ].]. کوئری ها بهینه شده اند تا درخواست های کمتری به نقاط پایانی ارسال شود و عملکرد سیستم را بهبود بخشد. در نهایت، سیستم اطلاعات را در یک ساختار QB4OLAP در حافظه اصلی جمع آوری می کند و مقادیر محاسبه شده و به کاربر بازگردانده می شود.
برخی از STrDW از مدل 5W1H برای نشان دادن مسیرهای معنایی پیروی می کنند ( شکل 5 را ببینید )، که در آن ابعاد سعی می کنند به سؤالات اصلی تحقیق یک واقعیت پاسخ دهند. جدول حقایق شامل اندازهگیریهای مکانی-زمانی برای نمونه ( نمونه ) است. به عنوان مثال، Duration زمان صرف شده بین نمونه فعلی و نقطه قبلی است. فاصله اندازه گیری فاصله بین نمونه فعلی و نمونه قبلی است. نمونه، نقطه فضا-زمان یک جسم (id، x، y، t) را نشان می دهد. یک نمونه متعلق به قسمتی است که می تواند توقف یا حرکت باشدانواع اپیزودهای توقف مانند عناصر مسیری را نشان میدهند که جسم در آن متوقف شده است، در حالی که قسمتهای نوع حرکت نشاندهنده عناصری هستند که جسم در آن در حرکت بوده است. در این سلسله مراتب است که ابعاد Who و Why مدل 5W1H پیدا می شود.
در مثال در شکل 5 ، بعد الگو از داده کاوی برای مرتبط کردن برخی از معنایی مرتبط با مسیر استفاده می کند. علاوه بر این، بعد الگو به نوع و معنایی تقسیم می شود . معناشناسی که با بعد “SemPattern” نشان داده می شود، تفسیر الگوی مسیر را بیان می کند. به عنوان مثال، مجموعه ای از مسیرها را می توان به عنوان یک گروه مسافران در حال حرکت از شمال به شرق تفسیر کرد. بعد Pattern_type الگوی تحرک گروهی از مسیرها را نشان میدهد، یعنی الگوی حرکتی اجسام چگونه است، به عنوان مثال: گله، جریان و خوشه [ 21 ]]. الگو و وسایل حمل و نقل اطلاعاتی را در مورد چگونگی پیمودن مسیر بیان می کند. ابعاد Activity، Time و Space به ترتیب نشان می دهد که اندازه گیری در جدول واقعیت به چه چیزی، چه زمانی و کجا اشاره دارد.
تا به امروز، هیچ برنامه کاربردی قادر به تجزیه و تحلیل عمیق از ویژگی های معنایی مسیرها یافت نشده است. از سوی دیگر، ایده های زیادی در مورد نحوه مدل سازی چنین برنامه هایی وجود دارد. مدلی که تلاش می کند 5W1H را در بر بگیرد چارچوب Baquara [ 32 ] است. این یک چارچوب مفهومی برای تجزیه و تحلیل و غنیسازی دادههای حرکتی است که شامل یک فرآیند سفارشیسازی برای غنیسازی دادههای حرکت معنایی و یک هستیشناسی است که یک مدل مفهومی برای تطبیق دادههای معنایی ارائه میدهد.
مدل دیگری بر اساس مفهوم 5W1H SWOT (Semantic Data Warehouse of Trajectories) است [ 41 ]. SWOT شامل دو لایه است: توافقی و تفسیری. لایه توافقی نشان دهنده جدول واقعیت و سه بعد اصلی است: مکان، زمان و مسیر. لایه تفسیری از اطلاعات توصیفی تشکیل شده است که بخش معنایی مدل را که در بیرونی ترین قسمت مدل مفهومی قرار دارد، یکپارچه می کند. این رویکرد امکان استفاده مجدد از داده های توافقی بین چندین برنامه کاربردی در حوزه های مختلف را فراهم می کند. تغییرات ایجاد شده در داده های تفسیری بر واقعیت ها تأثیر نمی گذارد.
Mob-Warehouse [ 31 ] یک مدل TDW بر اساس چارچوب 5W1H است، که در آن هر بعد از DW مربوط به تلاشی برای پاسخ به یک سوال معنایی است که در شکل 5 توضیح داده شده است. کار واگنر [ 31 ] یک مدل STrDW را با استفاده از هستی شناسی ها توصیف می کند و چارچوبی را ارائه می دهد که داده های ناهمگن از چندین منبع داده را در هستی شناسی به نام هستی شناسی مسیر معنایی عمومی ادغام می کند. این هستیشناسی تلاش میکند شی متحرک، محیط جغرافیایی درگیر، فعالیتهای انجامشده، حرکت شی، و معنایی زیرمجموعهها را توصیف کند.
در جدول 5 مشاهده می شود که بسیاری از آثار فقط مدل های مفهومی ( ستون نوع ) به ویژه تحقیقات STrDW هستند. جدول 5 همچنین سیستم های هر دو سطح عملیات و STrDW و نوع اطلاعات معنایی را که هر کدام مطابق مدل 5W1H نشان می دهد، ارائه می دهد. شاید عجیب به نظر برسد که سیستم هایی که با مسیرهای معنایی سروکار دارند، پارامتر When مدل 5W1H را برآورده نمی کنند . با این حال، این پارامتر بسیار بیشتر از یک تاریخ ساده در تقویم را نشان می دهد. این پارامتر به اطلاعات معنایی مرتبط با تاریخ در تقویم، مانند تعطیلات آخر هفته، تاریخ های سالگرد، تعطیلات و تاریخ های یادبود اشاره دارد.
5. تحلیل داده های مسیر
به طور فزاینده ای، برنامه هایی که حجم زیادی از داده ها را مدیریت می کنند، برخی تحلیل ها را انجام می دهند. تجزیه و تحلیل علم یا روشی است که برای بررسی چیزهای پیچیده استفاده می شود. هنگامی که تجزیه و تحلیل برای داده ها اعمال می شود، فرآیند استخراج دانش و بینش از آنها است [ 82 ]. مرحله تجزیه و تحلیل شامل بهره برداری از داده های خلاصه شده DW است. از آنجایی که هدف مطالعه، داده های مسیر، یعنی اطلاعات مکانی است، طبیعی است که از سیستم های اطلاعات جغرافیایی برای تحلیل و مشاهده داده ها استفاده شود.
ابزارهای تجزیه و تحلیل همچنین می توانند مستقیماً منابع داده دیگر را در فرآیندی به نام ETQ جستجو کنند. در این فرآیند، داده ها بر حسب تقاضا و به صورت مجازی در لحظه پرس و جو تبدیل می شوند. برخی از تحقیقات پیشنهادی از ETQ برای پرس و جوی معنایی داده های باز پیوندی [ 80 ] و برای گسترش ابعاد مکعب OLAP [ 83 ] استفاده می کنند. تجزیه و تحلیل داده های مرسوم و ادغام وب معنایی در یک سیستم BI منجر به یک دسته ابزار تجزیه و تحلیل جدید به نام OLAP اکتشافی [ 35 ] می شود. علاوه بر این، اغلب لازم است از یک ابزار OLAP با قابلیتهای فضایی، معروف به SOLAP (Spatial OLAP) استفاده شود [ 84 ]] زیرا داده های مسیر دارای اطلاعات جغرافیایی هستند. اگر ابزار تحلیلی داده های معنایی، داده های مکانی، داده های نیمه ساختار یافته و ساختار یافته را یکپارچه کند، ExpSOLAP [ 85 ] نامیده می شود.
با توجه به [ 82 ]، سیستم های تحلیلی را می توان به پنج نوع طبقه بندی کرد:
-
توصیفی: قادر به پاسخگویی به سوالاتی مانند “چه اتفاقی افتاده است؟” این سیستم ها فقط می توانند داده های خام جمع آوری شده را توصیف، خلاصه یا ارائه دهند. داده ها رمزگشایی می شوند، در یک زمینه تفسیر می شوند و سپس در قالب نمودارها، گزارش ها، آمار و غیره ارائه می شوند.
-
تشخیصی: سعی کنید بفهمید چرا چیزی در حال رخ دادن است.
-
کشف: سعی کنید به این سوال پاسخ دهید که چه اتفاقی افتاده است که هنوز مشخص نیست. برای این، استنباط اطلاعات غیر پیش پا افتاده، استدلال یا تکنیک های تشخیص به داده های خام اعمال می شود.
-
پیش بینی کننده: سعی کنید به این سوال پاسخ دهید که “احتمال دارد چه اتفاقی بیفتد؟”. برای انجام این کار، آنها از داده ها و دانش گذشته برای پیش بینی نتایج آینده و ارائه روش هایی برای ارزیابی کیفیت این پیش بینی ها استفاده می کنند.
-
تجویزی: سعی کنید این سوال را تجزیه و تحلیل کنید که در مورد آنچه اتفاق افتاده یا احتمال دارد چه کاری باید انجام شود.
با استفاده از VATookit میتوانیم تکامل زمانی سلولهای تقسیمکننده نقشه را ببینیم. برای هر سلول، یک مثلث اندازه گیری اختصاص داده می شود که تعداد اجسام و سرعت متوسط اشیاء درون یک سلول را نشان می دهد. بنابراین، می توان بر اساس ارتفاع و عرض مثلث ها، مناطق بالقوه تراکم را در نقشه پی برد. شکل 6 یک مثال گویا را نشان می دهد که نشان می دهد چگونه نگاشت مسیرها را می توان به سلول ها تقسیم کرد. انواع دیگری از تجزیه و تحلیل را می توان استفاده کرد، مانند نمودار دایره ای یا نمودار میله ای.
از سوی دیگر، رنسو و همکاران. [ 23 ] نوعی تجسم به نام نمودار زمانی را نشان می دهد که تکامل ترافیک را در طول هفته که از یکشنبه شروع می شود و در روز شنبه پایان می یابد، نشان می دهد. هر منحنی در نمودار مربوط به تعداد اشیاء در یک سلول در شبکه است. رنسو و همکاران [ 23 ] با نمودار زمان نشان می دهد که ترافیک شهر میلان (ایتالیا) در روز افزایش می یابد و در شب کاهش می یابد. در آخر هفته ترافیک کمتر از روزهای دیگر است.
برای TDW های مبتنی بر بخش، بسته به نحوه طراحی DW، هر مسیر را می توان به صورت جداگانه تجزیه و تحلیل کرد. در آندرینکو و آندرینکو، شکلی تحلیلی از جنبش به نام “دیدگاه چشم پرنده در مورد حرکت در زمینه” توصیف شده است [ 17 ].]. در آن نوع تحلیل، از تعمیم و تجمیع برای کشف الگوهای مکانی-زمانی استفاده می شود. دو نوع تحلیل در این دسته وجود دارد: بررسی تغییرات حضور اجسام متحرک در مکانهای مختلف مکان و زمان، و بررسی جریان اجسام بین مکانهای فضایی. برای تجزیه و تحلیل حضور شی متحرک، از نقشه چگالی استفاده می شود که در آن مناطق پربازدید با رنگ های تیره تر و مناطق کمتر بازدید شده با رنگ های روشن تر رنگ آمیزی شده اند. حضور جسم متحرک در یک مکان در طول یک بازه زمانی را می توان بر حسب تعداد اشیاء مختلفی که از آن مکان بازدید کرده اند و کل زمان سپری شده در آن مکان مشخص کرد [ 17 ].]. تجزیه و تحلیل حرکت را می توان با استفاده از یک نقشه جریان انجام داد که در آن مسیرهای مشابه را می توان جمع کرد. گاهی اوقات، در نظر گرفتن یک مسیر مشابه برای نقشه جریان به این معنی نیست که مسیرها یکسان هستند، بلکه مبدأ و مقصد یکسانی دارند.
تمام سیستم های ارائه شده در این مقاله تنها یک تحلیل توصیفی از مسیرها را انجام می دهند. یعنی آنها فقط تاریخچه داده ها را از طریق گزارش ها، نمودارها، جداول و غیره نشان می دهند. انجام انواع دیگر تجزیه و تحلیل هنوز یک چالش بزرگ است. STrDW یک حوزه جدید در علوم کامپیوتر است و نیاز به کار بیشتری دارد که عمدتاً شامل پنج نوع سیستم تحلیلی است.
6. Challenges in Big Data را برای Trajectory Analytics باز کنید
تحقیقات در مورد داده های خط سیر خام بسیار پیشرفته است. چندین مقاله وجود دارد که فرآیندهای فشرده سازی، نمایه سازی، اندازه گیری شباهت و ذخیره سازی مسیر را توصیف می کند [ 86 ]. ما در سالهای اخیر نیاز به ذخیرهسازی و جستجوی بزرگ دادههای مسیر حرکت بزرگ را درک کردیم.
کارهای ذخیرهسازی مسیرهای مختلف از پایگاههای داده مکانی استفاده میکنند و این پایگاههای داده را با دادههای مکانی-زمانی تطبیق میدهند [ 42 ، 46 ، 47 ]. در میان مقالات تجزیه و تحلیل شده، فقط داده های جغرافیایی درمان زمانی دریافت می کنند، اما سایر ویژگی های جسم متحرک ممکن است در طول زمان علاوه بر موقعیت جغرافیایی تغییر کند. DMBS به عنوان SECONDO و Temporal PostgreSQL + PostGIS [ 81 ] اجازه می دهد تا انواع زمانی را با هر دو نوع جغرافیایی و اولیه مرتبط کند. گسترش این قابلیت به فناوریهای دادههای بزرگ فضایی میتواند به افزایش قدرت بیان مسیر و سادهسازی پرسوجوهای زمانی مانند لحظه زمانی، دوره و سرعت کمک کند.
اکثر اجسام متحرک با استفاده از نمادهای نقطه نمایش داده می شوند زیرا اندازه اکثر اشیاء نظارت شده در مقایسه با مقیاس نقشه منطقه ای، قاره ای یا حتی جهانی ناچیز است. شاید رویکردی که تغییرات شکل برخی از اجسام متحرک را برای مدت طولانی، نه تنها مسیر حرکت، رصد میکند، بتواند به درک رفتار و پیشبینی رویدادهای آینده، مانند طوفان، لکههای نفتی دریا، گلهها، سؤالات رودخانهای و فرسایش کمک کند.
روند جدید در سیستم های خط سیر، تعبیه داده های معنایی در اطلاعات جمع آوری شده است [ 29 ]. با این حال، فرآیند ساخت مسیرهای معنایی انبار داده هنوز فاقد تحقیقات عمیق تر است. در زمینه مدلسازی مفهومی باقی می ماند زیرا گرفتن اطلاعات از بافت کاربر به روشی شفاف، بدون اینکه کاربر برای اطلاع رسانی سیستم در مورد زمینه فعلی آن مورد آزار و اذیت قرار گیرد، یک کار غیر ضروری است. از طریق تجزیه و تحلیل بافت جغرافیایی حرکت و استفاده از تکنیک های داده کاوی [ 72 ]، می توان رفتار اشیاء را برای پاسخ به سؤالات اساسی مدل 5W1H کشف یا استنباط کرد. همه این اطلاعات خلاصه شده ممکن است انبار داده مسیر معنایی را تشکیل دهند.
ساخت STrDW برای داده های بزرگ نه تنها به دلیل حجم اطلاعات، بلکه به دلیل تنوع گسترده داده ها، هنوز یک چالش است. به طور مشابه، یک سرور SOLAP که از داده های بزرگ پشتیبانی می کند هنوز در دست مطالعه است. ابزار Apache Kylin ( https://kylin.apache.org/ ) یک سرور OLAP برای Big Data است، اما همچنان فاقد گسترش فضایی است. Keskin و Yazici [ 87 ] یک معماری برای یک سرور OLAP مکانی-زمانی برای داده های بزرگ پیشنهاد می کنند. با این حال، مطالعات فعلی بیشتر بر روی دادههای هواشناسی تمرکز میکنند و نیاز به تطبیق معماری با دادههای مسیر دارند.
مرحله تجزیه و تحلیل توصیف شده در این نظرسنجی شامل اکتشاف داده های خلاصه شده DW است. با توجه به نوع ابزار تحلیلی، اکثر TDW ها فقط نوع تحلیل توصیفی را ارائه می دهند. برخی از برنامهها میتوانند مقصد کاربر یا هدف سفر او را بر اساس تاریخچه یا اطلاعات به جا مانده در رسانههای اجتماعی پیشبینی کنند، اما یک سیستم Analytics که دلیل رفتار مجموعهای از مسیرها، تأثیر آن رفتار و آنچه باید باشد را استنباط میکند. انجام شده هنوز مسائل باز در زمینه تحقیقات TDW هستند.
موضوع بسیار مهم دیگری که باید در تحقیق مسیرها مورد توجه قرار گیرد، مربوط به حریم خصوصی کاربر است [ 11 ، 13 ]. برخی از کارهای خط سیر می توانند به ایمنی جامعه کمک کنند، مانند تشخیص ناهنجاری ها، آدم ربایی ها، توقف های غیرمنتظره [ 11 ، 88 ]، اما مردم تا چه حد حاضرند حریم خصوصی خود را به دلایل امنیتی قربانی کنند؟ یک سازمان، دولتی یا خصوصی، ممکن است از یک سیستم نظارت فردی به نفع یا علیه خود شهروند استفاده کند. برای مثال، آثار [ 89 ] و [ 90 ] از تکنیکهای حفظ حریم خصوصی برای برخورد با دادههای مسیر استفاده میکنند.
7. ملاحظات نهایی
هدف این بررسی گردآوری چندین تحقیق در انبار داده های مسیر داده بزرگ از دیدگاه سیستم های OLAP است. در نتیجه، کارهای پژوهشی مورد بحث در مراحل زیر دسته بندی و ارزیابی شدند: ادغام، طراحی و تحلیل. مرحله یکپارچه سازی مربوط به مرحله جمع آوری و ذخیره داده های خط سیر خام است. مرحله طراحی شامل فرآیند ETL و ساخت TDW است. مرحله تجزیه و تحلیل مربوط به بررسی پیچیدگی داده ها با استفاده از منابع مختلف مانند جداول، نقشه ها، نمودارها و گزارش ها است.
مرحله جدید در تکامل سیستم های مسیری، جفت کردن اطلاعات متنی با داده ها، و در نتیجه، غنی سازی معنایی مسیر است. آثار اولیه سعی داشتند با چسباندن یک برچسب اطلاعاتی به مسیر، مسیر را غنی کنند. با پیشرفت تحقیقات در این زمینه، آثار بیشتری بر اساس مدل 5W1H پدید آمده است. این مدل همان است که گزارش ژورنالیستی را در توصیف واقعیت راهنمایی میکند و اکنون میتواند به غنیسازی مسیر شیء متحرک کمک کند. در حال حاضر، چالش جدید تنها استفاده از مدل 5W1H نیست، بلکه هرگونه اطلاعات شی متحرک و اطلاعات زمینه برای غنیسازی معنایی مسیر است. چنین اطلاعاتی را می توان با حسگرهایی مانند ضربان قلب، دما، نویز، روشنایی و غیره به دست آورد.
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| AIS | سیستم شناسایی خودکار |
| BI | هوش تجاری |
| DBMS | سیستم های مدیریت پایگاه داده |
| DP | داگلاس-پوکر |
| DSSP | بستر پشتیبانی از فضای داده |
| DW | پایگاه داده تحلیلی |
| ETL | استخراج، تبدیل و بارگذاری |
| ETQ | استخراج، تبدیل، پرس و جو |
| ExpSOLAP | SOLAP اکتشافی |
| جی پی اس | سیستم موقعیت یاب جهانی |
| GRASP-SemTS | GRASP برای تقسیمبندی مسیر نیمهنظارتشده |
| GRASP-UTS | روش جستجوی تطبیقی تصادفی حریصانه برای مسیر بدون نظارت |
| تقسیم بندی | |
| کلوب جی اس ام | سیستم جهانی ارتباطات سیار |
| HDFS | سیستم فایل توزیع شده Hadoop |
| ISO | سازمان بین المللی استاندارد سازی |
| LOD | داده های باز پیوند داده شده |
| MDX | بیان داده های چند بعدی |
| وزارت دفاع | در حال حرکت پایگاه داده شی |
| NoSQL | نه تنها SQL |
| OLAP | پردازش تحلیلی آنلاین |
| ORDBMS | DBMS شی – رابطه ای |
| RDD | ResilientDistributed Dataset |
| RDF | چارچوب شرح منابع |
| RFID | شناسایی فرکانس رادیویی |
| SDBMS | سیستم های مدیریت پایگاه داده های مکانی |
| SOLAP | فضایی OLAP |
| SPARQL | پروتکل SPARQL و زبان پرس و جو RDF |
| SQL | مخفف Structured Query Language است |
| STrDW | انبار داده مسیر معنایی |
| TD-TR | نسبت زمانی بالا به پایین |
| TDW | انبارهای داده مسیر |
| VGI | اطلاعات جغرافیایی داوطلبانه |
منابع
- ژنگ، ی. داده کاوی مسیر: مروری. ACM Trans. هوشمند سیستم تکنولوژی 2015 ، 6 ، 29. [ Google Scholar ] [ CrossRef ]
- وایسمن، ا. Zimányi, E. طراحی انبار داده مفهومی. در سیستم های انبار داده ; Springer: برلین، آلمان، 2014; صص 89-119. [ Google Scholar ]
- بوگورنی، وی. رنسو، سی. د آکینو، آر. د لوکا سیکیرا، اف. Alvares، LO Constant-یک مدل داده مفهومی برای مسیرهای معنایی اجسام متحرک. ترانس. GIS 2014 ، 18 ، 66-88. [ Google Scholar ] [ CrossRef ]
- Kolovson، CP; نعمت، کارشناسی ارشد; Potamianos، S. قابلیت همکاری مدیران داده های فضایی و ویژگی: مطالعه موردی . Springer: برلین، آلمان، 1993; جلد 692، ص 239–263. [ Google Scholar ]
- خو، جی. Güting، RH یک مدل داده عمومی برای اجسام متحرک. GeoInformatica 2013 ، 17 ، 125-172. [ Google Scholar ] [ CrossRef ]
- جین، ایکس. Wah، BW; چنگ، ایکس. وانگ، ی. اهمیت و چالش های تحقیقات کلان داده. کلان داده Res. 2015 ، 2 ، 59-64. [ Google Scholar ] [ CrossRef ]
- جی، م. بانگی، اچ. بوهنووا، بی. داده های بزرگ برای اینترنت اشیا: یک نظرسنجی. ژنرال آینده. محاسبه کنید. سیستم 2018 ، 87 ، 601-614. [ Google Scholar ] [ CrossRef ]
- شکر، س. گونتوری، وی. ایوانز، ام آر. یانگ، ک. چالش های فضایی بیگ داده متقاطع تحرک و محاسبات ابری. در مجموعه مقالات یازدهمین کارگاه بین المللی ACM در مورد مهندسی داده برای دسترسی بی سیم و موبایل، اسکاتسدیل، AZ، ایالات متحده آمریکا، 20 مه 2012. صص 1-6. [ Google Scholar ]
- Bédard، Y.; ریست، اس. Proulx، MJ Spatial Online Analytical Processing (SOLAP): مفاهیم، معماری ها و راه حل ها از دیدگاه مهندسی ژئوماتیک. در انبارهای داده و OLAP: مفاهیم، معماری و راهکارها . IGI Global: Pittsburgh, PA, USA, 2007; صص 298-319. [ Google Scholar ]
- پدر و مادر، سی. اسپاکاپیترا، اس. رنسو، سی. آندرینکو، جی. آندرینکو، ن. بوگورنی، وی. دامیانی، ام.ال. گکولالاس-دیوانیس، ع. مکدو، جی. پلکیس، ن. و همکاران مدلسازی و تحلیل مسیرهای معنایی. کامپیوتر ACM. Surv. 2013 ، 45 ، 42. [ Google Scholar ] [ CrossRef ]
- کنگ، ایکس. لی، ام. ما، ک. تیان، ک. وانگ، ام. نینگ، ز. Xia، F. داده های مسیر بزرگ: بررسی برنامه ها و خدمات. دسترسی IEEE 2018 ، 6 ، 58295–58306. [ Google Scholar ] [ CrossRef ]
- بیان، جی. تیان، دی. تانگ، ی. تائو، دی. بررسی بر روی تحلیل خوشهبندی مسیر. arXiv 2018 , arXiv:1802.06971. [ Google Scholar ]
- فنگ، ز. زو، ی. نظرسنجی در مسیر داده کاوی: تکنیک ها و کاربردها. IEEE Access 2016 ، 4 ، 2056-2067. [ Google Scholar ] [ CrossRef ]
- الصحفی، ت. المطیری، م. الماسری، ر. نظرسنجی در مسیر انبار داده. تف کردن Inf. Res. 2019 ، 28 ، 1-14. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فیلتو، ر. رافائتا، ا. رونکاتو، ا. ساسنتی، ج.ا. می، سی. کلاین، دی. مدل معنایی برای انبارهای داده حرکت. در مجموعه مقالات هفدهمین کارگاه بین المللی ذخیره سازی داده و OLAP، شانگهای، چین، نوامبر 2014. ص 47-56. [ Google Scholar ]
- ناردینی، اف.ام. اورلاندو، اس. پرگو، آر. رافائتا، ا. رنسو، سی. سیلوستری، سی. تحلیل مسیرهای کاربران موبایل: از انبارهای داده تا سیستمهای توصیهکننده. در یک راهنمای جامع از طریق تحقیقات بانک اطلاعاتی ایتالیا در 25 سال گذشته ؛ Springer: برلین، آلمان، 2018; ص 407-421. [ Google Scholar ]
- آندرینکو، NV; Andrienko, GL Visual Analytics of Movement: A Rich Palette of Techniques to Enable Understanding 2013. در دسترس آنلاین: https://www.cambridge.org/core/books/mobility-data/visual-analytics-of-movement-a-rich -palette-of-techniques-to-enable-denderstanding/D8CF79BD836291437ED501B4965498B8 (دسترسی در 31 ژانویه 2020).
- اعتماد، م. جونیور، ع. حسینی، ع. رز، جی. متوین، اس. الگوریتم تقسیمبندی مسیر بر اساس استراتژیهای تشخیص تغییر مبتنی بر درونیابی. کارگاه های آموزشی EDBT/ICDT. 2019. در دسترس آنلاین: https://ceur-ws.org/Vol-2322/BMDA_4.pdf (در 31 ژانویه 2020 قابل دسترسی است).
- سوآرس جونیور، آ. مورنو، BN; تایمز، وی سی. ماتوین، اس. Cabral، LdAF GRASP-UTS: الگوریتمی برای تقسیمبندی مسیر بدون نظارت. بین المللی جی. جئوگر. Inf. علمی 2015 ، 29 ، 46-68. [ Google Scholar ] [ CrossRef ]
- جونیور، ع. تایمز، وی سی. رنسو، سی. ماتوین، اس. کابرال، لس آنجلس یک رویکرد نیمه نظارت شده برای تقسیم بندی معنایی مسیرها. در مجموعه مقالات نوزدهمین کنفرانس بین المللی IEEE در مدیریت داده های تلفن همراه (MDM) 2018، آلبورگ، دانمارک، 28 ژوئن 2018؛ صص 145-154. [ Google Scholar ]
- Goodchild، MF Citizens as Sensors: The World of Volunteered Geography. ژئوژورنال 2007 ، 69 ، 211-221. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گرانل، سی. Shade، S. Hobona، G. دادههای مرتبط: زیرساختهای دادههای مکانی و اطلاعات جغرافیایی داوطلبانه را به هم متصل میکند. در خدمات وب جغرافیایی: پیشرفت در قابلیت همکاری اطلاعات ; IGI Global: Pittsburgh, PA, USA, 2011; ص 189-226. [ Google Scholar ]
- رنسو، سی. اسپاکاپیترا، اس. Zimányi, E. Mobility Data ; انتشارات دانشگاه کمبریج: کمبریج، MA، ایالات متحده آمریکا، 2013. [ Google Scholar ]
- ژنگ، ی. Xie, X. همبستگی مکان یادگیری از مسیرهای GPS. در مجموعه مقالات یازدهمین کنفرانس بین المللی 2010 در مدیریت داده های تلفن همراه، کانزاس سیتی، MO، ایالات متحده آمریکا، 21 ژوئن 2010. [ Google Scholar ]
- کروم، جی. Horvitz, E. Predestination: Inferring Destinations from Partial Trajectories ; Springer: برلین، آلمان، 2006; ص 243-260. [ Google Scholar ]
- یان، ز. چاکرابورتی، دی. پدر و مادر، سی. اسپاکاپیترا، اس. Aberer, K. SeMiTri: چارچوبی برای حاشیه نویسی معنایی مسیرهای ناهمگن. در مجموعه مقالات چهاردهمین کنفرانس بین المللی گسترش فناوری پایگاه داده، اوپسالا، سوئد، 21 مارس 2011; صص 259-270. [ Google Scholar ]
- اسپاکاپیترا، اس. پدر و مادر، سی. دامیانی، ام.ال. de Macedo، JA; پورتو، اف. وانگنوت، سی. دیدگاه مفهومی در مسیرها. دانستن داده ها مهندس 2008 ، 65 ، 126-146. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اسپاکاپیترا، اس. پدر و مادر، سی. افزودن معنی به قدم های شما . Springer: برلین، آلمان، 2011; صص 13-31. [ Google Scholar ]
- Laube, P. The Low Hanging Fruit Gone: Achievements and Challenges of Computational Movement Analysis. مشخصات SIGSPATIAL 2015 ، 7 ، 3-10. [ Google Scholar ] [ CrossRef ]
- نابو، آر جی. فیلتو، ر. نانی، م. Renso, C. حاشیه نویسی مسیرها با ترکیب آنها با پست های کاربران رسانه های اجتماعی. در مجموعه مقالات پانزدهمین سمپوزیوم برزیل در زمینه ژئوانفورماتیک (GeoInfo)، Campos do Jordão، برزیل، 29 نوامبر 2014; صص 25-36. [ Google Scholar ]
- واگنر، آر. de Macedo، JAF; رافائتا، ا. رنسو، سی. رونکاتو، ا. Trasarti, R. Mob-Warehouse: A Semantic Approach for Mobility Analysis with a Trajectory Data Warehouse ; Springer: برلین، آلمان، 2013; صص 127-136. [ Google Scholar ]
- فیلتو، ر. می، سی. رنسو، سی. پلکیس، ن. کلاین، دی. Theodoridis, Y. چارچوب مبتنی بر دانش Baquara2 برای غنی سازی معنایی و تجزیه و تحلیل داده های حرکت. دانستن داده ها مهندس 2015 ، 98 ، 104-122. [ Google Scholar ] [ CrossRef ]
- Mello، RdS; بوگورنی، وی. آلوارس، لو. سانتانا، LHZ؛ فررو، کالیفرنیا؛ فروزا، AA; شراینر، GA; Renso, C. MASTER: Aspect Aspect View در مسیرها. ترانس. GIS 2019 ، 23 ، 805-822. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مالینوفسکی، ای. Zimanyi, E. طراحی انبار داده پیشرفته-از کاربردهای معمولی تا مکانی و زمانی . سیستم ها و برنامه های داده محور؛ Springer: برلین، آلمان، 2008. [ Google Scholar ] [ CrossRef ]
- آبلو، ا. رومرو، او. پدرسن، سل؛ برلانگا، آر. Nebot، V. آرامبورو، ام جی; Simitsis، A. استفاده از فناوری های وب معنایی برای OLAP اکتشافی: یک بررسی. IEEE Trans. بدانید. مهندسی داده 2014 ، 27 ، 571-588. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- براز، اف جی. Orlando, S. Trajectory Data Warehouses: Proposal of Design and Application to Exploit Data. GeoInfo 2007 ، 9 ، 61-72. [ Google Scholar ]
- اورلاندو، اس. اورسینی، ر. رافائتا، ا. رونکاتو، ا. Silvestri, C. Trajectory Data Warehouses: Design and Implementation Issues. جی. کامپیوتر. علمی مهندس 2007 ، 1 ، 211-232. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مارکتوس، جی. فرنتزوس، ای. نتوتسی، آی. پلکیس، ن. رافائتا، ا. تئودوریدیس، ی. ساخت انبارهای مسیری در دنیای واقعی. در مجموعه مقالات هفتمین کارگاه بین المللی ACM در مورد مهندسی داده برای دسترسی بی سیم و موبایل، ونکوور، BC، کانادا، 13 ژوئن 2008. صص 8-15. [ Google Scholar ]
- لئوناردی، ال. مارکتوس، جی. فرنتزوس، ای. جیاتراکوس، ن. اورلاندو، اس. پلکیس، ن. رافائتا، ا. رونکاتو، ا. سیلوستری، سی. تئودوریدیس، Y. T-warehouse: تحلیل اولاپ بصری بر روی داده های مسیر. در مجموعه مقالات بیست و ششمین کنفرانس بین المللی مهندسی داده IEEE در سال 2010 (ICDE 2010)، لانگ بیچ، کالیفرنیا، ایالات متحده؛ 2010; صص 1141-1144. [ Google Scholar ]
- لئوناردی، ال. اورلاندو، اس. رافائتا، ا. رونکاتو، ا. سیلوستری، سی. آندرینکو، جی. آندرینکو، ن. چارچوبی کلی برای ذخیرهسازی دادههای مسیری و OLAP بصری. GeoInformatica 2014 ، 18 ، 273-312. [ Google Scholar ] [ CrossRef ]
- سیلوا، MCT; تایمز، وی سی. de Macêdo، JA; Renso، C. SWOT: مدل مفهومی انبار داده برای مسیرهای معنایی. در مجموعه مقالات هجدهمین کارگاه بین المللی ACM در مورد ذخیره سازی داده و OLAP، ملبورن، VIC، استرالیا، 19 اکتبر 2015. صص 11-14. [ Google Scholar ]
- بائو، جی. لی، آر. یی، ایکس. ژنگ، ی. مدیریت مسیرهای عظیم در ابر. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، برلینگیم، کالیفرنیا، ایالات متحده آمریکا، اکتبر 2016؛ پ. 41. [ Google Scholar ]
- گالیچ، ز. جریانهای دادههای مکانی-زمانی و پارادایم دادههای بزرگ. در جریانهای دادههای مکانی-زمانی ؛ Springer: Barlin، آلمان، 2016; صص 47-69. [ Google Scholar ]
- منا، م. Akaichi، J. مدل مفهومی انبار داده مسیری مبتنی بر هستی شناسی ; Springer: برلین، آلمان، 2016; صص 329-342. [ Google Scholar ]
- سوآرس جونیور، آ. رنسو، سی. Matwin, S. ANALYTiC: یک سیستم یادگیری فعال برای طبقه بندی مسیر. محاسبات IEEE. نمودار. Appl. 2017 ، 37 ، 28-39. [ Google Scholar ] [ CrossRef ]
- ژانگ، ز. جین، سی. مائو، جی. یانگ، ایکس. Zhou، A. Trajspark: یک سیستم مدیریت حافظه مقیاس پذیر و کارآمد برای داده های مسیر بزرگ ؛ Springer: برلین، آلمان، 2017; صص 11-26. [ Google Scholar ]
- اعرابی، ل. موکبل، MF; Musleh, M. St-hadoop: A Framework Mapreduce for Spatio-Temporal Data. GeoInformatica 2018 ، 22 ، 785-813. [ Google Scholar ] [ CrossRef ]
- دیویدینو، آر. سوآرس، آ. ماتوین، اس. ایزنور، AW؛ وب، اس. Brousseau، M. ادغام معنایی جریانهای داده ناهمگن زمان واقعی برای تصمیمگیری مرتبط با اقیانوس. مصنوع داده های بزرگ. هوشمند Mil. تصمیم می گیرد. ماک STO 2018 . [ Google Scholar ] [ CrossRef ]
- نیکیتوپولوس، پی. ولاچو، ع. دولکریدیس، سی. Vouros، GA DiStRDF: پرس و جوهای RDF فضایی-زمانی توزیع شده در Spark. در مجموعه مقالات کارگاه های آموزشی EDBT/ICDT، وین، اتریش، 26 مارس 2018؛ صص 125-132. [ Google Scholar ]
- سوآرس، آ. رز، جی. اعتماد، م. رنسو، سی. ماتوین، اس. ویستا: بستر تجزیه و تحلیل بصری برای حاشیه نویسی معنایی مسیرها. در مجموعه مقالات بیست و دومین کنفرانس بین المللی گسترش فناوری پایگاه داده (EDBT)، لیسبون، پرتغال، 26 مارس 2019؛ صص 570-573. [ Google Scholar ]
- جورجیو، اچ. کاراگیورگو، اس. کنتولیس، ی. پلکیس، ن. پترو، پ. اسکارلاتی، دی. تئودوریدیس، ی. تجزیه و تحلیل اشیاء متحرک: بررسی روشهای پیشبینی مکان و مسیر آینده. arXiv 2018 , arXiv:1807.04639. [ Google Scholar ]
- ژنگ، ی. ژو، X. محاسبات با مسیرهای فضایی . Springer Science & Business Media: برلین، آلمان، 2011. [ Google Scholar ]
- مراتنیا، ن. Rolf, A. تکنیک های فشرده سازی فضایی و زمانی برای اجسام نقطه متحرک . Springer: برلین، آلمان، 2004; صص 765-782. [ Google Scholar ]
- پوتامیاس، م. پاترومپاس، ک. سلیس، تی. نمونهبرداری از جریانهای مسیر با معیارهای مکانی-زمانی. در مجموعه مقالات هجدهمین کنفرانس بین المللی مدیریت پایگاه داده های علمی و آماری (SSDBM’06)، وین، اتریش، 3 تا 5 ژوئیه 2006. صص 275-284. [ Google Scholar ]
- لی، جی جی; کانگ، ام. داده های بزرگ جغرافیایی: چالش ها و فرصت ها. بیگ دیتا Res. 2015 ، 2 ، 74-81. [ Google Scholar ] [ CrossRef ]
- بارو، PA; مک دانل، آر. مک دانل، RA; Lloyd, CD Principles of Geographical Information Systems ; انتشارات دانشگاه آکسفورد: آکسفورد، بریتانیا، 2015. [ Google Scholar ]
- اسمیت، تی آر. منون، اس. ستاره، JL; Estes، JE الزامات و اصول برای پیاده سازی و ساخت سیستم های اطلاعات جغرافیایی در مقیاس بزرگ. بین المللی جی. جئوگر. Inf. سیستم 1987 ، 1 ، 13-31. [ Google Scholar ] [ CrossRef ]
- گالیچ، ز. مشکوویچ، ای. Osmanović، D. پردازش توزیع شده داده های تحرک بزرگ به عنوان جریان داده های مکانی-زمانی. Geoinformatica 2017 ، 21 ، 263-291. [ Google Scholar ] [ CrossRef ]
- فرانکلین، ام. هالیوی، ا. Maier, D. از پایگاه داده تا فضاهای داده: چکیده ای جدید برای مدیریت اطلاعات. ACM Sigmod Rec. 2005 ، 34 ، 27-33. [ Google Scholar ] [ CrossRef ]
- فرانکلین، ام. هالیوی، ا. Maier, D. A First, Tutorial on Dataspaces. Proc. VLDB Enddow. 2008 ، 1 ، 1516-1517. [ Google Scholar ] [ CrossRef ]
- هالیوی، ا. فرانکلین، ام. Maier, D. اصول سیستم های فضای داده. در مجموعه مقالات بیست و پنجمین سمپوزیوم ACM SIGMOD-SIGACT-SIGART در اصول سیستم های پایگاه داده، شیکاگو، IL، ایالات متحده آمریکا، 27 ژوئن 2006. صفحات 1-9. [ Google Scholar ]
- سازمان بین المللی استاندارد سازی. ISO 19108 اطلاعات جغرافیایی — طرح واره زمانی ; ISO/TC 211, I; سازمان بین المللی استانداردسازی: ژنو، سوئیس، 2002. [ Google Scholar ]
- سازمان بین المللی استاندارد سازی. ISO 19107 اطلاعات جغرافیایی — طرح واره فضایی ; ISO/TC 211, I; سازمان بین المللی استانداردسازی: ژنو، سوئیس، 2003. [ Google Scholar ]
- کربن، پ. کاتسیفودیموس، ا. ایون، اس. مارکل، وی. حریدی، س. Tzoumas، K. Apache flink: Stream and Batch Processing in a Single Engine. گاو نر محاسبات IEEE. Soc. فنی Comm. مهندسی داده 2015 ، 36 ، 28-38. [ Google Scholar ]
- مرز، ن. وارن، جی. دادههای بزرگ: اصول و بهترین روشهای مقیاسپذیر سیستمهای داده بلادرنگ ؛ منینگ انتشارات شرکت: نیویورک، نیویورک، ایالات متحده آمریکا، 2015; پ. 328. [ Google Scholar ]
- لنکا، RK; باریک، RK; گوپتا، ن. علی، س.م. راث، ا. Dubey، H. تجزیه و تحلیل مقایسه ای SpatialHadoop و GeoSpark برای تجزیه و تحلیل داده های بزرگ جغرافیایی. در مجموعه مقالات دومین کنفرانس بین المللی 2016 در محاسبات و انفورماتیک معاصر (IC3I)، نویدا بزرگ، هند، 14 تا 17 دسامبر 2016؛ ص 484-488. [ Google Scholar ]
- مارکو، OC; کوستان، ا. آنتونیو، جی. پرز-هرناندز، MS Spark در مقابل Flink: درک عملکرد در چارچوب های تجزیه و تحلیل داده های بزرگ. در مجموعه مقالات کنفرانس بین المللی IEEE 2016 در محاسبات خوشه ای (CLUSTER)، پکن، چین، 24-28 سپتامبر 2012. صص 433-442. [ Google Scholar ]
- پلکیس، ن. تئودوریدیس، ی. ووسیناکیس، اس. پانایوتوپولوس، تی. هرمس – چارچوبی برای مدیریت داده مبتنی بر مکان . Springer: برلین، آلمان، 2006; صص 1130–1134. [ Google Scholar ]
- سانتانا، LHZ؛ dos Santos Mello, R. Workload-Aware RDF Partitioning و SPARQL Query Caching برای نمودارهای عظیم RDF ذخیره شده در پایگاه های داده NoSQL. SBBD 2017 ، 32 ، 184-195. [ Google Scholar ]
- سورس، اس. مالیزیا، ا. جیانگ، پی. آترتون، ام. هریسون، دی. یک رابط بصری جدید برای تقویت نوآوری در مهندسی مکانیک و محافظت از نقض حق ثبت اختراع. J. Phys. 2018 , 1004 , 012024. [ Google Scholar ] [ CrossRef ]
- نیوزون، پی. Krumm, J. Hidden Markov Map Matching from Noise and Sparseness. در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، WA، ایالات متحده آمریکا، نوامبر 2009. صص 336-343. [ Google Scholar ]
- جیانوتی، اف. پدرشی، دی. تحرک، داده کاوی و حریم خصوصی: کشف دانش جغرافیایی . Springer Science & Business Media: برلین، آلمان، 2008. [ Google Scholar ]
- جیانوتی، اف. نانی، م. پدرشی، دی. Renso, C. GeoPKDD Geographic Privacy-aware Knowledge Discovery 2009. موجود به صورت آنلاین: https://pdfs.semanticscholar.org/f6c8/d0b66289c78b62e7877cbf60f1f09f1ba72e.pdf (دسترسی در ژانویه20).
- لوجان-مورا، اس. Trujillo, J. A Comprehensive Method for Data Warehouse Design. در مجموعه مقالات پنجمین کارگاه بین المللی طراحی و مدیریت انبارهای داده، DMDW’03، برلین، آلمان، 8 سپتامبر 2003. [ Google Scholar ]
- Sheth، AP; لارسون، JA سیستم های پایگاه داده فدرال برای مدیریت پایگاه های داده توزیع شده، ناهمگن و خودمختار. کامپیوتر ACM. Surv. (CSUR) 1990 ، 22 ، 183-236. [ Google Scholar ] [ CrossRef ]
- ریگو، پی. شول، ام. Voisard، A. پایگاه های داده فضایی: با کاربرد در GIS ; الزویر: آمستردام، هلند، 2001. [ Google Scholar ]
- Ponniah, P. Data Warehouse Fundamentals for IT Professionals ; جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2010. [ Google Scholar ]
- گومز، ال. کویجپرز، بی. مولانز، بی. Vaisman، A. پیشرفته ترین در انبار داده های مکانی-زمانی، OLAP و استخراج. در داده کاوی: مفاهیم، روش ها، ابزارها و کاربردها . IGI Global: Pittsburgh, PA, USA, 2013; صفحات 2021–2056. [ Google Scholar ]
- برکاتسولاس، اس. Pfoser، D.; سالاس، آر. Wenk, C. بر روی داده های ردیابی خودرو مطابق با نقشه. در مجموعه مقالات سی و یکمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، بنیاد VLDB، تروندهایم نروژ، آگوست 2005; صص 853-864. [ Google Scholar ]
- ابراگیموف، دی. شیلنگ، K. پدرسن، سل؛ Zimányi, E. Towards Exploratory OLAP over Linked Open Data—A Case Study. در فعال کردن هوش تجاری در زمان واقعی ؛ Springer: برلین، آلمان، 2014; صص 114-132. [ Google Scholar ]
- اچوری، ال. Vaisman، AA QB4OLAP: واژگانی جدید برای مکعب های OLAP در وب معنایی. در مجموعه مقالات سومین کنفرانس بین المللی مصرف داده های پیوندی، بوستون، MA، ایالات متحده آمریکا، 12 نوامبر 2012; جلد 905، ص 27–38. [ Google Scholar ]
- سیو، ای. تیروپانیس، تی. هال، W. تجزیه و تحلیل برای اینترنت اشیا: یک نظرسنجی. کامپیوتر ACM. Surv. 2018 ، 51 ، 74. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لیت، DFB؛ د سوزا باپتیستا، سی. د اولیویرا، ام جی; Acioli Filho، JAM; دا سیلوا، TE ExpOLAP: به سوی OLAP اکتشافی. در مجموعه مقالات سیزدهمین کنفرانس بین المللی سیستم ها و برنامه های کامپیوتری IEEE/ACS 2016 (AICCSA)، آگادیر، مراکش، 2 دسامبر 2016؛ صص 1-8. [ Google Scholar ]
- ریست، اس. Bédard، Y.; Proulx، MJ; Nadeau, M. SOLAP: نوع جدیدی از رابط کاربری برای پشتیبانی از کاوش و تحلیل داده های چند بعدی فضایی-زمانی. در مجموعه مقالات کارگاه مشترک ISPRS در مورد مدلسازی و تحلیل داده های فضایی، زمانی و چند بعدی، کبک، QC، کانادا، اکتبر 2003. ص 2-3. [ Google Scholar ]
- لیت، DFB؛ Baptista، CDS; Amorim، BDSP یک ابزار SOLAP اکتشافی برای دادههای باز مرتبط. بین المللی اتوبوس جی. Inf. سیستم 2019 ، 31 ، 391-413. [ Google Scholar ] [ CrossRef ]
- فورتادو، ع. پیلا، LL; Bogorny، V. یک استراتژی شاخه و محدود برای اندازه گیری تشابه مسیر سریع. دانستن داده ها مهندس 2018 ، 115 ، 16-31. [ Google Scholar ] [ CrossRef ]
- کسکین، اس. Yazici, A. مدل سازی و طراحی داده های بزرگ مکانی و زمانی برای تجزیه و تحلیل ; Springer: برلین، آلمان، 2018; صص 104-112. [ Google Scholar ]
- کنگ، ایکس. آهنگ، X. شیا، اف. گوا، اچ. وانگ، جی. Tolba، A. LoTAD: تشخیص ناهنجاری ترافیک درازمدت بر اساس دادههای مسیر اتوبوس جمعسپاری شده. شبکه جهانی وب 2018 ، 21 ، 825–847. [ Google Scholar ] [ CrossRef ]
- آندرینکو، ن. آندرینکو، جی. فوکس، جی. Jankowski، P. روش تجزیه و تحلیل بصری برای کشف مقیاس پذیر و حریم خصوصی-احترام معناشناسی مکان از داده های تحرک اپیزودیک . Springer: برلین، آلمان، 2015; صص 254-258. [ Google Scholar ]
- کنگ، ال. او، ال. لیو، XY; گو، ی. وو، من؛ لیو، ایکس. حسگر فشرده با حفظ حریم خصوصی برای بازیابی مسیر مبتنی بر حسگر جمعی. در مجموعه مقالات سی و پنجمین کنفرانس بین المللی IEEE در سال 2015 در مورد سیستم های محاسباتی توزیع شده، کلمبوس، OH، ایالات متحده آمریکا، 29 ژوئن 2015. صص 31-40. [ Google Scholar ]
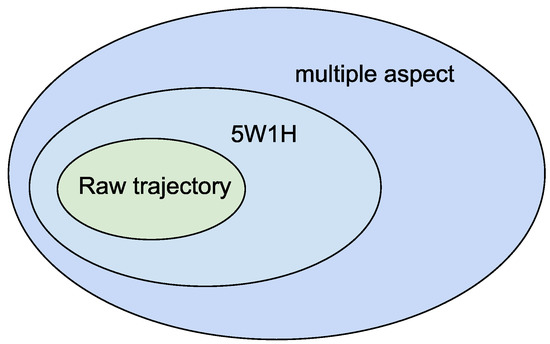
شکل 1. سطح غنی سازی معنایی.
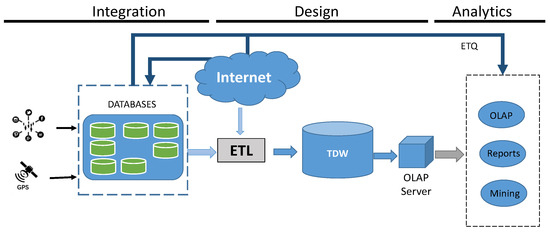
شکل 2. عناصر و جریان داده در یک مسیر DW.
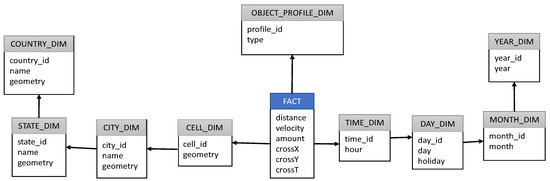
شکل 3. نمونه ای از طرح برف ریزه TDW مبتنی بر سلول.
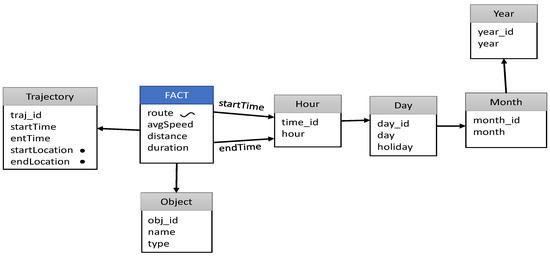
شکل 4. نمونه ای از طرح TDW مبتنی بر بخش.
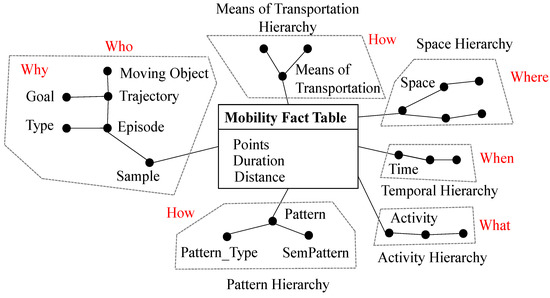
شکل 5. یک مدل طرح معنایی چند بعدی (اقتباس از [ 31 ]).
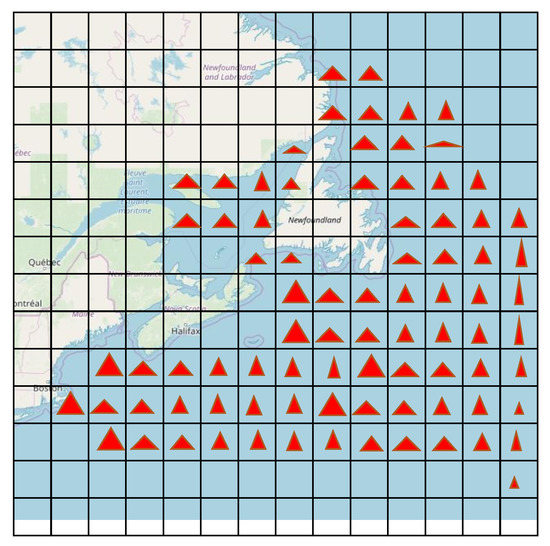
شکل 6. نقشه سلولی ترافیک کشتی.


بدون دیدگاه