

نقشه برداری خاک بر اساس درختان تصمیم گیری بهینه جهانی و تقلید دیجیتالی از رویکردهای سنتی
خلاصه

کلید واژه ها:
نقشه برداری دیجیتال خاک ; نقشه برداری سنتی خاک ; یادگیری ماشینی ؛ EVTREE ; منطقه بلگورود
1. معرفی
2. مواد و روشها
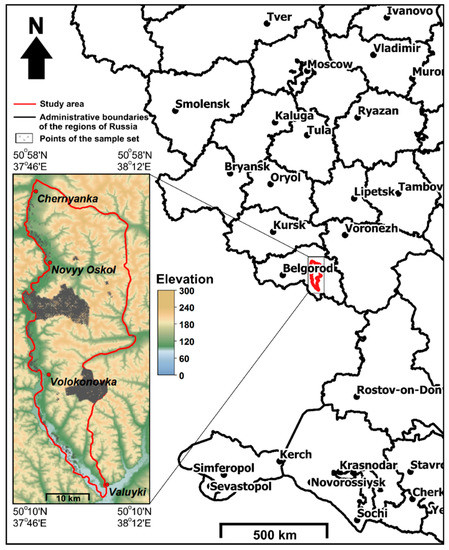
2.1. سایت تست
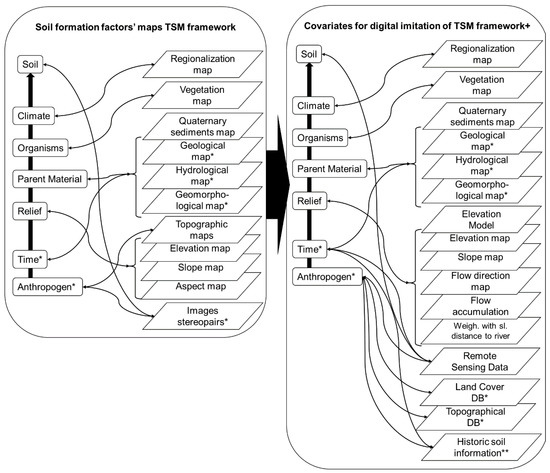
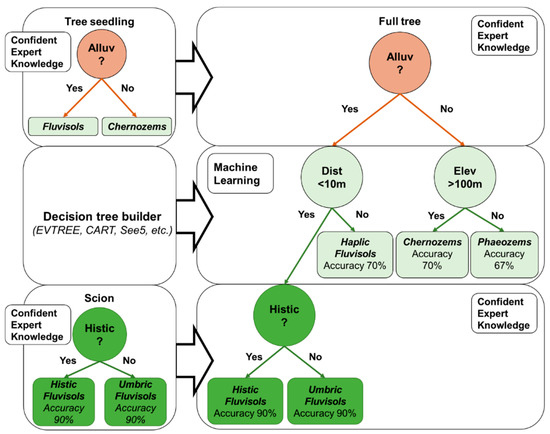
2.2. رویکرد پیشنهادی برای نقشه برداری خاک
برای اکثر برنامهها، الگوریتمهای بهینه جهانی، برخلاف الگوریتمهای بهینه محلی، پوشش بسیار کاملتری از فضای پارامتر را به شرح زیر ممکن میسازند:
جایی که vrمتغیرهای تقسیم را نشان می دهد، سrنشان دهنده قوانین تقسیم مرتبط برای گره های داخلی r و M نشان دهنده تعداد گره های پایانی است.
معادله (2) به دنبال درخت است Θ^که ضرر طبقهبندی نادرست را تحت معاوضه معیار اطلاعات بیزی (BIC) با تعداد گرههای پایانه به حداقل میرساند:
که در آن loss(·,·) یک تابع ضرر مناسب است. X بردار متغیر پیش بینی کننده; Y بردار متغیر پاسخ است. comp(·) یک تابع پیچیدگی است که به طور یکنواخت و بر اساس تعداد گره های انتهایی M درخت کاهش نمی یابد.Θاز جانب Θم; و فضای پارامتر کلی است Θ= ∪م=1ممترآایکسΘم; Θم، فضای درختان قابل تصور با گره های ترمینال M.
برای EVTREE، کیفیت درخت طبقهبندی معمولاً به عنوان تابعی از نرخ طبقهبندی اشتباه آن (MC) اندازهگیری میشود و پیچیدگی یک درخت با تابعی از تعداد گرههای پایانی M تعیین میشود :
که در آن N تعداد مقادیر متمایز متغیرهای پیش بینی است، comp تابع پیچیدگی یک درخت را توصیف می کند، و α یک پارامتر مشخص شده توسط کاربر است (مقدار پیش فرض α = 1). قابل توجه است که مقادیر منطقی دیگری از α [ 15 ] وجود دارد .
-
پایداری: از طریق تجزیه و تحلیل پراکندگی تعداد شاخه ها و از طریق تجزیه و تحلیل متخصص برای 10 اجرای یک الگوریتم تعیین می شود.
-
پیچیدگی: تعداد شرایط موجود در درختان.
-
سازگاری مفهومی: تفسیر مبتنی بر متخصص از یک درخت از هر الگوریتم.
-
میانگین و حداقل احتمالات قبلی طبقهبندی مناسب بهعنوان میانگین و حداقل تعداد نقاط طبقهبندی مناسب یک کلاس از مجموعه نمونه آموزشی در هر گره پایانه درخت تقسیم بر تعداد کل نقاط طبقهبندی مناسب و نامناسب در همان گره محاسبه شد.
-
عدم قطعیت فضایی در پیکسل: میانگین احتمال محتمل ترین کلاس برای 10 اجرای یک الگوریتم.
-
ارزیابی دقت نقشه: به طور کلی، دقت سازنده، کاربر و کاپا [ 48]. دقت کلی تعداد پیکسل های مشابه تصویر شده در نقشه های پیش بینی شده و مرجع ضرب در تعداد کل پیکسل ها را نشان می دهد. دقت سازنده نشان دهنده تعداد پیکسل هایی است که به عنوان بخشی از همان کلاس در تعداد کل پیکسل های آن کلاس در نقشه مرجع ضرب شده است. دقت کاربر تعداد پیکسل هایی است که در کلاس مشابه به تصویر کشیده شده اند اما در تعداد کل پیکسل های آن کلاس در نقشه پیش بینی شده ضرب شده است. دقت تولید کننده با خطای طبقه بندی اشتباه همراه است و دقت کاربر به خطای طبقه بندی بیش از حد اختصاص دارد. شاخص کاپا کوهن نشان دهنده دقت کلی با توجه به احتمال وقوع توافق است: κ≡پo-په1-په، که در آن p o توافق نسبی مشاهده شده بین ارزیاب ها است (یکسان با دقت کلی)، و p e احتمال فرضی توافق تصادفی است که از داده های مشاهده شده برای محاسبه احتمالات هر ناظری که به طور تصادفی هر دسته را می بیند استفاده می کند. برای دستههای k ، N مشاهدات برای دستهبندی و n ki تعداد دفعات رتبهدهنده که دسته k را پیشبینی کردم : په=1ن2∑کnک1nک2.
3. نتایج
-
افزودن نقشه های کمکی دقیق تر به تجزیه و تحلیل.
-
تصحیح درخت دستی؛
-
تغییر در قوانین کیفی؛
-
تغییر در قوانین کمی؛
-
-
تصحیح واحد نقشه خاک به صورت دستی
4. بحث
-
کار دستی پر زحمت همراه با تولید دو شکل از قوانین خاک به عنوان یک درخت طبقه بندی کلی و زنجیره قاعده خاص خاک است. یک راه حل ممکن استفاده از بسته ای با رابطی است که به فرد اجازه می دهد تا حد امکان تنظیمات را به آسانی انجام دهد. علاوه بر این، این روش باید تبدیل خودکار بین درختهای طبقهبندی و زنجیرهای از قوانین را فراهم کند.
-
تغییرات قابل توجه در درختان طبقه بندی هنگام استفاده از نقشه های کمکی به روز شده. با استفاده از روشهای آماری پیچیدهتر برای یافتن قوانین طبقهبندی و ترکیب دانش قبلی خاک در جستجوی قوانین میتوان بر این امر غلبه کرد.
-
نقشه برداری از طبقات خاک زمانی که ما نیاز به ترسیم خواص مداوم خاک یا توابع خاک داریم. انطباق با روش های دیگر راه حلی برای این مشکل فراهم می کند. در آن صورت، چارچوب پیشنهادی یک رابط با نقشههای خاک میراث ارائه میکند.
-
بهبودهای آماری دقت الگوریتم درخت طبقه بندی.
5. نتیجه گیری ها
-
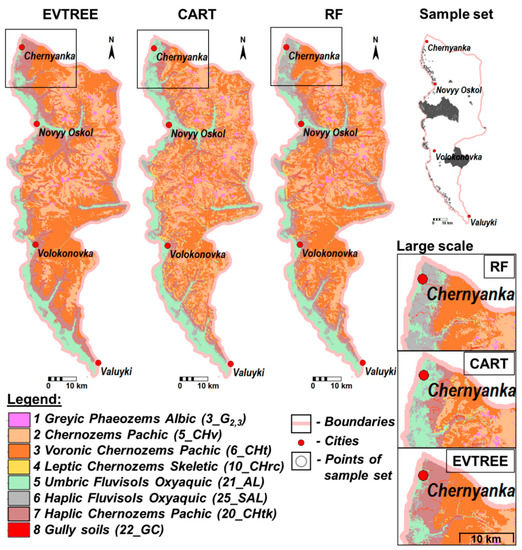
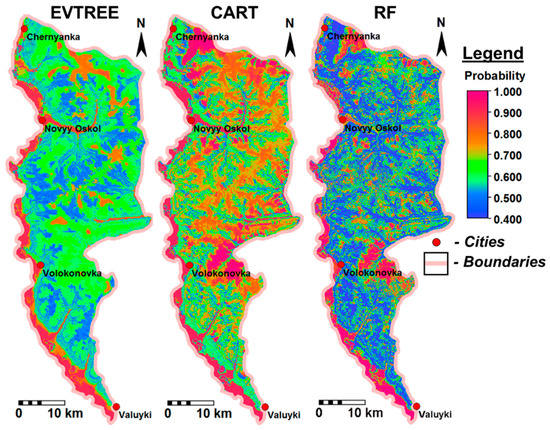
دقت کلی نقشه های خاک در منطقه مورد مطالعه برای EVTREE، CART و Random Forest به ترتیب 59، 67 و 87 درصد بود. دقت پیشبینی EVTREE برای منطقه مورد مطالعه کمی کمتر از آن برای CART و به طور قابلتوجهی کمتر از آن برای جنگل تصادفی بود. پس از کاهش اندازه مجموعه نمونه از 5001 به 1785 امتیاز، دقت برای EVTREE (59٪) یکسان باقی ماند، برای CART (61٪) کاهش یافت، و به طور قابل توجهی برای Random Forest (62٪) کاهش یافت. با مجموعه نمونه 1000 امتیازی، الگوریتم جنگل تصادفی اجرا نشد و EVTREE و CART به دقتی مشابه با 1785 امتیاز پی بردند. مجموعههای نمونه کاهشیافته همه خاکها و بیشتر ویژگیهای فاکتور تشکیل خاک کل مجموعه نمونه اصلی را پوشش میدهند. بنابراین، کیفیت طبقه بندی خاک تحت EVTREE بسیار کمتر به اندازه مجموعه نمونه وابسته بود.
-
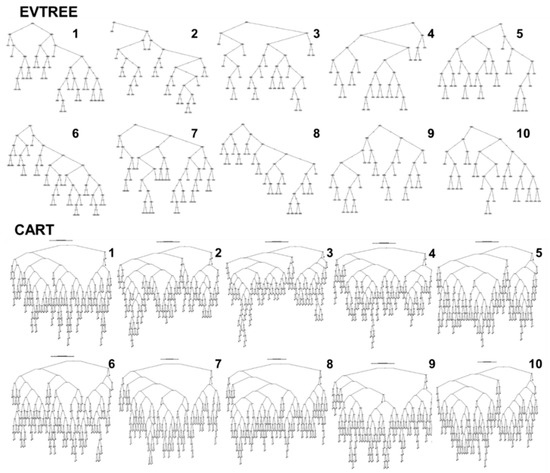
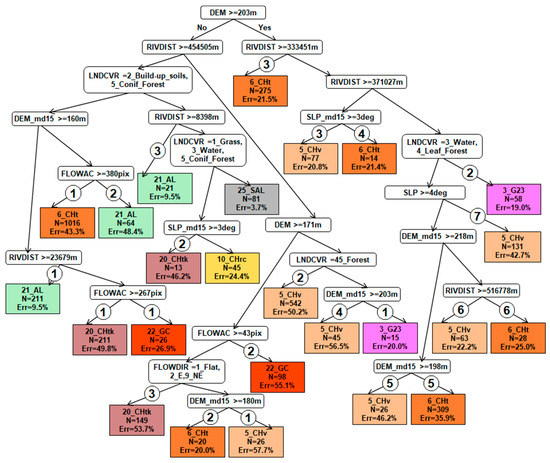
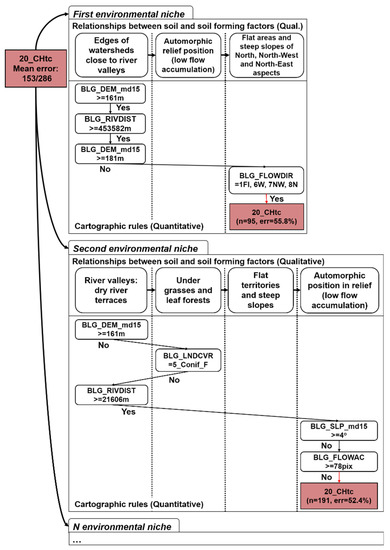
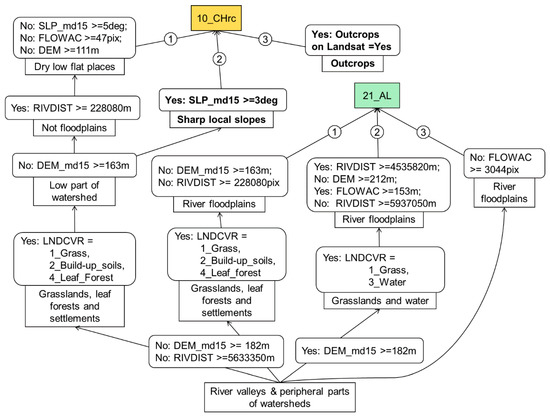
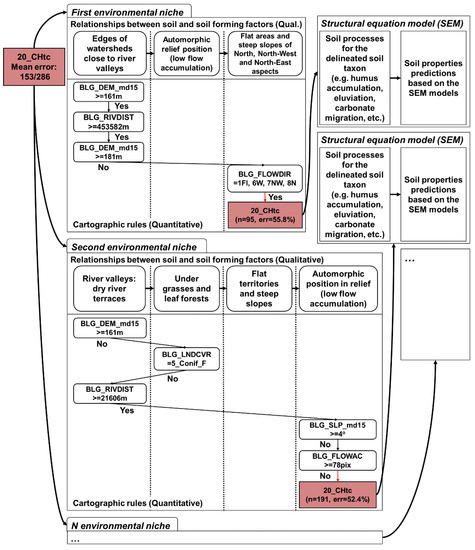
میانگین اندازه درختان در منطقه مورد مطالعه ساخته شده توسط EVTREE شامل 24 شرایط بود، در مقایسه با 154 شرایط برای درختان ساخته شده توسط CART. درختهای تصمیم فشرده که توسط EVTREE ساخته شدند هم برای ارزیابی کمی کیفیت و هم برای ردیابی تصوری مبتنی بر متخصص مناسب بودند.
-
نقشههای خاکی که با استفاده از EVTREE ایجاد شدهاند، سازگاری تصوری بسیار بالاتری نسبت به نقشههای ایجاد شده با استفاده از CART داشتند. قوانین فرموله شده توسط EVTREE برای تعیین Fluvisols و Phaeozems بسیار مستقیم تر از قوانین فرموله شده توسط CART بود. مدل های مستقیم ساخته شده توسط EVTREE برای نقشه برداری خاک برای برون یابی کامل یا جزئی به مناطق دوردست در جهان با شرایط محیطی مشابه مناسب هستند.
-
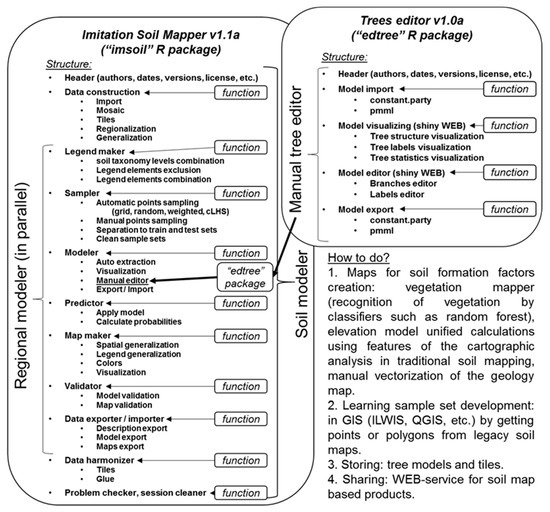
بسته R برای اصلاحات مدل درخت تصمیم دستی “constparty” لازم است، که می تواند شرایط و برچسب ها را اصلاح کند. ویژگی های انتخاب شاخه های درخت و پیوند درخت با نقشه خاک مرتبط برای نظارت آنلاین تغییرات مفید خواهد بود.
-
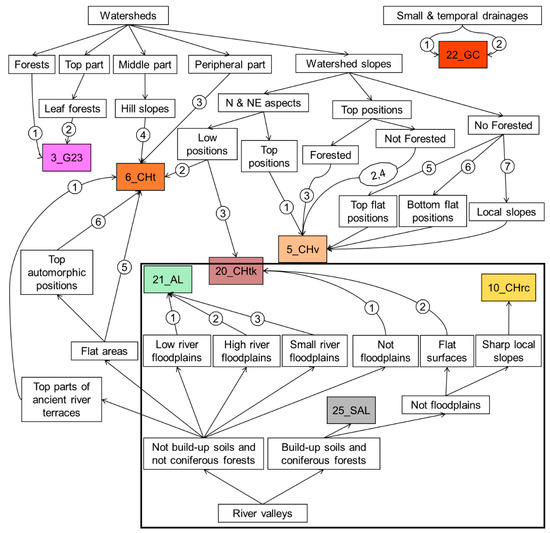
ما یک چارچوب نقشه برداری دیجیتالی خاک را توسعه دادیم که از فرآیند نقشه برداری سنتی خاک تقلید می کند و دانش کیفی در مورد جغرافیای خاک را در قوانین کمی برای ترسیم خاک ترکیب می کند. این مدل در قالب یک درخت تصمیم را می توان به صورت ماهرانه تحلیل کرد و می توان در لیست متغیرهای کمکی و سازگاری تصوری مدل بهبودهایی ایجاد کرد.
-
چالشها عبارتند از توسعه یک ویرایشگر درخت بصری با کاربری آسان و سریع، تبدیل خودکار درختان طبقهبندی به زنجیرههای قانون خاص خاک، ادغام خودکار آماری دانش قبلی خاک در فرآیند درختسازی و انطباق با روشهای دیگر برای نگاشت خواص مستمر خاک و توابع خاک
منابع
- Arrouays، D.; مک براتنی، AB; میناسنی، بی. Hempel، JW; Heuvelink، GBM؛ مک میلان، RA; McKenzie، NJ مشخصات پروژه GlobalSoilMap. در GlobalSoilMap: اساس سیستم اطلاعات فضایی جهانی خاک . CRC Press: Boca Raton، FL، USA، 2014. [ Google Scholar ]
- Arrouays، D.; Richer-de-Forges، AC; مک براتنی، AB; هارتمینک، AE; میناسنی، بی. ساوین، آی. Lagacherie, P. پروژه نقشه جهانی خاک: نمونه های گذشته، حال، آینده و ملی از فرانسه. گاو نر خاکی دوکوچایف. 2018 ، 95 ، 3-23. [ Google Scholar ] [ CrossRef ]
- Arrouays، D.; ساوین، آی. لینارز، جی. McBratney, AB (Eds.) GlobalSoilMap—نقشه دیجیتالی خاک از کشور تا جهان ; CRC Press: لندن، بریتانیا، 2017. [ Google Scholar ]
- لاگاچری، پ. مک براتنی، AB فصل 1. سیستمهای اطلاعاتی خاک و سیستمهای استنتاج فضایی خاک: دیدگاههایی برای نقشهبرداری دیجیتالی خاک: مقاله مروری. نقشه برداری دیجیتال خاک یک دیدگاه مقدماتی توسعه دهنده علم خاک 2007 ، 31 ، 137-150. [ Google Scholar ]
- Arrouays، D.; Leenaars، JG; Richer-de-Forges، AC; ادیکاری، ک. بالابیو، سی. گریو، ام. Heuvelink، G. نجات داده های میراث خاک از طریق GlobalSoilMap و سایر ابتکارات بین المللی و ملی. GeoResJ 2017 ، 14 ، 1-19. [ Google Scholar ] [ CrossRef ]
- گرونوالد، اس. تامپسون، جی. Boettinger، JL نقشه برداری و مدل سازی خاک دیجیتال در مقیاس قاره: یافتن راه حل برای مسائل جهانی. علم خاک Soc. صبح. J. 2011 ، 75 ، 1201-1213. [ Google Scholar ] [ CrossRef ]
- هنگل، تی. de Jesus, JM; Heuvelink، GB; گونزالس، ام آر. کلیبردا، م. بلاگوتیچ، آ. گوارا، MA SoilGrids250m: اطلاعات خاک شبکه بندی شده جهانی بر اساس یادگیری ماشین. PLoS ONE 2017 , 12 , e0169748. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Lagacherie, P. نقشه برداری خاک دیجیتال: به پیشرفته ترین. در نقشه برداری خاک دیجیتال با داده های محدود . Springer: Dordrecht، هلند، 2008; صص 3-14. [ Google Scholar ]
- مک براتنی، AB; د گرویتر، جی. Bryce, A. Pedometrics Timeline. Geoderma 2019 ، 338 ، 568-575. [ Google Scholar ] [ CrossRef ]
- مولدر، وی.ال. دی بروین، اس. Schaepman، ME; Mayr، TR استفاده از سنجش از دور در نقشه برداری خاک و زمین – یک بررسی. ژئودرما 2011 ، 162 ، 1-19. [ Google Scholar ] [ CrossRef ]
- چی، اف. Zhu، AX کشف دانش از نقشه های خاک با استفاده از یادگیری استقرایی. بین المللی جی. جئوگر. Inf. علمی 2003 ، 17 ، 771-795. [ Google Scholar ] [ CrossRef ]
- آنجلینی، من؛ Heuvelink، GBM؛ کمپن، بی. موراس، HJM نقشهبرداری از خاکهای منطقه پامپاس آرژانتین با استفاده از مدلسازی معادلات ساختاری. ژئودرما 2016 ، 281 ، 102-118. [ Google Scholar ] [ CrossRef ]
- Bui، EN; هندرسون، BL; Viergever، K. کشف دانش از مدل های ویژگی های خاک که از طریق داده کاوی توسعه یافته است. Ecol. مدلسازی 2006 ، 191 ، 431-446. [ Google Scholar ] [ CrossRef ]
- مک براتنی، AB; سانتوس، ام.ام. Minasny, B. در مورد نقشه برداری خاک دیجیتال. ژئودرما 2003 ، 117 ، 3-52. [ Google Scholar ] [ CrossRef ]
- Zhogolev، AV مقایسه ای از خاک گریدها با نقشه خاک تفکیک شده روسیه. در GlobalSoilMap—نقشه دیجیتالی خاک از کشور به کره زمین ؛ مطبوعات CRC: لندن، انگلستان، 2017؛ ص 49-52. [ Google Scholar ]
- Odgers، NP; سان، دبلیو. مک براتنی، AB; میناسنی، بی. کلیفورد، دی. تفکیک و هماهنگ کردن واحدهای نقشه خاک از طریق درختان طبقه بندی مجدد نمونه. ژئودرما 2014 ، 214 ، 91-100. [ Google Scholar ] [ CrossRef ]
- پاستور، ال. Laborczi، A.; تاکاچ، ک. Szatmári، G. باکاچی، ز. Szabó، J. DOSoReMI به عنوان اجرای ملی نقشه جهانی خاک برای قلمرو مجارستان. در GlobalSoilMap—نقشه دیجیتالی خاک از کشور به کره زمین ؛ CRC Press: لندن، انگلستان، 2017; صص 17-22. [ Google Scholar ]
- Caubet، M. Dobarco, MR; Arrouays، D.; میناسنی، بی. سابی، کشور ادغام NPA، پیشبینیهای قارهای و جهانی بافت خاک: درسهایی از مدلسازی گروهی در فرانسه. Geoderma 2019 ، 337 ، 99-110. [ Google Scholar ] [ CrossRef ]
- چینیلین، AV؛ Savin, IY نقشهبرداری دیجیتالی کربن آلی خاک با استفاده از الگوریتمهای یادگیری ماشین. گاو نر خاکی دوکوچایف. 2018 ، 91 ، 46-62. [ Google Scholar ] [ CrossRef ]
- هنگل، تی. نوسبام، م. رایت، MN; Heuvelink، GBM؛ Gräler، B. Random Forest به عنوان یک چارچوب عمومی برای مدلسازی پیشبینی متغیرهای مکانی و مکانی-زمانی. PeerJ 2018 , 6 , e5518. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- آنجلینی، من؛ Heuvelink، GBM؛ Kempen، B. نقشه برداری چند متغیره خاک با مدل سازی معادلات ساختاری. یورو J. Soil Sci. 2017 ، 68 ، 575-591. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- زو، ا. چنگ ژی، کیو. پنگ، ال. فی، دی. نقشه برداری دیجیتالی خاک برای کشاورزی هوشمند: روش SoLIM و پلتفرم های نرم افزاری. رودن جی. آگرون. انیمیشن. Ind. 2018 , 13 , 317–335. [ Google Scholar ] [ CrossRef ]
- زو، تبر; باند، LE; داتون، بی. Nimlos، TJ استنتاج خودکار خاک تحت منطق فازی. Ecol. مدلسازی 1996 ، 90 ، 123-145. [ Google Scholar ] [ CrossRef ]
- چی، اف. Zhu، AX مقایسه سه روش برای مدلسازی عدم قطعیت در کشف دانش از نقشههای خاک کلاس منطقه. محاسبه کنید. Geosci. 2011 ، 37 ، 1425-1436. [ Google Scholar ] [ CrossRef ]
- ژوگولف، ای وی. Savin, IY به روز رسانی خودکار نقشه های خاک در مقیاس متوسط. علم خاک اوراسیا 2016 ، 49 ، 1241-1249. [ Google Scholar ] [ CrossRef ]
- Bui، EN علم منطقه بحرانی مبتنی بر داده: یک پارادایم جدید. علمی کل محیط. 2016 ، 568 ، 587-593. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ما، YX; میناسنی، بی. مالون، BP; مک براتنی، AB پدولوژی و نقشه برداری دیجیتال خاک (DSM). یورو J. Soil Sci. 2019 ، 70 ، 216-235. [ Google Scholar ] [ CrossRef ]
- پاداریان، ج. موریس، جی. میناسنی، بی. مک براتنی، AB توابع انتقال و سیستم های استنتاج خاک ؛ Springer: برلین/هایدلبرگ، آلمان، 2018; صص 195-220. [ Google Scholar ]
- Lagacherie, P. Formalization des Lois de Distribution des Sols Pour Automatiser la Cartographie Pédologique à Partir d’un Secteur Pris Comme Reference. پایان نامه کارشناسی ارشد، Université de Montpellier، Institut National de la Recherche Agronomique، Montpellier، فرانسه، 1992. [ Google Scholar ]
- ترنو، TM; اتکینسون، EJ مقدمه ای بر پارتیشن بندی بازگشتی با استفاده از روال های RPART. 2018. در دسترس آنلاین: https://cran.r-project.org/web/packages/rpart/vignettes/longintro.pdf (در 28 فوریه 2019 قابل دسترسی است).
- گرابینگر، تی. زیلیس، ع. فایفر، KP Evtree: یادگیری تکاملی طبقهبندی بهینه جهانی و درختان رگرسیون در R. J. Stat. نرم افزار 2014 ، 61 ، 1-29. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بالستریرو، آر. بارانیوک، آر. تئوری اسپلاین یادگیری عمیق. در مجموعه مقالات سی و پنجمین کنفرانس بین المللی یادگیری ماشین، استکهلم، سوئد، 10 تا 15 ژوئیه 2018؛ جلد 80، ص 374–383. [ Google Scholar ]
- چیماتاپو، آر. هاگراس، اچ. استارکی، ا. اووسو، جی. هوش مصنوعی قابل توضیح و سیستمهای منطق فازی. در کنفرانس بین المللی تئوری و عمل محاسبات طبیعی ; Springer: برلین/هایدلبرگ، آلمان، 2018; صص 3-20. [ Google Scholar ]
- Savin، IY تقلید مبتنی بر کامپیوتر از نقشه برداری خاک. نقشه برداری دیجیتالی خاک: بررسی های نظری و تجربی . موسسه علوم خاک VV Dokuchaev: مسکو، روسیه، 2012; ص 26-34. (به روسی) [ Google Scholar ]
- اگوروف، وی وی. فریدلند، VM; ایوانوا، EN; Rozov، NN طبقه بندی و تشخیص خاک های اتحاد جماهیر شوروی . کولوس: مسکو، روسیه، 1977. (به زبان روسی) [ Google Scholar ]
- Shishov، LL; Tonkonogov، VD; لبدوا، دوم؛ گراسیموا، ششم (ویرایشگاه) طبقه بندی و سیستم تشخیصی خاک های روسیه ; Oikumena: اسمولنسک، روسیه، 2004. (به زبان روسی) [ Google Scholar ]
- گروه کاری IUSS WRB. پایگاه مرجع جهانی منابع خاک 2006 ; گزارش منابع خاک جهان 103; فائو: رم، ایتالیا، 2006. [ Google Scholar ]
- Ilyina، LP; میهایلووا، آر.پی. سیماکووا، ام اس؛ Shubina، IG گردآوری نقشه های خاک در مقیاس متوسط منطقه ای با نمایش الگوهای پوشش خاک . موسسه علوم خاک VV Dokuchaev: مسکو، روسیه، 1990. [ Google Scholar ]
- کارکنان بررسی خاک طبقهبندی خاک: سیستم پایه طبقهبندی خاک برای ساخت و تفسیر بررسیهای خاک ، ویرایش دوم. کتاب راهنمای کشاورزی، 436; خدمات حفاظت از منابع طبیعی: واشنگتن، دی سی، ایالات متحده; وزارت کشاورزی ایالات متحده: واشنگتن، دی سی، ایالات متحده آمریکا، 1999.
- روی، JA فیزیوگرافی و خاک. در دوره های خاک سنجی. موسسه بین المللی هوافضا و علوم زمین ITC: Enschede، هلند، 1988. [ Google Scholar ]
- Hengl, T. پیدا کردن اندازه پیکسل مناسب. محاسبه کنید. Geosci. 2006 ، 32 ، 1283-1298. [ Google Scholar ] [ CrossRef ]
- Xiong، LY; زو، تبر; ژانگ، ال. روش مبتنی بر شی حوضه زهکشی تانگ، GA برای طبقهبندی شکل زمین در مقیاس منطقهای: مطالعه موردی منطقه لس در چین. فیزیک Geogr. 2018 ، 39 ، 523-541. [ Google Scholar ] [ CrossRef ]
- جارویس، ا. رویتر، HI; نلسون، ا. Guevara, E. Hole-filled SRTM for the Globe نسخه 4. در دسترس آنلاین: https://srtm.csi.cgiar.org (در 28 فوریه 2019 قابل دسترسی است).
- Qin، CZ; زو، تبر; پی، تی. Li، BL; شولتن، تی. بهرنز، تی. Zhou، CH رویکردی برای محاسبه شاخص رطوبت توپوگرافی بر اساس حداکثر شیب پایین شیب. دقیق کشاورزی 2011 ، 12 ، 32-43. [ Google Scholar ] [ CrossRef ]
- هنگل، تی. Maathuis، BHP; وانگ، L. ژئومورفومتری در ILWIS. توسعه دهنده علم خاک 2009 ، 33 ، 309-331. [ Google Scholar ]
- هاثورن، تی. Zeileis, A. Partykit: یک جعبه ابزار مدولار برای پارتیبندی بازگشتی در R. J. Mach. فرا گرفتن. Res. 2015 ، 16 ، 3905-3909. [ Google Scholar ]
- بریمن، ال. فریدمن، جی. اولشن، ر. سنگ، ج. طبقه بندی و رگرسیون درختان. Wadsworth Int. گروه 1984 ، 37 ، 237-251. [ Google Scholar ]
- Rossiter، DG; زنگ، آر. Zhang، GL حسابداری فاصله طبقه بندی در ارزیابی دقت پیش بینی کلاس خاک. Geoderma 2017 ، 292 ، 118-127. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]


بدون دیدگاه