

نقشه برداری دیجیتالی خاک از مواد آلی خاک با الگوریتم های یادگیری عمیق


1
دانشکده علوم و مهندسی سایبری، دانشگاه ژنگژو، ژنگژو 450001، چین
2
دانشکده علوم و مهندسی حفاظت از آب، دانشگاه ژنگژو، ژنگژو 450001، چین
3
دانشکده مهندسی عمران، دانشگاه ژنگژو، ژنگژو 450001، چین
*
نویسنده ای که مسئول است باید ذکر شود.
دریافت: 28 فوریه 2022/بازبینی شده: 29 آوریل 2022/پذیرش: 2 مه 2022/تاریخ انتشار: 6 مه 2022
چکیده
:
نقشه برداری دیجیتالی خاک به عنوان یک روش جدید برای توصیف توزیع فضایی خاک به صورت اقتصادی و کارآمد پدیدار شده است. در این مطالعه، یک روش نقشه برداری مواد آلی خاک سبک (SOM) بر اساس شبکه باقیمانده عمیق، که ما آن را LSM-ResNet می نامیم، برای پیش بینی های دقیق با متغیرهای کمکی پس زمینه پیشنهاد شده است. ResNet نه تنها اطلاعات پس زمینه فضایی را در اطراف متغیرهای محیطی مشاهده شده یکپارچه می کند، بلکه مشکلاتی مانند از دست دادن اطلاعات را نیز کاهش می دهد، که یکپارچگی اطلاعات را تضعیف می کند و عدم قطعیت پیش بینی را کاهش می دهد. برای آموزش مدل، واحدهای خطی اصلاح شده، میانگین مربعات خطا و تخمین تکانه تطبیقی به ترتیب به عنوان تابع فعالسازی، تابع ضرر/هزینه و بهینهساز استفاده شد. این روش با Landsat5، داده های هواشناسی WorldClim، آزمایش شد. و 1602 نقطه نمونه برداری از سین شیانگ چین. عملکرد LSM-ResNet پیشنهادی با یک الگوریتم یادگیری ماشین سنتی، الگوریتم جنگل تصادفی (RF) مقایسه شد و یک مجموعه آموزشی (80٪) و یک مجموعه تست (20٪) برای آزمایش هر دو مدل ایجاد شد. نتایج نشان داد که LSM-ResNet (RMSE = 6.40، Rمدل 2 = 0.51) در هر دو ریشه میانگین مربعات خطا (RMSE) و ضریب تعیین ( R2 ) از مدل RF بهتر عمل کرد و دقت تمرین به طور قابل توجهی در مقایسه با RF (RMSE = 6.81، R2 = 0.46) بهبود یافت. مدل آموزشدیده LSM-ResNet برای پیشبینی SOM در Xinxiang، ناحیهای از زمین دشت در چین استفاده شد. نقشههای پیشبینی را میتوان بازتابی دقیق از تغییرپذیری فضایی توزیع SOM در نظر گرفت.
کلید واژه ها:
نقشه برداری دیجیتال خاک (DSM) ; مواد آلی خاک (SOM) ; یادگیری عمیق (DL) ؛ ری نت ; سنجش از دور
1. مقدمه
خاک پوست زنده زمین است و وسیله ای است که فعالیت انسان و رشد گیاهان و حیوانات را حفظ می کند [ 1 ]. درک دقیق و تفسیر منطقی از خصوصیات خاک و الگوهای توزیع مکانی، مبنای توسعه پایدار منابع خاک است. نقشه برداری دقیق از ویژگی های خاک در زمینه هایی مانند کشاورزی دقیق [ 2 ، 3 ]، برنامه ریزی کاربری زمین [ 4 ] و حفاظت از محیط زیست [ 5 ] تقاضای فوری دارد. نقشه برداری دیجیتالی خاک (DSM) یک روش نقشه برداری کارآمد و نوظهور است که به طور گسترده برای پیش بینی طبقات و ویژگی های خاک استفاده می شود [ 6 ، 7 ].
DSM الگوها و ویژگی های فرآیندهای تشکیل و توسعه خاک را با استفاده از روش های تحلیل مکانی و ریاضی به عنوان ابزاری فنی برای پیش بینی خواص خاک و روش های نقشه برداری منعکس می کند. در اغلب موارد، نقاط نمونه خاک با استفاده از جمع آوری مزرعه ای به دست می آید که منبع اصلی اطلاعات در مورد همبستگی مکانی خصوصیات خاک و دانش از رابطه بین خاک و متغیرهای محیطی است [ 1 ]. روش رایج فعلی نقشه برداری خاک بر اساس جمع آوری نقاط نمونه از رابطه بین ویژگی های خاک و متغیرهای کمکی محیطی برای نقشه برداری کمی استفاده می کند. رسمی سازی روش DSM با انتشار مک براتنی و همکاران تکمیل شد. [ 8 ]. دنبال کردن دوکوچایف [ 9] و جنی [ 10 ]، آنها اسکورپان را به عنوان رابطه کمی تجربی بین یک ویژگی خاک و عوامل سازنده فضایی ضمنی آن مدل کردند [ 11 ]. رابطه بین داده های ویژگی خاک و داده های محیطی جغرافیایی که در آن خاک تحت تغییرات مرتبط یا هم افزایی قرار می گیرد اغلب برای پیش بینی توزیع فضایی خاک استفاده می شود. چنین روشهایی مبتنی بر تحلیل رگرسیون خطی یا الگوریتمهای تحلیل رگرسیون غیرخطی هستند که شامل شبکههای عصبی مصنوعی (ANN) [ 12 ، 13 ، 14 ]، مدلهای درخت رگرسیون تقویتشده [ 15 ] و SVM [ 13 ] است.]. در این میان، جنگل تصادفی (RF) به یکی از محبوبترین تکنیکها در پیشبینی DSM تبدیل شده است [ 16 ، 17 ، 18 ].
محققان دریافتهاند که در پیشبینی ویژگیهای خاک با کمک پارادایم اسکورپان ، ویژگیهای خاک نه تنها به تغییرات در شاخصهای محیطی بین نقاط نمونهبرداری و مجموعه متغیرهای کمکی نشاندادهشده توسط نقاط مربوط میشود، بلکه به اطلاعات مکانی اشاره شده در آن نیز مربوط میشود. باید در نظر گرفته شود. دانشمندان آزمایش هایی را با روش هایی انجام داده اند که به طور همزمان متغیرهای محیطی و اطلاعات مکانی را در نقاط نمونه گیری در نظر می گیرند. یک روش درون یابی کوکریجینگ که بر اساس نظریه متغیرهای منطقه ای مشارکتی (همبستگی فضایی) است و از همبستگی هم افزایی بین متغیرهای هدف و محیطی برای ایجاد یک تابع کوواریانس متقاطع برای تخمین محلی متغیرهای هدف استفاده می کند، پیشنهاد شده است [ 19 ].]. برخی دیگر از کریجینگ رگرسیونی استفاده میکنند، که در آن عبارات باقیمانده مدل کریجینگ رگرسیونی با رگرسیون ویژگیهای خاک بر روی متغیرهای محیطی به متغیرهای منطقهای شده تبدیل میشوند و در نهایت به مقادیر پیشبینیشده مدل رگرسیون اضافه میشوند تا توزیع فضایی نهایی ویژگیهای خاک تولید شود [ 20 ]. . رگرسیونهای وزندار جغرافیایی، رگرسیونهای خطی محلی هستند که رگرسیونهای فضایی محلی ناپارامتری را بر اساس فاصله بین نقاط نمونه از مرکز رگرسیون مدلسازی میکنند و وزن تخمینهای پارامتر مدل را تعیین میکنند. ضرایب رگرسیون نقاط نمونه در مدل با موقعیت مکانی متفاوت است، بنابراین منعکس کننده تغییرات مکانی در سهم نقاط نمونه و متغیرهای محیطی در معادله رگرسیون است [ 21 ,22 ، 23 ]. با این حال، این روشها الزامات خاصی در مورد اندازه و توزیع دادهها دارند، و مدلسازی روابط غیرخطی بین ویژگیها یا طبقات خاک و متغیرهای کمکی متعدد مرتبط به هم مختصر نیست، و بنابراین با چالشهای اضافی همراه است (به عنوان مثال، پارامترهای زیادی برای تخمین زدن). [ 24 ]. چالشها عبارتند از: اگر نمونهها با فرض همواری مرتبه دوم مطابقت نداشته باشند، مدل از نظر محاسباتی نیازمند است، یا به یک فرآیند پیشپردازش دادههای دست و پا گیر نیاز دارد، که اغلب دستیابی به آن در کاربردهای عملی دشوار است [ 25 ، 26 ، 27 ].
با توسعه سریع داده های بزرگ، یادگیری عمیق (DL) ثابت کرده است که ابزار جدیدی برای تجزیه و تحلیل در بسیاری از زمینه ها است. بر خلاف سایر مدلهای فیزیکی که به شدت بر دانش قبلی پارامترها متکی هستند، روشهای DL از نمایشهای ویژگیهای مشتق شده از دادهها به تنهایی استفاده میکنند [ 28 ]. این روشها روابط غیرخطی، به ویژه روابط غیرخطی پیچیده بین ویژگیهای محیطی مختلف را از طریق تعداد زیادی از ویژگیهای فرآیند تولید شده در طول آموزش مدل، بهتر نشان میدهند، در حالی که دقت پیشبینی بالاتری در مقایسه با زمینآمار و سایر روشهای یادگیری ماشین سنتی (ML) دارند [ 29 ، 30 ] .
شبکه های عصبی کانولوشنال (CNN) [ 31 ] در یادگیری عمیق توجه زیادی را به خود جلب کرده اند، به ویژه به عنوان یک شبکه عصبی چندلایه به هم پیوسته که نتایج خوبی در حوزه های بینایی کامپیوتری مختلف به همراه داشته است. این الگوریتم یک نمایش ویژگی توزیع شده از داده ها را با استفاده از رویکرد پنجره کشویی در ترکیب با ویژگی های اساسی کشف می کند تا یک نمایش ویژگی سطح بالا انتزاعی تر را تشکیل دهد. از رویکرد پنجره کشویی برای استخراج ویژگیهای محلی و توزیعشده متغیرهای محیطی از منابع فضایی و مشاهدات هماهنگ خاک برای تخمینهای مکانی ویژگیهای خاک استفاده میکند [ 7 ].]. بنابراین، CNNها یک مسئله نسبتاً عمده روشهای یادگیری ماشین (ML) را حل میکنند، زیرا شبکهها از ساختار فضایی ورودی استفاده میکنند، نه فقط از اطلاعات کمکی نقاط نمونهبرداری شده، استفاده بهتری از اطلاعات کمکی پسزمینه میکنند، در حالی که الگوریتم اضافه میکند تعداد زیادی از ویژگی های توزیعی
CNN ها بیشتر برای مشکلات طبقه بندی در مطالعات بینایی کامپیوتری و سنجش از دور استفاده می شوند، به عنوان مثال، با مجموعه داده استفاده از زمین/منطقه پوشش زمین (LUCAS) توسط Veres و همکاران. [ 32 ]، CNN ها برای طبقه بندی طیفی خاک استفاده شدند. ولپی و همکاران [ 33 ] از CNN برای طبقه بندی پوشش زمین با استفاده از تصاویر سنجش از دور با وضوح بالا استفاده کرد. در حالی که برای تخمین فضایی ویژگیهای خاک، پتانسیل یادگیری عمیق در ساخت ویژگیهای چند مقیاسی زمین و اثربخشی نسبی آن در نقشهبرداری دیجیتالی خاک برای اولین بار در کار Behrens و همکارانش بیان شد. [ 34 ]. پاداریان و همکاران و وادوکس و همکاران پیشنهاد استفاده از CNN برای پیش بینی محتوای SOC [ 11 ، 35]. آنها گزارش می دهند که CNN ها نسبت به الگوریتم های استاندارد ML از نظر خطای پیش بینی مزیت دارند. تساکریدیس و همکاران یک چارچوب جدید با استفاده از یک CNN 1 بعدی چند کاناله محلی برای تخمین مداوم خواص مختلف خاک (به عنوان مثال، SOC) [ 36 ] ایجاد کرد. معماری CNN به طور مداوم در پیشبینی کسر اندازه ذرات خاک (PSF) از مدلهای RF بهتر بود [ 37 ].
ResNet به عنوان معماری شاخه ای از CNN ها در چند سال گذشته بیشتر مورد توجه قرار گرفته است. قدرت بیان شبکههای عصبی عمیق و توانایی استخراج ویژگیها با عمق شبکه افزایش مییابد، اما دقت مدل به سرعت کاهش مییابد زمانی که تعداد لایههای شبکه به تعداد معینی افزایش مییابد [ 38 ، 39 ]. برای حل مشکل تخریب شبکه به دلیل افزایش عمق، او و همکاران. چارچوب یادگیری عمیق ResNet را پیشنهاد کرد [ 40] که مفهوم نگاشت ثابت در شبکه را معرفی می کند و هر لایه را به عنوان یک تابع یادگیری باقیمانده به دلیل ورودی از طریق لایه مرجع به جای یادگیری تابع بدون مرجع، باز تعریف می کند، بنابراین آموزش شبکه را ساده می کند و تعداد مسیرهای انتقال اطلاعات را افزایش می دهد. ، و دقت سیستم را تا حد زیادی بهبود می بخشد. با توجه به عملکرد خوب ResNet، در بسیاری از زمینههای علوم کامپیوتر مانند تشخیص تصویر [ 41 ] و تقسیمبندی معنایی [ 42 ] استفاده شده است. سونگ و همکاران [ 43 ] یک شبکه باقیمانده برای طبقه بندی یخ دریا به نام SI-ResNet طراحی کرد که به دقت طبقه بندی خوبی دست یافت. ژانگ و همکاران [ 44] ResNet-V2 را برای طراحی یک ResNet کوچک برای تشخیص طبقه بندی سنجش از راه دور ترکیب کرد و دقت آن از طبقه بندی کننده کلاسیک بهتر بود. ResNet یکی از موثرترین چارچوب های شبکه یادگیری عمیق برای تشخیص و طبقه بندی تصاویر تا به امروز است.
بر اساس تحلیل فوق، روش های یادگیری عمیق برای استفاده برای DSM پیشنهاد شده است. این مطالعه یک معماری یادگیری عمیق سبک نوآورانه (LSM-ResNet) مبتنی بر ResNet را پیشنهاد میکند که یک فرآیند پایان به انتها را برای پیشبینی رگرسیون SOM با استفاده از منابع متعدد داده اجرا میکند. برای آموزش شبکه، یک مجموعه داده کمکی خاک بر اساس تصاویر RGB بر اساس همجوشی تصویر ساختیم. اثر اندازه پیش فریم بر خطای مدل مورد تجزیه و تحلیل قرار گرفت. ما SOM را به عنوان یک ویژگی خاک پیش بینی شده انتخاب کردیم، که شاخص مهمی از شاخص کیفیت خاک، حاصلخیزی خاک و سلامت خاک است. یک نقشه SOM دقیق و با کیفیت میتواند دادههای اساسی مهمی را برای مدلسازی اکوسیستم و توسعه سیاستهای اقلیمی فراهم کند [ 5 ، 45 ، 46 ، 47 ،48 ]. اطلاعات دقیق در مورد تغییرات فضایی در SOM برای برنامه ریزی کاربری زمین و سایر فعالیت های مرتبط با جنگلداری، کشاورزی، حفاظت از محیط زیست و مدیریت تخریب زمین مفید است [ 5 ]. عملکرد LSM-ResNet پیشنهادی در این مطالعه با RF مقایسه شد، زیرا الگوریتم RF اغلب برای DSM استفاده میشود و بنابراین یک مقایسه منطقی است.
2. روش شناسی
2.1. منطقه مطالعه
شین شیانگ در جنوب غربی دشت چین شمالی، تقریباً بین 34 درجه و 55 دقیقه شمالی تا 35 درجه و 50 دقیقه شمالی و 113 درجه و 30 دقیقه شرقی تا 115 درجه و 30 دقیقه شرقی ( شکل 1 ب)، با مساحتی در حدود 6434 کیلومتر واقع شده است. 2 دشت، 77.36 درصد از کل مساحت منطقه را به خود اختصاص داده است. آب و هوای موسمی گرم معتدل قاره ای با میانگین دمای سالانه 13 تا 15 درجه سانتی گراد و میانگین بارندگی سالانه 573.4 میلی متر بر آن غالب است. منطقه کوه فنگ هوانگ متعلق به منطقه تپه ای شمالی است. از شمال غربی به جنوب شرقی، شکل زمین از کوه به تپه و سپس به دشت انتقال می یابد. این منطقه گذار بین دشت آبرفتی رودخانه زرد و دشت آبرفتی پیش کوهستانی است. رودخانه هایهه و رودخانه زرد دو سیستم اصلی آبی هستند. بر اساس طبقه بندی خاک چین [ 49]، مقدار کمی خاک شنی زرد در مرکز وجود دارد و خاک قهوه ای و خاک دارچینی دو نوع اصلی خاک هستند [ 50 ، 51 ].
2.2. نمونه های خاک
این مطالعه از نمونههای خاک از پروژه ارزیابی بهرهوری زمینهای زراعی 2006 تا 2008 استفاده کرد. مکان، عمق نمونه برداری، ماده اولیه، نوع خاک، الگوی کاربری اراضی و سایر اطلاعات مرتبط برای هر نمونه با جزئیات ثبت شد.
تمام نمونه های خاک در هوا خشک شده و از الک 0.25 میلی متری عبور داده شدند و سپس با استفاده از روش حجمی دی کرومات پتاسیم [ 52 ] از نظر SOM مورد تجزیه و تحلیل قرار گرفتند. در مجموع 1602 نمونه خاک به سه مجموعه داده جداگانه تقسیم شدند که 80٪ از آنها برای آموزش و اعتبارسنجی مدل استفاده شد و بقیه برای اهداف آزمایش استفاده شد.
2.3. مجموعه داده و پیش پردازش
محتوای SOM توسط عوامل محیطی و اکولوژیکی متعدد و تعاملات آنها کنترل می شود [ 5 ]. بر اساس بررسی ادبیات [ 5 ، 15 ، 22 ، 45 ، 46 ، 53 ]، مجموعه ای از 13 متغیر کمکی نشان دهنده آب و هوا، توپوگرافی و سنجش از دور به عنوان متغیرهای پیش بینی کننده بالقوه برای پیش بینی SOM انتخاب شدند ( جدول 1 ). این متغیرها با وضوح فضایی 30 × 30 متر، مطابق با دادههای Landsat5 نمونهبرداری شدند. برای هر متغیر، مقادیر آن در پیکسلهای 30 × 30 متر که هر نمونه خاک در آن قرار داشت استخراج شد. چهار نمونه از داده های متغیر کمکی قابل انتخاب در شکل 2 نشان داده شده است.
به طور کلی، عوامل اقلیمی الگوی کلی محتوای SOM را تعیین می کند [ 5 ، 54 ]. میانگین بارش سالانه (MAP) یکی از پرکاربردترین عوامل اقلیمی در پیشبینیهای SOM است. برای به دست آوردن نقشه، از ArcGIS برای استخراج نقشه بر اساس اطلاعات ارائه شده توسط WorldClim 2.1 [ 55 ] استفاده شد که از نظر مکانی به 1 کیلومتر تفکیک شد و با استفاده از روش درون یابی مکعبی به 30 متر نمونه برداری شد. چهار فاکتور توپوگرافی از مدل ارتفاع دیجیتالی ماموریت توپوگرافی رادار شاتل (SRTM) با وضوح 30 متر ( https://gdex.cr.usgs.gov/gdex/ ) استخراج شد.(دسترسی در 14 آگوست 2021))، شامل ارتفاع، شیب، وجه (نما یک معیار دایرهای است که نمیتوان مستقیماً در مدلسازی از آن استفاده کرد و بنابراین به شمال و شرق تبدیل شد)، و شاخص رطوبت توپوگرافی (TWI) [ 56 ] .
برای دادههای RS، از پنج باند طیفی از Landsat5 ( https://gdex.cr.usgs.gov/gdex/ (دسترسی در 17 اوت 2021)) و سه شاخص RS [ 2 ] به عنوان پیشبینیکنندههای بالقوه استفاده کردیم. پنج باند طیفی مبتنی بر RS و دادههای RS با فیلتر کردن 38 تصویر Landsat5 از شهر Xinxiang که از ژوئن تا آگوست هر سال (زمان نمونهگیری سالانه) از سال 2006 تا 2008 گرفته شدهاند، استخراج شدند و مقدار متوسط محاسبه شد.
پیش پردازش داده های RS (به عنوان مثال، تصحیح رادیومتری و تصحیح جوی) با ENVI 5.3 انجام شد. در مطالعه خود، از تصاویر Landsat5 برای استخراج مقادیر بازتاب پنج باند استفاده کردیم: b1 (Band1، آبی)، b2 (Band2، سبز)، b3 (Band3، قرمز)، b4 (باند 4، NIR)، و b5 (باند 5). ، SWIR). شاخص های سنجش از دور نیز با استفاده از محصولات بازتابی Landsat5 محاسبه شدند: شاخص گیاهی تفاوت نرمال شده (NDVI) [ 57 ]، شاخص پوشش گیاهی افزایش یافته (EVI) [ 58 ]، و شاخص پوشش گیاهی تفاوت (DVI) [ 59 ]. میانگین سه شاخص سنجش از دور به عنوان پیش بینی محاسبه شد.
از رگرسیون گام به گام و ضریب همبستگی برای انتخاب مهم ترین متغیرهای کمکی محیطی برای مدل سازی محتوای SOM استفاده شد. در نهایت، Landsat5 b4 (باند 4، NIR)، MAP و NDVI متشکل از تصاویر سه کاناله RGB (که تعداد کانال های تصویری است که معمولا در بینایی کامپیوتر استفاده می شود) برای پیش بینی محتوای SOM منطقه مورد مطالعه انتخاب شدند. این به این دلیل است که این متغیرهای کمکی دارای عبارات مشخصه متمایز و SOM با همبستگی بالا هستند. به عنوان مجموعه داده های تصویر، متغیرهای کمکی انتخاب شده با تجمع (میانگین نمونه برداری مجدد) یا تجزیه (نمونه گیری مجدد دوخطی) به اندازه شبکه 30 متر نرمال شدند.
برای مقایسه منصفانهتر بین RF و LSM-ResNet، از فیلترهای میانگین با اندازههای همسایگی مختلف (شعاعهای 1، 3، 5، 7، 9، 15، 21، 29، و 50 پیکسل) برای متغیرهای چند مقیاسی مؤثر استفاده کردیم. استخراج اطلاعات [ 60 ]. این رویکرد بر روی متغیرهای شبانه عمل می کند: جنبه (جنبه به شمال و شرق)، MAP، شیب، ارتفاع، Landsat b4 (NIR)، TWI، Landsat5 Band 5 (SWIR)، و شاخص پوشش گیاهی نرمال شده (NDVI)، که در مجموع (NDVI) ایجاد می کند. 9 × 9) 81 متغیر کمکی جدید به عنوان متغیرهای مستقل (با استفاده از یک رویکرد دوخطی برای استخراج داده های متغیر کمکی) برای ساخت مدل RF. فیلتر میانگین رایج ترین روش مورد استفاده در مطالعات DSM برای نگاشت چند مقیاسی DEM است و برای فیلتر کردن متغیرهای کمکی جدید از روش ANOVA استفاده شد [ 18 ، 60 ، 61 ].]. شکل 3 روش شناسی تحقیق حاضر را نشان می دهد.
3. یادگیری عمیق
یادگیری عمیق یک روش تحقیق برگرفته از شبکه های عصبی مصنوعی است که می تواند نمایش داده ها را از طریق معماری های چند لایه قدرتمند بیاموزد. شبکه باقیمانده (ResNet) در بسیاری از زمینه های تصویربرداری به نتایج خوبی دست یافته است. به عنوان مثال می توان به تشخیص چهره، تشخیص هدف و تقسیم بندی معنایی اشاره کرد. ResNet و برخی از روش های مرتبط به کار رفته در مدل در این بخش معرفی می شوند.
3.1. ResNet
در این مقاله، اطلاعات زمینه ای که ما استفاده می کنیم برای نشان دادن متغیرهای کمکی مدل به عنوان یک تصویر مربعی در اطراف اندازه گیری خاک است. متغیرهای کمکی ممکن است توزیع SOM را از طریق شکل خاصی از زمین یا مشخصات دما و بارش توصیف کنند. با چندین تنظیمات جایگزین، هدف استخراج مرتبط ترین ویژگی ها از کل مجموعه داده کمکی است. در این مورد، CNN ها بهتر از ANN ها سازگار هستند. ResNet بر اساس شبکه باقیمانده عمیق پیشنهاد شده توسط He et al. مایکروسافت تحقیقات آسیا در سال 2015 [ 40 ]. هسته ResNet یک ساختار بلوک باقیمانده است، همانطور که در شکل 4 نشان داده شده است. از یک اتصال میانبر به نام اتصال متقاطع بین ورودی X و F(x) استفاده می کند که از طریق لایه های وزن انباشته به دست می آید، خروجی . به عنوان باقیمانده فرمول به شرح زیر است:
که در آن F تابع باقیمانده است، تابع فعال سازی غیرخطی واحدهای خطی اصلاح شده (ReLU) است و و لایه وزنی هستند. با فرض اینکه Y ماتریس ویژگی زمین خروجی 4 بعدی بلوک باقیمانده است، هنگامی که باقیمانده با نگاشت مساوی، همانطور که در رابطه (2 نشان داده شده است) متصل می شود، X عملیات کانولوشن و باقیمانده را انجام می دهد. به علاوه x Y را می دهد.
اگر ابعاد این دو متفاوت باشد، در این صورت یک نقشه خطی از ورودی x برای مطابقت با ابعاد همانطور که در رابطه (3) نشان داده شده است، مورد نیاز است.
جایی که نشان دهنده لایه وزنی و تابع نگاشت خطی را نشان می دهد.
بنابراین، اتصال چند لایه بلوک های باقیمانده ResNet با استفاده از خروجی لایه قبلی به طور مستقیم به عنوان ورودی به نتیجه لایه بعدی حاصل می شود. پس از عملیات اتصال چند لایه، به یادگیری و بهینه سازی باقیمانده ها تبدیل می شود . به این ترتیب، با افزایش عمق شبکه، گرادیان ناپدید نمیشود و همیشه تغییرات قابلتوجهی در فرآیند انتشار پسپشتی حفظ میکند و بهینهسازی را تسهیل میکند. بنابراین، شبکه می تواند به نتایج بهتری دست یابد.
3.2. افزایش داده ها
علاوه بر لایه حذف، از تکنیکهای افزایش دادهها برای جلوگیری از برازش بیش از حد و بهبود جهانی بودن مدل استفاده میشود. افزایش داده ها [ 31 ] فرآیندی است که از چندین تبدیل تصادفی برای تولید نمونه های آموزشی بیشتر از داده های آموزشی موجود استفاده می کند. مشخص است که راههای زیادی برای افزایش دادهها وجود دارد، و ویژگیهای همواری خاک بهعنوان ویژگیهای سطح پیکسل میتوانند اطلاعات خود تصاویر را تغییر دهند، در صورتی که با پاننگ، کشش و غیره بهبود پیدا کنند. این آزمایش دادههای آموزشی موجود را 90 درجه میچرخاند. 180 درجه و 270 درجه برای افزایش تعداد نمونه های آموزشی. هدف اصلی این است که به مدل اجازه دهد تا جنبه های بیشتری از نمونه های آموزشی را بررسی کند و در نتیجه توانایی جهانی بودن شبکه را بهبود بخشد.
3.3. استفاده از داده های نمونه خاک برای مدل سازی در ResNet
در طبقه بندی یا پیش بینی رگرسیون در بینایی کامپیوتر، ResNet از مجموعه داده های طبقه بندی تصویر برای حاشیه نویسی، مدل سازی و تجزیه و تحلیل استفاده می کند. بیشتر مجموعه داده ها در حوزه بینایی کامپیوتر برای طبقه بندی یا رگرسیون یک شی یا چندین کلاس از اشیا در یک تصویر استفاده می شود. در این آزمایش از کل تصویر به عنوان نمونه یادگیری استفاده می کنیم. مجموعه داده تصویر سه کاناله RGB با ترکیب چندین متغیر کمکی (به عنوان مثال، ویژگی های زمین یا داده های آب و هوا) تولید می شود. بنابراین، اطلاعات ویژگی فضایی متغیرهای کمکی دیگر با پیش پردازش، به عنوان مثال، با ادغام چند مقیاسی داده های کمکی در نظر گرفته نمی شود. در عوض، دادههای نمونه خاک مستقیماً در ResNet استفاده میشوند و از اطلاعات زمینهای مکانی از طریق یک رویکرد پسزمینه یا مبتنی بر پچ استفاده میکنند. سپس این تصاویر معادل تصاویر ورودی رایج هستند. برای هر نمونه، مساحت مربع اطراف نمونه از مجموعه داده های متغیر برش داده می شود. این تصاویر به عنوان تصاویر ورودی ResNet استفاده می شوند. با این حال، علاوه بر پارامترهای معمول ResNet، این نیاز به بهینه سازی اندازه وصله ها دارد.
3.4. تعریف مدل
در این مطالعه، ما یک ساختار شبکه عصبی عمیق به نام LSM-ResNet برای پیشبینی محتوای SOM با ترکیب دادههای NDVI، باند 4 (NIR) و MAP ساختیم. مجموعه داده کمکی SOM به طور تصادفی بین مجموعه آموزش و اعتبارسنجی (80٪) و مجموعه آزمون (20٪) اختصاص داده شد. تمام اندازهگیریهای خاک با استفاده از مقادیر حداقل و حداکثر مجموعه کالیبراسیون بین صفر و یک نرمال شد. علاوه بر این، تمام متغیرهای کمکی با میانگین 0 و انحراف استاندارد 1 مرکز و مقیاس بندی شدند. ساختار بر اساس AlexNet [ 31 ] و ResNet [ 40 ] است.]، با تغییرات و تنظیم شبکه اصلی برای اجازه دادن به تعداد کمی از دسته ها در تصاویر مجموعه داده به عنوان داده ورودی. در زمینه یادگیری ماشین، اندازههای مختلف وصله ورودیها میتوانند بر نتایج رگرسیون تأثیر بگذارند. بررسی تأثیر اندازههای مختلف پچ بر عملکرد بر اساس LSM-ResNet بسیار مهم است. برای ارزیابی مدلها معمولاً از ریشه میانگین مربعات خطا (RMSE)، میانگین خطای مطلق (MAE) و ضریب تعیین (R2 ) استفاده میشود. برای ارزیابی بیشتر نتایج رگرسیون LSM-ResNet، LSM-ResNet نیز با نتایج بدست آمده با استفاده از مدل جنگل تصادفی (RF) مقایسه شد. جزئیات ساختار LSM-ResNet، تخمین پارامتر و توابع ارزیابی که معمولاً در تحلیل رگرسیون استفاده میشوند در بخش 3.4.1 ارائه شدهاند.بخش 3.4.2 و بخش 3.4.3 به ترتیب.
3.4.1. LSM-ResNet برای نقشه برداری SOM
شبکههای عصبی میتوانند ارتباطات ذاتی بین جفتهای ورودی-هدف برقرار کنند که به خوبی همبستگی داشته باشند [ 62]. معماری از دو بخش تشکیل شده است: بخش اول فیلتر کانولوشن برای استخراج ویژگی سلسله مراتبی است و بخش دوم یک لایه کاملاً متصل است که از لایههایی از نورونهای کاملاً متصل با مقادیر ورودی متعدد تشکیل شده است. لایه کانولوشنال (Conv) به عنوان یک استخراج کننده ویژگی با در هم پیچیدن با داده های ورودی عمل می کند که معمولاً از چندین هسته با اندازه خاص استفاده می کند. سپس ویژگیهای در هم پیچیده توسط لایه فعالسازی غیرخطیسازی میشوند تا یک نگاشت ویژگی ایجاد شود. لایه ادغام نگاشت ویژگی ها را فشرده می کند تا افزونگی را کاهش دهد و خروجی را در یک فرآیند ادغام نهایی به بردار تبدیل می کند. لایه کاملا متصل (Fc) تمام ویژگی های آموخته شده در لایه قبلی را برای تعیین الگوی مورد نظر ترکیب می کند.
مدل های یادگیری عمیق به طور گسترده ای در رگرسیون تصویر استفاده شده اند [ 11 ، 37 ، 63 ، 64 ]. در بین مدلهای مختلف، مدلهای شبکه عصبی باقیمانده عمیق، بهویژه مدلهای ResNet، میتوانند با استفاده از روش اتصال میانبر اتصال متقاطع، مشکل انفجار گرادیان و ناپدید شدن گرادیان را حل کنند. بنابراین، بر اساس ویژگی های تصاویر Landsat TM و اصل مدل ResNet، ما یک مدل شبکه عصبی باقیمانده عمیق مبتنی بر پیکسل سبک وزن، LSM-ResNet، برای پیش بینی محتوای SOM طراحی کردیم ( شکل 5 )، و پیکربندی دقیق آن است. در جدول 2 نشان داده شده است.
مدل LSM-ResNet با مجموعهای از لایههای کانولوشن با اندازههای فیلتر 3×3 و 3×3 شروع میشود که در آن از تابع فعالسازی ReLU استفاده میشود [ 65 ]. آنها برای به دست آوردن ویژگی های همسایگی بزرگ مدل و حذف نویز تصویر استفاده می شوند. لایههای کانولوشن توسط یک لایه نگاشت ویژگی نمونه پایینتر با حداکثر اندازه استخر 2×2 (به عنوان مثال، کاهش ارتفاع و عرض ویژگیها) و یک لایه حذفی دنبال میشوند، در حالی که نیمه متصل بهطور تصادفی را جدا میکنند تا از برازش بیش از حد جلوگیری شود [ 66 , 67]. سپس از دو ماژول باقیمانده استفاده می شود که هر کدام در ابتدا به مسیر اصلی و یک میانبر تقسیم می شوند. مسیر اصلی دارای دو لایه کانولوشن برای استخراج ویژگی های عمیق نقشه ویژگی خاک است، در حالی که میانبر تنها دارای یک لایه کانولوشن برای تسهیل انتشار به سمت بالا باقیمانده ها در طول آموزش است. ویژگی های به دست آمده توسط مسیر اصلی و میانبر در انتهای ماژول باقیمانده بازسازی می شوند. همانطور که در بالا ذکر شد، بلوک های مدل LSM-ResNet در شکل 5 نشان داده شده اندب هر بلوک از سه لایه تشکیل شده است: یک لایه وزن (پارامترهای کانولوشن)، یک لایه فعال سازی ReLU و یک لایه نرمال سازی دسته ای (BN). BN در بالای خود بلوک های باقیمانده از ناپدید شدن و انفجار شیب ها در هر بلوک باقیمانده جلوگیری می کند، که می تواند به طور موثر کارایی تمرین را بهبود بخشد. پس از آن، استفاده از جمع بندی میانگین جهانی به جای مسطح کردن، می تواند تعداد پارامترها را به حداقل برساند. معماری مورد استفاده در این مقاله دارای سه لایه کاملاً متصل است که اطلاعات را دریافت کرده و بر اساس لایه قبلی پیشبینی میکنند.
برای مقایسه نتایج پیشبینی LSM-ResNet و روش مرجع، مدل RF را نیز کالیبره کردیم. یادگیری ماشین در DSM به دلیل عملکرد عالی خود شناخته شده است و RF از رگرسیون خطی چندگانه و حتی سایر تکنیک های یادگیری ماشین در اکثر مطالعات [ 66 ، 67 ، 68 ، 69 ] بهتر عمل می کند.]. در این آزمایش، یک روش بهینهسازی بیزی که تعداد بهینه درختهای تصمیم (n_estimators) و تعداد متغیرهای کمکی ورودی در هر زیر مجموعه تصادفی (m_estimators) را تنظیم میکند برای پیشبینی SOM مبتنی بر RF طراحی شد. مقادیر n_estimators از 50 تا 1000 و تعداد زیر مجموعه های مختلف از 2 تا 30 متغیر بود. بر اساس بهینه سازی بیزی، تعداد درخت های تصمیم در نهایت 700 و تعداد متغیرهای کمکی ورودی 5 تعیین شد. تابع RandomForestRegressor در کتابخانه scikit-learn، سایر پارامترها در RF به عنوان مقادیر پیش فرض باقی مانده اند. برای مقایسه منصفانه بین چندین مدل، ما از همان کالیبراسیون و مجموعه آزمایشی با اندازهگیریهای استاندارد SOM و متغیرهای کمکی استاندارد شده به عنوان ورودی استفاده کردیم.
3.4.2. تخمین پارامتر
هنگامی که مدل LSM-ResNet تعیین شد، حداقل MSE به عنوان تابع هدف برای تخمین پارامترها استفاده می شود و یک بهینه ساز برآورد حرکت تطبیقی (Adam) برای این آزمایش استفاده می شود. مدل با اندازه های مختلف پنجره تصاویر ورودی آموزش داده شد. ما مدلهای پیکسلهای متغیر ورودی را با اندازههای پنجره 3، 5، 7، 9، 15، 21، 29 و 50 مقایسه کردیم. این مقایسه بر اساس میانگین RMSE در مجموعه اعتبارسنجی انجام شد. شبکه پیشنهادی در پایتون با استفاده از بسته Keras نسخه 2.1.0 [ 68 ] و کتابخانه TensorFlow Google [ 69 ] پیاده سازی شد. هنگامی که اندازه پنجره ورودی انتخاب شد، بهینه سازی بیزی برای بهینه سازی فراپارامترهای معماری مدل اعمال شد [ 70]. بهینهسازی بیزی مقادیر بهینه را برای فراپارامترهای یادگیری ماشین در تکرارهای کمتری نسبت به جستجوی تصادفی پیدا میکند. در این کار، تعداد فیلتر، تعداد نورونها، اندازه دسته و نرخ یادگیری را با استفاده از 63 تکرار بهینه کردیم.
3.4.3. شاخص های اعتبارسنجی
پنج شاخص رایج، یعنی ریشه میانگین مربعات خطا (RMSE)، میانگین خطای مطلق (MAE)، ضریب همبستگی تطابق لین (CCC)، میانگین خطا (ME) و ضریب تعیین (R2 ) برای اعتبار سنجی استفاده شد. RMSE دقت پیش بینی مدل را نشان می دهد. MAE معیاری برای دقت مدل است، اما نسبت به RMSE حساسیت کمتری نسبت به نقاط پرت دارد. R2 بین 0 و 1 تغییر می کند و نزدیکی مقادیر پیش بینی شده را به خط رگرسیون متناسب بین مقادیر پیش بینی شده و مشاهده شده یا نسبت واریانس توضیح داده شده توسط پیش بینی کننده های مستقل نشان می دهد. سوگیری با میانگین خطا (ME) ارزیابی می شود.
جایی که و به ترتیب مقادیر پیش بینی شده و واقعی نقاط نمونه اعتبارسنجی هستند و مقدار واقعی مقدار میانگین است.
CCC [ 71 ] یک معیار قابلیت اطمینان مبتنی بر کوواریانس و مطابقت است، با خط همبستگی Lin از طریق مبدا، توافق بین مقادیر اندازهگیری شده و پیشبینیشده را برای یک خط 1:1 با شیب 1.0 ارزیابی میکند.
جایی که و میانگین و واریانس هر دو بردار اندازه گیری های واقعی هستند یا بردار مقادیر پیش بینی شده ، به ترتیب. ارزش نشان دهنده همبستگی بین و .
4. نتایج
شکل 6RMSE SOM را برای ابعاد مختلف محیطی تصویر ورودی برای مدل LSM-ResNet نشان می دهد. اطلاعات پس زمینه با نمایش داده های ورودی به عنوان یک تصویر مربعی در اطراف نقطه اندازه گیری خاک در نظر گرفته می شود. هر پیکسل دارای وضوح 30 متر × 30 متر است، بنابراین اندازه پنجره 3 × 3 پیکسل حاوی اطلاعات متنی تقریباً 45 متر است. هنگام استفاده از یک پنجره 5 × 5 پیکسل، RMSE به طور قابل توجهی کوچکتر می شود. کمترین میانگین RMSE با اندازه پنجره 15 × 15 پیکسل (اطلاعات متنی حدود 245 متر) یافت می شود. دادهها نشان میدهند که کالیبراسیون مدل از استفاده از اندازههای پنجره بزرگتر سودی نمیبرد، زیرا مقادیر RMSE برای اندازههای پنجره 29 × 29 پیکسل و 50 × 50 پیکسل در حال افزایش است. هنگام استفاده از LSM-ResNet برای پیش بینی، مدل اجازه استفاده از چندین اندازه پنجره ورودی را نمی دهد.
شکل 7 a,b نمودار پراکندگی مقادیر SOM پیشبینیشده و مشاهدهشده برای دادههای آزمایشی از مدلهای LSM-ResNet و RF را نشان میدهد. اکثر پیش بینی ها در یک خط 1:1 جمع آوری می شوند. به طور کلی، هر دو مدل LSM-ResNet و RF تمایل دارند مشاهدات SOM را بین 0 تا 10 گرم بر کیلوگرم بیش از حد تخمین بزنند و مشاهدات SOM بالای 30 گرم بر کیلوگرم را دست کم بگیرند، با اکثر مشاهدات بین 10 گرم بر کیلوگرم و 30 گرم بر کیلوگرم. در مقایسه با LSM-ResNet، پیشبینیها با استفاده از RF پراکندهتر بودند، با چندین پیشبینی بیش از حد در محدوده پایین مقادیر SOM اندازهگیریشده. بازرسی بصری در شکل 7 نشان می دهد که LSM-ResNet با دقت بیشتری نسبت به RF پیش بینی کرده است.
برای تأیید این ارزیابی کیفی، معیارهای عملکرد مدل تولید شد ( جدول 3 ) و برای هر دو مدل مقایسه شد. اندازه گیری های دقت LSM-ResNet به طور متوسط برابر یا بهتر از RF بود. بر اساس مقادیر RMSE و R2 ، LSM-ResNet (R2 = 0.51) عملکرد بهتری از RF (R2 = 0.46) داشت. CCC نشان می دهد که قابلیت اطمینان LSM-ResNet (CCC = 0.71) بر اساس متغیرهای کمکی و مطابقت ها بهتر از RF (CCC = 0.64) است. ME (بر حسب گرم بر کیلوگرم) نشان داد که پیشبینیهای هر دو مدل نسبتاً بیطرفانه هستند. مدل LSM-ResNet اندازه کوچکی از دقت را ارائه میکند (RMSE 6.40 در مقابل 6.81 برای مدل RF) در حالی که درجه بیشتری از پیشبینی مانند افتادن روی خط 1:1 از مبدأ را ارائه میدهد.
شکل 8 a,b نمودارهای پیش بینی SOM را بر اساس LSM-ResNet و بر اساس RF نشان می دهد. نتایج پیشبینی مدلهای یادگیری عمیق در یک نمودار صاف اما دقیق نشان داده شده است. نقشه پیشبینی نشان خوبی از روند تغییرات فضایی محتوای SOM سطح میدهد. مناطق با ارزش بالا در نقشه پیشبینی در بخشهای جنوب شرقی و مرکزی منطقه مورد مطالعه ظاهر میشوند و نقشه پیشبینی به طور دقیق ویژگیهای تنوع SOM در منطقه مورد مطالعه را تا حد معینی منعکس میکند. از شکل 8 مشاهده می شود که مناطق پر ارزش و کم ارزش در منطقه مورد مطالعه مشهود هستند و دارای ویژگی های توزیع فضایی آشکار هستند، نقشه SOM ( شکل 8).ب) تولید شده از مدل RF مشخص شد که به شدت به متغیر کمکی MAP متکی است، و به این ترتیب، الگوهای فضایی MAP در نقشه SOM مشهود است. منطقه کم ارزش (5 تا 9 گرم بر کیلوگرم) که در قسمت مرکزی ظاهر می شود به خوبی در نقشه پیش بینی LSM-ResNet ( شکل 8 الف) با تفاوت های آشکار با محتوای SOM اطراف منعکس شده است.
5. بحث
5.1. تأثیر اندازه پنجره ورودی
تأثیر اندازه پنجره تصویر ورودی بر دقت پیشبینی در شکل 6 نشان داده شده است و هنگام استفاده از تصاویر با اندازههای مختلف پنجره، اندازه تصویر بهینه 15 پیکسل است که مربوط به اطلاعات متنی در حدود 225 متر است. این مطالعه، و RMSE برای این اندازه تصویر نیز پایین ترین است. این نشان میدهد که اطلاعات متنی دادههای کمکی در 225 متر برای پیشبینی SOM مفیدتر از اطلاعات محلی یک نقطه خاص است که تنها یک اندازهگیری ویژگی خاک در دسترس است. این نیز نتیجه مورد انتظار گزارش شده توسط پاداریان و همکاران است. [ 11]. اندازه پنجره ارتباط نزدیکی با اطلاعات زمینه ای ارائه شده به مدل دارد. این مدل زمینه فضایی را با در نظر گرفتن پیکسل های کمکی در نزدیکی مکان های نمونه گیری یکپارچه می کند. پسزمینه بیشتر میتواند قدرت پیشبینی مدل را بهبود بخشد، اما اطلاعات پسزمینه بیش از حد مطمئناً نویز ایجاد میکند. پاداریان و همکاران [ 11 ] در مطالعات موردی که در آن ویژگی های توپوگرافی از DEM مورد استفاده در بررسی خاک مشتق شده بود، محدوده بهینه اندازه پنجره را یافت. با این حال، شایان ذکر است که اندازه پنجره بهینه در تحلیل DSM از مطالعه موردی به مطالعه موردی بسته به وضوح فضایی داده های ورودی و ویژگی های چشم انداز متفاوت است. برخی از نویسندگان مقادیر معادل محدوده مربوط به فضایی را برای SOM ارائه کرده اند. کومهلووا و همکاران [72 ] مقادیری را برای محدوده همبستگی فضایی مواد آلی بین 240 و 270 متر با استفاده از دادههای یک سایت آزمایشی در جمهوری چک گزارش کرد. به طور مشابه، Jian-Bing و همکاران. [ 73 ] یک محدوده همبستگی فضایی 309 متر برای یک حوزه آبخیز کوچک در شمال شرقی چین پیدا کرد. برای مطالعه خود، ما این فرضیه را با برازش تابع نیمه متغیر کروی به واریوگرام تجربی SOM آزمایش کردیم. مقدار مناسب برای محدوده 216 متر است، نزدیک به اندازه پنجره ای که ما پیدا کردیم. با این حال، نتیجه گیری بر اساس نتایج پیش بینی شده دشوار است. رابطه بین محدوده همبستگی اندازه پنجره و فاصله خودهمبستگی SOM باید بیشتر مورد بررسی قرار گیرد.
در مطالعه ما متوجه شدیم که اندازه پنجره بین 13 × 13 پیکسل و 18 × 18 پیکسل بهینه بود. DEM، به عنوان یکی از عوامل مهم مؤثر بر SOM، توسط چندین نویسنده دیگر به عنوان متغیر کمکی برای ترکیب تصاویر RGB انتخاب شد [ 11 ، 35]. اما در این آزمایش، مساحت دشت 78 درصد از کل مساحت را به خود اختصاص داده است. ویژگی های توپوگرافی منطقه دشت تنوع کمتری داشت و بیان ویژگی های توپوگرافی مانند ارتفاع مشخص نبود. مشخص شده است که پیشبینی ویژگیهای خاک در مناطق دشتی مشکل دشواری بوده است و دقت پیشبینی خوبی در این آزمایش بدون انتخاب ویژگیهای توپوگرافی به عنوان متغیرهای کمکی حاصل شد. خارج از این محدوده، دقت پیشبینی ممکن است 6 درصد کمتر از بالاترین مقدار دقت باشد. بنابراین، می توان فرض کرد که یک خودهمبستگی فضایی بین طیف معینی از اطلاعات زمینه ای و SOM مناطق دشت وجود دارد. با این حال، تحقیقات بیشتری برای نتیجهگیری کلی در مورد رابطه بین دامنه خودهمبستگی خصوصیات خاک و اندازه پنجره مورد نیاز است.60 ]. بررسی این موضوع مطمئناً گسترش ارزشمندی برای مطالعات آینده DSM خواهد بود.
5.2. افزایش داده ها
برای تعمیم و بهبود LSM-ResNet، دادههای جدیدی را با چرخاندن ورودی تصویر اصلی و تنها با استفاده از اطلاعات دادههای آموزشی ایجاد کردیم. افزایش داده ها در کاهش خطای مدل مؤثر بود ( شکل 9 )، و کاهش 3 درصدی در خطای مدل مشاهده شد. مطالعات به طور کلی نشان داده اند که “افزایش” داده ها می تواند دقت وظایف طبقه بندی را بهبود بخشد [ 74 ]]. فرض بر این است که با افزایش میزان داده های آموزشی می توان پدیده اضافه برازش LSM-ResNet را کاهش داد. از نظر خود همبستگی مکانی داده ها، باید در نظر بگیریم که در مورد افزایش داده ها، چهار نقطه نمونه برداری در یک مکان با محتوای SOM یکسان در نقاط نمونه گیری داریم، بنابراین با فرض مساوی 0 فاصله تفاوتی نمی کند. اگر فاصله را دقیقاً برابر با 0 در نظر بگیریم [ 35 ]. با این حال، به طور قابل توجهی خطای مدل (با و بدون افزایش داده) را کاهش نداد [ 11 ، 35]. تعداد کمی از مردم در این مورد بحث کرده اند، زیرا تصاویر کمکی دارای نمایش داده های متفاوتی نسبت به تصاویری هستند که اغلب در بینایی کامپیوتر استفاده می شوند. ما به طور آزمایشی فرض میکنیم که اثر افزایش دادههای تصاویر کمکی به متغیرهای کمکی انتخاب شده مرتبط است. DEM نسبت به سایر متغیرهای کمکی تحت شرایط یکسان (مثلاً آب و هوا و DEM) به بهبود دادههای بهتری دست مییابد، زیرا DEM ویژگیهای اطلاعات مکانی متمایزتری دارد و هنگام استخراج ویژگیهای دادههای کم عمق عملکرد بهتری دارد. با این حال، غیرقابل انکار است که یادگیری عمیق به تعداد زیادی نمونه برای آموزش مدل نیاز دارد، و افزایش داده ها می تواند برای نقشه برداری خاک بر اساس یادگیری عمیق بسیار مفید باشد [ 74 ].
5.3. تفسیر ویژگی های نقشه
در شکل 8a، ما نقشه محتوای SOM پیش بینی شده را با استفاده از معماری LSM-ResNet پیشنهادی ارائه می دهیم. فاصله محتوای کلی ماده آلی بین 2 تا 40 گرم بر کیلوگرم بود و به شدت در حاشیه 10 تا 20 گرم بر کیلوگرم متمرکز شد. نقشه نشان می دهد که محتوای SOM منطقه مورد مطالعه از شمال غربی به جنوب شرقی کاهش می یابد، با حاشیه کوه های Taihang در شمال غربی منطقه مورد مطالعه و رودخانه زرد در جنوب، و توپوگرافی با افزایش ارتفاع از تپه ها به دشت تغییر می کند. کاهش می دهد. به طور کلی اعتقاد بر این است که محتوای SOM به طور قابل توجهی و مثبت با ارتفاع همبستگی دارد و محتوای SOM در ارتفاع نسبتاً بالا (18 تا 25 گرم بر کیلوگرم ماده آلی) در شمال غربی بیشتر از سایر مناطق دشت است. در همین حال، ما خطوط جداکننده مواد آلی آشکاری را در لبه کوههای تای هانگ یافتیم. که در آن مواد آلی در پایین شیب بیشتر از پشته انباشته شده بود و تغییرات ماده آلی دارای تنوع فضایی آشکار بود. شهر سین شیانگ یک منطقه مهم تولید غلات در چین است که 78 درصد آن در منطقه دشت است، در حالی که منطقه مرکزی (19 تا 27 گرم بر کیلوگرم ماده آلی) دارای مقدار زیادی زمین کشاورزی است و اقدامات موثر مدیریت خاک به طور قابل توجهی انجام شده است. محتوای SOM را در ناحیه مرکزی افزایش داد. منطقه مرکزی کم ارزش تا حدی حوضه رودخانه زرد باستانی است که توسط خاک های شنی زرد غالب است که به داشتن محتوای آلی بسیار کمتر از خاک های دیگر شناخته شده است. به همین دلیل است که منطقه مرکزی دارای یک منطقه کم ارزش است. 78٪ آن در منطقه دشت است، در حالی که منطقه مرکزی (19-27 گرم بر کیلوگرم ماده آلی) دارای مقدار زیادی زمین کشاورزی است و اقدامات موثر مدیریت خاک به طور قابل توجهی محتوای SOM را در منطقه مرکزی افزایش داده است. منطقه مرکزی کم ارزش تا حدی حوضه رودخانه زرد باستانی است که توسط خاک های شنی زرد غالب است که به داشتن محتوای آلی بسیار کمتر از خاک های دیگر شناخته شده است. به همین دلیل است که منطقه مرکزی دارای یک منطقه کم ارزش است. 78٪ آن در منطقه دشت است، در حالی که منطقه مرکزی (19-27 گرم بر کیلوگرم ماده آلی) دارای مقدار زیادی زمین کشاورزی است و اقدامات موثر مدیریت خاک به طور قابل توجهی محتوای SOM را در منطقه مرکزی افزایش داده است. منطقه مرکزی کم ارزش تا حدی حوضه رودخانه زرد باستانی است که توسط خاک های شنی زرد غالب است که به داشتن محتوای آلی بسیار کمتر از خاک های دیگر شناخته شده است. به همین دلیل است که منطقه مرکزی دارای یک منطقه کم ارزش است. که به داشتن مواد آلی بسیار کمتر از خاک های دیگر شناخته شده است. به همین دلیل است که منطقه مرکزی دارای یک منطقه کم ارزش است. که به داشتن مواد آلی بسیار کمتر از خاک های دیگر شناخته شده است. به همین دلیل است که منطقه مرکزی دارای یک منطقه کم ارزش است.شکل 8 ب توزیع SOM را بر اساس مدل جنگل تصادفی پس از کالیبراسیون نشان می دهد. ما یک منطقه راه راه را در وسط جهت جنوب شرقی مشاهده کردیم که در نقشه پیشبینی LSM-ResNet وجود نداشت. ما فکر می کنیم دلیل آن این است که منطقه یک منطقه ساده است، برخی از متغیرهای کمکی (مانند DEM، Aspect) در پیش بینی RF تفاوت زیادی ندارند، و مدل بیشتر تحت تاثیر یک متغیر تکی (MAP) است، در حالی که LSM-ResNet می تواند از آن استفاده کند. از طریق یادگیری عمیق ویژگی های عمق بیشتری دارد و عملکرد بهتری در منطقه دشت دارد.
با مقایسه شکل 8 a و b، شاید یکی دیگر از مزایای مدل ResNet این باشد که می تواند از متغیرهای کمکی بهتر استفاده کند. این با این واقعیت نشان داده می شود که پیش بینی های مدل RF روند فضایی MAP را نشان می دهد، در حالی که ResNet از همان متغیرهای کمکی استفاده می کند اما این کار را نمی کند. بنابراین، شاید این اثر ResNet در محافظت از نقشههای DSM هنگام استفاده از مختصات به عنوان پیشبینیکننده رایج باشد. یک الگوی مشابه از تغییرات فضایی در SOM پیشبینیشده توسط هر دو مدل، با روند کاهشی از شمال غرب به جنوب شرق دیده میشود. همانطور که در شکل مشاهده می شود، میانگین نقشه نقشه برداری با استفاده از معماری LSM-ResNet یک الگوی صاف اما دقیق با تغییرات فضایی قابل توجه را نشان می دهد.
5.4. تجزیه و تحلیل نتایج ارزیابی دقت پیش بینی
در این مطالعه، یادگیری عمیق قدرت پیشبینی خوبی را ارائه کرد که توسط RMSE، MAE، CCC، ME و R2 نشان داده شده است . این معماری از یک مجموعه داده متشکل از سه متغیر کمکی استفاده کرد که از یادگیری ماشین سنتی بهتر عمل کرد. نتایجی که ما به دست آوردیم مشابه مطالعات اخیر با استفاده از یادگیری عمیق برای نقشه برداری خاک [ 61 ] است و نتیجه می گیرد که یادگیری عمیق از RF بهتر است. برخی از افراد از تصاویر باند 5 DEM، NDVI و Landsat TM 5 استفاده می کنند [ 35]. دلیل این امر می تواند این باشد که وقتی متغیرهای کمکی کمتری وجود دارد، عملکرد بهتر است، احتمالاً به این دلیل که مدل تعداد زیادی متغیرهای کمکی فوق العاده را از تصویر اصلی در طول فرآیند پیچیدگی تولید می کند، در حالی که RF صرفاً مبتنی بر داده است و قضاوت تجربی در مورد متغیرهای کمکی موجود علاوه بر این، یکی از دلایل عملکرد بهتر LSM-ResNet استفاده از یک شبکه باقیمانده برای جایگزینی لایه کانولوشن اصلی است. در مدل های یادگیری عمیق، هر چه عمق مدل بیشتر باشد، ویژگی های بیشتری استخراج می شود. زیر برازش مدل آسان است و اگر از مدلی با عمق نامناسب با پارامترهای خیلی کم استفاده شود، اضافه برازش رخ می دهد. مدل LSM-ResNet تطبیق بیش از حد مدل را کاهش می دهد. این باعث می شود مدل در آموزش داده های محدود عملکرد بهتری داشته باشد. لایه Flatten را با یک لایه Global Average Pooling جایگزین می کنیم. لایه Flatten ممکن است اطلاعات مکانی را که باید حذف شوند تا ویژگی های انتزاعی حذف شوند و لایه جمع میانگین جهانی [75 ] نقشه ویژگی آخرین لایه را با مقدار میانگین ترکیب می کند تا یک نقطه مشخصه را تشکیل دهد که از این نقاط ویژگی بردار ویژگی نهایی تشکیل شده است که اطلاعات مکانی را تا حد بیشتری حفظ می کند. در آزمایشهای ما، LSM-ResNet مسیرهای میانبر را برای فعال کردن ترکیب ویژگیها در سطوح مختلف اضافه میکند و به مدل LSM-ResNet اجازه میدهد سریعتر همگرا شود.
6. نتیجه گیری
در این مطالعه، ما یک رویکرد LSM-ResNet مبتنی بر یادگیری عمیق و مبتنی بر داده را برای تولید پیشبینیهای SOM در شهر Xinxiang، واقع در دشت مرکزی استان هنان، چین پیشنهاد میکنیم، در حالی که ما عملکرد پیشبینی یک دستگاه را ارزیابی و مقایسه میکنیم. مدل سنتی پیشبینی یادگیری ماشین، مدل RF. نتایج ما نشان میدهد که LSM-ResNet عملکرد نگاشت محتوای SOM بهتری در مقایسه با الگوریتم RF دارد. مزیت LSM-ResNet این است که به صراحت اطلاعات متنی متغیرهای کمکی را در مکان های مجاور ادغام می کند. علاوه بر این، LSM-ResNet، مانند سایر مدل های یادگیری ماشین، بر فرضیات آماری سفت و سخت در مورد توزیع خواص خاک متکی نیست. معماری LSM-ResNet پیشنهاد شده در این آزمایش برای پیشبینی مواد آلی خاک در دشتها مناسب است. و نقشه پیش بینی SOM دارای تنوع فضایی قابل توجهی است. علاوه بر این، مدل پیشنهادی می تواند برای پیش بینی سایر متغیرهای محیطی مورد استفاده قرار گیرد.
مشارکت های نویسنده
مفهوم سازی، آهنگ Pengyuan Zeng و Xuan. روش، Pengyuan Zeng; نرم افزار، Pengyuan Zeng; اعتبارسنجی، Pengyuan Zeng، Huan Yang و Ning Wei. تجزیه و تحلیل رسمی، Pengyuan Zeng و Huan Yang. تحقیق، Pengyuan Zeng و Xuan Song; منابع، آهنگ Xuan و Liping Du; مدیریت داده، نینگ وی. نوشتن – آماده سازی پیش نویس اصلی، Pengyuan Zeng; نوشتن-بررسی و ویرایش، آهنگ Xuan و Huan Yang. تجسم، Pengyuan Zeng و Ning Wei. نظارت، آهنگ Xuan; مدیریت پروژه، آهنگ ژوان و لیپینگ دو. کسب بودجه، آهنگ Xuan همه نویسندگان نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
منابع مالی
این تحقیق توسط برنامه تحقیق و توسعه کلید ملی چین (شماره 2017YFD0800605) پشتیبانی شد.
بیانیه در دسترس بودن داده ها
داده های ارائه شده در این مطالعه به درخواست نویسنده مسئول در دسترس است. داده ها به دلیل حفظ حریم خصوصی در دسترس عموم نیستند.
تضاد علاقه
نویسندگان هیچ تضاد منافع را اعلام نمی کنند.
منابع
- وو، تی. لو، جی. دونگ، دبلیو. سان، ی. شیا، ال. Zhang, X. نقشه برداری ماده آلی خاک مبتنی بر ژئو شی با استفاده از الگوریتم های یادگیری ماشین با داده های جغرافیایی-مکانی چند منبعی. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2019 , 12 , 1091–1106. [ Google Scholar ] [ CrossRef ]
- تقی زاده مهرجردی، ر. نبی اللهی، ک. نقشه برداری دیجیتالی کربن آلی خاک در اعماق چندگانه با استفاده از تکنیک های مختلف داده کاوی در منطقه بانه، ایران. Geoderma 2016 ، 266 ، 98-110. [ Google Scholar ] [ CrossRef ]
- کین، دی. بردفورد، MA; فولر، ای. اولدفیلد، EE; Wood, SA مواد آلی خاک از عملکرد ذرت ایالات متحده محافظت می کند و پرداخت بیمه محصولات را در شرایط خشکسالی کاهش می دهد. محیط زیست Res. Lett. 2021 , 16 , 044018. [ Google Scholar ] [ CrossRef ]
- میرسمنز، جی. د ریدر، اف. کانترز، اف. د باتس، اس. رویکرد رگرسیون چندگانه برای ارزیابی توزیع فضایی کربن آلی خاک (SOC) در مقیاس منطقهای (فلاندرز، بلژیک). ژئودرما 2008 ، 143 ، 1-13. [ Google Scholar ] [ CrossRef ]
- لی، QQ; یو، TX; وانگ، CQ; ژانگ، WJ; یو، ی. لی، بی. یانگ، جی. بای، GC مدلسازی فضایی مواد آلی خاک در سراسر چین: کاربرد رویکرد شبکه عصبی مصنوعی. کاتنا 2013 ، 104 ، 210-218. [ Google Scholar ] [ CrossRef ]
- Arrouays، D.; گراندی، ام جی؛ هارتمینک، AE; Hempel، JW; Heuvelink، GB; هنگ، سی. لاگاچری، پ. لیلیک، جی. مک براتنی، AB; McKenzie، NJ GlobalSoilMap: به سوی یک شبکه جهانی با وضوح خوب از خواص خاک. Adv. آگرون. 2014 ، 125 ، 93-134. [ Google Scholar ]
- هنگل، تی. مندس دی ژسوس، جی. Heuvelink، GB; رویپرز گونزالس، م. کلیبردا، م. بلاگوتیچ، آ. شانگگوان، دبلیو. رایت، MN; گنگ، ایکس. Bauer-Marschallinger, B. SoilGrids250m: اطلاعات خاک شبکه بندی شده جهانی بر اساس یادگیری ماشین. PLoS ONE 2017 , 12 , e0169748. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مک براتنی، AB; مندونسا سانتوس، ام ال. Minasny, B. در مورد نقشه برداری خاک دیجیتال. ژئودرما 2003 ، 117 ، 3-52. [ Google Scholar ] [ CrossRef ]
- دوکوچایف، وی . ج. 1; برنامه اسرائیل برای ترجمه های علمی: اورشلیم، اسرائیل، 1967. [ Google Scholar ]
- جنی، اچ. عوامل تشکیل خاک: سیستم کمی خاک شناسی . شرکت پیک: نورث چلمزفورد، MA، ایالات متحده آمریکا، 1994. [ Google Scholar ]
- پاداریان، ج. میناسنی، بی. مک براتنی، AB استفاده از یادگیری عمیق برای نقشه برداری دیجیتالی خاک. خاک 2019 ، 5 ، 79-89. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Guo، P.-T. وو، دبلیو. شنگ، ق.-ک. لی، M.-F. لیو، H.-B. وانگ، Z.-Y. پیش بینی مواد آلی خاک با استفاده از شبکه عصبی مصنوعی و شاخص های توپوگرافی در مناطق تپه ماهوری Nutr. چرخه Agroecosystems 2013 ، 95 ، 333-344. [ Google Scholar ] [ CrossRef ]
- هیونگ، بی. هو، اچ سی; ژانگ، جی. نادبی، ا. Bulmer، CE; اشمیت، ام جی مروری و مقایسه تکنیکهای یادگیری ماشینی برای اهداف طبقهبندی در نقشهبرداری دیجیتالی خاک. Geoderma 2016 ، 265 ، 62-77. [ Google Scholar ] [ CrossRef ]
- وو، دبلیو. لی، A.-D. او، X.-H. ما، ر. لیو، H.-B. Lv، J.-K. مقایسه ماشینهای بردار پشتیبان، شبکه عصبی مصنوعی و درخت طبقهبندی برای شناسایی طبقات بافت خاک در جنوب غربی چین. محاسبه کنید. الکترون. کشاورزی 2018 ، 144 ، 86-93. [ Google Scholar ] [ CrossRef ]
- وانگ، اس. ژوانگ، س. وانگ، کیو. جین، ایکس. هان، سی. نقشه برداری از ذخایر کربن آلی خاک و نیتروژن کل خاک در استان لیائونینگ چین. Geoderma 2017 ، 305 ، 250-263. [ Google Scholar ] [ CrossRef ]
- ویزمایر، ام. بارتولد، اف. خالی، بی. Kögel-Knabner, I. نقشه برداری دیجیتالی ذخایر مواد آلی خاک با استفاده از مدل سازی تصادفی جنگل در یک اکوسیستم استپی نیمه خشک. گیاه. خاک 2011 ، 340 ، 7-24. [ Google Scholar ] [ CrossRef ]
- تقی زاده مهرجردی، ر. نبی اللهی، ک. میناسنی، بی. تریانتافلیس، ج. مقایسه طبقهبندیکنندههای داده کاوی برای پیشبینی توزیع فضایی گروههای خاک خانواده USDA در منطقه بانه، ایران. Geoderma 2015 ، 253 ، 67-77. [ Google Scholar ] [ CrossRef ]
- تقی زاده مهرجردی، ر. اشمیت، ک. افتخاری، ک. بهرنز، تی. جمشیدی، م. دواتگر، ن. تومانیان، ن. شولتن، تی. استراتژیهای نمونهگیری مجدد مصنوعی و یادگیری ماشین برای نقشهبرداری دیجیتال خاک در ایران. یورو J. Soil Sci. 2020 ، 71 ، 352-368. [ Google Scholar ] [ CrossRef ]
- یانگ، ال. چی، اف. زو، تبر; شی، ج. An, Y. ارزیابی نمونه برداری گام به گام سلسله مراتبی یکپارچه برای نقشه برداری خاک دیجیتال. علم خاک Soc. صبح. J. 2016 ، 80 ، 637-651. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- موندال، ا. خاره، د. کندو، اس. موندال، اس. موکرجی، اس. Mukhopadhyay، A. پیشبینی کربن آلی خاک (SOC) با کریجینگ رگرسیون با استفاده از دادههای سنجش از دور. مصر. J. Remote Sens. Space Sci. 2017 ، 20 ، 61-70. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وانگ، ک. ژانگ، سی. Li، W. نقشهبرداری پیشبینیکننده نیتروژن کل خاک در مقیاس منطقهای: مقایسه بین رگرسیون وزندار جغرافیایی و کوکریجینگ. Appl. Geogr. 2013 ، 42 ، 73-85. [ Google Scholar ] [ CrossRef ]
- آهنگ، X.-D.; بروس، دی جی; لیو، اف. لی، دی.-سی. ژائو، Y.-G. یانگ، جی.-ال. ژانگ، جی.-ال. نقشه برداری محتوای کربن آلی خاک با رگرسیون وزنی جغرافیایی: مطالعه موردی در حوضه رودخانه هیهه، چین. ژئودرما 2016 ، 261 ، 11-22. [ Google Scholar ] [ CrossRef ]
- زنگ، سی. یانگ، ال. زو، تبر; Rossiter، DG; لیو، جی. لیو، جی. کوین، سی. Wang, D. نقشه برداری غلظت ماده آلی خاک در مقیاس های مختلف با استفاده از روش رگرسیون وزنی جغرافیایی مخلوط. Geoderma 2016 ، 281 ، 69-82. [ Google Scholar ] [ CrossRef ]
- Wadoux، AMJC; میناسنی، بی. مک براتنی، AB یادگیری ماشینی برای نقشه برداری دیجیتال خاک: کاربردها، چالش ها و راه حل های پیشنهادی Earth-Sci. Rev. 2020 , 210 , 103359. [ Google Scholar ] [ CrossRef ]
- هنگل، تی. گروبر، اس. Shrestha، DP کاهش خطا در پارامترهای زمین رقومی مورد استفاده در مدل سازی خاک-منظر. بین المللی J. Appl. زمین Obs. Geoinf. 2004 ، 5 ، 97-112. [ Google Scholar ] [ CrossRef ]
- هنگل، تی. Heuvelink، GB; Rossiter، DG درباره رگرسیون-کریجینگ: از معادلات تا مطالعات موردی. محاسبه کنید. Geosci. 2007 ، 33 ، 1301-1315. [ Google Scholar ] [ CrossRef ]
- کرسی، ن. Johannesson, G. کریجینگ رتبه ثابت برای مجموعه داده های مکانی بسیار بزرگ. JR Stat. Soc. سر. B (Stat. Methodol.) 2008 ، 70 ، 209-226. [ Google Scholar ] [ CrossRef ]
- زو، XX; تویا، دی. مو، ال. Xia، G.-S. ژانگ، ال. خو، اف. Fraundorfer, F. یادگیری عمیق در سنجش از دور: بررسی جامع و فهرست منابع. IEEE Geosci. سنسور از راه دور Mag. 2017 ، 5 ، 8-36. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مهدیان پری، م. صالحی، ب. رضایی، م. محمدی منش، ف. Zhang، Y. شبکههای عصبی کانولوشنال بسیار عمیق برای نگاشت پیچیده پوشش زمین با استفاده از تصاویر سنجش از دور چندطیفی. Remote Sens. 2018 , 10 , 1119. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، سی. Mishra, DR; Pennings, SC نقشه برداری خواص خاک باتلاق نمکی با استفاده از طیف سنجی تصویربرداری. ISPRS J. Photogramm. Remote Sens. 2019 , 148 , 221–234. [ Google Scholar ] [ CrossRef ]
- کریژفسکی، آ. سوتسکور، آی. هینتون، GE Imagenet طبقه بندی با شبکه های عصبی کانولوشن عمیق. Adv. عصبی Inf. سیستم پردازش 2012 ، 25 ، 1097-1105. [ Google Scholar ] [ CrossRef ]
- ورس، م. لیسی، جی. معماریهای یادگیری عمیق تیلور، GW برای پیشبینی خواص خاک. در مجموعه مقالات دوازدهمین کنفرانس سال 2015 در مورد چشم انداز رایانه و ربات، هالیفاکس، NS، کانادا، 3 تا 5 ژوئن 2015. صص 8-15. [ Google Scholar ]
- ولپی، م. Tuia, D. برچسب گذاری معنایی متراکم تصاویر با وضوح زیر دسی متر با شبکه های عصبی کانولوشن. IEEE Trans. Geosci. Remote Sens. 2016 , 55 , 881–893. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بهرنز، تی. اشمیت، ک. مک میلان، RA; مدل سازی فضایی زمینه ای چند مقیاسی Rossel، RV با فضای مقیاس گاوسی. Geoderma 2018 ، 310 ، 128-137. [ Google Scholar ] [ CrossRef ]
- Wadoux، AMJC; پاداریان، ج. میناسنی، ب. ادغام داده های چند منبعی برای نقشه برداری خاک با استفاده از یادگیری عمیق. خاک 2019 ، 5 ، 107-119. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تساکریدیس، NL; Keramaris، KD; Theocharis، JB; Zalidis، GC پیشبینی همزمان ویژگیهای خاک از طیفهای VNIR-SWIR با استفاده از یک شبکه عصبی کانولوشنال 1 بعدی چند کاناله محلی. Geoderma 2020 , 367 , 114208. [ Google Scholar ] [ CrossRef ]
- تقی زاده مهرجردی، ر. مهدیان پری، م. محمدی منش، ف. بهرنز، تی. تومانیان، ن. شولتن، تی. اشمیت، کی. Geoderma 2020 , 376 , 114552. [ Google Scholar ] [ CrossRef ]
- وو، زی. شن، سی. ون دن هنگل، A. گسترده تر یا عمیق تر: بازبینی مدل resnet برای تشخیص بصری. تشخیص الگو 2019 ، 90 ، 119-133. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سگدی، سی. لیو، دبلیو. جیا، ی. سرمانت، پ. رید، اس. آنگلوف، دی. ایرهان، د. ونهوک، وی. رابینوویچ، الف. با پیچیدگی ها عمیق تر می رویم. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. صفحات 1-9. [ Google Scholar ]
- او، ک. ژانگ، ایکس. رن، اس. Sun, J. یادگیری باقیمانده عمیق برای تشخیص تصویر. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، 27-30 ژوئن 2016. صص 770-778. [ Google Scholar ]
- وانگ، اف. جیانگ، م. کیان، سی. یانگ، اس. لی، سی. ژانگ، اچ. وانگ، ایکس. تانگ، X. شبکه توجه باقی مانده برای طبقه بندی تصویر. در مجموعه مقالات کنفرانس IEEE در مورد دید رایانه و تشخیص الگو، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ صص 3156–3164. [ Google Scholar ]
- لانگ، جی. شلهامر، ای. دارل، تی. شبکه های کاملاً پیچیده برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. صص 3431–3440. [ Google Scholar ]
- آهنگ، دبلیو. لی، ام. او، س. هوانگ، دی. پرا، سی. Liotta، A. یک شبکه عصبی پیچ خوردگی باقیمانده برای طبقه بندی یخ دریا با تصاویر Sentinel-1 SAR. در مجموعه مقالات کنفرانس بین المللی IEEE 2018 در کارگاه های داده کاوی (ICDMW)، سنگاپور، 17 تا 20 نوامبر 2018؛ صص 795-802. [ Google Scholar ]
- ژانگ، تی. یانگ، ی. شکر، م. می، سی. لی، XM؛ چنگ، ایکس. Hui, F. طبقهبندی یخ دریا مبتنی بر یادگیری عمیق با دادههای SAR کاملاً قطبی Gaofen-3. Remote Sens. 2021 , 13 , 1452. [ Google Scholar ] [ CrossRef ]
- بودند، ک. Bui، DT; دیک، Ø.B. سینگ، BR یک ارزیابی مقایسهای از رگرسیون بردار پشتیبان، شبکههای عصبی مصنوعی و جنگلهای تصادفی برای پیشبینی و نقشهبرداری ذخایر کربن آلی خاک در یک چشمانداز افرومونتان. Ecol. اندیک. 2015 ، 52 ، 394-403. [ Google Scholar ] [ CrossRef ]
- چن، دی. چانگ، ن. شیائو، جی. ژو، Q. Wu, W. ترسیم دینامیک مواد آلی خاک در زمینهای زراعی با دادههای MODIS و الگوریتمهای یادگیری ماشین. علمی کل محیط. 2019 ، 669 ، 844-855. [ Google Scholar ] [ CrossRef ]
- بات، ا. Benites, J. اهمیت ماده آلی خاک: کلیدی برای خاک مقاوم به خشکی و تولید مواد غذایی پایدار . سازمان غذا و کشاورزی سازمان ملل متحد: رم، ایتالیا، 2005. [ Google Scholar ]
- ژانگ، اف. لی، سی. وانگ، ز. وو، اچ. اثرات مدلسازی جایگزینهای مدیریتی بر ذخیرهسازی کربن خاک زمینهای کشاورزی در شمال غربی چین. Biogeosciences 2006 ، 3 ، 451-466. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گروه تحقیقاتی طبقهبندی خاک چین، I. کلیدهای طبقهبندی خاک چین . انتشارات دانشگاه علم و صنعت چین: هفی، چین، 2001; ص 205-206. [ Google Scholar ]
- ژانگ، جی. وانگ، ی. ژانگ، ز. اثر اشکال تراس بر فرسایش آب و خاکورزی در منظره تپهای در حوضه رودخانه یانگ تسه، چین. ژئومورفولوژی 2014 ، 216 ، 114-124. [ Google Scholar ] [ CrossRef ]
- کیائو، ز. ژانگ، ز. ون، کیو. وی، ایکس. مطالعه تغییرات مکانی-زمانی زمین های زیر کشت در شهر شین شیانگ با استفاده از سنجش از دور و GIS. در مجموعه مقالات کنفرانس بین المللی در مورد پردازش و تجزیه و تحلیل داده های مشاهده زمین (ICEODPA)، ووهان، چین، 28-30 دسامبر 2008. پ. 72854M. [ Google Scholar ]
- Yeomans، JC; Bremner, JM روشی سریع و دقیق برای تعیین معمول کربن آلی در خاک. اشتراک. علم خاک گیاه. مقعدی 1988 ، 19 ، 1467-1476. [ Google Scholar ] [ CrossRef ]
- کومار، اس. Lal, R. نقشه برداری از ذخایر کربن آلی خاک های سطحی با استفاده از درون یابی فضایی محلی. جی. محیط زیست. نظارت کنید. 2011 ، 13 ، 3128-3135. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- McLauchlan، K. ماهیت و طول عمر اثرات کشاورزی بر کربن و مواد مغذی خاک: بررسی. اکوسیستم 2006 ، 9 ، 1364-1382. [ Google Scholar ] [ CrossRef ]
- فیک، SE; Hijmans، RJ WorldClim 2: سطوح آب و هوایی با تفکیک مکانی جدید 1 کیلومتری برای مناطق خشکی جهانی. بین المللی جی.کلیماتول. 2017 ، 37 ، 4302-4315. [ Google Scholar ] [ CrossRef ]
- Beven، KJ; Kirkby, MJ مدلی مبتنی بر فیزیکی و متغیر منطقه کمک کننده از هیدرولوژی حوضه/Un model à base physique de zone d’appel variable de l’hydrologie du bassin versant. هیدرول. علمی J. 1979 ، 24 ، 43-69. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Rouse, JW; هاس، RH; شل، JA; Deering، DW نظارت بر سیستم های پوشش گیاهی در دشت های بزرگ با ERTS. مشخصات ناسا انتشار 1974 ، 351 ، 309. [ Google Scholar ]
- هیوت، ا. دیدان، ک. میورا، تی. رودریگز، EP; گائو، ایکس. Ferreira، LG مروری بر عملکرد رادیومتری و بیوفیزیکی شاخصهای پوشش گیاهی MODIS. سنسور از راه دور محیط. 2002 ، 83 ، 195-213. [ Google Scholar ] [ CrossRef ]
- ریچاردسون، ای جی; ویگاند، سی. تمایز پوشش گیاهی از اطلاعات پس زمینه خاک. فتوگرام مهندس Remote Sens. 1977 , 43 , 1541-1552. [ Google Scholar ]
- بهرنز، تی. زو، تبر; اشمیت، ک. Scholten، T. تجزیه و تحلیل زمین دیجیتال چند مقیاسی و انتخاب ویژگی برای نقشه برداری دیجیتالی خاک. ژئودرما 2010 ، 155 ، 175-185. [ Google Scholar ] [ CrossRef ]
- بهرنز، تی. اشمیت، ک. مک میلان، RA; Rossel, RAV نقشه برداری دیجیتال خاک با مقیاس چندگانه با یادگیری عمیق. علمی Rep. 2018 , 8 , 15244. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژانگ، ال. ژانگ، ال. Du, B. یادگیری عمیق برای داده های سنجش از راه دور: یک آموزش فنی در مورد وضعیت هنر. IEEE Geosci. سنسور از راه دور Mag. 2016 ، 4 ، 22-40. [ Google Scholar ] [ CrossRef ]
- سان، ی. وانگ، ایکس. تانگ، X. آبشار شبکه کانولوشنال عمیق برای تشخیص نقطه صورت. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، پورتلند، OR، ایالات متحده آمریکا، 23 تا 28 ژوئن 2013. صص 3476–3483. [ Google Scholar ]
- گارجه، م.ک. ملاکیار، ف. ونگ، کیو. فیضی زاده، ب. بلاشکه، تی. Lakes, T. یک الگوریتم شبکه عصبی کانولوشنال یادگیری عمیق خودکار به کار گرفته شده برای نقشه برداری توزیع شوری خاک در دریاچه ارومیه، ایران. Sci Total Env. 2021 ، 778 ، 146253. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- دومولن، وی. Visin، F. راهنمای محاسبات کانولوشن برای یادگیری عمیق. arXiv 2018 , arXiv:1603.07285. [ Google Scholar ]
- لی، اچ. گروس، آر. رانگانات، آر. Ng، AY شبکه های باور عمیق کانولوشن برای یادگیری بدون نظارت مقیاس پذیر نمایش های سلسله مراتبی. در مجموعه مقالات بیست و ششمین کنفرانس بینالمللی سالانه یادگیری ماشین، نیویورک، نیویورک، ایالات متحده آمریکا، 14 تا 18 ژوئن 2009. ص 609-616. [ Google Scholar ]
- سیرگان، دی. مایر، یو. Schmidhuber, J. شبکه های عصبی عمیق چند ستونی برای طبقه بندی تصویر. در مجموعه مقالات کنفرانس IEEE 2012 در مورد دید کامپیوتری و تشخیص الگو، پراویدنس، RI، ایالات متحده آمریکا، 16-21 ژوئن 2012. صص 3642–3649. [ Google Scholar ]
- کتکار، ن. مقدمه ای بر کراس. در یادگیری عمیق با پایتون ؛ Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2017؛ صص 97-111. [ Google Scholar ]
- آبادی، م. برهم، پ. چن، جی. چن، ز. دیویس، ا. دین، جی. دوین، ام. قماوت، س. ایروینگ، جی. Isard, M. Tensorflow: سیستمی برای یادگیری ماشینی در مقیاس بزرگ. در مجموعه مقالات دوازدهمین سمپوزیوم طراحی و پیاده سازی سیستم های عامل (OSDI’16)، ساوانا، GA، ایالات متحده آمریکا، 2 تا 4 نوامبر 2016. ص 265-283. [ Google Scholar ]
- اسنوک، جی. لاروچل، اچ. آدامز، RP بهینه سازی عملی بیزی الگوریتم های یادگیری ماشین. Adv. عصبی Inf. سیستم پردازش 2012 ، 25 . در دسترس آنلاین: https://dash.harvard.edu/bitstream/handle/1/11708816/snoek-bayesopt-nips-2012.pdf?sequence%3D1 (در 17 آگوست 2021 قابل دسترسی است).
- لارنس، آی. لین، ک. ضریب همبستگی تطابق برای ارزیابی تکرارپذیری. بیومتریک 1989 ، 45 ، 255-268. [ Google Scholar ]
- کومهلووا، جی. کومهلا، اف. کرولیک، م. Matějková، Š. تاثیر توپوگرافی بر خصوصیات و عملکرد خاک و اثرات شرایط آب و هوایی. دقیق کشاورزی 2011 ، 12 ، 813-830. [ Google Scholar ] [ CrossRef ]
- جیان بینگ، دبلیو. دو-نینگ، ایکس. زینگ یی، ز. شیو-ژن، ال. Xiao-Yu، L. تنوع فضایی کربن آلی خاک در رابطه با عوامل محیطی یک حوزه آبخیز کوچک معمولی در منطقه خاک سیاه، شمال شرق چین. محیط زیست نظارت کنید. ارزیابی کنید. 2006 ، 121 ، 597-613. [ Google Scholar ] [ CrossRef ]
- پرز، ال. Wang, J. اثربخشی افزایش داده ها در طبقه بندی تصویر با استفاده از یادگیری عمیق. arXiv 2017 , arXiv:1712.04621. [ Google Scholar ]
- لین، ام. چن، کیو. Yan, S. شبکه در شبکه. arXiv 2014 ، arXiv:1312.4400. [ Google Scholar ]
شکل 1. موقعیت جغرافیایی هنان در چین ( a )، منطقه مورد مطالعه در هنان ( b )، و توزیع مکانی نمونههای خاک بر روی یک ترکیب رنگی واقعی از تصاویر Landsat 8 ( c ) قرار گرفتهاند.

شکل 2. چهار نمونه از داده های متغیر کمکی قابل انتخاب، از جمله NDVI ( a )، band4 ( b )، MAP ( c )، و DEM( d ). NDVI: شاخص پوشش گیاهی نرمال. MAP: میانگین بارندگی سالانه. band4: Landsat5 Band4 (NIR); DEM: مدل رقومی ارتفاع.
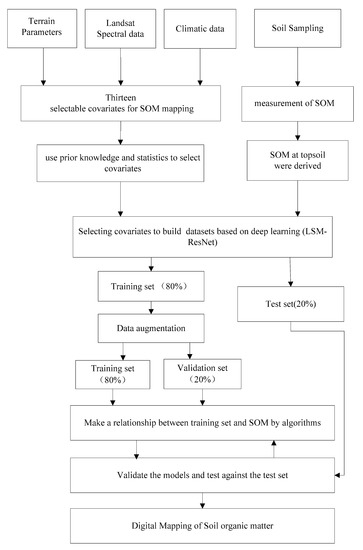
شکل 3. فلوچارت روش شناسی نقشه رقومی خاک در این مطالعه. SOM: لاگ محتوای مواد آلی خاک (g/kg) در سطح خاک.

شکل 4. ساختار بلوک باقیمانده ResNet.

شکل 5. در این مطالعه، یک مدل شبکه عصبی باقیمانده عمیق سبک وزن، LSM-ResNet، بر اساس یادگیری عمیق پیشنهاد شده است. ( a ) ساختار کلی LSM-ResNet را نشان می دهد و ( b ) ساختار ماژول باقیمانده LSM-ResNet را نشان می دهد. (Fc: لایه کاملاً متصل؛ ReLU: واحد خطی اصلاح شده؛ GAP: جمع میانگین جهانی).

شکل 6. اثر اندازه مجاورت تصویر ورودی. RMSE مربوط به خطای بین مقادیر پیش بینی شده و اندازه گیری شده در مجموعه تست است.

شکل 7. نمودار پراکندگی اندازه گیری شده در برابر SOM پیش بینی شده برای LSM-ResNet ( a ) و RF ( b )، همراه با خط 1:1.

شکل 8. نقشه های پیش بینی SOM. مقادیر بر حسب گرم بر کیلوگرم بیان می شود. ( الف ): بر اساس LSM-ResNet؛ ( ب ): بر اساس RF.

شکل 9. اثر استفاده از افزایش داده ها به عنوان پیش درمان بر روی یک آرایه 15×15 پیکسلی.


بدون دیدگاه