1. مقدمه
فضاهای سبز شهری عمومی، که به عنوان فضاهای پوشش گیاهی در داخل شهرها که برای عموم مردم قابل دسترسی است (مانند پارک های شهری، زمین های بازی عمومی) تعریف می شوند، با ارائه خدمات مختلف اکوسیستم، عامل مهمی برای کیفیت زندگی شهری هستند [ 1 ]. به عنوان مثال، آنها اثر جزیره گرمایی شهری [ 2 ] را کاهش می دهند و فضایی را برای شهروندان برای انجام فعالیت های تفریحی و فرهنگی مانند ورزش، تجربه طبیعت یا تبادل اجتماعی فراهم می کنند [ 3 ، 4 ، 5 ]. مطالعات اخیر حتی نشان می دهد که دسترسی کافی به فضاهای سبز عمومی مجاور برای رفاه و سلامت روانی شهروندان مفید است [ 6 ، 7 ، 8 ،9 ] و طبیعت شهری به عنوان زیرساخت انعطافپذیر در مواقع بحران، مانند همهگیری COVID-19 [ 10 ] دیده میشود. از این رو، ارائه اطلاعات لازم به شهروندان و برنامه ریزان شهری در مورد موقعیت و کیفیت فضاهای سبز عمومی شهری [ 11 ، 12 ] برای شناسایی نابرابری ها و در نظر گرفتن آنها در برنامه ریزی های آتی بسیار مهم است [ 13 ].
با این حال، مجموعه داده های جامع و باز در مورد فضاهای سبز شهری عمومی – به عنوان یک پیش نیاز ضروری برای چنین تحلیل هایی – برای اکثر شهرها با کیفیت کافی در دسترس نیست [ 14 ، 15 ]. اگرچه بیشتر و بیشتر شهرداریها، سازمانها و سایر ذینفعان دادههای خود را در مورد فضاهای سبز شهری منتشر میکنند، اما پوشش فضایی و موضوعی و همچنین کامل بودن این مجموعه دادهها بهطور قابل توجهی متفاوت است، زیرا مجموعههای داده برای اهداف مختلف و با تعاریف زیربنایی متفاوت تولید شدهاند. “فضای سبز عمومی” و با استفاده از روش های مختلف جمع آوری داده ها [ 14]. به عنوان مثال، مجموعه داده های شهرداری در مورد فضاهای سبز معمولاً فقط شامل آن فضاهای سبزی است که تحت مالکیت و نگهداری شهر هستند، مانند پارک های شهرداری. فضاهای سبز با مالکیت خصوصی که برای عموم قابل دسترسی است (به عنوان مثال، زمین های بازی متعلق به ساختمان های آپارتمانی) معمولاً در این مجموعه داده ها گنجانده نمی شوند. مجموعه داده های سراسر قاره ای یا ملی در چندین شهر سازگارتر است، اما فاقد وضوح فضایی کافی برای نشان دادن فضاهای سبز کوچک است. به عنوان مثال، اگرچه مجموعه داده پاناروپایی CORINE Land Cover [ 16 ] شامل یک کلاس تعیین شده “مناطق شهری سبز” است، اما فقط شامل فضاهای سبز بزرگتر از 25 هکتار است. اطلس شهری [ 17 ] برای اتحادیه اروپا یا مجموعه داده های Trust for Public Land’s ParkServe [ 18 ]] برای ایالات متحده حاوی اطلاعات کاربری زمین با وضوح بالاتر اما فقط برای شهرهای منتخب است. با توجه به این مسائل، نیاز به روشهای ادغام دادهها برای ایجاد مجموعه دادههای جامع فضای سبز شهری است که امکان تجزیه و تحلیل را در شهرهای مختلف فراهم میکند [ 14 ].
در دسترس بودن گسترده تصاویر ماهواره ای چندطیفی با وضوح بالا مانند ماموریت Sentinel-2 و ظهور پروژه های نقشه برداری مشترک مانند OpenStreetMap (OSM) امکانات جدیدی را برای نقشه برداری فضاهای سبز شهری در چندین شهر باز می کند. ماموریت Sentinel-2 تصاویری را که کل کره زمین را با وضوح فضایی تا 10 متر و سرعت بازبینی 2 تا 3 روز پوشش می دهد، می گیرد [ 19 ]. OSM یک نقشه دیجیتالی جهانی از محیط طبیعی و ساخته شده است که توسط داوطلبان ایجاد شده و تحت مجوز Open Data Commons Open Database (ODbL) منتشر شده است [ 20 ]]. هر دو مجموعه داده در سطح جهانی و رایگان در دسترس هستند که آنها را به ویژه برای نقشه برداری از فضاهای سبز شهری در مناطقی که هیچ داده معتبری در دسترس نیست، جالب می کند.
ثابت شده است که تصاویر Sentinel-2 برای نقشه برداری پوشش گیاهی [ 21 ] بسیار مناسب است و برای نقشه برداری و تحلیل فضاهای سبز شهری در مطالعات قبلی [ 22 و 23 ] استفاده شده است. با این حال، پتانسیل تصاویر Sentinel-2 در این زمینه محدود است، زیرا نمی تواند فضاهای سبز عمومی را از خصوصی تشخیص دهد و وضوح فضایی 10 متری آن نمی تواند ساختارهای شهری ریزدانه مانند درختان، درختچه ها یا ساختمان های کوچک را به تصویر بکشد [ 15 ] . علاوه بر این، اعوجاج جوی ممکن است باعث عدم قطعیت بیشتر در شناخت اشیاء کاربری زمین شود [ 24 ]. داده های OSM به تجزیه و تحلیل فضاهای سبز شهری عمومی محدود شده است، زیرا مناطق خصوصی معمولاً در OSM نقشه برداری نمی شوند [ 15 ]]. علاوه بر این، روشهایی که در آن فضاهای سبز در OSM نقشهبرداری میشوند همیشه سازگار نیستند [ 25 ، 26 ]، و سطح کامل بودن دادههای OSM در فضا متفاوت است [ 27 ، 28 ].
عدم قطعیت هایی مانند مواردی که در بالا توضیح داده شد را می توان معرفتی در نظر گرفت، به عنوان مثال، آنها به دلیل کمبود دانش هستند و می توانند با جمع آوری دانش بیشتر یا ادغام آن با منابع داده اضافی کاهش یابند [ 29 ]. برای ترکیب منابع دادههای مختلف در حضور چنین عدم قطعیتهایی، نظریه دمپستر-شفر توسط Shafer [ 30 ] ارائه شد. این روش قبلا در زمینه نقشه برداری پوشش زمین و کاربری اراضی استفاده شده است، اما تا آنجا که ما می دانیم، مطالعه ای وجود ندارد که کاربرد نظریه Dempster-Shafer را برای ترکیب داده های Sentinel-2 و OSM برای عموم بررسی کرده باشد. نقشه برداری فضای سبز شهری هنوز
هدف این مطالعه پیشنهاد و ارزیابی روشی برای نقشهبرداری فضاهای سبز شهری عمومی بر اساس تصاویر Sentinel-2 و دادههای OSM با استفاده از نظریه Dempster-Shafer بود که به طور خاص عدم قطعیتهای ذاتی منابع داده را در نظر میگیرد. به طور خاص، به سؤالات تحقیق زیر پرداخته شد:
-
RQ1: آیا داده های OSM می توانند وضوح فضایی ناکافی تصاویر Sentinel-2 را هنگام نقشه برداری فضاهای سبز شهری عمومی جبران کنند؟
-
RQ2: آیا می توان با استفاده از داده های OSM فضاهای سبز عمومی را از خصوصی تشخیص داد، علیرغم استفاده از تگ احتمالاً متناقض و کامل نبودن آن؟
-
RQ3: عدم قطعیت های ناشی از دو منبع داده و تجزیه و تحلیل چگونه بر دقت کلی مدل برای پیش بینی فضاهای سبز شهری عمومی تأثیر می گذارد؟
در گذشته، وضوح ناکافی تصاویر عمدتاً تا حدی از طریق وضوح فوق العاده یا تکنیک های شفاف سازی پان برطرف می شد. روشهایی برای استفاده از دادههای OSM برای دادههای نقشهبرداری کاربری زمین نیز همراه با رویکردهایی برای بهبود کیفیت دادههای آن پیشنهاد شدهاند [ 31 ، 32 ، 33 ]. با این حال، بیشتر این رویکردها عدم قطعیت های ذاتی مجموعه داده ها را در نظر نمی گیرند. سهم اصلی مطالعه ما تجزیه و تحلیل چگونگی انتشار انواع مختلف عدم قطعیت در طول ادغام تصاویر OSM و Sentinel-2 با استفاده از نظریه Dempster-Shafer است.
ساختار مقاله باقی مانده به شرح زیر است. بخش 2 خلاصه کوتاهی از مطالعات مرتبط در نقشه برداری فضای سبز شهری با استفاده از داده های Sentinel-2 و OSM ارائه می دهد. بخش 3 شامل مقدمه ای کوتاه بر نظریه دمپستر-شافر است و بخش 4 روش شناسی نقشه برداری از فضاهای سبز شهری عمومی را شامل توصیف منطقه مورد مطالعه در درسدن، آلمان و منابع داده مربوطه توصیف می کند. نتایج تجزیه و تحلیل در بخش 5 و سپس بحث و نتیجه گیری در بخش 6 و بخش 7 ارائه شده است.
2. کارهای مرتبط
روشهای متعددی برای نقشهبرداری فضاهای سبز شهری با استفاده از روشهای مختلف مانند طبقهبندی مبتنی بر قوانین فازی [ 34 ]، طبقهبندی تصادفی جنگل [ 35 ] یا شبکههای عصبی کانولوشنال [ 36 ] ارائه شده است. بسیاری از آنها به تصاویر سنجش از دور متکی هستند، زیرا پوشش گیاهی با استفاده از تصاویر نوری چند طیفی به خوبی قابل تشخیص است [ 37 ، 38 ]. تصاویر هوایی با وضوح بسیار بالا (VHR) [ 39 ]، داده های LIDAR [ 34 ، 40 ] یا تصاویر گرفته شده توسط وسایل نقلیه هوایی بدون سرنشین (UAV) [ 41 ]] منابع داده ارجح به منظور به تصویر کشیدن ساختارهای شهری ریزدانه هستند. اخیراً، روشهایی برای نقشهبرداری تک درختان [ 35 ] یا سبزی کنار جاده بر اساس تصاویر نمای خیابان [ 36 ] نیز اهمیت پیدا کردهاند.
این نوع مجموعه داده ها در همه جا در دسترس نیستند، به همین دلیل است که رویکردهای نقشه برداری مبتنی بر تصاویر با وضوح بالا تا متوسط مانند Sentinel-2 [ 22 ، 23 ، 42 ]، Landsat [ 43 ] یا تصاویر رادار دیافراگم مصنوعی (SAR) [ 44 ]. ] پیشنهاد شده است. به منظور جبران وضوح فضایی محدود این حسگرها، رویکردهای نقشه برداری مبتنی بر زیرپیکسل و سوپرپیکسل پیشنهاد شده است [ 45 ، 46 ]. برای تمایز فضای سبز عمومی از خصوصی، دادههای سنجش از دور با منابع دادهای اضافی مانند دادههای باز و معتبر [ 6 ، 47 ]، دادههای علم شهروندی تکمیل شدند.48 ]، کار میدانی محلی [ 49 ، 50 ] یا POI از داده های رسانه های اجتماعی [ 37 ، 38 ، 51 ].
پتانسیل داده های OSM برای تجزیه و تحلیل فضاهای سبز شهری عمومی نیز بررسی شده است. فلتینوفسکی و همکاران [ 14 ] و Le Texier و همکاران. [ 15 ] فضاهای سبز شهری را از OSM با استفاده از فهرستی از برچسب های OSM مربوط به فضای سبز بر اساس دانش تخصصی استخراج کرد. این مطالعات به این نتیجه رسیدند که فضاهای سبز شهری عمومی در OSM کاملاً شبیه فضاهای ترسیم شده در مجموعه داده های معتبر است، به ویژه در مراکز شهر که کیفیت داده ها احتمالاً بالاتر است [ 52 ]. مطالعات دیگری مانند Fonte et al. [ 53 ] و ارسنجانی و همکاران. [ 52] برچسبهای OSM را به نامگذاریهای اطلس شهری و پوشش زمین CORINE برای استخراج نقشههای کاربری شهری که شامل مناطق پوشش گیاهی غیرکشاورزی مصنوعی و فضاهای سبز شهری بود، نگاشت. روشهایی که دادههای OSM و سنجش از دور را ترکیب میکنند، بهطور خاص برای نقشهبرداری فضای سبز شهری پیشنهاد نشدهاند، بلکه برای نقشهبرداری کاربری زمین به طور کلی پیشنهاد شدهاند. در این مطالعات، دادههای OSM برای ایجاد نمونههای آموزشی برای طبقهبندی تصویر [ 31 ]، ایجاد چندضلعیهای بلوک خیابان به عنوان مبنایی برای طبقهبندی [ 37 ، 38 ، 51 ، 54 ] یا اصلاح طبقهبندی نهایی پوشش زمین با استفاده از دادههای OSM استفاده شد. 31 ، 32 ، 33 ].
نظریه Dempster-Shafer برای ادغام اطلاعات پوشش زمین از تصاویر سنجش از راه دور مختلف [ 55 ] و برای تشخیص تغییرات شهری [ 56 ] استفاده شده است، اما به طور خاص برای نقشه برداری فضای سبز شهری استفاده نشده است. در زمینه اطلاعات جغرافیایی داوطلبانه، Comber et al. [ 57 ] روشهای مختلفی از جمله نظریه Dempster-Shafer را برای ادغام طبقهبندیهای داوطلبان متعدد برای نقشهبرداری پوشش زمین و Liu و همکارانش ارزیابی کردند. [ 58 ] از نظریه Dempster-Shafer برای به روز رسانی داده های معتبر استفاده از زمین با داده های جمع آوری شده از داوطلبان از طریق کمپین های نقشه برداری درجا و آنلاین استفاده کرد. کاربردهای تئوری Dempster-Shafer برای ادغام OSM و داده های سنجش از راه دور در زمان نگارش این مقاله وجود نداشت.
3. پیشینه نظری در نظریه دمپستر-شفر
نظریه Dempster-Shafer چارچوبی برای ترکیب منابع داده های مختلف در حضور عدم قطعیت است که توسط Shafer [ 30 ] ارائه شده است. تئوری Dempster-Shafer را می توان برای ترکیب اطلاعات از منابع داده های مختلف (مثلاً حسگرهای مختلف) به کار برد، یا می تواند برای ترکیب اطلاعات مربوط به ویژگی های مختلف اشیا (مانند رنگ یا اندازه یک شی) استفاده شود.
در طول طبقه بندی، اشیاء باید به کلاس های متقابل اختصاص داده شوند. در نظریه Dempster-Shafer، این مجموعه از طبقات چارچوب تشخیص نامیده می شود θ={آ،ب،…}. 2θمجموعه توان را نشان می دهد θ، یعنی مجموعه همه زیر مجموعه های θ. مقدار شواهدی که برای شی x متعلق به یکی از کلاس های مجموعه A بر اساس منبع اطلاعاتی i صحبت می کند ، به عنوان جرم احتمال کدگذاری می شود. مترمن(آ). برخلاف روشهای احتمالی، تودههای احتمال را میتوان برای مجموعههایی که شامل یک یا چند کلاس هستند، تنظیم کرد، به عنوان مثال، مترمن({آ،ب})این باور را توصیف می کند که یک شی x ممکن است متعلق به کلاس های a یا b باشد. با اختصاص یک جرم احتمال غیر صفر به مجموعه ای از کلاس های متعدد، عدم قطعیت در مورد کلاس واقعی یک شی را می توان نشان داد.
3.1. تکلیف احتمالی پایه
فرآیند تخصیص تودههای احتمال به مجموعههایی از کلاسها بر اساس منابع اطلاعاتی مختلف، تخصیص احتمال پایه نامیده میشود. یک تخصیص احتمال اولیه برای مجموعه A حاوی یک یا چند کلاس معتبر است اگر شرایط زیر برآورده شود.
پس از تعریف توده های احتمال، می توان باور و معقول بودن مربوطه را از آن محاسبه کرد. باور مجموعه A شواهدی را که برای شی متعلق به یکی از کلاسهای مجموعه A صحبت میکنند، کمیت میکند . هر چه باور بالاتر باشد، اطلاعات قطعی تر است. باور یک مجموعه A به عنوان مجموع همه جرم های احتمالی مجموعه های B که در مجموعه A گنجانده شده است تعریف می شود.
معقول بودن یک مجموعه A نشان دهنده شواهدی است که علیه شی متعلق به یکی از کلاس های مجموعه A صحبت می کند. معقول بودن یک مجموعه A به عنوان مجموع همه جرم های احتمالی مجموعه های B که مجموعه A را قطع می کنند تعریف می شود.
تعریف تخصیص احتمال اساسی مهمترین بخش در کاربردهای نظریه دمپستر-شفر است. تخصیص احتمال اولیه رابطه بین ویژگیهای یک شی که باید طبقهبندی شود (مثلاً NDVI یک پیکسل) و تودههای احتمال مرتبط با موارد در چارچوب تشخیص را تعریف میکند. تنظیم یک انتساب احتمال اولیه را می توان بر اساس دانش تخصصی و/یا تجزیه و تحلیل داده ها انجام داد. این ممکن است کاملاً ذهنی به نظر برسد، اما انعطاف پذیری بالایی را در تعیین کمیت عدم قطعیت منابع اطلاعاتی امکان پذیر می کند.
3.2. قانون ترکیب دمپستر
دو جرم احتمال که بر اساس دو منبع اطلاعاتی متفاوت هستند را می توان با استفاده از قوانین ترکیبی مختلف به یک جرم احتمال مشترک ادغام کرد [ 59 ]. رایج ترین قانون ترکیب دمپستر است که اگر دو منبع مستقل از یکدیگر باشند می توان آن را اعمال کرد. این قاعده اطلاعات متضاد را در نظر نمی گیرد و بنابراین می تواند به عنوان یک قاعده ترکیبی ربطی در نظر گرفته شود. با استفاده از قانون ترکیب دمپستر، دو جرم احتمال متر1و متر2به یک جرم احتمالی متصل می شوند متر12برای مجموعه A با استفاده از
چه زمانی آ≠Øو متر12(Ø)=0،
K بدین ترتیب میزان تضاد بین دو توده احتمال را توصیف می کند متر1و متر2. B و C تنظیم شده اند متر1و متر2، به ترتیب، که تقاطع آن A است .
3.3. طبقه بندی و کمی سازی عدم قطعیت
برای تصمیم گیری و اختصاص یک کلاس به هر شی بر اساس باورهای فرموله شده با استفاده از نظریه دمپستر-شفر، احتمال پیگنیستی – احتمالی که یک فرد منطقی در صورت نیاز به تصمیم گیری به گزینه ای اختصاص می دهد – محاسبه می شود. و برچسب کلاس با بالاترین احتمال پیگنیستیک به هر شی اختصاص داده می شود. برای جزئیات بیشتر در مورد تعریف احتمال پیگنیستی لطفاً به اسمتس و کنس [ 60 ] مراجعه کنید.
عدم قطعیت در مورد یک شی متعلق به مجموعه A را می توان از طریق تفاوت بین معقول بودن مربوطه و باور مجموعه A تعیین کرد.
این عدم قطعیت را می توان در هر مرحله از فرآیند ادغام داده ها و برای مجموعه های مختلف برچسب های کلاس اندازه گیری کرد، بنابراین عدم قطعیت ها را می توان از منابع داده اولیه از طریق تجزیه و تحلیل تا محصول طبقه بندی نهایی منتشر کرد.
4. مواد و روش نقشه برداری فضای سبز شهری عمومی
4.1. منطقه مطالعه
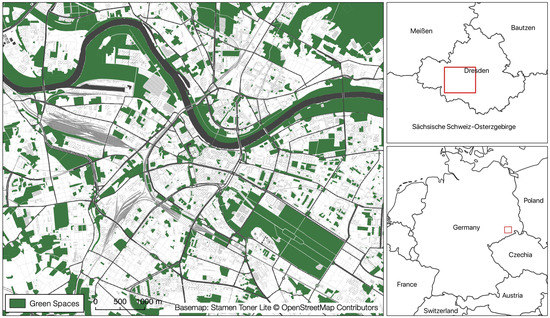
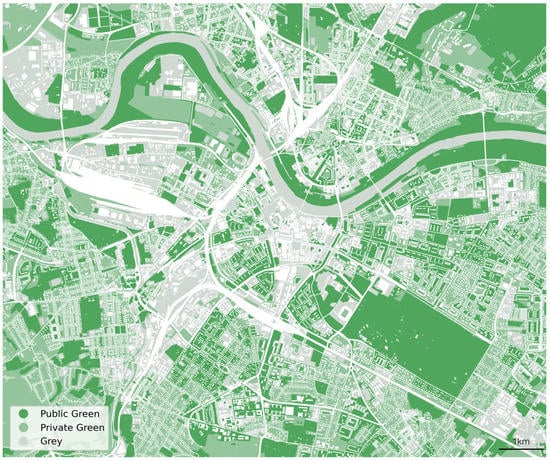
روش پیشنهادی در یک منطقه مورد مطالعه در شهر درسدن اعمال شد ( شکل 1 ). درسدن مرکز ایالت فدرال زاکسن است و در شرق آلمان با جمعیت 563011 نفر (2019) و مساحت کل 328.8 کیلومتر واقع شده است. 2. محل مطالعه انتخاب شده در مرکز شهر به مساحت 51.5 کیلومتر واقع شده است 2و حاوی ترکیبی از مناطق عمدتا مسکونی و همچنین برخی از مناطق تجاری و صنعتی است. رودخانه البه از جنوب شرقی تا شمال غربی امتداد دارد و چشم انداز شهر را با دشت های سیلابی از چمنزارهای نیمه طبیعی شکل می دهد. درون شهر دارای فضاهای سبز گسترده ای مانند پارک های شهری، خیابان های سبز و همچنین بسیاری از فضاهای سبز کوچک است که زیستگاه گیاهان و حیوانات تا حدی کمیاب و در معرض تهدید را فراهم می کند [ 61 ]. بزرگترین فضاهای سبز عبارتند از باغ بزرگ ، یک پارک بزرگ در مرکز درسدن که شامل یک باغ وحش و باغ گیاه شناسی، و Dresden Heath است.، جنگلی بزرگ در شمال شرقی مرکز شهر. علاوه بر این، بسیاری از فضاهای سبز کوچک پراکنده در سراسر شهر وجود دارد که برخی از آنها تحت مالکیت و نگهداری شهر هستند، اما همچنین تعداد زیادی از فضاهای سبز متعلق به خصوصی اما در دسترس عموم قرار دارند، مانند زمین های بازی متعلق به ساختمان های آپارتمانی.
4.2. داده ها
4.2.1. OpenStreetMap
OSM یک پروژه نقشه برداری مشترک با هدف ایجاد یک نقشه دیجیتال باز از جهان است. هرکسی میتواند با نقشهبرداری انواع مختلفی از اشیاء ژئوفضایی مانند ساختمانها، جادهها یا نقاط مورد علاقه (POI) در پروژه مشارکت کند. داده ها در دسترس همه هستند و تحت مجوز Open Data Commons Open Database (OdbL) مجوز دارند. ساختارهای داده هندسی مورد استفاده برای نمایش اشیا گره ها (نقاط)، راه ها و روابط (هم خطوط و هم چندضلعی ها) هستند. خصوصیات اشیاء با استفاده از برچسب های متشکل از یک کلید و یک مقدار توصیف می شوند، به عنوان مثال، بزرگراه=مسیر یا راحتی=نیمکت. هر ویژگی در OSM ممکن است حاوی یک یا چند برچسب با کلیدهای مختلف باشد. برای ثابت نگه داشتن داده ها، معنی و استفاده از برچسب ها توسط جامعه OSM مورد بحث قرار گرفته و در ویکی OSM [ 62 ] مستند شده است.
4.2.2. تصویرسازی Sentinel-2
ماموریت کوپرنیک سنتینل-2 که توسط آژانس فضایی اروپا انجام می شود از دو ماهواره در مدار قطبی، Sentinel-2A و Sentinel-2B تشکیل شده است که به ترتیب در ژوئن 2015 و مارس 2017 به فضا پرتاب شدند. آنها تصاویر چند طیفی را با وضوح فضایی 10 تا 60 متر و زمان بازبینی 2 تا 3 روز در سراسر جهان به دست می آورند. این تصاویر شامل 13 باند طیفی در طیف مرئی، مادون قرمز نزدیک و مادون قرمز موج کوتاه است. برای تجزیه و تحلیل ما، محصول L-1C ابزار چند طیفی Sentinel-2 (MSI) استفاده شد که بازتاب رادیومتری و هندسی بالای جو (TOA) را فراهم میکند. ما از باندهای 4 و 8 استفاده کردیم که تابش قرمز و مادون قرمز نزدیک را با وضوح فضایی 10 متر می گیرند.
4.2.3. تصویربرداری هوایی
برای اعتبارسنجی مدل سبزی (به بخش 4.3.2 مراجعه کنید )، یک تصویر هوایی چند طیفی با وضوح فضایی 40 سانتیمتر که در 19 ژوئیه 2017 گرفته شد، استفاده شد. این شامل چهار باند طیفی (قرمز، سبز، آبی، مادون قرمز) است. این تصاویر از آژانس فدرال کارتوگرافی و ژئودزی آلمان [ 63 ] به دست آمده است.
4.3. روش شناسی
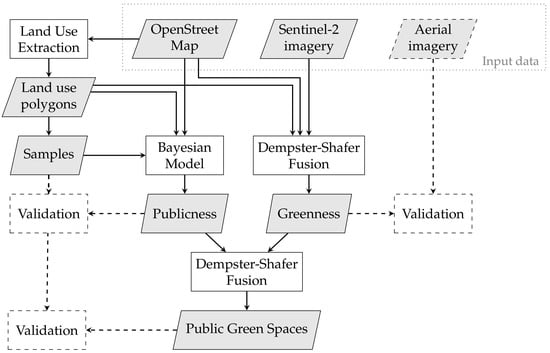
چارچوب مفهومی روش شناسی ما برای نقشه برداری فضاهای سبز عمومی شهری از چهار بخش تشکیل شده است ( شکل 2 ). ابتدا، شبکه ای از چند ضلعی های کاربری زمین همگن بر اساس داده های OSM استخراج شد (به بخش 4.3.1 مراجعه کنید.). این چند ضلعی ها اساس همه تحلیل های بعدی بودند. فضاهای سبز عمومی با “سبز بودن”، یعنی وجود پوشش گیاهی، و “دسترسی عمومی” آنها، یعنی دسترسی عموم مردم مشخص می شد. با این حال، این ویژگیها با استفاده از دادههای Sentinel-2 و OSM بهخوبی قابل اندازهگیری نیستند، به عنوان مثال، تصاویر Sentinel-2 برای ارزیابی اینکه آیا یک منطقه پوشش گیاهی دارد یا نه، مناسب است، اما نه اینکه آیا در دسترس عموم است یا خیر. بنابراین، این دو ویژگی به طور جداگانه مدلسازی شدند. سبزی با ادغام اطلاعات از تصاویر Sentinel-2 و داده های OSM با استفاده از نظریه Dempster-Shafer برآورد شد (به بخش 4.3.2 مراجعه کنید )، در حالی که دسترسی عمومی با استفاده از رویکرد رگرسیون لجستیک بیزی مدلسازی شد (به بخش 4.3.3 مراجعه کنید).). در آخرین مرحله، اطلاعات مدلسازیشده در مورد سرسبزی و دسترسی عمومی با استفاده از تئوری دمپستر-شفر برای ارائه نقشهای از فضاهای سبز عمومی ترکیب شدند (به بخش 4.3.4 مراجعه کنید ).
اعتبارسنجی برای نتایج مدلهای سرسبزی و دسترسی عمومی و همچنین نقشه نهایی فضاهای سبز عمومی شهری انجام شد. از تصاویر هوایی برای اعتبارسنجی نتایج مدل سبزی مبتنی بر OSM و Sentinel-2 استفاده شد. مدل دسترسی عمومی با استفاده از نمونههای دستهبندی شده دستی انتخاب شده از چند ضلعیهای کاربری زمین آموزش و اعتبارسنجی شد (به بخش 4.3.3 مراجعه کنید ). از این نمونه ها برای ارزیابی نقشه نهایی فضاهای سبز عمومی نیز استفاده شد.
کل تجزیه و تحلیل به جز تولید چند ضلعی های کاربری زمین در پایتون 3.7 [ 64 ] پیاده سازی شد. PyMC3 [ 65 ] برای مدلسازی بیزی و pyds [ 66 ] برای همجوشی Dempster-Shafer استفاده شد. تولید چند ضلعی های کاربری زمین با استفاده از نرم افزار FME [ 67 ] پیاده سازی شد. استخراج داده ها با استفاده از API ohsome [ 68 ] برای داده های OSM و موتور Google Earth [ 69 ] برای داده های Sentinel-2 انجام شد. همه داده ها و کد منبع پایتون را می توان در [ 70 ] یافت.
4.3.1. چند ضلعی های کاربری اراضی
این بخش به طور خلاصه روند ایجاد چند ضلعی های کاربری زمین همگن را از داده های OSM، که مبنایی برای نقشه برداری بعدی فضاهای سبز شهری بود، شرح می دهد. هدف اصلی این مرحله تولید شبکههای چندضلعی معنیدار در زمینه نقشهبرداری فضاهای سبز شهری عمومی بود. این چند ضلعی ها مناطقی از کاربری همگن را نشان می دهند که یک فضای فعالیت مستقل را تشکیل می دهند. آنها بر اساس مفروضات مربوط به موانع فیزیکی ناشی از مرزهای برخی از ترکیبات کلاس کاربری همسایه استخراج شده از OSM ترسیم شدند. فرآیند تولید چند ضلعی اساساً شامل دو مرحله بود: فرآیند تولید بلوک شهری بر اساس شبکه ترافیک و تقسیم بیشتر بلوکها به بلوکهای فرعی بر اساس اطلاعات کاربری زمین.
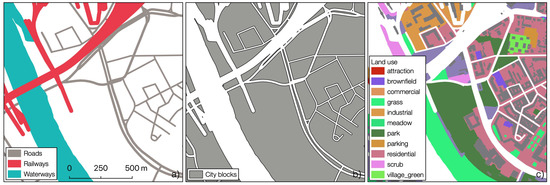
در مرحله اول، بلوکهای شهری، که گاهی به آن بلوکهای خیابانی نیز گفته میشود، با استفاده از شبکه جادهها، مسیرهای راهآهن و مرزهای آبراههای بزرگ تولید شدند ( شکل 3 a,b). ما از رویکرد مشابهی مانند گریپا و همکاران پیروی کردیم. [ 54 ] با این تفاوت که راه آهن را هم در نظر گرفتیم. میز 1شامل تمام تگ های OSM و انواع هندسه است که برای نمایش شبکه ترافیک استفاده می شود. بسته به نوع جاده، ویژگیهای خط با عرض بین 4 (به عنوان مثال، خیابانهای زندگی) و 10 متر (مثلاً خطوط راهآهن) بافر شدند. ویژگیهای آبراه مخصوصاً برای اطمینان از اینکه سواحل رودخانههای رودخانهها یا دریاچههای بزرگتر به خوبی در نقشه بلوک شهر نمایش داده میشوند، ضروری بودند. تمام ویژگی های حاصل با یکدیگر تلاقی کردند تا بلوک های شهر را تشکیل دهند. برای حذف چند ضلعی های برش، همه چند ضلعی های کمتر از 10 متر عرض با چند ضلعی همسایه با استفاده از معیار طولانی ترین لبه مشترک ادغام شدند.
در مرحله دوم، بلوکهای شهری بر اساس اطلاعات کاربری اراضی به دست آمده از OSM به بلوکهای فرعی تقسیم شدند ( شکل 3 ج). فهرست کاملی از برچسبهای کاربری زمین که در نظر گرفته شدهاند، در توضیح تخصیص احتمال اولیه بر اساس OSM در بخش 4.3.2 ارائه شده است. فقط ویژگیهای چند ضلعی OSM بزرگتر از 0.25 هکتار در این مرحله گنجانده شده است. برای حل چند ضلعی هایی که دارای کاربری مشابه هستند اما با استفاده از برچسب های مختلف نقشه برداری شده اند (مثلاً، کاربری = جنگل و طبیعی = چوبهر دو نشاندهنده جنگل هستند) برچسبهای OSM در کلاسهای کاربری زمین با استفاده از یک رویکرد مبتنی بر قانون گروهبندی شدند. اما این تجمیع فقط برای تولید هندسه ها انجام شد. تگ اصلی استفاده از زمین چند ضلعی های حاصل در جدول ویژگی حفظ شد. در صورتی که چندین تگ مرتبط با کاربری اراضی در یک چند ضلعی وجود داشته باشد، از تگ با بالاترین کسر مساحت استفاده می شود.
تقاطع بین بلوکهای شهر و دادههای کاربری زمین از قوانین خاصی پیروی میکرد که چند ضلعی با هم تداخل داشتند، به عنوان مثال، ویژگی تفریحی=پارک در داخل کاربری زمین=مسکونی . در این مورد، ویژگی کوچکتر موجود در بزرگتر برای به دست آوردن هندسه بلوک فرعی بدون همپوشانی در اولویت قرار گرفت. با این حال، هنگامی که دو چند ضلعی کاربری زمین را میتوان دید که یک موجودیت فضای سبز مشترک را تشکیل میدهند (به عنوان مثال، چند ضلعی اوقات فراغت = زمین بازی در یک چند ضلعی کاربری زمین = چمن )، آنگاه چند ضلعیها به روشی خودکار بر اساس قوانین از پیش تعریفشده ادغام شدند. اگر یک چند ضلعی کوچکتر تا حدی با یک چند ضلعی دیگر همپوشانی داشته باشد، آنگاه چند ضلعی کوچکتر به دو قسمت تقسیم می شود، مگر اینکه حاوی یک برچسب مربوط به فضای سبز باشد.اوقات فراغت = پارک . در این حالت، چند ضلعی بدون تغییر باقی می ماند و بر دیگری اولویت داده می شود. اگر یک ویژگی OSM دارای یک تگ access=* اضافی بود، به چند ضلعی کاربری مربوطه اختصاص داده می شد. به عنوان آخرین مرحله، ویژگیهای ساختمان از OSM با شبکه چند ضلعی کاربری زمین تلاقی داده شد.
4.3.2. مدل سبزی
سبز بودن هر چند ضلعی کاربری زمین از دادههای OSM و تصاویر ماهوارهای Sentinel-2 استخراج شد و متعاقباً با استفاده از نظریه Dempster-Shafer ترکیب شد. از آنجایی که این منابع را می توان مستقل در نظر گرفت، از قانون ترکیب دمپستر استفاده شد. چارچوب تشخیص برای این وظیفه ادغام داده ها به این صورت تعریف می شود θg={grههn،grهy}یعنی یک شی می تواند گیاهی یا غیر گیاهی باشد.
برای تعیین کمیت میزان پوشش گیاهی از تصاویر هوایی یا ماهواره ای، شاخص تفاوت عادی شده گیاهی (NDVI) اغلب استفاده می شود [ 21 ]. با استفاده از آن محاسبه می شود
جایی که نمنآرو آرEDبازتاب را در نوارهای مادون قرمز نزدیک و قرمز نشان می دهد.
باندهای 4 و 8 از تصاویر Sentinel-2 برای محاسبه NDVI با وضوح 10 متر استفاده شد. برای ثبت اوج سالانه حضور پوشش گیاهی در هر مکان از تصاویر Sentinel-2، حداکثر ترکیب تصویر NDVI با استفاده از موتور Google Earth ایجاد شد. در کامپوزیت حداکثر NDVI، چندین صحنه ماهواره ای با انتخاب بالاترین مقدار NDVI هر پیکسل در یک تصویر ترکیب می شوند تا یک ترکیب تصویری همگن و بدون ابر تولید کنند. تمام صحنههای Sentinel-2 گرفتهشده در سال ۲۰۱۹ که پوشش ابری کمتر از ۵ درصد داشتند، انتخاب شدند. به این ترتیب 40 صحنه بین 22 ژانویه 2019 و 11 اکتبر 2019 ثبت شد که برای ایجاد موزاییک تصویر استفاده شد.
تخصیص احتمال اولیه بر اساس Sentinel-2
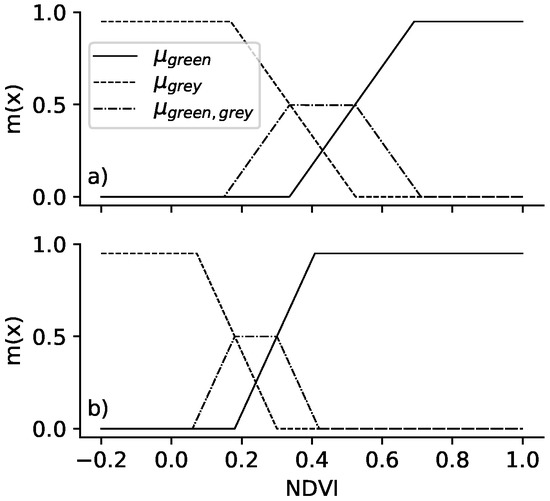
یک رابطه خطی بین NDVI و حضور پوشش گیاهی با مقادیر بالای NDVI وجود دارد که نشان دهنده مقادیر بالای پوشش گیاهی سالم است [ 71 ]. بنابراین، این باور در مورد اینکه آیا یک منطقه دارای پوشش گیاهی ( سبز ) یا غیر گیاهی ( خاکستری ) است را می توان بر اساس مقدار NDVI کمی سازی کرد. برای تخصیص احتمال اولیه، سه تابع تنظیم شد تا مقادیر NDVI را به تودههای احتمال ترسیم کند. متر({grههn})، متر({grهy})و متر({grههn،grهy})( شکل 4 الف). آخرین مورد نشان دهنده عدم قطعیت ناشی از پیکسل های مختلط در تصاویر است که هم مناطق پوشش گیاهی و هم مناطق غیر گیاهی را پوشش می دهد.
معادله ( 8 ) چگونگی جرم احتمال را نشان می دهد متر({grههn})محاسبه شد. مقادیر NDVI بالاتر از ساعتgrههnو کمتر از ساعتgrهyنشان می دهد grههnیا grهyمناطق با درجه اطمینان بالا، به عنوان مثال، متر({grههn})=0.95. حداکثر جرم احتمال به جای 1.0 روی 0.95 تنظیم شد، به طوری که همجوشی Dempster-Shafer نتایج غیر شهودی به همراه ندارد. مقادیر NDVI نزدیک به ساعتمترمنایکسهدتوده های احتمال تعیین شدند متر({grههn})=0.25، متر({grهy})=0.25و متر({grههn،grهy})=0.5. این نشاندهنده این باور است که این پیکسلها باید حداقل تا حدی دارای پوشش گیاهی و بدون پوشش گیاهی باشند، اما با درجه بالایی از عدم اطمینان در مورد نسبت دقیق. مقدار تغییر s طوری انتخاب شد که متر({grههn،grهy})=0.5در ساعتمترمنایکسهد.
جایی که ساعتgrههnنماینده ارزش NDVI برای منطقه پوشش گیاهی است، ساعتمترمنایکسهدنماینده مقدار NDVI برای پوشش زمین مخلوط است و s یک مقدار جابجایی است که باید تعریف شود تا متر({grههn،grهy})=0.5در ساعتمترمنایکسهد.
برای یافتن مقادیر نماینده NDVI برای مناطق پوشش گیاهی، بدون پوشش گیاهی و مختلط، خوشهبندی بدون نظارت با سه مرکز خوشه به صورت پراکنده برای تصاویر NDVI مشتقشده از تصویر هوایی و ماهوارهای اعمال شد. هر دو خوشه بندی منظم K-means [ 72 ] و C-means خوشه بندی فازی [ 73 ] مورد آزمایش قرار گرفتند. بر خلاف روشهای خوشهبندی معمولی، خوشهبندی C-means فازی بر اساس مجموعههای فازی به جای مقولههای واضح است و در نتیجه عدم قطعیت ذاتی در انتساب کلاس را در نظر میگیرد. فازی C-means خوشهبندی مراکز خوشهای را به دست میدهد که کلاس پوشش گیاهی، غیر گیاهی و مختلط را بهتر نشان میدهند، به همین دلیل است که نتایج این روش برای تخصیص احتمال اولیه انتخاب شدند ( جدول 2 ).
تخصیص احتمال اولیه برای چند ضلعی کاربری زمین با اعمال توابع در شکل 4 به مقادیر NDVI پیکسل هایی که چند ضلعی مربوطه را قطع می کنند به دست آمد. مقادیر به دست آمده با استفاده از میانگین جمع شدند تا جرم های احتمال را به دست آورند مترoسمتر(grههn)، مترoسمتر(grهy)و مترoسمتر(grههn،grهy)برای هر چند ضلعی این رویکرد برآوردهای سبزی خوبی را برای چند ضلعی های بزرگتر از اندازه پیکسل 10 متری تصاویر Sentinel-2 به همراه داشت، زیرا آنها حاوی هیچ پیکسل کاربری مخلوطی نبودند. با این حال، در محیط های شهری، وضوح 10 متر برای گرفتن دقیق اشیاء کاربری کوچک مانند کلبه های کوچک یا تکه های کاربری کوچک زمین کافی نیست. این در برآوردهای سبزی بسیار نامشخص برای این اشیاء منعکس شد.
تخصیص احتمال اولیه بر اساس OSM
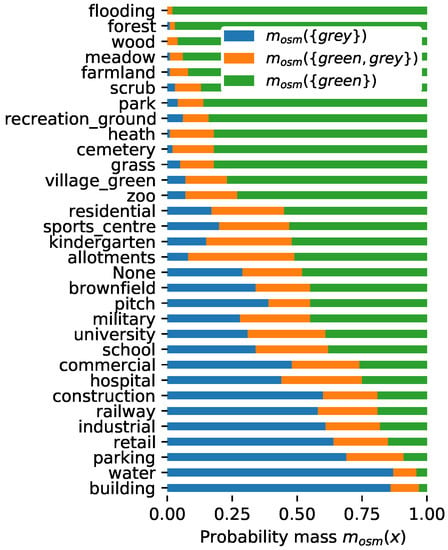
برای کاهش مشکل وضوح فضایی ناکافی تصاویر Sentinel-2، از دادههای OSM برای بهبود برآوردهای سبزی استفاده شد. برخی از برچسبهای OSM بیشتر از سایرین با سبز بودن مرتبط هستند، به عنوان مثال، یک شی با برچسب leisure=park بیشتر از یک شی با برچسب ساختمان =* دارای پوشش گیاهی است. با این حال، این ارتباط در همه جا به دلیل عوامل اقلیمی و فرهنگی یکسان نیست [ 74 ]. به جای کامپایل یک لیست ثابت از تگ های OSM که باید سبز در نظر گرفته شوندبر اساس دانش متخصص، اعتقاد به سبز بودن هر تگ OSM از دادههای Sentinel-2 مشتق شد. این کار با استخراج تنها پیکسل های NDVI انجام شد که به طور کامل در داخل اشیاء با برچسب مربوطه قرار داشتند. به این ترتیب، عدم قطعیت ناشی از پیکسل های مخلوط در لبه های اشیا حذف شد. تخصیص احتمال اولیه داده های Sentinel-2 ( شکل 4 الف) برای تمام مقادیر NDVI متعلق به یک تگ OSM اعمال شد. مقادیر به دست آمده با استفاده از میانگین جمع شدند تا جرم های احتمال را به دست آورند مترoسمتر(grههn)، مترoسمتر(grهy)و مترoسمتر(grههn،grهy)برای هر تگ OSM ( شکل 5 ).
یک مثال برای نشان دادن این فرآیند به صورت زیر توضیح داده می شود: فرض کنید دو پیکسل وجود دارد پ1و پ2که متعلق به همان کلاس کاربری زمین OSM t هستند. مقادیر NDVI آنها 0.5 و 0.65 است. اعمال تخصیص جرم احتمالی نشان داده شده در شکل 4 به این مقادیر NDVI به دست می آید مترپ1(grههn)=0.44، مترپ1(grهy)=0.06و مترپ1(grههn،grهy)=0.5و مترپ2(grههn)=0.84، مترپ2(grهy)=0و مترپ2(grههn،grهy)=0.16، به ترتیب. محاسبه میانگین این احتمالات به دست می آید مترoسمتر(grههn)=0.64، مترoسمتر(grهy)=0.03و مترoسمتر(grههn،grهy)=0.33به عنوان جرم احتمال برای برچسب t .
برچسبهای OSM که مناطق پوشش گیاهی مانند کاربری زمین=جنگل یا اوقات فراغت=پارک را توصیف میکنند مقادیر جرمی با احتمال بالایی را برای متر(grههn)، در حالی که مناطق ساخته شده مانند ساختمان ها یا پارکینگ ها مقادیر جرمی احتمال بالایی را نشان دادند متر(grهy). تخصیص احتمال اولیه برای ساختمان ها حاوی عدم قطعیت زیادی نیست، زیرا پیکسل های مختلط (یعنی به دلیل ساختمان های کوچک) برای استخراج توده های احتمال مبتنی بر OSM در نظر گرفته نشده اند. تخصیص احتمال اولیه برای برچسب landuse=allotments بالاترین مقدار را در نشان داد متر(grههn،grهy)و بنابراین بالاترین عدم قطعیت، زیرا کلبههای کوچک واقع در داخل این باغهای اجتماعی در OSM نقشهبرداری نشدهاند که منجر به تعداد زیادی پیکسل در این مناطق میشود.
اعتبار سنجی
دقت سبزی حاصل از Sentinel-2 و از ترکیب Sentinel-2 و OSM با مقایسه آنها با سبزی حاصل از تصویر هوایی با وضوح بالاتر ارزیابی شد (به بخش 4.2 مراجعه کنید ). ابتدا، تصویر هوایی با استفاده از نمونهگیری مجدد نزدیکترین همسایه با وضوح 1 متر نمونهبرداری شد که برای این اعتبارسنجی کافی بود و منابع پردازش را ذخیره کرد. متعاقباً NDVI محاسبه شد و از خوشهبندی C-means فازی برای تنظیم توابع انتساب احتمال اولیه به ویژگیهای طیفی تصاویر هوایی استفاده شد ( شکل 4 ب، جدول 2) .). ریشه میانگین مربعات خطا (RMSE) بین تودههای احتمال به دست آمده از تصاویر هوایی و دادههای Sentinel-2 و OSM برای ارزیابی پتانسیل OSM برای جبران وضوح فضایی ناکافی Sentinel-2 محاسبه شد. علاوه بر این، سه نقشه سبزی حاوی کلاسهای سبز و خاکستری بر اساس مجموعه دادههای مختلف (تصاویر هوایی، Sentinel-2 و Sentinel-2 + OSM) با اختصاص کلاس با بالاترین احتمال پیگنیستیک به هر چند ضلعی کاربری زمین ایجاد شد. اگر احتمال پیگنیستیک 0.5 بود، شی به عنوان نامشخص طبقه بندی می شد .
4.3.3. مدل دسترسی عمومی
هدف از مدل دسترسی عمومی، تمایز فضاهای سبز عمومی از خصوصی بود. دسترسی عمومی در این زمینه به این معنی است که یک منطقه بدون مجوز قبلی برای عموم آزادانه قابل دسترسی است. این به معنای فرضیاتی در مورد مالکیت منطقه نیست. جدای از فضاهای سبز شهری مانند پارک ها، این تعریف همچنین شامل مناطقی با مالکیت خصوصی است که برای عموم مردم قابل دسترسی است، مانند زمین های بازی که متعلق به بلوک های آپارتمانی هستند. دو کلاس هدف مدل عمومی و خصوصی بودند.
شاخصهایی در OSM برای پیشبینی دسترسی عمومی
از آنجایی که تصاویر ماهواره ای همیشه اطلاعات قابل اعتمادی در مورد کاربری زمین یک منطقه به دست نمی دهد، تنها از داده های OSM برای تشخیص فضاهای سبز عمومی از خصوصی استفاده شد. برخلاف فضاهای سبز خصوصی (مثلاً باغهای مسکونی)، فضاهای سبز عمومی معمولاً به خوبی در OSM نشان داده میشوند و با استفاده از برچسبهای مختلفی مانند اوقات فراغت=پارک ، کاربری زمین=علف یا کاربری=روستای_سبز نقشهبرداری میشوند . ویژگیهای OSM با این برچسبها را میتوان در دسترس عموم فرض کرد مگر اینکه یکی از برچسبها access=no یا access=خصوصینیز داده می شود. با این حال، عملکرد نقشه برداری در رابطه با فضاهای سبز عمومی در OSM همیشه سازگار نیست که منجر به سطوح ناهمگن فضایی کامل می شود. از چهار فضای سبز عمومی تنها سه فضای سبز به عنوان کاربری زمین = چمن ترسیم شده است . با این حال، فضای سبز عمومی بدون نقشه در وسط را می توان با استفاده از اطلاعات زمینه ای مانند وجود یک شبکه مسیر یا POI های خاص فضاهای سبز (مانند زمین بازی) به عنوان چنین تشخیص داد. برای منطقه درسدن، مسیرها و همچنین نیمکتها و زمینهای بازی اغلب در فضاهای سبز عمومی در OSM ترسیم میشوند و آنها را شاخصهای زمینهای خوبی برای شناسایی فضاهای سبز عمومی بدون نقشه در OSM میکند. این در یک مطالعه قبلی با انجام استخراج قوانین انجمن در پارک های نقشه برداری شده در OSM در شهرهای مختلف جهان مورد بررسی قرار گرفت [ 75]. بر اساس این نتایج، ویژگی های ذکر شده در جدول 3 برای تشخیص فضاهای سبز عمومی از خصوصی در نظر گرفته شد.
در نظر گرفتن وجود نیمکت ها یا زمین های بازی به عنوان متغیرهای باینری به جای تعداد مطلق نیمکت ها یا زمین های بازی در چند ضلعی منجر به تناسب بهتر مدل و همگرایی بهتر مدل ها می شود. برای فعال کردن نمونهبرداری بهتر در طول برازش مدل، طول و چگالی مسیر و همچنین تعداد و چگالی تقاطعها برای توزیع نرمالتر با استفاده از تبدیل Yeo Johnson [ 76 ] تغییر شکل دادند.
ساختار مدل
یک رویکرد رگرسیون لجستیک سلسله مراتبی بیزی برای مدلسازی دسترسی عمومی استفاده شد، زیرا همه شاخصها به صورت خطی با دسترسی عمومی مرتبط بودند و یک رویکرد سلسله مراتبی برای نشان دادن دستههای مختلف کاربری زمین مناسب به نظر میرسید. در طول ارزیابی مدل، پیکربندیهای مدل مختلف با هم مقایسه شدند: یک مدل تلفیقی که فقط شاخصهای زمینهای را در نظر میگیرد، اما اطلاعات مربوط به کاربری زمین را در نظر نمیگیرد و یک رویکرد چند سطحی با یک رهگیری جزئی ادغامشده αj[من]که نشان دهنده رده های کاربری اراضی j بود. همه رهگیری های کاربری خاص از یک توزیع نرمال مشترک با میانگین سرچشمه می گیرند μαو انحراف معیار σα2. مدل کامل چند سطحی شامل شاخصهای زمینهای به صورت تعریف شد
با
جایی که پ(yمن=1)احتمال عمومی بودن چند ضلعی i است ، αj[من]وقفه نیمه ادغام شده برای هر کلاس کاربری زمین j است، X بردار شاخص های زمینه ای است و βبردار حاوی ضرایب برای شاخص های زمینه ای.
دانش قبلی کمی در مورد مقادیر پارامترهای مدل وجود داشت. بنابراین، پیشینهای مدل به صورت ضعیف اما در فضاهای پارامتری معقول انتخاب شدند. حساسیت مدل نسبت به اولویت های مختلف برای اطمینان از همگرایی مدل و نتایج مدل معقول ارزیابی شد. از آنجایی که متغیرهای زمینه استاندارد شده بودند و بنابراین مقیاس یکسانی دارند، اولویتهای همه ضرایب به عنوان توزیعهای نرمال با اطلاعات ضعیف انتخاب شدند که توسط Lemoine [ 77 ] با میانگین پیشنهاد شد.μ=0و انحراف معیار σ=10. برای ایجاد واریانس کافی بین رهگیری ها که نشان دهنده برچسب های کاربری مختلف زمین هستند، قبل از رهگیری چند سطحی μαهمچنین به عنوان یک توزیع نرمال با اطلاعات ضعیف تنظیم شد که میانگین آن به عنوان توزیع نرمال با تعریف شد μ=0و σ=10و انحراف معیار آن σαطبق پیشنهاد پولسون و همکاران، به عنوان توزیع نیمه کوشی تعریف شد. [ 78 ] و Lemoine [ 77 ]. پارامتر مقیاس توزیع نیمه کوشی بر روی تنظیم شد β=5. این مدل با 3 زنجیره و 10000 تکرار آموزش داده شد.
آموزش و اعتبارسنجی مدل
برای آموزش و اعتبارسنجی مدل، 300 چند ضلعی کاربری زمین با استفاده از روش نمونه گیری تصادفی طبقه بندی شده بر اساس انواع کاربری اراضی چندضلعی ها انتخاب شدند (به بخش 4.3.1 مراجعه کنید ). این فضاهای سبز به صورت دستی بر اساس تصاویر هوایی و نمای خیابان گوگل [ 79 ] به عنوان فضاهای سبز عمومی یا خصوصی طبقه بندی شدند. 70 درصد نمونه ها برای آموزش مدل و 30 درصد بقیه برای آزمایش استفاده شدند. مقایسه مدل با استفاده از معیار اعتبار سنجی متقاطع ترک یک خارج (LOO) [ 80 ] انجام شد. از آنجایی که لگاریتم از LOO لog(LOO)استفاده شد، مقادیر بالاتر نشان دهنده کیفیت بالاتر مدل است.
تبدیل احتمالات پسین به توده های احتمالی
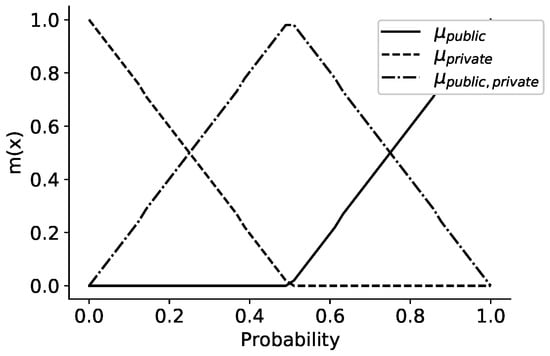
به منظور ادغام نتایج مدل در مورد دسترسی عمومی با اعتقاد به سبز بودن (به بخش 4.3.2 مراجعه کنید )، احتمالات پسین مدل بیزی باید به باورهایی تبدیل می شد که به صورت توده های احتمال بیان می شوند. چارچوب تشخیص این تخصیص احتمال اولیه بود θپ={پتوبلمنج،پrمنvآتیه}. تخصیص احتمال اولیه بر اساس توابع نشان داده شده در شکل 6 است. بالاترین اطمینان در انتساب کلاس زمانی داده شد که احتمال مدل بود پ(yمن=1)=0یا پ(yمن=1)=1. مقادیر احتمال با نزدیک شدن به مقدار 0.5 دارای عدم قطعیت فزاینده ای هستند. در این مرحله، عدم اطمینان در تکالیف کلاس در بالاترین حد است، بنابراین متر({پتوبلمنج،پrمنvآتیه})در حداکثر خود است. توابع تخصیص جرم اولیه احتمال به همه احتمالات پسین اعمال شد و مقادیر حاصل با استفاده از میانگین برای استخراج مقادیر اسکالر برای متر({پتوبلمنج})، متر({پrمنvآتیه})و متر({پتوبلمنج،پrمنvآتیه}).
4.3.4. تلفیقی از سبزی و دسترسی عمومی
در مرحله آخر، باورهای مشتق شده در مورد سبزی و دسترسی عمومی با استفاده از قانون ترکیب دمپستر برای تهیه نقشه ای از فضاهای سبز شهری عمومی ترکیب شدند. سبزی و دسترسی عمومی با استفاده از دو چارچوب تشخیص متفاوت نشان داده شد θg={grههn،grهy}و θپ={پتوبلمنج،پrمنvآتیه}. از آنجایی که فضای سبز و دسترسی عمومی به طور جداگانه مدلسازی شدهاند، میتوان آنها را مستقل از یکدیگر دید. بنابراین، ترکیب این دو قاب تشخیص با ساختن حاصلضرب دکارتی از آنها حاصل شد که چارچوب تشخیص مشترک جدید را به دست آورد. θپg
برای همجوشی نهایی، جرم احتمال دو مدل به چارچوب تشخیص جدید تبدیل شد. θپgاستفاده كردن
یک مثال باید اصل تبدیل را نشان دهد: اعتقاد در مورد سبز بودن چند ضلعی کاربری زمین هیچ اطلاعاتی در مورد دسترسی عمومی آن ندارد. بنابراین، جرم احتمال متر({grههn})از چارچوب تشخیص θgبه اتحاد عناصر (سبز، عمومی) و ( سبز ، خصوصی ) در چارچوب تشخیص جدید اختصاص داده شده است.θ، زیرا بر اساس این باور می تواند یکی از این دو باشد.
پس از ادغام باورهای مربوط به سبز بودن و دسترسی عمومی، احتمالات پیگنیستیک محاسبه شد و کلاسی که بالاترین احتمال پیگنیستیک را داشت به هر شی اختصاص داده شد، به عنوان مثال، ( عمومی ، سبز )، ( عمومی ، خاکستری )، ( خصوصی ، سبز ) یا ( خصوصی ، خاکستری ). با انتخاب تمام اشیاء طبقه بندی شده به عنوان ( عمومی ، سبز ) نقشه نهایی فضاهای سبز عمومی به دست آمد.
عدم قطعیت در مورد احتمال اینکه یک شی یک فضای سبز عمومی را نشان می دهد با محاسبه تفاوت بین معقول بودن و باور مجموعه {( عمومی ، سبز )} کمی سازی شد.
عدم قطعیت مرتبط با اطلاعات دسترسی عمومی یا سبز بودن به همان روش اما بر اساس مجموعههای {( عمومی ، سبز )، ( عمومی ، خاکستری )} و {( عمومی ، سبز )، ( خصوصی ، سبز )} محاسبه شد.
4.3.5. اعتبار سنجی
نقشه فضای سبز عمومی با استفاده از 300 نمونه استخراج شده از چند ضلعی کاربری زمین تایید شد (به بخش 4.3.3 مراجعه کنید ). آنها با استفاده از تصاویر هوایی و نمای خیابان گوگل [ 79 ] به صورت دستی در طبقات فضای سبز عمومی یا موارد دیگر طبقه بندی شدند. بر اساس این داده های اعتبارسنجی، یک ارزیابی دقت انجام شد که شامل دقت اندازه گیری، یادآوری و امتیاز f1 [ 81 ] بود.
5. نتایج
5.1. چند ضلعی های کاربری اراضی
در محدوده مورد مطالعه 3776 چند ضلعی کاربری ایجاد شد که از این تعداد 83.8 درصد به عنوان ساختمان، 5.2 درصد به عنوان کاربری = مسکونی ، 2.1 درصد به عنوان کاربری = چمن و 0.8 درصد به عنوان اوقات فراغت = پارک برچسب گذاری شدند. 2.7 درصد از چند ضلعی ها حاوی برچسب OSM مربوط به کاربری زمین نبودند. مقوله های کاربری زمین باقی مانده هر کدام کمتر از 0.5٪ را تشکیل می دادند. 8.4 درصد از چند ضلعی های غیرساختمانی شامل حداقل یک زمین بازی، 8.7 درصد شامل حداقل یک نیمکت و 29.3 درصد از چند ضلعی ها حاوی حداقل یک تقاطع مسیر پیاده روی بودند. دسترسی محدود، که از طریق حضور یکی از برچسبها نشان داده شده است، دسترسی=no|خصوصی|مشتریان ، تنها برای 2% از چند ضلعیهای غیرساختمانی داده شده است.
5.2. سبزی
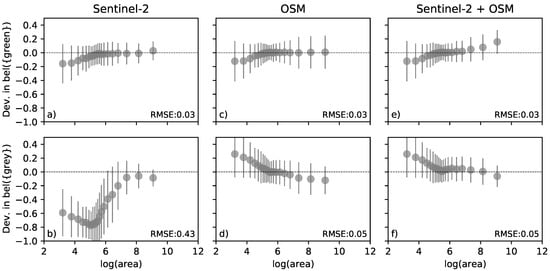
باورهای مربوط به سبز بودن بر اساس داده های Sentinel-2 و OSM با باور به دست آمده از تصویر هوایی به عنوان داده های مرجع مقایسه شد ( شکل 7 ). باورهای به دست آمده از تصاویر Sentinel-2 نسبت به باورهایی که از ترکیب داده های Sentinel-2 و OSM به دست آمده بودند، دقت کمتری داشتند. RMSE توده های احتمال متر({grهy})به دست آمده از داده های Sentinel-2 0.43 با بیشترین انحراف در بین چند ضلعی های کوچکتر از 500 متر بود. 2که به دلیل این واقعیت است که وضوح سنسور به اندازه کافی بالا نیست تا سبزی آنها را با دقت ثبت کند ( شکل 7 ب). این اشیاء بیشتر ساختمان هایی هستند که با کاملیت بسیار بالایی در OSM نقشه برداری شده اند. ادغام شواهد از Sentinel-2 و OSM منجر به بهبود شدید سبزی با کاهش RMSE به 0.05 شد ( شکل 7 f). پس از همجوشی، جرم احتمال متر({grهy})ساختمانهای بسیار کوچک مانند کلبهها در مقایسه با دادههای مرجع بیش از حد تخمین زده شد، که میتوان با این واقعیت توضیح داد که این کلبهها اغلب توسط درختان پوشیده شده بودند و بنابراین در تصاویر هوایی پوشش گیاهی به نظر میرسیدند ( شکل 7 d,f).
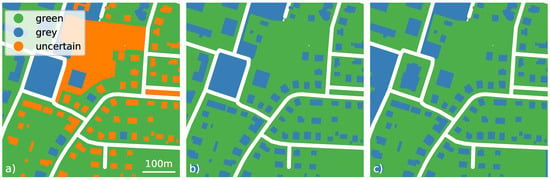
این تفاوتها را میتوان در طبقهبندیهای حاصل از باورها نیز مشاهده کرد ( شکل 8 ). هنگامی که فقط از تصاویر Sentinel-2 استفاده می شود، اکثر ساختمان های کوچک نمی توانند به طور قابل اعتمادی به عنوان سبز یا خاکستری طبقه بندی شوند ، اما به دلیل عدم قطعیت بالا ناشی از پیکسل های مخلوط نامشخص باقی می مانند ( شکل 8 a). اعتقاد برگرفته از OSM در مورد سبز بودن اجسام با تگ ساختمان=* به هر حال بسیار واضح بود متر(grهy)≥0.8( شکل 5 ب)). بنابراین ادغام باور مبتنی بر Sentinel-2 با شواهدی از OSM تعداد ساختمان هایی که به درستی به عنوان خاکستری طبقه بندی می شوند را به میزان قابل توجهی افزایش داد ( شکل 8 ب).
با توجه به انحراف در جرم احتمال متر({grههn})، RMSE کلی حتی پس از ادغام با داده های OSM در 0.03 باقی ماند ( شکل 7 a,e). برخی از انحرافات در مناطق با تغییر پویای پوشش زمین مانند سایت های ساخت و ساز یا مناطق کشاورزی (مانند زمین های کشاورزی، علفزار یا علفزار) رخ داده است. این انحرافات احتمالاً به دلیل تغییرات واقعی کاربری زمین بوده است که بین تاریخهای دریافت تصویر هوایی در سال 2017 و تصاویر Sentinel-2 در سال 2019 رخ داده است. از مناطق سبز به خصوص فضاهای سبز کوچک که اغلب در OSM با استفاده از برچسب landuse=grass نقشه برداری می شوند، با اطمینان بیشتری شناسایی شدند. در بین چند ضلعی های کاربری اراضی کوچکتر از 500 متر 2(به استثنای ساختمان ها) دقت کلی از 0.18 تنها با استفاده از Sentinel-2 به 0.48 با استفاده از Sentinel-2 و داده های OSM افزایش یافت. از این چند ضلعی های کوچک، 72٪ دارای یک برچسب OSM مانند استفاده از زمین = چمن (28٪)، کاربری زمین = مسکونی (16٪) یا امکانات رفاهی = زمین بازی (7٪) بودند.
5.3. دسترسی عمومی
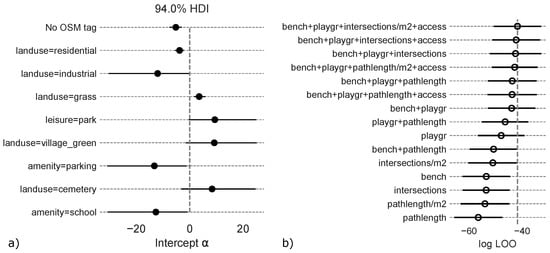
ابتدایی ترین مدل چند سطحی که فقط برچسب های کاربری زمین را در نظر می گیرد ( لog(LOO)= -63، دقت کلی = 0.88) به طور قابل توجهی بهتر از بهترین مدل تلفیقی که فقط شاخصهای زمینه را در نظر میگرفت، عمل کرد. لog(LOO)= -117، دقت کلی = 0.74). این نشان می دهد که اطلاعات کاربری زمین در OSM برای این مدل برای تشخیص فضاهای سبز عمومی از خصوصی بسیار مهم است. برچسبهای OSM مانند اوقات فراغت = پارک یا کاربری زمین = گورستان دارای رهگیریهای مثبت بودند که نشان میدهد آنها شاخصهای قوی برای فضاهای سبز عمومی هستند، در حالی که برچسبهای OSM مانند کاربری زمین=صنعتی یا امکانات رفاهی=پارکینگ خلاف آن را نشان میدهند ( شکل 9 الف). برای مناطق مسکونی یا چند ضلعی بدون برچسب کاربری زمین، رهگیری ها کمی منفی بود، که نشان می دهد این مناطق تنها در صورتی به عنوان عمومی طبقه بندی می شوند که شاخص های زمینه ای برای دسترسی عمومی به اندازه کافی قوی باشند.
برای تجزیه و تحلیل پتانسیل مدل برای شناسایی فضاهای سبز عمومی بدون نقشه، تأثیر شاخص های زمینه مختلف بر عملکرد مدل مورد بررسی قرار گرفت ( شکل 9 ب). مدل چند سطحی که فقط برچسبهای مربوط به کاربری زمین را در نظر میگرفت اما هیچ شاخص زمینهای را در نظر نمیگرفت، به دقت کلی 0.88 رسید. فراخوان برای طبقه عمومی تنها 0.77 بود، زیرا فضاهای سبز عمومی بدون نقشه به اشتباه به عنوان خصوصی طبقه بندی شدند .
گنجاندن تراکم تقاطعهای مسیرهای پیادهروی در مدل، کمی دقت کلی را به 0.90 افزایش داد. تعداد خطاهای حذف کاهش یافته است، زیرا برخی از فضاهای سبز عمومی بدون نقشه را می توان با استفاده از تقاطع های مسیر پیاده روی اضافی شناسایی کرد. با این حال، در همان زمان، تعداد اشتباهات کمیسیون افزایش یافت زیرا چند بلوک مسکونی خصوصی حاوی مسیرهای پیاده روی در امتداد خیابان ها یا مسیرهای دسترسی به خانه های مجردی به طور اشتباه به عنوان عمومی طبقه بندی شدند . اگرچه گنجاندن تراکم تقاطعهای مسیرهای پیادهروی در مدل برای شناسایی مطمئن تمام فضاهای سبز عمومی بدون نقشه کافی نبود، اما عدم قطعیت مرتبط با پیشبینیهای نمونهها متر({پتوبلمنج،پrمنvآتیه})در مقایسه با مدل چند سطحی که تراکم تقاطع های مسیرهای پیاده را در نظر نمی گرفت، به طور متوسط 22 درصد کاهش یافت.
به طور کلی، استفاده از چگالی به جای تعداد مطلق تقاطعها در هر چند ضلعی منجر به عملکرد بهتر مدل شد ( شکل 9 ب)، اما استفاده از تقاطعهای مسیر پیادهروی بهجای طول کلی مسیر تنها تا حدی بهتر عمل کرد. از آنجایی که محاسبه تقاطعها از نظر محاسباتی فشردهتر است، استفاده از طول مسیر به جای تقاطعهای مسیر پیادهروی به منظور صرفهجویی در منابع محاسباتی در صورتی که مدل در مناطق بزرگتر اعمال شود، قابل قبول است.
اضافه کردن حضور نیمکت ها و زمین های بازی به عنوان شاخص های معمولی برای فضاهای سبز عمومی در درسدن به مدل چند سطحی، دقت کلی را به 0.98 افزایش داد. عدم قطعیت مرتبط با پیش بینی ها متر({پتوبلمنج،پrمنvآتیه})به طور متوسط 33 درصد در مقایسه با مدل چند سطحی بدون هیچ شاخص زمینه کاهش یافت. دقت و یادآوری مدل بسیار بالا بود و همچنین نشان میدهد که مدل قادر به شناسایی بیشتر فضاهای سبز عمومی بدون نقشه بدون طبقهبندی نادرست مناطق مسکونی خصوصی است ( جدول 4 ). با این حال، یک خطای حذف برای چند ضلعی رخ داد که حاوی برچسب کاربری زمین یا نشانگر زمینه نبود. یک خطای کمیسیون برای چند ضلعی استفاده از زمین با برچسب کاربری زمین = چمن و دسترسی = خصوصی رخ داد. این خطای طبقه بندی حتی پس از گنجاندن تگ access=* در مدل قابل اجتناب نیست . برچسب landuse=grass یک شاخص قوی برای دسترسی عمومی است، اما تأثیر برچسبaccess=private در مدل خیلی کم بود. این نشان میدهد که مدل بهطور دقیق این واقعیت را که تگ access=private دلالت بر عدم دسترسی عمومی با درجه اطمینان بالایی دارد، نشان نداده است، که احتمالاً به دلیل این واقعیت است که تگ access=* فقط برای حدود 2٪ از موارد داده شده است. چند ضلعی های کاربری زمین
5.4. تلفیقی از سبزی و دسترسی عمومی
نقشه ای از فضاهای سبز شهری عمومی و خصوصی بر اساس داده های Sentinel-2 و OSM در شکل 10 ارائه شده است . در مقایسه با داده های معتبر در مورد فضاهای سبز عمومی که در شکل 1 نشان داده شده است ، پیش بینی ما وجود فضای سبز بسیار بیشتری را نشان می دهد. این به دلیل این واقعیت است که نقشه قبلی شامل فضاهای سبز متعلق به خصوصی اما قابل دسترسی عمومی نیست، زیرا این فضاها در داده های شهرداری گنجانده نشده است.
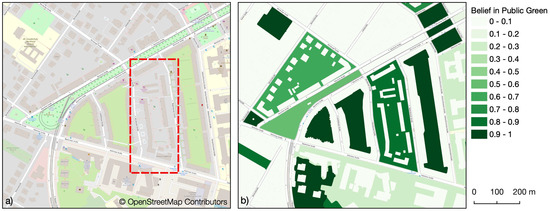
دقت کلی نقشه نهایی فضاهای سبز عمومی 95 درصد بود. فضاهای سبز عمومی که در OSM به عنوان اوقات فراغت = پارک یا کاربری زمین = چمن نقشه برداری شده بودند، همه به طور قابل اعتماد توسط مدل شناسایی شدند. در میان آنها بیشتر فضاهای سبز شهری هستند که در درسدن با سطح بالایی از کامل بودن نقشه برداری شدند و همچنین برخی از فضاهای سبز متعلق به خصوصی اما در دسترس عموم قرار گرفتند. فضاهای سبز عمومی که در OSM به طور صریح با استفاده از این برچسب ها نقشه برداری نشده اند نیز توسط مدل با باورهای کمی ضعیف تر شناسایی شدند ( شکل 11 ب). در کل منطقه مورد مطالعه، 180 مورد از چنین فضاهای سبز عمومی احتمالاً بدون نقشه شناسایی شدند که بیشتر آنها در مناطق مسکونی بودند. فضاهای سبز که با استفاده از برچسب خصوصی شدندaccess=* تا حدی توسط مدل به عنوان عمومی طبقه بندی شد.
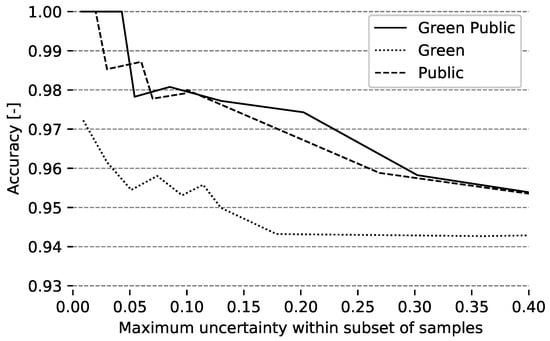
شکل 12 رابطه بین عدم قطعیت های پیش بینی ها و دقت کلی مدل را نشان می دهد. با افزایش سطح حداکثر عدم قطعیت در زیر مجموعههای نمونه، دقت مدل کاهش مییابد. این نشان دهنده رابطه خطی بین دقت مدل و برآورد عدم قطعیت نمونه ها است. همین الگو برای عدم قطعیت باور دسترسی عمومی قابل مشاهده بود که نشان میدهد عدم قطعیت کلی در پیشبینیهای مدل عمدتاً ناشی از عدم قطعیت مدل دسترسی عمومی است. از سوی دیگر عدم قطعیت در سبزی رابطه قوی با دقت مدل کلی نشان نمیدهد که نشان میدهد عدم قطعیت در سبزی بر دقت مدل تأثیر چندانی ندارد.
6. بحث
هدف از این مطالعه توسعه و آزمایش روشی برای کاهش محدودیتهای فعلی در نقشهبرداری فضای سبز شهری به دلیل عدم قطعیتهای ذاتی در دادههای Sentinel-2 و OSM بود. یک مشکل رایج استفاده از تصاویر Sentinel-2 برای نقشه برداری فضای سبز شهری، ناتوانی آن در گرفتن اشیاء کوچک به دلیل وضوح فضایی ناکافی (RQ1) است. این موضوع در این مطالعه تأیید شد، اما همچنین نشان داده شد که دادههای OSM میتوانند تا حدی این ناتوانیها را جبران کنند. به ویژه در میان اشیاء کاربری کوچک مانند ساختمان ها یا فضاهای سبز کوچکتر از 500 متر 2نرخ تشخیص با در نظر گرفتن عدم قطعیت های خاص منبع داده در طول ادغام داده ها با استفاده از تئوری Dempster-Shafer به طور قابل توجهی افزایش یافت.
یکی دیگر از محدودیتهای دادههای ماهوارهای در رابطه با نقشهبرداری فضای سبز شهری، ناتوانی در تشخیص فضاهای سبز عمومی از خصوصی است (RQ2). دادههای OSM برای جبران این مشکل و همچنین با استفاده از مدل رگرسیون لجستیک بیزی مناسب هستند. برای توضیح نمایش ناسازگار و ناقص فضاهای سبز عمومی در OSM، برچسبهای OSM خاص کاربری زمین و همچنین شاخصهای زمینهای برای دسترسی عمومی (به عنوان مثال، مسیرهای پیادهروی) در مدل در نظر گرفته شدند. به این ترتیب، میتوان هم فضاهای سبز عمومی نقشهبرداری شده و هم فضاهای سبز عمومی را که در OSM وجود ندارند، شناسایی کرد. با این حال، مدل را می توان بهبود بخشید، برای مثال، با تشخیص دقیق تر دسترسی محدود که با دسترسی=* نشان داده شده است.برچسب زدن اگرچه معنای این برچسب بسیار واضح است، اما تأثیر آن در مدل بسیار کم بود، زیرا تنها در 2٪ از نمونه ها رخ می دهد. برای افزایش نفوذ آن، تگ access=* را می توان از مدل حذف کرد و در عوض به عنوان یک منبع اطلاعاتی مستقل در نظر گرفت و به جرم احتمال تبدیل شد تا با نتایج مدل ترکیب شود. در این زمینه، تحلیل چگونگی دسترسی مشروط، به عنوان مثال، مناطق با هزینه دسترسی یا محدودیتهای دسترسی وابسته به زمان در محوطه مدرسه، میتواند از دادههای OSM استخراج شود نیز جالب خواهد بود.
مدلسازی فضای سبز و دسترسی عمومی به طور جداگانه و ترکیب آنها در مرحله نهایی با استفاده از نظریه دمپستر-شفر، انتشار عدم قطعیتها از منابع دادهای را از طریق تجزیه و تحلیل تا نقشه نهایی فضاهای سبز عمومی (RQ3) ممکن کرد. عدم قطعیت در مورد شواهد برای دسترسی عمومی تأثیر بیشتری بر دقت مدل نسبت به شواهد برای سبز بودن داشت. این اطلاعات به درک بهتری از قابلیت اطمینان نقشه نهایی فضاهای سبز کمک می کند و ممکن است به کاهش میزان نیاز به اعتبارسنجی دستی کمک کند تا مجموعه داده ها به اندازه کافی قابل اعتماد باشد تا در یک سیستم توصیه استفاده شود.
از آنجایی که تصاویر Sentinel-2 و دادههای OSM در سطح جهانی و رایگان در دسترس هستند، این روش در اصل برای شهرها یا مناطق دیگر نیز قابل اجرا است. مدل سبزی را می توان به طور خودکار در مناطق دیگر بدون مداخلات دستی اعمال کرد و با توجه به نرخ بازدید مجدد ماهواره های سنتینل-2 معمولاً تولید کامپوزیت های تصویر بدون ابر برای اکثر مناطق جهان امکان پذیر است.
با این حال، بسیار مهم است که تأکید کنیم که کیفیت نقشه نهایی فضای سبز عمومی به شدت به کیفیت دادههای OSM اساسی بستگی دارد. در منطقه مورد مطالعه ما، کامل بودن دادههای OSM در رابطه با ساختمانها، فضاهای سبز عمومی و شاخصهای زمینهای برای دسترسی عمومی بسیار بالا بود که امکان نتایج قابل اعتماد با کیفیت بالا را فراهم میکرد [ 75 ]، اما این نباید برای سایر مناطق جغرافیایی فرض شود. بدون تجزیه و تحلیل کیفیت داده های قبلی داده های OSM محلی. تجزیه و تحلیل کامل بودن ویژگی های OSM مربوطه بر اساس شاخص های کیفیت داده های ذاتی [ 82 ] می تواند اولین قدم قبل از انجام مراحل بعدی باشد. OSHDB و ohsome API [ 68] ممکن است به عنوان نقطه ورودی برای چنین تحلیلی عمل کند.
اگرچه یک تحلیل جامع از قابلیت انتقال روش به شهرهای دیگر خارج از محدوده این مقاله بود، اما در صورتی که کیفیت دادههای OSM کافی باشد و مدل دسترسی عمومی با دادههای OSM محلی تطبیق داده شود، استفاده موفقیتآمیز این روش در سایر شهرها ممکن است. . پیشبینی دسترسی عمومی بر اساس برچسبهای کاربری زمین و تراکم تقاطعهای مسیرهای پیادهروی نتایج خوبی با دقت کلی 0.9 به همراه داشت. از آنجایی که معنای این اشیاء OSM در رابطه با حضور فضاهای سبز عمومی را می توان در سراسر مناطق جغرافیایی تقریباً مشابه فرض کرد، این مدل باید نتایج قابل مقایسه ای را در هنگام آموزش و اعمال در شهرهای دیگر با سطوح کامل بودن مشابه به همراه داشته باشد. هنوز، گنجاندن شاخصهای زمینه خاص منطقه که برای فضاهای سبز عمومی در شهر مربوطه هستند، برای گرفتن قابل اعتماد فضاهای سبز عمومی بدون نقشه نیز مهم است. در مورد درسدن، نیمکتها و زمینهای بازی شاخصهای زمینه محلی مهمی بودند، اما در مناطق دیگر ممکن است از برچسبهای OSM متفاوتی استفاده شود، زیرا عناصر مشخصه فضاهای سبز عمومی بسته به فرهنگ محلی و شیوههای نقشهبرداری در OSM متفاوت است.74 ]. بنابراین، شناسایی شاخصهای زمینه مناسب که هم از نظر فرهنگی مربوط به فضاهای سبز عمومی محلی هستند و هم با سطح کافی از کامل بودن در OSM هنگام انتقال مدل به مناطق دیگر نقشهبرداری میشوند، بسیار مهم است. تکنیکهای انتخاب ویژگی مبتنی بر دادهها مانند استخراج قانون تداعی میتواند برای کمک به یافتن شاخصهای مناسب استفاده شود [ 75 ].
پتانسیل بهبود روش پیشنهادی با در نظر گرفتن داده های اضافی وجود دارد. اشیاء نقطه ای یا خطی در OSM مانند درختان یا ردیف درختان در این مطالعه در نظر گرفته نشدند، اما اگر علاوه بر این در نظر گرفته شوند، احتمالاً می توانند تخمین سبزی را بیشتر بهبود بخشند. به همین ترتیب، از جمله موانع فیزیکی مانند دیوارها یا حصارهای نقشه برداری شده در OSM می تواند تولید چند ضلعی کاربری زمین را بهبود بخشد. دادههای رسانههای اجتماعی میتواند به عنوان یک منبع شواهد اضافی برای بهبود دسترسی عمومی پیشبینیشده استفاده شود.
یک سوال مهم برای مطالعات آینده این است که نقشههای فضاهای سبز عمومی ایجاد شده با استفاده از این روش تا چه اندازه بین شهرهای مختلف قابل مقایسه هستند. آیا همه انواع فضاهای سبز به تصرف در می آیند یا سوگیری نسبت به گرفتن انواع خاصی از فضاهای سبز در برخی شهرها وجود دارد اما در برخی دیگر بسته به انتخاب شاخص های زمینه ای برای دسترسی عمومی وجود ندارد؟ این سوگیری ها تا چه حد تحت تأثیر کیفیت داده های OSM، شیوه های نقشه برداری جامعه محلی OSM و ویژگی های خاص منطقه فضای سبز شهری هستند؟ این مشکلات بالقوه باید با توسعه روشهای مناسب برای تضمین تولید نقشههای منسجم از فضاهای سبز شهری عمومی در سراسر شهرهای مختلف مورد تجزیه و تحلیل قرار گیرد و در صورت لزوم مورد بررسی قرار گیرد.11 ، 83 ] که مجموعه داده های مناسبی برای آنها هنوز در دسترس نیست. علاوه بر این، فضاهای سبز شهری که با استفاده از این روش به دست میآیند، میتوانند با افزایش آگاهی برای عدم کامل بودن یا شیوههای نقشهبرداری متناقض در رابطه با فضاهای سبز شهری مورد توجه جامعه OSM باشند.
7. نتیجه گیری
نتایج ما نشان داد که ادغام دادههای OSM و Sentinel-2 بر اساس نظریه Dempster-Shafer تخمینهای فضاهای سبز عمومی شهری را به میزان قابلتوجهی بهبود بخشید. این پتانسیل را برای ارزیابی های بهبود یافته از فضاهای سبز شهری و خدمات اکوسیستم متصل به آنها ارائه می دهد – حداقل در مناطقی با کیفیت داده OSM کافی. علاوه بر این، ما توانستیم نشان دهیم که داده های OSM را می توان برای تخمین دسترسی به فضاهای سبز در سطح معقولی از عدم قطعیت استفاده کرد. در نتیجه استفاده از شاخصهای زمینه اهمیت زیادی برای توضیح ناهماهنگی و ناقص بودن دادهها دارد. برای مدل ترکیبی، دقت کلی 95 درصد برای پیشبینی فضاهای سبز عمومی را میتوان برای منطقه مورد مطالعه ما به دست آورد. عدم قطعیت مرتبط با دسترسی عمومی پیشبینیشده تأثیر بیشتری بر دقت مدل ترکیبی نسبت به سبزی پیشبینیشده داشت. در حالی که نتایج امیدوارکننده است، مطالعات بیشتری برای آزمایش اینکه تا چه حد میتوان از این رویکرد برای مناطق شهری با کیفیت OSM متفاوت و با برنامهریزی شهری و زمینههای بیوفیزیکی متفاوت استفاده کرد، مورد نیاز است.




بدون دیدگاه