

کلید واژه ها:
ادغام داده ها ; تلاطم ; بهینه سازی ; سیستم های اطلاعات جغرافیایی
1. مقدمه
2. پس زمینه
2.1. اقدامات شباهت
2.2. استخراج روابط مسابقه
2.3. مدلهای ادغام بهینه
2.4. کارهای مرتبط
3. روش ها
3.1. یکپارچه سازی مدل تطبیق دو جهته (U-bimatching)
ما با توصیف داده های مشکل مورد نیاز شروع می کنیم. اول، ما به اندازه گیری شباهت بین دو ویژگی نامزد نیاز داریم. تطابق کامل نشان دهنده رابطه هویتی است و بدون جهت است. در مقابل، مسابقات جزئی نامتقارن و جهت دار هستند. اگر یک ویژگی منiدر مجموعه داده منIمربوط به بخشی از (یا متعلق به) ویژگی است jjدر مجموعه داده جیJ، jjلزوما متعلق به منiدر جهت مخالف. بنابراین، ما از فواصل هدایت شده (مانند فاصله هدایت شده هاسدورف) استفاده می کنیم. دijdijو د“ijd′ijبرای سنجش شباهت جهت ویژگی ها در تطابق جزئی. دij= 0dij=0اگر منiمنطبق با بخشی از jj، و به صورت متقارن د“ijd′ij د“ij= 0d′ij=0اگر j ∈ Jj∈Jمربوط به بخشی از من ∈ منi∈I. برای مسابقات کامل، از فاصله کلی استفاده می کنیم DijDij(مانند فاصله Hausdorff) برای اندازه گیری شباهت بین ویژگی های نامزد. فاصله کل به عنوان حداکثر دو فاصله جهتی تعریف می شود:
الگوریتم ادغام بهینه شده توسط مدل برنامه ریزی خطی عدد صحیح زیر بیان می شود (موسوم به مدل دوتطبیقی متحد (u-bimatching))، که می تواند توسط هر حل کننده استاندارد بهینه سازی ILP مانند IBM ILOG CPLEX یا کیت برنامه نویسی خطی گنو (GLPK) حل شود:
موضوع:
3.2. کاهش تکالیف جعلی با استفاده از اقدامات کمکی (شباهت نام)
انگیزه های بالا راه حل اختلاط بهینه را مخدوش می کند. این امر به ویژه زمانی صادق است که مدل تلفیقی محدود نباشد (مانند مشکل تخصیص). حتی با وجود محدودیتهای سازگاری، تطابقات جعلی همچنان میتواند رخ دهد. یک راه متداول برای کاهش بیشتر تطابقات ساختگی، استفاده از اقدامات اضافی مانند شباهت نام ها، شکل ها و جهت گیری دو جاده درگیر است. این در ادبیات با استفاده از فواصل رشته ها، مانند فاصله همینگ انجام شده است (به عنوان مثال، [ 9 را ببینید]). با این حال، تطبیق نام خیابان ها آنقدر که به نظر می رسد آسان نیست. در مجموعه داده آزمایشی که استفاده می کنیم، نام همان خیابان را می توان در فایل های OSM و TIGER بسیار متفاوت نوشت. به عنوان مثال، نوع خیابان “avenue” را می توان به صورت “Ave” در OSM و “Avenue” در TIGER نوشت. جهت خیابان در انتهای نام در یک مجموعه داده (به عنوان مثال، “Valerio E St”) و در جلو در مجموعه داده دیگر (به عنوان مثال، “خیابان Valerio شرقی”) نوشته شده است. مقایسه مستقیم رشته ها کاراکتر به کاراکتر، مانند فاصله هامینگ، می تواند نتایج اشتباهی را ارائه دهد. استانداردسازی آدرس یک راه حل بالقوه است، اما هنوز یک موضوع تحقیقاتی است که در این مقاله به دنبال آن نخواهیم بود. در عوض، ما از یک متریک ساده برای مقایسه رشته ها استفاده می کنیم: شمارش تعداد کاراکترهای رایج. ما این متریک را فاصله شمارش می نامیم. برای هر دو رشته، ما آن را به عنوان نسبت بین تعداد کاراکترهای مشترک آنها و طول رشته کوتاهتر تعریف می کنیم. به این معنا که:
جایی که متر12متر12تعداد کاراکترهای مشترک است و n1،n2n1،n2به ترتیب تعداد کاراکترهای دو رشته هستند. وقتی کوتاهتر از دو رشته خالی باشد، متریک (14) به بینهایت نزدیک میشود. بنابراین یک عدد کوچک (0.1) را در مخرج اضافه می کنیم تا از مقدار بی نهایت جلوگیری کنیم. بعد از ضرب فاصله شمارش در 100 متر، فاصله شمارش را به فاصله هدایت شده هاسدورف اضافه می کنیم. این تضمین می کند که دو معیار مختلف در یک مقیاس هستند. مقدار 100 متر در اینجا به عنوان مقدار تخمینی بزرگترین افست فضایی انتخاب شده است. برای بقیه این مقاله، فرض میکنیم که متریک فاصله برای همه مدلها (از جمله مدل همسانی u) متریک فاصله Hausdorff تقویتشده (با فاصله تعداد رشتهها) است.
4. نتایج
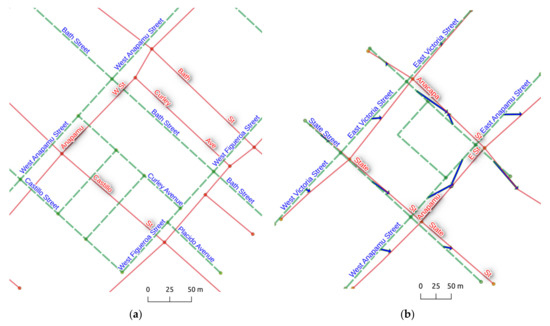
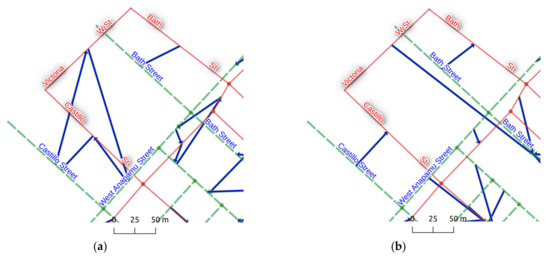
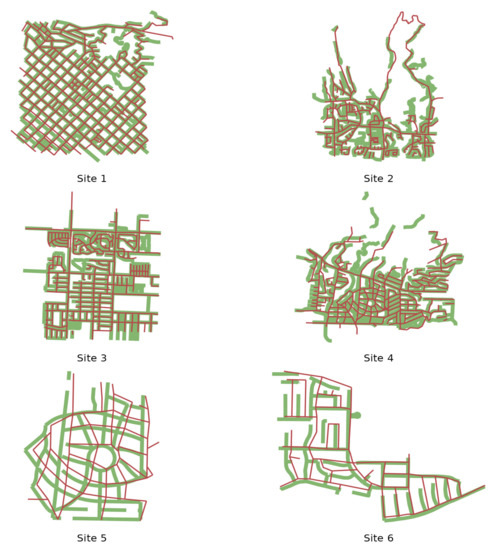
4.1. تنظیمات آزمایش
4.2. معیارهای ارزیابی
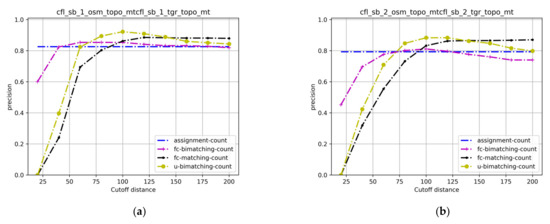
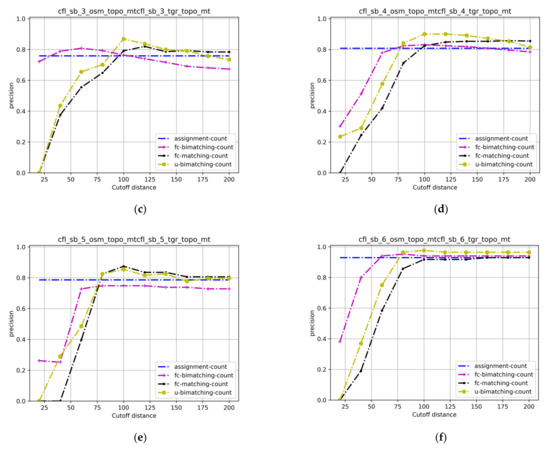
برای ارزیابی دقت مدلهای ترکیبی، از دو معیار استاندارد پرکاربرد استفاده کردیم: دقت و نرخ فراخوان. اینها همان معیارهای مورد استفاده در [ 9 ، 19 ] هستند. به طور خاص، دقت یک الگوریتم تطبیق با مقایسه مطابقت های ایجاد شده توسط الگوریتم با مواردی که توسط یک متخصص انسانی در حقیقت زمین برچسب گذاری شده بود، محاسبه شد:
جایی که TMTMو FMFMتعداد تطابق های واقعی (ویژگی هایی که به درستی مطابقت دارند) و موارد نادرست (ویژگی هایی که با اهداف اشتباه مطابقت دارند) هستند. TUTUو FUFUبه ترتیب تعداد True Unmatches (ویژگی هایی که به درستی بدون تطابق نگه داشته می شوند) و False Unmatches (ویژگی هایی که باید مطابقت داشته باشند اما به عنوان بی همتا نگه داشته می شوند) هستند. دقت (14) قدرت تمایز یک الگوریتم ترکیبی را اندازه گیری می کند. یک الگوریتم با دقت بالا، پیشبینیهای قابل اعتمادی در مورد منطبقات مثبت ایجاد میکند. تعداد کمی از تطابق ایجاد شده توسط چنین الگوریتمی نادرست هستند. از سوی دیگر، ممکن است “بیش از حد محتاط” باشد و مسابقات واقعی را از دست بدهد.
نرخ فراخوان به صورت زیر تعریف می شود:
جایی که ( TM + FU )TM+FUتعداد کل منطبقات در حقیقت زمینی است (که یا به درستی تطبیق داده شده اند یا به طور نادرست مطابقت ندارند). الگوریتمی با یادآوری بالا (15) بیشتر تطابقهای واقعی را ثبت میکند، اما ممکن است این کار را به قیمت ایجاد بسیاری از تطابقهای نادرست انجام دهد.
4.3. نتایج عملکرد
4.3.1. دقت، درستی
4.3.2. به خاطر آوردن
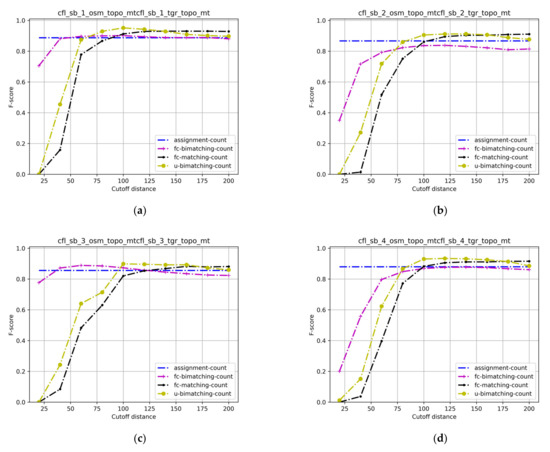
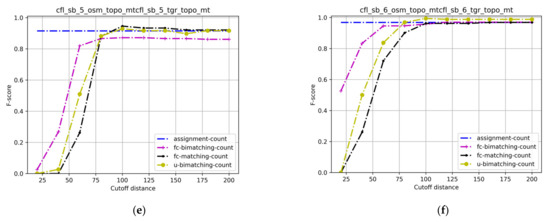
4.3.3. امتیاز اف
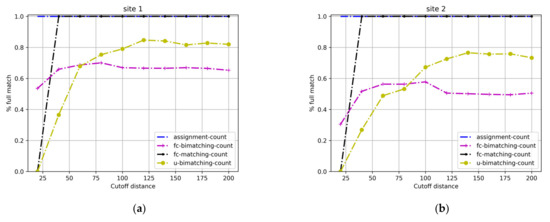
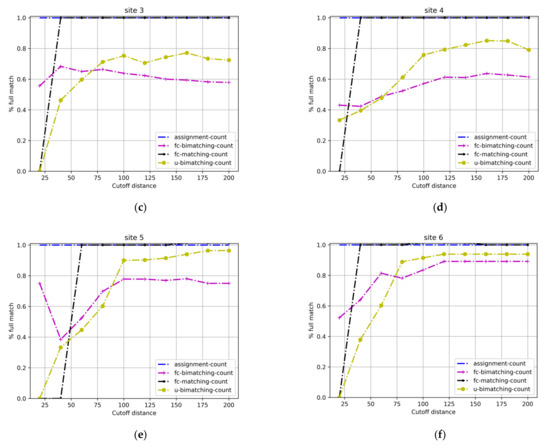
4.3.4. درصد مسابقات کامل
5. نتیجه گیری ها
منابع
- فرانک، AU چرا مقیاس توصیفگر مؤثری برای کیفیت داده است؟ منطق فیزیکی و هستی شناختی برای عدم دقت و سطح جزئیات. در گرایش های پژوهشی در علم اطلاعات جغرافیایی ; Springer: برلین/هایدلبرگ، آلمان، 2009; صص 39-61. [ Google Scholar ]
- Saalfeld، A. تبدیل سریع ورق لاستیکی با استفاده از مختصات ساده. صبح. کارتوگر. 1985 ، 12 ، 169-173. [ Google Scholar ] [ CrossRef ]
- Saalfeld، A. گردآوری خودکار نقشه Conflation. بین المللی جی. جئوگر. Inf. سیستم 1988 ، 2 ، 217-228. [ Google Scholar ] [ CrossRef ]
- والتر، وی. Fritsch، D. تطبیق مجموعه داده های مکانی: یک رویکرد آماری. بین المللی جی. جئوگر. Inf. علمی 1999 ، 13 ، 445-473. [ Google Scholar ] [ CrossRef ]
- مک کنزی، جی. یانوویچ، ک. Adams, B. یک روش وزنی چند ویژگی برای تطبیق نقاط مورد علاقه تولید شده توسط کاربر. کارتوگر. Geogr. Inf. علمی 2014 ، 41 ، 125-137. [ Google Scholar ] [ CrossRef ]
- Pendyala, RM توسعه ابزارهای ترکیبی مبتنی بر GIS برای یکپارچه سازی و تطبیق داده ها . بخش حمل و نقل فلوریدا: لیک سیتی، فلوریدا، ایالات متحده آمریکا، 2002. [ Google Scholar ]
- ماسویاما، الف. روشهایی برای تشخیص تفاوتهای ظاهری بین مجموعههای فضایی در مقاطع زمانی مختلف. بین المللی جی. جئوگر. Inf. علمی 2006 ، 20 ، 633-648. [ Google Scholar ] [ CrossRef ]
- خاویر، EMA؛ آریزا-لوپز، FJ; Ureña-Cámara, MA بررسی اقدامات و روشها برای تطبیق مجموعه دادههای برداری جغرافیایی. کامپیوتر ACM. Surv. 2016 ، 49 ، 1-34. [ Google Scholar ] [ CrossRef ]
- لی، ال. Goodchild، MF یک مدل بهینه سازی برای تطبیق ویژگی های خطی در ترکیب داده های جغرافیایی. بین المللی J. Image Data Fusion 2011 ، 2 ، 309-328. [ Google Scholar ] [ CrossRef ]
- بیری، سی. کانزا، ی. صفرا، ای. Sagiv، Y. همجوشی اشیاء در سیستم های اطلاعات جغرافیایی. در مجموعه مقالات سی امین کنفرانس بین المللی در مورد پایگاه های داده بسیار بزرگ، تورنتو، ON، کانادا، 31 اوت تا 3 سپتامبر 2004. جلد 30، ص 816–827. [ Google Scholar ]
- کورال، ا. مانولوپولوس، ی. تئودوریدیس، ی. Vassilakopoulos، M. الگوریتمهای پردازش پرسوجوهای k-closest-pair در پایگاههای داده فضایی. دانستن داده ها مهندس 2004 ، 49 ، 67-104. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Goodchild، MF; Hunter، GJ یک اندازه گیری دقت موقعیتی ساده برای ویژگی های خطی. بین المللی جی. جئوگر. Inf. علمی 1997 ، 11 ، 299-306. [ Google Scholar ] [ CrossRef ]
- تانگ، ایکس. لیانگ، دی. Jin, Y. روش تطبیق شی جاده خطی برای ادغام بر اساس بهینه سازی و رگرسیون لجستیک. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 824-846. [ Google Scholar ] [ CrossRef ]
- روزن، بی. Saalfeld، A. مطابقت با معیارها برای تراز خودکار. در مجموعه مقالات هفتمین سمپوزیوم بین المللی کارتوگرافی به کمک کامپیوتر (Auto-Carto 7)، واشنگتن، دی سی، ایالات متحده آمریکا، 11–14 مارس 1985; صص 1-20. [ Google Scholar ]
- کاب، MA; چانگ، ام جی. III، HF; پتری، FE; شاو، کیلوبایت؛ میلر، HV یک رویکرد مبتنی بر قانون برای ترکیب دادههای برداری نسبت داده شده. GeoInformatica 1998 ، 2 ، 7-35. [ Google Scholar ] [ CrossRef ]
- فیلین، اس. Doytsher, Y. تشخیص اشیاء مربوطه در ترکیب نقشه مبتنی بر خطی. Surv. Land Inf. سیستم 2000 ، 60 ، 117-128. [ Google Scholar ]
- لی، ال. Goodchild، MF بهینه شده تطبیق ویژگی در ترکیب. در مجموعه مقالات علم اطلاعات جغرافیایی: ششمین کنفرانس بین المللی، GIScience، زوریخ، سوئیس، 14-17 سپتامبر 2010. ص 14-17. [ Google Scholar ]
- لی، تی. لی، زی. تطبیق داده های فضایی بهینه برای ترکیب: یک رویکرد مبتنی بر جریان شبکه. ترانس. GIS 2019 ، 23 ، 1152-1176. [ Google Scholar ] [ CrossRef ]
- Lei، TL ترکیب داده های جغرافیایی: یک رویکرد رسمی مبتنی بر بهینه سازی و پایگاه های داده رابطه ای. بین المللی جی. جئوگر. Inf. علمی 2020 ، 34 ، 2296-2334. [ Google Scholar ] [ CrossRef ]
- Lei، TL ترکیب دادههای جغرافیایی در مقیاس بزرگ: چارچوب تطبیق ویژگی مبتنی بر بهینهسازی و تقسیم و تسخیر. محاسبه کنید. محیط زیست سیستم شهری 2021 ، 87 ، 101618. [ Google Scholar ] [ CrossRef ]
- ژانگ، ام. روشها و پیادهسازی تطبیق شبکه جادهای. Ph.D. پایان نامه، Technische Universität München، مونیخ، آلمان، 2009. [ Google Scholar ]
- Vilches-Blázquez، LM; راموس، جی. ترکیب معنایی در علم GIS: یک بررسی سیستماتیک کارتوگر. Geogr. Inf. علمی 2021 ، 48 ، 512-529. [ Google Scholar ] [ CrossRef ]
- Hackeloeer، A. کلاسینگ، ک. کریسپ، جی.ام. منگ، ال. تلفیق شبکه جاده: یک رویکرد سلسله مراتبی تکراری. در حال پیشرفت در خدمات مبتنی بر مکان 2014 ; Springer: برلین/هایدلبرگ، آلمان، 2015; صص 137-151. [ Google Scholar ]
- گوا، کیو. خو، X. وانگ، ی. لیو، جی. رویکرد تطبیق ترکیبی شبکههای جادهای تحت مقیاسهای مختلف با در نظر گرفتن محدودیتهای تعمیم نقشهبرداری. دسترسی IEEE 2019 ، 8 ، 944–956. [ Google Scholar ] [ CrossRef ]
- لیو، ال. دینگ، ایکس. زو، ایکس. فن، ال. Gong, J. یک رویکرد تکراری مبتنی بر اطلاعات زمینهای برای تطبیق مجموعه دادههای چند ضلعی چند ضلعی. ترانس. GIS 2020 ، 24 ، 1047-1072. [ Google Scholar ] [ CrossRef ]
- ممدو اوغلو، ا. Basaraner، M. رویکردی برای ادغام و غنی سازی داده های ساختمان شهری چند مقیاسی از طریق تطبیق هندسی و وب معنایی. کارتوگر. Geogr. Inf. علمی 2022 ، 49 ، 1-17. [ Google Scholar ] [ CrossRef ]
- Hillier، FS; لیبرمن، GJ مقدمه ای بر تحقیق در عملیات ، ویرایش هشتم. McGraw-Hill: نیویورک، نیویورک، ایالات متحده آمریکا، 2005; پ. 1088. [ Google Scholar ]
- خاویر، EM; آریزا-لوپز، FJ; Ureña-Cámara، MA MatchingLand، بستر آزمایش داده های مکانی برای ارزیابی روش های تطبیق. علمی داده 2017 ، 4 ، 170180. [ Google Scholar ] [ CrossRef ] [ PubMed ] [ نسخه سبز ]



بدون دیدگاه