

خلاصه
تعمیم سکونتگاه های موثر برای نقشه های مقیاس کوچک یک کار پیچیده و چالش برانگیز است. توسعه یک روش منسجم برای تعمیم نقشههای مقیاس کوچک توجه کافی را به خود جلب نکرده است، زیرا اکثر تحقیقات انجامشده تاکنون به مقیاسهای بزرگ مربوط میشوند. در مطالعه گزارش شده در اینجا، میخواهیم این شکاف را پر کنیم و ویژگیهای استقرار را بررسی کنیم، متغیرهای نامگذاری شده که میتوانند در انتخاب شهرک برای نقشههای مقیاس کوچک تعیینکننده باشند. ما 33 متغیر، هم موضوعی و هم توپولوژیکی را پیشنهاد می کنیم که ممکن است در فرآیند انتخاب اهمیت داشته باشند. برای یافتن متغیرهای ضروری و ارزیابی وزن و همبستگی آنها، ما از مدلهای یادگیری ماشین (ML)، بهویژه درختهای تصمیم (DT) و درختهای تصمیم پشتیبانی شده توسط الگوریتمهای ژنتیک (DT-GA) استفاده میکنیم. با استفاده از مدل های ML، ما به طور خودکار تسویه حساب ها را به عنوان انتخاب شده و حذف شده طبقه بندی می کنیم.
کلید واژه ها:
تعمیم نقشه کشی ; یادگیری ماشینی ؛ انتخاب شهرک ; در مقیاس کوچک
1. معرفی
تصمیم برای حذف یا نگهداری یک شی در حالی که سطح جزئیات را تغییر می دهد، مستلزم در نظر گرفتن بسیاری از ویژگی های خود شی و محیط اطراف آن است. این تصمیم عنصر اساسی تعمیم نقشهکشی را تشکیل میدهد که توسط ICA (انجمن بینالمللی کارتوگرافی) به عنوان انتخاب و سادهسازی اطلاعات متناسب با مقیاس و هدف یک نقشه تعریف شده است [ 1 ]. تعمیم نقشهکشی را میتوان هم بهعنوان فرآیند اکتشاف، مرتبط با انتزاع اطلاعات و هم بهعنوان یک ارتباط مرتبط با طراحی نقشه بهینه مشاهده کرد. با توجه به [ 2]، انتخاب، که به عنوان حذف نیز نامیده می شود، یکی از عملگرهای تعمیم را تشکیل می دهد. در میان سایر عملگرهای تعمیم مانند تجمع، فروپاشی، ادغام، ساده سازی و پالایش به عنوان عملگرهایی طبقه بندی می شود که بر کمیت بصری اشیا تأثیر می گذارد. انتخاب با حذف یک یا چند شی یا کلاس شی بدون جایگزینی سروکار دارد، بنابراین برای کاهش محتوای نقشه یا پایگاه داده با توجه به سطح جزئیات هدف استفاده می شود. همچنین به عنوان حذف، انتخاب کلاس، استخراج، نازک کردن یا هرس کردن نیز شناخته شده است [ 2 ]]. انتخاب معمولاً اولین عملیات تعمیم را تشکیل می دهد، بنابراین می تواند پیش نیاز تعمیم اشیاء مؤثر باشد. به خصوص در زمینه تعمیم سکونت و به ویژه، برای نقشه های مقیاس کوچک، انتخاب یک مرحله ضروری است زیرا یک عملیات ساده نیست. اگرچه شهودی است که سکونتگاههای بزرگ باید بر سکونتگاههای کوچکتر اولویت داشته باشند، این درست نیست که اگر پنج شهرک انتخاب شوند، اینها بزرگترین شهرکها هستند. یک سکونتگاه بزرگ که نزدیک به یک شهرک بزرگتر واقع شده است ممکن است کنار گذاشته شود، و یک سکونتگاه کوچکتر که در همسایگی هر یک بزرگتر دیگر نباشد ممکن است به دلیل اهمیت نسبی آن در نظر گرفته شود [ 3 ].
محققان در مورد نیاز به خودکارسازی کامل فرآیند تعمیم توافق دارند [ 4 ]. مراکز تحقیقاتی متعدد، آژانس های نقشه برداری و شرکت های تجاری تلاش های موفقیت آمیزی برای اجرای راه حل های تعمیم خاصی انجام داده اند [ 4 ، 5 ، 6 ، 7 ، 8 ، 9 ]. با این وجود، توسعه یک روش موثر و سازگار برای تعمیم نقشههای مقیاس کوچک توجه کافی را به خود جلب نکرده است. اکثر تحقیقات انجام شده تا کنون بر روی دستیابی به نقشه های بزرگ متمرکز بوده است [ 4]. هدف تحقیق ارائه شده پر کردن این شکاف با بررسی متغیرهای جدید است که در فرآیند انتخاب خودکار تسویه حساب در مقیاس های کوچک از اهمیت کلیدی برخوردار هستند. متغیرها به عنوان ویژگی های تسویه حساب شده، قابل اندازه گیری و مقایسه درک می شوند. این مقاله به صراحت به دو سوال تحقیق می پردازد:
-
کدام متغیرها در انتخاب سکونتگاه برای نقشه های مقیاس کوچک ضروری هستند؟
-
آیا بین متغیرهای پیشنهادی همبستگی وجود دارد؟
پرداختن به این مسائل یک گام اساسی به سمت پیشنهاد الگوریتم های جدید برای انتخاب تسویه موثر و خودکار است که به غنی سازی جعبه ابزار تعمیم مقیاس کوچک پراکنده کمک می کند. مقاله توسعه یافته تحقیق ارائه شده در بیست و نهمین کنفرانس بین المللی کارتوگرافی [ 10 ] است.
1.1. متغیرهای در نظر گرفته شده در انتخاب تسویه
نقشهنگاران نقشهها را با تعمیم دادههای دقیقتر و انتخاب اشیاء بر اساس بسیاری از ویژگیها – هم در رابطه با خود شی و هم در اطراف آن، طراحی میکنند. در طول تعمیم دستی، امکان تصمیم گیری بر اساس بازرسی نقشه بصری وجود داشت. این مشاهدات اجازه می دهد تا تراکم سکونتگاه ها و الگوهای شبکه سکونتگاهی در نظر گرفته شود. رسمی کردن چنین ملاحظاتی و تصمیم گیری ذهنی به منظور خودکار کردن فرآیند بسیار چالش برانگیز است. در انتخاب شی یا ارزیابی کمی از نتایج تعمیم، قانون رادیکال توسعه یافته توسط Topfer و Pillewizer [ 11] اغلب اعمال می شود. با این حال، جدای از دانستن تعداد بهینه اشیایی که باید روی نقشه باقی بمانند، باید تصمیم گرفت که کدام یک از آنها باید نگه داشته شوند و کدام یک را می توان حذف کرد [ 2 ]. این موضوع در تحقیقات قبلی [ 12 و 13 ] به آن پرداخته شده است.
سکونتگاه های قابل توجه باید دارای اولویت نگهداری و ارائه بر روی نقشه ها در مقیاس های کوچکتر باشند. با این حال، این اهمیت را می توان به روش های مختلف درک و اندازه گیری کرد. لازم به یادآوری است که برخی از سکونتگاه های مهم واقع در مجاورت مکان های مهم تر به دلیل خوانایی نقشه باید حذف شوند. در عین حال، سکونتگاه های کوچک واقع در فاصله قابل توجهی از دیگران ممکن است بر روی یک نقشه در مقیاس کوچک حفظ شوند، زیرا آنها وجود مناطق ساخته شده در یک منطقه معین را نشان می دهند و امکان تخمین تراکم شبکه سکونت را فراهم می کنند. 14 ].
هنگام انتخاب معیارهایی برای تعیین حفظ یا حذف اشیاء، موضوع، هدف و مقیاس نقشه باید در نظر گرفته شود. معیارهای قابل اندازه گیری اجازه می دهد تا اهمیت سکونتگاه ها تخصیص داده شود و سلسله مراتب آنها در یک طبقه بندی مشخص توسعه یابد. طبق نظر سیرکو [ 13 ]، ویژگی های در نظر گرفته شده در طبقه بندی باید شرایط اندازه گیری، استقلال، جمع و تغییرپذیری را داشته باشند. رایجترین معیار برای ارزیابی اهمیت یک سکونتگاه، و از این رو معیار انتخاب، اندازه آن است که با تعداد ساکنان اندازهگیری میشود. از جمله پیتکیویچ [ 15 ]، رادو [ 16 ] ، اوستروفسکی [ 17 ] این به عنوان مهم ترین معیار ذکر شده است.]، Baranowski و Grygorenko [ 18 ]، Ratajski [ 19 ] و Flewelling و Egenhofer [ 20 ].
در ادبیات مربوط به انتخاب سکونتگاه ها در تعمیم نقشه برداری، نویسندگان معیارهای انتخاب دیگری را پیشنهاد می کنند. سیرکو [ 13] خاطرنشان می کند که در نظر گرفتن معیارهای بیشتر باعث می شود تا حل و فصل به طور کامل توصیف شود و به ارزیابی عینی اهمیت آن کمک می کند. در همان زمان، سیرکو 9 معیار انتخاب شهرک را پیشنهاد می کند. بر اساس هر یک از ویژگی ها (متغیرها)، رتبه تسویه حساب محاسبه می شود. ارزش ترکیبی رتبه ها اطلاعات مربوط به وزن تسویه حساب را تشکیل می دهد. ویژگی هایی که سیرکو برای ارزیابی اهمیت سکونتگاه ها نشان می دهد، تعداد ساکنان، اهمیت اداری، سطح شهرنشینی، اهمیت اقتصادی، دسترسی حمل و نقل جاده ای، دسترسی حمل و نقل ریلی، اهمیت تاریخی، اهمیت گردشگری و موقعیت سکونتگاه با توجه به رودخانه است. شبکه. راتاجسکی [ 19] همچنین معیار مرکزیت را با در نظر گرفتن مجموعه تمام عملکردهای شهرک و همچنین معیارهای زیر ذکر می کند: اهمیت سکونتگاه به عنوان یک مکان مرکزی، انجام یک تابع خدماتی برای سایر شهرک ها در شبکه؛ به موقع بودن حل و فصل، بیانگر اهمیت موقت حل و فصل به دلیل رویدادها؛ گرایشهای تغییر که بهعنوان تمایل شهرکها به توسعه یا پسرفت درک میشود. و همچنین الگوهای استقرار، یعنی ارائه تفاوت در تراکم شبکه استقرار.
نیاز به در نظر گرفتن معیارهای مربوط به اهمیت عملکردی سکونتگاه ها، که با نقش آموزشی، گردشگری یا تاریخی آنها تعریف شده است، در ادبیات جغرافیایی و شهری نیز مورد تاکید قرار گرفت [ 21 ، 22 ، 23 ]. اولین تلاش ها برای در نظر گرفتن اهمیت عملکردی شهرک توسط کریستالر [ 24 ]، دیکسون [ 25 ]، کادمون [ 12 ]، ریچاردسون و مولر [ 3 ] انجام شد.
1.2. یادگیری ماشین در تعمیم نقشه کشی
ایده اصلی پشت این تحقیق استفاده از یادگیری ماشینی (ML) برای کشف متغیرهای جدید است که میتواند در تعمیم سکونتهای خودکار در مقیاسهای کوچک ارزشمند باشد. تاکنون چند رویکرد مبتنی بر استفاده از ML ارائه شده است. یکی از اولین تلاش ها برای تعیین پارامترهای تعمیم با استفاده از ML توسط Weibel و همکاران انجام شد. [ 26 ]. مطالب آموزشی مشاهده کار دستی نقشه کش بود. علاوه بر این، Mustière [ 27 ] سعی کرد دنباله بهینه عملگرهای تعمیم را برای جاده ها با استفاده از ML شناسایی کند. رویکرد متفاوتی توسط سستر [ 28 ] ارائه شد]. هدف استخراج دانش نقشهبرداری از ویژگیهای دادههای مکانی، بهویژه از ویژگیها و ویژگیهای هندسی اشیاء، نظمها و الگوهای تکراری بود که با استفاده از درختهای تصمیم بر انتخاب شیء حاکم است. لاگرانژ و همکاران [ 29 ] و همچنین Balboa و López [ 30 ] از تکنیک های ML، یعنی شبکه های عصبی برای تعمیم اشیاء خط استفاده کردند. اخیراً سستر و همکاران. [ 31 ] و فنگ و همکاران. [ 32 ] کاربرد یادگیری عمیق را برای کار تعمیم سازی پیشنهاد کرد.
با این حال، همانطور که توسط Sester و همکاران اشاره شده است. [ 31 ]، این ایدهها، اگرچه جالب بودند، اما تنها اثبات مفاهیم باقی ماندند. علاوه بر این، تحقیقات قبلی مربوط به پایگاههای اطلاعاتی توپوگرافی و نقشههای بزرگ مقیاس بود. نتایج امیدوارکننده انتخاب سکونتگاه خودکار در مقیاس های کوچک توسط کارزنیا و وایبل [ 33 ] گزارش شد.]. برای بهبود فرآیند انتخاب شهرک، آنها از غنی سازی داده و ML استفاده کردند. با توجه به مدلهای طبقهبندی مبتنی بر درختهای تصمیم، آنها متغیرهای جدیدی را بررسی کردند که در فرآیند انتخاب شهرک تعیینکننده هستند. با این وجود، آنها همچنین به این نتیجه رسیدند که احتمالا هنوز “دانش عمیق” بیشتری برای کشف وجود دارد که احتمالاً به متغیرهای دیگری مرتبط است که در کار آنها گنجانده نشده است. بنابراین، انگیزه این تحقیق پر کردن این شکاف و جستجوی متغیرهای ضروری و اضافی حاکم بر انتخاب سکونتگاه در مقیاسهای کوچک است.
2. مواد و روشها
دامنه این تحقیق انتخاب سکونتگاه خودکار از پایگاه داده عمومی اشیاء جغرافیایی (GGOD) در سطح جزئیات 1:250 000-1:500000 را پوشش می دهد.
داده های موجود در GGOD توسط مناطق جمع آوری و ذخیره می شود، که واحدهای مدیریتی سطح دوم در لهستان هستند، معادل LAU-1 و NUTS-4. در این تحقیق از نمونه 16 منطقه استفاده شد. این تقریباً 5 درصد از مناطق لهستانی را تشکیل می دهد. ولسوالی ها به چهار گروه منسجم از نظر تراکم جمعیت، تراکم سکونتگاه و نوع سکونت تقسیم شدند ( شکل 1 ، جدول 1 ).
سکونتگاه ها با استفاده از دو رویکرد تعمیم داده شده اند ( شکل 2 ). مرحله اولیه شامل به دست آوردن داده های منبع از GGOD (لایه های موضوعی سکونتگاه ها، جاده ها، گره های جاده، کاربری اراضی و مرزهای اداری)، غنی سازی داده های منبع با اطلاعات از پایگاه داده اشیاء توپوگرافی (ساختمان ها با عملکرد آنها) و از اطلس جمهوری لهستان 1: 500000 [ 34]. این نقشه در دهه 1990 به صورت دستی طراحی شد. متأسفانه، این آخرین نقشه موجود در مقیاس 1: 500000 است که کل کشور را پوشش می دهد. با توجه به اینکه شبکه سکونتگاهی دچار چنین تغییرات پویایی نشده است، نویسندگان پس از مشورت با نقشه نگاران، نقشه را به عنوان یک ماده مقایسه ای کافی در نظر گرفتند. مرحله پردازش داده شامل غنیسازی GGOD و تبدیل نقشه اطلس شطرنجی به دیجیتال، فرم برداری، قابل همکاری با GGOD بود. سپس شهرک ها بر اساس قوانین تعریف شده در دستورالعمل های حقوقی لهستان انتخاب شدند. این فرآیند رویکرد اساسی نامیده شد [ 35]. در مرحله دوم، مدلهای انتخاب سکونت خودکار بر اساس ML مورد استفاده قرار گرفتند و در این مقاله به عنوان رویکرد افزایش یافته از آن یاد میشود. بر اساس آیین نامه، شهرک ها باید با در نظر گرفتن چهار متغیر سه موضوعی و یک متغیر فضایی انتخاب شوند. متغیرهای ارائه شده در آیین نامه به شرح زیر است:
-
جمعیت (تعداد ساکنان)؛
-
وضعیت اداری (محل دفتر اداری)؛
-
نوع سکونتگاه (“شهر”، “روستا”، “دهکده” و غیره)؛
-
تراکم جمعیت (محاسبه در هر منطقه).
قوانین تعمیم مندرج در مقررات بیان می کند که الگوریتم های انتخاب برای همه مناطق در لهستان ثابت است. یک استثنا وجود دارد: برای مناطق با تراکم جمعیت کمتر از 50 نفر در کیلومتر مربع، پارامترهای الگوریتم با پارامترهای مربوط به مناطق پرتراکم تر متفاوت است.
اولین گام، در رویکرد بهبودیافته، ایجاد و تأیید فهرستی از ویژگیهای قابل اندازهگیری، با نام متغیرهایی بود که در انتخاب سکونت برای مقیاسهای کوچک ضروری هستند. سپس استفاده از مدلهای مبتنی بر ML امکان ارزیابی اهمیت متغیرهای پیشنهادی را با بررسی وزن آنها و همچنین همبستگی بین آنها فراهم کرد. دادههای منبع با 33 متغیر اضافی و وضعیت استقرار (انتخاب یا حذف شده توسط نقشهبردار) از نقشه اطلس مرجع [ 34 ] غنیسازی شد. از 33 متغیر، 16 متغیر قبلاً توسط کارزنیا و ویبل [ 33 ] در نظر گرفته شده بود و 17 متغیر در این تحقیق پیشنهاد شد. بنابراین، این کار روششناسی پیشنهادی کارزنیا و وایبل را گسترش داد [ 33]. لیست کامل متغیرهای در نظر گرفته شده در جدول 2 ارائه شده است . برای محاسبه متغیرها از ArcGIS نسخه 10.5 و Python 2.7.6 استفاده شد.
در نظر گرفتن مجموعه ای کامل از متغیرها، این امکان را فراهم می کند که تمام ویژگی های تسویه حساب که می تواند در فرآیند انتخاب تعیین کننده باشد، در نظر گرفته شود. همچنین به در نظر گرفتن ویژگی های استقرار که توسط یک نقشه کش باتجربه در طول تعمیم نقشه دستی در نظر گرفته می شود، کمک می کند. برای دستیابی به این هدف، ما متغیرهای مربوط به ویژگیهای سکونتگاهی کل نگر شامل مناطق مختلف سکونتگاهی (مسکونی، خدماتی، تجاری و صنعتی)، تراکم جمعیت، تراکم سکونتگاه و همچنین متغیرهای مربوط به روابط بین شهرکها و سایر اشیاء را که از نقطه نظر ارتباطی مهم هستند، اضافه کردیم. به عنوان مثال، تعداد گذرگاه ها، تعداد فرودگاه ها و تعداد راه آهن را مشاهده کنید. برای اندازه گیری تراکم، تراکم سکونتگاه ها را در نظر گرفتیم، در شبکه های مربع و شش ضلعی برای یافتن واحدهای شمارش معنادارتر محاسبه می شود. اندازه شبکه به صورت تجربی در نظر گرفته شد، به نحوی که تغییرات تراکم نشست و با در نظر گرفتن مقیاس هدف برجسته شود.
با این حال، در مورد ML، تعداد متغیرها نیز باید به دو دلیل بهینه شود. در درجه اول، از آنجایی که متغیرهای بیشتری در مدل گنجانده شده است، فرآیند به داده های آموزشی بیشتری نیاز دارد. ثانیاً باید توجه داشت که اطلاعات استخراج شده از متغیرهای عددی ممکن است زائد باشد. همچنین با توجه به دانش کارتوگرافی، متغیرها دارای سطوح مختلفی از اهمیت هستند. برخی از متغیرها – مانند جمعیت یا مساحت – باید به عنوان اولویت در نظر گرفته شوند. برخی دیگر – مانند تعداد جاده هایی که از محل سکونت عبور می کنند – در درجه دوم اهمیت قرار دارند. برای ارزیابی اینکه کدام متغیرها می توانند در فرآیندهای ML آینده حذف شوند، ارزیابی قدرت همبستگی بین متغیرهای پیشنهادی نیز انجام شد. به عنوان آخرین مرحله، مدلهای انتخاب خودکار بر اساس درختهای تصمیم ساخته شدند.
مدلهای طبقهبندی در RapidMiner 9.0، یک نرمافزار ML و دادهکاوی منبع باز، با استفاده از دو الگوریتم مختلف ML اجرا شدند: درختهای تصمیم (DT) و درختهای تصمیم با انتخاب ویژگی بهینهشده با استفاده از یک الگوریتم ژنتیک (DT-GA).
درخت تصمیم یک روش یادگیری ماشینی است که در آن یک درخت نشان دهنده تابع آموخته شده است. اگرچه درخت تصمیم به این دلیل شناخته شده است که بهترین روش کارآمد نیست، اما نقطه قوت آن در این واقعیت نهفته است که درختان همچنین می توانند به عنوان مجموعه ای از قوانین if-then برای بهبود خوانایی انسان دوباره نمایش داده شوند [ 36 ، 37 ]]. درختهای تصمیم، ویژگیها (در سکونتگاههای مورد ما) را با مرتبسازی درخت از ریشه تا گره برگ طبقهبندی میکنند، که طبقهبندی ویژگی را فراهم میکند. هر گره در درخت آزمایشی از برخی متغیرهای ویژگی را مشخص می کند و هر شاخه ای که از آن گره پایین می آید با یکی از مقادیر ممکن برای این متغیر مطابقت دارد. یک حل و فصل با شروع از گره ریشه درخت، آزمایش ویژگی مشخص شده توسط این گره، سپس حرکت به سمت پایین شاخه درخت مربوط به مقدار ویژگی در مثال داده شده طبقه بندی می شود. سپس این فرآیند برای زیردرختی که در گره جدید ریشه دارد تکرار می شود. متغیری که در ریشه درخت قرار می گیرد، مهمترین متغیر در فرآیند طبقه بندی است. تصمیم بر اساس نتیجه برگ پایانی گرفته می شود.
برای بهبود عملکرد طبقهبندیکننده درختهای تصمیم، میتوان از الگوریتمهای ژنتیک استفاده کرد. در ادامه از الگوریتم های ژنتیک برای بهینه سازی انتخاب متغیرهای ورودی استفاده کردیم. الگوریتم ژنتیک یک روش یادگیری مبتنی بر قیاس با تکامل بیولوژیکی است. با بهروزرسانی مکرر مجموعهای از فرضیهها به نام جمعیت (در مورد ما مجموعهای از متغیرهای تسویه حساب) عمل میکند. در هر تکرار، همه اعضای جامعه با توجه به تابع تناسب ارزیابی می شوند. سپس با انتخاب احتمالی مناسب ترین افراد از جمعیت فعلی، یک جمعیت جدید ایجاد می شود. برخی از این افراد انتخاب شده دست نخورده به نسل بعدی منتقل می شوند.36 ].
برای ساخت مدلهای طبقهبندی، از تمام تسویهها بهعنوان داده ورودی و اعتبارسنجی متقاطع 10 برابری برای تقسیم مکرر دادههای ورودی به یک فرآیند آموزشی و آزمایشی استفاده کردیم. در اعتبارسنجی متقاطع 10 برابری داده های ورودی به ده زیر مجموعه با اندازه مساوی تقسیم می شوند. از ده زیر مجموعه، یک زیرمجموعه به عنوان مجموعه داده های آزمایشی حفظ می شود و زیر مجموعه های باقی مانده به عنوان مجموعه داده های آموزشی استفاده می شوند. سپس فرآیند اعتبار سنجی متقابل ده بار تکرار می شود و هر یک از زیر مجموعه ها دقیقاً یک بار به عنوان داده های آزمایشی استفاده می شود. سپس نتایج حاصل از تکرارها را میتوان میانگین کرد (یا ترکیب کرد) تا یک تخمین واحد تولید شود [ 38 ، 39 ].
در هر دو رویکرد، وضعیت استقرار از نقشه اطلس، مبنی بر انتخاب یا حذف سکونتگاه در حین تعمیم نقشه دستی توسط نقشهبردار مجرب، به عنوان مرجع برای ارزیابی در نظر گرفته شد.
3. نتایج
در نتیجه تحقیق ارائه شده، مدل های خودکار انتخاب سکونتگاه از مقیاس 1:250،000 تا 1:500،000 برای هر 16 منطقه و مناطق تقسیم شده به چهار گروه ساخته شد. دقت انتخاب و صحت بصری آن با نتایج به دست آمده از رویکرد پایه و با وضعیت استقرار گرفته شده از نقشه اطلس مقایسه شد ( جدول 3 ).
در جدول 3 بهترین روش عملکرد پررنگ شده است و تفاوت بین بهترین روش عملکرد و رویکرد پایه بیان شده است. در این مقاله، ما تصمیم گرفتیم به نتایج، هر دو درخت تصمیم و نقشهها برای همه گروههای منطقه در نظر گرفته شده، دقیقتر نگاه کنیم. گروه 1 نشان دهنده نواحی با تراکم جمعیت بالا و تراکم سکونتگاه بالا است، در حالی که گروه 4 شامل مناطق با تراکم جمعیت بسیار کم و تراکم سکونتگاه پایین است، گروه 2 و 3 مربوط به تراکم جمعیت و سکونتگاه متوسط و کم است. در نقشه های ارائه شده، شبکه جاده اصلی از پایگاه داده GGOD، بدون تعمیم استفاده شد، زیرا ما در این مقاله به طور انحصاری بر انتخاب سکونتگاه تمرکز کردیم.
دقت انتخاب برای یادگیری ماشین با DT-GA بالاتر بود، بنابراین این نتایج به صورت بصری با نقشه اطلس و نتایج رویکرد پایه مقایسه شد. با توجه به گروه ناحیه 1، ارائه شده در شکل 3 و شکل 4 ، دقت رویکرد پایه 71.62٪ بود، در حالی که دقت بر اساس ML برابر با 78.02٪ برای مدل DT-GA بود. برای گروه ناحیه 2، نتایج در رویکرد ML به طور قابل توجهی بهتر بود (77.26٪ برای مدل DT و 80.90٪ برای DT-GA به ترتیب؛ شکل 5 و شکل 6 ) نسبت به رویکرد اصلی (71.02٪). هم بر اساس دقت اندازه گیری شده و هم بر اساس بازرسی بصری ( شکل 5) میتوانیم ببینیم که نتیجه بهدستآمده در رویکرد بهبودیافته به نقشه اطلس نزدیکتر از نتایج رویکرد پایه است. در مورد گروه ناحیه 3، درصد دقت انتخاب به طور قابل توجهی بیشتر نبود، یعنی در رویکرد پایه برابر 84.39٪ بود، در حالی که در مدل های ML به ترتیب در DT 84.57٪ و در DT-GA 85.87٪ بود ( شکل 7). و شکل 8 ). با این حال، ارزیابی بصری تراکم سکونتگاهها به ما اجازه داد تا بیان کنیم که انتخاب با استفاده از ML نتایجی شبیهتر به نقشه اطلس دارد ( شکل 7 ). برای منطقه گروه 4، ارائه شده در شکل 9 و شکل 10، دقت در بین تمام گروه های منطقه بالاترین بود. برای رویکرد پایه، برابر با 68.39٪ بود، در حالی که برای رویکرد پیشرفته، 80.23٪ برای مدل DT و 81.98٪ برای DT-GA برابر بود. دقت انتخاب تا چند درصد در مقایسه با رویکرد اصلی در همه مدلهای ML آزمایششده، برای همه گروههای ناحیه ارزیابیشده بهبود یافته است ( جدول 3 ). در حالی که انتخاب در رویکرد اصلی برای همه مناطق یکسان بود، در رویکرد توسعه یافته درخت تصمیم برای هر گروه منطقه به طور جداگانه، با پیروی از رویکرد Karsznia و Weibel [ 33 ]، برای در نظر گرفتن ویژگیهای سکونتگاهی مختلف توسعه یافت.
نرم افزار RapidMiner اجازه می دهد تا همبستگی بین تمام ویژگی ها (متغیرها) محاسبه شود و بر اساس این همبستگی ها بردار وزن تولید کند. همبستگی یک تکنیک آماری است که می تواند نشان دهد که آیا جفت ویژگی ها به هم مرتبط هستند یا خیر. یک مقدار مثبت برای همبستگی دلالت بر یک ارتباط مثبت دارد. در این مورد، قدرت درجه همبستگی مهم است، چه مثبت یا منفی. همبستگی بین متغیرهای پیشنهادی برای هر چهار گروه محاسبه و در جدول 4 ارائه شده است.
یکی از نتایج روش یادگیری مبتنی بر DT-GA برای هر چهار گروه، وزن نرمال شده صفات نشست ارائه شده در جدول 5 بود. بر اساس این مدل، مرتبطترین ویژگیهای مجموعه دادههای داده شده انتخاب شدند، که فرصتی برای توسعه یک الگوریتم انتخاب مؤثرتر ارائه میدهد.
4. بحث
نتایج بهدستآمده، مفروضات دانش نقشهنگاری فعلی را تأیید میکند که در نظر گرفتن متغیرهای موضوعی (ویژگیها) و مکانی بسیار مهم است.
با نگاهی به درخت تصمیم توسعه یافته برای منطقه گروه 1، دیدیم که اولین گام بررسی منطقه اداری شهرک بود ( شکل 4).). فقط یک ویژگی که در درخت تصمیم ظاهر می شود در مقررات ذکر شده است. چهار مرحله تصمیم گیری دیگر بر اساس متغیرهای جدید، با در نظر گرفتن مناطق استقرار، تراکم سکونت و همچنین تابع استقرار انجام می شود. در حالی که ما به نقشه ای که نتایج انتخاب را برای گروه 1 ارائه می کند، نگاه کردیم، متوجه شدیم که چگالی شبکه استقرار در نقشه طراحی شده با استفاده از ML بهتر از رویکرد اصلی حفظ شده است. با این حال، مناطقی وجود داشت که به اندازه کافی متراکم نبود (به عنوان مثال، بخش شمال غربی گروه منطقه). الگوریتم ML برخی از سکونتگاههایی را که نقشهبردار حذف کرده بود، حفظ کرد، بهعنوان مثال، آنهایی که در نزدیکی شهرهای بزرگتر قرار دارند ( شکل 3 ).
در مورد درختان تصمیم برای گروه های 2 و 3 ( شکل 6 و شکل 8 ) منطقه سکونت، یعنی منطقه مسکونی، برای گروه منطقه 2 و منطقه ساخته شده، برای گروه منطقه 3، معیارهای پیشرو را تشکیل می دهند. هر دو درخت تصمیم خیلی پیچیده نبودند، آنها شامل پنج مرحله برای گروه 2 و چهار مرحله برای گروه 3 بودند. در هر دو درخت تصمیم، متغیرهای تازه معرفی شده نقش مهمی در فرآیند انتخاب داشتند ( شکل 6 ، شکل 8 ).
درخت تصمیم توسعه یافته برای گروه منطقه 4 ( شکل 10 ) پیچیده تر از سایر گروه های منطقه بود. این شامل نه گام تعیین کننده بود. در مورد گروه های منطقه 1 و 4، منطقه مهم ترین متغیر بود – اداری یا ساخته شده. سپس، اهمیت سکونتگاه با تعداد ساکنان (درخت تصمیم برای گروه 1، شکل 4 ) یا عملکرد خاجی (درخت تصمیم برای گروه 4، شکل 10 ) ارزیابی شد. گامهای بعدی در فرآیند تصمیمگیری تنها معیارها را اصلاح کرد و هدف آن افزایش دقت انتخاب بود. برای هر دو گروه ناحیه، متغیر مربوط به تراکم نشست، یعنی تراکم نشست در شش ضلعی، بر روی درختان تصمیم ظاهر شد ( شکل 4).و شکل 10 ). اهمیت این متغیر بهعنوان متغیری که تراکم کل شبکه استقرار را مدل میکند، بهویژه در مورد گروه ناحیه 4 ( شکل 10 ) مشهود بود، جایی که نتیجه یادگیری ماشین از نظر چگالی استقرار به نقشه مرجع نزدیکتر بود تا نتیجه. ناشی از رویکرد اساسی نتیجه رویکرد اساسی برای این گروه یک شبکه سکونتگاهی را ارائه داد که بسیار متراکم بود.
4.1. کدام متغیرها در انتخاب سکونت برای نقشه های مقیاس کوچک ضروری هستند؟
مهمترین متغیر، همانطور که در فرآیند ML تأیید شد، ناحیه نمودار Voronoi بود ( جدول 5 ). این متغیر اطلاعاتی در مورد تراکم شبکه استقرار و فاصله تا نزدیکترین همسایه ها ارائه می کرد. هر چه مساحت بزرگتر باشد، احتمال انتخاب یک شهرک و نشان دادن آن روی نقشه بیشتر می شود. جای تعجب نیست که تعداد ساکنان (جمعیت) سکونتگاه به عنوان دومین متغیر مهم نشان داده شد. نقشه نگاران نیز در مطالعات قبلی بر اهمیت این موضوع تاکید کرده بودند. متغیرهای دیگر ویژگیهای هندسی شبکه، مانند سکونتگاهها و تراکم جمعیت در واحدهای شمارش مختلف (به عنوان مثال تراکم جمعیت در مناطق مسکونی برای گروههای ناحیه 2 و 3؛ شکل 6 وشکل 8). توابع سکونتگاه ها به عنوان متغیرهای تعیین کننده برای گروه منطقه 4 نزدیک به ریشه درخت (عملکرد خاجی) ظاهر شد، در حالی که برای گروه منطقه 1 تابع تجاری نزدیک به تصمیم نهایی در یکی از برگ های نهایی درخت ظاهر شد. این بدان معنی است که توابع ممکن است برای ویژگیهای سکونتگاهی مختلف اهمیت متفاوتی داشته باشند. در نواحی بسیار کم جمعیت که دارای تعداد کمی سکونتگاه هستند، وجود یک شیء مقدس مانند یک کلیسا می تواند یک سکونتگاه خاص را مهم تر کند. در حالی که در مناطق پرجمعیت، عملکرد تجاری سکونتگاه میتواند اهمیت داشته باشد، همانطور که در مورد گروه ناحیه 1 نشان داده شده است. اهمیت شهرک سازی،شکل 10 ).
4.2. آیا بین متغیرهای پیشنهادی همبستگی وجود دارد؟
ارزیابی همبستگی قوی متغیرهایی را نشان داده است که به هم مرتبط هستند (به عنوان مثال، وجود امکانات صنعتی و منطقه صنعتی). قوی ترین متغیرهای همبسته تابع تجاری، مساحت ساخته شده، تابع صنعتی و تعداد ساکنان بودند. ویژگی هایی که کمترین همبستگی را داشتند، مساحت نمودارهای ورونوی، وجود فرودگاه و تعداد جاده های عبوری از شهرک بود. این نشان دهنده اهمیت متغیرهای مربوط به تراکم شبکه استقرار و وجود اشیاء خاص مانند فرودگاه ها در فرآیند انتخاب است ( شکل 11 ).
متغیرهای موضوعی حل و فصل ثابت شد که بیشترین همبستگی را دارند ( جدول 4 ، شکل 11 ). این امر به عدم تخصصی بودن سکونتگاه ها و توسعه چند سویه آنها – از نظر عملکرد و نوع منطقه مربوط می شود. ویژگی های توزیع فضایی سکونتگاه با سایر ویژگی ها همبستگی زیادی نداشت. این امر غیر قابل جایگزینی آنها را در فرآیند انتخاب و نیاز به در نظر گرفتن خصوصیات هندسی شبکه سکونتگاه را ثابت می کند. توابع سکونتگاه با یکدیگر و با تعداد ساکنان همبستگی زیادی داشتند. این منطقی است و این واقعیت را تأیید می کند که سکونتگاه ها به صورت چند جهته توسعه یافته اند و سکونتگاه هایی با تخصص قوی نادر بوده اند.
موضوع انتخاب سکونتگاه برای نقشه های مقیاس کوچک پیچیده تر از تحقیقات قبلی است. بنابراین، تحقیقات آینده باید بر روی بررسی متغیرهای سکونتگاه ها در زمینه مجموعه داده های بزرگتر و متنوع تر تمرکز کند. مطالعه انجام شده سؤالات پژوهشی جالبی را برای مطالعات آینده باز کرد، یعنی:
-
چند متغیر تسویه برای یادگیری ماشین کارآمد بهینه خواهد بود؟
-
کدام متغیرها در فرآیند انتخاب تسویه حساب ضروری هستند؟
-
آیا گسترش نمونه داده بر نتایج یادگیری ماشین تأثیر می گذارد؟
بر اساس وزن و همبستگی متغیرهای پیشنهادی، که ارتباط آنها را با ویژگی برچسب نشان میدهد که نشاندهنده وضعیت حل و فصل (انتخاب یا حذف شده) برگرفته از نقشه مرجع، ممکن است حذف متغیرهای خاصی از تسویه حساب را در انتخاب در نظر بگیریم. روند. متغیرهای نمونه ای که در نظر گرفتیم می توانند در تحقیقات آینده حذف شوند به شرح زیر است: تعداد حداقل جاده های رتبه منطقه ای که از مرز سکونتگاه عبور می کنند، تعداد کل گره های ارتباطی در منطقه سکونتگاه، تراکم جمعیت در مناطق مسکونی یا عملکرد اداری. میتوانیم آنها را حذف کنیم زیرا روی درختهای تصمیم ظاهر نمیشوند و ارزش وزن بالایی ندارند. با این حال، از آنجایی که برنامه ریزی شده بود منطقه تحقیقاتی (از 16 به 89 منطقه) توسعه یابد، برای این مقاله، همه متغیرها باقی ماندند زیرا ما فقط می خواستیم اهمیت آنها را بررسی کنیم. با این حال، یکی دیگر از یافته های جالب این تحقیق این است که مهم ترین متغیرهای استقرار از نقطه نظر نتایج تحلیل همبستگی عبارتند از:
-
– جمعیت؛
-
– عملکرد خاجی؛
-
– فاصله تا نزدیکترین محله؛
-
– منطقه ساخته شده؛
-
– چگالی نشست محاسبه شده در یک شبکه.
5. نتیجه گیری ها
هدف این مطالعه پیشنهاد متغیرهای جدید برای پر کردن شکاف دانش در الگوریتمهای انتخاب برای نقشههای مقیاس کوچک بود. رویکرد، با فرض غنیسازی دادهها و ML، برای شامل متغیرهای مهمتر و کلنگرتر و همچنین تحلیل همبستگی متغیر گسترش یافت. مدل های ML ساخته شده در چهار گروه از مناطق نشان داد که متغیرهای مختلف بسته به منطقه برای انتخاب بسیار مهم هستند. دقت انتخاب به دست آمده در هر مورد آزمایش شده بهتر از انتخاب در رویکرد پایه بود. این واقعیت که دقت به 100٪ نمی رسد به این معنی است که کار بیشتر در مورد بهینه سازی مدل های مبتنی بر ML انتخاب حل و فصل توصیه می شود. همچنین لازم به ذکر است که هدف دستیابی به بازسازی کامل کار نقشهبر دستی نبود. زیرا فرآیند طراحی نقشه دستی ذهنی است و ممکن است با توجه به طراح نقشه درگیر متفاوت باشد. هدف نویسندگان دستیابی خودکار به نتایجی بود که از نقطه نظر نقشه برداری بهینه، قابل قبول و احتمالاً نزدیکترین به طراحی نقشه دستی باشد.
راه حل های ارائه شده در مقاله گامی بیشتر در جهت اتوماسیون کامل فرآیند انتخاب برای نقشه های مقیاس کوچک است. در حال حاضر تمرکز اصلی بر روی نقشههای مقیاس بزرگ است، اما میتوان فرض کرد که نقشههای مقیاس کوچک نقطهی توجه بعدی خواهند بود و در این زمینه است که تحقیق در مورد متغیرهای انتخاب ضروری، آیندهنگرترین به نظر میرسد.
منابع
- ICA، انجمن بین المللی کارتوگرافی. فرهنگ لغت چند زبانه اصطلاحات فنی نقشه کشی ; Franz Steiner Verlag: Wiesbaden، آلمان، 1973. [ Google Scholar ]
- استانیسلاوسکی، LV; باتنفیلد، BP; بروتر، پی. ساوینو، اس. اپراتورهای Brewer، CA Generalization. در چکیده اطلاعات جغرافیایی در جهان غنی از داده ; Burghardt, D., Duchêne, C., Mackaness, W., Eds.; Springer: Cham, Switzerland, 2014; صص 157-195. [ Google Scholar ]
- ریچاردسون، دی. مولر، جی.-سی. انتخاب قانون برای تعمیم نقشه در مقیاس کوچک. در تعمیم نقشه: ایجاد قوانین برای بازنمایی دانش . Buttenfield، BP، McMaster، RB، Eds. لانگمن: لندن، بریتانیا، 1991; صص 136-149. [ Google Scholar ]
- استوتر، جی. ون آلتنا، وی. پست، م. بورگاردت، دی. Duchêne, C. تعمیم خودکار در NMAها در سال 2016. در مجموعه مقالات The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, XLI-B4, XXIII ISPRS Congress, پراگ, جمهوری چک, 12-19 ژوئیه 2016. [ Google محقق ]
- استوتر، جی. ون اسمالن، جی. بیکر، ن. هاردی، پی. تعیین الزامات نقشه برای تعمیم خودکار داده های توپوگرافی. کارتوگر. J. 2009 , 46 , 214-227. [ Google Scholar ] [ CrossRef ]
- استوتر، جی. پست، م. ون آلتنا، وی. نیجهویس، آر. Bruns, B. تعمیم کاملاً خودکار نقشه 1:50k از داده 1:10k. کارتوگر. Geogr. Inf. علمی 2014 ، 41 ، 1-13. [ Google Scholar ] [ CrossRef ]
- Regnauld، کیفیت داده NG. در مجموعه مقالات آرشیو بین المللی فتوگرامتری، سنجش از دور و علوم اطلاعات فضایی، XL-3/W3، La Grande Motte، فرانسه، 28 سپتامبر تا 3 اکتبر 2015. ص 91-94. [ Google Scholar ]
- بورگاردت، دی. اشمید، اس. دوچن، سی. استوتر، جی. بائلا، بی. رگنولد، ن. روش های ارزیابی داده های تعمیم یافته به دست آمده با سیستم های تعمیم تجاری موجود. در مجموعه مقالات کارگاه ICA در مورد تعمیم و بازنمایی چندگانه، مونپلیه، فرانسه، 20-21 ژوئن 2008. [ Google Scholar ]
- Chaundhry، OZ; Mackaness، WA شناسایی خودکار مرزهای سکونتگاههای شهری برای پایگاههای اطلاعاتی چندگانه. محاسبه کنید. محیط زیست سیستم شهری 2008 ، 32 ، 95-109. [ Google Scholar ] [ CrossRef ]
- کارزنیا، آی. Sielicka، K. بررسی متغیرهای اساسی در انتخاب حل و فصل برای نقشههای مقیاس کوچک با استفاده از یادگیری ماشین. Abstr. بین المللی کارتوگر. دانشیار 2019 ، 1 ، 162. [ Google Scholar ] [ CrossRef ]
- تاپفر، اف. Pillewizer, W. اصول انتخاب. کارتوگر. J. 1966 ، 3 ، 10-16. [ Google Scholar ] [ CrossRef ]
- Kadmon, N. انتخاب خودکار سکونتگاه ها در تولید نقشه. کارتوگر. J. 1972 ، 9 ، 93-98. [ Google Scholar ] [ CrossRef ]
- Sirko, M. Teoretyczne i metodyczne aspekty obiektywizacji doboru osiedli na mapach [جنبه های نظری و روشمند عینیت بخشیدن به انتخاب سکونتگاه ها روی نقشه ها] در Rozprawy Wydziału Biologii i Nauk o Ziemi Uniwersytetu Marii Curie-Skłodowskiej, Rozprawy Habilitacyjne ; Wydawnictwo Uniwersytetu Marii Curie-Skłodowskiej: Lublin, Poland, 1988. [ Google Scholar ]
- ون کرولد، ام. ون اوستروم، آر. Snoeyink، J. انتخاب حل و فصل کارآمد برای نمایش تعاملی. در مجموعه مقالات کنوانسیون و نمایشگاه سالانه ACSM/ASPRS، سیاتل، WA، ایالات متحده آمریکا، 7-10 آوریل 1997. جلد 5، ص 287–296. [ Google Scholar ]
- Pietkiewicz, F. La carte de la Pologne au millionieme de L’Institut Geographique Militare ; Comptes Rondos du Congres، Travaux de la Section I; Institut Geographique Militare: Warszawa، لهستان، 1935; صص 286-289. [ Google Scholar ]
- Rado, S. Az 1:2 500 000 meretaranyu vilag terkep. Geodezia es Kartografia 1965 ، 17 ، 166-173. [ Google Scholar ]
- Ostrowski, J. Analiza doboru osiedli na Mapie Świata 1:2 500 000. Polski Przegląd Kartograficzny 1970 , 2 , 1–14. [ Google Scholar ]
- بارانوفسکی، م. گریگورنکو، دبلیو. Polski Przegląd Kartograficzny 1974 ، 6 ، 149-155. [ Google Scholar ]
- راتاجسکی، L. کمیسیون پنجم ICA: وظایفی که با آن روبروست. بین المللی سالب. کارتوگر. 1974 ، 14 ، 140-144. [ Google Scholar ]
- Flewelling، DM; Egenhofer، MJ اهمیت رسمی سازی: پارامترهای انتخاب سکونتگاه در یک پایگاه داده جغرافیایی. مجموعه مقالات Auto-Carto XI . 1993، صفحات 167-175. در دسترس آنلاین: https://cartogis.org/docs/proceedings/archive/auto-carto-11/pdf/formalizing-importance-parameters-for-settlement-selection-from-a-geographic-database.pdf (دسترسی در 2 مارس 2020).
- باتی، M. سلسله مراتب در شهرها و سیستم های شهر. در سلسله مراتب در علوم طبیعی و اجتماعی ; پومین، دی.، اد. Springer: آمستردام، هلند، 2006; صص 143-168. [ Google Scholar ]
- کارول، اچ. سلسله مراتب عملکردهای مرکزی در شهر. ان دانشیار صبح. Geogr. 1960 ، 50 ، 419-438. [ Google Scholar ] [ CrossRef ]
- اسمیت، روش RHT و هدف در طبقه بندی شهر عملکردی. ان دانشیار صبح. Geogr. 1965 ، 55 ، 539-548. [ Google Scholar ] [ CrossRef ]
- Christaller , W. Central Places در جنوب آلمان پرنتیس هال: نیویورک، نیویورک، ایالات متحده آمریکا، 1933. [ Google Scholar ]
- Dixon, OM انتخاب شهرها و سایر ویژگی ها در نقشه های اطلس نیجریه. کارتوگر. J. 1967 , 4 , 16-23. [ Google Scholar ] [ CrossRef ]
- ویبل، آر. کلر، اس. Reichenbacher, T. غلبه بر گلوگاه کسب دانش در تعمیم نقشه: نقش سیستم های تعاملی و هوش محاسباتی. در یادداشت های سخنرانی در علوم کامپیوتر ; مجموعه مقالات COSIT; Springer: برلین، آلمان، 1995; جلد 988، صص 139–156. [ Google Scholar ]
- Mustière, S. GALBE: تعمیم تطبیقی. نیاز به یک فرآیند تطبیقی برای تعمیم خودکار، مثالی در جاده ها. در مجموعه مقالات اولین کنفرانس GIS’PlaNet، لیسبون، پرتغال، 22 ژوئیه 1998. [ Google Scholar ]
- Sester, M. کسب دانش برای تفسیر خودکار داده های مکانی. بین المللی جی. جئوگر. Inf. علمی 2000 ، 14 ، 1-24. [ Google Scholar ] [ CrossRef ]
- لاگرانژ، اف. لندراس، بی. Mustiere, S. تکنیک های یادگیری ماشین برای تعیین پارامترهای الگوریتم های تعمیم نقشه برداری. بین المللی قوس. فتوگرام Remote Sens. 2000 , 33 , 718-725. [ Google Scholar ]
- بالبوآ، GJL; لوپز، طبقهبندی خطوط جاده تعمیممحور AFJ با استفاده از شبکه عصبی مصنوعی. Geoinformatica 2008 ، 12 ، 289-312. [ Google Scholar ] [ CrossRef ]
- سستر، ام. فنگ، ی. Thiemann, F. ساخت تعمیم با استفاده از یادگیری عمیق. آرشیو بین المللی فتوگرامتری حسگر از راه دور اسپات. Inf. علمی 2018 ، XLII-4 ، 565–572. [ Google Scholar ]
- فنگ، ی. تیمن، اف. Sester, M. آموزش تعمیم ساختمان نقشه برداری با شبکه عصبی کانولوشنال عمیق. بین المللی J. Geo-Inf. 2019 ، 8 ، 258. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کارزنیا، آی. Weibel, R. بهبود انتخاب سکونت برای نقشههای مقیاس کوچک با استفاده از غنیسازی داده و یادگیری ماشین. کارتوگر. Geogr. Inf. علمی 2018 ، 45 ، 111-127. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Polskie Przedsiębiorstwo Wydawnictw Kartograficznych im. Eugeniusza Romera SA In Atlas Rzeczypospolitej Polskiej [اطلس جمهوری لهستان] ; Główny Geodeta Kraju: ورشو، لهستان، 1993; صفحات 1993-1997.
- آئین نامه وزیر کشور و اداری مورخ 17 آبان 1390 در مورد پایگاه اشیاء توپوگرافی، پایگاه عمومی اشیاء جغرافیایی و شرح های استاندارد کارتوگرافی. 2011. در دسترس آنلاین: https://prawo.sejm.gov.pl/isap.nsf/DocDetails.xsp?id=WDU20112791642 (در 4 مارس 2020 قابل دسترسی است).
- میچل، TM یادگیری ماشین ; McGraw-Hill: نیویورک، نیویورک، ایالات متحده آمریکا، 1997. [ Google Scholar ]
- Alpaydin, E. Introduction to Machine Learning ; انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، 2010. [ Google Scholar ]
- مورفی، یادگیری ماشینی KP. دیدگاه احتمالی ; انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، 2012. [ Google Scholar ]
- راهنمای رفرنس ماینر سریع. در دسترس آنلاین: https://docs.rapidminer.com/latest/studio/operators/rapidminer-studio-operator-reference.pdf (در 19 ژانویه 2020 قابل دسترسی است).
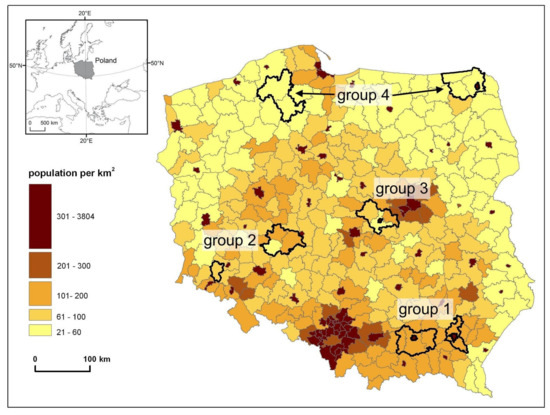
شکل 1. مکان مناطق تحقیقاتی (منبع: شرح خود بر اساس داده های GGOD).
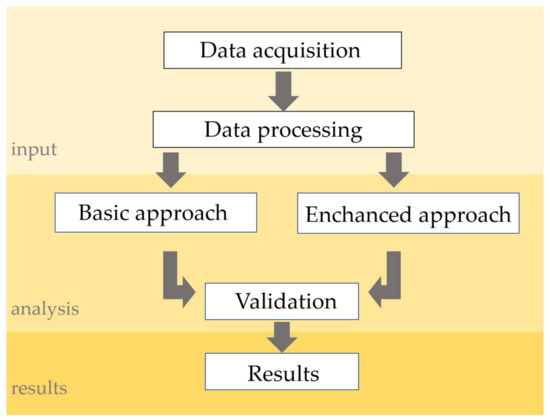
شکل 2. طرح تحقیق.
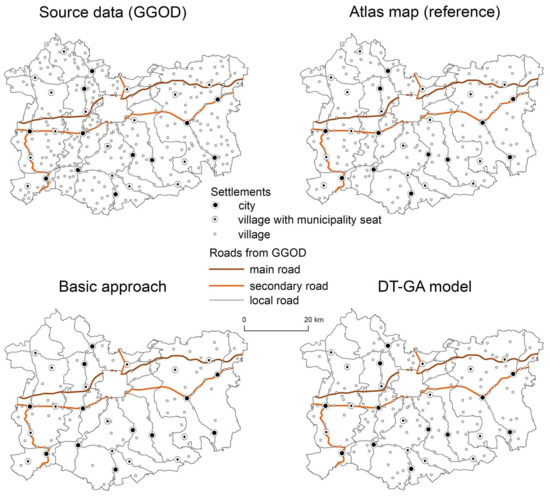
شکل 3. نقشه های مناطق برزسکی، تارنوفسکی و دبیکی. گروه 1.
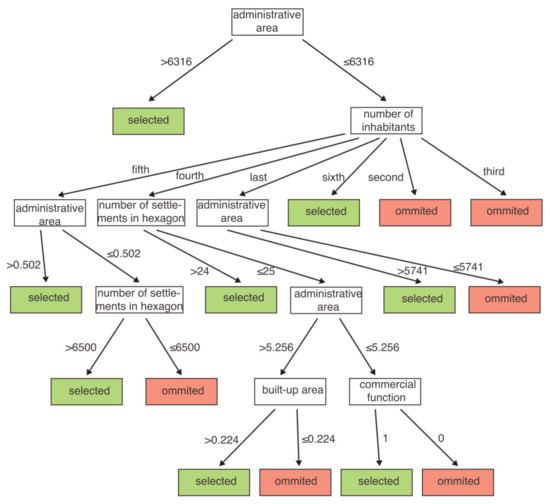
شکل 4. درخت تصمیم برای گروه 1، نتیجه یادگیری ماشین با استفاده از درخت تصمیم با انتخاب ویژگی بهینه شده با استفاده از مدل الگوریتم ژنتیک (DT-GA).
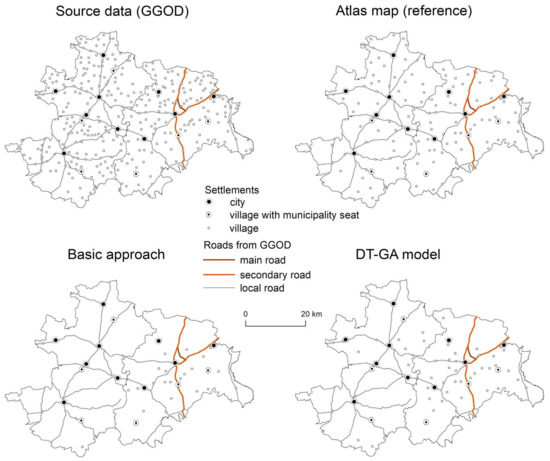
شکل 5. نقشه های مناطق کروتوسزینسکی، اوستروفسکی، میلیکی و زلوتوریسکی. گروه 2.
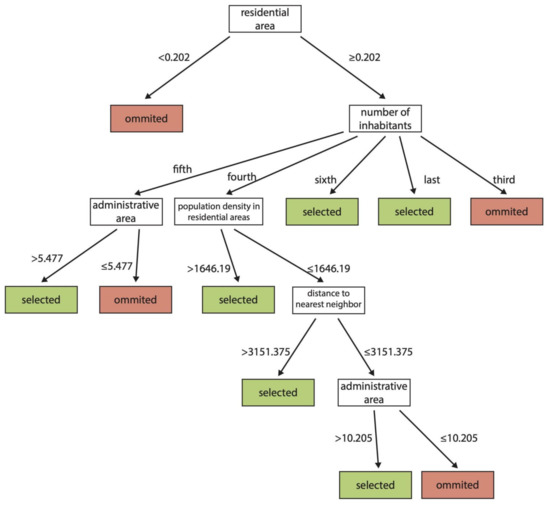
شکل 6. درخت تصمیم برای گروه 2، نتیجه یادگیری ماشین با استفاده از مدل DT-GA.
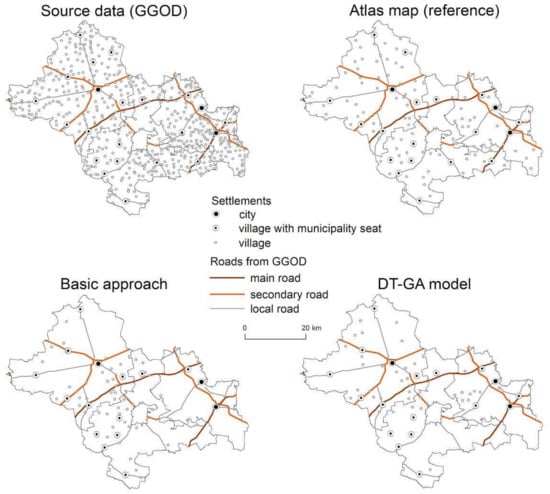
شکل 7. نقشه های مناطق Łowicki، Skierniewicki و Żyrardowski. گروه 3.
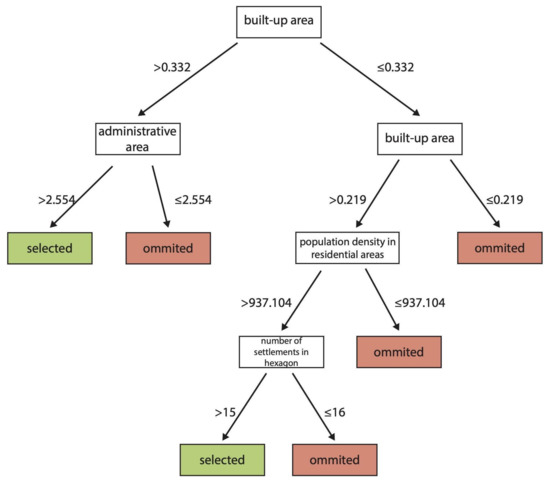
شکل 8. درخت تصمیم برای گروه 3، نتیجه یادگیری ماشین با استفاده از مدل DT-GA.
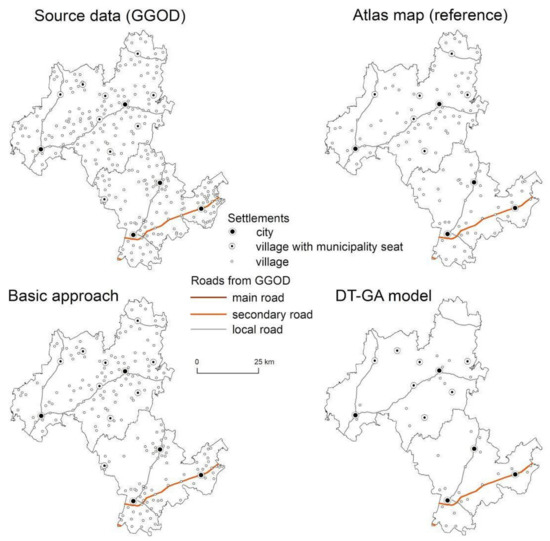
شکل 9. نقشه های مناطق بیتوفسکی و چوژنیکی. گروه 4.
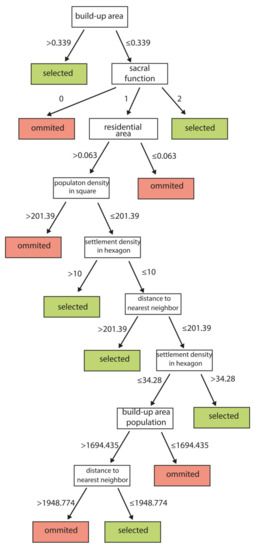
شکل 10. درخت تصمیم برای گروه 4، نتیجه یادگیری ماشین با استفاده از مدل DT-GA.
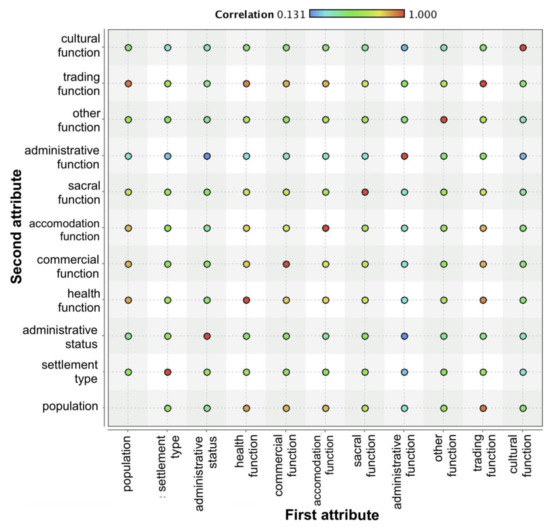
شکل 11. قدرت همبستگی متغیرها. برای هر چهار گروه منطقه محاسبه شده است.


بدون دیدگاه