


پردازش مبتنی بر یادگیری ماشین برای دانلود تصاویر نیمه خودکار Sentinel-2، فیلتر ابری، طبقه بندی و به روز رسانی مجموعه داده های کاربری اراضی و پوشش زمین
چکیده
کاربری زمین و پوشش زمین در دنیای امروز به طور مداوم در حال تغییر است. بنابراین، هر دو حوزه باید بر به روز رسانی منابع اطلاعاتی خارجی تکیه کنند که از آنها استفاده از زمین/پوشش زمین (طبقه بندی) استخراج می شود. تصاویر ماهواره ای به دلیل وضوح زمانی و مکانی، کاندیدای مکرر هستند. در مقابل، استخراج اطلاعات کاربری/پوشش زمین مربوطه از نظر پایگاه دانش و زمان بسیار سخت است. رویکرد ارائه شده یک خط لوله یادگیری ماشینی اثبات مفهوم را ارائه می دهد که از کل فرآیند پیچیده به روش زیر مراقبت می کند. تصاویر Sentinel-2 مربوطه از طریق خط لوله به دست آمده است. بعداً، پوشش ابری، از جمله درون یابی خطی فریم های زمانی با ویژگی های ادغام شده، انجام می شود. متعاقبا، آرایههای چهار بعدی با تمام دادههای آموزشی بالقوه ایجاد میشوند تا مبنایی برای تخمینزنان از کتابخانه scikit-learn شوند. سپس از برآوردگر LightGBM استفاده می شود. در نهایت، محتوای طبقهبندیشده برای پایگاههای داده کاربری باز و پوشش زمین باز اعمال میشود. راستیآزمایی آزمایش ارائهشده بر اساس دادههای دقیق کاداستر انجام شد، که آنتروپی شانون برای آن اعمال شد، زیرا تعداد کلاسهای اطلاعات کاداستر طبیعتاً سازگار بود. آزمایش دقت کلی خوب (OA) 85.9٪ را نشان داد. این یک نقشه کاربری زمین/پوشش زمین طبقه بندی شده از منطقه مورد مطالعه شامل 7188 کیلومتر مربع در بخش جنوبی منطقه موراویای جنوبی در جمهوری چک به همراه داشت. خط لوله یادگیری ماشینی اثبات مفهوم توسعهیافته تا زمانی که الزامات دادههای ورودی برآورده شود، قابل تکرار به هر حوزه مورد علاقه دیگری است. سپس از برآوردگر LightGBM استفاده می شود. در نهایت، محتوای طبقهبندیشده برای پایگاههای داده کاربری باز و پوشش زمین باز اعمال میشود. راستیآزمایی آزمایش ارائهشده بر اساس دادههای دقیق کاداستر انجام شد، که آنتروپی شانون برای آن اعمال شد، زیرا تعداد کلاسهای اطلاعات کاداستر طبیعتاً سازگار بود. آزمایش دقت کلی خوب (OA) 85.9٪ را نشان داد. این یک نقشه کاربری زمین/پوشش زمین طبقه بندی شده از منطقه مورد مطالعه شامل 7188 کیلومتر مربع در بخش جنوبی منطقه موراویای جنوبی در جمهوری چک به همراه داشت. خط لوله یادگیری ماشینی اثبات مفهوم توسعهیافته تا زمانی که الزامات دادههای ورودی برآورده شود، قابل تکرار به هر حوزه مورد علاقه دیگری است. سپس از برآوردگر LightGBM استفاده می شود. در نهایت، محتوای طبقهبندیشده برای پایگاههای داده کاربری باز و پوشش زمین باز اعمال میشود. راستیآزمایی آزمایش ارائهشده بر اساس دادههای دقیق کاداستر انجام شد، که آنتروپی شانون برای آن اعمال شد، زیرا تعداد کلاسهای اطلاعات کاداستر طبیعتاً سازگار بود. آزمایش دقت کلی خوب (OA) 85.9٪ را نشان داد. این یک نقشه کاربری زمین/پوشش زمین طبقه بندی شده از منطقه مورد مطالعه شامل 7188 کیلومتر مربع در بخش جنوبی منطقه موراویای جنوبی در جمهوری چک به همراه داشت. خط لوله یادگیری ماشینی اثبات مفهوم توسعهیافته تا زمانی که الزامات دادههای ورودی برآورده شود، قابل تکرار به هر حوزه مورد علاقه دیگری است. راستیآزمایی آزمایش ارائهشده بر اساس دادههای دقیق کاداستر انجام شد، که آنتروپی شانون برای آن اعمال شد، زیرا تعداد کلاسهای اطلاعات کاداستر طبیعتاً سازگار بود. آزمایش دقت کلی خوب (OA) 85.9٪ را نشان داد. این یک نقشه کاربری زمین/پوشش زمین طبقه بندی شده از منطقه مورد مطالعه شامل 7188 کیلومتر مربع در بخش جنوبی منطقه موراویای جنوبی در جمهوری چک به همراه داشت. خط لوله یادگیری ماشینی اثبات مفهوم توسعهیافته تا زمانی که الزامات دادههای ورودی برآورده شود، قابل تکرار به هر حوزه مورد علاقه دیگری است. راستیآزمایی آزمایش ارائهشده بر اساس دادههای دقیق کاداستر انجام شد، که آنتروپی شانون برای آن اعمال شد، زیرا تعداد کلاسهای اطلاعات کاداستر طبیعتاً سازگار بود. آزمایش دقت کلی خوب (OA) 85.9٪ را نشان داد. این یک نقشه کاربری زمین/پوشش زمین طبقه بندی شده از منطقه مورد مطالعه شامل 7188 کیلومتر مربع در بخش جنوبی منطقه موراویای جنوبی در جمهوری چک به همراه داشت. خط لوله یادگیری ماشینی اثبات مفهوم توسعهیافته تا زمانی که الزامات دادههای ورودی برآورده شود، قابل تکرار به هر حوزه مورد علاقه دیگری است. این یک نقشه کاربری زمین/پوشش زمین طبقه بندی شده از منطقه مورد مطالعه شامل 7188 کیلومتر مربع در بخش جنوبی منطقه موراویای جنوبی در جمهوری چک به همراه داشت. خط لوله یادگیری ماشینی اثبات مفهوم توسعهیافته تا زمانی که الزامات دادههای ورودی برآورده شود، قابل تکرار به هر حوزه مورد علاقه دیگری است. این یک نقشه کاربری زمین/پوشش زمین طبقه بندی شده از منطقه مورد مطالعه شامل 7188 کیلومتر مربع در بخش جنوبی منطقه موراویای جنوبی در جمهوری چک به همراه داشت. خط لوله یادگیری ماشینی اثبات مفهوم توسعهیافته تا زمانی که الزامات دادههای ورودی برآورده شود، قابل تکرار به هر حوزه مورد علاقه دیگری است.
کلمات کلیدی: یادگیری ماشینی کاربری زمین ؛ پوشش زمین ؛ تصاویر ماهواره ای ; نگهبان 2 ; طبقه بندی تصویر ; پوشش ابری ؛ برآوردگر LightGBM
1. مقدمه
کاربری زمین و پوشش زمین معمولاً به عنوان مترادف استفاده می شوند و اغلب در یک مجموعه داده واحد ادغام می شوند. برای این مفهوم از مخفف LULC (کاربری زمین/پوشش زمین) استفاده می شود. با این وجود کاربری و پوشش اراضی به پدیده های مختلفی اشاره دارد. تا حدی، ما میتوانیم کاربری اراضی را بهعنوان توسعهای از پوشش زمین در نظر بگیریم، با توجه به اینکه فعالیتهای انسانی را توصیف میکند، که بیشتر آنها به طور محکم به یک نوع سطح خاص (نوع پوشش زمین) متصل هستند.
فیشر، کامبر و وادسورث [ 1] استدلال کرد که ظهور سنجش از دور (RS) در دهه 1970 باعث تغییر در درک کاربری و پوشش زمین شد. پیش از این، تمایلی به جمعآوری دادههای کاربری زمین وجود داشت، زیرا آنها عمدتاً برای کاربردهای عملی (مانند ساختوساز زیرساختها و برنامهریزی سرزمینی و شهری) مفید بودند (و هنوز هم هستند). سهولت در اکتساب و استفاده از تصاویر ماهواره ای بر ضرر آن – فقدان اطلاعات متنی ضمنی – بیشتر بود. بنابراین استخراج بسیاری از طبقات کاربری زمین (در سطح بالا) غیرممکن بود، و آنچه که امروزه نقشه برداری می کنیم و از آن به عنوان “پوشش زمین” یاد می کنیم ممکن است اطلاعات کاربری زیادی را در خود جای دهد. لازم به ذکر است که در سالهای اخیر، مطالعات متعددی نتایج جالبی در استخراج اطلاعات کاربری خالص حتی از تصاویر ماهوارهای به دست آوردهاند . 3 ، 4 ، 5 ].
منبع دیگر سردرگمی به اهداف سازمانی [ 1 ] مربوط می شود. ترکیب معنایی LULC به وضوح در سیستم های طبقه بندی اصلی امروزی منعکس شده است [ 6 ، 7 ، 8 ]]. اینها از هر دو اصطلاح بر اساس داده های اولیه و بحث همزمان با کاربران استفاده کرده اند. آنها اغلب نیاز دارند تا سیستم های محلی را برای عملکرد در سطوح ملی یا بین المللی مرتبط کنند. این منجر به طبقهبندیهای چند لایهای شده است که عناصر آن سعی میکنند با بسیاری از سیستمهای قبلی مطابقت داشته باشند، و دلیل ترکیب کلاسهای LULC، نمایش یکنواخت آنها در یک فضای جغرافیایی وسیع است. اگر کاربری زمین را بهعنوان بلوک اصلی ساختمان در نظر بگیریم، طبقهبندی آن اغلب تمایز پیچیدهتر پوشش زمین در فضای طبیعی را حذف میکند. که منجر به همگن شدن بیش از حد آن در مناطق وسیع طبیعی می شود [ 1 ]. این برعکس در محیط شهری صدق می کند [ 9]. در واقع، این یک روش معمول برای مجموعه داده های جهانی LULC است که توسط پوشش زمین در مناطق با کاربری گسترده و با استفاده از زمین در مناطق با استفاده فشرده هدایت شوند [ 10 ]. امروزه بسیاری از برنامه های پایش زمین در دنیا وجود دارد که داده های LULC را به این روش طراحی می کنند. مثال توضیح داده شده در [ 1 ] سیستم طبقه بندی USGS (سازمان زمین شناسی ایالات متحده) بود، اما پوشش زمین CORINE اروپا (CLC) [ 11 ]، اطلس شهری (UA) [ 12 ]، و HILUCS (سیستم طبقه بندی کاربری اراضی INSPIRE سلسله مراتبی) ) [ 13 ] طبقه بندی ها به روشی مشابه تهیه شد.
چندین پایگاه داده باز LULC در دهه گذشته تولید شده است. از جمله، OSM (Open Street Map) Landuse Landcover پایگاه داده [ 14 ] از نقشه خیابان باز که به طور گسترده استفاده می شود مشتق شده است. این نقشه در حال حاضر اروپا را پوشش می دهد، در حالی که سایر قاره ها در حال پردازش هستند. GAP/LANDFIRE National Terrestrial Ecosystems 2011، که برای ایالات متحده آمریکا در دسترس است [ 15 ]، شامل نمونه ای از داده های موجود برای مناطقی غیر از اروپا است. منابع داده در دسترس جهانی مانند اشتراک پوشش جهانی زمین (GLC-SHARE) ارائه شده توسط فائو (سازمان غذا و کشاورزی سازمان ملل متحد) با وضوح فضایی نسبتاً پایینتری (مثلاً 1 کیلومتر در هر پیکسل) مشخص میشوند [ 16 ]
این مقاله توسعه یک خط لوله یادگیری ماشین مبتنی بر رصد زمین را برای بهروزرسانی دو محصول مرتبط LULC توصیف میکند: پایگاه داده استفاده از زمین باز (OLU) و پایگاه داده پوشش زمین باز (OLC). رویکرد ارائه شده را می توان به عنوان اثبات مفهومی درک کرد که اطلاعات مربوط به LULC را از تصاویر Sentinel-2 از طریق روش های یادگیری ماشین به دست می آورد. هدف اصلی مقاله ارائه شده ارائه یک خط لوله مبتنی بر یادگیری ماشین است که:
- (1)
-
تصاویر Sentinel-2 را جمع آوری می کند.
- (2)
-
ابری را از طریق بردارهای چند زمانی فیلتر می کند.
- (3)
-
امکان انجام خط لوله برای انجام طبقه بندی LULC بر روی تصاویر را بررسی می کند.
- (4)
-
بر این اساس پایگاه داده های OLU/OLC را به صورت نیمه خودکار به روز می کند.
رویکرد ارائه شده در نظر گرفته شده است که در صورت رعایت الزامات داده های ورودی، با توجه به هر منطقه مورد علاقه دیگر در جهان قابل تکرار باشد. ورودی های تصاویر ماهواره ای به پایگاه های داده LULC را می توان در زمان واقعی ارائه کرد. رویکرد ارائه شده از نظر روش شناختی از کار به دست آمده توسط Lubej [ 17 ، 18 ] نشات گرفته و بر اساس آن است.
2. تحقیقات مرتبط
ماموریت های ماهواره لندست تقریباً در 50 سال گذشته مبنایی برای اطلاعات LULC بوده است. اخیراً، دادههای Sentinel-2 وضوح فضایی بالاتری ارائه کردهاند (به بخش 3.1.1 مراجعه کنید . استفاده از زمین باز و پوشش زمین باز برای جزئیات بیشتر). داده های Sentinel-2 به عنوان دقیق ترین داده های ماهواره ای با دسترسی باز مناسب برای مشتقات LULC با پوشش جهانی شناخته می شوند. دادههای Sentinel – 2 برای اهداف مختلفی مانند پایش جنگل، کشاورزی، پایش مخاطرات طبیعی، توسعه شهری، اقلیمشناسی محلی و مشاهده رژیم هیدرولوژیکی استفاده میشوند ., 24 , 25 ].
بروزون و همکاران [ 26 ] نقشه برداری LULC را یکی از کاربردهای ضروری برای داده های Sentinel-2 عنوان کرد. بررسی ادبیات انجام شده توسط فیری و همکاران. [ 27 ] نشان داد که استفاده از دادههای Sentinel-2 میتواند دقت بالایی (بیش از 80%) با طبقهبندیکنندههای یادگیری ماشینی مناسب مانند جنگل تصادفی (RF) و ماشین بردار پشتیبان (SVM) ایجاد کند. در سطح اجرا، Cavur و همکاران. [ 28 ] از یک SVM برای پردازش داده Sentinel-2 به نقشه برداری LULC استفاده کرد. ژنگ و همکاران [ 4 ] از RF برای طبقه بندی تصاویر Sentinel-2 استفاده کرد، Weigand و همکاران. [ 29] این روش را با داده های درجا LUCAS (بررسی چارچوب کاربری و منطقه تحت پوشش) ترکیب کرد. نگوین و همکاران [ 30 ] همچنین عملاً کاربرد داده Sentinel-2 را برای نقشه برداری LULC در مناطق گرمسیری تأیید کرد. داده های Sentinel-2 را نیز می توان برای نقشه برداری LULC با استفاده از روش های یادگیری عمیق [ 31 ] پردازش کرد.
تصحیح اتمسفر برای طبقه بندی دقیق LULC خودکار ضروری است زیرا می تواند نتیجه طبقه بندی نهایی را تحت تاثیر قرار دهد و تغییر دهد [ 32 ]. درک خوب LULC و دینامیک آنها یکی از کارآمدترین ابزارها برای درک و مدیریت تحولات زمین است [ 33 ، 34 ]. پوشاندن ابرها بخش مهمی از تصحیح جو است، زیرا ابرها از سطوح روشن دیگر مانند برف و آب قابل تشخیص نیستند. به طور مشابه، تشخیص ابرهای نازک، مانند سیروس، که رفتار طیفی سطوح زیرین را تغییر می دهد، دشوار است [ 35 ]]. روشهای متعددی برای پوشش ابری توسعه داده شدهاند که از مدلهای طیفی و مبتنی بر شی استفاده میکنند [ 35 ، 36 ، 37 ]. هالشتاین و همکاران برای مثال، [ 37 ]، الگوریتمهای تشخیص ابر را در محیط پایتون از دیدگاه پیچیدگی، سرعت و قابلیت حمل و نقل ارزیابی کرد. آنها به این نتیجه رسیدند که طبقهبندیکننده کلاسیک بیزی و جنگلهای تصادفی کاندیدهای خوبی برای پوشش ابری پیشرفته در یک گردش کار مشخص هستند.
در میان محصولات دیگر، پردازنده های Fmask [ 38 ] و Sen2Cor محبوبیت گسترده ای به دست آورده اند. Fmask امروزه عمدتاً برای تصاویر Landsat استفاده می شود. با این حال، به روز رسانی های اخیر آن [ 39 ، 40 ] نتایج تشخیص امیدوارکننده ای را برای داده های Sentinel-2 نیز با دقت کلی (OA) تا 94٪ نشان داد. به دلیل خطاهای حذف ابرهای ارتفاع پایین، نویسندگان این به روز رسانی ها را برای Sentinel-2 در زمان نگارش این مقاله پیاده سازی نکرده اند [ 41 ]]. Sen2Cor، یک پردازنده بومی Sentinel-2، اصلاحات جوی و رادیومتری (مانند تصحیح سیروس) را معرفی کرد که منجر به تصویری در سطح پردازش Level-2A (L2A) می شود. این یک لایه طبقه بندی صحنه (SCL) با وضوح 20 متر با احتمالات ابر و چندین کلاس سطح زمین تولید می کند [ 42 ]. Baetens و همکاران [ 43 ] روش پوشاندن ابر یادگیری فعال خود را در برابر پردازندههای Fmask، Sen2Cor و MAJA [ 44 ] تأیید کردند. Sen2Cor به طور متوسط 6% دقت کمتری نسبت به دو مورد دیگر (با OA حدود 84%) انجام داد.
موضوع دیگر برای پردازش بعدی داده های تصحیح شده، خود طبقه بندی است. طیف گستردهای از طبقهبندیکنندهها از جمله طبقهبندیکنندههای پارامتریک (رگرسیون لجستیک) و طبقهبندیکنندههای یادگیری ماشین غیرپارامتری (k-نزدیکترین همسایگان، RF، SVM، افزایش گرادیان شدید، و یادگیری عمیق) را میتوان برای طبقهبندی LULC استفاده کرد [ 45 ، 46 ]. مقایسه اثرات این الگوریتم های طبقه بندی خارج از محدوده این مقاله است. برآوردگر LightGBM [ 47 ] برای طبقه بندی در محدوده این مقاله استفاده شد. برآوردگر LightGBM یک الگوریتم مبتنی بر روش یادگیری ماشین درخت تصمیم گیری افزایش گرادیان است [ 47 ]]. این الگوریتم به این دلیل انتخاب شد که برای پردازش مجموعه داده های آموزشی بزرگتر مناسب است و به دلیل اینکه نتایج به دست آمده را می توان با کار Lubej [ 17 ، 18 ] و eo-learn [ 48 ، 49 ] مقایسه کرد.
این مقاله بر روی رویکردهای معاصری که در بالا توضیح داده شد استوار است و آنها را تقویت می کند. علاوه بر این، توسعه خط لوله مبتنی بر یادگیری ماشین ارائه شده نشان دهنده اثبات مفهومی برای یک ذخیره داده صریح متشکل از پایگاههای داده OLU و OLC است.
3. مواد و روشها
3.1. مواد
3.1.1. کاربری زمین باز و پوشش زمین باز
OLU [ 50 ] یک پایگاه داده فضایی آنلاین و یک سیستم اطلاعات جغرافیایی (GIS) است که هدف آن ارائه داده های پاناروپایی LULC در مقیاس خوب و هماهنگ از منابع آزادانه در دسترس است [ 51 ]. OLU توسط Plan4All، یک سازمان غیرانتفاعی چتر ( https://www.plan4all.eu/ ) ایجاد و نگهداری می شود. از سال 2020، OLU آفریقا را نیز پوشش می دهد [ 52 ]. در پایان سال 2019، نتیجه اصلی OLU یک نقشه LULC بدون درز (نقشه پایه OLU) گردآوری شده بود [ 53]. دادهها در قالب فایل شکل ESRI قابل دانلود هستند یا از رابطهای کاربر برنامه استاندارد کنسرسیوم فضایی باز (API)—Web Map Service [ 54 ] و Web Feature Service [ 55 ] قابل دسترسی هستند. قابلیت همکاری انگیزه اصلی برای ارائه گزینه های دیگر برای بازیابی داده ها است که امکان بازیابی اتوماسیون و ساده سازی استفاده در سایر GIS را فراهم می کند.
ستون فقرات نقشه پایه OLU از دو مجموعه داده اروپایی LULC تشکیل شده است – Corine Land Cover و Urban Atlas:
-
UA یک مجموعه داده پاناروپایی LULC است که تحت ابتکار کمیسیون اروپا به عنوان بخشی از برنامه کوپرنیک ESA (آژانس فضایی اروپا) توسعه یافته است. داده ها فقط مناطق شهری کاربردی [ 56 ] اتحادیه اروپا (اتحادیه اروپا)، کشورهای EFTA (انجمن تجارت آزاد اروپا)، بالکان غربی و ترکیه را پوشش می دهند. جدیدترین مجموعه داده اطلس شهری مربوط به سال 2018 است. مناطق شهری را با حداقل واحد نقشه برداری (MMU) 0.25 هکتار و 17 طبقه شهری متمایز می کند و مناطق روستایی را با MMU 1 هکتار و 10 طبقه روستایی متمایز می کند [ 57 ].
-
CLC مجموعه داده اتحادیه اروپا LULC است که توسط آژانس محیط زیست اروپا ارائه شده است. این از داده های RS تهیه شده است: جدیدترین نسخه 2018 به ویژه با تصاویر ماهواره ای Sentinel-2 تکمیل شده است. CLC 2018 کشورهای EEA39 (آژانس محیط زیست اروپا) را پوشش می دهد و 44 طبقه کاربری ترکیبی و پوشش زمین را با MMU 0.25 هکتار از ویژگی های چند ضلعی و 100 متر ویژگی های خطی متمایز می کند. CLC همچنین دارای مشاهده تغییرات LULC با MMU 5 هکتاری است [ 58 ].
اگرچه این مجموعه دادهها احتمالاً با ارزشترین منابع LULC برای OLU هستند، چهار مسئله اصلی شناسایی شدهاند، و اعتقاد بر این است که اینها اهدافی هستند که OLU در تلاش است با آنها مقابله کند:
-
MMU CLC 0.25 هکتار (500×500 متر) و MMU UA در مناطق روستایی 1 هکتار (100×100 متر) است.
-
MMU UA به 0.1 هکتار (تقریباً 31×31 متر) در مناطق شهری کاهش می یابد، اما مجموعه داده فقط مناطق شهری کاربردی را پوشش می دهد و یکپارچه نیست.
-
دوره به روز رسانی برای هر دو مجموعه داده 6 سال است.
-
حتی ترکیبی از هر دو مجموعه داده برای پوشش مناطق خاصی در اروپا کافی نیست.
تیم توسعه OLU/OLC مجموعههای داده در سطح کشور را با اطلاعات LULC جمعآوری کرده است تا بهروزرسانیهای دقیقتر و مکرر را ارائه دهد. رجیستری شناسایی سرزمینی، نشانی ها و املاک [ 59 ] نمونه ای از چنین مجموعه داده ای برای منطقه جمهوری چک است. جمع آوری مجموعه داده های محلی در حال حاضر یکی از فرآیندهای کاری اصلی است. شکاف اطلاعاتی باقیمانده با روشهای RS از جمله طبقهبندی خودکار تصویر در موارد ناکافی یا مفقودی منابع، پر میشود.
آخرین کار با هدف استخراج یک پایگاه داده OLC. چنین اشتقاقی ویژگیهایی را از پایگاههای داده OLU/OLC وارد میکند و باید ویژگیهای پوشش زمین را از ماشینهای ماهوارهای اضافه کند. خط لوله شرح داده شده در این مقاله از OLC با داده های ورودی پوشش زمین مربوطه پشتیبانی می کند.
3.1.2. داده های Sentinel-2
در کنار ماهواره های لندست ناسا (اداره ملی هوانوردی و فضایی)، ماهواره های سنتینل آژانس فضایی اروپا (ESA) مهم ترین ارائه دهندگان داده های اخیر رصد زمین رایگان هستند. ماهوارههای چند طیفی Sentinel-2 که در سطح جهانی فعالیت میکنند، بخشی از برنامه کوپرنیک هستند که هدف اصلی آن نظارت بر محیطهای طبیعی و انسانی و همچنین ارائه ارزش افزوده برای شهروندان اروپایی است [ 57 ]. Sentinel-2 به طور کامل از سال 2015 به عنوان یک ماهواره Sentinel-2A فعال است. از سال 2017، با ماهواره Sentinel-2B تکمیل شد، که زمان بازدید مجدد را از 10 به 5 روز در بیشتر مکان ها کاهش داد [ 60 ]]. Sentinel-2 حسگر چندطیفی (MSI) را در 13 باند از مناطق نزدیک به VIS تا SWIR، در وضوح هندسی 10 متر در 4 باند، 20 متر در 6 باند، و 60 متر در 3 باند حمل می کند. جدول 1 [ 61 ] را ببینید . وضوح رادیومتریک همه باندها 12 بیت است که امکان تشخیص مقادیر شدت نور 4096 را فراهم می کند. عرض سنسور 290 کیلومتر است. سه سطح پردازش تصاویر Sentinel-2 وجود دارد که دو مورد از آنها برای دانلود در دسترس هستند: Level-1C (L1C) بازتاب بالای جو را فراهم می کند. L2A دارای اصلاحات رادیومتری اضافی است و بازتاب پایین جو را فراهم می کند. با این حال، فقط اروپا را پوشش می دهد و از سال 2018 در دسترس بوده است .]. تفاوت های جزئی در قرارگیری باند در طیف بین Sentinel-2A و Sentinel-2B وجود دارد. تصاویر Sentinel-2 را میتوان از منابع مختلفی دریافت کرد، مرکز دسترسی آزاد کوپرنیک https://scihub.copernicus.eu/ رسمی است (در 2 دسامبر 2020 قابل دسترسی است). در حالی که آنها به عنوان فایل های فشرده دانلود می شوند، فرمت اصلی آنها یک فایل SAFE است که دارای یک درخت پوشه رسمی با محصولات تک تصویری است [ 61 ]. پاناروپایی بودن، آزادانه در دسترس بودن و از بین بردن وضوح بالاتر در مقایسه با سایر ماهواره های معمولی رایگان (مانند Landsat 8) [ 62 ]]، Sentinel-2 دارای پتانسیل داده خوبی برای افزایش OLU/OLC با داده های طبقه بندی شده LULC است. در این مقاله، تصاویر چند زمانی Sentinel-2 به عنوان منبع داده کلیدی برای خط لوله پردازش در بخش 3.2.1 استفاده شد.
3.2. مواد و روش ها
3.2.1. توسعه خط لوله پردازش برای تکمیل OLU/OLC با داده های RS
اطلاعات کاربری زمین و پوشش زمین در OLU/OLC در برخی قسمت ها در دسترس نیست، خیلی درشت است یا به طور کامل وجود ندارد. دادههای رصد زمین و روشهای طبقهبندی تصویر طیفگرا منابع قابل اعتمادی برای کسب پوشش زمین مرتبط و تا حدی نیز اطلاعات کاربری زمین ثابت شدهاند [ 63 ، 64 ]. ستون فقرات روش ارائه شده از Lubej [ 17 ، 18 ] الهام گرفته شده است. فقط طبقهبندی تصاویر بر اساس روششناسی زیربنایی اجرا شد. روش شناسی لوبژ [ 17 ، 18] همچنین مجموعه ای از تصاویر Sentinel-2 و فیلتر ابری را شامل می شود. با این حال، او از زیرساخت پولی Sentinel Hub استفاده کرد. بنابراین، ویژگیهای زیر بهتازگی به روشی باز توسعه یافتهاند: مجموعه تصاویر Sentinel-2، فیلتر ابری، و بهروزرسانیهای نیمه خودکار پایگاههای داده OLU/OLC.
خط لوله پردازش طراحی شده از کتابخانه eo-learn [ 48 و 49 ] با قابلیت های سفارشی برای استخراج داده های LULC از تصاویر چند زمانی Sentinel-2 استفاده می کند. برآوردگرهای یادگیری ماشین (که به آنها طبقه بندی کننده نیز گفته می شود) از کتابخانه scikit-learn [ 65 ، 66 ] استفاده شد. تعدادی از عناصر طراحی از روشهای پیادهسازی برای نقشهبرداری پوشش زمین توسعهدهندگان کتابخانه [ 17 ، 18 ] و از اسناد رسمی eo-learn [ 48 ، 49 ] اقتباس شدند.]. در حالی که راه اندازی کلی خط لوله می تواند بر نتایج طبقه بندی تأثیر زیادی بگذارد، برخی از وظایف پردازش تصویر از پیش تعیین شده بودند (یا حذف شدند)، با توجه به اینکه این یک طرح مفهومی اثبات کننده است. پلت فرم Jupyter Hub در سرور تیم توسعه OLU/OLC برای نوشتن کد و تجسم نتایج تحلیلی استفاده شد. بخشهای فرعی زیر ابتدا کتابخانه eo-learn را شرح میدهند و سپس اصول طراحی خط لوله پردازش را شرح میدهند.
3.2.2. Eo-Learn: مرور کلی و منطق انتخاب
Eo-learn یک کتابخانه منبع باز است که در زبان برنامه نویسی پایتون توسعه یافته است. این یک محیط شی گرا است که تقریباً منحصراً برای پردازش داده های RS هدف گذاری شده است. از ویژگی های چندین کتابخانه غیر بومی پایتون، به ویژه NumPy، Matplotlib، Pandas و Geopandas استفاده می کند. برخی از عملکردهای مهم توسط بسته نیمه تجاری Sentinel Hub [ 67 ] ارائه شده است. چندین ویژگی eo-lean وجود دارد که منطق قوی برای استفاده از آن برای اصلاح اطلاعات LULC در OLU/OLC با داده های RS ارائه می دهد:
-
استفاده از eo-learn با الزامات مجوز باز OLU/OLC مطابقت دارد، زیرا OLU/OLC تاکنون با استفاده از نرم افزار منبع باز توسعه داده شده است تا از نظر مالی پایدار باشد.
-
باید امکان دستکاری و تغییر کد عملیات پردازش برای ادغام آن در OLU/OLC وجود داشته باشد. با توجه به نکته قبلی، اکثر راه حل های منبع باز، از جمله آموزش الکترونیکی، از چنین رویکردی پشتیبانی می کنند.
-
eo-learn در درجه اول برای داده های Sentinel-2 توسعه یافته است. با این حال، اگر به اندازه کافی از قبل پردازش شده باشد، می تواند هر تصویری را مدیریت کند.
Eo-learn اتصال عملکردی به پلتفرم Sentinel Hub [ 68 ] ارائه می دهد و تصاویر ماهواره ای پردازش شده را ارائه می دهد. این امر خرید و استفاده از آن را بسیار ساده می کند. این ویژگی مبتنی بر اشتراک است، به این معنی که چندین عملکرد دوباره ایجاد شده است تا بتوان خط لوله را به صورت رایگان اداره کرد. شرح ویژگیهای اصلی eo-learn در مواد تکمیلی ارائه شده است .
3.2.3. دستکاری با منطقه مورد علاقه
EOPatches (به مواد تکمیلی مراجعه کنید ) دارای داده هایی برای جعبه های محدود کننده مستطیلی هستند، بنابراین یک جعبه محدود کننده یک منطقه مورد نظر (AOI) یا یک EOPatch منفرد است یا می تواند به جعبه های محدود کننده کوچکتر (EOPatches) تقسیم شود. AOI به یک CRS دلخواه تبدیل می شود (WGS 84 UTM 33N برای اثبات مفهوم ارائه شده در این مقاله از قبل تعیین شده بود) و شکل آن (به عنوان یک قالب چند ضلعی شکل [ 69 ]) و ابعاد آن را به عنوان ورودی به کلاس Patcher ارائه می دهد. Patcher از تابع BBOxSplitter از کتابخانه Sentinel Hub [ 68]، که جعبه محدود کننده AOI را با توجه به ابعاد تقریبی آن تقسیم می کند. این تابع به طور خودکار تنها جعبههای محدودکنندهای را استخراج میکند که هندسه AOI در آن قرار دارند یا با هم قطع میشوند. علاوه بر این، Patcher به شخص اجازه میدهد تا یک ضریب وصله، ضریب تقسیم مبتنی بر ابعاد پیشفرض را انتخاب کند، بنابراین فرد را قادر میسازد تا دانهبندی تقسیم AOI را تغییر دهد. جعبههای مرزبندی تقسیمشده به GeoPandas GeoDataFrame [ 70 ] تجزیه میشوند که شامل هندسه، شناسهها و اطلاعات آنها برای اهداف تجسمی است.
3.2.4. پیش پردازش داده های آموزشی
دادههای آموزشی (یا آزمایشی) بهتر است به شکل شطرنجی با اطلاعات LULC به عنوان مقدار پیکسل وارد خط لوله شوند. اگر آنها در قالب برداری هستند، می توان از VectorToRaster EOTask eo-learn استفاده کرد. داده ها باید در WGS 84 UTM CRS باشند که در آن تصاویر Sentinel-2 نمایش داده می شود. از آنجایی که داده های آموزشی می توانند چندین شکل داشته باشند، پردازش تعمیم یافته اجرا نمی شود.
3.2.5. خرید سفارشی تصاویر Sentinel-2
برخی از توابع برای بازیابی داده ها، مانند CustomS2AL2AWCSInput EOTask، از پلت فرم Sentinel Hub استفاده می کنند. این پلتفرم تصاویر Sentinel-2 را از یک موزاییک از پیش پردازش شده استاندارد سرویس پوشش وب (WCS) بازیابی می کند [ 71 ]. بنابراین، چنین توابعی میتوانند دادهها را در قالب باندهای دلخواه به دست آورند که توسط جعبههای محدود انتخابی محدود شده و به وضوح تک نمونهبرداری میشوند. استفاده از پلتفرم Sentinel Hub مبتنی بر اشتراک است. بنابراین یک خط لوله سفارشی برای به دست آوردن و پردازش تصاویر Sentinel-2 با استفاده از کتابخانه های دیگر پایتون علاوه بر eo-learn ایجاد شد.
کلاس S2L2AIMages برای بازیابی تصاویر Sentinel-2 در سطح پردازش L2A ایجاد شده است. یک GeoDataFrame از جعبههای محدودکننده از کلاس Patcher را میپذیرد تا مجموع جعبه محدودکننده آنها را انتزاع کند. سپس از کتابخانه Sentinelsat [ 72 ] استفاده می کند که یک API پایتون ایجاد می کند و از مرکز دسترسی باز کوپرنیک [ 73 ] سوء استفاده می کند. کلاس S2L2AImages ویژگیهای Sentinelsat را میپوشاند تا ابتدا متادیتای تصویر موجود را در یک Pandas DataFrame نشان دهد [ 74 ] و اجازه میدهد تا انتخاب یک زیرمجموعه دانلود شود (بر اساس تاریخ دریافت تصویر). سپس تصاویر Sentinel-2 انتخاب شده به صورت انبوه به صورت فایل های فشرده دانلود می شوند و یک DataFrame از تصاویر دانلود شده برای کار بیشتر برگردانده می شود.
3.2.6. پردازش تصاویر Sentinel-2 برای EOPatches
تصاویر بهدستآمده در قالبی نامناسب (برای EOPatches) چند زمانی هستند که مجدداً نمونهگیری نشده و به یک AOI مقیاسبندی نشده است. همه این مسائل را می توان با استفاده از توابع مبتنی بر پلت فرم Sentinel Hub حل کرد. با این وجود، یک راه حل سفارشی توسعه داده شد. کلاس CustomInput به عنوان یک EOTask سفارشی ایجاد شد که EOPatches را تشکیل می دهد، تصاویر Sentinel-2 L2A را پردازش می کند و آن را در EOPatches ذخیره می کند. ورودی های این کلاس مسیری برای تصاویر دانلود شده و DataFrame آنها هستند که توسط کلاس S2L2AImages تولید شده اند. با استفاده از DataFrame، تصاویر یک به یک برای هر EOPatch به روش زیر پردازش می شوند.
یک فایل فشرده Sentinel-2 L2A با کلاس-ابجکت باز از کتابخانه GDAL [ 75 ] قابل دسترسی است. به لطف کنترل کننده های سیستم فایل مجازی GDAL [ 76 ]، نیازی به بازکردن تصویر از حالت فشرده نیست و کلاس-ابجکت باز می تواند هر فایلی را در یک بایگانی بخواند. از آنجا که تصاویر Sentinel-2 به طور خودکار شناسایی می شوند، فایل فراداده Sentinel-2 (XML) [ 61 ] به طور پیش فرض خوانده می شود و در نتیجه تصویر را به عنوان مجموعه داده Sentinel-2 GDAL [ 77 ] باز می کند. زیر مجموعههای داده آن گروههایی از باندها را بر اساس وضوح هندسی (10، 20 یا 60 متر) نشان میدهند. آنها توسط کتابخانه Rasterio برای باز کردن فرستاده می شوند [ 78] به عنوان فایل های درون حافظه [ 79 ]، به طوری که نتایج پردازش میانی به طور موقت ذخیره می شوند و پس از تکمیل زنجیره پردازش حذف می شوند.
تصمیم گرفته شد که فقط باندهای 10 و 20 متری (10 باند از 13 باند) پردازش شوند. باندهای 20 متری ابتدا با استفاده از روش سفارشی ارتقاء به اندازه پیکسل 10 متر نمونه برداری می شوند. درونیابی نزدیکترین همسایه به عنوان الگوریتم نمونهگیری مجدد انتخاب شد زیرا مقادیر پیکسل جدیدی ایجاد نمیکند. سپس تمام باندها توسط جعبه محدود کننده EOPatch مربوطه بریده می شوند. در پایان، باندها به یک آرایه NumPy تبدیل شده و دوباره بر اساس شماره باند مرتب می شوند.
وقتی همه تصاویر پردازش میشوند، از نظر زمان و باند در یک آرایه چهار بعدی با شکل NumPy زمان × عرض × ارتفاع × باند قرار میگیرند ( شکل 1 ). به این ترتیب، آنها در زیر باندهای کلیدی به عنوان DATA FeatureType در یک EOPatch ذخیره می شوند. تاریخ مصرف آنها به همان ترتیب در TIMESTAMP FeatureType ذخیره می شود. نام باند و شماره ترتیب درون آرایه آن بهعنوان جفتهای کلید/مقدار (فرهنگ لغت پایتون) به META_INFO FeatureType اضافه میشوند تا کاربر بتواند نحوه مرتبسازی باندها را در آرایههای تک تصویری تودرتو پیگیری کند.
3.2.7. پوشش ابری و بدون داده
برای استفاده هر چه بیشتر از تصاویر از محدوده زمانی دانلود شده، پوشش ابری باید اجرا شود. SCL (لایه طبقه بندی صحنه) یک رستر آماده برای استفاده در پوشه Sentinel-2 SAFE است و به عنوان یک راه حل اولیه پوشش ابری برای خط لوله پردازش استفاده شد.
کلاس AddMask پذیرفته شده، SCL را از یک آرشیو فشرده به طور مشابه مورد باندها خلاصه می کند. نوارها را تا 10 متر مجدداً نمونه برداری می کند و آنها را با جعبه محدود کننده مربوطه می چسباند. سپس SCL به یک آرایه بولی از پیکسلهای درست (واضح) و نادرست (ابر) به روشی مشابه با کارهای Baetens و همکارانش طبقهبندی میشود. [ 43 ]؛ با این حال، کلاس اشباع یا معیوب (پیکسل) معتبر شمرده شد. SCL همچنین شامل یک کلاس بدون داده است، که نشان دهنده مکان هایی است که صحنه Sentinel-2 در آن ها ضبط نشده است [ 42 ]. چنین پیکسل هایی نیز به عنوان داده های نادرست در نظر گرفته می شوند. ماسک ها در EOPatches تحت یک کلید دلخواه به عنوان MASK FeatureType، یک آرایه NumPy چهار بعدی ذخیره می شوند. برای هر تصویر یک ماسک وجود دارد ( شکل 2[ 80 ])، بنابراین ابعاد باند همیشه در اندازه یک است.
یک مکانیسم اضافی به دلیل نگرانیهای مربوط به صحت قابلیتهای پوشاندن ابر Sen2Cor SCL اجرا شد، زیرا برخی از ابرهای طبقهبندیشده اشتباه در تصاویر عمدتاً پوشیده از ابر ممکن است نتایج طبقهبندی را خراب کنند. از آنجایی که بارگیری اولیه تصاویر به دلیل پوشش ابری کل صحنه محدود شده است، هیچ توجهی به اعتبارسنجی EOPatches فردی صورت نگرفت. کلاس MaskValidation، با الهام از Lubej [ 17]، ماسک SCL را ارزیابی می کند و یک مقدار بولی برمی گرداند که نشان می دهد پیکسل های نامعتبر (نادرست) از آستانه تعریف شده توسط کاربر فراتر رفته اند یا خیر. Booleans به عنوان مقادیر تصمیم به EOTask SimpleFilterTask بومی فرستاده می شود، که به صورت جداگانه تصاویر ناخواسته را از هر EOPatch حذف می کند. به دلیل این مکانیسم، توزیع زمانی تصاویر ممکن است اکنون در بین EOPatches نامتعادل باشد.
3.2.8. ویژگی های چند تصویری Sentinel-2
با انطباق روش ابداع شده توسط Lubej [ 17 ]، یک کلاس جدید برای افزودن ویژگی های چند تصویری، مانند نسبت-تصاویر یا شاخص های عادی ایجاد شد. Index Database یک پایگاه داده جامع از فرمول ها برای محاسبه برخی از این ویژگی های چند تصویری، از جمله ویژگی های Sentinel-2 [ 81 ] است.
EOTask DerivateProduct سفارشی یک نام ویژگی چند تصویری تعریف شده توسط کاربر، باندهایی که برای محاسبات استفاده می شود و یک فرمول رشته ای را می پذیرد. سپس از جفتهای کلید/مقدار در META_INFO FeatureType استفاده میکند (به بخش 3.2.6 مراجعه کنید ) تا آرایههای باند صحیح را در یک EOPatch هدف قرار دهد.
3.2.9. پس از پردازش داده ها و نمونه برداری برای مرحله طبقه بندی
هنگامی که باندها و ویژگیهای چند تصویری در EOPatches ذخیره میشوند، باید برای طبقهبندی آماده شوند، که یک دامنه قوی برای یادگیری الکترونیکی است. برآوردگرهای Scikit-Learn حاوی تابع تناسب هستند که مدل طبقه بندی را آموزش می دهد. به عنوان یک ماده آموزشی، به بردارهای ویژگی پیکسل های مستقل از زمان و مستقل از باند (دو بعدی) نیاز دارد، که در آن هر یک از این بردارها متعلق به یک کلاس اطلاعاتی است که مدل باید بر روی آن قرار گیرد [ 66 ]. این روشی برای کاهش مداوم فضای ویژگی های طیفی در سطح پیاده سازی است. دادههای موجود در EOPatches باید قبل از کاهش ابعاد، ابتدا قالببندی شوند. فرآیند زیر، درخواست برای هر EOPatch به صورت جداگانه، از رویکرد Lubej [ 17 ] مشتق شده است.، 18 ].
نگه داشتن باندها و ویژگی های چند تصویری جدا از هم در EOPatches در این مرحله بی اثر است. بنابراین از MergeFeatureTask بومی ( شکل 3 را نیز ببینید ) برای به هم پیوستن تمام DATA FeatureTypes در امتداد بعد باند استفاده می شود. این یک آرایه چهار بعدی جدید با تمام داده های آموزشی بالقوه ایجاد می کند.
سپس باید EOTask LinearInterpolation بومی برای درونیابی فریمهای زمانی ویژگیهای ادغامشده در یک دوره انتخابی و بر اساس گام انتخابشده در روز معرفی شود. ابتدا ماسک های SCL مربوطه را روی تمام ویژگی های تصویر می سوزاند و پیکسل های کاذب را به مقادیر بدون داده تبدیل می کند. سپس فریمهای زمانی ویژگی جدید با توجه به روزهای مرحله انتخاب میشوند و نزدیکترین فریمهای زمانی ویژگی واقعی به این نقاط در زمان درونیابی میشوند. TIMESTAMP FeatureType از EOPatches توسط مهرهای زمانی جدید بازنویسی می شود. این عملیات تغییر بزرگی در مقدار اطلاعات ایجاد می کند زیرا نتایج آرایه هایی با مقادیر طیفی مصنوعی (درون یابی) هستند. با این وجود برای همه داده های تصویر در یک EOPatch سازگار است. به عنوان مثال، اگر 5 روز مرحله ای انتخاب شود، سری زمانی حاصل به گونه ای رفتار می کند که گویی از هر بازدید مجدد 5 روزه Sentinel-2 استفاده شده است. شکل 4 ).
یکی از دلایل درون یابی، عدم تعادل زمانی بالقوه فریم های زمانی ویژگی های واقعی در بین EOPatches است که توسط مکانیزم فیلتر اضافی ایجاد می شود (به بخش 3.2.7 مراجعه کنید ). مهمتر از همه، درون یابی مربوط به کاهش بیشتر فضای ویژگی و تغذیه چنین داده هایی به تخمینگر Scikit-learn است (به بخش 3.2.10 مراجعه کنید ). PointSamplingTask بومی برای نمونه برداری از تعداد پیکسل های تعریف شده توسط کاربر از داده های درونیابی استفاده می شود. این را می توان به عنوان کاهش فضای ویژگی پان پیکسل تصور کرد – نتیجه یک آرایه سه بعدی است که در آن هر پیکسل دارای پشته زمانی ویژگی ها (باندها و ویژگی های چند تصویری ترکیبی) است.
در نهایت، کلاس EstimatorParser ابعاد زمانی و باندی را از ویژگی های نمونه برداری شده کاهش می دهد و بنابراین بردار ویژگی مورد نیاز را برمی گرداند. شناسه های EOPatch را می پذیرد تا فقط وصله های انتخاب شده را انتخاب کند. همه ویژگی های نمونه برداری شده در یک آرایه واحد ادغام می شوند، که سپس به یک ماتریس دو بعدی تغییر شکل می دهد. ردیفها پیکسلها هستند و ستونها ویژگیهایی هستند که به طور موقت روی هم چیده شدهاند. اگر درون یابی معرفی نمی شد، این احتمال وجود داشت که برای یک کلاس و برآوردگر از بازه های زمانی نابرابر مرتب شده در چندین بردار ویژگی آموزش ببیند. بنابراین اطلاعات زمانی دقت طبقه بندی را خراب می کند.
دادههای LULC در MASK_TIMELESS FeatureType نیز ادغام میشوند. از آنجایی که آنها در حال حاضر یک آرایه سه بعدی هستند (هیچ اطلاعات زمانی وجود ندارد)، آنها برای مطابقت با توالی بردارهای ویژگی تغییر شکل داده شده اند، که برچسب های کلاس آموزشی را تشکیل می دهند. داده های آزمایش به طور مشابه به دست می آیند، اما با این وجود انتخاب EOPatches های مختلف معنادار است.
3.2.10. انتخاب برآوردگر، آموزش مدل، و پیش بینی
در این مرحله، دادههای Sentinel-2 برای برآوردگرهای یادگیری scikit آماده میشوند. بنابراین تصمیم گرفته شد که هیچ گونه عملکرد پوششی را برای رابط های کتابخانه یادگیری scikit پیاده سازی نکنیم، زیرا آنها مستقل در نظر گرفته می شوند و دارای عملکردهایی برای ارزیابی دقت طبقه بندی نیز هستند. علاوه بر این، برآوردگرها به تنظیمات متفاوتی برای پارامترهای خود نیاز دارند که موضوع پیچیده دیگری است. یک برآوردگر نمونه در بخش 3.3 استفاده شده است. برخی از برآوردگرها نمی توانند مقادیر بدون داده را مدیریت کنند، که می تواند در EOPatches وجود داشته باشد. این به طور خاص به دو مورد مربوط می شود:
-
اگر ویژگی های چند تصویری در فرآیند طبقه بندی گنجانده شود، بسته به فرمول، تقسیم بر صفر می تواند رخ دهد. eo-learn با جایگزین کردن یک مقدار بدون داده به جای نتیجه اشتباه، این مشکل را حل می کند.
-
اگر برخی از پیکسلها در کل سری زمانی توسط ماسک SCL پوشانده شوند، ناشناخته باقی میمانند و چیزی برای درونیابی آنها وجود ندارد.
خط لوله پردازش هنوز مشکل مقادیر بدون داده را حل نکرده است. با این حال، انتساب چند متغیره scikit-learn مقادیر از دست رفته [ 82] می تواند برای منتسب کردن نتایج EstimatorParser استفاده شود. با این حال، برای کاهش کاهش کیفیت طبقهبندی، NanRemover EOTask سفارشی معرفی شد تا مقادیر بدون داده را از پیکسلهای نمونهبرداری شده از تصاویر Sentinel-2 و دادههای آموزشی حذف کند. هنگامی که مدل آموزش داده شد، پیش بینی آن باید با قالب داده در EOPatches تنظیم شود. Eo-learn’s PredictPatch فرآیند مشابه EstimatorParser را با تمام دادهها در هر EOPatch تکرار میکند. تابع پیش بینی برآوردگر برای بردارهای ویژگی مربوطه اعمال می شود. این پیش بینی های LULC سپس به یک آرایه سه بعدی تغییر شکل داده و در EOPatch ذخیره می شوند. بعداً می توان آنها را به عنوان GeoTIFF (EOTask ExportToTiff) صادر کرد. ارزیابی دقت در خط لوله اجرا نشده است، اما به صورت دستی در آزمایش استفاده از نمونه انجام شد.
3.3. نمایش خط لوله
منطقه ای از منطقه موراویای جنوبی در جمهوری چک برای بررسی این خط لوله به عنوان یک نمایش امکان سنجی اثبات مفهوم انتخاب شد. دادههای کاداستر مرجع باز، علاوه بر CLC و UA، در مقیاس 1:2000 از اداره ثبت شناسایی سرزمین، آدرسها و املاک و مستغلات بهدست آمد. داده های کاداستر حاوی اطلاعات کاربری زمین در اصل در ده طبقه است. با این حال، تنها هشت مورد از آنها استفاده شد. کلاس های تعیین شده سایر سطوح و میدان هاپ نه مطلوب بودند و نه در منطقه مورد مطالعه قابل اجرا بودند.
نقشه کاداستر ورودی با مقدار پیکسل شماره کلاس اطلاعات پوشش زمین و اندازه سلول 10 متر (مطابق با وضوح هندسی Sentinel-2) شطرنجی شد. از آنجایی که برخی از بستههای کاداستر هنوز به شکل دیجیتالی در منطقه مورد مطالعه نبودند (در نتیجه وجود نداشتند)، آنها بهعنوان بدون داده در شطرنجی بهدستآمده استفاده میشدند. 56 تصویر Sentinel-2 به 9 EOPatches مقیاس بندی شدند، ماسک مبتنی بر SCL بازیابی و به طور یکسان مقیاس بندی شد. عملیات پردازش، شرح داده شده در بخش 3.2.6 ، بخش 3.2.7 ، بخش 3.2.8 و بخش 3.2.9، سپس بر روی داده ها انجام شد. آستانه پوشش ابری برای فیلتر کردن تصویر اضافی تا 10% تنظیم شد تا از مناطق بزرگ با مقادیر بدون داده جلوگیری شود، هنگامی که ماسک به ویژگی های ادغام شده در درون یابی سوزانده شد. در زیر شکل 5 ، دوره درونیابی از 30 مارس تا 16 اکتبر 2019 تعیین شد که نشان دهنده یک بازه 200 روزه است. مرحله درونیابی روی 10 روز تنظیم شد (تقریباً دو بازدید مجدد از Sentinel)، که منجر به 21 بازه زمانی درونیابی شد.
در مجموع، 100000 پیکسل چند زمانی (بردار ویژگی) به طور تصادفی از EOPatches نمونه برداری شد که به نسبت 5:4 از وصله های آموزشی به وصله های آزمایشی تقسیم شدند. تعادل کلاس اطلاعات در کاداستر به عنوان معیار انتخاب EOPatches برای تقسیم قطار/آزمایش داده ها انتخاب شد. از آنجا که تعداد کلاس های اطلاعات کاداستر به طور طبیعی در تمام EOPatches سازگار بود، آنتروپی شانون (H) برای داده های نمونه محاسبه شد [ 83 ]. برای نتایج به جدول 2 ، که شاخصی از تنوع بین (کلاس های LULC در یک EOPatch منفرد) است، از صفر تا لگاریتم (با هر پایه) تعداد کلاس های ارزیابی شده را ببینید. همانطور که در رابطه (1) نشان داده شده است محاسبه شد.
اچ=∑q– 1q∗پمن∗ ورودپمن
که در آن q تعداد کلاس های اطلاعاتی است، i یک کلاس است، و p نسبت فرکانس کلاس و مجموع مقادیر کلاس پیکسل های نمونه برداری شده در یک EOPatch است.
در اثبات مفهوم انجام شده، دامنه مقادیر H از 0 تا log (8) بود، زیرا در این آزمایش هشت کلاس اطلاعاتی وجود داشت. از یک مقدار H بالا، می توان فرض کرد که کلاس ها متنوع بوده و بنابراین در یک EOPatch متعادل هستند. EOPatches برای آموزش و آزمایش به طور متناوب با کاهش H انتخاب شدند، که با انتخاب برای آموزش شروع شد. در پایان 500000 نمونه منحصر به فرد هم برای آموزش و هم برای تست وجود داشت.
سپس فضای ویژگی ویژگیهای نمونهبرداری شده به بردارهای ویژگی کاهش یافت و با شماره کلاس اطلاعات LULC مربوطه برای مجموعههای آموزشی و آزمایشی تخصیص یافت.
برآوردگر LightGBM [ 47 ] برای طبقه بندی انتخاب شد تا حداقل تا حدی در دسترس باشد تا نتایج را با مثال در کار Lubej [ 17 ، 18 ] و eo-learn [ 48 ، 49 ] مقایسه کند. برآوردگر LightGBM یک الگوریتم مؤثر بر اساس روش یادگیری ماشین درخت تصمیم تقویت گرادیان (GBDT) است که باید برای مجموعه دادههای آموزشی بزرگتر (که مطمئناً دادههای کاداستر بودند) استفاده شود. بحث و تنظیم پارامترهای مختلف برای بهترین نتایج طبقه بندی برای تحقیقات آینده باقی مانده است. بنابراین، همان پارامترهایی که در [ 17، 49 ] استفاده شد.
قبل از تنظیم برآوردگر LightGBM باید یک تجزیه و تحلیل انجام می شد. با این حال، بیش از صد پارامتر تنظیم شناسایی شد. مقدار کار مورد نیاز به طور قابل توجهی از امکانات این مطالعه امکان سنجی محدود فراتر می رفت. تنظیم تمام پارامترهای مورد نیاز بر این اساس از نظر کار آینده یک امکان باقی می ماند. بردارهای ویژگی برچسبگذاری شده آموزش و پیشبینی شدند، پیشبینی بر روی دادههای تست تولید شده از تکههای باقیمانده آزمایش شد و بهترین نتیجه انتخاب شد. ماتریس سردرگمی، یک ابزار ارزیابی دقت طبقهبندی که معمولاً استفاده میشود [ 84 ]، برای بررسی نتایج بهدست آمد.
4. نتایج
4.1. خط لوله پردازش، خروجی های تجربی و ادغام با OLU/OLC
خط لوله پردازش برای طبقهبندی LULC با استفاده از تصاویر Sentinel-2 به دو ماژول پایتون سفارشی (به مواد تکمیلی مراجعه کنید ) و یک نوت بوک Jupyter با پیادهسازی در آزمایش استفاده از نمونه (همچنین در مواد تکمیلی ) تقسیم میشود. هر فایل با نظرات توضیحی توضیح داده میشود و کلاسها و روشهای آنها حاوی رشتههایی برای درک معنای آنها هستند.
4.2. خروجی های تجربی
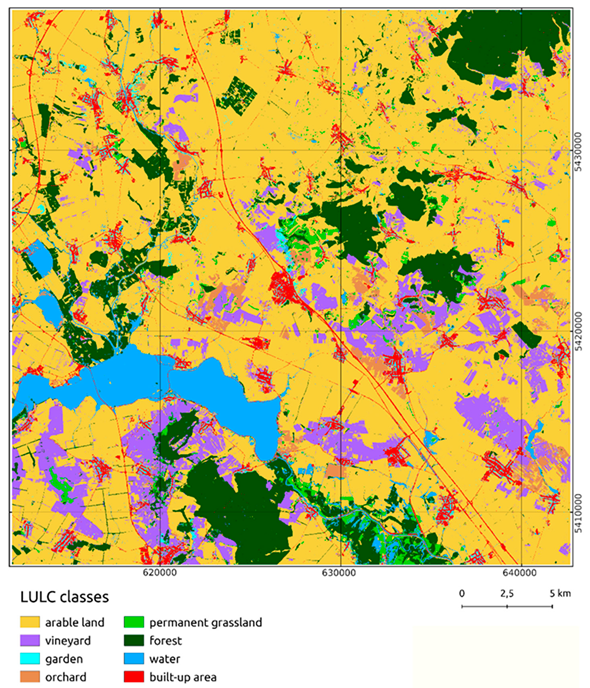
آزمایش استفاده، OA خوب 85.9٪ را نشان داد و یک نقشه طبقه بندی شده LULC از منطقه مورد مطالعه در بخش جنوبی منطقه موراویای جنوبی ( پیوست A ) به دست آورد.
ماتریس سردرگمی در جدول 3نشان می دهد که کلاس های LULC بسیار خوب و بسیار ضعیف پیش بینی شده وجود دارد (با توجه به دقت ارائه دهنده، به عنوان مثال، نسبت بین پیکسل های خوب پیش بینی شده و پیکسل های آزمایشی). بیشترین پیش بینی جنگل (91.5 درصد)، زمین زراعی (87.9 درصد) و آب (87.2 درصد) بود. از سوی دیگر، طبقه بندی در مراتع دائمی (45.2٪) که سطوح بسیار متنوعی هستند، بسیار ضعیف عمل کرد. آنها اغلب به اشتباه به عنوان زمین های قابل کشت و جنگل طبقه بندی می شدند. به همین ترتیب دقت پایینی در پیشبینی باغها مشاهده شد که به اشکال مختلف نیز ظاهر میشوند. مناطق ساخته شده نسبتاً خوب پیش بینی شده بودند (دقت 75%). آنها اغلب به اشتباه به عنوان زمین های زراعی، دارای رفتار طیفی مشابه پس از برداشت، و باغ ها، که در نزدیکی هستند، طبقه بندی می شدند. نتایج شگفت انگیزی در پیش بینی تاکستان ها با دقت 67.5 درصد به دست آمد. که می توان آن را به رفتار طیفی رایج اکثر نمونه های تاکستان نسبت داد. توضیح بیشتر در مورد فرآیند طبقه بندی در بخش بحث ارائه شده است.
در شکل 6 ، پیش بینی و داده های آموزشی کاداستر اصلی را می توان با هم مقایسه کرد. این پیشبینی مناطق و جنگلهای ساختهشده را ترجیح میدهد و آنها را کمی بر طبقات اطراف گسترش میدهد. برخی از مسیرها و جاده ها قطع شدند زیرا وضوح 10 متر برای تسهیل شناسایی پیکسل های پیوسته ویژگی های خطی کافی نبود. این پیشبینی همچنین تحتتاثیر اثر نمک و فلفل رایج قرار گرفت، که نویز داده ناشی از دستهبندی اشتباه پیکسلها در بدنه بزرگی از یک کلاس متفاوت است. این را می توان با تکنیک های مختلف حذف نویز حل کرد [ 84]؛ با این حال، این در این آزمایش به منظور مقایسه داده های خام انجام نشد. برخی از مکانها (به رنگ خاکستری نشان داده شدهاند) در دادههای کاداستر اصلی حاوی اطلاعات پوشش زمین نبودند. با توجه به اینکه داده های Sentinel-2 کل منطقه مورد مطالعه را در بر می گیرد، چنین مکان هایی به طور طبیعی پیش بینی می شدند. بنابراین می توان نتیجه گرفت که حتی در اطلاعات جامع کاداستر چک، برخی اطلاعات جدید ارائه شده است.
یک مقایسه تک نقشه در شکل 7 ارائه شده است ، که در آن دادههای کاداستر اصلی و پیشبینی LightGBM پاک شدند و نتیجه به یک شطرنجی باینری تغییر کلاس/بدون تغییر طبقهبندی شد. اگر جایگزینی بدون دادههای اصلی با مقادیر جدید در نظر گرفته نشود، طبقهبندی اشتباه LULC مربوط به علفزارهای دائمی بود که با نتایج کلی طبقهبندی مطابقت داشت. عدم تطابق طبقاتی در مکانهای پراکندهتر افزایش مییابد، بهویژه در مناطق ساختهشده، که اغلب از نظر فضایی با باغهای طبقهبندی ضعیف در هم تنیده شدهاند.
4.3. ادغام خط لوله به OLU/OLC
ادغام خط لوله پردازش و نتایج آن با OLU/OLC باید در چارچوبی با مدلهای داده OLU/OLC جدید (از دسامبر 2020 در دسترس عموم قرار نگیرد). این مدل برای رسیدگی به داده های کمک کننده جدا از داده های پردازش شده برای اطمینان از به روز رسانی روان و جلوگیری از مشکلات سازگاری طراحی شده است. نتایج حاصل از خطوط لوله پردازش در درجه اول در قالب شطرنجی هستند (GeoTiff در آزمایش استفاده). پیشنهاد می شود زمانی که مجموعه داده LULC در یک منطقه پیش بینی شد، EOPatches می تواند به عنوان پایه ای برای کاشی های نقشه استفاده شود. در خارج از نقشه OLU/OLC پردازش شده ذخیره می شوند، همچنان می توانند با پیش بینی های مکرر به روز شوند. با این وجود، کاشی ها باید بردار شوند و به فرآیند کامپایل OLU/OLC (به عنوان یک لایه LULC) ارسال شوند. اگر طبقه بندی پس از پردازش به طور کامل مورد بررسی قرار گیرد، هندسه های برداری شده می توانند اشیاء OLU/OLC را تشکیل دهند. ادغام خط لوله اثبات مفهوم توسعهیافته با OLU/OLC به عنوان مقاله بعدی با تأکید بر جنبههای مدلسازی دادهها آماده میشود.
5. بحث
جدول 4 مروری بر نتایج ارائه شده در این مقاله همراه با مقایسه با کار مرتبط ارائه می دهد.
نقاط منتخب با جزئیات بیشتر در بخش 5.1 و بخش 5.2 به عنوان بسط جدول 4 توضیح داده شده است.
5.1. چشم انداز خط لوله پردازش و اهمیت آن برای OLU/OLC
خط لوله پردازش یک راه حل باز اثبات مفهوم برای پالایش OLU/OLC است. اصل آن در پردازش تصاویر Sentinel-2 برای طبقه بندی نظارت شده مبتنی بر طیف نهفته است در حالی که داده های آموزشی می توانند آزادانه انتخاب شوند. خط لوله دادهها را برای برآوردگرهای یادگیری ماشینی با یادگیری اسکیتی آماده میکند. برخی از جنبه های طراحی از روش نقشه برداری LULC توسعه دهندگان کتابخانه eo-learn [ 17 ، 49 ]، که طبقه بندی پوشش زمین اسلوونی را بر اساس سیستم شناسایی قطعه زمین اسلوونی (LPIS) انجام دادند، اقتباس شدند و به OA خوبی دست یافتند. 91.2٪. خط لوله پردازش پیشنهادی از رویکرد آنها الهام گرفته شده است. با این حال، راه حل های سفارشی ارائه کرد ( جدول 4 را ببینیدبرای جزئیات).
منابع اصلی کمک کننده OLU/OLC در زمان نگارش این مقاله CLC و UA بودند. این مجموعه داده ها در کل گستره فضایی OLU/OLC تضمین شده بودند، به عنوان مثال، در مناطقی که اطلاعات دقیق LULC در دسترس نیست یا به طور کامل گم شده است. خط لوله پردازش زمینه را برای رهایی OLU/OLC از وابستگی به این مجموعه داده ها فراهم کرد. به ویژه سعی در افزایش وضوح فضایی، کاهش تناوب ایجاد مجموعه داده و ارائه اطلاعات LULC در مناطقی که دادههای CLC و UA وجود ندارند، بود.
لازم به ذکر است که خط لوله فرآوری هنوز به توانایی طبقه بندی کاربری اراضی به معنای واقعی کلمه دست نیافته است. اطلاعات کاربری زمین اغلب با استفاده از تکنیکهای طبقهبندی تصویر که اطلاعات زمینهای را در خود جای میدهد، به ویژه روشهای مبتنی بر شی [ 5 ، 90 ] بازیابی میشود. اینها باید بیشتر با توجه به خط لوله پردازش، ترجیحاً در هم افزایی با اطلاعات طیفی برای بهترین عملکرد مورد بررسی قرار گیرند [ 45 ]. ما و همکاران [ 3] با این وجود به این نتیجه رسید که روشهای مبتنی بر شی در سرزمینهای کوچک (با میانگین مساحت تنها 300 هکتار) انجام شدهاند، و کاربرد آنها در مناطق بزرگتر موضوعی برای تحقیقات آینده است. بسیاری از مطالعات مربوط به بازیابی اطلاعات کاربری زمین نیز به دنبال تصاویر تجاری با وضوح بسیار خوب هستند که نمی توانند آزادانه در OLU/OLC مورد استفاده قرار گیرند. واضح است که رویکرد پیکسل عاقلانه همراه با وضوح 10 تا 20 متر از تصاویر Sentinel-2، که در خط لوله استفاده می شود، برای بازیابی تغییرات معنایی ظریف کاربری های زمین (مانند رویکرد پالما [ 8 ]) بسیار درشت است. اتخاذ تکنیک های پیشرفته یک بهبود پیشنهادی در آینده برای خط لوله است.
یکی از بزرگترین مزایای خط لوله این است که می تواند به طور طبیعی تصاویر چند زمانی را مدیریت کند. اطلاعات زمانی یک ساختار حامل برای بردارهای ویژگی است که در این مقاله استفاده شده است. اعتبار سنجی طبقه بندی چند زمانی نیز می تواند مشکل ساز باشد زیرا داده های آموزشی یا آزمایشی (داده های حقیقت زمینی) ثابت می مانند در حالی که ویژگی های واقعی زمین می توانند در طول زمان تغییر کنند.
برای حفظ وضوح هندسی 10 متری نتیجه طبقه بندی نهایی، تنها از باندهای Sentinel-2 10 و 20 متری در خط لوله استفاده شد. این با رویکرد Lubej [ 18 ] مطابقت داشت، که به دقت طبقه بندی کلی بالایی حتی با باندهای کمتری که در این فرآیند استفاده می شد، دست یافت. تصمیم به ارتقای باندهای 20 متری به وضوح 10 متر گرفته شد، اگرچه تا حدی قابلیت اطمینان اطلاعات طیفی را کاهش داد. ژنگ و همکاران [ 4] به طور مشابه از درونیابی نزدیکترین همسایه برای ارزیابی اثرات افزایش مقیاس و کاهش مقیاس داده های Sentinel-2 استفاده کرد و ثابت کرد که دقت طبقه بندی هنگام افزایش باندهای 10 و 20 متر کاهش می یابد. با کمال تعجب، کاهش مقیاس نزدیکترین همسایه برای اهداف طبقهبندی LULC سودمندترین بود. بنابراین، برای توسعه آینده خط لوله، کاهش مقیاس باید برای دقت طبقه بندی بهتر اعمال شود، زیرا وضوح هندسی 20×20 متر هنوز از MMU CLC به طور کلی و MMU UA در مناطق روستایی بهتر است.
به لطف Sentinelsat API [ 72 ]، خط لوله دسترسی پیوسته به مرکز دسترسی باز کوپرنیک [ 73 ] و بنابراین، به سری تماموقت تصاویر Sentinel دارد. پردازش خودکار آنها چندین کار مانند دانلود و بازکردن تصاویر، مدیریت فرمت فایل، نمونهبرداری مجدد تصویر، زیرمجموعهسازی و پوشاندن را از اپراتور برون سپاری میکند، که سپس میتواند زمان بیشتری را به خود فرآیند طبقهبندی اختصاص دهد.
ویژگی خط لوله امکان پیشبینی LULC را در یک منطقه وسیع مورد علاقه فراهم میکند و در عین حال از نیازهای محاسباتی بالا به لطف مفهوم EOPatches جلوگیری میکند. این یک کلید برای گسترش سریع اطلاعات OLU/OLC LULC به مناطق خارج از محدوده CLC یا UA است. برای طبقهبندی LULC انبوه، بسیار مهم است که خط لوله بتواند به طور خودکار تصاویر را در آینده موزاییک کند و دوباره طرح کند. ادغام ویژگیهای چند تصویری در خط لوله هنوز یک راهحل اساسی است، بنابراین نمیتوان همه این ویژگیها را بهدست آورد (به عنوان مثال، تشدید پانل یا تجزیه و تحلیل اجزای اصلی تصویر). از سوی دیگر، حتی پوشش گیاهی ساده و سایر شاخص های طیفی به طور قابل اعتمادی برای تشخیص تغییر استفاده شده اند (به عنوان مثال، [ 24 ]])، که یکی دیگر از جهت گیری های بالقوه توسعه OLU/OLC است که به ویژه توسط سازمان چتر Plan4All تاکید شده است. در نسخه فعلی، eo-learn بیشتر شامل EOTasks برای محاسبه ماتریس هموقوع سطح خاکستری (GLCM) و استخراج متغیرهای بافتی مختلف است که میتواند بیشتر به ویژگیهای آموزشی در خط لوله اضافه شود. بر اساس بررسی خاتمی، مونترکیس و استهمن [ 9 ] (2016)، اطلاعات بافتی مؤثرترین ویژگی بهبود دقت برای طبقهبندی مبتنی بر طیف (بهبود OA به طور متوسط 12.1٪) بوده است.
5.2. بحث آزمایشی انجام شد
آزمایش استفاده از نمونه باید در درجه اول استفاده از خط لوله پردازش را بدون توجه اولیه به تنظیم پارامترهای طبقه بندی نشان دهد. برآوردگر LightGBM، با استفاده از سری زمانی 200 روزه تصاویر Sentinel-2 و اطلاعات LULC از کاداستر چک، OA 85.9٪ را ارائه کرد. برخی از کلاسهای LULC، مانند علفزارهای دائمی و باغها، با این وجود، طبقهبندی ضعیفی داشتند. مقایسه ای باید با کار Lubej [ 17 ، 18 ] و eo-Learn [ 48 ، 49 ] انجام شود.]، که خط لوله برخی از جنبه های طراحی خود را از آن اقتباس کرده است. آنها در نمونه نمایشگاه eo-learn خود، پوشش زمین را بر اساس LPIS اسلوونی طبقه بندی کردند. آنها سه طبقه دیگر داشتند (برف، تندرا، و بوته زار)، اما طبقه بندی مشابه آزمایش ارائه شده در این مقاله بود. با یک برآوردگر به همان اندازه تنظیم شده، آنها به OA بسیار بهتر (91.2٪) دست یافتند. با این وجود، آنها به دادههای از پیش پردازششده پلتفرم Sentinel Hub با الگوریتم پوشاندن ابری مبتنی بر یادگیری ماشین دسترسی داشتند و «دانش توسعهدهنده» کتابخانه eo-learn را داشتند.
استفاده از خط لوله پیشنهادی هنگام استقرار در OLU/OLC با چندین چالش مواجه شد. هشت کلاس اطلاعاتی برای تکمیل طبقه بندی خوب HILUCS کافی نیست. تعداد و شناسایی کلاسهای اطلاعاتی از مجموعه دادههای زیربنایی مورد استفاده، عمدتاً ساختار کاداستر چک، ناشی میشود. برای استفاده از خط لوله در مناطق دیگر، مدل باید دوباره در منظره معمولی آن مناطق آموزش داده شود و احتمالاً باید از یک مجموعه داده آموزشی سفارشی استفاده شود. همانطور که توسط نگوین و همکاران پیشنهاد شده است. [ 30]، به دلیل پیچیدگی محیط بیوفیزیکی (ابرها و مه) ممکن است برای مناطق گرمسیری تمدید فریم های زمانی با ویژگی های ادغام شده برای فیلتر ابری مورد نیاز باشد. از نظر تحقیقات آینده، با این وجود، بررسی نحوه رفتار پیشبینیهای LULC در صورت آموزش سایر مجموعههای داده بینالمللی، ملی یا منطقهای جالب است. این می تواند به ارزیابی مبادله برای تلاش کمتر برای جمع آوری داده های آموزشی کمک کند.
6. نتیجه گیری
نتیجه اصلی تحقیق توصیف شده در این مقاله، یک خط لوله پردازش مبتنی بر یادگیری ماشین اثبات مفهوم باز برای جمعآوری خودکار تصاویر Sentinel-2، فیلتر ابری، طبقهبندیهای LULC و بهروزرسانی OLU/OLC است. خط لوله در محیط پایتون، به ویژه با استفاده از کتابخانه eo-learn و برخی دیگر از کتابخانه های پایتون توسعه یافته است. میتواند تصاویر چندزمانی Sentinel-2 را به شکلی پردازش کند که میتواند به تخمینگرهای مختلف یادگیری scikit ارسال شود.
در مقایسه با مجموعه دادههای پسزمینه OLU/OLC فعلی، آخرین طراحی آن، همانطور که در آزمایش انجام شده دنبال میشود، نتایج دقیقتری را از لحاظ مکانی ارائه میکند که میتوانند در زمان واقعی بازیابی شوند. این امکان را برای OLU/OLC باز میکند تا دادههای LULC خود را اصلاح کند و وابستگی به مجموعه دادههای ورودی فرضی اولیه (مانند CORINE Land Cover و Urban Atlas) را کاهش دهد. اگرچه به صورت تجربی با یک نتیجه منصفانه (OA 85.9٪) آزمایش شده است، نتایج طبقه بندی هنوز ایده آل نیستند و تحقیقات بیشتری برای ارائه داده های قابل اعتماد مشابه کاربری زمین با دقت بالاتر و تعدادی کلاس اطلاعات باید انجام شود. در طی این فرآیند، وظایف مهندسی نرم افزار ابزار مهمی برای درک OLU/OLC به عنوان یک سیستم و انتخاب تصمیمات طراحی برای خط لوله پردازش بود.
علیرغم پیشرفت بهدستآمده در آزمایشهای انجامشده، کار بیشتری برای اصلاح اطلاعات ذاتی OLU/OLC LULC، بهویژه با بهبود فرآیند طبقهبندی، مورد نیاز است. به طور مشابه، احتمالات تأیید اطلاعات LULC در OLU/OLC باید بیشتر مورد بررسی قرار گیرد. همچنین باید توجه ویژه ای به شفاف سازی مدل مجوز OLU/OLC و تحلیل پیامدهای منفی ترکیب LULC های مختلف و سایر داده ها، اغلب از نظر معنایی متفاوت، شود.
مواد تکمیلی
موارد زیر به صورت آنلاین در https://www.mdpi.com/2220-9964/10/2/102/s1 موجود است : شکل S1: یک نمونه EOPatch شی با برخی از FeatureType های آن (مانند داده و ماسک) و موارد مورد نیاز مقدار بعد از کولون (یعنی دیکشنری های پایتون با آرایه های چند بعدی NumPy) [ 91 ، 92]. شکل S2: یک EOTask نمونه که یک ویژگی چند تصویری، مانند شاخص های تفاوت نرمال شده را محاسبه می کند. اجزای آن در نظرات پایتون توضیح داده شده است. شکل S3: یک نمونه EOWorkflow و EOExecutor که برای خط لوله EOTasks استفاده می شود. کامپوننت ها در نظرات پایتون توضیح داده شده اند. شکل S4: کد منبع ماژول aoi.py. شکل S5: کد منبع pipeline.py. شکل S6: نوت بوک Jupyter با پیاده سازی اعمال شده در آزمایش استفاده مثال.
مشارکت های نویسنده
مفهوم سازی، توماش Řezník و Jan Chytrý; روش شناسی، یان چیتری; اعتبارسنجی، Kateřina Trojanová; تحقیق، یان چیتری; مدیریت داده ها Jan Chytrý; نوشتن – آماده سازی پیش نویس اصلی، Tomáš Řezník; نوشتن-بررسی و ویرایش، توماش Řezník و Kateřina Trojanová. تجسم، Kateřina Trojanová; نظارت، Tomáš Řezník; تامین مالی، Tomáš Řezník. همه نویسندگان نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
منابع مالی
این مقاله بخشی از پروژه ای است که از برنامه تحقیقاتی و نوآوری افق 2020 اتحادیه اروپا تحت توافقنامه کمک مالی شماره 818346 با عنوان “رصدخانه خاک چین و اتحادیه اروپا برای مدیریت هوشمند کاربری زمین” (SIEUSOIL) دریافت کرده است. Jan Chytrý و Kateřina Trojanová نیز تحت موافقتنامه کمک مالی شماره MUNI/A/1356/2019 با عنوان “تحقیق پیچیده محیط جغرافیایی سیاره زمین” از سوی دانشگاه ماساریک حمایت شدند.
بیانیه در دسترس بودن داده ها
تمام داده های مربوط به مطالعه انجام شده در https://gitlab.com/chytryj/reznik-et-al-processing-pipeline-annex-repository به صورت عمومی در دسترس هستند .
تضاد علاقه
نویسندگان هیچ تضاد منافع را اعلام نمی کنند.
ضمیمه A. پیش بینی کاربری و پوشش زمین در بخش جنوبی منطقه جنوب موراویا، جمهوری چک، 2019
پیشبینی با برآوردگر LightGBM با استفاده از تصاویر چند زمانی Sentinel-2 (از 30.3.2019 تا 16.10. 2019 و دادههای آموزشی کاداستر چک (از نوامبر 2019) – به دقت کلی 85.9 درصد دست یافت.
منابع
- فیشر، پی اف. کامبر، ا. Wadsworth، R. استفاده از زمین و پوشش زمین: تضاد یا مکمل. در ارائه مجدد GIS ; جان وایلی: چیچستر، NH، ایالات متحده آمریکا، 2005; صص 85-98. [ Google Scholar ]
- کاستلوچیو، ام. پوگی، جی. سانسون، سی. وردولیوا، ال. طبقه بندی کاربری زمین در تصاویر سنجش از دور توسط شبکه های عصبی کانولوشن. ArXiv Comput. علمی 2015 ، 1-11. در دسترس آنلاین: https://arxiv.org/abs/1508.00092 (در 2 دسامبر 2020 قابل دسترسی است).
- ما، ال. لی، ام. ما، X. چنگ، ال. دو، پ. Liu, Y. مروری بر طبقهبندی تصویر پوشش زمین مبتنی بر شیء نظارت شده. ISPRS J. Photogramm. Remote Sens. 2017 , 130 , 277–293. [ Google Scholar ] [ CrossRef ]
- ژنگ، اچ. دو، پ. چن، جی. شیا، جی. دروغ.؛ خو، ز. لی، ایکس. Yokoya, N. ارزیابی عملکرد تصویرسازی Sentinel-2 Downscaling برای استفاده از زمین و طبقهبندی پوشش زمین بر اساس ویژگیهای طیفی- فضایی. Remote Sens. 2017 , 9 , 1274. [ Google Scholar ] [ CrossRef ]
- روزینا، ک. باتیستا و سیلوا، اف. ویزکاینو، پی. مارین هررا، ام. فریره، اس. Schiavina، M. افزایش جزئیات استفاده از زمین / داده های پوشش اروپا با ترکیب مجموعه داده های ناهمگن. بین المللی جی دیجیت. زمین 2020 ، 13 ، 602–626. [ Google Scholar ] [ CrossRef ]
- Čerba, O. Ontologie Jako Nástroj pro Návrhy Datových Modelů Vybraných Témat Příloh Směrnice INSPIRE. Ph.D. پایان نامه، دانشگاه چارلز، پراگ، جمهوری چک، 2012. موجود به صورت آنلاین: https://hdl.handle.net/20.500.11956/47841 (دسترسی در 2 دسامبر 2020).
- فیدن، ک. Kruse، F. Řezník، T. کوبیچک، پ. شنتس، اچ. ابرهارت، ای. Baritz, R. بهترین روش شبکه GS SOIL ارتقای دسترسی به اطلاعات خاک اروپایی، سازگار و سازگار با INSPIRE. در سیستم های نرم افزاری محیطی. چارچوب های محیط الکترونیکی ; پیشرفت های IFIP در فناوری اطلاعات و ارتباطات؛ Springer: برلین/هایدلبرگ، آلمان، 2011; ص 226-234. شابک 978-3-642-22284-9. [ Google Scholar ] [ CrossRef ]
- پالما، آر. رزنیک، تی. اسبری، م. چاروات، ک. Mazurek, C. یک واژگان مبتنی بر الهام برای انتشار داده های مرتبط کشاورزی. در مهندسی هستی شناسی ; نکات سخنرانی در علوم کامپیوتر; انتشارات بین المللی اسپرینگر: چم، سوئیس، 2016; صص 124-133. شابک 978-3-319-33244-4. در دسترس به صورت آنلاین: https://doi-org-443.webvpn.fjmu.edu.cn/10.1007/978-3-319-33245-1_13 (در 2 دسامبر 2020 قابل دسترسی است).
- خاتمی، ر. مونتراکیس، جی. Stehman، SV یک متاآنالیز از تحقیقات سنجش از دور بر روی فرآیندهای طبقهبندی تصویر پوشش زمین مبتنی بر پیکسل نظارت شده: دستورالعملهای کلی برای پزشکان و تحقیقات آینده. سنسور از راه دور محیط. 2016 ، 177 ، 89-100. [ Google Scholar ] [ CrossRef ]
- مشخصات دادههای INSPIRE در مورد پوشش زمین – دستورالعملهای فنی. در دسترس آنلاین: https://inspire.ec.europa.eu/id/document/tg/lc (در 2 دسامبر 2020 قابل دسترسی است).
- آژانس محیط زیست اروپا پوشش زمین CORINE. در دسترس آنلاین: https://land.copernicus.eu/pan-european/corine-land-cover (در 2 دسامبر 2020 قابل دسترسی است).
- برنامه کوپرنیک اطلس شهری در دسترس آنلاین: https://land.copernicus.eu/local/urban-atlas (در 2 دسامبر 2020 قابل دسترسی است).
- INSPIRE پوشش زمین و مشخصات داده های کاربری زمین. در دسترس آنلاین: https://eurogeographics.org/wp-content/uploads/2018/04/2.-INSPIRE-Specification_Lena_0.pdf (در 2 دسامبر 2020 قابل دسترسی است).
- OSM. زمین کاربری. در دسترس آنلاین: https://osmlanduse.org/#12/8.7/49.4/0/ (در 2 دسامبر 2020 قابل دسترسی است).
- USGS. بررسی اجمالی داده های پوشش زمین. در دسترس آنلاین: https://www.usgs.gov/core-science-systems/science-analytics-and-synthesis/gap/science/land-cover-data-overview?qt-science_center_objects=0#qt-science_center_objects (دسترسی در 2 دسامبر 2020).
- فائو اشتراک جهانی پوشش زمین (GLC-SHARE). در دسترس آنلاین: https://www.fao.org/uploads/media/glc-share-doc.pdf (در 2 دسامبر 2020 قابل دسترسی است).
- Lubej, M. طبقه بندی پوشش زمین با Eo-Learn: قسمت 1، متوسط. در دسترس آنلاین: https://medium.com/sentinel-hub/land-cover-classification-with-eo-learn-part-1-2471e8098195 (در تاریخ 2 دسامبر 2020 قابل دسترسی است).
- Lubej, M. طبقه بندی پوشش زمین با Eo-Learn: قسمت 2، متوسط. در دسترس آنلاین: https://medium.com/sentinel-hub/land-cover-classification-with-eo-learn-part-2-bd9aa86f8500 (در 2 دسامبر 2020 قابل دسترسی است).
- سیبندا، م. موتانگا، او. Rouget، M. بررسی پتانسیل وضوح طیفی Sentinel-2 MSI در تعیین کمیت زیست توده بالای زمین در تیمارهای مختلف کود. ISPRS J. Photogramm. Remote Sens. 2015 ، 110 ، 55-65. [ Google Scholar ] [ CrossRef ]
- پسری، م. کوربن، سی. جولیا، ا. فلورچیک، آ. سیریس، وی. Soille, P. Assessment of Added-Value Sentinel-2 for Detecting Built-up Areas. Remote Sens. 2016 , 8 , 299. [ Google Scholar ] [ CrossRef ]
- کورهونن، ال. هادی؛ پاکالن، پی. Rautiainen، M. مقایسه Sentinel-2 و Landsat 8 در برآورد پوشش تاج پوشش جنگلی و شاخص سطح برگ. سنسور از راه دور محیط. 2017 ، 195 ، 259-274. [ Google Scholar ] [ CrossRef ]
- وولو، اف. نوویرث، ام. ایمیتزر، ام. آتزبرگر، سی. Ng، W.-T. داده های چند زمانی Sentinel-2 چقدر طبقه بندی نوع محصول را بهبود می بخشد؟ بین المللی J. Appl. Obs زمین. Geoinf. 2018 ، 72 ، 122-130. [ Google Scholar ] [ CrossRef ]
- کابالرو، آی. رویز، جی. ماهوارههای ناوارو، G. Sentinel-2 ارزیابی زمان واقعی سیلهای فاجعهبار در غرب مدیترانه را ارائه میکنند. Water 2019 , 11 , 2499. [ Google Scholar ] [ CrossRef ]
- کوک، جی. Chormański، J. Sentinel-2 تصاویر برای نقشه برداری و نظارت بر نفوذ ناپذیری در مناطق شهری. ISPRS Int. قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2019 ، XLII-1/W2 ، 43–47. [ Google Scholar ] [ CrossRef ]
- Řezník، T. پاولکا، تی. هرمان، ال. لوکاس، وی. شیروچک، پ. لایتگب، ش. لایتنر، F. پیشبینی مناطق بهرهوری از Landsat 8 و Sentinel-2A/B و ارزیابی آنها با استفاده از اندازهگیریهای ماشینهای کشاورزی. Remote Sens. 2020 ، 12 ، 1917. [ Google Scholar ] [ CrossRef ]
- بروزون، ال. بوولو، اف. پاریس، سی. Solano-Correa، YT; زانتی، م. فرناندز-پریتو، دی. تجزیه و تحلیل تصاویر چند زمانی Sentinel-2 در چارچوب بهره برداری علمی ESA از ماموریت های عملیاتی. در مجموعه مقالات نهمین کارگاه بین المللی 2017 در مورد تجزیه و تحلیل تصاویر سنجش از دور چند زمانی (MultiTemp)، بروژ، بلژیک، 27-29 ژوئن 2017؛ IEEE: نیویورک، نیویورک، ایالات متحده آمریکا، 2017؛ ص 1-4. [ Google Scholar ] [ CrossRef ]
- فیری، دی. سیمواندا، م. سالکین، اس. Nyirenda، VR؛ مورایاما، ی. دادههای Ranagalage، M. Sentinel-2 برای نقشهبرداری پوشش زمین/استفاده: بررسی. Remote Sens. 2020 , 12 , 2291. [ Google Scholar ] [ CrossRef ]
- کاور، م. دوزگون، اچ اس. کمک، اس. Demirkan، DC طبقه بندی کاربری و پوشش زمین نگهبان 2-a: مطالعه موردی سنت پترزبورگ. ISPRS Int. قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2019 ، XLII-1/W2 ، 13–16. [ Google Scholar ] [ CrossRef ]
- ویگاند، ام. استاب، ج. ورم، م. Taubenböck، H. اثرات فضایی و معنایی نمونههای LUCAS بر طبقهبندی کاربری زمین/پوشش زمین کاملاً خودکار در دادههای Sentinel-2 با وضوح بالا. بین المللی J. Appl. Obs زمین. Geoinf. 2020 ، 88 . [ Google Scholar ] [ CrossRef ]
- نگوین، HTT؛ Doan، TM; تومپو، ای. McRoberts، RE استفاده از زمین/نقشهبرداری پوشش زمین با استفاده از تصاویر چندزمانی Sentinel-2 و چهار روش طبقهبندی-مطالعه موردی از Dak Nong، ویتنام. Remote Sens. 2020 , 12 , 1367. [ Google Scholar ] [ CrossRef ]
- ینکو، دی. اینتردوناتو، آر. گائتانو، آر. هو تانگ مین، دی. ترکیب سری زمانی تصاویر ماهواره ای Sentinel-1 و Sentinel-2 برای نقشه برداری پوشش زمین از طریق معماری یادگیری عمیق چند منبعی. ISPRS J. Photogramm. Remote Sens. 2019 ، 158 ، 11–22. [ Google Scholar ] [ CrossRef ]
- رومورا، ال. میلر، م. Medak، D. تأثیر اصلاحات جوی مختلف بر دقت طبقهبندی پوشش زمین Sentinel-2 با استفاده از طبقهبندیکنندههای یادگیری ماشین. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 277. [ Google Scholar ] [ CrossRef ]
- جین، م. دوا، د. مهتا، ر. دیمری، AP; Pandit، MK مانیتورینگ تغییر کاربری زمین و محرکهای آن در دهلی، هند با استفاده از دادههای ماهوارهای چند زمانی. سیستم زمین مدلسازی محیط زیست 2016 ، 2 . [ Google Scholar ] [ CrossRef ]
- تالوکدار، س. سینگا، پی. ماهاتو، س. شهفهد; پال، اس. لیو، Y.-A. رحمان، الف. طبقهبندی پوشش زمین کاربری زمین توسط طبقهبندیکنندههای یادگیری ماشین برای مشاهدات ماهوارهای – مروری. Remote Sens. 2020 , 12 , 1135. [ Google Scholar ] [ CrossRef ]
- لیو، سی.-سی. ژانگ، Y.-C. چن، P.-Y. لای، سی.-سی. چن، Y.-H.; چنگ، J.-H. کو، M.-H. طبقهبندی ابرها از تصاویر Sentinel-2 با یادگیری عمیق باقیمانده و تقسیمبندی تصویر معنایی. Remote Sens. 2019 , 11 , 119. [ Google Scholar ] [ CrossRef ]
- هاگول، او. هاک، ام. ویلا پاسکال، دی. Dedieu، G. یک روش چند زمانی و چند طیفی برای تخمین ضخامت نوری آئروسل بر روی زمین، برای تصحیح جوی تصاویر FormoSat-2، LandSat، VENμS و Sentinel-2. Remote Sens. 2015 ، 7 ، 2668–2691. [ Google Scholar ] [ CrossRef ]
- هالشتاین، ا. سگل، ک. گوانتر، ال. برل، ام. Enesco، M. روشهای آماده برای تشخیص ابر، سیروس، برف، سایه، آب و پیکسلهای آسمان صاف در تصاویر Sentinel-2 MSI. Remote Sens. 2016 , 8 , 666. [ Google Scholar ] [ CrossRef ]
- زو، ز. Woodcock، CE مبتنی بر اشیاء ابر و تشخیص سایه ابر در تصاویر Landsat. سنسور از راه دور محیط. 2012 ، 118 ، 83-94. [ Google Scholar ] [ CrossRef ]
- کیو، اس. زو، ز. او، B. Fmask 4.0: تشخیص سایه ابری و ابری بهبود یافته در تصاویر Landsats 4-8 و Sentinel-2. سنسور از راه دور محیط. 2019 , 231 . [ Google Scholar ] [ CrossRef ]
- زو، ز. وانگ، اس. Woodcock، CE بهبود و گسترش الگوریتم Fmask: تشخیص ابر، سایه ابر و برف برای تصاویر Landsats 4-7، 8 و Sentinel 2. سنسور از راه دور محیط. 2015 ، 159 ، 269-277. [ Google Scholar ] [ CrossRef ]
- سیل، ن. Gillingham, S. PythonFmask Documentation, Release 0.5.4. در دسترس آنلاین: https://www.pythonfmask.org/en/latest/#python-developer-documentation (در 2 دسامبر 2020 قابل دسترسی است).
- مین-نورن، ام. Pflug، B. لوئیس، جی. دباکر، وی. مولر-ویلم، U. گاسکون، اف. بروزون، ال. بوولو، اف. بندیکتسون، JA Sen2Cor برای Sentinel-2. در مجموعه مقالات پردازش تصویر و سیگنال برای سنجش از دور XXIII، ورشو، لهستان، 11–13 سپتامبر 2017. SPIE: واشنگتن، دی سی، ایالات متحده آمریکا، 2017; پ. 3. [ Google Scholar ] [ CrossRef ]
- بائتنز، ال. دژاردین، سی. اعتبار سنجی ماسک های ابری Copernicus Sentinel-2 از پردازنده های MAJA، Sen2Cor و FMask با استفاده از ماسک های ابر مرجع تولید شده با یک روش یادگیری فعال نظارت شده، Hagolle، O. Remote Sens. 2019 , 11 , 433. [ Google Scholar ] [ CrossRef ]
- مرکز ملی d’Études Spatiales. ماجا. در دسترس آنلاین: https://logiciels.cnes.fr/en/content/MAJA (در 2 دسامبر 2020 قابل دسترسی است).
- ژائو، بی. ژونگ، ی. Zhang, L. طبقهبندیکننده صحنه طیفی-ساختاری کیسهای از ویژگیها برای تصاویر سنجش از دور با وضوح فضایی بسیار بالا. ISPRS J. Photogramm. Remote Sens. 2016 ، 116 ، 73-85. [ Google Scholar ] [ CrossRef ]
- عملکرد پوشش زمین و طبقه بندی کاربری اراضی عبدی، AM الگوریتم های یادگیری ماشین در یک چشم انداز شمالی با استفاده از داده های Sentinel-2. GIScience Remote Sens. 2020 ، 57 ، 1-20. [ Google Scholar ] [ CrossRef ]
- بشکه.؛ منگ، کیو. فینلی، تی. وانگ، تی. چن، دبلیو. ما، دبلیو. بله، س. لیو، تی.-ای. LightGBM: درخت تصمیم برای تقویت گرادیان بسیار کارآمد. در پیشرفت در سیستم های پردازش اطلاعات عصبی ; Guyon, I., Luxburg, UV, Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds. 2017; صص 3146-3154. در دسترس آنلاین: https://arxiv.org/pdf/1810.10380.pdf (دسترسی در 2 دسامبر 2020).
- EO-LEARN. 0.4.1 مستندات. در دسترس آنلاین: https://eo-learn.readthedocs.io/en/latest/index.html# (در 2 دسامبر 2020 قابل دسترسی است).
- EO-LEARN. 0.7.4 مستندات. در دسترس آنلاین: https://eo-learn.readthedocs.io/en/latest/index.html (در 2 دسامبر 2020 قابل دسترسی است).
- OLU. کاربری زمین باز در دسترس آنلاین: https://sdi4apps.eu/open_land_use/ (در 2 دسامبر 2020 قابل دسترسی است).
- میلدورف، تی. جذب اطلاعات جغرافیایی باز از طریق خدمات نوآورانه بر اساس داده های مرتبط . گزارش نهایی؛ دانشگاه بوهمای غربی: پیلسن، جمهوری چک، 2017; 30p، در دسترس آنلاین: https://sdi4apps.eu/wp-content/uploads/2017/06/final_report_07.pdf (در 2 دسامبر 2020 قابل دسترسی است).
- کوژوچ، دی. Charvát، K. میلدورف، تی. نقشه کاربری زمین باز. در دسترس آنلاین: https://eurogeographics.org/wp-content/uploads/2018/04/5.Open_Land_Use_bruxelles.pdf (دسترسی در 2 دسامبر 2020).
- کوژوچ، دی. چربا، او. Charvát، K. Bērziņš، R.; Charvát, K., Jr. باز کردن نقشه کاربری زمین. 2015. در دسترس آنلاین: https://sdi4apps.eu/open_land_use/ (در 2 دسامبر 2020 قابل دسترسی است).
- OGC. مشخصات پیاده سازی سرور نقشه وب OpenGIS ; کنسرسیوم فضایی باز: Wayland، MA، USA. 85p، در دسترس آنلاین: https://www.ogc.org/standards/wms (در 2 دسامبر 2020 قابل دسترسی است).
- OGC. OpenGIS Web Feature Service 2.0 Interface Standard ; کنسرسیوم فضایی باز: Wayland، MA، USA. 253p، در دسترس آنلاین: https://www.ogc.org/standards/wfs (در 2 دسامبر 2020 قابل دسترسی است).
- دایکسترا، ال. پولمن، اچ. Veneri, P. تعریف اتحادیه اروپا-OECD از یک منطقه شهری کاربردی. در اسناد کاری توسعه منطقه ای OECD 2019 ؛ انتشارات OECD: پاریس، فرانسه، 2019؛ صص 1-19. ISSN 20737009. [ Google Scholar ] [ CrossRef ]
- کمیسیون اروپایی. کوپرنیک – چشمان اروپا روی زمین ; کمیسیون اروپا: بروکسل، بلژیک؛ در دسترس آنلاین: https://www.copernicus.eu/en (در 2 دسامبر 2020 قابل دسترسی است).
- کوزترا، بی. بوتنر، جی. سوکوپ، تی. سوزا، ا. رهنمودهای فنی Langanke، T. CLC2018. آژانس محیط زیست اروپا 2017 ; آژانس محیط زیست: وین، اتریش، 2017; 61p، در دسترس آنلاین: https://land.copernicus.eu/user-corner/technical-library/clc2018technicalguidelines_final.pdf (دسترسی در 2 دسامبر 2020).
- RÚIAN. رجیستری شناسایی قلمرو، نشانی ها و املاک. در دسترس آنلاین: https://geoportal.cuzk.cz/mGeoportal/?c=dSady_RUIAN_A.EN&f=paticka.EN&lng=EN (دسترسی در 2 دسامبر 2020).
- آژانس فضایی اروپا راهنمای کاربر – Sentinel-2. در دسترس آنلاین: https://sentinel.esa.int/web/sentinel/user-guides/sentinel-2-msi (در 2 دسامبر 2020 قابل دسترسی است).
- آژانس فضایی اروپا راهنمای کاربر Sentinel-2 ; ESA: پاریس، فرانسه؛ 64p، در دسترس آنلاین: https://sentinels.copernicus.eu/documents/247904/685211/Sentinel-2_User_Handbook (در 2 دسامبر 2020 قابل دسترسی است).
- سازمان زمین شناسی آمریکا آرشیو USGS EROS-Sentinel-2-مقایسه Sentinel-2 و Landsat. در دسترس آنلاین: https://www.usgs.gov/centers/eros/science/usgs-eros-archive-sentinel-2-comparison-sentinel2-and-landsat?qt-science_center_objects=0#qt-science_center_objects (دسترسی در 2 دسامبر 2020).
- کوسول، ن. لاورنیوک، ام. اسکاکون، س. Shelestov, A. طبقه بندی یادگیری عمیق پوشش زمین و انواع محصول با استفاده از داده های سنجش از دور. IEEE Geosci. سنسور از راه دور Lett. 2017 ، 14 ، 778-782. [ Google Scholar ] [ CrossRef ]
- وربورگ، پی اچ. نویمان، ک. Nol، L. چالش ها در استفاده از داده های کاربری و پوشش زمین برای مطالعات تغییر جهانی. گلوب. چانگ. Biol. 2011 ، 17 ، 974-989. [ Google Scholar ] [ CrossRef ]
- پدرگوسا، اف. واروکو، جی. گرامفورت، آ. میشل، وی. تیریون، بی. گریزل، او. بلوندل، م. پرتنهوفر، پی. ویس، آر. دوبورگ، وی. و همکاران Scikit-Learn: یادگیری ماشین در پایتون. جی. ماخ. فرا گرفتن. Res. 2011 ، 12 ، 2826-2830. در دسترس آنلاین: https://jmlr.org/papers/v12/pedregosa11a.html (در 2 دسامبر 2020 قابل دسترسی است).
- توسعه دهندگان SCIKIT-LEARN. مقدمه ای بر یادگیری ماشین با Scikitlearn—Scikit-Learn 0.23.1 Documentation. در دسترس آنلاین: https://scikit-learn.org/stable/tutorial/basic/tutorial.html (در 2 دسامبر 2020 قابل دسترسی است).
- SINERGISE. اسناد Sentinel Hub 3.0.2. در دسترس آنلاین: https://sentinelhubpy.readthedocs.io/en/latest/areas.html (در 2 دسامبر 2020 قابل دسترسی است).
- SINERGISE. مرکز نگهبان. در دسترس آنلاین: https://www.sentinel-hub.com/ (در 2 دسامبر 2020 قابل دسترسی است).
- Gillies, S. Shapely 1.8dev Documentation. در دسترس آنلاین: https://shapely.readthedocs.io/en/latest/manual.html#polygons (در 2 دسامبر 2020 قابل دسترسی است).
- توسعه دهندگان Geopandas. مستندات GeoPandas 0.7.0. در دسترس آنلاین: https://geopandas.org/ (در 2 دسامبر 2020 قابل دسترسی است).
- OGC Web Coverage Service (WCS) 2.1 استاندارد رابط ; کنسرسیوم فضایی باز: Wayland، MA، USA. 16p، در دسترس آنلاین: https://www.ogc.org/standards/wcs (در 2 دسامبر 2020 قابل دسترسی است).
- ویل، ام. Clauss, K. Sentinelsat 0.13 Documentation. در دسترس آنلاین: https://sentinelsat.readthedocs.io/en/stable/api.html (در 2 دسامبر 2020 قابل دسترسی است).
- ESA هاب دسترسی را باز کنید. در دسترس آنلاین: https://scihub.copernicus.eu/ (دسترسی در 2 دسامبر 2020).
- تیم توسعه پانداها Pandas.DataFrame—Pandas 1.0.3 Documentation. در دسترس آنلاین: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html (در 2 دسامبر 2020 قابل دسترسی است).
- OSGEO. GDAL/OGR Python API. در دسترس آنلاین: https://gdal.org/python/ (در 2 دسامبر 2020 قابل دسترسی است).
- OSGEO. سیستم های فایل مجازی GDAL. در دسترس آنلاین: https://gdal.org/user/virtual_file_systems.html (در 2 دسامبر 2020 قابل دسترسی است).
- OSGEO. محصولات Sentinel-2 – اسناد GDAL. در دسترس آنلاین: https://gdal.org/drivers/raster/sentinel2.html (در 2 دسامبر 2020 قابل دسترسی است).
- مپ باکس. Rasterio: دسترسی به داده های Raster Geospatial – اسناد Rasterio. در دسترس آنلاین: https://rasterio.readthedocs.io/en/latest/ (در 2 دسامبر 2020 قابل دسترسی است).
- مپ باکس. فایل های درون حافظه – اسناد Rasterio. در دسترس آنلاین: https://rasterio.readthedocs.io/en/latest/topics/memory-files.html (در 2 دسامبر 2020 قابل دسترسی است).
- آژانس فضایی اروپا تصاویر Sentinel-2 از 30 مارس 2019 تا 30 نوامبر 2019. در دسترس آنلاین: https://scihub.copernicus.eu/ (در 2 دسامبر 2020 قابل دسترسی است).
- پایگاه داده فهرست. در دسترس آنلاین: https://www.indexdatabase.de/ (در 2 دسامبر 2020 قابل دسترسی است).
- توسعه دهنده SCIKIT-LEARN. Imputation of Missing Values—Scikit-Learn 0.23.1 Documentation. در دسترس آنلاین: https://scikit-learn.org/stable/modules/impute.html (در 2 دسامبر 2020 قابل دسترسی است).
- لژاندر، پ. لژاندر، ال. اکولوژی عددی . الزویر: آمستردام، هلند، 2012; 990p، ISBN 9780444538680. [ Google Scholar ] [ CrossRef ]
- لیلسند، TM; کیفر، RW; Chipman، JW Remote Sensing and Image Interpretation ، 7th ed.; جان وایلی: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2015; پ. 736. شابک 978-1-118-34328-9. [ Google Scholar ]
- ČÚZK. Katastrální Mapa ČR ve Formátu SHP Distribuovaná po Katastrálních Územích (KM-KU-SHP). در دسترس آنلاین: https://services.cuzk.cz/shp/ku/epsg-5514/ (در 2 دسامبر 2020 قابل دسترسی است).
- شولتز، ام. ووس، ج. اوئر، ام. کارتر، اس. Zipf، A. پوشش زمین را از OpenStreetMap و سنجش از دور باز کنید. بین المللی J. Appl. Obs زمین. Geoinf. 2017 ، 63 ، 206-213. [ Google Scholar ] [ CrossRef ]
- Foody، GM تعیین اندازه نمونه برای ارزیابی دقت طبقه بندی تصویر و مقایسه. بین المللی J. Remote Sens. 2009 ، 30 ، 5273-5291. [ Google Scholar ] [ CrossRef ]
- اولوفسون، پی. فودی، جنرال موتورز; هرولد، ام. Stehman، SV; Woodcock، CE; Wulder, MA شیوه های خوب برای تخمین مساحت و ارزیابی دقت تغییر زمین. سنسور از راه دور محیط. 2014 ، 148 ، 42-57. [ Google Scholar ] [ CrossRef ]
- طرح های نمونه برداری Stehman، SV برای ارزیابی دقت پوشش زمین. بین المللی J. Remote Sens. 2009 ، 30 ، 5243-5272. [ Google Scholar ] [ CrossRef ]
- مالینوفسکی، آر. لوینسکی، اس. ریبیکی، ام. گرومنی، ای. جنروویچ، ام. کروپینسکی، م. نواکوفسکی، آ. ووتکوفسکی، سی. کروپینسکی، م. کراتزشمار، ای. و همکاران تولید خودکار نقشه پوشش زمین / کاربری اروپا بر اساس تصاویر Sentinel-2. Remote Sens. 2020 , 12 , 3523. [ Google Scholar ] [ CrossRef ]
- جامعه SCIPY. Numpy.array—NumPy v1.18. در دسترس آنلاین: https://numpy.org/doc/1.18/reference/generated/numpy.array.html (در 2 دسامبر 2020 قابل دسترسی است).
- Kern، R. NEP 1 – فرمت فایل ساده برای آرایه های NumPy، GitHub. در دسترس آنلاین: https://github.com/numpy/numpy (در 2 دسامبر 2020 قابل دسترسی است).

شکل 1. تجسم نحوه چیدمان باندهای تصویر در زمان، همانطور که در EOPatch (به عنوان DATA FeatureType) ذخیره می شود.

شکل 2. نمونه ماسک مبتنی بر لایه طبقهبندی صحنه (SCL) روی یک تصویر Sentinel-2 اعمال میشود. منبع داده: تصویر Sentinel-2 از 14.3.2019.

شکل 3. ویژگی های ادغام شده (سه نمونه از ویژگی های چند تصویری در بالای باندها) به عنوان نتیجه MergeFeatureTask در زمان انباشته شده اند. در این زمان، آنها قبلاً با آستانه گذاری ماسک های SCL مربوطه فیلتر شده اند (به بخش 3.2.7 مراجعه کنید ).

شکل 4. درون یابی خطی فریم های زمانی با ویژگی ادغام شده با پنج روز مرحله انتخاب شده.

شکل 5. سری زمانی Sentinel-2 فیلتر شده و درونیابی شده از 30.3.2019 تا 16.10.2019 فریم های زمانی ویژگی در مثال EOPatch با ID 7.
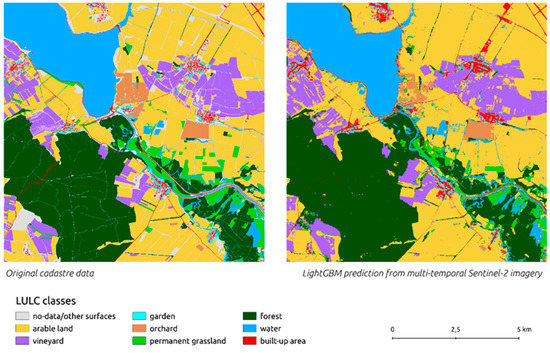
شکل 6. مقایسه داده های کاداستر اصلی و پیش بینی LightGBM. منابع: تصاویر Sentinel-2 از 30.3 تا 16.10 [ 80 ]، نقشه کاداستر چک [ 85 ].
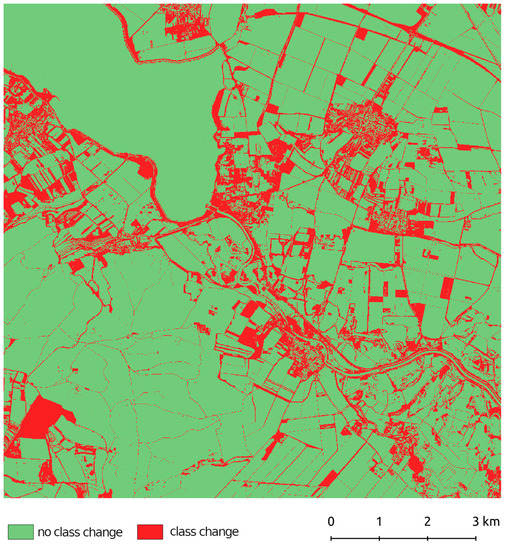
شکل 7. نظارت بر عدم تطابق کلاس بین دادههای کاداستر اصلی و پیشبینی LightGBM برای ارزیابی بصری نتایج طبقهبندی. منابع: تصاویر Sentinel-2 از 30.3 تا 16.10.2019 [ 80 ]، نقشه کاداستر چک [ 85 ].


بدون دیدگاه