1. معرفی
پیشبینی مکان به تخمین مکان پیشبینیشده در چندین مُهر زمانی بعدی بر اساس مسیر اخیر و وضعیت فعلی اشاره دارد [ 1 ]. پیشبینی مکان آینده اشیاء متحرک (ساکنان، اتومبیلها، کشتیها و غیره) برای طیف گستردهای از کاربردهای جدید مانند خدمات توصیه مبتنی بر مکان [ 2 ]، سیستمهای حملونقل هوشمند [ 3 ]، نظارت دریایی [ 4 ] اهمیت زیادی دارد. ] و نظارت بر هوانوردی [ 5] و غیره (به عنوان مثال، در صنعت دریایی، اگر مکان آینده شناورها در دوره زمانی آتی از قبل مشخص باشد، سیستم مدیریت دریایی می تواند خطر برخورد را ارزیابی کند یا رفتار غیرعادی را تشخیص دهد. در صورت وجود هرگونه خطر، کشتی ها هشدارهایی را از سیستم مدیریت برای تغییر مسیر از پیش برنامه ریزی شده دریافت خواهند کرد). مدیریت ترافیک و طرح های مسیر نیز بر اساس پیش بینی مکان وسایل نقلیه قابل اجراست. با این حال، پیشبینی مکان به دلیل پیچیدگی و تنوع رفتار تحرک، یک موضوع چالش برانگیز است. مکانهای آینده در تکامل مسیر، رویدادهای نامشخصی هستند که هم تحت تأثیر انگیزه درونی اجسام متحرک و هم از عوامل خارجی هستند. بنابراین، رویکردهای سنتی که بر معادله سینماتیک و مدل خطی تکیه میکنند، موفق به دستیابی به عملکرد رضایتبخش نمیشوند.
در چند سال گذشته، فناوری ناوبری و موقعیت یابی به سرعت توسعه یافته است. تعداد زیادی از وسایل نقلیه، دستگاه های تلفن همراه، و دستگاه های پوشیدنی مجهز به واحد عملکرد مکان یابی هستند. رکوردهای مسیر را می توان توسط این وسایل نقلیه و دستگاه های رایج در زمان واقعی و به صورت متوالی تولید و جمع آوری کرد [ 6 ]. داده های مسیر همه جا به ظهور روزافزون روش های پیش بینی مکان مبتنی بر داده منجر می شود [ 7 ]]، زیرا مسیر حرکت اجسام متحرک ناشی از تأثیر یکپارچه انگیزه داخلی و عوامل خارجی است. اطلاعات مکانی-زمانی که رفتار تحرک را توصیف می کند منبع ارزشمندی در داده های مسیر است. ما میتوانیم اطلاعات را با استخراج مسیر به دست آوریم و از آن برای پیشبینی مکان آینده اجسام متحرک استفاده کنیم. مسیر کاوی به شیوهای محرک داده، مزیت برجسته این است که پیوند آسان است، زیرا وابستگی به دانش دامنه را هنگام انجام کار پیشبینی مکان کاهش میدهد. فرآیند کاوش مسیر برای پیشبینی مکان شامل دو مرحله است: (1) آموزش مدل پیشبینی آفلاین با بهرهبرداری از مسیرهای تاریخ، و (2) پیشبینی مکان در زمان واقعی بر اساس مدل به خوبی آموزش دیده.
برخی از تکنیکهای پیشبینی بهطور گسترده بر اساس مسیر کاوی در مطالعات قبلی مانند تکنیکهای مبتنی بر محتوا [ 8 ]، تکنیکهای مبتنی بر الگو [ 9 ، 10 ] و تکنیکهای مبتنی بر نمایش، [ 11 ، 12 ] و غیره وجود دارد. زنجیره مارکوف مدل یک استراتژی معمولی از تکنیک های مبتنی بر محتوا است که در آن مکان بعدی وابسته به وضعیت فعلی فرض می شود. با ساخت یک ماتریس گذار بر اساس مسیرهای تاریخ آموزش داده می شود که احتمال انتقال بین مکان ها را نشان می دهد. مکان بعدی بسته به وضعیت فعلی و ماتریس انتقال [ 13]. هدف تکنیکهای مبتنی بر الگو، استخراج الگوهای تحرک موجود در مسیرهای تاریخ با استفاده از روشهای قانون تداعی است. سپس، الگوهای تحرک برای پیشبینی مکانهای آینده استفاده میشوند [ 9 ].
با این حال، روشهای فوق عمدتاً بر وضعیت فعلی اشیاء متحرک متمرکز شدهاند و از اطلاعات تاریخی موجود در توالی مکانیابی طولانیمدت غفلت میکنند. فقدان اطلاعات تاریخی به وضوح عملکرد پیشبینی را محدود میکند، به ویژه در پیشبینی بلندمدت. علاوه بر این، برای بسیاری از این روشها که به شیوهای گسسته هستند، مدلسازی مختصات مکان با ارزش واقعی دشوار است. در سالهای اخیر، تکنیکهای مبتنی بر بازنمایی که از الگوریتمهای یادگیری عمیق استفاده میکنند، توجه زیادی را به خود جلب کردهاند. تکنیکهای مبتنی بر بازنمایی اطلاعات تاریخی و ویژگیهای نشاندهنده مستلزم مسیرها را به اندازه کافی میآموزند. ویژگی های استخراج شده برای بهبود دقت پیش بینی مفید هستند [ 11]. با این وجود، هنوز برخی از تنگناها در روش های مبتنی بر بازنمایی فعلی وجود دارد. برای الگوریتمهای یادگیری عمیق مانند شبکه عصبی بازگشتی (RNN) [ 14 ] و شبکه عصبی کانولوشنال (CNN) [ 15 ]، که در انجام پیشبینی گسسته خوب هستند، پیشبینی مختصات مکان با ارزش واقعی دشوار است. روشهای پیشبینی موجود با هدف پیوسته و غیر تکراری اشتباه گرفته میشوند. اهداف پیشبینی برخی از مطالعات، اهداف گسستهای مانند سلولهای فضایی یا مکانهای قابل توجه [ 16] است و یک استراتژی گسستهسازی فضایی یا پردازش خوشهبندی برای تبدیل مختصات با ارزش واقعی پیوسته به اهداف گسسته معرفی میشود که همچنین ممکن است منجر به مسئله پراکندگی و نفرین شود. از ابعاد
با انگیزه محدودیتهای روشهای موجود در پیشبینی مختصات مکان بلندمدت، این مقاله را به یک رویکرد پیشبینی مکان مبتنی بر یادگیری عمیق اختصاص دادیم. هسته اصلی این رویکرد ساخت یک مدل شبکه تراکم مخلوط بازگشتی دو طرفه (BiRMDN) است. BiRMDN یک مدل یادگیری عمیق است که یک شبکه حافظه کوتاه مدت دو جهته (LSTM) [ 17 ] و شبکه چگالی مخلوط (MDN) [ 18 ] را یکپارچه می کند.]. شبکه LSTM گونه ای از یک شبکه عصبی بازگشتی است که در گرفتن وابستگی مکانی-زمانی طولانی مدت و اطلاعات متنی موجود در مسیرها برتر است. MDN به جای خروجی مستقیم مقدار دقیق مختصات پیشبینیشده، پارامترهای تابع توزیع مخلوط را برای مکانهای مدل تولید میکند. به عبارت دیگر، ما فقط محدوده احتمالی مکانهای آینده و احتمال مربوطه را پیشبینی کردیم.
به طور کلی، برتری اصلی مدل BiRMDN در موارد زیر نهفته است: (1) به دلیل استفاده از وابستگی مکانی-زمانی بلندمدت و اطلاعات متنی در دادههای مسیر، در بهبود دقت پیشبینی بهتر از روشهای یادگیری ماشین سنتی است. (2) با توجه به اینکه تکامل مسیر در واقع یک رویداد نامشخص است، این نوع پیشبینی فازی برای مدلسازی مختصات مکان با ارزش واقعی مناسب است. نتایج پیشبینی نهایی بهدستآمده از نمونهگیری از توزیعها به رفتار تحرک واقعی نزدیکتر است. علاوه بر این، نفرین ابعاد با موفقیت در این راه اجتناب می شود. (3) فرآیند یادگیری به صورت خودکار است و هیچ ویژگی پیچیده دست ساخته ای در آن وجود ندارد. پیوند این مدل به سناریوهای مختلف آسان است.
دادههای مسیر کشتی در دنیای واقعی [ 19 ] که توسط سیستم شناسایی خودکار (AIS) جمعآوری شدهاند، برای اجرای رویکرد پیشنهادی مورد استفاده قرار گرفتند. در آزمایشها، تأثیر پارامترهای مدل را تحلیل کردیم و مطالعه مقایسهای با سایر روشهای پرکاربرد انجام دادیم. ادامه این مقاله به شرح زیر سازماندهی شده است. در بخش 2 ، کارهای قبلی مربوط به پیشبینی مکان بررسی میشوند. بخش 3 روش پیشنهادی، به ویژه مدل BiRMDN را تشریح می کند. بخش 4 نتایج تجربی و ارزیابی مربوطه را ارائه می کند. در نهایت، بحث و نتیجه گیری در بخش 5 ارائه شده است.
2. کارهای مرتبط
داده های مسیر فراگیر منابع ارزشمندی برای داده کاوی و کشف دانش هستند. پیش بینی مکان به طور گسترده ای به عنوان یک موضوع کلیدی در استخراج مسیر در نظر گرفته شده است. در سال های اخیر، تعدادی روش برای بهبود کارایی و دقت پیش بینی مکان ابداع شده است. بیشتر روشهای مبتنی بر دادهها بر استخراج اطلاعات مکانی-زمانی و متنی از مسیرها متمرکز شدهاند. این روش ها را می توان به سه دسته طبقه بندی کرد: روش های مبتنی بر محتوا، روش های مبتنی بر الگو و روش های مبتنی بر نمایش.
روشهای مبتنی بر محتوا بر اساس این فرض ایجاد میشوند که مکان بعدی با وضعیت فعلی مرتبط است. مدل زنجیره مارکوف یک استراتژی معمولی از روش های مبتنی بر محتوا است. اشبروک و همکاران [ 20 ] سیستمی برای پیش بینی حرکت کاربران متعدد بر اساس مدل مارکوف پیشنهاد کرد. مکانهای مهم استخراجشده از دادههای مسیر برای ساخت زنجیره مارکوف استفاده شد. این سیستم هم برای کاربران مجرد و هم برای کاربران مشترک اعمال شد. سونگ و همکاران [ 13 ] دو روش پیشبینی مکان را از طریق دادههای Wi-Fi کاربران بررسی کرد: پیشبینیکنندههای مبتنی بر مارکوف و مبتنی بر فشردهسازی، و دریافتند که نتیجه پیشبینی مدل مارکوف مرتبه پایین دقیقتر از روش مبتنی بر فشردهسازی است. . علاوه بر این، متیو و همکاران. [ 21] پیشبینی تحرک انسان را بر اساس مدلهای پنهان مارکوف (HMM) پیشنهاد کرد. HMMها ویژگی های مکان را به عنوان پارامترهای مشاهده نشده در نظر می گیرند و با تأثیر عملکرد قبلی کاربران مرتبط است. کیائو و همکاران [ 22] یک روش پیشبینی مسیر مبتنی بر مدل مارکوف پنهان به نام HMTP* را توسعه داد. این روش مشکل حفظ حالت موجود در اکثر روشهای پیشبینی مبتنی بر HMM را حل کرد و دقت پیشبینی را تا حد زیادی بهبود بخشید. با این حال، بیشتر مدلهای مارکوف مرتبه پایین، وابستگی بلندمدت و اطلاعات زمینهای موجود در توالی مکانی-زمانی را در نظر نمیگیرند. عملکرد پیشبینی به دلیل فقدان اطلاعات زمینهای محدود میشود. علاوه بر این، مدل مارکوف به دلیل ماهیت گسستهاش برای پیشبینی مختصات پیوسته مناسب نیست.
رفتار تحرک اجسام متحرک را می توان به طور خلاصه به عنوان الگوهای مسیر پنهان در مسیرهای تاریخ توصیف کرد. هدف روشهای مبتنی بر الگو، استخراج الگوهای خاص موجود در مسیرها و استفاده از این الگوها برای پیشبینی مرحله حرکت بعدی است. مونریال و همکاران [ 9 ] یک روش مبتنی بر الگو به نام WhereNext پیشنهاد کرد و الگوهای مکانی-زمانی را از مسیرها استخراج کرد و الگوها را در یک ساختار درختی پیشوندی ذخیره کرد. سپس مکان بعدی بر اساس ساختار درختی پیش بینی شد. یینگ و همکاران [ 23 ] رویکردی را ارائه کرد که دانش جغرافیایی، زمانی و معنایی را از مسیرها به طور همزمان استخراج می کند. پیش بینی آنلاین را می توان بر اساس شباهت بین حرکت فعلی و الگوهای کشف شده پیاده سازی کرد. لی و همکاران [24 ] چارچوبی را برای به تصویر کشیدن الگوهای مکانی-زمانی رفتار حرکتی پس از استخراج مناطق محبوب با خوشه بندی ایجاد کرد. روابط متوالی کشف شده بین مناطق و احتمالات مربوط به زمان می تواند برای پیش بینی اطلاعات مکان مورد استفاده قرار گیرد. با این حال، روشهای مبتنی بر الگو که بر روی مناطق مورد علاقه (ROI) یا مکانهای مجزا ساخته شدهاند، برای مواجهه با مسئله پراکندگی کافی نیستند (به عنوان مثال، اگر مکان بعدی مسیر فعلی هرگز در مسیرهای تاریخ ظاهر نشده باشد، پیشبینی آن دشوار خواهد بود. با روش های مبتنی بر الگو).
در سالهای اخیر، تکنیکهای یادگیری عمیق دستاوردهای چشمگیری در بسیاری از زمینهها داشتهاند. روشهای مبتنی بر بازنمایی که از تکنیکهای یادگیری عمیق مانند RNN استفاده میکنند نیز به طور گسترده در پیشبینی مکان مورد مطالعه قرار میگیرند. با توجه به ویژگیهای متوالی و متنی دادههای مسیر، RNN و انواع آن میتوانند ویژگیهای نماینده را کارآمدتر از سایر الگوریتمهای یادگیری عمیق یاد بگیرند. نگوین و همکاران [ 25 ] یک مدل دنباله به دنباله بر اساس LSTM برای پیشبینی مسیر کشتیها از جمله مقصد و زمان تخمینی رسیدن پیشنهاد کرد. این مدل گرایش حرکت را از توالی شبکههای فضایی مسیر اخیر آموخت و از آن برای تخمین حرکت آینده کشتیها استفاده کرد. وو و همکاران [ 26] دو مدل مبتنی بر RNN طراحی کرد که وابستگی بلندمدت را نشان میداد و به محدودیتهای ساختار توپولوژیکی در مدلسازی مسیر پرداخت. در دو مدل، مسیرها در قالب توالی بخشهای جاده به جای شبکههای فضایی پرکاربرد بیان شد. لیو و همکاران [ 27 ] RNN را گسترش داد و با جایگزین کردن ماتریس انتقال در RNN با ماتریسهای انتقال خاص زمان، زمینههای مکانی-زمانی مسیرها را مدلسازی کرد. آنها همچنین هنگام پیش پردازش داده های مکان، ارزش مکانی و زمانی پیوسته را به Bin های مجزا تقسیم کردند. فنگ و همکاران [ 28] یک شبکه تکراری توجه به نام DeepMove برای پیش بینی تحرک انسان پیشنهاد کرد. DeepMove انتقال های متوالی پیچیده و تناوب چند سطحی در رفتار تحرک انسان را به تصویر می کشد، که در صحنه پیش بینی مکان گسسته اعمال می شود.
روشهای معرفیشده در بالا، مکانهای آینده مسیر را بهعنوان رویدادهای قطعی در نظر میگیرند و مختصات مکان پیوسته را به شبکههای فضایی، خوشهها یا دیگر رمزگذاریهای برچسبگذاری شده گسسته میکنند. عملیات گسسته سازی ممکن است منجر به لعنت بر ابعاد و مسائل مرزی تیز شود. علاوه بر این، این روش ها ماهیت نامشخص رفتار تحرک را نادیده می گیرند. از نظر مدلسازی رویدادهای نامشخص، MDN به عملکرد عالی دست یافت. گریوز و همکاران [ 29 ] از MDN برای پیشبینی و ترکیب دستخط بهره کامل برد. ژائو و همکاران [ 30 ] LSTM و MDN دو طرفه عمیق را برای تولید یک مسیر بسکتبال اعمال کرد. علاوه بر این، Xu و همکاران. [ 31] یک مدل یادگیری توالی مبتنی بر MDN برای پیشبینی بلادرنگ تقاضای تاکسی ایجاد کرد.
در این کار، BiRMDN که شبکه LSTM و MDN را ادغام میکند، این توانایی را دارد که اطلاعات متنی را از بخش اخیر مسیر یاد بگیرد و از تابع توزیع احتمال برای مدلسازی عدم قطعیت مکانهای آینده استفاده کند. بنابراین، می تواند نتایج پیش بینی امیدوارکننده ای را ارائه دهد.
3. روش ها
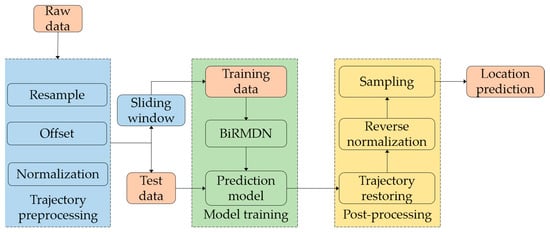
ما روش پیشبینی مکان را در این بخش ارائه میکنیم که شامل سه بخش متوالی است: (1) پیشپردازش مسیر. (2) ساخت مدل BiRMDN. و (3) پس پردازش برای بازگرداندن مسیر. شکل 1به طور خلاصه روند کلی روش پیشنهادی را نشان می دهد. در مرحله پیش پردازش مسیر، به جای انجام هر گونه استخراج ویژگی پیچیده، ما داده های مسیر را تنها از طریق سه مرحله ساده به داده های افست نرمال شده برای مدل BiRMDN تبدیل کردیم. مدل BiRMDN که به خوبی آموزش دیده است، میتواند ویژگیهای نماینده را از مسیرها و توزیع ترکیبی از افستهای آینده ایجاد کند. در مرحله پس پردازش، نتایج نهایی پیش بینی با نمونه برداری از توزیع های تولید شده به دست می آید. مسیرها با عملیات معکوس پیش پردازش مسیر بازیابی می شوند که دیگر در ادامه توضیح داده نخواهد شد.
3.1. فرمول مسأله
تعریف 1.
مسیر: اجازه دهید T={T1,T2,…,Ti,…Tm}�={�1,�2,…,��,…��}مجموعه ای از مسیرها باشد. یک مسیر فردی تیمن∈ تی��∈�از دنباله ای از نقاط مکانی و زمانی تشکیل شده است تیمن= {پمن1،پمن2, … ,پمنj, … ,پمنn}��={�1�,�2�,…,���,…,���}، جایی که پمن1�1�و پمنn���به ترتیب مبدا و مقصد (OD) هستند. پمنj= {ایکسمنj،تیمنj}���={���,���}هست j th�thنقطه مکانی-زمانی در تیمن��، جایی که ایکسمنj= { l ngمنj، l aتیمنj}ایکس�من={ل���من،لآتی�من}(یا ایکسمنj= { l ngمنj، l aتیمنj، h e i gساعتتیمنj}ایکس�من={ل���من،لآتی�من،ساعتهمن�ساعتتی�من}در سناریوهای سه بعدی) بردار مکان شامل ویژگی های طول و عرض جغرافیایی است و تیمنjتی�منمهر زمانی مربوطه است.
مشکل 1.
پیش بینی مکان: با توجه به بخش مسیر ناقص فعلی تی“= {پj − k + 1, … ,پj − 1،پj}تی”={پ�-ک+1،…،پ�-1،پ�}با ککنقاط مکانی-زمانی، جایی که مکان در زمان کنونی است تیjتی�و نقاط اخیر فضایی و زمانی در k − 1ک-1مهرهای زمانی قبلی شناخته شده است، به بعد مراجعه کنید للمکان ها {ایکسj + 1, … ,ایکسj + l}{ایکس�+1،…،ایکس�+ل}در موارد زمانی {تیj + 1, … ,تیj + l}{تی�+1،…،تی�+ل}.
در این اثر مجموعه ای از مسیرهای تاریخ تی= {تی1،تی2, … ,تیمن، …تیمتر}تی={تی1،تی2،…،تیمن،…تیمتر}برای آموزش مدل پیش بینی معرفی شده در بخش 3.3 استفاده شد. همانطور که در بخش 3.2 توضیح داده شد، تمام مسیرهای تاریخ و مسیرهای آزمایشی قبل از وارد شدن به مدل، پیش پردازش شدند .
3.2. پیش پردازش مسیر
داده های موقعیت یابی خام به روش زمانی در پایگاه داده ذخیره شدند. نقاط OD برای تقسیم داده های موقعیت یابی متوالی به مسیرهای منفرد استخراج شد. روش استخراج نقطه OD در کار قبلی ما [ 19 ] ارائه شده است. عملیات پاکسازی داده ها و درونیابی مسیر برای به دست آوردن داده های قابل استفاده انجام شد. با توجه به تعریف مسئله 1 از پیشبینی مکان، به منظور یکسان سازی قالب بخشهای مسیر ورودی و نتایج پیشبینی، مسیرها را مجدداً نمونهبرداری کردیم و فاصله زمانی بین دو نقطه مکانی-زمانی مجاور را در یک مقدار ثابت تنظیم کردیم.
تابع توزیع احتمال برای مدل سازی داده های مختصات مطلق مناسب نیست {ایکس1, … ,ایکسj، …ایکسn}{ایکس1،…،ایکس�،…ایکس�}، که داده های توالی غیر ثابت با تمایل هستند. از این رو، دنباله مختصات مطلق را به دنباله افست تبدیل کردیم { Δایکس2, … , Δایکسj + 1, … Δایکسn}{Δایکس2،…،Δایکس�+1،…Δایکس�}به detrend، که در آن Δایکسj + 1=ایکسj + 1–ایکسjΔایکس�+1=ایکس�+1-ایکس�افست از مکان قبلی است. هدف از پیش بینی مکان بعدی ایکسj + 1ایکس�+1تبدیل به پیش بینی افست می شود Δایکسj + 1Δایکس�+1. مختصات بتن ایکسj + 1=ایکسj+ Δایکسj + 1ایکس�+1=ایکس�+Δایکس�+1را می توان با بازگرداندن مسیر به دست آورد. به منظور جلوگیری از بروز مشکل اشباع تابع فعال سازی (که در بخش 3.3 معرفی خواهد شد ) در فرآیند پیشخور، داده های ورودی رخ می دهد. Δ xΔایکسقبل از وارد شدن به BiRMDN در محدوده 0 تا 1 نرمال شدند.
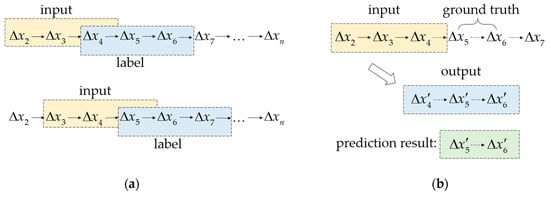
در فرآیند به دست آوردن داده های آموزشی، از روش پنجره کشویی برای تولید ورودی آموزش و برچسب آموزشی مربوطه استفاده کردیم. همانطور که در شکل 2 الف نشان داده شده است، طول توالی ورودی را فرض کردیم k = 3ک=3، و طول پیش بینی l = 2ل=2. در فرآیند آموزش، برچسب آموزشی با تاخیر انجام شد للمراحل زمانی نسبت به ورودی طول دنباله برچسب آموزشی برابر با ورودی بود. بخش آزمایش از دو بخش تشکیل شده است: ورودی و حقیقت زمین، همانطور که در شکل 2 ب نشان داده شده است. در فرآیند آزمایش، خروجی نیز به اندازه ورودی بود، اما در آخر فقط مقادیر بود للمهرهای زمانی به عنوان نتایج پیشبینی انتخاب شدند.
3.3. شبکه چگالی مخلوط برگشتی دو جهته
مسیر حرکت اجسام متحرک دنباله های زمانی هستند که توسط نقاط مکانی-زمانی تشکیل می شوند. با توجه به ویژگی های متوالی مسیر، ما به طور شهودی به استفاده از یک مدل پیش بینی فکر می کنیم که در برخورد با داده های سری به خوبی عمل می کند. شبکه LSTM گونهای از RNN است که تکنیکی پیشرفته در مدلسازی دادههای سری است. برجسته ترین ویژگی LSTM ساختار منحصر به فردی است که گیت ورودی، دروازه فراموشی و گیت خروجی را ادغام می کند. این ساختار آن را برای LSTM امکان پذیر می کند که وابستگی مکانی-زمانی بلندمدت و اطلاعات متنی ضمنی در مسیر را بگیرد. علاوه بر این، اگر اتصالات بین واحدهای LSTM در همان لایه شبکه دو طرفه باشد، اطلاعات متنی بیشتری منتقل و به اشتراک گذاشته خواهد شد [ 32 ].]. با این حال، برای یک شبکه LSTM معمولی پیشبینی دادههای مختصات مکان با ارزش واقعی دشوار است. به جای خروجی مستقیم نتایج مختصات، MDN پارامترهای توزیع چگالی احتمال مخلوط را خروجی می دهد. توزیع مخلوط در مدلسازی رویدادهای نامشخص مانند دادههای مکان با ارزش واقعی به خوبی عمل میکند. در این کار، ما یک ساختار اتصال دو طرفه را در هر لایه از شبکه LSTM اتخاذ کردیم. سپس، MDN را در بالای شبکه LSTM اضافه کردیم تا یک BiRMDN برای پیشبینی مکان آینده بسازیم.
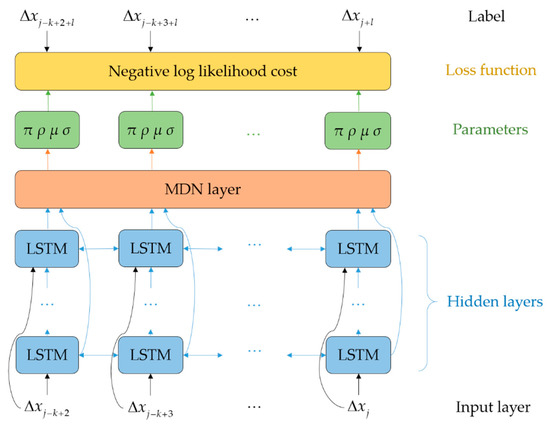
شکل 3 شماتیک ساختار مدل BiRMDN را نشان می دهد. ساختار بازشده BiRMDN از چندین لایه متوالی از جمله لایه ورودی، لایههای پنهان LSTM و لایه MDN تشکیل شده است. لایه ورودی توسط دنباله افست تشکیل می شود Δایکسمن(j−k+2≤i≤j)Δ��(�−�+2≤�≤�). را ΔxiΔ��بردار است {Δlngi,Δlati}{Δ����,Δ����}در هر مهر زمانی ti��. طول بازشده لایه ورودی برابر است با k−1�−1، طول دنباله افست شناخته شده.
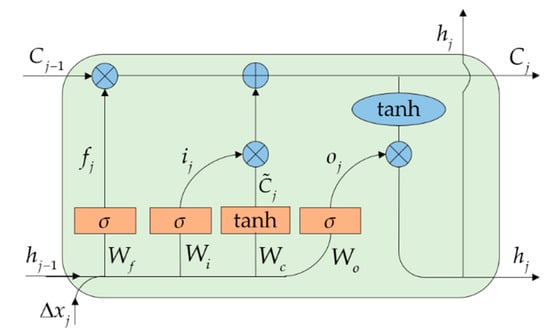
لایه های پنهان شامل چندین لایه LSTM روی هم هستند. سیگنال ورودی هر لایه پنهان شامل خروجی لایه قبلی و لایه ورودی است. لایه LSTM یک خروجی بر اساس سیگنال ورودی کدگذاری شده و وضعیت داخلی آن تولید می کند. اتصال دو طرفه در هر لایه LSTM توالی را در هر دو فرآیند جلو و عقب در طول زمان مدیریت می کند. خروجی تمام لایه های LSTM به عنوان خروجی یکپارچه لایه های پنهان به هم متصل می شود. هر یک از لایه های LSTM شامل چندین واحد LSTM متصل است. معماری واحد LSTM در شکل 4 نشان داده شده است که یک تابع لایه پنهان را برای رمزگذاری اطلاعات مفید بر اساس سه گیت به شرح زیر پیاده سازی می کند:
جایی که fj��، ij��، و oj��به ترتیب دروازه فراموش، گیت ورودی و گیت خروجی را نشان دهید. σ�و tanhtanhبه ترتیب تابع سیگموئید لجستیک و تابع مماس هذلولی را نشان می دهند که هر دو به عنوان تابع فعال سازی غیرخطی استفاده می شوند. ساعتj − 1ساعت�-1خروجی است j − 1 ام �-1 هفتمواحد در لایه LSTM ΔایکسjΔ��نشان دهنده سیگنال ورودی از لایه قبلی است. ماتریس های وزن دبلیوf��، دبلیومن��، دبلیوo��و تعصب مربوطه ب�مرتبط با این گیت ها متغیرهایی هستند که باید در طول فرآیند آموزش بهینه شوند.
عملکرد حفظ و به روز رسانی حالت سلولی، توانایی منحصر به فرد واحد LSTM است. سی˜j�˜�حالت سلول موقت است که برای به روز رسانی حالت سلول قدیمی استفاده می شود سیj − 1سی�-1به حالت جدید سیjسی�. فرآیند به روز رسانی حالت با همکاری دروازه فراموش تعیین می شود fj��و دروازه ورودی منjمن�. ماتریس های وزن دبلیوجدبلیوجو تعصب مربوطه ببمرتبط با حالات سلول نیز متغیرهایی هستند که باید بهینه شوند. در نهایت، وضعیت سلول به روز شده توسط تابع فعال سازی غیر خطی فعال می شود tanhtanhو توسط گیت خروجی کنترل می شود oj��برای تولید سیگنال خروجی ساعتjساعت�.
لایه MDN در بالای لایه های LSTM یک لایه کاملاً متصل به شرح زیر است:
جایی که ننتعداد لایه های LSTM روی هم را نشان می دهد و ساعت→njساعت→��و ساعت←njساعت←��خروجی رو به جلو و عقب هستند n ام � هفتملایه LSTM دو طرفه دبلیو-→ساعت→nyدبلیو→ساعت→��و دبلیو←-ساعت←nyدبلیو←ساعت←��ماتریس های وزنی را که به ترتیب لایه LSTM دو طرفه و لایه MDN را به هم متصل می کنند، نشان دهید. بyب�تعصب مربوطه است. و y˜j�˜�خروجی لایه MDN را نشان می دهد. خروجی لایه MDN برای پارامتری کردن توزیع چگالی احتمال مخلوط از افست های با ارزش واقعی استفاده می شود. توزیع توسط مماجزای وزن دار بخشی از خروجی برای تعیین وزن ها استفاده می شود، در حالی که بقیه برای پارامترهای هر جزء استفاده می شود. در این کار، ما تابع گاوسی دو متغیره را به عنوان مؤلفه برای مدلسازی توزیع بردار افست دو بعدی اتخاذ کردیم. Δ x = { Δ l n g, Δ l a t }Δایکس={Δل��،Δلآتی}. همانطور که در شکل 3 نشان داده شده است ، علاوه بر اوزان π�پارامترهای توزیع مخلوط گاوسی شامل مجموعهای از میانگینها است μ�، انحراف معیار σ�، و همبستگی ها ρ�:
همه پارامترها باید به عنوان خروجی نهایی در محدوده های معنی دار نرمال شوند y˜j�˜�از BiRMDN:
استراتژی های نرمال سازی با توجه به توزیع مخلوط گاوسی تعیین می شوند که در آن:
با توجه به خروجی نهایی yj��، تابع چگالی احتمال برچسب Δxj+lΔ��+�به صورت زیر تعریف می شود:
جایی که G�تابع گاوسی دو متغیره است:
تابع ضرر که اختلاف بین برچسب آموزشی و خروجی مدل را اندازه گیری می کند به عنوان تابع احتمال ورود به سیستم منفی تعریف می شود:
تابع از دست دادن تابع هدف است که در طول فرآیند آموزش با استفاده از نزول گرادیان بهینه می شود. به منظور اجتناب از موضوع انفجار گرادیان، که اغلب در فرآیند آموزش رخ می دهد، ما از استراتژی برش گرادیان [ 33 ] برای محدود کردن گرادیان به یک محدوده از پیش تعریف شده استفاده کردیم. محدود به حجم مجموعه داده آموزشی و پیچیدگی ساختار شبکه، برازش بیش از حد یک مسئله اجتناب ناپذیر برای مدل BiRMDN است. ما تکنیک ترک تحصیل را اتخاذ کردیم [ 34] برای حذف تصادفی بخشی از نورون های پنهان با احتمال مشخص در هر تکرار. تکنیک انصراف پیچیدگی شبکه و انطباق همزمان نورون ها را کاهش می دهد. بنابراین، تکنیک انصراف مسئله بیش از حد برازش را کاهش می دهد و به طور قابل توجهی توانایی تعمیم مدل پیش بینی را ارتقا می دهد.
4. نتایج تجربی
در این بخش، روش پیشبینی مکان را در مجموعه دادههای مسیر کشتی در دنیای واقعی پیادهسازی میکنیم و عملکرد را ارزیابی میکنیم. در بخش 4.1 ، ما یک مقدمه کوتاه در مورد مجموعه داده و تنظیمات آزمایشی ارائه میکنیم. با توجه به تأثیر پارامترها، ما عملکرد مدلها را با تنظیمات پارامترهای مختلف آزمایش میکنیم و پیکربندی بهینه را در بخش 4.2 تعیین میکنیم. آزمایشهای مقایسه با سایر روشهای پرکاربرد در بخش 4.3 انجام شده است.
4.1. مجموعه داده و تنظیم آزمایش
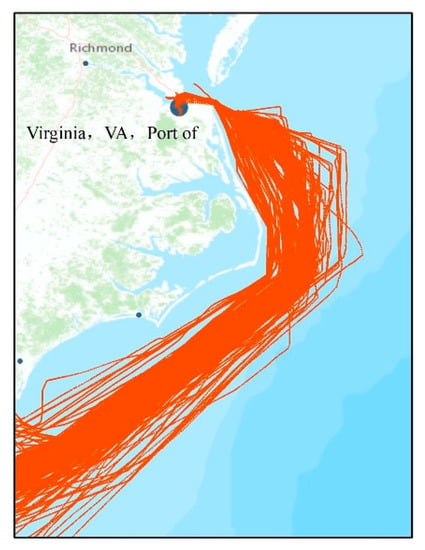
دادههای مسیر کشتی مورد استفاده برای ارزیابی، دادههای AIS بهدستآمده از MarineCadastre.gov بود. 35 ] بود.]. AIS یک سیستم مجهز به کشتی های بزرگ است که پیام ها را در فرکانس های زمانی مشخص به مرکز مدیریت ارسال می کند. دادههای AIS حاوی دادههای ثابت در مورد اطلاعات کشتی مانند هویت خدمات سیار دریایی (MMSI)، نام و اندازه و غیره، و دادههای پویا ثبت اطلاعات سفر مانند مکانها، مهرهای زمانی و سرعت روی زمین (SOG) و غیره است. نقطه مکانی-زمانی در ویژگی های داده های دینامیکی از جمله طول جغرافیایی، عرض جغرافیایی و مهر زمانی مربوطه تشکیل می شود. منطقه مورد مطالعه در آبهای شرقی ایالات متحده واقع شده است (از N31.8 ° تا N37.3 ° و W74.3 ° تا W78 °). مجموعه داده شامل 278 مسیر تکمیل شده از چندین نوع کشتی (بکسل، کشتی تفریحی، یدک کش، و کشتیهای باری) که بین تنگه فلوریدا و بندر ویرجینیا در چهار ماه متوالی از 1 می تا 31 اوت 2014 رفت و آمد داشتند. در فرآیند نمونهبرداری مجدد، مقدار ثابت فاصله زمانی بین دو نقطه مجاور روی 10 دقیقه تنظیم شد. ، با توجه به وضعیت قایقرانی کشتی عملی. مسیرهای قابل استفاده پس از پیش پردازش مشخص شده استشکل 5 .
ما از بخش مسیر ناقص دو ساعته برای پیشبینی مکانها در یک ساعت آینده استفاده کردیم (یعنی طول ورودی توالی مکان 13 و طول پیشبینی شش بود. ما بهطور تصادفی 10 درصد از مسیرها را به عنوان دادههای آزمون انتخاب کردیم و پس از پیش پردازش مسیر، در مجموع 31508 بخش مسیر برای آموزش مدل پیش بینی به دست آمد.
در فرآیند آموزش مدل، داده های آموزشی به صورت دسته ای به مدل BiRMDN وارد شدند. یکی از دستهها بهعنوان داده اعتبارسنجی برای تعیین اینکه آیا فرآیند آموزش همگرا میشود و چه زمانی خاتمه مییابد، خدمت میکرد. ما از بهینه ساز تخمین لحظه تطبیقی (آدام) [ 36 ] با نرخ یادگیری زوال برای بهینه سازی تابع هدف در فرآیند انتشار پس از طی زمان (BPTT) استفاده کردیم. احتمال ترک تحصیل برای مقابله با مشکل اضافه برازش روی 0.2 تنظیم شد.
مختصات مکان با طول و عرض جغرافیایی نشان داده می شود. ما از دو معیار عملکرد برای ارزیابی اثربخشی پیشبینی در هر مهر زمانی استفاده کردیم: میانگین خطای مطلق (MAE) و ریشه میانگین مربع خطا (RMSE):
جایی که x′i�′�و xi��به ترتیب نتیجه پیش بینی و حقیقت پایه را نشان می دهد. n�تعداد کل بخش های مسیر آزمایشی است.
4.2. تجزیه و تحلیل اثر پارامتر
ارزیابی تأثیر پارامترهای مهم بر عملکرد پیشبینی و تعیین پیکربندی بهینه مدل BiRMDN ضروری است. ما عملکرد تجربی مدلهایی را مقایسه کردیم که در آن سه پارامتر مهم با مقادیر مختلف از جمله تعداد لایههای پنهان LSTM دو طرفه تنظیم شدند. N�تعداد واحدهای LSTM در هر لایه L�و تعداد اجزای مخلوط در لایه MDN M�.
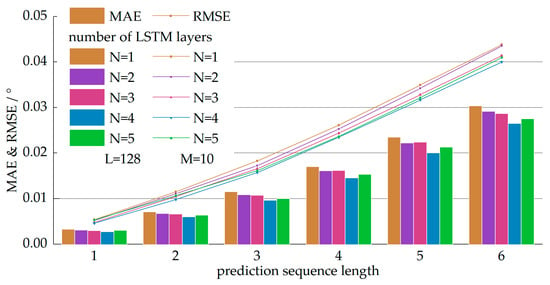
شکل 6 ، شکل 7 و شکل 8 عملکرد پیش بینی مدل ها را با مقادیر مختلف نشان می دهد. N�، L�، و Mم، به ترتیب. ما MAE و RMSE را در هر یک از شش مهر زمانی ارزیابی کردیم. مشاهده اینکه خطای پیشبینی با طولانیتر شدن طول پیشبینی افزایش مییابد، جای تعجب نداشت. شکل 6 عملکرد مدل ها را با تعداد متفاوتی از لایه های پنهان LSTM نشان می دهد که در آن دو پارامتر دیگر به صورت تنظیم شده بودند. L = 128�=128، M=10�=10. همانطور که در شکل 6 نشان داده شده است ، عملکرد پیش بینی با انباشته شدن لایه های LSTM بهتر شد. به طور کلی، نتایج پیشبینی بهدستآمده توسط شبکههای عمیقتر دقیقتر بود، بهویژه زمانی که طول پیشبینی طولانی بود. توجه داشته باشید که شبکه LSTM را می توان به عنوان یک شبکه عصبی عمیق حتی زمانی که تنها یک لایه وجود دارد، به دلیل عمق در بعد زمانی در نظر گرفت. بهترین عملکرد توسط شبکه با چهار لایه پنهان LSTM به دست آمد. بنابراین، ما انتخاب کردیم N=4�=4به عنوان مقدار بهینه تعداد لایه های پنهان LSTM.
به جز عمق شبکه، تعداد واحدهای LSTM در هر لایه نیز پیچیدگی شبکه و تعداد متغیرها را تعیین می کند که به طور قابل توجهی بر عملکرد پیش بینی تأثیر می گذارد. شکل 7 خطای پیشبینی مدلهایی را با تعداد واحدهای LSTM متفاوت در هر لایه نشان میدهد. N=4�=4و M=10�=10. بدیهی است که شبکه سبک وزن با 64 واحد LSTM در هر لایه به اندازه کافی برای انجام یک پیشبینی دقیق توانائی کافی را نداشت. عملکرد پیشبینی کلی مدلهای با 256 و 512 واحد نزدیک بود. با توجه به پیچیدگی شبکه، انتخاب کردیم L=256�=256به عنوان تعداد بهینه واحدهای LSTM در هر لایه.
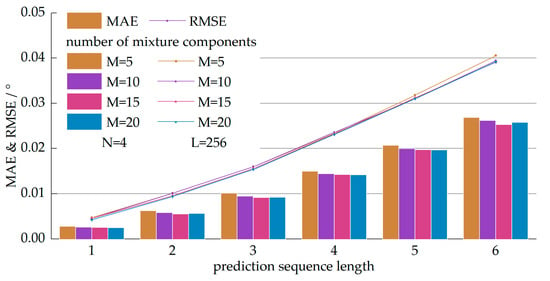
پس از تعیین پارامترهای معماری لایههای LSTM، مدلها را با تعداد متفاوتی از اجزای مخلوط در لایه MDN آزمایش کردیم. عملکرد آزمون در شکل 8 نشان داده شده است . اگرچه عملکرد کلی با افزودن اجزای مخلوط ارتقا مییابد، اثر ارتقاء در مقایسه با آن مشهود نبود N�و L�. عملکرد پیش بینی مدل ها با M=15�=15و M=20�=20تقریبا یکسان بودند تعداد متغیرهای قابل آموزش در لایه MDN متناسب بود M�. بنابراین، ما تعیین کردیم M=15�=15به عنوان تعداد بهینه اجزای مخلوط بر اساس مبادله بین عملکرد پیشبینی و حجم مجموعه متغیر.
پیکربندی پارامتر بهینه BiRMDN در جدول 1 آمده است.
4.3. مطالعه تطبیقی با سایر رویکردها
به منظور ارزیابی عملکرد مدل BiRMDN به طور نسبی، ما سه رویکرد پیشبینی پرکاربرد را برای مقایسه معرفی کردیم که شامل شبکه دو طرفه LSTM (BiLSTM)، شبکه عصبی عمیق با اتصال کامل (FCDNN) [ 37 ] و میانگین متحرک اتورگرسیو (ARMA) میشود. مدل [ 38 ].
شبکه BiLSTM همانطور که در بخش 3.3 توضیح داده شده است. تفاوت بین BiLSTM و BiRMDN در این واقعیت نهفته است که خروجی BiLSTM به جای پارامترهای توزیع احتمال مخلوط، مقدار مشخصی از افست های پیش بینی شده است. در این آزمایش، پیکربندی ساختار و پارامترهای مربوط به BiLSTM مانند BiRMDN بود.
شبکه عصبی کاملاً متصل اغلب برای مسائل پیشبینی استفاده میشود. برخلاف RNN، نورونهای یک لایه در یک شبکه عصبی کاملاً متصل مستقل از یکدیگر هستند. اتصالات فقط بین نورون های متعلق به لایه های مجاور وجود دارد. بنابراین، ویژگیهای ساختاری FCDNN عدم توانایی آن در یادگیری دانش زمینهای از توالی مکان را تعیین میکند. ما ساختار FCDNN را با همان پارامترهای BiRMDN ساختیم.
در مرحله پیش پردازش مسیر، دنباله مختصات مطلق را به دنباله افست تبدیل کردیم. مدل ARMA (میانگین متحرک اتورگرسیو) در مدلسازی و پیشبینی دنباله افست، که یک دنباله ثابت و بدون تمایل است، برتری دارد. ARMA از دو بخش تشکیل شده است: اتورگرسیو (AR) و میانگین متحرک (MA). در مرحله مدلسازی، ARMA هم ویژگیهای همبستگی خودکار و هم ویژگیهای نویز دنباله تاریخ را ضبط میکند، سپس از این ویژگیها برای پیشبینی در مرحله پیشبینی استفاده میکند.
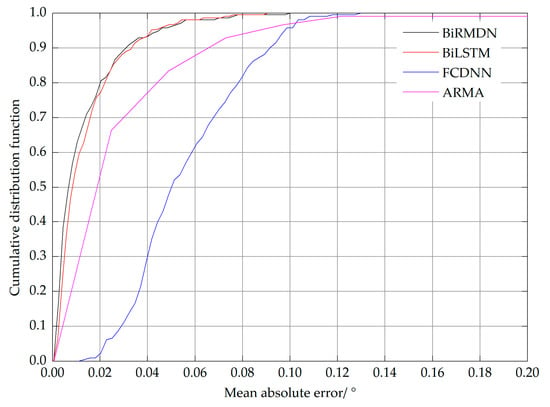
مقایسه عملکرد این آزمایش های پیش بینی در جدول 2 گزارش شده است . همانطور که در نشان داده شده است جدول 2 نشان داده شده استمدل BiRMDN ارائه شده در این کار بهترین عملکرد کلی را به همراه داشت. بدیهی است که گرایش تکاملی خطاهای پیشبینی این روشها در شش مهر زمانی مشابه بود. با افزایش طول پیش بینی، خطاها بزرگتر شدند. در مقایسه با گروههای FCDNN و ARMA، آزمایشهای مربوط به شبکه LSTM نشان داد که وابستگی مکانی-زمانی طولانیمدت و اطلاعات زمینهای گرفتهشده توسط LSTM برای پیشبینی بسیار مهم است. خطاهای پیشبینی BiLSTM زمانی که طول پیشبینی کوتاه بود، بهویژه در اولین مهر زمانی، کمتر از BiRMDN بود. با این حال، با پیشرفت زمان پیشبینی، خطاهای پیشبینی BLSTM سریعتر از BiRMDN متفاوت شد. ثابت شد که BiRMDN در پیشبینی بلندمدت برتر است.شکل 9 . گروه های BiRMDN و BiLSTM در مقایسه با FCDNN و ARMA منجر به بهبود عملکرد قابل توجهی شدند. همچنین در شکل 9 مشخص است که عملکرد کلی BiRMDN نسبت به BiLSTM برتر است. در آزمایشهای BiRMDN، میانگین خطای مطلق بیش از 90 درصد از بخشهای مسیر آزمون کمتر از 0.03 درجه و بیش از 80 درصد کمتر از 0.02 درجه بود.
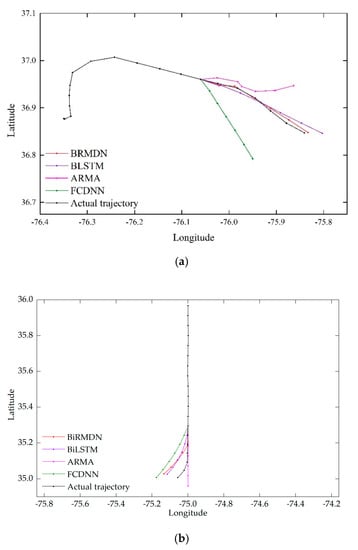
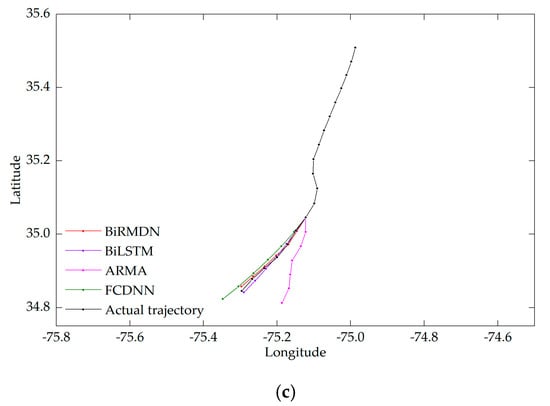
شکل 10 نتایج پیشبینی سه بخش مسیر آزمایشی را نشان میدهد. بخش مسیر نشان داده شده در شکل 10 در هر دو قسمت ورودی شناخته شده و قسمتی که باید پیش بینی شود منحنی است. بدیهی است که FCDNN و ARMA هر دو نتوانستند روند تکامل مسیر را به دلیل بی نظمی سیگنال ورودی یاد بگیرند. اگرچه نتایج پیشبینی BiLSTM تقریباً در یک جهت با مسیر واقعی بود، اما هنوز نتوانسته با نقطه خمش مطابقت کند. اختلاف بین حقیقت پایه و پیشبینی BiLSTM نیز در هر مهر زمانی آشکار بود. همانطور که انتظار میرفت، مکانهای پیشبینیشده BiRMDN به مکانهای واقعی نزدیکترین بودند، به خصوص در نقطه خمش. شکل 10b سناریویی را نشان می دهد که در آن قسمت شناخته شده مستقیم و یکنواخت است در حالی که قسمتی که باید پیش بینی شود خم شده است. پیش بینی این نوع عطف دشوار است. فقط BiRMDN، BiLSTM و FCDNN با موفقیت وقوع عطف را پیشبینی کردند. اگرچه خطاها برای همه روشها نسبتاً زیاد بود، BiRMDN هنوز نزدیکترین نتایج را به همراه داشت. شکل 10c یک مسیر یکنواخت با یک رادیان کوچک را نشان می دهد که BiRMND، BiLSTM و FCDNN همگی آن را به خوبی پیش بینی کردند. علاوه بر این، خطاهای پیشبینی BiRMDN کمترین میزان را داشت.
تجسم خروجی توزیع مخلوط گاوسی به درک مکانیسمی که توسط BiRMDN پیشبینی مکان را انجام میدهد کمک میکند. ما فرآیند نمونه برداری برای به دست آوردن نتایج نهایی از توزیع مخلوط را در شکل 11 نشان می دهیم . همانطور که در شکل 11 نشان داده شده است ، نقاط قرمز و نقاط سبز به ترتیب نشان دهنده مکان های ورودی و حقیقت زمین هستند. کانتور توزیع چگالی احتمال نرمال شده است. هنگامی که بخش مسیر ناقص به مدل تغذیه می شود، مجموعه ای از پارامترهای توزیع مخلوط گاوسی تولید می شود. همانطور که در شکل 11 نشان داده شده است، این پارامترها بیشتر برای مدل سازی توزیع هر مکان پیش بینی شده استفاده می شوندآ. سپس، استراتژی رولت را بر اساس وزن ها به کار گرفتیم π�برای تعیین اینکه کدام جزء گاوسی نتایج پیشبینی نهایی را ارائه میکند. مولفه گاوسی انتخاب شده کانتور نشان داده شده در شکل 11 ب است. در نهایت، ما مکانهای پیشبینیشده نهایی، نقاط صورتی نشاندادهشده در شکل 11c را با نمونهبرداری از توزیع گاوسی انتخابی به دست آوردیم.
5. بحث و نتیجه گیری
ما این مقاله را به روش پیشبینی مکان به روش یادگیری عمیق اختصاص دادیم که هسته اصلی آن ساخت مدل BiRMDN بود. این روش مکان های آینده اجسام متحرک را بر اساس مسیر کاوش پیش بینی می کرد. یک روش استخراج مسیر شامل پیش پردازش مسیر، ساخت مدل BiRMDN و پس پردازش ارائه شد. برای ارزیابی این روش از مجموعه داده مسیر کشتی استفاده شد. ما تجزیه و تحلیل پارامتر را برای تعیین پیکربندی بهینه BiRMDN در آزمایشها انجام دادیم. در مطالعه مقایسه ای با سایر تکنیک های پرکاربرد، روش ما نتایج امیدوارکننده و بهترین عملکرد را به همراه داشت که نشان دهنده برتری BiRMDN است.
مدل BiRMDN دارای سه ویژگی برجسته در مقایسه با روش های قبلی است. اول، توانایی یادگیری وابستگی طولانی مدت و اطلاعات متنی مسیرها را دارد که به طور قابل توجهی دقت پیش بینی را بهبود می بخشد. دوم، خروجی به شکل توزیع احتمال مخلوط در مدلسازی مسیرها کارآمد است. پیشبینی فازی مکانها به رفتار تحرک واقعی نزدیکتر است. این مدل همچنین می تواند مسئله چالش برانگیز پیش بینی مختصات با ارزش واقعی را حل کند و از نفرین ابعاد جلوگیری کند. در نهایت، انتظار میرود که این مدل به راحتی در سناریوهای مختلف پیادهسازی شود، زیرا فرآیند یادگیری خودکار و بدون مهندسی ویژگیهای دستساز است.
این کار یک روش معمولی برای برنامه های کاربردی پیش بینی مکان ارائه می دهد که می تواند در بسیاری از زمینه های عملی مانند نظارت بر ترافیک و هشدار اولیه، تشخیص مسیر غیرعادی و غیره کمک کند. برای کارهای آینده، مدل پیش بینی را می توان با افزودن اطلاعات بیشتر گسترش داد. اطلاعات تلفیقی از بافت مکانی و زمانی و معنایی برای انجام وظایف پیشبینی در سطوح مختلف سلسله مراتبی.







بدون دیدگاه