1. معرفی
مدلسازی گسترش اپیدمی بیماریها اغلب نیازمند اجرای یک روش جغرافیایی مستقل از بیماری مورد مطالعه است. با این حال، اغلب فقط مطالعات محلی و غیر فضایی رفتار پاتوژن ها انجام شده است. این مقاله نشان می دهد که چگونه می توان چنین پیاده سازی تخصص جغرافیایی را با استفاده از مثال به حداقل رساندن درمان های قارچ کش به دست آورد.
در بخش کشاورزی، همیشه خطر کاهش عملکرد به دلیل آلودگی های قارچی وجود دارد. برای کاهش این خطر، از محصولات حفاظتی گیاهی تا حد قابل توجهی استفاده شده است. اینها اغلب به طور منظم استفاده می شوند تا از آلودگی احتمالی جلوگیری شود. در سال 2016، این منجر به استفاده از 149430 تن قارچ کش و باکتری کش در کشاورزی در تمام ایالت های اتحادیه اروپا شد [ 1 ]. به منظور کاهش میزان استفاده از قارچ کش ها، دستورالعمل 2009/128/EC توسط پارلمان اروپا [ 2 ] برای دستیابی به استفاده پایدارتر از آفت کش ها به تصویب رسید.
یک رویکرد برای رسیدن به این هدف، کاهش کاربرد منظم قارچکشها با پیشبینی هدفمند هجومهای خطرناک قریبالوقوع است. در حال حاضر، مدلهای مختلفی برای پاتوژنهای مختلف وجود دارد، اما بیشتر مدلها تنها اثرات منفرد را توصیف میکنند و رویدادهای پیچیده در این زمینه را نشان نمیدهند [ 3 ، 4 ، 5 ، 6 ، 7 ، 8 ]. علاوه بر اثرات فردی تعیین شده در شرایط آزمایشگاهی، در سال های اخیر تلاش های زیادی برای شناسایی فرآیندهای عفونت با استفاده از روش های یادگیری ماشینی صورت گرفته است. با این حال، ماهواره ها و ارتوفوتوها عمدتاً برای شناسایی آلودگی های موجود استفاده شده اند [ 9 ، 10 ], 11 , 12 ].
هدف از این مطالعه تشخیص آلودگی نیست، بلکه ایجاد یک پیشبینی زمانی و مکانی از گسترش اپیدمی آلودگیها است که به ترکیبی بین رشتهای از روشها و دانش آسیبشناسی گیاهی و جغرافیایی نیاز دارد. روش توسعه یافته برای این منظور با استفاده از مثال سفیدک پودری، قارچی که گندم را آلوده می کند، نشان داده خواهد شد. برای گروه هدف مهمتر است که اگر مدل آلودگی مربوط به عملکرد را پیشبینی نکند، هیچ آلودگی رخ نمیدهد، برخلاف مدلی که به اشتباه یک آلودگی را پیشبینی میکند. برای دستیابی به این هدف، علاوه بر مجموعه دادههای متناظر متشکل از چندین سال دادههای آلودگی و آبوهوا، مشخص شد که کدام روشهای منطقهبندی و روشهای یادگیری ماشین برای انجام آن ضروری است.
2. مواد و روشها
2.1. منطقه مطالعه
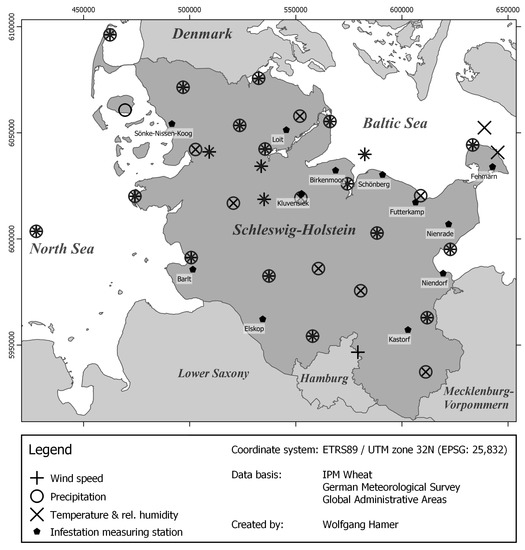
Schleswig-Holstein به عنوان یک منطقه مطالعه نمونه استفاده شد. شمالی ترین ایالت فدرال آلمان ( شکل 1 ) بین دریای شمال در غرب و دریای بالتیک در شرق قرار دارد.
پس از فرنزله [ 13 ]، منطقه تحقیقاتی به باتلاق ها و دشت های گلی در غرب، بقایای مورین های Saalian در شرق باتلاق ها، دشت های خارج از آب در مرکز، و ارتفاعات در شرق تقسیم شد که با یک سری پیشرفت های یخی مشخص می شود. بالاترین ارتفاع منطقه مورد مطالعه 164 متر، در ارتفاعات شرقی بود. به دلیل ترکیب خاک در منطقه مورد مطالعه، گندم عمدتاً در باتلاقها و گلزارها و ارتفاعات شرقی کشت میشود. در بقایای مورین های Saalian و دشت های بیرون زده، واقع در مرکز شلزویگ-هولشتاین، گندم کمتری کشت می شود [ 14 ].
آب و هوای این منطقه توسط غرب و موقعیت آن در ناحیه انتقالی بین اقیانوس اطلس شمالی و فلات قاره اروپا تعیین می شود [ 15 ]. تأثیر متقابل این تأثیرات در سیر فصلی آب و هوا، با بهار خنک و نسبتاً خشک، تابستان بارانی و نسبتاً گرم، و پاییز و زمستان آفتابی و معتدل منعکس می شود [ 15 ]. میانگین دماها به طور متوسط طولانی مدت بین 1.7 متغیر است ∘∘درجه سانتی گراد در زمستان، با دمای بالاتر در سواحل، و 16.5 ∘∘C در تابستان، با نفوذ قاره ای قوی تر و دماهای بالاتر در جنوب [ 16 ]. میانگین درازمدت بارندگی 809 میلیمتر در ساعت است که در بخش مرکزی و غربی منطقه مورد مطالعه مقادیر بالاتری دارد [ 16 ]. در نتیجه غرب، بیشترین سرعت باد منطقه مورد مطالعه در سواحل غربی است. به طور متوسط، سرعت باد در حدود 4.3 متر بر ثانیه (در 10 متر) ثبت شده است [ 16 ].
2.2. منابع داده های مورد استفاده
برنامه پایش IPM (مدیریت یکپارچه آفات) گروه آسیب شناسی گیاهی دانشگاه کیل، وقوع و پویایی چندین پاتوژن را در شلزویگ-هولشتاین از سال 1993 (به جز سال 2004) مورد مطالعه قرار داده است [ 17 ]، و در نتیجه مجموعه داده های منحصر به فردی ایجاد کرده است. مشاهدات میدانی رویدادهای آلودگی شکل 1 ایستگاه های نظارتی مورد استفاده از سال 1997 را نشان می دهد. توزیع شده در مناطق کشت گندم، نشان دهنده وضعیت بیماری در منطقه مورد مطالعه برای کاربرد نمونه رویکرد پیش بینی است. همانطور که توسط Verreet و همکاران توضیح داده شده است. [ 17]، روش نظارت به صورت هفتگی در طول دوره رویشی، از مرحله رشد (GS) 30 تا 75 به بعد در تمام سطوح برگ (F – 7 = هشت برگ بالایی تا F = برگ پرچم) انجام شد [ 18 ]]. در هر کرت مورد مطالعه، 30 بوته انتخاب شد و میزان بروز بیماری (درصد گیاهان یا برگهای آلوده در هر موقعیت برگ) و شدت بیماری (درصد سطح برگ پوشیده از پوسچول) سفیدک پودری و سایر بیماریها با شمارش ساختارهای قارچی خاص پاتوژن تعیین شد. . از آنجایی که مفهوم برنامه پایش IPM شامل مقایسه ذخایر گیاهی تیمار شده با قارچکشها در برابر ذخایر تیمار نشده بود، میتوان از دادههای کنترل برای رویکرد مدلسازی استفاده کرد. در حالی که بیشتر واریتههای گندم مورد مطالعه فقط برای یک زمان محدود در دسترس بودند، واریته Ritmo برای امکان مقایسه در طول دوره آزمایشی استفاده شد. کپک پودری به عنوان نمونه ای از کاربرد رویکرد مدل سازی انتخاب شد. در ادبیات کنونی به خوبی توصیف شده است، اما به دلیل رفتار بادکش پیش بینی آن نیز دشوار است. گسترش این پاتوژن عمدتاً تحت تأثیر شرایط آب و هوایی است. هاگ های بیماری زا برای انتشار به سرعت باد نیاز دارند، اما نمی تواند خیلی زیاد باشد، وگرنه هاگ ها به گیاهان نمی چسبند.19 ]. عفونت ناشی از این هاگ ها عمدتاً تحت تأثیر دمای هوا است [ 20 ، 21 ]: مقدار رطوبت نزدیک به 100٪ از پاتوژن پشتیبانی می کند و منجر به عفونت سریع می شود [ 21 ، 22 ]. بارش همچنین می تواند بر عفونت گیاه تأثیر بگذارد، اما تأثیر بارندگی بر عفونت معمولاً ناچیز است، به جز باران شدید، که می تواند هاگ ها را از سطوح گیاه پاک کند [ 23 ]. علاوه بر آب و هوا، وضعیت رشد گیاه نیز در فرآیند آلودگی مهم است. این را می توان به عنوان مثال با مقادیر دما که توسط یک تابع خاص گیاه اصلاح شده و جمع می شود (واحد حرارتی تجمعی (CTU)) نشان داد [ 24]. برای دامنه کار فعلی، بهجای پیشبینی بروز واقعی بیماری سفیدک پودری، روی تشخیص اینکه آیا یک رویداد آلودگی شدید رخ میدهد یا خیر، که با تجاوز از مقدار آستانه کنترل بیماری خاص پاتوژن پیشبینی شده بود، تمرکز کردیم. Klink [ 25 ] و Verreet و همکاران. [ 17 ] از مقدار آستانه 70٪ بروز بیماری برای شروع یک تیمار قارچ کش در گیاه استفاده کرد تا از آسیب مربوط به عملکرد توسط سفیدک پودری جلوگیری شود. بنابراین، تجاوز از این آستانه در روش ما برای پیشبینی رویدادهای آلودگی شدید استفاده شد.
برای تجزیه و تحلیل وضعیت اقلیمی و آب و هوایی در منطقه مورد مطالعه، مجموعه داده های بررسی هواشناسی آلمان از سرور داده باز [ 16 ] در دسترس است. سرور داده باز داده های آب و هوایی منطقه ای را به مدت 30 سال و برای سال های پس از 1995، داده های ساعتی آب و هوا را برای چندین مکان در شلزویگ-هولشتاین و بقیه آلمان ارائه می دهد. ایستگاه های اندازه گیری بررسی هواشناسی آلمان در شکل 1 نشان داده شده است. تعداد ایستگاه های موجود بسته به سال و پارامتر در نظر گرفته شده متفاوت است. در سال ۲۰۱۹ دما و رطوبت در ۲۶ ایستگاه، بارندگی در ۳۵ ایستگاه و سرعت باد در ۲۲ ایستگاه اندازهگیری شد.
2.3. روش های اعمال شده
مطابق با هدف این مقاله، یک رویکرد مدلسازی به عنوان ترکیبی از تکنیکهای مختلف درونیابی و یادگیری ماشین توسعه داده شد. یک نمای کلی از نحوه عملکرد این رویه ها در زیر آورده شده است.
روش های درونیابی فضایی به روش های قطعی و زمین آماری [ 26 ] تقسیم می شوند. در این تحقیق علاوه بر روش وزن دهی معکوس فاصله قطعی، از روش های زمین آماری کریجینگ معمولی، کریجینگ با رانش خارجی و کریجینگ تصادفی جنگل استفاده شد:
-
وزن دهی فاصله معکوس (IDW) یک روش متداول درونیابی فضایی قطعی است که به عنوان میانگین وزنی مقادیر نقطه داده تعریف می شود [ 27 ]. وزن خود تابعی از فاصله است:
جایی که z^(ایکس0)�^(ایکس0)مقداری است که باید در محل تخمین زده شود ایکس0ایکس0، z(ایکسمن)�(ایکسمن)مقدار شناخته شده در یک مکان خاص است ایکسمنایکسمن، دمندمنفاصله بین نقاط داده تخمینی و شناخته شده، p توان فاصله معکوس و n تعداد نقاط داده شناخته شده نزدیک به مکان تخمینی است. اگرچه IDW همبستگی مکانی متغیر هدف را مدل نمی کند (همانطور که روش های شرح داده شده در زیر انجام می دهند)، این روش هنوز هم می تواند به نتایج خوبی دست یابد. واگنر و همکاران [ 28 ] و بورخس و همکاران. برای مثال، [ 29 ] دریافت که درون یابی IDW بهترین نتایج را برای درونیابی بارش به دست آورد.
-
کریجینگ معمولی (OK) برای اولین بار توسط کریج [ 30 ] ایجاد شد و توسط ماترون [ 31 ] از نظر ریاضی مشتق شد . با استفاده از این روش درونیابی آماری، وابستگی مکانی متغیر فقط فرض نمیشود (همانطور که با روش IDW میشود)، بلکه در منطقهبندی تحلیل و ادغام میشود. تجزیه و تحلیل وابستگی فضایی مبتنی بر تنوع نگاری است: شباهت جفتهای نقطه (نیمه واریانس) با فاصله آنها مقایسه میشود و تابعی با نیمه واریانس تطبیق داده میشود که با افزایش فاصله ماترون کاهش مییابد [ 31 ]. با استفاده از این مدل واریوگرام، می توان وزن های ( λمن�من) که توسط آن مقادیر نقاط اطراف ( z(ایکسمن)�(ایکسمن)) بر اساس معادله کریگ ( 2 ) ضرب می شوند [ 31 ، 32 ]:
-
کریجینگ با رانش خارجی (KED) از ادغام متغیرهای مستقل در فرآیند درونیابی کریجینگ استفاده می کند. اصل این روش توسط Matheron [ 33 ] به عنوان ترکیبی از OK و رگرسیون خطی چندگانه متغیر وابسته (پارامتر مورد نظر) با متغیر مستقل (مثلاً مختصات یا یک مدل ارتفاع) ایجاد شد. همانطور که در رابطه ( 3 ) توضیح داده شد، یک رگرسیون خطی برای پیش بینی متغیر وابسته توسط متغیرهای مستقل (از قبل منطقه ای شده) به متغیرها برازش داده می شود. پیشبینی مکانی متغیر وابسته با استفاده از مدل رگرسیون شروع میشود ( متر^(ایکس0)متر^(ایکس0)) بر روی متغیرهای مستقل منطقه ای شده. به منظور افزایش دقت پیش بینی، روش کریجینگ ( z^(ایکس0)�^(ایکس0)مانند معادله ( 2 )، برای درونیابی باقیمانده های مدل رگرسیون استفاده می شود. سپس این دو مجموعه داده مکانی برای محاسبه متغیر هدف ( ه^(ایکس0)ه^(ایکس0)):
ادغام متغیرهای کمکی بسته به تأثیر این متغیرها می تواند به نتایج بسیار خوبی منجر شود. به همین ترتیب، KED به ویژه برای درون یابی دما [ 34 ] و سرعت باد [ 35 ] مناسب است.
-
کریجینگ تصادفی جنگل (RFK) مشابه روش KED است. با این حال، به جای رگرسیون خطی چندگانه، رابطه بین متغیرهای وابسته و مستقل با یک جنگل تصادفی نشان داده میشود. عملکرد چنین جنگل تصادفی با جزئیات بیشتری در توضیح روش های یادگیری ماشین توضیح داده شده است.
علاوه بر روش های درون یابی فضایی، روش های مختلف یادگیری ماشین استفاده شد. اینها معمولاً به تکنیک های بدون نظارت و نظارت شده تقسیم می شوند. رویه های نظارت نشده به طور مستقل الگوها را جستجو می کنند، در حالی که رویه های نظارت شده به یک متغیر وابسته (مانند هجوم) نیاز دارند که برای آن همبستگی با متغیرهای مستقل بررسی می شود. در این کار از سه روش یادگیری ماشینی نظارت شده استفاده شد:
-
درختهای تصمیم (DT) مبتنی بر ایده پارتیشنبندی بازگشتی هستند – دادهها را به طور مکرر به زیر مجموعههای کوچکتر تقسیم میکنند تا زمانی که در مورد متغیر هدف همگن شوند. از روشهای مختلف الگوریتمی ایجاد شده برای یافتن تقسیم ایدهآل، الگوریتم C5.0 DT (که توسط راس کوینلان به عنوان بهبود الگوریتم C4.5 [ 36 ] توسعه داده شد)، که از مفهوم آنتروپی برای ایجاد زیرمجموعههایی با حداکثر خلوص استفاده میکند. رایج ترین است. آنتروپی برای یک زیر مجموعه خاص به صورت زیر محاسبه می شود:
که در آن S زیر مجموعه است، c تعداد سطوح کلاس و پمنپمننسبت مقادیر در کلاس خاص است [ 37 ]. بنابراین، کیفیت تقسیمها بر اساس مقادیر آنتروپی مجموع همه زیر مجموعهها است:
با آنتروپی کل ( T ) و وزن ( wمن�من) با نسبت نمونه ها در زیر مجموعه به دست می آید [ 37 ]. مقادیر آنتروپی تقسیمهای پتانسیل با یکدیگر وزن میشوند و در نتیجه به دست آوردن اطلاعات شکافهای بالقوه میرسند که از بین آنها یکی با بالاترین بهره اطلاعات انتخاب میشود.
-
جنگلهای تصادفی (RF) که توسط Breiman [ 38 ] توسعه یافتهاند، DT فوقالذکر را با روش بستهبندی ترکیب میکنند، که از نمونهگیری بوت استرپ – نمونهگیری تصادفی با روش جایگزینی – برای تولید پیشبینیهای چندگانه برای یک مجموعه داده با استفاده از همان روش پیشبینی استفاده میکند [ 39 ] . نتایج منفرد در یک پیشبینی نهایی با استفاده از یک رأی کثرت برای طبقهبندی و مقدار متوسط برای خروجیهای عددی ترکیب میشوند. الگوریتم RF زیرمجموعه های تصادفی مجموعه داده را در هر گره درخت در حال توسعه ایجاد می کند [ 38 ]. تقسیمبندیها با استفاده از تخمینهایی ارزیابی میشوند، که درختان رشد یافته در حال انجام را در مواردی که هنوز در مدل ادغام نشدهاند، آزمایش میکنند تا تخمین خطا ارائه شود [ 38 ]]. در نتیجه، جنگلی از DT ها به طور تصادفی رشد می کنند. ترکیب این درختان به عنوان میانگین برای وظایف رگرسیون و به عنوان متداول ترین مقدار برای وظایف طبقه بندی، منجر به پیش بینی نهایی مدل RF می شود. فرض بر این است که RFها کمتر مستعد بیش از حد برازش هستند، زیرا تنها بخشهایی از مجموعه دادهها برای تولید درختهای منفرد استفاده میشوند [ 40 ]. علاوه بر این، فرض بر این است که آنها در یادگیری از مجموعه داده های بزرگتر با تعداد زیادی ویژگی بهتر هستند [ 37 ].
-
درختان تصمیم تقویت شده (BDT) از روش تقویت استفاده می کنند. مشابه روش بسته بندی که در بالا توضیح داده شد، روش تقویت تعدادی DT [ 41 ] ایجاد می کند. با این حال، برخلاف درختهای تصمیم RF، درختهای BDT از مجموعههای زیر دادههای تصادفی تشکیل نمیشوند. در ابتدا، تنها یک DT بر اساس کل مجموعه داده تولید می شود. وزن نمونههای طبقهبندیشده اشتباه در این درخت اول، پس از ایجاد درخت بعدی افزایش مییابد [ 42 ]. این روند تا رسیدن به تعداد درختان درخواستی تکرار می شود. پیش آگهی نهایی این روش با تصمیم اکثریت DTهای تولید شده داده می شود.
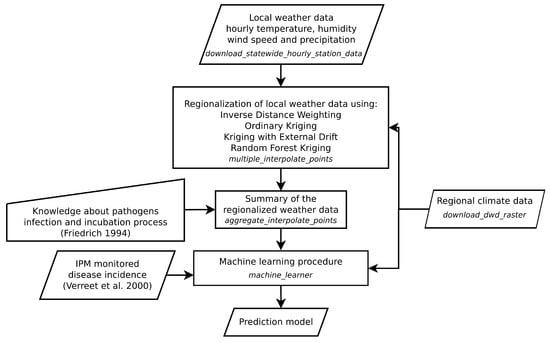
2.4. رویکرد مدلسازی
این بخش توضیح می دهد که چگونه روش های مختلف درون یابی فضایی و تکنیک های یادگیری ماشین که در بخش قبل توضیح داده شد در طرح فرآیند رویکرد پیش بینی پیشنهادی ترکیب می شوند. شکل 2)). کاربرد این طرح مستلزم آن است که دادههای پارامترهای مستقل در دسترس باشد که بر متغیر وابسته (یعنی آلودگی بررسیشده) تأثیر میگذارد. این داده ها همچنین باید یک توالی زمانی را منعکس کنند، اگر این برای آلودگی مورد مطالعه فرض شود. اگر این داده ها به صورت محلی در دسترس باشند، اولین گام طرح، درون یابی نقاط با استفاده از روش های منطقه بندی قطعی یا زمین آماری است. مرحله دوم، اختصاص مقادیر مربوط به پارامترهای مستقل منطقهای شده به رویدادهای عفونت است. این امر در صورتی ضروری است که آلودگی ناشی از شرایط فعلی نباشد، بلکه در اثر شرایط یک دوره گذشته ایجاد شود. این رویکرد امکان تجمیع داده های ساعتی چند روزه را با استفاده از مقادیر میانگین، حداقل و حداکثر فراهم می کند. انتساب آنها به یک آلودگی مشاهده شده چند روز بعد. این می تواند بسته به آلودگی مورد مطالعه متفاوت باشد.
با دادههای مستقل اصلاح شده به این روش و دادههای هجوم، در نهایت یک الگوریتم یادگیری ماشینی تحت نظارت آموزش داده شد. داده های آلودگی را می توان به عنوان متریک یا متغیر در نظر گرفت که بر اساس خطر طبقه بندی می شوند. با مدل تولید شده، بر اساس داده های مستقل به روز شده روزانه، می توان پیش بینی فضایی آلودگی یا احتمال کلاس های مربوطه را انجام داد.
2.5. مورد استفاده: رویدادهای آلودگی به کپک پودری را پیش بینی کنید
فصل های قبلی روش های اعمال شده و ترکیب این روش ها در رویکرد مدل سازی را تشریح کردند. سپس رویکرد مدلسازی با استفاده از آن برای پیشبینی کپک پودری پاتوژن ( بخش 2.2 ) برای منطقه مورد مطالعه Schleswig-Holstein ( بخش 2.1 ) آزمایش شد. هدف، پیشبینی احتمال رویدادهای آلودگی شدید بود که با طبقهبندی فراتر از مقدار آستانه 70 درصد بروز بیماری تعریف شد ( بخش 2.2 ). کد کامپیوتری که برای اعمال طرح فرآیند (همانطور که در زیر توضیح داده شد) و تولید نتایج ارائه شده در این مقاله برنامه ریزی شده است، در داده های تکمیلی موجود است . زبان برنامه نویسی R [ 44 موجود است ]، با اعمال توابع بسته papros [43 ] استفاده شد.
ابتدا، به دنبال توصیف رویکرد مدلسازی ( بخش 2.4 )، دادههای آب و هوای محلی ساعتی (از سرور داده باز [ 16 ]) درونیابی شدند. پارامترهای آب و هوا CTU، رطوبت، بارندگی، دما و سرعت باد در نظر گرفته شدند، زیرا مشخص شد که این پارامترها مربوط به فرآیند عفونت هستند ( بخش 2.2).). در مطالعه ما، هیچ انطباق فردی مدلها با خود همبستگی مربوطه امکانپذیر نبود، زیرا درونیابی پنج پارامتر برای هر ساعت از سالهای 1997-2019 انجام شد. بنابراین، درون یابی خودکار با استفاده از روش های شرح داده شده در بخش قبل مورد آزمایش قرار گرفت. متغیرهای کمکی مورد استفاده برای روشهای KED و RFK، طول و عرض جغرافیایی، و دادههای آب و هوای منطقهای (1981-2010) بودند که شامل میانگین دمای هوا [ 45 ] از مرکز دادههای آب و هوا برای درونیابی دما بود. واحد حرارتی تجمعی (CTU)، شاخص خشکسالی محاسبه شده بر اساس پیتزش و بیسلی [ 46 ]، برای درونیابی رطوبت. میانگین بارش برای درونیابی بارش؛ و میانگین سرعت باد [ 47] برای درونیابی سرعت باد. برای تعیین اینکه کدام یک از روشها برای این منظور مناسبتر است، اعتبارسنجی متقاطع ترک یک خروجی (LOOCV) برای هر یک از پارامترهای آب و هوا در 500 مقدار ساعتی تصادفی انتخاب شده انجام شد. این بدان معناست که برای هر یک از 500 اجرا برای هر پارامتر، هر ایستگاه سنجش آب و هوا حذف شد و با سایر ایستگاه هایی که اطلاعات پارامتر را در ساعت مربوطه داشتند، پیش بینی مکانی انجام شد. سپس برای هر ساعت و پارامتر آب و هوا، خطاهای میانگین مربعات ریشه نرمال شده (NRMSE) محاسبه شد که منجر به 500 مقدار NRMSE برای هر پارامتر در میانگین 15 مکان شد. پس از ارزیابی روش بهینه برای هر پارامتر، از این برای درونیابی دما، CTU، رطوبت، سرعت باد و بارش در مکانهای ایستگاههای اندازهگیری آلودگی استفاده شد.
در مرحله دوم، داده های آب و هوای منطقه ای خلاصه شد ( جدول 1 بر اساس دانش عفونت پاتوژن و فرآیندهای جوجه کشی ( بخش 2.2 ). بروز بیماری مشاهده شده در یک روز ناشی از آب و هوای همان روز نیست، بلکه بیشتر از شرایط آب و هوایی قبلی است. از آنجایی که تأثیر اصلی محیط در طی فرآیند آلودگی اتفاق می افتد، شناسایی و تجمیع شرایط آب و هوایی در حین آلودگی و مقایسه آنها با وقوع مشاهده شده پاتوژن چند روز بعد بسیار جالب است. این دوره بین پایان عفونت و مشاهده پاتوژن به عنوان انکوباسیون شناخته می شود. میانگین آلودگی و مدت زمان جوجه کشی برای سفیدک پودری، بسته به میانگین دمای هوا، با استفاده از معادلات فردریش محاسبه شد. 4 ] محاسبه شد.]، که منجر به یک زمان عفونت دو روزه و زمان انکوباسیون هفت روزه شد. بنابراین، دادههای آب و هوای دو روز با مقادیر حداقل، میانگین و حداکثر برای هر سلول شطرنجی برای هر متغیر آبوهوا خلاصه شد و به تاریخ هفت روز بعد اختصاص داده شد. بنابراین، وضوح ساعتی داده های آب و هوا به وضوح روزانه در دسترس توسط برنامه IPM کاهش یافت. این برای هر مشاهده در میدان رفتار پاتوژن در برنامه پایش IPM انجام شد. علاوه بر خلاصه دادههای هواشناسی، واحدهای دمای روزانه و تجمعی برای دوره آلودگی از اول اکتبر سال گذشته محاسبه شد. معادلات مورد استفاده برای انجام این کار بر اساس سلطانی و سینکلر [ 24 ] بود]. نتایج حاصل از مرحله دوم داده های آب و هوایی خلاصه شد. واحد دمای روزانه و تجمعی برای هر یک از ایستگاه های نظارت IPM در شکل 1 ارائه شده است و برای هر روز از 20 سال گذشته در Schleswig-Holstein اعمال می شود. سپس این داده ها به بروز بیماری مشاهده شده هفت روز پس از روزهای خلاصه شده اختصاص داده شد. به همین ترتیب، داده های آب و هوای منطقه و اطلاعات ارتفاع [ 48 ] به بروز بیماری مشاهده شده اختصاص داده شد.
سومین مرحله از فرآیند مدلسازی، استفاده از تکنیکهای یادگیری ماشین بود. همانند روشهای درونیابی فضایی، مناسب بودن روش یادگیری ماشین بسته به متغیر هدفی که باید مدلسازی شود و متغیرهای کمکی در نظر گرفته میشود، متفاوت است. یک تکنیک یادگیری نظارت شده با توانایی حل وظایف طبقه بندی و رگرسیون با تعداد زیادی متغیر مستقل برای پیش بینی رویدادهای آلودگی مورد نیاز است. درختان طبقه بندی و رگرسیون این الزامات را برآورده می کنند [ 37 ]. آنها همچنین این مزیت بزرگ را دارند که نشان میدهند چگونه و به کدام متغیرها پیشبینی مدل بستگی دارد. با این حال، به گفته بریمن [ 38]، دقت پیشبینیها را میتوان با استفاده از روشهای بستهبندی، مانند روشهایی که در جنگلهای تصادفی استفاده میشود، بهبود بخشید. با این حال، با استفاده از روش کیسهبندی، بینشی که رویه DT ارائه میدهد کاهش مییابد، زیرا دیگر فقط درختی نیست که موضوع تصمیمگیری است، بلکه تعداد زیادی درخت است که موضوع تصمیم اکثریت است. بنابراین، روش هایی مانند دقت کاهش میانگین برای به دست آوردن بینش در مورد اهمیت متغیرهای مدل استفاده شده است [ 49 ]. بر این اساس، مقایسه روشهای یادگیری ماشین فهرستشده در بخش 2.3 باید برای تعیین اینکه آیا مزیت ذکر شده توسط بریمن [ 38 ] استفاده شود.] را می توان به پیش بینی موارد سفیدک پودری نیز منتقل کرد یا اینکه آیا این اتفاق در اینجا رخ نمی دهد. با این حال، علاوه بر روش یادگیری ماشینی مورد استفاده، هدف فرآیند یادگیری را نباید در این مقایسه نادیده گرفت. روشهای یادگیری ماشین معمولاً با هدف ایجاد مدلی با بیشترین دقت ممکن آموزش داده میشوند – مانند تابع C5.0 [ 50 ] یا تابع جنگل تصادفی [ 51 ].]. در مورد پیشبینی رویدادهای آلودگی، تجاوز غیرقابل تشخیص از مقدار آستانه کنترل بیماری جدیتر از پایین آمدن آستانه تشخیص دادهشده بهعنوان بیش از حد در نظر گرفته میشود. بنابراین، ما تابعی ایجاد کردیم که تعداد درختها را در BDT و تعداد متغیرهایی که بهطور تصادفی بهعنوان کاندید برای هر تقسیم و وزن کلاسها برای الگوریتم RF با استفاده از ناحیه زیر منحنی مشخصه عملکرد گیرنده (ROC) نمونهگیری شدند، تغییر داد. ROC نرخ مثبت واقعی مدل (میزان مازاد بر پیشبینی صحیح) را در مقابل نرخ مثبت کاذب (نرخ مازاد پیشبینیشده اشتباه) ترسیم میکند [ 52]. تابع ما وزنی را جستجو می کند که بیشترین ناحیه ممکن را زیر منحنی ROC به دست آورد تا مدلی نه تنها با دقت خوب بلکه با حساسیت خوب نیز ایجاد کند. که نسبت مقادیر مثبت واقعی ترکیبی از مقادیر مثبت واقعی و منفی کاذب است، نه تجاوزهای پیش بینی شده [ 53 ]]. این جستجو در داخل تابع با اعتبار سنجی نگهدارنده داده های وارد شده برای ایجاد مدل انجام شد. اینها ابتدا با توجه به سالهای موجود به نسبت 70:30 تقسیم شدند. با 70 درصد دادهها، مدلهایی با وزنهای متفاوت به صورت تکراری تولید شدند. بر اساس 30 درصد دادههای باقیمانده، ناحیه مشخصه عملیاتی دریافتی زیر مقدار منحنی (ROC AUC) هر مدل بررسی شد و در نهایت وزندهی با بالاترین مقدار برای تولید مدلی بر اساس تمام دادههای استفاده شده در این مرحله استفاده شد. .
مشابه استفاده از LOOCV برای درونیابی فضایی داده های آب و هوا، پیش بینی احتمال هجوم بر اساس روش های یادگیری ماشین نیز با استفاده از LOOCV آزمایش شد. با این حال، بر خلاف درونیابی فضایی LOOCV، که در آن یک سایت منفرد حذف شد در حالی که پیشبینی با سایتهای اطراف انجام شد، آلودگیهای مشاهدهشده در یک سال کامل کنار گذاشته شدند و با پیشبینیهای یک مدل سازگار با مشاهدات دیگر مقایسه شدند. سال برای روش یادگیری ماشین LOOCV. مطابق با ایستگاه های IPM، این به طور متوسط منجر به 8 سایت مقایسه شد که هر یک به طور متوسط 12 مشاهده برای هر سال داشتند. مجموعه داده های مورد استفاده برای پیش بینی سال 2019 (91 مشاهده)، بنابراین شامل 2047 ورودی بود. هر یک از این ورودی ها شامل پارامترهای فهرست شده درجدول 1 . علاوه بر متغیر هدف (طبقه بندی بولین آلودگی)، اینها همچنین شامل بسیاری از متغیرهای مستقل بودند. بیشتر اینها دادههای آب و هوای ساعتی هستند که ابتدا با استفاده از روشهای فهرست شده در جدول 1 (انتخاب رویهها در نتایج توضیح داده شده است) منطقهای شدند و سپس با مقادیر حداقل، متوسط و حداکثر جمعآوری شدند. علاوه بر این، متغیرهای آب و هوایی بلندمدت که قبلاً توسط DWD [ 16 ] منطقه ای شده اند، بخش قابل توجهی از متغیرهای مستقل را تشکیل می دهند. تنها متغیری که مستقیماً به آب و هوا مربوط نمی شود، مدل ارتفاع است که آن نیز گنجانده شده است [ 48 ]. مدل ارتفاعی ویژگی های سایت را در بر می گیرد که به عنوان مثال، ساختار طبیعی منطقه مورد مطالعه را نشان می دهد.بخش 2.1 )، همانطور که توسط فرنزله [ 13 ] توضیح داده شده است. برای این منظور، طبقه بندی توصیف شده توسط فرنزله [ 13 ] نیز می تواند به عنوان یک متغیر مستقل مورد استفاده قرار گیرد، اما از آنجایی که مقادیر آلودگی مشاهده شده برای همه واحدهای طبیعی در دسترس نیست، برون یابی پیش بینی ها برای این مناطق امکان پذیر نبوده است. منجر به استفاده از مدل ارتفاع شد.
3. نتایج
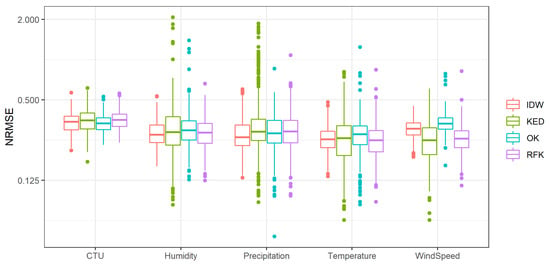
مناسب ترین روش درونیابی به رفتار فضایی متغیری که قرار است درونیابی شود و ویژگی های منطقه مورد بررسی بستگی دارد. به منظور یافتن اینکه کدام روش برای درونیابی دادههای آب و هوای ساعتی در منطقه مورد مطالعه مناسبترین روش است، اعتبارسنجی متقاطع چندگانه ترک یک خروجی برای هر یک از پارامترها برای 500 ساعت بهطور تصادفی انتخاب شده اعمال شد. برای هر اعتبارسنجی، NRMSE محاسبه شد که باید تا حد امکان پایین باشد ( بخش 2.5 ). شکل 3نمودارهای جعبه ای این مقادیر NRMSE را برای چهار روش درونیابی و پنج پارامتر مورد علاقه نشان می دهد. نمودارهای جعبه ای نشان می دهد که نتایج به دست آمده توسط روش ها مشابه بودند، اما روش های مختلف درون یابی، بسته به پارامترهایی که باید درون یابی شوند، کمترین خطا را به دست آوردند. علاوه بر تصویر ( شکل 3 )، آزمایش هایی برای تعیین اینکه آیا روش های درونیابی برای پارامترها به طور قابل توجهی متفاوت است انجام شد. آزمون مجموع رتبه ویلکاکسون [ 54] برای این منظور استفاده شد. کمترین خطا در درونیابی CTU به طور متوسط هنگام اعمال کریجینگ معمولی و وزن دهی معکوس فاصله بدست آمد. از آنجایی که OK NRMSE کمی پایین تر بود، این روش برای درون یابی انتخاب شد، حتی اگر توزیع خطاها تفاوت قابل توجهی با روش IDW نداشت. همانند سایر پارامترها، در صورتی که درون یابی خودکار با رویه OK امکان پذیر نبود (مثلاً به دلیل در دسترس بودن نقاط بسیار کمی) از روش IDW استفاده شود. هنگام درون یابی رطوبت، کمترین خطا با روش IDW به دست آمد که تفاوت قابل توجهی با سایر روش ها به جز کریجینگ تصادفی جنگل داشت.
برای سایر روش های درون یابی، رویه ای با کمترین خطا انتخاب شد: در این مورد، رویه IDW. کریجینگ با روش رانش خارجی برخی از نقاط دورافتاده بالایی را نشان داد که نشاندهنده پیشبینیهای بدتر در برخی موارد برای این پارامتر است. این امر در درونیابی بارش نیز مشاهده شد. باز هم، درونیابی IDW به کمترین NRMSE دست یافت و به طور قابل توجهی با سایر روش ها تفاوت داشت. تصویر متفاوتی با منطقهبندی دما پدیدار شد، جایی که روش RFK کمترین خطا را ایجاد کرد، اما تنها به طور قابلتوجهی با درونیابی OK تفاوت داشت. RFK برای درونیابی، با توجه به کوچکترین خطا انتخاب شد. منطقهبندی سرعت باد واضحتر و بدون ابهام بود، که در آن دو روش با استفاده از متغیرهای کمکی خطای قابلتوجهی کمتری نسبت به روشهای دیگر داشتند.
اعتبار سنجی متقاطع یک طرفه اعمال شده برای کل رویکرد مدلسازی ( بخش 2.5 ) امکان تخمین عملکرد رویکرد را در پیشبینی آلودگیهای خطرناک با سفیدک پودری فراهم میکند. شکل 4 نسبت رویدادهای شدید مشاهده شده (پایین) و پیش بینی شده را در طول سال های مختلف با استفاده از مقادیر مثبت واقعی، منفی واقعی، مثبت کاذب و منفی کاذب نشان می دهد. مقدار مثبت واقعی تعداد رویدادهای آلودگی شدید پیش بینی شده صحیح است، در حالی که تعداد رویدادهای پیش بینی نشده به عنوان منفی کاذب نامیده می شود. منفی واقعی، پیشبینیهای صحیح رویدادهای غیرقابل پیشبینی است، در حالی که مقدار مثبت کاذب، تعداد رویدادهای شدید پیشبینیشده را توصیف میکند که رخ ندادهاند.
نسبت رویدادهای خطرناک در طول سالهای مورد بررسی متفاوت بود، بدون هجوم در سال 1999 و نرخ آلودگی بالا در سالهای 2003، 2009 و 2010. این سالها بهویژه تفاوتهای بین روشهای مختلف یادگیری ماشینی مورد استفاده و نصب شده را نشان میدهند. در سال 1999، DT منجر به بالاترین مقادیر منفی واقعی و کمترین مقادیر مثبت کاذب شد، به دنبال آن روشهای BDT و RF قرار گرفتند که بر روی ROC AUC نبودند، بلکه به دقت و BDT برازش شده بودند.
روش RF برازش بالاترین میزان مثبت کاذب را نشان داد که نشان میدهد این روش بیشتر از سایر روشها هشدار میدهد. همین امر در سالهای هجوم زیاد در سالهای 2009 و 2010 مشهود بود. در این سالها، BDT و روش RF نامناسب حدود یک سوم هجومهای خطرناک را پیشبینی نکردند. این نسبت برای رویکرد جنگل تصادفی کمترین بود. در طول سال ها، می توان مشاهده کرد که نرخ منفی کاذب (که برای کشاورز خطرناک ترین است) برای RF نصب شده کمترین میزان بوده است. روش RF نصب شده به طور قابل توجهی با روش نامناسب متفاوت بود. در رویکرد BDT، این تفاوت کمتر مشهود بود اما در سالهای 2018 و 2019 قابل مشاهده است.
جدول 2 پارامترهای آماری پیشبینیهای تکراری حاصل از مقادیر مثبت واقعی، منفی درست، مثبت کاذب و منفی کاذب را نشان میدهد که در تمام سالها خلاصه شدهاند. دقت، نسبت پیشبینیهای صحیح را توصیف میکند، همچنین به عنوان نسبتهای مثبت و منفی واقعی در شکل 4 تجسم شده است . ویژگی نسبت مقادیر منفی واقعی ترکیبی از منفی های درست و مثبت کاذب است [ 53 ]. به این معنا که نسبت تمام کاهشها از مقدار آستانه همه افتهای پیشبینیشده است. دقت نسبت مقادیر مثبت واقعی ترکیب مقادیر مثبت درست و مثبت کاذب است. بنابراین، این نسبت تمام تجاوزهای رخ داده از همه تجاوزهای پیش بینی شده است [ 55]. بالاترین دقت با Decision Trees به دست آمد و کمی پس از آن درختان Boosted Decision نصب شده و نامناسب و جنگل های تصادفی نامناسب قرار گرفتند. جنگلهای تصادفی برازش دقت پایینتری را به دست آوردند، اما تا حد زیادی بالاترین حساسیت را نشان دادند. تقریباً 92 درصد از حوادث خطرناک پیشبینی شده بود. دومین روش برتر در این زمینه، DT، تنها موفق به انجام این کار با تقریبا 60٪. با این حال، حساسیت خوب به قیمت ویژگی بود، جایی که عملکرد جنگلهای تصادفی نصبشده به وضوح ضعیفتر از جنگلهای نامناسب بود. دقت برای همه رویه ها به طور مشابه پایین بود، با بالاترین مقادیر در درختان تصمیم. مقدار ROC AUC برای روش RF اقتباس شده بالاترین بود، که قابل انتظار بود. تفاوت بین مقدار ROC AUC و مقدار روش برازش دقت بیشتر از درخت تصمیم تقویتشده برازش شده و نامناسب بود. این مقادیر برای هر دو BDT کمتر از روش DT بود.
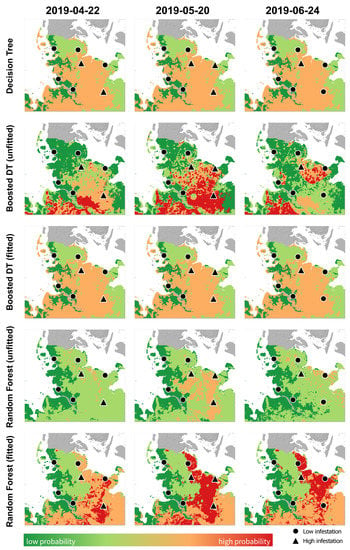
پیشبینی فضایی ارائهشده در شکل 5 ، تمایز واضحی از احتمال خطر هجومها بین سواحل شرقی و غربی منطقه مورد بررسی را نشان میدهد. در بروز بیماری های مشاهده شده نیز این امر مشهود بود. این تمایز در مورد جنگلهای تصادفی متناسب بارزتر است. در مقابل، پیشبینی درختهای تصمیم تقویتشده نامناسب، تمایز قویتری را بین شمال و جنوب نشان میدهد، که نشاندهنده تأثیر قویتر پارامترهای نشاندهنده قاره طولانیمدت است. علاوه بر این پویایی های فضایی، شکل 5همچنین تغییرات را در طول زمان نشان می دهد. رویکردهای DT و BDT نصب شده به سختی تغییری در پیشبینی احتمال آلودگیهای خطرناک نشان میدهند. این نشاندهنده یک جریان قوی از متغیرهای آب و هوایی غیر دینامیک زمانی و تأثیر محدود دادههای آبوهوای ساعتی بر پیشبینی مدل است. رویکردهای BDT و RF (غیر برازش) پویاتر بودند. مجدداً، رویکرد RF نشان میدهد که چگونه میتوان از آموزش در ROC AUC برای پیشبینی صحیح مازاد بر واقعی استفاده کرد، اما همچنین چگونه پیشبینیهای نادرستی در پایان دوره آلودگی در مورد تجاوزات غیرقابل رخ دادن انجام میشود. این را می توان در مثبت کاذب نوار سال 2019 در شکل 4 نیز مشاهده کرد. با این حال، احتمالات کمتر رویکرد RF نامناسب منجر به هجومهای خطرناک پیشبینی نشده و در نتیجه کسر منفی کاذب بزرگتر میشود.
4. بحث
کار قبلی با تمرکز بر استفاده از یادگیری ماشینی در زمینه هجومهای آسیبشناسی گیاهی نتایج رضایتبخشی را ایجاد کرده است. به عنوان مثال، لو و همکاران. [ 11 ] به دقت 74 درصد در شناسایی پوسیدگی طوقه آنتراکنوز دست یافت. چنین دقتی نتیجه ای قابل مقایسه با دقت کلی به دست آمده در مطالعه ما است ( جدول 2 ). مشابه بیشتر مطالعات منتشر شده در این زمینه، Lu et al. [ 11] از داده های فراطیفی استفاده کرد که با استفاده از یک پلت فرم تلفن همراه در میدان جمع آوری شد. بنابراین، هیچ پیشبینی بر اساس رفتار عامل بیماریزا انجام نشد، اما در عوض، طبقهبندی تصویری از برگهای گیاهان انجام شد. در سناریویی که ما به آن نگاه میکنیم، این پیشبینی و قابلیت انتقال به مقیاس شلزویگ-هولشتاین است که ما را قادر میسازد به سرعت نسبت به هجومهای خطرناک واکنش نشان دهیم. بر این اساس، مقایسه رویکرد ما با سیستمهای پیشبینی که بر رفتار پاتوژن تمرکز دارند مناسبتر است. در حال حاضر، تعدادی از سیستم های مدل سازی در این زمینه در دسترس هستند، مانند MEVA-PLUS [ 6 ]، WHEATPEST [ 8 ]، InfoCrop [ 56 ] و WHEGROSIM [ 7 ].]. این رویکردها همچنین به دقت قابل توجهی دست یافته اند، مانند مدل WHEGROSIM که ضریب تعیین بسیار بالایی 0.89 را به دست آورد [ 7 ]. ون و همکاران [ 57 ] از روش های یادگیری ماشینی مانند RF برای پیش بینی رفتار یک پاتوژن استفاده کرد. آنها گسترش هاگ های زنگ را پیش بینی کردند که تحت تأثیر آب و هوای قبلی قرار داشتند. برای ون و همکاران. [ 57]، روش RF بالاترین دقت 83% را در پیش بینی گسترش به دست آورد. با این حال، آنها از متغیر فاصله تا مبدا اسپورها استفاده کردند که قابلیت انتقال مدل را دشوار می کند. با این حال، مشابه سایر روشها، پارامترهایی که در مقیاس منطقهای و وسیعتر در دسترس نیستند (مانند مقدار آلودگی اولیه یا فاصله تا منشا اسپورها) برای دستیابی به این دقت مورد نیاز است. بر این اساس، این دقت ها را نمی توان به یک پیش بینی فضایی در مقیاس شلزویگ-هولشتاین منتقل کرد. اما گندم به صورت پراکنده کشت نمی شود. بخش مهمی از تغذیه روزانه اکثر افراد است. بر اساس گزارش سازمان خواربار و کشاورزی ملل متحد (فائو) در نتیجه، گندم در سال 2017 در منطقه ای به مساحت 260926 کیلومتر مربع در اتحادیه اروپا کشت شد.58 ]. این 46.85 درصد از کل مساحت مورد استفاده برای غلات در سال 2017 در اتحادیه اروپا را تشکیل می دهد که بر ضرورت پیش بینی های فضایی تأکید می کند. یک نمونه پیش بینی در این مقاله ارائه شده است. نتایج به وضوح نشان می دهد که پیش بینی فضایی ضروری است.
چنین پیشبینی فضایی در مقاله ما انجام شد، جایی که نتایج نشان داد که روشهای درونیابی مختلف با توجه به دادههای مختلف آبوهوای مورد استفاده بهترین نتایج را به دست میآورند ( شکل 3).). با این حال، این نتایج باید با احتیاط گرفته شوند و نباید برای پارامترها تعمیم داده شوند. حتی اگر روشهای مختلف بر اساس بهترین نتیجه انتخاب میشدند، تنها در مورد درونیابی سرعت باد، بهترین روش پیشبینی با سادهترین روش IDW قطعی تفاوت معنیداری داشت. این تأثیر به علل مختلفی متکی است. واریوگرام های تجربی و نظری لازم برای روش های تصادفی به دلیل تعداد زیاد درون یابی ها به طور خودکار تولید شدند. در طول پردازش، کنترل توسط مداخله متخصص بر روی مدلسازی و ادغام رفتار همبستگی متغیر هدف در نظر گرفته نشد. برای روشهای KED و RFK، که در آنها یادگیری ماشین پیادهسازی شد، تعداد کم ایستگاه های آب و هوایی در سال های اولیه ممکن است به این واقعیت منجر شده باشد که این مدل ها نماینده کل منطقه مورد مطالعه نیستند. انتخاب متغیرهای کمکی نیز باید در این روش ها در نظر گرفته شود. در آزمایشهای اولیه، مدل ارتفاعی نیز ادغام شد. اما این امر تأثیر مثبتی بر صحت پیشبینی نداشت. اگرچه بخش شرقی منطقه مورد مطالعه آسوده تر بود، اما حداکثر ارتفاع آن تنها 164 متر بود. در سایر زمینه ها، در نظر گرفتن این متغیر می تواند به ارتباط بیشتر روش های در نظر گرفتن متغیرهای کمکی منجر شود. این تاثیر مثبتی بر صحت پیشبینی نداشت. اگرچه بخش شرقی منطقه مورد مطالعه آسوده تر بود، اما حداکثر ارتفاع آن تنها 164 متر بود. در سایر زمینه ها، در نظر گرفتن این متغیر می تواند به ارتباط بیشتر روش های در نظر گرفتن متغیرهای کمکی منجر شود. این تاثیر مثبتی بر صحت پیشبینی نداشت. اگرچه بخش شرقی منطقه مورد مطالعه آسوده تر بود، اما حداکثر ارتفاع آن تنها 164 متر بود. در سایر زمینه ها، در نظر گرفتن این متغیر می تواند به ارتباط بیشتر روش های در نظر گرفتن متغیرهای کمکی منجر شود.
مقایسه روش های یادگیری ماشین نیز نشان داد که هیچ روش بهینه ای برای هر هدفی وجود ندارد. روش صحیح به هدف کاربر بستگی داشت. در مثال ما، بالاترین دقت کلی توسط مدل درخت تصمیم به دست آمد ( جدول 2). در بسیاری از موارد، این ممکن است با هدف کاربر نیز مطابقت داشته باشد. با این حال، برای مثال انتخاب شده در اینجا، یک پیش آگهی منفی خوب با بالاترین حساسیت ممکن مهمتر تلقی شد. بهبود جدید ایجاد شده رویکرد یادگیری ماشین با استفاده از ناحیه زیر منحنی ROC، حساسیت مدل ایجاد شده را بهینه میکند. با این حال، این منجر به کاهش دقت کلی مدل شد. تخمین بیش از حد وضعیت خطر – که با درصد دقت پایین نشان داده شده است – مرتبط با این بهینهسازی، برای پیشآگهی منفی خوب برای پیشبینی گسترش اپیدمی عوامل بیماریزا قابل قبول است. این بهبود تأثیر قویتری بر جنگلهای تصادفی نسبت به درختان تصمیمگیری تقویتشده داشت ( شکل 4).). این ممکن است در مورد درختان تصمیم تقویت شده باشد، زیرا فقط بر تعداد درختان تولید شده تأثیر می گذارد، در حالی که در مورد جنگل های تصادفی، وزن خود موارد را نیز شامل می شود. شکل 5 نشان می دهد که برازش با مقدار ROC AUC در پیش آگهی BDT با کاهش تعداد درخت های تصمیم که نتایج BDT های برازش را ایجاد می کنند، انجام می شود، زیرا پیش بینی فضایی درخت های تصمیم تقویت شده نصب شده مشابه درخت های تصمیم بود. با این حال، معیارهای آماری در جدول 2 و شکل 4 نشان می دهد که لزوماً همیشه اینطور نبوده است.
5. نتیجه گیری ها
در نتیجه، استفاده از روششناسی جغرافیایی برای پیشبینی گسترش اپیدمی آلودگیها مناسب است. ترکیبی از منطقهبندی زمینآماری، روشهای یادگیری ماشین، و سری دادههای آسیبشناسی گیاهی بلندمدت (همانطور که در شکل 2 نشان داده شده است) به پیشبینیهای قابل تاییدی دست یافته است (به عنوان مثال، جدول 2)) از رویدادهای آلودگی که محصول را به خطر می اندازد. در این زمینه، رویکرد جنگل تصادفی تطبیقی مناسبترین روش بود، زیرا پیشبینی بهبود یافته موارد واقعی که با این رویکرد بهبود یافته بود، بر افزایش نرخ مثبت کاذب برتری داشت. در کارهای آتی باید نتایج انتقال این مدل ها یا کل رویکرد به حوزه های دیگر بررسی شود. این حوزه های دیگر ممکن است نه تنها فضایی، بلکه موضوعی نیز باشند. بسته پاپروس [ 43] (که برای محاسبه نتایج کار ما استفاده شد) به صورت ماژولار طراحی شده است، به طوری که نه تنها می توان داده های آب و هوا از مناطق دیگر را به راحتی به دست آورد، بلکه می توان از داده های مکانی کاملاً متفاوت نیز استفاده کرد. همچنین باید بررسی شود که نتایج بهدستآمده با سایر روشهای یادگیری ماشین تا چه حد از نتایج ارائهشده در اینجا انحراف دارد. بعلاوه، کارهای آتی می تواند نشان دهد که آیا پارامترهایی که تاکنون در نظر گرفته نشده اند (مثلا آنهایی که بر اساس نظرات کارشناسان لحاظ نشده اند) می توانند بر پیش بینی تاثیر بگذارند و در نتیجه منجر به بهبود مدل و مدل شوند. دانش پاتوژن





بدون دیدگاه