

پیشرفت تحقیق و روند توسعه داده های بزرگ رسانه های اجتماعی (SMBD): تحلیل نقشه برداری دانش بر اساس CiteSpace
خلاصه
داده های بزرگ رسانه های اجتماعی (SMBD) به طور گسترده ای برای خدمت به توسعه اقتصادی و اجتماعی انسان ها استفاده می شود. با این حال، به عنوان یک زمینه تحقیق و عمل جوان، درک SMBD در دانشگاه کافی نیست و نیاز به تکمیل دارد. این مقاله مجموعه هسته Web of Science (WoS) را به عنوان منبع داده انتخاب کرد و از روشهای آماری سنتی و نرمافزار CiteSpace برای انجام تحلیل علمسنجی SMBD استفاده کرد که وضعیت پژوهش، نقاط داغ و روندها را در این زمینه نشان داد. نتایج نشان داد که: (1) توجه بیشتر و بیشتر به تحقیقات SMBD در دانشگاه ها معطوف شده است و تعداد مجلات منتشر شده در سال های اخیر افزایش یافته است، عمدتاً در موضوعاتی مانند مهندسی علوم کامپیوتر و ارتباطات.
نتایج در درجه اول در IEEE Access Sustainability and Future Generation Computer Systems در مجله بین المللی eScience و غیره منتشر شد. (2) از نظر مشارکت، چین، ایالات متحده، بریتانیا و سایر کشورها (مناطق) بیشترین مقالات را در SMBD منتشر کرده اند، موسسات پربازده نیز عمدتاً از این کشورها (مناطق). قبلاً چند تیم عالی در این زمینه وجود داشت، مانند تیم Wanggen Wan در دانشگاه شانگهای و تیم Haoran Xie از دانشگاه شهر هنگ کنگ. (3) ما نقاط داغ SMBD را در سالهای اخیر مورد مطالعه قرار دادیم و خلاصهای از مرز SMBD را بر اساس کلمات کلیدی و ادبیات استنادی، از جمله حفاری عمیق و ساخت فناوری رسانههای اجتماعی، بازتاب و نگرانیها در مورد سریع دریافتیم. توسعه رسانه های اجتماعی، و نقش SMBD در حل مشکلات توسعه اجتماعی انسانی. این مطالعات می تواند ارزش ها و مراجعی را برای محققان SMBD فراهم کند تا وضعیت تحقیق، نقاط داغ و روندها در این زمینه را درک کنند.
کلید واژه ها:
داده های بزرگ رسانه های اجتماعی ؛ تجسم ; CiteSpace ; کانون های تحقیقاتی ; گرایش های پژوهشی ؛ تجزیه و تحلیل کتاب سنجی
1. معرفی
رسانه های اجتماعی (SM) یک برنامه کاربردی اینترنتی با ویژگی های تعاملی آنلاین است که یکی از رسانه های اولیه برای استفاده مردم از اینترنت است. مشخصه آن یک شبکه اجتماعی تعاملی است که در آن کاربران شرکت می کنند، شکل می دهند و اطلاعات را به اشتراک می گذارند و در نهایت به کاربران متصل می شوند [ 1 ]. مردم میتوانند رویدادها، نظرات، نظرات و بینشهای مرتبط را در هر زمان و هر مکان از طریق رسانههای اجتماعی به جهان ارسال کنند [ 2 ]. رسانه های اجتماعی در حال حاضر به بخش مهمی از زندگی تبدیل شده اند [ 3 ]. با گسترش رسانههای اجتماعی، استفاده مردم از رسانههای اجتماعی دادههای ساختاریافته/بدون ساختار زیادی تولید کرده است [ 4]]. به طور خاص، ظهور رسانه های اجتماعی معمولی مانند فیس بوک، توییتر، تیک تاک، ویبو و غیره این امکان را برای عموم فراهم کرده است تا به اطلاعات و داده ها با سرعت و کارآمدی بیشتری از طریق اینترنت دسترسی داشته باشند [5 ] . داده های بزرگ رسانه های اجتماعی (SMBD) کاملاً نگرانی عمومی آکادمی را برانگیخته است.
بررسی مطالعات قبلی در مورد SMBD طیف وسیعی از موضوعات را شامل میشود، از جمله تعریف SMBD [ 6 ]، کاربرد [ 7 ]، الگوریتم [ 8 ]، مدل [ 9 ]، طبقهبندی [ 10 ]، روش تحلیل [ 11 ] و غیره. کپسلا [ 12 ] استدلال کرد که همگرایی کلان داده ها، محاسبات و رسانه های اجتماعی، تعامل انسانی و تأثیر هنجارهای اجتماعی را تغییر داد. این یک حوزه مطالعاتی مقطعی برای علوم اینترنتی، بازاریابی و علوم کامپیوتر بود. جیانگ و همکاران [ 13] یک شناسایی عاطفی از رویدادهای خبری در داده های بزرگ رسانه های اجتماعی انجام داد که بر اساس دو مرحله بود: محاسبه کلمه عاطفی و استخراج استاندارد کلمات عاطفی از کتابخانه. سیبوللا و همکاران [ 14 ] یک چارچوب تحلیلی برای مقابله با همبستگی پیچیده بین رسانههای اجتماعی و کلان دادههای پزشکی ایجاد کرد که میتواند برای راهنمایی مؤسسات مراقبتهای بهداشتی جامعه برای ادغام با دادههای بزرگ پزشکی از طریق رسانههای اجتماعی استفاده شود. ژانگ، دانیل [ 15] طرح کشف حقیقت مقیاس پذیر و قوی (SRTD) را توسعه داد که اعتبار مجموعه داده ها را برای شناسایی اطلاعات واقعی در مورد تحقیق در نظر گرفت. در همان زمان، SMBD همچنین به طور گسترده در توسعه اقتصادی و اجتماعی، ساخت و ساز شهری و روستایی، ایمنی تولید، پیشگیری و کنترل بلایا و سایر زمینه ها استفاده شد. به عنوان مثال، در طول شیوع کووید-19 در سال 2020 در چین، مگا موضوع “کمک جویی در ذات الریه” Weibo باعث مراقبت از گروه های نادیده گرفته شد. “داده های بزرگ در مورد مهاجرت جمعیت” Tencent پیش بینی مسیر و شدت انتقال ویروس را تسهیل کرد.16 ، 17 ].
با این حال، به عنوان یک حوزه تحقیقاتی و عملی نسبتاً جوان، درک جامعه دانشگاهی از کلان داده های رسانه های اجتماعی هنوز کافی نیست. به خصوص در وضعیت تحقیق، هنوز شکافی در روند نقاط داغ پژوهش وجود دارد. در همان زمان، محققان مختلف SMBD را از دیدگاههای حرفهای مختلف تفسیر و به کار بردند، که باعث شد تمرکز پژوهش بر روی زمینه SMBD مدام افزایش یابد [ 18 ]، و تحقیق پیچیدهتر و پیچیدهتر شده است. برای کمک به محققان و دست اندرکاران مربوطه در درک وضعیت فعلی و روندهای آینده تحقیقات SMBD، تجزیه و تحلیل سیستماتیک نتایج تحقیقات موجود ضروری بود.
بنابراین، این مقاله به تجزیه و تحلیل علم سنجی دستاوردهای تحقیقاتی SMBD در 10 سال گذشته (2010-2020) پرداخته و توسعه SMBD در این زمینه را در قالب نقشه برداری دانش به نمایش می گذارد که اطلاعات قابل اعتمادی را در اختیار محققان مربوطه قرار می دهد، دانش پایه. ساختار، و جهت اساسی تحقیقات پیشرفته. ادامه این مقاله به شرح زیر تنظیم شده است: ابتدا روند دقیق جمع آوری داده ها و اطلاعات خاص پلت فرم پشتیبانی را معرفی کردیم. سپس دادهها شامل تعداد انتشارات، نویسندگان، حوزههای مطالعه، کشورها/مناطق و شبکههای سازمانی را تجزیه و تحلیل کردیم. در مرحله بعد، ما یک تحلیل استنادی مشترک از SMBD، تجزیه و تحلیل نقطه داغ، و تجزیه و تحلیل مرزهای تحقیق را اجرا کردیم. سرانجام،
2. داده ها و روش ها
2.1. منابع اطلاعات
WoS (Web of Science) یک پلت فرم بازیابی اطلاعات است که توسط تامسون رویترز توسعه یافته است که شامل پایگاه های داده ای مانند SCIE، و A&HCI است [ 19 ]. WoS یک رکورد دقیق از تمام جنبه های انتشار مقاله نگه می دارد. بسیاری از محققان و محققان از پایگاه داده WoS به عنوان منبع داده کتاب سنجی و تجزیه و تحلیل ادبیات استفاده کردند [ 20 , 21]. بنابراین، برای اطمینان از صحت و قابلیت اطمینان داده ها، این مقاله از انتشارات پایگاه داده مجموعه هسته Web of Science به عنوان منبع داده نمونه برای تجزیه و تحلیل زمینه SMBD استفاده کرد. استراتژی بازیابی به این صورت بود: موضوع جدول بازیابی = “داده های بزرگ رسانه های اجتماعی” یا “تجسم رسانه های اجتماعی” یا “داده های بزرگ شبکه های اجتماعی” یا “تجسم شبکه های اجتماعی” را تنظیم کنید، زبان را روی “انگلیسی” تنظیم کنید، سند را انتخاب کنید. روی «مقاله» تایپ کنید، بازه زمانی مقاله را روی «2010–2020» تنظیم کنید. در مجموع 2493 نشریه موثر بازیابی شد و نتایج بازیابی در قالب متن ذخیره و خروجی شد، هر سند حاوی نویسندگان، مؤسسات، کلمات کلیدی، چکیده، تاریخ و اطلاعات دیگر بود.
2.2. ابزارهای تحلیل
برای دستیابی به یک بررسی عینی و جامع از نشریه در زمینه مطالعه، ما روش آماری سنتی و ابزار نقشهبرداری دانش علمی CiteSpace را برای توصیف وضعیت تحقیق، نقاط داغ و روند SMBD با جزئیات ترکیب کردیم (شکل 1) .). CiteSpace یک نرم افزار تجسم داده است که توسط تیم Chen Chaomei توسعه یافته است که به طور گسترده در بسیاری از زمینه ها مانند علم، اطلاعات و کتاب سنجی استفاده می شود. می تواند مکان و اندازه گره ها را در شبکه دانش تجسم کند. در این مقاله با استفاده از ماژولهای کشور، مؤسسه، نویسنده، کلیدواژه و مرجع، از نرمافزار برای تحلیل پایگاه دانش، کانونهای پژوهشی و زمینه توسعه استفاده شده است. این نرم افزار برای تجزیه و تحلیل بصری زمینه تحقیق SMBD و ترسیم نقشه دانش مربوطه استفاده شد. پارامترها به شرح زیر بود: نوع گره: انتخاب بر اساس تجزیه و تحلیل. دوره زمانی: 2010–2020; طول برش زمان = 1; معیارهای انتخاب آستانه: 25 برتر در هر برش. بقیه تنظیمات پیش فرض بودند. پارامترهای تفصیلی در گوشه سمت چپ بالای هر نقشه دانش فهرست شده بودند. N، E و Density به ترتیب تعداد گره ها، اتصال و تراکم شبکه را نشان می دهند. در نمودار خوشهای، از مقدار silhouette برای اندازهگیری همگنی شبکه استفاده شد. هر چه به 1 نزدیکتر باشد، همگنی شبکه بیشتر بوده و مقدار بالای 0.5 نشان می دهد که نتیجه خوشه معقول بوده است. در همین حال، رنگ و اندازه هر گره نشاندهنده سالهای مختلف و تعداد استنادها بود که برای نشان دادن تاریخچه استنادی ادبیات از زمان انتشار آن استفاده میشد.
3. تجزیه و تحلیل و بحث از نتایج
3.1. روند انتشار سالانه
به منظور تجزیه و تحلیل عمیق از روند SMBD، ما تعداد انتشارات را از مجموعه اصلی WoS از سال 2010 تا 2020 جمع آوری کردیم ( شکل 2 ). ما دریافتیم که تعداد انتشارات در SMBD از سال 2010 تا 2013 به آرامی افزایش یافت و تا سال 2014 روند رشد قابل توجهی را نشان نداد. از سال 2010 تا 2013، میانگین تولید سالانه 51 بود. در حالی که از سال 2014 تا 2016، میانگین تولید سالانه 201 بوده است. علاوه بر این، در پنج سال گذشته (2016-2020)، 78.42 درصد از مقالات (1955 از 2493) منتشر شده است. این نشان داد که تحقیقات در SMBD جدید بوده و حرارت تحقیق در پنج سال گذشته افزایش یافته است. لازم به ذکر است که ما اطلاعات کاملی برای سال 2020 نداریم زیرا تاریخ جمع آوری داده ها برای این انتشارات در سپتامبر 2020 به پایان رسیده است.
3.2. دسته بندی وب علم
از طریق تجزیه و تحلیل ادبیات SMBD، ما می توانیم به طور دقیق تمرکز تحقیقات علمی در این زمینه را درک کنیم. با توجه به سیستم رشته WoS، 2493 مقاله در SMBD را می توان به 110 حوزه / جهت تحقیقاتی تقسیم کرد. علاوه بر این، یک مقاله ممکن است یک یا چند زمینه تحقیقاتی را پوشش دهد، که تعداد مقالات مربوط به حوزه پژوهشی را بیشتر میکند و همچنین منعکسکننده ویژگی میان رشتهای حوزه SMBD است. میز 110 حوزه تحقیقاتی برتر را با بیش از 85 مقاله نشان می دهد. به طور کلی، SMBD عمدتاً در زمینه کامپیوتر و مهندسی مورد مطالعه قرار گرفت و علوم رایانه با مجموع 1338 مقاله که 53.67٪ از کل مقاله را به خود اختصاص داده است، برترین زمینه تحقیقاتی بود. بعد، مهندسی (568)، ارتباطات از راه دور (298)، فناوری علوم دیگر موضوعات (243)، اکولوژی علوم محیطی (215) و غیره زمینه های کلیدی تحقیق در SMBD بودند. در نهایت، علوم کتابداری علوم اطلاعات (5.93%)، علوم مدیریت تحقیقات عملیاتی (3.57%)، جغرافیای فیزیکی (3.45%) حوزههای بالقوه تحقیق SMBD بودند. به عبارت دیگر، SMBD توسط بسیاری از موضوعات مورد توجه قرار گرفته است، و SMBD منعکس کننده ویژگی های بین رشته ای، چند دامنه ای و یکپارچه سازی چند جهته است.
3.3. تجزیه و تحلیل مجله
با تجزیه و تحلیل توزیع مجلات در این زمینه، میتوانیم به طور دقیق بخش اصلی پژوهش دانشگاهی را شناسایی کنیم و مقالات منتشر شده در چنین مجلاتی میتوانند توسط تحقیقات دانشگاهی پشتیبانی شوند [22 ] . به طور کلی، هر چه مجلات Total Publications (TP) بیشتر باشد، سهم بیشتری در این زمینه داشته باشد، ضریب تأثیر مجله (IF) بیشتر باشد و هر چه شاخص H بالاتر باشد، تأثیر علمی مجله بیشتر خواهد بود [ 23 ] . جدول 210 مجله برتر که در مقالات تحقیقاتی SMBD منتشر شده اند را فهرست می کند. تعداد انتشارات این مجلات حدود 22.42 درصد از مجموع انتشارات در این زمینه بوده است. تعداد مقالات منتشر شده در IEEE Access با 137 مقاله که 5.495 درصد از کل مقاله را به خود اختصاص داده است، بیشترین تعداد را داشته است و ضریب تأثیر جامع در سال 2019 3.745 مقاله بوده است. مجله بین المللی eScience، با 62 مقاله (2.487٪). از نظر ضریب تاثیر و H-index مجله، Future Generation Computer Systems و International Journal of eScience بالاترین IF را داشتند. مجله PLoS One دارای بالاترین شاخص H بود، اما IF تنها 2.74 بود. IF و H-index مجلات IEEE Transactions on Visualization and Computer Graphics, Journal of Medical Internet Research,
3.4. تجزیه و تحلیل کشوری و نهادی
تعداد انتشارات ملی/منطقه ای نشان دهنده میزان مشارکت کشور/منطقه در تحقیق در این زمینه است. بر اساس داده های ادبیات منتشر شده توسط کشورهای دارای SMBD در مجموعه اصلی WoS، 10 کشور برتر بر اساس تعداد انتشارات منتشر شده مرتب شدند. همانطور که در شکل 3 نشان داده شده استچین در رتبه اول قرار گرفت (739 مقاله) که 29.643٪ از کل داده های جمع آوری شده را به خود اختصاص داد. سپس ایالات متحده (722 مقاله)، بریتانیا (240 مقاله) و کره جنوبی (159 مقاله) قرار گرفتند که 44.966٪ از کل انتشارات در مجموعه داده را پوشش دادند. مرکزیت شاخصی است که اهمیت گره ها را در شبکه اندازه گیری می کند و برای اندازه گیری اهمیت قطعات خاصی از گره ها در CiteSpace استفاده می شود. مرکزیت کشور نشان دهنده شناخت بین المللی یک کشور در زمینه تحقیقات توسعه SMBD است. مطابق جدول 3، انگلستان بالاترین درجه مرکزیت را داشت (مرکزیت = 0.2)، دومین کشور ایالات متحده بود (مرکزیت = 0.19). اگرچه چین از نظر تعداد نشریات منتشر شده در رتبه اول قرار داشت، اما مرکزیت کمتر از سایر کشورها بود. از این بخش، تأثیر ضعیف بینالمللی نتایج تحقیقات چین در SMBD علیرغم تعداد زیادی از انتشارات آن را منعکس میکند.
از CiteSpace برای ایجاد یک شبکه همکاری سازمانی استفاده شد تا میزان مشارکت و همکاری هر موسسه در زمینه تحقیقاتی SMBD را منعکس کند. شکل 4شبکه همکاری موسسه را نشان می دهد که از 385 گره سازمانی با 602 اتصال تشکیل شده است. خط اتصال ضخیمتر نشاندهنده همکاری نزدیکتر بین مؤسسات است و هر پیوند بین دو مؤسسه مختلف با طیفی از رنگهای مربوط به سالهای وقوع نشان داده میشود. ارزشهای سنتز مرکزی بالاتر عبارت بودند از آکادمی علوم چین، دانشگاه ووهان، دانشگاه Tsinghua، دانشگاه شهر هنگ کنگ، دانشگاه Huazhong، علم و فناوری دانشگاه Huazhong، دانشگاه ژجیانگ و دانشگاه پکن که نقشهای واسطه و پیشرو را ایفا کردند. همکاری نزدیک بین این نهادها را میتوان به وضوح از ارتباط مشاهده کرد. علاوه بر این، توزیع جهانی موسسات تحقیقاتی SMBD نابرابر بود.
3.5. تحلیل نویسنده
تجزیه و تحلیل شبکه تعاونی نویسندگان می تواند نویسندگان اصلی، شدت همکاری و استناد متقابل نویسندگان را در یک زمینه خاص منعکس کند و تأثیر مهم همکاری تیمی را بر تحقیقات دانشگاهی در این زمینه بررسی کند [24 ] . جدول 4 10 نویسنده پربار را فهرست می کند. نتایج نشان داد که لیو وای بیشترین انتشار را داشته است. سایر نویسندگان مرتبط عبارتند از Zhang Y (18 مقاله)، Chen Y (14 مقاله)، Wang Y (14 مقاله)، Liu YH (13 مقاله)، و Wang H (13 مقاله). بیشتر 10 نویسنده برتر از چین و متعلق به 9 موسسه تحقیقاتی بودند.
در شکل 5 ، هر گره در شبکه همکاری نویسنده نشان دهنده نویسنده است، تعداد مقالات منتشر شده توسط نویسنده با اندازه گره ها نشان داده شده است، و اتصالات بین گره ها نشان دهنده رابطه همکاری بین نویسندگان است. شبکه همکاری نویسنده در زمینه SMBD از 995 نویسنده و 479 پیوند مشارکتی تشکیل شده است. محققان مختلف تیم های تحقیقاتی مختلفی را بر اساس رابطه مشترک بین نویسندگان تشکیل دادند: (1) تیم Wanggen Wan از دانشگاه شانگهای کاربرد SMBD را در توسعه اجتماعی، از جمله مطالعه توزیع مکانی و زمانی فضاهای سبز شهری تجزیه و تحلیل کرد [ 25 ] و همچنین تحلیل ویدئویی، مکانی، زمانی و رسانه های اجتماعی جمعیت شهری [ 26]. (2) تیم Nicola Luigi Bragazzi از دانشگاه جنوا در ایتالیا بر روی کاربرد SMBD در پزشکی تمرکز کردند و دو مقاله پراستناد این تیم بر ارزش ایمونولوژیکی و روماتولوژیکی استفاده از SMBD [27] و رفتار دیجیتالی تمرکز داشتند . با استفاده از رفتار انفورماتیک برای تجزیه و تحلیل کل گسترش همه گیری [ 28 ]. (3) تیم Haoran Xie از دانشگاه شهر هنگ کنگ عمدتاً مشخصات شخصی و نیازهای اطلاعاتی کاربر را به منظور تحقق جستجوهای شخصی شده مورد مطالعه قرار دادند [ 29 ]، و نوعی شناسایی گروه کاربر بالقوه بر اساس فولکلور [ 30] را پیشنهاد کردند.]. (4) علاوه بر این، تیم های برجسته دیگری مانند تیم آنتونیو فراندزو از دانشگاه آلیکانته در اسپانیا و تیم هنریکی تنکانن از دانشگاه هلسینکی فنلاند نیز حضور داشتند.

3.6. موضوعات تحقیقاتی داغ در مورد SMBD
3.6.1. تحلیل ادبیات استنادی
هماستنادی عمیقاً نشاندهنده شالوده دانش نظری پژوهشهای مربوطه است و ادبیات استنادی با فراوانی بالا دستاوردهای پژوهشی بنیادی را در دورههای مختلف نشان میدهد و نقش مهمی در توسعه دانشگاهی این رشته دارد. شبکه استنادی مشترک در زمینه SMBD از 778 گره و 975 اتصال تشکیل شده است ( شکل 6 ). گره بیانگر ادبیات ذکر شده بود و اهمیت ادبیات با اندازه آن بیان شد. برچسب روی گره اولین نویسنده و سال انتشار مقاله بود. همانطور که در جدول 5 نشان داده شده است، 15 گره ادبیات کلیدی با تأثیر علمی مهم در این مقاله انتخاب شدند .
بولن و همکاران [ 31 ] هفت جنبه از احساسات عمومی را از متن توییتر استخراج کرد و آنها را با شاخص های اقتصادی مرتبط کرد. این یک ادبیات نماینده در مورد استفاده از SMBD در تحقیقات اقتصادی بود. چن و همکاران [ 32 ] به طور سیستماتیک در مورد فرصت ها و چالش ها، اصول فنی و روندهای تحقیقاتی آینده برای برنامه های کاربردی داده فشرده بحث کرد. لازر و همکاران [ 33 ] از Google Flu Trends (GFT) به عنوان استدلالی برای طرح سوالاتی در مورد کلان داده ها به عنوان جایگزینی برای روش ها و نظریه های آماری سنتی استفاده کرد و دو تناقض از روند آنفولانزای Google را پیشنهاد کرد: Hubris و Dynamics Algorithm. با گسترش گستردهتر دادههای بزرگ، بحثهای انتقادی در حال افزایش بود. بوید و همکاران [ 34] استدلال کرد که پرسشها و مفروضات انتقادی منطقی برای کلان دادهها، به عنوان یک تکنیک تحلیلی در حال ظهور، ضروری هستند. او شش نکته مهم را مطرح کرده است، از جمله (1) تغییرات در کل نظریه نظریه اجتماعی که ناشی از داده های بزرگ است، (2) مشکلات اجتناب ناپذیر داده های بزرگ از نظر عینی و دقت، (3) کیفیت تحقیق بر اساس میزان تناسب کلان داده ها با مشکل و بازنمایی داده ها، (4) نمایش گرافیکی رابطه بین افراد به معنای اطلاعات معادل نیست، (5) مسائل اخلاقی داده های بزرگ، ( 6) شکاف دیجیتالی ناشی از در دسترس بودن و دسترسی به داده های بزرگ.35 ]. به طور کلی، SMBD بین رشته ای بود و حوزه هایی مانند داده کاوی، یادگیری عمیق، تجسم داده ها و پردازش زبان طبیعی را پوشش می داد [ 36 ، 37 ]. رشد این رشته منجر به تکامل کسب و کار، وب و کاربردهای علمی خواهد شد [ 38 ].
3.6.2. همزمانی کلمات کلیدی
کلمات کلیدی تراکم و واکنش به محتوای اصلی مقاله هستند که می توانند موضوع داغ و روند توسعه مرتبط با حوزه تحقیق را منعکس کنند. ما ماژول «کلمه کلیدی» CiteSpaceⅤ را اجرا کردیم، برخی از تکرارهای معنایی را ادغام کردیم و نموداری از شبکه همروی کلمه کلیدی در تحقیقات SMBD، با 547 گره و 3631 اتصال ایجاد کردیم (شکل 7 ) . 10 کلیدواژه اصلی برای همزمانی و مرکزیت در جدول 6 نشان داده شده است . کلیدواژههای «دادههای بزرگ» و «رسانههای اجتماعی» از جدول 6بالاترین فرکانس را به ترتیب 696 و 408 نمایش داد. به دنبال آن کلیدواژههای «شبکه اجتماعی» (226)، «تجسم» (189)، «شبکه» (186) و «توئیتر» (181) قرار دارند. از تحلیل مرکزیت، کلمه کلیدی «شبکه اجتماعی» بالاترین ارزش مرکزی را نشان داد و پس از آن «تجسم»، «مرکزیت»، «الگو»، «طراحی»، «تحلیل شبکه اجتماعی» و … مورد توجه محققان قرار گرفته و تأثیرات خاصی را ایجاد کرده است.
CiteSpace برچسبگذاری خودکار شبکههای خوشهبندی را فراهم میکند و اجازه میدهد عبارات اسمی از عناوین، کلمات کلیدی یا چکیدهها از طریق سه الگوریتم (LSI، LLR و MI) استخراج شوند. آزمونهای نسبت Log-like (LLR) یک جنبه منحصر به فرد از یک خوشه را منعکس میکنند، که برای ایجاد خوشهبندی با کیفیت بالا با شباهت درون کلاسی و شباهت بین کلاسی مناسبتر است. ما نقشه کلمات کلیدی را با توجه به الگوریتم LLR در نرم افزار CiteSpace خوشه بندی کردیم تا نمای جدول زمانی 9 خوشه نشان داده شده در شکل 7 را بدست آوریم.، با برچسب خوشه در سمت راست و زمان در بالا. کلمات کلیدی یک خوشه در یک خط افقی قرار دارند و هر گره نشان دهنده یک کلمه کلیدی است، کلمات کلیدی در سالی که برای اولین بار ظاهر می شوند ثابت می شوند و با خطوط به هم متصل می شوند. از طریق جدول زمانی، میتوانیم بازه زمانی کلمات کلیدی همزمان و افزایش و سقوط محتوای تحقیقاتی خاص خوشهها را مشاهده کنیم. جدول 7 جزئیات بیشتری از این خوشه ها را نشان می دهد.
همانطور که در جدول 7 نشان داده شده است، یک مقدار یکنواختی داخلی (پروفایل) از 0.57 تا 1 نشان داد که عبارات برتر در خوشه به خوبی مطابقت دارند و خوشه قابل اعتماد است [ 39 ]. شماره 0 و 6 “رسانه های اجتماعی” و “تحقیق داده های بزرگ” بودند، که بر اهمیت داده های بزرگ رسانه های اجتماعی [ 40 ، 41 ، 42 ] تمرکز کردند و خطر و آینده داده های بزرگ رسانه های اجتماعی را بررسی کردند [ 43] .]. این مطالعه بر زمینههای کلیدی مانند دادههای بزرگ، قوانین انجمن، ارتباطات فرهنگی، جفتسازی دولایه، شبکههای اجتماعی، رسانههای اجتماعی، ویژگیهای استفاده از رسانههای اجتماعی، کاربران، اثر، خطوط هوایی و غیره متمرکز بود. شماره 1 “احساس منفی” بود و خوشه شامل مطالعه موردی، داده ها، نقش، ارزیابی تاب آوری ساحلی، سیل و سایر کلمات کلیدی بود. این خوشه عمدتاً از موارد فاجعه استفاده کرد تا نشان دهد که تحقیقات SMBD تأثیر منفی بر احساسات افراد دارد [ 44 ، 45 ]. شماره 2 “زنجیره تامین بشردوستانه” بود. این خوشه حاوی هوش مصنوعی، صنعت، دستاوردهای اجتماعی، اصول، عملیات سدسازی بود و این خوشه بر ارزش مهم داده های بزرگ رسانه های اجتماعی همراه با فناوری بلاک چین تمرکز داشت [ 46 ، 47]]. شماره 3 “مدیریت داده های میکروبلاگ ها” بود، این خوشه مطالعه ای از فناوری ها، مدل ها و چارچوب ها برای داده های بزرگ رسانه های اجتماعی [ 48 ، 49 ] بود، کلیدواژه های اصلی مرور، تکنیک های طبقه بندی، صداگذاری سیتاس، تشخیص خودکار، بهره برداری از فاکتور آکادمیک بود. شماره 4، 5، 7 و 8 “حوزه علمی”، “استفاده از داده های بزرگ”، “ارزیابی وضعیت زیرساخت شهری مقیاس پذیر” بودند، همه آنها کاربردهای خاص SMBD در تولید و زندگی انسان بودند. به عنوان مثال، Vargas-Quesada و همکاران. [ 50 ] از عملکرد هم افزایی دسته ها و شبکه اجتماعی آن برای پیش بینی بصری یا برچسب گذاری تحولات در زمینه علم استفاده کرد. لیو و همکاران [ 51 ] از SMBD برای طبقه بندی فضای سبز و ساختمان های شهر هوشمند استفاده کرد. علیپور و همکاران [52 ] چارچوبی برای توسعه و گسترش نظارت بصری زیرساخت های شهری و محیط های ساخته شده بر اساس SMBD ارائه کرد. اودوهرتی و همکاران [ 53 ] استفاده از داده های بزرگ برای سلامتی را بررسی کرد.
4. تحلیل روندهای تحقیق
روند تحقیق در یک زمینه می تواند منعکس کننده جهت توسعه آینده تحقیق باشد. با استفاده از تابع تشخیص انفجار در CitespaceⅤ، افزایش یا کاهش ناگهانی تعداد استنادهای کلمات کلیدی یا مقالات خاص می تواند آشکار شود [ 54 ]. یک کلمه کلیدی یا ادبیات با تعداد زیادی استناد که در مدت زمان کوتاهی افزایش یا کاهش یافته است ممکن است باعث تغییرات نرخ جهش شود و ما میتوانیم روندها و جهتهای آینده یک حوزه را از طریق کلمات کلیدی و روندهای تغییر در ادبیات درک کنیم.
4.1. تجزیه و تحلیل انفجار کلمات کلیدی
انبوه کلمات کلیدی می تواند منعکس کننده تغییرات موضوعات تحقیق و نقاط داغ در یک زمینه باشد. همانطور که در شکل 8 نشان داده شده است، ما 20 کلمه نوظهور را در تحقیقات SMBD با توجه به دو شاخص سال شروع و قدرت انتخاب کردیم. نتایج نشان داد که مرز تحقیقاتی SMBD در دهههای گذشته با گذشت زمان تغییر کرده است و قویترین کلمه تجسمسازی است. از جمله کلمات کلیدی با چرخه انفجاری طولانی تر، شبکه اجتماعی (2010-2015) و تصویرسازی نمودار (2012-2017) بودند، و تحقیقات مرتبط با این اصطلاحات تأثیر پایدارتری بر زمینه SMBD داشت. آخرین کلمات انفجاری، اعتبار سنجی، زمان واقعی، احساس، زمینه، برخی از داغ ترین موضوعات در سال 2018 تاکنون را نشان می دهد و همچنان دنبال خواهد شد.
4.2. انفجار ادبیات مشترک
تجزیه و تحلیل کلمات کلیدی فوق نشان داد که SMBD در دوره های مختلف از سال 2010 تا 2020 مرز پژوهش بوده است. علاوه بر این، آزمون انفجاری نیز شاخصی از مرز تحقیق برای ادبیات استنادی است. هر چه انبوه مقالات بیشتر باشد، میزان توجه در یک بازه زمانی مشخص بیشتر باشد، محتوای پژوهشی مقاله نشان دهنده نقطه داغ و مرز این رشته در یک بازه زمانی خاص است. قسمتهای قرمز رنگ در شکل 9 محدوده زمانی را نشان میدهند که در آن ادبیات ظاهر شد. ما ادبیات را با ویژگی های انفجاری و بدون “خنک کردن” فهرست کردیم تا مرز تحقیقاتی SMBD در سال های اخیر را تجزیه و تحلیل کنیم. در مورد قوی ترین استناد همزمان که در شکل 7 نشان داده شده است، 11 مقاله پر استناد در سال 2018-2020 وجود داشت. به طور عمده می توان آن را به سه جنبه تقسیم کرد:
(1) حفاری عمیق و ساخت فناوری رسانه های اجتماعی. میکولوف [ 55 ] مدل skip-gram را پیشنهاد کرد که میتواند تعداد زیادی از روابط نحوی و معنایی دقیق را به تصویر بکشد و بردارها را به خوبی میلیونها عبارت را بیان کند. این مدل پایهای روششناختی برای پیشبینی و تحلیل دادههای بزرگ رسانههای اجتماعی فراهم میکند. در همین حال، Schmidhuber [ 56 ] یادگیری عمیق را در شبکه های عصبی (NNS) بررسی کرد. این تحقیق محاسبات تکاملی SMBD، کاربرد الگوریتمهای هوش محاسباتی و پیشرفت تجسم را ارتقا داد. گاندومی و همکاران [ 57] رسانه های اجتماعی را بر اساس تحقیقات قبلی به تفصیل تشریح کرد و بر لزوم توسعه روش های تحلیلی مناسب و موثر تاکید کرد. آنها اشاره کردند که ویژگی کلیدی تحلیل رسانه های اجتماعی مدرن ماهیت داده محور بودن آن است و می توان آن را به تحلیل مبتنی بر محتوا و تحلیل مبتنی بر ساختار تقسیم کرد.
(2) بازاندیشی و نگرانی در مورد رشد سریع رسانه های اجتماعی. فرارا و همکاران [ 58 ] رفتار روباتهای اجتماعی را که در اکوسیستم رسانههای اجتماعی فراوان بودند، مانند رباتهای اجتماعی در توییتر، در تقلید از ویژگیهای مرتبط با الگوهای زمانی محتوا، شبکه، احساسات و فعالیتها بررسی کردند، این روباتها این ویژگی را ایجاد کردند. دستکاری اجتماعی مهندسی، که منجر به این نتیجه شد که روبات های خوب و ربات های بد وجود دارند. ظهور آنها ممکن است تهدیدی برای اکولوژی اینترنت و جامعه بشری باشد. علاوه بر این، بوشماف و همکاران. [ 59] خاطرنشان کرد که با استفاده گسترده از رسانه های اجتماعی آنلاین و افزایش تعداد کاربران، رسانه های اجتماعی آنلاین می توانند برای سرقت داده های کاربران و آسیب رساندن به اکوسیستم اینترنت در صورت عدم مدیریت صحیح مورد استفاده قرار گیرند، بنابراین باید یک نمونه اولیه از یک ربات اجتماعی ساخت. شبکه ای برای اجرای آزمایشات در فیس بوک در پاسخ به نفوذ انبوه. کائو و همکاران [ 60 ] حجم عظیمی از فعالیت های تهاجمی رسانه های اجتماعی را که امروزه وجود دارد تجزیه و تحلیل کرد و از یک تله همزمان به عنوان یک سیستم پردازش افزایشی برای مدیریت کارآمد داده های بزرگ در شبکه های اجتماعی بزرگ آنلاین با استقرار برنامه های کاربردی در فیس بوک و اینستاگرام برای افشای حساب های مخرب و حملات در شبکه های اجتماعی استفاده کرد. یک دوره زمانی کوتاه
(3) نقش SMBD در حل مشکلات توسعه اجتماعی انسانی. Eichstaedt و همکاران [ 61 ] از زبان توییتر برای پیش بینی مرگ و میر بیماری قلبی در سطح شهرستان استفاده کرد و اهمیت SMBD را در زمینه بیماری نشان داد. کریواشیو و همکاران [ 62 ] از داده های بزرگ در توییتر استفاده کرد تا نشان دهد که شبکه های اجتماعی آنلاین در مقیاس بزرگ می توانند به سرعت آسیب های ناشی از بلایای بزرگ را ارزیابی کنند. علاوه بر این، هیوستون و همکاران با ساخت چارچوب رسانه های اجتماعی فاجعه. [ 63 ] ایجاد ابزارهای رسانه های اجتماعی فاجعه، توسعه فرآیندهای پیاده سازی و مطالعه علمی اثرات آنها را تسهیل کرد. آلبوکرک و همکاران [ 64] از رسانه های اجتماعی به عنوان منبعی بالقوه برای بهبود مدیریت شرایط بحران استفاده کرد. او یک رویکرد جغرافیایی پیشنهاد کرد و از آن برای بررسی توییتهای تولید شده توسط پلتفرم توییتر (توئیتر) در طول سیلهای ژوئن 2013 در البه، آلمان استفاده کرد و پیامهای رسانههای اجتماعی را شاخصهای کمی قابل اعتماد در نظر گرفت. مدیریت بلایا در واکنش به بحران و نظارت پیشگیرانه از ارزش زیادی برخوردار بود.
5. نتیجه گیری و کمبودها
بر اساس تجزیه و تحلیل تحقیقات SMBD در بخش قبلی این مقاله، نتایج زیر را می توان استخراج کرد:
(1) تا آنجا که به تعداد مقالات منتشر شده مربوط می شود، تحقیقات SMBD روند افزایشی آشکاری را در ده سال گذشته نشان داده است، به ویژه تعداد مقالات منتشر شده در پنج سال گذشته 78.42٪ از کل تعداد مقالات را به خود اختصاص داده است. مقالات منتشر شده، که نشان می دهد تحقیق در مورد SMBD جدید است. تحقیق حاضر شامل علوم کامپیوتر، مهندسی، مخابرات و سایر رشتهها (رشتهها) میشود که منعکسکننده ویژگیهای SMBD بین رشتهای، چند زمینهای مشترک و ادغام متقابل چند جهته است. IEEE Access، Sustainability، IEEE Transactions on Visualization and Computer Graphics، PLoS One و مجلات دیگر تحقیقات زیادی در این زمینه جمع آوری کرده اند. تا آنجا که به نقطه قوت اصلی تحقیقات SMBD مربوط می شود، سازنده ترین نویسندگان در زمینه SMBD عمدتاً از چین بودند، تیم های دانشگاهی به رهبری Wanggen Wan، Haoran Xie و دیگران سهم قابل توجهی در این زمینه داشته اند. چین، ایالات متحده آمریکا، انگلستان و سایر کشورها بیشترین تعداد انتشارات را داشتند و مؤسسات تحقیقاتی اصلی آکادمی علوم چین، دانشگاه ووهان، دانشگاه تسینگهوا، دانشگاه سیتی هنگ کنگ و غیره بودند. با این حال، اگرچه تعداد مقالات منتشر شده توسط چین در رتبه اول، مرکزیت در سطح پایین باقی مانده است، که نشان می دهد نفوذ بین المللی نتایج تحقیقات چین در SMBD ضعیف است. بهبود نوآوری و جامعیت نتایج تحقیقات در آینده ضروری است. چین، ایالات متحده آمریکا، انگلستان و سایر کشورها بیشترین تعداد انتشارات را داشتند و مؤسسات تحقیقاتی اصلی آکادمی علوم چین، دانشگاه ووهان، دانشگاه تسینگهوا، دانشگاه سیتی هنگ کنگ و غیره بودند. با این حال، اگرچه تعداد مقالات منتشر شده توسط چین در رتبه اول، مرکزیت در سطح پایین باقی مانده است، که نشان می دهد نفوذ بین المللی نتایج تحقیقات چین در SMBD ضعیف است. بهبود نوآوری و جامعیت نتایج تحقیقات در آینده ضروری است. چین، ایالات متحده آمریکا، انگلستان و سایر کشورها بیشترین تعداد انتشارات را داشتند و مؤسسات تحقیقاتی اصلی آکادمی علوم چین، دانشگاه ووهان، دانشگاه تسینگهوا، دانشگاه سیتی هنگ کنگ و غیره بودند. با این حال، اگرچه تعداد مقالات منتشر شده توسط چین در رتبه اول، مرکزیت در سطح پایین باقی مانده است، که نشان می دهد نفوذ بین المللی نتایج تحقیقات چین در SMBD ضعیف است. بهبود نوآوری و جامعیت نتایج تحقیقات در آینده ضروری است. مرکزیت در سطح پایینی باقی ماند که نشان میدهد تأثیر بینالمللی نتایج تحقیقات چین در SMBD ضعیف است. بهبود نوآوری و جامعیت نتایج تحقیقات در آینده ضروری است. مرکزیت در سطح پایینی باقی ماند که نشان میدهد تأثیر بینالمللی نتایج تحقیقات چین در SMBD ضعیف است. بهبود نوآوری و جامعیت نتایج تحقیقات در آینده ضروری است.
(2) ما برای شناسایی پایگاه دانش SMBD از تحلیل هماستنادی استفاده کردیم و نتایج نشان داد که تحقیقات SMBD میان رشتهای بوده و زمینههایی مانند داده کاوی، یادگیری عمیق، تجسم دادهها و پردازش زبان طبیعی را پوشش میدهد. مشاهده می شود که ساختار دانش SMBD شروع به شکل گیری کرده است. ما بیشتر کلمات کلیدی را به 9 خوشه تقسیم کردیم و دریافتیم که تحقیقات داغ بر اهمیت تحقیقات SMBD، ترکیب با فناوری پیشرفته و کاربرد خاص در تولید و زندگی متمرکز است. کلان داده ها، رسانه های اجتماعی، شبکه های اجتماعی و تجسم بیشتر ظاهر شدند و شبکه های اجتماعی، تجسم، مرکزیت، الگو، طراحی دارای درجه مرکزی بالاتری بودند که نشان دهنده کانون های تحقیقاتی دهه گذشته بود.
(3) برای تجزیه و تحلیل مرزهای تحقیقاتی SMBD از دو ماژول، انفجار کلمه کلیدی و انفجار ادبیات مشترک استنادی استفاده کردیم. ما متوجه شدیم که قوی ترین کلمه کلیدی Visualization، طولانی ترین آنها شبکه های اجتماعی و تصویرسازی نمودار و جدیدترین آنها اعتبار سنجی، زمان واقعی، احساسات، زمینه بود. ما میتوانیم دریابیم که تجسم، شبکههای اجتماعی و موضوعات دیگر مرز آکادمیک را در مرحله آمادهسازی نشان میدهند. با بلوغ تئوری و توسعه فناوری، SMBD از تحقیقات نظری به کاربرد عملی تبدیل میشود. ما انبوه ادبیات استنادی را شناسایی کردیم و دریافتیم که مرز SMBD شامل کاوش عمیق و ساخت فناوریهای رسانههای اجتماعی، بازتابها و نگرانیهایی در مورد توسعه سریع رسانههای اجتماعی است. و نقش SMBD در حل مشکلات توسعه اجتماعی انسانی. این یافته ها اطلاعات ارزشمندی را برای محققان SMBD فراهم کرد تا وضعیت تحقیق و روندها در این زمینه را درک کنند.
اگرچه ما یک تحلیل اقتصاد سنجی موثر در زمینه SMBD انجام دادیم، هنوز محدودیت هایی در تحقیق فعلی وجود داشت. ابتدا، تجزیه و تحلیل در این مقاله با استفاده از پایگاه داده WoS محدود شد و ناقص بودن داده ها در گره زمانی وجود داشت، بنابراین داده های سایر پایگاه های داده یا جمع آوری شده در زمان های مختلف ممکن است نتایج و نتایج متفاوتی داشته باشند. ثانیاً، اگرچه کتاب سنجی ابزار و ابزار مؤثری برای توسعه حوزه تحقیق ارائه کرد، اما با بهبود بیشتر نرم افزارها و ابزار کتاب سنجی در عملکرد و روش ها، تحقیقات آتی به نتایج دقیق و ارزشمندتری می رسد، بنابراین نتیجه این مقاله این است که ارزش مطالعه بیشتر برای آزمایش و بهبود دارد.
منابع
- Hansen، DL; اشنایدرمن، بی. اسمیت، کارشناسی ارشد توییتر: جریان های اطلاعات، تأثیرگذاران و جوامع ارگانیک. در تجزیه و تحلیل شبکه های رسانه های اجتماعی با NodeXL ; مورگان کافمن: سن متئو، کالیفرنیا، ایالات متحده آمریکا، 2020؛ صص 161-178. [ Google Scholar ]
- عبدالله، GN; ثریا، ح. Abaker، THI تجزیه و تحلیل داده های بزرگ رسانه های اجتماعی: یک نظرسنجی. محاسبه کنید. هوم رفتار 2018 ، 101 ، 417-428. [ Google Scholar ]
- سیوارجاه، یو. ایرانی، ز. گوپتا، اس. نقش داده های بزرگ و تجزیه و تحلیل رسانه های اجتماعی برای پایداری کسب و کار: یک زمینه وب مشارکتی. بازار صنعتی مدیریت 2020 ، 86 ، 163-179. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- خیمنز مارکز، جی.ال. گونزالس-کاراسکو، آی. Lopez-Cuadrado، JL به سوی یک چارچوب کلان داده برای تجزیه و تحلیل محتوای رسانه های اجتماعی. بین المللی J. اطلاع دهید. مدیریت 2019 ، 44 ، 1-12. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یانگ، سی سی; مائو، دبلیو. ادغام، تجزیه و تحلیل و استخراج شبکه های اجتماعی با حفظ حریم خصوصی. در سیستم های هوشمند برای انفورماتیک امنیتی ; مطبوعات دانشگاهی: کمبریج، MA، ایالات متحده آمریکا، 2013; صص 51-67. [ Google Scholar ]
- گیلبرت، ای. Karahalios، K. پیش بینی قدرت کراوات با رسانه های اجتماعی. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی عوامل انسانی در سیستم های محاسباتی، بوستون، MA، ایالات متحده آمریکا، 4 تا 9 آوریل 2009. [ Google Scholar ]
- هاشم، IAT; یعقوب، ط. Anuar، NB ظهور “داده های بزرگ” در رایانش ابری: بررسی و باز کردن مسائل تحقیقاتی. آگاه کردن. سیستم 2015 ، 47 ، 98-115. [ Google Scholar ] [ CrossRef ]
- دیپامالا، ن. تحلیل محاسباتی و درک زبان های طبیعی: اصول، روش ها و کاربردها. در کتابچه راهنمای آمار ; Gudivada، VN، Rao، CR، Eds. Elsevier Science Ltd.: آمستردام، هلند، 2018؛ جلد 38، ص 429–462. [ Google Scholar ]
- فریدنتال، اس. مور، ا. Steiner, R. ادغام SysML در یک محیط توسعه سیستم. تمرین کنید. راهنمای SysML 2008 ، 39 ، 270-290. [ Google Scholar ]
- احمد، ای. یعقوب، ط. هاشم، IAT نقش تجزیه و تحلیل داده های بزرگ در اینترنت اشیا. محاسبه کنید. شبکه 2017 ، 129 ، 459-471. [ Google Scholar ] [ CrossRef ]
- کامبریا، ای. راجاگوپال، دی. اولشر، دی. تجزیه و تحلیل داده های اجتماعی بزرگ. در محاسبات کلان داده ؛ آکرکار، آر.، اد. چپمن و هال/CRC: نیویورک، نیویورک، ایالات متحده آمریکا، 2013; ص 401-414. [ Google Scholar ]
- Cappella، JN بردارها به آینده تحقیقات ارتباط جمعی و بین فردی: داده های بزرگ، رسانه های اجتماعی و علوم اجتماعی محاسباتی. هوم اشتراک. Res. 2017 ، 43 ، 545-558. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- جیانگ، دی. لو، ایکس. Xuan، J. محاسبات احساسات برای رویداد خبری بر اساس داده های رسانه های اجتماعی بزرگ. دسترسی IEEE 2017 ، 99 ، 2373-2382. [ Google Scholar ] [ CrossRef ]
- سیبولا، م. Tiko، I. ادغام رسانه های اجتماعی با کلان داده های مراقبت های بهداشتی برای ارائه خدمات بهبود یافته. اس افر. J. Ind. Eng. 2018 ، 20 ، 1-8. [ Google Scholar ]
- ژانگ، دی. وانگ، دی. ونس، ن. در مورد کشف حقیقت مقیاس پذیر و قوی در برنامه های کاربردی سنجش رسانه های اجتماعی داده های بزرگ. IEEE Trans. کلان داده 2019 ، 5 ، 195-208. [ Google Scholar ] [ CrossRef ]
- هان، ایکس. وانگ، جی. Zhang، M. استفاده از رسانه های اجتماعی برای استخراج و تجزیه و تحلیل افکار عمومی مرتبط با COVID-19 در چین. بین المللی J. Env. Res. میخانه Health 2020 , 17 , 2788. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، ی. لی، YB; یانگ، ب. ارزیابی ریسک COVID-19 بر اساس داده های چند منبعی از دیدگاه جغرافیایی. دسترسی IEEE 2020 ، 8 ، 125702–125713. [ Google Scholar ] [ CrossRef ]
- بهاراتی، پ. چاودری، الف. جذب نوآوری داده های بزرگ: بررسی نقش فناوری اطلاعات، رسانه های اجتماعی و سرمایه رابطه ای. آگاه کردن. سیستم جلو. 2019 ، 21 ، 1357–1368. [ Google Scholar ] [ CrossRef ]
- وانگ، XL; ژائو، HQ تجزیه و تحلیل آماری استناد WOS از مجله “Northern Horticulture”. شمال. هورتیک. 2016 ، 10 ، 198-201. [ Google Scholar ]
- هوانگ، ال. ژو، ام. Lv، J. روند در تحقیقات جهانی در ترسیب کربن جنگل: تجزیه و تحلیل کتاب سنجی. جی. پاک. تولید 2019 ، 252 ، 119908. [ Google Scholar ] [ CrossRef ]
- سی، اچ. شی، جی جی; Wu, G. نقشه برداری از تحقیقات اشتراک گذاری دوچرخه منتشر شده از سال 2010 تا 2018: یک بررسی علم سنجی. جی. پاک. تولید 2019 ، 213 ، 415-427. [ Google Scholar ] [ CrossRef ]
- لیو، ز. یین، ی. لیو، دبلیو. تجسم ساختار فکری و تکامل تحقیق سیستمهای نوآوری: تحلیل کتابسنجی. Scientometrics 2015 ، 103 ، 135-158. [ Google Scholar ] [ CrossRef ]
- Hirsch, JE شاخصی برای تعیین کمیت بازده تحقیقات علمی یک فرد. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2005 ، 102 ، 16569-16572. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Chen, C. CiteSpace II: تشخیص و تجسم روندهای نوظهور و الگوهای گذرا در ادبیات علمی. مربا. Soc. Inf. علمی تکنولوژی 2006 ، 57 ، 359-377. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- الله، اچ. وان، دبلیو. Haidery، SA تجزیه و تحلیل الگوهای مکانی-زمانی در فضاهای سبز برای مطالعات شهری با استفاده از داده های رسانه های اجتماعی مبتنی بر مکان. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 506. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ابراهیم پور، ز. Wan، WG; سروانتس، O. مقایسه رویکردهای اصلی برای استخراج ویژگیهای رفتاری از تحلیل جریان جمعیت. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 440. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Bragazzi، NL; وطاد، ع. Brigo, F. آگاهی از سلامت عمومی در مورد بیماری های خود ایمنی پس از مرگ یک سلبریتی. کلین روماتول. 2017 ، 36 ، 1911-1917. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Bragazzi، NL; آلیچینو، سی. تروکچی، سی. واکنش جهانی به شیوع اخیر ویروس زیکا: بینش از تجزیه و تحلیل داده های بزرگ. PLoS ONE 2017 , 12 , e0185263. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- کای، ی. لی، کیو. Xie, H. بررسی جستجوهای شخصیشده با استفاده از نمایههای کاربر مبتنی بر برچسب و نمایههای منابع در folksonomy. عصبی. شبکه 2014 ، 58 ، 98-110. [ Google Scholar ] [ CrossRef ]
- زی، اچ. لی، کیو. مائو، ایکس. غنیسازی نمایه کاربر آگاه از جامعه در جامعهشناسی. عصبی. شبکه 2014 ، 58 ، 111-121. [ Google Scholar ] [ CrossRef ]
- بولن، جی. مائو، اچ. Zeng، XJ توییتر حال و هوای بازار سهام را پیش بینی می کند. جی. کامپیوتر. Sci.-Neth. 2010 ، 2 ، 1-8. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چن، CLP; ژانگ، CY برنامهها، چالشها، تکنیکها و فنآوریهای فشرده داده: نظرسنجی درباره دادههای بزرگ. آگاه کردن. علمی 2014 ، 275 ، 314-347. [ Google Scholar ] [ CrossRef ]
- لازر، دی. کندی، آر. کینگ، جی. تمثیل آنفولانزای گوگل: تلهها در تحلیل دادههای بزرگ. Science 2014 , 343 , 1203. [ Google Scholar ] [ CrossRef ]
- بوید، دی. کرافورد، ک. سوالات مهم برای داده های بزرگ. Nform. اشتراک. Soc. 2012 ، 15 ، 662-679. [ Google Scholar ] [ CrossRef ]
- گینزبرگ، جی. محبی، م.ح. Patel, RS تشخیص اپیدمی های آنفلوانزا با استفاده از داده های جستجوی موتور جستجو. Nature 2009 ، 457 ، 1012-U4. [ Google Scholar ] [ CrossRef ]
- Manovich, L. Trending: The Promises and Challenges of Big Social Data. در بحث در علوم انسانی دیجیتال. در دسترس آنلاین: https://www.manovich.net/DOCS/Manovich_trending_paper.pdf (در 15 ژوئیه 2011 قابل دسترسی است).
- بلو-اورگاز، جی. یونگ، جی جی. کاماچو، دی. داده های بزرگ اجتماعی: دستاوردهای اخیر و چالش های جدید. آگاه کردن. فیوژن 2016 ، 28 ، 45-59. [ Google Scholar ] [ CrossRef ]
- چن، ام. مائو، اس. لیو، ی. داده های بزرگ: یک نظرسنجی. اوباش شبکه Appl. 2014 ، 19 ، 171-209. [ Google Scholar ] [ CrossRef ]
- بله، ن. کوئه، سل; Hou, L. تحلیل کتاب سنجی مسئولیت اجتماعی شرکت در توسعه پایدار. جی. پاک. تولید 2020 , 272 , 122679. [ Google Scholar ] [ CrossRef ]
- کانکانمگه، ن. Yigitcanlar، T. Goonetilleke، A. تعیین شدت فاجعه از طریق تجزیه و تحلیل رسانه های اجتماعی: آزمایش روش با توییت های South East Queensland Flood. بین المللی جی. فاجعه. کاهش ریسک 2020 , 42 , 101360. [ Google Scholar ] [ CrossRef ]
- مارنگو، دی. پولتی، آی. Settanni، M. تعامل بین روان رنجوری، برونگرایی و اعتیاد به رسانه های اجتماعی در کاربران جوان فیس بوک: آزمایش نقش واسطه ای فعالیت آنلاین با استفاده از داده های عینی. معتاد. رفتار 2019 ، 102 ، 106150. [ Google Scholar ] [ CrossRef ]
- Seo, EJ; پارک، جی دبلیو. چوی، YJ تأثیر ویژگیهای استفاده از رسانههای اجتماعی بر e-WOM، اعتماد، و ارزش ویژه برند: تمرکز بر کاربران رسانههای اجتماعی خطوط هوایی. پایداری 2020 ، 12 ، 1691. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- گروور، وی. لیندبرگ، ا. بن بساط، اول. خطرات و وعده های تحقیقات کلان داده در سیستم های اطلاعاتی. J. Assoc. Inf. سیستم 2020 ، 21 ، 9. [ Google Scholar ]
- کرمگام، دی. Mappillairaju، B. توزیع فضایی-زمانی احساسات منفی در توییتر در طول سیل در چنای، هند، در سال 2015: یک تجزیه و تحلیل post hoc. بین المللی J. Health Geogr. 2020 ، 19 ، 19. [ Google Scholar ] [ CrossRef ]
- وانگ، HW; پنگ، ZR؛ وانگ، DS ارزیابی و پیشبینی انعطافپذیری حملونقل تحت رویدادهای آب و هوایی شدید: یک رویکرد کانولوشنال نمودار انتشار. ترانسپ Res. قسمت C Emerg. تکنولوژی 2020 , 115 , 102619. [ Google Scholar ] [ CrossRef ]
- Tsan-Ming، C. هنگامی که بلاک چین با رسانه های اجتماعی روبرو می شود: آیا نتیجه به نفع تجزیه و تحلیل رسانه های اجتماعی برای مدیریت عملیات زنجیره تامین خواهد بود؟ ترانسپ Res. بخش E Logist. ترانسپ Rev. 2020 , 135 , 101860. [ Google Scholar ]
- رودریگز-اسپیندولا، او. چاودری، اس. Beltagui، A. پتانسیل فناوریهای مخرب نوظهور برای زنجیرههای تامین بشردوستانه: ادغام بلاک چین، هوش مصنوعی و چاپ سه بعدی. بین المللی J. Prod. Res. 2020 ، 58 ، 4610-4630. [ Google Scholar ] [ CrossRef ]
- مجدی، ا. عبدالحفیظ، ل. Kang، Y. مدیریت داده های میکروبلاگ: یک نظرسنجی. VLDB J. 2020 ، 29 ، 177-216. [ Google Scholar ] [ CrossRef ]
- آمالینا، اف. هاشم، IAT; Azizul، ZH ترکیب تجزیه و تحلیل داده های بزرگ: بررسی چالش ها و مطالعه اخیر. دسترسی IEEE 2019 ، 8 ، 3629–3645. [ Google Scholar ] [ CrossRef ]
- Vargas-Quesada، B. Moya-Anegon، FD; Chinchilla-Rodrfguez, Z. نمایش ساختار علمی اساسی یک حوزه علمی و تکامل آن. آگاه کردن. دیداری. 2010 ، 9 ، 288-300. [ Google Scholar ] [ CrossRef ]
- لیو، کیو. الله، اچ. Wan, W. طبقه بندی فضاهای سبز برای محیط زیست پایدار و معماری شهر هوشمند با استفاده از داده های بزرگ. Electronics 2020 , 9 , 1028. [ Google Scholar ] [ CrossRef ]
- علیپور، م. هریس، DK یک استراتژی تجزیه و تحلیل داده های بزرگ برای ارزیابی وضعیت زیرساخت های شهری مقیاس پذیر با استفاده از خودآموزی چند تبدیلی نیمه نظارت شده. J. Civ. ساختار. سلامت 2020 ، 10 ، 313-332. [ Google Scholar ] [ CrossRef ]
- O’Doherty، KC; کریستوفیدس، ای. ین، جی. اگر آن را بسازید، خواهند آمد: استفاده های ناخواسته در آینده از مجموعه های سازمان یافته داده های بهداشتی. BMC Med. اخلاق 2016 ، 17 ، 1-16. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کلینبرگ، جی. برستی و ساختار سلسله مراتبی در جریان ها. حداقل داده بدانید. دیسک. 2003 ، 7 ، 373-397. [ Google Scholar ] [ CrossRef ]
- Mikolov، T. نمایش های توزیع شده از کلمات و عبارات و ترکیب آنها. عصبی Inf. روند. سیستم 2013 ، 26 ، 3111-3119. [ Google Scholar ]
- Schmidhuber, J. یادگیری عمیق در شبکه های عصبی: یک مرور کلی. عصبی. شبکه 2015 ، 61 ، 85-117. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گندمی، ع. Haider, M. Beyond the hype: Big data مفاهیم، روش ها و تجزیه و تحلیل. بین المللی J. اطلاع دهید. مدیریت 2015 ، 35 ، 137-144. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فرارا، ای. وارول، او. دیویس، سی. ظهور ربات های اجتماعی. اشتراک. Acm. 2014 ، 59 ، 96-104. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بوشماف، ی. موسلوخوف، آی. Beznosov، K. طراحی و تجزیه و تحلیل یک بات نت اجتماعی. محاسبه کنید. شبکه 2013 ، 57 ، 556-578. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کائو، کیو. یانگ، ایکس. Yu, J. کشف گروه های بزرگی از حساب های مخرب فعال در شبکه های اجتماعی آنلاین. در مجموعه مقالات کنفرانس ACM SIGSAC 2014 در مورد امنیت رایانه و ارتباطات (CCS 2014)، اسکاتسدیل، AZ، ایالات متحده آمریکا، 3 تا 7 نوامبر 2014. [ Google Scholar ]
- Eichstaedt, JC; شوارتز، HA; Kern, ML زبان روانشناسی در توییتر مرگ و میر ناشی از بیماری قلبی در سطح شهرستان را پیش بینی می کند. روانی علمی 2015 ، 26 ، 159. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کریواشیو، ی. چن، اچ. Obradovich, N. ارزیابی سریع آسیب بلایا با استفاده از فعالیت رسانه های اجتماعی. علمی Adv. 2016 , 2 , e1500779. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- هیوستون، جی بی. هاثورن، جی. Perreault، MF رسانههای اجتماعی و بلایا: چارچوبی کاربردی برای استفاده از رسانههای اجتماعی در برنامهریزی، واکنش و تحقیق در بلایا. بلایا 2015 ، 39 ، 1-22. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- آلبوکرک، JP; هرفورت، بی. برنینگ، الف. یک رویکرد جغرافیایی برای ترکیب رسانه های اجتماعی و داده های معتبر به منظور شناسایی اطلاعات مفید برای مدیریت بلایا. بین المللی جی. جئوگر. Inf. علمی 2015 ، 29 ، 667-689. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
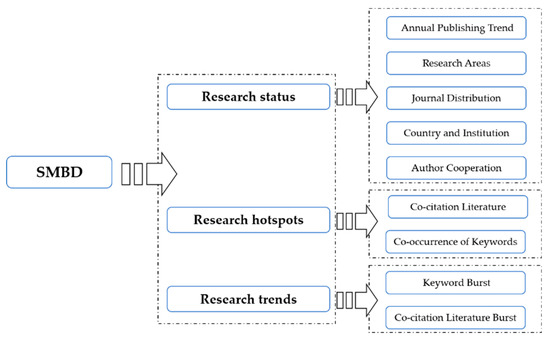
شکل 1. چارچوب تحقیق.
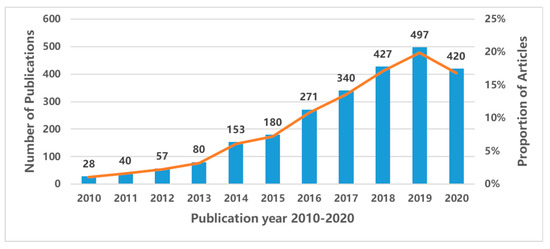
شکل 2. روند انتشار در رسانه های اجتماعی بزرگ داده (SMBD).
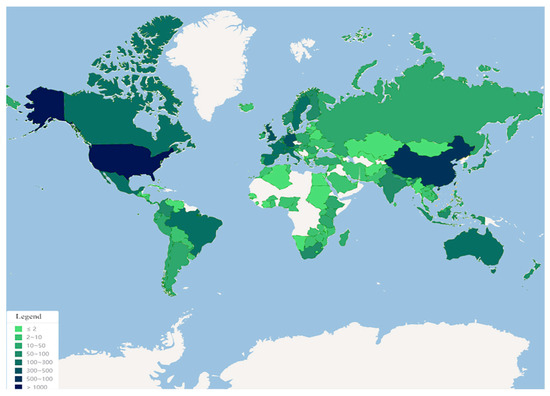
شکل 3. توزیع جهانی انتشارات SMBD.
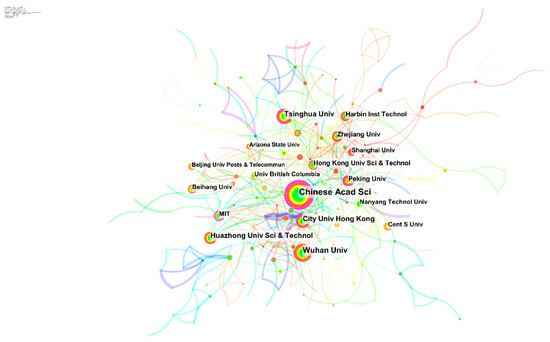
شکل 4. نقشه دانش همکاری موسسه در SMBD.
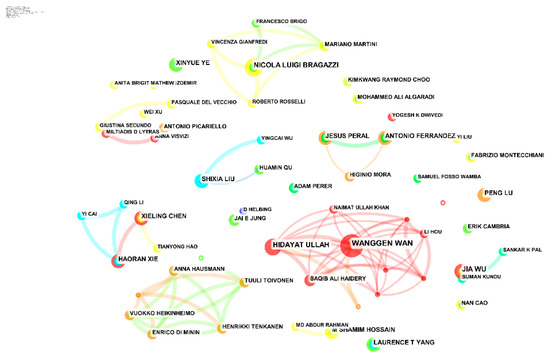
شکل 5. نقشه دانش همکاری نویسنده در SMBD.
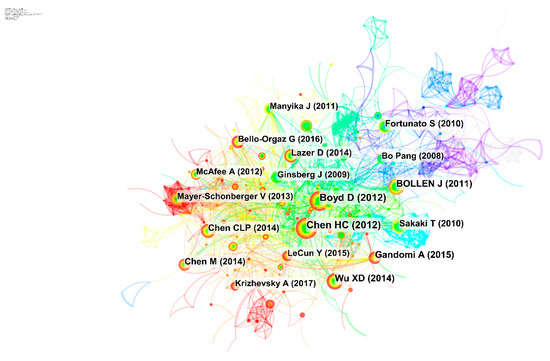
شکل 6. نقشه دانش ادبیات استنادی در SMBD.
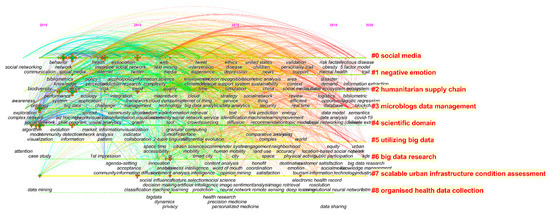
شکل 7. نقشه دانش خوشه کلمات کلیدی در SMBD.
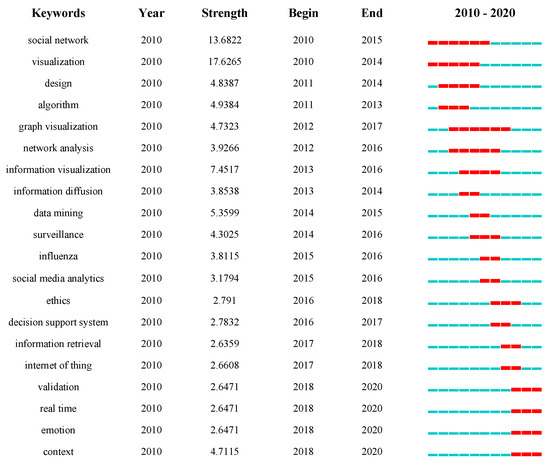
شکل 8. کلمات کلیدی با قوی ترین استناد در SMBD منفجر می شوند.
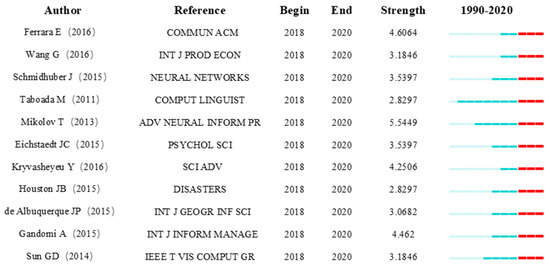
شکل 9. مقالات استنادی مشترک در SMBD.


بدون دیدگاه