

پیش بینی فقر با استفاده از داده های مکانی در تایلند
چکیده
آمار فقر به طور معمول با استفاده از داده های بررسی های اجتماعی و اقتصادی جمع آوری می شود. این مطالعه یک رویکرد جایگزین برای تخمین فقر را با بررسی اینکه آیا دادههای مکانی در دسترس میتواند به طور دقیق توزیع فضایی فقر در تایلند را پیشبینی کند، بررسی میکند. به طور خاص، دادههای مکانی مورد بررسی در این مطالعه شامل شدت نور شبانه (NTL)، پوشش زمین، شاخص پوشش گیاهی، دمای سطح زمین، مناطق ساختهشده و نقاط دیدنی است. این مطالعه همچنین عملکرد پیش بینی روش های مختلف اقتصادسنجی و یادگیری ماشینی مانند حداقل مربعات تعمیم یافته، شبکه عصبی، جنگل تصادفی و رگرسیون بردار پشتیبان را مقایسه می کند.

نتایج نشان میدهد که شدت NTL و سایر متغیرهایی که تراکم جمعیت را تقریب میکنند، به شدت با نسبت جمعیت یک منطقه که در فقر زندگی میکنند مرتبط است. تکنیک جنگل تصادفی بالاترین سطح دقت پیشبینی را در بین روشهای در نظر گرفته شده در این مطالعه به همراه داشت، در درجه اول به دلیل قابلیت آن در تناسب ساختارهای پیچیده حتی با مجموعه دادههای کوچک تا متوسط. این نتیجه بهدستآمده، کاربردهای بالقوه استفاده از دادههای مکانی در دسترس عموم و روشهای یادگیری ماشینی را برای پایش به موقع توزیع فقر نشان میدهد. با حرکت رو به جلو، مطالعات بیشتری برای بهبود قدرت پیشبینی و بررسی پایداری زمانی روابط مشاهدهشده مورد نیاز است. تکنیک جنگل تصادفی بالاترین سطح دقت پیشبینی را در بین روشهای در نظر گرفته شده در این مطالعه به همراه داشت، در درجه اول به دلیل قابلیت آن در تناسب ساختارهای پیچیده حتی با مجموعه دادههای کوچک تا متوسط. این نتیجه بهدستآمده، کاربردهای بالقوه استفاده از دادههای مکانی در دسترس عموم و روشهای یادگیری ماشینی را برای پایش به موقع توزیع فقر نشان میدهد. با حرکت رو به جلو، مطالعات بیشتری برای بهبود قدرت پیشبینی و بررسی پایداری زمانی روابط مشاهدهشده مورد نیاز است. تکنیک جنگل تصادفی بالاترین سطح دقت پیشبینی را در بین روشهای در نظر گرفته شده در این مطالعه به همراه داشت، در درجه اول به دلیل قابلیت آن در تناسب ساختارهای پیچیده حتی با مجموعه دادههای کوچک تا متوسط. این نتیجه بهدستآمده، کاربردهای بالقوه استفاده از دادههای مکانی در دسترس عموم و روشهای یادگیری ماشینی را برای پایش به موقع توزیع فقر نشان میدهد. با حرکت رو به جلو، مطالعات بیشتری برای بهبود قدرت پیشبینی و بررسی پایداری زمانی روابط مشاهدهشده مورد نیاز است. این نتیجه بهدستآمده، کاربردهای بالقوه استفاده از دادههای مکانی در دسترس عموم و روشهای یادگیری ماشینی را برای پایش به موقع توزیع فقر نشان میدهد. با حرکت رو به جلو، مطالعات بیشتری برای بهبود قدرت پیشبینی و بررسی پایداری زمانی روابط مشاهدهشده مورد نیاز است. این نتیجه بهدستآمده، کاربردهای بالقوه استفاده از دادههای مکانی در دسترس عموم و روشهای یادگیری ماشینی را برای پایش به موقع توزیع فقر نشان میدهد. با حرکت رو به جلو، مطالعات بیشتری برای بهبود قدرت پیشبینی و بررسی پایداری زمانی روابط مشاهدهشده مورد نیاز است.
کلید واژه ها:
فقر ؛ تایلند ؛ جغرافیایی ; فراگیری ماشین
1. مقدمه
در طول سه دهه گذشته، تولید ناخالص داخلی واقعی سرانه تایلند سالانه 3.35 درصد رشد داشته است. قبل از همهگیری کووید-19، رشد اقتصادی چشمگیر این کشور با کاهش نرخ فقر خانوارها همراه بود و از 61.41 درصد در سال 1988 به 5.04 درصد در سال 2019 کاهش یافت ( شکل 1 ). با این حال، فقرات قابل توجهی همچنان وجود دارد، به ویژه در مناطق روستایی که حدود 6.76 درصد از خانوارها فقیر در نظر گرفته می شوند [ 1 ]. علاوه بر این، همه گیری ناشی از COVID-19 ممکن است دستاوردهای کاهش فقر را در طول سال ها تضعیف کند.
از این رو، نظارت بر فقر یک وظیفه اساسی برای دست اندرکاران توسعه کشور است. در حال حاضر، شورای ملی توسعه اقتصادی و اجتماعی (NESDC) و اداره ملی آمار (NSO) مسئول تهیه آمار فقر در تایلند هستند. آمار فقر بر اساس نظرسنجی اجتماعی و اقتصادی خانوارها (HSES) است که هر دو سال یک بار داده های درآمد خانوار را جمع آوری می کند. حجم نمونه این نظرسنجی تخمینهایی را ارائه میکند که در سطوح ملی و استانی در سطوح قابل تحمل قابلاعتماد قرار میگیرند، اما معمولاً به اندازه کافی بزرگ نیستند که تخمینهای قابل اعتماد را در سطوح دقیقتر ارائه دهند. از سوی دیگر، افزایش فراوانی و حجم نمونه بررسی اغلب به دلیل هزینه بالا عملی نیست [ 2 ].
با توجه به نیاز به داده های به موقع و دقیق تر فقر که می تواند برای هدف قرار دادن بخش های جمعیتی که بیشترین نیاز به مداخله را دارند مورد استفاده قرار گیرد، محققان و دست اندرکاران توسعه رویکردهای روش شناختی جایگزین را بررسی کرده اند. برای مثال، تکنیکهای تخمین ناحیه کوچک (SAE) که پیمایشها را با سرشماری و دیگر انواع دادههای اداری ترکیب میکند، بهطور گستردهای برای تسهیل برآورد در سطوحی دقیقتر از آنچه که هنگام کار با نظرسنجی به تنهایی امکان پذیر است، استفاده شده است. با این حال، از آنجایی که SAE به داده های سرشماری نیاز دارد که اغلب در دسترس نیستند، نقشه های فقر به دست آمده لزوماً به موقع نیستند. همچنین ابتکاراتی برای استفاده از دادههای نوآورانه از سوابق جزئیات تماس، رسانههای اجتماعی، تراکنشهای دیجیتال و دادههای سنجش از راه دور برای جمعآوری آمار دقیقتر و به موقع فقر وجود دارد.3 ، 4 ، 5 ، 6 ، 7 ، 8 ، 9 ].
نقشه برداری توزیع فضایی فقر در تایلند منطقه ای است که می تواند از ادغام داده های سنجش از راه دور سود زیادی ببرد. در این زمینه، دو نوع چارچوب تحلیلی شایان ذکر است. نخست، با سرمایهگذاری بر پیشرفتهای جاری در تکنیکهای بینایی کامپیوتری و تصاویر ماهوارهای، چندین محقق نشان دادهاند که توسعه الگوریتمی امکانپذیر است که بتواند بهطور خودکار برآوردهای مبتنی بر نظرسنجی از فقر را با سطوح رضایتبخشی از دقت پیشبینی کند [ 2 ، 3 ، 4 ، 5 ].]. چنین رویکردی برای مواردی که جمعآوری دادههای نظرسنجی، بهویژه در مناطق دورافتاده و/یا صعب العبور، دشوار است، بسیار جذاب است و هیچ نوع دیگری از دادههای تکمیلی به آسانی در دسترس نیست. همچنین زمانی مفید است که افزایش حجم نمونه نظرسنجی بسیار پرهزینه باشد. با این حال، از آنجایی که ویژگیهای استخراجشده توسط تکنیکهای بینایی کامپیوتری نسبتاً انتزاعی هستند [ 2 ]، تعیین دقیق ویژگیهایی که کامپیوتر هنگام پیشبینی فقر دقیقاً چه ویژگیهایی را انتخاب میکند، دشوار است. در نتیجه، تأیید اینکه چه چیزی میتواند منجر به تخمین غیرمنتظره پایین یا زیاد فقر در صورت بروز چنین مواردی شود، نیز دشوار است. پذیرش گستردهتر این تکنیکهای جدید جمعآوری فقر نیز ممکن است در صورتی که ویژگیهایی را ایجاد نکنند که برای سیاستگذاران قابل تفسیر باشد، با مشکل مواجه شود.4 ].
از طرف دیگر، اگر دادههای جغرافیایی ساختاریافته به آسانی در دسترس باشند، میتوان یک مدل اقتصادسنجی قابل تفسیرتر و قابل تفسیرتر برای پیشبینی فقر ایجاد کرد. این را می توان با استفاده از داده های مکانی قابل تفسیر که قبلاً از پیش کامپایل شده یا به صورت غیرفعال جمع آوری شده اند به دست آورد. این رویکرد چارچوب محاسباتی قابل تفسیرتری را برای پیشبینی فقر تسهیل میکند. این مطالعه رویکرد دوم را بررسی میکند، جایی که فقر با شناسایی همبستگیها از دادههای مکانی از پیش تدوینشده پیشبینی میشود. با ارزیابی اینکه آیا امکان توسعه مدلی با عملکرد پیشبینی رضایتبخش وجود دارد یا خیر، به ادبیات موجود کمک میکند، حتی اگر ما صرفاً به مجموعه دادههای جغرافیایی از پیش کامپایل شده وابسته باشیم. که از نظر تئوری می تواند تنها کسری از تعداد متغیرهای کمکی در نظر گرفته شود که رویکرد اول به طور بالقوه می تواند ایجاد کند، شاهکاری که در مطالعات قبلی به طور کامل در زمینه تایلند بررسی نشده است. در اینجا، ما همچنین عملکرد تکنیکهای مختلف یادگیری ماشینی را مقایسه میکنیم، موضوعی که در مطالعات قبلی برآورد فقر با استفاده از منابع دادههای غیر سنتی به خوبی مورد بررسی قرار نگرفته است. در انجام این کار، هدف این مطالعه کمک به ادبیاتی است که سایر روشهای مقرونبهصرفه پیشبینی فقر را با استفاده از یک چارچوب محاسباتی قابل تفسیر که برای دادههای مکانی استفاده میشود، بررسی میکند. موضوعی که در مطالعات قبلی برآورد فقر با استفاده از منابع داده غیرسنتی به خوبی مورد بررسی قرار نگرفته است. در انجام این کار، هدف این مطالعه کمک به ادبیاتی است که سایر روشهای مقرونبهصرفه پیشبینی فقر را با استفاده از یک چارچوب محاسباتی قابل تفسیر که برای دادههای مکانی استفاده میشود، بررسی میکند. موضوعی که در مطالعات قبلی برآورد فقر با استفاده از منابع داده غیرسنتی به خوبی مورد بررسی قرار نگرفته است. در انجام این کار، هدف این مطالعه کمک به ادبیاتی است که سایر روشهای مقرونبهصرفه پیشبینی فقر را با استفاده از یک چارچوب محاسباتی قابل تفسیر که برای دادههای مکانی استفاده میشود، بررسی میکند.
بقیه این مقاله به شرح زیر سازماندهی شده است. بخش دوم به بررسی ادبیات مرتبط می پردازد، در حالی که بخش سوم و چهارم به ترتیب داده ها و روش های تحقیق را معرفی می کنند. بخش پنجم یافتههای کلیدی روشهای اقتصادسنجی و یادگیری ماشینی اتخاذ شده در این مطالعه را ارائه میکند. بخش آخر درس های آموخته شده را خلاصه می کند و توصیه های مختصری برای مطالعات آینده ترسیم می کند.
2. بررسی ادبیات
2.1. استفاده از داده های مکانی از پیش جمع آوری شده برای پیش بینی شاخص های اجتماعی و اقتصادی
ادبیات موجود طیف وسیعی از مطالعات موردی را ارائه میکند که کاربردهای مختلف تصاویر ماهوارهای و دادههای مکانی را برای تحلیلهای مرتبط با توسعه نشان میدهد. به عنوان مثال، دادههای مربوط به شدت NTL که از طریق برنامه ماهوارهای هواشناسی دفاعی (DMSP)/سیستم اسکن خط عملیاتی (OLS) و مشارکت مداری قطبی ملی Suomi (SNPP) – مجموعه تصویربرداری/رادیومتر مرئی و فروسرخ (VIIRS) گردآوری شدهاند، به طور گسترده مورد استفاده قرار میگیرند. بسیاری از مطالعات رابطه آماری معنی داری بین شدت NTL و داده های زمینی مختلف مانند تولید ناخالص داخلی، مصرف برق، نابرابری و نرخ مرگ و میر نوزادان پیدا کردند [ 6 ، 7 ، 8 ، 9 ، 10 ، 11 ، 12 ،13 ، 14 ].
علاوه بر شدت NTL، ماهوارههای Landsat، سازمان ملی اقیانوسی و جوی (NOAA) – ماهوارههای محیطی مدار قطبی (POES) و طیفسنجی تصویربرداری با وضوح متوسط Terra (MODIS) سطح زمین را با حسگرهای چند طیفی اسکن کردهاند. این دادههای چند طیفی توسط محققان مختلف برای جمعآوری تعدادی از شاخصهای جغرافیایی مانند تراکم ساختمان، پوشش آب، شاخص گیاهی تفاوت نرمال شده (NDVI)، دمای سطح زمین (LST)، NDWI (شاخص تفاوت عادی آب)، استفاده شده است. NDSI (شاخص تفاوت نرمال شده برف) NDSI (شاخص تفاوت نرمال شده خاک) و NDBI (شاخص ایجاد اختلاف نرمال شده). به طور مشخص، NDVI نشاندهنده الگوی مکانی-زمانی جنگلها و مناطق زیر کشت است و یکی از شاخصهای معمولی است که معمولاً در تجزیه و تحلیل سنجش از دور پوشش گیاهی استفاده میشود. NDVI با اندازه گیری تفاوت بین نور مادون قرمز نزدیک (که پوشش گیاهی منعکس می کند) و نور قرمز (که پوشش گیاهی جذب می کند) محاسبه می شود. برای کاربرد در مطالعات اجتماعی-اقتصادی، همبستگی بین گسترش شهری و کاهش NDVI مستند شده است.15 ، 16 ، 17 ]. به طور مشابه، رابطه آماری بین NDVI و توزیع فضایی نابرابری درآمد به صورت آماری تأیید شده است [ 18 ، 19 ، 20 ، 21 ].
داده های مربوط به دمای سطح زمین نوع دیگری از اطلاعات مکانی از پیش تدوین شده است که محققان برای پیش بینی درآمد از آن استفاده می کنند. به عنوان مثال، یک رابطه آماری معنادار بین دمای سطح زمین و درآمد از نظر آماری تایید شده است [ 22 ، 23 ، 24 ، 25 ، 26 ، 27 ، 28 ]. علاوه بر این، بسیاری از مطالعات همبستگی آماری معنی داری را بین میزان بارندگی بر درآمد، سرمایه انسانی و فعالیت اقتصادی در کشورهای در حال توسعه یافتند [ 29 ، 30 ، 31 ، 32 ، 33 ، 34 .].
علاوه بر این، مدلهای پیشبینی با استفاده از دما و NDVI برای پیشبینی خشکسالی و به نوبه خود، پیشبینی از دست دادن محصول کشاورزی و تأثیر آن بر درآمد کشاورزان فرموله شده است [ 35 ، 36 ].
تلاشها برای جمعسپاری دادههای مکانی نیز در حال گسترش است. یک مثال خوب OpenStreetMap است، یک پروژه مشترک که یک پایگاه داده جغرافیایی جمعسپاری شده تولید میکند و یکی از پلتفرمهای اصلی ترویج استفاده از دادههای مکانی در زمینههای اقدام بشردوستانه جهانی و توسعه جامعه است. پایگاه داده OpenStreetMap همچنین انواع دیگری از دادههای مکانی مانند وجود جادهها، رودخانهها، مناطق ساختهشده و نقاط مورد علاقه (POI) را نشان میدهد که امکان بررسی ارتباط بین ویژگیهای جغرافیایی و شرایط اجتماعی-اقتصادی را فراهم میکند. مطالعاتی مانند مطالعات Hu و همکاران. (2016)، یه و همکاران. (2019) و دنگ و همکاران. (2019) [ 37 ، 38 ، 39] نشان می دهد که OpenStreetMap می تواند جزئیاتی از توزیع فضایی جمعیت و فعالیت های اقتصادی ارائه دهد.
2.2. نقشه برداری فقر در تایلند
برای بسیاری از کشورها، فقر حتی قبل از شیوع بیماری همهگیر کووید-19 یک چالش توسعه حیاتی بود، با روندهای پیش از همهگیری در کاهش فقر نسبت به آنچه در گذشته مشاهده شده بود کاهش نسبتاً آهستهتری را نشان میداد. به عنوان مثال، در آسیای در حال توسعه، تا سال 2017، حدود 203 میلیون نفر زیر 1.9 دلار در روز زندگی می کردند، و شواهدی وجود دارد که نشان می دهد این بیماری همه گیر ممکن است ساعت فقر منطقه را بیشتر به عقب برگرداند.
نابرابری های فضایی در فقر در تعدادی از مطالعات تجربی به خوبی مستند شده است. به طور کلی، جغرافیا می تواند به عنوان دروازه ای برای استانداردهای زندگی بهتر عمل کند، به ویژه زمانی که یک مکان خاص دسترسی بیشتری به منابع طبیعی غنی تر داشته باشد، یا به عنوان دریچه ای برای فقر زمانی که یک منطقه بسیار دور است، فعالیت های اشتغال زایی-اقتصادی محدودی دارد، و دسترسی محدودی دارد. به خدمات اجتماعی مختلف از سوی دیگر، رویدادهای شدید اقلیمی مانند شوک های بارندگی و حتی تغییرات ملایم دما ممکن است برای افراد فقیر و آسیب پذیری که دسترسی محدودی به شبکه های ایمنی اجتماعی دارند، فرار از فقر را دشوار کند زیرا توانایی آنها برای انباشت دارایی و سرمایه گذاری در سرمایه انسانی است. مختل شده است.
تایلند به عنوان یک کشور با درآمد متوسط بالا، به عنوان یکی از موفقیت های بزرگ توسعه آسیا در نظر گرفته می شود. در کمتر از یک نسل، این کشور توانست از یک کشور کم درآمد دور شود. با این حال، مسیر توسعه آن توسط نابرابری های درآمد فضایی، در میان سایر چالش های توسعه، محدود شده است. تمرکز فقر در مناطق روستایی احتمالاً ناشی از نیروی تجمع بالای بانکوک و این واقعیت است که بیشتر فعالیت های اقتصادی در بانکوک و حومه آن متمرکز شده است [ 40 ]. از آنجایی که استان های روستایی دارای تنوع محدودی از فعالیت های اقتصادی هستند، محدودیت ایجاد مشاغل غیرکشاورزی دارند. روند شاخص های غیرمالی توسعه نیز نگران کننده است ( شکل 2). به عنوان مثال، نیمی از جمعیت شاغل کشور هنوز در مشاغل نامطمئن هستند. همچنین فضای زیادی برای بهبود در بخش آموزش وجود دارد زیرا مهاجران روستایی و فقرای شهری عموماً فاقد مهارتهای مورد نیاز مشاغل مدرن هستند.
همانطور که قبلاً ذکر شد، آمار رسمی فقر در تایلند بر اساس نظرسنجی اجتماعی و اقتصادی خانوارها است که تخمین های قابل اعتمادی را از سطح ملی تا استانی ارائه می دهد. با این حال، با درک اهمیت داشتن دادههای فقر تفکیکشدهتر جغرافیایی بهعنوان ورودی برای هدفگیری سیاست، NSO تایلند در سال 2003 با همکاری سایر شرکای توسعه مانند NESDC، موسسه تحقیقات توسعه تایلند، شروع به جمعآوری برآوردهای فقر در منطقه کوچک (در سطح تامبون یا زیر ناحیه) کرد. (TDRI) و بانک جهانی. از آن زمان، برآوردهای فقر منطقه کوچک در کشور برای سالهای زیر تهیه شده است: 2005، 2007، 2008، 2011، 2012، 2015، و 2017. خروجیها در سالهای 2003 و 2005 به طور مشترک توسط سه نهاد محلی، یعنی NESD تهیه شده است. ، NSO و TDRI، همراه با مشاوره فنی بانک جهانی. در سال 2015، بانک جهانی کمک های فنی بیشتری به NSO ارائه کرد تا ظرفیت خود را برای اجرای تخمین منطقه کوچک در میان کارکنان بیشتر NSO ایجاد کند. جزئیات فنی اضافی در مورد روند تهیه نقشه های فقر توسط Jitsuchon (2004) و Jitsuchon and Richter (2007) مستند شده است.41 ، 42 ].
با این حال، علیرغم در دسترس بودن ابزارهای تحلیلی برای گردآوری تخمینهای دانهای فقر، شناسایی روشهای جایگزین به دلیل محدودیتهای مرتبط با تکنیک مرسوم نقشهبرداری فقر، که به شدت بر در دسترس بودن دادههای سرشماری متکی است، مهم است. برای مثال، از آنجایی که سرشماریها معمولاً هر پنج تا ده سال یکبار انجام میشوند، مدلهای نگاشت فقر که از متغیرهای کمکی مشتقشده از سرشماری استفاده میکنند، دارای مفروضات محدودی قوی هستند [ 43 ].
گردآوری آمار فقر فرصت های هیجان انگیزی را برای ترکیب منابع داده سنتی و نوآورانه، به ویژه اطلاعات استخراج شده از تصاویر ماهواره ای ارائه می دهد [ 3 ]. همانطور که قبلاً بحث شد، انجام بررسیهای دقیق خانوار با حجم نمونه به اندازه کافی بزرگ که همه مناطق جغرافیایی و گروههای مختلف جمعیت را منعکس کند، ممکن است به دلیل هزینه بالا، گزینه عملی نباشد. علاوه بر این، اهمیت آمار فقر برای هدف گذاری سیاست ایجاب می کند که داده های دقیق به طور منظم در دسترس باشد. ترکیب دادههای نوآورانه میتواند به طور بالقوه محدودیتهایی را که منابع داده مرسوم با آنها مرتبط هستند برطرف کند.
در مطالعهای که اخیراً منتشر شد، محققان ADB چارچوب مرسوم تخمین فقر در مناطق کوچک را با بهرهبرداری از دادههای جغرافیایی استخراجشده از تصاویر روزانه و NTL از طریق الگوریتمهای یادگیری ماشینی برای ایجاد نقشههای فقر دانهای از فیلیپین و تایلند گسترش دادند [ 2 ، 4 ]. روش اتخاذ شده به طور خاص توسط ژان و همکاران الهام گرفته شده است. (2016) [ 3 ]، که بیشتر مورد استفاده قرار گرفت و/یا در مطالعات بعدی تقویت شد [ 44 ، 45 ، 46 ، 47]. این مطالعات تحت رشته ادبیاتی قرار میگیرند که به طور گسترده با هدف بررسی کاربردهای هوش مصنوعی و تکنیکهای بینایی کامپیوتری برای برآورد فقر انجام میشود. با این حال، همانطور که قبلا اشاره شد، این روش دارای چندین مشکل فنی است. اول، اعتبارسنجی پیشبینیهای ناهنجار یا غیرمنتظره چالش برانگیز میشود، زیرا ویژگیهایی که برای ارتباط فقر استفاده میشوند انتزاعی هستند. دوم، این روش به جای پیشبینی مستقیم فقر، از یک مرحله میانی استفاده میکند که در آن ابتدا الگوریتمی برای پیشبینی شدت NTL آموزش داده میشود. مرحله میانی در این زمینه ضروری است، زیرا منابع دادههای NTL، به ویژه تصاویر ماهوارهای، به آسانی در دسترس هستند و میتوانند به طور مقرونبهصرفه حجم زیادی از تصاویر برچسبگذاری شده را برای آموزش الگوریتم بینایی کامپیوتری ارائه دهند. چیزی که اگر بخواهیم فقر را به طور کامل پیش بینی کنیم، نمی توان به راحتی به آن دست یافت، زیرا داده های فقر در دسترس کاملاً دقیق نیستند. استفاده از دادههای شدت NTL بهعنوان نمایندهای برای فقر در مرحله میانی، مسلماً معتبر است اگر فرض شود مکانهایی که در شب روشنتر هستند نسبت به مکانهایی که نور کمتری دارند ضعیفتر هستند. با این حال، اگر مکانهایی وجود داشته باشند که به یک اندازه روشن هستند اما سطوح مختلفی از فقر را در زمین نشان میدهند، چنین گام میانی میتواند به طور بالقوه منجر به از دست رفتن اطلاعات حیاتی با پیشبینی مستقیم فقر شود. سوم، داشتن ویژگیهای تصویر ماهوارهای انتزاعی بهعنوان متغیرهای کمکی مدل که بهطور شهودی توسط دست اندرکاران توسعه و سیاستگذاران قابل درک نیستند، اتخاذ چنین تکنیکهایی را کمتر جذاب میکند.4 ].
این مطالعه به ادبیات موجود اندازهگیری فقر در تایلند با توسعه یک مدل پیشبینی کمک میکند که همبستگیهای آن از دادههای مکانی از پیش تدوینشده، که قابل تفسیر هستند، مشتق شدهاند. با انجام این کار، هدف ما ارزیابی امکان توسعه مدلی با عملکرد پیشبینی رضایتبخش است، حتی اگر به جای استفاده از تکنیکهای بینایی کامپیوتری برای استخراج خودکار ویژگیهای تصویر ماهوارهای که به طور بالقوه هستند، صرفاً به مجموعه داده(های) مکانی از پیش کامپایل شده وابسته باشیم. با فقر همبستگی دارد، شاهکاری که در مطالعات قبلی به طور کامل مورد بررسی قرار نگرفته است.
پیامدهای مورد توجه در این پژوهش شاخص های درآمد و فقر چند بعدی است. مشخصات مدل ما شامل چندین متغیر است. ابتدا، ما شدت NTL را در نظر می گیریم، که به عنوان معیاری برای سطح فعالیت اقتصادی در یک منطقه خاص عمل می کند. برای دریافت سطح شهرنشینی، دمای سطح زمین، کاربری زمین و شاخص پوشش گیاهی را نیز در نظر می گیریم. اندازه گیری تراکم نقاط مورد علاقه برای ثبت دسترسی به خدمات و همچنین سطح فعالیت اقتصادی استفاده می شود. داده های بارندگی عوامل اقلیمی را جمع آوری می کند که ممکن است خطر فقر را در یک مکان مشخص تقویت کند. جزئیات در بخش بعدی ارائه شده است.
3. داده ها
3.1. داده های ماهواره ای
داده های به دست آمده از موتور Google Earth
Google Earth Engine یک بستر باز ذخیرهسازی داده و محاسبات مبتنی بر ابر است که دسترسی رایگان به تصاویر ماهوارهای را فراهم میکند. در این مطالعه، ما اطلاعات زیر را از موتور Google Earth استخراج کردیم:
-
شدت نورهای شبانه (NTL)
-
گروه مخاطرات اقلیمی بارش مادون قرمز با داده های بارش ایستگاه (CHIRPS’)
-
دمای سطح زمین (LST)
-
شاخص تفاوت نرمال شده گیاهی (NDVI)
جدول 1 محدوده داده هایی را که می توان از موتور Google Earth به دست آورد، خلاصه می کند.
پروژه جهانی ردپای شهری (GUF) توسط مرکز داده سنجش از دور آلمان (DFD) مرکز هوافضای آلمان (DLR) داده های ژئوکدگذاری شده را گردآوری می کند که مناطق شهری، سطح زمین و بدنه های آبی را شناسایی می کند. داده های جغرافیایی در مناطق ساخته شده و غیر ساخته شده نیز از GUF موجود است.
لایه سکونت انسانی جهانی (GHSL)
پروژه لایه سکونت انسانی جهانی که عمدتاً توسط مرکز تحقیقات مشترک اداره کل کمیسیون اروپا پشتیبانی و نظارت می شود، یک مجموعه داده فضایی کاملاً باز و رایگان تولید کرده است. پایگاه داده جغرافیایی ایجاد شده شواهد آموزنده و بینش گسترده ای از حضور جهانی انسان ارائه می دهد.
USGS
این مجموعه داده جغرافیایی بر اساس مجموعه ده ساله (2001-2010) نقشه های پوشش زمین جهانی مبتنی بر MODIS (داده های نوع پوشش زمین MCD12Q1) تولید شده است. 16 طبقه بندی برای هر پیکسل وجود دارد که نوع پوشش زمین را بر اساس روش بالاترین اطمینان طی سال های 2001-2010 شناسایی می کند [ 48 ].
پوشش زمینی آژانس فضایی اروپا (ESA-LC)
در ابتدا، هدف اصلی ابتکار تغییر اقلیم آژانس فضایی اروپا (ESA) تولید یک طبقه بندی دقیق پوشش زمین است که بتواند در خدمت جامعه مدل سازی آب و هوا باشد. این پروژه مجموعه داده فضایی متغیر اقلیم اساسی (ECV) را بر اساس آرشیو گسترده داده های سنجش از دور توسعه داده است. این پایگاه داده سری های زمانی از سال 1992 تا 2017 را پوشش می دهد و شامل 38 کلاس پوشش زمین است که بر اساس سیستم طبقه بندی پوشش زمین سازمان ملل متحد است.
3.2. پایگاه داده جغرافیایی جمعسپاری شده (OpenStreetMap)
OpenStreetMap دادههای جمعسپاری شده در مکانهای زیرساختها، سکونتگاههای انسانی و فعالیتهای اقتصادی را نشان میدهد. در این مطالعه، ما اطلاعات زیر را از OpenStreetMap استخراج کردیم: تعداد جاده، طول جاده، نقطه مورد علاقه (POI)، و منطقه ساخته شده. ما POI ها را بر اساس فعالیت اقتصادی آن به 16 نوع دسته بندی کردیم که با طبقه بندی رسمی 16 بخش تولید و خدمات منتشر شده توسط NESDC مطابقت دارد.
شکل 3 ، شکل 4 ، شکل 5 و شکل 6 نمونه ای از توزیع های فضایی NTL، NDVI، دمای سطح زمین (روز) و بارندگی به دست آمده از موتور Google Earth است. شکل 7 شبکه حمل و نقل و توزیع POI مشتق شده از OpenStreetMap را نشان می دهد. برای جزئیات بیشتر، جدول A1 و جدول A2 پیوست A فهرستی از همه متغیرهای به دست آمده از داده های مکانی سال های 2015 و 2017 را ارائه می دهند.
3.3. داده های فقر
3.3.1. فقر مبتنی بر درآمد
همانطور که قبلا ذکر شد، نقشه برداری فقر یک ابتکار منظم است که توسط دولت تایلند انجام می شود. در این مطالعه، نسبت جمعیت زیر خط فقر ملی به ازای کل جمعیت در هر تامبون (یعنی زیر ناحیه) به عنوان یکی از متغیرهای وابسته در محاسبات ما استفاده شده است.
3.3.2. شاخص چند بعدی فقر
به عنوان یک معیار جایگزین برای فقر، NESDC و مرکز ملی فناوری الکترونیک و کامپیوتر (NECTEC) همچنین آماری را در مورد شیوع شاخص چند بعدی فقر (MPI) از سال 2017 جمع آوری می کنند. ابعاد موجود در محاسبه MPI شامل آموزش، زندگی سالم، شرایط زندگی، و امنیت مالی ( جدول 2 ).
داده ها بر اساس:
- (1)
-
داده های حداقل نیاز اساسی (BMN) مبتنی بر سرشماری، تحت نظارت اداره توسعه جامعه، وزارت کشور، که شامل جمعیتی حدود 36 میلیون نفر است.
- (2)
-
یک منبع داده مبتنی بر ثبت حدود 11.4 میلیون نفر که توسط وزارت دارایی از طریق برنامه کارت ملی رفاه جمع آوری شده است.
معیارهای مورد استفاده در شناسایی یک فرد فقیر چند بعدی از روش شاخص فقر چند بعدی که توسط ابتکار فقر و توسعه انسانی آکسفورد و برنامه توسعه سازمان ملل توسعه یافته است، الهام گرفته شده است.
شکل 8 توزیع فضایی تعداد جمعیت فقر را در سال 2017 نشان می دهد که از NSO تایلند به دست آمده است. به طور مشابه، شکل 9 توزیع MPI را در سال 2017 نشان می دهد که از داده های TPMAP مشتق شده است.
3.4. دوره مرجع
دوره مرجع هدف ما مصادف با دو سال اخیر است که برآوردهای سطح تامبون از فقر در تایلند در دسترس است: 2015 و 2017 برای فقر درآمدی، و 2017 برای شاخص فقر چند بعدی.
4. روش ها
شکل 10 چارچوب تحلیلی اعمال شده در این مطالعه را خلاصه می کند. پیش پردازش داده ها انجام شد، از جمله تبدیل وضوح فضایی، نرمال سازی متغیر [ 49 ]، و یکپارچه سازی داده ها. سپس، ما چهار روش محاسباتی، روش حداقل مربعات تعمیم یافته (GLS) و سه الگوریتم یادگیری ماشینی پرکاربرد دیگر را اعمال کردیم: شبکه عصبی (NN)، تخمین جنگل تصادفی (RF) و رگرسیون بردار پشتیبان (SVR). پیروی از رویکردهای فنی پیشنهاد شده توسط مک براید و نیکولز (2018) و هو و همکاران. (2022) [ 50 ، 51]، 50 درصد از داده ها برای آموزش تخصیص داده شد، در حالی که 50 درصد باقیمانده مجموعه اعتبار سنجی را تشکیل می داد. بر اساس این تخصیص، ما داده ها را 100 بار نمونه برداری مجدد کردیم. مقادیر معیارهای مورد استفاده برای مقایسه الگوریتمهای یادگیری ماشینی بر اساس میانگینهای این 100 مجموعه داده است.
4.1. حداقل مربعات تعمیم یافته
GLS اصلاحی از حداقل مربعات معمولی (OLS) در نظر گرفته می شود زیرا این فرض را که واریانس مشاهده بدون در نظر گرفتن متغیرهای توضیحی مرتبط با آن همگن است، راحت می کند. از نظر ریاضی، موضوع واریانس ناسازگار باقیمانده ها با تحمیل ماتریس وزن حاصل از تجزیه Cholesky اصلاح می شود. به طور خاص، اعمال ماتریس وزن در سراسر معادله رگرسیون، ماتریس واریانس کوواریانس اصلاح شده با ویژگی مستقل و توزیع شده یکسان (iid) را به دست میدهد که متعاقباً منجر به ضرایب رگرسیون بیطرف، سازگار و کارآمد میشود. نتیجه بهدستآمده از GLS معیاری برای مقایسه قدرت پیشبینی بین روش آماری مرسوم و سایر الگوریتمهای یادگیری ماشینی است.
4.2. شبکه عصبی
شبکه عصبی (NN) نمونه ای از مدل یادگیری ماشینی است که از شبکه عصبی بیولوژیکی که مغز انسان را تشکیل می دهد الهام گرفته شده است. همانند سایر انواع مدلهای یادگیری ماشینی، یک شبکه عصبی میتواند انجام وظایف مختلف را بدون برنامهریزی صریح برای انجام آن بیاموزد.
از نظر ساختاری، یک شبکه عصبی از گره ها و لبه های متعددی تشکیل شده است. یک گره می تواند یک متغیر یا یک تابع ریاضی باشد که توسط یال ها به هم متصل شده اند. این گره ها با هم ترکیب می شوند و لایه های مختلفی را در شبکه عصبی تشکیل می دهند. لایه ورودی داده های خام را می گیرد. در لایه های پنهان، هر گره یا نورون به عنوان یک فیلتر عمل می کند و هر بار که یک الگو یا ویژگی خاص را شناسایی می کند، فعال می شود. لایه خروجی به سادگی ویژگی های شناسایی شده را در یک دسته بندی مناسب سازماندهی می کند. همانطور که به طور متناوب توسط Anesti و همکارانش توصیف و مقایسه شد. (2021) [ 52]، روش OLS معمولی مورد خاصی از یک شبکه عصبی است که تنها از لایه های ورودی و خروجی منفرد تشکیل شده است، که در آن گره های ورودی رگرسیور هستند و لایه خروجی مقدار پیش بینی شده را به عنوان مجموع وزنی رگرسیون ها تولید می کند. بنابراین، شبکه عصبی به عنوان ساختار توسعه یافته OLS در نظر گرفته می شود که شامل یک فرآیند چند لایه ای از مجموع وزنی است.
همانطور که توسط Ciaburro و Venkateswaran (2017) [ 53 ] معرفی شد، این مطالعه از بسته R از nnet به عنوان ابزار اصلی برای انجام پیشبینی با استفاده از الگوریتم شبکه عصبی استفاده کرد. همه پارامترها از پیش فرض بسته nnet پیروی کردند [ 54 ].
4.3. جنگل تصادفی
در اصل، بریمن (2001) [ 55 ] روش پیشبینی را با استفاده از مجموعهای از درختهای تصمیم «دیگر همبستگی» معرفی کرد. هستی و همکاران (2009) [ 56 ] متعاقباً الگوریتمی را برای فرموله کردن تعداد زیادی درخت تصمیم پیشنهاد کرد. این توسعه روش جنگل تصادفی (RF) را تشکیل میدهد، یک تکنیک مبتنی بر درخت، که هر درخت بر روی یک زیرمجموعه تصادفی از دادههای آموزشی و یک زیر مجموعه تصادفی از متغیرهای مستقل ساخته میشود. این روش میتواند وظایف مربوط به طبقهبندی و/یا پیشبینی را با میانگینگیری نتایج انجام دهد. همچنین میتواند دقت پیشبینی و کنترل بیش از حد برازش مدل را بهبود بخشد.
این مطالعه از بسته تصادفی ForestSRC در R [ 57 ] استفاده کرد. با پیروی از آلشرکاوی و همکاران. (2021) [ 58 ]، همه پارامترها روی مقادیر پیش فرض تنظیم شدند. به طور خاص، تعداد کل 1000 درخت کافی است، همانطور که در Hu و همکاران نشان داده شده است. [ 51 ]. علاوه بر پیشبینی فقر، تحلیلهای اهمیت متغیر (VIMP) و عمق حداقل (MD) انجام شد. این معیارها از ویژگی های اصلی به دست آمده از همه درخت های تصمیم برای ارزیابی اهمیت نسبی متغیرهای توضیحی در انتخاب پیش بینی کننده های نهایی در مدل استفاده می کنند.
4.4. رگرسیون برداری پشتیبانی (SVR)
به طور معمول، هدف اصلی در چارچوب رگرسیون خطی، به حداقل رساندن یک تابع ضرر خاص است. به عنوان مثال، روش OLS با هدف به حداقل رساندن مجموع مربعات خطاها است. روشهایی مانند کمند یا رگرسیون برآمدگی، این چارچوب را با معرفی پارامترهای جریمه اضافی برای به حداقل رساندن پیچیدگی و/یا کاهش تعداد متغیرهای کمکی که به طور حاشیهای به عملکرد پیشبینی مدل کمک میکنند، گسترش میدهند.
از سوی دیگر، Vapnik (1998) [ 59 ] رگرسیون بردار پشتیبان (SVR) را معرفی کرد که یک چارچوب جایگزین ارائه کرد. به جای به حداقل رساندن یک تابع تلفات خاص، SVR فقط نگران کاهش آن تا حدی خاص است. این انعطاف پذیری بیشتری در تخمین می دهد و به مقابله با محدودیت های مربوط به ویژگی های توزیعی متغیرهای موجود در تحلیل ها کمک می کند. همانطور که در مورد پیشبینی نرخ فقر در سطح شهر در اندونزی نشان داده شده است [ 60 ]، انعطافپذیری با خطای مجاز، SVR را نسبت به سایر روشهای تخمین مرسوم که بر به حداقل رساندن یک تابع ضرر تثبیت شدهاند، برتری میدهد. این مطالعه از بسته e1071 در R [ 61] برای انجام پیشبینی مبتنی بر SVR. همه پارامترها روی مقادیر پیش فرض تنظیم شدند.
5. نتایج
5.1. تجزیه و تحلیل اولیه
به عنوان ابزار تخمین اولیه، ابتدا یک مدل کامل و مشخصات مدل مختلف را با استفاده از OLS و رگرسیون گام به گام برآورد کردیم. به طور کلی، ما دریافتیم که نسبت افرادی که زیر خط فقر مبتنی بر درآمد زندگی میکنند و مقدار شاخص فقر چند بعدی به طور منفی با شاخصهای جغرافیایی مرتبط است که نشاندهنده درجه شهرنشینی یک منطقه است، به عنوان مثال، شدت NTL، تراکم ساختمان. ، و تعدادی از نقاط مورد علاقه که با بخش های تولید و ابزار مرتبط است. از سوی دیگر، پیامدهای فقر با بارندگی، NDVI و سایر طبقات پوشش زمین که معمولاً با مناطق روستایی مرتبط هستند همبستگی مثبت دارند. در حالی که جهتهای این همبستگیها با انتظارات ما همسو هستند، مقادیر R-square تعدیلشده حاصل از 0 نسبتاً پایین هستند.
5.2. استفاده از الگوریتمهای یادگیری ماشینی برای پیشبینی نرخ فقر مبتنی بر درآمد
همانطور که قبلاً توضیح داده شد، هر چهار مدل پیشبینی با استفاده از مجموعه دادههای آموزشی ساخته شدند. سپس، مقادیر سرشمار فقر در سالهای 2015 و 2017 با اعمال مجموعه دادههای آزمایشی برای مدلهای ساخته شده پیشبینی شد. متعاقباً، مقایسه قدرت پیشبینی بر اساس خوب بودن برازش نتایج پیشبینیشده بود. شکل 11مقایسه ریشه میانگین مربعات خطا (RMSE) (میانگین در 100 آزمایش) از چهار روش محاسباتی را نشان میدهد، که نشان میدهد جنگل تصادفی کمترین مقادیر RMSE را به همراه داشت (به ترتیب 0.067 و 0.084 برای سالهای 2015 و 2017). تحت همین معیار، SVR رتبه دوم را داشت (به ترتیب با RMSE 0.129 و 0.161 برای سالهای 2015 و 2017)، و GLS سومین کمترین RMSE (به ترتیب 0.133 و 0.170 برای سالهای 2015 و 2017) را داشت. شایان ذکر است، شبکه عصبی بالاترین RMSE را برای سالهای 2015 و 2017 (به ترتیب با RMSE 0.419 و 0.549) ایجاد کرد. متناوبا، تصویر گرافیکی خوبی از تناسب ( شکل 12 و شکل 13) همچنین تأیید می کند که جنگل تصادفی بهترین عملکرد پیش بینی را در بین چهار روشی که در نظر گرفته ایم دارد و مقادیر پیش بینی شده نزدیک به مقادیر واقعی را ایجاد می کند.
بر اساس نتایج جنگل تصادفی، اهمیت متغیر (VIMP) و عمق حداقل (MD) بیشتر برای اولویتبندی اهمیت هر متغیر انجام شد. شکل 14 و شکل 15 نتیجه VIMP را برای سال های 2015 و 2017 نشان می دهد، در حالی که شکل 16 و شکل 17 نتایج محاسبات MD را نشان می دهد.
VIMP شدت NTL و متغیرهای مرتبط با تراکم جمعیت را به عنوان بزرگترین مشارکتکنندگان در مدل شناسایی کرد. در همین حال، پنج متغیر مثبت کاذب در نتایج VIMP برای سالهای 2015 و 2017 شناسایی شد که نشاندهنده بیربط بودن این متغیرها در پیشبینی نرخ سرشمار فقر است. از طرف دیگر، ممکن است اطلاعات ارائه شده توسط این متغیرها قبلاً توسط متغیرهای دیگر گرفته شده باشد. متغیرهای «غیرمهم» عبارتند از: منطقه تحت پوشش درخت یا درختچه (ESALC_12)، منطقه پوشیده از درخت (پهن برگ و برگریز بیش از 40%) (ESALC_61). منطقه تحت پوشش علفی موزاییک (بیش از 50%) (ESALC_110). منطقه پوشیده از درخت، سیل، آب شیرین یا شور (ESALC_160)؛ و مناطق برهنه (ESALC_200). رتبه های متغیر نشان داده شده توسط VIMP به همان اندازه مهم هستند، نمایش توزیع قدرت-قانون بزرگی های نسبی. به طور خاص، بزرگی سه متغیر برتر تقریباً سه برابر بزرگتر از متغیرهای پنجم و پایین تر است.
نتایج بهدستآمده از محاسبه عمق حداقل (MD) نتایج مشابهی را ایجاد کرد، که تأیید میکند که شدت NTL و متغیرهای مرتبط با تراکم جمعیت بسیار با تعداد افراد فقر مرتبط است. علاوه بر این، متغیرهای واقع در سمت راست خط چین در شکل 16 و شکل 17 دارای قدرت توضیحی پایین در نظر گرفته شده اند. نتایج مبتنی بر این معیار نشان میدهد که پنج متغیر دارای قدرت پیشبینی بسیار پایینی هستند – همان پنج متغیر که توسط VIMP به عنوان نامربوط به مدل شناسایی شدهاند. بنابراین می توان این متغیرها را در تحلیل بیشتر از مدل حذف کرد
5.3. استفاده از الگوریتم های یادگیری ماشینی برای پیش بینی شاخص فقر چند بعدی (MPI)
علاوه بر نرخ فقر مبتنی بر درآمد، ما همچنین از GLS، شبکه عصبی، جنگل تصادفی و SVM برای پیشبینی MPI استفاده کردیم.
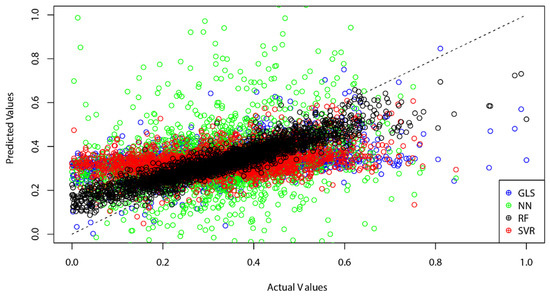
شکل 18 مقایسه خطای میانگین مربعات ریشه (RMSE) به دست آمده از چهار روش یادگیری ماشینی را نشان می دهد. مشابه با نرخ فقر درآمدی، روش جنگل تصادفی کمترین RMSE (0.0877) را به همراه داشت، در حالی که روش های SVR و GLS تقریباً یکسان هستند (به ترتیب 0.1631 و 0.1634). پیش بینی شبکه عصبی بزرگترین RMSE (0.2998) را تولید کرد. نمودار پراکندگی در شکل 19 MPI واقعی و مقادیر پیش بینی شده را مقایسه می کند. این نشان میدهد که بیشتر مقادیر پیشبینیشده تولید شده توسط جنگل تصادفی در نزدیکترین نقطه به خط 45 درجه قرار دارند، که نشان میدهد که بهترین تناسب را در بین چهار روش در نظر گرفته شده در این مطالعه دارد.
مجدداً، بر اساس نتیجه جنگل تصادفی، درجه قدرت توضیحی هر متغیر را با محاسبه VIMP و MD بررسی کردیم. شکل 20 نشان می دهد که بر اساس VIMP، متغیرهای مربوط به تراکم جمعیت مانند NTL، بارندگی، دمای سطح زمین (LST) و تراکم جاده سهم بالایی در پیش بینی تغییرات نرخ فقر دارند. مشابه نتایج VIMP پیشبینی تعداد سران فقر ( شکل 14 و شکل 15 )، ترتیب بزرگی توزیع قدرت-قانون قدرت توضیحی را نشان میدهد. به طور خاص، بزرگی چهار متغیر برتر تقریباً دو برابر بزرگتر از متغیرهای پنجم و پایین تر است.
نتیجه بهدستآمده از MD، همانطور که در شکل 21 نشان داده شده است، نتایج کیفی مشابهی را نیز نشان میدهد، که نشان میدهد NTL، LST، بارندگی، تراکم جاده، و منطقه تحت پوشش ساواناهای چوبی (USGS8) ویژگیهای جغرافیایی کلیدی مرتبط با مقدار MPI هستند.
به طور خلاصه، در بین روشهای به کار رفته در این مطالعه، تکنیک جنگل تصادفی بالاترین دقت را هنگام پیشبینی نرخ فقر درآمدی و شاخص فقر چند بعدی داشت. علاوه بر این، مدلهای جنگل تصادفی بهدستآمده به خوبی با مجموعه دادهها مطابقت دارند، همانطور که توسط مقادیر R-square تنظیم شده ارائه شده در جدول 3 پیشنهاد شده است.
6. بحث
در سطح جهانی، فقر و نابرابری از دغدغه های اصلی محققان و سیاست گذاران بوده است [ 62 ، 63 ، 64 ، 65 ، 66 ]. این چالش های توسعه به طور مشابه در سطح منطقه ای مورد توجه قرار گرفته اند [ 67 ، 68 ]. از این رو، دقت مکانی – زمانی دادهها که شرایط اجتماعی-اقتصادی را نشان میدهند برای نظارت و تدوین برنامههای توسعه بسیار ارزشمند است. در مورد تایلند، تحلیل فضایی فقر بسیار مهم است زیرا توسعه اقتصادی برای چندین دهه از نظر جغرافیایی نامتناسب بوده است [ 69 ، 70 ، 71 ].]. با افزایش دسترسی به داده های باز، کاربرد شاخص های مکانی برای تحلیل فقر توصیه شده است [ 72 ، 73 ، 74 ]. نقشه فقر و نابرابری با استفاده از داده های تک ماهواره ای توسعه یافته است [ 75 ، 76 ، 77 ، 78 ، 79 ]. از طرف دیگر، تخمین توزیع فضایی را می توان با استفاده از ترکیبی از سنجش از دور و شاخص های مکانی افزایش داد [ 80 ، 81 ، 82 ، 83]. به دنبال پیشرفت فنی بسیاری از انتشارات و در دسترس بودن داده ها، این مطالعه داده های به دست آمده از سیستم عامل های باز مانند Google Earth Engine [ 84 ]، OpenStreetMap [ 85 ، 86 ]، و Point of Interest (POI) [ 87 ] را یکپارچه کرد. به طور مشابه، با هدایت تجربه بینالمللی پیامدها، تکنیکهای یادگیری ماشینی برای پیشبینی شاخصهای فقر [ 50 ، 51 ، 88 ، 89 ، 90 ، 91 ، 92 ، 93 ، 94 ] استفاده شد.
نتایج بهدستآمده از این مطالعه نشان میدهد که جنگل تصادفی بالاترین قدرت پیشبینی را دارد که مطابق با یافتههای چندین نشریه قبلی [ 51 ، 88 ، 90 ، 91 ، 92 ، 95 ] است. به طور خاص، دقت به دست آمده بالاتر از 70٪ است، مشابه سایر مطالعات که از جنگل تصادفی برای پیش بینی فقر استفاده می کنند [ 51 ، 89 ، 90 ]. به همین ترتیب، بررسی انجام شده توسط بانک جهانی [ 93] پیشنهاد کرد که جنگل تصادفی می تواند به پیش بینی بسیار دقیق فقر کمک کند. اساساً، یکی از ویژگی های منحصر به فرد روش جنگل تصادفی، ترکیب درختان تصمیم است که به متغیرهای توضیحی گسسته و پیوسته اجازه می دهد تا خروجی را به طور مشترک پیش بینی کنند. علاوه بر این، جنگل تصادفی تجزیه و تحلیل های گسترده ای از VIMP و MD را امکان پذیر می کند و رتبه بندی قدرت توضیحی متغیرهای مستقل را تقویت می کند. نتایج بهدستآمده از دو روش نشان میدهد که NTL قدرت پیشبینی بسیار بالایی دارد، که مشابه مورد پیشبینی فقر در سطح شهرستان در چین [ 96 ] و بنگلادش [ 90 ] است.]. نتایج بهدستآمده مطابق با مقالات قبلی است، و نشان میدهد که چندین ویژگی جغرافیایی با فقر مرتبط هستند، مانند دسترسی به سفر [ 90 ، 97 ، 98 ]، نزدیکی به خدمات عمومی مهم [ 99 ]، و انواع کاربری زمین، به عنوان مثال. و همچنین محیط خانه [ 51 ، 100 ].
برآیند این مطالعه بر اهمیت شرایط جغرافیایی به عنوان عوامل حیاتی مؤثر بر وضعیت اجتماعی-اقتصادی خانوارها تأکید کرد. مشابه موارد آمریکای لاتین [ 101 ]، آفریقا [ 99 ] و کشورهای همسایه در آسیای جنوب شرقی [ 102 ]، کشاورزی و تولید مبتنی بر منابع عمده ترین فعالیت های اقتصادی خانواده های کم درآمد است. بنابراین، ویژگیهای جغرافیایی مرتبط با آن فعالیتها نشاندهنده تمرکز بالای فقر است. علاوه بر این، انزوای جغرافیایی از بازارها و سایر زیرساختها، محدودیت اصلی برای دسترسی به فرصتهای اقتصادی است که بر شرایط فقر شدید دلالت دارد [ 103 ].]. برعکس، نزدیکی به مناطق شهری و زیرساختها، دسترسی به فرصتهای شغلی، مراقبتهای بهداشتی، آموزش و پرورش و نیروی تجمع شهر را فراهم میکند [ 94 ]. بنابراین، سیاستهای توسعه میتواند با گسترش زیرساختها یا جابجایی خانوادههای کمدرآمد، فقر را کاهش دهد [ 104 ].
چندین زمینه وجود دارد که مستحق بررسی بیشتر است. در مرحله اول، تجزیه و تحلیل را می توان برای شامل سایر منابع داده (به عنوان مثال، داده های تلفن همراه و ویژگی های بافت)، گسترش داد که امکان بررسی چند بعدی تداعی های فضایی را فراهم می کند [ 79 ، 80 ، 105 ، 106 ]. ثانیاً، پوشش زمانی دادههای مبتنی بر نظرسنجی باید طولانیتر شود و به مجموعه دادههای بزرگتری برای مدلهای آموزشی اجازه دهد [ 107 ، 108 ]. ثالثا، تفکیک فضایی باید به منظور شناسایی فقرای شهری (یعنی محله های فقیر نشین) افزایش یابد، که بینش را در مورد نابرابری درون شهری گسترش می دهد [ 109 ، 110 ، 111 ].
منابع
- اداره ملی آمار. داده های آماری کلیدی ; اداره ملی آمار: بانکوک، تایلند، 2000.
- بانک انکشاف آسیایی نقشه برداری از فقر از طریق یکپارچه سازی داده ها و هوش مصنوعی: مکمل ویژه شاخص های کلیدی برای آسیا و اقیانوسیه. در یک مکمل ویژه از شاخص های کلیدی برای آسیا و اقیانوسیه 2020 ؛ ADB: مانیل، فیلیپین، 2020. [ Google Scholar ] [ CrossRef ]
- ژان، ن. بورک، ام. زی، ام. دیویس، دبلیو. لوبل، دی. ارمون، اس. ترکیب تصاویر ماهواره ای و یادگیری ماشینی برای پیش بینی فقر. Science 2016 ، 353 ، 790-794. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- هوفر، م. ساکو، تی. مارتینز، ای.، جونیور؛ آداوه، م. بولان، جی. دورانته، RL; مارتیلان، ام. استفاده از هوش مصنوعی در تصاویر ماهوارهای برای گردآوری آمار فقر دانهای. در سری مقالات کاری اقتصاد بانک توسعه آسیایی ; بانک توسعه آسیایی: مانیل، فیلیپین، 2020. [ Google Scholar ] [ CrossRef ]
- پیاجسی، اس. گووین، ال. تیزونی، م. کاتتوتو، سی. آدلر، ن. ورهولست، اس. یانگ، ا. قیمت، R. فرس، ال. پانیسون، الف. پیش بینی فقر شهر با استفاده از تصاویر ماهواره ای. در مجموعه مقالات کنفرانس IEEE/CVF در کارگاه های آموزشی بینایی کامپیوتری و تشخیص الگو (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 20 ژوئن 2019؛ ص 90-96. [ Google Scholar ]
- الویج، سی دی; باگ، KE; Kihn، EA; کروهل، HW; دیویس، ای آر. دیویس، CW رابطه بین ماهواره مشاهده شده انتشارات مادون قرمز نزدیک به مرئی، جمعیت، فعالیت اقتصادی و مصرف برق. بین المللی J. Remote Sens. 1997 ، 18 ، 1373-1379. [ Google Scholar ] [ CrossRef ]
- عروسک، CNH؛ جان پیتر، ام. Elvidge، CD-Night-Time Imagery به عنوان ابزاری برای نقشه برداری جهانی پارامترهای اجتماعی و اقتصادی و انتشار گازهای گلخانه ای. Ambio 2000 ، 29 ، 157-162. [ Google Scholar ] [ CrossRef ]
- عروسک، CNH؛ مولر، J.-P. مورلی، جی جی نقشه برداری فعالیت اقتصادی منطقه ای از تصاویر ماهواره ای نور در شب. Ecol. اقتصاد 2006 ، 57 ، 75-92. [ Google Scholar ] [ CrossRef ]
- ساتون، رایانه شخصی؛ الویج، سی دی; Ghosh, T. برآورد تولید ناخالص داخلی در مقیاس های زیر ملی با استفاده از تصاویر ماهواره ای شبانه. بین المللی جی. اکول. اقتصاد آمار 2007 ، 8 ، 5-21. [ Google Scholar ]
- هندرسون، JV; استوریگارد، ا. Weil، DN اندازه گیری رشد اقتصادی از فضا. صبح. اقتصاد Rev. 2012 , 102 , 994-1028. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بیکنباخ، اف. بود، ای. نوننکامپ، پی. سودر، ام. چراغ های شب و تولید ناخالص داخلی منطقه ای. کشیش جهانی اقتصاد. 2016 ، 152 ، 425-447. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فوربس، دی جی تجزیه و تحلیل چند مقیاسی رابطه بین آمار اقتصادی و تصاویر نور شب DMSP-OLS. GISci. Remote Sens. 2013 , 50 , 483-499. [ Google Scholar ] [ CrossRef ]
- لی، ایکس. خو، اچ. چن، ایکس. لی، سی. پتانسیل تصویربرداری نور شبانه NPP-VIIRS برای مدلسازی اقتصاد منطقهای چین. Remote Sens. 2013 , 5 , 3057–3081. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، دی. ژائو، ایکس. لی، ایکس. سنجش از دور انسان ها – چشم اندازی از نور شبانه. ژئو اسپات. Inf. علمی 2016 ، 19 ، 69-79. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سان، ج. وانگ، ایکس. چن، آ. ممکن است.؛ کوی، ام. Piao، S. NDVI ویژگی های تغییر پوشش گیاهی در کلان شهرهای چین را در سه دهه گذشته نشان داد. محیط زیست نظارت کنید. ارزیابی کنید. 2011 ، 179 ، 1-14. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لی، جی. چن، اس اس. یان، Y.-H. Yu, C. اثرات شهرنشینی بر تخریب پوشش گیاهی در دلتای رودخانه یانگ تسه چین: ارزیابی بر اساس SPOT-VGT NDVI. ج. طرح شهری. Dev.-Asce 2015 , 141 , 05014026. [ Google Scholar ] [ CrossRef ]
- جین، XM; وان، ال. ژانگ، YK؛ Schaepman، M. تاثیر رشد اقتصادی بر سلامت پوشش گیاهی در چین بر اساس GIMMS NDVI. بین المللی J. Remote Sens. 2008 , 29 , 3715-3726. [ Google Scholar ] [ CrossRef ]
- کریستیانسون، پی. رادنی، م. بالتن ویک، آی. اوگوتو، جی. Notenbaert، A. نقشه معیشت و فقر در یک سطح متوسط در کنیا همبستگی دارد. سیاست غذایی 2005 ، 30 ، 568-583. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- باتاچاریا، اچ. Innes، RD آیا پیوندی بین فقر و محیط زیست در روستاهای هند وجود دارد؟ در مجموعه مقالات نشست سالانه انجمن اقتصاد کشاورزی آمریکا، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 23 تا 26 ژوئیه 2006. [ Google Scholar ]
- موریکاوا، آر. ابزار سنجش از دور برای ارزیابی پروژههای کاهش فقر: مطالعه موردی در تانزانیا. Procedia Eng. 2014 ، 78 ، 178-187. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ابوراس، م.م. عبدالله، ش. رملی، م.ف. اشعاری، ZH اندازه گیری تغییر پوشش زمین در سرمبان، مالزی با استفاده از شاخص NDVI. Procedia Environ. علمی 2015 ، 30 ، 238-243. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ونگ، Q. ارزیابی از راه دور؟ GIS گسترش شهری و تأثیر آن بر دمای سطح در دلتای ژوجیانگ، چین. بین المللی J. Remote Sens. 2001 ، 22 ، 1999-2014. [ Google Scholar ] [ CrossRef ]
- بویانتویف، آ. وو، جی. جزایر گرمایی شهری و ناهمگونی چشمانداز: ارتباط تغییرات مکانی-زمانی در دمای سطح به پوشش زمین و الگوهای اجتماعی-اقتصادی. Landsc. Ecol. 2009 ، 25 ، 17-33. [ Google Scholar ] [ CrossRef ]
- هوانگ، جی. ژو، دبلیو. Cadenasso، ML آیا همه در شهر گرم هستند؟ الگوی فضایی دمای سطح زمین، پوشش زمین و ویژگی های اجتماعی-اقتصادی محله در بالتیمور، MD. جی. محیط زیست. مدیریت 2011 ، 92 ، 1753-1759. [ Google Scholar ] [ CrossRef ]
- روتیراکو، پی. دارنسواسدی، ر. Chatupote، W. شدت و الگوی دمای سطح زمین در شهر Hat Yai، تایلند. Walailak J. Sci. تکنولوژی 2015 ، 12 ، 83-94. [ Google Scholar ] [ CrossRef ]
- یونس زاده، س. امیری، ن. Pilesjö, P. اثر تغییر کاربری زمین بر دمای سطح زمین در هلند. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2015 ، 40 ، 745-748. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کوپر، لس آنجلس; بالانتاین، AP; هولدن، ZA; Landguth، EL Disturbance بر دمای سطح زمین و بهره وری اولیه ناخالص در غرب ایالات متحده تأثیر می گذارد. جی. ژئوفیس. Res. Biogeosci. 2017 ، 122 ، 930-946. [ Google Scholar ] [ CrossRef ]
- دیسانایکه، دی. موریموتو، تی. مورایاما، ی. راناگالاج، ام. Handayani، HH تاثیر ویژگیهای سطح شهری و متغیرهای اجتماعی-اقتصادی بر تغییرات فضایی دمای سطح زمین در شهر لاگوس، نیجریه. پایداری 2019 ، 11 ، 25. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ریچاردسون، سی جی، خشکسالی چقدر اهمیت داشت؟ ارتباط بارندگی و رشد تولید ناخالص داخلی در زیمبابوه. افر. Aff. 2007 ، 106 ، 463-478. [ Google Scholar ] [ CrossRef ]
- مکچینی، اس. یانگ، دی. زیر آب و هوا: سلامت، تحصیل، و پیامدهای اقتصادی بارندگی در اوایل زندگی. صبح. اقتصاد Rev. 2009 , 99 , 1006-1026. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- آرزو، ر. بروکنر، ام. بارندگی، توسعه مالی و حوالهها: شواهدی از جنوب صحرای آفریقا. J. Int. اقتصاد 2012 ، 87 ، 377-385. [ Google Scholar ] [ CrossRef ]
- شوک های بارندگی Thede، BC و نابرابری ثروت درون جامعه: شواهدی از اتیوپی روستایی. توسعه دهنده جهانی 2014 ، 64 ، 181-193. [ Google Scholar ] [ CrossRef ]
- سارسونز، اچ. بارندگی و درگیری: یک داستان هشدار دهنده. جی. دیو. اقتصاد 2015 ، 115 ، 62-72. [ Google Scholar ] [ CrossRef ]
- گیلمونت، ام. هال، جی. گری، دی. دادسون، اس. سیمپسون، ام. Abele, S. تجزیه و تحلیل رابطه بین بارندگی و رشد اقتصادی در ایالات هند. گلوب. محیط زیست تغییر 2018 ، 49 ، 56-72. [ Google Scholar ] [ CrossRef ]
- لروکس، ال. بارون، سی. زونگرانا، بی. ترائوره، اس بی؛ دیده شده، DL; Bégué، A. نظارت بر محصول با استفاده از پوشش گیاهی و شاخص های حرارتی برای برآورد عملکرد: مطالعه موردی غلات دیم در غرب آفریقا نیمه خشک. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2016 , 9 , 347–362. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سروثی، س. Aslam، MAM تجزیه و تحلیل خشکسالی کشاورزی با استفاده از داده های NDVI و دمای سطح زمین. مطالعه موردی منطقه رایچر. آکوات. Procedia 2015 ، 4 ، 1258-1264. [ Google Scholar ] [ CrossRef ]
- هو، تی. یانگ، جی. لی، ایکس. Gong, P. نقشه برداری کاربری زمین شهری با استفاده از تصاویر Landsat و داده های اجتماعی باز. Remote Sens. 2016 , 8 , 151. [ Google Scholar ] [ CrossRef ]
- هنوز.؛ ژائو، ن. یانگ، ایکس. اویانگ، ز. لیو، ایکس. چن، کیو. هو، ک. یو، دبلیو. چی، جی. لی، ز. و همکاران بهبود نقشهبرداری جمعیت برای چین با استفاده از دادههای سنجش از راه دور و نقاط مورد علاقه در یک مدل جنگلهای تصادفی. علمی کل محیط. 2019 ، 658 ، 936–946. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- دنگ، ی. لیو، جی. لیو، ی. Luo, A. تشخیص ساختار چندمرکزی شهری از داده های POI. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 283. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- شورا، گزارش NEaSD Human Achievement Index 2017 ; شورای ملی توسعه اقتصادی و اجتماعی: بانکوک، تایلند، 2017.
- Jitsuchon، S. نقشه فقر تخمین منطقه کوچک برای تایلند. در مجموعه مقالات موسسه تحقیقاتی SMERU و سمینار بین المللی بنیاد فورد، جاکارتا، اندونزی، 1 تا 2 دسامبر 2004. [ Google Scholar ]
- جیتسچون، اس. نقشه های فقر تایلند از ساخت و ساز تا کاربرد، ریشتر، کی. در بیش از یک تصویر زیبا: استفاده از نقشه های فقر برای طراحی سیاست ها و مداخلات بهتر . Bedi, T., Coudouel, A., Simler, K., Eds. بانک جهانی: واشنگتن، دی سی، ایالات متحده آمریکا، 2007. [ Google Scholar ]
- بدی، ت. کودوئل، ا. Simler, K. بیش از یک تصویر زیبا: استفاده از نقشه های فقر برای طراحی سیاست ها و مداخلات بهتر . بانک جهانی: واشنگتن، دی سی، ایالات متحده آمریکا، 2007. [ Google Scholar ]
- بابنکو، بی. هرش، جی. نیوهاوس، دی. راماکریشنان، ا. Swartz, T. Poverty Mapping با استفاده از شبکه های عصبی کانولوشنال آموزش دیده بر روی تصاویر ماهواره ای با وضوح بالا و متوسط، با یک برنامه کاربردی در مکزیک. arXiv 2017 , arXiv:1711.06323. [ Google Scholar ]
- Tingzon، I. اوردن، ا. سی، اس. سکارا، وی. وبر، آی. فاتحکیا، م. هرانز، م. کیم، دی. نقشه برداری از فقر در فیلیپین با استفاده از یادگیری ماشینی، تصاویر ماهواره ای، و اطلاعات جغرافیایی با منبع جمعیت. بین المللی قوس. فتوگرام Remote Sens. Spatial Inf. علمی 2019 ، XLII-4/W19 ، 425–431. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هایتمن، اس. Buri، S. برآورد فقر با تصاویر ماهوارهای در سطوح همسایگی: نتایج و درسهایی برای گنجاندن مالی از غنا و اوگاندا . شرکت مالی بین المللی – گروه بانک جهانی: واشنگتن، دی سی، ایالات متحده آمریکا، 2019؛ در دسترس به صورت آنلاین: https://www.ifc.org/wps/wcm/connect/industry_ext_content/ifc_external_corporate_site/financial+institutions/resources/poverty+estimation+with+satellite+imagery+at+neighborhood+ level (در تاریخ 1 ژانویه 20 قابل دسترسی است. ).
- بله، سی. پرز، آ. دریسکول، ا. آذری، گ. تانگ، ز. لوبل، دی. ارمون، اس. Burke, M. استفاده از تصاویر ماهواره ای در دسترس عموم و یادگیری عمیق برای درک رفاه اقتصادی در آفریقا. نات. اشتراک. 2020 ، 11 ، 2583. [ Google Scholar ] [ CrossRef ]
- براکستون، PD; زنگ، ایکس. سولا مناشه، د. Troch، PA یک اقلیم شناسی پوشش جهانی با استفاده از داده های MODIS. J. Appl. هواشناسی کلیماتول. 2014 ، 53 ، 1593-1605. [ Google Scholar ] [ CrossRef ]
- هان، جی. کمبر، م. پی، جی. داده کاوی: مفاهیم و تکنیک ها . Elsevier: Waltham, MA, USA, 2012. [ Google Scholar ] [ CrossRef ]
- مک براید، ال. نیکولز، الف. ابزار مجدد هدف گذاری فقر با استفاده از اعتبارسنجی خارج از نمونه و یادگیری ماشینی. اقتصاد بانک جهانی Rev. 2018 , 32 , 531-550. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هو، اس. Ge، Y. لیو، ام. رن، ز. Zhang، X. شناسایی فقر در سطح روستا با استفاده از یادگیری ماشین، تصاویر با وضوح بالا، و دادههای مکانی. بین المللی J. Appl. زمین Obs. Geoinf. 2022 ، 107 ، 102694. [ Google Scholar ] [ CrossRef ]
- آنستی، ن. کالامارا، ای. کاپتانیوس، جی. پیش بینی رشد تولید ناخالص داخلی انگلستان با پانل های نظرسنجی بزرگ . بانک انگلستان: لندن، بریتانیا، 2021. [ Google Scholar ]
- سیابورو، جی. Venkateswaran، B. شبکه های عصبی با R. Packt Publishing: بیرمنگام، بریتانیا، 2017. [ Google Scholar ]
- ریپلی، بی. شبکه های عصبی پیشروی و مدل های لاگ-خطی چندجمله ای. 2022. در دسترس آنلاین: https://cran.r-project.org/web/packages/nnet/nnet.pdf (در 29 آوریل 2022 قابل دسترسی است).
- بریمن، ال. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هستی، تی. طبشیرانی، ر. فریدمن، جی . عناصر یادگیری آماری: داده کاوی، استنتاج و پیش بینی . Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2009. [ Google Scholar ]
- Kogalur، U. randomForestSRC: Fast Unified Random Forests for Survival, Regression, and Classification (RF-SRC). 2022. در دسترس آنلاین: https://cran.r-project.org/web/packages/randomForestSRC/randomForestSRC.pdf (در 29 آوریل 2022 قابل دسترسی است).
- الشرقاوی، ع. الفتیانی، م. دواس، م. ساعده، ح. آلیامان، ام. طبقه بندی فقر با استفاده از یادگیری ماشینی: مورد اردن. پایداری 2021 ، 13 ، 1412. [ Google Scholar ] [ CrossRef ]
- Vapnik، VN نظریه یادگیری آماری ; Wiley: نیویورک، نیویورک، ایالات متحده آمریکا، 1998. [ Google Scholar ]
- ویجایا، دی. پارامیتا، NLPSP؛ اولویه، ع. رزا، م. زهرا، ع. پوسپیتا، دی. برآورد نرخ فقر در سطح شهر بر اساس دادههای تجارت الکترونیک با یادگیری ماشینی. الکترون. بازرگانی Res. 2022 ، 22 ، 195-221. [ Google Scholar ] [ CrossRef ]
- Meyer, D. Support Vector Machines: The Interface to Libsvm in Package e1071. 2017. در دسترس آنلاین: https://web.mit.edu/~r/current/arch/i386_linux26/lib/R/library/e1071/doc/svmdoc.pdf (در 29 آوریل 2022 قابل دسترسی است).
- ساکس، جی. کرول، سی. لافورچون، جی. فولر، جی. Woelm, F. Sustainable Development Report 2021 ; انتشارات دانشگاه کمبریج: کمبریج، بریتانیا، 2021. [ Google Scholar ]
- روبلز آگیلار، جی. سامنر، الف. فقرای جهان چه کسانی هستند؟ نمایه جدیدی از فقر چند بعدی جهانی توسعه دهنده جهانی 2020 , 126 , 104716. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آلسینا، ا. میکالوپولوس، اس. پاپایوآنو، ای. نابرابری قومی. ج. اقتصاد سیاسی. 2016 ، 124 ، 428-488. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- میلانوویچ، ب. نابرابری جهانی: رویکردی جدید برای عصر جهانی شدن . انتشارات دانشگاه هاروارد: کمبریج، MA، ایالات متحده آمریکا، 2016. [ Google Scholar ]
- گروه، فقر و رفاه مشترک جهانی 2016: مقابله با نابرابری . انتشارات بانک جهانی: واشنگتن، دی سی، ایالات متحده آمریکا، 2016. [ Google Scholar ]
- دویچ، جی. سیلبر، جی. وان، جی. ژائو، ام. شاخص های دارایی و اندازه گیری فقر، نابرابری و رفاه در آسیای جنوب شرقی. جی. اقتصاد آسیایی. 2020 , 70 , 101220. [ Google Scholar ] [ CrossRef ]
- وان، جی. وانگ، سی. ژانگ، ایکس. مثلث فقر-رشد-نابرابری: آسیا دهه 1960 تا 2010. Soc. اندیک. Res. 2021 ، 153 ، 795-822. [ Google Scholar ] [ CrossRef ]
- کودو، تی. Satoru، K. استراتژی رشد دو قطبی در میانمار: به دنبال توسعه “بالا” و “متوازن” . موسسه اقتصادهای در حال توسعه-سازمان تجارت خارجی ژاپن (IDE-JETRO): چیبا، ژاپن، 2012; در دسترس آنلاین: https://www.ide.go.jp/library/English/Publish/Reports/Brc/PolicyReview/pdf/08.pdf (در 1 ژانویه 2022 قابل دسترسی است).
- بانک انکشاف آسیایی بانک توسعه آسیایی گزارش پایداری 2015: سرمایه گذاری برای آسیا و اقیانوس آرام عاری از فقر ؛ بانک توسعه آسیایی: مانیل، فیلیپین، 2015. [ Google Scholar ]
- Puttanapong، N. رشد تک مرکزی و سرریز بهره وری در تایلند ; موسسه اقتصادهای در حال توسعه – سازمان تجارت خارجی ژاپن (IDE-JETRO) (دفتر بانکوک): بانکوک، تایلند، 2018؛ در دسترس آنلاین: https://www.ide.go.jp/library/English/Publish/Reports/Brc/pdf/23_03.pdf (در 1 ژانویه 2022 قابل دسترسی است).
- گوا، اچ. داده های زمین بزرگ: مرزی جدید در علوم زمین و اطلاعات. داده های بزرگ زمین 2017 ، 1 ، 4-20. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، جی.-جی. کانگ، ام. داده های بزرگ جغرافیایی: چالش ها و فرصت ها. بیگ دیتا Res. 2015 ، 2 ، 74-81. [ Google Scholar ] [ CrossRef ]
- کانساکار، پی. Hossain, F. مروری بر کاربردهای داده های رصد زمین ماهواره ای برای منافع اجتماعی جهانی و سرپرستی سیاره زمین. سیاست فضایی 2016 ، 36 ، 46-54. [ Google Scholar ] [ CrossRef ]
- ایوان، ک. Holobâcă، I.-H. بندیک، جی. Török، I. پتانسیل نورهای شبانه برای اندازه گیری نابرابری منطقه ای. Remote Sens. 2020 , 12 , 33. [ Google Scholar ] [ CrossRef ][ Green Version ]
- کمپر، تی. پسری، م. ارلیش، دی. شیاوینا، م. تشخیص الگوی فضایی نابرابری ها از سنجش از دور به سمت نقشه برداری از جوامع محروم و فقر . اتحادیه اروپا: لوکزامبورگ، 2018. [ Google Scholar ] [ CrossRef ]
- گالیمبرتی، جی. پیچلر، اس. Pleninger, R. اندازه گیری نابرابری با استفاده از داده های مکانی ; دانشگاه فناوری اوکلند، گروه اقتصاد: اوکلند، نیوزیلند، 2020. [ Google Scholar ]
- میرزا، MU; خو، سی. باول بس، v. ون نس اگبرت، اچ. شفر، ام. نابرابری جهانی از راه دور سنجش شده است. Proc. Natl. آکادمی علمی USA 2021 , 118 , e1919913118. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Blumenstock Joshua، E. مبارزه با فقر با داده ها. Science 2016 ، 353 ، 753-754. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- دوک، جی سی. پاتینو، جی. رویز، لس آنجلس؛ Pardo-Pascual، JE اندازه گیری فقر درون شهری با استفاده از معیارهای پوشش زمین و بافت به دست آمده از داده های سنجش از دور. Landsc. طرح شهری. 2015 ، 135 ، 11-21. [ Google Scholar ] [ CrossRef ]
- کلمنس، بی. کاپولا، ا. Shron, M. برآورد اقدامات محلی فقر با استفاده از تصاویر ماهواره ای: یک برنامه آزمایشی برای آمریکای مرکزی . بانک جهانی: واشنگتن، دی سی، ایالات متحده آمریکا، 2015. [ Google Scholar ]
- Watmough, GR; اتکینسون، PM؛ Hutton، CW بررسی پیوندهای بین سرشماری و محیط با استفاده از تصاویر حسگر ماهواره ای سنجش از دور. J. کاربری زمین علمی. 2013 ، 8 ، 284-303. [ Google Scholar ] [ CrossRef ]
- Watmough, GR; اتکینسون، PM؛ سایکیا، ع. هاتون، CW درک پایگاه شواهدی برای روابط فقر-محیط زیست با استفاده از داده های ماهواره ای سنجش از راه دور: نمونه ای از آسام، هند. توسعه دهنده جهانی 2016 ، 78 ، 188-203. [ Google Scholar ] [ CrossRef ]
- گولیک، ن. هنچر، م. دیکسون، ام. ایلیوشچنکو، اس. تاو، دی. Moore, R. Google Earth Engine: تجزیه و تحلیل جغرافیایی در مقیاس سیاره ای برای همه. سنسور از راه دور محیط. 2017 ، 202 ، 18-27. [ Google Scholar ] [ CrossRef ]
- فودی، جی. فریتز، اس. فونته، سی. باستین، ال. اولتئانو ریموند، A.-M.; مونی، پی. ببینید، L. آنتونیو، وی. لیو، H.-Y.; مینگینی، ام. و همکاران نقشه برداری و سنسور شهروندی در نقشه برداری و سنسور شهروند ; Ubiquity Press: لندن، بریتانیا، 2017؛ صص 1-12. [ Google Scholar ]
- Goodchild، M. شهروندان به عنوان حسگرهای داوطلبانه: زیرساخت داده های مکانی در دنیای وب 2.0. بین المللی جی. اسپات. زیرساخت داده Res. 2007 ، 2 ، 24-32. [ Google Scholar ]
- گائو، اس. یانوویچ، ک. کوکللیس، اچ. استخراج مناطق عملکردی شهری از نقاط مورد علاقه و فعالیت های انسانی در شبکه های اجتماعی مبتنی بر مکان. ترانس. GIS 2017 ، 21 ، 446-467. [ Google Scholar ] [ CrossRef ]
- هرش، جی. انگستروم، آر. Mann, M. داده های باز برای الگوریتم ها: نقشه برداری از فقر در بلیز با استفاده از ویژگی های مشتق شده از ماهواره باز و یادگیری ماشین. Inf. تکنولوژی توسعه دهنده 2021 ، 27 ، 263-292. [ Google Scholar ] [ CrossRef ]
- تیان، اف. وو، بی. زنگ، اچ. Watmough, GR; ژانگ، ام. لی، ی. تشخیص ارتباط بین استفاده از زمین های زراعی و فقر با استفاده از روش های یادگیری ماشین در دیدگاه جهانی. Geogr. حفظ کنید. 2022 ، 3 ، 7-20. [ Google Scholar ] [ CrossRef ]
- ژائو، ایکس. یو، بی. لیو، ی. چن، ز. لی، کیو. وانگ، سی. Wu, J. برآورد فقر با استفاده از رگرسیون تصادفی جنگل با داده های چند منبع: مطالعه موردی در بنگلادش. Remote Sens. 2019 , 11 , 375. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- براون، سی. Matteson، DS; مک براید، ال. هو، ال. لیو، ی. سان، ی. ون، جی. بارت، CB چند متغیره پیشبینی تصادفی جنگل فقر و شیوع سوء تغذیه. PLoS ONE 2021 , 16 , e0255519. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- خو، ی. مو، ی. زو، اس. نقشه برداری فقر در منطقه بسیار فقیر پیوسته دیان-گوی-کیان در جنوب غربی چین بر اساس داده های چندمنبعی جغرافیایی. Sustainability 2021 , 13 , 8717. [ Google Scholar ] [ CrossRef ]
- سوهنسن، ت. Stender، N. آیا جنگل تصادفی روشی برتر برای پیشبینی فقر است؟ یک ارزیابی تجربی: پیش بینی فقر. سیاست عمومی فقر 2017 ، 9 ، 118-133. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ام. هو، اس. Ge، Y. Heuvelink، GBM؛ رن، ز. هوانگ، X. استفاده از رگرسیون خطی چندگانه و جنگلهای تصادفی برای شناسایی عوامل تعیینکننده فقر فضایی در روستاهای چین. تف کردن آمار 2021 , 42 , 100461. [ Google Scholar ] [ CrossRef ]
- وانگ، اس. آگاروال، سی. لیو، اچ. شبکه های عصبی الهام گرفته از جنگل تصادفی. ACM Trans. هوشمند سیستم تکنولوژی 2018 ، 9 ، 69. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یو، بی. شی، ک. هو، ی. هوانگ، سی. چن، ز. وو، جی. ارزیابی فقر با استفاده از داده های ترکیبی نور شبانه NPP-VIIRS در سطح شهرستان در چین. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2015 ، 8 ، 1217-1229. [ Google Scholar ] [ CrossRef ]
- انگستروم، آر. هرش، جی. نیوهاوس، دی. فقر از فضا: استفاده از تصاویر ماهواره ای با وضوح بالا برای برآورد رفاه اقتصادی . مقاله کاری تحقیقات سیاست 8284; گروه بانک جهانی: واشنگتن، دی سی، ایالات متحده آمریکا، 2017. [ Google Scholar ] [ CrossRef ]
- وانگ، ز. هان، س. de Vries، B. استفاده از زمین/پوشش زمین و دسترسی: پیامدهای همبستگی برای استفاده از زمین و برنامه ریزی حمل و نقل. Appl. تف کردن مقعدی سیاست 2019 ، 12 ، 923-940. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Okwi Paul، O.; ندنگه، جی. کریستیانسون، پی. آرونگا، م. نوتنبرت، آ. اومولو، ا. هنینگر، ن. بنسون، تی. کاریوکی، پ. Owuor، J. عوامل فضایی تعیین کننده فقر در روستایی کنیا. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2007 ، 104 ، 16769-16774. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- واتموگ گری، آر. Marcinko Charlotte، LJ; سالیوان، سی. تشیرهارت، ک. موتو پاتریک، ک. پالم شریل، ای. Svenning، J.-C. استفاده آگاهانه از داده های سنجش از راه دور برای پیش بینی فقر خانوار روستایی. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2019 ، 116 ، 1213–1218. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- Vakis، RN; ریگولینی، جی. Luchetti, L. Left Behind: فقر مزمن در آمریکای لاتین و دریای کارائیب . بانک جهانی: واشنگتن، دی سی، ایالات متحده آمریکا، 2016. [ Google Scholar ]
- کوک، اس. پینکوس، جی. فقر، نابرابری و حمایت اجتماعی در آسیای جنوب شرقی: مقدمه. J. آسیای جنوب شرقی اقتصاد. 2014 ، 31 ، 1-17. [ Google Scholar ] [ CrossRef ]
- ساندرلین، WD; دیوی، اس. پونتودیو، الف. تحلیل چند کشوری فقر و جنگل ها از انجمن فضایی و راه حل های سیاست پیشنهادی . مرکز تحقیقات بین المللی جنگلداری: بوگور، اندونزی، 2007. [ Google Scholar ]
- یانگ، ی. د شربینین، ا. لیو، ی. اسکان مجدد فقرزدایی چین: پیشرفت، مشکلات و راه حل ها. Habitat Int. 2020 , 98 , 102135. [ Google Scholar ] [ CrossRef ]
- پخریال، ن. Jacques Damien, C. ترکیب منابع داده های متفاوت برای پیش بینی و نقشه برداری بهبود فقر. Proc. Natl. آکادمی علمی USA 2017 ، 114 ، E9783–E9792. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- استیل، جی. Sundsøy، روابط عمومی; پزولو، سی. آلگانا، VA; پرنده، تی جی; بلومن استاک، جی. بیلند، جی. Engø-Monsen، K. د مونتجویه، ی.-آ. اقبال، ع.م. و همکاران نقشه برداری از فقر با استفاده از تلفن همراه و داده های ماهواره ای JR Soc. رابط 2017 ، 14 ، 20160690. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- بورک، ام. دریسکول، ا. لوبل دیوید، بی. ارمون، اس. استفاده از تصاویر ماهواره ای برای درک و ترویج توسعه پایدار. Science 2021 , 371 , eabe8628. [ Google Scholar ] [ CrossRef ]
- استروبل، سی. Boulesteix, A.-L.; زیلیس، ع. Hothorn، T. Bias در معیارهای اهمیت متغیر تصادفی جنگل: تصاویر، منابع و یک راه حل. BMC Bioinform. 2007 ، 8 ، 25. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- انگستروم، آر. پاولسکو، دی. تاناکا، تی. Wambile، A. نقشه برداری از فقر و زاغه ها با استفاده از روش های متعدد در آکرا، غنا. در مجموعه مقالات رویداد مشترک سنجش از دور شهری 2019 (JURSE)، وان، فرانسه، 22 تا 24 مه 2019؛ صص 1-4. [ Google Scholar ]
- وانگ، جی. کوفر، م. Pfeffer, K. نقش ناهمگونی فضایی در شناسایی زاغه های شهری. محاسبه کنید. محیط زیست سیستم شهری 2019 ، 73 ، 95-107. [ Google Scholar ] [ CrossRef ]
- مولر، آی. تاوبنبوک، اچ. کوفر، م. وورم، ام. تصور نادرست از مکانهای زاغهنشین غالب؟ تحلیل فضایی مکانهای زاغهنشین از نظر توپوگرافی بر اساس دادههای رصد زمین. Remote Sens. 2020 , 12 , 2474. [ Google Scholar ] [ CrossRef ]
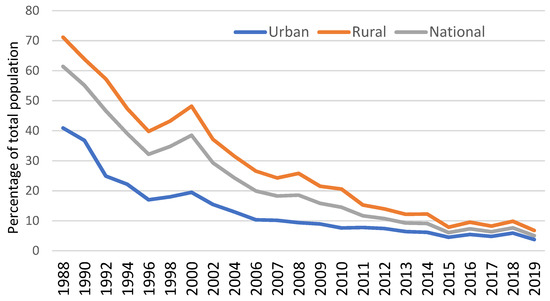
شکل 1. نسبت جمعیت تایلند که زیر خط فقر ملی آن زندگی می کنند. منبع: NSO تایلند. توجه: خط فقر تایلند بر اساس حداقل استاندارد مورد نیاز یک فرد برای تامین کالاهای اساسی غذایی و غیرخوراکی خود محاسبه می شود. جزئیات در گزارش NESDC (2015) ارائه شده است.
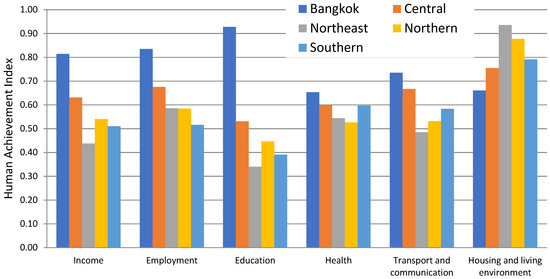
شکل 2. شاخص دستاوردهای انسانی در سال 2017. منبع: NESDC (2017). توجه: مقدار شاخص موفقیت انسانی از 0 (بدترین نتیجه) تا 1 (بهترین نتیجه) متغیر است.
شکل 3. توزیع فضایی NTL در سال 2017. منبع: Google Earth Engine.
شکل 4. توزیع فضایی NDVI در سال 2017. منبع: موتور Google Earth.
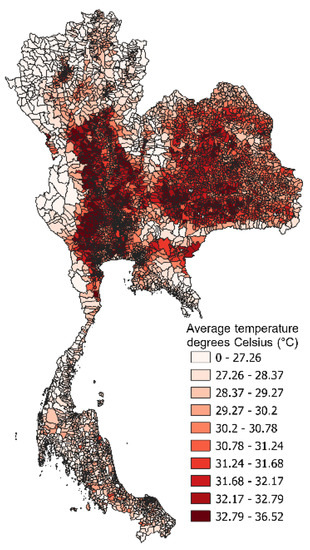
شکل 5. توزیع فضایی دمای سطح زمین (روز) در سال 2017. منبع: موتور Google Earth.
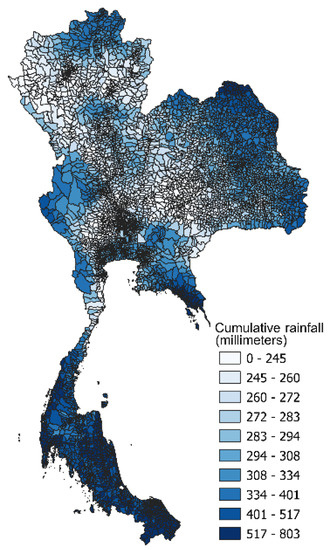
شکل 6. توزیع مکانی بارندگی در سال 2017 منبع: موتور گوگل ارث.
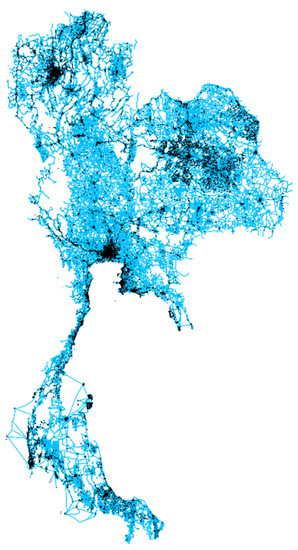
شکل 7. توزیع فضایی شبکه حمل و نقل و POI در سال 2017. منبع: OpenStreetMap.
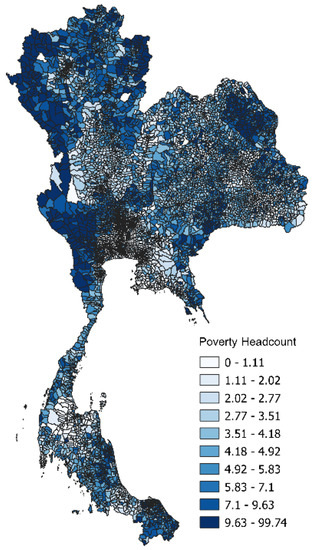
شکل 8. توزیع فضایی تعداد جمعیت فقر در سال 2017. منبع: NSO تایلند.
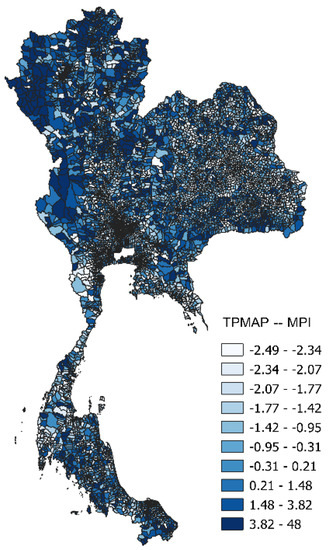
شکل 9. توزیع فضایی MPI (از داده های TPMAP) در سال 2017. منبع: NESDC.
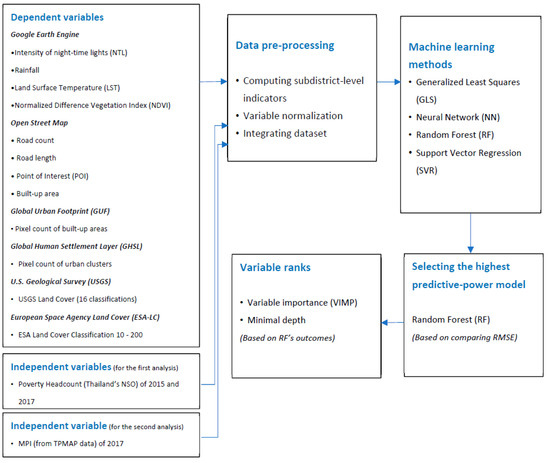
شکل 10. چارچوب تحلیلی این مطالعه. منبع: گرافیک تولید شده توسط نویسندگان.
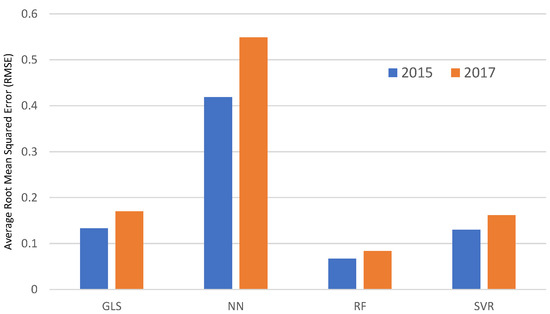
شکل 11. مقایسه میانگین ریشه میانگین مربعات خطا (RMSE) به دست آمده از چهار الگوریتم یادگیری ماشینی (در پیش بینی نرخ سرشماری فقر در سال های 2015 و 2017). منبع: محاسبه و گرافیک تولید شده توسط نویسندگان.
شکل 12. نمودار پراکندگی مقایسه نرخ واقعی و پیش بینی شده فقر در سال 2015 (به دست آمده از چهار الگوریتم یادگیری ماشینی). منبع: محاسبه و گرافیک تولید شده توسط نویسندگان.
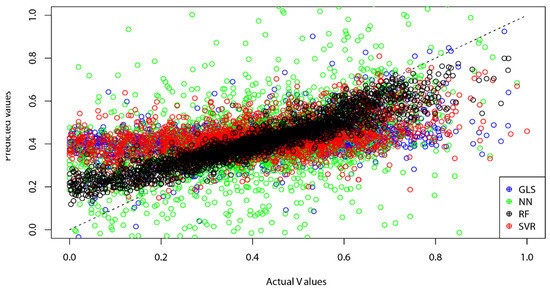
شکل 13. نمودار پراکندگی مقایسه نرخ واقعی و پیش بینی شده فقر در سال 2017 (به دست آمده از چهار الگوریتم یادگیری ماشینی). منبع: محاسبه و گرافیک تولید شده توسط نویسندگان.
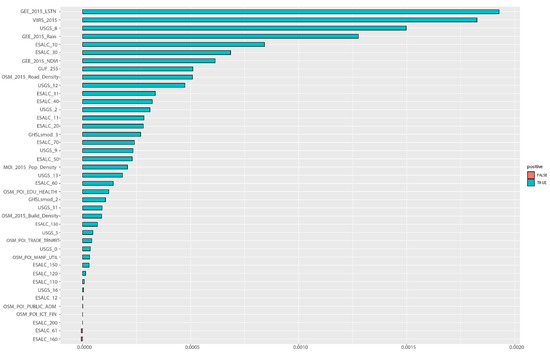
شکل 14. نتایج تجزیه و تحلیل اهمیت متغیر (VIMP) در پیش بینی نرخ سرشمار فقر در سال 2015 (بر اساس نتیجه RF). منبع: محاسبه و گرافیک تولید شده توسط نویسندگان.
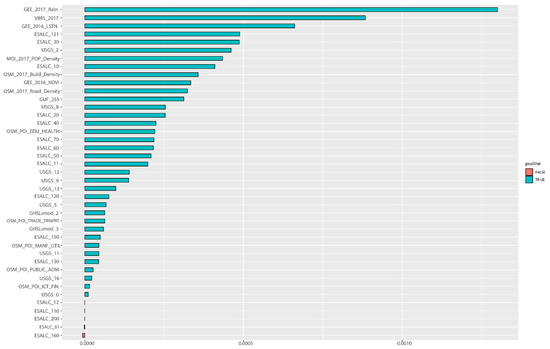
شکل 15. نتایج تجزیه و تحلیل اهمیت متغیر (VIMP) در پیش بینی نرخ سرشمار فقر در سال 2017 (بر اساس نتیجه RF). منبع: محاسبه و گرافیک تولید شده توسط نویسندگان.
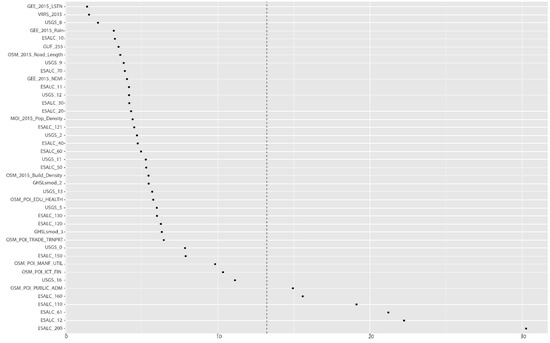
شکل 16. نتیجه تحلیل عمق حداقل (MD) در پیش بینی نرخ سرشمار فقر در سال 2015 (بر اساس نتیجه RF). منبع: محاسبه و گرافیک تولید شده توسط نویسندگان.
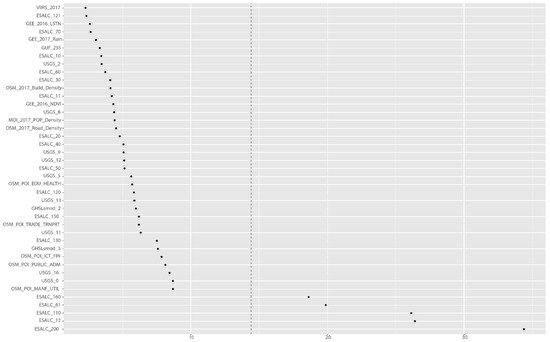
شکل 17. نتیجه تحلیل عمق حداقلی (MD) در پیش بینی نرخ سرشمار فقر در سال 2017 (بر اساس نتیجه RF). منبع: محاسبه و گرافیک تولید شده توسط نویسندگان.
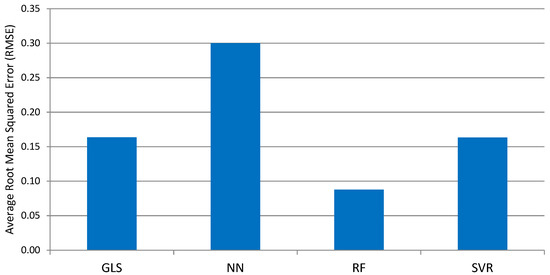
شکل 18. مقایسه میانگین میانگین مربعات ریشه خطا (RMSE) به دست آمده از چهار الگوریتم یادگیری ماشینی (در پیش بینی MPI سال 2017). منبع: محاسبه و گرافیک تولید شده توسط نویسندگان.
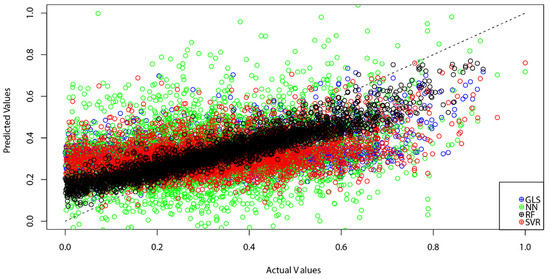
شکل 19. نمودار پراکندگی مقایسه MPI واقعی و پیش بینی شده 2017 (به دست آمده از چهار الگوریتم یادگیری ماشینی). منبع: محاسبه و گرافیک تولید شده توسط نویسندگان.
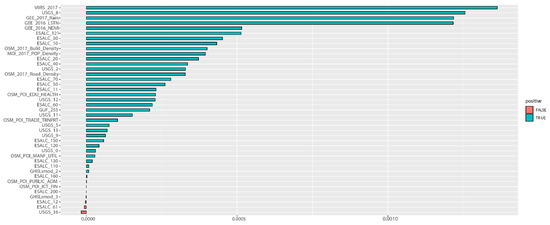
شکل 20. نتیجه تجزیه و تحلیل اهمیت متغیر (VIMP) در پیش بینی MPI سال 2017 (بر اساس نتیجه RF). منبع: محاسبه و گرافیک تولید شده توسط نویسندگان.
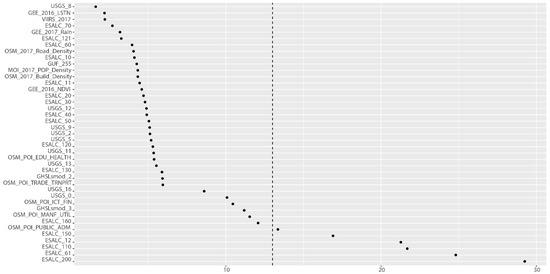
شکل 21. نتیجه تحلیل عمق حداقل (MD) در پیش بینی MPI سال 2017 (بر اساس نتیجه RF). منبع: محاسبه و گرافیک تولید شده توسط نویسندگان.


بدون دیدگاه