

خلاصه
کلید واژه ها:
پیش بینی جرم ; یادگیری گروهی ; یادگیری ماشینی ؛ پسرفت
1. معرفی
-
مشارکت 1: یک مدل پیشبینی جرم فضایی با استفاده از دادههایی که معمولاً در سرتاسر قاره ایالات متحده در دسترس است، در نتیجه امکان مقایسه فضایی را فراهم میکند.
-
مشارکت 2: یک استراتژی داده کارآمد مبتنی بر بررسی ادبیات چند رشتهای در مورد جرم و تکنیکهای پیشرفته پیشبینی ML.
-
مشارکت 3: مقایسه مختصری از عملکرد سه مدل پیش بینی، یعنی: رگرسیون پواسون، شبکه عصبی متوالی، و تقویت گرادیان.
-
مشارکت 4: مجموعه ای از آزمایش های گسترده بر روی مجموعه داده های دنیای واقعی از جنایات گزارش شده در شهرهای مختلف ایالات متحده، و بحث مفصلی از پیش بینی های احتمالی جرم محلی به دست آمده است.
2. پیشینه و کارهای مرتبط
2.1. پیش زمینه نظری
2.2. آثار مرتبط: ML و پیشبینی جرم
3. روش شناسی
3.1. استراتژی داده ها
3.1.1. منابع اطلاعات
-
داده های اجتماعی-اقتصادی و جمعیت شناختی از برآوردهای 5 ساله جامعه آمریکایی (ACS) [ 80 ] استخراج شد. در کار حاضر، ما از مجموعه برآوردهای 5 ساله ACS که دوره 2014-2018 را برای همه گروههای بلوک ایالات متحده پوشش میدهد، استفاده کردیم.
-
داده های آب و هوا (میانگین ماهانه مربوط به باد، بارندگی و دما) از پروژه WorldClim 2 [ 81 ] بازیابی شد.
-
داده های اجرای قانون بر اساس داده های Homeland Infrastructure مربوط به سازمان های مجری قانون محلی در ایالات متحده جمع آوری شد.
-
شمارش جرم برای جرایم خشن، جنایت دارایی، و دو مورد فرعی خاص (وندالیسم و سرقت وسایل نقلیه موتوری) در بازه زمانی 2014-2018 در سطح گروه سرشماری ایالات متحده از پایگاه داده باز جرم استخراج و جمعآوری شد . شهرهای تحت پوشش عبارتند از توسان، AZ. لس آنجلس، کالیفرنیا؛ سانفرانسیسکو، کالیفرنیا؛ شیکاگو، IL; لوئیزویل، KY; دیترویت، MI; کانزاس سیتی، MO; نیویورک، نیویورک؛ آستین، تگزاس؛ فورت ورث، تگزاس؛ و ویرجینیا بیچ، کالیفرنیا.
-
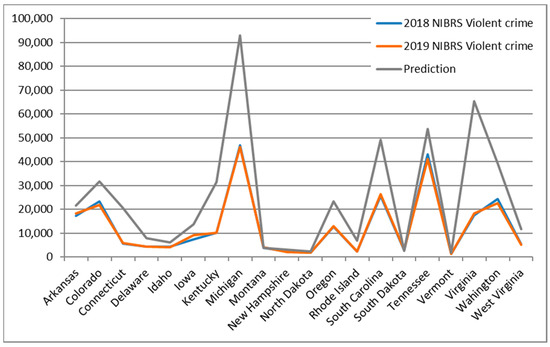
مجموع جنایات ایالتی از FBI Crime Data Explorer برای سالهای 2018 و 2019 استخراج شد.
3.1.2. پیش پردازش داده ها
3.2. روش پیشنهادی
اجازه دهید yمنمتغیر پاسخ باشد. ما این را فرض می کنیم yمناز توزیع پواسون با میانگین پیروی می کند λمنبه عنوان تابعی از متغیرهای کمکی تعریف می شود ایکسمن. تابع جرم احتمال پواسون با معادله زیر به دست می آید:
جایی که: λمن=E(yمن|ایکسمن)، و پبعد بردار متغیرهای کمکی گنجانده شده در مدل را تعریف می کند.
تعداد لایه ها به صورت تجربی با استفاده از 1 تا 10 لایه و 200 تا 1000 پرسپترون در هر لایه مورد آزمایش قرار گرفت. بهترین پیکربندی یافت شده بر اساس عملکرد مدل (یعنی متریک MAE) شامل 2 لایه پنهان است که اولی شامل 700 واحد و دومی شامل 25 واحد است. واحدهای ورودی خروجی خود را به واحدهای اولین لایه پنهان ارسال می کنند. هر یک از واحدهای لایه پنهان یک ثابت (“بایاس”) را به مجموع وزنی ورودی های خود اضافه می کند و سپس یک تابع فعال سازی نتیجه را محاسبه می کند، در مورد ما تابع فعال سازی ReLU :
4. نتایج و بحث
4.1. تنظیمات آزمایشی
4.2. معیارهای ارزیابی
به منظور ارزیابی کیفیت پیشبینیهای بهدستآمده با چارچوب پیشنهادی ما، ما به متداولترین معیارهای ارزیابی برای مشکلات رگرسیونی، یعنی میانگین خطای مطلق (MAE) و ریشه میانگین مربعات خطا (RMSE) تکیه کردیم.
جایی که rمنمقدار هدف حقیقت زمینی را برای i -امین نقطه داده نشان می دهد، r^مننشان دهنده مقدار هدف پیش بینی شده برای i -امین نقطه داده است و nتعداد کل نقاط داده است.
علاوه بر این، ما از یک متریک سوم برای تعیین کمیت درصد نزدیکی پیشبینیها در برابر حقیقت اصلی استفاده کردیم: MAE تقسیم بر میانگین مقادیر هدف. این به منظور اجتناب از قضاوت مدلهایی تعریف شد که در آن خطای نسبی (مثلاً با میانگین درصد مطلق خطا بیان میشود) زیاد است، اما خطای مطلق کم است. برای انجام این کار، ما MAE را با میانگین هدف به جای مقدار هدف مقایسه کردیم. این معیار که در این مقاله آن را دقت می نامیم، به صورت زیر تعریف می شود:
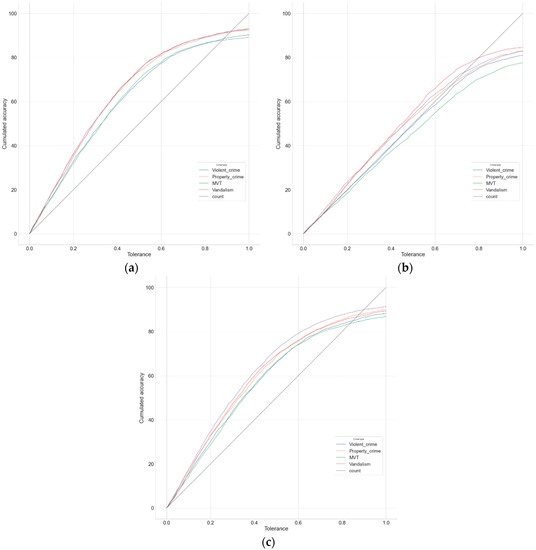
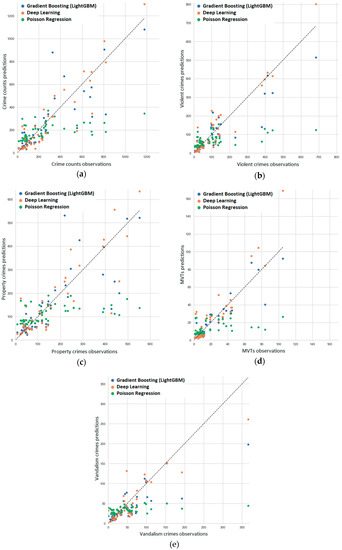
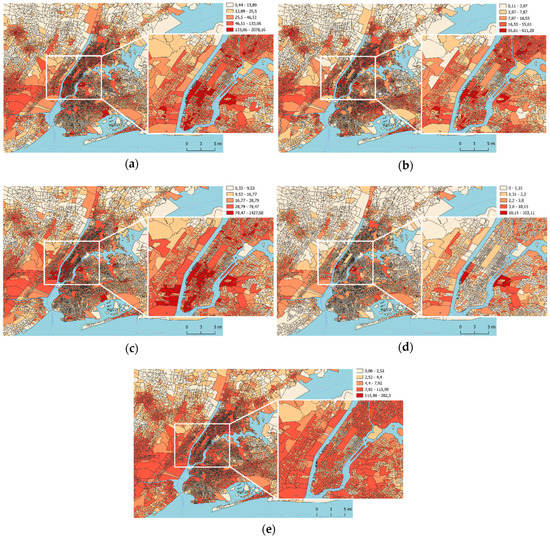
4.3. نتایج آزمایش
4.4. بحث
4.4.1. نتایج پیشبینی در نمونه آموزشی و آزمایشی
4.4.2. نتایج پیش بینی خارج از نمونه آموزش و آزمایش
4.4.3. محدودیت ها
5. نتیجه گیری ها
منابع
- کلنسی، جی. آیا ما هنوز “پرواز کور هستیم؟ داده های جرم و جنایت و پیشگیری از جرم محلی در نیو ساوت ولز. Curr. مسائل جرم. عدالت 2011 ، 22 ، 491-500. [ Google Scholar ] [ CrossRef ]
- Cichosz, P. پیشبینی خطر جرم شهری با استفاده از دادههای نقطهنظر. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 459. [ Google Scholar ] [ CrossRef ]
- عنایت الله، س. آینده پلیس: فراتر رفتن از خط آبی نازک. آتی 2013 ، 49 ، 1-8. [ Google Scholar ] [ CrossRef ]
- الماو، ع. Kadam, K. مقاله بررسی پیش بینی جرم با استفاده از رویکرد گروهی. بین المللی J. Pure Appl. ریاضی. 2018 ، 118 ، 133-139. [ Google Scholar ]
- پرابکاران، س. میترا، اس. بررسی تحلیل تکنیک های کشف جرم با استفاده از داده کاوی و یادگیری ماشینی. J. Phys. Conf. سر. 2018 , 1000 , 012046. [ Google Scholar ] [ CrossRef ]
- Alves، LGA؛ ریبیرو، HV; رودریگز، پیشبینی جرم FA از طریق معیارهای شهری و یادگیری آماری. فیزیک یک آمار مکانیک. برنامه آن است. 2018 ، 505 ، 435-443. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کادار، سی. ماکولان، آر. Feuerriegel، S. پشتیبانی تصمیمگیری عمومی برای مناطق با تراکم جمعیت پایین: مجموعهای از عدم تعادل آگاه برای پیشبینی جرم فضایی-زمانی. تصمیم می گیرد. سیستم پشتیبانی 2019 ، 119 ، 107–117. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لین، Y.-L. ین، M.-F. یو، ال.-سی. پیشبینی جرم مبتنی بر شبکه با استفاده از ویژگیهای جغرافیایی. ISPRS Int. J. Geo-Inf. 2018 ، 7 ، 298. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- مایجر، ع. وسلز، ام. پلیس پیش بینی: بررسی مزایا و معایب. بین المللی J. Public Adm. 2019 ، 42 ، 1031–1039. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Konkel، RH; راتکوفسکی، دی. Tapp, SN تأثیرات اختلالات فیزیکی، اجتماعی و مسکن بر جنایت محله: آزمون معاصر نظریه ویندوز شکسته. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 583. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Ashby، MPJ Studying Crime and Place with the Crime Open Database: Social and Behavioral Scienes. Res. داده J. Humanit. Soc. علمی 2018 . [ Google Scholar ] [ CrossRef ]
- شاو، CR; مک کی، HD بزهکاری نوجوانان و مناطق شهری ؛ انتشارات دانشگاه شیکاگو: شیکاگو، IL، ایالات متحده آمریکا، 1942. [ Google Scholar ]
- پرات، TC; کالن، FT ارزیابی پیشبینیکنندههای سطح کلان و نظریههای جرم: یک متاآنالیز. عدالت جنایی 2005 ، 32 ، 373-450. [ Google Scholar ] [ CrossRef ]
- Bursik، RJ بیسازمانی اجتماعی و نظریههای جرم و بزهکاری: مشکلات و چشماندازها. جرم شناسی 1988 ، 26 ، 519-552. [ Google Scholar ] [ CrossRef ]
- کورنهاوزر، RR منابع اجتماعی بزهکاری: ارزیابی مدل های تحلیلی . انتشارات دانشگاه شیکاگو: شیکاگو، IL، ایالات متحده آمریکا، 1978. [ Google Scholar ]
- سامپسون، آر. گرووز، ساختار جامعه و جرم و جنایت: آزمایش نظریه بیسازمانی اجتماعی. صبح. جی. سوسیول. 1989 . [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Bursik، RJJ; Grasmick، HG محرومیت اقتصادی و نرخ جرم محله 1960-1980. جامعه حقوقی Rev. 1993 , 27 , 263. [ Google Scholar ]
- سامپسون، RJ; Raudenbush، SW; Earls, F. Neighborhoods and Violent Crime: A Study Multilevel of Collective Efficiency. علوم 1997 ، 277 ، 918-924. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ویلسون، WJ افراد واقعاً محروم: شهر داخلی، طبقه پایین و سیاست عمومی . انتشارات دانشگاه شیکاگو: شیکاگو، IL، ایالات متحده آمریکا، 1987. [ Google Scholar ]
- کول، اسجی اثرات و جرم همسایگی اجتماعی و فیزیکی: گردهم آوردن دامنهها از طریق نظریه اثربخشی جمعی. Soc. علمی 2019 ، 8 ، 147. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- براونینگ، CR گستره اثربخشی جمعی: گسترش نظریه بیسازمانی اجتماعی به خشونت شریک. J. ازدواج فام. 2002 ، 64 ، 833-850. [ Google Scholar ] [ CrossRef ]
- مورنوف، جی دی. سامپسون، RJ; Raudenbush، نابرابری محله SW، اثربخشی جمعی، و پویایی فضایی خشونت شهری. جرم شناسی 2001 ، 39 ، 517-558. [ Google Scholar ] [ CrossRef ]
- سامپسون، RJ; Wikström، P.-OH نظم اجتماعی خشونت در محلههای شیکاگو و استکهلم: یک تحقیق مقایسهای. در نظم، درگیری و خشونت ؛ Shapiro, I., Kalyvas, SN, Masoud, T., Eds.; انتشارات دانشگاه کمبریج: کمبریج، انگلستان، 2008; صص 97-119. [ Google Scholar ] [ CrossRef ]
- کوهن، LE; فلسون، ام. تغییر اجتماعی و روند نرخ جرم: رویکرد فعالیت معمول. صبح. اجتماعی Rev. 1979 , 44 , 588-608. [ Google Scholar ] [ CrossRef ]
- ویزبرد، دی. گراف، ای آر. یانگ، اس.-ام. جرمشناسی مکان: بخشهای خیابان و درک ما از مسئله جرم ؛ انتشارات دانشگاه آکسفورد: آکسفورد، انگلستان، 2012. [ Google Scholar ]
- اسپانو، آر. فریلیچ، جی دی ارزیابی اعتبار تجربی و مفهومسازی مطالعات چند متغیره در سطح فردی نظریه سبک زندگی/فعالیتهای روتین منتشر شده از سال 1995 تا 2005. J. Crim. عدالت 2009 ، 37 ، 305-314. [ Google Scholar ] [ CrossRef ]
- آندرسن، کارشناسی ارشد، تحلیل فضایی جرم در ونکوور، بریتیش کلمبیا: ترکیبی از بیسازمانی اجتماعی و نظریه فعالیت معمول. می توان. Geogr./Le Géographe Can. 2006 ، 50 ، 487-502. [ Google Scholar ] [ CrossRef ]
- Furstenberg، FF; کوک، تی دی; اکلس، جی. Elder، GH; سامروف، الف. مدیریت ساختن آن: خانواده های شهری و موفقیت نوجوانان. مطالعات رشد موفق نوجوانان ; انتشارات دانشگاه شیکاگو: شیکاگو، IL، ایالات متحده آمریکا، 2000. [ Google Scholar ]
- بریسون، دی. رول، اس. تأثیر همسایگی بر جنایت و ایمنی: مروری بر شواهد. نول 2012 ، 9 ، 333-350. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کلمن، سرمایه اجتماعی JS در ایجاد سرمایه انسانی. صبح. جی. سوسیول. 1988 ، 94 ، S95–S120. [ Google Scholar ] [ CrossRef ]
- پاتنام، آردی بولینگ تنهایی: فروپاشی و احیای جامعه آمریکایی. در بولینگ تنهایی: فروپاشی و احیای جامعه آمریکایی ; Touchstone Books/Simon & Schuster: New York, NY, USA, 2000; پ. 541. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چیو، WH; مدن، پی دزدی و نابرابری درآمد. جی. اقتصاد عمومی. 1998 ، 69 ، 123-141. [ Google Scholar ] [ CrossRef ]
- حسیه، سی. Pugh، MD فقر، نابرابری درآمد، و جنایت خشونت آمیز: فراتحلیلی از مطالعات اخیر داده های کل. جنایت. Justice Rev. 1993 , 18 , 182-202. [ Google Scholar ] [ CrossRef ]
- کلی، ام. نابرابری و جنایت. کشیش Econ. آمار 2000 ، 82 ، 530-539. [ Google Scholar ] [ CrossRef ]
- Weatherburn, D. چه چیزی باعث جنایت می شود؟ دفتر آمار و تحقیقات جنایت NSW: سیدنی، استرالیا، 2001.
- Feldmeyer, B. اثرات تفکیک نژادی/قومی بر قتل لاتین و سیاهپوستان. اجتماعی Q. 2010 , 51 , 600-623. [ Google Scholar ] [ CrossRef ]
- کریو، ال جی. پترسون، RD; کوهل، جداسازی دی سی، ساختار نژادی، و جنایات خشونت آمیز همسایگی. صبح. جی. سوسیول. 2009 ، 114 ، 1765-1802. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پترسون، RD; Krivo، LJ جهانهای اجتماعی متفاوت: جنایتهای همسایگی و شکاف نژادی- فضایی . بنیاد راسل سیج: نیویورک، نیویورک، ایالات متحده آمریکا، 2010. [ Google Scholar ]
- Balkwell، JW نابرابری قومی و میزان قتل. Soc. نیروها 1990 ، 69 ، 53-70. [ Google Scholar ] [ CrossRef ]
- بلاو، PM; گلدن، ساختار متروپولیتن RM و خشونت جنایی. اجتماعی Q. 1986 , 27 , 15-26. [ Google Scholar ] [ CrossRef ]
- کوبرین، سی. ناهمگونی و جنایت نژادی: اندازه گیری اثرات ایستا و پویا. Res. جامعه اجتماعی 2000 ، 10 ، 189-219. [ Google Scholar ]
- وارنر، بی.دی. رانتری، روابط اجتماعی محلی PW در یک جامعه و مدل جرم: زیر سوال بردن ماهیت سیستمی کنترل اجتماعی غیررسمی. Soc. مشکل 1997 ، 44 ، 520-536. [ Google Scholar ] [ CrossRef ]
- شیمن، اس. ثبات مسکونی و تأثیر اجتماعی مضرات محله: مطالعه اثرات احتمالی جنسیت و نژاد. Soc. نیروها 2005 ، 83 ، 1031-1064. [ Google Scholar ] [ CrossRef ]
- برتون، وی اس، جونیور؛ کالن، FT; ایوانز، تی دی; الارید، LF; داناوی، RG جنسیت، خودکنترلی، و جنایت. J. Res. جنایت دلینق. 1998 ، 35 ، 123-147. [ Google Scholar ] [ CrossRef ]
- کارابین، ای. ایگانسکی، پی. جنوب، ن. لی، ام. پلامر، ک. تورتون، جی. ایگانسکی، پی. جنوب، ن. لی، ام. پلامر، ک. و همکاران جرم شناسی: مقدمه ای جامعه شناسانه ; Routledge: Arbington، UK، 2004. [ Google Scholar ] [ CrossRef ]
- کریسلر، جی سی. McCreary, DR Handbook of Gender Research in Psychology ; Springer: برلین/هایدلبرگ، آلمان، 2010; جلد 1. [ Google Scholar ]
- رو، دی سی؛ Vazsonyi، AT; تفاوتهای جنسی فلانری، دیجی در جنایت: آیا ابزارها و تنوع درون جنسی دلایل مشابهی دارند؟ J. Res. جنایت دلینق. 1995 ، 32 ، 84-100. [ Google Scholar ] [ CrossRef ]
- هیرشی، تی. گاتفردسون، ام. ایج و تبیین جنایت. صبح. جی. سوسیول. 1983 ، 89 ، 552-584. [ Google Scholar ] [ CrossRef ]
- Farrington، DP پرخاشگری کودکی و خشونت بزرگسالان: پیش سازهای اولیه و پیامدهای بعدی زندگی. توسعه دهنده درمان شود. کودک. پرخاشگری 1991 ، 5 ، 29. [ Google Scholar ]
- فلانگان، تی جی; Maguire, K. Sourcebook of Criminal Justice Statistics-1989 ; وزارت دادگستری، اداره آمار دادگستری: واشنگتن، دی سی، ایالات متحده آمریکا، 1990.
- سامپسون، RJ; مورنوف، جی دی. Gannon-Rowley، T. ارزیابی “اثرات همسایگی”: فرآیندهای اجتماعی و جهت گیری های جدید در پژوهش. آنو. کشیش سوسیول. 2002 ، 28 ، 443-478. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- زمین، KC; مک کال، PL; کوهن، LE متغیرهای ساختاری نرخ قتل: آیا هیچ گونه تغییری در زمان و فضای اجتماعی وجود دارد؟ صبح. جی. سوسیول. 1990 ، 95 ، 922-963. [ Google Scholar ] [ CrossRef ]
- مسنر، اس.اف. روزنفلد، آر. بامر، EP ابعاد سرمایه اجتماعی و نرخ قتل جنایی. صبح. اجتماعی Rev. 2004 , 69 , 882-903. [ Google Scholar ] [ CrossRef ]
- Lo, CC; ژونگ، اچ. پیوند نرخ جرم و جنایت با عوامل رابطه: استفاده از داده های جنسیتی خاص. جی. جنایت. عدالت 2006 ، 34 ، 317-329. [ Google Scholar ] [ CrossRef ]
- شارکی، پی تی پیمایش در خیابان های خطرناک: منابع و پیامدهای اثربخشی خیابان. صبح. اجتماعی Rev. 2006 , 71 , 826-846. [ Google Scholar ] [ CrossRef ]
- مک لاناهان، اس. Bumpass, L. پیامدهای بین نسلی از هم گسیختگی خانواده. صبح. جی. سوسیول. 1988 ، 94 ، 130-152. [ Google Scholar ] [ CrossRef ]
- مسنر، اس.اف. Sampson، RJ نسبت جنسی، اختلال در خانواده، و نرخ جرم و جنایت خشونت آمیز: پارادوکس ساختار جمعیتی. Soc. نیروهای 1991 ، 69 ، 693-713. [ Google Scholar ] [ CrossRef ]
- سامپسون، ساختار خانواده محله RJ و خطر قربانی شدن شخصی. در بوم شناسی اجتماعی جرم ; Springer: برلین/هایدلبرگ، آلمان، 1986; صص 25-46. [ Google Scholar ]
- لیون، سازمان CJ Community (Dis) و جنایت با انگیزه نژادی. صبح. جی. سوسیول. 2007 ، 113 ، 815-863. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فرای، وی. کنترل اجتماعی غیررسمی خشونت شرکای صمیمی علیه زنان: بررسی نگرش های شخصی و انسجام اجتماعی محله ادراک شده. J. روانی جامعه. 2007 ، 35 ، 1001-1018. [ Google Scholar ] [ CrossRef ]
- Cantillon، D. سازمان اجتماعی جامعه، والدین، و همسالان به عنوان میانجی ویژگی های بلوک همسایگی درک شده در فعالیت های بزهکارانه و اجتماعی. صبح. J. روانی جامعه. 2006 ، 37 ، 111-127. [ Google Scholar ] [ CrossRef ]
- بلیر، تعامل اجتماعی PE و جرم اجتماعی: بررسی اهمیت شبکه های همسایه. جرم شناسی 1997 ، 35 ، 677-704. [ Google Scholar ] [ CrossRef ]
- براونینگ، CR; دیتز، RD; فاینبرگ، SL پارادوکس سازمان اجتماعی: شبکه ها، اثربخشی جمعی و جنایت خشونت آمیز در محله های شهری. Soc. نیروهای 2004 ، 83 ، 503-534. [ Google Scholar ] [ CrossRef ]
- گیبسون، CL; ژائو، جی. Lovrich، NP; گافنی، ام جی ادغام اجتماعی، ادراکات فردی از کارآیی جمعی، و ترس از جنایت در سه شهر. عدالت Q. 2002 ، 19 ، 537-564. [ Google Scholar ] [ CrossRef ]
- ولز، LE; Weisheit، RA الگوهای جرم روستایی و شهری: مقایسه سطح شهرستان. جنایت. Justice Rev. 2004 , 29 , 1-22. [ Google Scholar ] [ CrossRef ]
- کایلن، ام تی؛ پرایدور، بیسازمانی اجتماعی و جرم و جنایت در جوامع روستایی: اولین آزمون مستقیم مدل سیستمی. برادر J. Criminol. 2013 ، 53 ، 905-923. [ Google Scholar ] [ CrossRef ]
- بوفارد، لس آنجلس; Muftić، LR “رمز روستایی”: بیسازمانی اجتماعی و خشونت فراتر از جوامع شهری. غرب. Criminol. Rev. 2006 , 7 , 56-66. [ Google Scholar ]
- لی، ی.-ای. ساختار اجتماعی و کنترل اجتماعی غیررسمی در جوامع روستایی. بین المللی J. Rural Criminol. 2011 ، 1 ، 63-88. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پیتی، TA; کوالسکی، GS مدل سازی نرخ جرم خشونت آمیز روستایی: آزمونی از نظریه بی سازمانی اجتماعی. اجتماعی تمرکز 1993 ، 26 ، 87-89. [ Google Scholar ] [ CrossRef ]
- Osgood، DW; چمبرز، JM بی سازمانی اجتماعی خارج از کلان شهر: تحلیلی از خشونت جوانان روستایی. جرم شناسی 2000 ، 38 ، 81-116. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ولز، LE; Weisheit، RA توضیح جنایت در جوامع متروپولیتن و غیر متروپولیتن. بین المللی J. Rural Criminol. 2013 ، 1 ، 153-183. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بارنت، سی. منکن، نظریه بیسازمانی اجتماعی FC و ماهیت بافتی جرم در شهرستانهای غیر شهری. جامعه روستایی 2002 ، 67 ، 372-393. [ Google Scholar ] [ CrossRef ]
- Osgood، DW; چمبرز، JM جامعه همبستگی خشونت جوانان روستایی. Juv. گاو عدالت. 2003 ، 1-12. در دسترس آنلاین: https://www.ncjrs.gov/pdffiles1/ojjdp/193591.pdf (در 29 اکتبر 2020 قابل دسترسی است).
- بخش، KC; کرشنر، EE; تامپسون، ای جی بیسازمانی اجتماعی و نرخ جرم روستایی/شهری: مقایسه عوامل مؤثر در سطح شهرستان. بین المللی J. روستایی. Criminol. 2018 ، 4 ، 43-65. [ Google Scholar ] [ CrossRef ]
- کایلن، م. پرایدور، WA; Roche, SP تأثیر تغییر ترکیب جمعیتی بر قربانی شدن حملات تشدید شده در طول انحطاط بزرگ جنایت آمریکا: تحلیل خلاف واقع نرخها در مناطق شهری، حومهای و روستایی. جنایت. Justice Rev. 2017 , 42 , 291-314. [ Google Scholar ] [ CrossRef ]
- کانگ، H.-W. کانگ، اچ.-بی. پیشبینی وقوع جرم از دادههای چندوجهی با استفاده از یادگیری عمیق. PLoS ONE 2017 , 12 , e0176244. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- هوانگ، سی. ژانگ، جی. ژنگ، ی. Chawla، NV DeepCrime: شبکههای تکراری سلسله مراتبی توجه برای پیشبینی جرم. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی ACM در مدیریت اطلاعات و دانش، CIKM ’18 ; انجمن ماشینهای محاسباتی: تورینو، ایتالیا، 2018؛ ص 1423-1432. [ Google Scholar ] [ CrossRef ]
- مارچانت، آر. هان، اس. کلنسی، جی. کریپس، اس. کاربرد یادگیری ماشینی در جرم شناسی: رگرسیون بیزی فضایی-دموگرافیک نیمه پارامتریک. امن آگاه کردن. 2018 ، 7 ، 1. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- اینگیلویچ، وی. ایوانف، اس. پیش بینی میزان جرم و جنایت در محیط شهری با استفاده از عوامل اجتماعی. Procedia Comput. علمی 2018 ، 136 ، 472-478. [ Google Scholar ] [ CrossRef ]
- اداره سرشماری ایالات متحده برآوردهای 5 ساله ACS 2014–2018. در دسترس آنلاین: https://www.census.gov/programs-surveys/acs/technical-documentation/table-and-geography-changes/2018/5-year.html (در 18 اوت 2020 قابل دسترسی است).
- فیک، SE; Hijmans، RJ WorldClim 2: سطوح جدید آب و هوایی با وضوح فضایی 1 کیلومتری برای مناطق زمینی جهانی. بین المللی جی.کلیماتول. 2017 ، 37 ، 4302-4315. [ Google Scholar ] [ CrossRef ]
- بریمن، ال. فریدمن، جی. استون، سی جی; اولشن، RA طبقه بندی و رگرسیون درختان ; Routledge & CRC Press: Abingdon، UK، 1984. [ Google Scholar ]
- پدرگوسا، اف. واروکو، جی. گرامفورت، آ. میشل، وی. تیریون، بی. گریزل، او. بلوندل، م. پرتنهوفر، پی. ویس، آر. دوبورگ، وی. و همکاران Scikit-Learn: یادگیری ماشینی در پایتون. جی. ماخ. فرا گرفتن. Res. 2011 ، 12 ، 2825-2830. [ Google Scholar ]
- ویرتانن، پی. گومرز، آر. Oliphant، TE; هابرلند، ام. ردی، تی. کورناپو، دی. بوروسکی، ای. پترسون، پی. وکسر، دبلیو. برایت، جی. و همکاران SciPy 1.0–الگوریتم های اساسی برای محاسبات علمی در پایتون. نات. روشها 2020 ، 17 ، 261-272. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آرمیتاژ، آر. مونچوک، ال. راجرسون، ام. به نظر خوب است، اما زندگی در آنجا چگونه است؟ بررسی تأثیر طراحی ابتکاری مسکن بر جرم و جنایت. یورو جی. جنایت. نتیجه سیاست 2011 ، 17 ، 29-54. [ Google Scholar ] [ CrossRef ]
- معتصم، ی. عزهید، رگرسیون EH پواسون و رگرسیون پواسون با تورم صفر: کاربرد در داده های بیمه درمانی خصوصی. یورو آکتوار. J. 2012 , 2 , 187-204. [ Google Scholar ] [ CrossRef ]
- فلاح، ن. گو، اچ. محمد، ک. سیدصالحی، س. نوریجلیانی، ک. اشراقیان، MR رگرسیون پواسون غیرخطی با استفاده از شبکه های عصبی: مطالعه شبیه سازی. محاسبات عصبی Appl. 2009 ، 18 ، 939. [ Google Scholar ] [ CrossRef ]
- فریدمن، تقریب تابع حریص JH: ماشین تقویت کننده گرادیان. ان آمار 2001 ، 29 ، 1189-1232. [ Google Scholar ] [ CrossRef ]
- Zhang, Z. تکنیک های تخمین پارامتر: یک آموزش با کاربرد در اتصال مخروطی . گزارش تحقیق RR-2676; INRIA: سوفیا آنتیپولیس، فرانسه، 1995; صص 59-76. [ Google Scholar ]
- بوگومولوف، آ. لپری، بی. استایانو، جی. الیور، ن. پیانسی، اف. Pentland، A. Once Upon a Crime: Towards Crime Prediction from Demographics and Mobile Data. در مجموعه مقالات شانزدهمین کنفرانس بین المللی تعامل چندوجهی، ICMI ’14، استانبول، ترکیه، 12-16 نوامبر 2014; انجمن ماشینهای محاسباتی: نیویورک، نیویورک، ایالات متحده آمریکا، 2014. ص 427-434. [ Google Scholar ] [ CrossRef ]
- او، ال. پائز، آ. جیائو، جی. آن، پ. لو، سی. مائو، دبلیو. لانگ، دی. جمعیت محیط و سرقت-سرقت: تحلیل فضایی با استفاده از داده های تلفن همراه. Isprs Int. J. Geo-Inf. 2020 ، 9 ، 342. [ Google Scholar ] [ CrossRef ]



بدون دیدگاه