

چکیده
کلید واژه ها:
تجزیه و تحلیل عدم قطعیت و حساسیت فضایی صریح ؛ محاسبات موازی و توزیع شده SEUSA به عنوان یک سرویس ؛ محاسبات ابری فضایی ; میکروسرویس ها تحلیل تصمیم گیری چند معیاره فضایی ; Python–Dask ; gRPC _ RasDaMan ; کوبرنتیس
1. مقدمه
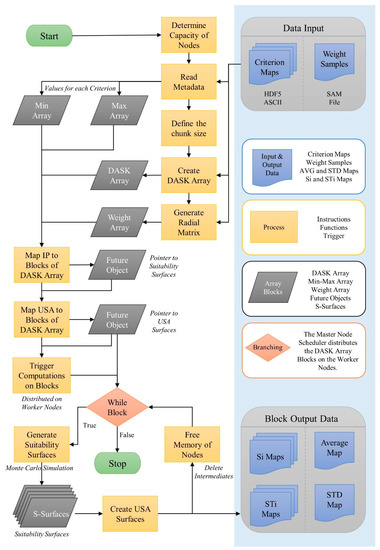
2. روش شناسی – رویکرد موازی و توزیع شده SEUSA
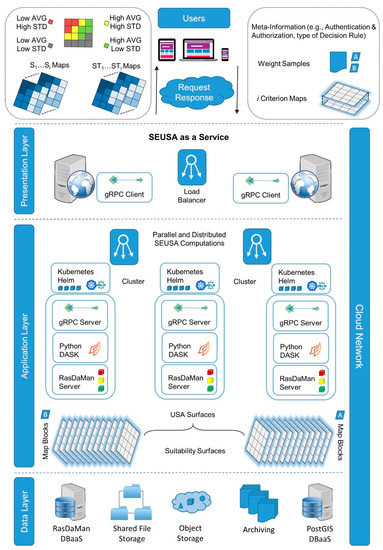
2.1. SEUSA: Python–Dask
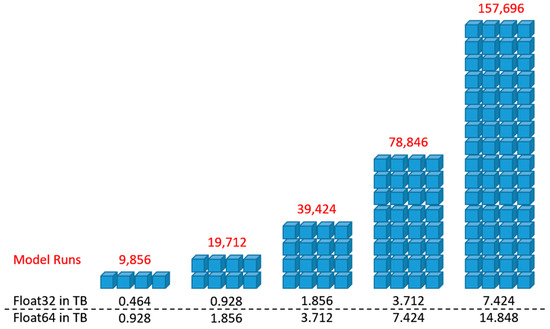
Erlacher، Desch، Anders، Jankowski و Paulus [ 19 ] یک رویکرد موازی و توزیع شده بر اساس Python-Dask برای کوتاه کردن زمان پردازش تولید پشته سطوح مناسب ارائه کردند. همانطور که حاجیدوکاس و همکاران بیان کردند. [ 24 ] (ص. 3)، چارچوب Dask مبتنی بر صف پیام است و از رویکرد مشتری-زمانبندی-کارگر پیروی می کند که عمدتاً محیط های رایانش ابری را هدف قرار می دهد. Dask از کتابخانه هایی مانند NumPy، Pandas، و Scikit-Learn پشتیبانی می کند و یک داشبورد بلادرنگ پاسخگو، یک رفتار تحمل پذیر خطا، و انواع مختلف زمانبندی را ارائه می دهد [ 25 ، 26 ]]. این پشته چندین میلیون مکان پیکسل و صد هزار شبیه سازی را در خود جای داده است. هر نتیجه شبیه سازی عملکرد جایگزین های مکان (مکان های پیکسل) را برای نمونه ای از مقادیر وزن معیار نشان می دهد. ایجاد نمونه های وزنی (SAM Files) با استفاده از طرح آزمایشی شبه تصادفی Sobol [ 27 ] اجرا می شود.] برای محاسبه ماتریس وزن شعاعی. راه حل مبتنی بر Python-Dask برای خوشه های محلی که از مجموعه ای از ایستگاه های کاری تشکیل شده اند قابل استفاده است. زمانبند اصلی مسئول مقیاسبندی و توزیع بار کاری بین گرهها است. متا اطلاعات مربوط به ظرفیتها (به عنوان مثال، تعداد رشتهها در هر هسته، حافظه موجود) گرههای کارگر، و بار کاری از پیش محاسبهشده برای همه عملیات پردازش، برای تضمین توزیع متعادل مجموعههای داده مرتبط هستند. همه گره های خوشه محلی به مجموعه داده های ورودی شطرنجی از طریق سیستم فایل شبکه (NFS) دسترسی مستقیم دارند. تعداد شبیهسازیها بر اندازههای قطعه آرایه Dask تأثیر میگذارد، جایی که شاخص اول یک نقشه معیار را مشخص میکند و دو شاخص باقیمانده به سطر و ستون یک نقشه معیار خاص اشاره میکنند. آرایه daskشامل آرایههای NumPy (بلوکهای) کوچکتر است که امکان انجام فرآیندها را روی آرایههای بزرگتر از حافظه موجود برای گرههای کارگر فراهم میکند. همه عملکردها، مانند تولید سطوح مناسب در حافظه و ایجاد نقشه میانگین و انحراف استاندارد، به بلوک ها نگاشت می شوند. این روش فقط محاسبه نقشه میانگین و انحراف استاندارد را به صورت موازی در بر می گیرد. توابع اضافی که برای تولید معیارهای حساسیت مرتبه اول (شاخصهای Si) و معیارهای حساسیت مرتبه کل (شاخصهای STi) برای هر معیار و مکان در مجموعه دادههای شطرنجی ضروری هستند، به هر بلوک از آرایه dask منتقل و نگاشت میشوند.. توابع نگاشت شده اشیاء آینده را تشکیل می دهند و نشانگرهایی به آرایه های مربوطه را شامل می شوند. این بهبود نشان دهنده ادغام موثرتری از تولید سطح حساسیت به صورت موازی است و منجر به افزایش عملکرد محاسباتی در مقایسه با راه حل متوالی می شود. تمام محاسبات رویکرد SEUSA برای هر بلوک با فراخوانی تابع () asarray NumPy اجرا می شود. پشته میانی سطوح تناسب شامل یک زیرمنطقه (دو بعد اول) از محل مطالعه است، که در آن بعد سوم مقادیر مناسب را برای هر اجرای شبیهسازی نشان میدهد. تعداد سطوح مناسب (معادله (1)) به وزن نمونه انتخابی (N) و تعداد معیارها (i) بستگی دارد:
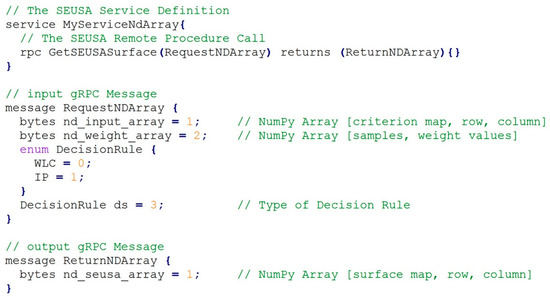
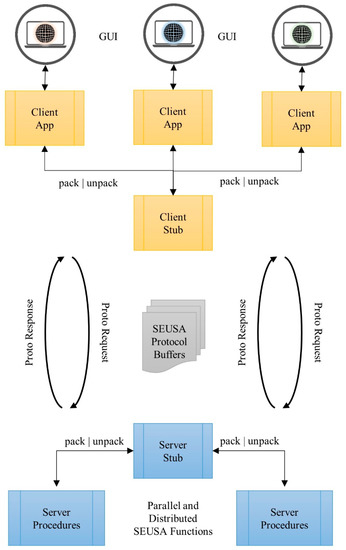
2.2. SEUSA: میان افزار
- (1)
-
Stub که می تواند توسط برنامه مشتری برای فراخوانی فراخوانی روش راه دور استفاده شود.
- (2)
-
سرویس دهنده، که رابط را برای سرویس های پیاده سازی شده تعریف می کند. و
- (3)
-
تابع Servicer _to_server که سرویس دهنده را به grpc.Server اضافه می کند.
3. SEUSA به Cloud-طراحی چارچوب
-
نیازهای عمومی برای مهاجرت ابری؛
-
SEUSA به عنوان یک سرویس برای تسهیل دسترسی برای جوامع کاربر.
-
مسائل محاسباتی موازی و توزیع شده؛
-
خدمات کاشی کاری مربوط به انجام محاسبات و تسهیل نمایش نقشه؛ و
-
الزامات مربوط به ذخیره سازی ابری برای ارائه در دسترس بودن داده ها و قابلیت اطمینان بالا برای تبادل اطلاعات بین برنامه ها.
3.1. پیش زمینه ی نظری
3.2. الزامات
3.3. طراحی معماری
4. بحث
5. نتیجه گیری ها
منابع
- کینان، PB; یانکوفسکی، ص. سیستمهای پشتیبانی تصمیم فضایی: سه دهه بعد. تصمیم می گیرد. سیستم پشتیبانی 2019 ، 116 ، 64–76. [ Google Scholar ] [ CrossRef ]
- Simon, HA علم جدید تصمیم مدیریت ; Prentice Hall PTR: Upper Saddle River، نیوجرسی، ایالات متحده آمریکا، 1977. [ Google Scholar ]
- Malczewski، J. یانکوفسکی، ص. روندهای نوظهور و مرزهای تحقیق در تحلیل چند معیاره فضایی. بین المللی جی. جئوگر. Inf. علمی 2020 ، 1–26. [ Google Scholar ] [ CrossRef ]
- Malczewski، J. Rinner, C. تجزیه و تحلیل تصمیم چند معیاره در علم اطلاعات جغرافیایی ; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2015. [ Google Scholar ]
- تیل، جی.-سی. تصمیم گیری و تجزیه و تحلیل چند معیاره فضایی ، چاپ اول. Routledge: لندن، بریتانیا، 1999. [ Google Scholar ] [ CrossRef ]
- سالتلی، ا. Annoni، P. چگونه از تجزیه و تحلیل حساسیت ظاهری اجتناب کنیم. محیط زیست مدل. نرم افزار 2010 ، 25 ، 1508-1517. [ Google Scholar ] [ CrossRef ]
- گنجی، ع. مایر، منابع انسانی؛ Dandy، GC یک روش تحلیل حساسیت Sobol اصلاح شده برای تصمیم گیری در مشکلات زیست محیطی. محیط زیست مدل. نرم افزار 2016 ، 75 ، 15-27. [ Google Scholar ] [ CrossRef ]
- لیگمان-زیلینسکا، آ. Jankowski، P. تجزیه و تحلیل عدم قطعیت و حساسیت یکپارچه فضایی صریح وزن معیارها در ارزیابی تناسب زمین چند معیاره. محیط زیست مدل. نرم افزار 2014 ، 57 ، 235-247. [ Google Scholar ] [ CrossRef ]
- لیگمان-زیلینسکا، آ. Jankowski، P. چارچوبی برای تحلیل حساسیت در ارزیابی چند معیاره فضایی. در GIScience 2008 ; Cova، TJ، Miller، HJ، Beard، K.، Frank، AU، Goodchild، MF، Eds. Springer: برلین/هایدلبرگ، آلمان، 2008; جلد LNCS 5266، ص 217-233. [ Google Scholar ]
- فرتی، اف. سالتلی، ا. تارانتولا، اس. روند در عمل تجزیه و تحلیل حساسیت در دهه گذشته. علمی کل محیط. 2016 ، 568 ، 666-670. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- شالاپ-آیچا، س. Jankowski، P. تجزیه و تحلیل تاثیر پارامترها و عدم قطعیت های مقیاس بر روی یک مدل ارزیابی کاربری اراضی چند معیاره محلی. استوک. محیط زیست Res. ارزیابی ریسک 2018 ، 32 ، 2699–2719. [ Google Scholar ] [ CrossRef ]
- لیلبرن، ال. تارانتولا، اس. تحلیل حساسیت مدلهای فضایی. بین المللی جی. جئوگر. Inf. علمی 2009 ، 23 ، 151-168. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سالتلی، ا. راتو، ام. تارانتولا، اس. Campolongo، F. شیوه های تحلیل حساسیت: استراتژی هایی برای استنتاج مبتنی بر مدل. Reliab. مهندس سیستم Saf. 2006 ، 91 ، 1109-1125. [ Google Scholar ] [ CrossRef ]
- هما، تی. Saltelli، A. اقدامات مهم در تحلیل حساسیت جهانی مدلهای غیرخطی. Reliab. مهندس سیستم Saf. 1996 ، 52 ، 1-17. [ Google Scholar ] [ CrossRef ]
- شالاپ-آیچا، س. Jankowski، P. ادغام ارزیابی چند معیاره محلی با تجزیه و تحلیل عدم قطعیت-حساسیت صریح فضایی. تف کردن شناخت. محاسبه کنید. 2016 ، 16 ، 106-132. [ Google Scholar ] [ CrossRef ]
- فیضی زاده، ب. یانکوفسکی، پ. Blaschke، T. رویکرد تحلیل عدم قطعیت و حساسیت صریح فضایی مبتنی بر GIS برای تجزیه و تحلیل تصمیم چند معیاره. محاسبه کنید. Geosci. 2014 ، 64 ، 81-95. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ارلاچر، سی. شالاپ-آیچا، س. یانکوفسکی، پ. Anders, K.-H.; Paulus, G. یک راه حل مبتنی بر GPU برای تسریع تجزیه و تحلیل عدم قطعیت و حساسیت فضایی صریح در تصمیم گیری چند معیاره. در مجموعه مقالات دقت فضایی، مونپلیه، فرانسه، 5-8 ژوئیه 2016. صص 305-312. [ Google Scholar ]
- ارلاچر، سی. یانکوفسکی، پ. بلاشکه، تی. پاولوس، جی. اندرس، ک.-اچ. یک رویکرد موازی سازی مبتنی بر GPU برای انجام تجزیه و تحلیل عدم قطعیت و حساسیت فضایی صریح در حوزه کاربردی ارزیابی منظر. Gi_Forum J. 2017 ، 2017 ، 44–58. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ارلاچر، سی. دش، آ. Anders, K.-H.; یانکوفسکی، پ. Paulus، G. محاسبات موازی و توزیع شده برای مسائل تجزیه و تحلیل تصمیم گیری چند معیاره فضایی مبتنی بر شطرنجی بزرگ: مقایسه عملکرد محاسباتی. GI_Forum J. 2019 ، 2019 ، 69–86. [ Google Scholar ] [ CrossRef ]
- Krämer, M. GeoRocket: یک فروشگاه داده مقیاس پذیر و مبتنی بر ابر برای فایل های بزرگ مکانی. SoftwareX 2020 , 11 , 100409. [ Google Scholar ] [ CrossRef ]
- سوئیل، پ. برگر، ا. دی مارکی، دی. کمپینرز، پی. رودریگز، دی. سیریس، وی. Vasilev, V. یک پلت فرم محاسباتی همه کاره با داده فشرده برای بازیابی اطلاعات از داده های بزرگ جغرافیایی. ژنرال آینده. محاسبه کنید. سیستم 2018 ، 81 ، 30-40. [ Google Scholar ] [ CrossRef ]
- یانگ، سی. یو، م. هو، اف. جیانگ، ی. Li, Y. استفاده از رایانش ابری برای رسیدگی به چالشهای بزرگ دادههای مکانی. محاسبه کنید. محیط زیست سیستم شهری 2017 ، 61 ، 120-128. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یانگ، سی. هوانگ، Q. لی، ز. لیو، ک. Hu, F. داده های بزرگ و رایانش ابری: فرصت ها و چالش های نوآوری. بین المللی جی دیجیت. زمین 2017 ، 10 ، 13-53. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- حاجیدوکاس، PE; برتزاقی، ع. شایدگر، اف. ایستریت، آر. بکاس، سی. Malossi، ACI torcpy: پشتیبانی از موازی کاری در پایتون. SoftwareX 2020 , 12 , 100517. [ Google Scholar ] [ CrossRef ]
- Matthew, R. Dask: محاسبات موازی با الگوریتمهای مسدود شده و زمانبندی وظایف. در مجموعه مقالات چهاردهمین کنفرانس علمی پایتون (SciPy 2015)، آستین، TX، ایالات متحده، 6 تا 12 ژوئیه 2015؛ صص 126-132. [ Google Scholar ]
- دانیل، JC Data Science با پایتون و Dask . Manning Publications Co.: Shelter Island، NY، ایالات متحده آمریکا، 2019. [ Google Scholar ]
- Sobol، برآورد حساسیت IM برای مدلهای ریاضی غیرخطی. ریاضی. مدل. محاسبه کنید. انقضا 1993 ، 1 ، 407-414. [ Google Scholar ]
- اشمیت، دی سی; Buschmann, F. الگوها، چارچوب ها و میان افزار: روابط هم افزایی آنها. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی مهندسی نرم افزار، پورتلند، OR، ایالات متحده آمریکا، 3-10 می 2003. صص 694-704. [ Google Scholar ]
- Schantz، RE; اشمیت، پیشرفت های تحقیقاتی DC در میان افزار برای سیستم های توزیع شده: وضعیت هنر. در مجموعه مقالات سیستم های ارتباطی: وضعیت هنر IFIP هفدهمین کنگره جهانی کامپیوتر — جریان TC6 در سیستم های ارتباطی، مونترال، QC، کانادا، 25 تا 30 اوت 2002. چاپین، ال.، اد. Springer: Boston, MA, USA, 2002; صص 1-36. [ Google Scholar ]
- بلیت، دی. الکاراز، ج. بینه، اس. چکانوف، SV ProIO: یک قالب جریان ورودی/خروجی مبتنی بر رویداد برای پیامهای پروتوباف. محاسبه کنید. فیزیک اشتراک. 2019 ، 241 ، 98-112. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Fürhoff, L. بازنگری در استفاده و تجربه خوشهبندی در نقشهبرداری وب . Springer: Cham، سوئیس، 2020؛ صص 3-22. [ Google Scholar ]
- هنگ، ال. الله، من. کیم، دی.-اچ. یک پلت فرم ایمن مزرعه ماهی مبتنی بر بلاک چین برای یکپارچگی داده های کشاورزی. محاسبه کنید. الکترون. کشاورزی 2020 , 170 , 105251. [ Google Scholar ] [ CrossRef ]
- وانگ، ال. فون لاژوسکی، جی. یانگ، ا. او، X. کونزه، ام. تائو، جی. Fu, C. Cloud Computing: A Perspective Study. نسل جدید. محاسبه کنید. 2010 ، 28 ، 137-146. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مل، پی. گرنس، تی. تعریف NIST از رایانش ابری. توصیه کنید. Natl. Inst. ایستادن. تکنولوژی 2011 . [ Google Scholar ] [ CrossRef ]
- Vaquero، LM; رودرو-مرینو، ال. کاسرس، جی. Lindner, M. A break in the clouds: Towards a cloud definition. محاسبات SIGCOMM. اشتراک. Rev. 2009 , 39 , 50-55. [ Google Scholar ] [ CrossRef ]
- اودون-آیو، آی. آنانیا، م. آگونو، اف. Goddy-Worlu, R. Cloud Computing Architecture: A Critical Analysis. در مجموعه مقالات 2018 هجدهمین کنفرانس بین المللی علوم و کاربردهای محاسباتی (ICCSA)، ملبورن، VIC، استرالیا، 2 تا 5 ژوئیه 2018؛ صص 1-7. [ Google Scholar ]
- بخاری، MU; شلال، QM; تماندانی، مدلهای سرویس محاسبات ابری YK: یک مطالعه تطبیقی. در مجموعه مقالات سومین کنفرانس بین المللی 2016 در محاسبات برای توسعه پایدار جهانی (INDIACom)، دهلی نو، هند، 16 تا 18 مارس 2016؛ صص 890-895. [ Google Scholar ]
- یانگ، سی. گودچایلد، م. هوانگ، Q. نبرت، دی. راسکین، آر. خو، ی. بامباکوس، ام. Fay, D. محاسبات ابری فضایی: علوم زمین فضایی چگونه می تواند از محاسبات ابری استفاده کند و به شکل گیری آن کمک کند؟ بین المللی جی دیجیت. زمین 2011 ، 4 ، 305-329. [ Google Scholar ] [ CrossRef ]
- Ujjwal, KC; گارگ، اس. هیلتون، جی. آریال، ج. Forbes-Smith، N. Cloud Computing در سیستم های مدل سازی مخاطرات طبیعی: روندهای تحقیقاتی فعلی و جهت گیری های آینده. بین المللی J. کاهش خطر بلایا. 2019 ، 38 ، 101188. [ Google Scholar ] [ CrossRef ]
- آهنگ، WW; جین، BX; لی، SH; وی، XY; لی، دی. Hu, F. ساخت بستر ابر فضایی-زمانی برای پشتیبانی از برنامه GIS. ISPRS Ann. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2015 ، II-4/W2 ، 55-62. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آگراوال، اس. گوپتا، RD Web GIS و معماری آن: بررسی. عرب جی. ژئوشی. 2017 ، 10 ، 518-530. [ Google Scholar ] [ CrossRef ]
- یائو، ایکس. لی، جی. شیا، جی. بن، جی. کائو، کیو. ژائو، ال. ممکن است.؛ ژانگ، ال. زو، دی. فعال کردن دادههای رصد بزرگ زمین از طریق محاسبات ابری و DGGS: فرصتها و چالشها. Remote Sens. 2020 , 12 , 62. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ی. دای، H.-N. وانگ، کیو. شوکلا، MK; عمران، ام. هواپیمای بدون سرنشین برای اینترنت همه چیز: فرصت ها و چالش ها. محاسبه کنید. اشتراک. 2020 ، 155 ، 66-83. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کاهلان، سی. مک کارتی، تی. McElhinney، CP MIMIC: ماشین حساب تراکم نقطه نقشه برداری موبایل. در مجموعه مقالات سومین کنفرانس بین المللی محاسبات برای تحقیقات و کاربردهای جغرافیایی، واشنگتن، دی سی، ایالات متحده آمریکا، 1 تا 3 ژوئیه 2012. ص 15:11–15:19. [ Google Scholar ]
- شانگ، اس. شن، جی. ون، جی.- آر. کالنیس، پی. درک عمیق دادههای مکانی بزرگ برای خودروهای خودران. محاسبات عصبی 2020 ، 308-309 . [ Google Scholar ] [ CrossRef ]
- یی، جی. دو، ی. لیانگ، اف. تو، دبلیو. چی، دبلیو. Ge, Y. نقشه برداری ردپای دیجیتالی انسان در فلات تبت از داده های بزرگ جغرافیایی چند منبعی. علمی کل محیط. 2020 , 711 , 134540. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- هو، اف. لی، ز. یانگ، سی. جیانگ، ی. یک رویکرد مبتنی بر نمودار برای شناسایی الگوهای حرکت گردشگران با استفاده از داده های رسانه های اجتماعی. کارتوگر. Geogr. Inf. علمی 2019 ، 46 ، 368-382. [ Google Scholar ] [ CrossRef ]
- گونزالس، اچ. هالیوی، ا. جنسن، CS; لانگن، آ. مدهاوان، ج. شپلی، آر. Shen, W. Google fusion tables: مدیریت داده، یکپارچه سازی و همکاری در ابر. در مجموعه مقالات اولین سمپوزیوم ACM در رایانش ابری، ایندیاناپولیس، IN، ایالات متحده آمریکا، 10-11 ژوئن 2010. صص 175-180. [ Google Scholar ]
- یانگ، سی. خو، ی. Nebert, D. تعریف مجدد امکان زمین دیجیتال و علوم زمین با محاسبات ابری فضایی. بین المللی جی دیجیت. زمین 2013 ، 6 ، 297-312. [ Google Scholar ] [ CrossRef ]
- یانگ، ی. لانگ، X. جیانگ، بی. روش K-Means برای گروه بندی در خوشه کاهش نقشه ترکیبی. جی. کامپیوتر. 2013 ، 8 ، 2648-2655. [ Google Scholar ] [ CrossRef ]
- لی، دبلیو. آهنگ، م. ژو، بی. کائو، ک. گائو، اس. تکنیکهای بهبود عملکرد برای خدمات وب جغرافیایی در یک محیط زیرساخت سایبری – مطالعه موردی با یک پورتال مدیریت بلایا. محاسبه کنید. محیط زیست سیستم شهری 2015 ، 54 ، 314-325. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، ز. گی، ز. هوفر، بی. لی، ی. شیدر، اس. Shekhar, S. فناوری های پردازش اطلاعات مکانی. در کتابچه راهنمای زمین دیجیتال ; Guo, H., Goodchild, MF, Annoni, A., Eds. اسپرینگر: سنگاپور، 2020؛ صص 191-227. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کرامر، ام. Senner, I. یک معماری نرم افزاری مدولار برای پردازش داده های بزرگ مکانی در ابر. محاسبه کنید. نمودار. 2015 ، 49 ، 69-81. [ Google Scholar ] [ CrossRef ]
- تان، ایکس. دی، ال. دنگ، م. هوانگ، اف. بله، X. شا، ز. سان، ز. گونگ، دبلیو. شائو، ی. هوانگ، سی. تجمیع خدمات زمین فضایی مبتنی بر عامل به عنوان یک سرویس در ابر: مطالعه موردی پاسخ سیل. محیط زیست مدل. نرم افزار 2016 ، 84 ، 210-225. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، ز. یانگ، سی. هوانگ، Q. لیو، ک. سان، م. Xia, J. مدل ساختمان به عنوان یک سرویس برای پشتیبانی از علوم زمین. محاسبه کنید. محیط زیست سیستم شهری 2017 ، 61 ، 141-152. [ Google Scholar ] [ CrossRef ]
- بوردل، بی. آلکاریا، آر. هرناندز، م. Robles، T. معضل مردم به عنوان یک سرویس: راه حل های محاسباتی انسانی در برنامه های کاربردی با کارایی بالا. مجموعه مقالات 2019 ، 31 ، 39. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لی، ی. یو، م. خو، ام. یانگ، جی. شا، د. لیو، کیو. یانگ، سی. داده های بزرگ و رایانش ابری. در کتابچه راهنمای زمین دیجیتال ; Guo, H., Goodchild, MF, Annoni, A., Eds. اسپرینگر: سنگاپور، 2020؛ صص 325-355. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مرکرت، آر. بوشل، جی. بک، MJ همکاری به عنوان یک سرویس (CaaS) برای یکپارچهسازی کامل حملونقل عمومی – درسهایی از سفرهای راه دور تا تصور مجدد تحرک به عنوان یک سرویس. ترانسپ Res. بخش A سیاست سیاست. 2020 ، 131 ، 267-282. [ Google Scholar ] [ CrossRef ]
- Malczewski، J. ترکیب خطی وزنی محلی. ترانس. GIS 2011 ، 15 ، 439-455. [ Google Scholar ] [ CrossRef ]
- هالاوی، ام جی; دین، جی. بلر، جی اس. براون، ام. هنریس، PA; واتکینز، جی. مقابله با چالش های علم باز قرن بیست و یکم و فراتر از آن: رویکرد آزمایشگاه علوم داده. Patterns 2020 , 1 , 100103. [ Google Scholar ] [ CrossRef ]
- هوانگ، دبلیو. ژانگ، دبلیو. ژانگ، دی. Meng, L. Elastic Spatial Query Processing در OpenStack Cloud Computing Environment برای تحلیل داده با محدودیت زمانی. ISPRS Int. J. Geo-Inf. 2017 ، 6 ، 84. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Iosifescu-Enescu، I.; ماتیس، سی. گکونوس، سی. Iosifescu-Enescu، CM; Hurni، L. معماریهای مبتنی بر ابر برای ژئوپورتالهای وب مقیاسپذیر خودکار به سمت ابری شدن GeoVITe Swiss Academic Geoportal. Isprs Int. J. Geo-Inf. 2017 ، 6 ، 192. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- گومز، VCF؛ کی روش، GR; فریرا، KR مروری بر پلتفرمها برای مدیریت و تجزیه و تحلیل دادههای رصد زمین بزرگ. Remote Sens. 2020 , 12 , 1253. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Baumann, P. Array Databases. در دایره المعارف سیستم های پایگاه داده ; Liu, L., Özsu, MT, Eds. Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2018؛ صص 165-177. [ Google Scholar ]
- باومن، پی. روسی، AP; بل، بی. کلمنتز، او. ایوانز، بی. هونیگ، اچ. هوگان، پی. کاکالتریس، جی. کلتسیدا، پ. مانتوانی، س. و همکاران تقویت علم زمین بین رشته ای از طریق تجزیه و تحلیل Datacube. در رصد زمین علم و نوآوری باز ; Mathieu, P.-P., Aubrecht, C., Eds. انتشارات بین المللی اسپرینگر: چم، سوئیس، 2018; صص 91-119. [ Google Scholar ]
- رینر، بی. هان، ک. هوفلینگ، جی. Baumann, P. پشتیبانی و مدیریت ذخیره سازی سلسله مراتبی برای سیستم های مدیریت پایگاه داده آرایه های چند بعدی در مقیاس بزرگ . Springer: برلین/هایدلبرگ، آلمان، 2002; صص 689-700. [ Google Scholar ]
- هاین، ن. Blankenbach، J. Vergleich von PostGIS و Rasdaman als Geodatenbanken für großvolumige Bilddatenbestände eines mobilen Mappingsystems. AGIT J. Angew. اطلاعات جغرافیایی 2017 ، 3 ، 2-12. [ Google Scholar ] [ CrossRef ]
- ابیلی، م. برتراند، ن. دلستر، او. گوربسویل، پی. دولوک، سی.-ام. تجزیه و تحلیل حساسیت جهانی فضایی استفاده از داده های توپوگرافی طبقه بندی شده با وضوح بالا در مدل سازی سیل شهری دوبعدی. محیط زیست مدل. نرم افزار 2016 ، 77 ، 183-195. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پرین، تی وی ای. روستنت، او. رومر، جی. آلاتا، او. ناولین، جی پی؛ ایدیر، دی. پدرروس، آر. مونکولون، دی. Tinard، P. تحلیل مولفه اصلی عملکردی برای تحلیل حساسیت جهانی مدل با خروجی فضایی. Reliab. مهندس سیستم Saf. 2021 ، 211 ، 107522. [ Google Scholar ] [ CrossRef ]
- هو، ایکس. مک.؛ هوانگ، پی. Guo، X. ارزیابی آسیبپذیری اکولوژیکی بر اساس روش AHP-PSR و تجزیه و تحلیل حساسیت تک پارامتری و خودهمبستگی فضایی آن برای حفاظت از محیط زیست – موردی از شهر ویفانگ، چین. Ecol. اندیک. 2021 ، 125 ، 107464. [ Google Scholar ] [ CrossRef ]
- کو، اچ. ایواناگا، تی. کروک، BFW؛ جیکمن، ای جی؛ یانگ، جی. وانگ، H.-H.; سان، ایکس. لو، جی. لی، ایکس. یو، تی. و همکاران مقاله موقعیت: تحلیل حساسیت مدلهای محیطی توزیعشده فضایی – یک چارچوب عملگرایانه برای اکتشاف منابع عدم قطعیت. محیط زیست مدل. نرم افزار 2020 , 134 , 104857. [ Google Scholar ] [ CrossRef ]
- لیگمان-زیلینسکا، A. “آیا می توانید آن را تعمیر کنید؟” استفاده از تحلیل حساسیت مبتنی بر واریانس برای کاهش فضای ورودی یک مدل مبتنی بر عامل تغییر کاربری زمین. در تحلیل جغرافیایی محاسباتی و مدلسازی سیستمهای منطقه ای ; Thill, J.-C., Dragicevic, S., Eds. انتشارات بین المللی اسپرینگر: چم، سوئیس، 2018; صص 77-99. [ Google Scholar ] [ CrossRef ]
- کانگ، J.-Y. Aldstadt, J. استفاده از الگوهای فضا-زمان مقیاس چندگانه در تجزیه و تحلیل حساسیت جهانی مبتنی بر واریانس برای مدلهای مبتنی بر عامل صریح فضایی. محاسبه کنید. محیط زیست سیستم شهری 2019 ، 75 ، 170-183. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- تارانتولا، اس. Becker, W. SIMLAB نرم افزار برای تجزیه و تحلیل عدم قطعیت و حساسیت. در کتابچه راهنمای کمی سازی عدم قطعیت ; غانم، ر.، هیگدون، د.، اوحدی، ح.، ویرایش. انتشارات بین المللی اسپرینگر: چم، سوئیس، 2017; صفحات 1979-1999. [ Google Scholar ] [ CrossRef ]
- هرمان، جی. Usher, W. SALib: یک کتابخانه منبع باز پایتون برای تجزیه و تحلیل حساسیت. J. نرم افزار منبع باز. 2017 ، 2 ، 97. [ Google Scholar ] [ CrossRef ]
- آیوس، بی. ویگا، SD؛ جانون، ا. Pujol، G. Sensitivity: تجزیه و تحلیل حساسیت جهانی خروجی های مدل، بسته R (≥3.0.0) نسخه 1.25.0. در دسترس آنلاین: https://cran.r-project.org/web/packages/sensitivity/index.html (در 30 مارس 2021 قابل دسترسی است).
- Kc، U.; گارگ، اس. هیلتون، جی. Aryal, J. چارچوب مبتنی بر ابر برای تجزیه و تحلیل حساسیت مدل های خطر طبیعی. محیط زیست مدل. نرم افزار 2020 , 134 , 104800. [ Google Scholar ] [ CrossRef ]
- ارلاچر، سی. یانکوفسکی، پ. شالاپ-آیچا، س. Anders, K.-H.; پاولوس، جی. توسعه قابلیتهای کارایی بالا برای حمایت از عدم قطعیت و تحلیل حساسیت فضایی صریح در تصمیمگیری چند معیاره. در مجموعه مقالات هشتمین کنفرانس بین المللی تحلیل حساسیت خروجی مدل، لو تامپون (رئونیون)، فرانسه، 30 نوامبر تا 3 دسامبر 2016. [ Google Scholar ]
- یانکوفسکی، پ. نجور، ع. زولینسکی، ز. Niesterowicz، J. ارزیابی تنوع زمین با داده های جمع سپاری و تجزیه و تحلیل چند معیاره فضایی. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 716. [ Google Scholar ] [ CrossRef ]
- شالاپ-آیچا، س. یانکوفسکی، پ. کلارک، کی سی; کیریاکیدیس، PC; نارا، A. یک رویکرد فرا مدلسازی برای تحلیل عدم قطعیت و حساسیت مکانی-زمانی: یک برنامه کاربردی برای یک مدل رشد شهری و تغییر کاربری زمین مبتنی بر اتوماتای سلولی. بین المللی جی. جئوگر. Inf. علمی 2018 ، 32 ، 637-662. [ Google Scholar ] [ CrossRef ]


بدون دیدگاه