1. معرفی
در کاربردهای مختلف با تکیه بر دادههای مکانی، دریافت بینش در مورد منابع دادههای جغرافیایی ناهمگن برای تصمیمگیری بسیار مهم است و توجه بسیاری را به خود جلب کرده است. تجزیه و تحلیل بصری یک زمینه تحقیقاتی پررونق و امیدوارکننده است که به اکتشاف گرافیکی تعاملی دادههای بزرگ و پیچیده که توسط روشهای محاسباتی خودکار تسهیل میشود اختصاص داده شده است [ 1 ، 2 ]. توجه شده است که تجزیه و تحلیل بصری مؤثر نیاز به داده های بزرگ و پیچیده ای دارد که به شیوه ای منسجم و با معنایی روشن سازماندهی شده اند. به طور خاص، جامعه پژوهشی تجزیه و تحلیل بصری دو چالش عمده را در مدیریت داده برای تجزیه و تحلیل بصری شناسایی کرده است، یعنی یکپارچه سازی داده ها و مدیریت معنایی [ 2] .]. به طور خاص، آنها استدلال کردند که «سیستم های مبتنی بر منطق، متعادل کردن قدرت سیستم های بیانی و هزینه محاسباتی نشان دهنده راه حل های پیشرفته هستند. تجزیه و تحلیل بصری می تواند تا حد زیادی از چنین رویکردی بهره مند شود […]» و «مرتبط با فعالیت های یکپارچه سازی داده ها، نیاز به مدیریت تمام معنایی داده ها به صورت متمرکز است، به عنوان مثال، با افزودن یک لایه منطق مجازی در بالای صفحه خود داده».
این مشکل در عصر کلان داده برجسته تر می شود. با استفاده فراگیر از موقعیتیابی مکان و فناوریهای ارتباطی، روزانه مقادیر عظیمی از دادههای مکانی جمعآوری میشوند، بهعنوان مثال، مسیر حرکت، متون رسانههای اجتماعی با برچسب جغرافیایی و تصاویر. این دادهها در قالبهای مختلفی هستند، از ساختار یافته، نیمه ساختاریافته تا بدون ساختار، و نشاندهنده انواع پدیدههای جغرافیایی هستند. در حالی که اکثر سیستمهای تحلیلی بصری موجود فقط قادر به مقابله با دادههای بزرگ جغرافیایی از انواع خاص هستند، توسعه رویکردهای تحلیلی بصری که میتواند مستقیماً روشهای تجسم را برای دادههای فرمتهای مختلف اعمال کند، که انواع مختلف پدیدهها را نشان میدهد، هنوز چالش برانگیز است. این مشکل در جامعه تجزیه و تحلیل جغرافیایی تصدیق شده است [ 3]، جایی که تاکید می شود تنوع یکی از موضوعات کلیدی در دستور کار تحقیقاتی مربوط به تجزیه و تحلیل بصری در زمینه داده های بزرگ جغرافیایی است. آنها «پتانسیل تحلیلی قابل توجهی را که میتواند از دادههای متنوعی که دیدگاههای مختلف را در مورد یک مشکل نشان میدهد به دست آید» تشخیص دادند و پیشنهاد کردند که «در حالی که ادغام دادههای بزرگ جغرافیایی یک مشکل است، مکان میتواند به عنوان مخرج مشترک استفاده شود، و مفهوم دادههای مرتبط همچنین امیدوار کننده».
چالش اصلی پژوهشی که در این مقاله به آن می پردازیم از این واقعیت ناشی می شود که بیان وظایف تحلیلی برای دانشمندان زمین شناسی به طور فزاینده ای دشوار می شود. هنگام کار با پدیدههای زمینفضایی، زمینشناسان برای فکر کردن به مفاهیم اصلی حوزه GIS، به عنوان مثال، موقعیت، زمان، مشاهده و رویداد استفاده میشوند [4] .]. هدف تحلیل (بصری) اساساً درک روابط موجود بین این مفاهیم است. با این حال، در واقعیت، دانشمندان زمینشناسی باید با دادههای ساختاریافته و سازماندهیشده احتمالاً به روشهای مختلف سروکار داشته باشند، به طوری که مطابقت بین این دادهها و مفاهیم اصلی مورد علاقه دانشمندان اغلب نامشخص است. صریح ساختن این مکاتبات مستلزم تلاش زیادی در یافتن داده های مناسب و تمیز کردن و آماده سازی آن برای تجزیه و تحلیل است. با این حال، اینها نباید وظایف اصلی دانشمندان زمین شناسی باشد. برای مثال، شرکت نفت نروژی Equinor (قبلاً Statoil)، گزارش داد که زمینشناسان در بخش اکتشاف باید تا 70 درصد از زمان خود را صرف یافتن و آمادهسازی دادهها کنند، بهجای اینکه تجزیه و تحلیل خود را انجام دهند [5 ]]. مشکل فوق به این دلیل است که دانشمندان زمین شناسی معمولاً مجبور به کار در سطح بسیار پایینی از انتزاع هستند و شکاف معنایی بزرگی بین داده های خام و اصطلاحاتی که معمولاً در حوزه حرفه ای آنها اتخاذ می شود وجود دارد. به عنوان مثال، به منظور کمک به اکتشاف نفت، شرکتهای نفتی چاههایی را حفاری میکنند که حفرههایی هستند که چاه را تشکیل میدهند و در حین حفاری حجم عظیمی از دادهها را جمعآوری میکنند که توسط بخش فناوری اطلاعات مدیریت میشود. هنگامی که زمین شناسان چنین داده هایی را تجزیه و تحلیل می کنند، باید بدانند که برای به دست آوردن همه چاه های معنی دار، باید جدول WELLBORE را بررسی کنند و مهمتر از آن، مقدار یک ستون خاص، یعنی REF_EXISTENCE_KIND ، باید ” واقعی ” باشد. ، اما نه هیچ مقدار دیگری [ 6]. چنین دانشی معمولاً فقط برای تیم مدیریت فناوری اطلاعات و نه برای زمین شناسان شناخته شده است. ما استدلال میکنیم که این چالش شکاف معنایی صرفاً یک مشکل مهندسی نیست، بلکه به نحوه ارتباط مفاهیم جغرافیایی و مجموعه دادههای خام مربوط میشود، و پرداختن به آن به روشی کافی و کلی نیازمند روشها و تکنیکهای جدید است.
در این کار، ما سعی میکنیم با توسل به ادغام دادههای مبتنی بر هستیشناسی (OBDI) و استفاده از آن در تجزیه و تحلیل بصری، شکاف تحقیقاتی ذکر شده در بالا را پر کنیم. هدف OBDI ارائه یک دیدگاه هستیشناختی (مجازی) منسجم از دادههای ناهمگن زیربنایی است، و از این رو برای سهولت در تجزیه و تحلیل و تصمیمگیری، برای ترکیب با تجزیه و تحلیل بصری مناسب است. به طور خاص، ما یک چارچوب مبتنی بر هستی شناسی (به نام یکپارچه سازی زمین داده مبتنی بر هستی شناسی برای تجزیه و تحلیل ژئوویژوال (GOdIVA)) برای یکپارچه سازی و تجزیه و تحلیل داده ها پیشنهاد می کنیم که از دو ماژول متمرکز بر یک هستی شناسی تشکیل شده است: (1) یک ماژول OBDI، که در آن نگاشت ها مشخص می شود. رابطه بین داده های اساسی و هستی شناسی دامنه؛ (2) یک ماژول تجزیه و تحلیل geovisual (GeoVA)، طراحی شده برای اکتشاف داده های یکپارچه،
در مقایسه با چارچوبهای تحلیلی کلاسیک، هستیشناسیها با جدا کردن چالشهای دسترسی به دادهها و تجزیه و تحلیل، نقش اصلی را در چارچوب GOdIVA ایفا میکنند: از یک سو، لایه هستیشناسی یک دید منسجم از دادههای موجود در منابع ارائه میکند، و جزئیات چگونگی را از بین میبرد. چنین داده هایی ساختار یافته هستند. از سوی دیگر، به عنوان واسطه ای برای تحلیل وظایف و کاوش بصری الگوهای مکانی-زمانی عمل می کند. در این مقاله، ما برای ماژول OBDI بر روی تمرین رایج ساخت هستی شناسی با استفاده مجدد و گسترش هستی شناسی های استاندارد، به عنوان مثال، هستی شناسی GeoSPARQL [7] برای ویژگی ها و روابط فضایی، هستی شناسی زمانی [ 8 ] برای موجودیت ها و روابط زمانی تکیه می کنیم. و هستی شناسی شبکه حسگر معنایی (SSN) [ 9] برای حسگرها و مشاهدات. اتخاذ چنین هستی شناسی های استاندارد همچنین استفاده مجدد از ابزارهای توسعه یافته برای ماژول GeoVA را تسهیل می کند.
با چارچوب GOdIVA ما سعی می کنیم یک فرآیند ارزش افزوده مضاعف مورد نیاز در عصر داده های بزرگ را نشان دهیم. ادغام منابع داده ناهمگن مبتنی بر هستی شناسی به عنوان یک تلاش اساسی به سمت زیرساخت داده های جغرافیایی قابل همکاری و مدیریت پذیر جهانی درونی می شود، در حالی که تجزیه و تحلیل ژئو بصری از برون سازی داده های یکپارچه به عبارات بصری متنوع اما به راحتی قابل درک پشتیبانی می کند. چیزی که جدید است نه رویکرد یکپارچه سازی مبتنی بر هستی شناسی و نه تجزیه و تحلیل زمین بصری است، بلکه شکل واحدی از این دو است.
ما یک نمونه اولیه از چارچوب را در یک سیستم تحلیلی بصری مبتنی بر وب با تکیه بر سیستم OBDI Ontop [ 10 ] توسعه دادیم و آزمایشی را در سناریویی انجام دادیم که الگوهای مکانی و زمانی و همبستگی بین دادههای هواشناسی و دادههای ترافیکی را در منطقه بررسی میکرد. تیرول جنوبی، ایتالیا برای انجام این کار، ما از هستیشناسیهای GeoSPARQL و SSN برای ادغام سریهای زمانی و دادههای مشاهده از چندین مجموعه داده باز ارائهشده توسط پورتال داده باز تیرول جنوبی (https://daten.buergernetz.bz.it/de/ ) استفاده کردیم. و توسط موسسه دولتی آمار استان خودمختار بوزن-بولزانو (ASTAT) ( https://astat.provinz.bz.it/de/default.asp ). مطالعات ما نشان می دهد که GOdIVAرویکرد واقعاً میتواند برای کاوش و درک دادههای جغرافیایی ناهمگن اتخاذ شود.
ساختار بقیه مقاله به شرح زیر است: در بخش 2 ، ما دانش پیشینه و کار مرتبط با نظرسنجی را ارائه می دهیم. در بخش 3 ، ما چارچوب خود را با جزئیات ارائه می کنیم. در بخش 4 ، ما یک مطالعه موردی را توصیف می کنیم که داده ها را از چندین منبع داده باز ادغام و تجزیه و تحلیل می کند. در بخش 5 مقاله را به پایان می رسانیم و چالش ها و فرصت های تحقیقاتی بیشتر را مورد بحث قرار می دهیم.
2. پیشینه و کارهای مرتبط
در این بخش، دانش پیشینه را ارائه می دهیم و چندین جهت تحقیق مرتبط با این کار را مورد بحث قرار می دهیم.
2.1. یکپارچه سازی داده های جغرافیایی مبتنی بر هستی شناسی
یکپارچهسازی دادههای مکانی فناوری کلیدی برای دستیابی به ارزش افزوده از منابع داده ناهمگن به خدمات زمینبصری است [ 11 ، 12 ]. ادغام معنایی توجه قابل توجهی را در قابلیت همکاری سیستم اطلاعات جغرافیایی (GIS) با هدف غلبه بر ناهمگونی معنایی به خود جلب کرده است [ 13 ، 14 ].
در هسته راه حل های مبتنی بر فناوری های معنایی، ما معمولاً یک هستی شناسی داریم. در علم کامپیوتر، اصطلاح «هستیشناسی» به مصنوع مشخصی اشاره میکند که یک حوزه مورد علاقه را مفهومسازی میکند و به فرد اجازه میدهد اطلاعات و دادههای مربوط به آن حوزه را به روشی منسجم بین همه بازیگران علاقهمند به آن حوزه به اشتراک گذاشته شود. چنین هستیشناسیهایی (که ما آنها را هستیشناسی دامنه مینامیم) معمولاً با هدف خاصی طراحی و استفاده میشوند، برخلاف هدف گرفتن مفاهیم کلی درباره جهان. برای سادهسازی اشتراکگذاری و استفاده مجدد از هستیشناسیها، کنسرسیوم وب جهانی (W3C) ( https://www.w3c.org/ ) زبانهای استانداردی را برای بیان آنها تعریف کرده است. ما در اینجا به چارچوب توصیف منابع (RDF) [ 15]، یک مکانیسم ساده برای تعریف واژگان مورد استفاده در یک دامنه خاص، و زبان هستی شناسی وب (OWL) [ 16 ]، ارائه یک زبان بسیار غنی که در آن شرایط پیچیده ای را که در حوزه مورد علاقه وجود دارد، رمزگذاری می کند. این دو استاندارد مهم هستند، از یک سو به این دلیل که داده های باز به طور فزاینده ای به عنوان نمودارهای دانش در RDF در دسترس می شوند [ 17 ]، و از سوی دیگر به این دلیل که بسیاری از هستی شناسی های حوزه بیان شده در OWL استاندارد شده اند. به عنوان مثال، گروه مورد علاقه داده های فضایی در وب ( https://www.w3.org/2017/sdwig/ )، تلاش مشترک W3C و کنسرسیوم فضایی باز (OGC)، به طور خاص بر روی به اشتراک گذاری داده های مکانی در وب با استفاده از فناوری های وب معنایی فعالیت های آنها شامل استانداردسازی هستی شناسی زمان [8 ] و هستی شناسی شبکه حسگر معنایی (SSN) [ 9 ]، و حفظ هستی شناسی GeoSPARQL [ 7 ].
در دو دهه گذشته، رویکرد مبتنی بر هستی شناسی به طور گسترده در حوزه GIScience برای غلبه بر موانع ادغام معنایی با یک نمایش صریح و رسمی از معناشناسی استفاده شده است [ 18 ، 19 ، 20 ]. بسیاری از تحقیقات، ژئوآنتولوژیهایی را برای نشان دادن دانش دامنه و پشتیبانی از یکپارچهسازی دادههای مکانی در کاربردهایی مانند استخراج مسیر [ 21 ]، پاسخ اضطراری زلزله [ 22 ] و کشف دادههای اقیانوسشناسی [ 23 ] پیشنهاد کردند. نمونههای دیگری از چنین هستیشناسیهایی برای پشتیبانی از وظایف کشف اطلاعات جغرافیایی [ 24 ]، بازیابی [ 25 ] و ادغام [ 26] توسعه یافتهاند.]. اکثر این کارها منابع جغرافیایی را با تبدیل داده های اصلی و تبدیل آنها به صورت RDF و سپس ذخیره آنها در یک فروشگاه سه گانه یکپارچه می کنند. این روش زمانی گران است که مجموعه داده ها بزرگ هستند یا زمانی که داده ها به طور مکرر تغییر می کنند.
دسترسی به دادههای مبتنی بر هستیشناسی (OBDA) که در ادبیات به عنوان نمودار دانش مجازی نیز شناخته میشود، یک الگوی محبوب است که کاربران نهایی را قادر میسازد از طریق هستیشناسی به منابع داده دسترسی داشته باشند. هستی شناسی با استفاده از نقشه برداری متشکل از مجموعه ای از ادعاهای نگاشت [ 27 ] به منبع داده پیوند معنایی دارد. زبان استاندارد نگاشت R2RML [ 28 ] است. بنابراین، هستی شناسی و نقشه برداری با هم، که مشخصات OBDA نامیده می شود، منبع داده زیربنایی را به عنوان یک نمودار RDF مجازی در معرض دید قرار می دهد و آن را در زمان پرس و جو با استفاده از SPARQL قابل دسترسی می کند. رویکرد مجازی از هزینه های بالای تحقق جلوگیری می کند.
یکپارچهسازی دادههای مبتنی بر هستیشناسی (OBDI) توسعهای از OBDA است که در آن دادهها در اصل در یک منبع داده واحد نیستند، بلکه از منابع دادههای متعددی میآیند که باید به روشی یکپارچه پرس و جو شوند. OBDI معمولاً به یک مرحله اضافی برای تنظیم یک پایگاه داده (یکپارچه) نیاز دارد تا بتوان پرس و جوهای SQL را به چندین منبع داده به طور همزمان صادر کرد. این را می توان با استفاده از یک موتور فدراسیون SQL، به عنوان مثال، Denodo ( https://www.denodo.com/ ) یا Dremio ( https://www.dremio.com/ )، برای اتصال به پایگاه داده های موجود، یا با استفاده از یک رویکرد ساده تر “یکپارچه سازی فیزیکی” برای وارد کردن همه منابع داده به یک سیستم پایگاه داده. پس از این مرحله، OBDI همان معماری مفهومی OBDA را حفظ می کند [ 29]. سیستمهای OBDI که این پارادایم را پیادهسازی میکنند شامل Mastro ( https://www.obdasystems.com/it/mastro/ ) [ 30 ]، Morph ( https://github.com/oeg-upm/morph-rdb/ ) [ 31 ]، Ontop [ 10 ]، Stardog ( https://www.stardog.com/ )، و Ultrawrap ( https://capsenta.com/ultrawrap/ ) [ 32 ]. اخیراً Ontop برای پشتیبانی از GeoSPARQL [ 33 ] توسعه یافته است . اگرچه از استانداردهای R2RML و OWL استفاده نمی کند، پروژه LinkedGeoData [ 34] یک کار پیشگام است که از اصل OBDI پیروی می کند و داده های OpenStreetMap (OSM) را به یک نمودار RDF تبدیل می کند و این داده ها را با سایر پایگاه های دانش باز RDF به هم مرتبط می کند. OBDI در بسیاری از موارد استفاده شده است [ 35 ]. به طور خاص، برای ارزیابی سازگاری دادههای جغرافیایی باز [ 36 ] و برای امنیت دریایی [ 37 ] استفاده شده است. در این کار، ما برای ادغام دادههای جغرافیایی به OBDI تکیه میکنیم.
2.2. تجزیه و تحلیل ژئوویژوال
تجزیه و تحلیل ژئوویژوال (GeoVA)، برگرفته از تجزیه و تحلیل بصری [ 1 ]، به علم استدلال تحلیلی با اطلاعات مکانی اشاره دارد که توسط رابط های بصری تعاملی تسهیل می شود [ 38 ]. این به مسائل مربوط به فضای جغرافیایی و اشیاء، رویدادها، پدیده ها و فرآیندهای مختلف در آن می پردازد [ 39 ]. رویکردهای GeoVA به طور گسترده برای اکتشاف کارآمد دادههای مکانی بزرگ، از جمله مسیر حرکت [ 40 ، 41 ، 42 ]، دادههای رسانههای اجتماعی با برچسب جغرافیایی [ 43 ، 44 ]، و جریانهای داده حسگر [ 45 ] استفاده میشوند.
تجزیه و تحلیل بصری معنی دار داده های جغرافیایی هنوز با چالش های معنایی اطلاعات ناهمگن مواجه است [ 3 ، 46 ، 47 ]. برخی تلاشها برای ادغام مدلهای هستیشناسی دامنه بهعنوان مؤلفه بازنمایی دانش در سیستمهای تحلیل بصری انجام شده است، به عنوان مثال، برای مدیریت ایمنی و نگهداری پل [48]، و در تجزیه و تحلیل مسیرها [ 49 ]. در مقایسه با رویکرد ارائه شده در مقاله ما، این آثار بر موارد استفاده خاص متمرکز بودند و مطالعات سیستماتیکی را در مورد موضوع ترکیب هستی شناسی ها و تحلیل های بصری انجام ندادند.
سیستم های تحلیل ژئو بصری مبتنی بر هستی شناسی به یک رابط کاربری گرافیکی تعاملی برای تجسم ژئو هستی شناسی ها و داده های RDF فضایی نیاز دارند. کتیفوری و همکاران [ 50 ] تکنیک های تجسم جامع را برای نمایش هستی شناسی ها بررسی کردند. لوتز و کلین [ 51 ] رویکردی را برای بازیابی اطلاعات جغرافیایی مبتنی بر هستی شناسی ارائه کردند و طراحی رابط را مورد بحث قرار دادند. چندین سیستم برای تجسم پرس و جوها و نتایج RDF و SPARQL بر روی داده های مکانی توسعه داده شده است. OptiqueVQS [ 52 ] یک سیستم پرس و جو بصری برای ساخت پرس و جوهای SPARQL است. GeoYASGUI [ 53 ] یک کتابخانه جاوا اسکریپت جلویی برای تجسم نتایج جستارهای GeoSPARQL بر روی نقشه است. سکسانت [ 54] یک سیستم مبتنی بر وب برای تجسم و اکتشاف دادههای مکانی مرتبط با تکامل زمان است. Spex ابزاری برای پرس و جوی اکتشافی نقاط انتهایی SPARQL در فضا و زمان است [ 55 ]. Brasoveanu و همکاران. [ 56 ] تجسم دانش مرتبط آماری را برای پشتیبانی تصمیم مورد مطالعه قرار داد. هوانگ و هری [ 57 ] یک رویکرد مبتنی بر دانش را برای نشان دادن رسمی دانش ژئوتصویرسازی در رابطه با مقیاس نقشهکشی، تصویر دادهها و منبع هندسه پیشنهاد کردند. همچنین به کار Dadzie و Pietriga مراجعه کنید [ 58] برای خلاصه ای از تحقیقات اخیر در مورد تجسم داده های مرتبط. اکثر این تحقیقات فرض میکنند که منابع دادهای که باید تجزیه و تحلیل شوند قبلاً یکپارچه شدهاند، اما ما استدلال میکنیم که ادغام و تجزیه و تحلیل ارتباط نزدیکی با هم دارند و باید با هم در یک چارچوب مدیریت شوند. علاوه بر این، بیشتر این ابزارهای تجسم سعی می کنند با هستی شناسی های دلخواه کنار بیایند، در حالی که ما بر هستی شناسی های استاندارد تمرکز می کنیم تا بتوانیم تجسم های اختصاصی و مناسب تری ایجاد کنیم.
2.3. تجزیه و تحلیل داده های حسگر
با پیشرفت در فناوری های حسگر، داده های حسگر (یا ژئوسنسور) به طور فزاینده ای برای نظارت بر محیط زیست و پویایی شهری جمع آوری شده است. به عنوان مثال، شبکه های حسگرهای هواشناسی برای نظارت بر فرآیندهای جوی و ارزیابی تغییرات آب و هوایی بلند مدت و رویدادهای آب و هوایی کوتاه مدت ضروری هستند. فناوریهای سنجش خودرو در اندازهگیری موقعیتهای ترافیکی بلادرنگ رایج هستند، که میتواند از تصمیمگیری در مدیریت ترافیک عمومی و برنامهریزی سفر فردی پشتیبانی کند. ادغام مقادیر وسیعی از داده های حسگر ناهمگن برای درک رفتار پدیده های پیچیده محیطی مفید است [ 59 ].
روش های تجزیه و تحلیل آماری معمولا برای تجزیه و تحلیل داده های حسگر استفاده می شود. در حوزه حمل و نقل، بسیاری از کارها روابط بین شرایط آب و هوایی و جریان ترافیک را بررسی کرده اند، به عنوان مثال، بر روی تأثیر بارندگی بر تصادفات جاده ای [60]، ایمنی جاده [ 61 ])، و تأثیر شرایط آب و هوایی بر عملکرد ترافیک و آلودگی هوا [ 62 ]. در بیشتر موارد، دادههای ناهمگن مربوطه باید از قبل پردازش شده و به صورت فضایی برای وظایف تحلیلی خاص به یکدیگر متصل شوند. سپس از روش های تحلیل آماری برای استخراج مقادیر آماری استفاده می شود. با این حال، این پیوستن فضایی یک ادغام موقتی از دادههای جغرافیایی است، در حالی که یک روش سیستماتیک برای انجام آن تا حد زیادی وجود ندارد.
چندین اثر قبلی وجود داشته است، به عنوان مثال، [ 63 ، 64]، بازرسی رویکرد مبتنی بر هستی شناسی برای تجزیه و تحلیل داده های حسگر. در این آثار دادهها برای هستیشناسی و استدلال مبتنی بر قاعده مادی میشوند، و بنابراین وقتی دادهها بسیار بزرگ هستند یا به صورت پویا در حال تغییر هستند، رویکرد به خوبی مناسب نیست. در مقابل، ما از رویکرد یکپارچهسازی مجازی استفاده میکنیم و بر ترجمه پرس و جو در لحظه تکیه میکنیم. تفاوت کلیدی دیگر ابزاری برای یافتن الگوها از داده های جغرافیایی بزرگ و استنباط دانش سطح بالا (به عنوان مثال، رویدادها، همبستگی ها، یا علل) است. رویکردهای قبلی بر مجموعه ای ثابت از قوانین از پیش تعریف شده تکیه می کنند، در حالی که در چارچوب ما، رابط بصری به کاربران انعطاف پذیری کشف الگوها را با پشتیبانی از پاسخگویی پرس و جوی سطح بالا و تعاملات کاربر که توسط تجسم های بصری هدایت می شوند، ارائه می دهد.
هنگامی که با جریان داده های حسگر در زمان واقعی سروکار داریم، پرس و جو کلاسیک SPARQL مناسب نیست زیرا فقط با نمودارهای RDF ایستا کار می کند. استدلال جریانی [ 65 ] منطقه ای است که استدلال را در زمان واقعی بر روی جریان های داده پیوسته مطالعه می کند. به طور خاص، RDF Stream Processing (RSP) از جریان های RDF به عنوان مدل داده استفاده می کند و می تواند الگوهایی را برای شناسایی در جریان ها بیان کند. در مورد زبان پرس و جو، چندین پسوند SPARQL با معنایی پیوسته پیشنهاد شده است [ 66 ، 67 ]. گروه جامعه پردازش جریان W3C RDF ( https://www.w3.org/community/rsp ) در تلاش برای تعریف یک زبان مشترک است و RSP-QL را شناسایی می کند [ 68]] به عنوان یک مدل مرجع که معناشناسی رویکردهای RSP موجود را متحد می کند. علاوه بر این، SPARQL ساده اغلب برای مدلسازی الگوهای زمانی پیچیده به اندازه کافی رسا نیست. برای غلبه بر این محدودیت، [ 69 ] یک زبان قانون بیانی مبتنی بر منطق زمانی متریک پیشنهاد کرد. مقاله فعلی تنها بر روی داده های ثابت بازیابی شده از طریق پرس و جوهای کلاسیک SPARQL تمرکز دارد، در حالی که جنبه بلادرنگ و پرس و جوهای زمانی گویاتر برای کارهای آینده باقی مانده است.
3. GOdIVA: چارچوبی که یکپارچهسازی ژئوداده مبتنی بر هستیشناسی و تجزیه و تحلیل بصری را متحد میکند
در این بخش، ما یک چارچوب جامع به نام یکپارچه سازی زمین داده مبتنی بر هستی شناسی برای تجزیه و تحلیل جغرافیایی (GOdIVA)، برای یکپارچه سازی و تجزیه و تحلیل داده های مکانی ارائه می کنیم. چارچوب GOdIVA از دو ماژول اصلی تشکیل شده است: (1) یکپارچه سازی داده های جغرافیایی مبتنی بر هستی شناسی (OBDI) و (2) تجزیه و تحلیل geovisual (GeoVA).
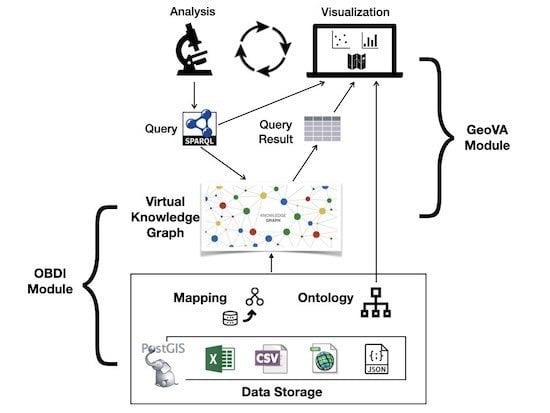
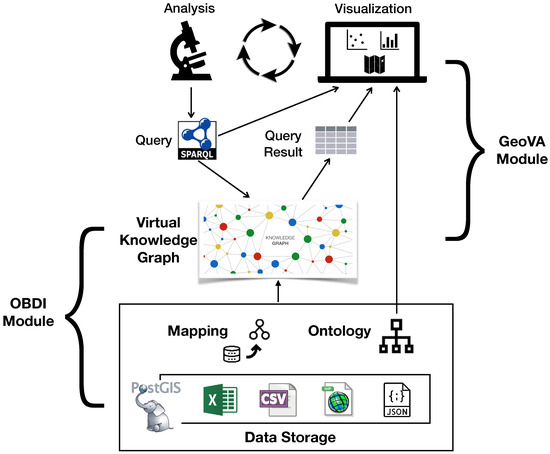
این چارچوب عملکردی را فراهم میکند که به کاربران اجازه میدهد وظایف تحلیلی خود را در ماژول GeoVA بر روی نمایش هستیشناختی دادههای زیربنایی که توسط ماژول OBDI در معرض دید قرار میگیرند، فرموله کنند. ما در شکل 1 نشان می دهیمساختار دو ماژول، جایی که فلش ها جریان اطلاعات را نشان می دهد. اکنون به طور خلاصه به اجزای اصلی آنها می پردازیم. ماژول OBDI یک نمای هستی شناختی از مجموعه داده های بارگذاری شده در مؤلفه ذخیره سازی داده ارائه می دهد. به طور دقیق تر، یک نگاشت اعلامی نحوه پر کردن کلاس ها و ویژگی های تعریف شده در هستی شناسی را با داده های زیرین مشخص می کند. نقشهبرداری و هستیشناسی با هم منابع داده زیربنایی را بهعنوان یک نمودار دانش مجازی یکپارچه نشان میدهند که میتوان از طریق پرسوجوهای SPARQL به آن دسترسی داشت. ماژول GeoVA به کاربران اجازه می دهد تا به صورت بصری با نمودار دانش مجازی تعامل داشته باشند. وظایف تجزیه و تحلیل را می توان به عنوان پرسش های SPARQL با استفاده از واژگان موجود در هستی شناسی فرموله کرد. سپس نتایج پرس و جو، همراه با هستی شناسی و پرس و جوها، با استفاده از تکنیک های تجسم چندگانه به کاربران ارائه می شود.1 ]، بر اساس نتایج تجسم، کاربران می توانند تجزیه و تحلیل جدیدی تولید و انجام دهند و داده ها را بیشتر بررسی کنند. در زیر بخش های بعدی، جزئیات بیشتری از این دو ماژول ارائه می دهیم.
3.1. ماژول ادغام ژئوداده مبتنی بر هستی شناسی
ماژول OBDI مفاهیم سطح بالایی را تعریف می کند که دامنه مورد نظر را بر اساس هستی شناسی OWL مدل می کند [ 16]. هستی شناسی مفاهیم معنایی زیربنایی پدیده های جغرافیایی را مدل می کند و می تواند برای هدایت فرمول پرس و جوهای مناسب برای هدف و داده مورد استفاده قرار گیرد. هستی شناسی ناهمگونی منابع داده زیربنایی را پنهان می کند. فرآیند یکپارچهسازی دادههای مبتنی بر هستیشناسی در واقع به دو مرحله تقسیم میشود: (1) مرحله یکپارچهسازی فیزیکی مسئول ادغام اقلام دادههای خام در یک پایگاه داده جغرافیایی است و اغلب نیاز به تمیز کردن دادهها و تبدیل قالب دارد. (2) مرحله ادغام معنایی با استفاده از فناوری OBDI یک دیدگاه هستیشناختی بر دادههای مکانی یکپارچه فیزیکی ارائه میکند. رابطه بین هستی شناسی و منابع داده با نگاشت های اعلانی مشخص می شود. ما رویکرد مجازی به OBDI را دنبال می کنیم، که از تحقق داده ها در هستی شناسی جلوگیری می کند. بجای،
فرآیند طراحی هستی شناسی ها و نگاشت ها را می توان به عنوان یک فرآیند مستندسازی/ حاشیه نویسی بر روی منبع داده در نظر گرفت. ساخت هستی شناسی را می توان بر اساس هستی شناسی های استاندارد موجود، به عنوان مثال، GeoSPARQL [ 7 ] برای ویژگی ها و هندسه ها، و SSN [ 9]] برای حسگرها و مشاهدات. هستی شناسی باید ماهیت پدیده فضایی مورد مطالعه را منعکس کند. به عنوان مثال، از آنجایی که آب و هوا یک پدیده فضایی پیوسته (یا میدانی در جامعه ژئومانستیک) است، میتوانیم یک ویژگی برای مرتبط کردن مشاهدات گسسته به ایستگاههای آنها اضافه کنیم، و همچنین مقادیر مشاهدهشده را به بردار دادههای شبکه درونیابی کنیم. این فرآیند نگاشت و ساخت هستی شناسی افزایشی و تکراری است: به طور معمول، ما با بخش کوچکی از داده ها شروع می کنیم و یک هستی شناسی ایجاد می کنیم و آیتم های داده را در واژگان هستی شناسی نگاشت می کنیم. قطعه اولیه را می توان با مشاهده پاسخ های پرس و جو و نتایج تجسم تأیید کرد. سپس با بخش بزرگتری از داده ها سروکار داریم. به این ترتیب، ساختار هر دو روش استقرایی (از پایین به بالا، داده به هستی شناسی) و قیاسی (از بالا به پایین، هستی شناسی به داده) را ترکیب می کند.
ماژول OBDI برای دستیابی به قابلیت همکاری متکی به فرمت های استاندارد است، از جمله R2RML [ 28 ] برای نگاشت، OWL 2 QL [ 70 ] و RDFS [ 71 ] برای هستی شناسی، RDF [ 15 ] برای گراف مجازی، و SPARQL [ 72 ] و GeoSPARQL [ 7 ] برای پرس و جوها. از این رو، هر موتور OBDI سازگار با این استانداردها را می توان در این معماری استفاده کرد. سپس راهاندازی OBDI بهعنوان یک نقطه پایانی استاندارد SPARQL نشان داده میشود، که به این معنی است که مشتریان میتوانند با استفاده از پروتکل استاندارد HTTP با نقطه پایانی ارتباط برقرار کنند [ 73 ].
3.2. ماژول تحلیل ژئوویژوال
ماژول GeoVA نمایشهای بصری مناسبی از نمای هستیشناختی یکپارچه منابع داده زیربنایی ارائه میدهد و کاربران را برای ساخت وظایف تحلیلی برای کشف دادهها راهنمایی میکند. به طور خاص، هستی شناسی می تواند برای انتخاب روش های تحلیل بصری مناسب برای منابع داده استفاده شود [ 74 ]. ماژول GeoVA به تحلیلگران اجازه می دهد تا بر روابط بین مفاهیم هستی شناختی تمرکز کنند. به عنوان مثال، زمانی که هستی شناسی SSN استفاده می شود، کاربران آماده هستند تا بر مفاهیم اصلی “پلتفرم ها”، “حسگرها” و “مشاهدات” تمرکز کنند و مجموعه ای از روش های تجسم متکی بر پرس و جوهای SPARQL را می توان برای این موارد اختصاص داد. مفاهیم.
همچنین متذکر می شویم که جداسازی ماژول OBDI و ماژول GeoVA قابلیت استفاده مجدد زیادی را در طراحی روش های تجسم به ارمغان می آورد. از آنجایی که روشهای تجسم تنها به بازنمایی هستیشناختی متکی هستند، چارچوب GOdIVA با توجه به تغییرات در لایه منبع داده قوی است. در واقع هنگامی که هستی شناسی پایدار است، افزودن منابع داده جدید فقط نیاز به افزودن نقشه های بیشتر از منابع جدید به مفاهیم ایجاد شده در ماژول OBDI دارد، اما روش های تجسم در ماژول GeoVA را می توان مجددا استفاده کرد.
ماژول GeoVA برای انتقال بصری اطلاعات زیر طراحی شده است: (1) مفاهیم موجود در هستی شناسی، و نحوه ارتباط آنها با یکدیگر، (2) نیازهای اطلاعاتی در قالب پرس و جوهای SPARQL، و (3) نتایج پرس و جو . رابط گرافیکی باید طوری طراحی شود که ویژگی های این نوع اطلاعات را منعکس کند [ 75 ]. از آنجایی که یک هستی شناسی معمولاً حاوی تعداد زیادی مفاهیم است که اغلب با روابط پیچیده به هم مرتبط هستند، اجتناب از بارگذاری بیش از حد کاربران با اطلاعات بیش از حد در مورد هستی شناسی بسیار مهم است. در عوض، تجسم باید بر محور مفاهیم کلیدی و الگوهای رایج در هستی شناسی طراحی شود [ 50]. زبان SPARQL مبتنی بر تطبیق الگوی نمودار است و الگوهای اصلی نمودار در SPARQL به طور طبیعی دارای یک نمایش گرافیکی هستند که میتوان از آن بهرهبرداری کرد. نتایج پرس و جو معمولاً حاوی اطلاعات غنی با ویژگی های مکانی-زمانی هستند که باید با استفاده از تکنیک های تجسم با تمرکز بر دیدگاه های مختلف آشکار شوند [ 45 ، 74 ].
یک سیستم تجزیه و تحلیل ژئو بصری موثر نیاز به یک رابط بصری مناسب با مجموعه ای از تکنیک های تجسم و محاسبات دارد که استدلال تحلیلی را تسهیل می کند. تکنیکهای تجسم مبتنی بر روشهای تجسم کارتوگرافی، تجسم اطلاعات و سایر نمایشهای گرافیکی است [ 75]]. به عنوان مثال، نقشه های حرارتی در انتقال توزیع فضایی یک مفهوم هستی شناختی که یک پدیده پیوسته را به تصویر می کشد، موثر هستند. این روشها به تجسم مجموعههای دادههای جغرافیایی پرسششده به روشهای متعدد کمک میکنند و امکان یک کاوش بصری هماهنگ را فراهم میکنند. عملکردهای تحلیلی از شناسایی الگوها و استخراج دانش سطح بالا (به عنوان مثال، رویدادها و همبستگی های پیچیده) پشتیبانی می کنند. روشهای تحلیل آماری میتوانند به انتزاع نتایج مورد نظر با معیارهای آماری، مانند مقادیر حداقل، حداکثر و ضرایب همبستگی بر روی مفاهیم هستیشناختی، به عنوان مثال، دما و بارش کمک کنند. این معیارها و نمایشهای گرافیکی آنها بینشهایی را در مورد ویژگیهای دادههای جغرافیایی یکپارچه به کاربران ارائه میدهند [ 38 ، 76 ].
4. مطالعه موردی
ما چارچوب GOdIVA را در مورد استفاده از دادههای حسگر ارزیابی میکنیم. به طور خاص، ما دادههای هواشناسی و حسگر ترافیک را ادغام میکنیم و الگوها و همبستگیهای مکانی-زمانی آنها را به صورت بصری تجزیه و تحلیل میکنیم. ما تمام مجموعه داده ها را در یک پایگاه داده PostGIS ذخیره می کنیم. برای OBDI، ما هستی شناسی و نقشه برداری را با استفاده از ویرایشگر هستی شناسی Protégé [ 77 ] با افزونه Ontop [ 10 ] می سازیم و یک نقطه پایانی SPARQL را با استفاده از Ontop تنظیم می کنیم. برای GeoVA، ما یک سیستم تجسم مبتنی بر وب را پیاده سازی کرده ایم که با نقطه پایانی SPARQL ارتباط برقرار می کند. رابط گرافیکی مبتنی بر چندین کتابخانه محبوب جاوا اسکریپت است، از جمله RDFLib.js ( https://github.com/linkeddata/rdflib.js/ )، Openlayers ( https://openlayers.org/ )، d3.js (https://d3js.org/ )، و vis.js ( https://visjs.org/ ). کد منبع، از جمله اسناد و مجموعه دادهها، در Github منتشر شده است ( https://github.com/dinglinfang/suedTirolOpenDataOBDA/ ).
4.1. منطقه آزمایش و داده ها
ما از استان تیرول جنوبی (به آلمانی: Südtirol؛ ایتالیایی: Alto Adige) در ایتالیا به عنوان منطقه آزمایشی استفاده می کنیم. این استان خودمختار در شمال ایتالیا با دو زبان رسمی آلمانی و ایتالیایی است. شکل 2 موقعیت جغرافیایی تیرول جنوبی را نشان می دهد.
در این مطالعه، ما از دادههای دو منبع داده استفاده میکنیم: (1) پورتال دادههای باز تیرول جنوبی (ODP) ( https://daten.buergernetz.bz.it/ )، و (2) موسسه دولتی آمار استان خودمختار Bozen-Bolzano (ASTAT) ( https://astat.provinz.bz.it/ ). ODP داده ها را از مقامات محلی، شرکت ها و ذینفعان مربوطه جمع آوری می کند. از 20 آوریل 2018، 458 مجموعه داده شامل 17 دسته در موضوعاتی مانند هواشناسی، فرهنگ، بهداشت منتشر کرده است. این دادهها و ابردادههای آنها در قالبهای مختلف، به عنوان مثال، JSON، XML، CSV و PDF ارائه میشوند. این پورتال همچنین دارای یک پورتال Geocatalog ( https://geokatalog.buergernetz.bz.it/geokatalog/ارائه داده های جغرافیایی عظیم در مرزهای اداری، تصاویر ماهواره ای و شبکه های حمل و نقل. این دادههای جغرافیایی در قالبهای ESRI SHP، AutoCAD، Google KML یا GeoJSON در دسترس هستند. ASTAT فعالیت های آماری رسمی در استان را هماهنگ می کند. این پایگاه داده تعاملی را در وب سایت خود ( https://astat.provinz.bz.it/de/datenbanken-gemeindedatenblatt.asp ) فراهم می کند، که در آن کاربران می توانند داده های اجتماعی-اقتصادی را به صورت تعاملی مشاهده و دانلود کنند. اکثر داده ها در قالب های XLS یا PDF هستند.
در این مورد، از داده های هواشناسی و ترافیک موجود از ODP و ASTAT استفاده می کنیم. به طور خاص، از ODP ما دادههای مرزهای شهرداری، ایستگاههای هواشناسی، حسگرها و اندازهگیریها را در 30 سال گذشته از 1980 تا 2017 دانلود میکنیم. از ASTAT دادههای آماری ترافیک در مورد حجم و سرعت ترافیک در سال 2017 را دانلود میکنیم. این مجموعه دادهها در مختلف سازماندهی شدهاند. ساختارها و در قالب های متنوع ارائه شده است. جدول 1 جزئیات این مجموعه داده ها را نشان می دهد. ما این داده ها را با تبدیل آنها به جداول رابطه ای و ذخیره آنها در PostGIS به صورت فیزیکی یکپارچه می کنیم.
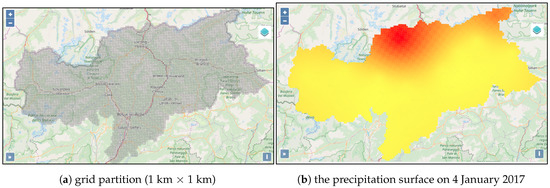
علاوه بر این، از آنجایی که اندازه گیری های هواشناسی نماینده یک پدیده جغرافیایی پیوسته موجود در فضا هستند، در این مطالعه این پدیده را به عنوان یک سطح با هر مکان یک ارزش پدیده منحصر به فرد مدل می کنیم. به طور خاص، منطقه مورد مطالعه را به سلولهای شبکه تقسیم میکنیم و سطح شبکه را با دادههای هواشناسی درونیابی میکنیم. با در نظر گرفتن وسعت منطقه مورد مطالعه، اندازه سلول شبکه را 1 کیلومتر در 1 کیلومتر تعیین کردیم که در مجموع 7793 سلول در داخل منطقه مورد مطالعه ایجاد شد. شکل 3a پارتیشن شبکه را نشان می دهد. سپس الگوریتم های درون یابی را به داده های اندازه گیری هواشناسی اعمال می کنیم. فرآیند درون یابی را می توان به عنوان درون یابی در نظر گرفت که یک مشاهده برای هر سلول ایجاد می کند. برای ایجاد بارش و سطوح دما، از روش درون یابی کریجینگ استفاده می کنیم. شکل 3 ب سطح بارش درون یابی شده در 4 ژانویه 2017 را نشان می دهد.
4.2. یکپارچه سازی داده های مبتنی بر هستی شناسی
ما نشان میدهیم که چگونه هستیشناسی و نقشهبرداری را بسازیم تا از ماژول OBDI برای ادغام مجموعههای داده استفاده کنیم.
4.2.1. هستی شناسی
برای مدلسازی دانش دادههای حسگر، هستیشناسی خود را بر روی دو هستیشناسی استاندارد، یعنی GeoSPARQL (با پیشوند geo: ) و شبکه حسگر معنایی (SSN، با پیشوندهای ssn: و sosa 🙂 میسازیم. لیست کامل پیشوندهای مورد استفاده در هستی شناسی ما در جدول 2 نشان داده شده است . شکل 4 بخش هایی از هستی شناسی را همانطور که در ویرایشگر Protégé نشان داده شده است نشان می دهد. در این مطالعه، کلاسهای اصلی که به آنها تکیه میکنیم عبارتند از geo:Feature ، sosa:Platform ، sosa:Sensor ، sosa:ObservableProperty و sosa:Observation.. برای نمایش موجودیت های خاص دامنه، هستی شناسی را به صورت زیر غنی کرده ایم:
-
ما دو کلاس WeatherStation و :TrafficStation را به عنوان زیر کلاس های هر دو sosa:Platform و geo:Feature ایجاد کرده ایم .
-
ما پنج زیر کلاس از sosa:Sensor ایجاد کردهایم ، به عنوان مثال،: MinTemperatureSensor و :TrafficSpeedSensor .
-
ما پنج نمونه از کلاس sosa:ObservableProperty ایجاد کردهایم ، به عنوان مثال، <minTemperature> و <trafficSpeed> .
-
ما یک کلاس :GridCell گسترش geo:Feature را برای نمایش یک پارتیشن بدون درز از یک منطقه جغرافیایی معرفی کرده ایم. سپس کلاس :Interpolator را به عنوان زیر کلاس ssn:System ایجاد می کنیم که نمونه آن بر روی یک پلت فرم :GridCell میزبانی می شود و نمونه هایی از :Observation را درون یابی می کند .
4.2.2. نقشه برداری
ما نقشه برداری را از جداول پایگاه داده به واژگان هستی شناسی می سازیم. یک ادعای نقشه برداری شکل می گیرد
که در آن id یک شناسه است، منبع یک پرس و جوی SQL، و هدف یک الگوی سه گانه است. قسمت هدف حاوی مکانهایی مانند ” {column} ” است که در آن ستون یک ستون خروجی در منبع است . در مجموع ما 23 ادعای نقشه برداری می سازیم. در جدول 3 ، ستون اول چهار نمونه ادعای نقشه برداری مربوط به ایستگاه های ترافیک، حسگرها و مشاهدات را که در نحو نقشه برداری Ontop [ 10 ] نوشته شده اند، فهرست می کند، ستون دوم داده های نمونه را نشان می دهد و ستون آخر سه گانه های ایجاد شده توسط ادعای نقشه برداری را نشان می دهد. بیش از داده های نمونه به عنوان مثال، اولین ادعای نقشه برداری M_traffic_station_info را در نظر بگیرید: از آنجایی که پاسخ های پرس و جوی SQL آن در پایگاه داده شامل (3، 'Pineta di Laives'، 'Steinmannwald') است ، می تواند سه گانه های ستون سوم جدول را ایجاد کند. به عنوان نتیجه ادغام، این چهار گروه از سه گانه، که توسط چهار ادعای نقشه برداری روی داده های نمونه ایجاد می شوند، یک نمودار RDF متصل را تشکیل می دهند، همانطور که در شکل 5 نشان داده شده است . این به وضوح نشان می دهد که این مجموعه داده ها یکپارچه شده اند.
علاوه بر سه گانه های ایجاد شده به صراحت توسط نگاشت، نمودار RDF نیز با استدلال هستی شناسی غنی می شود. به عنوان مثال، شکل 5 شامل دو سه گانه زیر است که توسط هستی شناسی استنباط شده است:
<traffic_station/3> یک sosa:Platform .
<traffic_volume_sensor/{station_code}/dailyTrafficVolume> یک sosa:Sensor. |
توجه داشته باشید که سه گانه های ایجاد شده توسط نقشه برداری و هستی شناسی نیازی به مادیت شدن ندارند، اما از طریق پرس و جوهای SPARQL با استفاده از تکنیک های بازنویسی SPARQL به SQL قابل دسترسی هستند. با اجتناب از تحقق سه گانه، افزودن منابع جدید و اصلاح مشخصات OBDA نسبتاً آسان می شود. در واقع، توسعه نقشهبرداری و هستیشناسی یک فرآیند تکراری است: زمانی که درک بهتری از دادهها داشته باشیم، نگاشت را تنظیم میکنیم. این نشان می دهد که رویکرد مجازی انعطاف پذیری زیادی را فراهم می کند.
4.2.3. پرس و جو
گراف RDF، پر شده توسط هستی شناسی و نگاشت روی پایگاه داده، می تواند با زبان SPARQL با استفاده از واژگان موجود در هستی شناسی پرس و جو شود. پاسخ پرس و جو از قابلیت های استدلال هستی شناختی بهره می برد. به عنوان مثال، هنگام پرس و جو از تمام نمونه های sosa:Sensor ، سیستم همچنین تمام نمونه های زیر کلاس های خود را در هستی شناسی بازیابی می کند، به عنوان مثال، :PrecipitationSensor و :TrafficSpeedSensor ، با استفاده از تعاریف SQL آنها در نقشه برداری. به این ترتیب، پرس و جوهای SPARQL به طور کلی قابل درک تر و فشرده تر از نسخه های SQL مربوطه خود هستند. این جنبه در بخش 4.5 مورد ارزیابی قرار خواهد گرفت ، جایی که نمونه های بیشتری از پرس و جوهای SPARQL ارائه شده است.
4.3. تجزیه و تحلیل ژئوویژوال
به عنوان اثبات مفهوم، ما یک سیستم تعاملی مبتنی بر وب را برای کاوش بصری دادههای مشاهده توسعه دادهایم. تجسم برای نشان دادن اطلاعات زیر در نظر گرفته شده است: (الف) مفاهیم اصلی هستی شناسی، (ب) ساختار جستجوهای SPARQL، (ج) توزیع فضایی ایستگاه ها، حسگرها و مشاهدات هواشناسی، به عنوان مثال، بارش و دما ، (د) الگوی زمانی مشاهدات در یک دوره زمانی تعریف شده، و (ه) همبستگیهای مکانی-زمانی بالقوه بین ویژگیهای قابل مشاهده متعدد. رابط بصری طراحی شده و مجموعه روش های تجسم و تحلیل آماری در زیر معرفی شده است.
رابط بصری مطابق با وظایف، ما رابط بصری را با چهار جزء اصلی بصری طراحی می کنیم که در شکل 6 نشان داده شده است . از چهار نمای مرتبط تشکیل شده است:
-
نمای دسترسی و تجزیه و تحلیل داده ها (بالا سمت چپ). این دیدگاه مفاهیم اصلی را به عنوان آیتم های اطلاعاتی فهرست می کند که مدل هستی شناسی و SPARQL را به هم متصل می کند. کاربران می توانند برای فرموله کردن یک پرس و جو برای دسترسی به داده ها، روی ویژگی های مورد نظر کلیک/بررسی کنند. طراحی این نما اساساً بر اساس واژگان اصلی موجود در هستی شناسی از جمله ایستگاه ها، حسگرها و ویژگی های قابل مشاهده است. یک پنجره زمانی برای انتخاب داده ها در یک شکاف زمانی خاص اضافه می شود. علاوه بر این، ما یک قابلیت اضافه می کنیم تا امکان کاوش بصری ارتباط بین داده های آب و هوا و ترافیک را فراهم کند. در حال حاضر، این نما به صورت دستی ساخته شده است، اما ما قصد داریم در آینده طبق هستی شناسی آن را به صورت خودکار تولید کنیم.
-
نمای جستجوی SPARQL (پایین سمت چپ). این نما به نمای دسترسی به داده پیوند داده شده است. هنگامی که پرس و جو فرموله می شود و برای نقطه پایانی SPARQL صادر می شود، یک نمودار شبکه ای از پرس و جو SPARQL ترسیم می کند و مستقیماً الگوهای نمودار اصلی پرس و جو را نشان می دهد. این امکان درک شهودی از مفاهیم درگیر و روابط پیچیده آنها را فراهم می کند.
-
نمای نقشه (بالا سمت راست). نمای نقشه با نمای دسترسی به داده و نمای آماری مرتبط است. برای نشان دادن توزیع فضایی اشیاء مورد بررسی، به عنوان مثال، مکان همه ایستگاههای هواشناسی و توزیع بارش طراحی شده است. علاوه بر این، کاربران می توانند به صورت تعاملی یک ویژگی را بر روی نقشه برای بررسی ویژگی های آن در نمای آماری مرتبط انتخاب کنند.
-
نمای نتیجه آماری (پایین سمت راست). به نمای دسترسی به داده ها و نمای نقشه مرتبط است و برای نشان دادن آمار مربوط به ویژگی انتخاب شده بر روی نقشه در دوره زمانی انتخاب شده طراحی شده است. ما سه تب طراحی کردهایم که به ترتیب اطلاعات اولیه ویژگی انتخاب شده (به عنوان مثال، شناسه ایستگاه ترافیک، و حداقل و حداکثر حجم ترافیک در این ایستگاه)، سری زمانی مشاهدات، و ضرایب همبستگی آب و هوا و ترافیک را نشان میدهند. در این ایستگاه
در شکل 6 ، پرس و جو “ایستگاه های ترافیک” در نمای دسترسی به داده ها برای دریافت تمام ایستگاه های ترافیکی اجرا شده است. به همین ترتیب، نمودار پرس و جو SPARQL فرموله شده در نمای پرس و جو SPARQL مشاهده می شود و ایستگاه های بازیابی شده در نمای نقشه نشان داده می شوند. پس از انتخاب ایستگاه با شناسه 3، نمای آمار اطلاعات اولیه آن و مقادیر حداقل و حداکثر حجم ترافیک و سرعت ترافیک را نشان می دهد.
تکنیک های تجسم تکنیکهای تجسم چندگانه در سیستم برای نشان دادن دادهها در دیدگاههای مختلف، با پیروی از اصول نقشهبرداری [ 78 ] استفاده میشود:
-
تجسم شبکه تجسم شامل گره ها و لبه ها است و به ویژه برای تجسم اشیا و روابط پیچیده درگیر در پرس و جوهای SPARQL مناسب است. شکل 6 نمودار پرس و جو را پس از انتخاب ایستگاه ترافیک با شناسه 3 برای بازیابی تمام اطلاعات مربوط به این ایستگاه نشان می دهد که در آن از گره های آبی پر شده برای نشان دادن IRI و literals و گره های پر نشده متغیر استفاده می شود.
-
نقشه های نقطه ای و نقشه های حرارتی . تکنیک های کارتوگرافی در انتقال الگوهای مکانی-زمانی موثر هستند. ما از نقشههای نقطهای برای نشان دادن توزیع مکانهای حسگر و ایستگاه، و نقشههای حرارتی برای نشان دادن سطوح توزیع پدیدههای پیوسته، به عنوان مثال، بارش و دما استفاده میکنیم.
-
نمودارهای پراکندگی و خطی 2 بعدی. آنها عمدتاً برای آشکار کردن الگوهای زمانی مشاهدات طراحی شدهاند. نمودارهای پراکندگی می توانند مقادیر متغیر منفرد هر روز را نشان دهند، در حالی که نمودارهای خطی روند زمانی را در یک دوره زمانی نشان می دهند.
-
ماتریس ضریب همبستگی تعاملی نمای ماتریسی می تواند نمای کلی نتایج ضریب محاسبه شده را در بین متغیرهای متعدد نشان دهد. این به کاربران کمک می کند تا همبستگی های قابل توجهی را پیدا کنند. یک طرح رنگ دوقطبی از آبی به قرمز برای نشان دادن همبستگی از مقادیر منفی به مثبت اعمال می شود. علاوه بر این، کاربران می توانند روی یک سلول در ماتریس کلیک کنند تا نمودار پراکندگی دو متغیر انتخاب شده را بررسی کنند.
روشهای تحلیل آماری ما چندین عملیات محاسباتی آماری را برای انتزاع مجموعه دادههای مورد بررسی با معیارهای آماری از جمله مقادیر حداقل، حداکثر مقادیر و ضرایب همبستگی پیادهسازی کردیم. این مقادیر به همراه نمایش های گرافیکی آنها به کاربران یک دید بصری در مورد مجموعه داده ها می دهد [ 56 ].
-
توابع مجموع . توابع مجموع عمدتاً مقادیر حداقل، حداکثر و میانگین هر متغیر را محاسبه می کنند. به عنوان مثال، در هر ایستگاه ترافیک، کاربران می توانند لیستی از مقادیر آماری اولیه را دریافت کنند. این مقادیر، مانند مقادیر حجم ترافیک روزانه، به کاربران یک دید کلی از جریان ترافیک در ایستگاه می دهد.
-
تحلیل ضریب همبستگی . همبستگی های مکانی و زمانی چند متغیره از منابع مختلف برای یافتن الگوهای جالب و استنتاج رویدادهای بالقوه مهم هستند. به عنوان نمونه، ما ضریب همبستگی پیرسون (برای دو مجموعه داده را اجرا کردیم ایکس=ایکس1،…،ایکسnو Y=y1،…،yn، ضریب همبستگی پیرسون است ρ(ایکس،Y)=∑من=1n(ایکسمن-ایکس¯)(yمن-y¯)∑من=1n(ایکسمن-ایکس¯)2∑من=1n(yمن-y¯)2.) و ضرایب را به صورت ماتریس تجسم کنید.
4.4. تحلیل و بررسی
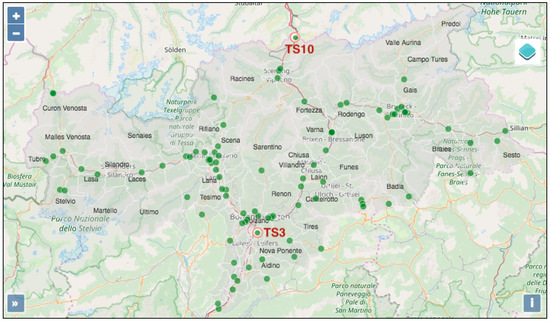
به عنوان نمایشی از سیستم، ما دو ماه از داده های ژانویه و جولای 2017 را برای تجزیه و تحلیل انتخاب می کنیم. به طور خاص، ما بر تجزیه و تحلیل سه نوع مشاهدات تمرکز می کنیم: بارش، حجم ترافیک و سرعت ترافیک. ما دو ایستگاه ترافیکی TS3 و TS10 (به ترتیب با ID 3 و ID 10 ) را برای تصویر انتخاب می کنیم، جایی که TS3 در نزدیکی پایتخت شهر بولزانو در تیرول جنوبی قرار دارد و TS10 در شمال استان و نزدیک به مرز قرار دارد. اتریش. شکل 7 مکان این دو ایستگاه را نشان می دهد. در زیر الگوهای مکانی و زمانی مشاهدات و همبستگیهای آنها را تحلیل میکنیم.
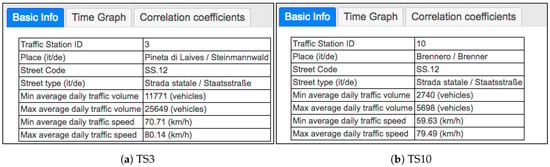
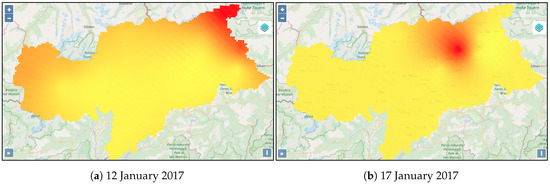
الگوهای فضایی اطلاعات اولیه TS3 و TS10 و مقادیر آماری تجمیع آنها در شکل 8 نشان داده شده است . TS3 و TS10 به ترتیب در مناطق “Pineta di Laives” و “Brennero” و در دو بخش جاده ای از خیابان سطح ملی با کد SS.12 واقع شده اند . ابتدا حجم و سرعت تردد در این دو ایستگاه را بررسی می کنیم. در ژانویه، برای حجم ترافیک، TS3 با توجه به میانگین حداقل و حداکثر و مقادیر بسیار «مشغولتر» از TS10 است. برای میانگین سرعت ترافیک روزانه، مقدار حداقل در ST3 بالاتر از مقدار در TS10 است، در حالی که حداکثر سرعت در TS3 و TS10 به دلیل محدودیت سرعت مشابه است. توزیع بارندگی در نقاط و روزهای مختلف به شدت متفاوت است. شکل 9بارش درونیابی شده در سلولهای شبکه را در 12 و 17 ژانویه 2017 نشان میدهد، با نقاط داغ بارش در مناطق مختلف.
الگوهای زمانی ما از نمودارهای پراکندگی دو بعدی و نمودارهای خطی برای نشان دادن تغییرات زمانی چند متغیره استفاده می کنیم. شکل 10 مقادیر بارندگی، سرعت ترافیک و حجم را در ژانویه و جولای 2017 در TS3 نشان می دهد. همانطور که انتظار می رود، بارش در ماه جولای به طور قابل توجهی بیشتر از ماه ژانویه است. علاوه بر این، بارندگی در هر دو ماه به طور چشمگیری تغییر می کند. برای سرعت و حجم ترافیک، یک همبستگی منفی آشکار وجود دارد. ما همچنین یک الگوی هفتگی واضح را مشاهده میکنیم که حجم ترافیک در روزهای هفته بیشتر و در آخر هفته کمتر است، اما سرعتها الگوی مخالفی را نشان میدهند. به طور کلی حجم ترافیک در ماه جولای بیشتر از ژانویه است، اما سرعت ترافیک در ژانویه و جولای مشابه است.
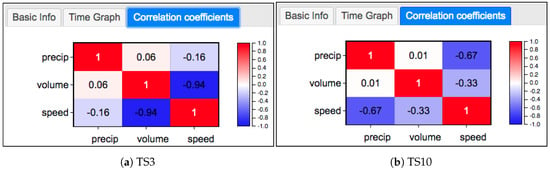
همبستگی مشاهدات. برای نشان دادن همبستگی ها از ماتریس ضریب همبستگی استفاده می کنیم ( ρ) در میان متغیرهای متعدد. شکل 11 ماتریس های ضریب همبستگی TS3 و TS10 را در ژانویه 2017 نشان می دهد. از شکل ها، می بینیم که به طور کلی هیچ همبستگی خطی وجود ندارد ( ρ~0) بین بارش و حجم در هر دو TS3 ( ρ=0.06) و TS10 ( ρ=0.01) در حالی که بارش با سرعت ترافیک همبستگی منفی دارد و در TS10 همبستگی معنی دارتر است ( ρ=-0.67) از TS3 ( ρ=-0.16). حجم ترافیک و سرعت یک همبستگی منفی آشکار دارند و در TS3 بسیار قوی است ( ρ=-0.94).
علاوه بر این، کاربران می توانند به طور تعاملی جزئیات همبستگی بین دو متغیر را با کلیک کردن روی یک سلول خاص در ماتریس بررسی کنند. شکل 12 سه نمودار دو متغیره را در TS3 در ژانویه 2017 نشان می دهد. شکل 12 a یک همبستگی خطی منفی بسیار واضح بین حجم و سرعت را نشان می دهد، در حالی که شکل 12 b,c هیچ همبستگی خطی را نشان نمی دهد، زیرا نقاط بیشتر در اطراف محور عمودی پراکنده شده اند.
4.5. مطالعات مقدماتی
ما ارزیابی چارچوب را با توجه به مناسب بودن آن در پشتیبانی از فرمولبندی وظایف تحلیل دادههای حسگر از طریق رابط بصری، فرمولبندی پرسشهای SPARQL و کاهش پیچیدگی از SPARQL به SQL انجام دادهایم. علاوه بر این، ما بازخوردهای کلی را از ذینفعان مختلف جمع آوری کرده ایم.
4.5.1. بررسی اثربخشی
ما اثربخشی را با تأیید اینکه آیا وظایف و پرس و جوهای تجزیه و تحلیل دادههای حسگر معمولی را میتوان در رابط بصری و هستیشناسیهایی که توسعه دادیم بیان کرد، اندازهگیری میکنیم. در زیر، سه کار قابل انجام از رابط کاربری گرافیکی را در نظر می گیریم. ما پرس و جوهای SPARQL ایجاد شده توسط رابط و نمایش های گرافیکی آنها را نشان می دهیم. علاوه بر این، کوئری های SQL را توضیح می دهیم. در زیر سه مورد از این کارها را ارائه می کنیم که آنها را به زبان طبیعی، در SPARQL، در نمایش گرافیکی مربوطه و در SQL فرمول بندی می کنیم. وظایف و پرس و جوها با پیچیدگی فزاینده ارائه می شوند.
وظیفه 1: “همه حسگرها و مکان آنها را دریافت کنید.” این کار را می توان تنها با یک کلیک بر روی کادر “Stations” در رابط بصری اجرا کرد. پرس و جوی SPARQL مربوطه و نمایش گرافیکی آن که در اینترفیس تجسم شده است عبارتند از:
این پرسش SPARQL فقط از واژگان هستی شناسی SOSA و GeoSPARQL استفاده می کند و درک آن بسیار آسان است. همانطور که در شکل 13 نشان داده شده است ، Ontop پرس و جوی SPARQL را به یک پرس و جوی SQL (که با خط NATIVE شروع می شود) ترجمه می کند تا در پایگاه داده ارزیابی شود، همراه با یک مرحله پس از پردازش (شروع با خط CONSTRUCT ) برای ساخت پاسخ های SPARQL. پرس و جوی SQL ترکیبی از 5 پرسش فرعی است و هر پرس و جوی فرعی ترکیبی از دو جدول است. ما خاطرنشان می کنیم که پرس و جوی SQL تولید شده در واقع بهینه است به این معنا که ساختار آن بسیار نزدیک به آنچه توسط متخصصان انسانی تولید می شود است. از این رو، در مقایسه با همتای SPARQL، درک و نوشتن دستی پرس و جو SQL بسیار دشوارتر است.
وظیفه 2: “در 1 ژانویه 2017 همه حسگرها، مکان و مشاهدات آنها را دریافت کنید.” این کار با یک کلیک دیگر با استفاده از تابع انتخاب زمان در رابط انجام می شود. کوئری SPARQL مربوطه و نمایش گرافیکی آن عبارتند از:
پرس و جوی SQL تولید شده، که به دلایل فضایی در اینجا نمی گنجانیم، ساختاری مشابه با تکلیف 1 دارد، اما ستون های بیشتری را طراحی می کند و از شرایط فیلتر بیشتری برای دوره زمانی انتخاب شده استفاده می کند.
وظیفه 3: “در 1 ژانویه 2017 همه حسگرها، مکان آنها و مشاهدات را در شهرداری بولزانو دریافت کنید.” این کار با یک کلیک دیگر روی نقشه بر روی شهرداری “Bolzano” در رابط انجام می شود. در مقایسه با پرس و جوی SQL تولید شده برای وظیفه 2، اکنون هر پرس و جو فرعی باید با استفاده از یک فیلتر فضایی به جدول دیگری از شهرداری بپیوندد. به دلایل فضایی، ما پرس و جوی تولید شده را در اینجا لحاظ نمی کنیم، و فقط مشاهده می کنیم که شکاف بین پرس و جو SPARQL و پرس و جو SQL حتی بیشتر از وظایف قبلی می شود.
به طور کلی، این ارزیابی نشان می دهد که (1) برای جمع آوری اطلاعات برای تجزیه و تحلیل، رابط کاربر می تواند پرس و جوهای SPARQL را ایجاد کند که به راحتی قابل درک هستند. (2) پرس و جوی SQL مربوطه بسیار بیشتر درگیر است و نوشتن و درک آن توسط متخصص انسانی دشوار است. این تأیید می کند که رویکرد ما می تواند به طور مؤثری از کاربران برای دریافت اطلاعات برای انجام وظایف تجزیه و تحلیل آنها پشتیبانی کند.
4.5.2. بازخورد
چارچوب GOdIVA برای اولین بار در نهمین کارگاه آموزشی “تحقیقات علوم کامپیوتر با کسب و کار” درباره GIS و خدمات مبتنی بر مکان ، که در 23 نوامبر 2017 ( https://www.unibz.it/en/events/126513 ) برگزار شد، ارائه شد. توسط دانشگاه آزاد Bozen-Bolzano (unibz). در میان حاضران، (1) Südtiroler Informatik AG (SIAG) ( https://www.siag.it/de/home/ )، که مدیریت OpenDataPortal، (2) ASTAT، که مسئول ترافیک محلی است، بودند. داده، (3) NOI Techpark ( https://noi.bz.it/en/ )، ارائه دهنده خدمات محلی برای شرکت ها، و (4) R3 GIS ( https://www.r3-gis.com/en/ )، یک SME متخصص در توسعه فناوری GIS. بازخورد شرکت کنندگان بسیار مثبت بود و آنها علاقه شدیدی به اتخاذ این رویکرد برای یکپارچه سازی و تجزیه و تحلیل منابع داده خود نشان دادند. آنها بهویژه از دیدن اینکه دادههایی که از ارائهدهندگان مختلف و در قالبهای مختلف میآیند، میتوانند یکپارچه و تجسم شوند، خوشحال شدند. از آن زمان، چندین جلسه پیگیری، از جمله دموهای اختصاصی و هکتون برای بازی با منابع داده بیشتر، با این ذینفعان برگزار شد، با هدف تعریف همکاری مشخص. در پایان، این فعالیتها مستقیماً دو پروژه صنعتی بزرگ را در زمینه یکپارچهسازی و تحلیل دادههای جغرافیایی آغاز کردهاند که در آن چارچوب GOdIVA به عنوان فناوری اصلی استفاده میشود.
-
IDEE: یکپارچه سازی داده ها برای بهره وری انرژی ( https://ideenergy.eu/ ) یک پروژه 3 ساله است که توسط صندوق توسعه منطقه ای اروپا (ERDF) پشتیبانی می شود. هدف پروژه IDEE توسعه یک زیرساخت فنآوری مبتنی بر فناوریهای معنایی برای یکپارچهسازی دادههای مربوط به ساختمانها، با تاکید بر دادههای مرتبط با انرژی، و ارائه تکنیکها و ابزارهایی برای تجسم و تحلیل این دادهها است. این کنسرسیوم متشکل از unibz (ارائهدهنده راهحل یکپارچهسازی دادههای جغرافیایی)، Alperia (ارائهدهنده دادههای مصرف انرژی) و R3 GIS (ارائهدهنده زیرساخت GIS) است و شهر Merano را به عنوان شریک اصلی مورد استفاده در ارائه نیازها و دادههای مربوط به شهر دارد. .
-
Open Data Hub-Virtual Knowledge Graph یک پروژه مشترک بین NOI techpark و Ontopic ( https://ontopic.biz/ ) برای گسترش OpenDataHub تیرول جنوبی ( https://opendatahub.bz.it/ ) با رابط Graph دانش است. https://sparql.opendatahub.bz.it/ ). فاز اول برای یکپارچه سازی داده های گردشگری (مثلاً درباره هتل ها و رویدادها) قبلاً تکمیل شده است و فاز دوم با هدف یکپارچه سازی داده های ترافیکی آغاز شده است. علاوه بر این، با پیروی از اصل GOdIVA ، ما یک مؤلفه وب ایجاد کردهایم ( https://webcomponents.opendatahub.bz.it/webcomponent/567cb2e2-3e5d-421a-bf85-b8ecc500aab9) که می تواند در هر صفحه وب مانند یک تگ استاندارد HTML تعبیه شود تا نتایج جستجوی SPARQL را به روش های مختلف از جمله نقشه های سفارشی شده تجسم کند.
5. نتیجه گیری و کار آینده
در این مقاله، ما چندین چالش را در یکپارچه سازی و تجزیه و تحلیل داده های مکانی ناهمگن مورد بحث قرار دادیم. ما با پیشنهاد چارچوبی به نام GOdIVA به این چالش ها می پردازیم که دو حوزه تحقیقاتی تثبیت شده یکپارچه سازی داده های مبتنی بر هستی شناسی و تجزیه و تحلیل زمین بصری را با قرار دادن یک هستی شناسی در مرکز متحد می کند. در GOdIVA، ماژول یکپارچه سازی مبتنی بر هستی شناسی با هدف ارائه یک زیرساخت داده های جغرافیایی سازگار و قابل مدیریت برای منابع داده ناهمگن است، در حالی که ماژول تجزیه و تحلیل geovisual از ساختار هستی شناسی بهره برداری می کند و عبارات بصری متنوع اما به راحتی قابل درک را برای درک و کاوش ارائه می دهد. برای آزمایش رویکرد خود، ما یک سیستم تحلیلی بصری مبتنی بر وب را پیادهسازی کردیم و از مشاهدات حسگر ناهمگن جمعآوریشده در استان تیرول جنوبی، ایتالیا به عنوان دادههای آزمایشی استفاده کردیم. ارزیابی اولیه انجام شده و دو پروژه صنعتی بعدی به طور خلاصه ارائه شده است. آزمایش فرضیه ما را تأیید کرد کهچارچوب GOdIVA برای اکتشاف و درک داده های جغرافیایی ناهمگن امکان پذیر است.
کار آینده. در این مقاله، ما از دادههای حسگر تاریخی برای یک سال به عنوان نمایش استفاده کردیم. ما قصد داریم دادههای سری زمانی طولانیمدت را برای تحلیلهای مکانی-زمانی بیشتر برای کشف روندهای بلندمدت و الگوهای دورهای بررسی کنیم. ما همچنین داده های سایر حوزه ها را در مطالعه خود قرار خواهیم داد. علاوه بر این، ما پردازش جریانهای دادههای حسگر بلادرنگ را در کار آینده خود در نظر میگیریم.
به منظور قابلیت همکاری، از چندین هستی شناسی استاندارد استفاده کرده ایم. در آینده، ما قصد داریم استانداردهای بیشتری را اتخاذ کنیم، به ویژه، ما علاقه مند به QB4ST ( https://www.w3.org/TR/qb4st/ ) از داده های فضایی در گروه کاری وب ، توسعه داده های RDF هستیم. مکعب واژگان ( https://www.w3.org/TR/vocab-data-cube/ ) برای اجزای فضایی و زمانی. جهت امیدوارکننده دیگر، ادغام داده های cityGML برای مدل های دیجیتال سه بعدی شهرها و مناظر است [ 79 ]. معنای پرس و جوی SPARQL [ 80 ] برای پشتیبانی از نگاشت را می توان بیشتر ساخت و بررسی کرد و مطمئن شد که پاسخ های دلخواه را دریافت می کنیم.
در مورد ماژول GeoVA، چندین جنبه وجود دارد که میتوانیم آن را بهبود بخشیم. ابتدا نمای دسترسی به داده را غنی میکنیم تا بتوان آن را بر اساس الگوهای دسترسی رایج هستیشناسی تولید کرد و کاربران میتوانند این الگوها را برای تشکیل پرسوجوهای پیچیدهتر ترکیب کنند. به عنوان مثال، استراتژی های طراحی داشبورد اطلاعاتی را می توان برای بهبود رابط بصری [ 81 ] اتخاذ کرد. علاوه بر این، ما تکنیک های تجسم مناسب تری را پیشنهاد خواهیم کرد، به عنوان مثال، با ترکیب تجسم علمی و تکنیک های نگاشت موضوعی برای دستیابی به اثرات هم افزایی [ 75]]. در حال حاضر، ما برخی از عملکردهای تجمع و ضریب همبستگی را برای اهداف نمایشی اجرا کردیم. آمارهای فضایی بیشتر و الگوریتمهای یادگیری ماشین برای تجزیه و تحلیل مکانی-زمانی ادغام خواهند شد. به طور کلی، ما عملکردهای اضافی را برای تولید خودکار بخش های قابل توجهی از رابط کاربری ارائه خواهیم داد، عملکردهای تجزیه و تحلیل بیشتری را ارائه خواهیم داد، و به طور کلی ماژول GeoVA را کاربر پسندتر خواهیم کرد.













بدون دیدگاه