1. معرفی
یافتن سریعترین مسیر در یک شبکه جاده ای یک کار رایج است که باید در کاربردهای مختلف مانند حمل و نقل، برنامه ریزی مسیر یا مدیریت ریسک بلایا حل شود (برای مثال، [1، 2، 3 ، 4 ] را ببینید ) .
برای برنامه های مسیریابی، از داده های جاده OpenStreetMap (OSM) اغلب استفاده می شود. دلیل اصلی این امر این است که OSM یکی از شناختهشدهترین پروژههای داوطلبانه اطلاعات جغرافیایی است و دادههای رایگان موجود در سراسر جهان و بهروزرسانیهای بلادرنگ را در اختیار دارد [ 5 ، 6 ]. با این حال، داده های OSM دارای معایبی در رابطه با کیفیت داده های شبکه جاده ای به دلیل ویژگی مشارکتی پروژه OSM است [ 1 ، 3 ، 4 ، 6 ، 7 ]. کامل بودن به طور قابل توجهی بین کشورهای مختلف در سراسر جهان متفاوت است، هم از نظر کامل بودن ویژگی و هم از نظر کامل بودن ویژگی [ 7 ].
اکثر برنامه های مسیریابی زمان سفر لینک را به عنوان پارامتر می خواهند زیرا اطلاعات مربوط به شبکه جاده ها بسیار مهم است. طبق گفته Stanojevic و همکاران. [ 8 ]، زمان سفر لینک میانگین زمانی است که یک وسیله نقلیه برای عبور از یک بخش جاده طول می کشد. اطلاعات سرعت متوسط همراه با طول یک بخش جاده می تواند برای محاسبه زمان سفر پیوند بخش جاده مربوطه استفاده شود. ما یک بخش جاده را شبیه به لبه شبکه جاده در یک نمایش توپولوژیکی از شبکه در نظر می گیریم.
در شبکه جاده ای OSM، نه زمان سفر لینک و نه اطلاعات سرعت متوسط، لازم برای برنامه های مسیریابی، مستقیماً در دسترس نیست. از طرف دیگر، اطلاعات حداکثر سرعت برای یک بخش جاده اغلب در صورت ارائه استفاده می شود. با این حال، 92.2٪ از کل کیلومترهای جاده در سراسر جهان در شبکه جاده ای OSM 2019 فاقد اطلاعات حداکثر سرعت است [ 9 ]. تنها حدود ده کشور بیش از 40 درصد از شبکه های جاده ای کیلومتر را با اطلاعات حداکثر سرعت برچسب گذاری شده اند. کامل بودن اطلاعات حداکثر سرعت در مناطق شهری بیشتر از مناطق روستایی است [ 9 , 10 , 11 , 12]. اگر اطلاعات حداکثر سرعت در دسترس باشد، گاهی اوقات این اطلاعات با یک ضریب برای تقریب سرعت متوسط به عنوان ورودی برای برنامه های مسیریابی ضرب می شود. اگر اطلاعات حداکثر سرعت گم شده باشد، اطلاعات سرعت ثابت برای هر کلاس جاده فرض می شود [ 5 ]. دومی باعث ایجاد جهش های ناپیوسته در انتقال بین کلاس های مختلف جاده می شود که باعث ایجاد اثرات نامطلوب برای برنامه های مسیریابی می شود. برای جلوگیری از این جهشها، ما اخیراً یک چارچوب فازی برای تخمین سرعت (Fuzzy-FSE) برای تخمین سرعت متوسط در جادههای روستایی با تکیه بر ویژگیهای ورودی چندگانه شبکه جادهای OSM پیشنهاد کردیم [9 ] . اگرچه Fuzzy-FSE عملکرد خوبی دارد، اما دقت پیشبینی آن به شدت به طراحی فردی قوانین و دانش تخصصی زیربنایی بستگی دارد.
اطلاعات سرعت متوسط بین مناطق روستایی و شهری متفاوت است زیرا شرایط متفاوتی باید در نظر گرفته شود. در مناطق روستایی، میانگین سرعت عمدتاً تحت تأثیر کیفیت جاده، شیب جاده یا عرض جاده است. همه این پارامترها را می توان از داده های جاده OSM استنتاج کرد. تقریب متوسط سرعت جاده ها در مناطق شهری به اطلاعاتی مانند جنبه های زمانی ترافیک نیاز دارد. این اطلاعات را نمی توان از داده های جاده OSM استنباط کرد.
1.1. انگیزه و هدف
انگیزه مطالعه ما این است که در داده های شبکه جاده ای OSM، 92.2٪ از کل کیلومترهای جاده در سراسر جهان اطلاعات حداکثر سرعت را از دست داده اند، به ویژه در مناطق روستایی. شبکه جاده ای OSM نیز اطلاعات میانگین سرعت را ارائه نمی دهد. علاوه بر این، Fuzzy-FSE، به عنوان تنها رویکرد موجود برای پیشبینی سرعت متوسط بر اساس دادههای شبکه جادهای OSM، به دانش دامنه زیادی نیاز دارد. در نتیجه، Fuzzy-FSE به طور کلی برای مجموعه داده های منطقه ای مختلف قابل اجرا نیست.
بنابراین، هدف ما این است که دادههای شبکه جاده OSM را با اطلاعات سرعت متوسط با استفاده از رویکردهای یادگیری ماشین (ML) تنها بر روی دادههای ورودی شبکه جاده OSM نسبت دهیم. هدف ما ارائه یک رویکرد مبتنی بر داده های عمومی تر برای پیش بینی این اطلاعات سرعت است که در حال حاضر وجود ندارد. بنابراین، اطلاعات سرعت پیشبینیشده را میتوان در برنامههای مسیریابی استفاده کرد. این قصد به طور طبیعی به یک سوال کلی اما جذاب منجر میشود: آیا رویکردهای ML مبتنی بر دادههای صرفاً میتوانند میانگین سرعت بخشهای جادهای روستایی را زمانی که بر روی دادههای عمومی ناهمگن شبکه جاده OSM آموزش داده میشوند، پیشبینی کنند؟برای پرداختن به این سوال کلی، ما یک چارچوب تخمین ML را به دنبال یک خط لوله پردازش معمولی ML توسعه میدهیم و دادههای ورودی زیربنایی را بررسی میکنیم. علاوه بر این، ما از مجموعه داده های مشابهی مانند Guth و همکاران استفاده می کنیم. [ 9 ] برای مقایسه پیشبینیهای چارچوب تخمین ML ما و نتایج حاصل از فازی-FSE. داده های مرجع موجود در این مجموعه داده ها مقادیر متوسط سرعت استخراج شده از Google Directions API (GD-API) هستند.
برخلاف رویکرد فازی-FSE، ما همچنین توانایی چارچوب تخمین ML را برای پیوند دادههای ورودی شبکه جاده OSM به دادههای GD-API بدون دانش دامنه بیشتر بررسی میکنیم. دادههای مرجع سرعت متوسط بهدستآمده از GD-API با مقادیر سرعت با واریانس زیاد در هر کلاس جاده مشخص میشوند (به بخش 2.1 مراجعه کنید ) و باعث ایجاد مجموعه دادههای ناهمگن میشوند. این مجموعه دادههای ناهمگن حتی در مناطق منفرد رخ میدهند، که یک کار چالش برانگیز برای کاربرد چارچوب تخمین ML است. علاوه بر این، ما شروع به ارزیابی ظرفیت تعمیم احتمالی چارچوب تخمین ML پیشنهادی با ترکیب مجموعه دادههای منطقهای مختلف میکنیم.
با توجه به جنبهها و چالشهای ذکر شده، هدف اصلی خود را به شرح زیر خلاصه میکنیم: هدف ما طراحی یک چارچوب تخمینی، از جمله رویکردهای ML موجود است که یک پیشبینی متوسط سرعت قوی در برابر تغییرات مختلف در دادههای ورودی شبکه جاده OSM ارائه میدهد. این چارچوب برآورد نیاز به رسیدگی به تعداد محدودی از داده های آموزشی ناهمگن برای رویکردهای ML دارد. ما آزادانه اجرای کل گردش کار روش شناختی خود را با یک مجموعه داده نمونه در GitHub [ 13 ] ارائه می کنیم. مشارکت های اصلی مرتبط با هدف مطالعه در موارد زیر خلاصه می شود:
-
توسعه یک چارچوب تخمینی برای سرعت متوسط در شبکههای جادهای روستایی با الهام از یک خط لوله معمولی ML به عنوان یک روش.
-
بررسی دقیق و ارزیابی پتانسیل چارچوب برآورد بر اساس ویژگی های ورودی شبکه جاده ای ناهمگن OSM برای پیش بینی سرعت متوسط.
-
انتخاب مهم ترین ویژگی ها برای تخمین سرعت متوسط بر اساس مدل های ML.
-
یک رویکرد جدید برای اعمال نقشه های خودسازماندهی (SOM) به عنوان یک رویکرد ML بدون نظارت برای ایجاد ویژگی های جدید.
-
استفاده از روش در دو منطقه مطالعاتی مجزا در شیلی و استرالیا و ارائه نتایج مربوطه.
-
مقایسه عملکرد رگرسیون چارچوب برآورد با پیشبینی فازی-FSE.
در بخش 1.2 ، پیشینه تحقیق به اختصار بیان شده است. ما سطوح مختلف چارچوب برآورد میانگین سرعت در شبکههای جادهای را در بخش 2 ارائه میکنیم . این بخش شامل روش روششناختی پیشنهادی با شرح سه مجموعه داده مختلف، مراحل پیشپردازش و تقسیمبندی دادهها، سطح ویژگی با تولید ویژگیهای اضافی و سطح مدل است. نتایج رگرسیون در بخش 3 ارائه شده است . متعاقبا، عملکرد چارچوب برآورد را ارزیابی و ارزیابی می کنیم ( بخش 4 ). در بخش 5 ، مطالعه ارائه شده با چشم انداز مطالعات بیشتر ترکیب شده است.
1.2. پیشینه تحقیق
در ادامه پیشینه تحقیق را به اختصار بیان می کنیم. از آنجایی که مطالعه ما بر تخمین اطلاعات سرعت متوسط بر اساس داده های شبکه جاده ای OSM متمرکز است، ابتدا نگاهی به امکانات محاسبه میانگین سرعت، زمان سفر پیوند، با داده های OSM می اندازیم. علاوه بر این، ما یک برنامه ML را با استفاده از داده های OSM برای حل وظایف طبقه بندی مختلف ارائه می کنیم.
برنامه های مسیریابی متعددی بر اساس داده های شبکه جاده ای OSM وجود دارد. به عنوان مثال OpenRouteService [ 14 ]، Open Source Routing Machine (OSRM) [ 5 ]، OpenTripPlanner [ 15 ] و YOURS [ 16 ] هستند. همه این مثالها باید بر چالش تخمین سرعت متوسط برای استخراج زمان سفر لینک غلبه کنند. OSRM، OpenTripPlanner، و YOURS از اطلاعات تگ OSM maxspeed برای محاسبه زمان سفر پیوند در صورت موجود بودن این برچسب استفاده می کنند. اگر اطلاعات حداکثر سرعت وجود نداشته باشد، محدودیت های سرعت از پیش تعریف شده برای هر کشور اعمال می شود [ 17]. جزئیات مربوط به این منابع اطلاعاتی جایگزین را می توان در ویکی OSM یافت. سایر اطلاعات برچسب مانند نوع جاده و تعداد خطوط برای استخراج مقادیر سرعت ثابت برای هر کلاس جاده استفاده می شود. به نظر میرسد OpenRouteService بر اساس محاسبه زمان سفر پیچیدهتر است، زیرا دارای اطلاعات اضافی مانند شیب یا نوع مسیر است. با این حال، محاسبه دقیق شفاف نیست.
در جامعه تحقیقاتی، مطالعات کمی وجود دارد که به زمان سفر پیوند در شبکه جاده ای OSM می پردازد. استانوجویچ و همکاران [ 8 ] از اطلاعات مبدا-مقصد و مهر زمانی تولید شده توسط ناوگان تاکسی و داده های جاده OSM برای محاسبه زمان سفر پیوند استفاده کنید. برآورد آنها ثابت می کند که 60٪ خطای کمتری در مناطق شهری نسبت به OSRM دارد. علاوه بر این، Steiger و همکاران. [ 18 ] شامل داده های ترافیکی بلادرنگ در OpenRouteService برای بهبود تخمین در مناطق شهری است. به طور کلی، اکثر مطالعات تحقیقاتی بر تخمین زمان سفر در مناطق شهری تمرکز دارند.
در مورد ترکیب رویکردهای ML و دادههای OSM، مطالعاتی انجام شده است که عمدتاً با وظایف طبقهبندی نظارت شده سروکار دارند. برای مثال، دادههای OSM و رویکردهای ML برای برچسبگذاری معنایی تصاویر رصد زمین استفاده میشوند [ 19 ]. شبکههای عصبی عمیق به دادههای OSM اعمال میشوند تا از دادههای OSM برای برچسبگذاری معنایی تصاویر هوایی و ماهوارهای استفاده کنند. شولتز و همکاران [ 20 ] از شصت تگ در داده های OSM برای تخصیص طبقه بندی کاربری زمین سطح 2 Corine Land Cover استفاده کنید. پتانسیل استفاده سریع از زمین و نقشه برداری پوشش زمین بر اساس تصاویر ماهواره ای Landsat سری زمانی و داده های OSM در جانسون و آیزوکا [ 21] ارزیابی شده است.]. علاوه بر این، رویکردهای ML برای حل وظایف طبقهبندی که به کیفیت دادههای OSM میپردازند، استفاده میشوند. برای مثال جیلانی و همکاران. [ 22 ] بر ارزیابی کیفیت داده های OSM تمرکز می کنند در حالی که Kaur و Singh [ 23 ] کیفیت داده OSM را بهبود می بخشند. جیلانی و همکاران [ 22 ] دقت معنایی دادههای شبکه خیابانی OSM را با آموزش یک مدل ML برای یادگیری هندسه و توپولوژی کلاسهای خیابانی مجزا بررسی میکند. در ادامه، مدل آموزشدیده برای تصحیح کلاس معنایی خیابانها اعمال میشود. کائور و سینگ [ 23] از یک مدل ML با ویژگی های OSM مانند طول جاده برای بهبود کیفیت داده های OSM با شناسایی و تصحیح خطاها در داده های OSM استفاده کنید. در این حالت، آنها گم شدن یا نادرست ویژگی های گره ها و راه ها در شبکه OSM را به عنوان خطا در نظر می گیرند. در یک مطالعه بیشتر، برون یابی نام های گمشده خیابان ها با رویکردهای ML مورد بررسی قرار می گیرد که می تواند توپولوژی و معنایی شبکه جاده OSM را بیاموزد [ 24 ]. چند مطالعه بر تصحیح برچسبهای OSM خاص با تکنیکهای ML نظارت شده، تشخیص خطاها در OSM، و به طور کلی بهبود کیفیت دادههای OSM از نظر دقت و سازگاری ویژگیها تمرکز دارند (برای مثال، [25، 26 ، 27 ] را ببینید . ).
رویکردهای ML هنوز برای کارهای رگرسیونی یا حتی برای تخمین اطلاعات سرعت متوسط، به ترتیب، زمان سفر به کار نمی روند. تنها یک رویکرد وجود دارد که میتواند برای تخمین سرعت متوسط جادههای روستایی تنها با دادههای شبکه جادهای OSM استفاده شود [ 9]]. این رویکرد بر دانش دامنه متکی است و چارچوب فازی برای تخمین سرعت (Fuzzy-FSE) نامیده می شود. بر خلاف رویکردهای ML، فازی-FSE به عنوان یک رویکرد صرفاً مبتنی بر داده طبقه بندی نمی شود. این متکی بر کنترل فازی با پارامترهای ورودی کلاس جاده، شیب جاده، سطح جاده و طول پیوند است که از شبکه جاده OSM و به صورت اختیاری، یک مدل ارتفاع دیجیتال آزادانه در دسترس (DEM) نشات میگیرد. یک قانون و پایگاه دانش که توابع اعضای خروجی را توصیف می کند و یک سیستم کنترل فازی که سرعت متوسط خروجی را محاسبه می کند، دو بخش Fuzzy-FSE هستند.
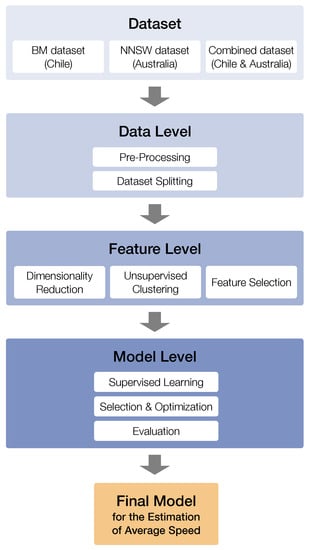
2. مجموعه داده ها و روش شناسی در چارچوب برآورد
به طور کلی، ما میتوانیم چندین رویکرد را هنگام استفاده از یادگیری ماشین (ML) برای وظایف رگرسیون اعمال کنیم (به عنوان مثال، [ 28 ، 29 ، 30 ] را ببینید). رویکردهای انتخاب شده به داده های مرجع موجود و کیفیت یا مقدار داده های موجود بستگی دارد. برای تکلیف رگرسیون زیربنایی تخمین سرعت متوسط برای بخشهای جاده مجزا با دادههای شبکه جادهای OSM، ما به یک چارچوب تخمینی برای فشردهسازی رویکردهای مناسب ML تکیه میکنیم ( شکل 1 را ببینید.). این چارچوب کار را در چهار سطح با پیروی از یک خط لوله معمولی ML ساختار می دهد و متدولوژی مطالعه ما را در بر می گیرد. (1) در سطح مجموعه داده، ما مجموعه داده استفاده شده و به طور خاص، داده های ورودی OSM و داده های مرجع مربوطه را توصیف می کنیم. (2) سطح داده شامل پیش پردازش و تقسیم مجموعه داده لازم برای آموزش و ارزیابی مدل های ML است. (3) در سطح ویژگی، کاهش ابعاد بدون نظارت، خوشهبندی بدون نظارت و انتخاب ویژگی را اعمال میکنیم. (4) سطح مدل شامل یادگیری نظارت شده، انتخاب مدل، بهینه سازی فراپارامترها و معیارهای ارزیابی مدل است. کد چارچوب تخمین برای یک مجموعه داده نمونه به صورت رایگان در GitHub در دسترس است [ 13]. توجه داشته باشید که به دلیل حق چاپ، ما نمی توانیم داده های مرجع اصلی را منتشر کنیم. بنابراین، ما داده های مرجع شبیه سازی شده را تولید کردیم (برای جزئیات به [ 13 ] مراجعه کنید).
ما از نماد ریاضی طبق Chapelle و همکاران استفاده می کنیم. [ 31 ]، جایی که ایکس=(ایکس1،…،ایکسن)مجموعه ای از N نقطه داده ورودی را نشان می دهدایکسمن∈ایکسبرای همه من∈[ن]:={1،…،ن}. هر نقطه داده ایکسمندر مورد ما، هر بخش جاده از ویژگی های ورودی M تشکیل شده است ( جدول 1 را ببینید ). برای رگرسیون مقادیر متوسط سرعت، مقادیر هدف داده های مرجع به معنای پیوسته هستند Y⊂آر. به عنوان داده مرجع، مقادیر متوسط سرعت برای نقاط داده ورودی انتخاب شده در دسترس است. ما مدلهای یادگیری تحت نظارت و بدون نظارت را در هر سه مجموعه داده در چارچوب تخمین پیشنهادی اعمال میکنیم ( شکل 1 را ببینید ). علاوه بر این، ما رویکردهای یادگیری بدون نظارت را در سطح ویژگی اعمال می کنیم و ویژگی های تولید شده را به داده های ورودی اضافه می کنیم. برای رویکردهای یادگیری تحت نظارت، yمن∈Yبا Y=(y1،…،yن)مقادیر متوسط سرعت نقاط داده است ایکسمن(بخش های جاده)، و مجموعه آموزشی به صورت جفت ارائه می شود Lتیمن=(ایکسمن،yمن). از این پس به ترکیب ویژگی های ورودی و داده های خروجی مورد نظر به عنوان نقطه داده اشاره می کنیم. قراردادهای نامگذاری متغیر اعمال شده در جدول A1 خلاصه شده است .
2.1. مجموعه داده ها
برای برآورد قابل اعتماد سرعت متوسط در شبکه های جاده ای با رویکردهای ML، چندین مجموعه داده برای آموزش و ارزیابی مدل های انتخاب شده مورد نیاز است. ما به مجموعه دادههایی که عمدتاً شامل دادههای شبکه جادهای OSM هستند، به دلیل در دسترس بودن رایگان و جهانی آنها تکیه میکنیم. مجموعه داده ها نشان دهنده سطح اول چارچوب تخمین هستند، همانطور که در شکل 1 نشان داده شده است . در این مطالعه، ما سه مجموعه داده را در نظر می گیریم: مجموعه داده BM (شیلی)، مجموعه داده NNSW (استرالیا)، و مجموعه داده ترکیبی (شیلی و استرالیا). هر یک از این مجموعه داده ها شامل داده های شبکه جاده OSM متراکم و مقادیر میانگین سرعت است. دومی از Google Directions API (GD-API) استخراج شده و به عنوان داده مرجع (یا داده های حقیقت زمینی) عمل می کند.
اولین مجموعه داده شامل داده های شبکه جاده OSM برای مناطق BioBío، Ñuble و Maule (BM) در مرکز شیلی است. منطقه Ñuble یک منطقه نسبتا جدید است که در سال 2018 با تقسیم منطقه BioBío سابق به دو منطقه جداگانه ایجاد شد. بنابراین، مجموعه داده BM مانند [ 9 ] است، حتی اگر اکنون از سه منطقه تشکیل شده است. مجموعه داده دوم شامل داده های شبکه جاده OSM برای بخش های آماری Mid-North Coast، Richmond-Tweed، و Northern در شمال نیو ساوت ولز در استرالیا (NNSW) است. سومین مجموعه داده ترکیبی از ادغام هر دو مجموعه داده تشکیل می شود. مناطق مورد مطالعه در شیلی و استرالیا از نظر اندازه قابل مقایسه هستند اما در مراحل مختلف توسعه هستند. گوث و همکاران [ 9] ویژگی های این مناطق را با جزئیات بیشتری ارائه می دهد. در ادامه، به طور خلاصه ویژگی ها و تفاوت های اصلی بین سه مجموعه داده را بیان می کنیم.
برخلاف شیلی، زیرساختهای جادهای استرالیا بیشتر توسعه یافته و شامل طیف گستردهای از جادههای آسفالتشده و سطح بالا است. در شیلی، جادههای آسفالتنشده زیادی وجود دارد که در آنها میانگین سرعت در مقایسه با کلاسهای جادهای مشابه در کشورهای توسعهیافتهتر در مورد زیرساختهای جادهای پایین است. هر دو منطقه دارای مناطق روستایی بزرگی هستند که جمعیت کمی دارند. بخشی از منطقه مورد مطالعه در شیلی در آند واقع شده است به طوری که دامنه شیب های مجموعه داده BM در مقایسه با منطقه کمتر کوهستانی NNSW گسترده است.
این مناطق به این دلیل انتخاب می شوند که کاربرد چارچوب تخمین داده محور را در مناطق جغرافیایی متنوع نشان می دهند. علاوه بر این، کیفیت و در دسترس بودن داده های شبکه جاده OSM در هر دو منطقه متفاوت است. مجموعه داده شبکه جاده ای OSM برای NNSW کامل تر است و حاوی اطلاعات اضافی بیشتری نسبت به مجموعه داده BM است. توجه داشته باشید که ما مقادیر میانگین سرعت تخمینی ML را با مقادیر سرعت تخمینی فازی کاملا مبتنی بر دانش Guth و همکاران مقایسه می کنیم. [ 9 ]. با این وجود، قابلیت های تعمیم با اعمال چارچوب به مجموعه داده ترکیبی نشان داده می شود.
مجموعه داده در داده های ورودی و داده های مرجع به عنوان خروجی مورد نظر برای کاربرد مدل های ML تقسیم می شود. داده های ورودی و داده های مرجع به ترتیب و متغیر هدف در قسمت زیر توضیح داده شده است.
2.1.1. داده های شبکه جاده ای OSM به عنوان ویژگی های ورودی
داده های جاده OSM به عنوان یک شبکه جاده به صورت سلسله مراتبی در بزرگراه، تنه، اولیه، ثانویه، ثالثی، طبقه بندی نشده با جاده های پیوند مربوطه خود، link_motoway، trunk_link، first_link، secondary_link، tertiary_link طبقه بندی شده اند . مشابه گوث و همکاران. [ 9 ]، کلاس های جاده های موجود بیشتر در این چارچوب برآورد در نظر گرفته نمی شوند. جزئیات در مورد سلسله مراتب طبقات جاده در شبکه جاده OSM در [ 4 ، 32 ] ارائه شده است.
برای تخمین سرعت متوسط در شبکههای جادهای با رویکردهای ML، هر بخش جاده از مجموعه داده شبکه جاده OSM به عنوان یک نقطه داده در نظر گرفته میشود. ویژگیهای موجود مربوط به این بخش جاده، ویژگیهای ورودی کار برآورد هستند و در جدول 1 فهرست شدهاند . در این مطالعه، ما به ویژگی های ورودی class_id، end_latitude، end_longitude، length، region_id، sinuosity، slope_1، slope_2، start_latitude، start_longitude، support_points_km، surface_id تکیه می کنیم . علاوه بر این، ما ویژگی های ورودی خود را با اعمال، به عنوان مثال، خوشه بندی بدون نظارت در سطح ویژگی چارچوب تخمین (سطح سوم در شکل 1 ) استخراج می کنیم.
جدول 2 نمای کلی از داده های شبکه جاده OSM هر سه مجموعه داده را ارائه می دهد. توزیع داده های جاده موجود در تمام کلاس های جاده نشان داده شده است. اطلاعات سطح در OSM به دو دسته اصلی سنگفرش و بدون سنگفرش طبقه بندی می شود . در برخی موارد، اطلاعات سطح دقیق تری مانند آسفالت در دسترس است . در صورت موجود بودن، از اطلاعات سطحی دقیق تر در چارچوب تخمین استفاده می کنیم. در مجموعه داده NNSW، سطح مشخصه دارای برچسبهای زیر است: آسفالت نشده (34.52٪ کیلومتر جاده)، آسفالت (22.09٪ کیلومتر جاده)، بدون اطلاعات (21.42٪ کیلومتر جاده)، آسفالت(8.59٪ کیلومتر جاده)، شن (7.60٪ کیلومتر جاده)، خاک (2.86٪ کیلومتر جاده)، بتنی (1.09٪ کیلومتر جاده)، زمین (0.86٪ کیلومتر جاده) و فشرده (0.72٪ جاده) کیلومتر). همه مقادیر دیگر در کمتر از 0.1٪ کیلومترهای جاده در NNSW نشان داده شده است.
در مجموعه داده BM، سطح مشخصه دارای برچسبهای زیر است: آسفالت (55.15٪ کیلومتر جاده)، آسفالت (17.16٪ کیلومتر جاده)، بدون اطلاعات (16.93٪ کیلومتر جاده)، آسفالت (8.69٪ کیلومتر جاده)، شن (1.26 درصد کیلومتر جاده)، بتن (0.31 درصد کیلومتر جاده)، زمین (0.19 درصد کیلومتر جاده) و خاک (0.13 درصد کیلومتر جاده). همه مقادیر دیگر در کمتر از 0.1٪ از کیلومترهای جاده در مناطق BM مشخص شده اند.
از آنجایی که مجموعه داده ترکیبی ادغام هر دو مجموعه داده منطقه ای است، مقادیر هر ویژگی در تمام کلاس های جاده متناسب با مجموعه داده BM و NNSW است.
2.1.2. اطلاعات سرعت متوسط به عنوان داده مرجع و متغیر هدف
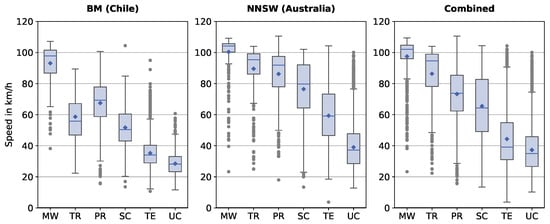
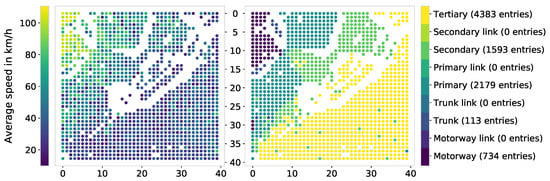
به عنوان متغیرهای هدف و بنابراین داده های مرجع، ما بر اطلاعات سرعت متوسط استخراج شده توسط GD-API تکیه می کنیم. GD-API به دو مکان به عنوان نقاط ورودی نیاز دارد و فاصله بین این مکانها را بر حسب متر، زمان سفر بر حسب ثانیه در یک زمان معین و مختصات نقاط جاده نزدیکترین نقطه به مختصات نقطه ورودی را ارائه میکند. نقشه های گوگل و اطلاعات جاده و ترافیک زیربنایی آن اساس سرویس GD-API هستند. اگرچه هنگام ادغام دادههای Google Maps و دادههای شبکه جادهای OSM چالشهای زیادی رخ میدهد (برای مثال، [ 9 ، 34 را ببینید])، اطلاعات میانگین سرعت استخراج شده توسط GD-API بهترین انتخاب داده های مرجع را در این زمینه نشان می دهد. بنابراین، ما فرض میکنیم که GD-API مقادیر میانگین سرعت بخش جاده مربوطه را بهعنوان دادههای مرجع علیرغم اختلافات کوچک احتمالی ایجاد کرده است. توزیع میانگین سرعت برای هر کلاس جاده از داده های مرجع در شکل 2 نشان داده شده است . مقادیر میانگین سرعت در هر کلاس جاده بسیار متفاوت است. واریانس رخ داده داده های مرجع یک کار چالش برانگیز برای رگرسیون ML است. ما فرض میکنیم که هرچه محدوده مقادیر متوسط سرعت کمتر باشد، مدلهای ML بهتر میتوانند دادههای شبکه جاده OSM مانند class_id یا surface_id را با مقادیر میانگین سرعت مربوطه مرتبط کنند.
2.2. سطح داده
سطح داده ها دومین سطح از چارچوب برآورد ارائه شده است. این به پیش پردازش ( بخش 2.2.1 ) و تقسیم داده ها ( بخش 2.2.2 ) تقسیم می شود.
2.2.1. پیش پردازش
پس از تجزیه و تحلیل نقاط داده هر سه مجموعه داده به صورت جداگانه، ما هر بخش جاده ای را که یکی از ویژگی های زیر را داشته باشد حذف کردیم: فاصله بین نقطه شروع یا پایان در بخش جاده در داده های ورودی و مرجع بزرگتر از 50 متر است. طول بخش جاده در ورودی و داده های مرجع بیش از 20٪ متفاوت است، بخش جاده کوتاه تر از 600 متر است، و همچنین زمانی که درخواست GD-API یک خطا یا یک مجموعه خالی را برگردانده است. به جز آستانه 600 متر، این حفاظت ها برای حذف داده های نادرست و ناسازگاری بین دو منبع داده اعمال می شوند. تشخیص پرت در قیاس با گوث و همکاران انجام می شود. [ 9] برای اطمینان از سازگاری. توجه داشته باشید که بخشهای جاده کوتاهتر از 600 متر را حذف میکنیم زیرا برای بخشهای جاده کوتاهتر، مقادیر میانگین سرعت استخراجشده توسط GD-API به دلیل تبدیل زمان سفر در ثانیه، دقت کمتری دارند (برای جزئیات، به بخش 3.3 در Guth و همکاران مراجعه کنید. [ 9 ]). داده های خام شبکه جاده OSM به برچسب ها و ویژگی های ورودی شرح داده شده در بخش 2.1.1 به حداقل می رسد .
به عنوان آخرین مرحله پیش پردازش، مجموعه داده ها را استاندارد می کنیم (مقیاس کننده استاندارد، [ 35 ]) تا از استقلال آموزش مدل ML از مقیاس ویژگی های ورودی اطمینان حاصل کنیم.
2.2.2. تقسیم مجموعه داده
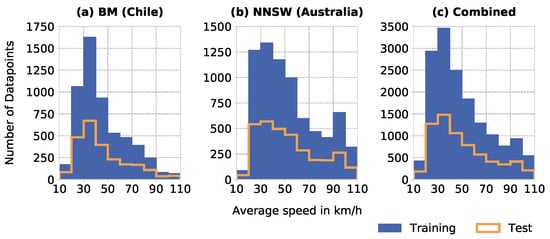
سه مجموعه داده (BM، NNSW، و ترکیبی از هر دو) به هم میریزند، و هر مجموعه داده بهطور تصادفی به دو زیر مجموعه تقسیم میشود تا توانایی تعمیم مدلهای ML انتخابی ما را ارزیابی کند. دو زیرمجموعه به وجود آمده آموزش و زیرمجموعه تست هستند.
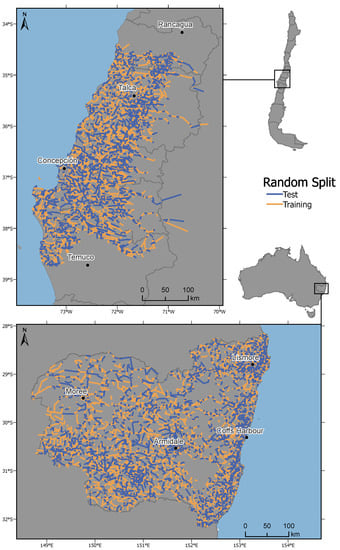
هر زیر مجموعه آموزشی شامل 70 درصد از نقاط داده کامل مجموعه داده است، در حالی که هر زیر مجموعه آزمایشی شامل 30 درصد نقاط داده باقی مانده است ( شکل 3 را ببینید ). شکل 4 توزیع فضایی تقسیم تصادفی را برای مجموعه داده BM و مجموعه داده NNSW به تصویر می کشد. شکل 3 توزیع متناظر مقادیر هدف (متوسط سرعت) را برای آموزش و زیر مجموعه های آزمایشی همه مجموعه داده ها نشان می دهد. جدول 3 توزیع شمارش را بین سه مجموعه داده نشان می دهد.
2.3. سطح ویژگی
در چارچوب برآورد ارائه شده (نگاه کنید به شکل 1 )، سطح ویژگی نشان دهنده سطح سوم است و شامل کاهش ابعاد بدون نظارت، خوشه بندی بدون نظارت و انتخاب ویژگی است. ما روی دو رویکرد تمرکز میکنیم: ما ویژگیهای جدید را با تجزیه و تحلیل مؤلفه اصلی (PCA، [ 36 ]) به عنوان یک رویکرد استاندارد کاهش ابعاد بدون نظارت استخراج میکنیم و ویژگیهای جدیدی را با رویکردی جدید با استفاده از نقشههای خودسازماندهی ایجاد میکنیم (SOMs, [ 37 , 38 ، 39 ]) به عنوان خوشه بندی بدون نظارت.
PCA داده های ورودی شبکه جاده OSM (به جدول 1 را ببینید ) به صورت متعامد با توجه به واریانس در امتداد محورهای جدید پیدا شده، اجزای اصلی، تبدیل می کند. بزرگترین واریانس مؤلفه اول را مشخص می کند. واریانس اجزای بعدی کاهش می یابد. از این رو، چند مؤلفه اصلی شامل بیشتر واریانس مجموعه داده است. ما بر دو جزء PCA تکیه میکنیم که از دادههای ورودی شبکه جادهای OSM با بسته Python با یادگیری scikit [ 35 ] محاسبه میشوند.
خوشهبندی به گروهبندی نقاط داده بر اساس یک متریک شباهت از پیش تعریفشده، عمدتاً به شیوهای بدون نظارت، نزدیک میشود. ما SOM ها را اعمال می کنیم که یک نوع کم عمق از شبکه عصبی مصنوعی [ 37 ] است که از یک لایه ورودی و یک شبکه دو بعدی (2 بعدی) به عنوان لایه خروجی تشکیل شده است. این دو لایه کاملاً به هم متصل هستند و نورون های شبکه خروجی بر اساس یک رابطه همسایگی به یکدیگر مرتبط می شوند. این رابطه همسایگی تعیین میکند که هر تغییری در یک نورون خروجی بر روی تمام نورونهای همسایگی آن در شبکه خروجی تأثیر میگذارد. علاوه بر تجسم قابل درک شبکه خروجی دوبعدی SOM، SOM نسبت به برازش بیش از حد مجموعه داده آموزشی حساس نیست.
برای تولید ویژگیهای جدید با SOM، ما خوشهبندی SOM بدون نظارت Riese و همکاران را اعمال میکنیم. [ 39 ] با استفاده از بسته SuSi Python [ 40 ]. Kohonen [ 37 ]، Riese and Keller [ 38 ] و Riese et al. [ 39 ] الگوریتم SOM بدون نظارت را با جزئیات شرح می دهد. SOM بدون نظارت، داده های شبکه جاده OSM را در یک شبکه خروجی 2 بعدی با یافتن بهترین واحد تطبیق (BMU) بر اساس فاصله اقلیدسی، خوشه بندی می کند. پس از آن، مقادیر سطر و ستون موقعیت BMU را به عنوان ویژگی های جدید انتخاب می کنیم. این ویژگی ها som_bmu_column و som_bmu_row نام دارند . علاوه بر این، ما خوشه های خروجی SOM را با یک خوشه بندی k-means با تعداد منحصر به فرد تقسیم می کنیم.مقادیر class_id به عنوان تعداد خوشه ها. در نهایت، دو ویژگی اضافی ایجاد میشود، som_column_clustered و som_row_clustered ، بهعنوان k-mean موقعیت مراکز خوشه. ویژگی های تولید شده توسط SOM لزوماً با ویژگی های دنیای واقعی داده های اساسی مطابقت ندارند. با این وجود، چنین مکاتباتی اغلب وجود دارد. علاوه بر این، ویژگیهای تولید شده توسط SOM، نمایش فشردهتر و تعمیمیافتهتری از یک بخش معین را در بر میگیرند، درست مانند اجزای اصلی PCA. برای تجزیه و تحلیل عمیق تر و مثال هایی برای ویژگی های تولید شده، به بخش 4.1 مراجعه کنید .
در مجموع، ما ترکیب های مختلفی از ویژگی های ورودی را برای مدل های ML و هر مجموعه داده به دست می آوریم. جدول 4 ترکیب هایی را که به عنوان ویژگی های ورودی برای مدل های ML اعمال می کنیم و در این مطالعه بیشتر مورد بحث قرار می دهیم، خلاصه می کند.
2.4. سطح مدل
ما مدلهای مناسب ML را برای تخمین اطلاعات سرعت متوسط روی ویژگیهای ورودی نسبتاً ناهمگن استخراجشده از دادههای شبکه جاده OSM انتخاب میکنیم. این مدلهای ML در چارچوب تخمین گنجانده شدهاند ( شکل 1 ، سطح چهارم را ببینید). مدلهای انتخابشده (به جدول A2 مراجعه کنید) از یک مدل رگرسیون خطی ساده (خطی) تا مدلهای رگرسیون پیچیدهتر مانند ماشینهای بردار پشتیبانی (SVM)، تقویت تطبیقی (AdaBoost)، رگرسیون بگینگ (Bagging)، تقویت گرادیان (GB)، متغیر است. درختان بسیار تصادفی (ET)، رگرسیون ریج (Ridge) تا مدل هایی که قادر به یادگیری بدون نظارت و همچنین تحت نظارت مانند نقشه های خودسازماندهی (SOM) هستند (برای مثال، [28] را ببینید .]). اکثر مدل های رگرسیون نظارت شده انتخاب شده با رگرسیون درختی مبتنی بر درخت های تصمیم (DTs) مرتبط هستند. آنها از یک ریشه و یک گره برگ تشکیل شده اند که توسط شاخه ها به هم مرتبط هستند. به طور کلی، DT مجموعه داده های آموزشی را در هر شاخه تقسیم می کند و بسته به، برای مثال، ویژگی های ورودی شبکه جاده ای OSM، زیرمجموعه هایی را تولید می کند [ 41 ].
در حالی که SOM در سطح ویژگی (به بخش 2.1 مراجعه کنید) به شیوه ای بدون نظارت اعمال می شود، SOM در سطح مدل به عنوان یک مدل رگرسیون نظارت شده عمل می کند. در این مورد خاص، وزنهای SOM نظارتشده با همان ابعاد متغیر هدف یعنی مقادیر میانگین سرعت مشخص میشوند. این وزنه ها تک بعدی هستند. در نهایت، ترکیب SOM بدون نظارت و نظارت شده قادر است وظیفه رگرسیون نظارت شده را به دلیل انتخاب BMU برای هر بخش جاده و پیوند BMU انتخاب شده به یک تخمین خاص انجام دهد (برای توصیف دقیق، به عنوان مثال، نگاه کنید به ، [ 39 ]).
فراپارامترهای مدل های رگرسیون مربوطه در جدول A2 خلاصه شده است . ابرپارامترها قبل از مرحله آموزش یک مدل ML انتخاب می شوند. ما فراپارامترها را با یک جستجوی شبکه پایه در ارتباط با برخی تنظیم دستی بدست می آوریم. در طول مرحله آموزش، مدلهای ML چارچوب برآورد بر روی سه مجموعه داده آموزشی مختلف که از سه مجموعه داده ناشی میشوند، آموزش داده میشوند: مجموعه داده BM، مجموعه داده NNSM، و مجموعه داده ترکیبی. هدف مرحله آموزش، پیوند دادن ویژگی های ورودی شبکه جاده OSM به اضافه ترکیب با ویژگی های مختلف جدید تولید شده (به بخش 2.3 مراجعه کنید ) به مقادیر میانگین سرعت است. همانطور که قبلا ذکر شد، تمام مدل های ML، به جز رگرسیون SOM، مرحله آموزش را صرفاً تحت نظارت انجام می دهند.
در طول مرحله آزمایش بعدی، مدلهای آموزشدیده چارچوب تخمین مقادیر میانگین سرعت را بر اساس ویژگیهای ورودی شبکه جاده OSM بهعلاوه ترکیبی با ویژگیهای مختلف جدید تولید شده هر یک از سه مجموعه داده آزمایشی پیشبینی میکنند. مقادیر میانگین سرعت پیش بینی شده (پیش بینی مدل) با مقادیر مرجع سرعت متوسط مقایسه می شود. عملکرد چارچوب برآورد برای هر مدل ML انتخاب شده بر اساس دو معیار ارزیابی می شود. ما ریشه میانگین مربعات خطا (RMSE) و ضریب تعیین را اعمال می کنیم آر2. اولی یک اندازه گیری خطا را در واحد متغیر هدف، کیلومتر در ساعت برمی گرداند، در حالی که دومی به عنوان یک اندازه گیری نسبی عمل می کند. آر2 مقادیر بین 0 و 1 را برمی گرداند که به موجب آن آر2=1(اینجا: آر2=100%) نشان می دهد که پیش بینی مدل ML کاملاً با داده ها مطابقت دارد. مدلهای مبتنی بر DT اهمیت ویژگیهای ورودی، اهمیت ویژگی، را به عنوان اطلاعات اضافی تولید میکنند. این اهمیت با اهمیت جینی یا میانگین کاهش ناخالصی برای هر ویژگی محاسبه می شودافjمطابق با معادله ( 1 ) (نگاه کنید به [ 42 ، 43 ]):
با تعداد درختان نتیrههستوسط مدل مبتنی بر درخت، درخت k-ام در مدل استفاده شده است φک، نسبت پ(تی)از بین نمونه هایی که به گره t می رسند ، ناخالصی کاهش می یابد Δمن(ستی،تی)از تقسیم s در گره t ، تعداد نمونه ها نتیدر گره t ، زیرمجموعه نمونه های یادگیری است Lتیافتادن به گره t ، برچسب y^تیاز گره t و گره های فرزند چپ و راست، تیلو تیr، از گره t .
3. نتایج
در این بخش، ما بر عملکرد چارچوب برآورد برای پیشبینی مقادیر متوسط سرعت، تأثیر ویژگیهای ورودی انتخابشده (به جدول 4 مراجعه کنید)، و مقایسه بین مقادیر پیشبینیشده و مرجع سرعت متوسط تمرکز میکنیم. علاوه بر این، ما نتایج چارچوب تخمین ML خود را با پیشبینی Fuzzy-FSE مبتنی بر قانون مقایسه میکنیم که به دانش دامنه [ 9 ] برای مجموعه داده BM و مجموعه داده NNSW نیاز دارد. علاوه بر این، هیچ رویکرد مبتنی بر ML در حال حاضر وجود ندارد که بتوانیم برای مقایسه خود از آن استفاده کنیم. در نتیجه، Fuzzy-FSE به طور کلی برای مجموعه داده های منطقه ای مختلف قابل اجرا نیست.
نتایج رگرسیون برای تخمین سرعت متوسط در همه مجموعههای داده با ویژگیهای ورودی پایه و ویژگیهای ورودی ترکیبی Basic + SOM در جدول 5 خلاصه شدهاند . ما نتایج چارچوب تخمینی را با ورودی ویژگی به حداقل رسیده، ویژگیهای SOM و PCA در جدول A3 ارائه میکنیم .
در بین تمام مدلهای انتخاب شده، ET بهترین نتایج رگرسیون را در سه مجموعه داده با حالتهای مختلف ویژگی ورودی به دست میآورد. RF، Bagging، GB، و همچنین تا حدی SVM منجر به یک رگرسیون متوسط همراه با ویژگی های ورودی Basic و Basic + SOM می شود. چارچوب تخمین ما مقادیر میانگین سرعت را با پیشبینی میکند آر2امتیازات در محدوده 78.39٪ تا 80.43٪ بر اساس داده های ورودی شبکه جاده OSM (ویژگی های ورودی اساسی) بسته به مجموعه داده های منطقه ای.
با توجه به مجموعه داده های ترکیبی، SVM، رگرسیون خطی، مدل Ridge و SOM نتایج بهتری را با ویژگی های ورودی پایه همراه با ویژگی های SOM ارائه می دهند. سایر مدل ها با ویژگی های ورودی Basic عملکرد بهتری دارند. در این حالت خاص از ویژگی های ورودی، بهترین عملکرد از آر2=80.43%توسط ET به دست می آید. برای حالت های ویژگی های ورودی پایه و پایه + SOM، محدوده RMSE برای همه مدل ها بین 10.35 کیلومتر در ساعت تا 14.36 کیلومتر در ساعت است، در حالی که کمترین مقدار RMSE متعلق به مدل ET است.
بدون هیچ ویژگی ورودی اضافی، ET نشان دهنده بهترین رگرسیور برای پیش بینی مقادیر متوسط سرعت با آن است آر2=79.34%در مجموعه داده BM. کمی ضعیف تر عمل می کند ( آر2=79.25%) در مورد ویژگی های ورودی پایه همراه با ویژگی های ورودی تولید شده SOM. اگر چه آر2نمرات کمتر از نمرات مجموعه داده های ترکیبی است، بهترین RMSE چارچوب برآورد توسط ET در مجموعه داده BM با 9.19کیلومتر در ساعت در مجموع، عملکرد رگرسیونی چارچوب تخمین ML از پیشبینی مبتنی بر قاعده فازی-FSE [ 9 ] با تقریباً 5 درصد نسبت به بهترین رگرسیون بهتر عمل میکند.
با تمرکز بر مجموعه داده NNSW، چارچوب تخمین به طور مشابه به مجموعه داده BM عمل می کند. باز هم، ET بهتر از سایر مدل های رگرسیون و رسیدن است آر2=78.39%با ویژگی های ورودی پایه به طور متوسط، میانگین عملکرد پیشبینی سرعت در مجموعه داده NNSW با چارچوب تخمین بدتر از پیشبینی با ویژگیهای ورودی دو مجموعه داده دیگر است. اکثر مدلهای ML از پیشبینی Fuzzy-FSE [ 9 ] مبتنی بر قانون از سرعت متوسط در مجموعه داده NNSW بهتر عمل میکنند.
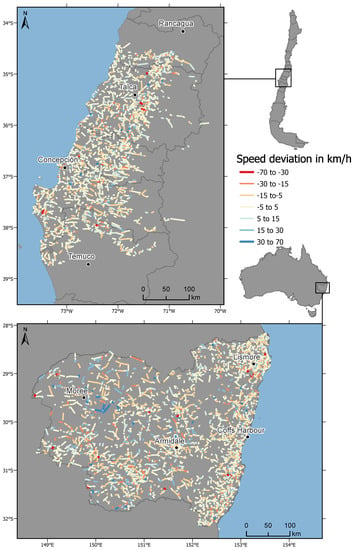
شکل 5 نمونه ای از نتایج رگرسیون مدل ET را در مقایسه با داده های مرجع در زیر مجموعه آزمایشی مجموعه داده ترکیبی نشان می دهد. انحراف سرعت بین مقادیر سرعت پیش بینی شده و واقعی محاسبه و رنگ آمیزی می شود. مقادیر منفی که به رنگ قرمز و نارنجی رنگ می شوند، نشان دهنده مقادیر سرعت پیش بینی شده کمتر از مقادیر سرعت مرجع هستند. این انحراف سازگاری عملکرد رگرسیون را در مورد یک بخش جاده خاص در مقیاس منطقه ای تسهیل می کند. در مورد تخمین سرعت متوسط، ET کمی دست کم می گیرد و سپس میانگین سرعت را بیش از حد برآورد می کند. تخمین بیش از حد عمدتاً دورتر از مناطق ساحلی، مناطق داخلی BM و منطقه NNSW رخ می دهد.
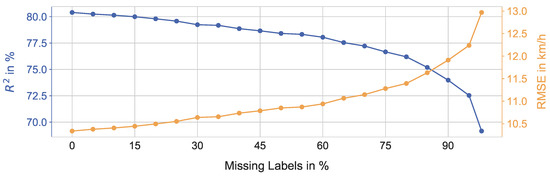
علاوه بر بررسیهای رسمی عملکرد تخمین، مطالعهای را برای تحلیل رفتار عملکرد رگرسیورهای ET برای مقدار دادههای برچسبگذاری شده طراحی کردیم. ما تغییری را با حذف نقاط داده برچسبگذاری شده برای شبیهسازی برچسبهای گمشده مجموعه داده آموزشی و در نتیجه در مرحله آموزش ایجاد میکنیم. بنابراین، تغییرات از آر2و آرماسEامتیاز بهترین مدل رگرسیون (ET) در شکل 6 نشان داده شده است . کیفیت پیش بینی کاهش می یابد آر2امتیاز از بالای 80% به تقریباً 75% می رسد و برای آن افزایش می یابد آرماسEامتیاز از کمتر از 10 کیلومتر در ساعت تا تقریباً 11.5کیلومتر در ساعت زمانی که 80 درصد برچسبهای زیرمجموعه آموزشی مجموعه داده ترکیبی از بین رفته باشد. هنگام تخمین سرعت متوسط با دادههای شبکه جادهای OSM، مدل ET با 80% برچسبهای گمشده، مشابه Fuzzy-FSE [ 9 ] مبتنی بر قانون، که برای کل زیر مجموعه آموزشی اعمال میشود، عمل میکند.
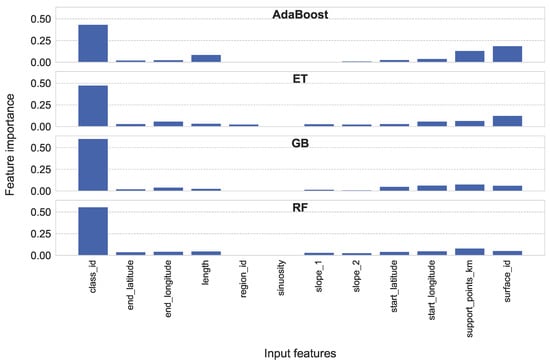
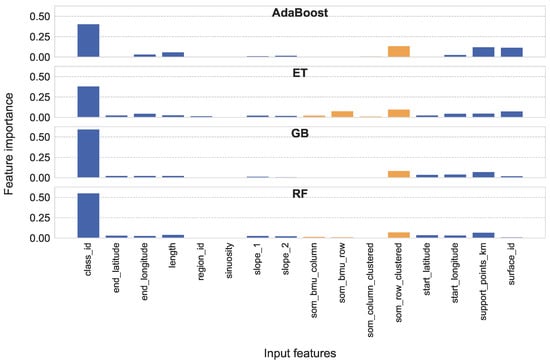
ما توزیع اهمیت ویژگی را برای ویژگی های ورودی پایه در شکل 7 نشان می دهیم . ترکیبی از ویژگی های ورودی پایه با چهار ویژگی ورودی تولید شده SOM در شکل 8 برای مدل های رگرسیون مبتنی بر درخت، AdaBoost، ET، GB و RF آورده شده است.
مهمترین ویژگی برای همه رگرسیورهای DT class_id است . ویژگی های اضافی توسط چهار مدل متفاوت ارزیابی شده است. با توجه به چهار ویژگی تولید شده SOM، این ویژگی ها در صورت گنجاندن، دومین ویژگی مهم برای چهار مدل هستند.
4. بحث
یکی از اهداف روششناختی اصلی، بررسی پتانسیل پیشبینی سرعت متوسط با توجه به دادههای ورودی شبکه جادهای OSM است. تا کنون، توجه کمی به استفاده از ML در زمینه تخمین اطلاعات سرعت متوسط، به ترتیب، زمان سفر، با مجموعه داده های OSM شده است. رویکردهای ML میتوانند رگرسیونها را بدون اعمال دانش (دامنه) بیشتر از بخش جاده که باید با اطلاعات سرعت متوسط برچسبگذاری شوند، انجام دهند. به طور کلی، این رویکردها بدون نیاز به مهندسی ویژگی های جدید مبتنی بر دانش دامنه، مانند رویکرد فازی-FSE، مبتنی بر داده هستند.
چارچوب تخمین ما برای سه مجموعه داده اعمال میشود که دو منطقه مجزا در شیلی و استرالیا و طیف وسیعی از مقادیر میانگین سرعت در هر کلاس جاده را پوشش میدهند ( شکل 2 را ببینید ). ما ترکیب های مختلفی از ویژگی های ورودی را تنظیم می کنیم: Basic، Basic + SOM، SOM، و PCA ( جدول 4 را ببینید ). بنابراین، ما می توانیم نتایج پیش بینی را بسته به مجموعه داده و ویژگی ورودی اعمال شده ارزیابی و تجزیه و تحلیل کنیم.
ابتدا، عملکرد و کاربرد چارچوب برآورد را در بخش 4.1 مورد بحث قرار می دهیم . علاوه بر این، یافتههای ضروری در مورد مجموعه دادههای مختلف و حالتهای ویژگی ورودی را خلاصه میکنیم. دوم، عملکرد چارچوب برآورد با فازی-FSE در مجموعه داده های BM و NNSW از یک دیدگاه کلی مقایسه می شود (به بخش 4.2 مراجعه کنید ). سوم، ما اهمیت ویژگی رگرسیورهای مبتنی بر درخت را در نظر می گیریم و ویژگی های مهم را با پارامترهای ورودی فازی-FSE با پارامترهای ورودی قوانین فازی-FSE در بخش 4.3 مقایسه می کنیم . در نهایت، ما محدودیتهای مربوط به کاربرد چارچوب تخمین مبتنی بر ML خود را مورد بحث قرار میدهیم (به بخش 4.4 مراجعه کنید ).
4.1. عملکرد و کاربرد چارچوب برآورد
هنگام ارزیابی چارچوب تخمین خود، به جای تجزیه و تحلیل منطقه ای مجموعه داده های زیربنایی، بر عملکرد و کاربرد آن تمرکز می کنیم. به طور کلی، نتایج رگرسیون چارچوب برآورد، کاربرد آن را هنگام پیشبینی میانگین سرعت بر اساس شبکه جادهای OSM نشان میدهد. چارچوب ما بدون خطاهای سیستماتیک کار می کند ( جدول 5 و جدول A3 و شکل 5 را ببینید )، اگرچه، برای برخی از مدل های ML، تنظیم هایپرپارامتر می تواند اندکی بهبود یابد. این یافته با توزیع تصادفی انحرافات سرعت متوسط برای مجموعه داده ترکیبی و حالت ویژگی ورودی پایه در شکل 5 تاکید شده است .
با توجه به سه مجموعه داده مورد استفاده برای مدلهای ML، چارچوب برآورد عملکرد خود را در مجموعه داده ترکیبی به دلیل افزایش نقاط داده بهبود میبخشد. مدل ET همیشه بهترین نتایج رگرسیون را ارائه می دهد. ET بهترین نتیجه خود را از آر2امتیاز در مجموعه داده ترکیبی با ویژگی های ورودی شبکه جاده ای اساسی OSM، اگرچه بهترین امتیاز RMSE در مجموعه داده BM رخ می دهد. این اثر محتمل به نظر می رسد زیرا مقدار بیشتری از نقاط داده مجموعه داده ترکیبی را مشخص می کند، اما به طور همزمان، داده ها ناهمگن تر از داده های BM هستند ( شکل 2 را ببینید ). در مجموعه داده BM، محدوده مقادیر سرعت ( شکل 3 را ببینید) کوچکتر از مجموعه داده NNSW است، که ممکن است یکی از دلایل عملکرد تخمین بهتر چارچوب در مجموعه داده BM باشد.
با توجه به حالتهای مختلف ویژگی ورودی، متوجه میشویم که حالت پایه با ویژگیهای ورودی شبکه جاده OSM به بهترین عملکرد رگرسیون کلی منجر میشود. تنها با استفاده از ویژگی های ورودی تولید شده SOM یا دو ویژگی ورودی PCA، نتایج رگرسیون مجموعه داده های منطقه ای با ویژگی های ورودی PCA بهتر است. با این حال، در مجموعه داده ترکیبی، ویژگی های ورودی تولید شده SOM برای چارچوب تخمین به دلیل توانایی SOM برای مقابله با مجموعه داده های ناهمگن ارزشمندتر هستند. این جنبه همچنین با نگاه کردن به جدول A3 قابل تشخیص است ، جایی که ویژگیهای تولید شده SOM به تنهایی اطلاعات کافی برای توانمندسازی مدل ET را در بر میگیرد. آر2=71.25و RMSE =12.52کیلومتر/ساعت. شکل 9 این نتایج را به صورت نمونه برای مجموعه داده BM نشان می دهد. در اینجا، som_column و som_row تولید شده با توجه به دو ویژگی معنی دار دنیای واقعی، کلاس جاده و سرعت متوسط رنگ می شوند. پس از تکمیل فرآیند آموزشی SOM بدون نظارت، کلاس های جاده غالب ( شکل 9 ، سمت راست) و مقادیر میانگین سرعت ( شکل 9)، سمت چپ) برای هر گره SOM منفرد نشان داده شده است. توجه داشته باشید که SOM اعمال شده داده های ورودی شبکه جاده OSM را به صورت بدون نظارت خوشه بندی می کند. ما برچسبهای کلاس جاده مربوطه و اطلاعات میانگین سرعت را فقط برای تجسم خوشهها اضافه کردیم. این خوشه های مختلف توسط کلاس های مشابه یا مقادیر میانگین سرعت مشابه ایجاد می شوند. بنابراین، ما اطلاعاتی در مورد شباهت های بین کلاس های جاده یا مقادیر سرعت به دست می آوریم. علاوه بر این، تفاوت بین نقاط داده از همان کلاس ها قابل تشخیص است. برای هر دو مورد، ساختار SOM تولید شده با شهود انسان طنین انداز می شود که کلاس جاده و میانگین سرعت عوامل اساسی در طبقه بندی جاده ها هستند. با این حال، میتوانیم تشخیص دهیم که برخی از جادهها متفاوت از جادههای دیگر از همان نوع یا مشخصات سرعت هستند. این یافته نشان میدهد که واریانس بینکلاسی نسبتاً بالاست و وظیفهای بزرگ برای هر مدل ML است. واریانس هنگام مشاهده نمودارهای یکسان برای مجموعه داده ترکیبی افزایش می یابد (نگاه کنید به شکل 10 ). ما متوجه شدیم که واریانس معنیدارتر منجر به نواحی شکافدار بیشتر در شبکه خروجی SOM دو بعدی میشود. با این وجود، ساختار کلی هنوز با شهود انسان سازگار است و بسیار قابل تفسیر است، که یکی از مزایای خوشهبندی SOM بدون نظارت است.
تولید داده های مرجع سرعت متوسط زمان بر و پرهزینه است، که اغلب منجر به داده های آموزشی پراکنده می شود. بنابراین، ما رفتار رگرسیور ET را روی مجموعه داده ترکیبی با ویژگیهای ورودی پایه با شبیهسازی برچسبهای گمشده در مجموعه داده آموزشی با کاهش تدریجی تعداد نقاط داده آموزشی بررسی میکنیم ( شکل 6 را ببینید ). را آر2نمرات از بالای 80٪ به 78٪ کاهش می یابد در حالی که برچسب های گم شده از 0٪ به 60٪ افزایش می یابد. این یافته نشان میدهد که میتوانیم از نیمی از دادههای برچسبگذاری شده مجموعه داده آموزشی بر روی مجموعه داده ترکیبی برای پیشبینی سرعت متوسط با دقت قابل قبول برای دو منطقه مختلف استفاده کنیم. برای تعمیم تحقیقات در مورد تعداد نقاط داده برچسبگذاری شده، باید مجموعه دادههای اضافی از مناطق مختلف تولید کنیم.
سرعت متوسط برای مجموعه داده های منطقه ای مختلف و مجموعه داده های ترکیبی توسط اکثر مدل های رگرسیون به خوبی پیش بینی می شود. این یافته بر اساس بهترین نتایج رگرسیون ثبت شده است آر2در محدوده 76.38٪ تا 80.43٪. رگرسیور ET امتیازات RMSE را بین 1.89 کیلومتر در ساعت تا 2.33 کیلومتر در ساعت کمتر از RMSE فازی-FSE به دست می آورد. عملکرد عالی نتیجه انتخاب مدل های ML مناسب و تقسیم تصادفی بین زیر مجموعه های آموزشی و آزمایشی است ( شکل 3 را ببینید ). از آنجایی که مقادیر میانگین سرعت به کلاسهای جادهای خاص مرتبط است، ما معمولاً گمراه میشویم که هر class_id ممکن است حاوی مقادیری در فاصله نزدیک به یکدیگر باشد. در واقع، همانطور که در شکل 2 نشان داده شده است، مشخصات سرعت پروفیل سرعت هر کلاس جاده تا حد زیادی متفاوت است و مقایسه کلاس های جاده مجموعه داده های منطقه ای مختلف با یکدیگر دشوار است. با توجه به تنوع مقادیر میانگین سرعت به عنوان یک متغیر هدف، چارچوب تخمین مبتنی بر ML اولین برداشت از قابلیت تعمیم آن را نشان میدهد. برای ارزیابی و تأیید کامل قابلیت تعمیم بالقوه، چارچوب تخمین باید برای مجموعه دادههای اضافی مناطق مختلف در سراسر جهان اعمال شود. بنابراین، چارچوب برآورد میانگین سرعت بخشهای جاده را با دادههای شبکه جاده OSM پیشبینی میکند. هیچ داده اضافی و دانش دامنه مورد استفاده یا مورد نیاز نیست. علاوه بر این، تنظیم پیچیدهتر فراپارامترها میتواند نتایج رگرسیون خوب را کمی بهبود بخشد.
4.2. مقایسه عملکرد چارچوب برآورد و فازی-FSE در مجموعه داده BM و NNSW
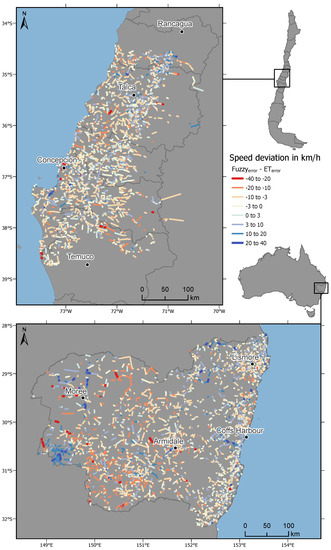
هنگام مقایسه عملکرد چارچوب تخمین ما با Fuzzy-FSE اخیراً پیادهسازی شده، متوجه میشویم که Fuzzy-FSE با دانش دامنه در مجموعه دادههای BM و NNSW نسبت به چارچوب ما در حالتهای ورودی PCA و SOM عملکرد بهتری دارد. جدای از این، چارچوب تخمین از تخمین فازی-FSE در مجموعه داده BM و NNSW با حالت ویژگی ورودی Basic و Basic + SOM بهتر عمل می کند. ما همچنین می خواهیم اضافه کنیم که ویژگی های ورودی پایه شبیه داده های ورودی مورد استفاده برای Fuzzy-FSE هستند. شکل 11 نمونه ای از انحراف سرعت بین خطای تخمین فازی-FSE و رگرسیور ET با ویژگی های ورودی پایه در زیر مجموعه تست BM و NNSW است. خطاهای فردی به شرح زیر محاسبه می شوند: Fuzzy_error = Fuzzy-FSE prediction - مقادیر سرعت مرجعو ET_error = پیش بینی ET - مقادیر سرعت مرجع . میانگین انحراف سرعت به صورت Fuzzy_error - ET_error تعریف می شود . این انحراف سرعت امکان مقایسه خطاهای سیستماتیک احتمالی را از دیدگاه منطقه ای فراهم می کند. همانطور که در شکل 11 نشان داده شده است، توزیع تصادفی انحرافات در دو منطقه عمدتاً در مناطق داخلی منطقه NNSW و منطقه ساحلی منطقه BM رخ می دهد. انحراف بین خطاهای پیشبینی در منطقه ساحلی NNWS و در امتداد Ruta 5 در BM مرکزی نسبتاً کم است. عملکرد تخمین پایینتر Fuzzy-FSE به ویژه در بخشهای جاده مرکزی و غربی دادههای NNSW زیرمجموعه آزمایشی قابل مشاهده است. مجدداً، عملکرد بهتر چارچوب تخمین و Fuzzy-FSE در مجموعه داده BM مستند شده است ( شکل 11 ، نقشه بالا را ببینید).
4.3. تجزیه و تحلیل اهمیت ویژگی DT
اهمیت ویژگی مدلهای DT ما را قادر میسازد تا دادههای شبکه جاده OSM را با میانگین سرعت بخشهای جاده بررسی، درک و پیوند دهیم. ما توجه می کنیم که اهمیت ویژگی را در درجه اول از منظر ML تجزیه و تحلیل می کنیم. شکل نمودارهای اهمیت ویژگی ( شکل 7 و شکل 8 را ببینید ) نسبتاً شبیه به چند ویژگی استاندارد است که برای هر رگرسیور DT برجسته شده است. با توجه به اهمیت ویژگی مدلهای DT در مجموعه داده ترکیبی با ویژگیهای ورودی Basic و همچنین Basic + SOM، یک ویژگی مهم class_id است . این اهمیت مربوط به میانگین سرعت یک بخش جاده است و مشابه پارامترهای ورودی ارزشمند کلاس جاده است.فازی-FSE. علاوه بر این، از نظر انسانی، class_id بهترین ویژگی برای مرتبسازی اطلاعات سرعت متوسط به نظر میرسد. برای حالت ویژگی ورودی پایه و مدل AdaBoost و ET، دومین ویژگی مهم، surface_id است . GB و RF support_points_km را به عنوان دومین ویژگی مهم فهرست می کنند. با این حال، عملکرد رگرسیون آنها ضعیف تر از عملکرد رگرسیونی مدل ET است. باز هم، surface_id به عنوان یک پارامتر ورودی برای ایجاد تابع عضویت در Fuzzy-FSE استفاده می شود. از این رو، اهمیت ویژگی رگرسیورهای مبتنی بر درخت و پارامترهای ورودی فازی-FSE شباهت هایی را نشان می دهد. از دیدگاه انسانی، اهمیت سطح_ idمنطقی است، زیرا سطح یک بخش جاده می تواند حتی در همان کلاس جاده متفاوت باشد.
هنگام استفاده از ویژگی های ورودی تولید شده SOM برای کار رگرسیون، همه رگرسیورهای مبتنی بر درخت، به جز رگرسیور RF، ویژگی som_row_clustered را به عنوان دومین ویژگی مهم بعد از class_id رتبه بندی می کنند . این یافته با نتیجه رگرسیون ترکیب شده است آر2=71.25%، نشان می دهد که ویژگی های تولید شده SOM حاوی اطلاعات کافی برای فعال کردن ET برای عملکرد رگرسیون خوب است. به طور کلی، سایر ویژگی های ورودی برای رگرسیورهای DT غیر قابل استفاده تر هستند.
4.4. محدودیت های چارچوب برآورد
با وجود عملکرد قوی چارچوب تخمین، محدودیتهای کمی وجود دارد و نیاز به بحث دارد. به عنوان اولین محدودیت، چارچوب ما بر روی سطح مجموعه دادههای شبکه جادهای OSM، که به صورت رایگان در دسترس است، و بر دادههای مرجع GD-API متکی است. دومی به صورت رایگان در دسترس نیست.
علاوه بر این، ما فرض میکنیم که GD-API مقادیر متوسط سرعت بخشهای جاده را تولید میکند که به عنوان دادههای مرجع قابل استفاده است، اما همچنین با اختلافات کوچک در مورد دادههای جاده OSM مشخص میشود. این عدم تطابق محدودیت دوم را تشکیل می دهد. از آنجایی که عملکرد مدلهای ML تحتتاثیر دقت و صحت دادههای مرجع قرار میگیرد، نتایج رگرسیون رگرسیون انتخابشده را میتوان با تطبیق بهتر دادههای شبکه جادهای OSM و مقادیر میانگین سرعت افزایش داد.
محدودیت سوم مربوط به تمایز اصلی بین شبکه راه های روستایی و شهری است. همانطور که قبلا ذکر شد، هدف ما صرفاً پیشبینی میانگین سرعت بخشهای جادهای روستایی است. چارچوب ارائه شده برای پیش بینی میانگین سرعت در شبکه های جاده ای شهری طراحی نشده است. از آنجایی که تخمین سرعت متوسط در مناطق شهری به پارامترهای اضافی مانند ترافیک بستگی دارد، چارچوب تخمین ما باید به طور اساسی برای رسیدگی به این وظیفه رگرسیون تطبیق داده شود. به عنوان مثال، بخش های جاده کوتاه تر از 600 مترباید در مجموعه داده گنجانده شود. دلیل اصلی این امر این است که شبکه راه های شهری عمدتاً از چنین جاده های کوتاهی تشکیل شده است. علاوه بر این، ویژگی های ورودی متفاوتی مانند داده های ترافیکی مورد نیاز است.
به عنوان چهارمین محدودیت، اشاره می کنیم که چارچوب تخمین ما به عنوان یک گام اولیه به سمت یک رویکرد عمومی و مبتنی بر داده برای تخمین میانگین سرعت تنها با داده های شبکه جاده ای OSM طراحی شده است. مطالعه ما توانایی چارچوب تخمین مبتنی بر ML پیشنهادی را برای پیشبینی مثالی سرعت متوسط برای مجموعه دادههای مختلف و مستقل از منطقه نشان داد. برای تأیید تعمیم، باید چارچوب تخمین را اصلاح و تقویت کنیم و آن را در مجموعه دادههای بیشتری اعمال کنیم. به عنوان مثال، برخی از مدلهای ML، اختلافات منطقهای در مجموعه دادههای BM و NNSW را به خوبی کنترل نمیکنند. این مدلها میتوانند با رویکردهای پیچیدهتر ML جایگزین شوند که میتوانند به طور همزمان با مجموعه دادههای بزرگتر کنار بیایند.
5. نتیجه گیری و چشم انداز
در این مقاله، ما یک چارچوب تخمینی برای سرعت متوسط در شبکههای جادهای روستایی بر اساس یک گردش کار معمولی ML و دادههای شبکه جاده OSM ایجاد و ارزیابی میکنیم. این چارچوب تخمین ML اولین رویکرد مبتنی بر داده برای پیشبینی سرعت متوسط تنها با دادههای شبکه جاده OSM به عنوان ورودی است. چارچوب برآورد در بخشهای جاده از سه مجموعه داده که مناطق مختلف را پوشش میدهند اعمال میشود: مجموعه داده BM، مجموعه داده NNSW و مجموعه داده ترکیبی. ما ویژگی های مجموعه داده ها و تولید داده های مرجع سرعت متوسط را بر اساس Goggle Directions API توصیف می کنیم. دو رویکرد ML بدون نظارت متمایز، SOM و PCA، در چارچوب تخمین گنجانده شده اند تا ویژگی های ورودی جدید ایجاد کنند. بخصوص، ویژگی های مبتنی بر SOM بینش عمیق تری نسبت به داده ها ارائه می دهند و در عین حال قادر به خوشه بندی داده ها به روشی معنادار هستند. یک ارزیابی دقیق از عملکرد رگرسیون با حالتهای مختلف ویژگیهای ورودی برای هر مدل رگرسیون ارائه شده است. ما نتایج رگرسیون بهترین مدل ML را برای دو منطقه مورد مطالعه تجسم میکنیم. علاوه بر این، ما عملکرد پیشبینی چارچوب تخمین مبتنی بر ML را با عملکرد پیشبینی فازی-FSE اخیر خود مقایسه میکنیم که بر اساس قوانین و دانش دامنه و تنها رویکرد موجود برای این کار رگرسیونی است.
همانطور که نشان داده شد، اکثر مدل های ML انتخاب شده ما می توانند وظیفه رگرسیون را در مجموعه داده های مختلف و ناهمگن به خوبی انجام دهند. بنابراین، ما میتوانیم سرعت متوسط را تنها با ویژگیهای ورودی شبکه جاده OSM تخمین بزنیم. در زمینه پیشبینی سرعت متوسط، ML یک جایگزین مبتنی بر داده برای رویکردهای رایج کاربردی در برنامههای مسیریابی مانند پروفایلهای سرعت ثابت و Fuzzy-FSE مبتنی بر قانون ارائه میکند که بر دانش دامنه متکی است. علاوه بر این، عملکرد تخمین چارچوب ما از عملکرد Fuzzy-FSE در دو مجموعه داده مجزا و مجموعه داده ترکیبی بهتر است. نتیجه می گیریم که درختان بسیار تصادفی مدل ML (ET) سودمندترین مدل در رابطه با وظایف رگرسیون اساسی است. علاوه بر این، SOM بدون نظارت قادر به مدیریت مجموعه دادههای ناهمگن برای تجسم اطلاعات کافی در ویژگیهای ورودی تولید شده برای فعال کردن مدل ET برای دستیابی به نتایج رگرسیون خوب است. به طور کلی، بهترین عملکرد چارچوب برآورد توسط مدل ET بر روی مجموعه داده ترکیبی به دست می آید. یکی از مزیتهای اصلی چارچوب ما، قابلیت کاربرد برای تنوع بخشهای جادهای از نظر کلاسهای جاده و وابستگی منطقهای آنها است. با این حال، چارچوب برآورد برای پیشبینی میانگین سرعت جادههای روستایی طراحی شده است. بنابراین، اگر چارچوب ما برای برآورد میانگین سرعت جادههای شهری اعمال شود، نیاز به تطبیق دارد. بهترین عملکرد چارچوب برآورد توسط مدل ET بر روی مجموعه داده ترکیبی به دست می آید. یکی از مزیتهای اصلی چارچوب ما، قابلیت کاربرد برای تنوع بخشهای جادهای از نظر کلاسهای جاده و وابستگی منطقهای آنها است. با این حال، چارچوب برآورد برای پیشبینی میانگین سرعت جادههای روستایی طراحی شده است. بنابراین، اگر چارچوب ما برای برآورد میانگین سرعت جادههای شهری اعمال شود، نیاز به تطبیق دارد. بهترین عملکرد چارچوب برآورد توسط مدل ET بر روی مجموعه داده ترکیبی به دست می آید. یکی از مزیتهای اصلی چارچوب ما، قابلیت کاربرد برای تنوع بخشهای جادهای از نظر کلاسهای جاده و وابستگی منطقهای آنها است. با این حال، چارچوب برآورد برای پیشبینی میانگین سرعت جادههای روستایی طراحی شده است. بنابراین، اگر چارچوب ما برای برآورد میانگین سرعت جادههای شهری اعمال شود، نیاز به تطبیق دارد.
برای نتیجهگیری، این مشارکت گامی اولیه به سمت یک رویکرد عمومی برای تخمین میانگین سرعت بخشهای مختلف جاده با دادههای شبکه جاده OSM به عنوان ورودی است. این یافته از آنجایی که بخشهای جادهای از دو منطقه مختلف در شیلی و استرالیا به عنوان مجموعه دادههای نمونه در مطالعه گنجانده شدهاند، تاکید میشود. چارچوب تخمین را می توان به عنوان مثال در موتورهای مسیریابی زمانی که از قبل بر روی داده های منطقه مورد مطالعه تنظیم شده است استفاده کرد. علاوه بر این، به عنوان ابزاری برای داده های شبکه جاده ای OSM برای تولید مقادیر متوسط سرعت گمشده عمل می کند. مطالعات و بررسیهای بیشتر در زیرساختهای حیاتی نیز میتواند از تخمین دقیقتری از مقادیر میانگین سرعت بهرهمند شود. هر گونه تغییر در بخش های روش شناختی اساسی ( شکل 1 را ببینید، سطح داده تا سطح مدل) صرفاً عملکرد تخمین خوب را بهبود می بخشد. با این حال، می توان به تنظیمات بیشتر چارچوب برآورد و اجرای آن نزدیک شد. برای مثال، مدلهای ML موجود در چارچوب تخمین را میتوان به کارآمدترین مدلها تقلیل داد. علاوه بر این، ترکیبی از رویکرد فازی مبتنی بر قانون و درختهای تصمیم، FuzzyDT، میتواند برای یادگیری قوانین فازی در طول یک مرحله آموزش بررسی شود. بررسیها همچنین میتوانند بر تخمین عمومیتر سرعت متوسط بر اساس چارچوب ما تمرکز کنند. این توانایی های تعمیم را می توان با در نظر گرفتن چندین بخش جاده از مناطق بسیار بیشتری در سراسر جهان فعال کرد. گنجاندن دادههای بیشتر، استفاده و ارزیابی مدلهای یادگیری عمیق را تقویت میکند.






بدون دیدگاه