

تشخیص خودکار جاده، در مناطق شهری متراکم، یک برنامه چالش برانگیز در جامعه سنجش از دور است. این عمدتاً به دلیل تغییرات فیزیکی و هندسی پیکسل های جاده، شباهت طیفی آنها با سایر ویژگی ها مانند ساختمان ها، پارکینگ ها و پیاده روها و انسداد توسط وسایل نقلیه و درختان است. این مشکلات موانع واقعی در تشخیص و شناسایی دقیق جاده های شهری از تصاویر ماهواره ای با وضوح بالا هستند. یکی از راهبردهای امیدوارکننده برای مقابله با این مشکل استفاده از داده های چند حسگر برای کاهش عدم قطعیت تشخیص است. در این مقاله، یک چارچوب تحلیل مبتنی بر شی یکپارچه برای شناسایی و استخراج انواع مختلف جادههای شهری از تصاویر نوری با وضوح بالا و دادههای Lidar توسعه داده شد. روش پیشنهادی با استفاده از یک رویکرد قانون مدار مبتنی بر استراتژی پوشش طراحی و اجرا شده است. دقت کلی (OA) نقشه راه نهایی 89.2 درصد و ضریب توافق کاپا 0.83 بود که کارایی و عملکرد روش را در شرایط مختلف و صداهای بین کلاسی نشان می دهد. نتایج همچنین توانایی بالای این روش مبتنی بر شی را در شناسایی همزمان طیف وسیعی از عناصر جاده در مناطق پیچیده شهری با استفاده از تصاویر ماهوارهای با وضوح بالا و دادههای Lidar نشان میدهد.
کلید واژه ها
تصاویر ماهواره ای با وضوح بالا ، داده های لیدار ، تجزیه و تحلیل مبتنی بر شی ، استخراج ویژگی
1. مقدمه
با توجه به اهمیت اطلاعات جغرافیایی شبکههای جادهای در مناطق شهری و برون شهری، در دهههای اخیر، تعداد زیادی کار تحقیقاتی برجسته در زمینه تشخیص خودکار جادهها انجام شده است [ 1 ] [ 2 ] . این روش تشخیص، به ویژه در مناطق شهری متراکم، یک مشکل چالش برانگیز واقعی در جامعه سنجش از دور است. این عمدتا به دلیل تغییرات طیفی و فضایی پیکسل های جاده، شباهت طیفی جاده ها به سایر ویژگی ها مانند ساختمان ها، پارکینگ ها و پیاده روها و انسداد توسط وسایل نقلیه و درختان است. این مشکلات موانع واقعی برای تشخیص و شناسایی دقیق جاده های شهری از تصاویر ماهواره ای با وضوح بالا هستند. دیشا و ساروها [ 4] دو روش خودکار و نیمه خودکار برای تشخیص جاده های شهری از تصاویر ماهواره ای با وضوح بالا پیشنهاد کرد. در روش نيمه اتوماتيك نياز به ارائه چند نقطه بذر با توصيف درشت جاده ها است. سپس از مدل مار برای استخراج شبکه جاده ای استفاده شده است. در روش خودکار، فازی C-Means (FCM)، به عنوان یک الگوریتم خوشهبندی بدون نظارت، برای طبقهبندی تصاویر ماهوارهای استفاده میشود. بنابراین، Hough Transform در پنجرهای اعمال میشود تا کاندیداهای بخش را دریافت کند، که استحکام روش را افزایش میدهد. یک تابع تناسب اندام نیز برای گروه بندی بخش ها استفاده می شود. مقادیر عضویت خطوط اتصال برای اتصال بخش های گروه بندی شده استفاده می شود. در نهایت، پیکسلهای جادهای که به اشتباه طبقهبندی شدهاند حذف میشوند و محورهای مرکزی جادهها استخراج میشوند. بهیرود و منگالا [ 5] یک روش تشخیص جاده را بر اساس ترکیب عملگر گرادیان و اسکلتسازی ارائه کرد. آنها از عملگرهای فرعی مانند فیلتر کردن و آستانه گذاری برای پیش پردازش داده ها استفاده کردند و در نهایت با استفاده از عملگرهای مورفولوژیکی برای شناسایی و نقشه برداری جاده ها در مناطق روستایی، یک طرح رنگی ایجاد کردند. موریا و همکاران [ 6 ] چارچوب تشخیص جاده دو مرحله ای را از تصاویر انجام داد. اول، استفاده از طبقهبندی بدون نظارت k-means برای خوشهبندی تصویر در پیکسلهای جاده و غیر جاده. این ممکن است برخی از پیکسلهای نامربوط، مانند پیکسلهای ساختمانها یا پارکینگها را در کلاس جاده به اشتباه طبقهبندی کند. بنابراین، در مرحله بعد، توابع مورفولوژیکی برای حذف این پیکسل های طبقه بندی اشتباه اعمال شد.
در تحقیقات یینگ و همکاران. [ 7 ]، یک الگوریتم سلسله مراتبی برای تشخیص جاده از مدل های رقومی ارتفاع استفاده شد. برای این منظور از عوامل مختلفی مانند ارتفاع، شدت، ویژگیهای مورفولوژیکی و سایر ویژگیهای محلی استفاده شده است. سپس، روشهای فیلتر مورفولوژیکی محلی، مرزها و جزئیات پروفیلهای جاده را شناسایی کردند. شما و ژائو [ 8] جاده ها را از داده های Lidar شناسایی کرد. ابتدا ابر نقطه لیدار به نقاط زمینی و طبقات بالای زمینی تقسیم شد. سپس ساختمان ها و درختان با به حداقل رساندن انرژی متمایز شدند. در مرحله بعد، قابهای ساختاری برای جستجوی جادهها در میان دادههای شدت طراحی و اجرا شدند. سپس عرض و جهت جاده با استفاده از نقشه نمره گذاری شد. این فرآیند جستجوی محلی فقط جاده های نامزد را تعیین می کند. پس از آن، یک شبکه مارکویی برای یافتن جاده های کشف نشده استفاده می شد. ترکیب تناسب اندام فریم محلی و میدان تصادفی مارکوف (MRF)، به طور کلی، به تشخیص دقیق تر و کامل تر جاده منجر می شود. پنگ [ 9] هم از شدت و هم ارتفاع از داده های لیدار برای تشخیص جاده شهری استفاده کرد. ابتدا دادههای لیدار فیلتر شدند و با استفاده از یک شبکه نامنظم مثلثی (TIN) به عنوان نقاط زمینی یا بالای زمین طبقهبندی شدند. سپس ابرهای نقطه لیدار که متعلق به کلاس زمینی هستند به دو دسته جاده ای و غیر جاده ای طبقه بندی شدند. این طبقه بندی بر اساس اطلاعات روشنایی انجام شد. بنابراین مدل TIN دقت تشخیص نقطه جاده را بهبود بخشید. سیلوا و همکاران [ 10 ] روشی مبتنی بر تبدیل رادون برای تشخیص جاده از دادههای Lidar و تصاویر هوایی با وضوح بالا معرفی کرد. این روش به طور مکرر بخش های خط را پیدا می کند و خطوط مرکزی جاده ها را تولید می کند که از این بخش ها شروع می شوند. چارچوبی مبتنی بر استفاده از ویژگی های متعدد توسط Xiangyun و همکاران پیشنهاد و ارزیابی شد. [ 11] . این روش خطوط مرکزی جاده را از نقاط زمین باقی مانده پس از فیلتر تشخیص می دهد. ایده اصلی این روش این است که به طور کارآمدی اولیههای هندسی صاف خطوط مرکزی جاده بالقوه را شناسایی کند و ویژگیهای غیر جادهای مانند پارکینگها و زمین خالی را از جادهها جدا کند. این روش از سه مرحله اصلی تشکیل شده است: 1) خوشه بندی فضایی بر اساس ویژگی های چندگانه با استفاده از یک تغییر میانگین تطبیقی برای تشخیص نقاط مرکزی جاده ها، 2) رای گیری تانسور استیک برای افزایش ویژگی های خطی برجسته، و 3) تبدیل Hough وزنی برای استخراج قوس اولیه خطوط مرکزی جاده آنها کامل بودن و صحت نسبتاً بالایی را برای دو مجموعه داده معیار ISPRS Vaihingen و Toronto به دست آوردند. همچنین، آنها اظهار داشتند که این روش می تواند عملکرد بهتری نسبت به روش های تطبیق قالب و دیسک کدگذاری شده فاز داشته باشد. جینلیانگ و همکاران [12 ] از یک مدل معنایی مبتنی بر مفهوم شئ-ویژگی-رابطه (OAR) شناخت انسان برای انجام یک مطالعه تجربی بر روی استخراج اطلاعات جاده از تصاویر چندطیفی Quick Bird استفاده کرد. نتایج نشان دهنده تشخیص نسبتا دقیق طول و عرض جاده ها بود.
برای تشخیص جاده، تصاویر پانکروماتیک یا چند طیفی، بهویژه در مناطق شهری، به دلیل پیچیدگیهای اضافی، نتایج مبهمی را به همراه خواهند داشت. برای مثال، در یک عکس هوایی یا یک تصویر ماهوارهای با وضوح بالا، جادهها و ساختمانها شبیه هم به نظر میرسند، زیرا مصالح ساختمانی آنها معمولاً یکسان است. در نتیجه، آنها را نمی توان به راحتی تشخیص داد [ 13 ]. این زمانی بدتر می شود که آنها در سایه باشند یا توسط سقف یا دیوارهای ساختمان های بلند پوشیده شوند. بر این اساس، نه روش خودکار و نه نیمه خودکار در این مناطق شهری متراکم کاملاً قابل اعتماد نخواهد بود [ 14 ].] . علاوه بر این، خروجی روش هایی که از تصاویر دو بعدی استفاده می کنند نسبت به روش هایی که ورودی های سه بعدی دارند مبهم تر است. دادههای نقطهای لیدار این پتانسیل را دارند که ویژگیهای سه بعدی را از یکدیگر متمایز کنند، سه بعدی را از دو بعدی متمایز کنند و ویژگیهای دو بعدی را از یکدیگر متمایز کنند. با این حال، دادههای شدت لیدار تحت تأثیر میزان بالای نویز قرار میگیرند و بنابراین قادر به تشخیص جادهها از ویژگیهایی با قدرت سیگنال برگشت مشابه نیستند. در نتیجه، پتانسیل کامل داده های Lidar را نمی توان از داده های خام [ 15 ] [ 16 ] بهره برداری کرد. به نظر می رسد ترکیب این دو نوع منبع داده مکمل برای استخراج جاده ها، مدل سازی سه بعدی شهری و غیره به طور منطقی امیدوار کننده باشد. [ 17 ]] . ایده اصلی پشت ادغام Lidar و تصاویر نوری این است که نقاط قوت یک نوع داده می تواند نقاط ضعف سایرین را جبران کند. به عنوان مثال، با کمبود اطلاعات طیفی، داده های Lidar دارای سردرگمی طبقه بندی بالایی بین اشیاء ساخته شده توسط انسان و طبیعی هستند، در حالی که داده های چند طیفی دارای سردرگمی طبقه بندی فزاینده ای بین اشیاء طیفی یکسان در مناظر پیچیده شهری هستند. در پرتو این یافتهها، این مقاله روشی را برای تشخیص طیف گستردهای از جادهها از جمله بزرگراهها، پلها، خیابانهای اصلی و فرعی و حتی کوچهها در سطح قابل قبولی از تصاویر با وضوح بالا و دادههای Lidar ارائه میکند. روش پیشنهادی ما از یک استراتژی مبتنی بر قانون سلسله مراتبی استفاده میکند و میتواند از بسیاری از ویژگیهای طیفی، هندسی، مفهومی و بافتی در یک روش سلسله مراتبی چند مرحلهای بهرهمند شود. در این روش،
2. مواد و روشها
2.1. مواد
در این تحقیق از دو مجموعه داده از منطقه ای در شهر سانفرانسیسکو استفاده شد. یک مجموعه داده شامل چهار باند R، G، B، و NIR Quick Bird با اندازه پیکسل زمینی 2.4 متر است ( شکل 1 (b)) و تصویر پانکروماتیک آن با اندازه پیکسل 60 سانتی متر ( شکل 1 (a)). مجموعه داده دیگر شامل ابر نقاط Lidar با تراکم 9 نقطه در متر مربع است ( شکل 1 (c)). مجموعه داده Lidar حاوی اطلاعاتی مانند شدت موج برگشتی و بازگشت های متعدد علاوه بر مختصات سه بعدی نقاط است.
2.2. روش پیشنهادی
مراحل اصلی روش پیشنهادی در شکل 2 نشان داده شده است. این مراحل عبارتند از: پیش پردازش داده های طیفی و Lidar، تقسیم بندی، طبقه بندی سلسله مراتبی، تجزیه و تحلیل ویژگی های مبتنی بر شی، پردازش پست مبتنی بر شی و در نهایت نقشه برداری جاده. در بخش های بعدی، جزئیات مربوط به هر مرحله ارائه شده است.
2.2.1. پیش پردازش داده های لیدار
برای تهیه داده های لیدار، سه عملیات پیش پردازش به شرح زیر اعمال شده است:
1) فیلتر کردن: این مرحله عمدتا برای حذف نویز از داده های خام و افزایش کیفیت داده های Lidar طراحی و اعمال می شود. فیلتر Octree برای کاهش نویز استفاده شد که فضای ذخیره سازی مورد نیاز برای این داده ها را نیز به حداقل می رساند. با این فیلتر، ابتدا یک مکعب در یک فضای کلی سه بعدی نصب می شود. سپس این مکعب به هشت مکعب کوچکتر تقسیم می شود تا زمانی که یک آستانه از پیش تعریف شده به دست آید.

شکل 1 . مجموعه داده های تحقیق (الف) تصویر پانکروماتیک؛ (ب) تصویر چند طیفی (NIR، R و G). (ج) ابر نقاط ارتفاع لیدار.

شکل 2 . مروری بر مراحل مختلف روش پیشنهادی
رسیده است. پس از آن، تمام نقاط کوچکترین مکعب حذف شده و با یک نقطه جدید در مرکز این نقاط قبلی [ 18 ] جایگزین می شود. این منجر به کاهش حجم داده در طول ابعاد مکعب می شود. اگر فقط یک نقطه در یک مکعب وجود داشته باشد، به عنوان نویز در نظر گرفته می شود و بنابراین از ابر نقاط حذف می شود.
2) مثلث سازی: پس از فیلتر کردن ابر نقاط لیدار. این داده ها وارد فرآیند مثلث سازی می شوند. دادههای لیدار را میتوان به دو شکل [x، y، z] یا [x، y، شدت] با استفاده از روش دلونی [ 19 ] مثلثبندی کرد.
3) درون یابی: در این فرآیند، یک تکنیک درون یابی، مانند درون یابی دوخطی، بر روی ارتفاع و داده های شدت اعمال شد تا تصاویر شطرنجی حاوی این اطلاعات تولید شود.
2.2.2. پردازش داده های ماهواره ای نوری
سیستم های تصویربرداری نوری دارای وضوح بالا و قابلیت های چند طیفی برای کاربردهای مختلف رصد زمین هستند. برای بهره مندی از این مزایا برای هدف تشخیص جاده، ترکیب داده ها می تواند راهی کارآمد برای تولید داده ها با ویژگی های فضایی و چند طیفی بالا باشد. در این مقاله از شارپنینگ طیفی گرم اشمیت استفاده شد [ 20 ].
2.2.3. تقسیم بندی تصویر
تقسیم بندی فرآیند تقسیم تصویر به چندین ناحیه همگن است که از پیکسل های مشابه تشکیل شده است. برای تقسیم بندی، مقادیر مقیاس، وزن ناهمگنی طیفی ( wرنگwcolor)، شکل ( wشکلwshapeصافی ( wصافwsmoothفشردگی ( wفشرده – جمع و جورwcompact) و وزن باندهای طیفی باید تعیین شود. علاوه بر این، سایر پارامترهای ناهمگونی طیفی ( ΔساعترنگΔhcolor 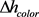 ، ناهمگونی شکل ( ΔساعتشکلΔhshape)، ناهمگونی فشرده ( Δساعتفشرده – جمع و جورΔhcompact) و ناهمگونی صاف ( ΔساعتصافΔhsmooth) برای هر جسم، بر اساس ناهمگنی طیفی و شکلی با استفاده از معادلات (1) تا (7) محاسبه میشوند [ 21 ]. در این معادلات، l محیط یک جسم را نشان می دهد، جایی که b محیط جعبه مرزی جسم است. در اینجا، تعیین وزن پارامتر ضروری است. پارامتری به نام ضریب مقیاس (f) توسط یک تابع خطی از تمام پارامترها برای هر جسم تشکیل می شود. دو شیء مجاور را می توان با هم ادغام کرد، مشروط بر اینکه ضریب مقیاس پس از ادغام بیشتر از مقدار تعیین شده قبلی نباشد. از آنجایی که هنوز یک روش بهینه سازی مناسب ایجاد نشده است، برای انتخاب این پارامترها، اکثر مطالعات از روش آزمون و خطا یا قوانین تجربی استفاده کرده اند.
، ناهمگونی شکل ( ΔساعتشکلΔhshape)، ناهمگونی فشرده ( Δساعتفشرده – جمع و جورΔhcompact) و ناهمگونی صاف ( ΔساعتصافΔhsmooth) برای هر جسم، بر اساس ناهمگنی طیفی و شکلی با استفاده از معادلات (1) تا (7) محاسبه میشوند [ 21 ]. در این معادلات، l محیط یک جسم را نشان می دهد، جایی که b محیط جعبه مرزی جسم است. در اینجا، تعیین وزن پارامتر ضروری است. پارامتری به نام ضریب مقیاس (f) توسط یک تابع خطی از تمام پارامترها برای هر جسم تشکیل می شود. دو شیء مجاور را می توان با هم ادغام کرد، مشروط بر اینکه ضریب مقیاس پس از ادغام بیشتر از مقدار تعیین شده قبلی نباشد. از آنجایی که هنوز یک روش بهینه سازی مناسب ایجاد نشده است، برای انتخاب این پارامترها، اکثر مطالعات از روش آزمون و خطا یا قوانین تجربی استفاده کرده اند.
f=wرنگ⋅ Δساعترنگ+wشکل⋅ Δساعتشکلf=wcolor⋅Δhcolor+wshape⋅Δhshape(1)
wرنگ+wشکل= 1wcolor+wshape=1(2)
wفشرده – جمع و جور+wصاف= 1wcompact+wsmooth=1(3)
Δساعتشکل=wفشرده – جمع و جور⋅ Δساعتc o m p a c t+wصاف⋅ ΔساعتصافΔhshape=wcompact⋅Δhcompact+wsmooth⋅Δhsmooth(4)
Δساعترنگ=∑جwج(nادغام⋅σج ، ادغام– (nobj1⋅σج ، موضوع 1+nobj2⋅σobj2) )Δhcolor=∑cwc(nmerge⋅σc,merge−(nobj1⋅σc,obj1+nobj2⋅σobj2))(5)
Δساعتصاف=nادغام⋅لادغامبادغام– (nobj1⋅لobj1بobj1+nobj2⋅لobj2بobj2)Δhsmooth=nmerge⋅lmergebmerge−(nobj1⋅lobj1bobj1+nobj2⋅lobj2bobj2)(6)
Δساعتفشرده – جمع و جور=nادغام⋅لادغامnادغام√– (no b j 1⋅لobj1nobj1√+nobj2⋅لobj2nobj2√)Δhcompact=nmerge⋅lmergenmerge−(nobj1⋅lobj1nobj1+nobj2⋅lobj2nobj2)(7)
مناطق شهری شامل اشیایی با تنوع زیادی از ناهمگونی طیفی در هر طبقه است. بر این اساس، وزن ناهمگونی طیفی باید کمتر باشد. در غیر این صورت، اجسام دارای اشکال هندسی نامتعادل خواهند بود و بیشتر شکل و ویژگی های هندسی از بین می رود. برای انتخاب وزنها برای پارامترهای صافی و فشردگی، تخصیص وزنهای بالاتر به فشردگی منجر به متراکم شدن اجسامی مانند جادهها، ساختمانها و غیره میشود. همچنین تشخیص اجسام خطی از غیرخطی چالش برانگیز خواهد بود. انتخاب یک مقدار بالاتر برای پارامتر وزن برای ناهمگونی شکل و همچنین مقادیر بالا برای پارامتر صافی بهترین نتایج را به همراه دارد.
2.2.4. طراحی مدل سلسله مراتبی
بهترین استراتژی برای شناسایی جاده بر اساس یک مدل گام به گام، شبیه به روش درخت تصمیم [ 22 ] است.] . این مدل دارای گرههای تصمیمگیری است که در هر کدام بخشی از پیکسلهای جاده از پیکسلهای غیرجاده جدا میشود. کلاسهای تصویر اولیه و غیر جادهای شامل پوشش گیاهی، ساختمانها و فضاهای باز مانند پیادهروها و پارکینگها است. این مدل در صورتی بهترین نتایج ممکن را ایجاد میکند که کلاسهای غیر جادهای به ترتیب بهینه طی شوند. در واقع کلاسی که حداکثر قابلیت تفکیک از جاده ها را دارد در مرحله اول باید جدا شود. این امر در مراحل بعدی امکان تمایز سایر طبقات از جاده ها را افزایش می دهد. برای شناسایی ترتیب بالا، روش انتخاب متوالی رو به جلو (SFS) که بر اساس معیار امکان تمایز فاصله اقلیدسی نرمال شده است، استفاده می شود. شکل 3 مدل سلسله مراتبی پیشنهادی را نشان می دهد.
مدل ارائه شده شامل چهار گره است. در گره اول، تصویر به دو دسته گیاهی و غیر گیاهی طبقه بندی می شود. مراحل فرآیند باقی مانده بر روی طبقات غیر گیاهی انجام می شود. در گره دوم،

شکل 3 . مدل سلسله مراتبی طراحی شده برای استخراج و نقشه برداری جاده ها.
مناطق بدون پوشش گیاهی به دو دسته مناطق مرتفع و پست تقسیم می شوند. اشیاء جغرافیایی مانند ساختمانها، پلها و رمپهای تبادلی متعلق به طبقه مناطق بالا هستند، در حالی که پیادهروها، پارکینگها، جادهها و سایر فضاهای باز جزو طبقه زمیندار و کم منطقه محسوب میشوند. در گره سوم، نواحی کم ارتفاع مجدداً به دو دسته جاده های کم ارتفاع و فضاهای باز طبقه بندی می شوند. در گره چهارم، مناطق مرتفع به ساختمان ها و راه های مرتفع تقسیم می شوند. به عنوان گام نهایی، دو کلاس جاده ادغام می شوند تا شبکه جاده ای نهایی ایجاد شود.
2.2.5. تجزیه و تحلیل ویژگی مبتنی بر شی
همانطور که گفته شد، مدل سلسله مراتبی طراحی شده دارای چهار گره است. برای هر گره، بر اساس اشیاء هدف، ویژگیهای خاصی را میتوان از دادههای ورودی استخراج کرد و برای جداسازی آنها از بقیه اشیاء استفاده کرد. استخراج ویژگی در هر گره به شرح زیر است:
گره اول: گره اول با هدف تقسیم منطقه مورد مطالعه به طبقات پوشش گیاهی و غیر گیاهی انجام می شود. با توجه به ویژگی های خاص پوشش گیاهی در مناطق طیفی قرمز و مادون قرمز نزدیک طیف الکترومغناطیسی، راه مناسب برای شناسایی این طبقه از طریق استفاده از شاخص های گیاهی مانند شاخص گیاهی تفاوت نرمال شده (NDVI) [ 23 ] و شاخص نسبت پوشش گیاهی (RVI) [ 24 ]:
نD Vمن=نمنR – R e dنمنR + R e dNDVI=NIR−RedNIR+Red(8)
RVI =NIRقرمزRVI=NIRRed(9)
گره دوم: گره دوم قصد دارد ناحیه بالا را از مناطق پایین شناسایی و جدا کند. ویژگی های مورد استفاده در این حالت عبارتند از Mean Difference to Neighbor، تفاوت میانگین با Darker Neighbor به ترتیب شامل ویژگی های f 1 ، f 2 و f 3 است که در زیر ارائه شده است.
f1= میانگین تفاوت با همسایه = ∑i = 1n( D Sمo– دی اسممن)nf1=Mean Diff to neighbor=∑i=1n(DSMo−DSMi)n(10)
f2= میانگین تفاوت به همسایه تیره تر = ∑i = 1متر( D Sمo– دی اسممن)مترf2=Mean Diff to Darker neighbor=∑i=1m(DSMo−DSMi)m(11)
f3=f1×f2 برای من که D S مo بزرگتر از D S است ممنf3=f1×f2 for i that DSMo is greater than DSMi(12)
با توجه به تنوع وسیع اندازه ها و ویژگی های طیفی ساختمان ها در منطقه مورد مطالعه، بدیهی است که نمی توان آنها را در یک سطح تقسیم بندی به عنوان یک شی قرار داد. بنابراین در چنین مواردی باید کمترین سطح مقیاس را برای این عناصر انتخاب کرد. با توجه به تنوع وسیع اندازه و ویژگی های طیفی ساختمان ها در منطقه مورد مطالعه، بدیهی است که نمی توان آنها را در یک سطح تقسیم بندی به عنوان یک شی قرار داد. بنابراین در چنین مواردی باید پایین ترین سطح مقیاس را برای این عناصر انتخاب کرد. بر اساس این ویژگی ها، برخی از ساختمان ها به دلیل اندازه بزرگ خود به عنوان چند شی تقسیم بندی می شوند. برای حل این مشکل، یک استراتژی پس پردازش بر اساس یک ویژگی مفهومی (f 4) اعمال شده است. برای انجام این کار، ابتدا این دو کلاس طبقه بندی می شوند. سپس برای اشیاء کلاس اشیاء ناحیه کم، درصد محیطی هر شیء مجاور با اشیاء طبقه بندی شده در کلاس مناطق بالا با استفاده از رابطه (13) محاسبه می شود. نتیجه مقادیر بین 0 و 1 خواهد داشت. این ویژگی در واقع اشیایی را در کلاس low regions که توسط کلاس ناحیه high احاطه شده اند جستجو می کند.
f4= اشیاء منطقه کم ارتباط .Border to High Region Objects =∑Lمنمحیط شی Lمن= Common Border to High Region Object i f4=Low Region Objects Rel.Border to High Region Objects =∑LiObject PerimeterLi=Common Border to high Region Object i(13)
در ویژگی دوم (f 5 )، به منظور بهبود نتایج هر شی در کلاس مناطق کم، تعداد اشیاء مجاور که به عنوان مناطق بالا طبقه بندی می شوند، بر تعداد کل اشیاء مجاور تقسیم شده و به عنوان یک ویژگی در نظر گرفته می شود. مقادیر این ویژگی نیز بین 0 و 1 مقیاس بندی شده است (معادله (14)). این ویژگی، در واقع، به دنبال اشیایی در کلاس مناطق کم است که از نظر آماری توسط اشیاء مناطق بالا احاطه شده اند.
f5=مترnf5=mnn: تعداد همسایگان برای شی.
متر: شماره همسایه منطقه بالا (14)
گره سوم: این گره برای تفکیک کلاس منطقه پست به دو طبقه فرعی کم راه و فضای باز می باشد. کلاس فضای باز شامل پیاده روها، فضاهای کنار بزرگراه، پارکینگ ها و پوشش گاه به گاه خاک است. ویژگی های مورد استفاده در این گره عبارتند از میانگین شدت موج برگشتی، لایه کانتور و شیب (معادله (15) تا (17)):
f6=∑ni = 1منnتیمنnf6=∑i=1nIntinn: تعداد پیکسل برای هر شی(15)
f7=∑ni = 1سیo u nتیمنnf7=∑i=1nCountinn: تعداد پیکسل برای هر شی(16)
f8=∑ni = 1اسl o pهمنnf8=∑i=1nSlopeinn: تعداد پیکسل برای هر شی(17)
از آنجایی که همیشه فضاهایی مانند پیاده رو بین جاده ها و ساختمان ها وجود دارد، از ویژگی زیر برای استفاده از اموال آن استفاده شده است.
f9= Rel.Border to Low Region Objects = _ ∑Lمنمحیط شی Lمن= Common Border to Low Region Object i f9=Rel.Border to Low Region Objects=∑LiObject PerimeterLi=Common Border to low Region Object i(18)
ویژگی بعدی، یعنی فاصله تا نزدیکترین مناطق کم، با هدف طبقه بندی و شناسایی اشیاء طبقه بندی شده قبلی بر اساس f 6 ، f 7 و f 8 است. در اینجا، نسبت فاصله بین مرکز جسم در نظر گرفته شده از طول در ناحیه پایین، و طول آن جسم در نظر گرفته شده است:
f10=DistancetoTheNearestlowRegionObjectطول جسم _ f10=DistancetoTheNearestlowRegionObjectLength of Object(19)
گره چهارم: مشابه گره های دو و سه، در گره چهارم می خواهیم اشیاء کلاس highroads را از سایر آبجکت های کلاس high regions شناسایی و جدا کنیم. با توجه به ماهیت خطی اجسام در کلاس جاده ها، از ویژگی های زیر که خصوصیات خطی اجسام را تعیین می کند نیز استفاده می شود.
f11=طولعرضf11=LengthWidth(20)
ویژگی عدم تقارن یک شی را در مقایسه با یک چندضلعی منظم توصیف می کند. یک بیضی جسم را به گونه ای احاطه می کند که این ویژگی به نسبت شعاع کوچک به شعاع قابل توجه بیضی می شود (معادله (21)).
f12= 1 –nمترf12=1−nm(21)
هر چه شکل اشیاء به یک چند ضلعی منظم نزدیکتر باشد، این مقدار به صفر نزدیکتر است. ویژگی بعدی نسبت طول به عرض برای خط اصلی جسم است (معادل (22)).
f13=طولعرض برای خط اصلی _ f13=LengthWidth for the main Line(22)
خروجی این مرحله شبکه راه های اولیه خواهد بود.
2.2.6. پس پردازش مبتنی بر شی
با توجه به پیچیدگی نواحی شهری و تراکم بالای اشیاء، انجام یک روش پس پردازشی برای بهبود نتایج اولیه ضروری است. برای این منظور از چندین ویژگی آماری، فضایی و مفهومی بر اساس نتایج طبقهبندی اولیه، از تمامی گرههای مدل سلسله مراتبی بهجز گره اول استفاده شده است که به شرح زیر است:
گره دوم: در این گره، برای کاهش اجسام مرتفع احاطه شده توسط اجسام با ارتفاع یکسان، نتایج تقسیم بندی نامناسب باید قبل از طبقه بندی با استفاده از ویژگی ها (f 1 – f 5 ) بهبود یابد. در اینجا، اشیایی که قدر مطلق تفاوت بین مقدار DSM آنها و میانگین این ویژگی در همسایگان کمتر از 30 سانتی متر است، با الگوریتم منطقه ادغام ادغام می شوند. پس از این بهبود نسبی، از معادله (23) برای ایجاد یک ویژگی با امکان تفکیک مناسبتر استفاده میشود.
f14=f1| میانگین DSM – میانگین DSM اشیاء همسایه | _f14=f1|Mean DSM−Mean DSM of Neighbors Objects|(23)
گره سوم: در اینجا مجدداً از یک ویژگی ترکیبی، یعنی فشردگی استفاده شده است. این ویژگی فشردگی هندسی یک شی را به جهاتی نشان می دهد. این ویژگی با تقسیم ضرب طول (m) و عرض (n) یک شی بر تعداد پیکسل آن ایجاد می شود.
فشردگی =m × nنCompactness=m×nN(24)
وقتی جسم مستطیلی شکل باشد، فشردگی برابر با 1 است. این ویژگی معیار با ترکیب ویژگی فشردگی و میانگین فاصله شی از اشیاء کلاس مناطق بالا به صورت زیر طراحی شده است:
f15=فشردگیMeanofDistancetoHighRegion Objectsf15=CompactnessMeanofDistancetoHighRegionObjects(25)
اجسام جاده های کم ارتفاع به دلیل فرم خطی شان ارزش فشردگی کمتری دارند. علاوه بر این، منطقاً در بین عناصر کلاس منطقه پایین، در مقایسه با عناصر منطقه بالا، فاصله بیشتری دارند. بر این اساس، اجسام کم جاده دارای مقدار کمتری از ویژگی 15 هستند. بدیهی است که بهبود نتایج در گره دوم و سوم، به دلیل کاهش نویز بین منطقه مرتفع و پایین، نتیجه گره چهار را بهبود می بخشد.
3. اجرا و نتایج تجربی
3.1. آماده سازی داده ها
همانطور که گفته شد، قبل از تقسیمبندی تصویر، دادهها از جمله تصاویر ماهوارهای و دادههای لیدار باید پیش پردازش شوند. مرحله پیش پردازش شامل تشخیص ویژگی اولیه از سطح TIN داده لیدار، انتقال آن به فضای شطرنجی و افزایش فضایی Quick Bird چند طیفی است.
برای فیلتر کردن داده های لیدار از فیلتر Octree استفاده شد. برای انجام این کار و بر اساس تفکیک مکانی یا نمونه برداری فاصله زمینی (GSD) داده های لیدار که 50 سانتی متر است، حذف نویز با آستانه 1 متر انجام می شود. پس از فیلتر کردن، از روش دلونی برای مثلث بندی اطلاعات ارتفاع و تولید یک مدل سطح دیجیتال (DSM) و همچنین خطوط خطوط استفاده می شود. همچنین، مثلث بندی شدت موج بازگشتی یک تصویر شدت شطرنجی درون یابی ایجاد می کند. در نهایت با استفاده از درون یابی دو خطی، تصاویر شطرنجی با وضوح 60 سانتی متر از مجموعه داده های لیدار تولید می شوند. این مقدار برای بدست آوردن داده های ارتفاع شطرنجی با همان اندازه و وضوح تصاویر ماهواره ای انتخاب می شود. به موازات آن، از روش گرام اشمیت برای تولید تصویر پان شارپ از داده های اصلی ماهواره استفاده شد.
3.2. تقسیم بندی تصویر
E cognition در مرحله تقسیم بندی به عنوان یک ابزار تجزیه و تحلیل تصویر مبتنی بر شی استفاده می شود که از رویکرد تکامل خالص فراکتال (FNEA) برای تقسیم بندی استفاده می کند. FNEA یک تکنیک در حال رشد منطقه ای بر اساس معیارهای محلی است و با اشیاء تصویر یک پیکسل شروع می شود [ 24 ]. برای تقسیم بندی، مقادیر مقیاس، شکل، فشردگی و وزن باندهای طیفی باید توسط کاربر تعیین شود. این خواص در جدول 1 ارائه شده است. آخرین ستون این جدول شامل کلاس هایی است که اشیاء آنها در سطح مربوطه تقسیم بندی شده اند. در واقع، در هر سطح، تقسیم بندی بر روی اشیاء هر کلاس انجام می شود که در سطح بعدی مورد تجزیه و تحلیل قرار خواهد گرفت.
3.3. طراحی مدل سلسله مراتبی
همانطور که گفته شد برای طراحی مدل سلسله مراتبی از روش SFS که مبتنی بر معیار امکان تمایز فاصله اقلیدسی نرمال شده است استفاده شده است. جدول 2 نتایج این روش را نشان می دهد.
همانطور که جدول نشان می دهد، طبقه پوشش گیاهی بالاترین امکان تبعیض را دارد. سپس ساختمان ها و فضاهای باز به ترتیب در رده های دوم و سوم قرار می گیرند که ابتدا از هم جدا می شوند. با توجه به این نتایج، مدلی مبتنی بر استراتژی پوشش دهی برای شناسایی جاده ها طراحی شده است. مدل سلسله مراتبی در واقع یک سیستم مبتنی بر قانون را برای دسته بندی کلاس ها به ترتیبی طراحی می کند که نویز را به حداقل می رساند و امکان تمایز را به حداکثر می رساند. این مدل کلاس ها را بر اساس تشخیص آسان کلاس ها ترتیب می دهد.
3.4. پیاده سازی مدل سلسله مراتبی
در این بخش با توجه به مدل سلسله مراتبی، نتایج هر گره ارائه شده است. ویژگی های مورد استفاده در کلاس های مختلف در جدول 3 نشان داده شده است.
با توجه به مدل پیشنهادی، گره اول با هدف تقسیم منطقه مورد مطالعه به طبقات پوشش گیاهی و غیر گیاهی انجام می شود. با توجه به جدول 3 و بر اساس ویژگی های NDVI و RVI، تفکیک طبقات پوشش گیاهی و غیر گیاهی در شکل 4 نشان داده شده است .

شکل 4 . نتایج در گره اول: پوشش گیاهی در مقابل غیر گیاهی.
در گره دوم، مناطق بالا از مناطق پایین جدا می شوند. بنابراین، تقسیم بندی فقط بر روی کلاس غیر گیاهی انجام شد ( جدول 1 ). نتیجه این گره در شکل 5 نشان داده شده است .
در گره سوم، کلاس منطقه پست به دو طبقه فرعی کم راه و فضای باز طبقه بندی می شود. سپس تقسیم بندی بر روی اشیاء مناطق پایین انجام شد ( جدول 1 ). شکل 6 اشیاء کلاس پایین جاده را پس از ادغام با اشیاء مجاور و حذف اشیاء با مناطق غیر قابل توجیه نشان می دهد.
در گره چهارم، هدف ما شناسایی و تفکیک اشیاء کلاس راههای بلند از سایر اشیاء کلاس منطقه مرتفع بود. بنابراین، تقسیم بندی بر روی اشیاء مناطق بالا انجام شد ( جدول 1 ). نتایج این گره در شکل 7 نشان داده شده است .
نتیجه ادغام جاده های مرتفع و جاده های کم ارتفاع، قبل از ( شکل 8 (الف)) و پس از ( شکل 8 (ب)) حذف اجسام کوچک، در شکل 8 ارائه شده است .
3.5. بهبود نتایج اولیه
با توجه به بحث در فصل پس پردازش مبتنی بر شی،

شکل 5 . نتایج اولیه جاده های کم ارتفاع با حذف اجسام با مساحت کوچک.

شکل 6 . نتایج اولیه جاده های کم ارتفاع با حذف اجسام با مساحت کوچک.

شکل 7 . نتایج اولیه گره چهارم.
 (الف)
(الف) (ب)
(ب)
شکل 8 . نتیجه اولیه ادغام طبقات جاده های بالا و پایین. (الف) قبل از برداشتن اشیاء ریز؛ ب) از بین بردن اجسام کوچک.
شکل 9 (الف) در گره دوم و شکل 9 (ب) در گره سوم، نتایج طبقه بندی بهبود یافته را نشان می دهد. از نتایج طبقه بندی می توان دریافت که مناطقی که در مرحله اول به اشتباه طبقه بندی شده اند، به درستی طبقه بندی شده اند.
نتایج نهایی و همچنین ادغام جاده های مرتفع و کم ارتفاع در شکل 10 نشان داده شده است.
 (الف)
(الف) (ب)
(ب)
شکل 9 . نتایج طبقه بندی بهبود یافته (الف) منجر به گره دوم شود. (ب) منجر به گره سوم شود.

شکل 10 . نتایج ادغام نهایی جاده های مرتفع و پایین.
همانطور که در شکل 10 مشاهده می شود ، برخی مناطق نامنظم که به عنوان جاده شناسایی شده اند، در قسمت سمت چپ تصویر وجود دارد. در تصویر اصلی، این قسمت شامل جاده های پر تراکم است. در مناطق دیگر، جاده ها دارای چروک هستند. مهم ترین دلیل این امر وجود وسایل نقلیه در جاده ها یا کنار و پوشش گیاهی مانند درختان و علف های کنار جاده ها است.
4. بحث
برای ارزیابی دقت تحلیلی، چندین نمونه آزمایش برای هر کلاس از مجموعه داده های اصلی به صورت بصری استخراج شده و برای محاسبه ماتریس سردرگمی استفاده می شود. جدول 4 نتایج ماتریس خطا تولید شده برای ارزیابی دقت را نشان می دهد. تعداد نمونه های کنترل در ارزیابی نتایج بر اساس درصد پوشش طبقات مختلف تعیین شد.
دقت کلی برای شناسایی کلاس های مختلف 89.2% و مقدار کاپا 0.83 است. شرح و تفسیر دقیق هر کلاس متعاقبا ارائه خواهد شد. در کلاس پوشش گیاهی، دقت تولیدکننده و استفاده کننده به ترتیب 99 درصد و 79 درصد بود. این نشان دهنده پتانسیل شاخص های طیفی شناخته شده، مانند NDVI و RV، با استفاده از طبقه بندی مبتنی بر شی برای استخراج پوشش های گیاهی است.
در مورد کلاس بالا، دقت برای تولید کننده و کاربر به ترتیب 91% و 100% بود. مشکل اولیه در این کلاس مربوط به دقت تولید کننده و نویز در برخی از نمونه ها در کلاس های فضای باز و ساختمان می باشد. به دلیل تراکم زیاد جاده در برخی از قسمت های تصویر، یک مشکل شناسایی در مرزهای اشیاء در این کلاس رخ می دهد. در برخی از لبه ها، خطای ادغام نتایج تقسیم بندی منجر به تولید جاده هایی با مناطق حاشیه از جمله پیاده روها و ساختمان ها شد. اگرچه چند طبقهبندی اشتباه بین ساختمانهای دارای فضای باز، پوشش گیاهی و جاده کم وجود دارد، دقت برای دقت تولیدکننده و کاربر به ترتیب 88% و 98% بود. در مورد کلاس فضای باز، دقت تولید کننده و کاربر به ترتیب 61% و 20% بود. کلاس فضای باز معمولاً از نظر طیفی شبیه جاده ها و از نظر مورفولوژیکی شبیه به سقف های ساختمان است. بنابراین، جداسازی این طبقه پوشش زمین از دو طبقه دیگر کاملاً مشکل ساز است. همچنین وجود سایههای ناشی از ساختمانها یا درختان در برخی مناطق، باعث شده است که برخی فضاهای باز به اشتباه در پوشش گیاهی طبقهبندی شوند. در کلاس جاده های کم، دقت تولید کننده و کاربر به ترتیب 93 و 93 درصد است. دلیل آن می تواند عملکرد مرحله پس از پردازش باشد. تفکیک مناسب طبقات مناطق مرتفع و پایین، شناسایی جاده های کم ارتفاع و همچنین ساختمان های احاطه شده توسط جاده های کم ارتفاع را بسیار تسهیل کرده است. سر و صدای جاده های مرتفع را می توان به عنوان نویز پیشرو این دسته از اجسام در نظر گرفت. همچنین جاده ها در برخی مناطق به دلیل سایه درختان یا ساختمان های مجاور تاریک می شوند. زیرا ماهیت این طبقات از نظر طیفی بافتی و هندسی شبیه به هم هستند. این باعث می شود که آن کلاس ها به اشتباه در فضای باز طبقه بندی شوند. همچنین، ادغام نادرست برخی از اشیاء دیگر در نزدیکی ساختمان ها، در مرحله تقسیم بندی، که بر مقادیر شیب تأثیر می گذارد، ممکن است دلیل این عدم طبقه بندی باشد.
5. نتیجه گیری ها
در این مقاله، یک چارچوب بهبودیافته بر اساس مدل طبقهبندی سلسله مراتبی برای شناسایی، استخراج و نقشهبرداری شبکههای جادهای در یک منطقه شهری متراکم پیشنهاد شد. روش پیشنهادی برای دادههای سنجش از دور چند منبعی از جمله تصاویر ماهوارهای با وضوح بالا و ابر نقاط لیدار اعمال شد. یکی از موضوعات ضروری در این مطالعه، معرفی برخی عملیات پس از پردازش برای بهبود نتایج بود. موضوع دیگر طراحی یک روش سلسله مراتبی گام به گام بر اساس تحلیل و بهینه سازی فضای ویژگی با استفاده از تحلیل امکان تمایز روش بهینه سازی بود.
برای به دست آوردن نتایج مطمئن تر، برای هر گره، بر اساس اشیاء مورد نظر، می توان ویژگی های خاصی را از داده های ورودی استخراج کرد و برای جداسازی آنها از بقیه اشیاء استفاده کرد. در اینجا ممکن است این سوال مطرح شود که چرا مرحله پس پردازش به عنوان یکی از مراحل پیشرو در این روش در نظر گرفته نمی شود؟ دلیل می تواند به شرح زیر باشد. اول، پایه و اساس بهبود نتیجه، استفاده از نتایج طبقه بندی اولیه اشیاء و تحلیل های آماری، مفهومی و حتی فضایی است. ثانیاً، طبقهبندی بر اساس مدل سلسله مراتبی پیشنهادی کاملاً به کلاسهای دیگر وابسته است. بنابراین نمی توان به تفکیک طبقاتی دقیق و گام به گام پی برد. بر این اساس یک عملیات پس از پردازش روی نتایج ضروری به نظر می رسد. با اينكه، پیچیدگی طیفی و فضایی صحنههای شهری، پتانسیل عالی ترکیب دادههای لیدار و تصاویر با وضوح بالا و تجزیه و تحلیل تصویر مبتنی بر شی را برای تشخیص جاده نشان میدهد. با این حال، داده های لیدار ممکن است برای بسیاری از مناطق شهری در دسترس نباشد. استفاده از داده های کمکی در دسترس بیشتر مانند مدل های سطح دیجیتال استخراج شده از تصاویر استریو به ویژه مطلوب است و تمرکز تحقیقات آینده ما خواهد بود.


بدون دیدگاه