

خلاصه
با افزایش استفاده از مجموعه دادههای مکانی در گروهها و دامنههای کاربری ناهمگن، ارزیابی تناسب برای استفاده به عنوان یک کار ضروری در حال ظهور است. کاربران با انتخاب فزاینده ای از داده ها از پورتال ها، مخازن و مراکز تسویه حساب های مختلف مواجه می شوند. در نتیجه، مقایسه کیفیت و ارزیابی تناسب استفاده از مجموعه دادههای مختلف چالشهای عمدهای را برای کاربران دادههای مکانی ایجاد میکند. در حالی که تلاش های استانداردسازی به طور قابل توجهی قابلیت همکاری متاداده را بهبود بخشیده است، انتخاب فزاینده استانداردهای ابرداده و تمرکز آنها بر تولید داده به جای استفاده و کاربرد بالقوه داده، اسناد فراداده معمولی را برای برقراری ارتباط موثر مناسب برای استفاده ناکافی می کند. بنابراین، تحقیقات بر چالش برقراری ارتباط مناسب برای استفاده متمرکز شده استدادههای مکانی، رویکرد « کاربر محور » بیشتری را برای ابردادههای مکانی پیشنهاد میکند. ما هستیشناسی فراداده کاربر محور جغرافیایی (GUCM) را برای برقراری ارتباط مناسب برای استفاده از مجموعه دادههای فضایی به کاربران در حوزههای مکانی و سایر حوزهها ارائه میکنیم تا آنها را قادر به تصمیمگیری آگاهانه برای انتخاب منبع داده کنند. GUCM توصیف ابرداده را برای اجزای مختلف یک مجموعه داده در زمینه حوزههای کاربردی مختلف فعال میکند. این فراداده های ارائه شده توسط تولید کننده و توصیف شده توسط کاربر را در قالب ساختاریافته با استفاده از مفاهیمی از هستی شناسی های مستقل از دامنه می گیرد. این کار تعامل بین ابرداده های مکانی و غیر مکانی را در پلت فرم های داده باز تسهیل می کند و ابزاری را برای جستجو/کشف فراهم می کند.داده های مکانی بر اساس معیارهای کیفیت و تناسب برای استفاده مشخص شده توسط کاربر.
کلید واژه ها:
فراداده مکانی ; تناسب اندام برای استفاده ؛ مدیریت عدم قطعیت در داده های مکانی فراداده کاربر محور ; هستی شناسی ; فراداده ساختاریافته ؛ قابلیت همکاری و سیستم های باز
1. معرفی
کیفیت داده های مکانی بیش از سی سال موضوع تحقیقات گسترده در جامعه GIS بوده است [ 1 ]. توجه قابل توجهی از سوی جامعه دانشگاهی و سازمان های دولتی و اخیراً از سوی صنعت جلب شده است. داده های جغرافیایی تابع فرآیندهایی مانند تعمیم، انتزاع و تجمیع هستند. در نتیجه، داده های تبدیل شده تنها می توانند تقریبی از دنیای واقعی ارائه دهند و اغلب از کیفیت ناقص رنج می برند [ 2 , 3]]. بنابراین، مصرف کنندگان داده همیشه در معرض سطحی از عدم قطعیت داده خواهند بود. کیفیت و عدم قطعیت دادههای مکانی دو مورد از مسائل نظری اساسی در علم اطلاعات جغرافیایی هستند، جایی که علاقه شدیدی به کمیسازی، مدلسازی و تجسم دقت دادههای مکانی به روشهای پیچیدهتر وجود دارد. علاوه بر این، امروزه زنجیرههای تامین دادههای مکانی دادهها را از طریق پورتالهای وب مکانی یا خدمات وب به کاربران منتقل میکنند. ارزش این اطلاعات به توانایی پیش بینی نیازهای کاربران و الزامات کیفی بستگی دارد. این رویکرد با توجه به ماهیت غیرقابل پیشبینی و متنوع نیازهای کاربر در زمینه حوزههای کاربردی مختلف مشکلساز است. ارزش محصولات داده های مکانی زمانی تحقق می یابد که دانش ارائه شده کاربران را قادر می سازد به اهداف مورد نظر خود دست یابند [ 4]].
کیفیت داده های مکانی به ادراک تولید کننده یعنی کیفیت داخلی و دیدگاه کاربر یعنی کیفیت خارجی بستگی دارد. معیارهای کیفی عینی داده های مکانی (کیفیت داخلی) به “تفاوت بین داده ها و واقعیتی که آنها نشان می دهند” مربوط می شود [ 5 ]. در حوزه GIS، کیفیت داخلی اغلب بر حسب عناصر « پنج معروف » کیفیت دادههای مکانی توصیف میشود. به عنوان مثال، دقت موقعیتی، دقت ویژگی، دقت زمانی، ثبات منطقی و کامل بودن . کیفیت داخلی داده ها را می توان در طول دوره ایجاد داده بهبود بخشید [ 3 ]. معیارهای ذهنی کیفیت (کیفیت خارجی) به یک منبع داده مربوط می شود“تناسب برای استفاده” ؛ به عنوان مثال، برای ارزیابی کیفیت داده ها، علاوه بر نیازهای واقعی کاربر، باید اطلاعاتی در مورد داده ها نیز داشته باشیم [ 6]]. این تا حد زیادی به نیازهای کاربر بستگی دارد و بنابراین یک محصول مشابه می تواند کیفیت متفاوتی برای کاربران مختلف داشته باشد. علیرغم تنوع در مفاهیم کیفیت داده های داخلی (عینی) و خارجی (ذهنی)، این دو مقوله ارتباط نزدیکی با هم دارند زیرا برای ارزیابی کیفیت داده های خارجی، کاربران اغلب به توصیف کیفیت داده عینی نیاز دارند. در حالی که روشهایی برای ارزیابی کیفیت داخلی دادههای مکانی وجود دارد، ارزیابی کیفیت خارجی هنوز یک موضوع باز باقی مانده است. از کارشناسان و کاربران دادههای مکانی انتظار میرود که نوع منبع دادههای مکانی مورد نیاز خود و اتاق تسویه یا ژئوپورتالی که این دادهها را در خود جای داده است، بدانند. حتی با وجود این اطلاعات موجود، کاربران همچنان با تصمیم گیری در مورد مناسب بودن برای استفاده، بر اساس فراداده های پیچیده، برای موارد معدودی که چنین ابرداده هایی وجود دارد، باقی مانده است.7 ].
برای رسیدگی به مسائل مربوط به کیفیت دادههای مکانی، سازمانهای استاندارد مانند سازمان بینالمللی استاندارد (ISO/TC211 ( https://committee.iso.org/home/tc211 ))، زیرساخت اطلاعات فضایی در اروپا (INSPIRE ( https:/ /inspire.ec.europa.eu/ )، کنسرسیوم فضایی باز (OGC ( https://www.opengeospatial.org/ ))، ابتکار فراداده هسته دوبلین (DCMI ( https://dublincore.org/ )) و فدرال کمیته داده های جغرافیایی (FGDC ( https://www.fgdc.gov/ )) فعالانه برای ایجاد، بهبود و گسترش استانداردهای داده های جغرافیایی و ابرداده کار می کنند.
در حالی که تلاشهای استانداردسازی بهطور قابلتوجهی قابلیت همکاری ابردادهها را بهبود بخشیده است، انتخاب فزاینده استانداردهای ابرداده تعدادی چالش را به همراه دارد: به عنوان مثال، (i) کدام استانداردها باید برای توصیف کیفیت استفاده شوند؟ (ii) چه مقدار ابرداده باید ارائه شود تا کاربران بتوانند منابع داده ای را که برای استفاده مورد نظرشان مناسب هستند شناسایی کنند؟ در نهایت، (iii) چه اطلاعات با کیفیتی باید ارائه شود تا ابرداده ها “مفید” و نه فقط “قابل استفاده” شوند [ 8 ، 9 ، 10 ، 11 ، 12 ]؟ علاوه بر این، علیرغم توصیههای دقیق سازمانهای استاندارد و وجود استانداردهای رسمی فراداده، اغلب اطلاعات کیفیت دادهها به روشی منسجم و استاندارد به کاربران منتقل نمیشود [ 13] .].
در حال حاضر کمبود تحقیقات تجربی مربوط به نحوه تفسیر و استفاده افراد از اطلاعات کیفیت داده های مکانی برای منابع داده فردی در یک محیط واقعی وجود دارد. مطالعهای که در زمینه کیفیت دادههای مکانی انجام شد، استدلال میکند که تناسب برای استفاده به طور خاص به هر مورد استفاده فردی مربوط میشود. در نتیجه، ارائه اطلاعات با کیفیت عمومی معمولاً برای مصرف کنندگان مفید نیست [ 3 ]. بنابراین، در طول دهه گذشته، تحقیقات بر چالش برقراری ارتباط مناسب برای استفاده از دادههای مکانی متمرکز شده است، و رویکردی « کاربر محور » بیشتر برای ابردادههای جغرافیایی [ 11] ارائه کرده است.]. محققان غنی سازی سوابق فراداده با ارجاع به ادبیات مربوطه را پیشنهاد کرده اند (اطلاعات نقل قول). نظرات رسمی کمتر از تولیدکنندگان داده؛ نظرات تخصصی کیفیت داده ها؛ و بازخورد کاربر در مورد استفاده از داده های قبلی [ 10 ، 14 ]. با این حال، بررسیهای اخیر نشان میدهد که این توصیهها هنوز عملی نشدهاند و هیچ ابزار عملی برای جمعبندی و جستجوی ابردادههای متمرکز بر کاربر وجود ندارد. علاوه بر این، بسیاری از سوابق فراداده ای که در دسترس هستند، در واقع ناقص هستند [ 15 ، 16 ].
تمرکز پژوهش ما این است که کیفیت دادههای مکانی را از نظر تناسب برای برآورده کردن برنامههای کاربردی متنوع به طور فزاینده ارتباط برقرار کنیم تا کاربران دادههای مکانی را قادر به تصمیمگیری آگاهانه برای انتخاب منبع داده کنند. برای رسیدن به این هدف، هدف مطالعه ما شناسایی اطلاعاتی است که مناسب بودن برای استفاده از منابع دادههای مکانی را به کاربران در حوزههای مکانی و غیرمکانی منتقل میکند و تولیدکنندگان و کاربران دادههای مکانی را قادر میسازد تا مناسب بودن برای استفاده و ابردادهها را برای مجموعه دادهها توصیف کنند. به طور خاص، مطالعه ما طراحی یک هستی شناسی را از طریق تجزیه و تحلیل استانداردهای جغرافیایی و مستقل از دامنه موجود و واژگان و استخراج الزامات از سازمان ها در چندین بخش از جمله شوراها، شرکت های خدماتی، ادارات دولتی و خدمات اجتماعی، نیروهای پلیس، بخش بهداشت ارائه می دهد. ، شرکت های بیمه، خدمات مهندسی، مشاوره و ساخت و ساز، شرکت های نرم افزاری و فناوری اطلاعات و بخش معدن. هدف مطالعه ما دستیابی به اهداف تحقیق زیر است:
- O1.
-
کفایت زبان : پشتیبانی از جمعآوری و نمایش فراداده و توصیفهای مناسب برای استفاده برای یک مجموعه داده در سطوح مختلف جزئیات . به عنوان مثال، مجموعه داده ، ویژگی ها و ویژگی های آن .
- O2.
-
سودمندی زبان : پشتیبانی از برقراری ارتباط مناسب برای استفاده از مجموعه داده ها، از طریق قادر ساختن تولیدکنندگان و کاربران داده های مکانی برای تولید فراداده و توضیحات مناسب برای استفاده، با استفاده از یک مدل واحد .
- O3.
-
توسعه پذیری زبان : پشتیبانی از استانداردها و واژگان مستقل از دامنه و به طور گسترده پذیرفته شده برای توصیف ابرداده به منظور تسهیل قابلیت همکاری بین توضیحات فراداده از حوزه های مکانی و غیر مکانی، در نتیجه باعث می شود منابع داده های مکانی در پورتال های داده باز قابل جستجو باشند .
هدف کلی ما این است که کاربران را قادر کنیم کیفیت داده های مکانی را در زمینه دامنه خود و برای اهداف و کاربردهای مورد نظر خود تفسیر کنند و از این طریق به کاربران ابزاری برای تصمیم گیری آگاهانه برای انتخاب منبع داده ارائه دهند. برای رسیدن به این هدف، ما یک هستی شناسی برای ارتباط ابرداده های مکانی و دانش ضمنی منابع داده های مکانی در برنامه ها و حوزه های مختلف طراحی کردیم. پذیرش مداوم فناوریهای وب معنایی [ 17 ]، ما را قادر ساخت تا واژگان را به فرمالیسمی پویاتر و مستدل تبدیل کنیم. یعنی یک هستی شناسی. در این مقاله، ما هستیشناسی فراداده کاربر محور جغرافیایی (GUCM) را معرفی میکنیم که متادادهها را جمعآوری و نمایش میدهد .توصیف مناسب برای استفاده از منابع داده های مکانی در کاربردها و حوزه های مختلف، با استفاده از مفاهیم قابل پردازش ماشینی تعریف شده در هستی شناسی های به طور گسترده پذیرفته شده. این به نوبه خود قابلیت همکاری بین ابرداده های مکانی و غیر مکانی را در پلت فرم های داده باز تسهیل می کند. به طور دقیق تر، این مقاله مشارکت های زیر را ارائه می دهد:
- (من)
-
برانگیختن دیدگاههای کاربر و تولیدکننده در مورد کیفیت دادههای مکانی و تناسب استفاده ، با انجام (الف) مصاحبههای نیمه ساختاریافته با تولیدکنندگان دادههای مکانی و کاربران از حوزهها و برنامههای مختلف؛ و (ب) نظرسنجی برای جمع آوری داده ها از جوامع متنوع GIS. این نظرسنجی با هدف بررسی یافتههای مشارکتهای صنعتی ما و شناسایی بالقوه مضامین کیفیت اضافی (از نظرات و پیشنهادات) برای ارزیابی و ارزیابی کیفیت دادههای مکانی و تناسب برای استفاده انجام شد.
- (II)
-
تجزیه و تحلیل کمی و کیفی تعاملات صنعت ما برای شناسایی شکاف هایی که بین کیفیت داخلی (تولیدکننده عرضه شده) و کیفیت خارجی (مصرف کننده توصیف شده) وجود دارد. این تجزیه و تحلیل از طراحی هستیشناسی فراداده کاربر محور جغرافیایی خبر داد.
- (iii)
-
طراحی هستیشناسی فراداده کاربر محور جغرافیایی ( GUCM ) ، برای برقراری ارتباط فراداده و مناسب برای استفاده از منابع دادههای مکانی به کاربران، به منظور توانمندسازی آنها برای تصمیمگیری آگاهانه برای انتخاب منبع داده.
1.1. انگیزه و اهمیت
هستی شناسی GUCM با استفاده از مفاهیمی از واژگان و هستی شناسی های مستقل از دامنه و به طور گسترده پذیرفته شده، ابرداده های فضایی و توصیف های مناسب برای استفاده مجموعه داده های فضایی را به اشتراک می گذارد. این اطلاعات ساختاریافته را می توان در وب داده [ 18 ]، و درگاه های باز داده مانند پلت فرم داده های عمومی دولت استرالیا ( https://data.gov.au )، بستری برای کشف، دسترسی و استفاده مجدد از داده های عمومی منتشر کرد. شکل 1 ). این به نوبه خود وسیله ای برای جستجو و کشف داده های مکانی بر اساس توضیحات استفاده از ابرداده و مجموعه داده، علاوه بر تسهیل قابلیت همکاری فراهم می کند.بین ابرداده برای مجموعه دادههای مکانی و ابرداده برای مجموعه دادههای حوزههای غیرمکانی.
هستی شناسی را می توان نه تنها برای ارزیابی تناسب برای استفاده از مجموعه داده ها در زمینه کاربردها و دامنه های خاص، بلکه برای شناسایی موارد استفاده و کاربران مختلف مجموعه داده ها، همانطور که آنها تناسب برای استفاده را در زمینه خود توصیف می کنند، استفاده کرد. دامنه های کاربردی علاوه بر این، تولیدکنندگان میتوانند ابردادههای تعریفشده توسط کاربر را در معیارهای کیفیت عینی محصولات خود بگنجانند و به ارائهدهندگان اجازه میدهند تا نیازهای خاص کاربران را برآورده کنند. علاوه بر این، واژگان را می توان برای تکمیل ابرداده تولید کننده با ارائه توضیحات مناسب برای استفاده تعریف شده توسط کاربر برای کاربردهای مختلف یک مجموعه داده استفاده کرد. علاوه بر این، ساختار سلسله مراتبی هستی شناسی ها، ابرداده ها و توضیحات مناسب برای استفاده را قادر می سازد تا اجزای مختلف را هدف قرار دهند.یک مجموعه داده به عنوان مثال، مجموعه داده، نوع ویژگی، یا نوع ویژگی. این به نوبه خود، جستجو و کشف مجموعه داده ها را بر اساس ابرداده و توضیحات استفاده برای اجزای مجموعه داده خاص تسهیل می کند. علاوه بر این، هستیشناسی نمایههای کاربرانی را که تجربیات آنها با مجموعه دادههای فضایی را در زمینه موارد استفاده خاص توصیف میکنند، ضبط میکند. این نمایهها میتوانند برای ارزیابی تناسب استفاده از مجموعه دادههای فضایی در پرتو ویژگیهایی مانند سطح تخصص، دامنه کاربرد و نقشهای کاربرانی که این توصیفها را ارائه میدهند، استفاده شوند.
هستیشناسی GUCM هم تولیدکنندگان و هم کاربران دادههای مکانی را قادر میسازد تا با استفاده از یک مدل ، به جای مدلهای تولیدکننده و کاربر مجزا، ابرداده و توصیفهای مناسب برای استفاده ایجاد کنند . به عبارت دیگر، هستیشناسی فرادادههای ارائهشده توسط تولیدکننده را بهعلاوه تجربیات، بازخوردها و توصیفهای مناسب برای استفاده کاربران، جمعآوری و نمایش میدهد. علاوه بر این، GUCM تولیدکنندگان و کاربران را قادر میسازد تا دادهها و تناسب آن برای استفاده را در زمینه موارد استفاده خاص ارتباط برقرار کرده و بحث کنند . شکل 2 نمونه هایی از بحث های پرسش و پاسخ بین کاربران داده های مکانی، تولیدکنندگان و کارشناسان را نشان می دهد.
1.2. کار مرتبط
در این بخش، ما یک نمای کلی از تلاشهای مرتبط و استانداردها و مشخصات موجود در مورد کیفیت دادهها را با تأکید ویژه بر ارتباط مناسب برای استفاده از دادههای مکانی و رویکردهای «کاربر محور» به ابردادههای مکانی ارائه میکنیم.
توصیف کیفیت داده ها بر حسب ویژگی های ذاتی داده به این معنی است که ما با مفهوم سازی چند بعدی کیفیت داده ها موافقت می کنیم [ 19 ]. به طور خلاصه، این ویژگی های ذاتی، که ابعاد کیفیت داده نیز نامیده می شود، شامل مفاهیمی مانند دقت، ارتباط، دسترسی، ارز، به موقع بودن و کامل بودن است. کار اولیه که مفهوم سازی چند بعدی کیفیت داده را ایجاد کرد، بیش از 200 بعد را در سازمان های مورد بررسی از صنایع مختلف شناسایی کرد [ 20]]. برای بیشتر کاربردهای داده، تنها تعداد انگشت شماری از ابعاد به اندازه کافی مهم برای اندازه گیری و ارزیابی رسمی تلقی می شوند. ابعاد اندازه گیری شده در ارزیابی کیفیت داده ها باید برای نشان دادن تناسب داده ها برای استفاده خاص ضروری باشد.
یک مطالعه اخیر چارچوب مرجعی را پیشنهاد کرد که از اندازه گیری کیفیت کلی مجموعه داده ها پشتیبانی می کند [ 21 ]. این چارچوب شامل هشت آیتم با کیفیت است که سه مورد از آنها (دقت، کامل بودن و سازگاری) به ویژه برای ارزیابی کیفیت اطلاعات مکانی مرتبط هستند. این موارد عبارتند از دقت، کامل بودن، سازگاری، افزونگی (همچنین به عنوان مختصر در نظر گرفته می شود)، خوانایی، دسترسی و در دسترس بودن، سودمندی و اعتماد (که جنبه قابلیت اطمینان را پوشش می دهد).
یک مطالعه تجربی دیگر، ابرداده معنایی را تولید میکند تا به کاربران امکان جستجو، فیلتر کردن و رتبهبندی مجموعه دادهها را بر اساس تعدادی از معیارهای کیفی دهد، در نتیجه کاربران را قادر میسازد تا مجموعه دادههای مرتبط و مناسب برای استفاده را با توجه به نیازهای خود کشف کنند [22 ] .
آژانس نقشه برداری ملی ایرلند، Ordnance Survey Ireland (OSi)، مسئول دیجیتالی کردن زیرساخت های جزیره در رابطه با نقشه برداری است. OSi دانش خود را در چارچوبی با تولید داده از حسگرهای مختلف (مثلاً حسگرهای فضایی) ساخته است. زیرمجموعه ای از دانش بدست آمده توسط این چارچوب به داده های مرتبط با جغرافیا تبدیل می شود. یک ابتکار اخیر یک چارچوب ارزیابی کیفیت دادههای پیوندی مقیاسپذیر را در خط لوله OSi ایجاد کرده است تا به طور مداوم دادههای تولید شده را به منظور رسیدگی به هرگونه مشکل کیفیت قبل از انتشار ارزیابی کند [23 ] .
DaVe، واژگان ارزش دادهای است که امکان نمایش جامع ارزش داده را فراهم میکند، کاربران را قادر میسازد تا آن را با استفاده از ابعاد ارزش دادهای که در یک زمینه خاص مورد نیاز است گسترش دهند. DaVe اجماع را در مورد آنچه که ارزش داده را مشخص می کند و نحوه مدل سازی آن را امکان پذیر می کند. این واژگان کاربران را قادر میسازد تا ارزش دادهها را در طول تلاشهای ایجاد ارزش یا بهرهبرداری از دادهها نظارت و ارزیابی کنند. همچنین امکان ادغام معیارهای مختلف را فراهم می کند که شامل بسیاری از ابعاد ارزش داده است. این واژگان بر اساس الزامات تعدادی از موارد استفاده ارزیابی ارزش استخراج شده از ادبیات [ 24 ] است.
ارزیابی کیفیت و سازگاری داده ها نیازمند استانداردهای داده است. استانداردهای داده ابزارهایی هستند که قابلیت همکاری و ارتقای کیفیت داده ها را امکان پذیر می کنند. به عبارت دیگر کیفیت داده ها با شناسایی ابعاد مهم و اندازه گیری آنها ارزیابی می شود. سازمانهای بینالمللی کلیدی که استانداردهایی را برای اطلاعات مکانی ایجاد میکنند عبارتند از: (i) سازمان بینالمللی استانداردسازی (ISO) کمیته فنی 211 برای اطلاعات جغرافیایی/ژئوماتیک (https://www.isotc211.org/ ) و (ii) کنسرسیوم فضایی باز. OGC ( https://www.opengeospatial.org/ )). کنسرسیوم ISO، OGC و به طور فزاینده وب جهانی (W3C ( https://www.w3.org/)) استانداردها مجموعهای از ساختارها را ارائه میدهند که دادهها را قادر میسازد تا به شیوهای استاندارد شده و قابل همکاری ارائه شوند. این استانداردها چارچوبی را ارائه می دهند که در آن محصولات داده توسعه می یابند. بر اساس ISO 9000 [ 25 ]، (بخش 3.1.5 (ایزو 8402 سابق: 1994))، کیفیت به عنوان “مجموعه ویژگی های یک موجودیت که بر توانایی آن در برآوردن نیازهای اعلام شده و ضمنی بستگی دارد” تعریف می شود. و “هدف از توصیف کیفیت داده های جغرافیایی تسهیل مقایسه و انتخاب مجموعه داده ای است که به بهترین وجه مناسب با نیازها یا الزامات برنامه است” [ 26 ]. تعریف ISO تاکید می کند که کیفیت با استفاده مورد نظر مطابقت دارد; به عنوان مثال، یک مجموعه داده می تواند مطابقت کامل با یک مورد خاص باشد، در حالی که برای نیازهای کاربر دیگر مناسب نیست. بنابراین اعتبارسنجی کیفیت اطلاعات جغرافیایی یک نیاز کلیدی برای کاربران و تولیدکنندگان اطلاعات مکانی است. این به نوبه خود ارزیابی تناسب با هدف برای کاربردهای خاص را تسهیل می کند، به ویژه در زمینه گزارش سیاسی و تصمیم گیری [ 27 ]. اعتبار سنجی تضمین شده با کیفیت باید از اصول شفافیت، قابلیت ردیابی، استقلال، دسترسی و نمایندگی پیروی کند.
کمیته فنی ISO ISO/TC 211، مجموعه ای از استانداردهای بین المللی را ایجاد کرده است که یک چارچوب مدل سازی مفهومی برای اطلاعات مکانی فراهم می کند. این شامل سازههایی است که تعریف میکنند چگونه جنبههای خاص اطلاعات مکانی بدون توجه به کاربرد، مدلسازی شوند. این استانداردها چارچوبی را ارائه میکنند که در آن مدلهای اطلاعاتی را میتوان برای حوزههای کاربردی مختلف به شیوهای سازگار توسعه داد. هم استانداردهای چارچوب ISO و هم طرح کاربردی توسعه یافته از آنها «استانداردهای اطلاعاتی» هستند. به طور خاص، ISO 19115-1:2014 مبانی ابرداده اطلاعات جغرافیایی [ 28] طرحی را برای توصیف اطلاعات و خدمات جغرافیایی از طریق ابرداده تعریف می کند. اطلاعات مربوط به کیفیت، جنبه های مکانی و زمانی، گستردگی، مرجع مکانی، توزیع و سایر ویژگی های داده ها و خدمات جغرافیایی دیجیتال را نشان می دهد. ISO 19157:2013 اطلاعات جغرافیایی — کیفیت داده [ 26 ]، اصولی را برای توصیف کیفیت داده های جغرافیایی ایجاد می کند و مجموعه ای از معیارهای کیفیت داده را برای استفاده در ارزیابی و گزارش کیفیت داده ها تعریف می کند. همچنین عناصر کیفی مانند: کامل بودن، سازگاری منطقی، دقت موقعیتی، کیفیت زمانی، دقت موضوعی و قابلیت استفاده را تعریف و وضوح ارائه میکند. ISO/TS 19158:2012 اطلاعات جغرافیایی – تضمین کیفیت عرضه داده [ 29]، نشان دهنده چارچوبی برای تضمین کیفیت است که مختص اطلاعات جغرافیایی است. این بر اساس اصول کیفیت و تکنیک های ارزیابی کیفیت اطلاعات جغرافیایی مشخص شده در ISO 19157:2013 [ 26 ] و اصول کلی مدیریت کیفیت تعریف شده در ISO 9000 [ 25 ] است. چارچوب تعریف شده در این استاندارد به مشتریان این اطمینان را می دهد که تامین کنندگان داخلی و خارجی قادر به ارائه اطلاعات جغرافیایی با کیفیت مورد نیاز هستند.
در حالی که این استانداردها چارچوبی عالی برای انتقال کیفیت به جامعه کاربر فراهم میکنند، اما برای ارزیابی تناسب استفاده از منابع دادههای مکانی کافی نیستند، زیرا بیشتر بر فرآیندهای مورد استفاده در تولید داده متمرکز هستند، نه روشهای بالقوهای که در آن دادهها در کاربردها و حوزه های مختلف استفاده می شود. در اکثر موارد، ابردادهها ارائه نمیشوند یا ناقص هستند و در جایی که ابردادههای مکانی ارائه میشوند، اطلاعات پیچیده است و برای درک و تفسیر نیاز به تخصص و دانش تخصصی دارد. علاوه بر این، محصولات نهایی اغلب از منابع مختلفی مشتق می شوند و مجموعه داده ها در برنامه ها و حوزه های مختلف استفاده می شوند. بنابراین، یک سند فراداده معمولی برای برقراری ارتباط مؤثر «مناسب برای استفاده» به مصرفکنندگان از حوزهها و سطوح مختلف تخصص کافی نیست.11 ]. به عبارت دیگر، صدور عبارات ساده در مورد کیفیت یک مجموعه داده یا برچسب گذاری یک مجموعه داده خاص به عنوان “بهترین” دشوار است.
بازخورد کاربر جغرافیایی (GUF ( https://www.opengeospatial.org/standards/guf )) یک استاندارد OGC است که یک مدل داده مفهومی را تعریف می کند (OGC 15-097 ( https://docs.opengeospatial.org/is /15-097r1/15-097r1.html ) و یک کدگذاری XML عملی از مدل مفهومی (OGC 15-098 ( https://docs.opengeospatial.org/is/15-098r1/15-098r1.html)). بازخورد کاربر جغرافیایی، ابردادههایی را ارائه میکند که عمدتاً توسط مصرفکنندگان محصولات دادههای مکانی هنگام استفاده و کسب تجربه با آن محصولات تولید میشوند. این استاندارد به کاربران امکان می دهد موارد بازخورد مانند رتبه بندی ها، نظرات، گزارش های کیفیت، نقل قول ها، رویدادهای مهم و غیره را در مورد نحوه استفاده از داده ها مستند کنند. موارد بازخورد را می توان در مجموعه ها جمع کرد و خلاصه مجموعه ها را نیز می توان شرح داد. این استاندارد، روشهای رایج فراداده را تکمیل میکند، جایی که اسنادی که ویژگیهای مجموعه داده و گردشهای کاری تولید را توصیف میکنند توسط تولیدکننده یک محصول داده تولید میشوند. در حالی که این استاندارد کمک قابل توجهی به ابرداده های کاربر محور است، از قابلیت همکاری بین ابرداده های مکانی و ابرداده های سایر حوزه ها پشتیبانی نمی کند.
پروژه GeoViQua FP7 ( https://www.geoviqua.org/ ) کمک قابل توجهی به سیستم جهانی مشاهده زمین از سیستم ها (GEOSS ( https://www.earthobservations.org/geoss.php )) زیرساخت مشترک (GCI ( https ://www.earthobservations.org/gci_gci.shtml )) با افزودن نمایش های دقیق کیفیت داده به جستجو و تجسم عملکردهای GEO Portal ( https://www.geoportal.org/ )، با اولویت دادن به قابلیت همکاری همیشه. GeoViQua داده های مکانی را با اطلاعات مربوط به کیفیت داده ها و خدمات پردازش در کاتالوگ های GEOSS ترکیب می کند. GeoViQua به یک برچسب GEO پیشرفته، کاربر محور و کاربردی کمک کرد ( https://www.geoviqua.org/GeoLabel.htm) و در نتیجه افزایش قابل اعتماد بودن کاربر را در مورد ارائه خدمات و داده های GEOSS فعال کرد. برچسب GEO بهعنوان یک شاخص ارزش برای دادههای مکانی و مجموعه دادههای قابل دسترسی از طریق GEOSS پیشنهاد شد و در نتیجه با ارائه نشانههای بصری کیفیت مجموعه دادهها و احتمالاً ارتباط، به فعالیتهای جستجو کمک میکند. در حالی که نمایش گرافیکی پارامترهای فراداده به کاربران امکان می دهد داده ها را به راحتی غربال کنند، مدل کیفیت GeoViQua بر اساس چارچوب کیفیت تولید کننده و مدل بازخورد کاربر نوآورانه آن برای داده های مکانی است (https://www.geoviqua.org/Docs/GeoViQua_book_v3.pdf ) . . این برخلاف مدل پیشنهادی GUCM است که هدف آن جمعآوری و نمایش ابردادههای ارائهشده توسط تولیدکننده و توصیفشده توسط کاربر با استفاده از یک مدل واحد است.
BIOME یک هستی شناسی سبک وزن است که برای مدیریت مجموعه داده ها در حوزه تنوع زیستی طراحی شده است [ 30 ]. ابردادههای خاص دامنهای که توسط هستیشناسی ضبط میشوند مطابق با دستورالعمل INSPIRE [ 31 ] هستند. به منظور ارتقای قابلیت همکاری، هستی شناسی برای ایجاد روابط بین مفاهیم INSPIRE و مفاهیم از هستی شناسی های پرکاربرد، مانند Dublin Core ( https://dublincore.org/ )، FOAF ( https://xmlns.com/foaf/ ) طراحی شده است. spec/ )، و هستی شناسی های CERIF ( https://www.eurocris.org/ontologies/semcerif/1.3/index.html ). در نتیجه، سوابق فراداده تنوع زیستی را می توان به عنوان داده باز پیوندی منتشر کرد [ 18]]. در حالی که این ابتکار عمل همکاری را ترویج میکند، اما بر توصیفگرهای سطح داده متمرکز است تا مجموعه دادههای تنوع زیستی را قابل جستجو و قابل درک توسط متخصصان دامنه کند. ما این را با هستیشناسی فراداده کاربر محور جغرافیایی (GUCM) معرفی شده در این مقاله، که توصیف ابرداده را در سطوح مختلف دانهبندی مجموعه دادهها، به عنوان مثال، مجموعه داده، انواع ویژگیها و انواع ویژگیها برای همه مجموعههای داده، صرف نظر از دامنه، تسهیل میکند. مهمتر از آن، مدل GUCM بین ابردادههایی که صرفاً توسط تولیدکنندگان ایجاد و نگهداری میشوند و ابردادههایی که توسط کاربران ایجاد میشوند، تفاوت قائل میشود. علاوه بر این، GUCM بحث و ارتباط بین تولیدکنندگان و کاربران دادههای مکانی را تسهیل میکند.
افزایش روزافزون داده های مکانی نیاز به ادغام یکپارچه با سایر داده ها در وب را افزایش داده است. تلاشها برای شفافسازی، رسمیسازی و هماهنگسازی استانداردهای فضایی و وب اخیراً توسط گروه کاری دادههای فضایی در وب (SDWWG ( https://www.opengeospatial.org/projects/groups/sdwwg ) تکمیل شده است.))، همکاری بین OGC و کنسرسیوم وب جهانی (W3C). به طور خاص، هدف SDWWG این بوده است: (1) تعیین اینکه چگونه اطلاعات مکانی میتواند به بهترین شکل با سایر دادههای موجود در وب یکپارچه شود. (ب) کشف کنید که چگونه ماشینها و افراد میتوانند تعیین کنند که حقایق مختلف در مجموعه دادههای مختلف یک مکان را نشان میدهند، بهویژه زمانی که «مکان» به روشهای مختلف و در سطوح مختلف دانهبندی بیان میشود. (iii) روشها و ابزارهای فعلی را شناسایی و ارزیابی کرده و مجموعهای از بهترین شیوهها را برای استفاده از آنها تعیین میکند. و (IV) استانداردسازی فناوریهای غیررسمی را که قبلاً در حال استفاده گسترده هستند، تکمیل کنید.
واژگان کاتالوگ داده (DCAT ( https://www.w3.org/TR/vocab-dcat/ )) یک چارچوب توصیفی منبع (RDF ( https://www.w3.org/RDF/ )) است که برای قابلیت همکاری بین کاتالوگ های داده منتشر شده در وب را فعال کنید. نمایه برنامه DCAT برای پورتال های داده در اروپا (DCAT-AP ( https://ec.europa.eu/isa2/solutions/dcat-application-profile-data-portals-europe_en)) مشخصاتی را ارائه می دهد که بر اساس DCAT است و برای توصیف مجموعه داده های بخش عمومی در اروپا طراحی شده است. این مشخصات، کشف مجموعههای داده را با جستجو در پورتالهای داده امکانپذیر میسازد، در نتیجه دادههای بخش عمومی را در مرزها و بخشها بهتر میتوان جستجو کرد. این را می توان با تبادل توضیحات مجموعه داده ها در میان پورتال های داده به دست آورد. GeoDCAT-AP ( https://joinup.ec.europa.eu/release/geodcat-ap/v101 ) توسعهای از DCAT-AP است که مجموعه دادههای جغرافیایی و خدمات را توصیف میکند. این یک پیوند نحوی RDF برای اتحاد عناصر فراداده تعریف شده در نمایه اصلی ISO 19115:2003 [ 32 ]، و آنهایی که در چارچوب دستورالعمل INSPIRE [ 31] تعریف شده اند، فراهم می کند.]. هدف آن تسهیل جستجو و کشف مجموعه دادههای مکانی، سری دادهها و خدمات در پورتالهای دادههای عمومی است و در نتیجه باعث میشود اطلاعات جغرافیایی در سراسر مرزها و بخشها قابل جستجوتر باشد. این را می توان با تبادل توضیحات مجموعه داده ها در میان پورتال های داده به دست آورد.
هستیشناسی فراداده کاربر محور جغرافیایی (GUCM) ارائهشده در این مقاله با هدف پر کردن شکاف بین دیدگاههای تولیدکننده و کاربر در مورد کیفیت دادههای مکانی و تناسب برای استفاده است. نه تنها هستی شناسی تجربیات کاربران را جذب می کندبا منابع دادههای مکانی در زمینه کاربردها و حوزههای مختلف، اما همچنین اطلاعاتی را که کاربران برای ارزیابی تناسب برای استفاده ضروری میدانند، مانند ساختار مجموعه داده، جمعآوری میکند. به عنوان مثال، جزئیات انواع ویژگی ها و انواع ویژگی ها، روابط و پیوندهای آنها، مقادیر مجاز، مقادیر مناسب برای موارد استفاده خاص، بررسی های تخصصی داده ها در سطوح مختلف دانه بندی. به عنوان مثال، بررسی مجموعه داده، ویژگیها و ویژگیهای آن، نمایه تولیدکننده، استنادات مجموعه داده و توزیع دادهها. علاوه بر این، GUCM توصیف ابرداده را برای یک مجموعه داده و همه اجزای آن تسهیل میکند، به عنوان مثال، توصیف ابرداده، بررسی یک متخصص، یا بازخورد کاربر، میتواند با یک مجموعه داده، یک نوع ویژگی یا یک نوع ویژگی مرتبط باشد. در نهایت، GUCM ابرداده ها را با استفاده از مفاهیمی از هستی شناسی های مستقل از دامنه و به طور گسترده پذیرفته شده نشان می دهد.
2. مواد و روشها
در این بخش، ما به یک هدف کلیدی مطالعه خود می پردازیم، به عنوان مثال، برانگیختن دیدگاه های کاربر و تولیدکننده در مورد کیفیت داده های مکانی و مناسب بودن برای استفاده. در مرحله استخراج نیازمندیهای مطالعه ما، در مجموع 28 مصاحبه نیمه ساختاریافته با تولیدکنندگان و کاربران دادههای مکانی از حوزهها و برنامههای مختلف انجام دادیم. پس از مصاحبه های نیمه ساختاریافته، ما یک نظرسنجی آنلاین برای جمع آوری داده ها از جوامع GIS بزرگتر و متنوع تر انجام دادیم. این نظرسنجی با هدف بررسی یافتههای حاصل از مصاحبهها و شناسایی بالقوه مضامین و مفاهیم کیفی اضافی (از نظرات و پیشنهادات) که در ارزیابی و ارزیابی کیفیت دادههای مکانی و تناسب برای استفاده مؤثر هستند، انجام شد.
2.1. مصاحبه های نیمه ساختاریافته با تولیدکنندگان و کاربران داده های مکانی
ما شرکتکنندگان را از طیف گستردهای از صنایع انتخاب کردیم تا بتوانیم طیف گستردهای از الزامات را برای ارائه و انتقال ابردادههای مکانی شناسایی کنیم و روشی را که کاربران با سطوح مختلف تخصص و صلاحیت در حوزه جغرافیایی، ابردادههای مکانی را تفسیر میکنند، تعیین کنیم. هدف از این مصاحبه ها شناسایی روش هایی بود که در آن داده های مکانی برای کاربردها و اهداف مختلف تولید، ارزیابی و ارزیابی می شوند. بحث با مجموعهای از سؤالات هدایت میشد که بهعنوان خطهای تحقیق سطح بالا استفاده میشد. مصاحبه با کاربران دادههای مکانی با هدف ایجاد الزامات کاربر سطح بالا برای ارزیابی و ارزیابی تناسب برای استفاده از منابع دادههای مکانی انجام شد (به الگوی مصاحبههای کاربر مراجعه کنید). مصاحبه با تولیدکنندگان دادههای مکانی با هدف کشف چگونگی توصیف تولیدکنندگان دادههای مکانیکی کیفیت منابع دادههای خود (به الگوی مصاحبههای تولیدکننده مراجعه کنید). ما مصاحبههایی با شوراهای محلی، شرکتهای آب و برق (مانند ملبورن آب)، ادارات دولتی و خدمات اجتماعی (مانند اداره آمار استرالیا، وزارت حملونقل و جادههای اصلی، وزارت امور خارجه و کابینه)، سازمانهای ارائهدهنده خدمات معماری و برنامهریزی انجام دادیم. خدمات پلیس، سازمان هایی که برای دولت های محلی کار می کنند (این سازمان ها ادارات یا سازمان های دولتی نیستند)، بخش بهداشت، بخش معدن، شرکت های نرم افزار و فناوری اطلاعات، سازمان های ارائه دهنده خدمات زیست محیطی، شرکت های بیمه، خدمات مهندسی، مشاوره و ساخت و ساز و کار و کسب های خرد. شرکتکنندگان از طیف متنوعی از پیشینهها بودند که 46 درصد آنها به مدت دو تا نه سال با دادههای مکانی کار کردهاند. اکثر مصاحبه های ما از طریق تماس تلفنی انجام شد، در حالی که تعداد کمی به صورت مصاحبه حضوری انجام شد. در اکثر مصاحبه ها، یک تا دو نفر از کارشناسان موضوعی سازمان مورد مصاحبه حضور داشتند. اکثر مصاحبه ها حدود یک ساعت به طول انجامید، به استثنای چند مورد که مصاحبه ها بیش از دو ساعت طول کشید.
مصاحبه های نیمه ساختاریافته ما ضبط شد و فایل های صوتی ضبط شد. رونوشت ها برای شناسایی الزامات سطح بالا برای ارزیابی تناسب برای استفاده از مجموعه داده های فضایی تجزیه و تحلیل شدند. تجزیه و تحلیلها بر شناسایی جنبههای کیفی و استخراج نیازمندیهای کاربر دقیق که به طور خاص به ارزیابی کیفیت منابع داده برای تصمیمگیری انتخاب منبع داده مربوط میشوند، متمرکز است. از آنجایی که دادههای جمعآوریشده کیفی بودند، رونوشتها را با استفاده از تجزیه و تحلیل دادههای موضوعی ، «روشی برای شناسایی، تجزیه و تحلیل و گزارش الگوها (مضامین) درون دادهها» [ 33 ، 34 ]، برای شناسایی الگوهای معنا در میان دادههای مطالعه، تجزیه و تحلیل کردیم.
پس از چندین بار بررسی رونوشت ها، اولین کتاب کد برش را تولید کردیم. بیش از 45 کد در این مرحله شناسایی شد. در مرحله بعد، چندین دور تلفیق و کاهش داده را در کدنویسی خود با مقایسه تکههای متن و تعاریف برای تشابه انجام دادیم. این فرآیند تکراری کدگذاری استقرایی منجر به شناسایی 20 کد، از جمله 11 کد مربوط به “ابعاد کیفیت” و نه کد مربوط به “الزامات مناسب برای استفاده” شد. سپس کدگذاری استقرایی خود را با عناصر کیفیت داده که از بررسی ادبیات ما پدید آمده بود مقایسه کردیم تا اطمینان حاصل کنیم که هر کد را با برچسبی که بهترین توصیف کننده کد است نامگذاری می کنیم. در جایی که برچسبهای مناسب یافت میشد، برای نامگذاری کدها در کدگذاری نهایی استفاده میشد. علاوه بر این، در طول تجزیه و تحلیل، از یادداشت برداری و یادداشت برداری برای اصلاح ایده های خود استفاده کردیم [34 ]، که از دسته بندی کدها پشتیبانی می کند. دسته بندی کدها با در نظر گرفتن شباهت و تفاوت ایده های زیربنایی آنها انجام شد. این منجر به گروه بندی سه کد شامل دقت موقعیتی/مکانی، دقت ویژگی/موضوع و دقت زمانی به عنوان سه زیربعد کیفیت بعد کیفیت دقت شد. با این حال، این مرحله آخر هیچ تغییری در کدهای نشان دهنده الزامات مناسب برای استفاده ایجاد نکرد.
2.2. بررسی کیفیت داده ها
پس از مصاحبههای نیمه ساختاریافته با تولیدکنندگان و کاربران دادههای مکانی، ما یک نظرسنجی برای جمعآوری دادهها از جوامع مختلف GIS انجام دادیم (به بررسی کیفیت دادهها مراجعه کنید). این نظرسنجی برای بررسی یافتههای مصاحبههای ما و شناسایی بالقوه مضامین کیفی دیگری که در انتخاب منابع داده مناسب برای استفاده مؤثر هستند، طراحی شده است. پرسشنامه آنلاین بر اساس نتایج تجزیه و تحلیل مصاحبه های ما با شرکت کنندگان در صنعت طراحی شده است. این پرسشنامه شامل 32 سوال بود:
-
سؤالات 1-10 اطلاعات کلی در مورد شرکت کنندگان را در بر می گیرد (به عنوان مثال، شناسایی شرکت کنندگان به عنوان کاربران داده های مکانی، تولید کنندگان یا هر دو؛ شناسایی سطح تخصص شرکت کنندگان در داده های مکانی و فراداده).
-
سؤالات 11-17 و 26-28 با هدف جمع آوری نظرات شرکت کنندگان در مورد عناصر و عناصر فرعی کیفیت داده های جغرافیایی (که در جدول 1 آمده است ).
-
سؤالات 18-25 و 29 با هدف جمعآوری دیدگاههای شرکتکنندگان در مورد الزامات ارزیابی تناسب برای استفاده از مجموعه دادهها (در جدول 2 مشخص شده است ).
-
سؤالات 30 و 31 با هدف برانگیختن دیدگاه شرکت کنندگان در مورد سودمندی واژگان فراداده کاربر محور جغرافیایی برای برقراری ارتباط با کیفیت مجموعه داده و تناسب استفاده از آنها بود.
-
سوال 32 نظرات و پیشنهاداتی را در مورد واژگان فراداده کاربر محور جغرافیایی، اطلاعاتی که باید با آن ارتباط برقرار کند و نقش بالقوه آن در قادر ساختن کاربران به شناسایی مجموعه دادههایی که برای اهداف مورد نظرشان مناسب هستند را در بر میگیرد.
یک مقیاس لیکرت هفت درجهای، از «بسیار بیاهمیت» تا «بسیار مهم» برای اندازهگیری اهمیت عناصر کیفیت دادهها و الزامات برای ارزیابی تناسب برای استفاده از منابع داده از دیدگاه شرکتکنندگان استفاده شد. این پرسشنامه توسط چندین متخصص صنعت بررسی شد که منجر به به روز رسانی و اصلاحات جزئی شد. شرح پروژه و پیوندی به پرسشنامه نظرسنجی برای شرکت کنندگان از طیف وسیعی از صنایع ایمیل شد تا اطمینان حاصل شود که نتایج نظرسنجی نشان دهنده انواع موارد استفاده و الزامات طیف گسترده ای از کاربران است. نمونهگیری گلوله برفی نیز برای دستیابی به شرکتکنندگان بالقوه بیشتر، علاوه بر چندین یادآوری، استفاده شد تا اطمینان حاصل شود که تا حد امکان پاسخها را جمعآوری کردهایم. در مجموع، ما 15 پاسخ دریافت کردیم. یعنی یک پاسخ از هر یک از 15 سازمان مجزا که در نظرسنجی شرکت کردند. مانند سازمانهایی که با آنها مصاحبه کردیم، این سازمانها عمدتاً از دادههای مکانی در حوزه کاری خود در استرالیا و نیوزلند استفاده میکنند، بنابراین تعداد محدودی از شرکتکنندگان در نظرسنجی وجود دارد.
3. نتایج
3.1. تحلیل کیفی مصاحبه ها
تجزیه و تحلیل ما عناصر کیفیت دادههای مکانی و عناصر فرعی مورد استفاده یا مورد نیاز شرکتکنندگان را برای ارزیابی تناسب برای استفاده از منابع دادههای مکانی شناسایی کرد. جدول 1 این عناصر و عناصر فرعی کیفیت داده، تعاریف آنها و نقل قول های مستقیم را نشان می دهد. علاوه بر این، ما موضوعات کیفی و جنبههای اطلاعاتی منابع دادههای مکانی را شناسایی کردیم که برای ارزیابی تناسب استفاده مفید و مهم تلقی میشوند. این مضامین کیفیت و جنبه های اطلاعاتی در سراسر این مقاله به عنوان ” الزامات مناسب برای استفاده ” نامیده می شوند . جدول 2 این الزامات، تعاریف آنها و نقل قول های مستقیم از شرکت کنندگان را ارائه می دهد.
جدول 3 و جدول 4 تعداد فراوانی عناصر کیفیت داده و الزامات مناسب برای استفاده را که از مصاحبه های ما شناسایی شده اند، نشان می دهد. به عنوان مثال، تعداد شرکتکنندگانی که هر یک از عناصر کیفی و نیازهای تناسب برای استفاده را به عنوان تأثیرگذار در ارزیابی و ارزیابی تناسب برای استفاده از دادههای مکانی شناسایی کردند. توجه می کنیم که اگر از روش شمارش آرا در طول مصاحبه ها استفاده می کردیم، این اعداد می توانست بیشتر باشد. با این حال، ما از این تکنیک اجتناب کردیم، زیرا مصاحبه ها به عنوان روشی اکتشافی و نه تاییدی برای جمع آوری داده ها انجام شد.
علاوه بر این، شرکتکنندگان تقریباً در تمام مصاحبهها نشان دادند که اگرچه شناسایی جنبههای اطلاعاتی منابع دادههای مکانی که در ارزیابی تناسب برای استفاده مؤثر هستند، مهم است، همچنین مهم است که کاربران را قادر به کشف دادههای مکانی در پورتالهای داده باز با استفاده از این موارد کند. جنبه های اطلاعاتی به عنوان معیارهای جستجو به منظور تسهیل جستجو و کشف دادههای مکانی، ابردادههای مکانی باید در پورتالهای داده باز منتشر شوند و با ابردادههای حوزههای غیرمکانی قابل همکاری باشند. در نهایت، ما همچنین متذکر می شویم که شرکت کنندگان در مورد اهمیت “سهولت دسترسی”، “مجوز”، “رزولوشن” و “تالارهای آنلاین” اظهار نظر کردند. این موضوعات در تجزیه و تحلیل ما گنجانده نشده اند، زیرا عناصر کیفیت و الزامات مناسب برای استفاده را در بر می گیرند که در جدول 1 وجدول 2 ; به عنوان مثال، «رتبهبندیهای کاربر» و «توصیهها و توصیههای جامعه» که بهعنوان الزامات مناسب برای استفاده در جدول 2 مشخص شدهاند ، الزامات خاصتر موضوع گستردهتر، «تالارهای آنلاین» هستند.
3.2. تجزیه و تحلیل نتایج نظرسنجی
ما داده های جمع آوری شده از نظرسنجی را با استفاده از نرم افزار SPSS Statistics 23 [ 35 ] تجزیه و تحلیل کردیم. تجزیه و تحلیل پاسخ به ده سوال اول نشان داد که:
-
80% از شرکت کنندگان خود را هم به عنوان کاربر و هم تولید کننده داده های مکانی معرفی کردند.
-
اکثر شرکت کنندگان در “کشاورزی، جنگلداری و ماهیگیری” (26٪) یا “سایر خدمات” (33٪) کار می کنند. ما از طبقهبندی استاندارد صنعتی استرالیا و نیوزلند ( https://www.abs.gov.au/ausstats/ abs@.nsf /0/20C5B5A4F46DF95BCA25711F00146D75?opedocument ) برای شناسایی صنعت ارائهشده توسط هر شرکتکننده استفاده کردیم.
-
93٪ از شرکت کنندگان از داده های ارائه دهندگان داده های خارجی استفاده می کنند.
-
86% از شرکت کنندگان طیف وسیعی از منابع داده را برای انتخاب دارند.
-
46٪ از شرکت کنندگان با داده های مکانی برای دو تا نه سال کار کرده اند.
-
93٪ از شرکت کنندگان تصمیمات انتخاب منبع داده را بر اساس دانش و تجربه قبلی می گیرند.
-
53 درصد از شرکتکنندگان انتخاب مجموعه دادههای متناسب با نیازهایشان را کاری چالشبرانگیز میدانند.
-
80% از شرکت کنندگان هنگام انتخاب منابع داده، سوابق فراداده یا سایر اطلاعات پشتیبانی را در نظر می گیرند.
-
53٪ از شرکت کنندگان معتقدند که تا 25٪ تلاش دستی در درک مناسب برای استفاده از منابع داده دخیل است.
-
6.7٪ از شرکت کنندگان معتقدند که ابرداده توصیف کننده کیفیت مجموعه داده ها از هیچ استانداردی پیروی نمی کند. 26.7٪ معتقدند که چنین ابرداده ای ارائه نشده است. 33.3 درصد معتقدند که ابرداده هایی که کیفیت داده ها را توصیف می کنند ناقص هستند. و 33.3% معتقدند که این ابرداده از استانداردهای پذیرفته شده پیروی می کند.
-
53٪ از شرکت کنندگان نشان دادند که سازمان آنها حداقل یک بار تحت تأثیر عدم درک (یا درک نادرست) تناسب برای استفاده از یک مجموعه داده قرار گرفته است.
جدول 5 و جدول 6 به ترتیب نتایج آمار توصیفی را برای اهمیت عناصر کیفیت داده و الزامات مناسب برای استفاده نشان می دهند. همانطور که در جدول 5 نشان داده شده است، میانگین پاسخ ها به هر یک از ده عنصر کیفیت داده بالاتر از 5 است، که نشان دهنده اهمیت عناصر کیفیت داده در ارزیابی تناسب برای استفاده از منابع داده است. به طور دقیق تر، «ثبات منطقی» و «نسب/منشأ» کمترین میانگین (20/5) را دارند، در حالی که «ارتباط» بالاترین میانگین (47/6) را دارد که آن را به مهم ترین عنصر کیفیت از دیدگاه شرکت کنندگان تبدیل می کند. علاوه بر این، همانطور که در جدول 6 نشان داده شده است”اطلاعات کیفی کمی” بالاترین میانگین (5.60) را دارد که نشان دهنده اهمیت آن در ارزیابی تناسب برای استفاده از منابع داده است، در حالی که “استنادات مجموعه داده” (میانگین: 3.13) و “رتبه بندی کاربران” (میانگین: 3.67) دارای امتیاز هستند. مقدار متوسط زیر نقطه خنثی، نشان دهنده اهمیت کمتر آنها در مقایسه با سایر الزامات است. علاوه بر این، تجزیه و تحلیل ها نشان می دهد که شرکت کنندگان برای شناسایی منابع داده ای که به بهترین وجه برای اهداف خاص آنها مناسب است، عناصر کیفیت داده را بالاتر از الزامات مناسب برای استفاده به دست آورده اند.
علاوه بر این، تجزیه و تحلیل توصیفی سؤالات 30 و 31 نشان داد که: (1) 86٪ از شرکت کنندگان معتقدند که واژگان فوق داده کاربر محور جغرافیایی در تصمیم گیری آگاهانه انتخاب منبع داده مفید خواهد بود و (ii) 93 درصد از شرکت کنندگان معتقدند که توصیف فراداده در سطوح مختلف دانه بندی، به عنوان مثال، توصیف ابرداده برای یک مجموعه داده، انواع ویژگی ها و انواع ویژگی های آن، در ارزیابی تناسب برای استفاده از مجموعه داده ارزشمند خواهد بود.
در نهایت، نقاط پرت برای عناصر کیفیت داده و الزامات مناسب برای استفاده شناسایی شدند. موارد پرت برای عناصر کیفیت داده عبارتند از:
-
ویژگی/ دقت موضوعی: تنها یک شرکتکننده در حوزه خدمات مالی و بیمهای، این عنصر کیفی را پایین آورده است (2).
-
سازگاری منطقی: تنها یک شرکتکننده در حوزه خدمات حرفهای، علمی و فنی، این عنصر کیفیت را پایین آورده است (2).
-
کامل بودن: تنها یک شرکت کننده در خدمات تخصصی، علمی و فنی، این عنصر کیفی را پایین آورده است (2).
-
اصل و نسب/منشأ: تنها یک شرکتکننده از دامنه «سایر خدمات» امتیاز پایینی به این عنصر کیفیت کسب کرد (2).
موارد پرت برای الزامات مناسب برای استفاده به شرح زیر است:
-
انطباق با استانداردهای بین المللی: دو شرکت کننده از حوزه «سایر خدمات» امتیاز پایینی به این نیاز کسب کردند (2).
-
توصیهها و توصیههای جامعه (بازخورد کاربر): فقط یک شرکتکننده از دامنه «سایر خدمات» این نیاز را پایین آورده است (2).
-
شهرت ارائهدهنده مجموعه داده (نمایه تولیدکننده): دو شرکتکننده (یکی از دامنه «خدمات اداری و پشتیبانی» و دیگری از دامنه «سایر خدمات») این نیاز را بسیار پایین کسب کردند (1).
-
اطلاعات کیفی کمی: تنها یک شرکتکننده از حوزه «سایر خدمات» این نیاز را پایین آورده است (2).
-
قابلیت اطمینان کلی: تنها یک شرکتکننده از دامنه «سایر خدمات» امتیاز 4 را به این شرط داده است.
-
ارتباط: تنها یک شرکتکننده از حوزه «خدمات حرفهای، علمی و فنی» به این شرط امتیاز 4 داد. همه پاسخهای دیگر به این شرط بیش از 4 امتیاز دادند.
-
فرهنگ لغت داده (توضیح یک مجموعه داده و اجزای آن؛ به عنوان مثال، انواع ویژگی ها و انواع ویژگی ها و روابط آنها): تنها یک شرکت کننده از “حوزه خدمات اداری و پشتیبانی” این نیاز را پایین آورده است (2).
3.3. هستی شناسی فراداده کاربر محور جغرافیایی
این بخش هستی شناسی فراداده کاربر محور جغرافیایی ( GUCM ) را شرح می دهد. الزاماتی که زیربنای طراحی هستی شناسی GUCM هستند از تحلیل های ارائه شده در بخش 3.1 و بخش 3.2 پدیدار شده اند.. فعالیتهای صنعتی ما نیاز به واژگانی را تأیید کرد که کیفیت دادههای مکانی و تناسب استفاده را به هم منتقل میکند. به طور خاص، تجزیه و تحلیل تعاملات ما نشان داد که 93٪ از شرکت کنندگان از داده های ارائه دهندگان داده های خارجی استفاده می کنند و تصمیمات انتخاب منبع داده را بر اساس دانش و تجربه قبلی می گیرند. بیش از نیمی از شرکتکنندگان (53%) اظهار داشتند که انتخاب منابع دادهای که برای استفاده مناسب هستند، یک کار چالش برانگیز است و معتقدند که تا 25٪ تلاش دستی در درک تناسب برای استفاده از منابع داده دخیل است. علاوه بر این، 80٪ از شرکت کنندگان نشان دادند که آنها سوابق فراداده یا سایر اطلاعات پشتیبانی را برای انتخاب مجموعه داده ها در نظر می گیرند. با این حال، سوابق فراداده معمولاً گم یا ناقص هستند. علاوه بر این، 86 درصد از شرکت کنندگان اظهار داشتند که یک واژگان،
مدل دادههای GUCM از استانداردها و واژگان موجود مجدداً استفاده مجدد میکند و در صورت لزوم این واژگان را گسترش میدهد تا اطلاعاتی را که از تعاملات صنعت ما برای برانگیختن دیدگاههای کاربر در مورد کیفیت دادههای مکانی و تناسب برای استفاده به دست میآید، مدلسازی کند. GUCM با استفاده از Protégé ساخته شده است، یک ویرایشگر هستی شناسی رایگان و منبع باز که برای ایجاد راه حل های مبتنی بر دانش در حوزه های متنوعی مانند زیست پزشکی، تجارت الکترونیک و مدل سازی سازمانی استفاده می شود [36 ] . به طور خاص، ما از نسخه 5.5.0 Protégé استفاده کردیم که پشتیبانی کامل از زبان هستی شناسی وب OWL 2 ( https://www.w3.org/TR/owl-overview/ ) و اتصالات مستقیم درون حافظه به منطق توصیف را ارائه می دهد. استدلال هایی مانند HermiT و Pellet ( https://owl.cs.manchester.ac.uk/tools/list-of-reasoners/) که برای اعتبار سنجی هستی شناسی در طول مرحله توسعه استفاده شد.
از نقطه نظر مفهومی، هستی شناسی GUCM ( https://crcsiprojres.s3-ap-southeast-2.amazonaws.com/gucmetadata-v1.owl ) شامل سه جزء اصلی است: (i) طرح واره مجموعه داده، (ii) قابلیت همکاری فراداده، و (iii) بازخورد کاربر.
به هستی شناسی می توان از مخزن هستی شناسی جامعه ESIP ( https://cor.esipfed.org/ont?iri=https://reference.data.gov.au/def/ont/gucmetadata ) دسترسی پیدا کرد. بخشهای زیر هر جزء را با استفاده از نمایه زبان مدلسازی یکپارچه هستیشناسی (UML) نشان میدهند. به عنوان مثال، یک مشخصات رسمی از نمایه UML برای طرحواره RDF (RDFS) و زبان هستی شناسی وب (OWL) [ 37 ]. کلاسهای OWL بهعنوان کلاسهای UML، ویژگیهای داده بهعنوان ویژگیهای کلاس، ویژگیهای شی بهعنوان نقشهای ارتباطی، افراد بهعنوان اشیاء و محدودیتهای کاردینالیتی در کلاس دامنه انجمن بهعنوان ویژگیهای UML نشان داده میشوند.
تجزیه و تحلیل ما نشان داد که اکثر شرکت کنندگان (80٪) هم کاربران و هم تولیدکنندگان داده های مکانی هستند. بنابراین، GUCM هم تولیدکنندگان داده های مکانی و هم کاربران را قادر می سازد تا ابرداده ها را توصیف و ارجاع دهند. با این حال، به منظور اطمینان از یکپارچگی و قابل اعتماد بودن فراداده توصیف شده، GUCM تولید کننده و کاربر فراداده را که توسط هر یک از اجزای آن ارائه می شود، تعریف می کند (لطفاً به اطلاعات «تولیدکننده فراداده» و «مصرف کننده فراداده» که برای هر یک از اجزای GUCM توضیح داده شده است، مراجعه کنید. در بخش 3.3.1 ، بخش 3.3.2 و بخش 3.3.3 ).
مؤلفه Dataset Schema در هستیشناسی GUCM، ابردادههای مکانی را با استفاده از واژگان خاص حوزه جغرافیایی جذب میکند. ابرداده مکانی که توسط این مؤلفه گرفته می شود می تواند یک مجموعه داده یا هر یک از اجزای آن را هدف قرار دهد. به عنوان مثال، یک نوع ویژگی یا یک نوع ویژگی. به عبارت دیگر، ابرداده های مکانی را می توان برای یک مجموعه داده در سطوح مختلف دانه بندی توصیف کرد.
اطلاعات بخش عمومی به طور فزاینده ای به عنوان داده های باز در سال های اخیر منتشر شده است. دولت ها در سراسر جهان به مزایای بالقوه انتشار اطلاعات خود به عنوان داده های باز پی می برند. این مزایا شامل شفافیت بیشتر، افزایش کارایی و اثربخشی دولت و منافع اجتماعی و اقتصادی است. مزایای در دسترس قرار دادن مجموعه داده ها به عنوان داده های باز برای بخش خصوصی نیز صدق می کند. دادههای جغرافیایی، مانند نقشههای توپوگرافی و دادههای زیربنایی رصد زمین، به دلیل تقاضای زیاد کاربران برای انتشار بهعنوان دادههای دولتی باز در فهرست برتر قرار دارند. در راستای این ابتکار، مؤلفه متاداده متقابل هستیشناسی GUCM، ابردادههای فضایی را با استفاده از هستیشناسیها و واژگان مستقل از دامنه و به طور گسترده پذیرفته شده نشان میدهد.
مؤلفه بازخورد کاربر در هستی شناسی GUCM با هدف انتقال بازخورد، مناسب بودن برای استفاده و تجربیات استفاده از مجموعه داده های مکانی به تولیدکنندگان و کاربران داده های مکانی است. همانند مؤلفه Dataset Schema، مؤلفه بازخورد کاربر در GUCM این امکان را فراهم می کند که بازخورد، تناسب برای استفاده و توصیفات استفاده از مجموعه داده با یک مجموعه داده یا هر یک از اجزای آن مرتبط شود. به عنوان مثال، یک نوع ویژگی یا یک نوع ویژگی. علاوه بر این، همانطور که در مورد مؤلفه متاداده تعاملی وجود دارد، بازخورد کاربر با استفاده از واژگان مستقل از دامنه و به طور گسترده پذیرفته شده گرفته و نشان داده می شود، در نتیجه کارکرد متقابل بین ابرداده گرفته شده توسط این مؤلفه و ابرداده در پلت فرم های داده باز را تسهیل می کند.
3.3.1. طرح واره مجموعه داده
تجزیه و تحلیل ما اهمیت عناصر کیفیت داده های مکانی ( جدول 1 ) و اهمیت توصیف یک مجموعه داده و اجزای آن را برجسته کرد. به عنوان مثال، انواع ویژگی ها و انواع ویژگی ها و روابط آنها (فرهنگ داده ها در جدول 2 ). علاوه بر این، همانطور که در بخش 3.2 ذکر شده است93 درصد از شرکتکنندگان بیان کردند که توصیف ابرداده در سطوح مختلف جزئیات، به عنوان مثال، توصیف ابرداده برای یک مجموعه داده، انواع ویژگیها و انواع ویژگیهای آن، در ارزیابی تناسب برای استفاده از مجموعه داده ارزشمند است. بنابراین، مؤلفه طرحواره مجموعه داده از هستیشناسی GUCM با استفاده از طرحواره کاربردی توسعهیافته مطابق با استاندارد ISO 19109:2015 (https://www.iso.org) با هدف ارائه شرح کاملی از محتوا و ساختار یک مجموعه داده جغرافیایی است . /standard/59193.html). به طور خاص، این مؤلفه از مدل ویژگی عمومی (GFM) از ISO 19109:2015 اطلاعات جغرافیایی – قوانین برای طرحواره برنامه استفاده می کند. مدل ویژگی عمومی متامالگویی برای تعریف ویژگی ها است. معنای انواع ویژگی و ویژگیهای ویژگی مرتبط با آنها، عملیات ویژگی و تداعی ویژگیهای موجود در طرح برنامه را تعریف میکند. محتویات و ساختار یک مجموعه داده، که مطابق با مدل ویژگی عمومی تعریف شده است، توسط مؤلفه طرحواره مجموعه داده برای توصیف و مرتبط کردن ابرداده مجموعه با اجزای خاص یک مجموعه داده، به عنوان مثال، مجموعه داده، نوع ویژگی یا نوع ویژگی استفاده می شود. فراداده مطابق با استانداردهای ISO 19115-1:2014 و ISO 19157:2013، که مختص حوزه جغرافیایی است، توصیف شده است.
شکل 3 مولفه Dataset Schema از هستی شناسی GUCM را نشان می دهد. همانطور که در شکل 3 نشان داده شده است، مؤلفه طرحواره مجموعه داده GUCM را می توان از نظر مفهومی به دو بخش اصلی تقسیم کرد: (1) قسمت 1 که ساختار یک مجموعه داده جغرافیایی را مدل می کند، و (2) قسمت 2 که متادیتا را تعریف و با مجموعه داده مرتبط می کند. انواع ویژگی و انواع ویژگی آن. هر دو بخش در زیر مورد بحث قرار گرفته است.
مفهوم مرکزی قسمت 1 gucm:DatasetSchema است که (gucm: dataset) ساختار یک مجموعه داده جغرافیایی (مدل سازی شده توسط gucm:Dataset ) را توصیف می کند. یک gucm:DatasetSchema (gucm:DatasetSchema.featureType) انواع ویژگی های مجموعه داده را تعریف می کند (مدل سازی شده توسط gfm:FeatureType ). یک نوع ویژگی (مدلسازیشده توسط gfm:AttributeType ) (gfm:ValueAssignment.carrierOfCharacteristics) به یک نوع ویژگی (مدلسازیشده توسط gfm:FeatureType ) از طریق تخصیص مقدار (مدلسازیشده توسط gfm:ValueAssignment ) اختصاص داده میشود.
بخش 2 از مؤلفه طرحواره مجموعه داده GUCM، توصیف ابرداده را در سطوح مختلف جزئیات تسهیل میکند. به عنوان مثال، طرح داده (مدلسازیشده توسط gucm:DatasetSchema ) فرادادههای (gucm:DatasetSchema.metadata) (مدلسازیشده توسط MetadataInformation:MD_Metadata ) را برای مجموعه داده زیربنایی (مدلسازیشده توسط gucm:Dataset ) توصیف میکند. همچنین میتوان فراداده (gfm:FeatureType.featureTypeMetadata) را برای یک نوع ویژگی (مدلسازی شده توسط gfm:FeatureType )، یا برای (gfm:AttributeType.featureAttributeMetadata) یک نوع ویژگی (مدلسازی شده توسط gfm:AttributeType ) توصیف کرد. سازنده (gucm:DatasetSchema.producer) یک gucm:DatasetSchema توسط ISO19115-1:CI_Responsibility نشان داده شده است.. نمونه هایی از ابرداده توصیف شده توسط مؤلفه طرحواره مجموعه داده را ببینید.
تولید کننده فراداده: فراداده های تولید کننده محور که توسط این مؤلفه نمایش داده می شود، توسط تولیدکنندگان داده های مکانی برای ارجاع توسط کاربران داده های مکانی توصیف و نگهداری می شوند.
مصرف کننده فراداده: تولیدکنندگان و کاربران داده های مکانی، مصرف کنندگان ابرداده تولید شده توسط این مؤلفه هستند. کاربران میتوانند به ابردادههای ارائهشده توسط این مؤلفه مراجعه کنند تا درک درستی از مجموعه داده و ساختار آن به دست آورند. به عنوان مثال، جزئیات انواع ویژگی ها و انواع ویژگی ها، روابط و پیوندهای آنها. علاوه بر این، کاربران میتوانند به ابرداده تعریفشده برای یک مجموعه داده، انواع ویژگیها و انواع ویژگیهای آن ارجاع دهند. علاوه بر این، ابرداده ارائه شده توسط این مؤلفه می تواند به عنوان مرجع برای توصیف ابرداده از طریق مؤلفه بازخورد کاربر GUCM استفاده شود. به عنوان مثال، کاربران می توانند تجربیات، مسائل، محدودیت ها و پیشنهادات خود را با یک مجموعه داده یا هر یک از اجزای آن، همانطور که توسط این مؤلفه تعریف شده است، مرتبط کنند. به عنوان مثال، یک محدودیت می تواند با یک مجموعه داده، یک نوع ویژگی یا یک نوع ویژگی مرتبط باشد.
3.3.2. متاداده های تعاملی
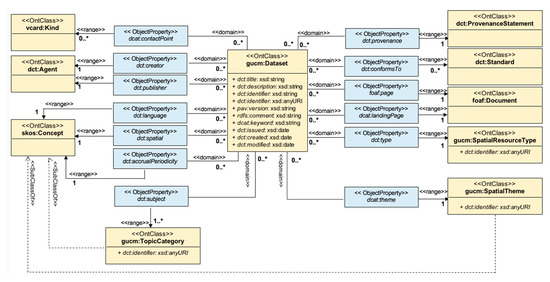
تجزیه و تحلیل مصاحبه های نیمه ساختاریافته ما با تولیدکنندگان و کاربران داده های مکانی، نیاز به جستجو و کشف مجموعه داده ها را برجسته کرد (لطفاً به بخش 3.1 مراجعه کنید.). برای این منظور، مؤلفه متاداده متقابل GUCM با هدف تسهیل قابلیت همکاری بین توضیحات فراداده از حوزههای مکانی و غیرمکانی، به منظور ایجاد مجموعه دادههای مکانی، سری دادهها و خدمات قابل جستجو در پورتالهای داده عمومی است. مؤلفه طرحواره مجموعه داده در GUCM توصیف ابرداده را با استفاده از استانداردهایی که مختص حوزه جغرافیایی هستند، تسهیل می کند. بنابراین، توضیحات فراداده تولید شده توسط مؤلفه Dataset Schema را نمی توان با توضیحات فراداده از حوزه های غیر مکانی مبادله کرد. به منظور تسهیل همکاری متقابل بین ابردادههای فضایی گرفتهشده توسط مؤلفه Dataset Schema و ابردادههای سایر حوزهها در پلتفرمهای داده باز، مؤلفه متاداده متقابل از هستیشناسی GUCM، ابردادههای گرفتهشده توسط مؤلفه Dataset Schema را ارائه میکند.https://joinup.ec.europa.eu/release/geodcat-ap/v101 ). GeoDCAT-AP یک توسعه از نمایه برنامه DCAT (DCAT-AP ( https://joinup.ec.europa.eu/solution/dcat-application-profile-data-portals-europe )) برای پورتال های داده در اروپا برای توصیف است. مجموعه داده های جغرافیایی، سری داده ها و خدمات. DCAT-AP نمایه ابرداده ای را ارائه می دهد که هدف آن ارائه یک قالب تبادلی برای پورتال های داده ای است که توسط کشورهای عضو اتحادیه اروپا اداره می شوند. DCAT-AP با واژگان W3C Data Catalog (DCAT ( https://www.w3.org/TR/vocab-dcat/ )) مطابقت دارد و بر اساس آن است. GeoDCAT-AP همچنین یک اتصال نحوی در RDF ارائه میکند ( https://www.w3.org/RDF/) برای اتحاد ابعاد فراداده مشخصات اصلی ISO 19115:2003 و عناصر فراداده تعریف شده در چارچوب دستورالعمل INSPIRE [ 30 ]. شکل 4 ، شکل 5 و شکل 6 متادیتا را برای توصیف مجموعه داده ها مطابق با مشخصات GeoDCAT-AP نسخه 1.0.1 نشان می دهد.
جزء Interoperable Metadata GeoDCAT-AP Core و GeoDCAT-AP Extended را پیاده سازی می کند. GeoDCAT-AP Extended یک ابر مجموعه از GeoDCAT-AP Core است. GeoDCAT-AP Core شامل پیوندهایی برای عناصر فراداده فراداده INSPIRE و عناصر فراداده در مشخصات هسته هسته ISO 19115:2003 است که DCAT-AP برای آن پیوند نحوی RDF ارائه میکند. آن دسته از عناصر فراداده ای که DCAT-AP برای آنها یک اتصال ارائه نمی کند، بخشی از نمایه GeoDCAT-AP Extended هستند. GeoDCAT-AP Core به منظور فعال کردن برداشت و استفاده مجدد از سوابق فراداده مکانی از طریق برنامهها و سرویسهای منطبق با DCAT-AP، از جمله پورتالهای داده و APIها است. ترازهای عناصر فراداده INSPIRE و ISO 19115:2003 که در GeoDCAT-AP Core گنجانده نشدهاند، در GeoDCAT-AP Extended تعریف شدهاند. علاوه بر این،
مشخصات GeoDCAT-AP برای تسهیل قابلیت همکاری بین ابرداده مجموعه داده های مکانی و غیر مکانی در پورتال های داده در اروپا استفاده می شود. پیوندهای تعریف شده در GeoDCAT-AP برای نمایش RDF فراداده INSPIRE و مشخصات اصلی ISO 19115:2003 بر اساس واژگان به طور گسترده پذیرفته شده، مانند DCAT-AP است. بنابراین، این مشخصات همچنین میتواند برای تسهیل تبادل توضیحات فراداده برای مجموعه دادههای مکانی، سری دادهها و خدمات در میان پورتالهای داده در سایر نقاط جهان استفاده شود. با این حال، لیستهای کد خاصی که توسط مشخصات GeoDCAT-AP توصیه میشوند، میتوانند جایگزین شوند تا با بافت محلی سازگاری بیشتری داشته باشند. برای مثال، مضامین داده های مکانی INSPIRE ( https://inspire.ec.europa.eu/theme) را می توان با مضامین داده های مکانی جایگزین کرد که ممکن است به بافت محلی مرتبط تر باشد. به عنوان مثال، در زمینه این مطالعه، ما از مضامینی استفاده کردیم که توسط پلتفرم دانش اطلاعات مکان بنیاد دادههای مکانی (LINK ( https://link.fsdf.org.au/ ) تعریف شدهاند. نمونههایی از ابردادهها را ببینید که توسط مؤلفه متاداده تعاملی توضیح داده شده است.
تولیدکننده فراداده: این مؤلفه ابرداده توصیف شده در مؤلفه Dataset Schema را با استفاده از نگاشتهای شناسایی شده توسط مشخصات GeoDCAT-AP نسخه 1.0.1 نشان می دهد. به منظور جلوگیری از ورود مضاعف داده و ناسازگاری داده ها، باید از یک فرآیند خودکار برای افزودن و به روز رسانی مقدار عناصر برای مؤلفه متاداده تعاملی استفاده شود، زیرا عناصر مربوطه در مؤلفه طرحواره مجموعه داده اضافه و به روز می شوند.
مصرف کننده فراداده: فراداده هایی که توسط واژگان مستقل از دامنه و به طور گسترده پذیرفته شده، مطابق با مشخصات GeoDCAT-AP نسخه 1.0.1، نشان داده می شوند، می توانند در ابر داده های پیوندی و پورتال های داده باز [18]، مانند عموم دولت استرالیا منتشر شوند . پلت فرم داده ( https://data.gov.au ) در زمینه مطالعه تحقیقاتی ما. این به نوبه خود قابلیت همکاری بین ابرداده های حوزه های مکانی و غیر مکانی را تسهیل می کند ( شکل 1 ). بنابراین، کاربران و تولیدکنندگان دادههای مکانی، از جمله کاربران و تولیدکنندگان دادههای مکانی در ابر دادههای پیوندی و پورتالهای داده باز، مصرفکنندگان ابردادههای ارائهشده توسط این مؤلفه هستند.
3.3.3. بازخورد کاربر
تجزیه و تحلیلهای ما موضوعات کیفی و جنبههای اطلاعاتی منابع دادههای مکانی را شناسایی کرد که کاربران آنها را برای ارزیابی تناسب برای استفاده مرتبط و مهم میدانستند ( جدول 2 ). مؤلفه بازخورد کاربر در هستیشناسی GUCM، این الزامات مناسب برای استفاده را شامل میشود، از جمله ابردادههایی که دانش ضمنی کاربران را نشان میدهند.مجموعه داده های فضایی؛ به عنوان مثال، دانش نشان دهنده تجربیات کاربران با مجموعه داده ها در زمینه حوزه های کاربردی خاص. این ابردادهها شامل بازخورد کاربر، تجربیات، نظرات، پرسشها و پاسخها، شرح مشکلات مواجه شده، راهحلهای پیشنهادی و انتشاراتی که آن مشکلات را توصیف میکنند، رتبهبندی مجموعه دادهها و توضیحات مناسب برای استفاده مجموعه دادههای مکانی را در بر میگیرد. ابردادههای گرفتهشده توسط مؤلفه Dataset Schema نشاندهنده ویژگیهای مجموعه داده و گردشهای کاری تولیدی است که توسط تولیدکننده یک مجموعه داده فضایی ایجاد میشود. فرادادههای گرفتهشده توسط مؤلفه بازخورد کاربر، با ارائه بازخورد کاربر، نظرات و توضیحات مناسب برای استفاده برای برنامههای مختلف یک مجموعه داده، متادادههای گرفتهشده توسط مؤلفه Dataset Schema را تکمیل میکنند. علاوه بر این،شکل 2 نمونه ای از پرسش و پاسخ بین تولیدکنندگان و کاربران یک مجموعه داده را نشان می دهد.
مؤلفه بازخورد کاربر در هستیشناسی GUCM از واژگان استفاده از مجموعه داده (DUV ( https://www.w3.org/TR/vocab-duv/ )) برای توصیف تجربیات کاربر، نقلقولها و بازخورد درباره یک مجموعه داده استفاده میکند. گروه کاری Data on the Web Best Practices ( https://www.w3.org/TR/dwbp/ )، که یک توصیه W3C برای انتشار و استفاده از داده ها در وب است، DUV را برای استناد به داده های منتشر شده و انتقال بازخورد توصیه می کند. بین کاربران و تولیدکنندگان، و تعریف ابرداده توصیفی که بینش هایی را در مورد نحوه استفاده از مجموعه داده های منتشر شده به کاربران ارائه می دهد. DUV توسعه داده کاتالوگ (DCAT ( https://www.w3.org/TR/vocab-dcat/ است)) واژگان نسخه 1.0، که ابرداده را برای استناد، توصیف استفاده، و انتقال بازخورد در مورد مجموعه داده ها و توزیع های منتشر شده فراهم می کند. به عنوان واژگانی مستقل و باز، DUV تولیدکنندگان را تشویق میکند تا ابردادههای توصیفی متناسب با نیازهای دامنه خاص کاربران را اضافه کنند . فراداده DUV امکان شناسایی و ارجاع متقابل اطلاعات استفاده را در میان مجموعه داده ها در طول تبادل و استفاده مجدد از داده های منتشر شده فراهم می کند. DUV به شدت به استفاده مجدد از واژگان متکی است و از چهار مدل فرعی، یعنی DCAT، Citation، Usage و Feedback برای پشتیبانی از نیازهای مختلف پزشکان تشکیل شده است.
مؤلفه بازخورد کاربر، ابرداده را بر اساس DUV، که از مفاهیم واژگان مستقل از دامنه استفاده می کند، مدل می کند. بنابراین، ابردادههای ارائهشده توسط مؤلفه بازخورد کاربر GUCM با ابردادههای حوزههای غیرمکانی قابل همکاری است. علاوه بر این، این مؤلفه دارای ابرداده تعریف شده توسط بازخورد کاربر مکانی (GUF ( https://www.opengeospatial.org/standards/guf )) است. این کار در پرتو یک ابتکار اخیر انجام می شود که هدف آن افشای ابرداده GUF به عنوان DUV در خروجی GeoDCAT-AP GeoNetwork است ( https://www.plan4all.eu/2018/03/team-8-exposing-guf-metadata- as-duv-in-the-geodcat-ap-output-of-geonetwork/ ).
فرادادههای جمعآوریشده توسط این مؤلفه را میتوان نه تنها برای ارزیابی تناسب برای استفاده از مجموعههای داده، بلکه برای شناسایی موارد استفاده و کاربران مختلف مجموعههای داده استفاده کرد، زیرا آنها تجربیات خود را در زمینه برنامهها و حوزههای خاص توصیف میکنند. علاوه بر این، تولیدکنندگان میتوانند این ابردادهها را در معیارهای کیفی عینی محصولات خود بگنجانند، و به ارائهدهندگان اجازه میدهند تا محصولات داده خود را بهبود بخشند و نیازهای خاص کاربران را برآورده کنند. شکل 7 ساختار این جزء را نشان می دهد. همانطور که در شکل 7 نشان داده شده است ، یک بازخورد کاربر (مدل سازی شده توسط gucm:UserFeedback ) مربوط به (gucm:dataset) یک مجموعه داده (مدل سازی شده توسط gucm:Dataset )، ایجاد شده (dct:creator) توسط یک کاربر (مدل سازی شده توسط foaf:Agent) است.)، با انگیزه (oa:motivatedBy) یک دلیل (مدل شده توسط oa:Motivation )، تعریف شده (gucm:UserFeedback.applicationDomain) در زمینه یک دامنه برنامه (مدل سازی شده توسط gucm:TopicCategory ) و نرخ گذاری (duv:hasRating) زیربنایی مجموعه داده با استفاده از یک سیستم رتبه بندی (مدل سازی شده توسط skos:Concept ).
ساختار مجموعه داده تعریف شده توسط مؤلفه Dataset Schema توسط مؤلفه User Feedback برای فعال کردن بازخورد کاربر برای هدف قرار دادن یک مجموعه داده یا هر یک از اجزای آن استفاده می شود. همانطور که در شکل 7 نشان داده شده است ، یک gucm:UserFeedback (oa:hasTarget) یک مجموعه داده (مدل سازی شده توسط gucm:Dataset )، یک نوع ویژگی (مدل سازی شده توسط gfm:FeatureType ) یا یک نوع ویژگی (مدل سازی شده توسط gfm:AttributeTypes، subclass) را هدف قرار می دهد. :PropertyType).
یک gucm:UserFeedback میتواند پاسخی به (gucm:UserFeedback.isReplyTo) بازخورد کاربر دیگری باشد (مدلسازی شده توسط gucm:UserFeedback ). یک مشکل کشف شده با یک مجموعه داده (مدل سازی شده توسط gucm:DiscoveredIssue )، یک نوع gucm:UserFeedback، می تواند در (biro:isReferencedBy) یک نشریه (مدل شده توسط biro:BibliographicRecord )، طبقه بندی شده توسط (gucm:DiscoveredIssue.aspectCode) استناد شود. کد (مدل سازی شده توسط gucm:IssueAspectCode ). یک gucm:DiscoveredIssue می تواند (gucm:DiscoveredIssue.alternativeResource) یک منبع جایگزین برای مجموعه داده (مدل سازی شده توسط gucm:Dataset ) شناسایی کند. همچنین می تواند (gucm:DiscoveredIssue.fixedResource) منبع ثابت (مدل شده توسطgucm:Dataset )؛ یعنی منبعی که مشکل کشف شده در آن حل شده است. نمونههایی از ابردادهها را ببینید که توسط مؤلفه بازخورد کاربر توضیح داده شده است.
تولیدکننده فراداده: فرادادههای ارائهشده توسط این مؤلفه عمدتاً توسط کاربران دادههای مکانی توصیف میشوند. با این حال، تولیدکنندگان و کارشناسان دادههای مکانی نیز میتوانند به تولید ابرداده کمک کنند. همانطور که در بالا ذکر شد، DUV تولیدکنندگان را تشویق میکند تا ابردادههای توصیفی متناسب با نیازهای دامنه خاص کاربران را اضافه کنند. در زمینه مولفه بازخورد کاربر GUCM، یک تولیدکننده میتواند پاسخی به سؤالی که توسط کاربر مطرح میشود ارائه دهد یا ابردادهای را درباره یک مجموعه داده یا هر یک از اجزای آن توصیف کند. به عنوان مثال، توصیف مقادیر ممکن برای یک ویژگی از نوع ویژگی و کاربردهای مناسب آنها در زمینه ها و برنامه های خاص. شکل 2نمونههایی از ابردادههای جمعآوریشده توسط مؤلفه بازخورد کاربر را نشان میدهد، در حالی که مشارکت تولیدکنندگان و کاربران در تولید فراداده را نشان میدهد.
مصرف کننده فراداده: تولیدکنندگان و کاربران داده های مکانی، مصرف کنندگان فراداده تولید شده توسط این مؤلفه هستند. کاربران از این ابرداده ها استفاده می کنند تا تعیین کنند که آیا یک مجموعه داده برای اهداف خاص آنها مناسب است یا خیر، و با شرکت در بحث های پرسش و پاسخ از تولیدکنندگان داده ها راهنمایی بگیرند ( شکل 2 ). تولیدکنندگان میتوانند از بازخورد و تجربیات کاربران با مجموعه دادهها برای بهبود محصولات داده خود و برآورده کردن نیازها و نیازهای دامنه خاص کاربران استفاده کنند. به عبارت دیگر، بازخورد کاربر ایجاد شده توسط این مؤلفه را می توان در طول زمان تجزیه و تحلیل کرد و برای پالایش و بهبود ابرداده ارائه شده توسط مؤلفه Dataset Schema استفاده کرد. این به نوبه خود فراداده های ارائه شده توسط تولید کننده را با نیازها و نیازهای خاص کاربران مرتبط تر می کند. شکل 2مثالی از کاربر درخواست اطلاعات در مورد مقادیر احتمالی یک ویژگی را نشان می دهد. اگر این اطلاعات به طور مداوم توسط کاربران درخواست شود، مولفه Dataset Schema را می توان به روز کرد تا مقادیر احتمالی ویژگی های انواع ویژگی را در بر گیرد.
4. بحث
هستی شناسی فراداده کاربر محور جغرافیایی (GUCM) ارائه شده در این مقاله با هدف برقراری ارتباط با کیفیت و تناسب استفاده از منابع داده های مکانی به کاربران، به منظور قادر ساختن آنها به تصمیم گیری آگاهانه برای انتخاب منبع داده است. به طور خاص، GUCM قصد دارد شکاف بین دیدگاه تولیدکننده و کاربر در مورد کیفیت دادههای مکانی و تناسب برای استفاده را پر کند. هدف از تعاملات صنعتی ما شناسایی این شکاف و ایجاد الزامات کاربران برای شناسایی مجموعه دادههایی است که برای استفاده و اهداف مورد نظر آنها مناسب است. هستی شناسی GUCM بر اساس الزاماتی طراحی شده است که از تجزیه و تحلیل ارائه شده در بخش 3.1 و بخش 3.2 پدید آمده است .
4.1. کمک به دانش
همانطور که در بخش Related Work ذکر شد، مطالعات و ابتکارات قبلی سعی کردهاند با گرفتن بازخورد کاربران در مورد منبع داده یا ارائه نشانههای بصری کیفیت مجموعه دادهها و احتمالاً ارتباط، با کیفیت دادههای مکانی ارتباط برقرار کنند. ویژگی های اصلی که به وضوح هستی شناسی GUCM را از تلاش های قبلی متمایز می کند به شرح زیر است:
-
گرفتن فراداده به شکل ساختاریافته – همانطور که در بخش مقدمه ذکر شد، یکی از اهداف این مطالعه، جستجوی منابع داده های مکانی در پورتال های داده باز (O3) است. هستی شناسی GUCM با استفاده از مفاهیمی از واژگان و هستی شناسی های مستقل از دامنه و به طور گسترده پذیرفته شده، فراداده ها و توصیف های مناسب برای استفاده مجموعه داده های فضایی را ضبط و نشان می دهد. فراداده ساختار یافته توصیف شده و ضبط شده توسط هستی شناسی GUCM را می توان در پورتال های داده باز و وب داده ها [ 18 ] منتشر کرد و علاوه بر تسهیل، ابزاری برای جستجو و کشف داده های مکانی بر اساس فراداده و معیارهای مناسب برای استفاده فراهم کرد. قابلیت همکاری بین ابرداده های مکانی و غیر مکانی در پلت فرم های داده باز
-
ارائه ابردادههای ارائهشده توسط تولیدکننده و توصیفشده توسط کاربر با استفاده از یک مدل واحد – همانطور که در بخش مقدمه ذکر شد، یکی از اهداف این مطالعه (O2) این است که هم تولیدکنندگان و هم کاربران دادههای مکانی را قادر به توصیف ابرداده و مناسب برای استفاده کنند. توصیف مجموعه داده ها با استفاده از یک مدل واحد کیفیت داخلی، مدلسازی شده توسط مؤلفه Dataset Schema ، و کیفیت خارجی، مدلسازی شده توسط مؤلفه «بازخورد کاربر»، به جای مدلهای مجزای تولیدکننده و کاربر ، با استفاده از یک مدل گرفته شده و نشان داده میشوند. همانطور که در بخش 3.3 ذکر شدبرای اطمینان از یکپارچگی و قابل اعتماد بودن توضیحات فراداده، این مدل بین ابردادههایی که صرفاً توسط تولیدکنندگان ایجاد و نگهداری میشوند (شکل دادهها) و ابرداده ایجاد شده توسط کاربران، تولیدکنندگان و کارشناسان (بازخورد کاربر) تفاوت قائل میشود.
-
فعال کردن توصیف ابرداده در سطوح مختلف جزئیات – یکی از اهداف این مطالعه (O1) تسهیل توضیحات فراداده و مناسب برای استفاده برای مجموعه دادهها و اجزای آن است. ساختار سلسله مراتبی هستی شناسی، ابرداده ها و توضیحات مناسب برای استفاده را قادر می سازد تا اجزای مختلف یک مجموعه داده را هدف قرار دهند. به عنوان مثال، مجموعه داده، نوع ویژگی یا نوع ویژگی. این به نوبه خود، جستجو و کشف مجموعه داده را بر اساس ابرداده و توضیحات استفاده برای اجزای خاص یک مجموعه داده تسهیل می کند.
-
تسهیل ارتباط و بحث بین تولیدکنندگان و کاربران دادههای مکانی – هستیشناسی GUCM تولیدکنندگان و کاربران دادههای مکانی را قادر میسازد تا ابرداده و توصیفهای مناسب برای استفاده را با استفاده از همان مدل (O2) تولید کنند. این به نوبه خود ارتباط و بحث بین تولیدکنندگان و کاربران داده های مکانی را تسهیل می کند. مولفه بازخورد کاربر GUCM ارتباط و بحث بین کاربران داده های مکانی، تولیدکنندگان و کارشناسان را تسهیل می کند ( شکل 2 ). علاوه بر این، ابردادههای جمعآوریشده توسط مؤلفه بازخورد کاربر میتواند برای بهبود فرادادههای ارائهشده توسط تولیدکننده (شکل مجموعه داده) در طول زمان استفاده شود. این امر فراداده های ارائه شده توسط تولید کننده را با نیازها و نیازهای خاص کاربران مرتبط تر می کند.
-
ارائه اطلاعات زمینهای برای ابرداده – هستیشناسی GUCM نمایههایی از کاربران را به تصویر میکشد که تجربیات آنها را با منابع دادههای مکانی توصیف میکنند و با به اشتراک گذاشتن بینش و دانش ضمنی خود از منابع داده، به ابردادههای کاربر محور کمک میکنند. علاوه بر این، هستیشناسی کاربردها و حوزههایی را که متادیتا در آن توصیف میشوند، ضبط میکند. نمایههای کاربر و اطلاعات دامنه برنامه مرتبط با ابرداده میتواند برای قرار دادن متاداده و توصیفهای مناسب برای استفاده در هنگام ارزیابی مناسب بودن منابع داده برای کاربردها و اهداف خاص مورد استفاده قرار گیرد.
4.2. محدودیت های مطالعه
این مطالعه همچنین تعدادی محدودیت را شناسایی کرده است که در زیر مورد بحث قرار می گیرد:
-
ما بسیار مراقب بودیم تا اطمینان حاصل کنیم که تعاملات صنعت ما برای استخراج نیازهای کاربران طیف وسیعی از صنایع را نشان میدهد (لطفاً به بخش 2.1 برای فهرست کامل صنایع شرکتکننده مراجعه کنید). با این حال، ما نتوانستیم با برخی از صنایع مانند ارتش مصاحبه کنیم. هدف کار آینده شامل صنایعی است که در مرحله جمعآوری نیازمندیهای این مطالعه حضور نداشتند یا از دست رفته بودند.
-
ما کاربران و تولیدکنندگان زمین فضایی را از جوامع مختلف GIS در زمینه محلی خود، به عنوان مثال، استرالیا و نیوزلند درگیر کردیم. با این حال، به منظور ایجاد راه حلی فراگیر برای ارزیابی تناسب استفاده از داده های مکانی، استخراج نیازمندی ها باید شامل گروه وسیع تری از کاربران و تولیدکنندگان زمین فضایی از سراسر جهان باشد. به عنوان مثال، گروه کاری کیفیت دادههای مکانی کمیته فنی کنسرسیوم فضایی باز ( https://www.opengeospatial.org/projects/groups/dqdwg )، که بررسی آنلاین کیفیت دادههای مکانی را در سال 2008 ( https://portal) انجام داد. .opengeospatial.org/files/?artifact_id=30415)، از روش نمونه تصادفی برای دستیابی به تعداد زیادی از کاربران و فروشندگان GIS استفاده کرد، جایی که پاسخ دهندگان از هفت قاره بودند. کار آینده ما همچنین بر گسترش همکاری که با شرکای اروپایی ما در طول این ابتکار تحقیقاتی آغاز شد، متمرکز خواهد بود. به طور خاص، ما به همکاری با شبکه تبادل دانش کیفیت (QKEN ( https://eurogeographics.org/knowledge-exchange/qken/ ادامه خواهیم داد.)) از EuroGeographics، به منظور به اشتراک گذاشتن بینش ها و تجربیات و کشف جنبه های اطلاعاتی اضافی از داده های مکانی که برای ارزیابی تناسب استفاده از منابع داده های مکانی تأثیرگذار است. این اطلاعات برای اصلاح مدل GUCM استفاده خواهد شد، که به نوبه خود منجر به واژگانی فراگیرتر میشود تا کاربران دادههای مکانی را قادر میسازد تا تناسب استفاده از دادههای مکانی را ارزیابی کنند.
5. نتیجه گیری ها
در این مقاله، به مشکل برقراری ارتباط با کیفیت دادههای مکانی و تناسب برای استفاده پرداختیم تا کاربران بتوانند منابع دادههای مکانی را شناسایی کنند که برای کاربردهای مورد نظرشان در زمینه برنامهها و حوزههای خاص مناسبتر هستند. ما هستیشناسی فراداده کاربر محور جغرافیایی (GUCM) را برای برقراری ارتباط مناسب برای استفاده از منابع دادههای مکانی به کاربران در حوزههای مکانی و سایر حوزهها معرفی کردیم. الزاماتی که از تجزیه و تحلیل تعاملات صنعت ما پدید آمدند، پایه ای را ارائه کردند که هستی شناسی GUCM بر اساس آن طراحی شد. هدف تحلیلهای ما شناسایی شکافهایی بود که بین کیفیت داخلی (تولیدکننده عرضه شده) و کیفیت خارجی (توضیح مصرفکننده) وجود دارد.بخش 4.1 )، هستیشناسی برای جمعآوری و نمایش فراداده طراحی شده است، زیرا موارد استفاده در طول زمان ظاهر میشوند یا تکامل مییابند. به عنوان مثال، به دلیل تغییر در نیازهای کاربر یا اشیاء فیزیکی یا پدیده های طبیعی. به عبارت دیگر، توصیف ابرداده با موارد استفاده محدود نمیشود، زیرا اطلاعات زمینهای مانند برنامه، دامنه و نمایههای کاربر برای قرار دادن فراداده در متن ضبط میشوند.
کار آینده بر ادامه این ابتکار در مرحله اعتبار سنجی و استفاده متمرکز خواهد شد تا ارزش عملی هستی شناسی GUCM و تأثیر بالقوه آن را نشان دهد. هستیشناسی GUCM توسط اداره اطلاعات سرزمین استرالیای غربی، یعنی Landgate ( https://www0.landgate.wa.gov.au/ ) در حال پیادهسازی است . Landgate آنتولوژی را در پورتال وب خود، که توسط CKAN ( https://ckan.org/ ) پشتیبانی می شود، به منظور آزمایش و اعتبارسنجی طراحی در یک محیط واقعی پیاده سازی می کند. علاوه بر این، هدف این پروژه پیاده سازی واژگان در پلت فرم داده های عمومی دولت استرالیا ( https://data.gov.au) است.)، بستری برای کشف، دسترسی و استفاده مجدد از داده های عمومی. برای رسیدن به این هدف، پروژه با گروه کاری داده های مرتبط با دولت استرالیا ( https://linked.data.gov.au/) در ارتباط خواهد بود.) برای انتشار هستی شناسی GUCM با استفاده از بخشی از دامنه data.gov.au. پیادهسازی هستیشناسی GUCM در پلتفرم data.gov.au این پروژه را قادر میسازد تا سودمندی آن را برای برقراری ارتباط ابرداده با کاربران دادههای مکانی و تسهیل قابلیت همکاری بین ابردادههای مکانی و غیرمکانی ارزیابی کند. علاوه بر این، پیادهسازی میزانی را ارزیابی میکند که هستیشناسی GUCM همکاری بین تولیدکنندگان و کاربران دادههای مکانی را برای برقراری ارتباط ابردادههای مکانی و تناسب برای استفاده از مجموعه دادههای مکانی در زمینه کاربردها و حوزههای مختلف تسهیل میکند. درسهای آموختهشده از پیادهسازی GUCM در پلتفرمهای داده عمومی Landgate و دولت استرالیا برای اصلاح طراحی هستیشناسی استفاده خواهد شد. نتیجه این فرآیند طراحی تکراری به کاربران داده های مکانی اطلاع داده خواهد شد، از طریق Landgate و پلتفرمهای داده عمومی دولت استرالیا و بازخورد از طیف گستردهتری از شرکتکنندگان از طریق پرسشنامه آنلاین درخواست خواهد شد. علاوه بر این، هدف این پروژه جمع آوری بینش از یک جامعه متخصص با شرکت در برنامه نوآوری کنسرسیوم فضایی باز (OGC) است.https://www.opengeospatial.org/ogc/programs/ip ) برای نمونه سازی اولیه و آزمایش هستی شناسی.
توجه به این نکته مهم است که هستی شناسی GUCM از بسیاری از هستی شناسی ها و واژگان به طور گسترده پذیرفته شده استفاده مجدد می کند. در زمان طراحی هستی شناسی، برخی از این واژگان، تنها به صورت فایل RDF یا OWL در دسترس بودند و در هیچ دامنه ای منتشر نشدند. نمونه هایی از این واژگان عبارتند از ISO 19109:2015 و استاندارد GUF. بنابراین، هستیشناسی GUCM تمام هستیشناسیهایی را که دوباره استفاده میکند وارد میکند. در نتیجه، با وجود این واقعیت که GUCM یک هستی شناسی بسیار سبک وزن است، حاوی تعداد زیادی واژگان وارداتی است. کار آینده همچنین بر جداسازی این هستی شناسی ها از GUCM متمرکز خواهد بود، به عنوان مثال، انتشار آنها یا کار با سایر نهادهای استاندارد برای انتشار آنها در وب داده ها، جایی که می توان با استفاده از URI های منتشر شده خود به آنها دسترسی مطمئن داشت. این به نوبه خود اندازه و پیچیدگی GUCM را کاهش می دهد، آن را به یک هستی شناسی بسیار سبک تبدیل می کند که می تواند به راحتی و به طور موثر به روز و نگهداری شود. این به عنوان بخشی از افشای G-NAF (https://www.psma.com.au/products/g-naf )، مجموعه داده ای شامل تمام آدرس های فیزیکی در استرالیا، به داده های باز پیوند داده شده و برای ارجاع G-NAF به تعاریف استاندارد برای مفاهیم مرتبط با آدرس که در فضای جغرافیایی اعمال می شود. دامنه ( https://pid.data.gov.au/websrv/reference/def/ont/iso19160-1-address ). به عنوان یک تمرین کوتاه مدت، هستی شناسی GUCM را می توان از هستی شناسی هایی که مجددا استفاده می کند جدا کرد و همه هستی شناسی ها را می توان در یک سرور منتشر کرد. GUCM را می توان برای دسترسی به این هستی شناسی ها با استفاده از URI های موجود تغییر داد. با این حال، به عنوان یک ابتکار بلند مدت، به عنوان مثال، به منظور انتشار هستی شناسی در دامنه data.gov.au، می توان یک “شناسه دائمی” رسمی را در data.gov.au از طریق گروه کاری داده های مرتبط با دولت استرالیا جستجو کرد. https://linked.data.gov.au/) و سپس تمام URI ها می توانند به فضای دائمی خود هدایت شوند.
در نهایت، شایان ذکر است که پیاده سازی GUCM یک کار بسیار مهم است، زیرا داده ها، ابرداده ها، برنامه ها و موارد استفاده دائما در حال تغییر هستند. از این رو، GUCM باید برای سازگاری با چنین تغییراتی تکامل یابد. هدف ما ارائه رابطهای برنامهنویسی کاربردی (API) برای سادهسازی فرآیند جمعآوری و نمایش ابرداده است، زیرا دادهها و نیازهای کاربر در طول زمان تغییر میکنند. APIها همچنین ادغام ابردادههای GUCM با ابردادههای حوزههای فضایی و غیرمکانی در سایر پلتفرمها، مانند پلتفرمهای داده باز را تسهیل میکنند. ما انتظار داریم که این یک فرآیند تکراری باشد که از طریق آن این APIها پالایش خواهند شد. هدف ما به حداقل رساندن تلاش مورد نیاز برای بهروزرسانی و سفارشیسازی APIها، با تکامل دادهها، نیازهای کاربر، موارد استفاده و برنامهها است.
منابع
- دیویلر، آر. استین، ا. Bédard، Y.; کریسمن، ن. فیشر، پی. Shi, W. سی سال تحقیق در مورد کیفیت داده های مکانی: دستاوردها، شکست ها و فرصت ها. ترانس. GIS 2010 ، 14 ، 387-400. [ Google Scholar ] [ CrossRef ]
- Goodchild، MF به اشتراک گذاری داده های ناقص. در به اشتراک گذاری اطلاعات جغرافیایی ; Onsrud, HJ, Rushton, G., Eds. مرکز تحقیقات سیاست شهری: نیوبرانزویک، نیوجرسی، ایالات متحده آمریکا، 1995; صص 413-425. [ Google Scholar ]
- دیویلر، آر. Jeansoulin، R. کیفیت داده های فضایی: مفاهیم. در مبانی کیفیت داده های مکانی ; Devillers, R., Jeansoulin, R., Eds. ISTE Ltd.: لندن، انگلستان، 2006; صص 31-42. [ Google Scholar ]
- آرنولد، ال. زنجیره تامین داده های مکانی و چارچوب های کاربر نهایی: به سوی هستی شناسی برای خلق ارزش. در کارگاه GeoValue ; دانشگاه کرتین: پرت، استرالیا، 2016. [ Google Scholar ]
- Goodchild، MF پیشگفتار. در مبانی کیفیت داده های مکانی ; Devillers, R., Jeansoulin, R., Eds. ISTE Ltd.: لندن، انگلستان، 2006; صص 13-16. [ Google Scholar ]
- کریسمن، NR جزء خطا در داده های مکانی. در سیستم های اطلاعات جغرافیایی: مروری بر اصول و کاربردها ; Maguire، DA، Goodchild، MF، Rhind، DW، Eds. Longman: White Plains، NY، USA، 1991; صص 165-174. [ Google Scholar ]
- ایوانووا، آی. مورالس، جی. de By, RA; بشه، تی اس; Gebresilassie، MA جستجو برای منابع داده های مکانی بر اساس تناسب برای استفاده. جی. اسپات. علمی 2013 ، 58 ، 15-28. [ Google Scholar ] [ CrossRef ]
- گاهگان، م. گرید. تولیدکنندگان و مصرف کنندگان داده را به هم نزدیک می کنیم؟ در کارگاه آموزشی NIEeS فعال سازی ابرداده ; انتشارات دانشگاه کمبریج: کمبریج، انگلستان، 2005. [ Google Scholar ]
- Longhorn، استانداردهای جغرافیایی RA، قابلیت همکاری، معنایی فراداده و زیرساخت داده های مکانی. در کارگاه آموزشی NIEeS فعال سازی ابرداده ; انتشارات دانشگاه کمبریج: کمبریج، انگلستان، 2005. [ Google Scholar ]
- کامبر، ای جی. فیشر، پی اف. Wadsworth، RA ابرداده های متمرکز بر کاربر برای داده های مکانی، اطلاعات جغرافیایی و ارزیابی کیفیت داده ها. در مجموعه مقالات دهمین کنفرانس بین المللی AGILE در علم اطلاعات جغرافیایی، دانشگاه آلبورگ، آلبورگ، دانمارک، 8 تا 11 مه 2007. صص 1-13. [ Google Scholar ]
- Goodchild، MF اجرای تحقیق در عمل. در جنبه های کیفی داده کاوی فضایی ; Stein, A., Shi, W., Bijker, W., Eds. CRC Press: Boca Raton، FL، USA، 2009; صص 345-356. [ Google Scholar ]
- براون، ام. شارپلز، اس. هاردینگ، جی. پارکر، سی. بیرمن، ن. مگوایر، ام. فارست، دی. هاکلی، م. جکسون، ام. قابلیت استفاده از اطلاعات جغرافیایی: چالش های فعلی و جهت گیری های آینده. Appl. ارگون. 2013 ، 44 ، 855-865. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- بوین، AT; Hunter، GJ آیا مصرف کنندگان داده های مکانی واقعاً اطلاعات کیفیت داده ها را درک می کنند؟ در مجموعه مقالات هفتمین سمپوزیوم بین المللی ارزیابی دقت فضایی در منابع طبیعی و علوم محیطی، لیسبون، پرتغال، 5-7 ژوئیه 2006. صص 215-224. [ Google Scholar ]
- کامبر، ای جی. فیشر، پی اف. رویکردهای Wadsworth، RA برای ارائه فراداده مربوط به کاربر و ارزیابیهای کیفیت دادهها. در کنفرانس تحقیقات علم اطلاعات جغرافیایی انگلستان (GISRUK) ; مرکز ملی محاسبات جغرافیایی، دانشگاه ملی ایرلند: Maynooth، ایرلند، 2007; صص 79-82. [ Google Scholar ]
- Goodchild، MF آینده زمین دیجیتال. ان GIS 2012 ، 18 ، 93-98. [ Google Scholar ] [ CrossRef ]
- ایلول، سی. فورد، جی. Mooney, J. ساخت ابرداده قابل استفاده در یک محیط تحقیقاتی چند ملیتی. Appl. ارگون. 2013 ، 44 ، 909-918. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- برنرز لی، تی. هندلر، جی. Lassila, O. وب معنایی. علمی صبح. 2001 ، 284 ، 34-43. [ Google Scholar ] [ CrossRef ]
- بیزر، سی. هیث، تی. Berners-Lee, T. داده های مرتبط: داستان تاکنون. در خدمات معنایی، قابلیت همکاری و برنامه های کاربردی وب: مفاهیم نوظهور ; IGI Global: Hershey، PA، USA، 2011; ص 205-227. [ Google Scholar ]
- لی، YW; پیپینو، LL; فانک، جی دی. وانگ، RY سفر به کیفیت داده ; موسسه فناوری ماساچوست: کمبریج، MA، ایالات متحده آمریکا، 2006. [ Google Scholar ]
- وانگ، RY؛ دقت قوی، DM فراتر: کیفیت داده برای مصرف کنندگان داده به چه معناست. جی. مناگ. Inf. سیستم 1996 ، 12 ، 5-33. [ Google Scholar ] [ CrossRef ]
- باتینی، سی. Scannapieco, M. داده ها و کیفیت اطلاعات ; انتشارات بین المللی اسپرینگر: چم، سوئیس، 2016; جلد 43. [ Google Scholar ]
- دباتیستا، جی. لانگ، سی. اوئر، اس. کورتیس، دی. ارزیابی کیفیت ابر LOD: یک بررسی تجربی. SWJ 2018 ، 9 ، 859–901. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دباتیستا، جی. کلینتون، ای. برنان، آر. ارزیابی کیفیت دادههای مرتبط جغرافیایی-تجارب از Ordnance Survey Ireland (OSi). در مجموعه مقالات کنفرانس SEMANTiCS، وین، اتریش، 11-13 سپتامبر 2018. [ Google Scholar ]
- عطارد، جی. برنان، آر. واژگان ارزش داده معنایی که از ارزیابی ارزش داده و ادغام اندازه گیری پشتیبانی می کند. در مجموعه مقالات بیستمین کنفرانس بین المللی سیستم های اطلاعات سازمانی، مادیرا، پرتغال، 21 تا 24 مارس 2018. [ Google Scholar ]
- ISO ISO 9000:2015 سیستم های مدیریت کیفیت – مبانی و واژگان ; ISO: ژنو، سوئیس، 2015.
- ISO ISO 19157:2013 اطلاعات جغرافیایی — کیفیت داده ; ISO-Standard و استاندارد SIS سوئدی؛ ISO: ژنو، سوئیس، 2013.
- Congalton، RG ارزیابی دقت و اعتبارسنجی سنجش از دور و سایر اطلاعات فضایی. بین المللی J. Wildland Fire 2001 ، 10 ، 321-328. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ISO ISO 19115-1:2014 اطلاعات جغرافیایی-فراداده-بخش 1: مبانی ; سازمان بین المللی استاندارد: ژنو، سوئیس، 2014.
- ISO ISO 19158:2012 اطلاعات جغرافیایی — تضمین کیفیت تامین داده ها ; ISO: ژنو، سوئیس، 2012.
- دا سیلوا، جی آر. کاسترو، جی. ریبیرو، سی. هونرادو، جی. لومبا، Â. Gonçalves، J. Beyond INSPIRE: هستی شناسی برای رکوردهای فراداده تنوع زیستی. در مجموعه مقالات کنفرانس های بین المللی کنفدراسیون OTM “در حال حرکت به سوی سیستم های اینترنتی معنادار”، آمانتیا، ایتالیا، 27 تا 31 اکتبر 2014. Springer: برلین/هایدلبرگ، آلمان، 2014; صص 597-607. [ Google Scholar ]
- کمیسیون اروپایی. دستورالعمل 2007/2/EC پارلمان اروپا و شورای 14 مارس 2007 برای ایجاد زیرساخت برای اطلاعات فضایی در جامعه اروپایی (INSPIRE). خاموش J. Eur. اتحادیه 2007 ، 50 ، 1-14. [ Google Scholar ]
- ISO ISO 19115:2003 اطلاعات جغرافیایی-فراداده ; سازمان بین المللی استاندارد (ISO): ژنو، سوئیس، 2003.
- براون، وی. کلارک، وی. استفاده از تحلیل موضوعی در روانشناسی. کیفیت Res. روانی 2006 ، 3 ، 77-101. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مایل، مگابایت؛ هوبرمن، AM; Saldana, J. تجزیه و تحلیل داده های کیفی: کتاب منبع روش ها . انتشارات Sage: Thousand Oaks، CA، USA، 2018. [ Google Scholar ]
- جورج، دی. Mallery, P. IBM SPSS Statistics 23 گام به گام: راهنمای ساده و مرجع . Routledge: لندن، بریتانیا، 2016. [ Google Scholar ]
- جناری، ج. Musen، MA; فرگرسون، RW; گروسو، ما؛ کروبیزی، ام. اریکسون، اچ. Noyb، NF; Tu, SW تکامل Protégé: محیطی برای توسعه سیستم های مبتنی بر دانش. بین المللی جی. هوم. محاسبه کنید. گل میخ. 2003 ، 58 ، 89-123. [ Google Scholar ] [ CrossRef ]
- گاشوویچ، دی. جوریک، دی. Devedžic، V. توسعه مهندسی و هستی شناسی مبتنی بر مدل ؛ Springer Science & Business Media: برلین/هایدلبرگ، آلمان، 2009. [ Google Scholar ]
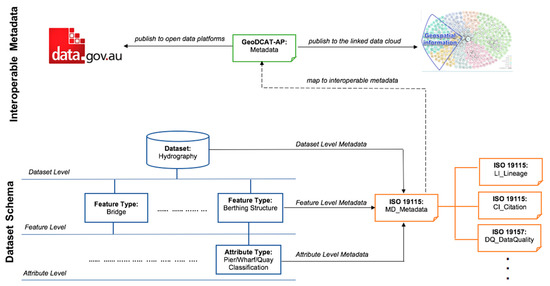
شکل 1. قابلیت همکاری فراداده از حوزه های مکانی و غیر مکانی در داده های باز پیوندی و پورتال های داده باز.
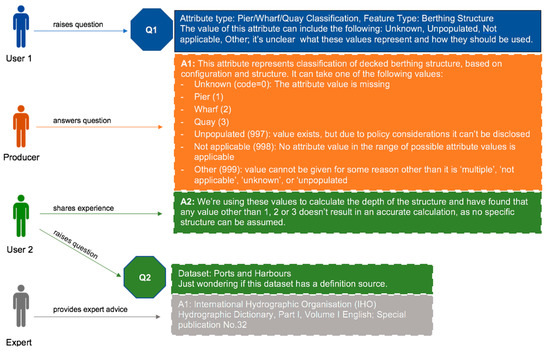
شکل 2. نمونه هایی از ابرداده های بازخورد کاربر و ارتباط بین کاربران، تولیدکنندگان و کارشناسان داده های مکانی.
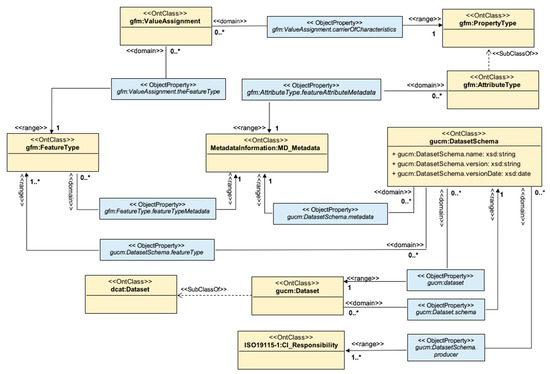
شکل 3. مؤلفه طرحواره مجموعه داده از هستی شناسی GUCM.
شکل 4. متاداده متقابل – مدل های شخص مسئول و نقطه تماس فراداده، نوع منبع، مکان یاب منبع، زبان منبع و زبان فراداده، دسته موضوع، اصل و نسب، نام استاندارد فراداده، نسخه استاندارد فراداده، و اطلاعات نگهداری.
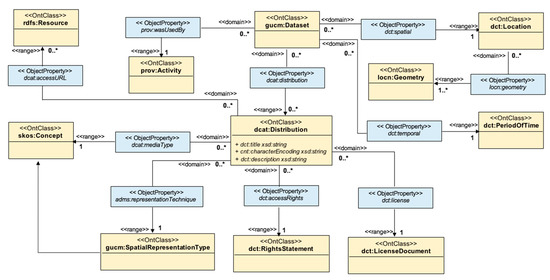
شکل 5. متاداده متقابل – مدل های مرجع زمانی و تاریخ فراداده، شرایط دسترسی به مجموعه داده ها و محدودیت ها، فرمت کدگذاری و توزیع، نوع نمایش مکانی، پوشش مکانی، انطباق و کیفیت داده ها.
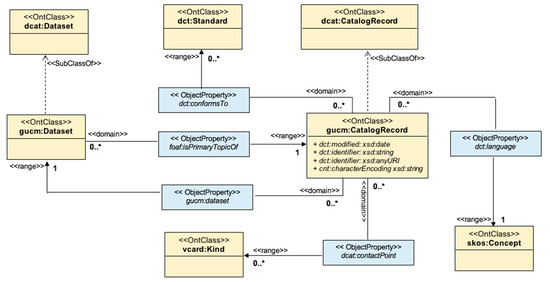
شکل 6. متاداده متقابل – مدل های متاداده بر روی ابرداده (از طریق dcat:CatalogRecord)، نام استاندارد فراداده، نسخه استاندارد فراداده، زبان ابرداده، شخص مسئول و نقطه تماس فراداده.
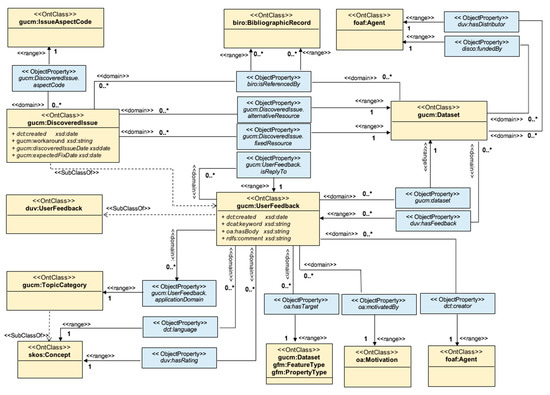
شکل 7. جزء بازخورد کاربر از هستی شناسی GUCM.


بدون دیدگاه