

کلید واژه ها:
شبکه های اجتماعی مبتنی بر مکان ؛ توصیه های مورد علاقه ترجیحات مبتنی بر حافظه ؛ چسبندگی نقطه مورد علاقه ; فیلتر مشارکتی
1. مقدمه
-
ما مفهوم چسبندگی POI را معرفی کردیم که به شدت به دفعات بازدید از POI مرتبط است و نشان دهنده بازدید مجدد و حفظ یک فرد در یک POI است. نتایج روش ما نشان میدهد که چسبندگی POI یک شاخص معنادار برای توصیههای POI در تشخیص POIهای مهمی است که بازدیدهای مکرر یک فرد را از POIهای غیرمهم جذب میکنند که در آنها فرد فقط یک یا دو بار بررسی میکند.
-
ما یک چارچوب فیلتر مشترک مبتنی بر کاربر جدید برای توصیههای POI پیشنهاد کردیم که هم ترجیحات مبتنی بر حافظه و هم تأثیر چسبندگی POI را در نظر میگیرد. اثر حافظه بر تضعیف پویا ترجیحات سفر یک فرد تأکید می کند و چسبندگی POI علایق پایدار فرد را که بر تصمیمات رفتاری افراد در مورد تحرک غالب است، بررسی می کند.
-
نتایج آزمایشهای ارزیابی ما نشان داد که روش پیشنهادی ما به طور قابلتوجهی بهتر از سایر روشها عمل میکند. بنابراین، استفاده از سریهای زمانی و دفعات بازدید از دادههای ورود به سیستم به جای آمار ساده، روشی مؤثر برای پردازش دادهها در شبکههای اجتماعی مبتنی بر مکان است.
2. کارهای مرتبط
2.1. توصیه های POI مبتنی بر فیلترینگ مشارکتی
2.2. توصیه های POI با فاکتور زمانی پیشرفته
2.3. تعداد دفعات بازدید در داده های اعلام حضور مبتنی بر مکان
3. مقدمات
برای یک کاربر هدف توتو، شباهت های بین کاربر را محاسبه می کنیم توتوو سایر کاربران از طریق شباهت کسینوس، که به طور گسترده برای داده های بازخورد ضمنی استفاده می شود. به طور خاص، شباهت کسینوس سu ، vستو،�بین کاربر توتوو کاربر v�در رابطه (1) تعریف شده است.
سپس با توجه به نتیجه حاصل از رتبه بندی شباهت، بهینه را انتخاب می کنیم ک�نزدیکترین همسایگان برای هر کاربر. در نهایت، از شباهت به عنوان وزنه ای برای پیش بینی امتیازات توصیه برای کاربر هدف استفاده می کنیم تو�برای POI های بازدید نشده، که نشان دهنده امکان کاربر است تو�چک کردن در POI پ�. امتیاز توصیه rˆu , p�^�,�با استفاده از رابطه (2) محاسبه می شود.
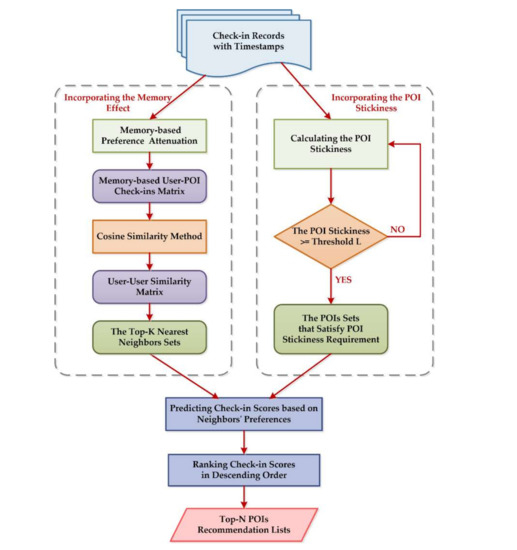
4. روش ها
4.1. مروری بر روش پیشنهادی ما
4.2. گنجاندن اثر حافظه افراد
با این حال، رفتارهای سفر افراد معمولاً تحت تأثیر تجربیات و خاطرات آنها از POI قرار میگیرد و احتمال اینکه افراد بیشتر به سراغ POIهای آشناتر بروند تا موارد ناآشنا [ 21 ]. این الگوی رفتاری که توسط حافظه هدایت می شود، به شدت با تکامل علاقه افراد به POI مرتبط است [ 22 ]. برای بررسی بیشتر تکامل ترجیحات سفر مبتنی بر حافظه افراد، ما تضعیف اولویت مبتنی بر حافظه را در مدل خود در نظر گرفتیم. تئوری حافظه ابینگهاوس استدلال می کند که تکامل حافظه یک فرد از یک فرآیند نامتعادل پیروی می کند و سرعت فراموشی در ابتدا بسیار سریع است اما سپس به تدریج در طول زمان کاهش می یابد [ 26 ]]. با در نظر گرفتن تکامل حافظه انسانی، ما یک مکانیسم تضعیف مبتنی بر حافظه برای استخراج ماتریس ورود کاربر-POI با ترجیحات مبتنی بر حافظه ایجاد کردیم که در کار قبلی ما به تفصیل شرح داده شد [ 22 ]. در این مکانیسم، برای یک POI معین، رفتارهای ورود اخیر تأثیر بیشتری بر ترجیحات سفر فرد در آینده نزدیک نسبت به رفتارهای ورود قبلی دارد. تابع تضعیف ترجیحات مبتنی بر حافظه افراد به صورت نشان داده شده است
جایی که د0د0نشان دهنده زمان ورود فعلی است، ددنشان دهنده زمان ورود تاریخی است، اچاچنشان دهنده آستانه زمانی بین د0د0و دد، و f( د،د0)�(د،د0)نشان دهنده ضریب کاهش زمان (مقدار حافظه) بین است د0د0و دد. یک فاصله زمانی بزرگتر بین ورود فعلی و ورود تاریخی مربوط به یک عامل کاهش زمان کمتر در ورود تاریخی است، که شبیه به تکامل حافظه یک فرد است.
با توجه به ملاحظات بالا، ما تأثیر فرکانس ورود و ترجیحات سفر مبتنی بر حافظه فردی را در ماتریس ورود کاربر-POI گنجانده ایم. به طور خاص، ما ابتدا از عامل تضعیف زمان به عنوان وزنه ای برای به دست آوردن ترجیحات سفر افراد در زمان فعلی استفاده کردیم. مثلاً با توجه به زمان فعلی د0د0، ارزش ورود جu , p( د،د0)جتو،پ(د،د0)کاربر توتودر POI پپدر زمان ددابتدا به صورت نمایش داده می شود
جایی که جu , p , dجتو،پ،دنشان می دهد که آیا کاربر توتواز POI بازدید کرده است پپدر زمان دد. اگر کاربر توتواز POI بازدید کرده است پپدر زمان دد، تنظیم کردیم جu , p , d = 1جتو،پ،د = 1; در غیر این صورت، جu , p , d = 0 جتو،پ،د = 0. سپس، مقدار check-in جˆu , pج^تو،پکاربر توتودر POI پپدر زمان فعلی د0د0به عنوان نشان داده شده است
جایی که n uمترu , p ,د0�تومترتو،پ،د0کل زمان ورود کاربر را نشان می دهد توتودر POI پپقبل از زمان فعلی د0د0.
از آنجا که افراد مشابه تمایل دارند در POI یکسان بررسی کنند [ 8 ]، ما باید نزدیکترین همسایگان را برای هر فرد از ماتریس ورود کاربر–POI با تضعیف اولویت مبتنی بر حافظه کشف کنیم. به طور خاص، ما ابتدا شباهت های کاربر-کاربر را از طریق روش کسینوس محاسبه کردیم. به عنوان مثال، شباهت کسینوس من هستم ( u , v ) _سمنمتر(تو،�)بین کاربر توتوو v�با استفاده از رابطه (6) محاسبه می شود.
یک مقدار بزرگتر از من هستم ( u , v ) _سمنمتر(تو،�)مربوط به شباهت بیشتر بین کاربران است توتوو v�. سپس، با توجه به مقادیر شباهت ترجیحی مبتنی بر حافظه، ما بالا را انتخاب کردیم. کککاربران به عنوان کک-نزدیکترین مجموعه محله کاربر هدف توتو، که با نشان داده می شود n e i gh b o r ( u , k )�همن�ساعتب��(تو،ک). محاسبه نزدیکترین مجموعه همسایگی در الگوریتم 1 توضیح داده شده است.
| الگوریتم 1. محاسبه نزدیکترین مجموعه همسایگی |
| ورودی: (1) سوابق ورود با مهر زمانی، (2) تعداد همسایگان کک. |
| خروجی: n e i gh b o r (تومن، ک )�همن�ساعتب��(تومن،ک)از هر کاربر تومن∈ Uتومن∈�، U= {تو1،تو2، …تومتر}�={تو1،تو2،…تومتر}. |
| 1: مقدار حافظه را محاسبه کنید f( د،د0)�(د،د0)بین زمان ورود فعلی د0د0و زمان ورود تاریخی ددبا استفاده از رابطه (3). |
| 2: برای هر کاربر تومنتومن انجام دادن |
| 3: برای هر POI پj∈ پپ�∈پ، پ= {پ1،پ2، … ،پn}پ={پ1،پ2،…،پ�} انجام دادن |
| 4: مقادیر ورود را محاسبه کنید جتومن،پj( د،د0)جتومن،پ�(د،د0)از تومنتومندر پjپ�در زمان ددبا استفاده از معادله (4) |
| 5: مقدار ورود را محاسبه کنید جˆتومن،پjج^تومن،پ�از تومنتومندر پjپ�در زمان د0د0با استفاده از معادله (5) |
| 6: ماتریس ورود کاربر–POI (تومن،پj) ←ج⌢تومن،پj(تومن،پ�)←ج⌢تومن،پ� |
| 7: پایان برای |
| 8: پایان برای |
| 9: برای هر کاربر تومنتومن انجام دادن |
| 10: یا هر کاربر توg∈ U، گ≠ منتو�∈�،�≠من انجام دادن |
| 11: تشابه کسینوس را محاسبه کنید من هستم ( _تومن،توg)سمنمتر(تومن،تو�)بین کاربر تومنتومنو توgتو�با استفاده از معادله (6) |
| 12: ماتریس شباهت کاربر-کاربر (تومن،توg) ←(تومن،تو�)← من هستم ( _تومن،توg)سمنمتر(تومن،تو�) |
| 13: پایان برای |
| 14: ماتریس شباهت کاربر-کاربر (تومن, 🙂 ← _(تومن،:)←ماتریس شباهت مرتب سازی (تومن، 🙂 _(تومن،:)به ترتیب نزولی |
| 15: n e i gh b o r (تومن، ک ) ←�همن�ساعتب��(تومن،ک)←بالا گرفتن ککاز ماتریس شباهت کاربر-کاربر (تومن، 🙂 _(تومن،:) |
| 16: پایان برای |
4.3. ترکیب چسبندگی POI
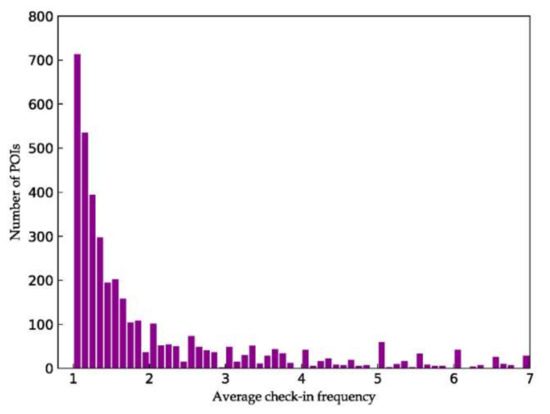
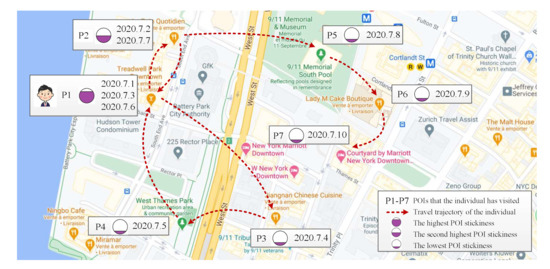
برای شناسایی POI های مهمی که بر رفتارهای سفر افراد غالب است، مفهوم چسبندگی POI را برای بررسی بیشتر ترجیحات اساسی در پشت هر ورود معرفی کردیم. چسبندگی اصطلاحی است که معمولاً برای توصیف فراوانی، عمق و مدت بازدید از یک وب سایت [ 17 ] یا برای نشان دادن تمایل اساسی افراد برای بازدید مجدد از یک شبکه اجتماعی استفاده می شود [ 49 ]. این مفهوم همچنین برای نشان دادن وفاداری کاربر به یک وب سایت [ 50 ] و تعهد عمیق به وب سایت [ 51 ] استفاده می شود.]. در مورد توصیه های POI، ما از چسبندگی POI برای نشان دادن بازدید مجدد توسط یک فرد و حفظ آن در یک POI در LBSN ها استفاده می کنیم. در این مقاله، مفهوم چسبندگی POI به عنوان یک شاخص مهم از ترجیحات افراد برای POI در نظر گرفته شده است. کاربران درجه ترجیح بیشتری برای این POI با چسبندگی POI بالا دارند و احتمال اینکه به طور مکرر در این مکان ها بررسی شوند، بیشتر است. در مقابل، کاربران درجه ترجیح کمتری برای آن دسته از POIهایی با چسبندگی POI پایین دارند و به طور مکرر از این مکان ها بازدید نخواهند کرد. چسبندگی POI POI پپبا نشان داده می شود s t i c k i n e s s ( p )ستیمنجکمن�هسس(پ)به شرح زیر است:
جایی که Uپ�پمجموعه ای از کاربرانی که در POI ثبت نام کرده اند را نشان می دهد پپ، |Uپ|�پنشان دهنده تعداد کل کاربرانی است که در POI ثبت نام کرده اند پپ، و nu , p�تو،پنشان دهنده دفعات ورود کاربر است توتودر POI پپ.
برای گنجاندن چسبندگی POI در مدل خود، چسبندگی هر فرد را با توجه به هر POI با استفاده از معادله 7، مانند بالا، محاسبه کردیم. سپس، برای انتخاب POI هایی که بازدید مکرر افراد را به خود جلب می کردند و برای حذف مواردی که افراد به سختی به آنها مراجعه می کردند، POI هایی با چسبندگی بالاتر از آستانه انتخاب کردیم. L�از کل مجموعه داده ما همچنین مجموعهای از آزمایشهای اعتبارسنجی را برای آزمایش تأثیرات توصیهها تحت مقادیر مختلف آستانه چسبندگی POI انجام دادیم. L�. محاسبه تأثیر چسبندگی POI در الگوریتم 2 توضیح داده شده است.
| الگوریتم 2. محاسبه تأثیر چسبندگی POI |
| ورودی: (1) ثبت ورود با مهر زمانی، (2) آستانه چسبندگی POI L� |
| خروجی: مجموعه POI پLپ�که شامل POI هایی است که نیاز چسبندگی را برآورده می کند |
| 1: برای هر POI پj∈ پپ�∈پ، پ= {پ1،پ2، … ،پn}پ={پ1،پ2،…،پ�} انجام دادن |
| 2: محاسبه s t i c k i n e s s ( p )ستیمنجکمن�هسس(پ)از POI پjپ�با استفاده از معادله (7) |
| 3: اگر s t i c k i n e s s ( p ) ≥ستیمنجکمن�هسس(پ)≥آستانه L� سپس |
| 4: پLپ�اضافه کردن پjپ� |
| 5: پایان برای |
4.4. یک چارچوب پیشنهادی POI مبتنی بر کاربر
با توجه به ترجیحات سفر مبتنی بر حافظه همسایگان مشابه و چسبندگی POI مربوطه، مقادیر ورود کاربر مورد نظر را محاسبه کردیم. توتودر POIهایی که آنها برای نشان دادن احتمال اینکه کاربر هدف را نشان دهد، بازدید نکرده بودند توتودر آینده نزدیک از این POI ها بازدید خواهد کرد. به طور خاص، برای هر کاربر هدف توتو، ابتدا POIهایی را که آنها بازدید نکرده بودند از مجموعه POIهایی که الزامات چسبندگی POI را برآورده می کردند، انتخاب کردیم. سپس، بر اساس ترجیحات سفر همسایگان مشابه آنها، نمرات ورود کاربر هدف را پیش بینی کردیم. توتوبرای این POI های بازدید نشده ما با استفاده از من هستم ( u , v ) _سمنمتر(تو،�)به عنوان وزن نمرات ورود جˆv , pج^�،پاز کک-نزدیک ترین همسایه ها برای به دست آوردن امتیازات مربوط به بررسی مبتنی بر حافظه کاربر هدف توتودر POI پپ، که با نشان داده می شود s c r o e ( u , p )سج��ه(تو،پ).
در نهایت، نمرات پیشبینیشده ورود را مرتب کردیم s c r o e ( u , p )سج��ه(تو،پ)از این POI های بازدید نشده به ترتیب نزولی و توصیه می شود ننPOI به کاربر هدف توتو. روش پیشنهادی یکپارچه POI پیشنهادی ما در الگوریتم 3 توضیح داده شده است.
| الگوریتم 3. یک روش توصیه یکپارچه POI با استفاده از اثر حافظه و چسبندگی POI |
| ورودی: (1) n e i gh b o r (تومن، ک )�همن�ساعتب��(تومن،ک)از هر کاربر تومنتومن; (2) ماتریس ورود کاربر–POI. (3) ماتریس شباهت کاربر-کاربر. (4) مجموعه POI پLپ�; (5) تعداد کل توصیه POI نن |
| خروجی: لیست POIهای نامزد برای هر کاربر تومن∈ Uتومن∈�، U= {تو1،تو2، …تومتر}�={تو1،تو2،…تومتر} |
| 1: برای هر کاربر تومنتومن انجام دادن |
| 2: برای هر POI پj∈ پLپ�∈پ� انجام دادن |
| 3: اگر تومنتومندر چک در پjپ� سپس |
| 4: احتمال ورود را محاسبه کنید s c r o e (تومن،پj)سج��ه(تومن،پ�)از تومنتومندر پjپ�با استفاده از معادله (7) |
| 5: مقادیر پیشبینیشده اعلام حضوری تنظیم شده است V�از تومنتومناضافه کردن s c r o e (تومن،پj)سج��ه(تومن،پ�) |
| 6: پایان برای |
| 7: V←�←مرتب سازی V�به ترتیب نزولی |
| 8: اوج بگیرید نناز جانب V� |
| 9: پایان برای |
5. آزمایش ها و ارزیابی
5.1. مجموعه داده
5.2. معیارهای ارزیابی
ما سه معیار ارزیابی کلاسیک را اتخاذ کردیم، یعنی دقت، یادآوری، و مقدار F ، که اغلب برای ارزیابی دقت بالا استفاده میشود. ننتوصیه ها [ 8 ، 31 ، 52 ]. این سه معیار با نشان داده می شوند پR E@ Nپآر�@ن، R Eسی@ Nآر�سی@ن، و اف@ Nاف@ن، به ترتیب، در کجا ننتعداد نتایج توصیه را نشان می دهد. دقت، نسبت POIهای توصیه شده را که واقعاً از آنها بازدید می شود، اندازه گیری می کند ننPOI های توصیه شده فراخوان نسبت POI های توصیه شده را که در واقع خارج از POI های واقعی در مجموعه آزمایشی بازدید شده اند، اندازه گیری می کند. مقدار F به طور جامع دقت و فراخوانی الگوریتم را در نظر می گیرد. اجازه دهید R ( u )آر(تو)POI های توصیه شده و تی( تو )تی(تو)POI های واقعی در مجموعه آزمایشی باشند. این پR E@ Nپآر�@نبه عنوان … تعریف شده است
این R Eسی@ Nآر�سی@نبه عنوان … تعریف شده است
این اف@ Nاف@نبه عنوان … تعریف شده است
علاوه بر این، از آنجایی که توصیه POI به کیفیت لیست بسیار حساس است، ما یک معیار رتبهبندی پرکاربرد را اتخاذ کردیم، سود تجمعی تنزیل شده نرمال شده (NDCG) [ 53 ]. NDCG نرمالسازی اندازهگیری سود تجمعی تنزیلشده (DCG) است که مجموع وزنی درجه ارتباط اقلام رتبهبندیشده است. وزن تابع کاهشی رتبه (موقعیت) جسم است. را ندی سیG @ Nن�سیجی@نبه عنوان … تعریف شده است
جایی که ننتعداد نتایج توصیه را نشان می دهد، r eلمن�هلمننشان دهنده ارتباط موقعیت است منمن، و | R ELن|آر��نمجموعه ای از بالا را نشان می دهد نننتایجی که به ترتیب نزولی مرتبط مرتب شده اند، که مجموعه ای است که نتایج را به روشی بهینه مرتب می کند. یک بالاتر ندی سیG @ Nن�سیجی@نبا عملکرد بهتر توصیه مطابقت دارد.
5.3. روش های پایه
-
U-CF: روش U-CF روش توصیه POI فیلترینگ مشترک مبتنی بر کاربر (CF) است که در بخش 3 توضیح داده شده است.
-
LRT [ 37 ] : LRT یک چارچوب توصیه مکان با اثرات زمانی است. از آنجایی که رفتارهای ورود افراد با زمان تغییر میکند، این روش هر فرد را با بردارهای پنهان مختلف برای بازههای زمانی مختلف مدلسازی کرد و نمرات پیشبینیشده برای همه زمانها را به عنوان امتیازهای توصیه خلاصه کرد. در این مقاله، الگوهای هفتگی (روز هفته) ترجیحات ورود موقت افراد را در نظر گرفتیم.
-
LORE [ 43 ] : LORE یک روش توصیه مکان با تأثیر متوالی است. این روش تأثیر متوالی بر رفتارهای ورود افراد را بررسی کرد و احتمال بازدید فردی از یک POI جدید را بر اساس زنجیره مارکوف افزودنی (AMC) استخراج کرد.
-
U-CF-Memory [ 22 ] : روش U-CF-Memory روش توصیه POI با تضعیف اولویت مبتنی بر حافظه است که در کار قبلی ما به تفصیل ارائه شد.
-
چسبندگی U-CF: روش U-CF-Stickiness یک روش جدید توصیه CF POI مبتنی بر کاربر با چسبندگی POI است که فقط چسبندگی افراد در POI را در روش سنتی CF مبتنی بر کاربر قرار می دهد.
-
U-CF-Memory-Stickiness: روش U-CF-Memory-Stickiness روش پیشنهادی یکپارچه POI پیشنهادی ما است که تأثیر ترجیحات مبتنی بر حافظه یک فرد و تأثیر چسبندگی POI را برای یک فرد در نظر می گیرد.
5.4. جزئیات آزمایش
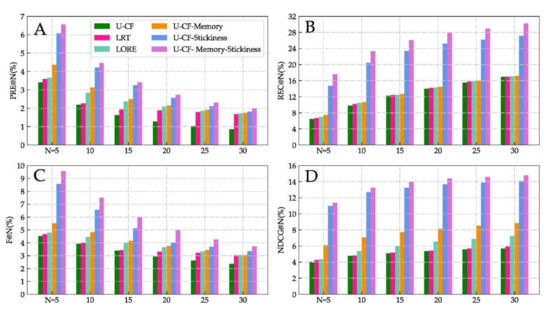
5.5. بهبود عملکرد توصیه
5.5.1. روشهای ترکیب تأثیر زمانی
5.5.2. روشهای ترکیب چسبندگی POI
5.5.3. روش یکپارچه
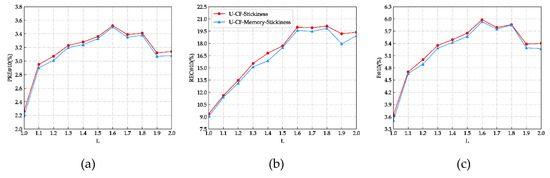
5.6. تأثیر آستانه چسبندگی POI L
6. بحث و نتیجه گیری
منابع
- ژو، ایکس. ماسکولو، سی. ژائو، زی. شبکههای حافظه تقویتشده با موضوع برای توصیه شخصیشده نقطهنظر. در مجموعه مقالات KDD’19: مجموعه مقالات بیست و پنجمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی. انجمن ماشینهای محاسباتی (ACM): نیویورک، نیویورک، ایالات متحده آمریکا، 2019؛ صفحات 3018–3028. [ Google Scholar ]
- لیو، سی. لیو، جی. خو، اس. وانگ، جی. لیو، سی. چن، تی. جیانگ، تی. یک شبکه کانولوشنال متسع فضایی-زمانی برای توصیه نقطه مورد علاقه. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 113. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- چانگ، ایکس. لی، اچ. رانگ، جی. ژائو، ایکس. Li، A. تجزیه و تحلیل ثبات ترافیک و ظرفیت برای جریان ترافیک مختلط با جوخه های وسایل نقلیه متصل هوشمند. فیزیک یک آمار مکانیک. Appl. 2020 , 557 , 124829. [ Google Scholar ] [ CrossRef ]
- ژو، ال. ژانگ، اس. یو، جی. چن، ایکس (مایکل) شبکههای عصبی تانسور عمیق فضایی-زمانی برای پیشبینی سرعت شبکه شهری در مقیاس بزرگ. IEEE Trans. هوشمند ترانسپ سیستم 2020 ، 21 ، 3718–3729. [ Google Scholar ] [ CrossRef ]
- هایکینهایمو، وی. تنکانن، اچ. برگروث، سی. جرو، او. هیپالا، تی. Toivonen, T. درک استفاده از فضاهای سبز شهری از اطلاعات جغرافیایی تولید شده توسط کاربر. Landsc. طرح شهری. 2020 ، 201 ، 103845. [ Google Scholar ] [ CrossRef ]
- لی، ام. لو، اف. ژانگ، اچ. چن، جی. پیشبینی مکانهای آینده اجسام متحرک با شبکههای فازی-LSTM عمیق. ترانسپ ترانسپ. علمی 2018 ، 16 ، 119-136. [ Google Scholar ] [ CrossRef ]
- ژانگ، T.-W. یو، اس. وانگ، ال. یانگ، جی. الگوریتم توصیه اجتماعی بر اساس تجزیه ماتریس گرادیان تصادفی در شبکه اجتماعی. J. محیط. هوشمند اومانیز. محاسبه کنید. 2019 ، 11 ، 601–608. [ Google Scholar ] [ CrossRef ]
- یوان، Q. کنگ، جی. ما، ز. سان، ا. Magnenat-Thalmann، N. توصیه زمان آگاه از نقطه علاقه. در مجموعه مقالات سی و ششمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات – SIGIR ’13، دوبلین، ایرلند، 28 ژوئیه تا 1 اوت 2013. صص 363-372. [ Google Scholar ]
- هان، پی. شانگ، اس. سان، ا. ژائو، پی. ژنگ، ک. Kalnis، P. AUC-MF: توصیه نقطه مورد علاقه با AUC Maximization. در مجموعه مقالات سی و پنجمین کنفرانس بین المللی مهندسی داده IEEE 2019، ماکائو، چین، 8 تا 12 آوریل 2019؛ صفحات 1558-1561. [ Google Scholar ]
- یانگ، سی. بای، ال. ژانگ، سی. یوان، Q. هان، جی. پل زدن فیلتر مشارکتی و یادگیری نیمه نظارت شده: یک رویکرد عصبی برای توصیه POI. در KDD’17: مجموعه مقالات بیست و سومین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی . انجمن ماشینهای محاسباتی (ACM): نیویورک، نیویورک، ایالات متحده آمریکا، 2017؛ ص 1245-1254. [ Google Scholar ]
- تانگ، ال. کای، دی. دوان، ز. ما، جی. هان، م. Wang, H. کشف جامعه سفر برای توصیه POI در شبکه های اجتماعی مبتنی بر مکان. پیچیدگی 2019 ، 2019 ، 1-8. [ Google Scholar ] [ CrossRef ]
- Mak، BKL; جیم، سی وای پیوند دادن ویژگیهای جمعیتی-اجتماعی کاربران پارک و ترجیحات مربوط به بازدید برای بهبود پارکهای شهری. شهرها 2019 ، 92 ، 97–111. [ Google Scholar ] [ CrossRef ]
- مک کرچر، بی. شوال، ن. نگ، ای. Birenboim، A. رفتار بازدیدکنندگان اول و تکراری: ردیابی GPS و تجزیه و تحلیل GIS در هنگ کنگ. تور. Geogr. 2012 ، 14 ، 147-161. [ Google Scholar ] [ CrossRef ]
- یو، سی. شیائو، بی. یائو، دی. دینگ، ایکس. جین، اچ. استفاده از ویژگیهای اعلام حضور برای پارتیشنبندی مکانها برای کاربران فردی در شبکههای اجتماعی مبتنی بر مکان. Inf. فیوژن 2017 ، 37 ، 86-97. [ Google Scholar ] [ CrossRef ]
- گان، م. گائو، ال. هان، ی. آیا الگوی سفر روزانه ترجیح مردم را فاش می کند؟ در مجموعه مقالات پنجاهمین کنفرانس بین المللی هاوایی در علوم سیستم (2017)، روستای هیلتون وایکولا، HI، ایالات متحده آمریکا، 4 تا 7 ژانویه 2017. صص 1-10. [ Google Scholar ]
- لی، ی. لیو، بی. وانگ، سی. مطالعه تکامل رفتار علاقه کاربر آنلاین. در مجموعه مقالات پانزدهمین کنفرانس بین المللی هوش محاسباتی و امنیت (CIS) 2019، ماکائو، چین، 13 تا 16 دسامبر 2019؛ صص 166-171. [ Google Scholar ]
- شائو، ز. ژانگ، ال. چن، ک. ژانگ، سی. بررسی رضایت و چسبندگی کاربر در سایتهای شبکههای اجتماعی از یک لنز مقرون به صرفه فناوری: کشف اثر تعدیلکننده تجربه کاربر. Ind. Manag. سیستم داده 2020 ، 120 ، 1331-1360. [ Google Scholar ] [ CrossRef ]
- راجا، DRK; پوشپا، اس. راجا، ک. توصیه مبتنی بر تازگی با استفاده از فاکتورسازی ماتریس یکپارچه و بهینهسازی خوشهبندی آگاهانه زمانی. بین المللی J. Commun. سیستم 2020 , 33 , e3851. [ Google Scholar ] [ CrossRef ]
- ممکن است.؛ گان، ام. کاوش چندین اطلاعات مکانی-زمانی برای توصیه نقطه مورد علاقه. محاسبات نرم. 2020 ، 24 ، 18733-18747. [ Google Scholar ] [ CrossRef ]
- خزاعی، ا. علیمحمدی، ع. توصیه موقعیت مکانی گروه محور آگاه به زمینه در شبکه های اجتماعی مبتنی بر مکان. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 406. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- هان، X.-P. وانگ، ب. تأثیر فاصله و حافظه در پیدایش الگوی حرکتی مقیاسپذیر انسان. فیزیک Procedia 2010 ، 3 ، 1907-1911. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گان، م. Gao, L. کشف ترجیحات مبتنی بر حافظه برای توصیه POI در شبکه های اجتماعی مبتنی بر مکان. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 279. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- پارک، اس.-م. بایک، D.-K. کیم، ی.-جی. تحلیل احساسات کاربر بر اساس منحنی فراموشی در محیطهای موبایل. در مجموعه مقالات پانزدهمین کنفرانس بین المللی IEEE 2016 در زمینه انفورماتیک شناختی و محاسبات شناختی (ICCI*CC)، پالو آلتو، کالیفرنیا، ایالات متحده آمریکا، 22 تا 23 اوت 2016؛ ص 207-211. [ Google Scholar ]
- Loftus, GR ارزیابی منحنی های فراموشی. J. Exp. روانی فرا گرفتن. مم شناخت. 1985 ، 11 ، 397-406. [ Google Scholar ] [ CrossRef ]
- زنگ، ال. Lin, L. یک سیستم یادگیری تعاملی واژگان بر اساس فهرست های فراوانی کلمات و منحنی فراموشی ابینگهاوس. در مجموعه مقالات کارگاه 2011 در مورد رسانه های دیجیتال و مدیریت محتوای دیجیتال، هانگژو، چین، 15-16 مه 2011; صص 313-317. [ Google Scholar ] [ CrossRef ]
- اورل، ال. Heathcote، A. شکل منحنی فراموشی و سرنوشت خاطرات. جی. ریاضی. روانی 2011 ، 55 ، 25-35. [ Google Scholar ] [ CrossRef ]
- بوبادیلا، جی. اورتگا، اف. هرناندو، ا. Gutiérrez, A. بررسی سیستم های توصیه کننده. بدانید. سیستم مبتنی بر 2013 ، 46 ، 109-132. [ Google Scholar ] [ CrossRef ]
- یو، ی. چن، ایکس. بررسی توصیههای نقطهنظر در شبکههای اجتماعی مبتنی بر مکان. در مجموعه مقالات بیست و نهمین کنفرانس AAAI در مورد هوش مصنوعی، آستین، TX، ایالات متحده، 25-30 ژانویه 2015. صص 53-60. [ Google Scholar ]
- بله، م. یین، پی. لی، دبلیو.-سی. لی، دی.-ال. بهرهبرداری از نفوذ جغرافیایی برای توصیههای نقطهنظر مشترک. در مجموعه مقالات سی و چهارمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات. انجمن ماشین های محاسباتی: پکن، چین، 2011; صص 325-334. [ Google Scholar ] [ CrossRef ]
- لیو، بی. شیونگ، اچ. پاپادیمیتریو، اس. فو، ی. یائو، زی. یک مدل عامل احتمالی جغرافیایی عمومی برای توصیه نقطه مورد علاقه. IEEE Trans. بدانید. مهندسی داده 2015 ، 27 ، 1167-1179. [ Google Scholar ] [ CrossRef ]
- بارال، ر. لی، تی. بهره برداری از نقش جنبه ها در سیستم های توصیه گر POI شخصی. حداقل داده بدانید. کشف کنید. 2017 ، 32 ، 320-343. [ Google Scholar ] [ CrossRef ]
- گائو، آر. لی، جی. لی، ایکس. آهنگ، سی. چانگ، جی. لیو، دی. وانگ، سی. STSCR: بررسی تأثیر متوالی مکانی-زمانی و اطلاعات اجتماعی برای توصیه مکان. محاسبات عصبی 2018 ، 319 ، 118-133. [ Google Scholar ] [ CrossRef ]
- هوانگ، ال. ممکن است.؛ لیو، ی. Sangaiah، AK تعبیه بیزی چندوجهی برای توصیه نقطهنظر در شبکههای سایبری فیزیکی-اجتماعی مبتنی بر مکان. آینده. ژنر. محاسبه کنید. سیستم 2020 ، 108 ، 1119-1128. [ Google Scholar ] [ CrossRef ]
- سانچز، پی. Bellogín، A. آگاهی از زمان و توالی در معیارهای تشابه برای توصیه. Inf. روند. مدیریت 2020 , 57 , 102228. [ Google Scholar ] [ CrossRef ]
- ژانگ، ی. شی، ز. زو، دبلیو. یو، ال. لیانگ، اس. Li, X. زنجیره های مارکوف شخصی شده مشترک با تعبیه شبکه اجتماعی برای توصیه شروع سرد. محاسبات عصبی 2020 ، 386 ، 208-220 . [ Google Scholar ] [ CrossRef ]
- چن، جی. ژانگ، دبلیو. ژانگ، پی. یینگ، پی. نیو، ک. Zou, M. بهره برداری از توصیه های مکانی و زمانی برای نقطه مورد علاقه. پیچیدگی 2018 ، 2018 ، 1-16. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گائو، اچ. تانگ، جی. هو، ایکس. لیو، اچ. بررسی اثرات زمانی برای توصیه مکان در شبکههای اجتماعی مبتنی بر مکان. در مجموعه مقالات هفتمین کنفرانس ACM در مورد سیستم های توصیه کننده، هنگ کنگ، چین، 12 تا 16 اکتبر 2013. صص 93-100. [ Google Scholar ]
- ژانگ، J.-D. چاو، سی.-ای. TICRec: یک چارچوب احتمالی برای استفاده از همبستگیهای تأثیر زمانی برای توصیههای مکان آگاه به زمان. IEEE Trans. خدمت محاسبه کنید. 2015 ، 9 ، 633-646. [ Google Scholar ] [ CrossRef ]
- ژائو، اس. ژائو، تی. یانگ، اچ. لیو، ام آر؛ King, I. STELLAR: رتبهبندی پنهان مکانی-زمانی برای توصیههای پی در پی نقطهی علاقه. در مجموعه مقالات سی امین کنفرانس AAAI در مورد هوش مصنوعی، فینیکس، AZ، ایالات متحده آمریکا، 12 تا 17 فوریه 2016; صص 315-321. [ Google Scholar ]
- دینگ، آر. چن، ز. Li, X. جاسازی متریک فاصله زمانی-مکانی برای توصیه POI خاص زمان. IEEE Access 2018 ، 6 ، 67035–67045. [ Google Scholar ] [ CrossRef ]
- هوانگ، جی. لیو، ی. چن، ی. جیا، سی. توصیه پویا از توالی POI در پاسخ به مسیر تاریخی. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 433. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- چنگ، سی. یانگ، اچ. لیو، ام آر؛ King, I. جایی که دوست دارید در مرحله بعد بروید: توصیه نقطه مورد علاقه پی در پی. در مجموعه مقالات بیست و سومین کنفرانس مشترک بین المللی هوش مصنوعی، پکن، چین، 3 تا 9 اوت 2013. صص 2605-2611. [ Google Scholar ]
- ژانگ، J.-D. Chow, C.-Y.; Li, Y. LORE: بهرهبرداری از تأثیر متوالی برای توصیههای مکان. در مجموعه مقالات بیست و دومین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، دالاس، تگزاس، ایالات متحده آمریکا، 4-7 نوامبر 2014. صص 103-112. [ Google Scholar ]
- لیو، تی. لیائو، جی. وو، زی. وانگ، ی. وانگ، جی. بهرهبرداری از توجه آگاهی جغرافیایی-زمانی برای توصیههای مورد علاقه بعدی. محاسبات عصبی 2020 ، 400 ، 227-237 . [ Google Scholar ] [ CrossRef ]
- لو، ی.-اس. هوانگ، اس.-اچ. GLR: یک مدل نمایش نهفته مبتنی بر نمودار برای توصیه های پی در پی POI. آینده. ژنر. محاسبه کنید. سیستم 2020 ، 102 ، 230-244. [ Google Scholar ] [ CrossRef ]
- یو، سی. لیو، ی. یائو، دی. جین، اچ. لو، اف. چن، اچ. دینگ، کیو. ویژگیهای ثبت نام کاربر ماینینگ برای طبقهبندی مکان در شبکههای اجتماعی مبتنی بر مکان. در مجموعه مقالات سمپوزیوم IEEE 2015 در زمینه کامپیوتر و ارتباطات (ISCC)، لارناکا، قبرس، 6 تا 9 ژوئیه 2015؛ صص 385-390. [ Google Scholar ]
- کاتو، ی. Yamamoto, K. یک سیستم توصیه مکان دیدنی که تعداد بازدید کاربران را در نظر می گیرد. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 411. [ Google Scholar ] [ CrossRef ]
- خو، ی. لی، ی. یانگ، دبلیو. Zhang, J. یک مدل پیشنهادی POI تأثیرگذار چند عاملی بر اساس فاکتورسازی ماتریس. در مجموعه مقالات دهمین کنفرانس بین المللی 2018 در زمینه هوش محاسباتی پیشرفته (ICACI)، شیامن، چین، 29 تا 31 مارس 2018؛ صص 514-519. [ Google Scholar ]
- المنسترلی، دی. علی، ف. Steedman، C. رفتار چسبندگی اعضای جامعه سفر مجازی: چگونه و چه زمانی ایجاد می شود. بین المللی جی. هاسپ. مدیریت 2020 , 88 , 102535. [ Google Scholar ] [ CrossRef ]
- لین، JC-C. چسبندگی آنلاین: مقدمات و تأثیر آن بر قصد خرید. رفتار Inf. تکنولوژی 2007 ، 26 ، 507-516. [ Google Scholar ] [ CrossRef ]
- لی، دی. براون، GJ; Wetherbe, JC چرا کاربران اینترنت به یک وب سایت خاص می چسبند؟ چشم انداز رابطه. بین المللی جی. الکترون. بازرگانی 2006 ، 10 ، 105-141. [ Google Scholar ] [ CrossRef ]
- خو، جی. تانگ، ز. مک.؛ لیو، ی. دانشمند، م. الگوریتم توصیه فیلتر مشارکتی بر اساس اعتماد کاربر و زمینه زمانی. جی الکتر. محاسبه کنید. مهندس 2019 ، 2019 ، 1-12. [ Google Scholar ] [ CrossRef ]
- وانگ، ی. وانگ، ال. لی، ی. او، دی. چن، دبلیو. لیو، تی.-ای. تجزیه و تحلیل نظری معیارهای رتبه بندی NDCG. در مجموعه مقالات بیست و ششمین کنفرانس تئوری یادگیری، COLT 2013، پرینستون، نیوجرسی، ایالات متحده آمریکا، 12 تا 14 ژوئن 2013. صص 25-54. [ Google Scholar ]


بدون دیدگاه