

خلاصه
خندق ها هم کیفیت و هم کمیت زمین های مولد را کاهش می دهند و تهدیدی جدی برای کشاورزی پایدار و در نتیجه امنیت غذایی محسوب می شوند. الگوریتمهای یادگیری ماشین (ML) ابزارهای ضروری در شناسایی خندقها هستند و میتوانند به تصمیمگیری استراتژیک مرتبط با حفاظت از خاک کمک کنند. با این وجود، شناسایی دقیق خندق ها تابعی از الگوریتم های انتخاب شده ML، تصویر و تعداد کلاس های مورد استفاده، یعنی دودویی (دو کلاس) و چند کلاسه است. ما از تجزیه و تحلیل تشخیص خطی (LDA)، ماشین بردار پشتیبان (SVM) و جنگل تصادفی (RF) روی یک تصویر Systeme Pour l’Observation de la Terre (SPOT-7) برای استخراج آبکندها استفاده کردیم و بررسی کردیم که آیا رویکرد چند طبقه (m) می تواند دقت طبقه بندی بهتری نسبت به رویکرد باینری (b) ارائه دهد. با استفاده از اعتبارسنجی متقاطع k-fold مکرر، 36 مدل تولید کردیم. یافتههای ما نشان داد که از این مدلها، هر دو RFb (98.70٪) و SVMm (98.01٪) از نظر دقت کلی (OA) بهتر از LDA عمل کردند. با این حال، LDAb (99.51٪) بالاترین دقت تولید کننده (PA) را ثبت کرد، اما دقت کاربر متناظر پایینی (UA) با 18.5٪ داشت. رویکرد باینری به طور کلی بهتر از رویکرد چند کلاسه بود. با این حال، در سطح کلاس، رویکرد چند طبقه بهتر از رویکرد باینری در شناسایی خندق عمل کرد. علیرغم وضوح طیفی کم، محصول SPOT-7 با پان تیز کردن، خندق ها را با موفقیت شناسایی کرد. روش پیشنهادی نسبتاً ساده، اما عملاً صحیح است و میتواند برای نظارت بر خندقها در داخل و خارج از منطقه مورد مطالعه استفاده شود. LDAb (99.51٪) بالاترین دقت تولید کننده (PA) را ثبت کرد، اما دقت کاربر متناظر پایینی (UA) با 18.5٪ داشت. رویکرد باینری به طور کلی بهتر از رویکرد چند کلاسه بود. با این حال، در سطح کلاس، رویکرد چند طبقه بهتر از رویکرد باینری در شناسایی خندق عمل کرد. علیرغم وضوح طیفی کم، محصول SPOT-7 با پان تیز کردن، خندق ها را با موفقیت شناسایی کرد. روش پیشنهادی نسبتاً ساده، اما عملاً صحیح است و میتواند برای نظارت بر خندقها در داخل و خارج از منطقه مورد مطالعه استفاده شود. LDAb (99.51٪) بالاترین دقت تولید کننده (PA) را ثبت کرد، اما دقت کاربر متناظر پایینی (UA) با 18.5٪ داشت. رویکرد باینری به طور کلی بهتر از رویکرد چند کلاسه بود. با این حال، در سطح کلاس، رویکرد چند طبقه بهتر از رویکرد باینری در شناسایی خندق عمل کرد. علیرغم وضوح طیفی کم، محصول SPOT-7 با پان تیز کردن، خندق ها را با موفقیت شناسایی کرد. روش پیشنهادی نسبتاً ساده، اما عملاً صحیح است و میتواند برای نظارت بر خندقها در داخل و خارج از منطقه مورد مطالعه استفاده شود. علیرغم وضوح طیفی کم، محصول SPOT-7 با پان تیز کردن، خندق ها را با موفقیت شناسایی کرد. روش پیشنهادی نسبتاً ساده، اما عملاً صحیح است و میتواند برای نظارت بر خندقها در داخل و خارج از منطقه مورد مطالعه استفاده شود. علیرغم وضوح طیفی کم، محصول SPOT-7 با پان تیز کردن، خندق ها را با موفقیت شناسایی کرد. روش پیشنهادی نسبتاً ساده، اما عملاً صحیح است و میتواند برای نظارت بر خندقها در داخل و خارج از منطقه مورد مطالعه استفاده شود.
کلید واژه ها:
تجزیه و تحلیل تفکیک خطی ; جنگل تصادفی ; ماشین بردار پشتیبانی ; طبقه بندی تصویر ; فرسایش
چکیده گرافیکی
1. معرفی
علیرغم دههها تحقیقات علمی متمرکز و نگرانیهای اجتماعی [ 1 ]، فرسایش خاک توسط آب، یکی از دلایل اصلی تخریب زمین باقی مانده و به طور فزایندهای کشاورزی را در کشورهای توسعه یافته و در حال توسعه تهدید میکند [ 2 ]. در سطح جهان، تقریباً 12 میلیون هکتار از زمین های مولد به دلیل فرسایش خاک از بین می رود [ 1 ، 3 ]. مداخله فوری نه تنها برای جلوگیری از آسیب های بیشتر به زمین های مولد بلکه جلوگیری از از دست دادن غیرقابل برگشت خدمات اکوسیستم مورد نیاز است [ 3 ، 4 ]. فرسایش خاک ناشی از عوامل طبیعی است، اما تصور میشود که فعالیتهای انسانی از جمله شیوههای استفاده ناپایدار از زمین، فرسایش خاک را تسریع میکند [ 2 ، 5 ], 6 , 7 , 8 ]. فرسایش خاک توسط آب می تواند خود را در منیفولدها، یعنی فرسایش ورقه ای، شیاردار و خندقی نشان دهد [ 9 ]. فرسایش خندقی مضرترین نوع فرسایش است زیرا می تواند به سرعت مقادیر زیادی خاک را حذف و انتقال دهد [ 10 ]. در سطح جهانی، گزارش شده است که خندق ها حدود 50 تا 80 درصد از کل تولید رسوب در مناطق نیمه خشک را تشکیل می دهند [ 11 ]. خندق ها می توانند به زیرساخت هایی مانند جاده ها و ساختمان ها آسیب بزنند [ 12 ، 13 ]. آفریقای جنوبی، یک کشور نیمه خشک، در میان کشورهای به شدت فرسایش یافته در آفریقا قرار دارد که بیش از 70 درصد از زمین های آن در معرض فرسایش با شدت های مختلف است [ 14 ].]. فرسایش خاک پیامدهای گسترده ای برای آفریقای جنوبی از نظر محیطی و اجتماعی و اقتصادی دارد. هافمن و اشول [ 15 ] گزارش کردند که آفریقای جنوبی حدود 836 میلیون دلار در سال هزینههای مرتبط با فرسایش، از جمله هزینههای خارج از محل برای تصفیه آب سدها را متحمل میشود. فرسایش خاک، به ویژه خندق ها، تهدیدی جدی برای کشاورزی معیشتی در اکثر مناطق روستایی آفریقای جنوبی است [ 16 ، 17 ].
سنجش از دور، که به عنوان علم یا عمل به دست آوردن داده در مورد ویژگی های سطح زمین از راه دور تعریف می شود [ 18 ، 19 ]، نه تنها مقرون به صرفه و سریع در مقایسه با اندازه گیری های میدانی سنتی است، بلکه مهمتر از آن، داده های به دست آمده از طریق سنجش از دور است. به آسانی در قالب دیجیتال در دسترس است [ 20 ]. از جنبه دسترسی، نمی توان بر مزایای استفاده از فناوری سنجش از دور در نقشه برداری فرسایش خندقی، به ویژه در نقاط دوردست تاکید کرد. مطالعات با استفاده از سنجش از دور در چند سال گذشته به سرعت رشد کرده است [ 21 , 22 , 23 , 24 , 25 , 26]، به دنبال بهبود قدرت پردازش کامپیوتر همراه با افزایش دسترسی به داده های سنجش از راه دور رایگان مانند ASTER، Landsat و Sentinel. با این حال، وضوح فضایی درشتتر این حسگرها معمولاً توانایی آنها را برای شناسایی خودکار خندقها با جزئیات کافی مهار میکند [ 27 ]. حتی در مقیاسهای منطقهای، برخی از تلاشهای قبلی برای طبقهبندی خودکار فرسایش از حسگرهای با وضوح پایین عموماً دقت پایینی را به همراه داشت [ 26 ]]. حسگرهای با وضوح فضایی بالا مانند WorldView یا GeoEye میتوانند برای شناسایی خندقها مناسب باشند، اما هزینههای نسبتاً بالای کسب آنها میتواند کاربران احتمالی را محدود کند. با این حال، میتواند بین دقت و هزینه یک معاوضه وجود داشته باشد، و تصمیم در مورد استفاده از سنسور به اهداف مطالعه و در دسترس بودن منابع مالی بستگی دارد. ظاهراً، حسگرهای کمهزینه مانند دادههای Systeme Pour l’Observation de la Terre (SPOT) ممکن است مصالحه معقولی بین هزینههای اکتساب و دقت حسگر باشد، حداقل در زمینه کشورهای در حال توسعه، به ویژه آفریقای جنوبی، که دادههای SPOT قابل دستیابی با هزینه های بسیار کم و حتی رایگان.
مانند انتخاب سنسور، انتخاب یک روش طبقه بندی تصویر مناسب به همان اندازه مهم است. یادگیری عمیق (DL) اخیراً در جامعه سنجش از دور مورد توجه قرار گرفته است [ 28 ، 29 ، 30 ]. برخی از مزایای DL نسبت به الگوریتمهای یادگیری ماشین معمولی (ML) شامل سطح بالای اتوماسیون، سازگاری با چالشهای جدید در آینده، و میتواند مسائل بسیار پیچیده را حل کند [ 31 ]. علیرغم پتانسیل بالای آن، یک اشکال عمده DL این است که برای عملکرد خوب به مقادیر زیادی داده نیاز دارد و آموزش آن از نظر محاسباتی گران است [ 32 , 33 , 34]. در نتیجه، الگوریتمهای ML مانند درخت تصمیم (DT)، جنگل تصادفی (RF)، ماشینهای بردار پشتیبان (SVM)، شبکه عصبی مصنوعی (ANN) و تجزیه و تحلیل متمایز (DA) هنوز به طور گسترده استفاده میشوند [ 35 ، 36 ، 37 ]. روشهای ML به دلیل سرعت و دقت نسبتاً بالا، همراه با توانایی تطبیق غیرخطی و چند خطی [ 10 ، 38 ، 39 ]، در مطالعات فرسایش خاک در چند سال گذشته محبوب شدهاند [ 25 ، 40 ، 41 ، 42 ]. ، 43 ]. در میان این روشهای ML، SVM و RF به طور مداوم عملکرد بهتری را نسبت به سایر روشهای ML نشان دادند.44 ]، اما هنگامی که بین خود (SVM و RF) مقایسه میشوند، هنوز مشخص نیست که کدام روش میتواند از دیگری بهتر عمل کند. معمولاً نتایج از یک منطقه مورد مطالعه به منطقه دیگر متفاوت است [ 41 ]. این تغییر، در بیشتر موارد، می تواند به این واقعیت نسبت داده شود که فرسایش خندقی یک پدیده پیچیده است، که از نظر مکانی، طیفی و حتی زمانی در مناطق مختلف مورد مطالعه بسیار متفاوت است [ 45 ].]. اگرچه روشهای SVM و RF بهطور گسترده مورد استفاده قرار گرفتهاند، تلاشها برای ارزیابی عملکرد آنها در استخراج ویژگی خندق در دو یا چند منطقه مطالعاتی مستقل فضایی (با یک منطقه به عنوان آموزش و دیگری به عنوان آزمایش استفاده میشود) نادر است. این رویکرد پتانسیل بیش از حد برازش را از بین میبرد، یک مشکل جدی مرتبط با طبقهبندیکنندههای قدرتمند مانند روشهای مبتنی بر ML، که در آن طبقهبندیکننده دادههای آموزشی را چنان دقیق ترسیم میکند که قادر به تعمیم خوبی نیست [ 46 ]. در اینجا، ما مدلها را در یک منطقه مورد مطالعه آموزش دادیم و آنها را با اعتبارسنجی متقاطع مکرر در دو ناحیه مستقل فضایی دیگر آزمایش کردیم، که میتواند از معیارهای نتیجه قابل اعتماد پشتیبانی کند که از تعمیم بهتر این طبقهبندیها پشتیبانی میکند. در حالی که این رویکرد اخیراً در استخراج ویژگی های فروچاله استفاده شده است [ 47] و در استخراج ویژگی خندق [ 48 ]، کاربرد روش های SVM و RF گزارش نشده است. با این وجود، این مطالعات انگیزه ای برای آزمایش عملکرد این روش های ML، از جمله تجزیه و تحلیل تشخیص خطی (LDA)، یکی دیگر از روش های امیدوارکننده ML فراهم می کند.
در این مطالعه، روشهای انتخابشده ML برای یک محصول چندطیفی SPOT-7 تازه راهاندازی شده (پان-شارپن) که پتانسیل آن در استخراج ویژگی خندق قبلاً آزمایش نشده است، اعمال میشود. علاوه بر این، تاکنون هیچ تلاش مستقیمی برای ارزیابی تأثیر عدد کلاس بر دقت طبقهبندی فرسایش خندقی صورت نگرفته است. با این حال، شماره کلاس یکی از عوامل اصلی موثر بر طبقه بندی تصویر است، بنابراین، دقت حاصل [ 49 ]]. ما یک روش ساده، اما عملا مرتبط متشکل از سه الگوریتم ML (RF، SVM، LDA) × دو رویکرد از اعداد کلاس (دودویی و چند کلاسه) × شش ترکیب از مناطق مطالعه به عنوان مجموعههای قطار و آزمایش پیشنهاد کردیم. هدف اصلی این مطالعه ارزیابی دقت روشهای LDA، SVM و RF در استخراج ویژگی خندق در سه منطقه مطالعاتی مستقل فضایی بود. فرضیه های ما به شرح زیر بود: (1) محصول SPOT-7 پان تیز می تواند دقت طبقه بندی قابل قبولی از فرسایش خندقی ارائه دهد، (2) استفاده از رویکرد چند کلاسه می تواند منجر به دقت طبقه بندی بهتر در رابطه با دوتایی (فرسایش شده و غیر فرسایش شده) شود. رویکرد.
2. مواد و روشها
2.1. منطقه مطالعه
منطقه مورد بررسی ما در استان کیپ شرقی، آفریقای جنوبی واقع شده است و شامل سه منطقه مطالعاتی (s1-s3) است که هر کدام 1.26 کیلومتر مربع را پوشش میدهند ( شکل 1)). ویژگیهای فرسایشی گسترده، عمدتاً خندقها، معمولاً در شیبهای نسبتاً ملایم رخ میدهند، در حالی که رودخانهها در مناطق شیبدار یافت میشوند. این منطقه ترکیبی از انواع کاربری اراضی از جمله مناطق ساخته شده است که با سکونتگاه های روستایی پراکنده، شبکه های جاده ای آسفالت نشده و فعالیت های کشاورزی مشخص می شود. کشاورزی از جمله کشاورزی و دامپروری در این منطقه رایج است. آب و هوا نیمه خشک است: زمستان غالباً خشک و سرد است و در تابستان با بارندگی های گهگاهی شدید همراه است. میانگین بارندگی سالانه 671 میلی متر و دمای سالانه آن بین 7 تا 30 درجه سانتی گراد متغیر است. توپوگرافی در سراسر منطقه بسیار ناهموار است. دامنه آن از حدود 1098 متر در بخش های مرکزی تا بیش از 1500 متر در قسمت های تپه ای شمالی و شرقی منطقه مورد مطالعه است. پوشش گیاهی عمدتاً علفزار است که در نواحی مرتفع و کوهستانی پراکنده شده است.
2.2. اکتساب داده ها و پیش پردازش
داده های مورد استفاده در این مطالعه شامل تصویر SPOT-7 است که از آژانس فضایی ملی آفریقای جنوبی (سانسا) به دست آمده است. در آفریقای جنوبی، تصویر SPOT-7 بدون هیچ هزینهای برای اهداف آموزشی یا تحقیقات دکترا، در مورد ما، و/یا پروژههای تحقیقاتی که مورد علاقه عمومی کشور هستند، در دسترس است. این تصویر شامل چهار باند چند طیفی است: قرمز، سبز، آبی (در مجموع RGB) و مادون قرمز نزدیک (NIR) با وضوح هندسی 5.5 متر و یک نوار پانکروماتیک با وضوح بالا (1.5 متر). ما وضوح هندسی پایین تصویر چند طیفی SPOT-7 را با استفاده از باند پانکروماتیک از همان سنسور بهبود دادیم. روش پان-شارپنینگ Gram-Schmidt استفاده شد که یک تکنیک ترکیبی تصویر به طور گسترده مورد استفاده و پذیرفته شده برای تصاویر به دست آمده از همان سنسور است [ 50 ، 51 ،52 ]. از نرم افزار ENVI برای تیز کردن پان استفاده شد (ENVI نسخه 5.3—Exelis Visual Information Solutions، Boulder، Colorado).
2.3. استخراج ویژگی گلی از تصویر ماهواره ای
به منظور استخراج ویژگی های خندق، ما از سه روش ML استفاده کردیم: RF، SVM، و DA. به عنوان پرکاربردترین روش های ML، روش های ML انتخاب شده در بسته های نرم افزاری مختلف تعبیه شده اند [ 53 ]. در این مطالعه، ما هر سه روش ML را در محیط برنامه نویسی پایتون اجرا کردیم.
2.3.1. جنگل تصادفی (RF)
RF یک طبقهبندیکننده ناپارامتریک قوی است که مستقل از فرضیات در مورد توزیع دادهها یا همسانی است. الگوریتم از چند صد درخت تصمیم با بسته بندی استفاده می کند [ 54 ]. همه درختان دارای مجموعه ای منحصر به فرد از موارد هستند که از مجموعه داده قطار نمونه برداری شده است. نمونهگیری با انتخاب تصادفی و راهاندازی با جایگزینهای برگرفته از مشاهدات اصلی انجام میشود، بهعنوان مثال، یک مورد مشابه میتواند ظاهر چندگانه در تحققها داشته باشد [ 55 ]. علاوه بر این، تعداد متغیرهای درگیر برای درختان تصمیم، جذر تعداد کل متغیرها است. هر درخت تصمیم یک رای واحد به طبقه بندی می دهد و کلاسی که اکثریت رای دارد به عنوان نتیجه طبقه بندی نهایی انتخاب می شود [ 44 ، 56]. هرچه تعداد متغیرها بیشتر باشد، درختان متنوع تر می شوند. با توجه به نمونه گیری متغیر، الگوریتم اهمیت متغیر را تعیین می کند، یعنی اگر یک متغیر حذف شده منجر به کاهش زیاد در دقت متوسط شود، مهم تلقی می شود. RF دقیق در نظر گرفته می شود و با موفقیت برای چندین کار از جمله، اما نه محدود به تبعیض گونه های علفزار [ 57 ]، شناسایی گونه های مهاجم [ 58 ]، نقشه برداری فرسایش خاک [ 56 ، 59 ، 60 ]، نقشه برداری ذخایر کربن آلی خاک [ 61 ] استفاده شد. ]، طبقه بندی گونه های درختی [ 62 ]، و استخراج ویژگی های مرتبط با آب [ 63]. ما از مدل RF برای استخراج ویژگیهای فرسایش خندقی استفاده کردیم. در مدل RF، پارامتر ntree (تعداد tress) را روی 100 قرار دادیم و ناخالصی Gini به عنوان معیار تقسیم انتخاب شد. پارامتر mtry (تعداد ویژگی ها در هر تقسیم) در مقدار پیش فرض خود باقی مانده است (یعنی mtry = 2).
2.3.2. ماشینهای بردار پشتیبانی (SVM)
پیشنهاد شده توسط Vapnik [ 64 ]، مدل SVM بر اساس نظریه یادگیری آماری برای غلبه بر مشکلات مربوط به رگرسیون و طبقه بندی است [ 65 ، 66 ، 67 ]. از زمان معرفی، این مدل به طور گسترده در چندین تحقیق مورد استفاده قرار گرفته است [ 35 ، 44 ، 56 ، 68 .]. مدل سطح مرزی سمت راست را در میان نقاط داده متعلق به کلاس های مختلف جستجو می کند. هدف یافتن یک مرز مسطح به نام hyperplane است که میتواند کلاسها را به پارتیشنهای همگن جدا کند که در آن هر پارتیشن فقط حاوی نقاط داده یک کلاس معین است. این مدل فقط با فضای دادههای خطی به خوبی کار میکند، و در موارد فضای پیچیده و ابعاد بالاتر، به اصطلاح «ترفند هسته» برای تبدیل دادههای غیرخطی به خطی استفاده میشود که در آن ابرصفحهها میتوانند اعمال شوند [ 69 ]. SVM دو پارامتر مهم دارد. (i) پارامتر C طبقهبندیهای نادرست را جریمه میکند: یک مقدار C کم منجر به یک مدل ساده با حاشیه نرم میشود، در حالی که مدلی با مقدار C بزرگ ، طبقهبندی کامل را در اولویت قرار میدهد. و (II)پارامتر γ نقش یک پیکسل آموزشی منفرد را مشخص می کند: مقادیر بسیار کوچک منجر به مدل های محدود می شود، در حالی که مقادیر بسیار بزرگ منجر به بیش از حد برازش می شوند، و مقادیر γ کوچک و بزرگ می توانند با مجموعه داده آزمایشی ضعیف عمل کنند [ 70 ]. چندین تابع هسته رایج برای مدل SVM عبارتند از خطی، تابع پایه شعاعی (RBF)، چند جمله ای و سیگموئید [ 49 ]. در مطالعه حاضر، مدل SVM را با تابع هسته RBF به کار بردیم.
2.3.3. تجزیه و تحلیل تشخیص خطی (LDA)
تجزیه و تحلیل متمایز (DA) یک روش طبقهبندی پارامتریک است که به توزیع نرمال چند متغیره، ماتریسهای کوواریانس برابر نیاز دارد و تعداد مساوی موارد را در دستهها ترجیح میدهد [ 71 ]. در این مطالعه، ما از یک DA خطی (LDA)، یک تکنیک ترتیببندی، یعنی کاهش ابعاد، استفاده کردیم که متغیرهای اصلی (باندها) را با توابع متمایز (DFs) جایگزین میکند. امتیازات DF در فضای بعدی m تعریف شده توسط متغیرهای ورودی محاسبه میشود (که m تعداد دستههای پیشینی است)، در مورد ما به معنای انواع پوشش زمین است، بر اساس مرزهای تصمیم، که میتوانند از توابع خطی یا درجه دوم باشند [ 51 ، 72 ]. LDA با موفقیت در تخریب زمین استفاده شده بود [73 ]. ما توابع خطی را برای طبقه بندی خندق ها اعمال کردیم.
2.4. جمع آوری داده های مرجع و ارزیابی دقت
ما دادههای مرجع را بر اساس نظرسنجی میدانی، تصویر SPOT با وضوح بالا و دادههای جانبی (Google Earth) جمعآوری کردیم. داده های مرجع به صورت عمومی در دسترس نیست، اما می تواند در صورت درخواست به هر کسی ارائه شود. ما مناطقی را مشخص کردیم که پوشش زمین هم در میدان و هم در تصاویر قابل شناسایی بود. بنابراین، هفت طبقه پوشش زمین متمایز شد: پوشش گیاهی متراکم (DV)، پوشش گیاهی تحت تنش (SV)، خندق (G)، خاک برهنه (BS)، خاک لخت مخلوط (MS)، یعنی سنگهای در معرض، جادههای آسفالت نشده، خاکهای لخت. و غیره، آبادی (S) و راهها (R). علاوه بر این، ما قصد داشتیم موردی را آشکار کنیم که پوشش زمین تنها به دو دسته تقسیم شده است: مناطق خندقی و غیر خندقی. بنابراین، به عنوان یک رویکرد دیگر، موردی را بررسی کردیم که تمام کلاسهای غیر خندقی در یک کلاس مجدداً طبقهبندی شدند. در ادامه مطلب
ما دقت طبقهبندی الگوریتمها را با اعتبارسنجی متقاطع 10 برابری با استفاده از سه تکرار ارزیابی کردیم. ما از نمونهگیری تصادفی طبقهای از کل مجموعه دادهها (به ترتیب 20795، 31784 و 22512 داده در مناطق s1، s2 و s3) استفاده کردیم: ما 1000-1000 مورد را برای رویکرد باینری و 350 مورد در هر دسته را برای رویکرد چند طبقه انتخاب کردیم. از کل مجموعه داده مرجع، بسته به تعداد داده های موجود در هر کلاس و برای جلوگیری از همبستگی خودکار (انتخاب پیکسل های مجاور). این رویکرد نیازی به پایگاه داده آموزش و آزمایش نداشت، زیرا کل مجموعه داده به طور تصادفی به 10 نمونه فرعی تقسیم شد و 9 مورد برای آموزش مدلها و 1 مورد برای آزمایش استفاده شد و زمانی که همه زیرنمونهها بهعنوان مجموعهای آزمایشی در برابر سایر نمونهها استفاده شدند، این روش به پایان میرسد. نمونه های فرعی [ 74 ، 75]. در نهایت سه بار تکرار شد و می توان از معیارهای دقت 30 مدل برای ارزیابی عملکرد مدل ها با میانه و چارک استفاده کرد.
اگرچه اعتبارسنجی متقابل ابزار قابل اعتمادی است، اما اطلاعاتی در مورد دقت سطح کلاس ارائه نمی دهد. بنابراین، ما از ماتریس سردرگمی نیز استفاده کردیم. این ماتریس دقت های خاص کلاس مانند دقت تولید کننده (PA) و دقت کاربر (UA) را ارائه می دهد که به ترتیب خطاهای کمیسیون و حذف را نشان می دهد [ 18 ، 19 ، 76 ]. PA احتمالی است که یک پیکسل از یک کلاس معین به درستی طبقه بندی شده است در حالی که UA احتمالی است که یک پیکسل معین در کلاسی که قرار بود باشد پیش بینی شود [ 77 ، 78 ، 79 ]. جدول 1 اطلاعات اولیه در مورد محاسبه شاخص های دقت مورد استفاده را ارائه می دهد.
دقت کلی (OA)، که نسبتی از پیکسلهای طبقهبندی شده درست است، نیز محاسبه شد، اما به روش معمول: ما سه ناحیه مطالعه (s1-s3) داشتیم، و یکی برای آموزش مدل و دیگری برای آزمایش آن استفاده شد. به عبارت دیگر، دادههای قطار یک منطقه مورد مطالعه (مثلا s1) برای انجام مدلسازی استفاده شد و این مدل بر روی دادههای کاملاً مستقل دو منطقه مورد مطالعه دیگر (s2 و s3) اعمال شد. ما این روش را در تمام ترکیبات مناطق مورد مطالعه تکرار کردیم. بنابراین، در مجموع ما 36 مدل داشتیم: 3 الگوریتم ML (RF، SVM، LDA) × 2 رویکرد اعداد کلاس (دودویی و چند کلاسه) × 6 ترکیب مناطق مطالعه به عنوان مجموعههای قطار و آزمایش (s1→s2، s2→s1، s2. →s3، s3→s2، s1→s3، s3→s1).
2.5. ارزیابی آماری
برای بررسی فرض توزیع نرمال از آزمون Shapiro-Wilk استفاده شد [ 80 ]. دادههای مرجع طبقات پوشش زمین کج شد، اما معیارهای دقت طبقهبندی (UA، PA، OA) از توزیع نرمال پیروی کردند. ما از آزمون فرضیه برای بررسی اینکه آیا طبقات پوشش زمین دارای میانه های یکسان (H0) هستند یا با یکدیگر (H1) متفاوت هستند، استفاده کردیم. به عنوان مثال، ما مجموعه داده های آموزشی را از جنبه تفاوت در بازتاب ارزیابی کردیم. برای مثال، اگر مقادیر بازتاب متفاوت باشد، میتوانیم فرض کنیم که طبقهبندی تصویر ماهوارهای میتواند با موفقیت خندقها را از سایر کلاسهای پوشش زمین متمایز کند. در مورد رویکرد باینری، ما آزمون یوئن را با مقدار 0.2 تریم و 599 بار راهاندازی اعمال کردیم [ 81 ]]، در حالی که برای رویکرد چند کلاسه، ANOVA قوی با یک آزمون تعقیبی بر اساس میانگینهای بریده شده (با استفاده از بسته WRS2 R) استفاده شد. برای آزمون یوئن، اندازه اثر (ξ) را نیز ارزیابی کردیم که یک معیار استاندارد شده برای تعیین کمیت مقدار تفاوت است. بنابراین، می توان آن را با تجزیه و تحلیل انجام شده در مجموعه داده های مختلف مقایسه کرد. محاسبه اندازه اثر برای رویکرد چند کلاسه برای ANOVA قوی تعریف نشده است. بنابراین، ما از آزمون دانت [ 82 ] استفاده کردیم] با استفاده از خندق ها به عنوان شاهد و سایر طبقات پوشش زمین با آن مقایسه شد. به این ترتیب، ما توانستیم فواصل اطمینان تفاوتها را به جای اندازههای اثر محاسبه کنیم، اما همچنین میتوانیم ببینیم که چگونه تفاوتها حول صفر توزیع شدهاند. در همان زمان، تعداد مقایسهها و میزان آزادی را محدود کردیم (با اجتناب از مقایسه کامل فاکتوریل). ضمناً با توجه به هدف این مطالعه که استخراج آبکندها بود، این اقدام منطقی بود.
عملکرد مدل انجام شده بر روی معیارهای دقت طبقهبندی با مدلسازی خطی عمومی (GLM) با استفاده از مناطق مورد مطالعه، تعداد کلاسها (یعنی باینری یا چند کلاسه) و الگوریتمها به عنوان عوامل در ترکیبهای مختلف و UA و PA به عنوان متغیرهای وابسته ارزیابی شد. در این مورد، ما ω 2 را به عنوان معیار اندازه اثر اعمال کردیم، که با توجه به حجم نمونه کم (در مورد ما، به نتایج 36 مدل محدود شد)، همانطور که توسط لوین [ 83 ] پیشنهاد شد، سوگیری کمتری دارد. تجزیه و تحلیل های آماری در نرم افزار R 3.6.2 [ 84 ]، با WRS2 [ 85 ]، jamovi 1.2 انجام شد. [ 86 ]، و با ماژول GAMLj [ 87 ].
3. نتایج
3.1. تفاوت در مقادیر بازتاب
نتایج تایید کرد که، به طور کلی، همه باندها مقادیر قابل توجهی متفاوت در مورد رویکرد باینری داشتند. تنها استثنا در مورد نوار آبی، در منطقه مطالعه #1 مشاهده شد ( شکل 2 ). با این حال، اندازههای اثر فقط اثر کوچک را برای نوارهای قرمز و آبی، متوسط برای سبز و بزرگ برای NIR نشان میدهند ( جدول 2 ). بنابراین، باند NIR بیشترین ارتباط را در تشخیص خندق ها داشت. در مرحله بعد، تجزیه و تحلیل را با رویکرد چند کلاسه ( شکل 3 )، با استفاده از هفت دسته تکرار کردیم، و آزمون ANOVA قوی مدل های قابل توجهی را برای هر ترکیبی از باندها و مناطق مورد مطالعه تایید کرد ( جدول 3 ).
از آنجایی که ANOVA تنها گزارش می دهد که حداقل یک دسته بندی به طور قابل توجهی متفاوت وجود دارد، یک آزمون تعقیبی برای آشکار کردن تفاوت بین دسته ها مورد نیاز بود. با هفت دسته، ترکیبات بسیار زیادی با مقایسه زوجی وجود دارد. بنابراین، با توجه به هدف اولیه این مطالعه، تنها بر تفاوت در خندق و سایر دستهها تمرکز کردیم. خندق ها معمولاً تفاوت معنی داری داشتند، اما بیشتر در نوارهای قرمز و سبز، تفاوت ها با پوشش گیاهی تحت تنش و جاده ها معنی دار نبود ( جدول 3 ). در این مورد، ما میانگین تفاوت دستههای پوشش زمین را ارائه کردیم. فواصل اطمینان مطابق با آزمون تعقیبی بود، به جز در منطقه مورد مطالعه شماره 2 (s2) که در آن آزمون تعقیبی قوی تفاوت معنی داری را نشان داد ( جدول 4).، در حالی که فواصل اطمینان ( شکل 4 ، بر اساس آمار آزمون Dunnett) عدم اهمیت بین خندق ها و جاده ها را نشان داد.
3.2. استخراج ویژگی خندق
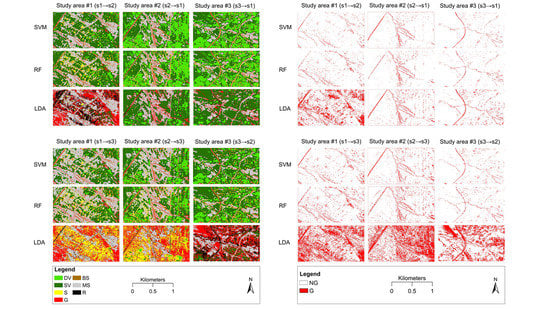
نتایج طبقه بندی گلی بر اساس رویکرد چند کلاسه و باینری به ترتیب در شکل 5 و شکل 6 ارائه شده است. SVM و RF کم و بیش نتایج مشابهی را نشان دادند، در حالی که LDA نتایج کاملاً متفاوتی را به همراه داشت، به ویژه در منطقه مطالعه #1 (s1→s2، s1→s3)، منطقه مطالعه #2 (s2→s3)، و منطقه مطالعه #3. (s3→s2). با این حال، در برخی موارد، به عنوان مثال، منطقه مطالعه #2 (s2→s1) و منطقه مطالعه #3 (s3→s1)، LDA تقریباً نتایج مشابهی با SVM و RF نشان داد. به طور کلی، به نظر می رسد رویکرد چند کلاسه و باینری تقریباً نتایج یکسانی را از نظر استخراج خندق به همراه داشته است، اگرچه تفاوت های جزئی در نتایج دقت وجود دارد، همانطور که در بخش های فرعی بعدی ارائه شده است ( بخش 3.3 و بخش 3.4 ).
3.3. ارزیابی عملکرد کلی مدل
دقت کلی، بر اساس سه بار، تکرار 10 برابر اعتبار متقاطع (یعنی نتایج 30 مدل)، نشان داد که اگر از الگوریتمهای طبقهبندی RF یا SVM استفاده کنیم، شناسایی خندق میتواند موفقیتآمیز باشد. هر دو RF و SVM دقت های مشابهی ارائه کردند. میانگین بین 92 تا 96 درصد بود. رویکرد باینری منجر به مقادیر OA بهتری شد. با این وجود، طبقه بندی چند کلاسه (m) تنها 2٪ بدتر از باینری (b) بود ( شکل 7). رتبه در تمام مناطق مورد مطالعه در سه مکان اول یکسان بود: SVMb، RFb، LDAb با رویکرد باینری، سپس طبقهبندیهای چند کلاسه در مکان چهارم بین SVMm و RFm اختلاط داشتند، اما LDAm همیشه بدترین عملکرد را داشت. با توجه به دو مکان اول، SVMb فقط یک برتری جزئی (<0.5٪) داشت و علاوه بر این، چارک های پایین تر برای RFb بالاتر بود. بنابراین، به طور کلی، این مدل ها را می توان به عنوان قابل اعتماد تر در نظر گرفت. علاوه بر این، رویکرد چند کلاسه به اندازه رویکرد باینری مؤثر نبود، حتی چارکهای پایین LDAb در همه مناطق مورد مطالعه بالاتر از چارک بالایی بهترین راهحل چند کلاسه بود و تفاوتها 2 تا 8 درصد بود.
3.4. ارزیابی عملکرد مدل در سطح کلاس
ارزیابی سطح کلاس فقط با معیارهای دقت خندق ها انجام شد. نتایج نشان داد که اکثر طبقهبندیکنندهها قادر به تولید مقادیر بالای PA و UA نیستند ( شکل 8 ). بدترین عملکردها متعلق به الگوریتم LDA بود، مقادیر UA طبقهبندی چند کلاسه زیر 30 درصد بود، طبقهبندیهای نادرست به معنای تعداد زیادی خطای کمیسیون بود، تعداد زیادی پیکسل به عنوان خندق طبقهبندی شدند که به دستههای دیگر تعلق داشتند. اگرچه، ما همچنین باید توجه داشته باشیم که مدل های موفقی نیز وجود داشت (Lm-2-1 به خوبی برخی از مدل های RF و SVM بود). با توجه به بهترین سه ماهه 80-80٪ ( شکل 8) 4 مدل RF و 3 مدل SVM، 2 نوع باینری و 5 نوع چند کلاسه وجود داشت. در این سه ماهه که خطاها در حد معقول بود، بالاترین UA به Rb-2-3 (86.0%) و Rm-2-3 (83.8%) تعلق داشت، در حالی که PA به ترتیب 95.1% و 96.1% بود. با این وجود، بالاترین PA متعلق به Rb-3-2 (93.7٪) بود، اما UA مربوطه تنها 79.4٪ بود. بهترین PA متعلق به یک مدل LDA (Lb-2-3) با 99.5٪ بود اما UA آن تنها 18.5٪ بود.
3.5. ارزیابی آماری عملکرد سطح کلاس بایاس عوامل
GLM نشان داد که حوزههای مطالعه و الگوریتمها میتوانند توضیحاتی را برای کارایی متفاوت مدلهای طبقهبندی ارائه دهند. R2 های تعدیل شده 59.3 درصد واریانس را برای UA و 56.1 درصد را برای PA نشان داد ( جدول 5 و جدول 6 ). منطقه مورد مطالعه بر هر دو نتایج PA و UA تأثیر معنیداری داشت، اما الگوریتم اعمال شده تنها بر PA تأثیر مستقیم معنیداری داشت.
در مورد PA، تعامل بین الگوریتم ها و مناطق مورد مطالعه معنی دار نبود. اندازه اثر (ω²) اثر بزرگی را برای مناطق مورد مطالعه برای PA، و برای الگوریتمها برای UA نشان داد. علاوه بر این، تعامل بین الگوریتمهای کاربردی و نوع (تعداد دستهها) معنیدار بود، یعنی الگوریتمهای طبقهبندی با رویکردهای باینری یا چند کلاسه متفاوت عمل میکنند.
4. بحث
با وجود ناهمگونی طیفی خندقها، تفاوتهای طیفی باندهای SPOT-7 نشان داد که نقشهبرداری خندق با دادههای سنجش از دور میتواند معقول باشد. میانگین نتایج OA به دست آمده با رویکرد باینری (93.68٪) و چند کلاسه (74.27٪) این ادعا را توجیه می کند. تقریباً همه باندها، به جز نوار آبی در منطقه مطالعه شماره 1، مقادیر قابل توجهی متفاوتی در روش باینری داشتند، بنابراین OA بالا بود. با این حال، شایان ذکر است که صرفاً تکیه بر اهمیت آماری می تواند گمراه کننده باشد. علیرغم تفاوتهای معنیدار: اندازه اثر در مورد باندهای RGB فقط کوچک (گاهی متوسط) بود، فقط باند NIR اثر بزرگ (با این وجود، در این مورد بسیار بزرگ) را نشان داد. بر این اساس، در حالی که ص-مقادیر فقط نشان میدهند که تفاوتها را میتوان معنیدار یا غیرمعنادار در نظر گرفت، اندازههای اثر بزرگی را بیان میکنند، و همانطور که معیارهای استاندارد ارتباط تفاوتها را با دستههای پوشش زمین نیز ثابت کردند: حتی با محدودههای بینچارکی بزرگتر، تفاوتها میتوانند قابل توجه باشند، اما در طبقه بندی این تفاوت های کوچک (که با اندازه اثر <0.3 نشان داده می شود) منجر به طبقه بندی اشتباه می شود. چنین تفسیری مطابق با یافته های Szabó و همکاران است. [ 88 ].
اگر چه اندازه اثر برای جفت پوشش زمین از رویکرد چند طبقه محاسبه نشد، فواصل اطمینان اطلاعات ارزشمندی در مورد تفاوت ها ارائه کردند. معمولاً، همه جفتها تفاوتهای قابلتوجهی داشتند و فواصل اطمینان در محدوده کوچکی بودند به جز برخی از دستههای پوشش زمین: خندقها و پوشش گیاهی و جادهها تفاوتهای غیر قابل توجهی در باندهای RGB (بیشتر در نوارهای قرمز و سبز) داشتند، اما باند NIR همیشه تفاوت های قابل توجهی گزارش شده است. با این حال، با توجه به فواصل اطمینان، باند NIR در تشخیص جاده ها و خندق ها بسیار موفق بود: محدوده اطمینان 95٪ نزدیک به خط “صفر” بود که نشان دهنده عدم اهمیت بود ( شکل 9 ). این توسط مقادیر p امضا نشده بود (همه آنها p بودند< 0.001)؛ با این حال، اگر از محدوده اطمینان و فاصله آنها از صفر به عنوان اندازه اثر استفاده کنیم، این موارد مقادیر کم با کارایی کمتر را برای تشخیص دسته ها نشان می دهد. با این حال، با وجود منتقدان ارزیابی آماری، با توجه به نتایج، میتوان پذیرفت که مجموعه دادههای مرجع حاوی دادههای قابل اعتمادی در مورد دستههای پوشش زمین بوده و احتمالاً میتوان از آن در مدلهای طبقهبندی استفاده کرد.
از آنجایی که طبقهبندیکنندههای مختلف اعمال شدند، عملکرد کلی آنها را ارزیابی کردیم. RF و SVM الگوریتمهای قوی هستند، زیرا توزیع دادهها نتایج را سوگیری نمیکند، بهعنوان مثال، نقاط پرت تنها تأثیر کمی بر دقت طبقهبندی دارند، در حالی که LDA نرمال بودن چند متغیره و تعداد عنصر متعادل را در دستهها فرض میکند [ 89 ، 90 ]. این در مطالعه ما نیز صادق بود زیرا RFb و SVMm هر دو از LDA بهتر عمل کردند. اما لازم به ذکر است که LDAb در حالت باینری نتایج طبقه بندی بهتری نسبت به RFm و SVMm داشت. مقادیر OA طبقه بندی های چند طبقه کمتر از دودویی بود. بنابراین، می توان فکر کرد که در صورت امکان فقط از دسته بندی ها استفاده کنیم، یعنی در مورد ما از دسته های خندقی و غیر خندقی استفاده کنیم. بیگلزیمر و همکاران [ 91] همچنین دریافت که رویکرد باینری می تواند بهتر از چند کلاسه عمل کند. برای به دست آوردن این نتیجه، نویسندگان یک روش جدید “وزن داده شده یک در برابر همه” را توسعه دادند. با این حال، در مورد ما، واقعیت این است که این نتیجه فقط به طور کلی درست است، در سطح دسته، رویکرد چند طبقه در مورد شناسایی خندق کارآمدتر بود. این یافته ها با یافته های Allwein و همکاران همخوانی بالایی دارد. [ 92]. یافتههای ما نشان داد که راهحلهای چند کلاسه با طبقهبندی 7 کلاس عملکرد بهتری داشتند، تنها دو مدل رویکرد باینری در بهترین ربع 80٪ (تشخیصشده توسط UA و PA) با طبقهبندیکنندههای RF و SVM قرار داشتند. عملکرد LDA متفاوت بود و مدلها نتایج مبهم ارائه کردند: سه مدل اول در 36 مدل LDA با استفاده از رویکرد باینری، و دومین بهترین یک LDA در انواع چند کلاسه بر اساس PA بود. با این حال، مقادیر UA مربوطه بسیار پایین بود (به عنوان مثال، بهترین PA، 99.51٪، متعلق به Lb-2-3 و UA تنها 18.5٪ بود). بنابراین، در این مناطق مطالعه با این مجموعه دادههای مرجع، متوجه شدیم که مدلهای LDA بهشدت توسط نقاط پرت تعصب داشتند، در حالی که RF و SVM بر این مشکل غلبه کردند و نتایج دقیقی را با دادههای قطار ورودی یکسان ارائه کردند.
ما از GLM برای بررسی قابلیت اطمینان مجموعه دادههای قطار با استفاده از مدلهای آموزشدیده شده با آنها در دو حوزه دیگر استفاده کردیم. همه مناطق از نظر ویژگی های طیفی مشابه بودند، اما شش ترکیب نشان داد که در مورد منطقه مطالعه #2، PA ها بالاتر از دو ناحیه دیگر قرار داشتند، اما برای UA هایی که منطقه مطالعه شماره 3 بیشترین مقدار را داشت، درست نیست ( جدول 5). و جدول 6 ؛ شکل 9). اگرچه مناطق مورد مطالعه در مورد داده های مرجع تفاوت هایی داشتند، هر دو RF و SVM PA و UA را بالاتر از 75٪ ارائه کردند که با توجه به فقدان داده های جانبی (به عنوان مثال، یک مدل ارتفاع دیجیتال) نسبتاً بالا است. مدلهای LDA وابستگی زیادی به کیفیت دادههای آموزشی داشتند و بنابراین، خطای کمیسیونها بسیار بزرگ بود (میانگینها خطاهای بیش از 50٪ را نشان دادند).
GLM اثرات چند متغیره را بر PA و UA نشان داد و ارتباط الگوریتمهای طبقهبندی را تأیید کرد. تعداد کلاس ها (باینری یا چند کلاسه) تأثیر معنی داری نداشت. اگرچه نتایج اعتبارسنجی متقاطع 10 برابری نشان داد که طبقهبندیهای باینری عملکرد بهتری دارند، مقایسههای سطح کلاس این یافته را در مورد خندقها پشتیبانی نمیکند. با این وجود، این مطالعه نشان داد که تصاویر فضایی مانند SPOT-7 را می توان با موفقیت برای شناسایی خودکار خندق ها با استفاده از الگوریتم های ML مرتبط به کار برد. اگرچه باندهای طیفی SPOT-7 نقش کلیدی در تمایز خندقها در میان دیگر دستههای پوشش زمین ایفا کردند، تیز کردن تابه نیز تا حدی به استخراج موفقیتآمیز خندقها کمک کرد. تشخیص خودکار خندق ها با سنجش از دور یک چالش است،23 ]. در نتیجه، تفسیر بصری تصاویر با وضوح بالا برای نظارت بر خندق ها در مناطق بزرگ ترجیح داده شده است. در مقیاس کشور، Mararakanye و Le Roux [ 27 ] تفسیر بصری تصویر SPOT-5 را برای نظارت بر فرسایش خندقی در آفریقای جنوبی انجام دادند. اخیراً، Karydas و Panagos [ 93 ] یک ارزیابی اولیه در مورد حضور آبکندهای زودگذر در یونان از طریق تفسیر بصری تصاویر Google Earth انجام دادند. بدون شک، نیاز به روشهای مطمئنتری وجود دارد که میتواند به شناسایی خودکار مناطق تحت تأثیر خندقها کمک کند [ 22 ، 23 ]]. این به نوبه خود نظارت مداوم بر توسعه خندق در مکان و زمان را تضمین می کند. استفاده از الگوریتمهای ML مناسب و تصاویر ماهوارهای برای این بررسیها کافی به نظر میرسد، اما بدون مدلهای ارتفاعی دیجیتال (DEMs)، طبقهبندی ساده میتواند ناقص باشد. با این حال، در مناطقی که میتوان خندقها را به صورت بصری شناسایی کرد، بازتاب طیفی اجازه میدهد تا خندقها از دیگر دستههای پوشش زمین، همانطور که در مطالعه حاضر وجود داشت، متمایز شوند. به عنوان مثال، بیشتر خندقها روی سطح خاک لخت قرار داشتند، اما با وضوح هندسی بهبود یافته، محصول تابهتراشی اعمال شده با موفقیت خندقها را از خاک لخت جدا کرد، اگرچه هنوز جای بهبود وجود دارد. در صورت وجود، تحقیقات آینده باید دادههای جانبی (یعنی DEM) را برای تشخیص دقیق خندقها از شبکه جادهای آسفالتشده/آسفالتنشده در بر بگیرد. محدودیت عمده در این مطالعه، تمایز جاده های آسفالت نشده از خاک برهنه و سنگ های در معرض دید بود. در عوض، این انواع پوشش زمین در یک طبقه به نام خاک لخت مخلوط (MS) گروه بندی شدند، اما این روی خندق، طبقه هدف تأثیری نداشت. اگرچه این مطالعه در مناطق کوچک انجام شده است، روش استفاده شده می تواند برای کاربرد در مناطق بزرگتر اتخاذ شود.
5. نتیجه گیری ها
فرسایش آبکندی مشکلی حیاتی است که امروزه کشاورزی پایدار با آن مواجه است و اگر بخواهیم کشاورزی پایدار محقق شود، نمی توان آن را بی وقفه رها کرد. این مطالعه از سه الگوریتم رایج ML شامل DA، SVM و RF در استخراج ویژگی خندق استفاده کرد. با استفاده از این الگوریتمهای ML، ما بر دو رویکرد متفاوت از شماره کلاس تکیه کردیم: باینری و چند کلاسه. بر اساس یافته های این مطالعه، نتایج زیر را به دست آوردیم:
-
علیرغم داشتن تعداد کمی از باندها (RGB و NIR)، محصول پان شارپن شده از تصویر چندطیفی SPOT-7 با موفقیت خندق ها (با OAs >95٪) را تشخیص داد.
-
اعتبارسنجی متقاطع k-fold مکرر ابزاری کارآمد برای تجزیه و تحلیل بازنمایی داده های مرجع همانطور که در الگوریتم های طبقه بندی مختلف منعکس شده است. این نشان داد که رویکرد باینری بهتر از رویکرد چند کلاسه عمل میکند (یعنی OAهای بالاتر با دامنههای بین چارکی باریک) با همه طبقهبندیکنندهها.
-
GLM به طور موثر عوامل بایاس یک کلاس معین، در این مورد خندق ها، معیارهای دقت (PA و UA) را با گزینه تعامل آماری شناسایی کرد، بر این اساس، ما نشان دادیم که الگوریتم ها با رویکرد باینری یا چند کلاسه در مورد PA متفاوت عمل می کنند، در حالی که هیچ تعاملی در مورد UA وجود نداشت، یعنی تعداد کلاسها بر UAها در عملکرد طبقهبندیکنندههای مختلف تأثیری نداشت.
-
LDA حداقل از دیدگاه PA می تواند خندق ها را با دقت شناسایی کند، اما معمولاً مقادیر UA متناظر پایینی داشتند.
-
SVM و RF عملکرد بهتری را در مقایسه با LDA در شناسایی خندقها نشان دادند، معمولاً با بیش از 80 درصد PA و UA در مناطق مختلف.
به طور کلی، نتیجه میگیریم که استفاده از حوزههای مطالعاتی مختلف برای آموزش و پیشبینی، شرایط مستقلی را برای مدلها تضمین میکند، که امکان ارزیابی احتمالات تعمیم مطالعات موردی را فراهم میکند. OA ها می توانند گمراه کننده باشند، زیرا دقت می تواند در سطح کلاس متفاوت باشد. در مورد ما، طبقهبندیکنندهها بهترین عملکرد را با رویکرد باینری، طبق OA نشان دادند، اما رویکرد چند کلاسه در شناسایی خندق بر اساس PA و UA در سطح کلاس کارآمدتر بود. هدف ما به دست آوردن بهترین نمایش از خندق ها بود. بنابراین، ما پیشنهاد می کنیم از چندین کلاس به جای تنها دو کلاس (یعنی باینری) برای استخراج بهتر ویژگی خندق استفاده شود.
منابع
- فرسایش خاک فائو: بزرگترین چالش برای مدیریت پایدار خاک در دسترس آنلاین: https://www.fao.org/3/ca4395en/ca4395en.pdf (در 13 ژانویه 2020 قابل دسترسی است).
- والنتین، سی. پوسن، جی. Li, Y. فرسایش خندقی: اثرات، عوامل و کنترل. کاتنا 2005 ، 63 ، 132-153. [ Google Scholar ] [ CrossRef ]
- بلیک، WH; رابینوویچ، آ. وینتز، ام. کلی، سی. ناصری، م. نگوندیا، آی. پاتریک، ای. متی، ک. مونیشی، ال. Boeckx، P. و همکاران فرسایش خاک در شرق آفریقا: رویکردی بین رشته ای برای تحقق تغییر مدیریت زمین شبانی محیط زیست Res. Lett. 2018 ، 13 ، 1-12. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رودریگو-کامینو، جی. نویمان، ام. رمکه، ا. Ries، JB ارزیابی تغییرات محیطی در تاکستانهای متروک آلمان. درک مسائل کلیدی برای طرح های مدیریت مرمت آویزان شد. Geogr. گاو نر 2018 ، 67 ، 319-332. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کاکمبو، وی. Rowntree، KM رابطه بین کاربری زمین و فرسایش خاک در زمین های مشترک نزدیک شهر Peddie، کیپ شرقی، آفریقای جنوبی. L. Degrad. توسعه دهنده 2003 ، 14 ، 39-49. [ Google Scholar ] [ CrossRef ]
- غلامی، وی. تأثیر جنگل زدایی بر تولید رواناب و فرسایش خاک (مطالعه موردی: حوضه آبخیز کسیلیان). جی. برای. علمی 2013 ، 59 ، 272-278. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کرتز، آ. Křeček, J. تخریب چشم انداز در جهان و در مجارستان. آویزان شد. Geogr. گاو نر 2019 ، 68 ، 201–221. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فینزی، ک. Ngetar، NS دینامیک کاربری زمین/پوشش زمین و فرسایش خاک در حوضه آبریز Umzintlava (T32E)، کیپ شرقی، آفریقای جنوبی. ترانس. R. Soc. اس افر. 2019 ، 74 ، 223-237. [ Google Scholar ] [ CrossRef ]
- جکاب، جی. سابو، جی. Szalai، Z. مروری بر اندازهگیریهای فرسایش ورق در مجارستان. J. Landsc. Ecol. 2015 ، 13 ، 89-103. [ Google Scholar ]
- عربامری، ع. چن، دبلیو. لوچه، م. ژائو، ایکس. لی، ی. لومباردو، ال. سردا، ا. پرادان، بی. Bui، DT مقایسه مدلهای یادگیری ماشین برای نقشهبرداری حساسیت فرسایش خندقی. Geosci. جلو. 2019 ، 1-12. [ Google Scholar ] [ CrossRef ]
- پوسن، جی. Vandekerckhove، L. Nachtergaele, J.; Oostwoud Wijdenes، D.; ورستراتن، جی. van Wesmael, B. فرسایش خندقی در محیط های خشک. در رودخانه های خشک: هیدرولوژی و ژئومورفولوژی نیمه خشک . Bull, LJ, Kirkby, MJ, Eds. John Wiley & Sons Ltd.: Chichester, UK, 2002; صص 229-262. [ Google Scholar ]
- تاکن، آی. کروک، جی. Lane, P. آستانه هایی برای راه اندازی کانال در خروجی های تخلیه جاده. Catena 2008 ، 75 ، 257-267. [ Google Scholar ] [ CrossRef ]
- زگلوبیکی، دبلیو. باران-زگلوبیکا، بی. گاوریسیاک، ال. Telecka، M. تاثیر آبکندهای دائمی بر استفاده از زمین و کشاورزی امروزی در مناطق لس (E. لهستان). Catena 2015 ، 126 ، 28-36. [ Google Scholar ] [ CrossRef ]
- گارلند، GG; هافمن، ام تی; تاد، اس. تخریب خاک: بررسی ملی تخریب زمین در آفریقای جنوبی . موسسه ملی تنوع زیستی آفریقای جنوبی: پرتوریا، آفریقای جنوبی، 2000; صص 69-107. [ Google Scholar ]
- هافمن، تی. اشول، الف. طبیعت تقسیم شده: تخریب زمین در آفریقای جنوبی . انتشارات دانشگاه کیپ تاون: لنزدان، آفریقای جنوبی، 2001; پ. 179. [ Google Scholar ]
- De Villiers, MC; نل، جی پی؛ بارنارد، RO; هنینگ، A. خاک های متاثر از نمک: آفریقای جنوبی. Available online: https://www.researchgate.net/profile/Anoop_Srivastava7/post/I_am_looking_for_a_recent_soil_salinity_map_of_Africa/attachment/59d654de79197b80779ac3f2/AS: 523166767423489@1501744085582 /download/faosodicrza+%283%29.doc ( accessed on 15 February 2020).
- فینزی، ک. نگتار، NS نقشهبرداری فرسایش خاک در یک حوضه آبریز چهارتایی در کیپ شرقی با استفاده از سیستم اطلاعات جغرافیایی و سنجش از دور. اس افر. J. Geomatics 2017 ، 6 ، 11-29. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کمپبل، جی بی. Wynne, RH مقدمه ای بر سنجش از دور . Guilford Press: نیویورک، نیویورک، ایالات متحده آمریکا، 2011; پ. 718. [ Google Scholar ]
- لیلسند، تی. کیفر، RW; Chipman, J. Remote Sensing and Image Interpretation , 7th ed.; جان وایلی و پسران: نیویورک، نیویورک، ایالات متحده آمریکا، 2015; پ. 768. [ Google Scholar ]
- ریچاردز، جی. Xiuping, J. Remote Sensing Digital Image Analysis: An Introduction , 4th ed.; Springer: برلین، آلمان، 2006; پ. 494. [ Google Scholar ]
- Fulajtár، E. شناسایی خاکهای به شدت فرسایش یافته از داده های سنجش از دور آزمایش شده در ریشنووتس، اسلواکی. در مجموعه مقالات دهمین نشست بین المللی حفاظت از خاک، ایندیاناپولیس، IN، ایالات متحده آمریکا، 24-29 مه 1999. [ Google Scholar ]
- Vrieling، A. رودریگز، SC; بارتولومئوس، اچ. Sterk، G. شناسایی خودکار خندقهای فرسایشی با تصاویر ASTER در سرادوس برزیل. بین المللی J. Remote Sens. 2007 , 28 , 2723-2738. [ Google Scholar ] [ CrossRef ]
- D’Oleire-Oltmanns، S. مارزولف، آی. تاید، دی. Blaschke, T. تشخیص نواحی آسیب دیده خندق با استفاده از تجزیه و تحلیل تصویر مبتنی بر شی (OBIA) در منطقه Taroudannt، مراکش. Remote Sens. 2014 , 6 , 8287–8309. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- برتالان، ال. توری، ز. Szabó، G. فتوگرامتری UAS و تجزیه و تحلیل تصویر مبتنی بر شی (GEOBIA): پایش فرسایش در کازار بدلند، مجارستان. Landsc. محیط زیست 2016 ، 10 ، 169-178. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پورقاسمی، HR; یوسفی، س. کورنژادی، ع. Cerdà، A. ارزیابی عملکرد تکنیکهای دادهکاوی فردی و گروهی برای مدلسازی فرسایش خندقی. علمی کل محیط. 2017 ، 609 ، 764-775. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژیژالا، دی. ژوریکووا، آ. زادورووا، تی. Zelenková، K. Minařík، R. نقشه برداری تخریب خاک با استفاده از داده های سنجش از دور و داده های جانبی: جنوب شرقی موراویا، جمهوری چک. یورو J. Remote Sens. 2019 ، 52 ، 108–122. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Mararakanye, N.; نقشه برداری موقعیت مکانی Le Roux، JJ Gully در مقیاس ملی برای آفریقای جنوبی. اس افر. Geogr. J. 2012 ، 94 ، 208-218. [ Google Scholar ] [ CrossRef ]
- چن، ی. لین، ز. ژائو، ایکس. وانگ، جی. Gu، Y. طبقه بندی مبتنی بر یادگیری عمیق داده های ابرطیفی. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2014 ، 7 ، 2094–2107. [ Google Scholar ] [ CrossRef ]
- کوسول، ن. لاورنیوک، م. اسکاکون، س. Shelestov, A. طبقه بندی یادگیری عمیق پوشش زمین و انواع محصول با استفاده از داده های سنجش از دور. IEEE Geosci. سنسور از راه دور Lett. 2017 ، 14 ، 778-782. [ Google Scholar ] [ CrossRef ]
- وتریول، ا. گرکه، ام. کرل، ن. نکس، اف. Vosselman, G. تشخیص آسیب فاجعه از طریق استفاده هم افزایی از یادگیری عمیق و ویژگیهای ابر نقطه سه بعدی که از تصاویر هوایی مورب با وضوح بسیار بالا و یادگیری چند هستهای به دست میآیند. ISPRS J. Photogramm. Remote Sens. 2018 ، 140 ، 45–59. [ Google Scholar ] [ CrossRef ]
- توپ، JE; اندرسون، دی.تی. چان، CS بررسی جامع یادگیری عمیق در سنجش از دور: نظریهها، ابزارها و چالشهای جامعه. J. Appl. Remote Sens. 2017 ، 11 ، 1–54. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، ال. Xia، GS; وو، تی. لین، ال. Tai, XC Deep Learning برای درک تصویر سنجش از دور. J. Sensors 2016 ، 4 ، 22-40. [ Google Scholar ] [ CrossRef ]
- چن، جی. ژانگ، ایکس. وانگ، کیو. دای، اف. گونگ، ی. Zhu، K. شبکههای کاملاً کانولوشنال عمیق میانبر متقارن برای تقسیمبندی معنایی تصاویر سنجش از دور با وضوح بسیار بالا. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2018 , 11 , 1633–1644. [ Google Scholar ] [ CrossRef ]
- ما، ال. لیو، ی. ژانگ، ایکس. بله، ی. یین، جی. جانسون، کارشناسی یادگیری عمیق در کاربردهای سنجش از دور: یک متاآنالیز و بررسی. ISPRS J. Photogramm. Remote Sens. 2019 , 152 , 166–177. [ Google Scholar ] [ CrossRef ]
- سابو، ال. بورای، پ. دیاک، بی. دایک، جی جی; Szabó، S. ارزیابی کارایی تصاویر چند طیفی ماهواره ای و هوابرد برای نقشه برداری پوشش زمین در یک محیط آبی با تاکید بر کاتروپ آب (Trapa natans). بین المللی J. Remote Sens. 2019 , 40 , 5192–5215. [ Google Scholar ] [ CrossRef ]
- مناندار، س. دیو، اس. لی، YH; منگ، YS؛ وینکلر، اس. یک رویکرد داده محور برای پیش بینی دقیق بارش. IEEE Trans. Geosci. Remote Sens. 2019 , 57 , 9323–9331. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کای، دبلیو. جینی، جی. Nan, Z. ارزیابی ظرفیت حفاظتی منبع آب حوضه رودخانه لیائوهه غربی بر اساس مدل سرمایه گذاری. در مجموعه مقالات کنفرانس بین المللی 2019 در زمینه شبکه هوشمند و اتوماسیون الکتریکی (ICSGEA)، IEEE، Xiangtan، چین، 10-11 اوت 2019؛ صص 443-447. [ Google Scholar ]
- دریک، جی.ام. راندین، سی. Guisan، A. مدلسازی سوله های اکولوژیکی با ماشین های بردار پشتیبان. J. Appl. Ecol. 2006 ، 43 ، 424-432. [ Google Scholar ] [ CrossRef ]
- گلدبلات، آر. تو، دبلیو. هانسون، جی. Khandelwal، AK تشخیص مرزهای مناطق شهری در هند: مجموعه داده ای برای طبقه بندی تصاویر مبتنی بر پیکسل در موتور گوگل ارت. Remote Sens. 2016 ، 8 ، 634. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- گوتام، آر. پانی گراهی، س. فرانزن، دی. سیمز، الف. پیشبینی نیترات خاک از تصاویر و اطلاعات غیرتصویری با استفاده از تکنیک شبکه عصبی. Biosyst. مهندس 2011 ، 110 ، 20-28. [ Google Scholar ] [ CrossRef ]
- Bui، DT; شیرزادی، ع. شهابی، ح. چاپی، ک. امیداور، ای. فام، بی تی؛ اصل، DT; خالدیان، ح. پرادان، بی. پناهی، م. و همکاران یک رویکرد جدید هوش مصنوعی مجموعه ای برای نقشه برداری فرسایش خندقی در یک حوضه آبخیز نیمه خشک (ایران). Sensors 2019 , 19 , 2444. [ Google Scholar ]
- چن، ال. رن، سی. لی، ال. وانگ، ی. ژانگ، بی. وانگ، ز. Li، L. ارزیابی مقایسه ای از روش های زمین آماری، یادگیری ماشینی، و ترکیبی برای نقشه برداری محتوای کربن آلی خاک سطحی. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 174. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- هاتفرد، اف. دولتی، پ. حیدری، ع. ذوالفقاری، AA ارزیابی عملکرد مدل های درخت تصمیم و شبکه عصبی در نقشه برداری خواص خاک. J. Mt. Sci. 2019 ، 16 ، 1833-1847. [ Google Scholar ] [ CrossRef ]
- آدام، ای. موتانگا، او. اودیندی، ج. عبدالرحمن، طبقهبندی EM کاربری زمین/پوشش در یک چشمانداز ساحلی ناهمگن با استفاده از تصاویر RapidEye: ارزیابی عملکرد طبقهبندیکنندههای ماشینهای بردار تصادفی جنگل و پشتیبانی. بین المللی J. Remote Sens. 2014 ، 35 ، 3440-3458. [ Google Scholar ] [ CrossRef ]
- فینزی، ک. Ngetar، NS ارزیابی فرسایش ناشی از آب در سطح حوضه با استفاده از RUSLE مبتنی بر GIS و سنجش از دور: یک بررسی. بین المللی حفظ آب خاک Res. 2019 ، 7 ، 27–46. [ Google Scholar ] [ CrossRef ]
- ماکسول، AE; وارنر، TA; Fang, F. پیادهسازی طبقهبندی یادگیری ماشینی در سنجش از دور: یک بررسی کاربردی. بین المللی J. Remote Sens. 2018 , 39 , 2784–2817. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- عنیدی، پ. پاپ، م. کواچ، ز. تاکاچ-سیلاگی، ال. Szabó، S. کارایی تکنیکهای حداقل محلی و GLM در استخراج چاله از یک مدل زمین مبتنی بر LiDAR. بین المللی جی دیجیت. زمین 2019 ، 12 ، 1067–1082. [ Google Scholar ] [ CrossRef ]
- شروتی، RBV; کرل، ن. جتن، V. استخراج ویژگی خندق مبتنی بر شی با استفاده از تصاویر با وضوح فضایی بالا. ژئومورفولوژی 2011 ، 134 ، 260-268. [ Google Scholar ] [ CrossRef ]
- وانگ، اف. ژن، ز. وانگ، بی. Mi، Z. مطالعه تطبیقی بر روی مدلهای طبقهبندی آب و هوا مبتنی بر KNN و SVM برای پیشبینی کوتاهمدت انرژی PV خورشیدی در روز آینده. Appl. علمی 2018 ، 8 ، 28. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Maurer, T. نحوه شفاف کردن تصاویر با استفاده از روش gram-schmidt pan-sharpen—یک دستور العمل. در مجموعه مقالات کارگاه آموزشی ISPRS هانوفر، هانوفر، آلمان، 21 تا 24 مه 2013. [ Google Scholar ]
- ابریها، د. کواچ، ز. نینسوات، س. برتالان، ال. بالاز، بی. Szabó، S. شناسایی مصالح سقف با تجزیه و تحلیل تابع متمایز و طبقهبندیکنندههای تصادفی جنگل بر روی تصاویر جهانبینی-2 تشدید شده-مقایسه. آویزان شد. Geogr. گاو نر 2018 ، 67 ، 375-392. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گروچالا، ا. Kedzierski، M. روشی برای اصلاح تصویر پانکروماتیک برای تلفیق داده های تصاویر ماهواره ای. Remote Sens. 2017 , 9 , 639. [ Google Scholar ] [ CrossRef ][ Green Version ]
- Ge، W. چنگ، کیو. تانگ، ی. جینگ، ال. گائو، سی. طبقهبندی سنگشناسی با استفاده از دادههای Sentinel-2A در مجتمع افیولیتی شیبانجینگ در مغولستان داخلی، چین. Remote Sens. 2018 , 10 , 638. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بریمن، L. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رودریگز-گالیانو، وی اف. قیمیر، بی. روگان، جی. چیکا اولمو، م. Rigol-Sanchez، JP ارزیابی اثربخشی طبقهبندیکننده تصادفی جنگل برای طبقهبندی پوشش زمین. ISPRS J. Photogramm. Remote Sens. 2012 ، 67 ، 93-104. [ Google Scholar ] [ CrossRef ]
- شهابی، ح. جاریانی، ب. توکلی پیرعلیلو، س. چیتلبورو، دی. آوند، م. قربانزاده، او. تشخیص شبکه های آبکی نیمه خودکار مبتنی بر شی با استفاده از مدل های مختلف یادگیری ماشین: مطالعه موردی حوضه آبریز بوون، کوئینزلند، استرالیا. Sensors 2019 , 19 , 4893. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بورای، پ. دیاک، بی. والکو، او. Tomor, T. طبقه بندی پوشش گیاهی علفی با استفاده از تصاویر ابرطیفی هوابرد. Remote Sens. 2015 ، 7 ، 2046–2066. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ساباط تومالا، ع. Raczko, E. مقایسه الگوریتمهای ماشین بردار پشتیبان و جنگل تصادفی برای طبقهبندی گونههای مهاجم و گسترده با استفاده از دادههای ابرطیفی هوابرد. Remote Sens. 2020 , 12 , 516. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شروتی، RBV; کرل، ن. جتن، وی. Stein، A. پیشبینی سیستم خندقی مبتنی بر شی از تصاویر با وضوح متوسط با استفاده از جنگلهای تصادفی. ژئومورفولوژی 2014 ، 216 ، 283-294. [ Google Scholar ] [ CrossRef ]
- فینزی، ک. نگتار، NS; Ebhuoma، O. ارزیابی خطر فرسایش خاک در حوضه آبریز Umzintlava (T32E)، کیپ شرقی، آفریقای جنوبی، با استفاده از RUSLE و الگوریتم جنگل تصادفی. اس افر. Geogr. J. 2020 ، 1-24. [ Google Scholar ] [ CrossRef ]
- Szatmári، G. Pásztor, L. مقایسه روشهای مختلف مدلسازی عدم قطعیت بر اساس الگوریتمهای زمین آمار و یادگیری ماشین. Geoderma 2019 , 337 , 1329–1340. [ Google Scholar ] [ CrossRef ]
- دنگ، س. کاتوه، م. یو، ایکس. Hyyppä، J.; گائو، تی. مقایسه طبقهبندیهای گونههای درختی در سطح درخت با ترکیب دادههای ALS و تصاویر RGB با استفاده از الگوریتمهای مختلف. Remote Sens. 2016 ، 8 ، 1034. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- بالاز، بی. بیرو، تی. دایک، جی. سینگ، SK; Szabó، S. استخراج ویژگیهای مرتبط با آب با استفاده از دادههای بازتاب و تجزیه و تحلیل مؤلفههای اصلی تصاویر Landsat. هیدرول. علمی J. 2018 ، 63 ، 269-284. [ Google Scholar ] [ CrossRef ]
- Vapnik, V. The Nature of Statistical Learning Theory , 2nd ed.; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2013; پ. 311. [ Google Scholar ]
- برنینگ، الف. مدلهای پیشبینی فضایی برای خطرات زمین لغزش: بررسی، مقایسه و ارزیابی. نات. سیستم خطرات زمین. علمی 2005 ، 5 ، 853-862. [ Google Scholar ] [ CrossRef ]
- Otukei، JR; Blaschke، T. ارزیابی تغییر پوشش زمین با استفاده از درخت های تصمیم، ماشین های بردار پشتیبان و الگوریتم های طبقه بندی حداکثر احتمال. بین المللی J. Appl. زمین Obs. Geoinf. 2010 ، 12 ، 27-31. [ Google Scholar ] [ CrossRef ]
- دی بویسیو، اف. سوین، بی. کوداهی، تی. مانگیاس، م. شورل، اس. اونگ، سی. راجر، ا. موریزوت، پی. لاوکمپ، سی. لاو، آی. و همکاران نقشه برداری سنگ سنگی-زمین شناسی با ماشین بردار پشتیبان: مطالعه موردی بر روی پریدوتیت های دارای نیکل هوازده، کالدونیای جدید. بین المللی J. Appl. زمین Obs. Geoinf. 2018 ، 64 ، 377-385. [ Google Scholar ] [ CrossRef ]
- وو، ی. Zhang، X. طبقهبندی گونههای درختی مبتنی بر شی با استفاده از تصاویر ابرطیفی هوا و دادههای LiDAR. جنگلها 2020 ، 11 ، 32. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- قلی زاده، ع. بورووکا، ال. صابریون، م. Vašát, R. یک رویکرد یادگیری مبتنی بر حافظه در مقایسه با سایر الگوریتمهای داده کاوی برای پیشبینی بافت خاک با استفاده از طیفهای بازتابی منتشر. Remote Sens. 2016 , 8 , 341. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لانتز، بی. یادگیری ماشینی با R: تکنیکهای خبره برای مدلسازی پیشبینیکننده برای حل همه مشکلات تجزیه و تحلیل دادههای شما ، ویرایش سوم. Packt Publishing Ltd: بیرمنگام، انگلستان، 2015; پ. 427. [ Google Scholar ]
- هارل، FE; لی، KL مقایسه تمایز تجزیه و تحلیل متمایز و رگرسیون لجستیک تحت نرمال بودن چند متغیره. Biostat. آمار بیومد. شفای عمومی محیط زیست علمی 1985 ، 1985 ، 333-343. [ Google Scholar ]
- Tharwat، A. خطی در مقابل تجزیه و تحلیل تفکیک درجه دوم طبقه بندی: یک آموزش. بین المللی J. Appl. تشخیص الگو 2016 ، 3 ، 145-180. [ Google Scholar ] [ CrossRef ]
- دوبی، تی. موتانگا، او. سیبندا، م. سئوتلوعلی، ک. شوکو، سی. استفاده از داده های سری Landsat برای تجزیه و تحلیل تغییرات مکانی و زمانی تخریب زمین در یک محیط خاک پراکنده: موردی از شهرداری محلی پادشاه ساباتا دالیندیبو در استان کیپ شرقی، آفریقای جنوبی. فیزیک شیمی. زمین 2017 ، 100 ، 112-120. [ Google Scholar ] [ CrossRef ]
- تسلط بر یادگیری ماشین. در دسترس آنلاین: https://machinelearningmastery.com/ (در 21 فوریه 2020 قابل دسترسی است).
- هکل، ک. شهری، م. شراتز، پی. ماهچا، MD; Schmullius، C. پیشبینی پوشش جنگلی در اکوسیستمهای متمایز: پتانسیل ترکیب دادههای چند منبع Sentinel-1 و -2. Remote Sens. 2020 , 12 , 302. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Congalton، RG مروری بر ارزیابی دقت طبقهبندی دادههای سنجش از دور. سنسور از راه دور محیط. 1991 ، 37 ، 35-46. [ Google Scholar ] [ CrossRef ]
- سینگ، SK; Srivastava، PK؛ سابو، اس. پتروپولوس، GP; گوپتا، م. اسلام، T. تبدیل چشمانداز و معیارهای فضایی برای ترسیم پویایی فضایی و زمانی پوشش زمین با استفاده از مجموعه دادههای رصد زمین. Geocarto Int. 2017 ، 32 ، 113-127. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لامین، اس. پتروپولوس، GP; سینگ، SK; سابو، اس. بچاری، NEI; Srivastava، PK؛ Suman، S. کمی سازی پویایی الگوی منظر مکانی-زمانی پوشش زمین/پوشش زمین از Hyperion با استفاده از طبقه بندی کننده SVMs و FRAGSTATS® . Geocarto Int. 2018 ، 33 ، 862-878. [ Google Scholar ] [ CrossRef ]
- Congalton، RG; گرین، ک. ارزیابی دقت دادههای سنجش از راه دور: اصول و روشها ، ویرایش سوم. CRC Press: بوکا راتون، فلوریدا، ایالات متحده آمریکا، 2019؛ پ. 319. [ Google Scholar ]
- محد رزعلی، ن. Bee Wah، Y. مقایسات قدرت آزمون های Shapiro-Wilk، Kolmogorov-Smirnov، Lilliefors و Anderson-Darling. J. Stat. مدل. مقعدی 2011 ، 2 ، 21-33. [ Google Scholar ]
- فیلد، ا. مایلز، جی. Field, Z. کشف آمار با استفاده از R ; انتشارات SAGE: لندن، انگلستان، 2012; پ. 957. [ Google Scholar ]
- تالاریدا، RJ; موری، آزمون RB Dunnett (مقایسه با یک کنترل). در کتابچه راهنمای محاسبات فارماکولوژیک ، ویرایش 2. Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 1987; صص 145-148. [ Google Scholar ]
- لوین، TR; Hullett، CR Eta Squared، Partial Eta Squared، و گزارش نادرست اندازه اثر در تحقیقات ارتباطی. هوم اشتراک. Res. 2002 ، 28 ، 612-625. [ Google Scholar ] [ CrossRef ]
- پروژه R برای محاسبات آماری. در دسترس آنلاین: https://www.r-project.org (در 21 فوریه 2020 قابل دسترسی است).
- مایر، پی. Wilcox, R. روش های آماری قوی در R با استفاده از بسته WRS2. رفتار Res. Methods 2019 ، 52 ، 1-25. [ Google Scholar ] [ CrossRef ]
- جاموی. در دسترس آنلاین: https://www.jamovi.org/about.html (در 21 فوریه 2020 قابل دسترسی است).
- Gallucci، M. GMLj: تجزیه و تحلیل عمومی برای مدل های خطی. در دسترس آنلاین: https://gamlj.github.io (در 21 فوریه 2020 قابل دسترسی است).
- سابو، اس. برتالان، ال. Kerekes، Á. نواک، تی جی امکان تحلیل تغییر کاربری زمین در یک منطقه روستایی کوهستانی: یک رویکرد روش شناختی. بین المللی جی. جئوگر. Inf. علمی 2016 ، 30 ، 708-726. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بلژیک، م. Drăgu، L. جنگل تصادفی در سنجش از دور: بررسی برنامهها و جهتهای آینده. ISPRS J. Photogramm. Remote Sens. 2016 ، 114 ، 24–31. [ Google Scholar ] [ CrossRef ]
- Xiong، K. آدیکاری، BR; استاماتوپولوس، کالیفرنیا؛ ژان، ی. وو، اس. دونگ، ز. دی، بی. مقایسه روشهای مختلف یادگیری ماشین برای نقشهبرداری حساسیت جریان زباله: مطالعه موردی در استان سیچوان، چین. Remote Sens. 2020 , 12 , 1-20. [ Google Scholar ] [ CrossRef ]
- بیگلزیمر، ا. لنگفورد، جی. Zadrozny، B. وزن یک در برابر همه. صبح. دانشیار آرتیف. هوشمند 2004 ، 2 ، 720-725. [ Google Scholar ]
- Allwein، EL; Schapire، RE; Singer, Y. Reducing multiclass به باینری: رویکردی متحد کننده برای طبقه بندی کننده های حاشیه. جی. ماخ. فرا گرفتن. Res. 2000 ، 1 ، 113-141. [ Google Scholar ]
- کاریداس، سی. Panagos, P. Towards a Assessment of the Ephemeral Erosion Gully Erosion در یونان با استفاده از Google Earth. Water 2020 , 12 , 603. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
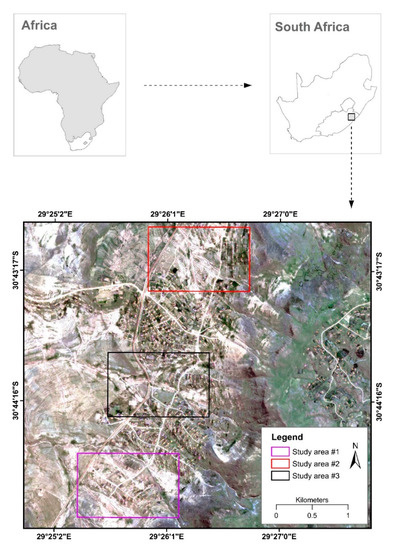
شکل 1. موقعیت جغرافیایی منطقه مورد مطالعه.

شکل 2. توزیع مقادیر بازتاب تصویر Systeme Pour l’Observation de la Terre (SPOT-7) بر اساس باندهای (قرمز، سبز، آبی (RGB) و مادون قرمز نزدیک (NIR))، مناطق مطالعه (s1–s3) و طبقه بندی دسته ها (NG: غیر خندق، G: خندق).
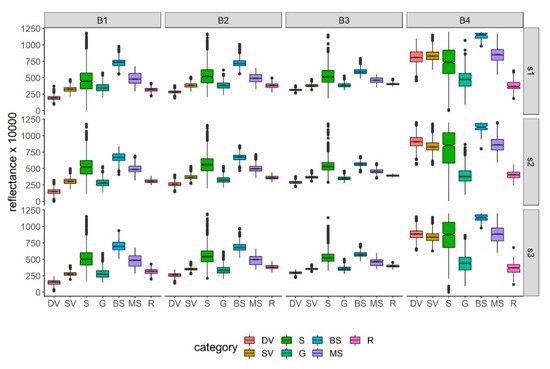
شکل 3. توزیع مقادیر بازتاب تصویر SPOT-7 بر اساس باندها (RGV+NIR)، مناطق مورد مطالعه (s1–s3)، و دسته بندی طبقه بندی (DV: پوشش گیاهی متراکم، SV: پوشش گیاهی تحت تنش، S: نشست، G: خندق، BS: خاک برهنه، MS: خاک لخت مخلوط، R: جاده).
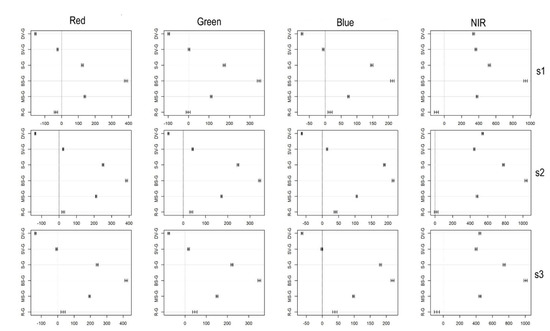
شکل 4. تفاوت میانگین بین خندق ها (G) و سایر دسته های پوشش زمین (میانگین ± 95% فواصل اطمینان؛ 95% فواصل اطمینان منطبق با 0 تفاوت معنی داری ندارند، P> 0.05؛ DV: پوشش گیاهی متراکم، SV: پوشش گیاهی تحت تنش، S : نشست، BS: خاک لخت، MS: خاک لخت مخلوط، R: جاده ها) توسط باندهای SPOT 7 (ستون ها) و مناطق مورد مطالعه (ردیف).
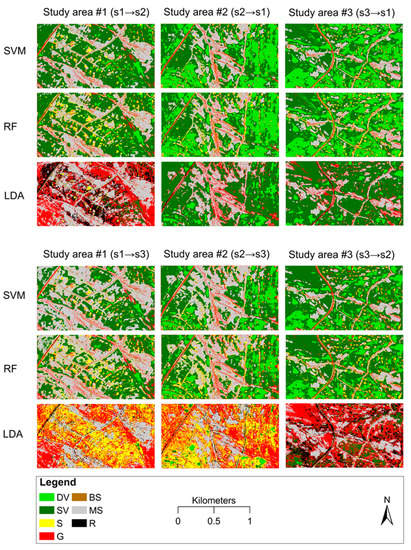
شکل 5. نتایج طبقه بندی رویکرد چند طبقه (DV: پوشش گیاهی متراکم، SV: پوشش گیاهی تحت تنش، S: استقرار، G: خندق، BS: خاک لخت، MS: خاک لخت مخلوط، R: جاده).
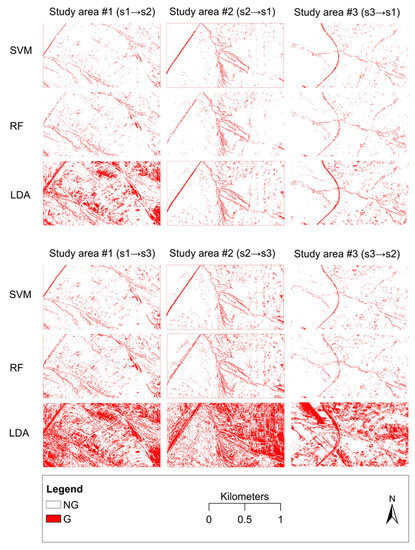
شکل 6. نتایج طبقه بندی رویکرد باینری (G: خندق، NG: غیر خندقی).
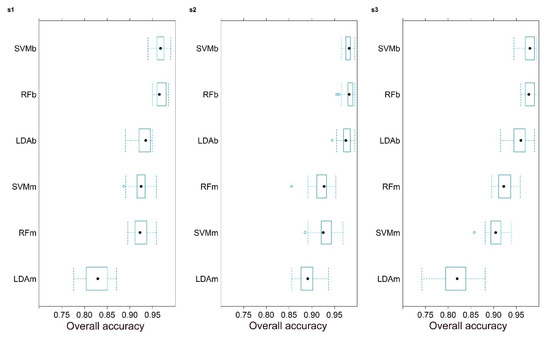
شکل 7. نتایج طبقهبندی الگوریتمهای کاربردی رتبهبندی شده بر اساس دقت کلی 30 مدل (10 برابر اعتبار متقابل با سه تکرار) بر اساس مناطق مورد مطالعه (LDA: تجزیه و تحلیل تشخیص خطی، RF: جنگل تصادفی، SVM: ماشین بردار پشتیبان؛ b: باینری، m: چند کلاسه).
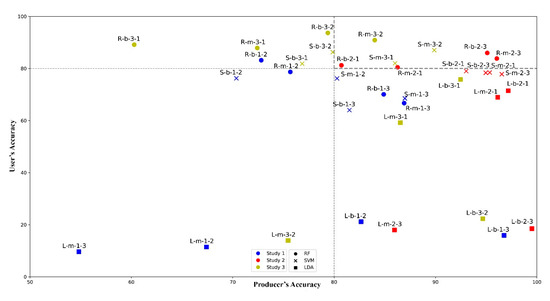
شکل 8. معیارهای دقت سطح کلاس طبقهبندیهای مختلف خندقها بر اساس الگوریتمها، تعداد دستهها و مناطق مورد مطالعه (S: SVM، R: RF، L: LDA؛ b: باینری، m: چند کلاسه، شماره اول: تعداد ناحیهای که در آن مدلها اعمال شد، شماره دوم: تعداد ناحیهای که مدل در آن آموزش داده شده است؛ بخشهای خط خط تیره (بالا سمت راست) نشاندهنده یک چهارم دقت بیش از 80 درصد است.
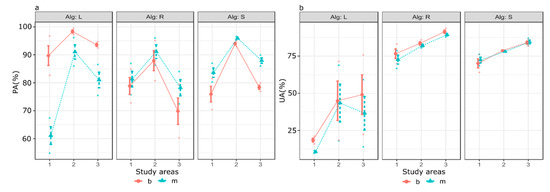
شکل 9. مقادیر PA ( a ) و UA ( b ) (میانگین ± ربع) خندق ها بر اساس الگوریتم های طبقه بندی (Alg: الگوریتم؛ L: LDA، R: RF، S: SVM)، تعداد کلاس ها (b: باینری؛ m : چند کلاسه) و مناطق مطالعه (1-3).


بدون دیدگاه