1. مقدمه
زمین لغزش های سریع اغلب باعث افزایش تعداد افراد و اموال در معرض خطر زمین لغزش می شود [ 1 ، 2 ، 3 ]. انبوهی از بلایای زمین لغزش باعث تعداد زیادی تلفات، تلفات اموال و خسارات زیرساختی شده است [ 4 ، 5 ]. در چین، از سال 2008 تا 2017 در مجموع 101993 رانش زمین گزارش شده است که منجر به 1041 مجروح و 5527 کشته، حداقل خسارت اقتصادی 7,082,873,650 دلار آمریکا ( https://www.stats.gov.cn/ ) شده است.) (در 22 دسامبر 2020 قابل دسترسی است). پهنه بندی خطر و پیشگیری زودهنگام از زمین لغزش ها برای جان و مال شهروندان در مناطق بالقوه مستعد زمین لغزش اهمیت زیادی دارد. به عنوان یک ابزار پهنه بندی خطر، نقشه حساسیت زمین لغزش (LSM) می تواند اطلاعات مفیدی را برای کاهش تلفات فاجعه آمیز فراهم کند و به هدایت برنامه ریزی کاربری پایدار کمک کند (همه مخفف ها و توضیحات آنها در مورد این تحقیق را می توان در ضمیمه A در پایان یافت. کاغذ). در همین حال، برای افراد بدون تخصص مربوطه نیز راه حلی برای درک موقعیت منطقه خطرناک زمین لغزش است [ 5 ، 6 ].
چندین روش و تکنیک برای تعیین حساسیت زمین لغزش پیشنهاد شده است. به طور کلی، این روش ها را می توان به دو نوع تقسیم کرد: روش های قطعی و روش های مبتنی بر آمار [ 7 ، 8 ]. روش های قطعی اغلب برای مطالعات مناطق کوچک یا شیب های منفرد استفاده می شود، روش های مبتنی بر آمار اغلب برای نقشه برداری و برنامه ریزی در مقیاس بزرگ استفاده می شود [ 9 ، 10 ]. ایده اصلی روش های آماری، یافتن رابطه بین وقوع زمین لغزش تاریخی و عوامل تأثیر و پیش بینی احتمال وقوع زمین لغزش در آینده بر اساس این رابطه است. برای جستجوی این رابطه، محققان روش های زیادی را پیشنهاد کرده اند [ 11]. روشهای مبتنی بر آمار در دهههای اخیر از روشهای آماری ساده به یادگیری ماشینی پیچیده تبدیل شدهاند.
روش آماری ساده بسیاری از روشها را شامل میشود، مانند نسبت فرکانس (FR) [ 12 ]، فرآیندهای سلسله مراتبی تحلیلی (AHPs) [ 13 ] و وزن شواهد (WoE) [ 14 ]. چنین رویکردهایی معمولاً به راحتی قابل درک هستند، فرآیندهای واضحی دارند و در برخی مکان ها به خوبی عمل می کنند. با این حال، درک این روش ها برای افراد بدون تخصص در زمین شناسی یا خطرات دشوار است، و حل موقعیت ها با مقادیر زیاد داده دشوار است.
با توسعه سیستم اطلاعات جغرافیایی (GIS) و هوش مصنوعی (AI)، یادگیری ماشینی (ML) به پرکاربردترین روش مبتنی بر آمار در LSM در حال حاضر تبدیل شده است [ 15 ]. یادگیری ماشینی صدها الگوریتم را در بر می گیرد. LR به دلیل عملکرد خوب و قابلیت تفسیر آن، پرکاربردترین روش است [ 8 ]. لی [ 16 ] یک مدل نسبت درستنمایی و یک مدل LR را در Janghung، کره مقایسه کرد و نتایج نشان داد که مدل LR از دقت پیشبینی بالاتری نسبت به مدل نسبت درستنمایی برخوردار است. ANN مدل عالی دیگری است که به طور گسترده نیز مورد استفاده قرار می گیرد. هارموزی و همکاران [ 17 ] یک نقشه قابل اعتماد حساسیت زمین لغزش توسط طبقه بندی کننده ANN بر روی عوامل فیزیکی مختلف در مراکش تولید کرد. مویدی و همکاران [18 ] از الگوریتم بهینه سازی ازدحام ذرات (PSO) برای بهینه سازی ANN و تولید یک مدل ترکیبی PSO-ANN برای پیش بینی LSM استفاده کرد، مدل PSO-ANN در مقایسه با ANN بهتر عمل کرد: مقادیر R2 0.9717 و 0.99131 برای آموزش یافت شد. مجموعه داده سایر الگوریتم های یادگیری ماشین مانند SVM درخت تصمیم، روش های ساده بیز و غیره نیز به طور گسترده در مناطق مختلف آزمایش می شوند [ 19 ، 20 ]. علاوه بر این، برخی از مطالعات روشهای یادگیری ماشین را با الگوریتم بهینهسازی یا یادگیری گروهی برای بهتر کردن نتایج بهبود دادهاند. یانگ و همکاران [ 21] یک روش یکپارچه جدید را تحت چارچوب سلسله مراتبی بیزی برای LSM در مقیاس محلی، به نام B-GeoSVC توسعه داد. دقت پیشبینی مدل B-GeoSVC 86.09 درصد بود، نشان داد که مدل قادر به دستیابی به LSM در مقیاس محلی نسبتاً دقیق است. در سالهای اخیر، روشهای یادگیری عمیق در LSM رایج شدهاند و به عملکرد خوبی دست یافتهاند [ 22 ]. به عنوان مثال، هوانگ و همکاران. [ 23] از یک شبکه عصبی رمزگذار خودکار پراکنده کاملا متصل برای LSM استفاده کرد و نتایج نشان میدهد که مدل یادگیری عمیق میتواند ویژگیهای غیرخطی بهینه را از عوامل با موفقیت استخراج کند. به طور کلی، یادگیری ماشین و یادگیری عمیق در حال حاضر به طور گسترده در LSM استفاده می شود. با این حال، هیچ یک از مدل ها به طور قابل توجهی بهتر از مدل های دیگر نیست، و مدل یادگیری ماشین منفرد نمی تواند تحت شرایط مختلف و مناطق مختلف به خوبی عمل کند [ 24 ، 25 ]. برای ایجاد نقشه بهینه حساسیت زمین لغزش برای یک منطقه مورد مطالعه خاص، یک راه حل ممکن مقایسه چندین روش مختلف و انتخاب خودکار روش بهینه است.
علاوه بر مدل ها، انتخاب عامل نیز نقش زیادی در نتایج LSM ایفا می کند. روش های LSM مبتنی بر آمار بر اساس دو فرض اساسی است: (1) زمین لغزش ها تحت تأثیر عوامل بسیاری قرار می گیرند و (2) لغزش های جدید بیشتر در جایی که زمین لغزش رخ داده است یا در شرایط مشابه رخ می دهد [ 26 ، 27 ]. انتخاب فاکتورهای مناسب یک پیش نیاز برای LSM است، فقدان فاکتورهای لازم نتایج را کمتر واقع بینانه می کند، در حالی که بسیاری از عوامل زائد باعث می شود مدل دقت کمتری داشته باشد [ 28 ]. تجزیه و تحلیل چند خطی و روش ارزیابی صفات همبستگی دو روش پرکاربرد برای انتخاب عوامل شرطی هستند [ 29 ]. به عنوان مثال، لی و همکاران. [ 10] چند خطی بودن را با محاسبه عوامل تورم واریانس تشخیص داد. حذف فاکتورها با هم خطی بودن بر مدل های آماری اثر افزایشی دارد. با این حال، دادههای مکانی دارای ویژگیهای خاصی هستند که آمارهای رایج فاقد آن هستند: خودهمبستگی مکانی و ناهمگنی فضایی. بنابراین، استفاده از ابزارهایی که همبستگی فضایی و ناهمگنی فضایی را اندازه گیری می کنند برای انتخاب عوامل شرطی زمین لغزش برای LSM بسیار مهم است.
برای حل این مسائل، ما یک خوشه یادگیری ماشین شامل ANN، BN، LR، و SVM برای منطقه هدف طراحی میکنیم تا نقشه بهینه حساسیت زمین لغزش را بهطور خودکار بدست آوریم. علاوه بر این، ما یک روش انتخاب فاکتور معنادار فیزیکی را با تعریف عوامل زائد موثر ارائه میکنیم تا انتخاب عوامل شرطی زمین لغزش را معقولتر کنیم. روش ترکیبی در شهرستان Xiaojin، چین اعمال می شود، نتایج با استفاده از شاخص های مختلف مورد بررسی قرار گرفت.
2. مواد و روشها
2.1. منطقه و داده های مطالعه
2.1.1. منطقه مطالعه
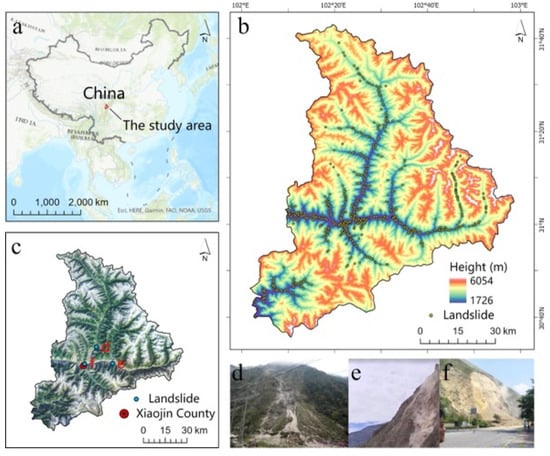
شهرستان Xiaojin بین طولهای جغرافیایی 102 درجه و 01 دقیقه شرقی تا 102 درجه و 59 دقیقه شرقی و عرضهای جغرافیایی 30 درجه و 35 دقیقه شمالی تا 31 درجه و 43 دقیقه شمالی در بخشی از استان خودمختار آبا تبت و کیانگ، استان سیچوان، چین واقع شده است ( شکل 1 ) شهرستان در منطقه فلات با مساحت حدود 5582 کیلومتر مربع است و زمین آن در شمال شرقی مرتفع و در جنوب غربی پست است. خط الراس متوسط کوه حدود 4500 متر با کوه سیگونیانگ در شرق است که ارتفاع آن به 6250 متر می رسد. مساحت دره بیش از 3000 متر و فاصله عمودی آن 1500-2500 متر است.
شهرستان Xiaojin واقع در دره کوهستانی در لبه فلات چینگهای-تبت، بین منطقه فعالیت لرزه ای منطقه گسل Longmen Shan و منطقه فعالیت لرزه ای منطقه گسل رودخانه Xian Shui قرار گرفته است. در طول زلزله ونچوان و زلزله لوشان، تعداد زیادی بلایای زمین شناسی در منطقه مورد مطالعه رخ داد که منجر به تلفات جانی و خسارات مالی جدی شد [ 3 ]. آب و هوای منطقه مورد مطالعه یک منطقه اقلیمی نیمه گرمسیری موسمی است. میانگین بارندگی سالانه 613 میلی متر است و دوره بارندگی عمدتاً از ژوئن تا سپتامبر است. رودخانه فوبیان و رودخانه شیائوجین رودخانه های اصلی این منطقه هستند. طول، میانگین جریان چند ساله، و میانگین رواناب سالانه چند ساله رودخانه فوبیان و رودخانه شیائوجین 83 کیلومتر و 150 کیلومتر، 37.43 متر مکعب است ./s و 103 متر مکعب بر ثانیه، 2.9 میلیارد متر مکعب و 1.2 میلیارد متر مکعب به ترتیب. گفتنی است افت این دو رودخانه بسیار زیاد بوده و به ترتیب به 1960 متر و 2340 متر می رسد.
2.1.2. نقشه موجودی زمین لغزش
در مجموع، 616 زمین لغزش از سال 1949 تا 2015 بر اساس تفسیر تصویر سنجش از دور و بررسی خطرات زمینشناسی میدانی توسط موسسه نقشهبرداری و طراحی ژئوتکنیک سیچوان چوانجیان ( https://www.sccjk.com/ ) به دست آمد (در 22 دسامبر 2020) شکل 1 ). این تصاویر از ماهواره منابع سه (ZY-3) با وضوح پیکسل زمینی 2.1 متر تفسیر شده است. این تفاسیر و بررسیها با تصویب نقشه ملی زمین ( https://www.mnr.gov.cn/ ) مطابقت دارد.) (در 22 دسامبر 2020 قابل دسترسی است). این فهرست زمین لغزش شامل جریان (جریان آوار، جریان گل)، ریزش (سقوط سنگ، سنگریزه/ریزش سنگ)، و لغزش (لغزش سنگ، شن/ماسه/لغزش زباله) است. این انواع زمین لغزش توسط نسخه جدید سیستم طبقه بندی Varnes [ 27 ] تعریف شده است ( شکل 1 d-f). برخی از مناطق در منطقه مورد مطالعه توسط یخچال ها و برف پوشیده شده است که در تصویر سنجش از دور در شکل 1 ب به رنگ سفید نشان داده شده است. این مطالعه بهمن های یخی را به عنوان یک نوع لغزش در نظر نگرفت.
2.1.3. عوامل شرطی
انتخاب عوامل شرطی مناسب در مدلسازی [ 30 ] بسیار مهم است. بر اساس تنظیمات جغرافیایی و محیطی منطقه مورد مطالعه و ادبیات [ 4 ، 31 ]، همه 19 عامل شرطی انتخاب و در پنج خوشه طبقه بندی شده اند: (1) مورفولوژیکی (6 متغیر)، (2) زمین شناسی (3 متغیر)، (iii) پوشش زمین (3 متغیر)، (IV) هیدرولوژیکی (4 متغیر)، و (v) سایر عوامل (3 متغیر) ( جدول 1 ). همه متغیرهای پیوسته با استفاده از روش شکست طبیعی به پنج دسته مجدد طبقه بندی شدند، در حالی که متغیرهای گسسته بر اساس ویژگی های داده ها تقسیم شدند ( شکل 2 ).
- (من)
-
عوامل مورفولوژیکی
شش عامل مورفومتریک شامل ارتفاع، شیب، جهت، منحنی نیم رخ، منحنی پلان و شاخص موقعیت توپوگرافی (TPI) انتخاب شدند. داده های ارتفاعی از مجموعه داده ASTER GDEM V2.0 توزیع شده به دست آمد (رزولیشن مکانی 30 متر). شیب، جنبه، منحنی نمایه، منحنی پلان، و برخی متغیرهای مرتبط در خوشههای دیگر (یعنی TWI، SPI) نیز از این مجموعه داده مشتق شدهاند.
ارتفاع تاثیر بسزایی در وقوع زمین لغزش دارد [ 10 ، 32 ]. در این منطقه مورد مطالعه، بیشتر منطقه بین 2000 تا 4000 متر بالاتر از سطح دریا قرار دارد و دارای اختلاف ارتفاع محلی زیادی است که شرایط را برای توسعه زمین لغزش ها فراهم می کند ( شکل 2 الف). به طور کلی تپه هایی با شیب های تند بیشتر مستعد ناپایداری هستند [ 33 ]. در این منطقه مورد مطالعه، 80 درصد شیبها با زاویه شیب بین 20 تا 40 درجه و تندترین زاویه شیب بیش از 70 درجه است ( شکل 2 ب). جنبه عمدتاً با تأثیر بر تابش خورشیدی و جریان هوا بر پایداری شیب تأثیر می گذارد ( شکل 2)ج). دو انحنای مختلف، متغیرهای مورفومتریک بودند که عبارتند از انحنای نیم رخ و پلان. منحنی پروفیل بر شتاب و کاهش جریان تأثیر می گذارد که به نوبه خود بر فرسایش و رسوب تأثیر می گذارد. در مقابل، منحنی پلان بر همگرایی و پراکندگی جریان تأثیر می گذارد. TPI یک پارامتر زمین است که توسط اندرو وایس در سال 2001 برای توصیف زمین [ 34 ] پیشنهاد شد ( شکل 2 د).
- (II)
-
عوامل زمین شناسی
شرایط زمین شناسی عوامل کنترل کننده بلایای زمین لغزش هستند [ 35 ]. این منطقه تحت تأثیر فعالیت های زمین ساختی ناحیه گسلی لانگمن شان قرار گرفت که منجر به تغییر شکل و تشکیل ساختارهای پیچیده زمین شناسی شد. بنابراین، سنگ شناسی، شدت لرزه ای و فاصله تا گسل به عنوان متغیرهای زمین شناسی انتخاب شدند. گسل لانگمن شان در شرق و خارج از محدوده مورد مطالعه قرار دارد، بنابراین فاصله تا گسل به تدریج از شرق به غرب افزایش می یابد، همانطور که در شکل 2 نشان داده شده است.g. از نظر زمین شناسی لایه های این ناحیه عمدتاً رسوبات دریایی تریاس بالایی هستند. رسوبات در معرض عمدتاً طبقات تریاس و ژوراسیک هستند. سنگ شناسی عمدتاً ماسه سنگ دگرگونی و گرانیت بلند است. گروه سنگ مهندسی تحت سلطه سنگ نرمتر و سنگ سخت است و سنگ نرم و سنگ سخت در ناحیه کوچک جنوب مخلوط شده اند ( شکل 2 e). شدت لرزه ای نشان دهنده شدت تاثیر زلزله بر سطح و ساختمان های مهندسی است. شدت لرزه در اکثر نقاط شهرستان VI و VII است. در شرق، شدت VIII است ( شکل 2 f). داده های شدت لرزه ای تحت استاندارد ملی “نقشه منطقه بندی پارامتر زلزله چین” (GB18306-2001) فرموله شده است.
- (iii)
-
عوامل پوشش اراضی
پوشش زمین بر پایداری زمین و شیب ها تأثیر می گذارد [ 16 ، 36 ]. خوشه پوشش زمین شامل کاربری اراضی، NDVI و فرسایش خاک است. منطقه مورد مطالعه توسط جنگل ها و مراتع پوشیده شده است که به ترتیب 67٪ و 27٪ را تشکیل می دهند ( شکل 2 h). تحت تأثیر ترکیبی آب و هوا و خاک، چوب ها و چمن ها سرسبز نیستند و تأثیرات مثبت آنها بر پایداری شیب قوی نیست [ 6 ]. نقشه NDVI می تواند رشد گیاهان سبز روی سطح را تعیین کند که ارتباط نزدیکی با پایداری شیب [ 37 ] دارد ( شکل 2 i). فرسایش خاک نتیجه تعامل و محدودیت های متقابل عوامل مختلف در محیط جغرافیایی است.38 ] ( شکل 2 j). منطقه مورد مطالعه عمدتا دارای فرسایش هیدرولیکی و فرسایش یخ-ذوب، شامل 4 سطح با توجه به الزامات عمومی استاندارد صنعتی جمهوری خلق چین SL 190-96 “استاندارد طبقه بندی برای طبقه بندی فرسایش خاک” است.
- (IV)
-
عوامل هیدرولوژیکی
بارش، رودخانه، شاخص قدرت جریان (SPI) و شاخص رطوبت توپوگرافی (TWI) به عنوان عوامل هیدرولوژیکی انتخاب شدند. نفوذ آب ممکن است پایداری شیب را کاهش دهد و بارندگی شدید مداوم می تواند مستقیماً زمین لغزش ها را تحریک کند [ 39 ]. منطقه مورد مطالعه به دلیل محصور در خشکی و فلات بودن، بارندگی چندانی ندارد و رواناب رودخانه نیز کم است. SPI نیروی فرسایشی جریان آب را اندازه گیری می کند و در مدل های مختلف استفاده شده است [ 40 ]. TWI اندازه گیری فرضی مقدار تجمعی جریان آب شاخص در هر نقطه از حوضه است، TWI توسط نرم افزار SAGA-GIS ( https://saga-gis.org ) (دسترسی در 22 دسامبر 2020) محاسبه شد [ 32 ] .
- (v)
-
عوامل انسانی
عوامل انسانی شامل شدت فعالیت انسانی سطح زمین (HAILS)، سکونتگاه و جاده است. HAILS یک شاخص سنتز برای توصیف اثر و تأثیر سطح زمین است [ 41 ، 42 ] ( شکل 2 k). HAILS میزان استفاده، بازسازی و توسعه سطح طبیعی زمین توسط انسان است. به عنوان یک شاخص ترکیبی جدید، در برخی از مطالعات مورد استفاده قرار گرفته و نتایج خوبی به دست آورده است [ 43 ]. HAILS با تقسیم زمین ساخت و ساز بر مساحت کل منطقه محاسبه می شود [ 42]. وجود سکونتگاه ها و ساخت راه ها از فعال ترین فعالیت های انسان در دامنه های طبیعی است. فاصله چند بافری تا محل سکونت و جاده به ترتیب برای تعیین کمیت تأثیر سکونتگاه و جاده استفاده شد ( شکل 2 l).
2.2. مواد و روش ها
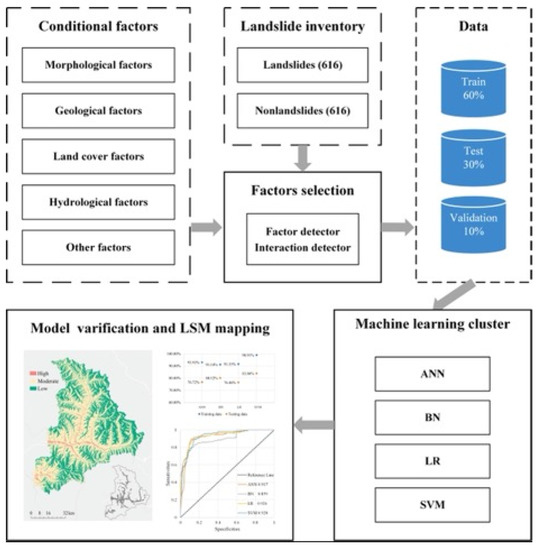
این گردش کار عمدتاً شامل انتخاب عامل شرطی، مدل سازی LSM و اعتبارسنجی مدل است ( شکل 3 ). اول، انتخاب عامل شرطی شامل روش های Factor-detector و Interaction-detector در GeoDetector است. نرم افزار GeoDetector به صورت رایگان از https://www.geodetector.cn/ در دسترس است (در 22 دسامبر 2020 قابل دسترسی است). سپس از یک خوشه یادگیری ماشینی با چهار الگوریتم برای مدلسازی LSM استفاده شد. در نهایت، دقت پیشبینی و منحنیهای ROC برای اعتبارسنجی نتایج استفاده شد.
قبل از انتخاب فاکتور و ساخت مدل، منطقه مورد مطالعه به شبکه های منظم با تفکیک فضایی 60 متر تقسیم شد. انتخاب اندازه شبکه با راندمان محاسباتی تعیین می شود، علاوه بر این، انتخاب 60 متر می تواند به طور موثر از برش بی نظم شبکه برای عوامل جلوگیری کند (اکثر عوامل دارای وضوح فضایی 30 متر هستند). در نتیجه، 1،709،680 واحد نقشه برداری به دست می آید. این باعث می شود که گرید و عوامل با واحد عوامل شرطی مطابقت خوبی داشته باشند. تعداد نقاط لغزش در هر واحد نقشه برداری برای بدست آوردن متغیر y برای ژئودتکتور محاسبه می شود. در مجموع 616 نقطه لغزش بین 616 واحد نقشه برداری توزیع شده است که متغیر y را به یک متغیر باینری تبدیل می کند. 19 لایه گسسته متغیر x و لایه متغیر y تحت تجزیه و تحلیل پوشش فضایی قرار می گیرند.
2.2.1. انتخاب عامل مشروط
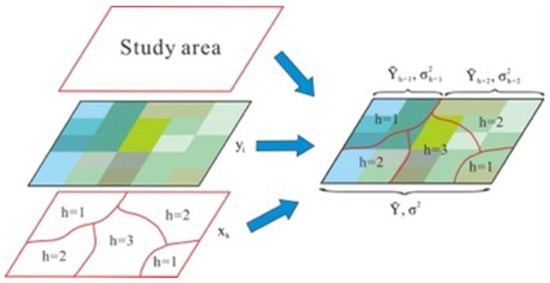
انتخاب عامل شرطی مناسب و تعریف عوامل زائد مؤثر بر عملکرد نقشه برداری LSM تأثیر می گذارد. اثرات عوامل عمدتا فردی و تعاملی است، که هر دو بسیار مهم هستند، با این حال اکثر مطالعات فعلی بر روی اثرات متقابل تمرکز ندارند. روش GeoDetector می تواند اثرات عوامل را به صورت جداگانه محاسبه کند و همچنین تعاملات بین عوامل را تشخیص دهد [ 44 ]. این روش برای اولین بار در نقص لوله عصبی [ 45 ] اعمال شد. متعاقباً، GeoDetector در بسیاری از مناطق، از جمله خطرات زمین لغزش [ 46 ]، کاربری زمین [ 47 ]، اقتصاد منطقه ای [ 48 ] و اکوسیستم [ 49 ] استفاده شد.
فرضیه اصلی GeoDetector این است که اگر یک متغیر مستقل بر یک متغیر وابسته تأثیر بگذارد، توزیعهای فضایی متغیر مستقل و متغیر وابسته باید مطابقت داشته باشند [ 44 ، 45 ، 50 ]. اصل GeoDetector در شکل 4 نشان داده شده است . آشکارساز عامل می تواند تشخیص دهد که عامل X چقدر توزیع فضایی متغیر Y را توضیح می دهد . اصل فاکتور آشکارساز به شرح زیر است:
که در آن مقدار q متریک عامل X است . L طبقات (رده) X یا Y است. N h و N به ترتیب تعداد اقشار h و اقشار جهانی هستند. σ2ساعت�h2و σ2�2به ترتیب واریانس های متغیر وابسته Y اقشار h و واریانس کل ناحیه هستند.
آشکارساز تعامل می تواند برای شناسایی تعاملات بین متغیرهای شرطی X s استفاده شود. می تواند ارزیابی کند که آیا عوامل X 1 و X 2 قدرت توضیحی متغیر وابسته Y را هنگامی که با هم کار می کنند تغییر می دهند یا تأثیر این عوامل بر γ�مستقل است در روش ارزیابی، مقادیر q X 1 و X 2 برای Y: q( Y| ایکس1)�(�|�1)و q( Y| ایکس2)�(�|�2)ابتدا جداگانه محاسبه می شوند. سپس، X 1 و X 2 برای تشکیل یک لایه جدید روی هم قرار می گیرند و مقدار ایکس1∩ایکس2�1∩�2برای Y: q( Y| ایکس1∩ایکس2)�(�|�1∩�2). در نهایت، ارزش q( Y| ایکس1)�(�|�1)، q( Y| ایکس2)�(�|�2)، و q( Y| ایکس1∩ایکس2)�(�|�1∩�2)برای قضاوت در مورد تعامل مقایسه می شوند.
2.2.2. خوشه یادگیری ماشینی
خوشه یادگیری ماشین شامل چهار MLT معمولی است: شبکه های عصبی مصنوعی، شبکه بیزی، رگرسیون لجستیک و ماشین های بردار پشتیبانی. ایده خوشه یادگیری ماشینی از یادگیری ماشین خودکار (AutoML) می آید. AutoML می تواند به عنوان طراحی یک سری از سیستم های کنترل پیشرفته برای عملکرد مدل یادگیری ماشینی دیده شود تا مدل بتواند به طور خودکار پارامترها و تنظیمات مناسب را بدون دخالت دستی یاد بگیرد [ 51 ، 52 ].
مجموعه داده برای مدل سازی شامل نمونه مثبت و منفی است. مجموعه نمونه مثبت شامل 616 نقطه فاجعه بررسی میدانی است. مجموعه نمونه منفی برای حفظ تعادل نمونه های داده که 100 متر از نقاط لغزش شناخته شده فاصله دارند (نمونه های مثبت) استفاده می شود. یک مجموعه نمونه شامل 616 نقطه غیر لغزش به طور تصادفی انتخاب شده است. در مجموع 1232 امتیاز به طور تصادفی به سه گروه داده نمونه تقسیم می شوند. 60 درصد از داده های نمونه به عنوان مجموعه داده های آموزشی، 30 درصد از داده های نمونه به عنوان مجموعه داده های آزمایشی و 10 درصد دیگر از داده ها مجموعه داده های اعتبار سنجی هستند.
- (من)
-
شبکه عصبی مصنوعی (ANN)
شبکههای عصبی مصنوعی تقریبکنندههای توابع غیرخطی عمومی هستند که در سالهای اخیر به طور گسترده در مدلسازی حساسیت زمین لغزش استفاده شدهاند [ 53 ]. ANN نه تنها دارای ویژگی های مشترک سیستم های غیرخطی عمومی است، بلکه دارای ویژگی های آن است، مانند ابعاد بالا، اتصال گسترده بین نورون ها و خود انطباق [ 17 ، 54 ]. یک شبکه عصبی استاندارد از تعداد زیادی پردازنده ساده و متصل به نام نورون ها تشکیل شده است که هر کدام دنباله ای از فعال سازی های با ارزش واقعی را تولید می کنند. چنین سیستمهایی با در نظر گرفتن مثالها، معمولاً بدون برنامهریزی با قوانین خاص، انجام وظایف را یاد میگیرند.
MLP (پرسپترون چند لایه) و RBF (تابع پایه شعاعی) دو ساختار شبکه مشترک ANN هستند. یک MLP به بهای احتمالی افزایش زمان آموزش و امتیازدهی، روابط پیچیده تری را امکان پذیر می کند. یک RBF ممکن است زمان تمرین و امتیاز کمتری داشته باشد، به قیمت احتمالی کاهش قدرت پیش بینی در مقایسه با MLP. توانایی طبقهبندی و زمان آموزش MLP و RBF بر روی دادهها در این مطالعه بررسی شد، لایههای پنهان بهطور خودکار محاسبه شدند و از الگوریتم تقویت برای افزایش دقت مدلها استفاده شد. نتایج نشان می دهد که هزینه زمانی برای MLP و RBF تقریباً یکسان است: به ترتیب 156 ثانیه و 139 ثانیه. با این حال، دقت MLP 92.9٪ است که بالاتر از RBF در 85.5٪ است. بنابراین MLP به طور قابل توجهی بهتر از RBF بود،
- (II)
-
شبکه بیزی (BN)
شبکه بیزی یک مدل گرافیکی است که متغیرها (معمولاً گره نامیده می شود) و احتمالات آنها را در یک مجموعه داده و همچنین شرایط و استقلال بین این متغیرها را نشان می دهد. این تکنیک با موفقیت برای ارزیابی حساسیت زمین لغزش استفاده شده است [ 55 ، 56 ]. در این مطالعه از مدل ساده بیز (NB) برای ایجاد یک مدل شبکه بیزی استفاده شده است. نسبت درستنمایی به عنوان یک آزمون مستقل استفاده می شود. احتمال مشترک شبکه های بیزی را می توان به صورت حاصل ضرب احتمال لبه هر گره بیان کرد:
که در آن P ( L ) احتمال قبلی است که احتمال شرطی بدون گره های والد است، پ( م| ل )�(�|�)احتمال شرطی است که احتمال وقوع M در شرایط L است، پ( ن| ل ، م)�(�|�,�)احتمال شرطی است که احتمال وقوع N در شرایط L و M است.
- (iii)
-
رگرسیون لجستیک (LR)
رگرسیون لجستیک یک مدل آماری است که از یک تابع لجستیک برای مدلسازی یک متغیر وابسته باینری و چندین متغیر مستقل استفاده می کند. اصل کار آن ایجاد یک رابطه رگرسیونی بین متغیرهای باینری و متغیرهای مستقل برای قضاوت در مورد احتمال یک رویداد تحت شرایط خاص است. اگر یک رویداد زمین لغزش به عنوان یک رویداد دو طبقه ای در نظر گرفته شود (رویداد یا رخ نمی دهد)، مدل رگرسیون لجستیک دو جمله ای برای مدل سازی حساسیت زمین لغزش بسیار مناسب است [ 30 ، 57 ]. معادله اصلی حاکم بر مدل LR به شرح زیر است:
جایی که α�یک اصطلاح ثابت است، ایکس1، x2… xnx1,x2…xnمتغیرهای مستقل هستند و β1، β2… βn�1, �2… ��ضرایب رگرسیونی هستند که باید تعیین شوند. احتمال خروجی، مقدار Pi ، از 0 تا 1 متغیر است، جایی که 0 به این معنی است که احتمال لغزش در واحد نقشه برداری i 0 است و 1 به این معنی است که احتمال لغزش در واحد نقشه برداری i برابر با 1 است.
- (IV)
-
ماشین بردار پشتیبانی (SVM)
SVM یک طبقهبندی خطی تعمیمیافته است که دادهها را به صورت باینری بر اساس یادگیری نظارت شده طبقهبندی میکند. مدل اصلی آن یک طبقهبندی خطی با بیشترین بازه تعریف شده در فضای ویژگی است. ایده اصلی یادگیری SVM حل ابر صفحه جداسازی است که می تواند مجموعه داده های آموزشی را به درستی تقسیم کند و بیشترین بازه هندسی را دارد. SVM همچنین شامل تکنیک های هسته است که آن را اساساً یک طبقه بندی کننده غیر خطی می کند. دقت پیشبینی یک SVM تحت تأثیر انتخاب توابع هسته مانند تابع پایه سیگموئید، چند جملهای، خطی و شعاعی (RBF) قرار میگیرد. تابع هسته RBF که بر اساس فاصله اقلیدسی تعریف شده است، پرکاربردترین تابع هسته برای ارزیابی حساسیت زمین لغزش است. معادله اصلی حاکم بر RBF به شرح زیر است:
کجا با σ > 0�>0، پارامتری که عرض RBF را تعیین می کند، k ( . , . )ک(.،.)یک تابع هسته است، ایکسمنایکسمن، ایکسjایکسjبه ترتیب بردارهای بردار نمونه آموزشی ith و jth هستند.
2.2.3. تایید
در مطالعه حاضر، دقت پیشبینی، روش منحنی ROC و روش شاخص سطح سلول بذر (SCAI) برای تایید و مقایسه مدلها میباشد. دقت پیشبینی برای ارزیابی کمی دقت پیشبینیهای صفر و یک ارزش و دقت پیشبینی کلی استفاده شد. منحنی ROC نموداری مبتنی بر حساسیت (همچنین به عنوان نرخ مثبت واقعی شناخته میشود) و ویژگی 1 (همچنین به عنوان نرخ مثبت کاذب شناخته میشود) با آستانههای برش مختلف است. برای ارزیابی کمی دقت پیشبینی استفاده میشود [ 58]. سطح زیر منحنی های ROC (AUC) را می توان به عنوان خلاصه آماری عملکرد کلی در نظر گرفت. AUC معمولاً به عنوان مفیدترین آمار دقت برای مدلسازی حساسیت زمین لغزش شناخته میشود. SCAI نسبت سطح درصد هر کلاس حساسیت به درصد زمین لغزش هایی بود که در هر طبقه رخ می دهد [ 59 ]. در مقایسه با دقت پیشبینی و ROC، SCAI میتواند جزئیات بیشتری در مورد نتایج طبقهبندی مدلها ارائه دهد.
3. نتایج
3.1. نتایج انتخاب شرطی
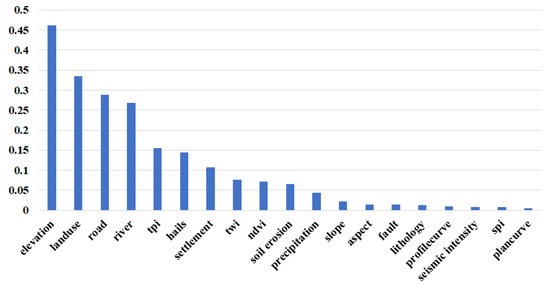
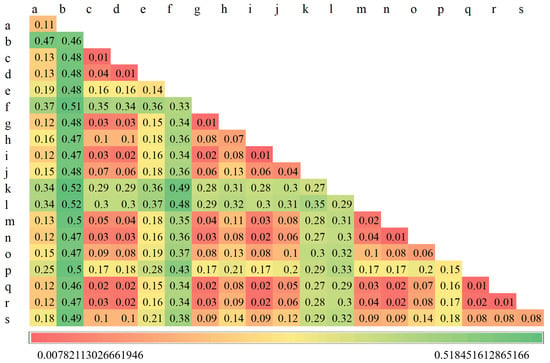
نتایج تحلیل همپوشانی فضایی برای محاسبه به ژئودتکتور وارد شده و مقدار q هر عامل شرطی به دست میآید. در همان زمان، مقدار p هر عامل شرطی نیز محاسبه می شود. p-value پارامتری است که برای تعیین نتایج آزمون فرضیه استفاده می شود. نتایج محاسبات Factor-detector و Interaction-Detector به ترتیب در شکل 5 و شکل 6 نشان داده شده است.
ارتفاع مهمترین عامل (با q برابر 46/0) است که پس از آن کاربری اراضی (33/0)، جاده (29/0) و رودخانه (27/0) قرار دارند. و q منحنی پلان، چگالی لرزه ای، SPI و منحنی پروفیل همگی کمتر از 0.01 هستند، آنها عوامل زاید در نظر گرفته می شوند [ 44 ]]. علاوه بر این، مقادیر p برای هر دو TWI و منحنی پروفایل بیشتر از 0.05 است و بنابراین نتایج از نظر آماری معنیدار نیستند. در نتیجه منحنی پلان، چگالی لرزه ای، SPI، منحنی پروفیل و TWI باید حذف شوند. با این حال، نتیجه آشکارساز تعامل اطلاعات و بینش بیشتری فراتر از نتایج فوق ارائه می دهد. ما به وضوح میتوانیم ببینیم که شدت لرزهای نقش مثبتی در برهمکنش با عوامل دیگر ایفا میکند، همانطور که با افزایش غیرخطی اثرات متقاطع با هر یک از عوامل نشان میدهد، در حالی که سایر عوامل تأثیر چندانی ندارند. بنابراین سعی کردیم شدت لرزه را حفظ کنیم و چهار عامل دیگر را حذف کنیم.
برای آزمایش اینکه آیا تصمیم برای حذف عامل اضافی درست بوده است، یک مدل جنگل تصادفی ساده ایجاد کردیم و از میانگین خطای مطلق (MAE) برای ارزیابی سودمندی حذف استفاده کردیم. MAE معیاری است که معمولاً برای سودمندی حذف فاکتور استفاده می شود که میانگین قدر مطلق خطا بین مقادیر مشاهده شده و واقعی را نشان می دهد. هرچه مقدار آن کوچکتر باشد، عملکرد مدل بهتر است. مدلهای جنگل تصادفی قابلیت تعمیم خوبی دارند و اغلب در چنین آزمایشهایی استفاده میشوند. در این کار، مدل جنگل تصادفی با استفاده از scikit-learn با n_estimators روی 100، random_state بر روی 0 و تمام پارامترهای دیگر به عنوان پیشفرض باقی مانده ساخته شد. نتایج نشان داد که MAE با 19 عامل حفظ شده 0.420، با پنج عامل (منحنی طرح، چگالی لرزهای، SPI، منحنی پروفیل، 0.395) بود. و TWI) حذف شد و تنها 0.391 با چهار عامل (منحنی طرح، SPI، منحنی پروفایل و TWI) حذف شد. چنین نتایجی نشان می دهد که GeoDetector برای غربالگری فاکتورها موثر است. بنابراین، مجموعه داده عامل شرطی بدون عوامل اضافی برای مدلسازی یادگیری ماشین استفاده شد.
3.2. ارزیابی دقت کلاستر یادگیری ماشین
تأیید و مقایسه مدل شامل دقت پیشبینی، منحنی ROC و SCAI بود. شکل 7 دقت پیش بینی و منحنی ROC خوشه یادگیری ماشین را با داده های آموزشی و داده های آزمایشی نشان می دهد. نتایج SCAI در جدول 2 نشان داده شده است.
برای دقت پیشبینی چهار MLT، همه مدلها در مجموعه آموزشی به خوبی عمل کردند، بیش از 90٪ و SVM حتی به بیش از 98٪ رسید. در حالی که برای داده های تست، SVM با 83.86% بهترین عملکرد را دارد و هیچ مدل دیگری از 80.5% فراتر نمی رود. برای AUC، BN با امتیاز تنها 85.9٪ ضعیف ترین عملکرد را دارد. در حالی که سه الگوریتم دیگر عملکرد مشابهی داشتند و SVM همچنان بالاترین ارزش را داشت. نتایج SCAI نشان داد که طبقات با دقت بالا در چهار مدل تقسیم شدند ( جدول 2).). طبقات حساسيت بالا داراي مقادير SCAI بسيار پايين (<1) در همه مدل ها مي باشند كه نشان دهنده وجود زمين لغزش هاي تاريخي زياد در مناطق با حساسيت بالا مي باشد. و کلاس های حساسیت کم دارای مقادیر SCAI بالایی هستند (>3). در میان آنها، ارزش SCAI SVM در مقایسه با مدلهای دیگر برجستهتر است: پایینترین مقدار کلاس حساسیت بالا. در کل، SVM بهترین عملکرد را تحت سه شاخص تأیید دارد. بنابراین، خوشه یادگیری ماشین به طور خودکار SVM را به عنوان مدل بهینه برای محاسبه و خروجی نتایج انتخاب می کند.
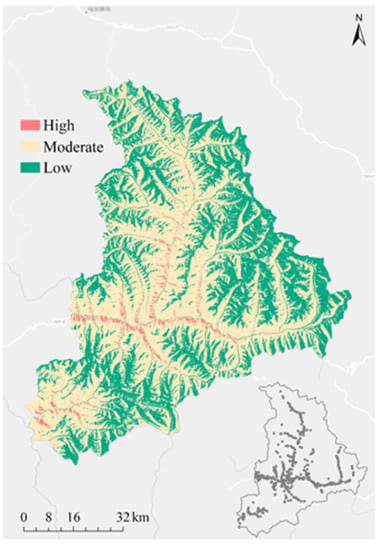
3.3. نقشه برداری حساسیت زمین لغزش
LSM با تولید شاخصهای حساسیت زمین لغزش (LSIs) و طبقهبندی مجدد کلاس تهیه شد. LSI بر اساس خوشه یادگیری ماشین آموزش دیده محاسبه شد. با استفاده از روش شکست های طبیعی، LSM به سه کلاس حساسیت بالا، متوسط و کم طبقه بندی شد ( شکل 8 ). دلیل طبقه بندی حساسیت به پنج کلاس یا بیشتر این است که اگر آنها به پنج طبقه یا بیشتر تقسیم می شدند، مناطق با حساسیت بالا فقط سهم بسیار کمی را اشغال می کردند و در نتیجه نشان دادن آنها بر روی نقشه دشوار است. همانطور که در شکل 8 نشان داده شده استمناطق با حساسیت زیاد، متوسط و کم دارای ویژگی های پهنه بندی مشخصی هستند. نسبت مناطق اشغال شده توسط مناطق مرتفع، متوسط و پست به ترتیب 03/6%، 52/37% و 45/56% است، در حالی که نسبت زمین لغزش مربوط به آنها به ترتیب 87/60%، 98/31% و 14/7% است. مناطق با حساسیت بالا در مناطق شهری و در مناطقی که بلایای قبلی رخ داده بود، که همچنین در نزدیکی جاده ها و رودخانه ها متمرکز شده بودند، متمرکز شدند.
4. بحث
4.1. عامل – آشکارساز و تعامل – آشکارساز
در نتیجه اثر مشترک بین فرآیندهای طبیعی و فعالیت های انسانی، زمین لغزش تا حد زیادی با شرایط محیطی طبیعی مرتبط است. و حساسیت زمین لغزش باید این واقعیت عینی را به خوبی درک کند. جغرافیدانان، زمین شناسان و بوم شناسان اقدامات زیادی را برای توصیف شرایط مختلف محیطی جغرافیایی و تأثیر فعالیت های انسانی مرتبط با زمین لغزش کشف و ایجاد کرده اند. این شرایط جهانی نیست بلکه در مکان های مختلف و حتی در زمان های مختلف متفاوت است. انتخاب عوامل شرطی زمین لغزش و تعیین عوامل زائد موثر برای منطقه مورد مطالعه حیاتی است. یک استراتژی این است که ابتدا عوامل مشروط جامع از جمله زمین شناسی، هیدرولوژی، فعالیت های انسانی،
نتایج Factor-detector نشان می دهد که ارتفاع مهمترین عامل است و این نتیجه با بسیاری از مطالعات مطابقت دارد [ 60 ]. هنگامی که ارتفاع در یک منطقه بسیار تغییر می کند، ارتفاع به یک عامل مهم در وقوع زمین لغزش تبدیل می شود. نتایج همچنین اهمیت سه متغیر مرتبط با انسان را نشان می دهد: جاده ها، HAILS و سکونتگاه ها ( شکل 5 ). با توجه به توزیع مکانی دادههای زمین لغزش و موقعیت جادهها و مناطق مسکونی، فعالیتهای انسانی در این منطقه تأثیر قوی بر زمین لغزشها دارد. در مطالعات دیگر، عوامل مرتبط با فعالیتهای انسانی تأثیر قابل توجهی بر وقوع زمین لغزش در نظر گرفته شده است [ 61 ].]. در مناطق کوهستانی، ساخت جادهها ممکن است شیبهایی را که پایدار بودهاند، کاهش دهد و در نتیجه تعادل اولیه را از بین ببرد. هرچه به جاده نزدیکتر باشد، شیب آسیب بیشتری دیده و احتمال رانش زمین بیشتر می شود. علاوه بر این، جاده های بد ساخته شده خطرات جدی تری برای شیب ها نسبت به جاده های خوب ساخته شده در شرایط یکسان ایجاد می کنند. ناهمگونی فضایی فعالیت های انسانی بسیار بیشتر از شرایط محیطی طبیعی است. پراکندگی زمین لغزش ها در منطقه مورد مطالعه با این ناهمگونی مطابقت دارد. به همین دلیل است که فعالیت های انسانی می تواند به شدت بر توزیع زمین لغزش ها تأثیر بگذارد.
شیب و جنبه نقش زیادی در تأثیرگذاری بر وقوع زمین لغزش نداشتند ( شکل 5 ). شیب و جنبه عموماً از عوامل مهم در LSM در نظر گرفته می شوند. با این حال، بسیاری از مطالعات بر این باورند که شیب و جنبه خیلی مهم نیست، که با نتایج مطالعه ما مطابقت دارد [ 21 ، 62 ]]. در این منطقه مورد مطالعه، زمین لغزش ها عمدتاً در مناطقی با شیب کم توزیع شده است. این توزیع باعث می شود که مدل بر این باور باشد که وقوع زمین لغزش زمانی که شیب در محدوده بزرگتری تغییر می کند تغییر نمی کند، بنابراین شیب سهم کمی دارد. به طور محلی، این جاده است، نه شیب یا جنبه ای که شکل اصلی شیب و رانش زمین را مختل می کند. چگالی لرزه ای در نتیجه آشکارساز فاکتور امتیاز بالایی ندارد اما در آشکارساز تعامل بسیار فعال است. تعامل آن با بیشتر عوامل یک افزایش غیر خطی است. چون در مساحت ده ها کیلومتر مقدار ثابتی دارد یعنی همان لرزه در یک مکان و جای دیگر در ده کیلومتری آن. این منجر به این می شود که عامل به دلیل ناهمگونی فضایی ضعیف، سهم کمی دارد.
آشکارساز تعامل می تواند تعامل بین عوامل مختلف را محاسبه کند ( شکل 6 ). در این مطالعه، نتایج آشکارساز برهمکنش همخوانی بالایی با نتایج آشکارساز فاکتور دارد. علاوه بر این، آشکارساز تعامل می تواند عمل متقابل را در بین عواملی که تشخیص عامل نادیده می گیرد، بیابد. در این راستا، نقش آشکارساز تعاملی برجسته می شود زیرا بر تعامل بین عوامل تأکید می کند. شدت زمین لرزه قوی در مکان هایی که زاویه شیب کم است باعث لغزش نمی شود، اما در مکان هایی که زاویه شیب زیاد است، زمین لغزش زیادی ایجاد می کند. به طور مشابه، رودخانه ها به سختی باعث تغییر شکل سطح در جنگل می شوند، در حالی که می توانند به راحتی در شیب های نزدیک بزرگراه باعث ناپایداری شوند.
با ترکیب نتایج آشکارساز عامل و آشکارساز تعامل، TWI، منحنی پروفایل، SPI و منحنی پلان را به عنوان عوامل زاید در نظر گرفتیم. با مقایسه اثرات قبل و بعد از استفاده از Factor-detector و Interaction-detector، به راحتی می توان تغییر قابل توجهی در مقادیر MAE مشاهده کرد. هنگامی که از آشکارساز فاکتور استفاده می شود، MAE از 0.420 به 0.395 کاهش می یابد و هنگامی که نتایج آشکارساز تعامل بر این اساس در نظر گرفته می شود، MAE به 0.391 کاهش می یابد. این نتایج نشان دهنده برتری روش مورد استفاده در این کار است.
4.2. عملکرد خوشه یادگیری ماشینی
هنگامی که داده های ورودی وارد کلاستر یادگیری ماشین می شود، به طور خودکار مناسب ترین مدل را با توجه به عملکرد مدل انتخاب می کند. در این مورد SVM بهترین عملکرد را در این منطقه مورد مطالعه داشت و برای نقشهبرداری حساسیت زمین لغزش انتخاب شد. عملکرد مدل با محاسبه دقت پیشبینی، آمار ROC و SCAI مورد ارزیابی قرار گرفت. SCAI نشان می دهد که کلاس های حساسیت بالا دارای مقادیر SCAI پایین با کمتر از 1 هستند، به این معنی که هر چهار مدل نتایج قابل قبولی دارند. دقت پیشبینی مجموعه داده آموزشی و مجموعه داده آزمایشی SVM به ترتیب 98.91 درصد و 83.86 درصد است. دقت پیشبینی سه مدل دیگر حداقل 3 درصد کمتر است. علاوه بر این، AUC SVM نیز با 0.928 در مجموعه داده های آزمایشی بالاتر از مدل های دیگر است. در مورد همان داده های ورودی، مدل های مختلف عملکرد متفاوتی دارند از یک طرف، چون ساختار خود مدل متفاوت است، معیارهای طبقه بندی داده ها نیز متفاوت است. از سوی دیگر، چون عوامل مختلف در مدلهای مختلف نقشهای متفاوتی دارند، یعنی عواملی که سهم کمی در یک مدل دارند، ممکن است برای دیگری مفید بوده و تأثیر بسزایی در مدل داشته باشند. این همچنین نشان می دهد که برای یک منطقه مطالعاتی خاص، مقایسه مدل های متعدد و انتخاب مناسب ترین آنها منطقی است. به طور کلی، مشاهده شد که SVM بهترین عملکرد را در کلاستر یادگیری ماشین دارد، بنابراین خوشه SVM را به عنوان الگوریتم خروجی نهایی انتخاب میکند و این نتیجه با کار قبلی مطابقت دارد [ معیارهای طبقه بندی برای داده ها نیز متفاوت است. از سوی دیگر، چون عوامل مختلف در مدلهای مختلف نقشهای متفاوتی دارند، یعنی عواملی که سهم کمی در یک مدل دارند، ممکن است برای دیگری مفید بوده و تأثیر بسزایی در مدل داشته باشند. این همچنین نشان می دهد که برای یک منطقه مطالعاتی خاص، مقایسه مدل های متعدد و انتخاب مناسب ترین آنها منطقی است. به طور کلی، مشاهده شد که SVM بهترین عملکرد را در کلاستر یادگیری ماشین دارد، بنابراین خوشه SVM را به عنوان الگوریتم خروجی نهایی انتخاب میکند و این نتیجه با کار قبلی مطابقت دارد [ معیارهای طبقه بندی برای داده ها نیز متفاوت است. از سوی دیگر، چون عوامل مختلف در مدلهای مختلف نقشهای متفاوتی دارند، یعنی عواملی که سهم کمی در یک مدل دارند، ممکن است برای دیگری مفید بوده و تأثیر بسزایی در مدل داشته باشند. این همچنین نشان می دهد که برای یک منطقه مطالعاتی خاص، مقایسه مدل های متعدد و انتخاب مناسب ترین آنها منطقی است. به طور کلی، مشاهده شد که SVM بهترین عملکرد را در کلاستر یادگیری ماشین دارد، بنابراین خوشه SVM را به عنوان الگوریتم خروجی نهایی انتخاب میکند و این نتیجه با کار قبلی مطابقت دارد [ این همچنین نشان می دهد که برای یک منطقه مطالعاتی خاص، مقایسه مدل های متعدد و انتخاب مناسب ترین آنها منطقی است. به طور کلی، مشاهده شد که SVM بهترین عملکرد را در کلاستر یادگیری ماشین دارد، بنابراین خوشه SVM را به عنوان الگوریتم خروجی نهایی انتخاب میکند و این نتیجه با کار قبلی مطابقت دارد [ این همچنین نشان می دهد که برای یک منطقه مطالعاتی خاص، مقایسه مدل های متعدد و انتخاب مناسب ترین آنها منطقی است. به طور کلی، مشاهده شد که SVM بهترین عملکرد را در کلاستر یادگیری ماشین دارد، بنابراین خوشه SVM را به عنوان الگوریتم خروجی نهایی انتخاب میکند و این نتیجه با کار قبلی مطابقت دارد [63 ]. SVM یک الگوریتم کارآمد برای پارتیشن بندی ابر صفحه داده های باینری است که مشکل طبقه بندی داده های باینری را با یافتن حداقل بردار پشتیبانی بین داده ها و ابر صفحه حل می کند. این ویژگی به SVM اجازه می دهد تا در ارزیابی حساسیت زمین لغزش که زمین لغزش ها به عنوان داده های باینری نمایش داده می شوند، سودمند باشد.
یک روش سنتی اغلب تنها یک مدل را برای آموزش و پیشبینی انتخاب میکند، که ممکن است سایر مدلهای بالقوه بهتر را نادیده بگیرد. در این مطالعه، ما چندین MLT معمولی را برای پردازش زمین لغزش ها و عوامل شرطی انتخاب کردیم و در نهایت LSM منطقه مورد مطالعه را به دست آوردیم. نتایج خوشه یادگیری ماشین نشان می دهد که خوشه بندی راه حل خوبی برای انتخاب مدل و LSM است.
4.3. مشارکت های جدید و چشم انداز مدل
همانطور که قبلا ذکر شد، روش های یادگیری ماشین به طور گسترده ای در LSM استفاده شده است. فام و همکاران [ 61 ] یک مدل ترکیبی جدید از بهینه سازی حداقل متوالی و SVM (SMOSVM) برای LSM دقیق پیشنهاد کرد. نتایج نشان داد که مدل جدید (AUC = 0.824) عملکرد بهتری نسبت به SVM و درختان ساده بیز (NBT) دارد. مطالعه حاضر نیز یافتههای مشابهی با این مطالعه دارد که نشان میدهد SVM یک روش عالی و پیوسته قابل بهینهسازی است. یانگ و همکاران [ 46 ] روش جدیدی را بر اساس ژئودتکتور و مدل LR فضایی پیشنهاد کرد، دقت پیشبینی روش جدید 1/86 درصد بود که نسبت به مدل سنتی LR 9/11 درصد بهبود داشت. در مقایسه با [ 46]، مطالعه ما به عملکرد برهمکنش عامل GeoDetector عمیقتر میپردازد و این تابع را برای انتخاب ضریب تاثیر زمین لغزش اعمال میکند. این رویکرد دیدگاه جدیدی را به مسئله انتخاب عامل در علم زمین گسترده تر ارائه می دهد. دوو و همکاران [ 62] قابلیت پیشبینی الگوریتمهای ML ترکیبی SVM را بررسی و ارزیابی کرد. نتایج نشان داد که مدل تقویتکننده SVM عملکرد بهتری از SVM-Stacking، SVM و SVM-Bagging دارد، که نشان میدهد که یادگیری گروهی لزوماً اثر افزایشی بر روی یک الگوریتم ندارد. این بیشتر نشان می دهد که انتخاب یک مدل مناسب برای LSM حیاتی است، که با مطالعه ما سازگار است. مطالعه ما یک رویکرد ساده و مؤثر برای LSM پیشنهاد میکند: قرار دادن چندین روش یادگیری ماشین معمولی در یک خوشه و انتخاب بهترین مدل در خوشه برای مناطق مختلف مطالعه.
در نتیجه، در مقایسه با مطالعات فوق، مشارکتهای جدید این مطالعه (1) یک روش انتخاب عامل مبتنی بر آشکارساز فاکتور و آشکارساز تعاملی، و (2) راهحلی برای انتخاب مدل یادگیری ماشین است.
5. نتیجه گیری ها
هدف این مطالعه بهبود قابلیت اطمینان LSM با استفاده از GeoDetector و یک خوشه یادگیری ماشینی بود. به همین دلیل، 616 زمین لغزش و 19 عامل شرطی زمین لغزش در شهرستان شیائوجین در GIS تهیه شد. استفاده از آشکارساز عامل و آشکارساز تعاملی برای تجزیه و تحلیل کمی اثرات فردی و تعاملی عوامل شرطی زمین لغزش یک رویکرد موثر و معقول است. این رویکرد روشی موثر برای شناسایی و حذف عوامل زائد ارائه میکند، نتایج نشان میدهد که منحنی پلان، SPI، منحنی پروفایل و TWI عوامل زائد هستند. ما یک مدل جنگل تصادفی را برای آزمایش اثر حذف عوامل اضافی طراحی کردیم و MAE پس از حذف از 0.420 به 0.391 کاهش یافت که نشان دهنده برتری GeoDetector است. خوشه یادگیری ماشینی شامل انواع MLTها است، و می تواند به طور خودکار بهترین مدل را انتخاب کند. در این مورد، SVM انتخاب شده دارای دقت پیشبینی 83.86 درصد و مقدار AUC 0.928 بود. بنابراین، GeoDetector و خوشه یادگیری ماشین برای ایجاد یک نقشه حساسیت زمین لغزش منطقه مورد مطالعه بسیار امکان پذیر است. این رویکردها یک راه حل کلی ارائه می دهند که به طور دقیق عوامل شرطی و مدل های یادگیری ماشین را انتخاب می کند، که می تواند قابلیت اطمینان نقشه های حساسیت زمین لغزش را افزایش دهد.






بدون دیدگاه