

خلاصه
کلید واژه ها:
PCIB _ جنگل تصادفی ; K-به معنی ; ISODATA ; نقشه برداری محصول ; طبقه بندی بدون نظارت GF-1
1. معرفی
2. مواد
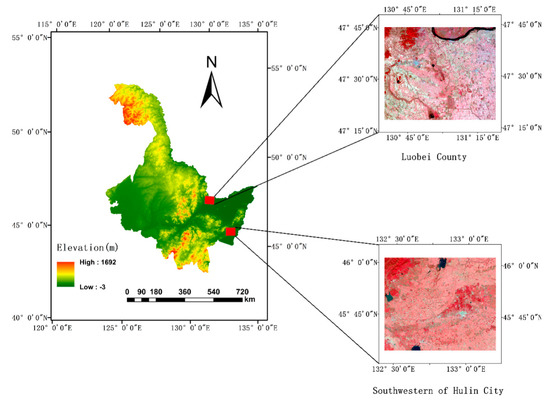
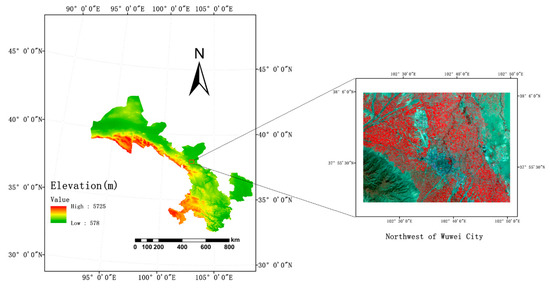
2.1. منطقه مطالعه
2.2. منابع اطلاعات
2.2.1. داده های چند زمانی GF-1
2.2.2. داده های نمونه فیلد
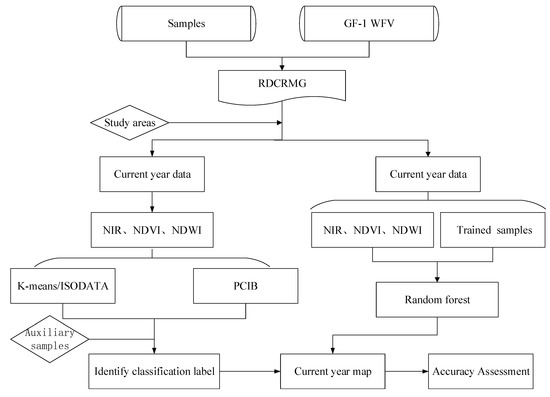
3. روش ها
3.1. پیش پردازش داده ها
تصاویر GF-1 و دادههای نمونه میدانی با استفاده از سیستم شبکه چندشبکهای (RDCRMG) مجموعه دادههای Raster Clean and Reconstitution Multi-Grid (RDCRMG) که توسط دانشگاه کشاورزی چین توسعه داده شده است، ذخیره شدند. بر اساس C# و کتابخانه انتزاع داده های جغرافیایی (GDAL)، رویه هایی مانند کالیبراسیون رادیومتری، تصحیح عمودی و ثبت تصویر برای همه داده ها انجام شد [ 45 ، 46]]. کالیبراسیون رادیومتریک برای حذف خطاهای ایجاد شده توسط سنسور و تبدیل مقدار عدد دیجیتال بدون بعد (DN) ثبت شده توسط سنسور به روشنایی تشعشع یا بازتاب لایه بالایی اتمسفر استفاده شد. بر اساس ضریب کالیبراسیون رادیومتریک رسمی به روز شده توسط مرکز برنامه کاربردی ماهواره منابع چین، ما داده های GF-1 را به صورت رادیومتری به صورت زیر کالیبره کردیم:
که در آن L e ( λe ) روشنایی تابش پس از تبدیل است، DN مقدار بار ماهواره مشاهده شده، Gain شیب کالیبراسیون است، و Offset به افست ضریب کالیبراسیون مطلق اشاره دارد .
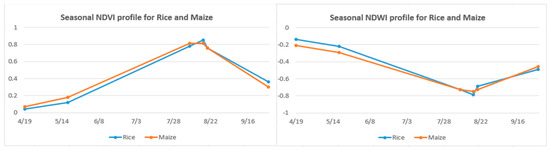
3.2. انتخاب ویژگی برای طبقه بندی
3.3. طبقه بندی تصادفی جنگل
3.4. طبقه بندی بدون نظارت
3.4.1. K-Means
3.4.2. ISODATA
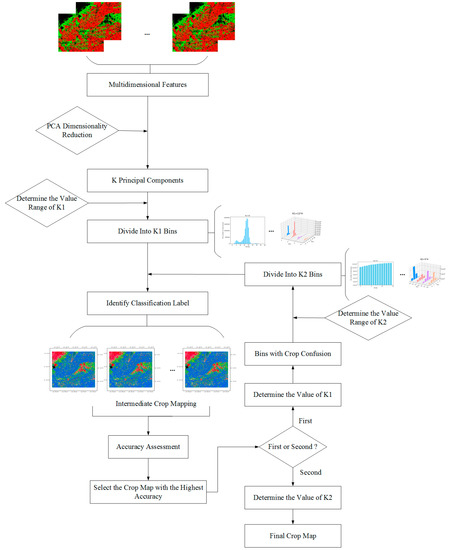
3.5. طبقه بندی ایزومتریک باینینگ اجزای اصلی
3.5.1. کاهش ابعاد PCA
اجازه دهید m تعداد پیکسل ها در ناحیه مورد نظر را نشان دهد، و فرض کنیم که n متغیر ویژگی است، سپس ماتریس ایکسمی توان برای نمایش داده های m × n به صورت زیر استفاده کرد:
جایی که ایکسمترnنشان دهنده ارزش مترپیکسل ام و بردار ویژگی n ام. ماتریس ضریب همبستگی آرسپس به صورت زیر محاسبه می شود:
جایی که r ij ( i = 1,2,…, m , j = 1,2,…, n ) ضریب همبستگی است ایکسمنو x j . معادله ویژه |λE − R| = 0 برای مقدار ویژه حل می شود λj( j=1،2،…،n) و λ1≥λ2≥…≥λn≥0. بردار ویژه e j ( j=1،2،…،n) با مقدار ویژه مطابقت دارد λj. هنگامی که نرخ مشارکت تجمعی اجزای اصلی به دنبال تبدیل بردار ویژه به درصد بالایی می رسد، کاهش ابعاد مورد نیاز داده ها به دست می آید.
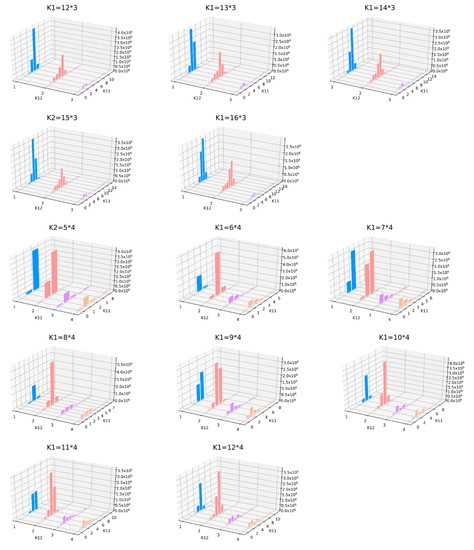
3.5.2. اجزای اصلی باینینگ ایزومتریک
مجموعه داده اصلی را به ک- ابعاد برای به دست آوردن ماتریس Y، به شرح زیر است:
که در آن k تعداد مولفه های اصلی به دنبال کاهش ابعاد و m تعداد پیکسل ها در ناحیه مورد مطالعه است. ماتریس Y به سطلهایی با فاصله مساوی تقسیم میشود که بعداً به آنها تقسیم میشوند ک1سطل زباله مراحل دقیق به شرح زیر است:
- (من)
-
اولین جزء اصلی [r11…rمتر1]تقسیم می شود ک11فواصل تمام پیکسلهایی که در هر بازه قرار میگیرند، با فاصله بن جمعآوری میشوند ساعت1=rj1-rمن1ک11، جایی که rj1حداکثر مقدار ستون و rمن1حداقل مقدار است.
- (II)
-
دومین جزء اصلی [r12…rمتر2]تقسیم می شود ک11فواصل مربوط به نتیجه باینینگ اولین جزء اصلی. سپس هر بازه به تقسیم می شود ک12فواصل فرعی تمام پیکسل ها در هر زیر بازه به یک bin تقسیم می شوند و فاصله بین h = rj2-rمن2ک12، جایی که r j 2 و rمن2حداکثر و حداقل مقادیر ستون هستند.
- (iii)
-
k -امین مولفه اصلی [r1ک…rمترک]تقسیم می شود ک11* ک12*…* ک1کسطل زباله، یعنی k 1 = k 11 * ک12*…* ک1ک، تا آخر یک هیستوگرام توزیع فرکانس برای نشان دادن وضعیت binning به طور مستقیم ترسیم شده است.
3.6. تعیین برچسب دسته
3.7. ارزیابی دقت
یک سوم کل حجم نمونه جمعآوریشده در میدان به عنوان نمونه تأیید، با ماتریس سردرگمی برای ارزیابی دقت نتایج طبقهبندی استفاده شد. شاخص های ارزیابی شامل کل، دقت تولید کننده و کاربر و ضریب کاپا است:
که در آن TP و FN به دسته واقعی نمونه ها به عنوان مثال های مثبت اشاره می کنند و پیش بینی مدل به ترتیب به عنوان مثال های مثبت و منفی به دست می آید. TN و FP به نمونه های منفی دسته واقعی نمونه ها اشاره می کنند که توسط مدل به ترتیب به عنوان مثال های منفی و نمونه های مثبت پیش بینی می شوند. N تعداد کل نمونه های واقعی است.
4. نتایج
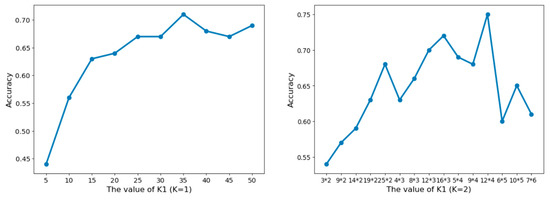
4.1. اثر انتخاب پارامتر
چه زمانی ک=2، کداده های بعدی به k 1 = k 11 * k 12 سطل تقسیم می شوند. نرخ مشارکت اولین جزء اصلی بیشتر از مؤلفه اصلی دوم است، k 11 > k 12 ، و 5 ≤ k 11 * k 12 ≤ 50، بنابراین، 51 ترکیب از k 11 و k 12 وجود دارد که برآورده می کند شرایط فوق ( جدول 4 ). با توجه به یک فاصله زمانی مشخص، 15 مقدار k 1 نسبتاً یکنواخت انتخاب می شوند. شکل 5(راست) دقت طبقه بندی مربوط به هر مقدار را نشان می دهد. دقت طبقه بندی اوج برای مشاهده شده است ک12=3و ک12=4. بنابراین، k 1 به صورت زیر تنظیم می شود:
با در نظر گرفتن جنوب غربی شهر Hulin به عنوان مثال، محدوده ارزش از ک2به روشی مشابه مشتق شده است. ما در ابتدا تنظیم کردیم 3≤ک2≤20. با توجه به متفاوت ک(تعداد اجزای اصلی)ارزش های، ک2سپس به صورت زیر تعیین می شود:
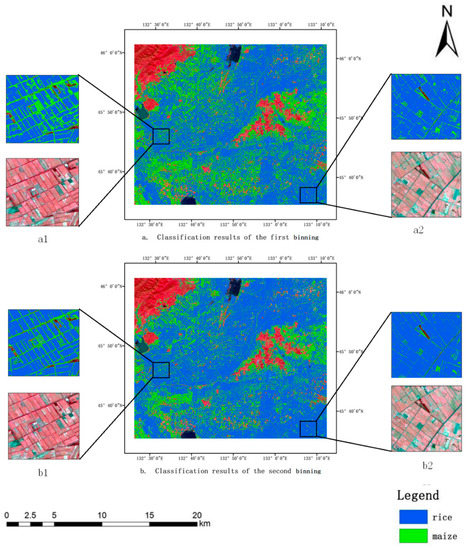
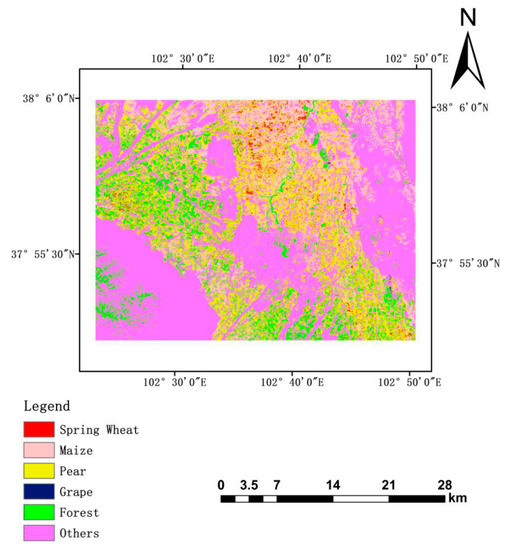
4.2. مقایسه نتایج PCIB
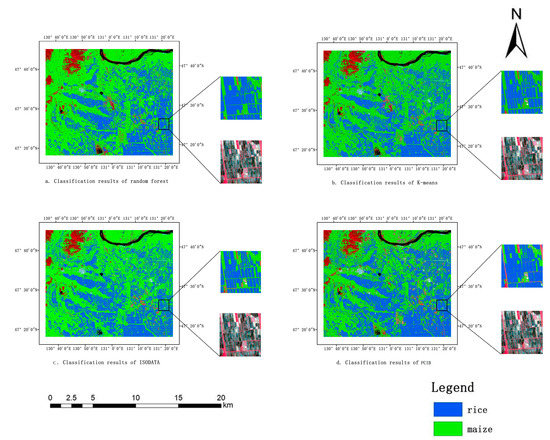
4.3. مقایسه روش های طبقه بندی
5. بحث
5.1. مزایا، کاستی ها و پیشرفت های PCIB
5.2. تجزیه و تحلیل منابع خطاها
5.3. مقایسه پیچیدگی محاسباتی سه الگوریتم خوشه بندی
5.4. آزمایش های اضافی
6. نتیجه گیری
- (1)
-
دقت کلی روش PCIB در جنوب غربی شهر Hulin در سال 2016 به 82 درصد می رسد که از الگوریتم های K-means و ISODATA فراتر می رود. در سال 2017، شهرستان لوبی از شهر هگانگ کمترین دقت طبقهبندی PCIB را نشان داد و سه روش دیگر نیز دقت پایینی را نشان دادند (به ترتیب 79، 74 و 75 درصد برای جنگل تصادفی، K-means و ISODATA). اگرچه دقت کلی PCIB کمی کمتر از طبقهبندیکننده جنگل تصادفی است، اما برای سالهایی که مقادیر زیادی از نمونههای میدانی وجود ندارد، الزامات دقت نقشهبرداری را برآورده میکند.
- (2)
-
PCIB پیوند ایزومتریک k اجزای اصلی را مستقیماً پس از کاهش ابعاد PCA انجام می دهد. تکرارهای متعدد در هر پیکسل مورد نیاز نیست و پیچیدگی زمانی خطی است. این در نتیجه کارایی محاسباتی را در مقایسه با طبقهبندیکنندههای K-means و ISODATA مبتنی بر فاصله اقلیدسی بهبود میبخشد.
- (3)
-
وابستگی به تعداد زیادی از نمونه های میدانی برای طبقه بندی کاهش می یابد. علاوه بر این، اطلاعات توزیع مکانی محصولات به موقع و دقیق تعیین می شود. روش پیشنهادی ما میتواند به طور بالقوه برای نقشهبرداری طبقهبندی محصولات به کار رود.
منابع
- یانگ، BJ سنجش از دور نظارت بر شرایط کشاورزی ، چاپ اول. چاپ کشاورزی چین: پکن، چین، 2005. [ Google Scholar ]
- آهنگ، X. پوتاپوف، PV؛ کریلوف، آ. کینگ، ال. دی بلا، سی ام. هادسون، ا. خان، ا. آدوسی، بی. Stehman، SV; هانسن، MC نقشه برداری و تخمین مساحت سویا در مقیاس ملی در ایالات متحده با استفاده از تصاویر ماهواره ای با وضوح متوسط و بررسی میدانی. سنسور از راه دور محیط. 2017 ، 190 ، 383-395. [ Google Scholar ] [ CrossRef ]
- گوو، دبلیو. ژائو، سی. Gu، XH; هوانگ، WJ; Ma، ZH نظارت سنجش از دور منطقه کاشت ذرت در سطح شهر. ترانس. CSAE 2011 ، 27 ، 69-74. [ Google Scholar ]
- لی، ی. زو، ی. دای، تی. تیان، ی. Cao, W. روابط کمی بین شاخص سطح برگ و طیف بازتاب تاج پوشش گندم. چانه. J. Appl. Ecol. 2006 ، 17 ، 1443-1447. [ Google Scholar ]
- واردلو، بی.دی. اگبرت، اس ال. Kastens، JH تجزیه و تحلیل داده های شاخص پوشش گیاهی سری زمانی MODIS 250 متر برای طبقه بندی محصولات در دشت های بزرگ مرکزی ایالات متحده. سنسور از راه دور محیط. 2007 ، 108 ، 290-310. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یانگ، YJ; ژان، ی.ال. تیان، کی جی. Gu، XF; یو، تی. Wang, L. طبقه بندی محصولات بر اساس سری زمانی GF-1/WFV NDVI. ترانس. CSAE 2015 ، 31 ، 155-161. [ Google Scholar ]
- هائو، پی. وانگ، ال. ژان، ی. Niu, Z. استفاده از نمایههای موقتی NDVI با وضوح متوسط برای نقشهبرداری محصول با وضوح بالا در سالهای عدم وجود دادههای مرجع زمینی: مطالعه موردی شهرستانهای Bole و Manas در سینکیانگ، چین. ISPRS Int. J. Geo-Inf. 2016 ، 5 ، 67. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یانگ، ن. لیو، دی. فنگ، Q. Xiong، Q. ژانگ، ال. اجاره دادن.؛ ژائو، ی. زو، دی. Huang, J. نقشه برداری محصول در مقیاس بزرگ بر اساس یادگیری ماشین و محاسبات موازی با شبکه ها. Remote Sens. 2019 ، 11 ، 1500. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کای، ی. گوان، ک. پنگ، جی. وانگ، اس. سیفرت، سی. واردلو، بی. Li، Z. یک سیستم طبقهبندی با کارایی بالا و در فصل انواع محصولات در سطح مزرعه با استفاده از دادههای سری زمانی Landsat و رویکرد یادگیری ماشین. سنسور از راه دور محیط. 2018 ، 210 ، 35-47. [ Google Scholar ] [ CrossRef ]
- ژانگ، ال. لیو، ز. اجاره دادن.؛ لیو، دی. ما، ز. تانگ، ال. ژانگ، سی. ژو، تی. ژانگ، ایکس. Li, S. شناسایی مزارع ذرت بذر با وضوح فضایی بالا و سنجش از دور طیفی چندگانه با استفاده از طبقهبندی جنگل تصادفی. Remote Sens. 2020 , 12 , 362. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، اچ. ژانگ، سی. ژانگ، اس. پیتر، ام. طبقهبندی محصول از سریهای زمانی پهپاد باند L تمام قطبی با استفاده از الگوریتم جنگل تصادفی. بین المللی J. Appl. زمین Obs. 2020 , 87 , 102032. [ Google Scholar ] [ CrossRef ]
- ماموکوما گریس، ام. آدریان ون، ن. Zama Eric، M. طبقه بندی پیش از برداشت انواع محصول با استفاده از سری زمانی Sentinel-2 و یادگیری ماشینی. محاسبه کنید. الکترون. کشاورزی 2020 ، 169 ، 105164. [ Google Scholar ]
- ژونگ، LH؛ هو، LN؛ ژو، اچ. طبقه بندی چندزمانی محصولات مبتنی بر یادگیری عمیق. سنسور از راه دور محیط. 2019 ، 221 ، 430-443. [ Google Scholar ] [ CrossRef ]
- گارنو، VSF؛ لندریو، ال. جووردانو، اس. چهاتا، N. مبادله زمانی-فضایی در مدلهای یادگیری عمیق برای طبقهبندی محصول در سریهای زمانی تصویر چند طیفی ماهوارهای. در مجموعه مقالات IGARSS 2019-2019 IEEE بین المللی زمین شناسی و سمپوزیوم سنجش از دور، یوکوهاما، ژاپن، 28 ژوئیه تا 2 اوت 2019؛ صص 6247–6250. [ Google Scholar ]
- هو، کیو. وو، دبلیو. آهنگ، س. لو، ام. ویژگی های زمانی و طیفی در طبقه بندی محصولات در استان هیلونگجیانگ، چین چگونه اهمیت دارد؟ JIA 2017 ، 16 ، 324-336. [ Google Scholar ] [ CrossRef ]
- گالیگو، جی. کریگ، ام. Michaelsen, J. بهترین روش ها برای تخمین سطح محصول با سنجش از دور . GEOSS: Ispra، ایتالیا، 2008. [ Google Scholar ]
- هائو، پی. وانگ، ال. ژان، ی. وانگ، سی. نیو، ز. Wu، M. طبقهبندی محصول با استفاده از دانش محصول سال قبل: مطالعه موردی در جنوب غربی کانزاس، ایالات متحده. یورو J. Remote Sens. 2016 ، 49 ، 1061-1077. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، ال. لیو، ز. لیو، دی. Xiong، Q. Yang, N. نقشه برداری محصول بر اساس نمونه های تاریخی و نمونه های آموزشی جدید در استان هیلونگجیانگ، چین. پایداری 2019 ، 11 ، 5052. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لورنزو، بی. لوئیس، جی. گوستاوو، سی. Javier, C. Mean Map Kernel Methods for Semi-supervised Cloud Classification. IEEE. ترانس. Geosci. Remote Sens. 2010 , 48 , 207-220. [ Google Scholar ]
- لیو، ی. ژانگ، بی. وانگ، LM؛ وانگ، ن. رویکرد SVM نیمه نظارت شده خودآموز برای طبقه بندی پوشش زمین سنجش از دور. محاسبه کنید. Geosci. 2013 ، 59 ، 98-107. [ Google Scholar ] [ CrossRef ]
- غوگلی، ن. ملگانی، اف. رویکرد SVM ژنتیکی به طبقهبندی چند زمانی نیمه نظارت شده. IEEE Geosci. سنسور از راه دور Lett. 2008 ، 5 ، 212-216. [ Google Scholar ] [ CrossRef ]
- بروزون، ال. چی، م. Marconcini، M. SVM انتقالی جدید برای طبقهبندی نیمه نظارت شده تصاویر سنجش از دور. IEEE Geosci. Remote Sens. 2006 , 44 , 3363–3373. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هو، تی. هوانگ، ایکس. لی، جی. Zhang، LF یک رویکرد جدید آموزشی مشترک برای نقشه برداری پوشش زمین شهری با تصاویر سری زمانی نامشخص Landsat. سنسور از راه دور محیط. 2018 ، 217 ، 144-157. [ Google Scholar ] [ CrossRef ]
- نیتا، اس. Saroj, K. طبقه بندی نیمه نظارت شده تصاویر سنجش از دور با استفاده از روش کارآمد یادگیری محله. مهندس Appl. آرتیف. هوشمند 2020 ، 90 ، 103520. [ Google Scholar ]
- راتل، اف. کمپ، جی. وستون، جی. شبکه های عصبی نیمه نظارت شده برای طبقه بندی تصویر ابرطیفی کارآمد. IEEE Trans. Geosci. Remote Sens. 2010 , 48 , 2271–2282. [ Google Scholar ] [ CrossRef ]
- سولانو، YT; بوولو، اف. Bruzzone, L. A Semi-Supervised Crop-type Classification بر اساس سری زمانی تصاویر ماهواره ای Sentinel-2 NDVI و پارامترهای فنولوژیکی. در مجموعه مقالات IGARSS 2019-2019 IEEE بین المللی زمین شناسی و سمپوزیوم سنجش از دور، یوکوهاما، ژاپن، 28 ژوئیه تا 2 اوت 2019؛ صص 457-460. [ Google Scholar ]
- وان، ال. ژانگ، اچ. Lin, G. یک شبکه عصبی کانولوشنال با وصله کوچک برای نقشه برداری حرا در سطح گونه با استفاده از تصویر سنجش از دور با وضوح بالا. ان GIS 2019 ، 25 ، 45-55. [ Google Scholar ] [ CrossRef ]
- گوما، MK; ثنكبيل، ص. Teluguntla، P. نقشه برداری مناطق آیش برنج برای تشدید حبوبات دانه فصل کوتاه در جنوب آسیا با استفاده از داده های سری زمانی MODIS 250m. بین المللی جی دیجیت. زمین 2016 ، 9 ، 981-1003. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شیونگ، جی. پراساد، س. مورالی، ک. نقشه برداری خودکار زمین های زراعی قاره آفریقا با استفاده از محاسبات ابری موتور Google Earth. ISPRS J. Photogram. Remote Sens. 2017 ، 126 ، 225–244. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هائو، WP; Mei، XR; استخراج کاشت محصول Cai، XL بر اساس دادههای سنجش از راه دور چندگانه در شمال شرقی چین. ترانس. CSAE 2011 ، 27 ، 201-207. [ Google Scholar ]
- Cai، XL; استخراج ساختار کاشت محصول Cui، YL در مناطق آبی از دادههای سنجش از دور چند سنسور و چند زمانی. ترانس. CSAE 2009 ، 25 ، 124-130. [ Google Scholar ]
- شری، دبلیو. جورج، ا. دیوید، بی. نقشه برداری نوع محصول بدون برچسب های سطح زمین: انتقال تصادفی جنگل و تکنیک های خوشه بندی بدون نظارت. سنسور از راه دور محیط. 2019 ، 222 ، 303-317. [ Google Scholar ]
- یونوس، ج. ار-راکی، س. المتصدق، الف. استفاده از رویکرد نظارت نشده شبکه عصبی احتمالی (PNN) برای طبقه بندی کاربری زمین از تصاویر ماهواره ای چند زمانی. Appl. محاسبات نرم. 2015 ، 30 ، 1-13. [ Google Scholar ] [ CrossRef ]
- ونکاتا سوبرامانیان، ن. سراوانان، ن. Bhuvaneswari، S. K-means مبتنی بر شبکه عصبی احتمالی (KPNN) برای طراحی ماشین فیزیکی – طبقه بندی کننده. IJITEE 2019 ، 9 ، 800–804. [ Google Scholar ]
- لاولند، TR; رید، ق.م. براون، ج.اف. Ohlen، DO; Zhu, Z. توسعه پایگاه داده خصوصیات پوشش زمین جهانی و پوشش IGBP DIS از 1 کیلومتر داده AVHRR. بین المللی J. Remote Sens. 2000 ، 21 ، 1303-1330. [ Google Scholar ] [ CrossRef ]
- ژای، YG; طبقه بندی Qu، ZY بر اساس کاهش ابعاد غیرخطی با استفاده از تصاویر سنجش از دور سری زمانی. ترانس. CSAE 2018 ، 34 ، 177-183. [ Google Scholar ]
- یان، ال. روی، DP طبقهبندی پوشش زمین سریهای زمانی را با کاهش ابعاد غیرخطی تطبیقی-مشاهدهای بهبود بخشید. سنسور از راه دور محیط. 2015 ، 158 ، 478-491. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پل، اس. Kumar، DN ارزیابی تکنیکهای انتخاب ویژگی و استخراج ویژگی در تصاویر Landsat-8 چند زمانی برای طبقهبندی محصول. سیستم سنسور از راه دور زمین. علمی 2019 ، 197–207. [ Google Scholar ] [ CrossRef ]
- عابدینی، م. فوزیه، الف. رویکرد خوشهبندی در طبقهبندی پوشش اراضی کاربری اراضی Landsat TM بر روی حوضه آبریز Ulu Kinta. WAS J. 2012 , 17 , 809-817. [ Google Scholar ]
- سنتیلناث، جی. Omkar، SN; مانی، ن. طبقهبندی مرحله زراعی دادههای فراطیفی با استفاده از تکنیکهای بدون نظارت. IEEE J.-STARS 2013 ، 6 ، 861-866. [ Google Scholar ] [ CrossRef ]
- دارانی، م. Sreenivasulu، G. تشخیص تغییر کاربری و پوشش زمین با استفاده از تجزیه و تحلیل اجزای اصلی و عملیات مورفولوژیکی در کاربردهای سنجش از دور. IJCA 2019 ، 1-10. [ Google Scholar ] [ CrossRef ]
- هستی، تی. طبشیرانی، ر. فریدمن، جی. عناصر یادگیری آماری: داده کاوی، استنتاج و پیش بینی سری اسپرینگر در آمار . Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2009. [ Google Scholar ]
- قهوهای مایل به زرد، PN; اشتاین باخ، ام. Kumar, V. Introduction to Data Mining , 1st ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2005. [ Google Scholar ]
- هو، LY; چن، ییل. Xu, Y. نقشهبرداری 30 متری پوشش زمین چین با الگوریتم خوشهبندی کارآمد CBEST. علمی علوم زمین چین 2014 ، 57 ، 2293-2304. [ Google Scholar ] [ CrossRef ]
- آره.؛ لیو، دی. Yao, X. RDCRMG: یک معماری چندشبکه ای تمیز و بازسازی مجموعه داده شطرنجی برای نظارت سنجش از راه دور خشکی پوشش گیاهی. Remote Sens. 2018 , 10 , 1376. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Xiong، Q. وانگ، ی. لیو، دی. آره.؛ دو، ز. لیو، دبلیو. هوانگ، جی. سو، دبلیو. زو، دی. یائو، ایکس. و همکاران یک رویکرد تشخیص ابر بر اساس ویژگیهای ترکیبی چندطیفی با آستانههای دینامیکی برای تصاویر سنجش از دور GF-1. Remote Sens. 2020 , 12 , 450. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بریمن، ال. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، جی. فنگ، Q. Gong, J. نقشهبرداری گندم زمستانه با استفاده از طبقهبندی جنگل تصادفی همراه با دادههای چند زمانی و چند سنسوری. بین المللی جی دیجیت. زمین 2018 ، 11 ، 783–802. [ Google Scholar ] [ CrossRef ]
- سوامی، ا. Jain, R. Scikit-Learn: Learning Machine in Python. جی. ماخ. Res را یاد بگیرید. 2013 ، 12 ، 2825-2830. [ Google Scholar ]
- Kulkarni، NM Crop Identification با استفاده از ISODATA بدون نظارت و K-Means از تصاویر سنجش از دور چندطیفی. IJERA 2017 ، 7 ، 45-49. [ Google Scholar ] [ CrossRef ]
- جولیف، مؤلفههای اصل فناوری اطلاعات در تحلیل رگرسیون. تجزیه و تحلیل مولفه های اصلی ; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 1986; صص 129-155. [ Google Scholar ]
- عبدی، ح. ویلیامز، LJ تجزیه و تحلیل مؤلفه اصلی. وایلی اینتردیسیپ. ریور کامپیوتر. آمار 2010 ، 2 ، 433-459. [ Google Scholar ] [ CrossRef ]
- ایستمن، جی آر. Fulk، M. ارزیابی سری های زمانی توالی طولانی با استفاده از مؤلفه های اصلی استاندارد شده. فتوگرام مهندس Remote Sens. 1993 , 59 , 991-996. [ Google Scholar ]
- هیروساوا، ی. مارش، SE; کلیمان، DH استفاده از تجزیه و تحلیل مؤلفه های اصلی استاندارد مشخصه سازی پوشش زمین با استفاده از داده های AVHRR چند زمانی. سنسور از راه دور محیط. 1996 ، 58 ، 267-281. [ Google Scholar ] [ CrossRef ]
- بلون، بی. Bégué، A. لو سین، دی. دی آلمیدا، کالیفرنیا؛ Simões, M. یک رویکرد سنجش از دور برای نقشهبرداری در مقیاس منطقهای سیستمهای کاربری اراضی کشاورزی بر اساس سری زمانی NDVI. Remote Sens. 2017 , 9 , 600. [ Google Scholar ] [ CrossRef ][ Green Version ]
- مدل های ناپارامتری و نیمه پارامتریک Härdle، WK ; Springer Science & Business Media: نیویورک، نیویورک، ایالات متحده آمریکا، 2012. [ Google Scholar ]
- هو، QW; شو، ن. مطالعه یک مدل مخلوط گاوسی برای نقشه برداری پوشش زمین شهری بر اساس تصاویر سنجش از دور VHR. بین المللی J. Remote Sens. 2016 ، 37 ، 1-13. [ Google Scholar ]
- Qu، YR; Cai, H. شبکه های عصبی مبتنی بر محصول برای پیش بینی پاسخ کاربر. در مجموعه مقالات شانزدهمین کنفرانس بین المللی داده کاوی (ICDM) IEEE 2016، بارسلون، اسپانیا، 12 تا 15 دسامبر 2016. [ Google Scholar ]
- ژانگ، WN; Du، TM یادگیری عمیق بر روی داده های دسته بندی چند زمینه ای ; ECIR Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2016. [ Google Scholar ]
- اولیویرا، ALI; Costa، FRG تشخیص تازگی با شبکه های عصبی احتمالی سازنده محاسبات عصبی 2008 ، 71 ، 1046-1053. [ Google Scholar ] [ CrossRef ]


بدون دیدگاه