

چکیده
کلید واژه ها:
طبقه بندی مسیر ; یادگیری عمیق ؛ شبکه های عصبی ؛ بینایی کامپیوتری ؛ پردازش توزیع شده پردازش جریانی ؛ نظارت بر کشتی در زمان واقعی ؛ فشرده سازی مسیر ; AIS
1. مقدمه
-
الگوهای تحرک در حوزه دریایی از نظر بصری متمایز هستند. این تمایز بصری اجازه می دهد تا عملکرد طبقه بندی مسیر را افزایش دهد.
-
طبقهبندی تصویر امکان طبقهبندی مسیر را فراهم میکند حتی زمانی که دادهها در فواصل ثابت (مثلاً ساعتی) مانند پروتکل AIS ( https://help.marinetraffic.com/hc/en-us/articles/217631867-How-often ) ارسال نمیشوند. -do-the-positions-of-the-vessels-get-updated-on-MarineTraffic- ، قابل دسترسی در 7 آوریل 2021). این برخلاف روشهای سری زمانی [ 2 ] است که ذاتاً برای چنین وظایفی مناسب نیستند و به نقاط داده در نقاط زمانی ثابت نیاز دارند.
-
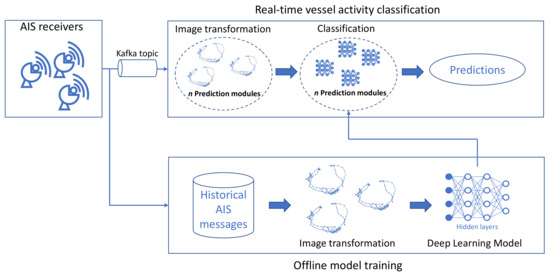
رویکردهای طبقهبندی مسیری که در ادبیات [ 4 ، 10 ، 14 ، 15 ] یافت میشوند، نیازمند یک مرحله پیش پردازش مانند درک و تجزیه و تحلیل دادهها و انتخاب ویژگیهایی هستند که فقط برای الگوهای تحرک طبقهبندی شوند. این بدان معنی است که ویژگی های انتخاب شده برای یک الگوی تحرک خاص را نمی توان برای الگوهای دیگر نیز اعمال کرد [ 14]. یک رویکرد طبقه بندی تصویر برای طبقه بندی مسیر به طور کامل از مرحله پیش پردازش فوق الذکر صرف نظر می کند. همین تکنیک برای طبقهبندی یک تصویر (مثلاً CNN) میتواند برای طبقهبندی همه الگوهای حرکتی استفاده شود، زیرا آنها به تصاویر تبدیل میشوند. بنابراین، یک رویکرد طبقهبندی تصویر برای طبقهبندی مسیر، یک رویکرد جهانی امیدوارکننده برای طبقهبندی الگوهای تحرک ایجاد میکند.
-
تقریباً 16000 پیام AIS در هر ثانیه از 200000 کشتی در سراسر جهان تولید می شود که در نتیجه 46 گیگابایت داده در روز تولید می شود. در حوزه دریایی، تنها در سالهای اخیر محققان شروع به مقابله با مشکل پردازش جریان در زمان واقعی با استفاده از پیامهای AIS کردهاند [ 6 ، 7 ، 8 ، 9 ، 10 ]. تا جایی که ما می دانیم، این اولین بار در ادبیات حوزه دریایی است که از تکنیک های بینایی کامپیوتری به صورت بلادرنگ برای طبقه بندی مسیرها استفاده می شود. الگوریتم های یادگیری عمیق مانند VGG16 [ 16 ]، InceptionV3 [ 17 ]، NASNetLarge [ 18 ] و DenseNet201 [ 19 ]] به صورت توزیع شده و جریانی استفاده می شوند که زمان پاسخگویی کم و تشخیص زودهنگام رویدادهای مشکوک در دریا را ممکن می سازد.
-
خوشه بندی مسیرها اغلب یک گام اولیه را در هنگام برخورد با طبقه بندی مسیر تشکیل می دهد. بسیاری از الگوریتم های خوشه بندی به خوبی تثبیت شده نیاز به پارامترهای ورودی دارند که تعیین آنها سخت است (Optics [ 20 ]، Traclus [ 21 ]، DBSCAN [ 22 ]) و در نهایت تأثیر قابل توجهی بر نتایج خوشه بندی دارند. همانطور که در بالا گفته شد، از آنجایی که روش ما به طور کامل از این مرحله عبور می کند، نیاز به پارامترهای دلخواه یا تجربی تعریف شده توسط کاربر را حذف کردیم و رویکرد خود را مقیاس پذیر و قوی ساختیم.
-
با توجه به این مقادیر بینظیر دادههای مسیر، که به نوبه خود میتواند رویکردهای تحلیل انسانی را تحت الشعاع قرار دهد، چندین تکنیک فشردهسازی به منظور به حداقل رساندن اندازه دادههای مسیر و در عین حال به حداقل رساندن تأثیر بر روشهای تحلیل مسیر اعمال شد. بنابراین، ما برخی از آزمایشهای اولیه را به منظور نشان دادن اثر فشردهسازی مسیر بر دقت طبقهبندی الگوهای تحرک انجام دادیم.
2. کارهای مرتبط
2.1. طبقه بندی مسیر
2.2. طبقه بندی تصویر
3. روش شناسی
3.1. الگوهای دریایی
3.2. بازنمایی تصویر
3.2.1. شکل مسیر
مسیرهای فعالیت کشتی یکسان الگوهای مشابهی را تشکیل می دهند. با این حال، از آنجایی که مسافتی که هر کشتی در فضا طی می کند متفاوت است (به عنوان مثال، یک کشتی ماهیگیری در اقیانوس اطلس مسافت بیشتری را در مقایسه با یک کشتی ماهیگیری در دریای ایرلند طی می کند)، جعبه مرزی یا منطقه نظارتی که کشتی در آن حرکت می کند باید عادی شود. بنابراین، برای ثبت و قرار دادن شکل مسیر به طور موثر در داخل یک جعبه مرزی نرمال شده، ابتدا باید فاصله کل هر دو محور x و y که کشتی در آن حرکت می کند، تعریف شود. به همین دلیل، ما فاصله افقی کل ( x— معادله ( 1 )) و فاصله عمودی کل ( y— معادله ( 2 ) را محاسبه کردیم.)) کشتی به ترتیب بر اساس حداقل و حداکثر طول و عرض جغرافیایی حرکت می کند. کل فاصله افقی به صورت زیر تعریف می شود:
به طور مشابه، کل مسافت عمودی که کشتی طی کرده است به صورت زیر تعریف می شود:
سپس مسافتی را که هر موقعیت AIS m طی کرده است از حداقل طول و عرض جغرافیایی به ترتیب از معادلات ( 3 ) و ( 4 ) به صورت زیر محاسبه می شود:
و:
از معادلات ( 1 )–( 4 )، میتوانیم درصد کل مسافتی را که هر موقعیت AIS m تا کنون طی کرده است، از حداقل مختصات در هر دو محور x و y محاسبه کنیم :
و:
با توجه به اندازه تصویر از پیش تعریف شده ن×ن، موقعیت دقیق m در داخل یک تصویر را می توان به صورت زیر محاسبه کرد:
و:
3.2.2. سرعت
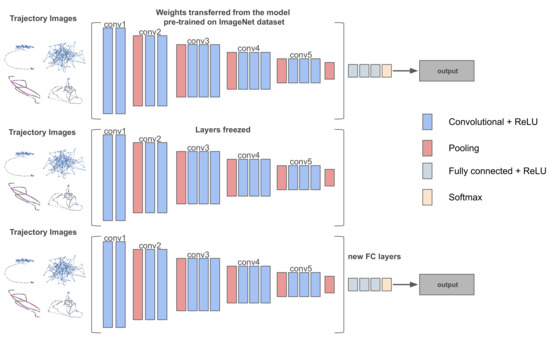
3.3. یادگیری عمیق برای طبقه بندی الگوی کشتی
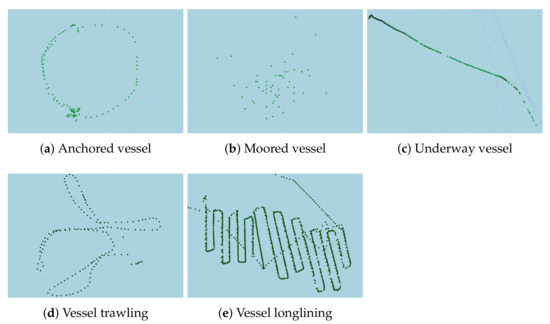
دادههای مسیر تاریخی به تصاویر تبدیل شدند و بر اساس حاشیهنویسی الگوهای تحرک بتن به چهار کلاس برچسبگذاری شدند. آnجساعتorهد، مترoorهد، توnدهrwآy، fمنسساعتمنng). این تصاویر به عنوان ورودی به مدلهای مختلف یادگیری عمیق برای آموزش وارد شدند. برچسب ها در بردارهای یک داغ کدگذاری شدند، و سپس، هر مدل از طریق یک عملیات پس انتشار آموزش داده شد تا فرآیند بهینه سازی تابع هدف همگرا شود. همه CNN های مورد بررسی دارای برخی از فراپارامترهای مشترک بودند. تصاویر ورودی به اندازه ثابت مقیاس بندی شدند 224×224پیکسل ها آموزش برای 25 دوره برای همه مدل های از پیش آموزش دیده با نرخ یادگیری 1 × 10-3 و اندازه دسته ای 8 انجام شد. خروجی لایه های پیچشی توسط تابع فعال سازی غیر خطی به نام واحد خطی اصلاح شده فعال می شود. ReLU)، که تابع را محاسبه می کند:
ReLU به دلیل کاهش احتمال ناپدید شدن گرادیان ها و محاسبه کارآمد آن به عنوان تابع فعال سازی انتخاب شد. پس از هر لایه پیچشی، لایه ادغام برای انجام عملیات نمونه برداری پایین معرفی شد که ابعاد درون صفحه نقشه های ویژگی را کاهش داد. عملیات Downsamp بعد از لایههای کانولوشن، یک تغییر ناپذیری ترجمه را برای جابجاییها و اعوجاجهای کوچک ایجاد میکند و تعداد پارامترهای قابل یادگیری بعدی را کاهش میدهد. ادغام میانگین [ 63 ] به عنوان استراتژی ادغام استفاده شد، که یک نوع کاهش ابعاد شدید را انجام داد، که در آن یک تانسور با ابعاد ساعت×w×دنمونه برداری شد به a 1×1×دآرایه به سادگی با گرفتن میانگین همه عناصر در هر یک ساعت×wنقشه ویژگی، در حالی که عمق نقشه های ویژگی حفظ شد. تعداد پارامترهای قابل یادگیری کاهش یافت و از برازش بیش از حد جلوگیری شد. نقشههای ویژگی خروجی لایه نهایی صاف شده و به لایههای کاملاً متصل متصل شدند، که در آن هر ورودی با وزن قابل یادگیری به هر خروجی متصل میشد. لایه خروجی با استفاده از تابع softmax، توزیع احتمال را بر روی برچسب های طبقه بندی ایجاد کرد:
که در آن x بردار خروجی شبکه است. تابع softmax احتمالات هر کلاس را محاسبه می کند من=1،2،…،مندر تمام کلاس های هدف ممکن
خطا بین خروجی واقعی هر کلاس محاسبه شد تیمنو خروجی تخمین زده شده از f(س)منبا استفاده از “categorical_crossentropy” به عنوان تابع ضرر:
جایی که f(س)به معادله ( 10 ) اشاره دارد. “categorical_crossentropy” توزیع پیش بینی ها را با توزیع واقعی مقایسه می کند. کلاس واقعی به عنوان یک بردار رمزگذاری شده یک داغ نشان داده میشود و هر چه خروجیهای مدل به آن بردار نزدیکتر باشد، تلفات کمتر میشود.
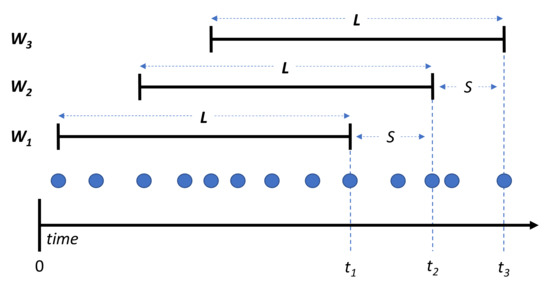
3.4. طبقه بندی کشتی های جریانی
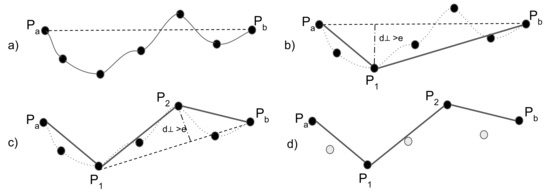
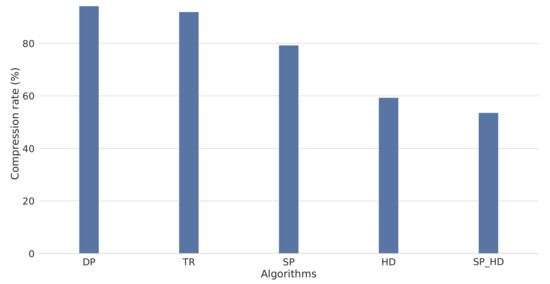
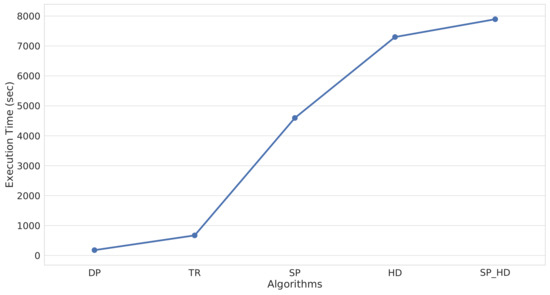
3.5. فشرده سازی مسیر
-
داگلاس-پوکر (DP)
-
نسبت زمانی (TR)
-
بر اساس سرعت (SP)
-
بر اساس سرفصل (HD)
-
بر اساس سرعت سرفصل (SP_HD)
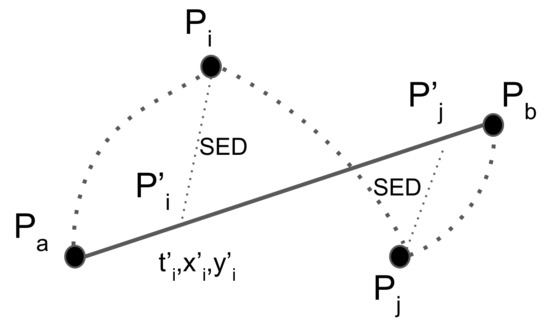
برای هر نقطه در مسیر اصلی مانند پمن، نقطه هماهنگ زمانی پمن”در مسیر تقریبی قرار دارد تیrپآ-پبو مختصات ( ایکسمن”، yمن”) از پمن”را می توان با استفاده از درون یابی خطی به صورت زیر محاسبه کرد:
4. ارزیابی تجربی
-
دقت طبقه بندی به دست آمده و عملکرد طبقه بندی کلی روش یادگیری عمیق را نشان می دهد ( بخش 4.2 )،
-
تأخیر و توان عملیاتی به دست آمده و عملکرد کلی اجرا را نشان می دهد ( بخش 4.3 )،
-
تأثیر الگوریتم های فشرده سازی مسیر را بر عملکرد طبقه بندی کار در دست نشان دهید ( بخش 4.4 ).
4.1. توضیحات مجموعه داده
-
0: در حال انجام است
-
1: لنگر انداخته
-
5: پهلو گرفته
-
ماهیگیری (صیادی و لانگ لاین)
-
لنگر انداخته است
-
در حال انجام
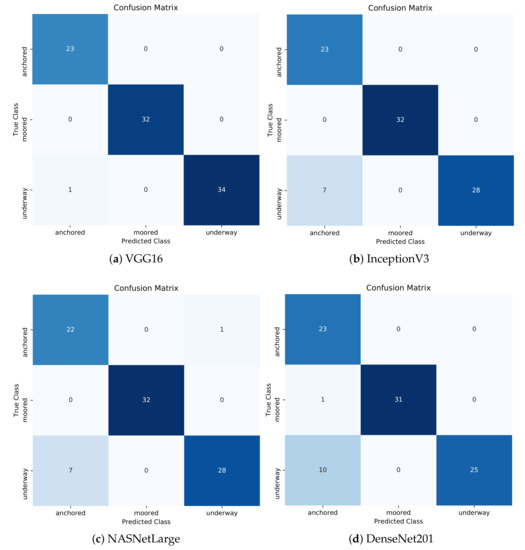
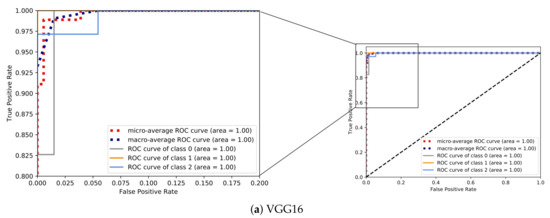
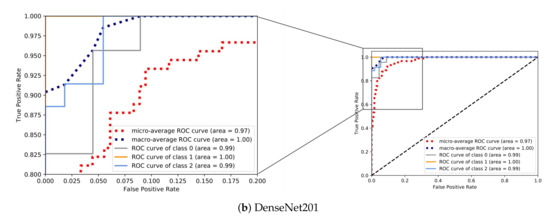
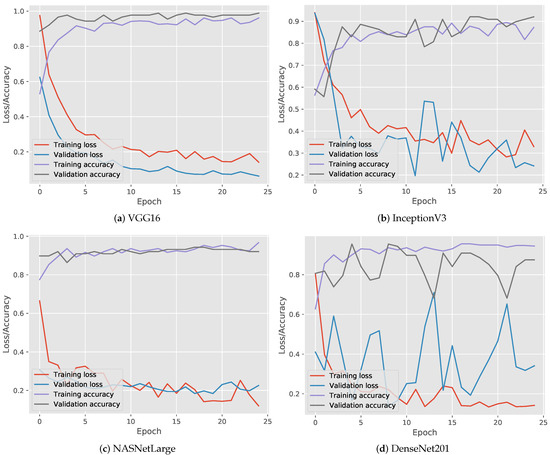
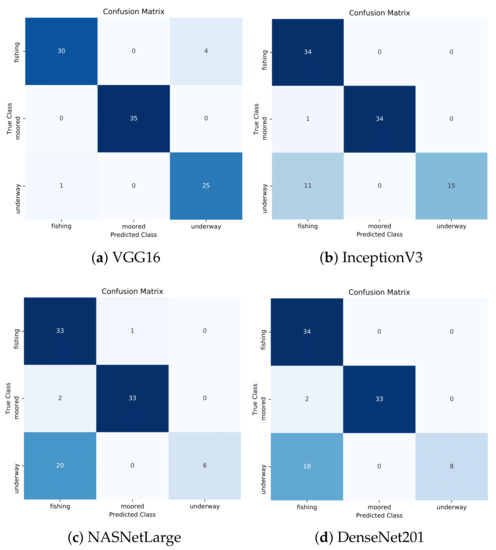
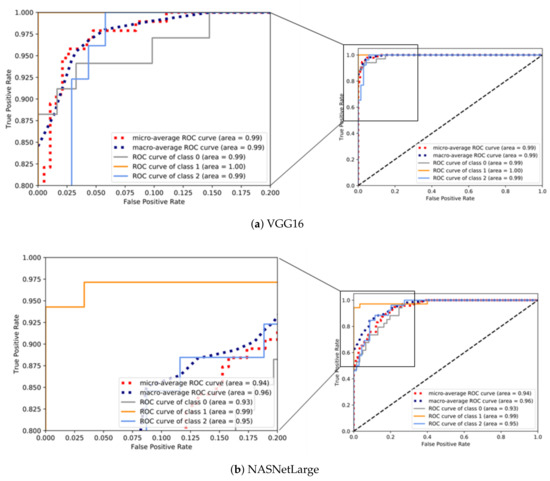
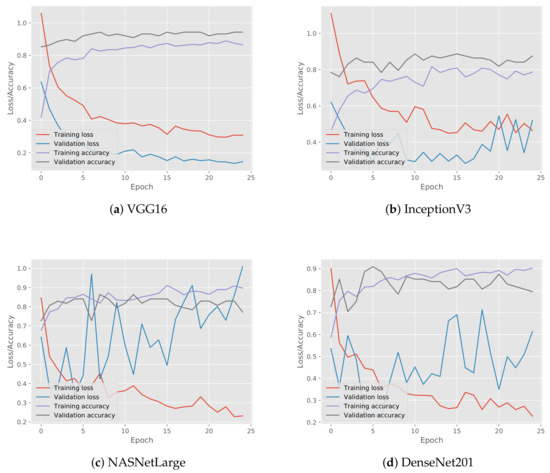
4.2. ارزشیابی یادگیری عمیق
به منظور ارزیابی عملکرد طبقهبندی، چندین معیار طبقهبندی رایج مورد استفاده قرار گرفتند: دقت (ACC)، دقت، یادآوری (حساسیت)، و امتیاز F1. آججتوrآجyنشان می دهد که چگونه یک الگوریتم طبقه بندی می تواند طبقات مسیرها را در مجموعه آزمایشی متمایز کند. همانطور که در معادله ( 13 ) نشان داده شده است، آسیسیرا می توان به عنوان نسبت برچسب های صحیح پیش بینی شده ( TP + TN ) به تعداد کل برچسب ها ( N ) تعریف کرد.
پrهجمنسمنonهمانگونه که در رابطه ( 14 ) نشان داده شده است، نسبت برچسب های صحیح پیش بینی شده به تعداد کل برچسب های واقعی است ، در حالی که آرهجآللنسبت برچسب های صحیح پیش بینی شده به تعداد کل برچسب های پیش بینی شده است، همانطور که در رابطه ( 15 ) نشان داده شده است. یادآوری همچنین به عنوان حساسیت یا نرخ مثبت واقعی (TPR) شناخته می شود.
امتیاز F 1 از میانگین هارمونیک دقت و یادآوری تشکیل شده است، که در آن دقت، دقت متوسط در هر کلاس و یادآوری، میانگین یادآوری در هر کلاس است، همانطور که در معادله ( 16 ) نشان داده شده است.
-
M1: روش یادگیری عمیق پیشنهادی این مقاله (طبقه بندی تصویر با استفاده از مدل VGG16، زیرا بهترین نتایج دقت طبقه بندی را ارائه می دهد).
-
M2: طبقه بندی جنگل های تصادفی با ویژگی های استخراج شده از پیام های AIS مسیرها.
-
M3: طبقهبندیکننده ماشینهای بردار پشتیبان با ویژگیهای استخراجشده از پیامهای AIS مسیرها.
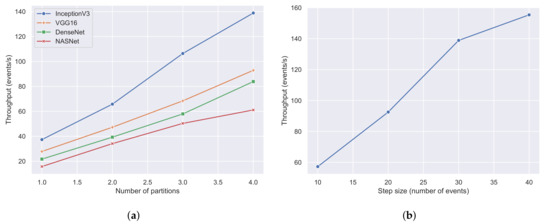
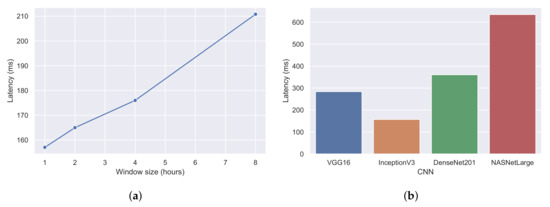
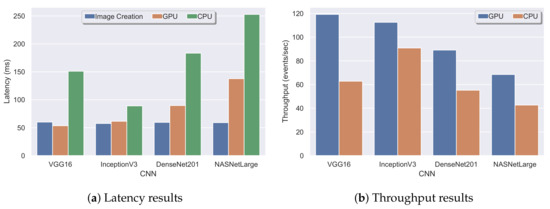
4.3. ارزیابی جریان
-
مقیاس پذیری،
-
توان عملیاتی،
-
تاخیر،
-
عملکرد اجرا با یک GPU
4.4. ارزیابی فشرده سازی
5. بحث
6. نتیجه گیری و کار آینده
منابع
- لی، جی. هان، جی. لی، ایکس. Gonzalez, H. TraClass : طبقهبندی مسیر با استفاده از خوشهبندی مبتنی بر منطقه سلسله مراتبی و مبتنی بر مسیر. Proc. VLDB Enddow. 2008 ، 1 ، 1081-1094. [ Google Scholar ] [ CrossRef ]
- کاپادایس، ک. وارلامیس، آی. ساردیانوس، سی. Tserpes، K. چارچوبی برای تشخیص الگوهای جستجو و نجات با استفاده از طبقهبندی Shapelet. اینترنت آینده 2019 ، 11 ، 192. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- مازارلا، اف. وسپه، م. دامالاس، دی. Osio, G. کشف فعالیت های کشتی در دریا با استفاده از داده های AIS: نقشه برداری از ردپای ماهیگیری. در مجموعه مقالات هفدهمین کنفرانس بین المللی در همجوشی اطلاعات، FUSION 2014، سالامانکا، اسپانیا، 7-10 ژوئیه 2014. صص 1-7. [ Google Scholar ]
- داسیلوا، CL; پتری، LM; Bogorny, V. بررسی و مقایسه روش های طبقه بندی مسیر. در مجموعه مقالات هشتمین کنفرانس برزیل در سیستم های هوشمند (BRACIS) 2019، سالوادور، برزیل، 15 تا 18 اکتبر 2019؛ صص 788-793. [ Google Scholar ]
- وانگ، دی. میوا، تی. موریکاوا، تی. داده کاوی مسیر بزرگ: بررسی روش ها، کاربردها و خدمات. Sensors 2020 , 20 , 4571. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- باچار، م. الیملک، جی. گات، آی. سوبول، جی. ریوتی، ن. Gal، A. Venilia، یادگیری آنلاین و پیشبینی مقصد کشتی. در مجموعه مقالات دوازدهمین کنفرانس بین المللی ACM در مورد سیستم های توزیع شده و مبتنی بر رویداد، DEBS 2018، همیلتون، نیوزیلند، 25-29 ژوئن 2018؛ Hinze, A., Eyers, DM, Hirzel, M., Weidlich, M., Bhowmik, S., Eds.; ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2018؛ ص 209-212. [ Google Scholar ] [ CrossRef ]
- بودونوف، او. اشمیت، اف. مارتین، ای. بریتو، ا. Fetzer، C. مقصد بلادرنگ و پیشبینی ETA برای ترافیک دریایی. در مجموعه مقالات دوازدهمین کنفرانس بین المللی ACM در مورد سیستم های توزیع شده و مبتنی بر رویداد، DEBS 2018، همیلتون، نیوزیلند، 25-29 ژوئن 2018؛ Hinze, A., Eyers, DM, Hirzel, M., Weidlich, M., Bhowmik, S., Eds.; ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2018؛ ص 198-201. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کونتوپولوس، آی. اسپیلیوپولوس، جی. زیسیس، دی. Chatzikokolakis، K. Artikis، A. مقابله با مسمومیت جریان بلادرنگ: معماری برای تشخیص جعل کشتی در جریان داده های AIS. در مجموعه مقالات شانزدهمین کنفرانس بین المللی IEEE 2018 در مورد محاسبات قابل اعتماد، خودمختار و ایمن، شانزدهمین کنفرانس بین المللی در مورد هوش فراگیر و محاسبات، چهارمین کنفرانس بین المللی در مورد هوش و محاسبات کلان داده ها و کنگره علوم و فناوری سایبری، DASC/PiCome/PiComy/DASC/PiCome20 ، آتن، یونان، 12–15 اوت 2018؛ انجمن کامپیوتر IEEE: واشنگتن، دی سی، ایالات متحده آمریکا، 2018؛ ص 981-986. [ Google Scholar ]
- کونتوپولوس، آی. Chatzikokolakis، K. زیسیس، دی. تسرپس، ک. Spiliopoulos، G. تشخیص ناهنجاری دریایی در زمان واقعی: تشخیص خاموش شدن عمدی AIS. بین المللی J. هوش کلان داده. 2020 ، 7 ، 85-96. [ Google Scholar ] [ CrossRef ]
- کونتوپولوس، آی. Chatzikokolakis، K. تسرپس، ک. Zissis، D. طبقه بندی فعالیت کشتی در جریان داده ها. در مجموعه مقالات DEBS ’20: چهاردهمین کنفرانس بین المللی ACM در مورد سیستم های توزیع شده و مبتنی بر رویداد، مونترال، QC، کانادا، 13 تا 17 ژوئیه 2020؛ Gascon-Samson, J., Zhang, K., Daudjee, K., Kemme, B., Eds. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2020؛ صص 153-164. [ Google Scholar ] [ CrossRef ]
- روات، دبلیو. وانگ، زی. شبکههای عصبی کانولوشنال عمیق برای طبقهبندی تصویر: بررسی جامع. محاسبات عصبی 2017 ، 29 ، 2352-2449. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ژونگ، اس. لیو، ی. لیو، ی. یادگیری عمیق دوخطی برای طبقه بندی تصاویر. در مجموعه مقالات نوزدهمین کنفرانس بین المللی ACM در چند رسانه ای، اسکاتسدیل، AZ، ایالات متحده، 28 نوامبر تا 1 دسامبر 2011. صص 343-352. [ Google Scholar ] [ CrossRef ]
- وو، جی. یو، ی. هوانگ، سی. یو، ک. یادگیری چند نمونه عمیق برای طبقه بندی تصویر و حاشیه نویسی خودکار. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. صص 3460–3469. [ Google Scholar ] [ CrossRef ]
- سوزا، ای. بوئردر، ک. Worm, B. بهبود تشخیص الگوی ماهیگیری از AIS ماهواره ای با استفاده از داده کاوی و یادگیری ماشین. PLoS ONE 2016 , 11 , e0158248. [ Google Scholar ] [ CrossRef ]
- جیانگ، ایکس. نقره، DL; هو، بی. د سوزا، EN; متوین، اس. تشخیص فعالیت ماهیگیری از داده های AIS با استفاده از رمزگذارهای خودکار. In Advances in Artificial Intelligence — بیست و نهمین کنفرانس کانادایی در زمینه هوش مصنوعی، هوش مصنوعی کانادا 2016، ویکتوریا، BC، کانادا، 31 مه تا 3 ژوئن 2016 ؛ خوری، ر.، دراموند، سی.، ویرایش. Springer: برلین/هایدلبرگ، آلمان، 2016; جلد 9673، ص 33–39. [ Google Scholar ] [ CrossRef ]
- سیمونیان، ک. زیسرمن، الف. شبکه های پیچیده بسیار عمیق برای تشخیص تصویر در مقیاس بزرگ. در مجموعه مقالات سومین کنفرانس بینالمللی بازنماییهای یادگیری، ICLR 2015، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 7 تا 9 مه 2015. [ Google Scholar ]
- سگدی، سی. ونهوک، وی. آیوف، اس. شلنز، جی. Wojna, Z. بازاندیشی در معماری آغازین برای بینایی کامپیوتر. در مجموعه مقالات کنفرانس IEEE 2016 در مورد بینایی کامپیوتری و تشخیص الگو، CVPR 2016، لاس وگاس، NV، ایالات متحده آمریکا، 27 تا 30 ژوئن 2016؛ ص 2818-2826. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- زوف، بی. واسودوان، وی. شلنز، جی. Le, QV Learning Architectures Transferable for Scalable Image Recognition. در مجموعه مقالات کنفرانس IEEE 2018 در مورد دید رایانه و تشخیص الگو، CVPR 2018، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ صص 8697-8710. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هوانگ، جی. لیو، ز. ون در ماتن، ال. واینبرگر، شبکههای کانولوشن با اتصال متراکم KQ. در مجموعه مقالات کنفرانس IEEE 2017 در مورد دید رایانه و تشخیص الگو، CVPR 2017، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ ص 2261-2269. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آنکرست، م. برونیگ، MM; کریگل، اچ پی؛ Sander, J. OPTICS: نقاط ترتیب برای شناسایی ساختار خوشه بندی. ACM Sigmod Rec. 1999 ، 28 ، 49-60. [ Google Scholar ] [ CrossRef ]
- لی، جی. هان، جی. Whang، K. خوشهبندی مسیر: یک چارچوب پارتیشن و گروهی. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD در مدیریت داده ها، پکن، چین، 12 تا 14 ژوئن 2007. صص 593-604. [ Google Scholar ] [ CrossRef ]
- کونتوپولوس، آی. وارلامیس، آی. Tserpes، K. چارچوب توزیع شده برای استخراج الگوهای ترافیک دریایی. بین المللی جی. جئوگر. Inf. علمی 2020 ، 1–26. [ Google Scholar ] [ CrossRef ]
- Vouros، GA; ولاچو، ع. Santipantakis، جنرال موتورز; دولکریدیس، سی. پلکیس، ن. جورجیو، HV; تئودوریدیس، ی. پاترومپاس، ک. Alevizos، E. آرتیکیس، ا. و همکاران تجزیه و تحلیل داده های بزرگ برای پیش بینی تحرک حیاتی زمان: پیشرفت اخیر و چالش های تحقیقاتی. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی گسترش فناوری پایگاه داده، EDBT 2018، وین، اتریش، 26 تا 29 مارس 2018؛ صص 612-623. [ Google Scholar ] [ CrossRef ]
- چویسی، بی. Kiattisin، S. شناسایی رفتار شناورهای ماهیگیری برای مبارزه با ماهیگیری IUU: فعال کردن قابلیت ردیابی در دریا. سیم. پارس اشتراک. 2020 ، 115 ، 2971-2993. [ Google Scholar ] [ CrossRef ]
- ساینی، ر. روی، پی. Dogra, D. یک طبقهبندی مسیر مبتنی بر HMM با استفاده از الگوریتم ژنتیک. سیستم خبره Appl. 2017 ، 93 ، 169-181. [ Google Scholar ] [ CrossRef ]
- وانگ، ایکس. ما، KT; Ng، GW; گریمسون، تحلیل مسیر WEL و مدلسازی ناحیه معنایی با استفاده از مدل بیزی ناپارامتریک. در مجموعه مقالات کنفرانس IEEE Computer Society در سال 2008 در مورد دید رایانه و تشخیص الگو (CVPR 2008)، Anchorage، AK، ایالات متحده آمریکا، 24-26 ژوئن 2008. [ Google Scholar ] [ CrossRef ]
- هو، دبلیو. لی، ایکس. تیان، جی. Maybank، SJ; Zhang, Z. یک روش افزایشی مبتنی بر DPMM برای خوشهبندی مسیر، مدلسازی و بازیابی. IEEE Trans. الگوی مقعدی ماخ هوشمند 2013 ، 35 ، 1051-1065. [ Google Scholar ] [ PubMed ]
- جیانگ، ایکس. د سوزا، EN; پسرانقادر، ع. هو، بی. نقره، DL; Matwin, S. Trajectorynet: یک نمایش مسیر GPS تعبیه شده برای طبقه بندی مبتنی بر نقطه با استفاده از شبکه های عصبی مکرر. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی سالانه علوم کامپیوتر و مهندسی نرم افزار، مارکهام، ON، کانادا، 6 تا 8 نوامبر 2017؛ صص 192-200. [ Google Scholar ]
- ژانگ، آر. زی، پی. وانگ، سی. لیو، جی. Wan, S. طبقه بندی حالت و سرعت حمل و نقل از داده های مسیر از طریق یادگیری عمیق چند مقیاسی. محاسبه کنید. شبکه 2019 ، 162 ، 106861. [ Google Scholar ] [ CrossRef ]
- جیانگ، ایکس. لیو، ایکس. د سوزا، EN; هو، بی. نقره، DL; Matwin, S. بهبود طبقهبندی مسیر AIS مبتنی بر نقطه با واحدهای بازگشتی دروازهدار پارتیشن. در مجموعه مقالات کنفرانس مشترک بین المللی 2017 در مورد شبکه های عصبی (IJCNN)، انکوریج، AK، ایالات متحده آمریکا، 14-19 مه 2017؛ صفحات 4044-4051. [ Google Scholar ]
- لین، سی ایکس؛ هوانگ، TW; گوا، جی. Wong، MDF MtDetector: یک آشکارساز ترافیک دریایی با کارایی بالا در مقیاس جریان. در مجموعه مقالات دوازدهمین کنفرانس بین المللی ACM در مورد سیستم های توزیع شده و مبتنی بر رویداد، DEBS’18، همیلتون، نیوزیلند، 25 تا 29 ژوئن 2018؛ انجمن ماشینهای محاسباتی: نیویورک، نیویورک، ایالات متحده آمریکا، 2018؛ ص 205-208. [ Google Scholar ] [ CrossRef ]
- Chatzikokolakis، K. زیسیس، دی. ووداس، م. اسپیلیوپولوس، جی. Kontopoulos، I. یک سرویس تشخیص ناهنجاری دریایی با رعد و برق توزیع شده. در مجموعه مقالات OCENS 2019، مارسی، فرانسه، 17 تا 20 ژوئن 2019؛ صص 1-8. [ Google Scholar ] [ CrossRef ]
- بویاروف، آ. Tyantov، E. تشخیص نقطه عطف در مقیاس بزرگ از طریق یادگیری عمیق متریک. در مجموعه مقالات بیست و هشتمین کنفرانس بین المللی ACM در مدیریت اطلاعات و دانش، تورین، ایتالیا، 22 تا 26 اکتبر 2019؛ صص 169-178. [ Google Scholar ]
- شن، دی. وو، جی. Suk, HI یادگیری عمیق در تجزیه و تحلیل تصویر پزشکی. آنو. کشیش بیومد. مهندس 2017 ، 19 ، 221-248. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کریژفسکی، آ. سوتسکور، آی. هینتون، GE Imagenet طبقه بندی با شبکه های عصبی کانولوشن عمیق. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، دریاچه تاهو، NV، ایالات متحده، 3-6 دسامبر 2012. ص 1097-1105. [ Google Scholar ]
- مکریس، ع. کونتوپولوس، آی. Tserpes، K. COVID-19 تشخیص از تصاویر اشعه ایکس قفسه سینه با استفاده از یادگیری عمیق و شبکه های عصبی کانولوشنال. در مجموعه مقالات یازدهمین کنفرانس یونانی هوش مصنوعی، آتن، یونان، 2 تا 4 سپتامبر 2020؛ صص 60-66. [ Google Scholar ]
- لیو، اس. لیو، اس. کای، دبلیو. پوژول، اس. کیکینیس، آر. Feng, D. تشخیص زودهنگام بیماری آلزایمر با یادگیری عمیق. در مجموعه مقالات یازدهمین سمپوزیوم بین المللی IEEE در تصویربرداری زیست پزشکی (ISBI) 2014، پکن، چین، 29 آوریل تا 2 می 2014. ص 1015–1018. [ Google Scholar ]
- وانگ، دی. خسلا، ع. گرگیا، ر. ارشاد، ح. Beck, AH یادگیری عمیق برای شناسایی سرطان سینه متاستاتیک. arXiv 2016 , arXiv:1606.05718. [ Google Scholar ]
- هو، TKK; گواک، جی. پراکاش، او. آهنگ، جی. پارک، CM با استفاده از مدلهای آموزش عمیق از پیش آموزش دیده برای تشخیص خودکار سل ریوی با استفاده از رادیوگرافی قفسه سینه. در مجموعه مقالات کنفرانس آسیایی اطلاعات هوشمند و سیستم های پایگاه داده، یوگیاکارتا، اندونزی، 8 تا 11 آوریل 2019؛ صص 395-403. [ Google Scholar ]
- لکون، ی. بوتو، ال. بنژیو، ی. هافنر، پی. یادگیری مبتنی بر گرادیان برای شناسایی اسناد به کار می رود. Proc. IEEE 1998 ، 86 ، 2278-2324. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کریژفسکی، آ. سوتسکور، آی. هینتون، GE ImageNet طبقه بندی با شبکه های عصبی پیچیده عمیق. اشتراک. ACM 2017 ، 60 ، 84–90. [ Google Scholar ] [ CrossRef ]
- نیر، وی. واحدهای خطی Hinton، GE Rectified ماشینهای بولتزمن محدود را بهبود میبخشند. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی یادگیری ماشین (ICML-10)، حیفا، اسرائیل، 21 تا 24 ژوئن 2010. ص 807-814. [ Google Scholar ]
- سگدی، سی. لیو، دبلیو. جیا، ی. سرمانت، پ. رید، اس. آنگلوف، دی. ایرهان، د. ونهوک، وی. رابینوویچ، الف. با پیچیدگی ها عمیق تر می رویم. در مجموعه مقالات کنفرانس IEEE 2015 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015؛ صفحات 1-9. [ Google Scholar ]
- آرورا، اس. بهاسکارا، ا. جنرال الکتریک، آر. Ma, T. مرزهای قابل اثبات برای یادگیری برخی بازنمایی های عمیق. در مجموعه مقالات سی و یکمین کنفرانس بین المللی یادگیری ماشین، 21 تا 26 ژوئن 2014؛ Xing, EP, Jebara, T., Eds. PMLR: پکن، چین، 2014; جلد 32، ص 584–592. [ Google Scholar ]
- سگدی، سی. آیوف، اس. ونهوک، وی. عالمی، AA Inception-v4، Inception-ResNet و تاثیر اتصالات باقیمانده بر یادگیری. در مجموعه مقالات سی و یکمین کنفرانس AAAI در مورد هوش مصنوعی، AAAI’17، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 فوریه 2017؛ مطبوعات AAAI: پالو آلتو، کالیفرنیا، ایالات متحده آمریکا، 2017؛ صص 4278-4284. [ Google Scholar ]
- او، ک. ژانگ، ایکس. رن، اس. Sun، J. یادگیری باقیمانده عمیق برای تشخیص تصویر. در مجموعه مقالات کنفرانس IEEE 2016 در مورد بینایی کامپیوتری و تشخیص الگو، CVPR 2016، لاس وگاس، NV، ایالات متحده آمریکا، 27 تا 30 ژوئن 2016؛ صص 770-778. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Chollet، F. Xception: یادگیری عمیق با پیچیدگی های قابل جداسازی عمیق. در مجموعه مقالات کنفرانس IEEE 2017 در مورد دید رایانه و تشخیص الگو، CVPR 2017، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ صفحات 1800–1807. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چن، آر. چن، ام. لی، دبلیو. وانگ، جی. Yao، X. Mobility آگاهی از مسیرهای مبتنی بر خوشهبندی و شبکه عصبی کانولوشنال را تنظیم میکند. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 208. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- چن، ایکس. کمالاسودان، ا. Zhang, X. کاربرد شبکه عصبی کانولوشن برای استخراج الگوهای حرکت رگ. در مجموعه مقالات پنجمین کنفرانس بین المللی اطلاعات و ایمنی حمل و نقل (ICTIS)، لیورپول، بریتانیا، 14 تا 17 ژوئیه 2019؛ ص 939-944. [ Google Scholar ]
- اندو، ی. تودا، اچ. نیشیدا، ک. Ikedo، J. طبقه بندی مسیرهای فضایی با استفاده از یادگیری بازنمایی. بین المللی J. Data Sci. مقعدی 2016 ، 2 ، 107-117. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، پی. ژائو، جی. تعهدات یک کشتی لنگردار برای جلوگیری از برخورد در دریا. جی. ناویگ. 2013 ، 66 ، 473-477. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پیتسیکالیس، م. کونتوپولوس، آی. آرتیکیس، ا. Alevizos، E. دلونای، پی. پوسل، جی. درئو، آر. ری، سی. کاموسی، ای. جوسلمه، آ. و همکاران الگوهای رویداد ترکیبی برای نظارت دریایی. در مجموعه مقالات دهمین کنفرانس یونانی در زمینه هوش مصنوعی، SETN 2018، پاتراس، یونان، 9 تا 12 ژوئیه 2018؛ ص 29:1-29:4. [ Google Scholar ] [ CrossRef ]
- پیتسیکالیس، م. آرتیکیس، ا. درئو، آر. ری، سی. کاموسی، ای. Jousselme, A. شناسایی رویداد ترکیبی برای نظارت دریایی. در مجموعه مقالات سیزدهمین کنفرانس بین المللی ACM در مورد سیستم های توزیع شده و مبتنی بر رویداد، DEBS 2019، دارمشتات، آلمان، 24 تا 28 ژوئن 2019؛ صص 163-174. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- الگوریتم Gaol، FL Bresenham: پیاده سازی و تجزیه و تحلیل در شکل شطرنجی. جی. کامپیوتر. 2013 ، 8 ، 69-78. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پان، SJ; یانگ، Q. نظرسنجی در مورد یادگیری انتقالی. IEEE Trans. بدانید. مهندسی داده 2009 ، 22 ، 1345-1359. [ Google Scholar ] [ CrossRef ]
- یاماشیتا، آر. نیشیو، م. انجام دهید، RKG; توگاشی، ک. شبکه های عصبی کانولوشن: مروری و کاربرد در رادیولوژی. Insights Imaging 2018 ، 9 ، 611–629. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چن، ی. جیانگ، اچ. لی، سی. جیا، ایکس. غمیسی، ص. استخراج ویژگی های عمیق و طبقه بندی تصاویر فراطیفی بر اساس شبکه های عصبی کانولوشن. IEEE Trans. Geosci. Remote Sens. 2016 , 54 , 6232–6251. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Bengio، Y. یادگیری عمیق بازنمایی ها برای یادگیری بدون نظارت و انتقالی. در مجموعه مقالات آموزش بدون نظارت و انتقال – کارگاه برگزار شده در ICML 2011، Bellevue، WA، ایالات متحده آمریکا، 2 ژوئیه 2011. جلد 27، ص 17-36. [ Google Scholar ]
- دوناهو، جی. جیا، ی. وینیالز، او. هافمن، جی. ژانگ، ن. تزنگ، ای. Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. در مجموعه مقالات سی و یکمین کنفرانس بین المللی یادگیری ماشین، ICML 2014، پکن، چین، 21 تا 26 ژوئن 2014. جلد 32، ص 647–655. [ Google Scholar ]
- Mohanty، SP; هیوز، DP; Salathé، M. استفاده از یادگیری عمیق برای تشخیص بیماری گیاهی مبتنی بر تصویر. جلو. علوم گیاهی 2016 ، 7 ، 1419. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- دنگ، ج. دونگ، دبلیو. سوچر، آر. لی، ال جی; لی، ک. لی، F.-F. Imagenet: پایگاه داده تصویر سلسله مراتبی در مقیاس بزرگ. در مجموعه مقالات کنفرانس IEEE 2009 در مورد بینایی کامپیوتری و تشخیص الگو، میامی، FL، ایالات متحده آمریکا، 20-25 ژوئن 2009. ص 248-255. [ Google Scholar ]
- Zeiler، MD; Fergus, R. تجسم و درک شبکه های کانولوشن. در Computer Vision—ECCV 2014—سیزدهمین کنفرانس اروپایی، زوریخ، سوئیس، 6 تا 12 سپتامبر 2014 ؛ قسمت اول؛ Fleet, DJ, Pajdla, T., Schiele, B., Tuytelaars, T., Eds. Springer: برلین/هایدلبرگ، آلمان، 2014; جلد 8689، صص 818–833. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لین، ام. چن، کیو. Yan, S. شبکه در شبکه. arXiv 2013 , arXiv:1312.4400. [ Google Scholar ]
- Kingma، DP; Ba, J. Adam: روشی برای بهینه سازی تصادفی. arXiv 2014 ، arXiv:1412.6980. [ Google Scholar ]
- هینتون، جنرال الکتریک؛ سریواستاوا، ن. کریژفسکی، آ. سوتسکور، آی. Salakhutdinov، RR بهبود شبکه های عصبی با جلوگیری از سازگاری مشترک آشکارسازهای ویژگی. arXiv 2012 ، arXiv:1207.0580. [ Google Scholar ]
- هاوکینز، DM مشکل بیش از حد برازش. جی. شیمی. Inf. محاسبه کنید. علمی 2004 ، 44 ، 1-12. [ Google Scholar ] [ CrossRef ]
- پرز، ال. Wang, J. اثربخشی افزایش داده ها در طبقه بندی تصویر با استفاده از یادگیری عمیق. arXiv 2017 , arXiv:1712.04621. [ Google Scholar ]
- مکریس، ع. تسرپس، ک. آناگنوستوپولوس، دی. یک پروتکل جدید قرار دادن شی برای به حداقل رساندن میانگین زمان پاسخ عملیات دریافت در فروشگاههای ارزش کلیدی توزیع شده. در مجموعه مقالات کنفرانس بینالمللی IEEE 2017 درباره دادههای بزرگ، BigData 2017، بوستون، MA، ایالات متحده آمریکا، 11–14 دسامبر 2017؛ صص 3196–3205. [ Google Scholar ] [ CrossRef ]
- مکریس، ع. تسرپس، ک. آناگنوستوپولوس، دی. Altmann, J. Load Balancing برای به حداقل رساندن میانگین زمان پاسخ عملیات دریافت در فروشگاه های توزیع شده کلید-مقدار. در مجموعه مقالات چهاردهمین کنفرانس بین المللی IEEE 2017 در مورد شبکه، سنجش و کنترل (ICNSC)، بوستون، MA، ایالات متحده، 11 تا 14 دسامبر 2017؛ صص 263-269. [ Google Scholar ]
- مکریس، ع. تسرپس، ک. اسپیلیوپولوس، جی. آناگنوستوپولوس، دی. ارزیابی عملکرد MongoDB و PostgreSQL برای داده های فضایی-زمانی. در مجموعه مقالات کارگاه های کنفرانس مشترک EDBT/ICDT 2019، EDBT/ICDT 2019، لیسبون، پرتغال، 26 مارس 2019؛ جلد 2322. [ Google Scholar ]
- مکریس، ع. تسرپس، ک. اسپیلیوپولوس، جی. زیسیس، دی. Anagnostopoulos، D. MongoDB در مقابل PostgreSQL: یک مطالعه مقایسه ای در مورد جنبه های عملکرد. GeoInformatica 2021 ، 25 ، 241-242. [ Google Scholar ] [ CrossRef ]
- مکریس، ع. تسرپس، ک. آناگنوستوپولوس، دی. نیکولایدو، م. de Macedo، مقایسه سیستم پایگاه داده JAF بر اساس عملکرد مکانی – زمانی. در مجموعه مقالات بیست و سومین سمپوزیوم مهندسی و برنامه های کاربردی پایگاه داده بین المللی، آتن، یونان، 10 تا 12 ژوئن 2019؛ صص 1-7. [ Google Scholar ]
- مراتنیا، ن. de By, RA دیدگاهی جدید در مورد تکنیک های فشرده سازی مسیر. در مجموعه مقالات کمیسیون ISPRS II و IV، WG II/5، II/6، IV/1 و IV/2 کارگاه مشترک مدل سازی و تحلیل داده های مکانی، زمانی و چند بعدی، شهر کبک، QC، کانادا، 2-3 اکتبر 2003. [ Google Scholar ]
- Leichsenring، YE; بالدو، اف. ارزیابی الگوریتمهای فشردهسازی اعمال شده در مسیر حرکت جسم متحرک. بین المللی جی. جئوگر. Inf. علمی 2020 ، 34 ، 539-558. [ Google Scholar ] [ CrossRef ]
- ماکل، جی. هوانگ، جی. لاوسون، سی تی. Ravi، الگوریتمهای SS برای فشردهسازی دادههای مسیر GPS: یک ارزیابی تجربی. در مجموعه مقالات هجدهمین سمپوزیوم بینالمللی ACM SIGSPATIAL در مورد پیشرفتها در سیستمهای اطلاعات جغرافیایی، ACM-GIS 2010، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 3 تا 5 نوامبر 2010. ص 402-405. [ Google Scholar ] [ CrossRef ]
- پوتامیاس، م. پاترومپاس، ک. سلیس، تی. نمونهبرداری از جریانهای مسیر با معیارهای مکانی-زمانی. در مجموعه مقالات هجدهمین کنفرانس بین المللی مدیریت پایگاه داده های علمی و آماری، وین، اتریش، 3 تا 5 ژوئیه 2006. صص 275-284. [ Google Scholar ]
- ماکل، جی. هوانگ، جی. پاتیل، وی. لاوسون، سی تی. پینگ، اف. Ravi، SS SQUISH: یک رویکرد آنلاین برای فشرده سازی مسیر GPS. در مجموعه مقالات دومین کنفرانس و نمایشگاه بین المللی محاسبات برای تحقیقات و کاربردهای جغرافیایی، واشنگتن، دی سی، ایالات متحده آمریکا، 23 تا 25 مه 2011. ص 13:1-13:8. [ Google Scholar ] [ CrossRef ]
- ترایچفسکی، جی. کائو، اچ. شوئرمن، پی. ولفسون، او. Vaccaro، D. کاهش داده های آنلاین و کیفیت تاریخچه در پایگاه داده های اشیاء متحرک. در مجموعه مقالات پنجمین کارگاه بین المللی ACM در زمینه مهندسی داده برای دسترسی بی سیم و موبایل، Mobide 2006، شیکاگو، IL، ایالات متحده آمریکا، 25 ژوئن 2006. صص 19-26. [ Google Scholar ] [ CrossRef ]
- دریتساس، ای. کاناووس، ا. تریگکا، م. سیوتاس، س. Tsakalidis، A. خوشهبندی مسیر کارآمد ذخیرهسازی و k-nn برای حفظ حریم خصوصی قوی پایگاههای داده مکانی-زمانی. الگوریتمها 2019 ، 12 ، 266. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- مراتنیا، ن. de By، تکنیک های فشرده سازی فضایی-زمانی RA برای اجسام نقطه متحرک. In Advances in Database Technology—EDBT 2004، نهمین کنفرانس بین المللی گسترش فناوری پایگاه داده، هراکلیون، کرت، یونان، 14-18 مارس 2004 . Bertino, E., Christodoulakis, S., Plexousakis, D., Christophides, V., Koubarakis, M., Böhm, K., Ferrari, E., Eds.; Springer: برلین/هایدلبرگ، آلمان، 2004; جلد 2992، ص 765–782. [ Google Scholar ] [ CrossRef ]
- داگلاس، دی اچ. Peucker، الگوریتم های TK برای کاهش تعداد نقاط مورد نیاز برای نشان دادن یک خط دیجیتالی یا کاریکاتور آن. Cartographica 1973 , 10 , 112-122. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کونتوپولوس، آی. ووداس، م. اسپیلیوپولوس، جی. تسرپس، ک. Zissis، D. مجموعه داده ردیابی کشتی گیرنده AIS تک زمینی. 2020. در دسترس آنلاین: https://zenodo.org/record/3754481#.YG7dGD8RWbg (در 1 آوریل 2021 قابل دسترسی است).
- Sayood, K. Introduction to Data Compression , 3rd . سری مورگان کافمن در اطلاعات و سیستمهای چندرسانهای. الزویر: آمستردام، هلند، 2006. [ Google Scholar ]
- ماکل، جی. اولسن، PW; هوانگ، جی اچ. لاوسون، سی تی. راوی، اس. فشرده سازی داده های مسیر: ارزیابی جامع و رویکرد جدید. GeoInformatica 2014 ، 18 ، 435-460. [ Google Scholar ] [ CrossRef ]
- لیو، جی. ایوای، م. Sezaki، K. روشی برای ساده سازی مسیر آنلاین با متریک ناحیه محصور. در مجموعه مقالات ششمین کنفرانس بین المللی محاسبات تلفن همراه و شبکه های فراگیر، اوکیناوا، ژاپن، 23 تا 25 مه 2012. [ Google Scholar ]



بدون دیدگاه