1. مقدمه
بهعنوان بخش اساسی شبکههای جادهای در مناطق شهری، اتصالات جادهای، جادههای اولیه را در جهات مختلف به هم متصل میکنند. وسایل نقلیه و عابران پیاده اغلب برای رسیدن به مقصد مورد نظر خود نیاز به چرخش در تقاطع های جاده ای دارند. بنابراین، اتصالات جاده ای نقش مهمی در سیستم های حمل و نقل مدرن ایفا می کنند. با این حال، ساختارهای اتصالات جاده ها اغلب به صراحت در پایگاه داده های فضایی موجود ثبت نمی شوند. از این رو، مکان یابی اتصالات جاده ای و طبقه بندی الگوهای آنها یک جزء مهم برای بسیاری از کاربردها است. به عنوان مثال، Ulugtekin و همکاران. [ 1 ] تاکید کرد که تقاطع های جاده ای باید به شیوه ای مناسب برای کاربرد ناوبری خودرو نشان داده شوند. Mackaness و Mackechnie [ 2 ]، Touya [ 3 ] و Yang و همکاران. [ 4] تاکید کرد که شناخت ساختارهای اتصالات برای تعمیم شبکه جاده ای با حفظ الگو ضروری است. علاوه بر این، شناخت اتصالات جادهای به تجزیه و تحلیل و مدیریت ترافیک [ 5 ، 6 ، 7 ] و برنامهریزی شهری و طراحی منظر [ 8 ] کمک میکند.
اتصالات جاده ای را می توان به طور کلی به دو دسته ساده یا پیچیده طبقه بندی کرد. تقاطعهای ساده، مانند چهارراههای مسطح و تقاطعهای جادهای T شکل، به عنوان تقاطعهایی تعریف میشوند که جادهها مستقیماً به هم میرسند، در حالی که اتصالات پیچیده دو یا چند جاده اصلی را از طریق جادههای لغزنده یا رمپ به هم متصل میکنند. اتصالات پیچیده شامل دو سناریو مختلف است: سازه های مسطح با جاده های لغزنده برای گردش صاف و مبادلات جدا از هم با سطح شیب دار که به وسایل نقلیه اجازه می دهد بدون وقفه از یک جاده به جاده دیگر حرکت کنند [ 9 ، 10 ، 11 ]]. به طور کلی، تقاطع های پیچیده مکان هایی هستند که جاده ها به صورت پیچیده به هم می رسند. بنابراین، اتصالات پیچیده دارای ساختارهای درونی پیچیده و اشکال مختلف خارجی هستند که تشخیص آنها و شناسایی الگوهای آنها را دشوار می کند. در عمل، تشخیص اتصالات پیچیده همچنان به بازرسی بصری دستی بستگی دارد که مستلزم هزینه های کار و زمان بالایی است.
در طول چند دهه گذشته، چندین رویکرد برای خودکارسازی تشخیص اتصالات پیچیده در شبکههای جادهای توسعه یافته است. به عنوان مثال، Mackaness و Macchechnie [ 2 ] روشی را برای مکان یابی اتصالات پیچیده با جستجوی مناطقی که گره های جاده در آنها پراکنده شده اند، پیشنهاد کردند. ایدههای مشابهی توسط Touya [ 3 ] و Zhou و Li [ 11 ] ایجاد شد، که اتصالات پیچیده را با خوشهبندی گرههای مشخصه جاده، از جمله گرههای Y شکل، Y شکل، چنگالشکل و چند پا شناسایی کردند. یانگ و همکاران با هدف حفظ یکپارچگی اتصالات پیچیده. [ 4 ] اصول طراحی راه را برای روشن کردن مرزهای توپولوژیکی اتصالات پیچیده معرفی کرد. لی و همکاران [ 9] از یک مدل تشخیص هدف، یعنی شبکه عصبی کانولوشنال با منطقه سریعتر، برای شناسایی مکانهای تبادل بر اساس نمایشهای شطرنجی شبکههای جادهای استفاده کرد. یانگ و همکاران [ 10 ] یک رویکرد یادگیری عمیق مبتنی بر نمودار را برای شناسایی بخشهای متعلق به مبادلات در شبکههای جادهای توسعه داد. ساختارهای تبادلی با خوشه بندی بخش های مبادله شناسایی شده به دست آمد.
رویکردهای فوق بر شناسایی محل اتصالات پیچیده در شبکه های جاده ای متمرکز شدند. در مقایسه، مطالعات کمی بر طبقه بندی الگوی اتصالات پیچیده شناسایی شده متمرکز شده اند. یک مطالعه اولیه توسط Xu و Yan [ 12 ] انجام شد که یک رویکرد مبتنی بر تطبیق الگو را برای طبقه بندی الگوهای اتصال پیچیده ایجاد کردند. در این رویکرد، یک تقاطع جاده برای اولین بار به عنوان یک نمودار ویژگی-رابطه جهتی نشان داده شد. سپس الگوی این اتصال با جستجوی الگوی با بیشترین شباهت در کتابخانه بر اساس نمایش نمودارها و قوانین از پیش تعریف شده طبقهبندی شد. وانگ و همکاران [ 13] از ویژگی های توپولوژیکی برای توصیف ساختارهای اتصال استفاده کرد تا با محاسبه شباهت توپولوژیکی، الگوی تطبیقی برای هر اتصال را شناسایی کند. با توجه به تنوع الگوهای پیوند پیچیده، این رویکردها دارای محدودیت هایی هستند. اول، آنها به شدت بر ویژگیهای طراحی دستی تکیه کردند و کتابخانههای الگو را ساختند، و در نتیجه در طبقهبندی اتصالات پیچیده با ساختارهای نامنظم مشکل داشتند. دوم، آنها به ناچار از مشکل تعیین آستانه در هنگام تعیین الگوهای ساختاری رنج می بردند.
در سالهای اخیر، شبکههای عصبی کانولوشنال (CNN) به سرعت توسعه یافتهاند و به موفقیتهای زیادی در زمینههای مختلف، از جمله تشخیص اشیا [ 14 ]، پردازش زبان طبیعی [ 15 ] و تشخیص گفتار [ 16 ] دست یافتهاند. در مقایسه با روشهای یادگیری ماشینی سنتی، CNNها میتوانند ویژگیهای سطح بالا را از ویژگیهای کم عمق به تصویر بکشند. این مزیت محققان را برانگیخته است تا از CNN و انواع آنها برای مدیریت داده های مکانی استفاده کنند [ 17 , 18 , 19]. از منظر شناخت بصری مصنوعی، طبقهبندی اتصالات جادهای مشابه طبقهبندی تصویر است. مطالعات اخیر پتانسیل CNN ها را برای توصیف و طبقه بندی اتصالات پیچیده بررسی کرده اند. ابتدا، پردازش تصویر برای تبدیل اتصالات مبتنی بر برداری به نمایش تصویر پیادهسازی شد و سپس یک طبقهبندی مبتنی بر CNN، مانند AlexNet [ 20 ]، U-net [ 21 ]، یا GoogLeNet [ 22 ] برای یادگیری ساخته شد. ویژگی های سطح بالا از نمونه های تصویر و طبقه بندی الگوهای اتصالات پیچیده. با غلبه بر محدودیتهای ویژگیهای طراحی شده مصنوعی، مدلهای یادگیری مبتنی بر CNN میتوانند عملکرد طبقهبندی اتصالات پیچیده را بهبود بخشند.
با این حال، این رویکردها دارای اشکالاتی هستند. یک مسئله معمولی این است که رویکردهای موجود از یک پوشش جغرافیایی ثابت برای تولید نمونههای تصویر استفاده میکنند. با توجه به اینکه اتصالات پیچیده اغلب از نظر اندازه و شکل متفاوت هستند، پوشش منطقه نمونه ثابت نمی تواند یکپارچگی و وضوح اتصالات اصلی را تضمین کند، که ممکن است منجر به نتایج طبقه بندی نادرست شود. به طور خاص، اگر پوشش منطقه برای یک اتصال پیچیده خیلی کوچک باشد، تصویر تولید شده نمی تواند ساختار اتصال را به طور کامل نشان دهد، و گرفتن ویژگی های کلی اتصال را دشوار می کند. برعکس، با پوشش منطقه بزرگتر، ساختارهای پیچیده محل اتصال دست نخورده هستند، اما وضوح تصویر کمتر است و اطلاعات خالی زیادی در تصویر وجود دارد که منجر به طبقه بندی اشتباه تصاویر شطرنجی می شود.
برای پرداختن به این موضوع، این مطالعه یک روش یادگیری گروه انباشته (SE) را برای طبقهبندی الگوهای اتصالات جادهای پیچیده پیشنهاد میکند. با ساخت و ترکیب الگوریتمهای یادگیری ماشینی متعدد، یادگیری مجموعهای میتواند بر معایب ناچیز بودن توزیع دادهها یا توانایی نمایش محدود یک مدل یادگیری غلبه کند و عملکرد طبقهبندی را بهبود بخشد [ 23 ، 24 ، 25 ، 26 ]. روش یادگیری گروهی را می توان به سه روش اجرا کرد: بسته بندی، تقویت و انباشتگی. در میان آنها، الگوریتم SE از یک استراتژی یادگیری برای ترکیب پیشبینیهای دو یا چند مدل برای دستیابی به عملکرد بهتر استفاده میکند. 27 ].]، که از نظر پایداری نسبت به استراتژیهای میانگینگیری یا رأیدهی مورد استفاده در دو الگوریتم گروه دیگر، مزایایی دارد. به طور خاص، الگوریتم SE ابتدا داده های آموزشی را به طور جداگانه با چندین طبقه بندی کننده (یعنی طبقه بندی کننده های پایه) پردازش می کند، سپس از یک طبقه بندی کننده جدید (یعنی متا طبقه بندی کننده) برای دریافت خروجی های طبقه بندی کننده های پایه به عنوان ورودی استفاده می کند و دوباره برای به دست آوردن آموزش می دهد. نتیجه طبقه بندی نهایی برای طبقهبندی اتصالات جادهای پیچیده، با توجه به عدم قطعیت توزیع فضایی آنها، ابتدا هر تقاطع را به تصاویری با پوششهای منطقه نمونهبرداری متعدد تبدیل کردیم. متعاقباً چندین طبقهبندی پایه با استفاده از نمونههایی با پوششهای سطح متفاوت آموزش داده شدند و بیشتر برای پیشبینی احتمالات هر پیوند متعلق به الگوهای مختلف مورد استفاده قرار گرفتند. سرانجام، یک متا طبقهبندی کننده برای ترکیب خروجیهای طبقهبندیکننده پایه و یادگیری طبقهبندی نهایی طراحی شده است. در این مطالعه، AlexNet [28 ] و GoogLeNet [ 29 ] به عنوان طبقهبندیکننده پایه، و الگوریتم جنگل تصادفی (RF) [ 30 ] بهعنوان متا طبقهبندیکننده پیادهسازی شد. برای تأیید اثربخشی روش پیشنهادی، یک مجموعه داده جدید و در دسترس عموم شامل اتصالات جادهای پیچیده با هفت نوع الگو برای آموزش و آزمایش طبقهبندیکنندههای پایه و متا ساخته شد.
ادامه این مقاله به شرح زیر سازماندهی شده است. روش پیشنهادی در بخش 2 توضیح داده شده است . بخش 3 نتایج تجربی، تجزیه و تحلیل و بحث را ارائه می دهد. بخش 4 نتیجه گیری را ارائه می کند.
2. روش شناسی
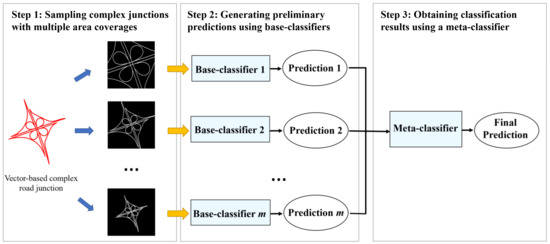
این مطالعه یک روش یادگیری SE را برای طبقهبندی الگوهای تقاطعهای جادهای پیچیده پیشنهاد میکند. هدف استراتژی یادگیری گروهی یافتن نتایج بهینه طبقهبندی با ترکیب خروجیهای دو یا چند طبقهبندیکننده پایه مبتنی بر CNN است که برای طبقهبندی انواع الگوی تقاطعهای جادهای با جمعآوری نمونههای تصویری با پوششهای منطقه نمونهبرداری مختلف ساخته شدهاند. شکل 1 چارچوب کلی روش پیشنهادی را نشان می دهد که شامل سه بخش اصلی است.
-
نمونهبرداری از اتصالات پیچیده با پوششهای چندگانه: برای هر پیوند پیچیده مبتنی بر برداری، چندین تصویر شطرنجی با اندازه ثابت با پوششهای ناحیه مختلف تولید میشوند تا به عنوان نمونههای ورودی برای طبقهبندیکنندههای پایه استفاده شوند.
-
ایجاد پیشبینیهای اولیه با استفاده از طبقهبندیکنندههای پایه متعدد: بر اساس نمونههای تصویری بهدستآمده برای هر منطقه پوشش، یک طبقهبندی پایه مبتنی بر CNN برای پیشبینی احتمالات اولیه هر اتصال پیچیده ساخته میشود.
-
به دست آوردن نتایج طبقه بندی با استفاده از یک متا طبقه بندی کننده: احتمالات اولیه برای هر اتصال پیچیده ایجاد شده توسط چندین طبقه بندی پایه به عنوان یک بردار ویژگی جدید ترکیب می شوند که به عنوان ورودی یک متا طبقه بندی کننده مبتنی بر RF برای خروجی نتیجه طبقه بندی نهایی عمل می کند.
2.1. نمونه برداری از اتصالات مجتمع با پوشش های مختلف
شکل 2 روند تولید یک تصویر شطرنجی از یک تقاطع جاده ای مبتنی بر برداری را نشان می دهد. ابتدا، برای یک اتصال جاده پیچیده استخراج شده از شبکه جاده بردار، مختصات X- و Y- نقطه میانی هر بخش جاده مرتبط محاسبه شد. دوم، مرکز هندسی ساختار تقاطع با میانگین مختصات نقاط میانی تمام بخشهای جاده محاسبه شد. بر اساس مرکز هندسی، یک مساحت مربع با طول معین، یعنی پوشش منطقه نمونه برداری، برای نمونه برداری از این اتصال برش داده شد. در نهایت، یک تصویر شطرنجی باینری با پسزمینه سیاه و بخشهای جاده به رنگ سفید برای تحقق شطرنجیسازی تقاطع جاده ایجاد شد.
برای هر اتصال پیچیده، تصاویر شطرنجی متعدد با تغییر پوشش منطقه نمونهبرداری تولید شد. تمام تصاویر شطرنجی تولید شده اندازه پیکسل یکسانی دارند. در طول فرآیند شطرنجی، توجه به این نکته مهم است که عرض خطوط بخش های اتصال به طور قابل توجهی بر تصاویر شطرنجی تولید شده تأثیر می گذارد. عرض کوچکتر ممکن است منجر به نمایش ناچیز ساختارهای اتصال شود، در حالی که عرض بزرگتر ممکن است باعث شود قطعات اتصال به یکدیگر بچسبند و اطلاعات ساختاری اتصال را از دست بدهند. برای توضیح این مشکل، پنج تصویر شطرنجی تولید شده با عرض خطوط مختلف در شکل 3 نشان داده شده است. در این تحقیق، با در نظر گرفتن شفافیت تصویر شطرنجی و داده های مورد نیاز برای ورودی مدل، اندازه تصاویر شطرنجی 250 × 250 پیکسل تعیین شد و عرض خط بخش های جاده با در نظر گرفتن تصویر به صورت تجربی روی دو پیکسل تنظیم شد. وضوح.
2.2. ایجاد پیشبینیهای اولیه با استفاده از طبقهبندیکنندههای پایه
بر اساس تصاویر شطرنجی بهدستآمده با پوششهای چند ناحیه، طبقهبندیکنندههای پایه متعدد برای پیشبینی احتمالات هر اتصال متعلق به انواع الگوهای مختلف ساخته شد. به عنوان یک نوع شبکه عصبی پیشخور با معماری عمیق [ 31 ]، CNN ها با ویژگی های هر لایه تولید شده توسط نواحی محلی لایه بالایی از طریق هسته های کانولوشن با وزن های مشترک مشخص می شوند که آنها را برای یادگیری و نمایش تصویر مناسب می کند. امکانات. بنابراین، این مطالعه از CNN به عنوان طبقهبندیکننده پایه استفاده کرد. دو معماری معروف CNN، AlexNet [ 28 ] و GoogLeNet [ 29]، به ترتیب به عنوان طبقهبندیکننده پایه برای به دست آوردن پیشبینی اولیه الگوهای تقاطعهای جادهای مورد استفاده قرار گرفتند. بخش های زیر عملیات اصلی در CNN ها و دو معماری را شرح می دهند.
2.2.1. عملیات اساسی در CNN ها
علاوه بر لایههای ورودی و خروجی، یک معماری معمولی CNN شامل چندین لایه کانولوشن و ادغام و یک یا چند لایه کاملاً متصل است.
(1) لایه های کانولوشن
لایه های کانولوشن ویژگی های مختلفی را از داده های تصویر خام از طریق عملیات کانولوشن استخراج می کنند. به عنوان مثال، لایه کانولوشنال پایین ویژگی های سطح پایین آشکار مانند لبه ها، گوشه ها و خطوط را استخراج می کند، در حالی که لایه کانولوشنال بالاتر ویژگی های سطح بالا پنهان را استخراج می کند. در لایه کانولوشن، نقشه ویژگی لایه قبلی با یک هسته کانولوشن کشویی در هم می پیچد و یک نقشه ویژگی جدید با استفاده از یک تابع فعال سازی غیرخطی به شرح زیر ایجاد می شود:
جایی که f( . )�.نشان دهنده تابع فعال سازی است، به عنوان مثال، تابع Softmax . g( من ، ج )�من،�و h ( i , j )ساعتمن،�نشان دهنده مقادیر ویژگی در موقعیت است ( من ، ج )من،�به ترتیب در نقشه ویژگی جدید و لایه قبلی؛ w ( k , l )�ک،لو ببهسته های کانولوشنال با اندازه هستند ک× Lک×�و تعصب
(2) لایه ادغام
هدف لایه ادغام به دست آوردن ویژگی های فضایی ثابت و فشرده سازی آنها با کاهش وضوح نقشه های ویژگی است. با نمایش داده ها در یک منطقه، یعنی پنجره ادغام، به عنوان یک مقدار واحد پیاده سازی می شود. Max-pooling به طور گسترده برای طراحی معماری CNN استفاده می شود. این عملیات حداکثر مقدار منطقه را به عنوان مقدار پس از ادغام انتخاب می کند که برای فیلتر کردن نویز و اطلاعات بی فایده پس زمینه زمانی که فقط بخشی از اطلاعات مفید در ویژگی ها وجود دارد مناسب است. نتایج حداکثر ادغام به صورت زیر محاسبه می شود:
جایی که g( من ، ج )�من،�و h ( i , j )ساعتمن،�نشان دهنده مقادیر ویژگی در موقعیت است ( من ، ج )من،�در نقشه ویژگی جدید پس از حداکثر ادغام و لایه قبلی به ترتیب. ککو L�به ترتیب اندازه پنجره ادغام را مشخص کنید. ممو نناندازه گام هستند.
(3) تابع Softmax
برای اطمینان از اینکه نتیجه طبقه بندی خروجی نهایی با توزیع احتمالات مطابقت دارد، یعنی هر مقدار از 0 تا 1 و مجموع آن 1 است، یک لایه Softmax طراحی شده است. احتمال تعدیل شده پ(اسمن)پاسمنبرای نوع اسمن ( 1 ≤ i ≤ n )اسمن 1≤من≤�به صورت زیر محاسبه می شود:
جایی که gمن�منو gj��مقدار خروجی قبلی این نوع را نشان می دهد و n�تعداد انواع را نشان می دهد. تابع Softmax نیز اغلب به عنوان یک تابع فعال سازی برای لایه های کانولوشن استفاده می شود.
2.2.2. الکس نت
AlexNet توسط Krizhevsky و همکاران پیشنهاد شد. [ 28 ]، و در رقابت ImageNet با اختلاف زیادی نسبت به سایر الگوریتمهای شبکههای عصبی پیروز شد. AlexNet یک CNN 8 لایه است، همانطور که در شکل 4 نشان داده شده است. پنج لایه اول لایه های کانولوشن، سه لایه آخر لایه های کاملاً متصل هستند و در لایه آخر از Softmax استفاده شده است.
الکس نت مرز بین شبکه های عصبی کم عمق و عمیق است. در مقایسه با شبکههای عصبی سنتی، برای اولین بار از تکنیکهای بسیاری از جمله واحدهای خطی اصلاحشده ( ReLU ) و Dropout برای تسریع آموزش مدل و بهبود قابلیت نمایش مدل استفاده میکند. همچنین یک لایه نرمال سازی پاسخ محلی (LRN) را معرفی کرد که نرمال سازی جزئی خروجی ReLU را با همسایگان خود در یک محدوده مشخص انجام می داد. مقادیر نرمال شده بمن( x ، y)بایکس،�منبه صورت زیر محاسبه شدند:
جایی که آمن( x ، y)آایکس،�مننشان دهنده خروجی در موقعیت است ( x ، y)ایکس،�هسته کانولوشن i-ام بعد از تابع ReLU .n�تعداد همسایگان است آمن( x ، y)آایکس،�من، که خود تعریف می شود. ننتعداد کل هسته های کانولوشن است. α�، β�، ککضرایب خود تعریف شده هستند. معرفی LRN به همگرایی سریع کمک می کند و توانایی تعمیم مدل را برای یادگیری ویژگی بهبود می بخشد.
2.2.3. GoogleNet
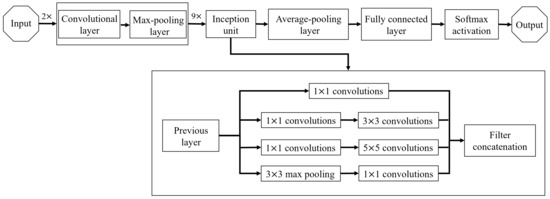
GoogLeNet یک معماری عمیق است که توسط Szegedy و همکارانش پیشنهاد شده است. [ 29 ] که در آن سال در مسابقه ImageNet مقام اول را کسب کرد. در GoogLeNet، یک واحد نورون پایه، یعنی ساختار Inception ، برای ساختن یک شبکه عملکرد محاسباتی پراکنده اما بالا طراحی شده است، همانطور که در شکل 5 نشان داده شده است. واحد Inception می تواند از منابع محاسباتی بهینه استفاده کند و ویژگی های بیشتری را با همان مقدار محاسبات استخراج کند و در نتیجه نتایج آموزشی را بهبود بخشد.
واحد Inception از یک ساختار موازی با چهار شاخه تشکیل شده است. از طریق این چهار شاخه، می توان نقشه های مشخصه در مقیاس های مختلف را به دست آورد و سپس در جهت عمق برای به دست آوردن یک نقشه ویژگی جدید به هم متصل کرد. یک مدل 22 لایه GoogLeNet بر اساس واحد Inception ساخته شد. تصویر ورودی پس از دو لایه کانولوشن و حداکثر لایه ادغام به 9 واحد Inception داده شد. تغییر GoogLeNet به دلیل طراحی ماژولار واحدهای Inception آسانتر است. شبکه در نهایت از ادغام متوسط به جای لایه کاملا متصل استفاده کرد اما همچنان از Dropout استفاده کرد. علاوه بر این، برای جلوگیری از ناپدید شدن گرادیان، دو وسیله کمکی اضافی وجود دارد Softmax کمکی اضافی وجود داردتوابع برای هدایت شیب به جلو اضافه شدند.
2.3. به دست آوردن نتایج نهایی طبقه بندی با استفاده از یک متا طبقه بندی کننده
همانطور که در شکل 6 نشان داده شده است، طبقه بندی کننده های پایه آموزش دیده برای پیش بینی نوع اتصال ورودی استفاده شدند. خروجیهای این طبقهبندیکنندههای پایه، که نشاندهنده این احتمال است که اتصال ورودی به انواع الگوهای مختلف تعلق دارد، سپس به عنوان ورودی ویژگی برای متا طبقهبندیکننده ترکیب شدند تا نتایج طبقهبندی نهایی را به دست آورند. در این مطالعه، یک مجموعه انباشته با استفاده از مدل RF برای ترکیب نتایج پیشبینی از طبقهبندیکنندههای پایه فردی برای تصمیم نهایی اتخاذ شد.
به عنوان یک الگوریتم یادگیری ماشینی انعطافپذیر و کارآمد، مدل RF نتایج رضایتبخشی را بدون تنظیم فراپارامتر پیچیده ایجاد میکند. مدل RF شامل درخت های تصمیم گیری چندگانه است و کلاس هایی که خروجی می دهد توسط حالت کلاس هایی که درختان خروجی می دهند تعیین می شوند. از آنجایی که درختهای تصمیم ادغام شده در مدل RF مستقل از یکدیگر هستند، آموزش سریع و آسان به موازیسازی میشود و مدل RF را برای کارهای طبقهبندی مناسب میکند. عملکرد مدل RF تحت تأثیر چندین پارامتر از جمله n_estimators است که تعداد درخت های تصمیم را نشان می دهد و max_depth می باشد.، که بیانگر حداکثر عمق درختان تصمیم است. در طول آموزش مدل، این پارامترها باید به طور مناسب با توجه به مجموعه داده تنظیم شوند تا دقت مدل بهبود یابد.
3. آزمایشات
آزمایشهایی برای اعتبارسنجی روش پیشنهادی انجام شد. این بخش مجموعه دادههای آزمایشی، تنظیمات، نتایج، تحلیلها و بحث را شرح میدهد.
3.1. داده های تجربی و پیش پردازش
3.1.1. داده های تجربی
داده های تجربی به صورت دستی از شبکه های جاده ای 30 شهر در چین، از جمله ووهان، شانگهای، هانگژو و نانجینگ استخراج و از OpenStreetMap (OSM) دانلود شدند ( www.openstreetmap.org ، در 20 مارس 2021 مشاهده شد). این شهرها دارای مناطق نسبتاً وسیع، امکانات حمل و نقل جاده ای فراوان و اتصالات جاده ای با انواع و ساختارهای متنوع هستند. با توجه به ویژگیهای مورفولوژیکی و شکل، اتصالات جادهای پیچیده جمعآوریشده به هفت نوع معمولی، از جمله پروانه، برگ شبدر، الماس، T شکل، ترومپت، توربین و موارد دیگر طبقهبندی شدند که در شکل 7 نشان داده شده است. در مجموع 150 نمونه برای هر نوع اتصال جمع آوری شد که در مجموع 1050 نمونه بود.
3.1.2. افزایش نمونه
تعداد کافی نمونه برای اطمینان از ثبات آموزشی و بهبود دقت طبقه بندی مدل نظارت شده CNN مهم است. بنابراین، دو روش افزایش داده ها برای افزایش تعداد اتصالات جمع آوری شده به کار گرفته شد. از آنجایی که تغییر جهت یک تقاطع جاده بر تشخیص الگو تأثیر نمی گذارد، ابتدا یک روش چرخشی اجرا شد. به طور خاص، هر نمونه اتصال مبتنی بر بردار 90 درجه، 180 درجه و 270 درجه چرخانده شد. دوم، عملیات آینه ای برای هر نمونه در جهت بالا-پایین و چپ-راست استفاده شد. در نتیجه تعداد نمونه های اتصال به 6300 نمونه رسید که شش برابر نمونه های اولیه بود. متعاقباً، تمام نمونهها با نسبت 6:2:2 به مجموعههای آموزشی، اعتبارسنجی و آزمایشی با تعداد کل نمونهها به ترتیب 3780، 1280 و 1280 تقسیم شدند.
3.2. تنظیمات پارامتر
برای تعیین پوشش منطقه نمونهبرداری مناسب و همچنین تعداد طبقهبندیکنندههای پایه در مدلهای SE، اندازههای حداقل مربعهای مرزی [ 22 ] برای همه اتصالات جادهای جمعآوریشده شمارش شد، و توزیعها در شکل 8 نشان داده شدهاند .
پوششهای منطقه نمونههای پیوند جمعآوریشده بسیار متفاوت بود، با حداکثر پوشش بیش از 2000 × 2000 متر مربع و حداقل پوشش کمتر از 250 × 250 متر مربع . طبق آمار، سه پوشش مختلف منطقه، یعنی 500 × 500 متر مربع ، 1000 × 1000 متر مربع ، و 1500 × 1500 متر مربع ، برای تولید تصاویر شطرنجی برای هر نمونه اتصال تنظیم شد. نمونه هایی از هفت نوع نمونه اتصال تحت پوشش سه منطقه در جدول 1 فهرست شده است.
در آموزش مدل GoogLeNet، برخی از پارامترها چندین بار مطابق با ویژگی های اتصالات جمع آوری شده تنظیم شدند. در نهایت، نرخ یادگیری روی 0.02، اندازه دسته روی 16، حداکثر تعداد تکرار روی 30000، مقدار Dropout روی 0.8، و کاهش وزن روی 0.00004 تنظیم شد تا از همگرایی اطمینان حاصل شود. مدل ها. برای مدل AlexNet، نرخ یادگیری، اندازه دستهای و Dropout مانند مدل GoogLeNet، حداکثر تکرار روی 20000 و کاهش وزن روی 0.0005 تنظیم شد. برای مدل RF، پارامتر n_estimators و max_depthبه ترتیب روی 200 و 10 تنظیم شدند. علاوه بر این، یک گره باید حداقل دو نمونه آموزشی داشته باشد تا بتواند منشعب شود، و هر فرزند یک گره بعد از یک شاخه باید حداقل یک نمونه برای اطمینان از کارایی و دقت آموزش داشته باشد.
3.3. معیارهای ارزیابی
عملکرد طبقهبندی کلی نمونههای آزمایشی به صورت کمی با استفاده از متریک دقت ، که به عنوان نسبت تعداد نمونههای طبقهبندی صحیح به تعداد کل نمونهها تعریف میشود، ارزیابی شد. علاوه بر این، برای هر نوع الگو، از سه معیار، یعنی دقت ، یادآوری و F 1 برای ارزیابی نتایج طبقهبندی استفاده شد. سه معیار به صورت زیر محاسبه شد:
که در آن TP ، FP ، و FN به ترتیب تعداد نتایج طبقه بندی مثبت درست، مثبت کاذب و منفی کاذب هستند.
3.4. نتایج و تجزیه و تحلیل
نتایج طبقهبندی برای مجموعه آزمون با استفاده از طبقهبندیکنندههای پایه مختلف و روش SE در جدول 2 فهرست شدهاند . اول، دقت طبقهبندی طبقهبندیکنندههای پایه مبتنی بر GoogLeNet و مدل SE به طور قابلتوجهی بالاتر از طبقهبندیکنندههای پایه مبتنی بر AlexNet و مدل SE بود. این نتیجه ممکن است به قابلیت نمایش مدل های CNN نسبت داده شود. مهمتر از آن، مدلهای SE به طور قابلتوجهی بهتر از طبقهبندیکنندههای پایه آموزشدیده با استفاده از نمونههایی با پوشش منطقه نمونهگیری ثابت عمل کردند. متریک دقت مدل SE مبتنی بر AlexNet به 78.9 درصد رسید که 5 تا 6 درصد بیشتر از طبقهبندیکنندههای پایه با پوشش منطقه متفاوت بود. برای مدل SE مبتنی بر GoogLeNet، دقتمتریک به 92.4٪ رسید که 6 تا 14٪ بیشتر از طبقه بندی های پایه بود.
سه نمونه از نتایج طبقه بندی در ارائه شده است جدول 3 ارائه شده است. از طریق یادگیری گروهی، اتصالات با پوشش منطقه بسیار کوچک یا بزرگ که در برخی از پوششهای منطقه نمونهبرداری اشتباه طبقهبندی شده بودند، میتوانند اصلاح شوند (مورد 1 و مورد 2). برای برخی از اتصالات که از نظر شکل و ساختار کلی شبیه به انواع دیگر اتصالات هستند (مورد 3)، ویژگی های محلی در یک منطقه کوچک پوشش برای شناسایی الگوهای آنها مهم است و یادگیری مجموعه می تواند از این تفاوت های جزئی به خوبی استفاده کند. ویژگی های محلی برای به دست آوردن نتایج طبقه بندی صحیح. نتایج نشان میدهد که یادگیری گروهی مزایای دستهبندیهای پایه قبلی را حفظ میکند و کاستیهای طبقهبندی برخی از اتصالات را برطرف میکند. در نتیجه، عملکرد طبقه بندی به طور قابل توجهی بهبود یافت، که کارایی روش پیشنهادی را تأیید می کند.
جدول 4 و جدول 5 ماتریس های سردرگمی و سه معیار نتایج طبقه بندی را برای اتصالات جاده آزمایشی با استفاده از مدل های SE مبتنی بر AlexNet و GoogLeNet به ترتیب فهرست می کنند. دقت و یادآوری _معیارهای اتصالات از نوع Cloverleaf در هر دو مدل بالا بود زیرا آنها شامل چهار بخش جاده هستند که ویژگی های بصری آنها را قابل توجه می کند. برای برخی از اتصالات نوع پروانه و نوع توربین، هر دو مدل دارای طبقه بندی نادرست بودند و مدل SE مبتنی بر AlexNet دارای طبقه بندی بیشتری بود. مدل SE مبتنی بر GoogLeNet عملکرد نسبتاً خوبی در طبقه بندی اتصالات نوع الماس و ترومپت داشت، در حالی که مدل SE مبتنی بر AlexNet برخی از اتصالات نوع الماس را به عنوان اتصالات T شکل یا ترومپت شناسایی کرد و برخی از T را به اشتباه طبقه بندی کرد. اتصالات شکل و شیپور. علاوه بر این، طبقهبندی نادرستی بین اتصالات نوع دیگر و شش نوع دیگر از اتصالات وجود داشت که در مدل مبتنی بر AlexNet حتی جدیتر بود.
علاوه بر این، برخی از نمونههای اتصالات طبقهبندی نشده برای کشف دلایل احتمالی، همانطور که در شکل 9 نشان داده شده است، تجزیه و تحلیل شدند.. مشاهده می شود که اگر مورفولوژی یک اتصال به طور قابل توجهی با اتصالات معمولی آن متفاوت باشد، مدل احتمالاً یک طبقه بندی نادرست ایجاد می کند، علیرغم این واقعیت که اتصالات بین بخش های جاده آنها تقریباً یکسان است. این نتیجه نشان میدهد که مدلهای پیشنهادی بیشتر بر مورفولوژی و ساختار کلی اتصالات در طول طبقهبندی تمرکز میکنند. با این حال، اتصالات بین بخشهای جاده نیز معیارهای مهمی برای طبقهبندی دستی هستند، اگرچه در فرآیند مدلهای یادگیری ماشینی مبتنی بر تصویر ضعیف میشوند. در این شرایط، رابطه توپولوژیکی بین بخشهای جاده باید بیشتر مورد توجه قرار گیرد و یک مدل یادگیری عمیق مبتنی بر نمودار ممکن است یک راهحل بالقوه برای این منظور باشد.
3.5. بحث
برای بررسی تأثیر تعداد مختلف طبقهبندیکنندههای پایه بر روی یادگیری گروه انباشته، تصاویر شطرنجی برای اتصالات با پوششهای ناحیه نمونهبرداری متفاوت برای آموزش طبقهبندیکنندههای پایه و متا تولید شد. به طور خاص، ما دو پوشش منطقه 500 × 500 متر مربع و 1500 × 1500 متر مربع را برای مطابقت با دو طبقهبندی پایه طراحی کردیم. چهار پوشش منطقه 500 × 500 متر مربع ، 750 × 750 متر مربع ، 1000 × 1000 متر مربع ، و 1500 × 1500 متر مربع مربوط به چهار طبقه بندی پایه. و پنج منطقه نمونه برداری 500 × 500 متر مربع , 750 × 750 متر مربع , 1000 × 1000 متر مربع , 1250 × 1250 متر مربع، و 1500 × 1500 متر مربع2 مربوط به پنج طبقه بندی پایه. دقت طبقه بندی مدل های SE با تعداد مختلف طبقه بندی کننده پایه در جدول 6 ارائه شده است.
مشاهده شد که دقت طبقهبندی مدلهای SE مبتنی بر AlexNet و GoogLeNet در ابتدا افزایش مییابد و سپس با افزایش تعداد طبقهبندیکنندههای پایه کاهش مییابد و زمانی که تعداد طبقهبندیکنندههای پایه سه بود به بالاترین حد خود رسید. این نتیجه نشان میدهد که تعداد طبقهبندیکنندههای پایه بر دقت طبقهبندی یادگیری گروه تأثیر میگذارد. افزایش مناسب در تعداد طبقهبندیکنندههای پایه میتواند به طور موثری دقت یادگیری گروه را بهبود بخشد. با این حال، لزوما بهتر نیست. یکی از دلایل احتمالی این نتیجه این است که افزایش تعداد طبقهبندیکنندههای پایه منجر به افزایش سریع بعد ویژگی ورودی به متا طبقهبندیکننده میشود، بنابراین بر عملکرد طبقهبندی متا طبقهبندیکننده تأثیر میگذارد. در این مطالعه،
3.6. تست در شهرهای دیگر
برای تأیید بیشتر توانایی تعمیم روش یادگیری گروهی، اتصالات جاده از چهار شهر دیگر، به عنوان مثال، پکن، چنگدو، گوانگژو، و چونگ کینگ، برای انجام یک آزمایش اضافی استفاده شد. رویکرد معرفی شده در [ 10 ] برای شناسایی اتصالات جاده ای پیچیده از شبکه های جاده ای این شهرها استفاده شد. در نتیجه، 217، 90، 109 و 156 تقاطع پیچیده به ترتیب در پکن، چنگدو، گوانگژو و چونگ کینگ شناسایی شدند. توزیع انواع اتصالات در هر شهر در جدول 7 ارائه شده است .
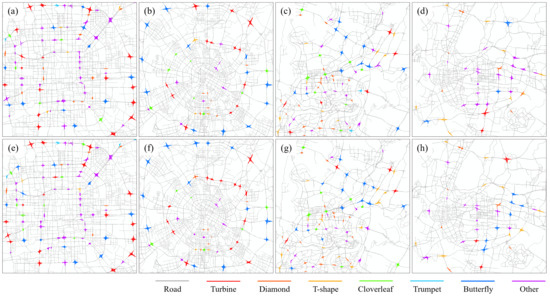
نتایج طبقه بندی اتصالات پیچیده در چهار شهر با استفاده از مدل های SE مبتنی بر AlexNet و GoogLeNet در شکل 10 نشان داده شده است ، که در آن از رنگ های مختلف برای علامت گذاری انواع مختلف اتصالات استفاده می شود. دقت طبقه بندی اتصالات در چهار شهر با استفاده از مدل های SE در جدول 8 فهرست شده است.
همانطور که در جدول 8 نشان داده شده است ، اگرچه توزیع تعداد انواع مختلف اتصالات در هر شهر بسیار متفاوت است، بیش از 70 درصد از اتصالات در چهار شهر به درستی طبقه بندی شده اند. دقت طبقهبندی مدل SE مبتنی بر GoogLeNet برای چهار شهر بیشتر از مدل SE مبتنی بر AlexNet است که با نتایج آزمایشهای قبلی دادهها مطابقت دارد. به طور کلی، این نتیجه تأیید می کند که روش پیشنهادی اتصالات در شهرهای مختلف را به خوبی طبقه بندی می کند و توانایی تعمیم مدل را اثبات می کند.
4. نتیجه گیری
این مطالعه یک روش یادگیری گروهی را برای طبقهبندی الگوهای تقاطعهای جادهای پیچیده ارائه میکند. برخلاف روشهای طبقهبندی مبتنی بر یادگیری عمیق موجود، روش پیشنهادی شامل چند طبقهبندی پایه و یک متا طبقهبندیکننده است. هر طبقهبندیکننده پایه، نوع هر تقاطع جادهای پیچیده را با یادگیری ویژگیهای تصاویر شطرنجی تولید شده از اتصالات مبتنی بر برداری با پوششهای ناحیه نمونهبرداری متفاوت، پیشبینی میکند. سپس، متا طبقهبندیکننده، پیشبینیهای اولیه این دستهبندیکنندههای پایه را برای به دست آوردن پیشبینی نهایی ترکیب میکند. دو معماری یادگیری عمیق محبوب، AlexNet و GoogLeNet، برای ساختن طبقهبندیکنندههای پایه استفاده شدند و مدل RF به عنوان متا طبقهبندیکننده استفاده شد.
نتایج تجربی نشان می دهد که عملکرد طبقه بندی پس از استفاده از روش SE بهبود یافته است. متریک دقت مدل SE مبتنی بر GoogLeNet به 92.4 درصد رسید که 6 تا 14 درصد بیشتر از طبقهبندیکنندههای پایه بود. یعنی مدلهای GoogLeNet با استفاده از تصاویر شطرنجی از یک منطقه نمونهبرداری منفرد آموزش دیدهاند. ایندقتمتریک مدل SE مبتنی بر AlexNet به 78.9٪ رسید که 5 تا 6٪ بیشتر از طبقه بندی های پایه است. این نتایج نشان میدهد که روش SE پیشنهادی میتواند به طور موثر مشارکتهای طبقهبندیکنندههای مختلف را که بر اساس نمایشهای شطرنجی اتصالات پیچیده با پوششهای ناحیه مختلف آموزش داده شدهاند، ترکیب کند. علاوه بر این، ثابت شده است که این روش قابلیت تعمیم خوبی دارد و می تواند برای طبقه بندی تقاطع های جاده ای در شهرهای مختلف استفاده شود.
کار آینده بر افزایش تنوع نمونه ها برای بهبود جهانی بودن روش پیشنهادی برای طبقه بندی اتصالات جاده ای پیچیده متمرکز خواهد بود. علاوه بر این، اتصالات توپولوژیکی بین بخشهای جاده را میتوان برای بهبود کمبود مدل مبتنی بر شطرنجی در نظر گرفت، مانند ساخت یک مدل یادگیری عمیق مبتنی بر نمودار بهعنوان یک طبقهبندی پایه برای مشارکت در یادگیری گروهی. علاوه بر این، استراتژیهای مختلف یادگیری گروهی دیگر، مانند ادغام دادههای چند منبع (مسیرها، و غیره)، برای بهبود بیشتر دقت طبقهبندی، مستحق توجه هستند.











بدون دیدگاه