1. معرفی
شیوع خاکستر زمرد (EAB, Agrilus planipennis Fairmaire ) در ایالت های دریاچه های بزرگ ایالات متحده و جنوب غربی انتاریو، کانادا برای اولین بار در سال 2002 کشف شد [ 1 ، 2 ]. به دلیل ماهیت مخفیانه و مخرب خود و بدون دشمنان طبیعی در آمریکای شمالی، EAB به طور تهاجمی به میلیون ها درخت خاکستر در این مناطق حمله کرده و آنها را کشته و به طور پیوسته دامنه خود را در طول زمان گسترش داده است [ 1 ، 2 ]. استراتژیهای تشخیص و کنترل آلودگی EAB در کانادا عمدتاً به بررسیهای بصری و حذف انتخابی درختان بستگی دارد [ 3 ]]، که راهبردهای دشواری برای انجام در مناطق وسیع هستند. علاوه بر این، قابل شناسایی ترین علائم معمولاً تنها یک سال پس از آلودگی اولیه آشکار می شوند [ 4 ، 5 ]، که ممکن است برای اجرای استراتژی های کاهش بسیار دیر باشد. در نتیجه پیشگیری و کنترل شیوع سوسک امری ضروری شده است. برای دستیابی به این اهداف، مهم است که با دقت بالا گسترش EAB در مکانهای درخت خاکستر در حال حاضر بیتأثیر پیشبینی شود. در این راستا، استفاده از مدلهای توزیع گونهها (SDMs) ابزار مفیدی برای پیشبینی مناطق با سطح خطر بالا و همچنین شناسایی عوامل خطر مربوطه فراهم میکند.
مدل های خطی تعمیم یافته (GLMs) به طور گسترده در تحقیقات محیطی برای SDM ها که متغیرهای پاسخ طبقه بندی مرتبط هستند استفاده می شود [ 6 ]. با تجزیه و تحلیل مکانهای بررسیشده (دادههای آموزشی) با استفاده از GLM، مهمترین پیشبینیکنندهها برای افتراق درختان خاکستر سالم از آنهایی که در حال حاضر آلوده هستند، شناسایی میشوند. مدلهای تولید شده برای پیشبینی سطوح خطر آلودگی EAB در سالهای آینده مفید هستند، که مبنایی برای ابداع استراتژیهای کاهش خطر و تستهای حساسیت برای تشخیص قرار گرفتن در معرض خطر فراهم میکند. گسترش GLMها، مانند مدلهای افزایشی تعمیمیافته (GAMs) و مدلهای رگرسیون وزندار جغرافیایی (GWR)، رویکردهای قوی هستند که به طور گسترده برای مدلسازی پیشبینیکنندههای غیرخطی و اثرات محلی هر پیشبینیکننده استفاده میشوند [ 7 ، 8 ]]. با این حال، GLM ها و الحاقات آنها ممکن است لزوماً در برخورد با داده هایی که از نظر مکانی همبستگی خودکار دارند، مؤثر نباشند و مسائل آماری را در تخمین و پیش بینی ایجاد کنند [ 8 ، 9 ]. به عنوان مثال، همبستگی خودکار داده ها اغلب منجر به یک مدل بیش از حد برازش می شود که توانایی پیش بینی یک مجموعه داده مستقل را ندارد.
یک روش ساده برای کاهش اثرات مخدوش کننده خودهمبستگی، نمونه برداری از یک مشاهده در هر محله بر اساس یک آستانه از پیش تعیین شده است [ 9 ]. با این حال، این استراتژی ایده آل نیست، زیرا از داده های میدانی بالقوه مهم ممکن است به طور کامل مورد بهره برداری قرار نگیرد. به عنوان مثال، در مناطقی که همبستگی فضایی بالا آشکار است، نمونههای بیشتری باید حذف شوند، که میتواند تأثیر نامطلوبی بر توانایی پیشبینی مدل داشته باشد. روش دیگر، مدلهای اثرات مختلط، مانند مدلهای مختلط خطی (LMMs)، مدلهای متغیر پنهان (LVMs)، و مدلهای مختلط خطی تعمیمیافته (GLMMs) میتوانند مسئله همبستگی درون خوشهای را برطرف کنند [ 10 ، 11 ، 12 ، 13 ، 14 .].
با این رویکردهای اثر مختلط، می توان از ساختار مدل سلسله مراتبی برای تجزیه و تحلیل سطوح چندگانه داده استفاده کرد. سطح پایه کل منطقه مورد مطالعه جغرافیایی را با پیش بینی کننده های خطر مورد علاقه مدل می کند. در سطوح بالاتر، خوشه های فضایی جداگانه، که به عنوان اثرات تصادفی نامیده می شوند، می توانند برای گروه بندی داده ها به منظور اندازه گیری حضور خود همبستگی گنجانده شوند. در این زمینه، GLMM ها به طور گسترده برای تجزیه و تحلیل داده های اکولوژیکی، از جمله داده های حضور-غیاب، تعداد گونه های بیش از حد پراکنده، و داده های پوشش درصد گسسته استفاده می شوند [ 15 ، 16]، که می تواند برای تجزیه و تحلیل فضایی داده های گونه EAB مفید باشد. با این حال، اجرای GLMMها به ساختار مناسبی از اثرات تصادفی برای ارائه خوشههای مناسب در مرحله برازش مدل نیاز دارد. این مطالعه به دنبال توسعه روشهای خوشهبندی فضایی مؤثر برای طبقهبندی دادههای گونهها و یک GLMM با خوشههای فضایی برای ساخت SDMs برای شناسایی پیشبینیکنندههای خطر مهم و پیشبینی توزیع EAB است.
در ارزیابی ریسک مرسوم، نشان داده شده است که عوامل آب و هوایی تأثیر مهمی بر پراکنش گونه های مهاجم دارند [ 17 ، 18 ]. در یک منطقه جغرافیایی بزرگ، دمای سطح کلی، بارندگی و سرعت باد می تواند ترجیحات زیستگاه گونه ها را آشکار کند. در همین حال، تحقیقات دیگر [ 4 ، 19 ، 20] به تأثیرات غیرمستقیم عوامل انسانی که می تواند با تکثیر گونه های دوردست مرتبط باشد، پرداخته است. از این رو، در مقایسه با رویکردهای سنتی، مطالعه EAB در سراسر منطقه جنوبی انتاریو میتواند پیچیده باشد و شرایط از سالی به سال دیگر ممکن است متفاوت باشد. برای اجازه دادن به این امر، ما عوامل مکانی و زمانی را در SDMs مورد استفاده در این تحقیق قرار دادیم [ 9 ، 21 ، 22 ]]. این عوامل شامل سال بررسی میدانی، فاصله بین نمونه ها و نزدیکترین نقاط حضور گونه از بررسی قبلی بود. ما عوامل خطر مختلف را در SDMs پیشنهادی، مانند عوامل اقلیمی، جغرافیایی فیزیکی، زیستی، انسانی، و مکانی-زمانی ادغام کردیم و ارتباط آنها را با توزیع گسترش EAB از طریق SDM های مختلف تجزیه و تحلیل کردیم.
برای برآورد اهمیت عوامل خطر و کاهش پیچیدگی مدل، از انتخاب مدل گام به گام بر اساس اطلاعات بیزی استفاده شد. ما دقت طبقهبندی نقاط حضور و غیاب را از طریق اعتبارسنجی متقاطع بررسی کردیم. نتایج مدلسازی GLMM با دو اثر تصادفی فضایی پیشنهادی با مدل رگرسیون لجستیک مقایسه شد. مدلی که بالاترین دقت پیشبینی را ارائه میدهد برای تولید نقشه ریسک برای توزیع EAB استفاده شد و یک تحلیل سناریوی جامع برای ارزیابی ریسک انجام شد.
2. مواد و روشها
2.1. داده ها
2.1.1. داده های گونه
داده های گونه مورد استفاده در این تحقیق از سال 2006 تا 2012 توسط آژانس بازرسی مواد غذایی کانادا (CFIA) جمع آوری شد [ 23 ]]. اکثر نمونهها از طریق تلههای منشور سبز و بررسیهای بصری بهدست آمدند، با نسبت کمتری از نمونهها از طریق نمونهگیری شاخهای. تلههای منشوری و بررسیهای بصری نشان میدهند که آیا درختان آلوده هستند یا خیر، در حالی که نمونهبرداری شاخه تعداد مشخصی از سوسکهای EAB شناساییشده را فراهم میکند و همچنین پرهزینهتر و کار فشردهتر است. نمونهبرداری در مناطق خاصی انجام شد که EAB به طور بالقوه میتوانست از طریق فعالیتهای انسانی مانند مناطقی با کاهش گونههای خاکستر قابل مشاهده، مراکز شهری، پارکهای استانی، اردوگاهها، توقفگاههای استراحت در امتداد راهروهای حملونقل اصلی، و انبارهای مهد کودک خاکستر معرفی شود. از نظر جابجایی عمومی مکانهای نظرسنجی از یک سال به سال دیگر، هر بار که حضور EAB در یک شهرستان در منطقه مورد مطالعه از سال 2004 تأیید میشد، شهرستان تنظیم شده اعلام شد و نمونه برداری در سالهای بعد در همان شهرستان انجام نخواهد شد. یک نمای کلی از نقاط حضور و غیاب EAB بر اساس این داده ها نمایش داده می شودشکل 1 و خلاصه سالانه نقاط حضور و غیبت در جدول 1 ارائه شده است .
در مجموع، 11229 نقطه غیبت و 250 نقطه حضور در سراسر جنوب انتاریو بین سالهای 2006 و 2012 جمعآوری شد. نقاط حضور هجومهای شناخته شده EAB در 23 از 46 شهرستان در منطقه مورد مطالعه شناسایی شد، و بیشتر آنها در منطقه عمومی بودند. دریاچههای ایری و انتاریو، نزدیک به مرز کانادا و ایالات متحده و در یا مجاور شهرهای بزرگ. بسیاری از درختان زبان گنجشک در بخشهای شمالی منطقه مورد مطالعه سالم ماندند و هیچ حضور EAB در این مناطق بین سالهای 2006 و 2012 مشاهده نشد. از آنجایی که مناطق شناساییشده فقط یک بار بازدید شدند، نمونههای بیشتری بین سالهای 2006 و 2008 نسبت به سالهای بعد به دست آمد. به عنوان مثال، در سال 2008، بررسی های میدانی بیشترین تعداد نقاط حضور را شناسایی کردند و در سال بعد نقاط نمونه کمتری به دست آمد. نتایج استراتژی نمونه گیری،جدول 1 ، این پتانسیل را دارد که منجر به نمونه های متناقض و مغرضانه شود [ 3 ، 9 ]. با این حال، از آنجایی که یکی از اهداف این تحقیق، تحلیل حرکت EAB در طول زمان است، میتوان یک الگوی گسترش را در طول دوره تحقیق مورد بررسی قرار داد. از این رو، در اعتبارسنجی مدل، تأثیر زمان بر گسترش سوسک گنجانده شد. ساده ترین رویکرد برای تعیین کمیت این عامل، استفاده از تاریخ نقاط نمونه برداری بود که در این مطالعه اتخاذ شد.
2.1.2. پیش بینی کننده های ریسک
بر اساس Hoque et al. (2020) [ 9 ]، چهار پیش بینی کننده خطر مختلف جمع آوری و برای روابط بالقوه با توزیع مکانی-زمانی EAB ( جدول 2 ) تجزیه و تحلیل شدند. مقادیر کمکی پیشبینیکنندههای ریسک بهدلیل منابع داده، با توجه به واحدها و اشکال مختلف اندازهگیری آنها، بهطور متمایز متغیر بود. برای غلبه بر این، هر پیشبینیکننده خطر به شبکهای 1 کیلومتر در 1 کیلومتر تنظیم شد که با دادههای گونه جمعآوریشده در بررسیهای میدانی همسو بود. علاوه بر این، برای تایید تخمین مدلهای پیشبینی، مقادیر کمکی همه پیشبینیکنندههای ریسک در همان سطح عددی استاندارد شدند.
از آنجایی که عوامل اقلیمی اطلاعات مهمی در رابطه با تناسب زیستگاه و پراکنش گونه های مهاجم مانند EAB [ 22 ] ارائه می دهند، در این تحقیق از چهار متغیر مختلف اقلیمی استفاده شد. در جنوب انتاریو، اوج ظهور بزرگسالان EAB در ژوئن ارائه می شود [ 3 ، 23 ]. در نتیجه، داده های اقلیمی در ماه ژوئن برای هر سال جمع آوری شد. میانگین ماهانه بارندگی و تابش خورشیدی از داده های جهانی آب و هوا نسخه 2 World-Clim با وضوح مکانی 1 کیلومتر در 1 کیلومتر در استوا به دست آمد [ 24 ]]. عامل مهم دیگر سرعت باد محلی است که می تواند بر گسترش EAB تأثیر بگذارد. رکوردهای میانگین سرعت باد با دامنه 30 تا 80 متر از سطح زمین از وزارت منابع طبیعی انتاریو به دست آمد [ 25 ]. از آنجایی که حداکثر ارتفاع درختان خاکستر سبز بالغ تقریباً 30 متر است، داده های سرعت باد در ارتفاع 30 متری از سطح زمین جمع آوری شد. علاوه بر این، افزایش دمای سطح زمین ممکن است باعث تغییراتی در زیستگاه شود و در نهایت منجر به گسترش EAB از جنوب انتاریو به مناطق شمالی شود [ 26 ]]. از این رو، دادههای ماهواره MODIS/Terra بهعنوان MOD21A2 استفاده شد که توسط الگوریتم جداسازی انتشار دما (EST) تولید شد. داده های دمای سطح زمین به عنوان یک خروجی مرکب هشت روزه بر اساس تابش از سه باند مادون قرمز حرارتی MODIS 21، 31، و 32 [ 27 ] استخراج شد. ما وضوح را به 1 کیلومتر در 1 کیلومتر تنظیم کردیم تا وضوح مکانی سایر متغیرها را حفظ کنیم.
مجموعه عوامل جغرافیایی فیزیکی توسط یک مدل رقومی ارتفاع (DEM) در وضوح فضایی 30 متر در 30 متر ارائه شد [ 28 ]. این متغیرهای پیشبینیکننده شامل ارتفاع، شیب و جهت بودند که بهعنوان گرادیانهای محیطی غیرمستقیم عمل میکنند. تأثیر آنها بر گسترش EAB ممکن است بیشتر به وضعیت عمومی درختان خاکستر مربوط باشد تا مکانیسم گسترش EAB. نشان داده شده است که متغیرهای مشتق شده از DEM تأثیرات کمتری بر توزیع فضایی گونه ها دارند [ 22 ]، اما نشان دهنده سطح تنش درختان خاکستر ناشی از آلودگی EAB است. مطالعات [ 29 ، 30] نشان می دهد که مناطقی با شیب های تندتر (بیش از 45 درجه) و سابقه برگ زدایی بیشتر احتمال دارد که درختان خاکستر تحت تنش داشته باشند. همانطور که در جدول 2 نشان داده شده است ، مقادیر ابعاد از 0 تا 360 درجه متغیر است. همچنین در این مطالعه، تبدیلهای متفاوتی از مقادیر، مانند گروهبندی آنها در جهتهای کلی مختلف (شمال، شرق، جنوب و غرب) را امتحان کردیم. برای هیچ یک از موارد مورد بررسی، جنبه متغیر عامل مهمی برای کنترل گسترش EAB نبود. در نتیجه، داده های جنبه اصلی نگهداری شدند.
شاخص تفاوت نرمال شده گیاهی (NDVI) به عنوان یکی از عوامل زیستی مورد استفاده قرار گرفت. این از باندهای نقشهبردار موضوعی (TM) Landsat 5 از وبسایت کاوشگر زمین توسط سازمان زمینشناسی ایالات متحده (USGS) مشتق شده است. صحنه های بین ماه می و آگوست برای هر سال در بازه زمانی بررسی های میدانی استفاده شد. به طور تصادفی، همانطور که قبلا ذکر شد، این فصل اوج رشد درختان زبان گنجشک است [ 31 ]. فاصله زمانی بین یک نقطه نمونه جدید و نزدیکترین مکان حضور آن از سال قبل به عنوان دومین عامل زنده [ 9 ] اندازه گیری شد که می تواند اطلاعات مکانی-زمانی مفید نقاط حضور EAB و گسترش آن را نشان دهد.
عوامل انسانی نشان دهنده تأثیر انسان بر پراکندگی مصنوعی EAB در مسافت های طولانی فراتر از حداکثر گستره پرواز آن است. برای اندازهگیری این، ما اطلاعاتی را از آمار کانادا در مورد مکانهای مراکز جمعیتی متوسط و بزرگ برای نشان دادن تراکم جمعیت بهدست آوردیم. اطلاعات مربوط به مکانهای تأسیسات پردازش جنگل از وزارت منابع طبیعی انتاریو جمعآوری شد و به دلیل احتمال پراکندگی به دلیل تماس مستقیم با سیاهههای خاکستر بالقوه آلوده، در تجزیه و تحلیل گنجانده شد. شبکه حمل و نقل توسط Land Information Ontario (قابل دسترسی از طریق https://geohub.lio.gov.on.ca/ ) ارائه شده است. مکانهای بنادر در انتاریو نیز از SeaRates جمعآوری شد ( https://www.searates.com/و محل های کمپ، که سوزاندن سیاهههای خاکستر بالقوه آلوده ممکن است باعث انتشار حشرات شود، از مجموعه داده های اقامتی ایجاد شده توسط DMTI Spatial Inc. ( https://www.dmtispatial.com/ ) استخراج شدند.
2.1.3. خودهمبستگی فضایی بین پیش بینی کننده های ریسک
خود همبستگی فضایی در پیشبینیکنندههای خطر در میان دادههای نمونهبرداری شده در بالا مشهود بود. به عنوان مثال، یک نمودار پراکندگی سه بعدی برای سه پیش بینی کننده (میانگین سرعت باد در ژوئن، فاصله تا نزدیکترین مکان مثبت EAB و فاصله تا تأسیسات پردازش الوار) که مربوط به سه شهرستان است در شکل 2 نشان داده شده است . سه خوشه به وضوح مشهود است. این نشان می دهد که نقاط نمونه برداری شده در یک منطقه همسایه جغرافیایی ویژگی های مشابهی دارند. خوشههای شهرستانهای دریاچههای کاوارتا و لنوکس و ادینگتون به دلیل مجاورت فضاییشان در مقایسه با شهرستان واترلو که در پایین نمودار پراکندگی نشان داده شده است، به هم نزدیکتر بودند.
خود همبستگی فضایی در داده ها معمولاً توسط Moran’s I و Geary’s C اندازه گیری می شود [ 22 ، 32 ]. این آمار میزان وابستگی را ارزیابی می کند و شدت روابط جغرافیایی را برای داده های جمع آوری شده از همان محله تخمین می زند. فرض کنید مشاهدات y 1 ; y 2 ; … y n همبستگی فضایی با میانگین μ دارند. آماره مورن I با معادله (1) به دست می آید.
که در آن، w ij وزن فضایی را نشان می دهد که می توان آن را بر اساس فاصله اقلیدسی بین مشاهدات i و j به دست آورد. مقادیر Moran’s I برای 22 شهرستان در انتاریو با نقاط حضور شناخته شده محاسبه شد و نتایج در جدول 3 نشان داده شده است. خود همبستگی فضایی در نیمی از 22 شهرستان از نظر آماری معنادار است ( ص<0.05)، و همچنین در آلگوما، همیلتون، لمبتون و تورنتو نسبتاً بالاست. من کلی موران برای دادههای EAB تقریباً 0.109 برآورد شد، با مقدار P بسیار معنیدار نزدیک به 0. بنابراین، همبستگی فضایی کلی در بین نقاط نمونهگیری از نظر آماری معنیدار بود و ممکن است این همبستگی در برخی از شهرستانها بالاتر از میانگین باشد. .
2.2. روش شناسی
همانطور که قبلا ذکر شد، GLMM ها در این مطالعه برای مدل سازی گسترش EAB توسعه یافتند. با استفاده از لایه های سلسله مراتبی در تجزیه و تحلیل، GLMM ها را می توان برای مقابله با مواردی که پراکندگی بیش از حد و همبستگی مشهود است استفاده کرد. در بحث زیر، اصول اولیه GLMM و کاربرد آن در مدل سازی اسپرد EAB شرح داده شده است.
فرض کنید n نقطه نمونه در یک منطقه مورد مطالعه جمع آوری شده و بر اساس عوامل مکانی به k گروه تقسیم شده است. Y1= {y11، y12, … , y1n1} ، Y2= {y21، y22, … , y2n2} ،…، Yک= {yk 1، yk 2, … , yکnک}�1={�11, �12, …, �1�1}, �2={�21, �22, …, �2�2}, …, ��={��1, ��2, …, ����}، و مجموع نمونه ها n برابر است با ∑کi = nnمن∑�=����. GLMM ها رابطه بین مقدار میانگین متغیر پاسخ را تخمین می زنند E(yمن ج|ایکسمن ج) =پمن ج�(���|���)=���و پیشبینیکنندههای ریسک، که با تابع پیوند g(·) همانطور که در رابطه (2) نشان داده شده است، به هم متصل میشوند.
جایی که i = 1 ، 2 ، … ، k �=1, 2, …, �و j = 1 ، 2 ، … _ nمن�=1, 2, …, ��. پیش بینی خطی شامل دو اثر مختلف، یعنی اثرات ثابت و اثرات تصادفی است. همه نمونه ها {Y1، Y2, … , Yک}تی{�1, �2, …, ��}تیبین k خوشهها بر اساس پیشبینیکنندهها اثر ثابت یکسانی دارند ایکسمن ج���، که دارای ضرایبی هستند β�. استنتاج آماری در مورد پارامتر β�سطح معنی داری پیش بینی کننده ها را نشان می دهد. اثرات تصادفی به عنوان نشان داده شده است γمن={γمن 1، γمن 2, … , γمن ق}تی��={��1, ��2, …, ���}�به طور یکسان از یک چگالی مشترک با میانگین صفر توزیع می شوند E(γمن) = 0�(��)=0و کوواریانس c o v (γمن) = جی���(��)=�. در معادله (2) zمن��نشانهای از این است که نمونههای خوشهی یکم اثر تصادفی را به اشتراک میگذارند γمن��، که می تواند یک متغیر رهگیری و ضریب تصادفی باشد. به طور خاص، نمونه ها Yمن��درون خوشه i با متغیر مدلسازی میشوند γمن��، نشان دهنده اثر تصادفی در گروه خود است. از این رو، نمونههای درون خوشههای مختلف با اثرات تصادفی متفاوت مدلسازی میشوند.
از آنجایی که مقادیر میانگین اثرات تصادفی صفر است، هر کدام γمن��تأثیری بر میانگین کل جمعیت ندارد. با این حال، با اثرات تصادفی مختلف، پیشبینیکنندههای خطی در معادله (2) میتوانند برای نمونههای درون خوشههای مختلف متفاوت باشند، که میتواند استحکام مدل را افزایش داده و همبستگی خودکار ذکر شده قبلی را که در دادههای پیشبینیکننده مشهود است، حل کند. برای درک اثرات تصادفی، مثالی از برازش خط برای داده های خوشه ای را در نظر بگیرید، جایی که برازش خط استاندارد یک خط را برای همه نقاط داده ایجاد می کند. با این حال، هنگام در نظر گرفتن اثرات تصادفی، خطوط مختلفی را می توان برای جا دادن نقاط داده در خوشه های مختلف ایجاد کرد. در این مطالعه، هر یک از نکات مشاهده شده است yمن ج���می تواند یک نقطه حضور یا عدم حضور باشد که با تابع پیوند لجستیک مدل شده است. نمونه های مشاهده شده از یک همسایگی جغرافیایی را می توان در یک خوشه فضایی گروه بندی کرد و بنابراین، انواع مختلفی از اثرات تصادفی فضایی را می توان در GLMM های پیشنهادی استفاده کرد.
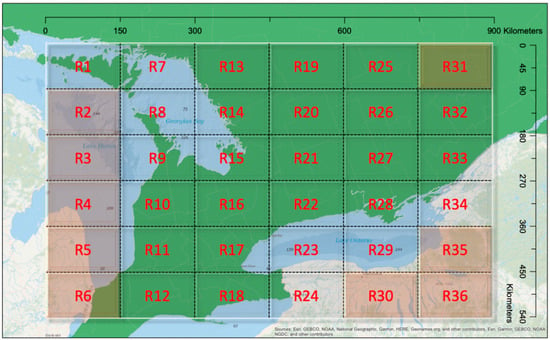
برای دادههای مورد استفاده در این مطالعه، همانطور که در شکل 2 نشان داده شده است ، الگوهای خوشهای از شهرستانهای مختلف آشکار شد و بنابراین، نمونهها بر اساس شهرستان در مدل اول گروهبندی شدند. 46 شهرستان در داده های گونه وجود دارد که می توان آنها را نشان داد γمن��، با i = 1 ، 2 ، … ، 46 �=1, 2, …, 46. بر اساس دادههای جمعآوریشده، برخی از شهرستانها نمونههای حضور زیادی داشتند، در حالی که برخی دیگر عاری از هرگونه آلودگی EAB بودند. مرزهای شهرستان عمدتاً برای اهداف اداری و بدون ملاحظات زیست محیطی اساسی تعریف می شوند. از این رو، آنها می توانند به طور قابل توجهی در وسعت فضایی و شرایط محیطی متفاوت باشند. با توجه به این، یک مدل اثرات تصادفی نیز بر اساس موقعیت جغرافیایی هر نمونه اجرا شد. برای تطبیق با این موضوع، ما جنوب انتاریو را به 36 منطقه با اندازه تقریباً مساوی 90 کیلومتر در 150 کیلومتر تقسیم کردیم ( شکل 3 ).
هر منطقه یک خوشه فضایی را نشان داد و یک اثر تصادفی را به اشتراک گذاشت γمن��. نه منطقه، یعنی R2، R3، R4، R5، R6، R30، R31، R35، و R36، هیچ داده بررسی شده ای نداشتند، بنابراین این مناطق در مدل اثرات تصادفی استفاده نشدند. در مقایسه با استفاده از اثرات تصادفی شهرستان، ساختار شبکه را می توان برای سازگاری با سناریوهای مختلف تنظیم کرد. به عنوان مثال، خوشهها میتوانند در ساختار فضایی خود بر اساس ویژگیهای محیطی محلی یا عوامل دیگر بهطور ناهموار شکل بگیرند. بنابراین، دو مدل برای تجزیه و تحلیل توزیع EAB، از جمله یک GLMM با اثرات تصادفی شهرستان و دیگری GLMM با اثرات تصادفی منطقهای استفاده شد.
برآورد ضرایب رگرسیون β^�^و اثرات تصادفی γمن^��^می توان از طریق روش های ادغام عددی به دست آورد و احتمالات پیش بینی با تابع پیوند لجستیک محاسبه شده از
در مدل پیش بینی، پارامترهای برآورد شده است β^�^خواص مجانبی قوام و نرمال بودن را حفظ کنید. بنابراین، ما می توانیم استنتاج آماری را در مورد هر پیش بینی کننده با اطمینان انجام دهیم. در همین حال، γمن^��^مقادیر بهترین پیش بینی های خطی بی طرفانه (BLUPs) هستند. یک برش تصادفی در مدل برای هر خوشه استفاده می شود، که اجازه می دهد تا اثرات خاص خوشه را متمایز کنند. برای مثال، در خوشههایی که نمونههای بیشتری وجود دارد، نتیجه پیشبینی ممکن است تأثیر ریسک مهمتری نسبت به گروههایی با ریسک پایینتر ارائه دهد.
به منظور ارزیابی اهمیت هر یک از پیشبینیکنندهها و عملکرد کلی GLMMs پیشنهادی، میتوان از روشهای آماری مختلفی استفاده کرد. یک رویکرد بررسی برازش مدل با انحراف باقیمانده نشان داده شده در رابطه (4) است. این آماری است که تفاوت احتمالات برآورد شده را اندازه گیری می کند L^(β^)�^(�^)(مدل پیشنهادی با پارامترهای مورد نظر) و L^(θ^)�^(�^)(مدل اشباع، که می تواند برای هر نمونه بیش از حد پارامتریزه شود)، یعنی،
که از توزیع کای دو پیروی می کند. از این مقدار می توان برای انجام آزمون فرضیه برای تجزیه و تحلیل پیش بینی کننده ها در مدل و مقایسه مدل ها با پیش بینی کننده های مختلف استفاده کرد. علاوه بر این، برای انتخاب پیشبینیکنندههای ریسک با بهترین تناسب و کنترل پیچیدگی مدل، میتوانیم مدل را بر اساس معیار اطلاعات بیزی (BIC) اعتبارسنجی کنیم، یعنی:
این عبارت شامل حداکثر احتمال ورود به سیستم بر اساس مدل کاندید در زیر مجموعه s و تعداد پارامترهای k است که سطح پیچیدگی را نشان می دهد. مدل با کمترین مقادیر معیار اطلاعات بیزی بهترین مدل برازش را نشان می دهد. سایر آمارها، مانند معیار اطلاعات آکایک، ضریب تعیین تعدیل شده (R 2 )، و آماره Cp، می توانند برای مقایسه مدل های مختلف کاندید مورد استفاده قرار گیرند. نتایج انتخاب مدل مشابهی را می توان در بیشتر موارد انتظار داشت، در حالی که BIC معیار محدودتری برای مقابله با مدل اضافه برازش برای نمونه بزرگ است.
ما انتخاب متغیر را برای مدل ها با استفاده از یک فرآیند گام به گام انجام دادیم و مقادیر BIC را با هر مرحله به عنوان معیار انتخاب تخمین زدیم. ترتیب اضافه کردن یک پیشبینیکننده در هر مرحله بر اساس سطح اهمیت هر پیشبینیکننده بود و مقادیر BIC بهطور مکرر با هم مقایسه شدند تا مشخص شود کدام متغیر باید در مدل نگهداری شود. علاوه بر این، دقت پیشبینی یکی دیگر از معیارهای انتخاب پیشنهادی در فرآیند انتخاب مرحلهای بود. ما یک اعتبارسنجی متقابل پنج برابری با تکرار 100 برابری برای بررسی قدرت پیشبینی هر مدل اعمال کردیم. از آنجایی که مدلهای نامزد برای تجزیه و تحلیل گسترش فضایی EAB پیشنهاد شدهاند، مجموعههای آموزشی اطلاعات یکپارچه را در تمام مکانهای مورد بررسی در تحقیق نشان میدهند. در هر خوشه فضایی، ما بهطور تصادفی 80 درصد از دادههای حضور-غیاب را نمونهبرداری کردیم و آنها را به عنوان گروه آموزشی برای برازش هر مدل ترکیب کردیم. دادههای باقیمانده برای انجام اعتبارسنجی برای دقت طبقهبندی استفاده شد.
برای مقایسه، یک مدل رگرسیون لجستیک، یکی از مفیدترین GLMها برای پاسخهای باینری (دادههای حضور-غیاب)، پیادهسازی شد. از آنجایی که مدل استقلال بین مشاهدات را فرض میکند، ابتدا باید خودهمبستگی فضایی موجود در دادههای EAB حذف شود. برای انجام این کار، فاصله اقلیدسی بین تمام مکانهای نمونه را بر اساس مختصات زمین اندازهگیری کردیم و نقاط را با استفاده از خوشهبندی در 1000 محله گروهبندی کردیم. با نمونه گیری تصادفی یک مشاهده از هر محله کوچک، زیر مجموعه ای با 1000 نمونه به دست آمد. برای این زیرمجموعه، آمار کلی Moran’s I با مقدار p بزرگ به 0 کاهش یافت، که نشان میدهد خودهمبستگی فضایی به سطح ناچیز کاهش یافته است. از این رو، مدل رگرسیون لجستیک را می توان با اطمینان به داده های تست برای مقایسه مدل اعمال کرد. برنامه نویسی مدل پیشنهادی با استفاده از تابع R بسته ‘lme4’ انجام شد (https://www.r-project.org/ ).
3. نتایج
عملکرد کلی هر پیشبینیکننده ریسک ابتدا برای سطح معنیداری و خوبی برازش آن با اعمال GLMM با اثرات تصادفی منطقهای پیشنهادی مورد آزمایش قرار گرفت و نتیجه تحلیل تک متغیره در جدول 4 نشان داده شده است . این نشان میدهد که بیشتر پیشبینیکنندهها به طور قابلتوجهی با توزیع حضور-غیاب EAB مرتبط بودند، و انحراف برآورد شده نشان داد که برازش مدل مشابه است. با این حال، تجزیه و تحلیل همه پیشبینیکنندهها در یک مدل میتواند باعث برازش بیش از حد آن شود که منجر به تخمین نادرست و استنتاج نامعتبر میشود. در نتیجه، تعیین پیشبینیکنندههای موجود در SDMs پیشنهادی مهم است.
فرآیند انتخاب متغیر بر اساس نتایج نشان داده شده در جدول 4 انجام شد. به عنوان مثال، در بین همه پیشبینیکنندهها، مدل با میانگین سرعت باد در ماه ژوئن، تخمینی را با کمترین مقدار p ارائه کرد که نشاندهنده اطمینان بالا یا معنیداری آماری است. در نتیجه این پیش بینی در اولین قدم معرفی شد. هر ستون نشان داده شده در جدول 5 مراحل انتخاب متغیر را نشان می دهد. معیار انتخاب بر اساس BIC در افزودن یک پیشبینیکننده در مقایسه با سایر معیارها محدودتر است، که در اجتناب از مدل اضافه برازش مفید است.
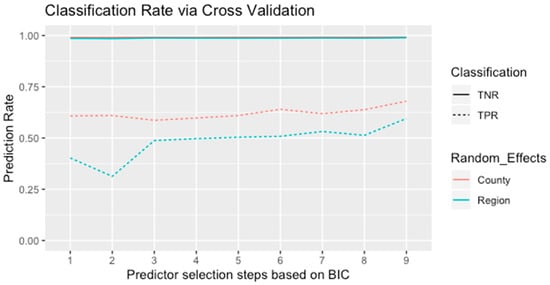
مدل سازی اثرات تصادفی بر اساس شهرستان، مقادیر کلی BIC کمتری را در مقایسه با مدل با اثرات تصادفی منطقه ای ایجاد کرد ( جدول 5 ). این نشان می دهد که اثرات تصادفی با 46 خوشه فضایی تناسب کلی بهتری را برای داده های EAB نسبت به مدل های دیگر ارائه می دهد. علاوه بر این، اعتبارسنجی متقاطع نتایج ثابتی را نشان داد که در شکل 4 نشان داده شده است. از آنجایی که دادههای گونهها از نظر فراوانی نقاط غیبت نامتعادل بودند، نرخ منفی واقعی دادههای اعتبارسنجی در همه مدلها نزدیک به 100٪ بود. در همین حال، نرخ طبقهبندی نقاط حضور حدود 40 تا 60 درصد بود و به طور کلی، نرخهای مثبت واقعی با نتایج انتخاب مدل گام به گام مطابقت داشت. مرحله نهایی فرآیند انتخاب، هفت پیشبینیکننده را با کمترین مقادیر BIC و بالاترین نرخهای طبقهبندی، که عمدتاً شامل عوامل اقلیمی و انسانی بود، برای اعتبارسنجی مدل ارائه کرد.
بر اساس نتیجه نهایی فرآیند انتخاب متغیر، برآورد هر دو GLMM با اثرات تصادفی شهرستان و GLMM با اثرات تصادفی منطقه ای در جدول 6 نشان داده شده است. مقادیر ضرایب برای یک پیش بینی کننده به طور متفاوتی بین دو مدل و همچنین در سطوح معناداری پیش بینی کننده ها تخمین زده می شود. نتایج نشان میدهد که با گروهبندی نمونههای حضور و غیاب از طریق خوشههای فضایی مختلف (شهرستانها یا مناطق)، اندازههای اثر کلی پیشبینیکنندهها یکسان نیستند. از آنجایی که یک منطقه فرعی ممکن است دارای چندین شهرستان باشد، همانطور که در شکل 3 نشان داده شده است، اثر کلی پیشبینیکنندههای خطی در هر زیرمنطقه به طور مشخص از شهرستانهای داخل آن منطقه پارامتر میشود. در نتیجه، استنتاج آماری پیشبینیکنندهها با اثرات تصادفی متفاوت، نتایج تخمین متفاوتی را ارائه میدهد.
به طور کلی، عوامل اقلیمی با الگوی گسترش از دو مدل ارتباط منفی دارند. علاوه بر این، هر دو اثر تصادفی فضایی با یک واریانس مشابه تقریباً 42 برآورد میشوند. این نشان میدهد که میانگین اثر در هر مکان جغرافیایی دارای درجه پراکندگی آماری یکسانی است که مزایای اجرای GLMMs در این تحقیق را تقویت میکند. از این رو، مقادیر میانگین اثرات جغرافیایی در مکانهای مختلف در جنوب انتاریو میتواند یک محدوده عددی وسیع با انحراف تقریبی 6.5 ایجاد کند و این تفاوت میتواند فواصل پیشبینی را بزرگتر کرده و قدرت پیشبینی مدلها را بهبود بخشد.
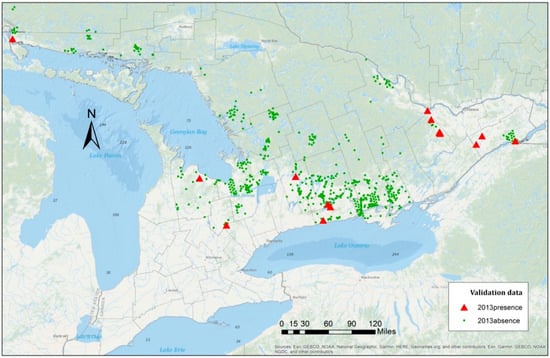
دادههای حضور-غیاب توزیع EAB از سال 2013 برای آزمایش مدلهای پیشنهادی استفاده شد. نمونه ها شامل 22 نقطه حضور و 876 نقطه غیبت بود ( شکل 5 ). نتایج پیشبینی بر اساس سه مدل مورد بحث در بخش قبل ( جدول 7 ) ارائه شد. GLMMها عملکرد کلی بهتری را در مقایسه با مدل رگرسیون لجستیک ارائه کردند. در واقع، دقت پیشبینی 20 درصد بهبود یافته است. از آنجایی که دادهها با غیاب بیشتر از نقاط حضور از دادههای گونهها نامتعادل بودند، همه مدلها به درستی نقاط غیبت را در دادههای آزمایش طبقهبندی کردند و نرخهای منفی واقعی (ویژگی) بالای تقریباً 99٪ را تولید کردند.
در همین حال، با معرفی اثرات تصادفی مختلف در مدلهای پیشنهادی، نرخ مثبت واقعی (حساسیت) از GLMM با اثرات تصادفی شهرستان به 63.64٪ افزایش یافت و با اثرات تصادفی منطقه به حداکثر دقت 95.45٪ رسید. این نشان میدهد که GLMM به دادههای مرتبط با هر خوشه اجازه میدهد تا اطمینان حاصل کند که تمام اطلاعات مفید در تجزیه و تحلیل مورد بهرهبرداری قرار میگیرند، و اثرات تصادفی مشخص شده میتواند به طور موثر عوامل خطر را در میان خوشههای مختلف متمایز کند. در نتیجه، مدل پیشنهادی دقت پیشبینی کلی 97.04 درصد برای دادههای سال 2013 تولید کرد.
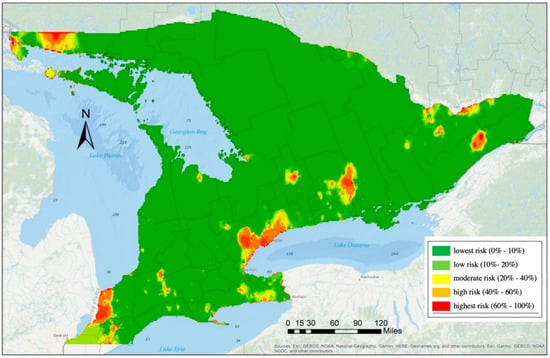
GLMM با اثرات تصادفی منطقه برای برآورد قرار گرفتن در معرض خطر توزیع EAB استفاده شد. پنج سطح خطر برای احتمال حضور تعیین شد پ(yمن ج= 1 |ایکسمن ج، منطقهمن)پ(�من�=1|ایکسمن�، منطقهمن)یعنی کمترین خطر (0٪ – 10٪)، کم خطر (10٪ – 20٪)، خطر متوسط (20٪ – 40٪)، ریسک بالا (40٪ -60٪)، و بالاترین خطر (60٪ – 100 درصد. اعتبار سنجی نقشه ریسک در سال 2013 ( شکل 6 ) نشان می دهد که توزیع EAB خطر بالاتری را در نزدیکی شهرهای بزرگ و در مکان هایی در امتداد مرز کانادا-ایالات متحده نشان می دهد. مناطقی که شناساییهای قبلی داشتند نیز در معرض EAB قرار گرفتند، و قرار گرفتن در معرض خطر تهاجم گونهها در آینده به عوامل اقلیمی و انسانی محلی بستگی دارد که در تجزیه و تحلیل نشان داده شده است.
4. بحث و نتیجه گیری
در GLMM های پیشنهادی، دو نوع اثر تصادفی بر اساس اطلاعات جغرافیایی ارائه شده با داده های EAB ایجاد شد. یکی بر اساس مرزهای شهرستان (مدل 1) و دیگری بر اساس شبکه های منظم (مدل 2) بود. GLMM با اثر تصادفی منطقه ای نتایج بهتری با دقت کلی 97 درصد ایجاد کرد ( جدول 7 ). علاوه بر این، عملکرد پیشبینی GLMs در مقایسه با نتایج بهدستآمده توسط GLMs به طور قابلتوجهی افزایش یافت.
برای مقابله با خود همبستگی در داده های مشاهده شده در GLMM با اثرات تصادفی منطقه ای، منطقه مورد مطالعه به شبکه های 6 در 6 پیکسل (90 در 150 کیلومتر) تقسیم شد ( شکل 3 ). اندازه شبکه به طور تجربی با در نظر گرفتن دو جنبه زیر تعیین شد: اگر اندازه مناطق خیلی بزرگ بود، همبستگی خودکار بین دادهها باقی میماند. از سوی دیگر، مناطق کوچکتر می تواند منجر به جذب ناکافی ویژگی های داده ها شود که منجر به طبقه بندی نادرست داده های آزمایش می شود.
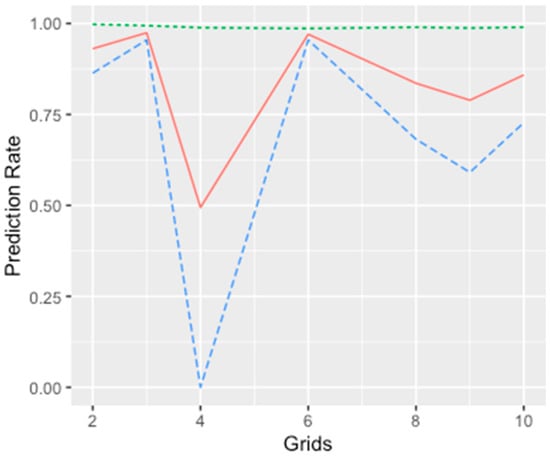
آزمایشها با اندازههای شبکه مختلف (متغیر از 2 در 2 تا 10 در 10 پیکسل) انجام شد. نتایج پیشبینی GLMM با اندازههای مختلف مناطق در شکل 7 نشان داده شده است. حتی اگر دقت کلی بر اساس اندازه سلول شبکه متفاوت نباشد، نرخ نتایج منفی واقعی و مثبت واقعی به نحوه مشخص شدن اثرات تصادفی بستگی دارد. علاوه بر این، نشان داده شد که اندازه شبکه 6 در 6 پیکسل استفاده شده در این مطالعه بهترین دقت را ایجاد می کند. قابل توجه است که از مناطق با اندازه شبکه منظم استفاده شده است. در تحقیقات آتی می توان اثرات تصادفی عامل منطقه ای را با اندازه ها، شکل ها و پوشش جغرافیایی مختلف در محدوده مورد مطالعه بررسی کرد. تجزیه و تحلیل داده ها می تواند برای خوشه بندی داده ها انجام شود و خوشه های تولید شده می توانند به عنوان واحدهای مدل سازی GLMM در نظر گرفته شوند.
معیار اطلاعات بیزی در رابطه (5) برای انتخاب متغیرهای پیش بینی کننده پیشنهاد شد. در مقایسه با معیار اطلاعات آکایک، عبارت جریمه log(n)k معیار اطلاعات بیزی در معادله (5) تا حد زیادی پیچیدگی مدل را در برابر مشکل اضافه برازش متعادل کرد ( جدول 5).). اگرچه هفت پیشبینیکننده ریسک مختلف با اثرات تصادفی فضایی، مدلی با هشت پارامتر را تشکیل دادند، فرآیند انتخاب، مدل پیشنهادی را با کوچکترین BIC تأیید کرد. علاوه بر این، از آنجایی که نمونههای حضور-غیاب جمعآوریشده توسط بررسی میدانی اطلاعات قابلتوجهی ارائه میکردند، چالشهای دادههای نامتعادل کنترل شدند. طبق پیشبینی دادههای اعتبارسنجی، طبقهبندی صحیح نمونههای غیبت بالاتر از نمونههای حضوری است. این را می توان به داده های 98.7 درصد نمونه های غیبت نسبت داد که باعث موارد مثبت کاذب در پیش بینی می شود. در همین حال، موارد طبقهبندی اشتباه را میتوان از طریق اعتبارسنجی متقاطع کاهش داد ( شکل 4 )، و مدل پیشنهادی بالاترین دقت طبقهبندی را ارائه کرد.
در این تحقیق، سال جمع آوری داده ها/پیش بینی ریسک به عنوان متغیر پیش بینی در نظر گرفته شد. نمونههایی که با یک بازدید یکباره و در مکانهای از پیش طراحیشده جمعآوری شدهاند، میتوانند همبستگی مکانی و زمانی داشته باشند. گسترش EAB یک فرآیند زمانی فضایی بود. یک مدل خطی (یا GLM یا GLMM) باید شامل پیشبینیکنندههایی برای نمایش عوامل زمانی و مکانی باشد. بنابراین، سال تشخیص برای نشان دادن عامل زمانی گنجانده شد. علاوه بر این، از نتایج با مدلهای تک متغیره نشان داده شد ( جدول 4، که اثر زمان (سال) بر گسترش EAB مثبت، تقریباً 0.057 و معنی دار (با مقدار p کوچک) بود. این نشان می دهد که انتظار می رود سطح ریسک کلی برای سال های بعدی در جنوب انتاریو افزایش یابد. گنجاندن متغیر سال در مدلسازی خطی سادهترین راه برای در نظر گرفتن عامل زمانی بود. رویکرد دیگر گنجاندن تحلیل سری زمانی در مدل خطی بود که در کارهای آینده دنبال خواهد شد.
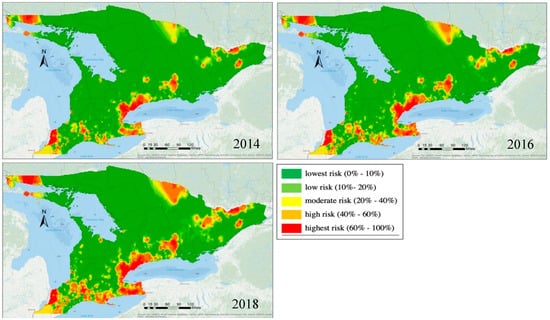
GLMM با اثر تصادفی منطقهای میتواند برای تهیه نقشههای ریسک مورد انتظار برای سالهای آینده برای تصمیمگیری استفاده شود. به عنوان مثال، ما گسترش EAB را برای سال های 2014، 2016 و 2018 بدون هیچ گونه اقدامات کاهشی بیشتر و تحت همان محیط، مانند عوامل اقلیمی و غیره شبیه سازی کردیم. نقشه های خطر پیش بینی شده در شکل 8 نشان داده شده است.. همانطور که شرکت کرد، نشان داده شد که آلودگی EAB بدون هیچ گونه اقدامات کاهشی شدیدتر خواهد بود. از نظر فضایی، نتایج نشاندهنده مناطقی است که سطح ریسک مورد انتظار برای یک سال معین بیشترین بود. چنین اطلاعاتی می تواند توسط شهرداری ها در تصمیم گیری برای مدیریت جنگل/درخت استفاده شود. ذکر این نکته ضروری است که ما در این سه سال داده های EAB را برای تایید نتایج نداشتیم. با این حال، روندها با گسترش کلی EAB گزارش شده در انتاریو در این بازه زمانی سازگار بود.
نتایج GLMM با اثرات تصادفی منطقهای نشان داد که از میان پانزده پیشبینیکننده خطر که از چهار دسته مختلف مورد بررسی قرار گرفتند، عوامل اقلیمی مانند سرعت باد ژوئن، دمای سطح زمین و تشعشع و همچنین فعالیتهای انسانی مانند فاصله تا جنگل. تأسیسات پردازش و بنادر و مراکز جمعیتی بیشترین تأثیر را در گسترش EAB داشتند. هیچ یک از متغیرهای زیستی و توپوگرافی در مدل ها انتخاب نشدند. با این حال، بر اساس تجزیه و تحلیل مدل تک متغیره ( جدول 4 )، نشان داده شد که تأثیر این عوامل بر گسترش EAB به دلیل همبستگی آنها با سایر عواملی که تأثیرات معنی داری بیشتری داشتند، معنی دار بود [ 32 ]. علاوه بر این، همانطور که در [ 32]، تفاوت در متغیرهای زنده و توپوگرافی بین مکانهای حضور و غیاب EAB در مقایسه با عوامل اقلیمی و انسانی زیاد نبود. در تفسیر اثرات این عوامل خطر بر گسترش EAB باید احتیاط کرد. برای برخی از عوامل، مانند فاصله تا تأسیسات پردازش جنگل، بسته به چگونگی مشخص شدن اثرات تصادفی، تأثیرات می تواند مثبت یا منفی باشد. برای بررسی این اثرات باید مطالعات بیشتری انجام شود.
در تحقیقات بیشتر، ساختار پراکندگی را می توان برای مدل سازی اثرات تصادفی فضایی با توزیع وابستگی به فاصله گنجاند. تغییرات برآورد شده از طریق اثرات تصادفی را می توان با ترکیب همبستگی های زمانی و مکانی در هر خوشه فضایی به دست آورد. این رویکرد به طور فشرده برای گسترش بیماریهای عفونی مورد تجزیه و تحلیل و مدلسازی قرار گرفته است، که میتواند برای اجزای اثر مختلط برای دستیابی به تخمین قویتر پیشنهاد شود. به این ترتیب، پیشبینی الگوی گسترش EAB میتواند اثرات تصادفی اضافی را ایجاد کند. به عنوان مثال، ضرایب تصادفی عوامل خطر، مانند اثر زمان در خوشه های فضایی مختلف، می تواند با تنظیمات فعلی یکپارچه شود. با معرفی داده های چند متغیره با سطوح سلسله مراتبی مختلف،33 ]. با اطلاعات بیشتر مربوط به دادههای گونهها، یک الگوریتم انتخاب اثرات تصادفی میتواند برای فیلتر کردن عوامل مهم محیطی محلی اتخاذ شود.






بدون دیدگاه