

طوفان هاروی در سال 2017 انتقال مهمی را رقم زد که در آن بسیاری از قربانیان فاجعه از رسانه های اجتماعی به جای سیستم بارگذاری شده 911 برای جستجوی نجات استفاده کردند. این مقاله یک آشکارساز مبتنی بر یادگیری ماشینی از درخواستهای نجات از پیامهای توییتر مربوط به هاروی را ارائه میکند که با در نظر گرفتن تأثیرات بالقوه کدهای پستی بر روی آمادهسازی نمونههای آموزشی و عملکرد مدلهای مختلف یادگیری ماشین، خود را از پیامهای موجود متمایز میکند. . ما بررسی می کنیم که چگونه نتایج فیلتر کد پستی ما با نتایج یک مطالعه مشابه اخیر از نظر تولید داده های آموزشی برای مدل های یادگیری ماشین متفاوت است. در دنباله این، آزمایشهایی برای آزمایش اینکه چگونه وجود کدهای پستی بر عملکرد مدلهای یادگیری ماشینی با شبیهسازی درصدهای مختلف نمونههای مثبت با برچسب کد پستی تأثیر میگذارد، انجام میشود. یافتهها نشان میدهند که (1) همه طبقهبندیکنندههای یادگیری ماشین به جز K-نزدیکترین همسایهها و Naïve Bayes به عملکرد پیشرفتهای در تشخیص درخواستهای نجات از رسانههای اجتماعی دست مییابند. (2) استفاده از فیلتر کردن کد پستی می تواند اثربخشی جمع آوری درخواست های نجات را برای آموزش مدل های یادگیری ماشین افزایش دهد. (3) مدلهای یادگیری ماشینی بهتر میتوانند درخواستهای نجات مرتبط با کدهای پستی را شناسایی کنند. بنابراین، ما هر قربانی نجاتی را تشویق میکنیم که هنگام ارسال پیامها در رسانههای اجتماعی، کد پستی را درج کند.
کلید واژه ها:
درخواست نجات ؛ توییتر ; یادگیری ماشینی ؛ طوفان هاروی ؛ یادگیری عمیق
1. مقدمه
نجات قربانیان از راه آسیب در هنگام بلایا یک جزء حیاتی در واکنش به بلایا است. شیوه های کارآمد نجات می تواند به موقع جان افراد بیشتری را نجات دهد. با این حال، در حوادث فاجعهبار سریع مقیاس بزرگ مانند طوفان و سیل، بسیاری از درخواستهای نجات اغلب به طور همزمان انجام میشوند، سیستم پاسخدهنده را بیش از حد بارگذاری میکند و تلاشهای نجات را دشوارتر میکند. به عنوان مثال، طوفان هاروی در سال 2017 منطقه هیوستون را درنوردید و منجر به سیل عظیم و نیازهای فوری برای نجات شد. تماسهای زیادی با 911 وجود داشت که سیستم تماس را از کار انداخت و ساکنان را وادار کرد تا برای درخواست نجات به رسانههای اجتماعی و ابزارهای دیگر متوسل شوند [ 1 ، 2 ].
رسانه های اجتماعی در حال تغییر روش ما برای نجات در شرایط فاجعه هستند. ظهور سایتهای شبکههای اجتماعی مانند توییتر و فیسبوک به مردم این امکان را میدهد که نه تنها زندگی شخصی خود را به اشتراک بگذارند، بلکه درخواستهای نجات را نیز ارسال کنند و با پاسخدهندگان بلایا ارتباط برقرار کنند [ 1 ، 3 ، 4 ، 5 ، 6 ، 7 ، 8 ]. این پیامهای رسانههای اجتماعی از سوی مردم میتواند دادههای ارزشمندی برای بهبود واکنش و انعطافپذیری در برابر بلایا باشد [ 5]. با این حال، به عنوان یک نوع محتوای تولید شده توسط کاربر (UGC)، پیام های رسانه های اجتماعی ساختاری ندارند و اغلب حاوی نویزها و محتوای غیر آموزنده هستند. این فشار بر پاسخ دهندگان اضطراری برای فیلتر کردن تعداد زیادی از پیام های رسانه های اجتماعی [ 9 ] تحمیل شده است. با وجود این، محققان تلاش کرده اند تا اطلاعاتی را از رسانه های اجتماعی استخراج و نجات دهند.
این تلاش ها اغلب شامل آموزش مدل های یادگیری ماشین برای دستیابی به استخراج خودکار اطلاعات است [ 10 ، 11 ، 12 ، 13 ]. مدلهای مورد استفاده در این مطالعات شامل درخت تصمیم [ 11 ]، پرسپترون چندلایه [ 11 ]، K-نزدیکترین همسایگان [ 14 ، 15 ]، درختان طبقهبندی و رگرسیون (CART) [ 15 ]، بیز ساده [ 10 ، 13 ، 14 ]، Log رگرسیون [ 11 ، 12 ، 14 ، 15 ]، جنگل تصادفی [ 10 ]، ماشین بردار پشتیبان [10 ، 11 ، 12 ، 15 ]، شبکه عصبی کانولوشن [ 11 ، 12 ، 16 ]، حافظه کوتاه مدت بلند مدت [ 12 ]، و نمایش رمزگذار دو جهته از ترانسفورماتورها (BERT) [ 16 ]. مشابه اکثر برنامه های کاربردی یادگیری ماشین در پردازش زبان طبیعی، گردش کار آنها به طور کلی از سه مرحله اصلی زیر پیروی می کند:
- (1)
-
استخراج زیر مجموعه ای از توییت های طوفان هاروی و برچسب گذاری دستی آنها بر اساس طرح طبقه بندی.
- (2)
-
آموزش مدل های یادگیری ماشینی با درصد مشخصی از این زیر مجموعه (داده های آموزشی) برای ساخت طبقه بندی کننده.
- (3)
-
ارزیابی عملکرد مدل با داده های تست
هدف اصلی آنها اغلب آموزش و آزمایش مدلهای مختلف برای طبقهبندی بهترین پستهای فاجعه بر اساس یک طرح طبقهبندی معین است. با این حال، بیشتر این طرحوارهها برای اولین پاسخدهندگان بسیار گسترده هستند که بتوانند مستقیماً درخواستهای نجات را از تعداد زیادی پیام دیگر متمایز کنند [ 10 ، 13 ، 14 ]. چندین استثنا شامل Yang et al. [ 15 ]، دواراج، مورتی و دونتولا [ 11 ]، کبیر و مادریا [ 12 ]، ژو و همکاران. [ 16]. بخش بعدی جزئیات بیشتری را در مورد این مطالعات مرتبط پوشش می دهد. متفاوت از این مطالعات موجود، تحقیق حاضر بر استخراج درخواستهای نجات تمرکز دارد که بهطور دقیق به عنوان پیامهای نجات طلب با آدرس تعریف میشوند، زیرا تنها چنین توییتهایی میتوانند برای اولین پاسخدهندگان قابل اجرا باشند. به طور مستقیم، آدرس ها اغلب شامل کدهای پستی هستند که ممکن است به عنوان یک ویژگی مفید برای جدا کردن درخواست های نجات از پیام های دیگر عمل کنند. با این حال، مطالعات کمی سهم این ویژگی را در استخراج درخواستهای نجات از حجم زیادی از پیامهای رسانههای اجتماعی بررسی کردهاند. اهداف اولیه این مقاله دو مورد است: (1) بررسی مزایای بالقوه فیلتر کردن کد پستی در بازیابی درخواستهای نجات برای مدلهای آموزشی. (2) بررسی تأثیر حضور کد پستی بر عملکرد مدلهای یادگیری ماشین در شناسایی پستهای جستجوی نجات. این مطالعه میتواند با روشن کردن یک ویژگی خاص در درخواستهای نجات که توسط اکثر تحقیقات دیگر نادیده گرفته شده است، به ادبیات کمک کند.
2. کارهای مرتبط
ما دو جریان اصلی کار مرتبط را در بازیابی اطلاعات نجات و/یا کمک از دادههای رسانههای اجتماعی شناسایی میکنیم.
2.1. طبقه بندی پست های رسانه های اجتماعی مرتبط با بلایا برای آگاهی از موقعیت
برای بهبود آگاهی موقعیتی در موقعیتهای فاجعه، محققان طبقهبندیکنندههایی را برای استخراج پیامهای مفید و آموزنده از پستهای رسانههای اجتماعی فاجعه ایجاد کردهاند [ 5 ، 10 ، 13 ، 14 ، 17 ، 18 ، 19 ]. برخی از طبقه بندی کننده ها باینری هستند. به عنوان مثال، هوانگ و همکاران. [ 19 ] توییتهای سیلآمیز را به دو دسته طبقهبندی کرد، از جمله «در موضوع» و «خارج از موضوع»، و هوانگ و همکاران. [ 18 ] استخراج کننده ای طراحی کرد تا به طور خودکار توییت های مرتبط با سیل را برچسب گذاری کند. طبقهبندیکنندههای چند طبقهای نیز در تلاش برای به حداکثر رساندن استخراج اطلاعات توسعه یافتهاند. دو آلبوکرک [ 17] مجموعه ای از توییت های سیل را در چندین گروه موضوعی از جمله «اقدامات داوطلبانه»، «گزارش های رسانه ای»، «شرایط ترافیک»، «مشاهدات دست اول»، «اقدامات رسمی»، «خسارت زیرساخت» و «سایر» طبقه بندی کرد. عمران و همکاران [ 13 ] توییت های مربوط به گردباد جوپلین 2011 را در پنج دسته کلی از جمله «احتیاط و توصیه»، «افراد تحت تأثیر»، «زیرساخت ها/خدمات»، «نیازها و کمک های مالی» و «سایر» طبقه بندی کرد. دسته «افراد آسیبدیده» نشاندهنده «گزارشها و/یا سؤالهایی درباره افراد گمشده یا یافت شده» است که ممکن است به بهترین شکل به تعریف ما از درخواستهای نجات در میان دستههای دیگر مربوط باشد. عمران [ 10] یک طرح برچسبگذاری را توسعه داد که در آن «افراد گمشده، به دام افتاده یا یافت شده» به درخواستهای نجات مرتبطتر از هشت برچسب دیگر در این طرح است. همچنین یک طرح طبقه بندی ریز دانه وجود دارد که توسط هوانگ و همکاران توسعه یافته است. [ 14 ] که در آن توییتهای طوفان سندی به چهار کلاس اصلی (یعنی آمادگی، پاسخ، تأثیر، بازیابی) و 47 زیر کلاس طبقهبندی شدند. یک زیر کلاس به نام “نجات” در کلاس “پاسخ” “نجات قربانیان فاجعه” را ضبط می کند. اگرچه این برچسبگذاری بسیار نزدیک به تعریف ما از درخواستهای نجات است، اما عمدتاً برای فعال کردن آگاهی موقعیتی مفید است. این دسته بندی ها، مطابق با بحث در بخش مقدمه، بسیار کلی هستند و نمی توانند به ویژه برای اولین پاسخ دهندگان مفید باشند.
2.2. استخراج درخواست های فوری / نجات از پست های فاجعه
مطالعات اندکی درخواستهای فوری/نجات را استخراج کردهاند که مستقیماً برای تلاشهای نجات مفید هستند. فقط چندین استثنا در ادبیات یافت می شود، از جمله یانگ و همکاران. [ 15 ]، دواراج، مورتی و دونتولا [ 11 ]، کبیر و مادریا [ 12 ]، ژو و همکاران. [ 16 ]. یانگ و همکاران [ 15 ] چندین مدل یادگیری ماشینی را بر اساس 1000 توییت مشروح دستی آموزش و مقایسه کرد. بهترین مدل آنها از SVM بود که امتیاز F 68.7٪ را به دست آورد. کبیر و مادریا [ 12] چندین مدل یادگیری ماشین را آموزش داد تا «Rescue Needed» را از دستههای دیگر مانند «Water Needed»، «Injured»، «Sick» و «Flood» متمایز کند. بهترین مدل آنها از یک مدل پیشرفته CNN با امتیاز F 87.2٪ بدست آمد. دواراج، مورتی و دونتولا [ 11 ] چندین طبقهبندیکننده باینری را با استفاده از تکیه ماشین برای تمایز «درخواستهای فوری» از سایر پیامهای فاجعه توسعه دادند. بهترین مدلهای آنها (یعنی ماشین بردار پشتیبانی (SVM) و طبقهبندیکننده شبکه عصبی کانولوشنال (CNN)) همان امتیاز F1 87% را دریافت کردند. ژو و همکاران [ 16] چندین طبقهبندی کننده برای جمعآوری توییتهای درخواست نجات با استفاده از مدلهای زبانی از پیش آموزشدیده طراحی کرد، که در آن بهترین مدل (یک مدل رمزگذار دوطرفه از ترانسفورماتورها (BERT) با طبقهبندیکننده CNN) امتیاز F ۹۱.۹٪ را کسب کرد.
در شرایط اضطراری، قربانیان فاجعه توییتهای درخواست نجات را متفاوت مینویسند و شناسایی کلمات کلیدی را که میتوانند به بهترین شکل پیامهای درخواست نجات را از دادههای پر سر و صدا تولید شده در رسانههای اجتماعی به چالش بکشند، دشوار میسازد [ 1 ]. مطالعات فوق نشان دادهاند که درخواستهای فوری/نجات با استفاده از رسانههای اجتماعی نسبتاً نادر است و بهدست آوردن نمونههای آموزشی کافی را دشوار میکند. به عنوان مثال، دواراج، مورتی و دونتولا [ 11] دریافت که درخواست های فوری در طوفان هاروی “غیر معمول” است و یافتن موارد مثبت برای آماده شدن برای داده های آموزشی بسیار چالش برانگیز است. آنها از کلمات کلیدی مرتبط با نجات از جمله «کمک»، «نجات» و «911» برای فیلتر کردن درخواستهای فوری توییتهای هاروی استفاده کردند. با این حال، این کلمات کلیدی به طور موثر درخواست های نجات را از پیام های دیگر جدا نمی کنند زیرا هر پیامی که حاوی این کلمات کلیدی باشد درخواست نجات نیست. مطالعه آنها در واقع گزارش داد که بیش از 90 درصد توییت هایی که با این کلمات کلیدی فیلتر شده اند، پیام های نجات طلب نیستند.
بنابراین، این مطالعه به این سوال می پردازد: آیا راه های جایگزینی برای فیلتر کردن درخواست های نجات از پست های فاجعه وجود دارد؟ به طور خاص، آیا پست های درخواست نجات دارای ویژگی خاصی هستند که می تواند آنها را از سایر پیام های فاجعه متمایز کند؟ آیا مدلهای یادگیری ماشینی از این ویژگی در طبقهبندی درخواستهای نجات سود میبرند؟ به یاد بیاورید که درخواست های نجات طبق تعریف ما باید دارای آدرس باشند. بنابراین، بررسی اینکه آیا ویژگی های جغرافیایی در این آدرس ها به شما کمک می کند، ارزش دارد. این مطالعه بر روی کدهای پستی متمرکز است، زیرا کدهای پستی اغلب در آدرس ها گنجانده می شوند و ماهیت ساختاری آنها می تواند شناسایی آنها را آسان کند.
3. داده ها و مدل ها
3.1. مجموعه توییت های طوفان هاروی
طوفان هاروی که از یک موج گرمسیری توسعه یافته بود، در 17 اوت 2017 به وضعیت طوفان گرمسیری رسید. هشت روز بعد، هاروی به طوفان رده 4 تبدیل شد و اولین بار به جزیره سن خوزه، تگزاس رسید. دومین فرود هاروی در صبح روز 26 اوت در نزدیکی شمال شرقی خلیج کوپانو، تگزاس رخ داد. هاروی پس از کاهش رتبه به یک طوفان استوایی در نزدیکی خط ساحلی تگزاس، بارندگی زیادی را به منطقه شهری هیوستون آورد ( شکل 1 ).
توییتهای طوفان هاروی که بین 17 آگوست 2017 و 7 سپتامبر 2017 ارسال شدهاند، از Gnip ( https://support.gnip.com/sources/twitter/ ، در تاریخ 10 مه 2018) بر اساس روش جستجوی کلمه کلیدی خریداری شدهاند. یعنی توییتهایی که حاوی هر یک از کلیدواژههای زیر هستند جمعآوری و بهعنوان فایلهای JSON ذخیره شدند:
طوفان، هاروی، فاجعه، نیروی دریایی Cajun، طوفان هاروی، txdps، txtf1، رد صلیب، گارد ساحلی، پلیس هوستون، هوستونوم، ارتش نجات، سیل، sos، سیل، طوفان، نجات، ارسال کمک، ارتش کاجونوی، fema
این منجر به 45 میلیون توییت شد. بازه زمانی توییتهای جمعآوریشده بر اساس سه مرحله مدیریت بلایا، شامل آمادگی، واکنش و بازیابی بود [ 2 ].
3.2. داده های آموزش و آزمون
ما از توییتهای هاروی ارسال شده بین ۲۷ اوت ۲۰۱۷ تا ۳۱ اوت ۲۰۱۷ (۴.۱ میلیون توییت) برای انتخاب دادههای آموزشی و آزمایشی استفاده کردیم. گردش کار برای آماده سازی داده های آموزشی و آزمون در شکل 2 نشان داده شده است . توجه داشته باشید که ریتوییت ها در این مجموعه داده گنجانده نمی شوند زیرا پیام های تکراری توییت های اصلی آنها هستند. به طور کلی، سه نوع اطلاعات جغرافیایی را می توان در پیام های توییتر یافت، از جمله مکان های نمایه، مکان های GPS (سیستم های موقعیت یابی جهانی) و مکان ها در محتوای متنی [ 4 ].]. مکانهای نمایه مکانهایی هستند که توسط کاربران توییتر گزارش میشوند (به عنوان مثال، ایالتها، شهرها و شهرستانها) که حاوی اطلاعات دقیقی برای تلاشهای نجات نیستند. مکانهای GPS را تنها زمانی میتوان بدست آورد که دستگاهها GPS داخلی را روشن کرده باشند، که در نتیجه این توییتهای دارای برچسب جغرافیایی نادر است [ 3 ]. با توجه به کیفیت مکان های نمایه و نادر بودن مکان های GPS، اولین پاسخ دهندگان اغلب به مکان های موجود در محتوای متنی توییتر (به عنوان مثال، آدرس های جغرافیایی در درخواست های نجات) برای مکان یابی قربانیان فاجعه تکیه می کنند.
همانطور که در بخش مقدمه ذکر شد، با توجه به اینکه کدهای پستی اغلب در آنها گنجانده شده است، میتوان یک فیلتر کد ZIP برای استخراج توییتهای هاروی حاوی آدرسها پیادهسازی کرد. فیلتر کردن کد پستی نیز یک روش جستجوی کلمه کلیدی است، در حالی که کلمات کلیدی آن همه اعداد (کدهای پستی) هستند. فهرستی از کدهای پستی برای منطقه آماری شهری هوستون (MSA) رعایت شد. توییتهای هاروی حاوی هر کد پستی در این لیست برای ساخت مجموعه دادهای به نام Harvey_ZIP_tweets که از 2804 توییت تشکیل شده است، به دست آمدهاند. این توییت ها با توجه به کد پستی آنها در شکل 3 جدول بندی و نقشه برداری شدندآ. نقشه نشان میدهد که این توییتها در سه شهرستان جمعآوری میشوند، جایی که هریس شهرستان مرکزی هیوستون MSA است و برازوریا و گالوستون دو شهرستان ساحلی هستند.
موارد مثبت موارد مثبت با طبقه بندی دستی Harvey_ZIP_tweets به دست آمد . این طبقه بندی باینری منجر به یک کلاس مثبت (درخواست نجات) به نام positive_ZIP و یک کلاس منفی به نام negative_ZIP شد. در مجموع 2106 توییت مثبت_زیپ (درخواست نجات) از طریق این مرحله به دست آمد. یعنی 75 درصد از توییتهای هاروی که با کدهای پستی فیلتر شدهاند، درخواستهای نجات هستند. این با کار دواراج، مورتی و دونتولا متفاوت است [ 11]، که در آن کمتر از 8 درصد از توییتهای آنها با کلمات کلیدی مرتبط با نجات مانند «کمک»، «نجات» و «911» فیلتر شدهاند، به عنوان درخواستهای فوری در طوفان هاروی برچسبگذاری شدهاند. این تفاوت قابل توجه را می توان به روش های فیلتر متمایز نسبت داد – فیلتر کد پستی ما از وضعیت “سوزن در انبار کاه” جلوگیری می کند. همچنین مشاهده میکنیم که برخی از کلیدواژههای دیگر مانند «گیر» و «به دام افتاده» در درخواستهای نجات توسط دواراج، مورتی و دونتولا نادیده گرفته شدند [ 11 ]. این ممکن است تا حدی مشکل آنها را در به دست آوردن داده های آموزشی بزرگتر توضیح دهد. موارد مثبت نیز بر اساس کد پستی آنها در شکل 3 ترسیم شدb، که در آن دو خوشه شامل شهرستان های هریس و گالوستون یافت می شود. این آدرسهای همراه با درخواستهای نجات میتوانند به مکانیابی قربانیان بلایا و برنامهریزی تلاشهای نجات کمک کنند، در حالی که نقشههای شکل 3 برای آگاهی از موقعیت و تخصیص منابع اضطراری مفید هستند.
موارد منفی یک کلاس منفی negative_ZIP با طبقه بندی باینری بالا به دست آمد. با این حال، نمونههای منفی جامع باید از سه نوع زیر تشکیل شوند: (1) توییتهایی که حاوی کدهای پستی هستند اما مربوط به نجات نیستند، یعنی negative_ZIP ، (2) توییتهایی که حاوی کد پستی نیستند اما مربوط به نجات هستند، به عنوان مثال، negative_rescue ، (3) توییت هایی که نه حاوی کد پستی هستند و نه مربوط به نجات هستند، یعنی negative_none. توجه داشته باشید که اولین نوع از نمونههای منفی برای مقابله با تأثیر ویژگی کد پستی حفظ شد تا یادگیری ماشین تنها بر این ویژگی تکیه نکند تا درخواستهای نجات را از سایر توییتها متمایز کند. برای به دست آوردن نمونه های منفی نوع دوم، ما به طور تصادفی 2000 توییت حاوی “نجات” یا “کمک” را از کل توییت های هاروی انتخاب کردیم و آنها را غربال کردیم تا مطمئن شویم که آنها درخواست های نجات نیستند. ما همچنین 1302 توییت را به طور تصادفی از توییت های هاروی انتخاب کردیم تا نمونه های منفی نوع سوم را به دست آوریم. به این ترتیب در مجموع 4000 نمونه منفی به دست آمد.
تقسیم قطار-آزمون. در نهایت، کل مجموعه داده (هر دو منفی / مثبت، 6106 توییت) به داده های آموزشی (80٪) و داده های آزمون (20٪) تقسیم شد.
3.3. داده های پیش بینی
پس از حذف دادههای آموزشی و دادههای آزمایش، ما از توییتهای باقیمانده هاروی در 28 آگوست به عنوان دادههای پیشبینی استفاده کردیم. این داده ها شامل 995732 توییت هاروی است. طبقهبندیکننده آموزشدیده ما سپس برای طبقهبندی دادههای پیشبینی و شناسایی درخواستهای نجات بر این اساس استفاده شد.
3.4. پاکسازی و تبدیل متن
پیام های توییتر اغلب حاوی کلماتی هستند که برای تحلیل ما بی معنی هستند. بنابراین، تمیز کردن متن برای کمک به فیلتر کردن این کلمات و به دست آوردن یک مجموعه تمیز ضروری است. توییتها در دادههای آموزشی و دادههای آزمایشی با مراحل زیر پاک شدند:
- (1)
-
URL ها را حذف کنید
- (2)
-
کلمات توقف را حذف کنید.
- (3)
-
اعداد 5 رقمی را با کلمه ی “zcode” جایگزین کنید. این برای تغییر همه کدهای پستی به یک ویژگی است.
- (4)
-
حذف کلمات تنها با 1 حرف.
- (5)
-
علائم نگارشی را حذف کنید.
- (6)
-
تبدیل به حروف کوچک
مراحل فوق به جز مرحله 3، تمیز کردن متن استانداردی بود که در بسیاری از مطالعات موجود استفاده شد [ 13 ، 14 ]. متون را نمیتوان مستقیماً توسط برخی از مدلهای یادگیری ماشین پردازش کرد، مگر اینکه به شکلهای عددی تبدیل شوند. یک روش متداول برای تبدیل متن، فرکانس فرکانس معکوس سند (TF-IDF) است که به صورت زیر محاسبه می شود:
t f– من df( t , d) = t f( t , d) × من دf( تی )تی�-مند�(تی،د)=تی�(تی،د)×مند�(تی)
جایی که t f( t , d)��(�,�)تعداد دفعات یک کلمه را نشان می دهد تی�که در یک توییت خاص ظاهر می شود د�، و من df( تی )���(�)از رابطه زیر بدست می آید من df( t ) = l o g1 + n1 + df( تی )+ 1���(�)=���1+�1+��(�)+1، با n�نشان دهنده تعداد کل توییت ها و دf( تی )��(�)نشان دهنده تعداد توییت های حاوی کلمه است تی�.
3.5. مدل های یادگیری ماشین
همه الگوریتمهای یادگیری ماشینی که در اینجا مورد بحث قرار میگیرند، یادگیری ماشینی تحت نظارت هستند. یعنی یک طبقهبندیکننده با نگاشت ویژگیها (پیشبینیکنندهها) به متغیر کلاس پاسخ دلخواه بر اساس یک مدل داده شده آموزش داده میشود [ 20 ]. در یک سناریوی طبقه بندی باینری، ویژگی ها به یک پاسخ باینری (0/1) نگاشت می شوند. در مورد شناسایی درخواست نجات، طبقهبندیکنندهای را آموزش دادیم تا با یادگیری ویژگیهای این توییتها، توییتهای هاروی را به عنوان درخواست نجات یا دیگران دستهبندی کند. چندین مدل رایج یادگیری ماشین و دو مدل یادگیری عمیق برای آموزش یک طبقهبندی کننده باینری استفاده شد. توجه داشته باشید که کتابخانه scikit-learn در پایتون [ 21 ] برای آموزش و آزمایش این مدلهای یادگیری ماشینی استفاده شد، در حالی که یک چارچوب یادگیری عمیق پایتون، یعنی Keras ( https://keras.io )، در 5 آگوست 2021 مشاهده شد) برای دو مدل یادگیری عمیق استفاده شد. علاوه بر این، توجه داشته باشید که یادگیری عمیق از تبدیل متن TF-IDF همانطور که در بالا توضیح داده شد استفاده نمی کند. با توجه به اینکه مدلهای یادگیری عمیق اغلب شامل مقدار زیادی فراپارامترها میشوند، ما ترجیح دادیم از تنظیماتی استفاده کنیم که در تحقیقات قبلی موفقیتآمیز بودهاند تا اینکه از ابتدا تنظیم پرهزینه داشته باشند.
3.5.1. رگرسیون لجستیک
به دلیل سادگی و قابلیت تفسیر بالا، رگرسیون لجستیک (LR) به طور گسترده در بسیاری از زمینه ها برای طبقه بندی داده های باینری استفاده شده است. در اینجا برای مدلسازی احتمال درخواستهای نجات استفاده شد. آموزش رگرسیون لجستیک فقط شامل چند فراپارامتر مانند حل کننده، پنالتی و منظم سازی است. تنظیمات فراپارامتر برای این مدل را می توان در جدول A2 یافت .
3.5.2. K-نزدیکترین همسایه ها
K-نزدیکترین همسایه (kNN) یک الگوریتم یادگیری ماشینی نظارت شده ساده است با این فرض که چیزهای نزدیک شبیه تر هستند. kNN یک توییت جدید هاروی را با یافتن k نزدیکترین توییت آموزشی به آن پیشبینی یا طبقهبندی میکند. نزدیکی را می توان با معیارهای فاصله مانند فاصله اقلیدسی، فاصله منهتن و فاصله مینکوفسکی اندازه گیری کرد. kNN دارای فراپارامترهای محدودی برای تنظیم است، در حالی که k اشاره به تعداد نزدیکترین همسایه ها مهمترین مورد است. تنظیمات فراپارامتر آن را می توان در جدول A1 یافت .
3.5.3. بیز ساده لوح
ساده بیز (NB) یک الگوریتم یادگیری نظارت شده است که بر اساس قضیه بیز ساخته شده است. اصطلاح “ساده لوح” به این فرض اشاره دارد که همه ویژگی ها کاملاً مستقل از یکدیگر هستند [ 22 ]. تعداد کمی از فراپارامترهای حیاتی در NB نیاز به تنظیم دارند.
3.5.4. جنگل تصادفی
جنگل تصادفی (RF) یک مدل یادگیری گروهی است که با چند طبقهبندی درخت تصمیم مطابقت دارد. درخت تصمیم منعکس کننده فرآیند تصمیم گیری انسانی است و می تواند با ساختاری شبیه به فلوچارت تجسم شود. درخت تصمیم با تقسیم یا عدم تقسیم هر گره تصمیم به دو گره فرعی به صورت بازگشتی (یعنی پارتیشن بندی بازگشتی) رشد می کند. معیارهای انتخاب ویژگی (ASM) مانند افزایش اطلاعات، شاخص جینی و نسبت بهره اغلب به عنوان معیار تقسیم استفاده میشوند. جنگل تصادفی مجموعه ای از بسیاری از درختان تصمیم است که در آن هر درخت بر اساس یک نمونه بوت استرپ از داده های آموزشی ساخته می شود. این پیشبینی هر درخت تصمیم را جمعآوری میکند (با میانگینگیری) برای بهبود دقت پیشبینی و کنترل بیش از حد برازش. توجه داشته باشید که هنگام تقسیم یک گره برای رشد درخت تصمیم، پارتیشن دیگر بر اساس همه ویژگی ها نیست. در عوض، بهترین تقسیم در میان زیرمجموعهای تصادفی از ویژگیها انتخاب میشود. فراپارامترهای جنگل تصادفی شامل تعداد درختان، تعداد ویژگی هایی که باید در هنگام جستجوی بهترین تقسیم در نظر گرفته شود، حداکثر عمق درخت، حداقل تعداد نمونه های مورد نیاز برای تقسیم یک گره داخلی و حداقل تعداد نمونه های مورد نیاز است. قرار گرفتن در یک گره برگ، و دیگران.جدول A3 تنظیمات فراپارامتر آن را گزارش می کند.
3.5.5. ماشین بردار پشتیبانی
ماشین بردار پشتیبان (SVM) با اشیاء (تویت های هاروی) به عنوان نقاطی در فضایی با ابعاد بالا رفتار می کند و یک ابر صفحه را پیدا می کند تا آنها را به دو دسته تقسیم کند. اگرچه طبقهبندیکنندههای دیگری بر اساس ابرصفحهها وجود دارد، SVM راه خود را برای انتخاب ابر صفحه جداسازی بهینه دارد [ 23 ]]. این روش (یعنی ابرصفحه ماکزیمم حاشیه) فاصله ابر صفحه جداکننده تا نزدیکترین نقطه داده را به حداکثر می رساند و بزرگترین جداسازی (حاشیه) را پیدا می کند. همه داده ها به صورت خطی قابل تفکیک نیستند، به این معنی که افراد همیشه نمی توانند به طور کامل نقاط داده را از هم جدا کنند و SVM باید اجازه داشته باشد که خطاهای طبقه بندی را مرتکب شود. با توجه به این، یک فرمول حاشیه نرم معرفی شده است تا امکان نقض هایپرپلان در حین معامله خارج از حاشیه را فراهم کند. هنگامی که با معرفی یک حاشیه نرم، هنوز نمیتوان نقاط داده را از هم جدا کرد، تابع هسته میتواند برای افزودن بعد جدیدی به فضای بعدی نقاط داده اعمال شود، و سپس یک ابر صفحه جداکننده را میتوان در این فضای ابعاد بالاتر یافت. فراپارامترهای مهم SVM شامل تنظیم، هسته و غیره است. جدول A4تنظیمات هایپرپارامتر این مدل را لیست می کند.
3.5.6. حافظه بلند مدت کوتاه مدت
LSTM (حافظه کوتاه مدت بلندمدت) یک نوع منحصر به فرد از RNN (شبکه عصبی بازگشتی) است که ذخیره سازی حافظه بلندمدت را از طریق یک واحد سلول حافظه که برای جمع آوری سیگنال های خارجی به خود متصل است، امکان پذیر می کند [ 24 ]. یک واحد LSTM رایج از یک سلول، یک دروازه ورودی، یک دروازه خروجی و یک دروازه فراموشی تشکیل شده است. این مطالعه از جاسازی GloVe بر اساس توییتر از استانفورد استفاده کرد (منبع باز در: https://nlp.stanford.edu/projects/glove/، قابل دسترسی در 20 اکتبر 2021). پس از لایه جاسازی، یک لایه پیچشی 1 بعدی (128 فیلتر) ابتدا در مدل LSTM اعمال شد تا تعداد ویژگی ها کاهش یابد. سپس یک لایه دو طرفه (128 فیلتر) با نسبت حذف 0.5 اجرا شد. دو لایه متراکم به دنبال لایههای دو طرفه اضافه شدند که هر یک از آنها دارای 512 فیلتر با ReLU [ 25 ] به عنوان تابع فعالسازی بود. در نهایت، یک لایه متراکم با یک نورون اضافه شد و یک تابع سیگموئید با توجه به ماهیت دوتایی این طبقهبندی اعمال شد. تنظیمات فراپارامتر برای این مدل را می توان در جدول A5 یافت .
3.5.7. شبکه عصبی کانولوشنال تعبیه شده کلمه (CNN)
یکی دیگر از رویکردهای رقیب طبقه بندی در این مطالعه، CNN تعبیه شده با کلمه است که در اصل توسط کیم طراحی شده است [ 26 ]. در این مطالعه، ساختار آن را به دنبال طراحی معماری هوانگ و همکاران اصلاح کردیم. [ 18 ]. به طور خاص، ما بردارهای کلمه را از طریق Word2Vec، یک شبکه عصبی کم عمق با یک لایه پنهان به دست آوردیم، اما ثابت کردیم که در ارائه بردارهایی که ویژگی های کلمه را نشان می دهند، قدرتمند است [ 27 ]. لطفا به Huang و همکاران مراجعه کنید. [ 18 ] برای کلمه دقیق طراحی معماری CNN تعبیه شده است. تنظیمات فراپارامتر آن را می توان در جدول A6 یافت .
3.6. ارزیابی مدل
برای انتخاب بهترین مدل پیشبینی، باید عملکرد طبقهبندیکنندههای یادگیری ماشین آموزشدیده را با دادههای آزمایشی ارزیابی کنیم. معیارهایی از جمله یادآوری، دقت، دقت و F1 تا حد زیادی در ارزیابی عملکرد استفاده شده است. این معیارها از یک جدول احتمالی دو به دو ( شکل 4 ) مشتق شدهاند که در آن سلولها به ترتیب شامل تعداد مثبت واقعی ( TP )، مثبت کاذب (FP)، منفی واقعی (TN) و منفی کاذب (FN) هستند.
معیارها با معادلات زیر تعریف می شوند:
پr e c i s i o n = Tپ/ ( تیپ+ افپ)پ�هجمنسمن��=تیپ/(تیپ+افپ)
R e c a l l = Tپ/ ( تیپ+ افن)آرهجآلل=تیپ/(تیپ+افن)
A c c u r a c y= ( تیپ+ تین) / ( تیپ+ افپ+ تین+ افن)آججتو�آج�=(تیپ+تین)/(تیپ+افپ+تین+افن)
اف1 = 2 × R e c a l l × Pr e c i s i o n / ( R e c a l l + Pr e c i s i o n )اف1=2×آرهجآلل×پ�هجمنسمن��/(آرهجآلل+پ�هجمنسمن��)
به طور معمول، نمره بالاتر نشان دهنده عملکرد بهتر مدل است. مسلما، R e c a l lآرهجآللامتیاز باید در تشخیص درخواست نجات بیشتر مورد توجه قرار گیرد، زیرا منفی کاذب ترجیح داده می شود تا حد امکان پایین باشد تا بسیاری از درخواست های نجات نادیده گرفته شوند.
4. نتایج
توجه داشته باشید که تمام نمونه های مثبت (یعنی positive_ZIP ) در داده های آموزش و آزمون حاوی کد پستی هستند. با این حال، این به طور دقیق واقعیت را منعکس نمی کند زیرا افزودن کدهای پستی به آدرس ها می تواند یک عمل تصادفی باشد. مردم انتظار دارند که برخی از آدرس ها دارای کد پستی نباشند. با توجه به این موضوع، ما هشت آزمایش انجام دادیم تا بررسی کنیم که کدهای ZIP چگونه بر عملکرد مدل تأثیر میگذارند، که در آن هر آزمایش بر اساس مجموعه دادهای بود که با حذف کدهای پستی از درصد معینی از positive_ZIP ایجاد شده بود.. قابل ذکر است، نسبت موارد مثبت که با کد پستی بدون برچسب هستند، تنها تفاوت بین هشت مجموعه داده است که نتایج آزمایشهای مربوطه را قابل مقایسه میکند. ما آزمایشها را به دو گروه تقسیم کردیم: گروه اکثریت کد پستی و گروه اقلیت کد پستی. گروه اکثریت کد پستی بیش از 50 درصد از نمونه های مثبت خود را با کد پستی برچسب گذاری می کنند، در حالی که گروه اقلیت کمتر از 50 درصد از نمونه های مثبت با کد پستی دارند.
نرخ تقسیم آموزش-آزمون برای همه آزمایشها در این تحقیق 80/20 درصد تعیین شد. برای مقابله با مشکل اضافه برازش بالقوه، اعتبارسنجی متقاطع k -fold برای تقسیم داده های آموزشی ما به پنج ( k = 5) برابر استفاده شد که یک تا یک مجموعه اعتبار سنجی و چهار برابر باقی مانده به عنوان مجموعه آموزشی است. این تقسیم پنج بار ( k = 5) تکرار شد تا هر فولد بتواند به عنوان مجموعه اعتبار سنجی عمل کند. برای هر تکرار، مدل با مجموعه آموزشی آموزش داده شد و بر روی مجموعه اعتبارسنجی ارزیابی شد. GridSearchCV در scikit-learn برای اعتبارسنجی متقابل و تنظیم فراپارامتر استفاده شد. نتایج فرآیند اعتبار سنجی متقابل را می توان با میانگین و انحراف معیار نمرات ارزیابی مدل خلاصه کرد ( شکل 5 را ببینید.به عنوان مثال). در زیر ارزیابیهای مدل بهدستآمده با 100٪ موارد مثبت که با کد پستی برچسبگذاری شدهاند، و همچنین ارزیابیهای مدلهایی با تنها بخشی از موارد مثبت را گزارش میکنیم.
4.1. ارزیابی مدل با همه موارد مثبت که با کد پستی برچسب گذاری شده اند
همانطور که در شکل 5 نشان داده شده است ، kNN دارای دقت قابل توجهی بالاتر (0.962) به قیمت نرخ فراخوان پایین (0.632) است. این نشان میدهد که دستهبندی توییتهای هاروی به عنوان درخواستهای نجات به قیمت نرخ منفی کاذب بالاتر را در اولویت قرار میدهد. قابل ذکر است، جنگل تصادفی بالاترین امتیاز را در دقت ، یادآوری و افاف1 بنابراین، بهترین طبقه بندی کننده در این سناریو است.
طبقهبندیکنندههای بهدستآمده با دادههای آموزشی، سپس بر روی دادههای آزمون ارزیابی شدند. نتایج ارزیابی برای مقایسه در شکل 6 نشان داده شده است. در مقایسه با مدلهای دیگر، طبقهبندیکننده جنگل تصادفی دوباره بهترین عملکرد مدل را داشت زیرا بالاترین امتیازات را در دقت ، یادآوری و F 1 به دست آورد. به عبارت دیگر، جنگل تصادفی بیشتر ثابت شد که تشخیص دقیقتری از درخواستهای نجات از توییتهای هاروی را نشان میدهد. . سپس از این طبقهبندیکننده تصادفی جنگلی آموزشدیده برای شناسایی درخواستهای نجات از دادههای پیشبینی استفاده شد. برخی از درخواستهای نجات پیشبینیشده توسط کدهای پستی برچسبگذاری نشدهاند ( جدول 1). به یاد داشته باشید که همه درخواستهای نجات در دادههای آموزشی و آزمایشی ما حاوی کدهای پستی در آدرسهایشان هستند و ما مطمئن نبودیم که طبقهبندیکننده آموزشدیده ما بتواند آن موارد بدون برچسب (در صورت وجود) را با موفقیت شناسایی کند. بنابراین، این درخواستهای نجات پیشبینیشده در جدول 1 ، تا حدی، اثربخشی طبقهبندیکننده ما را تأیید میکند.
4.2. ارزیابی مدل با برخی موارد مثبت که با کد پستی برچسب گذاری شده اند
ما نتایج ارزیابی را بعد از محاسبه سناریوهای مختلف کد پستی در جدول 2 ، که بهترین مدل (بر اساس افاف1 و نمرات یادآوری ) در هر گروه اکثریت با فونت پررنگ و مورب برجسته شده است، در حالی که بهترین مدل در هر گروه اقلیت فقط با قلم برجسته مشخص شده است.
جدول 2 نشان می دهد که اگر هر گروه اکثریتی را با گروه اقلیت متناظر آن مقایسه کنیم، بهترین مدل ها همه از گروه های اکثریت کد پستی هستند. بهترین مدل ها در این دو گروه داشتند افاف1 امتیاز از 0.001 تا 0.004 متفاوت است. تفاوت 0.001 تا 0.02 در امتیاز Recall بین مدل های برتر وجود داشت. استفاده كردن تیتیآمار، ما بیشتر ارتباط آماری تفاوت های فوق را بررسی کردیم. نتایج نشان میدهد که بهترین مدلها در گروه اکثریت بهطور معنیداری امتیازهای یادآوری (آمار = 2.902، p -value = 0.027) را از مدلهای گروه اقلیت داشتند. اگرچه تفاوت در افاف1 از نظر آماری معنی دار نبود، یک بهبود جزئی در چنین وضعیت مرگ یا زندگی همچنان می تواند جان افراد بیشتری را نجات دهد. این آزمایشها را میتوان بهعنوان تحلیل حساسیت نیز در نظر گرفت، که ثابت میکند مدلهای یادگیری ماشین ما (به جز kNN و NB) پس از شبیهسازی سناریوهای مختلف کد پستی، همچنان عملکرد عالی دارند (بالاتر از 0.9 برای همه امتیازات ارزیابی).
رتبهبندی بهترین مدلها بر اساس امتیازهای Recall نشان میدهد که چهار مدل برتر همگی زمانی به دست میآیند که نمونههای برچسبگذاری شده با کد پستی بیش از ۵۰ درصد از کل دادههای مثبت را تشکیل میدهند. علاوه بر این، نمونه های مثبت با 100٪ برچسب کد پستی بهترین آشکارساز را آموزش می دهند، در حالی که دومین طبقه بندی کننده با 90٪ موارد مثبت با کد پستی به دست می آید. این نشان می دهد که کدهای پستی یک ویژگی مفید برای مدل ها برای یادگیری درخواست های نجات هستند. اگرچه نتایج یک رابطه خطی کامل بین موارد مثبت با برچسب کد پستی و عملکرد مدلهای یادگیری ماشین نشان نمیدهد، توصیه میکنیم هر قربانی درخواستهای نجات خود را با کدهای پستی به دو دلیل زیر برچسبگذاری کند:
- (1)
-
درخواستهای نجات با برچسب کد پستی بیشتر توسط مدلهای یادگیری ماشین شناسایی میشوند. بنابراین، تشویق هر قربانی امدادگر برای گنجاندن کد پستی در پستهای خود، درخواستهای نجات با برچسب کد پستی را تا 90 درصد و بالاتر افزایش میدهد و در نتیجه احتمال شناسایی درخواستهای قربانیان را افزایش میدهد.
- (2)
-
گنجاندن کدهای پستی برای ایجاد آدرس های کامل، پاسخ دهندگان و داوطلبان را قادر می سازد تا مکان قربانیان را بهتر بیابند، به ویژه با توجه به اینکه برخی افراد ممکن است فراموش کنند اطلاعات جغرافیایی دیگر مانند شهرها را در آدرس خود وارد کنند.
5. نتیجه گیری ها
رسانه های اجتماعی رویکرد جدیدی را برای قربانیان فراهم می کند تا در بلایا به دنبال نجات باشند. جمع آوری این درخواست های نجات می تواند به واکنش در بلایا کمک کند. با این حال، بیشتر طبقهبندیکنندههای موجود دادههای رسانههای اجتماعی مرتبط با فاجعه، برای استخراج اطلاعاتی به اندازه درخواستهای نجات، عمومیت بیشتری دارند. این مقاله یک مطالعه امکانسنجی آموزش آشکارساز درخواست نجات با یادگیری ماشین و توییتهای طوفان هاروی را نشان میدهد. با در نظر گرفتن درصدهای مختلف درخواستهای نجات با برچسب کد پستی در فرآیند آموزش، همه طبقهبندیکنندههای یادگیری ماشین بهجز kNN و NB عملکرد بسیار خوبی در تمایز درخواستهای نجات از پیامهای دیگر به دست آوردند – نمرات ارزیابی مدل آنها همگی بالاتر از 0.9 بود و وضعیتی را ارائه میکردند. اجرای هنری در ادبیات که اکثر طبقه بندی کنندگان افافنمرات 1 و Recall کمتر از 0.9 بود (برای آخرین نمونه به Devaraj، Murthy و Dontula [ 11 ] مراجعه کنید). این را می توان با جنبه های زیر توضیح داد.
ابتدا، دادههای ما از Gnip خریداری شد، که مشمول محدودیت درخواست اعمال شده بر روی رابطهای برنامهنویسی برنامه کاربردی رایگان توییتر (API) نیست. این حجم دادههای آموزشی ما را بزرگتر کرد و منجر به مدلهای یادگیری بهتر شد.
دوم، ما روی درخواستهای نجات عملی (باید حاوی آدرسهای جغرافیایی باشد) تمرکز کردیم، که ویژگیهایی مانند «کمک»، «رستگاری»، «rd (جاده)» و «dr (drive)» میتواند خود را از سایر توییتهای فاجعهآمیز متمایز کند.
سومین و مهمتر از آن، ما یک روش منحصر به فرد فیلتر کردن کد پستی را معرفی کردیم که به طور قابل توجهی دشواری غربالگری درخواستهای نجات غیرمعمول از حجم زیادی از پیامهای فاجعه را کاهش داد. در مقایسه با مطالعات موجود، این تحقیق حتی با تعریف دقیقتری از درخواستهای نجات (باید حاوی آدرسهای جغرافیایی) و منطقه مطالعاتی کوچکتر (Houston MSA) توئیتهای جستجوی نجات بیشتری را به دست آورد. علاوه بر این، پس از شبیهسازی سناریوهایی با درصدهای مختلف موارد مثبت برچسبگذاری شده با کد پستی، دریافتیم که بهترین آشکارساز درخواست نجات، ردیابهایی بود که با ۱۰۰ درصد نمونههای مثبت برچسبگذاری شده توسط کدهای پستی آموزش دیده بودند، و پس از آن دومین نمونه برتر آموزش دیده با ۹۰ درصد بود. نمونه های مثبت با برچسب کد پستی. علاوه بر این، همه بهترین مدلها در گروههای اکثریت از بهترین مدلها در گروههای اقلیت بهتر عمل کردند. از این رو،
برای نشان دادن بیشتر ظرفیت فیلتر کردن کد پستی، از کدهای پستی لوئیزیانا برای فیلتر کردن مستقیم درخواستهای نجات در طوفان آیدا از توییتهای عمومی ارسال شده در 30 اوت 2021 استفاده کردیم. این فیلتر منجر به 414 توییت شد. به دلیل محدودیت منابع، این توییت ها به صورت دستی طبقه بندی نشدند، اما یک تخمین محافظه کارانه پس از غربالگری خودسرانه این است که بیش از 40٪ می تواند درخواست های نجات باشد. بنابراین، ما استدلال میکنیم که این فیلتر کردن کد پستی ساده میتواند به اولین پاسخدهندگان کمک کند تا در شرایطی که طبقهبندیکنندههای یادگیری ماشین در دسترس نیستند، درخواستهای نجات یا اضطراری را بهتر بازیابی کنند.
نکته قابل توجه، جنگل تصادفی به عنوان یک مدل یادگیری ماشین سنتی در چندین سناریو از دو مدل یادگیری عمیق بهتر عمل کرد، که نشان میدهد که دومی نباید همیشه به عنوان بهترین راهحل بدون مقایسه آن با روشهای سنتی در نظر گرفته شود. این یافته با برخی از کارهای موجود مطابقت دارد [ 11 ، 28 ]. به عنوان مثال، Devaraj، Murthy و Dontula [ 11 ] همچنین دریافتند که طبقه بندی کننده SVM می تواند بالاتر باشد. افاف1 نسبت به مدل CNN در تشخیص درخواست های فوری در توییت های هاروی.
6. بحث
در طول طوفان هاروی، درخواستهای نجات از رسانههای اجتماعی توسط داوطلبان و اولین پاسخ دهندگان از رسانههای اجتماعی به صورت دستی جمعآوری میشد که زمانبر است و به نیروی انسانی شدید نیاز دارد. فراتر از این مطالعه امکان سنجی، هدف نهایی ما توسعه یک طبقه بندی کننده عمومی قابل اجرا برای خودکار کردن تشخیص درخواست های نجات در بلایای مختلف است. کار آینده طبقهبندیکنندهها را با پیامهای رسانههای اجتماعی مرتبط با سایر طوفانها و بلایا آزمایش خواهد کرد. برای مثال، نحوه عملکرد طبقهبندیکنندههای ما در استخراج درخواستهای نجات در طوفان آیدا را بررسی خواهیم کرد. یک سوال تحقیقاتی جالب می تواند بر این اساس مطرح شود: آیا طبقه بندی کننده های آموزش دیده در این مطالعه در یک رویداد طوفانی دیگر به خوبی تعمیم می یابند؟
بسیاری از تجزیه و تحلیل رسانه های اجتماعی از جمله شبکه [ 29 ، 30 ]، مکانی و/یا زمانی [ 31 ، 32 ، 33 ]، و تحلیل معنایی [ 31 ، 32 ، 33 ] برای مطالعه طوفان هاروی توسعه یافته اند. تجزیه و تحلیل پایان نامه ها اغلب بر اساس پیام های فاجعه کلی بود، در حالی که توجه کمتری به فعالیت های رسانه های اجتماعی مربوط به یک موضوع خاص (به ویژه درخواست های نجات) شده است. به کمک استخراج درخواستهای نجات ما، این تجزیه و تحلیلها میتوانند برای درک بهتر استفاده از رسانههای اجتماعی در شرایط مرگ یا زندگی و ارائه بینشهای بیشتری در مورد واکنش در برابر بلایا و انعطافپذیری بهبود یابند.
رویکرد در نظر گرفتن و آزمایش برخی از ویژگیها در مدلسازی یادگیری ماشین ممکن است به زمینههای دیگر نیز مرتبط باشد، زیرا دادههای رسانههای اجتماعی تا حد زیادی در بسیاری از مطالعات علوم اجتماعی مورد استفاده قرار گرفتهاند. توصیه ما این است که برای استخراج نوع خاصی از پیامهای رسانههای اجتماعی در طول یک رویداد مانند پیامهای درخواست نجات، ترجیحاً کلمات کلیدی را شناسایی کنید که در پیامهای هدف رایج هستند اما در دیگران کمتر رایج هستند. همچنین انجام شبیهسازیها برای تست اینکه مدلها چگونه به این کلمات کلیدی یا ویژگیها حساس هستند، مهم است. کدهای پستی به عنوان یک ویژگی جغرافیایی در بهبود عملکرد یادگیری ماشین در این مطالعه مفید هستند. بنابراین، ویژگی های جغرافیایی را نباید در استخراج پیام های هدف مبتنی بر یادگیری ماشین نادیده گرفت.
منابع
- میهونوف، وی وی. لام، NSN; زو، ال. وانگ، ز. وانگ، ک. استفاده از توییتر در نجات بلایا: درس های آموخته شده از طوفان هاروی. بین المللی جی دیجیت. زمین 2020 ، 13 ، 1454-1466. [ Google Scholar ] [ CrossRef ]
- زو، ال. لام، NSN; شمس، س. کای، اچ. مایر، MA; یانگ، اس. تره فرنگی.؛ پارک، اس جی. ریمز، کارشناسی ارشد نابرابریهای اجتماعی و جغرافیایی در استفاده از توییتر در طول طوفان هاروی. بین المللی جی دیجیت. زمین 2019 ، 12 ، 1300-1318. [ Google Scholar ] [ CrossRef ]
- وانگ، ز. بله، X. Tsou، MH تجزیه و تحلیل فضایی، زمانی و محتوای توییتر برای خطرات آتش سوزی. نات. خطرات 2016 ، 83 ، 523-540. [ Google Scholar ] [ CrossRef ]
- وانگ، ز. Ye, X. تجزیه و تحلیل رسانه های اجتماعی برای مدیریت بلایای طبیعی. بین المللی جی. جئوگر. Inf. علمی 2018 ، 32 ، 49-72. [ Google Scholar ] [ CrossRef ]
- وانگ، ز. Ye, X. فضا، زمان و آگاهی موقعیتی در خطرات طبیعی: مطالعه موردی طوفان سندی با داده های رسانه های اجتماعی. سبد خرید Geogr. Inf. علمی 2019 ، 46 ، 334-346. [ Google Scholar ] [ CrossRef ]
- وانگ، ز. لام، NSN; اوبرادویچ، ن. بله، X. آیا جوامع آسیب پذیر به صورت دیجیتالی در واکنش های اجتماعی به بلایای طبیعی عقب مانده اند؟ شواهدی از طوفان سندی با داده های توییتر. Appl. Geogr. 2019 ، 108 ، 1-8. [ Google Scholar ] [ CrossRef ]
- هوانگ، ایکس. وانگ، سی. لی، زی. بازسازی احتمال طغیان سیل با افزایش تصاویر نزدیک به زمان واقعی با سنجها و توییتهای بیدرنگ. IEEE Trans. Geosci. Remote Sens. 2018 , 56 , 4691–4701. [ Google Scholar ] [ CrossRef ]
- زو، ال. لام، NSN; کای، اچ. Qiang، Y. استخراج دادههای توییتر برای درک بهتر مقاومت در برابر بلایا. ان صبح. دانشیار Geogr. 2018 ، 108 ، 1422-1441. [ Google Scholar ] [ CrossRef ]
- هیوز، آل. Palen, L. نقش در حال تحول افسر اطلاعات عمومی: بررسی رسانه های اجتماعی در مدیریت اضطراری. جی. هومل. امن ظهور. مدیریت 2012 ، 9 . [ Google Scholar ] [ CrossRef ]
- عمران، م. میترا، پ. کاستیلو، سی. توییتر به عنوان یک راه نجات: مجموعه توییتر مشروح انسانی برای NLP پیام های مرتبط با بحران. arXiv 2016 , arXiv:1605.05894. [ Google Scholar ]
- دورج، ع. مورتی، دی. دونتولا، الف. روشهای یادگیری ماشینی برای شناسایی درخواستهای مبتنی بر رسانههای اجتماعی برای کمک فوری در طول طوفان. بین المللی J. کاهش خطر بلایا. 2020 , 51 , 101757. [ Google Scholar ] [ CrossRef ]
- کبیر، من; Madria, S. یک رویکرد یادگیری عمیق برای طبقه بندی توییت و برنامه ریزی نجات برای مدیریت موثر بلایا. در مجموعه مقالات GIS: مجموعه مقالات سمپوزیوم بین المللی ACM در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، شیکاگو، IL، ایالات متحده آمریکا، 10 اوت 2010; انجمن ماشینهای محاسباتی: نیویورک، نیویورک، ایالات متحده آمریکا، 2019؛ ص 269-278. [ Google Scholar ]
- عمران، م. الباسونی، اس. کاستیو، سی. دیاز، اف. Meier, P. استخراج قطعات اطلاعاتی از پیام های مربوط به فاجعه در رسانه های اجتماعی. ایسکرام 2013 ، 201 ، 791-801. [ Google Scholar ]
- هوانگ، Q. Xiao، Y. آگاهی موقعیت جغرافیایی: توییتهای استخراج برای آمادگی در برابر بلایا، واکنش اضطراری، تأثیر و بازیابی. ISPRS Int. J. Geo-Inf. 2015 ، 4 ، 1549-1568. [ Google Scholar ] [ CrossRef ]
- نی، جی.-ای. موسسه مهندسان برق و الکترونیک. در مجموعه مقالات انجمن کامپیوتر IEEE 2017 کنفرانس بین المللی IEEE در مورد داده های بزرگ، بوستون، MA، ایالات متحده آمریکا، 11-14 دسامبر 2017. ISBN 9781538627150. [ Google Scholar ]
- ژو، بی. زو، ال. مصطفوی، ع. لین، بی. یانگ، م. غرایبه، ن. کای، اچ. عابدین، ج. Mandal, D. VictimFinder: Harvesting Rescue Requests in Disaster Response از رسانه های اجتماعی با BERT. محاسبه کنید. Env. سیستم شهری 2022 ، 95 ، 101824. [ Google Scholar ] [ CrossRef ]
- د آلبوکرک، جی پی; هرفورت، بی. برنینگ، آ. Zipf، A. یک رویکرد جغرافیایی برای ترکیب رسانه های اجتماعی و داده های معتبر به سمت شناسایی اطلاعات مفید برای مدیریت بلایا. بین المللی جی. جئوگر. Inf. علمی 2015 ، 29 ، 667-689. [ Google Scholar ] [ CrossRef ]
- هوانگ، ایکس. لی، ز. وانگ، سی. نینگ، اچ. شناسایی رسانههای اجتماعی مرتبط با فاجعه برای واکنش سریع: معماری CNN ترکیبی بصری-متن. بین المللی جی دیجیت. زمین 2020 ، 13 ، 1017–1039. [ Google Scholar ] [ CrossRef ]
- هوانگ، ایکس. وانگ، سی. لی، ز. نینگ، اچ. یک رویکرد ترکیبی بصری-متن برای برچسبگذاری خودکار توییتهای مرتبط با سیل در طول یک رویداد سیل. بین المللی جی دیجیت. زمین 2019 ، 12 ، 1248-1264. [ Google Scholar ] [ CrossRef ]
- ابونیمه، س. ناپا، دی. وانگ، ایکس. Nair, S. مقایسه تکنیک های یادگیری ماشین برای تشخیص فیشینگ. در مجموعه مقالات گروه های کاری ضد فیشینگ، دومین نشست سالانه پژوهشگران جنایت الکترونیکی، پیتسبورگ، PA، ایالات متحده آمریکا، 4 تا 5 اکتبر 2007. صص 60-69. [ Google Scholar ]
- پدرگوسا، اف. واروکو، جی. گرامفورت، آ. میشل، وی. تیریون، بی. گریزل، او. بلوندل، م. پرتنهوفر، پی. ویس، آر. دوبورگ، وی. و همکاران Scikit-Learn: یادگیری ماشین در پایتون Gaël Varoquaux Bertrand Thirion Vincent Dubourg Alexandre Passos Pedregosa، Varoquaux، Gramfort و همکاران. جی. ماخ. فرا گرفتن. Res. 2011 ، 12 ، 2825-2830. [ Google Scholar ]
- سوریا، دی. گاریبالدی، ج.م. آمبروگی، اف. بیگانزولی، EM; الیس، IO یک نسخه «غیر پارامتریک» از طبقهبندی کننده سادهلوح بیز. بدانید. سیستم مبتنی بر 2011 ، 24 ، 775-784. [ Google Scholar ] [ CrossRef ]
- Noble, WS ماشین بردار پشتیبان چیست؟ نات. بیوتکنول. 2006 ، 24 ، 1565-1567. [ Google Scholar ] [ CrossRef ]
- ساندرمایر، ام. شلوتر، آر. Ney, H. LSTM شبکه های عصبی برای مدل سازی زبان. در سیزدهمین کنفرانس سالانه انجمن بین المللی ارتباطات گفتار . 2012. در دسترس آنلاین: https://www.isca-speech.org/archive_v0/archive_papers/interspeech_2012/i12_0194.pdf (در 18 فوریه 2022 قابل دسترسی است).
- Agarap، AF یادگیری عمیق با استفاده از واحدهای خطی اصلاح شده (relu). arXiv 2018 , arXiv:1803.08375. [ Google Scholar ]
- یون، K. شبکه های عصبی کانولوشنال برای طبقه بندی جملات. در مجموعه مقالات کنفرانس 2014 در مورد روشهای تجربی در پردازش زبان طبیعی (EMNLP)، دوحه، قطر، 26-28 اکتبر 2014. صفحات 1746-1751. [ Google Scholar ]
- توماس، م. چن، ک. کورادو، جی. Dean, J. برآورد کارآمد نمایش کلمات در فضای برداری. arXiv 2013 , arXiv:1301.3781. [ Google Scholar ]
- جیائو، اس. گائو، ی. فنگ، جی. لی، تی. یوان، ایکس. آیا یادگیری عمیق همیشه از رگرسیون خطی ساده در تصویربرداری نوری بهتر است؟ انتخاب کنید Express 2020 , 28 , 3717. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- راجپوت، AA; لی، کیو. ژانگ، سی. مصطفوی، الف. تحلیل شبکه زمانی ارتباطات بین سازمانی در رسانه های اجتماعی در هنگام بلایا: مطالعه طوفان هاروی در هیوستون. بین المللی J. کاهش خطر بلایا. 2020 , 46 , 101622. [ Google Scholar ] [ CrossRef ]
- فن، سی. جیانگ، ی. یانگ، ی. ژانگ، سی. مصطفوی، الف. جمعیت یا هاب: الگوهای انتشار اطلاعات در شبکه های اجتماعی آنلاین در بلایا. بین المللی J. کاهش خطر بلایا. 2020 , 46 , 101498. [ Google Scholar ] [ CrossRef ]
- یانگ، جی. یو، م. کین، اچ. لو، ام. یانگ، سی. چارچوب اعتبار داده های توییتر – طوفان هاروی به عنوان یک مورد استفاده. ISPRS Int J. Geo-Inf. 2019 ، 8 ، 111. [ Google Scholar ] [ CrossRef ]
- هاواس، سی. رسچ، ب. قابل حمل بودن روشهای یادگیری ماشین معنایی و مکانی-زمانی برای تجزیه و تحلیل رسانههای اجتماعی برای پایش بلایای نزدیک به زمان واقعی. نات. خطرات 2021 ، 108 ، 2939-2969. [ Google Scholar ] [ CrossRef ]
- چن، اس. مائو، جی. لی، جی. مک.؛ کائو، ی. کشف احساسات و الگوهای بازتوییت توییتهای مرتبط با فاجعه از دیدگاه فضایی-زمانی – مطالعه موردی طوفان هاروی. Telemat. به اطلاع رساندن. 2020 , 47 , 101326. [ Google Scholar ] [ CrossRef ]

شکل 1. منطقه مطالعه، مسیر طوفان هاروی، و بارش تجمعی (27-31 اوت 2017).
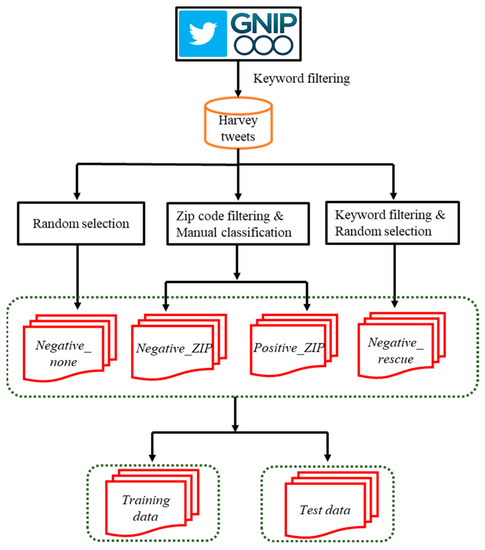
شکل 2. گردش کار برای آماده سازی داده های آموزشی و آزمایشی برای مدل های یادگیری ماشینی درخواست های نجات.

شکل 3. نقشههای Choropleth که توزیع جغرافیایی توئیتهای Harvey_ZIP ( a ) و positive_ZIP ( b ) را نشان میدهد.

شکل 4. جدول احتمالی برای تصمیمات باینری.

شکل 5. نتایج ارزیابی مدل پس از تنظیم هایپرپارامتر و اعتبارسنجی متقاطع (نوارها انحرافات استاندارد را نشان می دهند). توجه: اگرچه RF و CNN امتیاز F1 یکسانی دارند (0.950)، RF انحراف استاندارد کمتری دارد (0.006 در مقابل 0.007).

شکل 6. نتایج ارزیابی مدل پس از اعمال طبقهبندیکنندههای آموزش دیده برای دادههای آزمایشی.


بدون دیدگاه