1. معرفی
تولید تخمینی از ارزش واقعی بازار یک ملک یک گام مهم در هر معامله املاک و مستغلات، از جمله فرآیند تامین مالی است [ 1 ]. تخمین مالک از قیمت بازار ملک خود را می توان به عنوان مبنایی برای استفاده در بازار اتخاذ کرد، همانطور که در برخی مطالعات استفاده شده است [ 2 ]، اما بدون تعصب مالک نیست [ 3 ] ]. از بین چندین روش ارزیابی دارایی، فرآیند ارزیابی جایگزین بسیار بهتری است و در حال حاضر پرکاربردترین روش برای تخمین ارزش بازار است [ 4 ]]. برای تخمین ارزش واقعی بازار با استفاده از این روش، ملک موضوع با املاک مشابهی که اخیراً فروخته شده است مقایسه شده و قیمت تخمینی محاسبه می شود. این مقایسه بر اساس اطلاعات فروش املاک قابل مقایسه یا مقایسه مکان آنها و وضعیت فعلی آنها است. این مقایسه ها توسط متخصصانی انجام می شود که در محله های خود متخصص هستند و در قضاوت های خود بی طرف هستند. شهود آنها بر اساس دانش مناطق تمرکز آنها است و از طریق ترکیبی از آموزش و تجربه کامل شده است. کین و کویگلی [ 5 ] رابطه قوی بین برآورد ارزش واقعی یک دارایی و شهود ارزیاب را تایید کردند. دیاز [ 6] مطالعه ای را انجام داد که به این نتیجه رسید که ارزیاب ها تحت تأثیر برآوردهای قبلی ارزش متخصصین برای املاک قرار نگرفته اند. اتکا به این متخصصان توسط صنایع املاک و مستغلات و مالی نیازمند تحلیلهای عمیقتر و پیچیدهتر در مورد دادههایی است که تولید میکنند و کاربرد آن فراتر از فرآیند ارزیابی.
یکی دیگر از موضوعات مالی در املاک و مستغلات، شناسایی محله است. محله ها مناطق محلی هستند که ویژگی های مشابهی دارند، و مرزهای آنها را می توان از طریق لنزهای مختلف تعریف کرد: کدهای پستی (پستی)، مناطق مدرسه، بخش های سرشماری، یا درک خود ساکنان از منطقه. تخمین محلهها هنوز توسط شرکتهای املاک و مستغلات برای قیمتگذاری قابل مقایسه در نظر گرفته میشود [ 7 ]، و در سطح شدید، روند رد کردن وام در محلهها و جوامع بر اساس جمعیتشناسی [ 8 ]]، نمونه دیگری از استفاده از تخمین همسایگی برای سود مالی است. روش های متعددی وجود دارد که از طریق آنها می توان مناطق را به همسایگی ترسیم کرد و در چند دهه اخیر تکنیک های زیادی برای آن ابداع شده است. با این حال، آنها از تشبیه ترسیم محلهها به یک مشکل طبقهبندی [ 9 ] به رویکرد جدیدتر برآورد محله مبتنی بر داده حرکت کردهاند. بوراسا و همکاران [ 10 ] تحلیل خوشهبندی k-means را بر روی دادههای نظرسنجی خانوار برای تعریف بازارهای فرعی مسکن اعمال کرد. کائوکو [ 11 ] از نقشه های خود سازمان دهی (SOM)، یک تکنیک شبکه عصبی بدون نظارت [ 12 ] استفاده کرد.]، برای یافتن مناطق فرعی در آمستردام بر اساس تغییرات قیمت، ویژگیهای فیزیکی، و جنبههای تفکیک اقتصادی و فرهنگی. Hipp، Faris و Boessen [ 13 ] محله هایی را بر اساس پیوندهای اجتماعی بین ساکنان ایجاد کردند، در حالی که McKenzie و همکاران. [ 14 ] از فهرست املاک اجاره ای دارای برچسب جغرافیایی برای شناسایی نام محله ها استفاده کرد.
هیچ یک از مطالعات ذکر شده در بالا از اطلاعات ارزیابی در تعیین مرزهای محله ها استفاده نکردند. با توجه به اینکه ارزیابی ها توسط متخصصانی انجام می شود که در منطقه خود متخصص هستند، ما لازم می دانیم که از دانش آنها در یک مشکل تخمین محله استفاده کنیم. مطالعه ای توسط Coulton و همکاران. از ساکنان خواست تا نقشه های محله های خود را ترسیم کنند و نقشه ها را با بلوک های سرشماری مقایسه کردند [ 15 ]. آنها دریافتند که واحدهای ایجاد شده توسط ساکنان فضای متفاوتی را پوشش میدهند و مقادیر شاخص اجتماعی متفاوتی نسبت به واحدهای تولید شده توسط واحدهای سرشماری تولید میکنند. Sun و Mason معیارهای مختلف منطقهبندی را مقایسه کردند و دریافتند که بخشبندیهای پیشنهادی توسط کارشناسان و مشاوران املاک به طور قابلتوجهی با کدهای پستی و سرشماریها متفاوت است. 16 ]]. علاوه بر این، چاپل و همکاران. محلههایی را مطالعه کرد که با احساس تعلق ساکنان با مرزهای شهری تعریف شده بود و پیشنهاد کرد که مرزهای اداری باید تجربه ذهنی زندگی در یک منطقه را منعکس کند [ 17 ]]. این نشان دهنده این است که چگونه مطالعات در مورد اثرات محله می تواند مغرضانه باشد، زمانی که هیچ ورودی از ساکنان یا کارشناسان منطقه برای محله های تعریف شده در نظر گرفته نمی شود. یکی دیگر از زمینه های مورد بحث، تعداد زیادی برآوردگرهای مورد نیاز برای حل این مشکل است. یک ارزیاب با در نظر گرفتن ویژگیهای فیزیکی قابل مقایسه که ممکن است به اشتراک بگذارند، تصمیم میگیرد که کدام ویژگیها مشابه هستند، بنابراین خود دانش درباره این که چه ویژگیهایی قابل مقایسه نامیده میشوند، باید کافی باشد تا بتواند مرزهای همسایگی را تعریف کند که در آن ویژگیها دارای ویژگیهای مشابه هستند.
با توجه به این علاقه، کار ما به این مرحله ضروری از ترکیب فرآیند ارزیابی با ترسیم محله می پردازد. مشارکت های خاص کار ما در دو سؤال تحقیق (RQ) زیر مشخص شده است.
RQ1:
آیا میتوانیم از فاصله جغرافیایی بین موضوع و ویژگیهای قابل مقایسه برای تخمین همسایگی استفاده کنیم؟
RQ2:
آیا این محلهها هنگام پیشبینی ویژگیهای یک ملک، بهتر از جدولهای استاندارد شده در ایالات متحده (کدهای پستی و بخشهای سرشماری) عمل میکنند؟
ابتدا تحقیقات قبلی مرتبط با این موضوع را مورد بحث قرار خواهیم داد و سپس مروری بر داده ها و روش شناسی خواهیم داشت. سپس به سوالات تحقیق در بخش نتایج پاسخ داده و در نهایت نتیجه گیری خود را ارائه خواهیم کرد.
2. کارهای مرتبط
به طور معمول، داده های اجتماعی-اقتصادی و جمعیت شناختی برای تعیین محله ها استفاده می شود. اسپیلمن و تیل [ 18 ] از مجموعه دادهای از 79 متغیر استفاده کردند که بخشهای سرشماری در شهر نیویورک را برای ایجاد طبقهبندی جغرافیایی جمعیتی با استفاده از نقشههای خود سازماندهی توصیف میکنند. Arribas-Bel، Nijkamp و Scholten [ 19 ] از پایگاه داده حسابرسی شهری، یک مجموعه داده بزرگ با بیش از 300 متغیر از جنبه های اجتماعی-اقتصادی و زیست محیطی، برای ترسیم پراکندگی شهری در اروپا استفاده کردند. همچنین مطالعاتی وجود دارد که در آن از داده های غیر سنتی برای تخمین مرزهای محله استفاده شده است. پورتویس [ 20 ] الگوریتم های بهینه سازی را برای توئیت های دارای برچسب جغرافیایی برای استخراج محله ها در منطقه بروکلین اعمال کرد. راتی و همکاران [ 21] از بیش از 12 میلیارد تماس تلفنی برای ترسیم مجدد نقشه منطقه ای بریتانیا استفاده کرد. این مطالعات از الگوریتمهای شبکه عصبی استفاده کردند که به مجموعه وسیعی از ویژگیها برای آموزش یک مدل نیاز دارند. ما امیدواریم که داده های ورودی مورد نیاز برای تولید محله را تنها به یک ویژگی فشرده کنیم: فاصله بین موضوع و ویژگی های قابل مقایسه از طریق داده های ارزیابی. به این ترتیب، محله ها را می توان برای مناطقی که مقادیر زیادی از داده های جمعیتی و اجتماعی-اقتصادی در دسترس نیست، تخمین زد.
لازم به ذکر است که مطالعاتی که تنها از فاصله جغرافیایی بین املاک و یا اطلاعات ارزیابی برای تخمین مرزهای محله استفاده کند، وجود ندارد. با این حال، ما درباره آثاری بحث میکنیم که یا از فاصله بین واحدها به عنوان یکی از متغیرهای کمکی استفاده میکنند، یا بینش ارزیاب را در تخمین خطوط همسایگی و قیمتهای بازار تکرار میکنند. کاچین و همکاران [ 22 ] روش تخمین همسایگی اجتماعی- فضایی (SNEM) را بررسی کرد که برای ایجاد مرزهای محله با اطلاعات مفهومی طراحی شده است. به عنوان یک گام مهم، آنها برای تأیید تغییرات و اصلاحاتی که باید در ترسیمها انجام شود، زمان را بر روی زمین سپری کردند و در منطقه مورد مطالعه حرکت کردند. گونزالس و فرموسو [ 23] از فواصل بین ساختمان های تجاری و یک منطقه تجاری مرکزی به عنوان یکی از عوامل در تخمین ارزش گذاری املاک با استفاده از سیستم های مبتنی بر قوانین فازی استفاده کرد. به طور مشابه، Antipov و Pokryshevskaya [ 24 ] از فاصله بین یک خانه و نزدیکترین ایستگاه زیرزمینی به عنوان برآورد کننده ارزش ملک مسکونی استفاده کردند.
یکی از دلایل مقایسه محله های تولید شده با کدهای پستی، استفاده از دومی در تحلیل های فضایی و جمعیتی در ایالات متحده است. الناکات، گومز و بوث [ 25 ] تأثیرات ویژگی های اجتماعی-اقتصادی و جمعیت شناختی ساکنان را بر استفاده از انرژی در سطح کد پستی بررسی کردند. Drewnowski، Rehm و Solet [ 26 ] و Acevedo-Garcia [ 27 ] از فاکتورهای سطح کد ZIP برای مطالعات بهداشتی استفاده کردند. با این حال، Grubesic [ 28 ] دریافت که کدهای پستی همیشه برای ارزیابی در تحلیلهای فضایی و اقتصادی-اجتماعی مناسب نیستند و در عوض بلوکهای سرشماری را به عنوان جایگزین توصیه میکنند. همانطور که در آثار Ananat [ 29 ] دیده می شود، از راه های سرشماری نیز برای اندازه گیری تفکیک مسکونی بر مبنای اجتماعی-اقتصادی استفاده می شود.] و کرامر و همکاران. [ 30 ]. بلوکها و بخشهای سرشماری هر دهه یکبار بهروزرسانی میشوند که باعث میشود منطقه جغرافیایی راکد از جمعیت در حال تکامل جمعیت باقی بماند. مردم وارد و خارج می شوند، مشاغل ظاهر و ناپدید می شوند و ارتباطات جدید ایجاد می شود. با توجه به این دلیل، مقایسه محلههای مبتنی بر ارزیابی با مناطق سرشماری نیز منطقی است، بنابراین میتوان جایگزین جدیدی را ارائه کرد که نماینده خوبی از گروهی از املاک با ویژگیهای مشابه است و با گذشت زمان تکامل مییابد.

3. داده ها
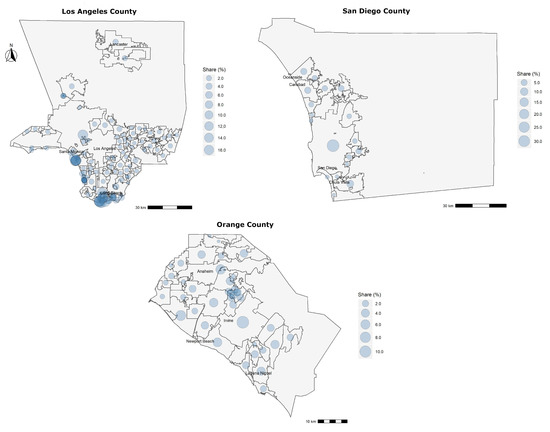
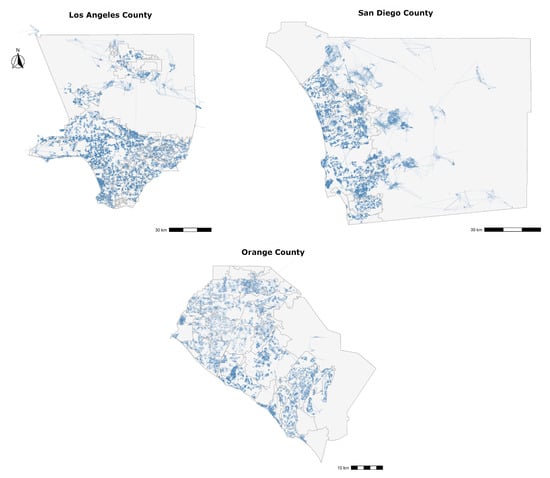
ما از یک عکس فوری از داده های ارزیابی ارائه شده توسط CoreLogic® [ 31] استفاده می کنیم]، ارائهدهنده پیشرو در بینشها و راهحلهای دارایی، برای شهرستان لس آنجلس، شهرستان سن دیگو، و شهرستان اورنج، کالیفرنیای جنوبی در ایالات متحده. این عکس فوری شامل نمونهای از تمام ارزیابیهای داخلی انجامشده توسط شرکت برای این شهرستانها، بین سالهای 2014 تا 2018 است و شامل موقعیتهای جغرافیایی سوژهها و ویژگیهای قابل مقایسه مرتبط با آنها در قالب مختصات طول و عرض جغرافیایی است. این مختصات از چند ضلعی های بسته و منابع مختلف شهرستان استخراج می شود و موقعیت مکانی یک ملک را با دقت بالا ترسیم می کند. هر ویژگی موضوعی با چندین ویژگی قابل مقایسه از طریق یک شناسه منحصربهفرد متصل میشود که ما از آن برای تشخیص یک ارزیابی واحد استفاده کردیم. همچنین آدرس خیابان فقط برای املاک موضوعی به ما داده شد. شکل 1سهم داده ها را برای سه شهرستان بر اساس هر شهر نشان می دهد. از آنجایی که مجموعه داده خام شامل دادههای ارزیابی است که مختص CoreLogic ® است و حاوی برخی اطلاعات خصوصی است، نمیتوانیم آن را در اینجا لحاظ کنیم. با این حال، خوانندگانی که مایل به تکرار این مطالعه هستند، ممکن است این کار را با استفاده از دادههایی که از طریق پایگاههای اطلاعاتی دفتر ثبت/ارزیابی منطقه در اینترنت در دسترس عموم قرار گرفته است، انجام دهند.
از آنجایی که همه دارایی ها در یک شهرستان در محدوده 4 ساله ارزیابی نشده اند، ما انتظار داریم که راه حل کلی برای ترسیم محله ارائه دهیم. به این معنا که تخمین ها باید برای مناطقی که توسط داده ها پوشش داده نشده اند نیز نمایش دهند. با توجه به آن، ابتدا تعریف می کنیم که پوشش یک ویژگی موضوعی چیست و چگونه ویژگی هایی را پوشش می دهد که در داده ها وجود ندارند.
تصویر در شکل 2 نحوه تعریف پوشش را برای یک ویژگی موضوعی نشان می دهد. موضوع، که با رنگ قرمز مشخص شده است، توسط ویژگیهای مختلفی احاطه شده است، که از میان آنها، ویژگیهای آبی رنگ بهعنوان ویژگیهای قابل مقایسه در طی یک ارزیابی انتخاب شدند، که منجر به این نتیجه شد که حداقل منطقه به رنگ سبز توسط ارزیاب برای یافتن چهار ویژگی قابل مقایسه انتخاب شده است. و اکنون به عنوان پوشش این موضوع تعریف شده است. از طریق این چند ضلعی های پوششی، ما همچنین می توانیم موضوعاتی را پیدا کنیم که بیشترین همپوشانی دارند و می توانند ویژگی های مشابهی را ارائه دهند.
4. روش شناسی
4.1. فیلتراسیون فضایی
ما علاقه مند به تولید محله ها با استفاده از موقعیت جغرافیایی موضوعات و ویژگی های قابل مقایسه آنها هستیم. به عنوان گام اولیه، ابتدا مقدار فعلی آن رابطه را در داده ها ترسیم کردیم. شکل 3یک نقشه شبکه ارائه می دهد که در آن هر موضوع با استفاده از یک بخش خط به یک ویژگی قابل مقایسه مرتبط است. برای هر 3 شهرستان، مناطقی از پیوندهای متراکم، به ویژه در مناطق شهری وجود دارد، و خود مناطق متراکم با مناطق کوچک مرز مانند با پیوندهای کم یا بدون پیوند از هم جدا شده اند. همپوشانی قطعات خط در یک منطقه کوچک به همپوشانی در پوشش موضوعات اشاره می کند، و اینکه این موضوعات دارای ویژگی های مشابه هستند، یا حتی یک موضوع مشخص می شود که یک ویژگی قابل مقایسه برای موضوع دیگر است. مناطق با پیوندهای کمتر، مناطق شبکه متراکم را از یکدیگر جدا میکنند تا نشان دهند که همپوشانی پوشش موضوع بین دو منطقه متراکم کم است و ارزیابیکنندگان به ندرت وارد منطقه متراکم دوم میشوند تا ویژگیهای قابل مقایسه برای سوژهها را در منطقه اول پیدا کنند.
برای ترسیم محله هایی که نمایانگر خصوصیات مشابه هستند، ابتدا باید بار اضافی پوشش را در مناطق متراکم کاهش دهیم. برای انجام این کار، از فواصل بین سوژه ها و ویژگی های قابل مقایسه آنها استفاده می کنیم و از آنها در یک فیلتر فضایی برای هرس این مناطق استفاده می کنیم. پس از اعمال فیلترها، میتوانیم یک الگوریتم خوشهبندی را برای ترسیم محلهها اعمال کنیم. دمشار و همکاران [ 32 ] کاربردهای دقیق تجزیه و تحلیل مؤلفه های اصلی (PCA) بر روی داده های مکانی برای کاهش ابعاد، در حالی که هیوز و هاران [ 33] همچنین در مورد بدست آوردن نتایج با کاهش ابعاد در داده های فضایی غیر گاوسی بحث کرد. علاوه بر این، الگوریتم تکنیک تجزیه و تحلیل داده خودسازماندهی تکراری (
ISODATA) یک گزینه محبوب برای تقسیمبندی بدون نظارت دادههای مکانی است، همانطور که توسط [ 34 ، 35 ] نشان داده شده است، برای تقسیمبندی تصاویر سنجش از دور. با این حال، این الگوریتمهای کاهش و تقسیمبندی نیاز به یک فضای ویژگی چند بعدی دارند و به دلیل حساسیت آنها به ابعاد، زمانی که تعداد ابعاد افزایش مییابد، سرعت ضعیفی از خود نشان میدهند [ 36 ].
فضای ویژگی ما فقط از یک مقدار فاصله بین سوژهها و ویژگیهای قابل مقایسه آنها تشکیل شده است، و ما میخواهیم اطمینان حاصل کنیم که کاهش تنها بر اساس نزدیکی بین ویژگیهایی که مستقیماً در ارزیابی نقش دارند، رخ میدهد. کدگذاری این اطلاعات در مورد اینکه کدام خصوصیات در ارزیابی گنجانده شده اند، برای اعمال هر یک از الگوریتم هایی که قبلاً مورد بحث قرار گرفتیم، باعث ایجاد فضای ویژگی بسیار بزرگ می شود. این فضای ویژگی همچنین بر اساس میزان روستایی یا شهری بودن منطقه متمرکز مقیاس می شود. برای این منظور، ما در عوض از مجموعه ای از فیلترهای فضایی ساده اما بسیار سریع استفاده کردیم که در زیر توضیح می دهیم. این فیلترها بهطور هوشمندانه ویژگیهای قابل مقایسه را از دادهها بر اساس نزدیکی به ویژگیهای موضوع خود حذف میکنند و نه بر اساس موقعیت مکانی آنها در نقشه جغرافیایی. پس از کاهش پوشش،
4.1.1. فیلتر 1
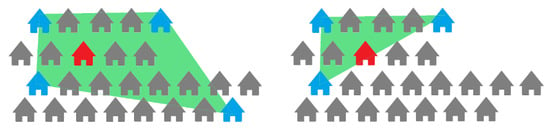
اولین الگوریتم فیلتر، تمام ویژگیهای قابل مقایسه را از دادههایی حذف میکند که نسبت به مقدار آستانه میانگین تعیینشده برای هر منطقه، از ویژگی موضوع دورتر هستند. آستانه بر اساس موقعیت جغرافیایی منطقه، اندازه پوشش موضوع، و تعداد املاک قابل مقایسه برای آن است. با استفاده از مختصات جغرافیایی، می توانیم داده ها را به صورت هوشمند فیلتر کنیم. شکل 4 نشان می دهد که چگونه پوشش یک سوژه قبل و بعد از اعمال این فیلتر تغییر می کند.
4.1.2. فیلتر 2
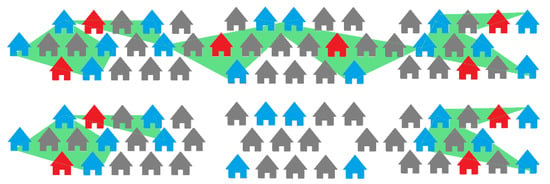
این الگوریتم فیلتر از آدرس خیابان هر موضوع موجود در داده ها استفاده می کند. این یک شکل تهاجمیتر از فیلتر 1 است که در آن اکنون اگر ویژگیهای قابل مقایسه در مقایسه با بخش خیابانی که یک ویژگی موضوع در آن قرار دارد، دورتر از آستانه فاصله باشند، آنها را نیز هرس میکنیم. این فیلتر نحوه درک سوژه ها را در صورت جمع شدن با هم در نظر می گیرد. اگر دو ویژگی موضوعی در یک خیابان قرار داشته باشند، به احتمال زیاد ویژگیهای مشابهی دارند، و مجموعهای از ویژگیهای مشابه آنها را میتوان به عنوان بخشی از یک استخر بزرگتر برای آن خیابان در نظر گرفت، که سپس میتوانیم آن را هرس کنیم تا بتونی بیشتری پیدا کنیم. ساختار تخمین محله ما، همانطور که در شکل 5 مشاهده می شود. فیلتر انفرادی (فیلتر 1) روی این سوژه ها اعمال نمی شود و به جای آن، یک فیلتر خیابانی برای استفاده از وجود سوژه های متعدد در یک خیابان اعمال می شود. ما اضافه می کنیم که صرف نظر از اینکه کدام فیلتر اعمال می شود، موقعیت نسبی سوژه ها و ویژگی های قابل مقایسه آنها تغییر نمی کند و فیلترها یکپارچگی روابط ذاتی بین ویژگی های ارزیابی شده را حفظ می کنند.
4.1.3. فیلتر 3
تنها اطلاعاتی که ما در خیابانهای یک منطقه داریم، مکان ملکهای موضوعی است که در آنها قرار دارد. در مورد هر خیابان منطقه، طول آن، چند تقاطع و شکل کلی آن اطلاعاتی نداریم. این ویژگیها میتوانند در بررسی نحوه مشاهده املاکی که در سراسر بزرگراه یا خیابان هستند، زمانی که به دنبال خواص مشابه برای یک موضوع میگردند، آموزنده باشند. این فیلتر از این دانش برای خواص هرس بیشتر استفاده می کند. با استفاده از این فیلتر، دادههای سوژههایی را که در امتداد بزرگراهها یا خیابانهای طولانی قرار دارند حذف میکنیم، زیرا احتمال اینکه دو سوژه در دو انتهای یک خیابان طولانی قرار داشته باشند یا از طریق زنجیرهای از ویژگیهای مشابه به یکدیگر متصل شوند، وجود دارد. دو ناحیه به هم پیوسته متراکم که از طریق یک سری از چند ویژگی قابل مقایسه به هم متصل می شوند، نباید به عنوان یک منطقه حساب شوند، و این فیلتر آن را به حساب می آورد. این فیلتر بر ساختار پوشش در دو طرف خیابان مورد نظر تأثیر نمی گذارد، همانطور که در زیر مشاهده می شودشکل 6 ، و فقط موضوعات پل زدن و ویژگی های قابل مقایسه حذف شده اند.
ما شبه کد سه فیلتر را در الگوریتم 1 ارائه می کنیم. آستانه تیبرای اطمینان از اینکه محلههای تولید شده برای مناطق روستایی و شهری بر این اساس مقیاسبندی میشوند، پارامتر شده است. حالت متربر اساس فیلتر اعمال شده روی true یا false تنظیم می شود.
شکل 7 نقشه پیوندی را پس از اعمال این فیلترهای فضایی نشان می دهد. با مقایسه آن با نقشه فیلتر نشده، در شکل 3 ، توجه می کنیم که مناطقی از پیوندهای متراکم هنوز وجود دارند اما اکنون قابل تفکیک تر هستند. ما این مناطق را به عنوان مناطق تمرکز ارزیابی می گوییم، زیرا بیشترین همپوشانی پوشش موضوعات را نشان می دهند، فیلتر شده و از اطلاعات ارزیابی استخراج شده اند، و به این واقعیت اشاره می کنند که در بیشتر مواقع، یک ویژگی برای یک موضوع در یکی از این موارد قابل مقایسه است. مناطق تمرکز به احتمال زیاد از همان منطقه تمرکز هستند. ما این فرضیه را در بخش نتایج تایید خواهیم کرد.
| الگوریتم 1: فیلتر فضایی برای کاهش مجموعه داده ها. |
 |
4.2. ترسیم محله
هنگامی که همه فیلترها اعمال می شوند و یک نقشه هرس شده پیدا می شود، می توانیم یک الگوریتم خوشه بندی فضایی را برای جداسازی مناطق اتصال متراکم به محله های جداگانه اعمال کنیم. خوشه بندی فضایی مبتنی بر چگالی سلسله مراتبی با کاربرد نویز (HDBSCAN) یک الگوریتم یادگیری ماشینی بدون نظارت است که از یک سلسله مراتب برای استخراج یک خوشه بندی مسطح بر اساس پایداری خوشه ها استفاده می کند [ 37 ]. این خوشهها به محلههای تخمینی ما تبدیل میشوند، که از املاکی تشکیل شدهاند که ویژگیهای مشابهی دارند، از دید یک ارزیاب، و میتوانند به جای یکدیگر بهعنوان املاک قابل مقایسه برای یکدیگر استفاده شوند.
HDBSCAN همچنین وجود مناطقی با تراکم های مختلف در داده ها را به حساب می آورد و می تواند برخی از نقاط داده را به عنوان نویز اختصاص دهد، یعنی نقاطی که متعلق به هیچ خوشه ای نیستند و باید حذف شوند. الگوریتم از یک پارامتر استفاده می کند، حداقل تعداد نقاط داده مورد نیاز برای تعریف یک خوشه. برای هر بخش از منطقه، مقدار بهینه این پارامتر را از طریق کاربرد تکراری HDBSCAN بر روی مختصات جغرافیایی همه ویژگیهای قابل مقایسه پیدا میکنیم. مطالعات درباره الگوریتمهای خوشهبندی بدون پارامتر [ 38 ، 39 ] و بهویژه کار با دادههای مکانی [ 40 ] بحث کردهاند.]. با این حال، این برنامهها اهمیت مناطق با چگالی بالا یا کم در دادهها را قربانی میکنند. در عوض، با یک فرآیند تکراری، پارامتری را پیدا میکنیم که تعادل بین تعداد خوشهها و تعداد نقاط نویز را بهینه میکند. برای هر خوشه تولید شده، مرز آن را با استفاده از الگوریتم بدنه مقعر [ 41 ] تعریف می کنیم. بدنه مقعر از رویکرد k-Nearest Neighbors برای تخمین مرز مناسب برای مجموعه ای از نقاط استفاده می کند و حداکثر مساحت را پوشش نمی دهد، همانطور که یک چند ضلعی بدنه محدب ممکن است انجام دهد. از آنجایی که یک محله می تواند از مجموعه ای متشکل از ده ملک در خیابان های مجاور تا شامل یک شهر کوچک متفاوت باشد، بدنه مقعر برای مرز تضمین می کند که اندازه و شکل واقعی یک محله نشان داده شود.
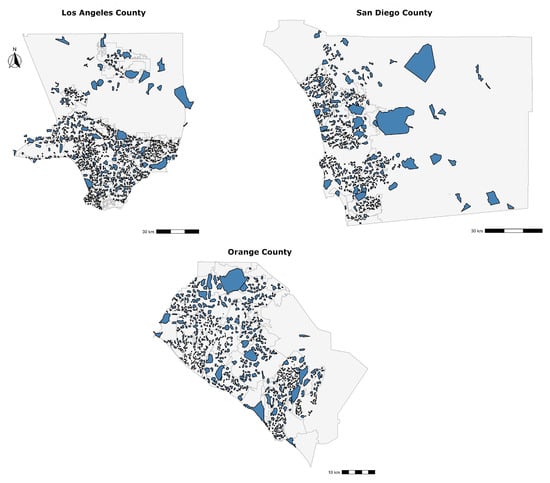
شکل 8 محله های مشخص شده برای سه شهرستان کالیفرنیای جنوبی را نشان می دهد. ما محله هایی با شکل ها و اندازه های مختلف یافتیم که از چندین ملک تا چند صد ملک تشکیل شده است. ما متوجه شدیم که وقتی این روش در مناطق روستایی – شمال شهرستان لس آنجلس و غرب شهرستان سن دیگو – به کار گرفته شد، اندازه محلهها بسیار افزایش مییابد، زیرا داراییها در مکانهای پراکندهتر قرار دارند و هنگام انجام یک ارزیابی، فاصله بیشتری پوشش داده میشود. برای پاسخ به سوال اول تحقیق، از فیلترهای فضایی و الگوریتم خوشهبندی استفاده شده است که تنها بر روی فاصله جغرافیایی بین موضوعات و ویژگیهای قابل مقایسه آنها برای تخمین همسایگیها اعمال میشود. اعتبار این همسایگی ها را در قسمت نتایج بحث خواهیم کرد.
جدول 1 زمان اجرای روش اعمال شده را برای همه شهرستان ها نشان می دهد. ما همچنین تعداد خواص قابل مقایسه قبل و بعد از اعمال فیلترهای فضایی را نشان می دهیم. الگوریتم به زبان برنامه نویسی R [ 42 ] نوشته شده بود و بر روی یک پردازنده 24 هسته ای Intel Xeon با حافظه 264 گیگابایتی اجرا شد. از آنجایی که هیچ زمانی برای آموزش یک مدل با داده های نمونه صرف نمی شود، مانند مورد تکنیک های شبکه عصبی، یا پیش پردازش داده ها برای اعمال PCA و سایر الگوریتم های مشابه برای کاهش، روش پیشنهادی همسایه ها را به سرعت تولید می کند و فقط با اندازه ی نمونه.
5. نتایج
ما ابتدا محلههای تولید شده را با کد پستی و خطوط سرشماری مقایسه میکنیم و نشان میدهیم که کدام جدول کمترین تغییر را در ویژگیهای دارایی نشان میدهد، همچنین رگرسیون خطی خود را با این جدولها نشان میدهیم تا بفهمیم کدام یک بهترین پیشبینیکننده ویژگیهای دارایی مانند ارزیابی است. ، متراژ، قیمت فروش، قیمت هر فوت مربع و سن. در مرحله بعد، ثبات هر محله را از منظر ارزیابی ها نشان خواهیم داد و اینکه کدام محله در طول سال ها رشد کرده یا کوچک شده است.
برای مقایسه محلههای مشخص شده با کد پستی و بخشهای سرشماری، از مجموعه دادههای کوچکتری استفاده کردیم که حاوی اطلاعاتی در مورد پنج ویژگی دارایی برای هر موضوع است. ما پس از برآورد محلهها، کد پستی و اطلاعات تراکت سرشماری را برای همه داراییها استخراج کردیم و آن را با دادههای ویژگیها برای انجام آزمایشهایمان ملحق کردیم.
5.1. ضریب تغییر
ضریب تغییرات نمونه ( سیv) همچنین به عنوان نسبت انحراف معیار به میانگین نمونه تعریف می شود [ 43 ]. پراکندگی یک متغیر را به گونه ای توصیف می کند که به واحد اندازه گیری متغیر بستگی ندارد. ما از آن برای مقایسه نحوه توضیح هر معیار جدول بندی (محله تخمینی، کد پستی، تراکت سرشماری) استفاده می کنیم. همانطور که ضریب را روی یک نمونه محاسبه کردیم، مقادیر تخمین بی طرفانه ضریب تغییرات جمعیت را مقایسه کردیم ( سی^v) بجای:
جایی که سیvضریب تغییرات نمونه، S واریانس نمونه است، ایکس¯میانگین نمونه است، سی^vتخمین بی طرفانه ضریب تنوع جمعیت است و N حجم نمونه است.
برای هر ویژگی ملک، ما محاسبه کردیم سی^vبرای هر گروه در یک جدول بندی و میانگین کلی برآورد بی طرفانه برای هر معیار جدول بندی را گزارش کرد. در سراسر سه شهرستان، ما متوجه شدیم که محله های مشخص شده، ایجاد شده با استفاده از موقعیت جغرافیایی املاک ارزیابی شده، کوچکترین سی^vبرای هر مشخصه ویژگی، همانطور که در جدول 2 مشاهده می شود . کوچکترین سی^vمقادیر برای هر ویژگی با رنگ قرمز مشخص شده است. در مقایسه، یک کد پستی به طور قابل توجهی بزرگتر از یک محله متوسط و یک منطقه سرشماری است، بنابراین این تغییرات برای دو معیار جدول بندی اخیر کاهش شدیدی دارد. محله های تخمین زده شده نیز در کاهش تنوع در ویژگی های دارایی در آنها، از مناطق سرشماری با اندازه مساوی بهتر عمل می کند. این نتیجه نشان میدهد که ما توانستیم محلههایی تولید کنیم که در واقع حاوی ویژگیهایی هستند که از نظر خصوصیات مشابه یکدیگر هستند و میتوانند به عنوان ویژگیهای قابل مقایسه برای افراد در همان محله استفاده شوند. نتایج همچنین قابل توجه هستند، زیرا آنها سه منطقه مختلف را با تراکم جمعیت متفاوت پوشش میدهند، بنابراین فیلتر فضایی ما که با آستانهای بر اساس مکانهای ویژگیهای موضوع اعمال میشود، نیز به خوبی کار کرده است. ANOVA یک طرفه [44 ] تأثیر معنیداری معیارهای جدولبندی را بر برآوردهای بیطرفانه ضریب تغییرات، در همه ویژگیهای ویژگی نشان داد ( 001/ 0p <). جدول مفصلی با نتایج آزمون ANOVA در پیوست A ارائه شده است.
ما در مرحله بعد یک سری از مدلهای رگرسیون خطی [ 45 ] را بر روی دادههای نمونه برای پیشبینی هر ویژگی، با استفاده از هر معیار جدولبندی بهعنوان پیشبینیکننده برای هر مدل، و مقدار R-squared تعدیلشده را گزارش کردیم [ 46 ]. مقدار R-squared یا ضریب تعیین، معیاری آماری است که نشان می دهد داده ها چقدر به خط رگرسیون برازش نزدیک هستند. درصد تغییرات یک متغیر را که توسط پیش بینی کننده ها توضیح داده شده است را نشان می دهد. از آنجایی که از چند صد محله مشخص شده و بخش سرشماری به عنوان پیشبینیکننده برای مدلهای رگرسیون خطی منفرد استفاده کردیم، مقدار مربع R تنظیمشده را گزارش کردیم، که ضریب را برای استفاده از پیشبینیکنندههای بیش از حد جریمه میکند. معادله ( 3) فرمول مقدار R-squared تنظیم شده را می دهد:
جایی که آرآدjتوستیهد2مقدار مربع R تنظیم شده است، N اندازه کل نمونه است، آر2مقدار مربع R از مدل تخمین زده شده است و p تعداد کل پیش بینی کننده ها است.
جدول 3 عملکرد هر یک از معیارهای جدول بندی را به عنوان پیش بینی کننده یک ویژگی ویژگی نشان می دهد. بالاترین آرآدjتوستیهد2مقادیر برای هر ویژگی با رنگ قرمز مشخص شده است. یک مدل رگرسیون خطی میتواند یک رابطه خطی بین یک مقدار پیوسته و مجموعهای از پیشبینیکنندهها را توضیح دهد و یک مقدار R-squared بالا به این معنی است که پیشبینیکنندههای انتخابشده قادر به توضیح واریانس زیادی در مقدار پیوسته مستقل هستند. به عنوان یک مرحله اضافه، ما بوت استرپ را برای مدل های رگرسیون خطی خود اعمال کردیم. بوت استرپینگ [ 47] یک رویکرد ناپارامتریک برای استنتاج آماری است که خطاهای استاندارد و بایاس ضرایب واقعی مدل را نشان می دهد. با کشیدن نمونه های تصادفی از داده ها و با محاسبه آمار روی هر یک از آن نمونه ها کار می کند. این مرحله سطح دیگری از دقت را به مدل های ما اضافه می کند. ما مقادیر تنظیمشده R-squared انباشته شده، بایاسهای آنها و خطاهای استاندارد را پس از نمونهبرداری مجدد از دادهها 100 بار در جدول ارائه میکنیم. ما نشان میدهیم که محلههای مشخصشده عملکرد بهتری نسبت به محلههای کد پستی و پروکسی تراکت سرشماری در شهرستانهای اورنج و سن دیگو داشتند، و به جز چند استثنا، با مناطق سرشماری در شهرستان لسآنجلس همتراز بودند. ما همچنین جدولی با مقادیر مربع R تنظیم شده را نشان میدهیم که با برازش یک سری مدلهای رگرسیون خطی بدون راهاندازی در پیوست B محاسبه شده است.. نتایج در اینجا نه تنها از نقطه نظر آماری، بلکه از این نظر که ما فقط از یک ویژگی واحد برای تولید این محلهها استفاده کردیم، قابل توجه است. عملکرد بالای محلههای ما نیز به دلیل مزیت عددی نبود، زیرا تعداد مناطق سرشماری در شهرستان لس آنجلس بیشتر از تعداد محلههای تولید شده در آنجا بود، و ما مقادیر مربع R تعدیلشده را ارائه میکنیم، که این مقادیر را به حساب میآورند. برآوردگرهای مورد استفاده در مدل رگرسیونی
با استفاده از این دو آزمون، به سوال دوم پژوهشی که در این مقاله مطرح کردیم پاسخ دادیم. با استفاده از مکانهای املاک ارزیابیشده، ما نه تنها محلههایی را مشخص کردهایم که دارای ویژگیهای یکنواخت و مشابه هستند، بلکه تنوع بیشتری را در ویژگیهای یک ملک نسبت به محلههای پراکسی کد پستی و سرشماری توضیح میدهند.
5.2. ترتیب خطی موضوع جفت شدن
ما بحث خود را با تعریف پوشش یک موضوع آغاز کردیم که شامل ویژگی هایی است که در این تحلیل استفاده نمی شود. از آنجایی که محلههای تخمینی ما بر اساس همپوشانی پوشش موضوعات مختلف ساخته شدهاند، میخواستیم آزمایش دیگری انجام دهیم تا اطمینان حاصل کنیم که املاکی که در یک محله واحد قرار گرفتهاند در واقع میتوانند به عنوان قابل مقایسه با یکدیگر استفاده شوند. برای انجام این کار، از نقطه نظر ارزیابی، بررسی کردیم که موضوعات در یک محله چقدر به هم مرتبط هستند. یک ارزیاب می تواند از یک ملک واحد به عنوان قابل مقایسه برای دو یا چند موضوع، در طول بازرسی های مختلف استفاده کند. یک موضوع در یک ارزیابی همچنین می تواند یک ویژگی قابل مقایسه برای موضوع دیگر باشد. اگر دو موضوع از طریق یک یا چند ویژگی قابل مقایسه به هم مرتبط شوند، میتوانیم تخمین بزنیم که چند جفت موضوع در یک محله وجود دارد.شکل 9 جفت موضوع را نشان می دهد. اگر همه ویژگیهای قابل مقایسه به رنگ آبی باشند، و ما روی ویژگی موضوع به رنگ قرمز تمرکز کنیم، آنگاه دو ویژگی به رنگ نارنجی یک جفت مرتبه اول نسبت به موضوع قرمز هستند. یعنی آنها در یک دارایی قابل مقایسه مشترک هستند. سپس مشخصه موضوع به رنگ زرد یک جفت مرتبه دوم نسبت به موضوع قرمز خواهد بود، زیرا پیوند از حداقل یک ویژگی موضوعی عبور می کند تا آنها را به هم متصل کند.
درصد بالایی از جفتهای مرتبه اول و دوم که متعلق به یک محله هستند، این واقعیت را برجسته میکند که این محلهها در واقع از املاکی تشکیل شدهاند که توسط یک ارزیاب تخمین زده شده است که مشابه هستند. ما تلاش کردیم تا از داده های اصلی و بدون فیلتر برای این تحلیل استفاده کنیم. حتی اگر همسایههای مشخص شده نهایی با استفاده از دادهها پس از اعمال فیلترها تولید میشوند، جایی که ما برخی از ویژگیهای قابل مقایسه و موضوعی را حذف کردیم و شبکه را با یک عامل هرس کردیم، میخواستیم اطمینان حاصل کنیم که محلههای تولید شده همچنان قادر به نمایش هر نمونه از دادهها هستند. برای یک منطقه یا مکان جدید ما نرخ ضربه، میانگین درصد یک جفت سفارش متعلق به یک محله را برای سه شهرستان در کالیفرنیای جنوبی ارائه میکنیم. جدول 4نرخ ضربه را برای جفت های مرتبه اول و دوم نشان می دهد. درصدهای بالا نشان می دهد که اغلب یک جفت مرتبه اول یا دوم از یک موضوع در همان محله ای که موضوع به آن تعلق دارد یافت می شود. یعنی آزمودنیهایی که از طریق یک یا چند مقایسه با موضوعات دیگر مرتبط میشوند، به احتمال زیاد در یک همسایگی قرار دارند. با توجه به اینکه، املاک در یک محله را می توان به عنوان ویژگی های قابل مقایسه برای یک موضوع با سهولت و کارایی بسیار انتخاب کرد. این آزمون بسط قانون اول توبلر است، “همه چیز به هر چیز دیگری مربوط است، اما چیزهای نزدیک بیشتر از چیزهای دور مرتبط هستند” [ 48 ].]. جفتهای موضوع از قبل نزدیک قرار گرفتهاند و بنابراین درصد نرخ ضربه باید بهطور قابلتوجهی بالا باشد، و در حالی که ما اهمیت خودهمبستگی فضایی را نادیده نمیگیریم، روششناسی پیشرفت قابلتوجهی نسبت به روش رایج موجود در صنعت است.
5.3. شیفت سالانه
داده های ارزیابی ارائه شده توسط CoreLogic®شامل نمونهای از ارزیابیهای انجامشده بین سالهای 2014 و 2018 است. اکنون که مرزهای قطعی برای محلهها ایجاد کردهایم، و اعتبار آنها را ثابت کردهایم، اکنون بر روی مشاهده چگونگی رشد یا کوچک شدن محلهها در طول سالها تمرکز میکنیم. بحث استفاده از تراکت های سرشماری این است که آنها به مدت 10 سال (در ایالات متحده) راکد می مانند و با تغییر بازار تغییر نمی کنند. ظهور یک محله جدید، فروش مجموعه ای از املاک، و حتی اعیانی شدن، فوراً در نظر گرفته نخواهد شد. با توجه به این واقعیت، انجام تحلیل املاک و مستغلات در سطح سرشماری فاقد اعتبار خواهد بود. تجزیه و تحلیل سری زمانی قیمت املاک در یک شهر یا منطقه در توسعه درک بازار املاک و در پیش بینی کاهش قیمت ها در آینده، همانطور که توسط Quan و Titman [ 49 ] استفاده می شود، بسیار رایج است.]، و چیانگ، لی و ویسن [ 50 ]. برای این تحلیل، ما بر تغییر شکل یک محله تمرکز می کنیم. یک محله ترسیم شده که دائماً رشد می کند به رشد بیشتر در سال های آینده اشاره می کند. اگر بتوانیم محلههایی را پیدا کنیم که در تمام چهار سال در محدوده ما دائماً رشد یا کوچک شدهاند، میتوانیم پیشبینی کنیم که آنها در آینده نیز به این کار ادامه خواهند داد.
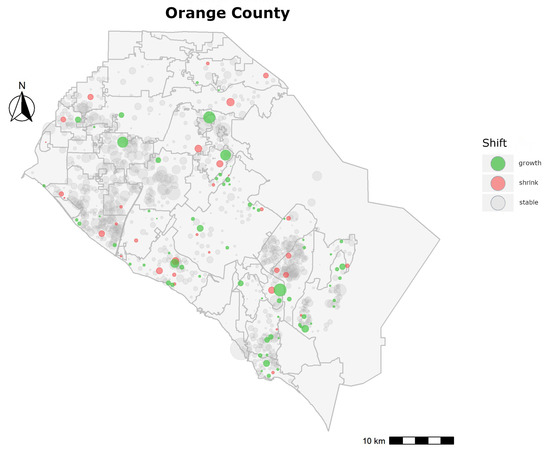
برای محاسبه شیفت سالانه برای یک محله، ابتدا دو جهت را پیدا کردیم که بیشتر املاک در آن قرار دارند، نسبت به مرکز محله. این به ما اجازه داد تا بر روی منطقه ای در محله ای تمرکز کنیم که بیشترین فعالیت را داشت و باید برای هر تحلیل بین محله ای از آن استفاده کرد. برای آن جهتها، ما سپس میانگین فواصل بین ویژگیها و مرکز را محاسبه کردیم و ارزیابی کردیم که آیا فاصله در طول سالها به طور مداوم در حال افزایش یا کاهش است. معیار انتخاب ما محافظه کارانه بود، و ما یک محله را تنها در صورتی طبقه بندی کردیم که در حال رشد یا کوچک شدن باشد، میانگین فاصله یک محله هر سال افزایش یا کاهش یابد. با توجه به تنظیم دقیق، مشاهده کردیم که اکثر محله ها هیچ نشانه ای از رشد یا انقباض را نشان نمی دهند، همانطور که در شکل 10 مشاهده می شود.. هر دایره به محله ای برای اورنج کانتی اشاره می کند و اندازه آن بر اساس وسعت محله است. دایرههای خاکستری نشاندهنده محلههایی بدون تغییر هستند، در حالی که دایرههای سبز نشانگر رشد هستند و دایرههای قرمز نشان دهنده کوچک شدن هستند. رشد ثابت، در تمام سالها، به این واقعیت اشاره دارد که ارزیاب اکنون دورتر سفر میکند تا ویژگیهای قابل مقایسه برای یک موضوع در همسایگی را بیابد و مرز آن نیز باید تغییر کند، تا به طور بالقوه داراییهایی را پوشش دهد که ممکن است در سالهای آینده به عنوان قابل مقایسه مورد استفاده قرار گیرند. .
این همچنین بر بازار املاک در داخل و اطراف یک محله تأثیر می گذارد. اگر ارزیاب هنگام انجام ارزیابی در سال 2015، املاک قابل مقایسه را فراتر از مرز محله سال 2014 بیابد، نشان می دهد که املاک داخل محله دیگر از نظر خصوصیات مشابه ملک مورد نظر نیستند و ساکنان خانه های خود را بهبود می بخشند، که پس از آن پتانسیل دعوت از خریداران از زمینه های اقتصادی متنوع تر. منطقه ای با محله های مجاور با رشد ثابت، نشانه قوی از تغییر در بازار است و به یک بازار فرعی در حال ظهور با زمین های توسعه نیافته اشاره می کند که ممکن است در سال های آینده به کانون بازار املاک تبدیل شود.
داشتن توانایی رشد با گذشت زمان، در مقایسه با مرزهای ایستا کدهای پستی و بخشهای سرشماری، مزیت بیشتری به محلههای مشخصشده میدهد. برای مطالعات جمعیت شناختی، اجتماعی و اقتصادی آینده، می توان تحلیل هایی را در سطح این محله ها انجام داد که تفکیک دقیق تری از املاک و ساکنان را فراهم می کند. شکل 11 نمونه ای از املاک را نشان می دهد که بر اساس ویژگی های فیزیکی (اندازه و تعداد طبقه ها) و مکان (ملاک های ساحلی برای تصاویر در ردیف آخر) در محله های مختلف قرار گرفته اند.
6. نتیجه گیری
در این مقاله، ما یک رویکرد جدید برای حل مشکل ترسیم محلهها در یک منطقه که دارای ویژگیهای مشابه هستند، با استفاده از فاصله جغرافیایی بین موضوع و ویژگیهای قابل مقایسه، در یک ارزیابی ارائه میکنیم. محدودیت این رویکرد این است که محله های برآورد شده کل منطقه را پوشش نمی دهند. دادههای نمونه ارزیابیها را برای هر دارایی جداگانه پوشش نمیدهند، و از طریق استفاده از فیلترهای فضایی و الگوریتم خوشهبندی که برخی ویژگیها را به عنوان نویز در نظر میگیرد، در نهایت به بخش قابلتوجهی از ویژگیها میرسیم که در هیچ همسایگی نیستند. با این حال، رویکرد ما فقط از فاصله بین موضوع و ویژگیهای قابل مقایسه برای ترسیم این همسایگیها استفاده میکند، و اگر قرار بود این رویکرد در سطح بزرگتری مقیاسبندی شود، اگر رویکرد شبکه عصبی را در پیش گرفته بودیم، فقط به اطلاعات ارزیابی برای یافتن همسایگی برای مناطق جدید، در مقایسه با نیاز به داشتن همه ویژگیهای مشخصه، نیاز داریم. این محدودیت، برای یک مطالعه آینده شامل ترسیم محلهها با استفاده از فاصله فضایی بین خواص، میتواند با استفاده از الگوریتمهای مولد که در آن مرزهای مهم محلهها ابتدا ترسیم میشوند و به طور مکرر گسترش مییابند، تا زمانی که کل منطقه توسط محلههای ترسیمشده پوشانده شود، برطرف شود. الگوریتم ما، در اصل، قادر است دانش جمعآوریشده توسط ارزیابها را در طول سالها، در مورد مناطق تمرکز خاص آنها، با تخمینهای بازار آن مناطق مرتبط کند. بر اساس رویکرد ما بر داده های ارزیابی،
ما محله هایی ایجاد می کنیم که رابطه بین املاک مشابه را حفظ می کنند، شهود ارزیاب برای یک منطقه را برجسته می کنند، و توانایی رشد یا کوچک شدن در بازارهای املاک را دارند. محلههای ما همچنین پیشرفتهایی در کدهای پستی و سرشماریها هستند که معمولاً در تحلیلهای جمعیتی و اجتماعی-اقتصادی، در پیشبینی ویژگیهای دارایی و توضیح تنوع آنها استفاده میشوند.











بدون دیدگاه