

خلاصه
کلید واژه ها:
توصیه مکان سفر ؛ فاکتورسازی ماتریسی ; شبکه عصبی کانولوشنال ; مشکل شروع سرد
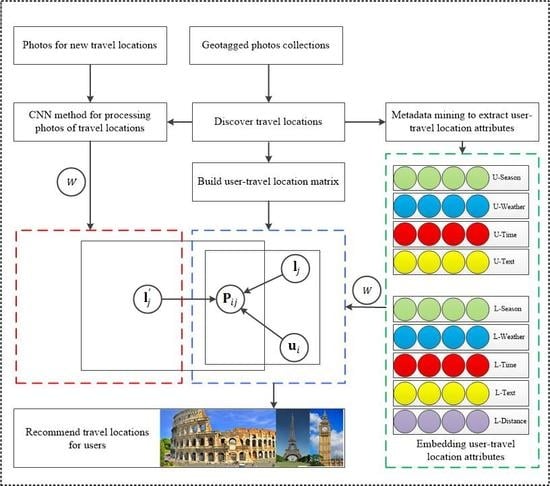
چکیده گرافیکی
1. معرفی
-
یک روش CNNMF پیشنهاد کنید که CNN و WMF را ادغام کند. اگر یک مکان مسافرتی هیچ گونه بررسی قبلی نداشته باشد، این روش از CNN برای تخمین بازنمایی عامل پنهان آن از عکسهایش استفاده میکند.
-
از وزنهای شباهت بین کاربران (و مکانهای سفر) برای بهرهبرداری از ویژگیهای متنی (یعنی زمان، آب و هوا و فصل)، ویژگیهای متنی (یعنی برچسبها) و ویژگیهای جغرافیایی (یعنی فاصله) استفاده کنید.
-
روش پیشنهادی را بر روی مجموعه داده های CCGP که نه شهر محبوب در سراسر جهان را پوشش می دهد، ارزیابی کنید. نتایج تجربی نشان میدهد که CNNMF میتواند به طور موثر مشکل شروع سرد مکان سفر را برطرف کند و به عملکرد توصیه رقابتی دست یابد.
2. کارهای مرتبط
2.1. توصیه مکان سفر مبتنی بر CCGP
2.2. استفاده از داده های اضافی برای رفع مشکل شروع سرد محل سفر
3. مقدمات و تعریف مسئله
تعریف 1
تعریف 2
تعریف 3
تعریف 4
تعریف 5
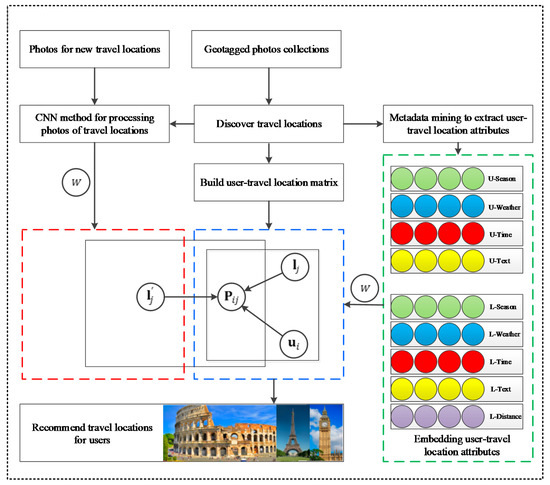
4. روش شناسی
4.1. کشف مکان های سفر از CCGP
4.2. به دست آوردن اطلاعات صریح
4.2.1. مدل سازی اطلاعات متنی
-
زمان روز: صبح روز هفته، بعد از ظهر روز هفته، صبح آخر هفته و بعد از ظهر آخر هفته.
-
فصل: بهار (مارس-آوریل-مه)، تابستان (ژوئن-ژوئیه-اوت)، پاییز (سپتامبر-اکتبر-نوامبر) و زمستان (دسامبر-ژانویه-فوریه).
-
دمای هوا: گرم (≥25 درجه سانتیگراد)، گرم (15-25 درجه سانتیگراد)، خنک (5-15 درجه سانتیگراد) و سرد (<5 درجه سانتیگراد).
-
وضعیت آب و هوا-آسمان: آفتابی، ابری، بارانی، برفی و مه آلود.
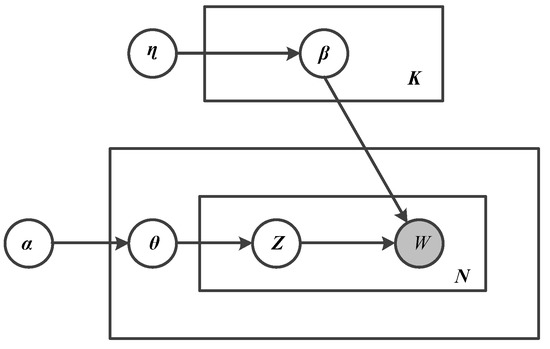
4.2.2. مدل سازی اطلاعات متنی
-
پارامترها را انتخاب کنید θمن��-𝐷𝑖 r ( α�)، جایی که θمن��توزیع موضوعی سند است i�و 𝐷𝑖 r ( α�) توزیع دیریکله پارامتر 𝛼 است.
-
برای هر کلمه:
-
یک موضوع را انتخاب کنید z�چند جمله ای ( θi��).
-
یک کلمه را انتخاب کنید w�چند جمله ای ( βz��).
-
4.3. به دست آوردن اطلاعات صریح
پس از به دست آوردن ویژگی های صریح، ویژگی های کاربر و مکان سفر به عنوان ساخته می شوند u=(wu,su, tu,txtu)�=(��,��, ��,����)و l=(wl, sl, tl، تی xتیل، dمنسل) �=(��, ��, ��, ����, ����) . ترکیبی از ویژگی های کاربر و مکان سفر در فاکتورسازی ماتریس اعمال می شود. مl l���نشان دهنده ماتریس شباهت بین دو مکان سفر است، و متو تو���نشان دهنده ماتریس شباهت بین دو کاربر است. هر دو مl l���و متو تو���برای کمک به فاکتورسازی ماتریس مکان کاربر-سفر استفاده می شود. مقدار شباهت بین 0 و 1 است و مقدار بزرگ نشان دهنده شباهت زیاد است. dمن هستم (لj،لک)���(��,��)فاصله جغرافیایی بین دو مکان سفر است. شباهت مکان سفر-مکان سفر را می توان با معادله (1) محاسبه کرد:
جایی که ایکسj q���و ایکسk q���نماینده qتی ساعت��ℎویژگی مکان های سفر لj��و لک��، به ترتیب. y�تعداد امکانات است. شباهت کاربر-کاربر را می توان با معادله (2) محاسبه کرد:
جایی که ایکسمن g���و ایکسk g���. نماینده gتی ساعت��ℎویژگی کاربران تومن��و توک��، به ترتیب. y“�′. تعداد امکانات است. وزن مکان های سفر و شباهت کاربران را می توان به ترتیب با معادلات (3) و (4) محاسبه کرد.
جایی که یک ،�,و ب _�,. نشان دهنده وزن شباهت بین مکان های سفر و ج�وزن شباهت بین کاربران را نشان می دهد که برای کمک به فاکتورسازی تعامل مکان کاربر-سفر استفاده می شود. وزن ها به شرح زیر تعیین می شود: a = b =15/a=b=15و c =14/c=14.
4.4. فاکتورسازی تعامل کاربر-محل سفر
تعامل مکان کاربر و سفر نقش مهمی در زمینه توصیه مکان سفر ایفا می کند. اجازه دهید rمن ج���تعداد دفعات آن کاربر باشد من�از مکان سفر بازدید کرده است j�، که می توان از بررسی های گذشته دریافت کرد. برای محاسبه اثر وزنی کاربر و مکان سفر، از الگوریتم WMF [ 35 ] استفاده می کنیم. اجازه دهید پمن ج���ترجیح کاربر باشد من�به محل سفر j�، که از باینریزه کردن به دست می آید rمن ج���همانطور که در رابطه (5) نشان داده شده است. اجازه دهید سیمن ج���اعتماد به نفس باشد پمن ج���که از رابطه (6) بدست می آید.
جایی که γ�و ϵ�پارامترهای هایپر هستند. فرض کنید که تومن∈آرن× k��∈ℝ�×�ترجیحات پنهان کاربران باشد، لj∈آرم× k��∈ℝ�×�مکان های سفر خواص نهفته باشد. روش اصلی توصیه مکان سفر تقریبی است تومن“س��′�ترجیحات نهفته در یک بازدید نشده لj��با حل مسئله بهینه سازی زیر.
جایی که سیمن ج∈آرن× م���∈ℝ�×�چک در وزن ماتریس با است سیمن ج= 1���=1نشان می دهد که تومن��در ثبت نام کرده است لj��، سیمن ج= 0���=0در غیر این صورت. به دنبال کار قبلی [ 9 ]، اطلاعات شباهت ناهمگن، شباهت کاربر-کاربر را معرفی می کند و شباهت مکان سفر-محل سفر می تواند برای محدود کردن یک WMF برای توصیه مکان سفر، که در معادله (8) ارائه شده است، استفاده شود:
جایی که تومن��بردار عامل پنهان کاربر است من�، و لj��بردار عامل پنهان مکان سفر است j�، دو اصطلاح تنظیم ∥تومن∥2اف‖��‖�2و ∥لj∥2اف‖��‖�2برای جلوگیری از نصب بیش از حد استفاده می شود و G ( i )�(�)و Q ( j )�(�)شباهت های کاربر و مکان سفر کاربر است من�و محل سفر j�، به ترتیب. λ1�1و λ2�2پارامترهای غیرمنفی هستند که برای کنترل شرایط منظم سازی و شباهت اصطلاحات منظم سازی استفاده می شوند.
4.5. بهره برداری از محتوای بصری
4.6. تخمین فاکتور نهفته از عکس ها
برآورد عوامل پنهان برای یک مکان سفر معین از CCGP مربوطه یک مشکل رگرسیونی است. از آنجایی که عوامل پنهان دارای ارزش واقعی هستند، هدف اصلی به حداقل رساندن میانگین مربعات خطای برآوردها است. اجازه دهید لj��بردار عامل پنهان مکان باشد j�، که توسط WMF بدست می آید و ل“j��′پیش بینی مربوطه توسط CNN است. سپس مسئله کمینه سازی به صورت زیر ارائه می شود:
4.7. توصیه مکان سفر
نمایش چارچوب CNNMF در شکل 2 نشان داده شده است . با ادغام رابطه (8) و معادله (9)، تابع هدف CNNMF را می توان به صورت زیر نوشت:
جایی که λ3�3و λ4�4پارامترهایی هستند که برای کنترل تخمین عامل نهفته و اصطلاحات منظمسازی استفاده میشوند. معادلات (11) تا (13) که بر اساس نزول گرادیان است، برای به روز رسانی کاربر استفاده می شود. تومن��و محل سفر لj��، به ترتیب.
4.8. الگوریتم یادگیری CNNMF
| الگوریتم 1. چارچوب پیشنهادی CNNMF |
| ورودی: P ، ماتریس ترجیحی مکان کاربر-سفر Sim u (u i ، u k ): شباهت های کاربر-کاربر Sim l ( l j ، l k ): مکان سفر-شباهت های مکان سفر پ𝒫l j برای l j ∈ Lℒ خروجی : بردار عامل پنهان کاربر و مکان سفر u i , l j ; 1: مقداردهی اولیه وزن VGG-16 در پایگاه داده مکان 2: مقداردهی اولیه u i , l j و ل“j��′ 3: برای هر u i انجام می دهم 4: به روز رسانی با معادله (10) 5: پایان برای 6: برای هر l j انجام 7: به روز رسانی با معادله (11) 8: پایان برای 9: اگر مکان سفر j جدید است ، 10: برآورد ل“j��′توسط CNN ( W , f j ) 11: به روز رسانی توسط معادله (12) 12: پایان اگر 13: برگرداندن مکان های برتر سفر توسط P ij |
5. آزمایشات
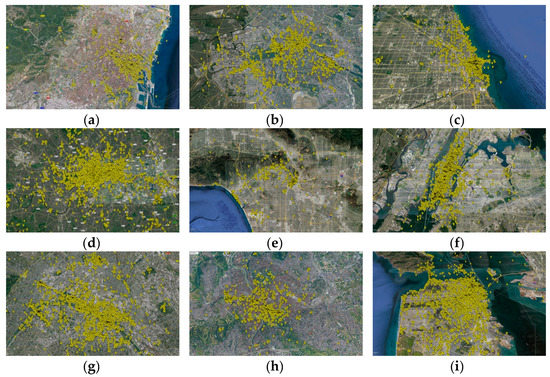
5.1. مجموعه داده
5.2. تنظیمات پارامتر
-
برای فعال کردن P-DBSCAN برای شناسایی مکان های سفر از CCGP ها، یک تنظیم می کنیم ممن n Us e r s = 50��������=50، شعاع ε ( e p s i l o n ) = 100 � (�������)=100متر و نسبت چگالی ω = 0.5�=0.5.
-
برای به دست آوردن اطلاعات تعامل کاربر-محل سفر، به طور تجربی آستانه مدت زمان بازدید را تعیین کردیم v i s iتیتی ه آر= 6 ������ℎ�=6ساعت
-
در تمام آزمایشهای زیر بر اساس روشهای فاکتورسازی ماتریسی، پارامترها را تنظیم میکنیم λ1= 0.01�1=0.01، λ2= 0.1�2=0.1، λ3= 0.001�3=0.001، λ4= 1�4=1، و α = 0.5�=0.5.
-
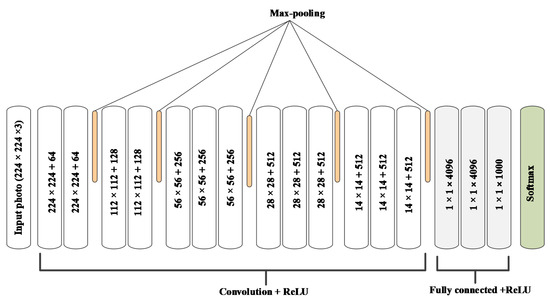
سی ان ان برای تخمین عوامل پنهان مکان های سفر جدید استفاده می شود. پارامتر نرخ یادگیری است 0.0010.001برای 6060اندازه دوره و مینی بچ 128 است. تکانه 0.9 است. کاهش وزن 0.0005 است. وزن ها به طور تصادفی پس از کار قبلی [ 40 ] مقداردهی اولیه می شوند.
در آزمایشهای زیر، با توجه به زمان بازدید، مجموعه داده را تقسیم کردیم D�به مجموعه آموزشی Dt r a i n������(80%) و مجموعه تست Dt e s t�����(20%). سپس، استفاده از معیارهای ارزیابی، یعنی MAP@n و AP@n ، برای ارزیابی اثربخشی توصیهها با معادلات محاسبهشده (13) و (14) به کار گرفته شد.
جایی که n�تعداد مکان های پیشنهادی سفر را نشان می دهد و مترمترتعداد کاربران را نشان می دهد. ارزش ربط من _کj= 1لمنک�=1اگر کاربر از مکان سفر بازدید کرده باشد. در غیر این صورت، من _کj= 0لمنک�=0.
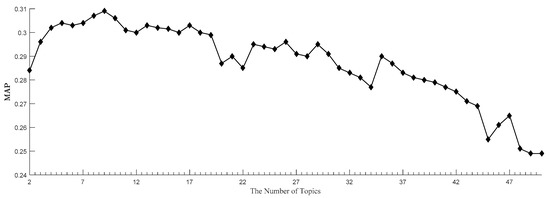
5.3. تاثیر شماره موضوع
5.4. تأثیر انواع گوناگون اطلاعات
-
انواع مختلف اطلاعات عملکرد توصیه را به درجات مختلف افزایش می دهد. بر اساس درجه نفوذ، اطلاعات را می توان به صورت زیر رتبه بندی کرد: اطلاعات فصل > اطلاعات آب و هوا > اطلاعات متنی > اطلاعات زمانی > اطلاعات فاصله جغرافیایی. عملکرد حذف اطلاعات “فصل” کمترین است، به این معنی که اطلاعات “فصل” مهمترین اطلاعات برای توصیه مکان سفر است. عملکرد حذف اطلاعات «فاصله جغرافیایی» بالاترین است، به این معنی که اطلاعات «فاصله جغرافیایی» بیاهمیتترین اطلاعات است، زیرا اکثر مکانهای سفر از یکدیگر دور نیستند.
-
نقشه روش پیشنهادی به طور قابلتوجهی بهتر از پنج نوع دیگر است، که نشان میدهد روش پیشنهادی اطلاعات متنی، متنی و جغرافیایی را با هم ادغام میکند و بنابراین میتواند توصیههای بهبود یافته را ارائه دهد.
5.5. مقایسه عملکرد روشهای پیشنهادی
-
مدل موضوع پویا و فاکتورسازی ماتریس (DTMMF): DTMMF مدل موضوع را با فاکتورسازی ماتریس ادغام می کند تا مکان های سفر را توصیه کند. DTM برای به دست آوردن اطلاعات ضمنی استفاده می شود، در حالی که اطلاعات صریح از بررسی های گذشته و محتوای بصری (به عنوان مثال، سن و جنسیت) برای ساخت پروفایل های کاربر و مکان سفر به دست می آید [9 ] .
-
فیلتر مشارکتی مبتنی بر شبکه عصبی (NCF): NCF فاکتورسازی ماتریس را با پرسپترون چند لایه ترکیب میکند تا تعاملات مکان سفر-کاربر غیرخطی را ثبت کند [ 41 ]. محتوای بصری در نظر گرفته نمی شود.
-
مدل عاملسازی ماتریس احتمالی بصری (VPMF): VPMF از ویژگیهای بصری برای یادگیری ترجیحات کاربر با استفاده از بررسیهای گذشته کاربران استفاده میکند. سپس، ترجیحات کاربر را با محدودیت های مکان سفر برای برنامه ریزی سفر یکپارچه می کند [ 42 ].
-
رتبهبندی شخصی بیزی بصری (VBPR): VBPR ویژگیهای بصری را از عکسها با استفاده از یک روش از پیش آموزشدیده بدون هیچ گونه اطلاعات زمینه استخراج میکند [ 5 ]. ویژگی بصری استخراج شده برای پیش بینی امتیازات نظرات افراد استفاده می شود.
-
توصیه POI افزایش یافته محتوای بصری (VPOI): VPOI از یادگیری مشترک طبقه بندی عکس، تجزیه ماتریس، و وظایف استخراج ویژگی بصری [ 29 ] برای توصیه مکان های سفر به کاربر استفاده می کند. تفاوت با روش پیشنهادی این است که VPOI از عکسها برای یادگیری مشترک بازنماییهای بردار فاکتور پنهان استفاده میکند.
-
روش پیشنهادی به ترتیب از روشهای دیگر، یعنی DTMMF، NCF، VPMF، VBPR و VPOI، بهترتیب بهطور میانگین 35.21، 32.65، 31.22، 22.87، 9.5 درصد برتری دارد.
-
VPMF بهتر از DTMMF عمل می کند، که ممکن است به این دلیل باشد که VPMF ویژگی های بصری را مستقیماً از کل عکس استخراج می کند، در حالی که DTMMF فقط برخی از ویژگی ها (یعنی سن و جنسیت) را بر اساس تشخیص چهره استخراج می کند.
-
VPOI بهتر از VBPR کار میکند، این ممکن است به این دلیل باشد که VPOI عکسها را هم برای کاربران و هم برای مکانهای سفر مدلسازی میکند در حالی که VBPR فقط عکسها را برای مکانهای سفر مدل میکند.
-
روش پیشنهادی به طور قابل توجهی بهتر از VPOI است. این به دلیل ترکیب اطلاعات زمینه ای (یعنی زمان، آب و هوا و فصل)، متنی (یعنی برچسب ها) و جغرافیایی (یعنی فاصله) است، در حالی که VPOI فقط از عکس ها برای یادگیری مشترک بازنمایی های بردار عامل پنهان استفاده می کند.
-
به طور کلی، با ارائه مشکل شروع سرد مکان سفر، عملکرد همه روش ها کاهش می یابد. به عنوان مثال، عملکرد DTMMF از نظر MAP@10 تا 14.65٪ کاهش می یابد.
-
روش پیشنهادی برای مکانهای سفر با شروع سرد به ترتیب به ترتیب 40.17%، 41.43، 40.17%، 29.06%، 11.63% از روشهای دیگر مانند DTMMF، NCF، VPMF، VBPR و VPOI میگذرد.
-
کاهش عملکرد VBPR بسیار کمتر از DTMMF است، زیرا VBPR یک لایه اضافی را برای بهره برداری از ابعاد بصری یاد می گیرد، که می تواند به کاهش مشکل شروع سرد مکان سفر کمک کند، در حالی که DTMMF از محتویات بصری فقط برای استخراج ویژگی ها استفاده می کند (یعنی سن. و جنسیت) بر اساس تشخیص چهره.
-
روش پیشنهادی CNNMF به طور قابل توجهی بهتر از VPOI است، در حالی که هر دو روش از محتوای بصری استفاده می کنند. تفاوتهای بین CNNMF و VPOI عبارتند از: CNNMF مستقیماً فاکتور پنهان را از عکسهای خود به عنوان توضیحات مکانهای سفر به دست میآورد. در حالی که VPOI از عکس ها برای کمک به یادگیری بازنمایی بردار فاکتور پنهان استفاده می کند.
6. نتیجه گیری و کار آینده
منابع
- مجید، ع. چن، ال. چن، جی. میرزا، ح.ت. حسین، من. Woodward, J. یک سیستم توصیه مسافرتی شخصیشده آگاه از زمینه مبتنی بر دادهکاوی رسانههای اجتماعی دارای برچسب جغرافیایی. بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 662-684. [ Google Scholar ] [ CrossRef ]
- لیو، جی. ژانگ، ز. لیو، سی. کیو، ا. Zhang، F. بهرهبرداری از تأثیرات اجتماعی دو بعدی جغرافیایی و ترکیبی برای توصیه مکان. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 285. [ Google Scholar ] [ CrossRef ]
- سان، ایکس. هوانگ، ز. پنگ، ایکس. چن، ی. لیو، ی. ساخت یک رویکرد توصیه شخصی مبتنی بر مدل برای جاذبههای گردشگری از دادههای رسانههای اجتماعی دارای برچسب جغرافیایی. بین المللی جی دیجیت. زمین 2019 ، 12 ، 661–678. [ Google Scholar ] [ CrossRef ]
- وانگ، ز. ژانگ، دی. ژو، ایکس. یانگ، دی. یو، ز. Yu, Z. کشف و نمایه سازی جوامع همپوشانی در شبکه های اجتماعی مبتنی بر مکان. IEEE Trans. سیستم مرد سایبرن. سیستم 2014 ، 44 ، 499-509. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یانگ، دی. ژانگ، دی. یو، ز. Wang, Z. یک سیستم توصیه موقعیت مکانی شخصی سازی شده با احساسات. در مجموعه مقالات بیست و چهارمین کنفرانس ACM در مورد فرامتن و رسانه های اجتماعی، پاریس، فرانسه، 1 تا 3 مه 2013. صص 119-128. [ Google Scholar ]
- ژانگ، جی دی. Chow، CY iGSLR: توصیه موقعیت جغرافیایی-اجتماعی شخصی: یک رویکرد تخمین چگالی هسته. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، اورلاندو، فلوریدا، ایالات متحده آمریکا، 5 تا 8 نوامبر 2013. صص 334-343. [ Google Scholar ]
- خو، ز. چن، ال. Chen, G. روش توصیه سفر مبتنی بر زمینه آگاه با استفاده از عکسهای دارای برچسب جغرافیایی. محاسبات عصبی 2015 ، 155 ، 99-107. [ Google Scholar ] [ CrossRef ]
- شی، ی. سردیوکوف، پ. هانجالیچ، ع. لارسون، ام. توصیه شاخص غیر ضروری با استفاده از عکسهای دارای برچسب جغرافیایی. ACM Trans. هوشمند سیستم تکنولوژی 2013 ، 4 ، 1-27. [ Google Scholar ] [ CrossRef ]
- خو، ز. چن، ال. دای، ی. چن، جی. یک مدل موضوع پویا و روش توصیه سفر مبتنی بر فاکتورسازی ماتریس با بهرهبرداری از دادههای همه جا حاضر. IEEE Trans. چندتایی. 2017 ، 19 ، 1933-1945. [ Google Scholar ] [ CrossRef ]
- کیم، دی. پارک، سی. اوه، جی. لی، اس. یو، اچ. فاکتورسازی ماتریس کانولوشنال برای توصیه آگاه از زمینه سند. در مجموعه مقالات دهمین کنفرانس ACM در مورد سیستمهای توصیهکننده، بوستون، MA، ایالات متحده آمریکا، 15 تا 19 سپتامبر 2016. صص 233-240. [ Google Scholar ]
- کای، جی. تره فرنگی.؛ Lee, I. سیستم توصیهکننده برنامه سفر با استخراج الگوی مسیر معنایی از عکسهای دارای برچسب جغرافیایی. سیستم خبره Appl. 2018 ، 94 ، 32-40. [ Google Scholar ] [ CrossRef ]
- گائو، اچ. تانگ، جی. لیو، اچ. gSCorr: مدلسازی همبستگیهای جغرافیایی-اجتماعی برای بررسیهای جدید در شبکههای اجتماعی مبتنی بر مکان. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی ACM در مدیریت اطلاعات و دانش، مائوئی، HI، ایالات متحده آمریکا، 29 اکتبر تا 2 نوامبر 2012. صص 1582-1586. [ Google Scholar ]
- گائو، اچ. تانگ، جی. لیو، اچ. پرداختن به مشکل شروع سرد در توصیه مکان با استفاده از همبستگی های جغرافیایی-اجتماعی. حداقل داده بدانید. کشف کنید. 2015 ، 29 ، 299-323. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شی، اچ. چن، ال. خو، ز. لیو، دی. توصیه موقعیت مکانی شخصی شده با استفاده از اطلاعات استفاده از تلفن همراه. Appl. هوشمند 2019 ، 49 ، 3694–3707. [ Google Scholar ] [ CrossRef ]
- ون دن اوورد، آ. دیلمان، اس. Schrauwen، B. توصیه موسیقی مبتنی بر محتوای عمیق. In Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5-8 دسامبر 2013 ; NeurIPS: سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 2013; صص 2643-2651. [ Google Scholar ]
- Kim, Y. شبکه های عصبی کانولوشن برای طبقه بندی جملات. در مجموعه مقالات کنفرانس روشهای تجربی در پردازش زبان طبیعی (EMNLP)، دوحه، قطر، 25-29 اکتبر 2014. صفحات 1746-1751. [ Google Scholar ]
- یو-هی نگ، جی. یانگ، اف. دیویس، LS بهره برداری از ویژگی های محلی از شبکه های عمیق برای بازیابی تصویر. در مجموعه مقالات کنفرانس IEEE در کارگاه های آموزشی بینایی کامپیوتری و تشخیص الگو، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. صص 53-61. [ Google Scholar ]
- جیانگ، اس. کیان، ایکس. می، تی. Fu, Y. توصیه توالی سفر شخصی شده در رسانه های اجتماعی بزرگ چند منبعی. IEEE Trans. کلان داده 2016 ، 2 ، 43-56. [ Google Scholar ] [ CrossRef ]
- لیو، سی. لیو، جی. خو، اس. وانگ، جی. لیو، سی. چن، تی. جیانگ، تی. یک شبکه کانولوشنال متسع فضایی-زمانی برای توصیه نقطه مورد علاقه. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 113. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژنگ، YT; ژا، زجی؛ الگوهای سفر معدن Chua، TS از عکس های دارای برچسب جغرافیایی. ACM Trans. هوشمند سیستم تکنولوژی 2012 ، 3 ، 1-18. [ Google Scholar ] [ CrossRef ]
- چن، سی. چن، ایکس. وانگ، ز. وانگ، ی. Zhang، D. ScenicPlanner: برنامه ریزی مسیرهای سفر خوش منظره با استفاده از ردپای دیجیتال ناهمگون تولید شده توسط کاربر. جلو. محاسبه کنید. علمی 2017 ، 11 ، 61-74. [ Google Scholar ] [ CrossRef ]
- مجید، ع. چن، ال. میرزا، ح.ت. حسین، من. Chen, G. سیستمی برای استخراج مکانهای گردشگری جالب و توالی سفر از عکسهای برچسبگذاری شده جغرافیایی عمومی. دانستن داده ها مهندس 2015 ، 95 ، 66-86. [ Google Scholar ] [ CrossRef ]
- چنگ، ای جی؛ چن، YY; هوانگ، YT; Hsu، WH; Liao، HYM با استخراج ویژگیهای افراد از عکسهای ارائهشده توسط جامعه، توصیه سفر شخصیسازی شده است. در مجموعه مقالات نوزدهمین کنفرانس بین المللی ACM در چند رسانه ای، اسکاتسدیل، AZ، ایالات متحده، 28 نوامبر تا 1 دسامبر 2011. صص 83-92. [ Google Scholar ]
- چن، YY; چنگ، ای جی؛ Hsu، WH توصیه سفر با استخراج ویژگی های افراد و انواع گروه های سفر از عکس های ارائه شده توسط جامعه. IEEE Trans. چندتایی. 2013 ، 15 ، 1283-1295. [ Google Scholar ] [ CrossRef ]
- Ke، X. زو، جی. Niu, Y. حاشیه نویسی خودکار تصویر از انتها به انتها بر اساس cnn عمیق و تقویت داده های چند برچسبی. IEEE Trans. چندتایی. 2019 ، 21 ، 2093–2106. [ Google Scholar ] [ CrossRef ]
- کوانگ، اچ. زو، اس. السادیک، الف. تقویت پیش بینی موقعیت جغرافیایی برای تصاویر وب از طریق یکپارچه سازی منابع دانش متعدد. در مجموعه مقالات پنجمین کنفرانس بین المللی ACM در مورد بازیابی چند رسانه ای، شانگهای، چین، 23 تا 26 ژوئن 2015. صص 559-562. [ Google Scholar ]
- زینگ، اس. وانگ، کیو. ژائو، ایکس. لی، تی. توصیههای نقطهنظر از محتوا مبتنی بر شبکه عصبی کانولوشنال. Appl. هوشمند 2019 ، 49 ، 858-871. [ Google Scholar ] [ CrossRef ]
- ویاند، تی. کوستریکوف، آی. فیلبین، جی. موقعیت جغرافیایی عکس سیاره با شبکه های عصبی کانولوشنال. در مجموعه مقالات چهاردهمین کنفرانس اروپایی بینایی کامپیوتری-ECCV 2016، آمستردام، هلند، 11 تا 14 اکتبر 2016؛ صص 37-55. [ Google Scholar ]
- وانگ، اس. وانگ، ی. تانگ، جی. شو، ک. رانگانات، اس. لیو، اچ. تصاویر شما چه چیزی را نشان میدهند: بهرهبرداری از محتوای بصری برای توصیههای مورد علاقه. در مجموعه مقالات بیست و ششمین کنفرانس بینالمللی وب جهانی، پرث، WA، استرالیا، 3 تا 7 آوریل 2017؛ صص 391-400. [ Google Scholar ]
- کراندال، دی جی; بکستروم، ال. هاتنلوچر، دی. کلینبرگ، جی. نقشه برداری از عکس های جهان. در مجموعه مقالات هجدهمین کنفرانس بین المللی وب جهانی، مادرید، اسپانیا، 20-24 آوریل 2009; صص 761-770. [ Google Scholar ]
- یو، ی. ژائو، ی. یو، جی. وانگ، جی. الگوهای معادن از مسیرهای عکس اینستاگرام برای توصیه مسیرهای مسافرتی محبوب. جلو. محاسبه کنید. علمی 2017 ، 11 ، 1007–1022. [ Google Scholar ] [ CrossRef ]
- کیسیلویچ، اس. منزمن، اف. Keim, D. P-DBSCAN: الگوریتم خوشهبندی مبتنی بر چگالی برای اکتشاف و تجزیه و تحلیل مناطق جذاب با استفاده از مجموعه عکسهای دارای برچسب جغرافیایی در مجموعه مقالات اولین کنفرانس بین المللی و نمایشگاه محاسبات برای تحقیقات و کاربردهای جغرافیایی، واشنگتن، دی سی، ایالات متحده آمریکا، 21 تا 23 ژوئن 2010. صص 1-4. [ Google Scholar ]
- ماتسو، اس. شیمودا، دبلیو. Yanai, K. توئیتر موقعیت جغرافیایی عکس با استفاده از ویژگی های متنی و بصری. در مجموعه مقالات سومین کنفرانس بین المللی IEEE درباره داده های بزرگ چندرسانه ای، لاگونا هیلز، کالیفرنیا، ایالات متحده آمریکا، 19 تا 21 آوریل 2017؛ ص 22-25. [ Google Scholar ]
- Blei، DM; Ng، AY؛ جردن، MI تخصیص دیریکله نهفته. جی. ماخ. فرا گرفتن. Res. 2003 ، 3 ، 993-1022. [ Google Scholar ]
- هو، ی. کورن، ی. وولینسکی، سی. فیلترینگ مشترک برای مجموعه داده های بازخورد ضمنی. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد داده کاوی، پیزا، ایتالیا، 15-19 دسامبر 2008. صص 263-272. [ Google Scholar ]
- سیمونیان، ک. Zisserman, A. شبکه های پیچیده بسیار عمیق برای تشخیص تصویر در مقیاس بزرگ. در مجموعه مقالات کنفرانس بینالمللی نمایشهای یادگیری 2015، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 7 تا 9 مه 2015. ص 1409-1556. [ Google Scholar ]
- دوناهو، جی. جیا، ی. وینیالز، او. هافمن، جی. ژانگ، ن. تزنگ، ای. Darrell, T. Decaf: یک ویژگی فعالسازی پیچیده عمیق برای تشخیص بصری عمومی. در مجموعه مقالات سی و یکمین کنفرانس یادگیری ماشینی، پکن، چین، 21 تا 26 ژوئن 2014. صص 647-655. [ Google Scholar ]
- شریف رضویان، ع. عزیزپور، ح. سالیوان، جی. Carlsson، S. CNN ویژگیهای خارج از قفسه: یک خط پایه شگفتانگیز برای شناسایی. در مجموعه مقالات بیست و هفتمین کنفرانس IEEE در کارگاه های آموزشی بینایی کامپیوتری و تشخیص الگو، کلمبوس، OH، ایالات متحده، 24-27 ژوئن 2014. ص 806-813. [ Google Scholar ]
- او، ک. Sun، J. شبکه های عصبی کانولوشنال با هزینه زمانی محدود. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. صص 5353–5360. [ Google Scholar ]
- ژو، بی. لاپدریزا، ا. شیائو، جی. تورالبا، ا. Oliva, A. یادگیری ویژگی های عمیق برای تشخیص صحنه با استفاده از پایگاه داده مکان ها. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی 27: کنفرانس سالانه سیستمهای پردازش اطلاعات عصبی 2014، مونترال، QC، کانادا، 8 تا 13 دسامبر 2014. صص 487-495. [ Google Scholar ]
- او، ر. McAuley, J. VBPR: رتبهبندی شخصیشده بیزی از بازخورد ضمنی. در مجموعه مقالات سی امین کنفرانس AAAI در مورد هوش مصنوعی، فینیکس، AZ، ایالات متحده آمریکا، 12 تا 17 فوریه 2016. [ Google Scholar ]
- ژائو، پی. خو، سی. لیو، ی. شنگ، VS; ژنگ، ک. شیونگ، اچ. Zhou, X. Photo2trip: بهرهبرداری از محتوای بصری در عکسهای دارای برچسب جغرافیایی برای توصیه تور شخصیشده. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی ACM در چند رسانه ای، دره سیلیکون، کالیفرنیا، ایالات متحده، 23 تا 27 اکتبر 2017. [ Google Scholar ]



بدون دیدگاه