

خلاصه
کلید واژه ها:
توصیه نقطه مورد علاقه ; انبساط علّی ; بلوک باقی مانده ؛ ترجیح فضایی ؛ ترجیح زمانی
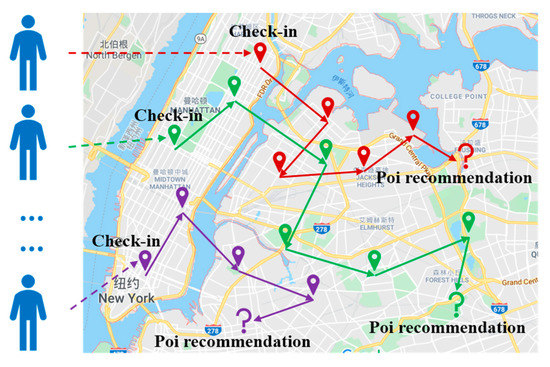
1. معرفی
-
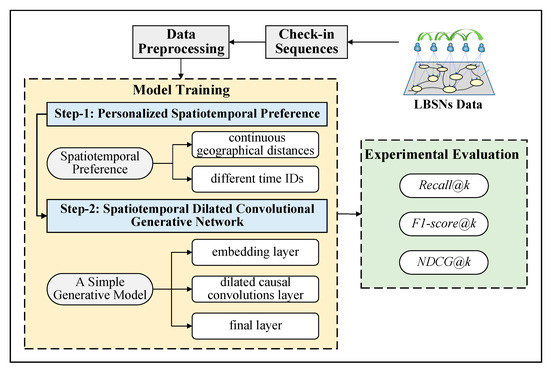
ما یک چارچوب پیشنهادی جدید POI را بر اساس مدل WaveNet پیشنهاد کردیم، که در آن از مدل مولد شرطی و پیچیدگیهای علّی متسع برای فعال کردن میدانهای دریافتی بسیار بزرگتر و مدلسازی توالی بررسی دوربرد پیچیده استفاده میشود. این چارچوب نه تنها به عملکرد توصیههای بالاتری دست مییابد، بلکه به نظر میرسد در مقایسه با روشهای پیشنهادی POI پیشرفته، سطح پایینتری از پیچیدگی مدل دارد.
-
با توجه به اهمیت اطلاعات متنی مکانی-زمانی، ما ترجیحات فضایی شخصی کاربر را با مدلسازی فواصل جغرافیایی پیوسته به دست میآوریم، و ترجیحات زمانی شخصی کاربر را با مدلسازی شناسههای زمانی پیوسته خاص، که الگوها را در دو مقیاس زمانی یکپارچه میکنند (به عنوان مثال، ساعتها در روز و روز در هفته).
-
ما آزمایشهایی را برای مطالعه ویژگیهای مکانی-زمانی رفتار ورود کاربران بر روی دو مجموعه داده واقعی انجام دادیم و ST-DCGN را با هفت رویکرد پایه توصیه POI مقایسه کردیم و آزمایشهای گسترده نشان داد که ST-DCGN مؤثر بوده و عملکرد بهتری از وضعیت نشان میدهد. روش های مدرن به طور قابل توجهی
2. کارهای مرتبط
2.1. روشهای پیشنهادی POI مرسوم
2.2. روش های توصیه POI مبتنی بر یادگیری عمیق
3. روش پیشنهادی
3.1. فرمول مسأله
3.2. اولویت مکانی-زمانی شخصی
3.2.1. اولویت فضایی شخصی
ما ترتیب ورود هر کاربر را تغییر می دهیم ایکستو={ایکس1تو،ایکس2تو،⋯،ایکستیتو}به دنباله ای با طول ثابت Eایکستو={ایکس1تو،ایکس2تو،⋯،ایکسکتو}، جایی که k نشان دهنده حداکثر طولی است که در نظر می گیریم. اگر طول دنباله بزرگتر از k باشد ، ما فقط جدیدترین رکوردهای ثبت ورود k را در نظر می گیریم . اگر طول دنباله کمتر از k بود، موارد بالشتکی را به سمت چپ اضافه میکردیم تا طول به k تبدیل شود. بنابراین، میتوانیم دنبالههای فاصله جغرافیایی پیوسته با طول ثابت را بدست آوریم Eاستو={r1تو،r2تو،⋯،rکتو}، و ماتریس فاصله جغرافیایی پیوسته برای همه کاربران m به شرح زیر ارائه شده است.
3.2.2. اولویت زمانی شخصی شده
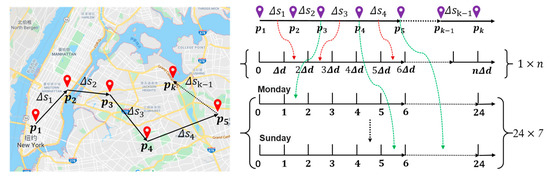
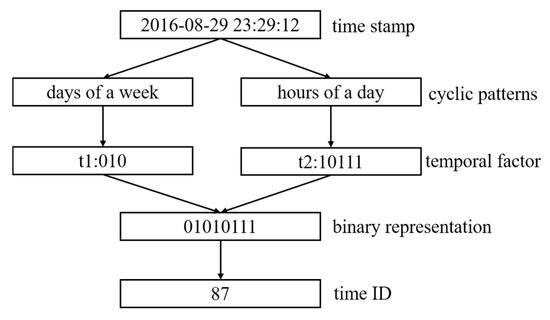
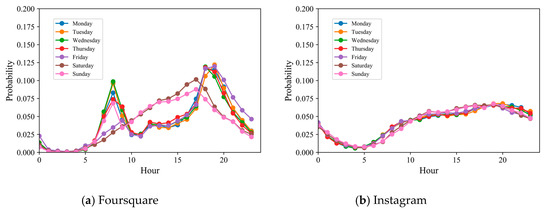
کارهای قبلی نشان داده است که رفتار ورود کاربران ویژگی های دوره ای را نشان می دهد [ 7 ، 16 ]. به عنوان مثال، کاربران تمایل دارند از ساعت 18:00 تا 20:00 عصر سه شنبه و پنجشنبه در اطراف باشگاه مراجعه کنند، اما ترجیح می دهند برای خرید در روز شنبه از ساعت 15:00 تا 17:00 به بازار مراجعه کنند. بنابراین، میتوان الگوی تناوبی زمانی را به دو مقیاس تقسیم کرد: ساعتهای مختلف در یک روز و روزهای مختلف در هفته. برای ثبت دو الگوی دوره ای از رفتارهای ورود کاربران، ما یک طرح نمایه سازی زمان دو برشی [ 16 ] را معرفی می کنیم. همانطور که در شکل 3 نشان داده شده است ، ابتدا دنباله مهر زمانی را بدست می آوریم {تی1تو،تی2تو،⋯،تیکتو}مطابق با ترتیب ورود کاربر {ایکس1تو،ایکس2تو،⋯،ایکسکتو}و سپس هر مهر زمان را تقسیم کنید تیمنتودر بازه زمانی مشخص یک هفته و یک روز. به طور خاص، یک مهر زمانی از نظر روز هفته و ساعت به دو بخش تقسیم می شود. علاوه بر این، ما یک هفته را به هفت روز (یعنی یکشنبه تا شنبه) و یک روز را به 24 ساعت (یعنی 1 تا 24) تقسیم می کنیم. سپس از 3 بیت برای نشان دادن روز در یک هفته و 5 بیت برای تعیین ساعت در یک روز استفاده می کنیم. در نهایت، کد باینری را به یک رقم اعشاری منحصر به فرد به عنوان شناسه زمان تبدیل می کنیم. در این طرح نمایه سازی زمانی، می توانیم به دست آوریم تی=7 ×24=168برش های زمانی شکل 4 روند رمزگذاری یک مهر زمانی نمونه را نشان می دهد، “2016-08-29 23:29:12”. بنابراین، میتوانیم دنبالههای ID زمان پیوسته با طول ثابت را بدست آوریم Eتیتو={تی1تو،تی2تو،⋯،تیکتو}، و ماتریس ID زمان پیوسته برای همه m کاربران به صورت زیر ارائه شده است.
3.3. یک مدل مولد تحت شرایط مکانی و زمانی
در این بخش، یک مدل مولد جدید را معرفی میکنیم که مستقیماً بر روی ترتیب ورود کاربر عمل میکند. راه حل ارائه شده در اینجا از ایده WaveNet [ 23 ] الهام گرفته شده است، یک مدل تولیدی برای صدای خام بر اساس معماری PixelCNN [ 46 ]. WaveNet یک چارچوب عمومی و انعطافپذیر برای مقابله با بسیاری از برنامههایی که بر تولید صدا متکی هستند (به عنوان مثال، متن به گفتار، موسیقی، بهبود گفتار، تبدیل صدا، جداسازی منبع) ارائه میکند. به طور مشابه، ما توالی بررسی سابقه کاربر را در نظر می گیریم Eایکستو={ایکس1تو،ایکس2تو،⋯،ایکسکتو}، یک مدل با پارامتر داده می شود θ. هدف ما خروجی مقدار بعدی است ایکس^ک+1تومشروط به تاریخچه توالی ورود. اجازه دهید پ(Eایکستو|θ)احتمال مشترک ترتیب ورود باشد {ایکس1تو،ایکس2تو،⋯،ایکسکتو}; علاوه بر این، ما می توانیم فاکتورسازی کنیم پ(Eایکستو|θ)به عنوان حاصل ضرب احتمالات شرطی توسط قانون زنجیره ای به شرح زیر است:
که در آن نمونه POI ایکسک+1توبنابراین مشروط به نمونه های تمام POI های قبلی است {ایکس1تو،ایکس2تو،⋯،ایکسکتو}.
همانطور که گفته شد، ما اطلاعات زمینه مکانی و زمانی را در توصیه POI در نظر گرفتیم. بنابراین، توالی فاصله جغرافیایی پیوسته را نیز در نظر می گیریم Eاستو={r1تو،r2تو،⋯،rکتو}و توالی های ID زمان پیوسته Eتیتو={تی1تو،تی2تو،⋯،تیکتو}به عنوان ورودی های مشروط، هنگام پیش بینی ترتیب ورود کاربر Eایکستو={ایکس1تو،ایکس2تو،⋯،ایکسکتو}. علاوه بر این، میتوانیم توزیع شرطی را مدل کنیم پ(Eایکستو|θ)از ترتیب ورود با توجه به این ورودی ها. اکنون معادله (3) تبدیل می شود
که در آن توزیع احتمال شرطی با استفاده از لایههای پشتهای از پیچشهای متسع مدلسازی میشود که بعداً توضیح خواهیم داد.
3.4. جاسازی لایه جستجو
3.5. لایه پیچیدگی های علتی متسع
به طور رسمی تر، با توجه به یک ورودی توالی یک بعدی ایکس∈ℝکو یک فیلتر f:{0،1،⋯،g-1}→ℝ، پیچیدگی گشاد شده یک بعدی F روی عنصر s دنباله به صورت تعریف می شود
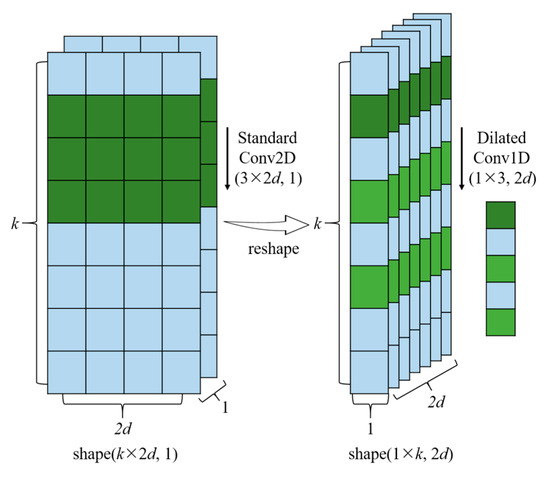
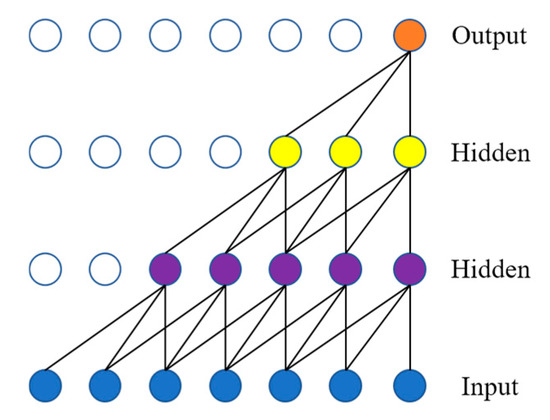
که در آن f تابع فیلتر، g اندازه فیلتر، l ضریب اتساع، و س-ل·منجهت گذشته را به حساب می آورد. واضح است که الگوریتم کانولوشن علّی گشاد شده میتواند وابستگیهای دنباله ورود طولانیمدت را بدون استفاده از لایههای شبکه بیشتر و فیلترهای بزرگتر بهتر دریافت کند. در عمل، برای افزایش بیشتر میدان های پذیرنده و ظرفیت مدل، فقط باید ساختار پیچش گشاد شده در شکل 7 را با انباشته کردن تکرار کنیم (به عنوان مثال، 1، 2، 4، 8، 1، 2، 4، 8).
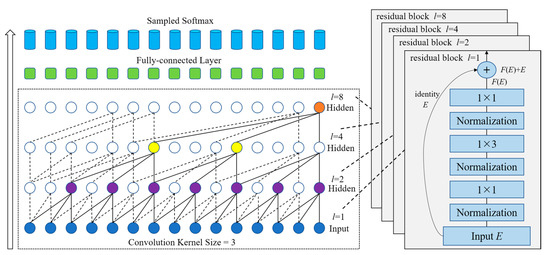
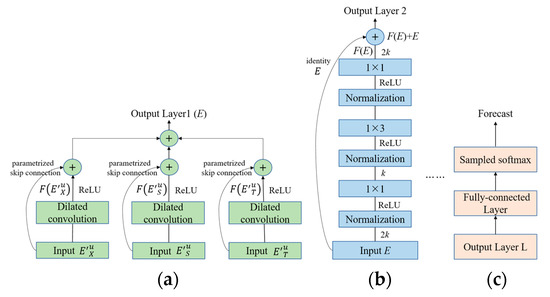
همانطور که در [ 22 ] بحث شد، به منظور یادگیری بازنمایی ویژگی های سطح بالاتر از وابستگی های توالی دوربرد، یک روش بصری افزایش تعداد لایه ها در شبکه ما است. با این حال، در عمل نیز به راحتی منجر به مشکل تخریب می شود که روند تمرین را بسیار سخت تر می کند. برای حل این مشکل، ما اتصالات باقیمانده [ 33 ، 47 ] را در روش خود معرفی می کنیم. همانطور که در شکل 7 و شکل 8 ب نشان داده شده است، یک بلوک باقیمانده شامل دو شاخه است. یک شاخه تبدیل لایه ورودی E به F از طریق یک سری از لایههای شبکه، از جمله پیچیدگی علت گشاد شده با نرمالسازی لایه [ 48 ] است.]، فعال سازی (به عنوان مثال، ReLU [ 49 ])، و 1 × 1 کانولوشن در یک ترتیب خاص. شاخه دیگر یک طرح مستقیم از ورودی E است. نقشه برداری باقیمانده اف(E)را می توان به صورت زیر محاسبه کرد:
جایی که ϕنشان دهنده عادی سازی لایه است. W 1 , W 2 , W 3 , b 1 , b 2 و b 3 مجموعه ای از وزن ها و بایاس ها برای بلوک باقیمانده هستند. به طور خاص، W 2 تابع وزن پیچیدگی علت گشاد شده با اندازه فیلتر g = 3 و فاکتورهای اتساع l = 1، 2، 4، 8 را نشان می دهد. W 1 و W 3 نشان دهنده تابع وزن پیچشی استاندارد 1×1 است.
نگاشت مورد نظر اکنون دوباره به آن تبدیل شده است اف(E)+Eبا افزودن عنصری این به طور موثر به لایهها اجازه میدهد تا تغییرات نقشهبرداری هویت را به جای کل تحول بیاموزند، که در ادبیات قبلی مفید بودن آن در شبکههای عمیقتر ثابت شده است [ 22 ، 33 ، 47 ]. در چارچوب خود، ما تأثیرات جغرافیایی و الگوهای دورهای زمانی را با مدلسازی اطلاعات مکانی و زمانی خاص میگیریم. بنابراین، ما باید دنباله فاصله جغرافیایی پیوسته و دنباله شناسه زمانی خاص را در شبکه خود ادغام کنیم. همانطور که در شکل 8 الف نشان داده شده است، ورودی ترتیب ورود Eایکس”توو شرایط مکانی و زمانی خاص (به عنوان مثال، Eاس”توو Eتی”تو) از طریق کانولوشن علّی متسع ذوب می شوند و با اتصالات پرش پارامتری شده در لایه اول جمع می شوند. نتیجه لایه اول ورودی در لایه کانولوشن متسع بعدی با یک اتصال باقیمانده از ورودی به خروجی کانولوشن است ( شکل 8 ب را ببینید). به جای اتصال باقیمانده استاندارد، ما از اتصال پرش پارامتری شده در لایه اول استفاده میکنیم و به صورت پویا پارامترهای وزن را تنظیم میکنیم تا اطمینان حاصل کنیم که مدل ما به درستی روابط لازم بین پیشبینی و هر دو ورودی ترتیب ورود و شرایط مکانی-زمانی خاص را استخراج میکند. شرطی شدن در دنباله فاصله جغرافیایی پیوسته Eاس”توو دنباله شناسه زمانی خاص Eتی”توبا محاسبه تابع فعال سازی کانولوشن در لایه اول به صورت زیر انجام می شود:
جایی که wایکس، wr، و wتیفیلتر کانولوشن قابل یادگیری هستند، ∗لنشان دهنده یک عملگر پیچیدگی و E نشان دهنده نتیجه همجوشی دنباله چند متغیره است.
3.6. آموزش لایه نهایی و شبکه
4. نتایج تجربی و تجزیه و تحلیل
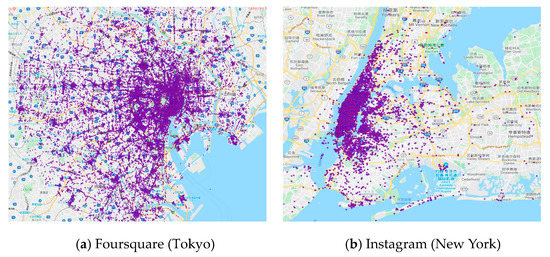
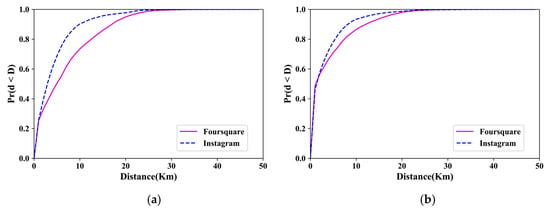
4.1. توصیف و تجزیه و تحلیل مجموعه داده ها
4.2. رویکردهای پایه
-
رتبهبندی شخصی بیزی (BPR): این کار معیار بهینهسازی عمومی BPR-OPT را ارائه میکند که از حداکثر تخمینگر خلفی برای رتبهبندی شخصیشده بهینه [ 51 ] مشتق شده است. BPR یک روش پایه کلاسیک برای توصیه عمومی POI است.
-
GRU: RNN برای کار توصیه POI موثر است، و ما یک توسعه RNN به نام GRU را برای گرفتن وابستگی طولانی مدت اعمال کردیم [ 52 ].
-
FPMC-LR: یک روش زنجیره مارکوف پیشرفته برای توصیه POI. این روش بر اساس زنجیره مارکوف مرتبه اول طراحی شده است و از همسایگان به عنوان نمونه های منفی استفاده می کند [ 18 ].
-
PRME-G: یک روش تعبیه متریک پیشرفته برای توصیه POI، و فاصله مکانی به عنوان وزن در نظر گرفته می شود [ 12 ].
-
Caser: یک روش استاندارد دو بعدی مبتنی بر CNN برای توصیههای متوالی top-N شخصی شده [ 45 ]، و ما Caser را در توصیه POI به کار بردیم.
-
Distance2Pre: یک مدل پیشرفته مبتنی بر GRU برای پیشبینی POI، که اولویت مکانی را با مدلسازی فواصل بین POIهای متوالی بدست میآورد [ 13 ].
-
ST-RNN: یک مدل مبتنی بر RNN پیشرفته برای توصیه POI [ 19 ]، که هر دو زمینه انتقال زمانی و مکانی محلی را در بر می گیرد.
4.3. معیارهای ارزیابی و تنظیم آزمایش
با بهترین دانش ما، Recall@ k ، F1-score@ k، و NDCG@ k (به ترتیب با R@ k ، F1@ k، و NDCG@ k مشخص میشوند ) سه معیار k بالا محبوب هستند که برای ارزیابی نتایج توصیههای POI استفاده میشوند. مانند [ 2 ، 8 ، 13 ، 19 ]. در این تحقیق سه معیار به صورت زیر فرموله شده است:
که در آن k تعداد POI های توصیه شده به کاربر را نشان می دهد. ما R@ k ، F1@ k، و NDCG@ k را با k = 5، 10، و 20 در آزمایشهای خود گزارش میکنیم. آرتو(ک)لیست Top- k توصیه شده به کاربر را نشان می دهد. تیتونشان دهنده تعداد POI هایی است که کاربر بازدید کرده است. rهلnارتباط n امین نقطه به کاربر را نشان می دهد. Yتوحداکثر مقدار DCG کاربر u را نشان می دهد.
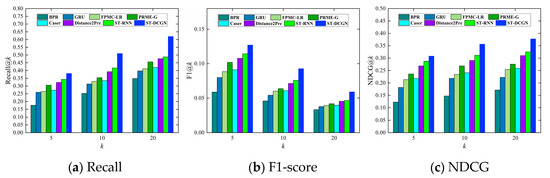
4.4. عملکرد توصیه
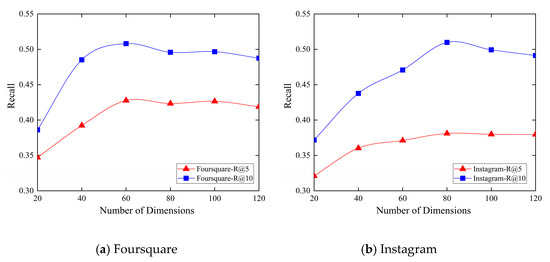
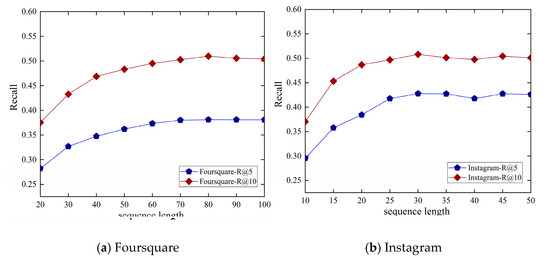
4.5. تجزیه و تحلیل حساس پارامترها
5. نتیجه گیری و کار آینده
منابع
- گائو، اچ. تانگ، جی. لیو، اچ. بررسی روابط اجتماعی-تاریخی در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات ششمین کنفرانس بین المللی AAAI در وبلاگ ها و رسانه های اجتماعی، دوبلین، ایرلند، 4 تا 7 ژوئن 2012. [ Google Scholar ]
- دینگ، آر. Chen, Z. RecNet: یک شبکه عصبی عمیق برای توصیه های شخصی شده POI در شبکه های اجتماعی مبتنی بر مکان. بین المللی جی. جئوگر. Inf. علمی 2018 ، 32 ، 1631-1648. [ Google Scholar ] [ CrossRef ]
- مجید، ع. چن، ال. چن، جی. میرزا، ح.ت. حسین، من. Woodward, J. یک سیستم توصیه مسافرتی شخصیشده آگاه از زمینه مبتنی بر دادهکاوی رسانههای اجتماعی دارای برچسب جغرافیایی. بین المللی جی. جئوگر. Inf. علمی 2018 ، 27 ، 662-684. [ Google Scholar ] [ CrossRef ]
- وان، ال. هونگ، ی. هوانگ، ز. پنگ، ایکس. Li, R. یک روش یادگیری گروه ترکیبی برای توصیههای مسیرهای توریستی بر اساس شبکههای اجتماعی برچسبگذاری شده جغرافیایی. بین المللی جی. جئوگر. Inf. علمی 2018 ، 32 ، 2225-2246. [ Google Scholar ] [ CrossRef ]
- لی، ایکس. کنگ، جی. لی، XL; فام، TAN; کریشناسوامی، S. Rank-geofm: یک روش فاکتورگیری جغرافیایی مبتنی بر رتبه بندی برای توصیه نقطه مورد علاقه. در مجموعه مقالات سی و هشتمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، سانتیاگو، شیلی، 9 تا 13 اوت 2015. صص 433-442. [ Google Scholar ]
- بله، م. یین، پی. لی، WC; لی، دیال. بهرهبرداری از نفوذ جغرافیایی برای توصیههای نقطهنظر مشترک. در مجموعه مقالات سی و چهارمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، پکن، چین، 24 تا 28 ژوئیه 2011. صص 325-334. [ Google Scholar ]
- یوان، Q. کنگ، جی. ما، ز. سان، ا. Thalmann، NM توصیه نقطه مورد علاقه آگاه از زمان. در مجموعه مقالات سی و ششمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، دوبلین، ایرلند، 28 ژوئیه تا 1 اوت 2013. صص 363-372. [ Google Scholar ]
- کای، ال. خو، جی. لیو، جی. Pei, T. ادغام زمینه های مکانی و زمانی در یک مدل فاکتورسازی برای توصیه POI. بین المللی جی. جئوگر. Inf. علمی 2018 ، 32 ، 524-546. [ Google Scholar ] [ CrossRef ]
- گان، م. Gao, L. کشف ترجیحات مبتنی بر حافظه برای توصیه POI در شبکه های اجتماعی مبتنی بر مکان. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 279. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- هوانگ، ال. ممکن است.؛ وانگ، اس. Liu, Y. یک شبکه LSTM فضایی-زمانی مبتنی بر توجه برای توصیه POI بعدی. IEEE Trans. خدمت محاسبه کنید. 2019 , 99 . [ Google Scholar ] [ CrossRef ]
- Tobler, WR یک فیلم کامپیوتری شبیه سازی رشد شهری در منطقه دیترویت. اقتصاد Geogr. 1970 ، 46 ، 234-240. [ Google Scholar ] [ CrossRef ]
- فنگ، اس. لی، ایکس. زنگ، ی. کنگ، جی. Chee, YM; یوان، Q. تعبیه متریک رتبه بندی شخصی برای توصیه POI جدید بعدی. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی مشترک هوش مصنوعی، بوئنوس آیرس، آرژانتین، 25 تا 31 ژوئیه 2015. [ Google Scholar ]
- کوی، کیو. تانگ، ی. وو، اس. وانگ، L. Distance2Pre: ترجیح فضایی شخصی برای پیشبینی نقطهی علاقه بعدی. در مجموعه مقالات کنفرانس اقیانوس آرام-آسیا در مورد کشف دانش و داده کاوی، ماکائو، چین، 14 تا 17 آوریل 2019؛ صص 289-301. [ Google Scholar ]
- گائو، اچ. تانگ، جی. هو، ایکس. لیو، اچ. بررسی اثرات زمانی برای توصیه مکان در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات هفتمین کنفرانس ACM در مورد سیستم های توصیه کننده، هنگ کنگ، چین، 12 تا 16 اکتبر 2013. صص 93-100. [ Google Scholar ]
- کفالاس، پ. مانولوپولوس، ی. یک سیستم توصیهگر فضایی-متن آگاه از زمان. کارشناس. سیستم Appl. 2017 ، 78 ، 396-406. [ Google Scholar ] [ CrossRef ]
- وانگ، دبلیو. یین، اچ. دو، X. نگوین، QVH؛ Zhou، X. TPM: یک مدل شخصی سازی شده زمانی برای توصیه اقلام فضایی. ACM Trans. هوشمند سیستم تکنولوژی 2018 ، 9 ، 1-25. [ Google Scholar ] [ CrossRef ]
- چنگ، سی. یانگ، اچ. کینگ، آی. لیو، MR فاکتورسازی ماتریس ذوب شده با نفوذ جغرافیایی و اجتماعی در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات بیست و ششمین کنفرانس AAAI در مورد هوش مصنوعی، تورنتو، ON، کانادا، 22 تا 26 ژوئیه 2012. [ Google Scholar ]
- چنگ، سی. یانگ، اچ. لیو، ام آر؛ King, I. جایی که دوست دارید در مرحله بعد بروید: توصیه نقطه مورد علاقه پی در پی. در مجموعه مقالات بیست و سومین کنفرانس مشترک بین المللی هوش مصنوعی، پکن، چین، 3 تا 19 اوت 2013. [ Google Scholar ]
- لیو، کیو. وو، اس. وانگ، ال. Tan, T. پیشبینی مکان بعدی: یک مدل تکرارشونده با زمینههای مکانی و زمانی. در مجموعه مقالات سیامین کنفرانس AAAI در مورد هوش مصنوعی، فینیکس، AZ، ایالات متحده آمریکا، 12 تا 17 فوریه 2016. [ Google Scholar ]
- ژائو، پی. زو، اچ. لیو، ی. لی، ز. خو، جی. شنگ، در مقابل کجا برویم بعدی: یک مدل LSTM فضایی-زمانی برای توصیه POI بعدی. arXiv 2018 , arXiv:1806.06671. [ Google Scholar ]
- لیو، سی. لیو، جی. وانگ، جی. خو، اس. هان، اچ. Chen, Y. یک شبکه واحد مکرر دردار مکانی-زمانی مبتنی بر توجه برای توصیه نقطه مورد علاقه. ISPRS Int. J. Geo Inf. 2019 ، 8 ، 355. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یوان، اف. کاراتزوگلو، ع. آراپاکیس، آی. خوزه، جی.ام. او، X. یک شبکه مولد کانولوشن ساده برای توصیه مورد بعدی. در مجموعه مقالات دوازدهمین کنفرانس بین المللی ACM در جستجوی وب و داده کاوی، ملبورن، استرالیا، 11 تا 15 فوریه 2019؛ صص 582-590. [ Google Scholar ]
- Oord، AVD; دیلمان، اس. ذن، اچ. سیمونیان، ک. وینیالز، او. گریوز، ا. کالچبرنر، ن. ارشد، ا. Kavukcuoglu، K. Wavenet: یک مدل تولیدی برای صدای خام. arXiv 2016 , arXiv:1609.03499. [ Google Scholar ]
- یانگ، دی. ژانگ، دی. ژنگ، فولکس واگن؛ Yu, Z. مدلسازی اولویت فعالیت کاربر با اعمال نفوذ ویژگیهای زمانی مکانی کاربر در LBSN. IEEE Trans. سیستم مرد سایبرن. سیستم 2014 ، 45 ، 129-142. [ Google Scholar ] [ CrossRef ]
- چانگ، بی. پارک، ی. پارک، دی. کیم، اس. Kang, J. مدل تعبیه سلسله مراتبی نقطه مورد علاقه محتوا آگاه برای توصیه های پی در پی POI. در مجموعه مقالات کمیته برنامه بیست و هفتمین کنفرانس بین المللی مشترک هوش مصنوعی، استکهلم، سوئد، 13 تا 19 ژوئیه 2019؛ صص 3301–3307. [ Google Scholar ]
- لیان، دی. ژائو، سی. Xie، X. سان، جی. چن، ای. Rui, Y. GeoMF: مدلسازی جغرافیایی مشترک و فاکتورسازی ماتریسی برای توصیه نقطهنظر. در مجموعه مقالات بیستمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، نیویورک، نیویورک، ایالات متحده آمریکا، 24 تا 27 اوت 2014. صص 831-840. [ Google Scholar ]
- کوراشیما، تی. ایواتا، تی. هوشیده، ت. تکایا، ن. مدل موضوعی فوجیمورا، K. Geo: مدلسازی مشترک حوزه فعالیت و علایق کاربر برای توصیه مکان. در مجموعه مقالات ششمین کنفرانس بین المللی ACM در جستجوی وب و داده کاوی، رم، ایتالیا، 4 تا 8 فوریه 2013. صص 375-384. [ Google Scholar ]
- ژانگ، جی دی. Chow، CY iGSLR: توصیه موقعیت جغرافیایی-اجتماعی شخصی: یک رویکرد تخمین چگالی هسته. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، اورلاندو، فلوریدا، ایالات متحده آمریکا، 5 تا 8 نوامبر 2013. صص 334-343. [ Google Scholar ]
- لی، اچ. Ge، Y. هونگ، آر. زو، اچ. توصیههای نقطهی علاقه: یادگیری ورود احتمالی از دوستان. در مجموعه مقالات بیست و دومین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، هتل هیلتون، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 13 تا 17 اوت 2016؛ ص 975-984. [ Google Scholar ]
- یانگ، دی. ژانگ، دی. یو، ز. Wang, Z. یک سیستم توصیه موقعیت مکانی شخصی سازی شده با احساسات. در مجموعه مقالات بیست و چهارمین کنفرانس ACM در مورد فرامتن و رسانه های اجتماعی، پاریس، فرانسه، 1-3 مه 2013. صص 119-128. [ Google Scholar ]
- متیو، دبلیو. راپوسو، آر. مارتینز، بی. پیشبینی مکانهای آینده با مدلهای پنهان مارکوف. در مجموعه مقالات کنفرانس ACM 2012 در محاسبات همه جا حاضر، پیتسبورگ، PA، ایالات متحده آمریکا، 5-8 سپتامبر 2012. ص 911-918. [ Google Scholar ]
- کریژفسکی، آ. سوتسکور، آی. هینتون، GE ImageNet طبقه بندی با شبکه های عصبی کانولوشن عمیق. Adv. عصبی Inf. Proc. سیستم 2012 ، 60 ، 1097-1105. [ Google Scholar ] [ CrossRef ]
- او، ک. ژانگ، ایکس. رن، اس. Sun, J. یادگیری باقیمانده عمیق برای تشخیص تصویر. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، 27-30 ژوئن 2016. صص 770-778. [ Google Scholar ]
- ایرسوی، او. Cardie, C. شبکه های عصبی بازگشتی عمیق برای ترکیب در زبان. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی سیستم های پردازش اطلاعات عصبی، مونترال، QC، کانادا، 8 تا 13 دسامبر 2014. ص 2096-2104. [ Google Scholar ]
- دونگ، ال. یانگ، ن. وانگ، دبلیو. وی، اف. لیو، ایکس. وانگ، ی. Hon, HW Unified Language Model Pre-training for Natural Language Understanding and Generation. arXiv 2019 ، arXiv:1905.03197. [ Google Scholar ]
- هینتون، جی. دنگ، ال. یو، دی. دال، جی. محمد، ع. جیتلی، ن. Sainath، T. شبکه های عصبی عمیق برای مدل سازی صوتی در تشخیص گفتار. سیگنال IEEE Proc. Mag. 2012 ، 29 ، 82-97. [ Google Scholar ] [ CrossRef ]
- عمودی، د. Ananthanarayanan، S. آنوبهای، آر. بای، جی. باتنبرگ، ای. کیس، سی. چن، جی. سخنرانی عمیق 2: تشخیص گفتار پایان به انتها به زبان انگلیسی و ماندارین. در مجموعه مقالات سی و سومین کنفرانس بین المللی کنفرانس بین المللی یادگیری ماشین، نیویورک، نیویورک، ایالات متحده آمریکا، 19 تا 24 ژوئن 2016؛ صص 173-182. [ Google Scholar ]
- ژانگ، اس. یائو، ال. سان، ا. Tay, Y. سیستم توصیهگر مبتنی بر یادگیری عمیق: نظرسنجی و دیدگاههای جدید. کامپیوتر ACM. Surv. 2019 ، 52 ، 5. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- میکولوف، تی. سوتسکور، آی. چن، ک. کورادو، جی اس. Dean, J. توزیع کلمات و عبارات و ترکیب آنها. در مجموعه مقالات بیست و ششمین کنفرانس بین المللی سیستم های پردازش اطلاعات عصبی، دریاچه تاهو، NV، ایالات متحده، 5-10 دسامبر 2013. صص 3111-3119. [ Google Scholar ]
- لیو، ایکس. لیو، ی. لی، ایکس. کاوش در زمینه مکانها برای توصیههای مکان شخصیشده. در مجموعه مقالات بیست و پنجمین کنفرانس مشترک بین المللی هوش مصنوعی، نیویورک، نیویورک، ایالات متحده آمریکا، 9 تا 15 ژوئیه 2016؛ صص 1188-1194. [ Google Scholar ]
- فنگ، اس. کنگ، جی. آن، ب. Chee, YM Poi2vec: نمایش نهفته جغرافیایی برای پیشبینی بازدیدکنندگان آینده. در مجموعه مقالات سی و یکمین کنفرانس AAAI در مورد هوش مصنوعی، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 فوریه 2017. [ Google Scholar ]
- کنگ، دی. Wu, F. HST-LSTM: یک شبکه حافظه بلند مدت کوتاه مدت مکانی-زمانی سلسله مراتبی برای پیش بینی مکان. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی مشترک هوش مصنوعی، استکهلم، سوئد، 13 تا 19 ژوئیه 2018؛ صص 2341–2347. [ Google Scholar ]
- فنگ، جی. لی، ی. ژانگ، سی. سان، اف. منگ، اف. گوا، ا. جین، دی دیپموو: پیشبینی تحرک انسان با شبکههای تکراری توجه. در مجموعه مقالات کنفرانس وب جهانی 2018 در وب جهانی، لیون، فرانسه، 23 تا 27 آوریل 2018؛ ص 1459-1468. [ Google Scholar ]
- وانگ، اس. وانگ، ی. تانگ، جی. شو، ک. رانگانات، اس. لیو، اچ. تصاویر شما چه چیزی را نشان میدهند: بهرهبرداری از محتوای بصری برای توصیههای مورد علاقه. در مجموعه مقالات بیست و ششمین کنفرانس بین المللی وب جهانی، پرت، استرالیا، 3 تا 7 آوریل 2017؛ صص 391-400. [ Google Scholar ]
- تانگ، جی. Wang, K. توصیه متوالی top-n شخصی شده از طریق جاسازی توالی کانولوشنال. در مجموعه مقالات یازدهمین کنفرانس بین المللی ACM در جستجوی وب و داده کاوی، لس آنجلس، کالیفرنیا، ایالات متحده آمریکا، 5 تا 9 فوریه 2018؛ صص 565-573. [ Google Scholar ]
- Oord، AVD; کالچبرنر، ن. Kavukcuoglu، K. Pixel شبکه های عصبی بازگشتی. arXiv 2016 , arXiv:1601.06759. [ Google Scholar ]
- او، ک. ژانگ، ایکس. رن، اس. Sun, J. نگاشت هویت در شبکه های باقیمانده عمیق. در کنفرانس اروپایی بینایی کامپیوتر. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر ; آمستردام، هلند، 11-14 اکتبر 2016، صفحات 630-645.
- Ba، JL; کیروس، جی آر. نرمال سازی لایه هینتون، جنرال الکتریک. arXiv 2016 , arXiv:1607.06450. [ Google Scholar ]
- نیر، وی. واحدهای خطی Hinton، GE Rectified ماشینهای محدود بولتزمن را بهبود میبخشند. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی یادگیری ماشین، حیفا، اسرائیل، 21 تا 24 ژوئن 2010. ص 807-814. [ Google Scholar ]
- ژان، اس. چو، ک. میمیشویچ، آر. Bengio، Y. در مورد استفاده از واژگان هدف بسیار بزرگ برای ترجمه ماشین عصبی. arXiv 2014 ، arXiv:1412.2007. [ Google Scholar ]
- رندل، اس. فرودنتالر، سی. گانتنر، ز. اشمیت-تیمه، L. BPR: رتبه بندی شخصی بیزی از بازخورد ضمنی. در مجموعه مقالات بیست و پنجمین کنفرانس عدم قطعیت در هوش مصنوعی، مونترال، QC، کانادا، 18-21 ژوئن 2009. ص 452-461. [ Google Scholar ]
- چو، ک. ون مرینبور، بی. گلچهره، سی. بهداناو، د. بوگارس، اف. شونک، اچ. Bengio، Y. آموزش نمایش عبارات با استفاده از رمزگذار-رمزگشا RNN برای ترجمه ماشینی آماری. arXiv 2014 ، arXiv:1406.1078. [ Google Scholar ]
- آیالا گومز، اف. داروچی، BZ; ماتیوداکیس، م. بنزور، آ. Gionis، A. کجا می توانیم برویم؟ توصیه هایی برای گروه ها در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات کنفرانس ACM 2017 در علوم وب، تروی، نیویورک، ایالات متحده آمریکا، 25 تا 28 ژوئن 2017؛ صص 93-102. [ Google Scholar ]
- رندل، اس. ژانگ، ال. کورن، ی. در مورد دشواری ارزیابی خطوط پایه: مطالعه ای در مورد سیستم های توصیه کننده. arXiv 2019 , arXiv:1905.01395. [ Google Scholar ]



بدون دیدگاه