1. مقدمه
در سال های اخیر، فناوری پیش بینی جرم مکانی – زمانی به سرعت توسعه یافته است. با استخراج داده هایی که شامل تعداد حوادث جرم، تراکم جمعیت، متغیرهای آب و هوا و غیره می شود، الگوهای مکانی-زمانی حمله، سرقت، سرقت، یا انواع دیگر جنایات را می توان با کمک یادگیری ماشینی (به ویژه یادگیری عمیق) پیش بینی کرد. روش های دیگر [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8]. از قبل ارجاعات و پیش بینی هایی را در مورد زمان و مکان کانون جرم برای پلیس ارائه می کند، بنابراین به پیشگیری از جرم و همچنین تخصیص بهتر منابع پلیس کمک می کند. با توجه به عملی بودن، دقت پیشبینی جرم را میتوان مهمترین شاخص دانست.
به منظور ایجاد مدلهای دقیق پیشبینی جرم مکانی – زمانی، ماشین بردار پشتیبان (SVM)، جنگل تصادفی (RF) و سایر الگوریتمهای یادگیری ماشین برای پیشبینی توزیعهای مکانی و زمانی انواع مختلف جرایم به کار گرفته شدند. به عنوان مثال، Ingilevich و Ivanov [ 9 ] یک مطالعه مقایسه ای در مورد سه مدل پیش بینی (رگرسیون خطی، رگرسیون لجستیک و تقویت گرادیان) انجام دادند و اشاره کردند که دقت مدل تقویت گرادیان (که یک مدل یادگیری ماشین معمولی است) بسیار است. بالاتر از دو مدل دیگر مبتنی بر آمار است. یو و همکاران [ 10] یک روش ST-cokriging جدید برای پیشبینی جرم در مقیاسهای هفتگی، دوهفتهای و چهار هفتهای پیشنهاد کرد و نتایج اعتبارسنجی نشان داد که حداقل ریشه میانگین مربعات خطا (RMSE = 0.145) در مقیاس هفتگی است. در مقایسه با پیشبینی مکانی-زمانی، پیشبینی سری زمانی جرم توسط محققان بیشتری با استفاده از چارچوبهای یادگیری ماشین مورد مطالعه قرار گرفته است. دش و همکاران [ 11 ] از دادههای مختلف شهر عمومی برای پیشبینی سریهای زمانی تعداد حوادث جنایی شیکاگو در ایالات متحده استفاده کرد و گزارش داد که عملکرد پیشبینی رگرسیون بردار پشتیبان بالاتر از روشهای چند جملهای و خود رگرسیون است. چن و همکاران [ 12] از روش ماشین بردار پشتیبان مبتنی بر دانه بندی اطلاعات فازی برای تحلیل و پیش بینی نرخ جرم و جنایت در یکی از شهرهای چین استفاده کرد و نتایج نشان داد که دقت این مدل بسیار بهتر از ARIMA است. Pillai [ 13 ] مدلهای
یادگیری ماشینی تقویت گرادیان شدید (XGBoost)، جنگل تصادفی و غیره را برای پیشبینی تخلفات و جرایم مواد مخدر در شیکاگو اتخاذ کرد و دریافت که XGBoost با بالاترین R
2 از همه مدلهای دیگر بهتر عمل کرد.ارزش 88% و ارزش RMSE 2.57 نسبت به حوادث جنایی. به طور کلی، روشهای مبتنی بر یادگیری ماشینی در پیشبینی سریهای زمانی موفقتر از پیشبینیهای مکانی-زمانی جرایم هستند. یکی از مهم ترین کاستی ها ممکن است ناکافی بودن توانایی استخراج ویژگی های فضایی این مدل ها باشد.
در دهههای گذشته، شبکههای عصبی عمیق به یک رویکرد پربار برای رسیدگی به مشکلات مهندسی ویژگیهای پیچیده با ظرفیت خودآموز قدرتمند تبدیل شدند. شبکههای عصبی عمیق تحریک شدهاند و به طور گسترده در زمینههای بینایی کامپیوتری اعمال شدهاند [ 14 ، 15 ]. با یادگیری عمیق، ویژگیهای پیچیده مکانی-زمانی جنایات را میتوان برای پیشبینی الگوهای آتی جنایات بهکار گرفت. لی و همکاران [ 16 ] با استفاده از شبکههای عصبی پس انتشار (BP) و الگوریتمهای ژنتیک، تعداد رویدادهای جرم مالکیت سالانه یک شهر (با وضوح فضایی 100 متر × 100 متر) را که در جنوب چین واقع شده است، پیشبینی کرد. ژانگ و همکاران [ 17] پیشبینی ساعتی الگوهای جرم و جنایت در شهر سوژو در چین را بر اساس مدل شبکههای باقیمانده مکانی-زمانی (ST-ResNet) مورد مطالعه قرار داد: یک روش تفکیک مکانی تطبیقی برای یافتن بهترین وضوح مکانی برای پیشبینی خطر جرم پیشنهاد شد، و نتایج نشان داد که وضوح فضایی 2.4 کیلومتری میتواند بهترین عملکرد را برای پیشبینی جرم به دست آورد (RMSE = 7.81). کیان و همکاران [ 18 ] مدل GeST را بر اساس تقسیم شبکه برای پیشبینی تعداد جرایم سرقت در شهر نیویورک از سال 2011 تا 2018 ایجاد کرد: نتیجه آزمایشی روی مجموعه آزمایشی بهتر از مدلهای ARIMA، LSTM و دیگر بود. ژانگ و همکاران [ 19] با استفاده از الگوریتم شبکه عصبی BP، یک روش مدلسازی بهینهسازی جدید برای پیشبینی جرم را بر اساس مفهوم مدیریت شبکه طراحی کرد که با دادههای چهار جرم مختلف در شیکاگو تأیید شد و نتایج نشان داد که RMSE این روش تقریباً کاهش یافته است. به طور متوسط 9٪ در مقایسه با مدل های سنتی بدون مش. هان و همکاران [ 20 ] یک مدل یکپارچه از پیشبینی جرم را با ترکیب LSTM با ST-GCN برای پیشبینی خطر جرم مکانی – زمانی جوامع شهری در شیکاگو پیشنهاد کرد، و نتیجه نشان داد که این مدل با مثالهای عملی تأیید شده و به پیشبینی برتری دست یافته است. مدلهای ریج، جنگل تصادفی و LSTM.
همانطور که در مقالات قبلی گزارش شده است، به نظر می رسد روش های یادگیری عمیق برای پیش بینی جرم مکانی-زمانی مناسب تر از الگوریتم های یادگیری ماشین سنتی هستند. با این حال، برای اهداف حمایت از تصمیم گیری برای پلیس، هنوز سه شکاف اصلی وجود دارد. اولاً، بیشتر مطالعات قبلی به دلیل دقت ناکافی مدلها، بر مقیاسهای سالانه، ماهانه یا هفتگی به جای مقیاس روزانه متمرکز بودند. چند مطالعه بر مقیاس روزانه (حتی ساعتی) متمرکز شدند، اما معمولاً خطاهای نسبتاً بزرگتری از نظر RMSE یا MAPE به دست آوردند [ 9 ، 10 ، 16 ، 17 ، 18 ، 19 ، 20]. با توجه به بازرسی امنیتی و گشت زنی، و همچنین سایر مشاغل مرتبط، پلیس ممکن است علاقه بیشتری به نتایج موثر پیش بینی جرم روزانه داشته باشد. ثانیا، تعداد قابل توجهی از مطالعات مبتنی بر شبکههای مکانی-زمانی منظم برای تقسیمبندی فضایی [ 9 ، 16 ، 17 ، 18 ، 19 است]، اما این با حوزه های اداری واقعی ناسازگار است. به طور کلی، راهبردهای پلیسی باید در همان حوزه اداری (مانند جامعه یا ناحیه پلیس) سازگار باشد. به عنوان یک عنصر جبران خطر، ممکن است بر توزیع مکانی – زمانی جرایم تأثیر بگذارد. بنابراین، چارچوبهای یادگیری عمیق مبتنی بر شبکه ممکن است از نظر پیشبینی جرم مکانی-زمانی دقت محدودی داشته باشند. ثالثاً، مدلهای پیشبینی جرم مکانی-زمانی نیز باید به راحتی و امکانسنجی توجه کنند. با این حال، بیشتر اتصالات ماژول های مدل های حاضر “آفلاین” هستند، به این معنی که ماژول پیش بینی مکانی و ماژول پیش بینی زمانی از هم جدا هستند، نه “آنلاین”. این ممکن است بر راحتی آن در کاربردهای عملی تأثیر بگذارد.
برای رفع این کاستی ها، یک مدل نمودار یکپارچه “آنلاین” بر اساس مکانیسم توجه برای پیش بینی جرم مکانی-زمانی در این مطالعه پیشنهاد شده است. این مدل یک شبکه عصبی باقیمانده (ResNet)، شبکه کانولوشن گراف (GCN) و LSTM را برای استخراج ویژگیهای مکانی-زمانی از دادههای جرم ترکیب میکند. علاوه بر این، رابطه توپولوژیکی بین مناطق مختلف شهری نیز گرفته شده است و مکانیسم توجه در این مدل گنجانده شده است. توزیع احتمال توجه می تواند وزن بالایی به اطلاعات حیاتی بدهد در حالی که اطلاعات نامربوط را در مدل پیشنهادی رد می کند. در نهایت، ترکیب ویژگی ها از طریق محاسبه وزنی ویژگی های متعدد تکمیل می شود. در همین حال، مشکل “آفلاین” نیز حل شده است. برای اعتبارسنجی این مدل نمودار یکپارچه «آنلاین»، داده های سرقت و حمله روزانه در مقیاس ناحیه پلیس شهر شیکاگو در ایالات متحده از 1 ژانویه 2015 تا 7 ژانویه 2020 استفاده می شود. برای ارزیابی کمی این مدل از شاخصهای میانگین خطای مطلق (MAE) و RMSE استفاده میشود. علاوه بر این، تحلیل تطبیقی نیز در این مطالعه با هشت مدل دیگر به کار رفته در مطالعات قبلی انجام شده است.
بقیه این مقاله به شرح زیر سازماندهی شده است. بخش 2 منطقه مورد بررسی را توصیف می کند. داده های مورد استفاده برای اعتبارسنجی مدل را ارائه می دهد. الگوریتم پیشبینی جرم مکانی – زمانی و طرحهای اعتبارسنجی را شرح میدهد. بخش 3 در مورد نتایج و بحث های پیش بینی است. در نهایت، بخش 4 مشارکت های اصلی ما را خلاصه می کند و مجموعه ای از توصیه ها را برای مطالعه بیشتر ارائه می کند.
2. مواد و روشها
2.1. منطقه مطالعه و توصیف داده ها
شهر شیکاگو به عنوان منطقه مورد بررسی انتخاب شد. این شهر پرجمعیت ترین شهر ایلینویز و سومین شهر بزرگ ایالات متحده پس از نیویورک و لس آنجلس است. تا پایان سال 2020، جمعیت تخمینی شیکاگو 2,746,388 نفر است (منبع: https://www.census.gov/، قابل دسترسی در 1 اکتبر 2020). شیکاگو در مرکز قاره آمریکای شمالی قرار دارد و یکی از مهم ترین مراکز مالی بین المللی است. شیکاگو به عنوان یک شهر بزرگ معمولی از تعداد زیادی جرایم از جمله انواع حمله، سرقت، سرقت و غیره رنج می برد، بنابراین برای اعتبارسنجی مدل های پیش بینی جرم بسیار مناسب است. تعدادی از مطالعات قبلی نیز این شهر را برای تأیید روشهای پیشبینی جرم پیشنهادی خود انتخاب کردند که میتواند مقایسههایی را برای این تحقیق فراهم کند.
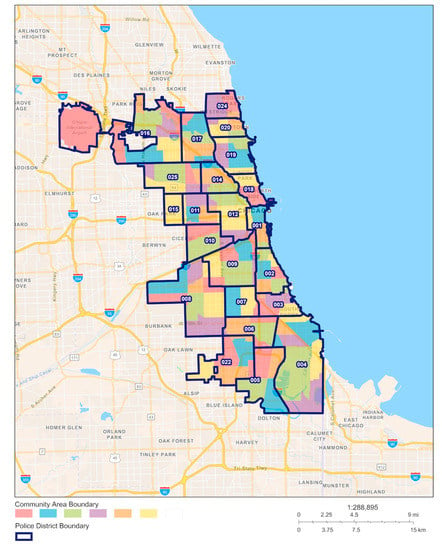
این شهر دارای 22 ناحیه پلیس است که با 77 جامعه همپوشانی دارند (همانطور که در شکل 1 نشان داده شده است ). در برخی از مناطق پلیس، یک پاسگاه پلیس ممکن است به چندین جامعه خدمات رسانی کند، در حالی که ممکن است یک جامعه تحت پوشش بیش از یک ناحیه پلیس باشد. به عنوان کوچکترین سلول یک شهر، جامعه معمولاً به عنوان واحد فضایی برای پیش بینی الگوهای مکانی-زمانی جرم در مطالعات قبلی انتخاب می شود [ 6 ، 20 ، 21 ، 22 ، 23 .]. با این حال، در این مطالعه، مناطق فضایی توسط مناطق پلیس تقسیم شده است. همانطور که مشخص است، خطر جرم نه تنها تحت تأثیر تراکم جمعیت، محیط ترافیک، سطح اقتصادی و غیره است، بلکه به طور قابل توجهی تحت تأثیر کار پلیس (مانند گشت زنی، بازرسی امنیتی و غیره) است که باید به عنوان یک عامل جبران خطر غیر قابل چشم پوشی در نظر گرفته می شود. در همان ناحیه پلیس، استراتژی پلیس معمولاً دارای همگنی فضایی است. در مقابل، راهبردها ممکن است بین مناطق مختلف پلیس متفاوت باشد به طوری که تأثیرات پلیس بر خطرات جرم ممکن است کاملاً متفاوت باشد. به همین دلیل است که ما مناطق پلیس (به جای جوامع) را برای تقسیم فضایی شهر انتخاب کردیم. دلیل دیگر این است که پیشبینی جرم مکانی – زمانی منجر به یک ناحیه پلیسی خاص میشود که میتواند مستقیماً برای حمایت از تصمیمگیری با توجه به تخصیص منابع پلیس در این منطقه اعمال شود. همانطور که در نشان داده شده استدر شکل 1 ، 22 ناحیه پلیس شیکاگو از 1 تا 25 شماره گذاری شده اند، به استثنای 13، 21، و 23، که در آن، بزرگترین و کوچکترین ناحیه پلیس به ترتیب دارای مساحت 816.6 کیلومتر مربع و 79.9 کیلومتر مربع هستند .
مجموعه داده مورد استفاده برای آموزش و آزمایش مدل ایجاد شده از پورتال داده باز شیکاگو ( https://data.cityofchicago.org/ ) مشتق شده است.، قابل دسترسی در 1 اکتبر 2020)، که یک
پلت فرم جستجو و اکتشاف داده در دسترس عموم است که توسط مرکز شهری دانشگاه شیکاگو برای محاسبات و داده ها توسعه یافته (و در حال حاضر مدیریت می شود). دادههای جرم از مجموعه داده «Crimes-2001 to present» جمعآوری شد، مجموعهای واقعی از نمونههایی که رویدادهای جرم و جنایت در شیکاگو را از سال 2001 تا کنون توصیف میکند و در آن مخزن هر هفته بهروزرسانی میشود. از مجموعه داده «جنایت-2001 تا کنون»، ما اعداد حوادث سرقت (به عنوان یکی از جرایم مالکیت معمولی) و حمله (به عنوان یکی از جرایم خشونتآمیز معمول) را در 22 ناحیه پلیس طی پنج سال (1833 روز) از 1 جمعآوری کردیم. ژانویه 2015، تا 7 ژانویه 2020. در مرحله پیش پردازش داده، داده های از دست رفته حذف شدند، و تعداد حوادث سرقت و حمله در 22 منطقه پلیس شیکاگو در مقیاس روزانه شمارش شد. در مجموع 404269 قطعه داده معتبر شامل 308020 قطعه داده سرقت و 96249 قطعه داده حمله به دست آمد.شکل 2 توزیع زمانی تعداد حوادث سرقت و حمله را در 22 ناحیه پلیس شیکاگو نشان می دهد. همانطور که در شکل 2 نشان داده شده است ، تغییرات فصلی و روزانه دزدی و حمله قابل مشاهده است.
شکل 3 الگوهای فضایی تعداد حوادث سرقت و حمله در شیکاگو را نشان می دهد. حوادث سرقت در شیکاگو عمدتاً در مناطق شمال شرقی متمرکز است، در حالی که حوادث حمله با مناطق گرم در جنوب شرقی نشان داده می شود. بر اساس این رقم، تعداد سرقت های انباشته در حوزه هجدهم پولیس به حدود 30000 می رسد که نسبت به سایر ولسوالی ها بسیار بیشتر است که نشان می دهد سرقت از تجمع فضایی قابل توجهی برخوردار است. آمار توصیفی اعداد وقایع سرقت و حمله در حوزه های 22 گانه پلیس در جدول A1 آمده است.. تعداد حوادث سرقت (M = 18.754، SD = 7.397) بیشتر از حوادث حمله است (M = 1.939، SD = 1.472). در اینجا، M مقدار میانگین تعداد حوادث جرم است، و SD انحراف معیار تعداد حوادث جرم را نشان می دهد.
نمودار توپولوژیکی 22 ناحیه پلیس در شیکاگو نیز برای آموزش مدل مورد استفاده قرار گرفت. با توجه به رابطه همسایگی بین مناطق پلیس شیکاگو، نقشه توپولوژیکی مناطق پلیس مجاور همانطور که در شکل 4 نشان داده شده است به دست آمده است .
مطالعات قبلی نشان داد که علاوه بر ویژگیهای مکانی-زمانی جرایم، متغیرهای آب و هوا نیز به عنوان ویژگیهای خارجی برای ساختن مدلهای پیشبینی جرم یادگیری عمیق استفاده میشوند [ 20 ، 22 ، 24 ، 25 ، 26 ]. دلیل آن این است که ثابت شده است که دما و رطوبت نسبی با برخی از انواع جرایم، از جمله حمله، سرقت، سرقت، تجاوز جنسی و غیره رابطه دارند [ 27 ، 28 ، 29 ]. شاخص های تنش گرمایی به خوبی می توانند ترکیبی از تأثیرات دما و رطوبت نسبی را بر میزان جرم و جنایت نشان دهند. بنابراین، ما شاخص ناراحتی استرس گرمایی (DI) را انتخاب کردیم [ 20 ، 27، 28 ] به عنوان یکی از ویژگی های خارجی، و شرح DI در پیوست B ارائه شده است. به غیر از DI، ویژگیهای «آخر هفته» و «تعطیلات» نیز به عنوان ویژگیهای خارجی اعمال شدند. توضیحات این ویژگی ها در جدول 1 آمده است.
2.2. چارچوب مدل
در این مطالعه، یک مدل نمودار یکپارچه مبتنی بر مکانیسم توجه برای پیشبینی جرم مکانی-زمانی ایجاد شد که میتواند ویژگیهای مکانی-زمانی اعداد وقایع جرم را استخراج کرده و آنها را با ویژگیهای خارجی ترکیب کند. معماری مدل پیشنهادی در شکل 5 ارائه شده است. این مدل شامل دو ماژول بود: (1) ماژول استخراج ویژگیهای مکانی-زمانی و (ب) ماژول ترکیب ویژگی و آموزش. در ماژول استخراج ویژگی، ویژگیهای مکانی – زمانی جرایم، ویژگیهای توپولوژیکی حوزههای پلیس و ویژگیهای خارجی مانند «DI»، «تعطیلات» و غیره از دادهها استخراج شد. در ماژول ادغام ویژگی و آموزش، همه ویژگی ها در توجه LSTM ادغام شدند تا یک مدل آموزش دیده را تشکیل دهند. در نهایت، از مجموعه دادههای آزمون برای ارزیابی عملکرد پیشبینی مدل استفاده شد و نتایج با استفاده از همان مجموعه آزمون با نتایج سایر الگوریتمها مقایسه شد.
2.2.1. ماژول استخراج ویژگی های مکانی-زمانی
برای ایجاد ماژول استخراج ویژگیهای مکانی-زمانی، از شبکههای عصبی باقیمانده عمیق (ResNet) استفاده شد. ResNet اولین بار در سال 2015 توسط He et al. [ 30 ] برای حل ناپدید شدن گرادیان، انفجار گرادیان، تخریب شبکه، و سایر مشکلات پیچیده ناشی از افزایش تعداد لایهها در شبکه عصبی کانولوشنال (CNN). ResNet یک پشته از “بلوک های باقیمانده” است که در شکل 6 نشان داده شده است. همانطور که در پانل (a) نشان داده شده است، x نشان دهنده ورودی بلوک باقیمانده، F(x) + x خروجی، لایه وزنی یک لایه پیچشی است، و واحد خطی اصلاح شده (ReLU) نشان دهنده یک لایه فعال سازی است [ 31 ].
در این مطالعه، یک بلوک باقیمانده بهبود یافته برای افزایش سرعت تمرین و همچنین دقت اتخاذ شد که در پانل سمت راست شکل 6 نشان داده شده است [ 32 ].]. بلوک باقیمانده بهبود یافته، نرمال سازی دسته ای (BN) و ReLU را در جلوی لایه کانولوشن (Conv) تنظیم می کند. BN برای استانداردسازی داده ها استفاده می شود که می تواند به طور قابل توجهی همگرایی آموزش شبکه را تسریع کند. با وارد کردن داده های پردازش شده در ReLU برای فعال سازی، پراکندگی شبکه و رابطه غیرخطی بین لایه ها را می توان افزایش داد. در همین حال، تأثیر مشکل بیش از حد برازش قابل کاهش است. داده های فعال شده برای استخراج ویژگی به لایه Conv تبدیل شدند. با افزودن یک لایه حذفی بین لایههای Conv، احتمال اضافه شدن شبکه را میتوان کاهش داد. علاوه بر این، سه ویژگی اصلی برای دریافت ویژگیهای مکانی-زمانی از دادههای جرم طراحی شد، از جمله ویژگیهای نزدیکی، ویژگیهای دورهای و ویژگیهای روند [ 17 ،20 ، 26 ، 33 ]. به طور خاص، برای پیشبینی الگوی جرم در یک روز معین، تعداد وقوع جرم روزانه سه روز قبل به عنوان ویژگی نزدیکی استخراج شد. تعداد حوادث جرم روزانه در روزهای هفتم، چهاردهم و بیست و یکمین روز قبل از روز به عنوان ویژگی های دوره ای استخراج شد و تعداد حوادث جرم روزانه در تاریخ های مربوطه در سه سال گذشته به عنوان روند استخراج شد. امکانات. داده های جرم و جنایت فوق در دو واحد باقیمانده بهبود یافته وارد شد و از یک لایه اتصال کامل برای اتصال به ماژول بعدی استفاده شد.
رویدادهای جنایی در یک ولسوالی خاص نه تنها از نظر زمانی با تعداد رویدادهای جنایی در گذشته مرتبط است، بلکه از نظر فضایی نیز تحت تأثیر ولسوالی های اطراف آن قرار دارد. در این مطالعه، شبکه کانولوشن گراف برای دریافت وابستگی توپولوژی شبکه و توصیف همبستگی فضایی جرایم با دقت بیشتری استفاده شد [ 34 ]. انتشار رو به جلو GCN به صورت زیر محاسبه می شود:
که در آن X ماتریس ویژگی است، A ماتریس مجاورت گراف است، آیا ماتریس مجاورت با خود گردشی اضافه شده است، D ماتریس درجه است، و W و b به ترتیب ماتریس وزن و بایاس هستند [ 35 ، 36 ، 37 ]. در این مقاله، ResNet به عنوان حامل GCN برای ساخت شبکه انتخاب شد و ویژگی های توپولوژیکی به لایه GCN و دو واحد باقیمانده بهبود یافته وارد شد. علاوه بر این، یک لایه اتصال کامل برای اتصال ماژول فیوژن ویژگی استفاده شد. در مورد ویژگی های خارجی، داده های پردازش شده در دو لایه LSTM وارد شدند و یک لایه اتصال کامل نیز برای انتقال نتایج به ماژول بعدی استفاده شد.
2.2.2. ویژگی فیوژن و ماژول آموزشی
در مقایسه با مدل شبکه عصبی بازگشتی سنتی (RNN)، LSTM واحدهای حافظه را به هر واحد عصبی لایه پنهان اضافه می کند تا اطلاعات حافظه قابل کنترل در سری های زمانی را به دست آورد [ 38 ، 39 ، 40 ]. با این حال، هنگام مقابله با دادههای چند بعدی و چند متغیره عظیم، مدل LSTM ممکن است برخی از اطلاعات سری زمانی حیاتی را در استفاده عملی نادیده بگیرد و در نتیجه عملکرد ضعیفی داشته باشد. بنابراین، ما مکانیسم توجه مبتنی بر LSTM را برای ترکیب ویژگیها اتخاذ کردیم. این روش میتواند محدودیت معماری رمزگشای رمزگشا و نمایش داخلی با طول ثابت را بشکند. مکانیسم توجه می تواند برای شبیه سازی مکانیسم توجه مغز انسان استفاده شود [ 41 ، 42]. توجه LSTM حالت های میانی رمزگذار LSTM را حفظ می کند و به طور انتخابی این حالت های میانی را از طریق مدل آموزشی یاد می گیرد. مدل LSTM می تواند با مکانیسم توجه ترکیب شود تا وزن های متفاوتی به ویژگی های ورودی LSTM بدهد و ویژگی های تأثیرگذار حیاتی را بدون افزایش هزینه های محاسباتی و ذخیره سازی مدل برجسته کند و به LSTM کمک کند تا قضاوت دقیق تری داشته باشد [ 43 ]. اجازه دهید ماتریس X ∈ R m × n خروجی LSTM باشد، جایی که m مراحل زمانی است، و n نشان دهنده تعداد ویژگی ها در هر مرحله زمانی است. سپس، فرمولبندی ریاضی خروجی مبتنی بر توجه ( O Attention) به شرح زیر ارائه می شود:
که در آن A یک ماتریس وزن با همان شکل X است، ” نشان دهنده محصول هادامارد، f نشان دهنده لایه کاملا متصل، و W و b به ترتیب نشان دهنده ماتریس وزن و بایاس هستند [ 44 ]. در این ماژول، ترکیب ویژگی ها از طریق محاسبه وزنی ویژگی های متعدد تکمیل شد. ماژول پیشبینی مکانی و ماژول پیشبینی زمانی در مدل پیشنهادی از هم جدا نشدند. بنابراین، مشکل “آفلاین” نیز حل شد. نتایج حاصل از ماژول استخراج ویژگیهای مکانی-زمانی به LSTM توجه وارد شد، که توسط یک لایه کاملاً متصل دیگر برای خروجی نتایج نهایی دنبال شد.
2.3. مطالعه موردی
2.3.1. پیکربندی مدل
مدل پیشنهادی توسط Keras و TensorFlow پیاده سازی شد. سخت افزار سیستم سرور مورد استفاده ما شامل یک CPU با دو هسته (Intel Xeon E5 Core *20)، چهار پردازنده گرافیکی (Nvidia Tesla P100 16GB)، چهار ماژول حافظه (Kingston 64GB 2666MHz) و سه هارد دیسک (4TB) بود. برای آموزش این مدل از داده های سرقت و حمله از 1 ژانویه 2015 تا 31 دسامبر 2019 استفاده شد و از داده های حادثه از 1 ژانویه تا 7 ژانویه 2020 به عنوان مجموعه آزمایشی استفاده شد. نرخ تقسیم اعتبار 0.2 برای کالیبره کردن مدل تنظیم شد. ابعاد تانسورهای جاری در مدل پیشنهادی در شکل 7 نشان داده شده است. از نظر بخش پردازش داده های جرم، اولین بلوک باقیمانده در ماژول استخراج ویژگی های مکانی-زمانی دارای 32 فیلتر بود، در حالی که بلوک دوم دارای 64 فیلتر بود. اندازه هسته 3×3 بود و لایه کاملاً متصل از 22 نورون تشکیل شده بود. بخش پردازش ویژگی های توپولوژیکی ابتدا از یک لایه GCN عبور کرد و سپس پیکربندی باقیمانده مانند قسمت پردازش داده های جرم بود. دو بلوک باقیمانده به ترتیب دارای 32 و 64 فیلتر بودند. اندازه هسته 3×3 بود و لایه کاملاً متصل از 22 نورون در آن مورد تشکیل شده بود. در مورد بخش پردازش داده های خارجی، دو لایه LSTM به ترتیب شامل 128 و 276 نورون بودند و لایه های کاملاً متصل شامل 22 نورون بودند. برای فیوژن ویژگی و ماژول آموزشی، LSTM توجه و لایه های کاملاً متصل نهایی شامل 128 و 22 نورون بود. به ترتیب. علاوه بر این، ما آموزش سرتاسری را برای بهینه سازی مدل اتخاذ کردیم. میانگین مربعات خطا (MSE) به عنوان تابع ضرر استفاده شد. بهینه ساز “NAdam” با نرخ یادگیری 0.001 بود.
2.3.2. مدل های پایه
در این مطالعه، هشت الگوریتم با مدل ما برای تأیید عملکرد آن مقایسه شد، از جمله ARMIA [ 45 ]، رگرسیون پشته [ 46 ]، رگرسیون بردار پشتیبان (SVR) [ 47 ]، جنگل تصادفی [ 48 ]، XGBoost [ 49 ]، LSTM [ 50 ]، CNN [ 51 ] و Conv-LSTM [ 52 ]. تنظیمات خاص در جدول 2 نشان داده شده است.
2.4. معیارهای ارزیابی
برای ارزیابی عملکرد پیشبینی مدل پیشنهادی، از MAE و RMSE به عنوان معیارهای ارزیابی استفاده شد. فرمول ریاضی MAE و RMSE به شرح زیر است:
جایی که مقدار مشاهده شده است، مقدار پیش بینی شده است و n اعداد نمونه پیش بینی شده است. مقدار کوچکتر MAE و RMSE نشان دهنده دقت پیش بینی بالاتر مدل است [ 53 ، 54 ]. در این مطالعه، 9 مدل پیشبینی بر اساس مجموعه دادههای مشابه آموزش و آزمایش شدند.

3. نتایج و بحث
برای تجزیه و تحلیل نتایج تجربی و ارزیابی عملکرد مدل پیشنهادی، دادهها در 22 ناحیه پلیس از 1 ژانویه 2020 تا 7 ژانویه 2020 (7 روز) برای ساخت مجموعه آزمایشی انتخاب شدند. شکل 8 (برای سرقت) و شکل 9 (برای حمله) الگوهای فضایی حوادث جرم مشاهده شده، پیش بینی اعداد وقایع جرم و خطای مطلق (AE) را در سه روز نمایندگی (یعنی 1، 4، و 6 ژانویه 2020) نشان می دهد. و همچنین مقادیر تجمعی از 1 تا 7 ژانویه 2020. در بین سه روز انتخاب شده، 1 ژانویه 2020 تعطیل است، 4 ژانویه 2020 یک روز هفته و 6 ژانویه 2020 یک تعطیلات آخر هفته است.
همانطور که در شکل 8 نشان داده شده استالگوهای پیشبینیشده سرقت بسیار نزدیک به توزیعهای واقعی هستند و همانطور که در نقشهها نشان داده شده است، مدل پیشنهادی نه تنها در سه روز انتخابشده بلکه برای نتایج انباشته شده بهطور دقیق مناطق داغ فضایی سرقت را به تصویر میکشد. به طور خاص، در 1 ژانویه 2020، منطقه 1 دارای حداکثر AE (2.57) در بین 22 ناحیه پلیس است. در 4 ژانویه 2020 و 6 ژانویه 2020، منطقه 19 شاهد حداکثر AE به ترتیب 2.80 و 4.87 است. علاوه بر این، منطقه 19 همچنین دارای حداکثر AE (24.81) برای مقادیر تجمعی است. از نظر 22 ناحیه پلیس، میانگین AE در 1 ژانویه 2020، 4 ژانویه 2020، 6 ژانویه 2020 و انباشت هفت روزه 1.24، 1.24، 1.22 و 9.63 است که نشان می دهد مدل پیشنهادی دقت قابل اعتمادی دارد. این آزمایش الگوهای مکانی دزدی نشان می دهد که منطقه 1 و 19 نسبت به سایرین دارای خطاهای مطلق بزرگ تری هستند. همانطور که بررسی شد، هر دو منطقه فوق در شمال شرقی شیکاگو قرار دارند که جاذبه های اصلی توریستی با مناطق مرکزی بسیاری از این شهر هستند. بنابراین یکی از شلوغ ترین مناطق است و معمولاً به عنوان کانون سرقت گزارش می شود، بنابراین عوامل مختلفی مانند تراکم جمعیت، نرخ بیکاری، وضعیت ترافیک و غیره ممکن است به طور جامع بر میزان جرم و جنایت تأثیر بگذارد که دشواری را افزایش می دهد. در پیش بینی دقیق اعداد سرقت روزانه در این مناطق.
با توجه به حمله، شکل 9 گزارش میدهد که الگوهای مکانی-زمانی پیشبینیشده در مجموعه آزمایشی مطابقت نزدیکی با مشاهدات دارند. به طور خاص، مناطق گرم فضایی حمله توسط مدل پیشبینی پیشنهادی از نظر مقادیر تجمعی گرفته میشوند. توزیع خطا در پانل سمت راست شکل 9اشاره می کند که منطقه 15 شاهد حداکثر AE (2.31) در بین 22 ناحیه پلیس در 1 ژانویه 2020 است، منطقه 8 دارای حداکثر AE (1.84) در 4 ژانویه 2020 است، و منطقه 7 دارای حداکثر AE 2.21 در 6 است. ژانویه 2020. میانگین فضایی AE در 1، 4 و 6 ژانویه 0.88، 0.71، و 0.65 است که ثابت می کند این مدل می تواند الگوی فضایی حمله را با میانگین خطای کمتر از یک حادثه به دقت پیش بینی کند. در مورد الگوهای فضایی حمله، مناطق پلیس با خطاهای مطلق بزرگ عمدتاً در جنوب غربی شیکاگو، به ویژه ناحیه 7 قرار دارند. ناحیه 7 به دلیل ترکیب قومی پیچیده و نابرابری شدید در درآمد، حوادث خشونت بار زیادی دارد. بنابراین، دلیل بزرگتر بودن منطقه هفتم نسبت به سایر مکانها ممکن است این باشد که عوامل اجتماعی مختلفی با جرایم مرتبط هستند.
شکل 10 و شکل 11 به ترتیب پیش بینی تعداد حوادث سرقت و حمله را در 22 ناحیه پلیس در شیکاگو نشان می دهد. همانطور که در شکل 10 و شکل 11 نشان داده شده است، مقدار پیش بینی شده از نظر سرقت و حمله کاملاً به مقدار واقعی نزدیک است. اگرچه نوسانات شدیدی در حوادث سرقت در مناطق 1، 18 و 19 و در حوادث حمله در مناطق 4، 7 و 22 مشاهده می شود، اما این مدل می تواند روندهای زمانی را با خطاهای محدود پیش بینی کند. بنابراین، از این دو شکل، ما میتوانیم دریابیم که الگوهای زمانی سرقت و حمله به طور دقیق در مجموعه آزمایشی پیشبینی شدهاند، که عملکرد قابل اعتماد این مدل نمودار یکپارچه را نشان میدهد.
به منظور بررسی کمی عملکرد کلی این مدل، از معیارهای ارزیابی (MAE و RMSE) استفاده شد. MAE و RMSE ARIMA، رگرسیون پشته، SVR، جنگل تصادفی، XGBoost، LSTM، CNN و Conv-LSTM نیز به عنوان مقایسه محاسبه شدند. در آزمایشهای مقایسهای، از مجموعه دادههای مشابه و ویژگیهای استخراجشده در بین همه مدلها استفاده شد. نتایج به دست آمده در جدول 3 نشان داده شده است. مقادیر متوسط شاخصها کمتر از دو حادثه برای سرقت (MAE = 1.3778، RMSE = 1.6318) و یک حادثه برای حمله (MAE = 0.7457، RMSE = 0.8851) است که نشان میدهد این مدل عملکرد خوبی در فضای زمانی – زمانی دارد. پیش بینی جنایت در مقایسه با مدلهای دیگر، مدل پیشنهادی از نظر MAE و RMSE عملکرد بهتری دارد زیرا دومین پایینترین MAE (RMSE) سرقت 1.5574 (1.8736) از Conv-LSTM است، در حالی که مدل حمله 0.8269 (0.9863) است که همچنین از Conv-LSTM است. علاوه بر این، نتایج در این جدول همچنین نشان می دهد که عملکرد ARIMA، رگرسیون پشته، SVR، جنگل تصادفی یا XGBoost به طور قابل توجهی بدتر از مدل های یادگیری عمیق LSTM، CNN و Conv-LSTM است. دلیل ممکن است این باشد که برای SVR (و سایر مدلهای یادگیری ماشین مبتنی بر آمار و سنتی) دشوار است که ویژگیهای پیچیده را از دادههای جرم مکانی-زمانی دریافت کنند. برای مدل های یادگیری عمیق، عملکرد LSTM به طور قابل توجهی بدتر از CNN و Conv-LSTM است. همانطور که مشخص است، دو مورد اخیر در کاوش خود همبستگی فضایی متغیرها و استخراج ویژگی های پیشرفته توزیع فضایی روزانه جرایم خوب هستند. از آنجایی که اطلاعات مکانی معمولاً نقش مهمی در پیشبینی جرم مکانی-زمانی ایفا میکند، CNN و Conv-LSTM برای این سناریو مناسبتر از LSTM اصلی هستند، که فقط قادر به بررسی الگوهای زمانی است. جالب توجه است که مدل نمودار یکپارچه ارائه شده در این مطالعه عملکرد بسیار بهتری نسبت به سه مدل یادگیری عمیق دیگر دارد. دلیل ممکن است این باشد که سه مدل یادگیری عمیق دیگر بر اساس شبکههای مکانی-زمانی منظم برای تقسیم فضایی هستند. با این حال، بسیاری از همبستگیهای فضایی نهفته در میان مناطق اداری واقعی (مانند مناطق پلیس) را نمیتوان به خوبی دریافت کرد، که ممکن است بر عملکرد پیشبینی چنین مدلهایی تأثیر منفی بگذارد. در مقابل، مدل پیشنهادی روابط توپولوژیکی 22 ناحیه پلیس در شهر را با استفاده از ResNet و GCN استخراج میکند. مکانیسم توجه نیز برای ترکیب ویژگی های پیچیده از طریق محاسبات وزنی بررسی شده است. این نشان میدهد که مدل نمودار یکپارچه راهحلی عملی و مؤثر برای پیشبینی جرم مکانی-زمانی است و همچنین با توجه به کاربردهای عملی راحت و امکانپذیر است. بسیاری از همبستگی های فضایی نهفته در میان مناطق اداری واقعی (مانند مناطق پلیسی) را نمی توان به خوبی دریافت کرد، که ممکن است بر عملکرد پیش بینی چنین مدل هایی تأثیر منفی بگذارد. در مقابل، مدل پیشنهادی روابط توپولوژیکی 22 ناحیه پلیس در شهر را با استفاده از ResNet و GCN استخراج میکند. مکانیسم توجه نیز برای ترکیب ویژگی های پیچیده از طریق محاسبات وزنی بررسی شده است. این نشان میدهد که مدل نمودار یکپارچه راهحلی عملی و مؤثر برای پیشبینی جرم مکانی-زمانی است و همچنین با توجه به کاربردهای عملی راحت و امکانپذیر است. بسیاری از همبستگی های فضایی نهفته در میان مناطق اداری واقعی (مانند مناطق پلیسی) را نمی توان به خوبی دریافت کرد، که ممکن است بر عملکرد پیش بینی چنین مدل هایی تأثیر منفی بگذارد. در مقابل، مدل پیشنهادی روابط توپولوژیکی 22 ناحیه پلیس در شهر را با استفاده از ResNet و GCN استخراج میکند. مکانیسم توجه نیز برای ترکیب ویژگی های پیچیده از طریق محاسبات وزنی بررسی شده است. این نشان میدهد که مدل نمودار یکپارچه راهحلی عملی و مؤثر برای پیشبینی جرم مکانی-زمانی است و همچنین با توجه به کاربردهای عملی راحت و امکانپذیر است. مدل پیشنهادی روابط توپولوژیکی 22 ناحیه پلیس در شهر را با استفاده از ResNet و GCN استخراج میکند. مکانیسم توجه نیز برای ترکیب ویژگی های پیچیده از طریق محاسبات وزنی بررسی شده است. این نشان میدهد که مدل نمودار یکپارچه راهحلی عملی و مؤثر برای پیشبینی جرم مکانی-زمانی است و همچنین با توجه به کاربردهای عملی راحت و امکانپذیر است. مدل پیشنهادی روابط توپولوژیکی 22 ناحیه پلیس در شهر را با استفاده از ResNet و GCN استخراج میکند. مکانیسم توجه نیز برای ترکیب ویژگی های پیچیده از طریق محاسبات وزنی بررسی شده است. این نشان میدهد که مدل نمودار یکپارچه راهحلی عملی و مؤثر برای پیشبینی جرم مکانی-زمانی است و همچنین با توجه به کاربردهای عملی راحت و امکانپذیر است.
4. نتیجه گیری
در این مطالعه، یک مدل نمودار یکپارچه «آنلاین» بر اساس مکانیزم توجه برای پیشبینی الگوهای جرم مکانی – زمانی شهری در مقیاس روزانه پیشنهاد شدهاست. این مدل نمودار یکپارچه ResNet، GCN و LSTM را با مکانیسم توجه ترکیب میکند تا ویژگیهای مکانی-زمانی، نمودارهای توپولوژیکی و ویژگیهای خارجی را از دادههای حوادث جرم استخراج و ترکیب کند. برای اعتبارسنجی این مدل، دادههای سرقت و حمله روزانه در مقیاس ناحیه پلیس شهر شیکاگو در ایالات متحده از 1 ژانویه 2015 تا 7 ژانویه 2020 استفاده شد. شاخصهای MAE و RMSE برای ارزیابی کمی این مدل و همچنین هشت مدل دیگر (که به عنوان مقایسهها استفاده شدهاند) در مطالعات قبلی ارائه شدهاند. یافته های اصلی این مطالعه به شرح زیر خلاصه می شود:
(1) الگوهای مکانی-زمانی پیشبینیشده با استفاده از مدل پیشنهادی مطابقت نزدیکی با مشاهدات دارند. در همین حال، مقادیر متوسط دو معیار (MAE و RMSE) کمتر از دو حادثه برای سرقت و یک حادثه برای حمله است، که نشان میدهد این مدل به دقت فوقالعاده بالایی برای پیشبینی الگوهای جرم مکانی – زمانی دست مییابد. علاوه بر این، مدل پیشنهادی از نظر MAE و RMSE عملکرد بسیار بهتری نسبت به تمام هشت مدل دیگر دارد. این نتایج نشان میدهد که مدل نمودار یکپارچه میتواند به طور موثر توزیع مکانی – زمانی جرایم شهری را در مقیاس روزانه پیشبینی کند.
(2) این روش پیشبینی تقسیمبندیهای نامنظم در مناطق شهری را اتخاذ میکند تا بتوان تعداد حوادث جنایت را در مناطق مختلف پلیس پیشبینی کرد. علاوه بر این، ادغام ویژگی ها با وزن دادن به ویژگی ها از طریق مکانیسم توجه حاصل می شود، که یک چارچوب «آنلاین» برای حمایت از تصمیم گیری برای پلیس، از جمله گشت زنی و تحقیق، و همچنین سایر کارهای تخصیص منابع پلیس را فراهم می کند.
عملکرد این مدل نمودار یکپارچه هنوز جای بهبود دارد. نتایج تجربی ما نشان میدهد که دقت پیشبینی این مدل در مناطقی که عوامل اجتماعی پیچیده تجمیع شدهاند کمتر است. اگر دادههای همزمان و در مقیاس پلیس منطقه، مانند قیمت خانه، تراکم جمعیت، وضعیت ترافیک و نرخ بیکاری، در تحقیقات آینده گنجانده شود، انتظار میرود عملکرد این مدل بیشتر بهبود یابد.















بدون دیدگاه