

خلاصه
اکثر سیستمهای اطلاعات زمین (LIS) متمرکز، سیستمهای پردازش تراکنش مبتنی بر سیستمهای مدیریت پایگاهدادهای رابطهای برای ذخیرهسازی، مدیریت و بازیابی دادهها هستند. این سیستمهای مدیریت پایگاه داده سنتی عمدتاً مبتنی بر معماری اشتراک همه چیز یا دیسک اشتراکی هستند و در برآوردن الزامات عملکرد و مقیاسپذیری سیستمهای توزیعشده، از جمله LIS با چالشهایی مواجه هستند. آنها از مقیاس پذیری عمودی و نه افقی پشتیبانی می کنند که در سیستم های توزیع شده از اهمیت ویژه ای برخوردار است. در برخی موارد، به دلیل محدودیت های قانونی، اداری یا زیرساختی، LIS به جای سیستم های متمرکز نیاز به توزیع دارد. سیستم های محاسباتی توزیع شده و معماری اشتراک هیچ چیز بسیار محبوب شده اند، از جمله پلتفرمها و چارچوبهای پردازش داده جدید با مقیاسپذیری افقی و قابلیت تحمل خطا. در این مقاله، ما cdrLIS را ارائه میکنیم – یک هسته عمومی و توسعهپذیر از LIS بر اساس استانداردهای بینالمللی مرتبط و سیستم مدیریت پایگاه داده NewSQL (DBMS) که اجرای LIS سازگار، توزیعشده، بسیار در دسترس و انعطافپذیر را امکانپذیر میسازد. یک هسته عمومی در زبان برنامهنویسی Go پیادهسازی میشود و میتوان آن را به راحتی گسترش داد و به سمت اجرای یک نمایه کشوری خاص استفاده کرد. cdrLIS میتواند بر روی یک خوشه کامپیوتری یا بر روی پلتفرمهای رایانش ابری مستقر شود و بنابراین از طراحی و ساخت نسل جدیدی از برنامههای کاربردی و سیستمهای اطلاعاتی مبتنی بر داده توزیعشده و انعطافپذیر در حوزه مدیریت زمین پشتیبانی میکند. ما cdrLIS را ارائه میکنیم – یک هسته عمومی و توسعهپذیر از LIS بر اساس استانداردهای بینالمللی مرتبط و سیستم مدیریت پایگاه داده NewSQL (DBMS) که اجرای LIS سازگار، توزیعشده، بسیار در دسترس و انعطافپذیر را امکانپذیر میسازد. یک هسته عمومی در زبان برنامهنویسی Go پیادهسازی میشود و میتوان آن را به راحتی گسترش داد و به سمت اجرای یک نمایه کشوری خاص استفاده کرد. cdrLIS میتواند بر روی یک خوشه کامپیوتری یا بر روی پلتفرمهای رایانش ابری مستقر شود و بنابراین از طراحی و ساخت نسل جدیدی از برنامههای کاربردی و سیستمهای اطلاعاتی مبتنی بر داده توزیعشده و انعطافپذیر در حوزه مدیریت زمین پشتیبانی میکند. ما cdrLIS را ارائه میکنیم – یک هسته عمومی و توسعهپذیر از LIS بر اساس استانداردهای بینالمللی مرتبط و سیستم مدیریت پایگاه داده NewSQL (DBMS) که اجرای LIS سازگار، توزیعشده، بسیار در دسترس و انعطافپذیر را امکانپذیر میسازد. یک هسته عمومی در زبان برنامهنویسی Go پیادهسازی میشود و میتوان آن را به راحتی گسترش داد و به سمت اجرای یک نمایه کشوری خاص استفاده کرد. cdrLIS میتواند بر روی یک خوشه کامپیوتری یا بر روی پلتفرمهای رایانش ابری مستقر شود و بنابراین از طراحی و ساخت نسل جدیدی از برنامههای کاربردی و سیستمهای اطلاعاتی مبتنی بر داده توزیعشده و انعطافپذیر در حوزه مدیریت زمین پشتیبانی میکند. LIS بسیار در دسترس و انعطاف پذیر. یک هسته عمومی در زبان برنامهنویسی Go پیادهسازی میشود و میتوان آن را به راحتی گسترش داد و به سمت اجرای یک نمایه کشوری خاص استفاده کرد. cdrLIS میتواند بر روی یک خوشه کامپیوتری یا بر روی پلتفرمهای رایانش ابری مستقر شود و بنابراین از طراحی و ساخت نسل جدیدی از برنامههای کاربردی و سیستمهای اطلاعاتی مبتنی بر داده توزیعشده و انعطافپذیر در حوزه مدیریت زمین پشتیبانی میکند. LIS بسیار در دسترس و انعطاف پذیر. یک هسته عمومی در زبان برنامهنویسی Go پیادهسازی میشود و میتوان آن را به راحتی گسترش داد و به سمت اجرای یک نمایه کشوری خاص استفاده کرد. cdrLIS میتواند بر روی یک خوشه کامپیوتری یا بر روی پلتفرمهای رایانش ابری مستقر شود و بنابراین از طراحی و ساخت نسل جدیدی از برنامههای کاربردی و سیستمهای اطلاعاتی مبتنی بر داده توزیعشده و انعطافپذیر در حوزه مدیریت زمین پشتیبانی میکند.
کلید واژه ها:
پایگاه داده توزیع شده SQL توزیع شده برو ؛ LADM ; LIS ; NewSQL
1. معرفی
اکثر سیستمهای اطلاعات زمین موجود (LIS) عمدتاً سیستمهای پردازش تراکنش آنلاین (OLTP) متمرکز هستند که بر اساس سیستمهای مدیریت پایگاهداده رابطهای یا شی – رابطهای (DBMS) مانند Oracle، Microsoft SQL Server، IBM ساخته شدهاند. DB2، MySQL و PostgreSQL. این DBMS های سنتی فناوری کلیدی برای ذخیره سازی، بازیابی و مدیریت داده ها بوده اند. اگرچه همه آنها نسخه توزیع شده دارند، اما در دوره متفاوتی طراحی شده اند، زمانی که مشخصات سخت افزاری بسیار متفاوت از امروز بود: (i) پردازنده ها هزاران بار سریعتر هستند. (ii) حافظه ها هزاران بار بزرگتر هستند. و (iii) حجم دیسک به شدت افزایش یافته است. این DBMS ها به دلیل پارادایم “یک اندازه متناسب با همه” مورد انتقاد قرار گرفته اند، به عنوان مثال،1 ].
محیط محاسباتی مدرن تا حد زیادی در حال توزیع است. شرکت ها و موسسات دارای مراکز داده توزیع شده و به هم پیوسته هستند و سیستم های توزیع شده را تشکیل می دهند. به طور مشابه، به دلیل محدودیت های قانونی، اداری یا زیرساختی در حوزه مدیریت زمین، نیاز به طراحی و پیاده سازی LIS توزیع شده به جای متمرکز وجود دارد. با این حال، DBMS های سنتی به اشتراک گذاری همه چیز برای استفاده از محاسبات توزیع شده طراحی نشده اند و در برآوردن مقیاس پذیری، سازگاری، انعطاف پذیری و الزامات عملکرد برنامه ها و سیستم های پرمصرف داده توزیع شده با مشکلات جدی مواجه می شوند. آنها فقط از مقیاس بندی عمودی (مقیاس بالا) به جای افقی (مقیاس کردن) پشتیبانی می کنند، که پیش نیاز ساخت نسل جدیدی از LIS توزیع شده است.
آژانس های مدیریت زمین (LA) اغلب پردازنده ها و حافظه های اضافی را در سرورهای پایگاه داده خریداری و نصب می کنند تا قدرت بیشتری از این سیستم ها دریافت کنند. با این حال، این رویکرد استاندارد برای مقیاس بندی عمودی پرهزینه است، به سخت افزار گران قیمت و ارتقاء DBMS نیاز دارد، همچنین پیچیدگی توسعه را اضافه می کند و هزینه های سربار و نگهداری را افزایش می دهد. مشکل اساسی در مقیاس عمودی این است که رشد هزینه ها خطی نیست: ماشینی با دو برابر CPU، RAM و ظرفیت دیسک نسبت به دیگری معمولاً بسیار بیشتر از دو برابر هزینه دارد، اما به دلیل تنگناها، نمی تواند دو برابر حجم کار را تحمل کند. . بنابراین، این معماری ساخت LIS توزیعشده را که انعطافپذیری، ثبات و قابلیت نگهداری مورد انتظار را ارائه میکند، پیچیده میکند.
در طول دو دهه گذشته، پیشرفتهای فناوری وب، دستگاههای تلفن همراه و اینترنت اشیاء منجر به انفجار دادههای ساختاریافته، نیمه ساختاریافته و بدون ساختار شده است. در نتیجه، ساخت برنامهها و سیستمهای مبتنی بر داده، الزامات مختلفی را بر DBMS تحمیل کرد، از جمله: (1) مقیاسپذیری افقی. (ii) در دسترس بودن/تحمل خطا بالا، به عنوان مثال، انعطاف پذیری. (iii) قابلیت اطمینان تراکنش برای پشتیبانی از داده های کاملاً سازگار. و (IV) قابلیت نگهداری طرحواره پایگاه داده. این واقعیت که دستیابی به این الزامات انحصاری متقابل از طریق DBMS سنتی بسیار دشوار یا حتی غیرممکن است [ 2 ] باعث توسعه NoSQL DBMS شد.
یکی از ویژگی های کلیدی NoSQL DBMS نادیده گرفتن تراکنش های ACID و مدل رابطه ای به نفع سازگاری نهایی است. اگرچه سازگاری نهایی امکان دسترسی بالا را فراهم میکند، حذف پشتیبانی قوام قوی (ACID) و حذف SQL منجر به بازگشت به یک رابط برنامهنویسی سطح پایین DBMS شد، بنابراین پیچیدگی برنامه برای مدیریت دادههای ناسازگار بالقوه به طور قابل توجهی افزایش مییابد [ 3 ].]. اگر یک پارتیشن شبکه اتفاق بیفتد، NoSQL DBMS نتیجه پرس و جو را برمی گرداند، حتی اگر نتیجه در آن لحظه زمانی مشخص نباشد. بنابراین، جای تعجب نیست که NoSQL DBMS برای بسیاری از برنامهها و سیستمهای سازمانی، از جمله LIS، مرتبط نبوده است، زیرا این برنامهها و سیستمها نمیتوانند از الزامات تراکنش و سازگاری دقیق چشم پوشی کنند.
تراکنش واحدی از عملیات خواندن و نوشتن مداوم و قابل اعتماد است. LIS یک سیستم OLTP معمولی است و خدمات تراکنش یک سیستم مدیریت داده زیربنایی باید ویژگی های ACID را ارائه دهد [ 4 ، 5 ]:
-
Atomicity اجرای همه یا هیچ تراکنش ها را تضمین می کند. به عبارت دیگر، تراکنش ها اتمی هستند و هر تراکنش به عنوان یک «واحد» واحد در نظر گرفته می شود که یا به طور کامل موفق می شود یا کاملاً شکست می خورد.
-
سازگاری نشان می دهد که اجرای تراکنش فقط می تواند پایگاه داده را از یک وضعیت معتبر به حالت دیگر برساند.
-
انزوا به این واقعیت اشاره دارد که هر تراکنش باید طوری به نظر برسد که گویی هیچ تراکنش دیگری همزمان اجرا نمی شود، یعنی اثرات معاملات همزمان از یکدیگر محافظت می شود تا زمانی که انجام شود.
-
دوام تضمین می کند که اثرات یک تراکنش متعهد در پایگاه داده دائمی است و هرگز نباید از بین برود.
سیستمهای توزیعشده، محاسبات خوشهای، و معماری اشتراک-هیچ چیز در دهه گذشته بسیار محبوب شدند، از جمله بسیاری از پلتفرمها/چارچوبهای پردازش کلان داده با مقیاسپذیری و قابلیت تحمل خطا. آنها از مقادیر زیادی سخت افزار کالا برای ذخیره و تجزیه و تحلیل حجم زیادی از داده ها به روشی بسیار توزیع شده، مقیاس پذیر و مقرون به صرفه استفاده می کنند. این سیستمهای جدید (Apache Hadoop [ 6 ]، Apache Spark [ 7 ]، و Apache Flink [ 8 ] در میان سایرین) برای محاسبات گسترده دادههای موازی، از جمله توسعهها و سازگاریهای آنها برای دادههای مکانی و مکانی-زمانی بهینهسازی شدهاند: SpatialHadoop [ 9 ، 10 ]، GeoSpark [ 11 ]، و MobyDick [12 ]. متاسفانه این سیستم ها خدمات تراکنش ندارند و به همین دلیل برای ساخت سیستم های OLTP مانند LIS مناسب نیستند.
جای تعجب نیست که NewSQL – کلاس جدیدی از DBMS های رابطه ای مدرن – ظهور کرده است. DBMS های NewSQL همانند NoSQL DBMS دارای توان عملیاتی و عملکرد بالایی هستند، تراکنش های دقیق ACID را تضمین می کنند و مدل رابطه ای شامل SQL را حفظ می کنند ( جدول 1 ). این ویژگیها و قابلیتها برنامهها را قادر میسازد تا تعداد زیادی از تراکنشهای همزمان را با استفاده از SQL اجرا کنند، و توسعهدهندگان مجبور نیستند منطق بنویسند تا با سازگاری نهایی مقابله کنند، همانطور که در یک DBMS NoSQL [ 3 ، 13 ] انجام میدهند.
در برخی موارد، به دلیل محدودیت های قانونی، اداری یا زیرساختی، LIS باید به عنوان یک سیستم توزیع شده و نه متمرکز طراحی و اجرا شود. با این حال، هیچ مدرکی (منتشر شده) وجود ندارد که نشان دهد پیشرفته ترین DBMS های توزیع شده، به ویژه NewSQL، با موفقیت در ساخت LIS توزیع شده به کار گرفته شده است. کار ارائه شده در [ 14 ] همچنین تأیید کرد که اگرچه پذیرش NoSQL/NewSQL DBMS توزیع شده در بسیاری از بخشها در حال وقوع است، جذب مقیاسپذیر در ساختمان LIS ناچیز است.
مدل داده های مدیریت زمین (LADM) [ 15 ، 16] یک استاندارد بین المللی شناخته شده برای حوزه اداره زمین است. این یک مدل دامنه مفهومی و عمومی برای طراحی و ساخت LIS است و قبلاً برای تعدادی از پروفایل های خاص گسترش یافته و تطبیق داده شده است. این مدل مولفه های مربوط به داده های اساسی مدیریت زمین را پوشش می دهد: (من) داده های مربوط به حزب. (ii) دادههای مربوط به حقوق، محدودیتها و مسئولیتها (RRR) و واحدهای اداری اساسی که در آن RRR اعمال میشود. و (iii) داده های مربوط به واحدهای فضایی و نقشه برداری و توپولوژی/هندسه. LADM یک مبنای توسعهیافته برای توسعه و اصلاح LIS، بر اساس معماری مبتنی بر مدل (MDA) فراهم میکند. چندین نمایه کشوری مبتنی بر LADM ایجاد شده است، اما تنها تعداد محدودی از آنها پیاده سازی شده و عملیاتی هستند [ 17 ]]. اخیراً، فعالیتهایی برای ساخت نمونههای اولیه در حوزه سهبعدی انجام شده است، اما این نمونههای اولیه عمومی نبودند و اساساً بر روی تجسم واحدهای فضایی سهبعدی [ 18 ، 19 ، 20 ، 21 ] یا به میزان کمتر، نقشهبرداری از زبان مدلسازی یکپارچه تمرکز داشتند. (UML) مدل مفهومی به طرح پایگاه داده یا قالب تبادل داده [ 22 ].
به طور کلی، بیشتر LIS از ابتدا توسعه یافته است (ما تطبیق یک LIS از قبل موجود را با یک زمینه خاص کشور مربوط به بحث خود نمی دانیم)، و تا آنجا که می دانیم، هیچ استاندارد عمومی منطبق با LADM وجود ندارد. کتابخانه نرم افزاری که می تواند گسترش یابد و در توسعه LIS مورد استفاده مجدد قرار گیرد. در این مقاله، ما توسعه مداوم خود را از یک نمونه اولیه عمومی و قابل توسعه از LIS سازگار، توزیعشده و انعطافپذیر مطابق با استاندارد LADM ارائه میکنیم. تازگی رویکرد ما این است که از ابتدا به روشی کلی و جامع برای پشتیبانی از ساخت کلاس جدیدی از LIS بر اساس LADM طراحی شده است.
هدف و سهم اصلی این مقاله دو چیز است:
- (من)
-
برای ارائه بسته های نرم افزاری سازگار با LADM عمومی و قابل توسعه که در زبان برنامه نویسی Go پیاده سازی شده اند. بسته ها را می توان در توسعه LIS، به صورت متمرکز یا توزیع، مجدداً مورد استفاده قرار داد و گسترش داد.
- (II)
-
برای نشان دادن اجرای یک LIS توزیع شده تک سایتی با استفاده از جدیدترین DBMS NewSQL. پیادهسازی LIS توزیعشده با تکرار جغرافیایی با استفاده از یک NewSQL DBMS دارای قابلیت فضایی ساده است.
بقیه مقاله به شرح زیر سازماندهی شده است. در بخش 2 ، ویژگیهای اصلی DBMS توزیعشده و NewSQL را مورد بحث قرار میدهیم که برای طراحی و ساختن نسل جدیدی از سیستمها و برنامههای اطلاعات زمین سازگار، بسیار در دسترس و انعطافپذیر حیاتی هستند. یک نمای کلی از کتابخانه هسته عمومی و قابل توسعه سازگار با LADM، از جمله برخی پیاده سازی های خاص در زبان برنامه نویسی Go، در بخش 3 نشان داده شده است . بخش 4 معماری نمونه اولیه و اطمینان از انعطاف پذیری، قابلیت اطمینان و ثبات را ارائه می دهد. بخش 5 مقاله را به پایان می رساند و مسیرهای آینده را مورد بحث قرار می دهد.
2. پیشرفته ترین: توزیع شده و NewSQL DBMS
قبل از ادامه، این بخش یک مرور مختصر از پیشرفته ترین DBMS های توزیع شده و NewSQL و همچنین ویژگی های اصلی و اهمیت آنها برای ایجاد نسل جدیدی از LIS سازگار، توزیع شده و انعطاف پذیر ارائه می دهد.
سیستم توزیعشده مجموعهای از عناصر محاسباتی مستقل (گرهها) است که بهعنوان یک سیستم منسجم به نظر کاربرانش میرسد. یک گره می تواند یک دستگاه سخت افزاری یا یک فرآیند نرم افزاری باشد و سیستم های توزیع شده مدرن از انواع گره ها، از کامپیوترهای بسیار بزرگ با کارایی بالا تا کامپیوترهای پلاگین کوچک تشکیل شده است [ 23 ]. اخیراً، سیستمهای محاسباتی توزیعشده و معماری اشتراک-هیچ بسیار محبوب شدهاند، از جمله پلتفرمها/چارچوبهای جدید پردازش داده با قابلیتهای مقیاسپذیری و تحمل خطا. این سیستمها/چارچوبهای جدید از مقادیر زیادی سختافزار کالا برای ذخیره، مدیریت و تحلیل دادهها به روشی بسیار توزیعشده، مقیاسپذیر و مقرونبهصرفه استفاده میکنند.
هدف اولیه یک سیستم توزیع شده از نظر مفهومی ساده است: در حالت ایده آل باید فقط یک نسخه مقاوم در برابر خطا و مقیاس پذیرتر از یک سیستم متمرکز باشد. یک سیستم توزیع شده باید سادگی و سازگاری یک سیستم متمرکز را حفظ کند، توزیع اهرمی و تکرار را برای افزایش دسترسی بالا و تحمل خطا و انعطاف پذیری با پوشاندن خرابی ها، ارائه مقیاس پذیری و کاهش تأخیر حفظ کند [ 24 ].
دلایل مختلفی برای ایجاد LIS توزیع شده وجود دارد، به عنوان مثال، برای توزیع یک پایگاه داده LIS در چندین گره:
- (من)
-
توزیع و خودمختاری واحدهای اداره زمین: واحدها/دفاتر غیرمتمرکز اداره زمین از نظر اداری و جغرافیایی توزیع شده اند. هر واحد/دفتر ممکن است اختیار ایجاد داده های محلی خود را داشته باشد که می خواهد آن ها را کنترل کند.
- (II)
-
هزینه های ارتباطات داده و قابلیت اطمینان: اگرچه هزینه های ارتباطات داده اخیراً کاهش یافته است، هزینه انتقال مقادیر زیادی از داده های مکانی در سراسر شبکه های ارتباطی یا رسیدگی به حجم زیادی از تراکنش ها از دفاتر/واحدهای راه دور می تواند گران باشد. در چنین مواردی، مکان یابی داده ها و برنامه های کاربردی نزدیک به محل مورد نیاز مقرون به صرفه تر است. علاوه بر این، وابستگی به ارتباطات داده همیشه خطری را به همراه دارد، بنابراین قرار دادن دادهها از نظر جغرافیایی نزدیک به کاربران میتواند راهی قابل اعتماد برای پشتیبانی از دسترسی سریع به دادهها باشد [ 25 ].
- (iii)
-
مقیاس پذیری: اگر حجم داده یا حجم کار تراکنش بزرگتر از توان یک گره منفرد باشد، داده ها و حجم کار می توانند در چندین گره توزیع شوند.
- (IV)
-
دسترسی بالا/ تحمل خطا/ انعطاف پذیری: LIS باید سیستم های بسیار در دسترس، مقاوم به خطا و انعطاف پذیر باشد. هر زمان که خرابی رخ دهد، یعنی هر زمان که بخشی از سیستم از کار بیفتد، سیستم باید در دسترس باشد و به درستی به کار خود ادامه دهد.
پایگاه داده توزیع شده مجموعه ای از پایگاه داده های متعدد و منطقی مرتبط با یکدیگر است که در گره های سیستم های توزیع شده قرار دارند. DBMS توزیع شده سیستم نرم افزاری است که پایگاه داده توزیع شده را مدیریت می کند و توزیع را برای کاربران نامرئی می کند. کاربران یک پایگاه داده یکپارچه را مشاهده می کنند، در حالی که داده های اساسی به طور فیزیکی در سراسر گره ها توزیع می شوند. یکی از ویژگی های مهم DBMS توزیع شده این است که از نظر منطقی یکپارچه است، اما از نظر فیزیکی توزیع شده است، یعنی یک پایگاه داده منطقی واحد است که به طور فیزیکی در سراسر گره ها در مکان های متعدد متصل شده توسط یک شبکه ارتباطی داده پخش می شود. یک سیستم پایگاه داده توزیع شده به طور مشترک به پایگاه داده توزیع شده و DBMS توزیع شده اشاره دارد [ 5]. در نتیجه، یک LIS توزیع شده، یک LIS است که بر روی یک سیستم پایگاه داده توزیع شده ساخته شده است.
دو نوع ممکن از LIS/DBMS توزیع شده وجود دارد:
- (من)
-
یک سایت، معمولاً با یک خوشه رایانه در یک مرکز داده مشخص می شود.
- (II)
-
توزیع جغرافیایی؛ سایت ها (به عنوان مثال، مراکز داده) توسط شبکه های گسترده (WAN) متصل می شوند.
در اینجا باید تاکید کرد که یک LIS متمرکز را می توان با استفاده از یک DBMS توزیع شده تک سایتی ایجاد کرد. علاوه بر این، می توان یک LIS توزیع شده ساخت که دارای چندین خوشه تک سایتی است که توسط یک WAN به هم متصل شده اند.
دو روش استاندارد برای توزیع داده ها در چندین گره [ 26 ] وجود دارد:
- (من)
-
تکرار: مفهومی اساسی از سیستم های توزیع شده برای دستیابی به تمرکززدایی قابل اعتماد، دسترسی کم تاخیر به داده ها، مقیاس پذیری، در دسترس بودن بالا، تحمل خطا و انعطاف پذیری. Replication شامل ایجاد و توزیع کپی از همان داده ها در سراسر گره ها و اطمینان از سازگاری آنها است.
- (II)
-
پارتیشن بندی: تقسیم یک مجموعه داده بزرگ به پارتیشن ها، توزیع آنها در سراسر گره ها و اطمینان از سازگاری آنها. انگیزه اصلی پارتیشن بندی مقیاس پذیری است: پارتیشن های مختلف را می توان در گره های مختلف در یک خوشه اشتراک-هیچ ذخیره کرد و بار پرس و جو را می توان در بسیاری از گره ها توزیع کرد.
NewSQL DBMS همانندسازی و پارتیشن را با هم ترکیب می کند به طوری که کپی های هر پارتیشن در چندین گره ذخیره می شود. پیشرفته ترین DBMS های NewSQL ویژگی های مشترک زیر را دارند: (i) مدل داده های رابطه ای و SQL توزیع شده. (2) سازگاری قوی از طریق تراکنش ACID. (iii) مقیاسپذیری افقی با استفاده از پارتیشن دادهها در خوشههای اشتراک هیچ ماشینهای کالا. و (IV) در دسترس بودن و انعطاف پذیری بالا از طریق تکرار داده ها. آنها عبارتند از (بر اساس حروف الفبا): ClustrixDB [ 27 ]، CockroachDB [ 28 ]، FaunaDB [ 29 ]، HyPer [ 30 ]، MemSQL [ 31 ، 32 ]، NuoDB [ 33 ]، SAP HANA [ 34 ] 35 ، Spanner]، TiDB [ 36 ]، VoltDB [ 37 ] و YugabyteDB [ 38 ]. آنها بر اساس معماریهای توزیعشدهای هستند که بر روی خوشههای اشتراکگذاری هیچ کار میکنند و دارای مؤلفههایی برای پشتیبانی از ثبات، در دسترس بودن بالا، تحمل خطا، و انعطافپذیری و همچنین SQL توزیعشده هستند.
این بسیار مهم است زیرا به DBMS اجازه میدهد تا پرس و جو را به دادهها بفرستد نه رویکرد سنتی آوردن دادهها به پرس و جو، که منجر به ترافیک شبکه به میزان قابل توجهی میشود. در نهایت، بسیاری از تکنیکهایی که NewSQL DBMS به کار میرود، در DBMS سنتی، دانشگاهی یا تجاری وجود دارد. با این حال، آنها فقط یکبار در یک DBMS منفرد و هرگز همه با هم پیاده سازی شدند. آنچه در مورد NewSQL DBMS واقعاً نوآورانه است این است که آنها این تکنیک ها را در پلتفرم های منفرد ترکیب و پیاده سازی می کنند [ 13 ].
با این حال، تنها تعداد کمی از آنها از مدل شی-رابطه ای و انواع داده های مکانی پشتیبانی می کنند (SAP HANA و YugabyteDB، اولی یک COTS و دومی یک DBMS منبع باز است؛ MemSQL از مجموعه بسیار محدودی از انواع داده های جغرافیایی و عملیات مبتنی بر پشتیبانی می کند. بر روی یک مدل کروی شبیه به Google Earth)، بنابراین آنها را به طور بالقوه در طراحی و ساخت نسل جدید LIS قابل استفاده می کند. ما قبلاً شاهد پشتیبانی تدریجی مکانی در DBMS سنتی بوده ایم. بنابراین، میتوان انتظار داشت که در آینده، NewSQL DBMS بیشتری از مدل رابطهای شی استفاده کند و بنابراین مستقیماً از ساخت نسل جدیدی از LIS توزیعشده (اعم از توزیعشده جغرافیایی یا تکسایتی) با مجموعهای از ویژگیهای متمایز پشتیبانی کند. ، که ما قوام قوی، مقیاس پذیری افقی را برجسته می کنیم،
در اینجا لازم به ذکر است که با استفاده از نسخه توزیع شده DBMS سنتی (اوراکل، DB2، سرور SQL) و مجموعه دیگری از محصولات، می توان یک LIS سازگار، توزیع شده و بسیار در دسترس ساخت. با این حال، ابزارهایی که با آن می توان به این امر دست یافت، بسیار پیچیده تر و گران تر است. این رویکرد به تعدادی لایههای فنآوری اضافی نیاز دارد، و هنوز هم، سیستم میتواند ناهنجاریهای بالقوه پرهزینه را در پایگاه داده اجازه دهد و ممکن است مشکلات مقیاسپذیری افقی داشته باشد. به عنوان مثال، یک سیستم مبتنی بر اوراکل توزیع شده و بسیار در دسترس معمولاً به تعدادی از محصولات دارای مجوز اضافی نیاز دارد: خوشه برنامه واقعی (RAC) / محافظ داده فعال، خدمات داده جهانی و اشتراک گذاری که به طور قابل توجهی پیچیدگی و هزینه سیستم را افزایش می دهد. برعکس،
3. بسته های LADM عمومی و قابل توسعه
مطابق با اصول معماری مبتنی بر مدل (MDA)، ما از زبان برنامه نویسی Go [ 39 ] برای ساختن یک مدل خاص پلت فرم عمومی و قابل توسعه استفاده می کنیم. متأسفانه، ابزارهای مدلسازی و توسعه MDA (مانند Sparx Enterprise Architect، Rational Software Architect و غیره) از تبدیل PIM به PIS برای زبانهای برنامهنویسی جدیدتر پشتیبانی نمیکنند: Go، Scala، Kotlin، و Rust و غیره. Go یک زبان برنامه نویسی منبع باز برای ساختن نرم افزار ساده، قابل اعتماد و کارآمد [ 40 ] است که می تواند از مزایای سیستم های توزیع شده استفاده کند، اما رویکردی کاملاً متفاوت برای برنامه نویسی شی گرا دارد.
چیزی که پارادایم شی گرا در Go را از زبان های برنامه نویسی شی گرا مبتنی بر کلاس (مانند جاوا، C++، Objective-C) متفاوت می کند این است که به طور صریح از هیچ یک از کلاس ها یا وراثت پشتیبانی نمی کند (یک رابطه است). زمانی که برنامه نویسی شی گرا رایج شد، وراثت به عنوان یکی از بزرگترین مزیت های آن در نظر گرفته شد. با این حال، پس از چند دهه، مشخص شد که وراثت در حفظ سیستمهای بزرگ دارای اشکالات جدی است. در نتیجه، به جای استفاده از تجمیع و وراثت مانند بسیاری از زبان های شی گرا دیگر، Go از ایجاد انواع سفارشی و تجمیع (has-a) از طریق جاسازی پشتیبانی می کند. در اینجا نمونه ای از جاسازی VersionedObjectas یک فیلد ناشناس در داخل LASpatialUnit آورده شده است.:
نوع VersionedObject struct {
BeginLifespanVersion time.Time
EndLifespanVersion *time.Time
کیفیت *metadata.DQ_Element
منبع *metadata.CI_ResponsibleParty
}
ساختار LASpatialUnit {
مشترک.VersionedObject
ExtAddressID *external.ExtAddress
. . .
ReferencePoint *geometry.GMPPoint
SuID مشترک.Oid
SurfaceRelation *LASurfaceRelationType
RelationSu []LARequiredRelationshipSpatialUnit // relationSu
. . .
Baunit []SuBAunit // subBaunit
SuHierarchy *SuHierarchy // suHierarchy
SpatialUnitGroups []SuSuGroup // suSuGroup
MinusBfs []BfsSpatialUnitMinus // منهای
PlusBfs []BfsSpatialUnitPlus // plus
}
عملیات تعریف شده در کلاس LA_SpatialUnit UML به عنوان متدهایی پیاده سازی می شوند که گیرنده آنها از نوع LASpatialUnit مجموع است :
func (su LASpatialUnit) AreaClosed() bool {
بسته، _ := geos.Must(su.Boundary()).IsClosed()
بازگشت بسته
}
func (su LASpatialUnit) ComputeArea() LAAreaValue {
var av LAAreaValue
multiSurface:= su.CreateArea()
area, _ := multiSurface.Area()
av.AreaSize، av.Type = مساحت (منطقه)، CalculatedArea
بازگشت خیابان
}
func (su LASpatialUnit) CreateArea() *geometry.GMMultiSurface {
msBoundary := geos.Must(su.Boundary())
tempMultiSurface := geos.Must(geos.EmptyPolygon())
var ms []*geos.Geometry
nGeometry، _ := msBoundary.NGeometry()
برای من := 0; i < nهندسه; i++ {
. . .
ms = اضافه (ms، سطح)
tempMultiSurface = geos.Must(tempMultiSurface.Union(سطح))
}
multiSurface:= geos.Must(tempMultiSurface.Clone())
برای _، سطح := محدوده ms {
اگر مرتبط باشد، _ := surface.RelatePat(multiSurface, "2FF1FF212"); مربوط {
multiSurface = geos.Must(multiSurface.Difference(سطح))
}
}
بازگشت &geometry.GMMultiSurface{GMObject:
geometry.GMObject{هندسه: *multiSurface}
}
}
در نتیجه، LAlegalSpaceBuildingUnit
ساختار LAlegalSpaceBuildingUnit {
مشترک.VersionedObject
واحد فضایی *LASpatialUnit
ExtPhysicalBuildingUnitID *external.ExtPhysicalBuildingUnit
*LABuildingUnitType را تایپ کنید
}
به عنوان مثال، فیلد انبوه نامگذاری شده SpatialUnit می تواند از روش های تعریف شده در LA_SpatialUnit استفاده کند.
یکی از جنبه های خاص برنامه نویسی شی گرا در Go این است که رابط ها، مقادیر و متدها از هم جدا نگهداری می شوند: اینترفیس ها برای مشخص کردن امضاهای متد استفاده می شوند. انواع ساختار ( ساختارها ) برای تعیین مقادیر تجمیع شده و تعبیه شده استفاده می شود. و متدها برای تعیین عملیات روی انواع سفارشی استفاده می شوند. هیچ ارتباط صریحی بین روشهای یک نوع سفارشی و هر رابط خاص وجود ندارد – اما اگر یک نوع یک اینترفیس را برآورده کند، به عنوان مثال، دارای تمام روشهایی باشد که رابط مورد نیاز است، آن نوع نمونهای از آن رابط در نظر گرفته میشود [ 40 ، 41 ].
این رویکرد نسبت به وراثت سنتی منعطفتر است، زیرا هر شیء بهطور سست جفت میشود، و تغییرات به یک نوع واقعاً باعث تغییرات چشمگیر در خط نمیشود. در اصل، ترکیبات ترکیب شده با رابط ها، بدون پیچیدگی و محدودیت های وراثت، تمام خواسته های یک سیستم شی گرا را برآورده می کنند.
ما از نوع رابط CRUDer استفاده کردیم (و از قرارداد Go برای نامهای رابط پیروی کردیم، که باید با “er” ختم شود) برای بیان انتزاعهایی درباره رفتارهای همه انواع در زمینه عملیات CRUD در لایه پایداری:
نوع رابط CRUDer {
ایجاد (واسط مقدار{}) (رابط{}، خطا)
خواندن (where ...interface{}) (رابط{}، خطا)
ReadAll(where ...interface{}) (رابط{}، خطا)
بهروزرسانی (واسط مقدار{}) (رابط{}، خطا)
خطای Delete(value interface{}).
}
همه CRUD های بتنی LADM/cdrLIS در زمینه نگاشت شی-رابطه ای نمونه هایی از رابط CRUDer هستند، به عنوان مثال، آنها رابط را با داشتن تمام روش هایی که این رابط نیاز دارد برآورده می کنند. در اینجا یک مثال برای عملیات ایجاد LASpatialUnit آورده شده است :
ساختار LASpatialUnitCRUD {
DB *gorm.DB
}
func (crud LASpatialUnitCRUD) Create(spatialUnitIn interface{}) (Interface{}, error) {
tx := crud.DB.Begin()
SpatialUnit := spatialUnitIn.(ladm.LASpatialUnit)
spatialUnit.ID = spatialUnit.SuID.String()
currentTime := time.Now()
spatialUnit.BeginLifespanVersion = currentTime
spatialUnit.EndLifespanVersion = صفر
writer := tx.Set("gorm:save_associations", false).Create(&spatialUnit)
if writer.Error != nil {
tx.Rollback()
بازگشت صفر، نویسنده. خطا
}
commit := tx.Commit()
if commit.Error != nil{
بازگشت صفر، commit.Error
}
بازگشت و واحد فضایی، صفر
}
از آنجایی که رابط CRUDer باید عمومی باشد، آرگومان های متدها رابط های ناشناس هستند. اجرای بتن CRUDer روی شی بتنی عمل می کند، بنابراین داده های ورودی ابتدا باید به یک نوع شی بتنی ریخته شوند. شی آماده شده با فراخوانی متد DB...Create() در پایگاه داده باقی می ماند و تمام اشیاء مرتبط با تنظیم GORMoption save_associations روی false قبل از فراخوانی DB...Create() نادیده گرفته می شوند . ایجاد و ماندگاری اشیاء مرتبط توسط CRUD های مربوطه آنها انجام می شود .
هسته عمومی ما به بستههای gogeos [ 42 ] برای مدیریت و استفاده از انواع دادههای مکانی و عملیات روی آنها متکی است. بستههای gogeos پیوندهایی را به کتابخانه GEOS C++ [ 43 ] ارائه میکنند که مدل هندسی و API را مطابق با مشخصات ویژگیهای ساده OGC برای SQL و [ 44 ] پیادهسازی میکند.
مدل مفهومی LADM، که به عنوان مجموعهای از نمودارهای کلاس UML، زبان Go، و NewSQL DBMS توصیف میشود، در پارادایمهای مختلفی پایهگذاری شدهاند – دو مورد اول در شی گرا، دومی در رابطه. هر فناوری مستلزم آن است که کسانی که از آن استفاده می کنند دیدگاه خاصی نسبت به جهان گفتمان داشته باشند. ناسازگاری بین این دیدگاه ها به صورت مشکلات عدم تطابق امپدانس شی-رابطه ای آشکار می شود. یک برنامه شی-رابطه ای مصنوعات را از هر دو پارادایم شی گرا و رابطه ای ترکیب می کند و توسعه نرم افزار به حل مشکلات عدم تطابق امپدانس نیاز دارد [ 45 ]]. به منظور جداسازی پارادایم شی گرا از پارادایم رابطه ای (یعنی از نیاز به درک زبان SQL و طرحواره LADM پایگاه داده NewSQL)، از بسته نگاشت شی-رابطه ای GORM [ 46 ] استفاده کردیم.
در اینجا، ما فقط سطح بستههای نرمافزاری Go عمومی و قابل توسعه خود را خراشیدیم. جزئیات پیاده سازی و کد منبع در سایت GitHub cdrLIS [ 47 ] موجود است.
4. معماری، انعطاف پذیری و ثبات
4.1. مدل داده های منطقی موجودیت-رابطه
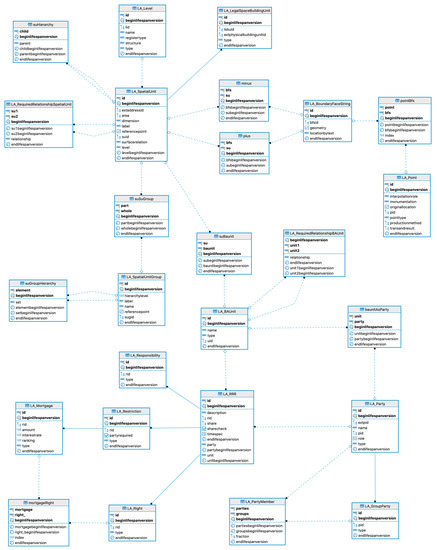
شکل 1 مدل داده های منطقی موجودیت-رابطه cdrLIS (ER) را نشان می دهد که از موجودیت های LADM اصلی و روابط بین آنها تشکیل شده است. همانطور که در بخش 3 بیان شد ، نسخه فعلی نمونه اولیه ما بر روی 2 بعدی متمرکز شده است، بنابراین موجودیت های مربوط به سه بعدی در حال حاضر حذف شده اند.
علاوه بر این، برای سادگی، موجودیتهای LA_AdministrativeSource، LA_SpatialSource، LA_LegalSpaceUtilityNetwork، و همچنین انواع دادههای ویژگی نشان داده نمیشوند.
4.2. معماری نرم افزار
معماری نرم افزار cdrLIS از چهار لایه تشکیل شده است که در چهار بسته Go متناظر کپسوله شده اند: (i) لایه برنامه اصلی. (ب) لایه کنترل کننده http. (iii) لایه CRUD. و (IV) لایه مدل. در اینجا خیلی مختصر آنها را توضیح می دهیم.
- (من)
-
لایه برنامه اصلی:
cdrLIS به عنوان یک وب سرویس REST پیاده سازی شده است و این لایه بالایی فقط حاوی متد Go main است که کل برنامه را اجرا می کند و ارتباط بین اجزای متقابل مستقل لایه های پایین را برقرار می کند. فقط این لایه از جزئیات پیاده سازی خاصی مانند: اتصال پایگاه داده، کنترل کننده های http و CRUD های آنها ، URL های نقطه پایانی، پورت سرویس وب و غیره آگاه است.
func main() { ... db، خطا := gorm.Open(dbDialect، dbArgs) defer db.Close() . . . sunitCRUD := crud.LASpatialUnitCRUD{DB: db} sunitHandler := handler.SpatialUnitHandler{SpatialUnitCRUD: sunitCRUD، LevelCRUD: levelCRUD} روتر := httprouter.New() router.GET("/spatialunit",sunitHandler.GetSpatialUnits) router.POST("/spatialunit",sunitHandler.CreateSpatialUnit) router.GET("/spatialunit/:namespace/:localId",sunitHandler.GetSpatialUnit) router.PUT("/spatialunit/:namespace/:localId",sunitHandler.UpdateSpatialUnit) router.DELETE("/spatialunit/:namespace/:localId",sunitHandler.DeleteSpatialUnit) . . . handler := cors.Default().Handler(روتر) http.ListenAndServe(":3000"، handler) } - (II)
-
لایه کنترل کننده Http:
این لایه هندلرهای http را برای وب سرویس REST API تعریف می کند. هر کنترل کننده حاوی منطق نحوه رسیدگی به درخواست های GET، POST، PUT، و DELETE است که CRUD ها باید فراخوانی شوند و نحوه برگرداندن نتایج. در اینجا یک تصویر از کنترل کننده GET برای SpatialUnit آمده است :
ساختار SpatialUnitHandler { SpatialUnitCRUD CRUD LevelCRUD CRUDer } func (هندلر *SpatialUnitHandler) GetSpatialUnit (w http.ResponseWriter، r *http.درخواست، p httprouter.Params) { uid := common.Oid{Namespace:p.ByName("namespace"),LocalID:p.ByName("localId")} suUnit، خطا := handler.SpatialUnitCRUD.Read(uid) . . . answerJSON(w, 200, suUnit) } - (iii)
-
لایه CRUD:اجزای این لایه (انواع ساختار و روش ها) ماندگاری مقادیر نوع ساختار (اشیاء) را در پایگاه داده پیاده سازی می کنند. انتزاع اولیه در این لایه رابط CRUDer است که روش های نمونه اولیه را برای عملکردهای CRUD (خواندن، خواندن همه، ایجاد، به روز رسانی، حذف) تعریف می کند. هر نوع داده ای که از رابط CRUDer استفاده می کند باید پیاده سازی CRUDer خود را داشته باشد. یک پیاده سازی مشخص از CRUDer روشی را که هر شی در یک پایگاه داده باقی می ماند را تعریف می کند. پیاده سازی CRUDer فقط به بسته GORM بستگی دارد، نه به پایگاه داده خاص. رابط CRUDer و نمونه ای از متد Create برایSpatialUnit در بخش 3 نشان داده شده است.
- (IV)
-
لایه مدل:این لایه در واقع نگاشت مدل LADM به یک مدل مخصوص پلتفرم است، به عنوان مثال، نگاشت کلاس های UML به انواع ساختار Go مربوطه ( ساختارها ). از آنجایی که ما از GORM استفاده می کنیم، تعاریف نوع ساختار همچنین شامل تگ های GORM برای نگاشت رابطه شی و همچنین تگ های JSON برای سریال سازی می شود.
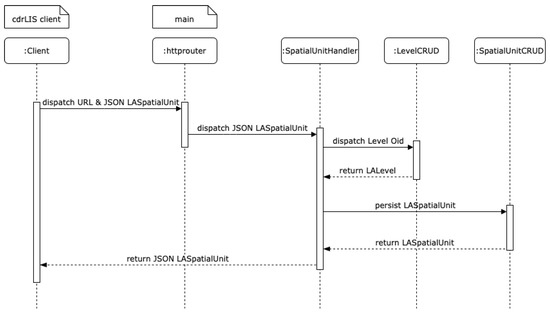
نمودار توالی UML در شکل 2 نقش ها و ارتباطات بین این لایه ها را در مورد ایجاد یک شی LASpatialUnit نشان می دهد.
صرف نظر از فرآیندهای تجاری خاص کشوری که باید توسط LIS پشتیبانی شوند، هر LIS خاص کشور به عملیات CRUD روی همه نهادها/اشیاء LADM نیاز دارد. این دقیقاً هسته نمونه اولیه ما است. پذیرش هسته و نمونه اولیه ما در مورد افزودن ساده موجودیت ها/اشیاء به دو مرحله نیاز دارد: (1) گسترش مدل پایگاه داده. و (ii) گسترش هر سه لایه برنامه، یعنی CRUD، http handler و main. افزودن کلاسها و ویژگیهای جدید به لایه CRUD میتواند به سادگی با استفاده از مفهوم embedding موجود در زبان Go انجام شود. از منظر مهندسی نرم افزار، گسترش کنترل کننده http و لایه های اصلی نیازی به مداخله برنامه نویسی رادیکال ندارد و می تواند بی اهمیت تلقی شود.
با این حال، ما همچنین باید به این واقعیت اشاره کنیم که هر فرآیند تجاری خاص کشور و قوانین تجاری در حوزه اداره زمین و کاداستر ممکن است به عملیات پیچیده تری نسبت به مجموعه عملیات در لایه CRUD ما نیاز داشته باشد. در این مورد، ساختن یک LIS خاص کشور با استفاده از هسته عمومی و نمونه اولیه ما نیاز به اجرای عملیات CRUD پیچیدهتر، از جمله رابطهای کاملاً جدید دارد، و تلاش اجرای کلی میتواند به طور قابل توجهی سنگینتر باشد. متأسفانه، هسته عمومی و نمونه اولیه ما شامل پشتیبانی از فرآیندهای عمومی جمع آوری داده های اولیه، نگهداری داده ها و انتشار داده نمی شود. در همین راستا، اجرای این فرآیندها که مشخصات آن در ویرایش دوم LADM اعلام و انتظار میرود [ 48 ]]، می تواند دامنه و پیچیدگی هسته عمومی و نمونه اولیه ما را به طور قابل توجهی افزایش دهد، اما از سوی دیگر، تلاش های اجرایی در ساخت یک LIS خاص کشور را کاهش دهد.
4.3. معماری سیستم
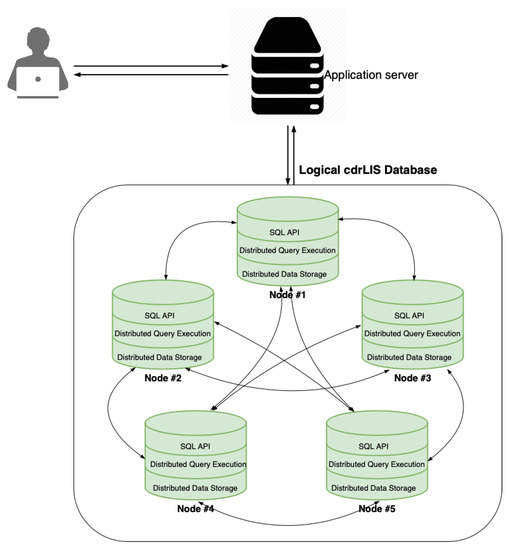
شکل 3 معماری سیستم ساده شده نمونه اولیه cdrLIS توزیع شده تک سایتی ما را نشان می دهد. مطابق با اصول معماری مبتنی بر مدل، ما از YugabyteDB – یک DBMS توزیع شده NewSQL – و مدل شی – رابطه ای آن به عنوان یک مدل خاص پلت فرم پایگاه داده استفاده کردیم. این یک مشتق منبع باز از Google Spanner [ 35 ] است که برای (i) مقیاس پذیری افقی، (2) سازگاری قوی، و (iii) انعطاف پذیری در برابر بلایا طراحی شده است و بر روی یک موتور ذخیره سازی کلید/مقدار سفارشی ساخته شده است که از RocksDB جدا شده است. [ 49 ]. خوشه پنج گره به عنوان یک پایگاه داده توزیع شده بسیار در دسترس و انعطاف پذیر با ضریب تحمل خطا عمل می کند. �تی= 2 (یعنی سیستم می تواند دو شکست گره را تحمل کند؛ بخش 4.4 را ببینید )، که در آن هر گره عملیات CRUD را انجام می دهد. در مورد ما، گره ها ماشین های فیزیکی کالایی هستند که سیستم عامل لینوکس را اجرا می کنند، اما می توانند ماشین های مجازی یا کانتینرها نیز باشند.
کلاینت ها می توانند به هر یک از گره ها متصل شوند تا عملیات CRUD را در خوشه پایگاه داده cdrLIS انجام دهند. آنها با یک لایه پرس و جوی توزیع شده SQL که داده ها را با استفاده از موتور ذخیره سازی کلید/مقدار که قبلا ذکر شد، به شدت سازگار و توزیع شده، تکرار، ذخیره و بازیابی می کند، تعامل دارند.
لایه اجرای پرس و جو توزیع شده پرس و جوها را در بین گره های خوشه توزیع می کند. پرس و جوها توسط یک گره رهبر پذیرفته می شوند، که سپس از سایر گره ها (فالوورها) درخواست می کند تا بخشی از پرس و جو را اجرا کنند و نتایج جمع آوری شده را برای مشتری ارسال می کند.
cdrLIS را می توان بر روی یک ابر عمومی، مرکز داده داخلی، به عنوان مثال، روی یک خوشه از ماشین های کالا، یا یک کانتینر Docker [ 50 ] مستقر کرد. همچنین می تواند به صورت بومی، به عنوان یک برنامه کاربردی حالت دار، در Kubernetes [ 51 ] و محیط های مشابه کانتینر ارکستراسیون برای خودکارسازی استقرار، مقیاس بندی و مدیریت برنامه اجرا شود. با توجه به ویژگیهای موروثی YugabyteDB، cdrLIS یک سیستم سازگار و طبق نظریه CAP [ 52 ]، سیستم متحمل پارتیشن (CP) است. تمام ویژگی های یک سیستم توزیع شده NewSQL را دارد که در دو بخش بعدی با جزئیات بیشتر توضیح خواهیم داد.
4.4. تحمل خطا، قابلیت اطمینان و انعطاف پذیری
قابلیت اطمینان هم به انعطاف پذیری یک سیستم در برابر انواع خرابی ها و هم به قابلیت بازیابی از آنها اشاره دارد. یک LIS توزیع شده باید در برابر خرابی های سیستم مدارا کند و حتی در صورت بروز خرابی به ارائه خدمات ادامه دهد. یک هدف مهم در طراحی و پیاده سازی LIS توزیع شده، ساختن سیستمی است که قادر به بازیابی خودکار از خرابی های جزئی بدون تأثیر بر عملکرد کلی باشد. به ویژه، هر زمان که خرابی رخ دهد، LIS باید در حین انجام تعمیرات به کار خود ادامه دهد. به عبارت دیگر، انتظار می رود که یک LIS توزیع شده قابل اعتماد، تحمل خطا و انعطاف پذیر باشد. همانطور که در بخش 2 اشاره کردیم ، تکرار برای دستیابی به تحمل خطا، در دسترس بودن بالا و انعطاف پذیری اساسی است.
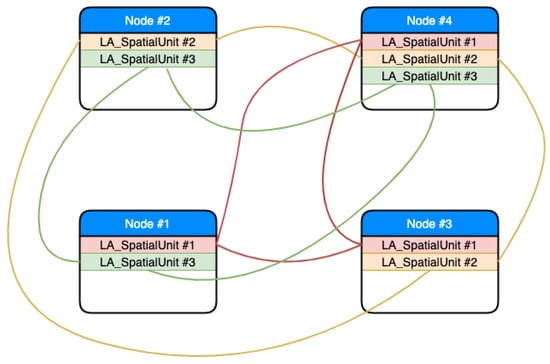
پسوند یک پایگاه داده جاسازی شده با ارزش کلیدی مسئول پارتیشن بندی، تکرار، تراکنش ها و ماندگاری است. پایگاه داده cdrLIS به صورت فیزیکی به عنوان مجموعه ای جداگانه از اسناد ذخیره می شود و هر سند به مقادیر کلید در RocksDB نگاشت می شود – موتور ذخیره سازی هر گره زیربنایی. جداول cdrLIS توسط RocksDB به صورت چند پارتیشن افقی مدیریت می شوند ( شکل 4 ). جداول به طور خودکار به چند پارتیشن تقسیم می شوند و کلید اصلی برای هر ردیف به طور منحصر به فرد پارتیشن را مشخص می کند و پارتیشن بندی را برای کاربران نامرئی می کند. پارتیشن بندی یا توسط هش کلید اصلی یا با محدوده کلید اصلی انجام می شود.
برای دستیابی به تحمل خطا �تی(به عنوان مثال، توانایی یک سیستم برای ارائه خدمات خود حتی در صورت وجود خطا – در شرایط ما، این حداکثر تعداد خرابی گره هایی است که سیستم می تواند در عین حفظ صحت داده ها زنده بماند)، خوشه پایگاه داده cdrLIS دارای با ضریب تکرار پیکربندی شود ��=2�تی+1. این بدان معناست که هر پارتیشن روی آن تکرار می شود ��گره ها ( شکل 5 )، یعنی سیستم می تواند تحمل کند (��-1)/2شکست های گره
هر پارتیشن شامل مجموعه ای از همتایان پارتیشن است که هر کدام یک کپی از داده های متعلق به پارتیشن را ذخیره می کند. وجود دارد ��پارتیشن همتاها برای پارتیشن میزبانی شده در ��گره های مختلف در یک خوشه
این سیستم بر اساس یک تکرار همزمان است، به عنوان مثال، همه نوشتهها قبل از اینکه متعهد در نظر گرفته شوند به حد نصاب کپی از پارتیشنها منتشر میشوند. داده ها با نوشتن همزمان در سراسر گره ها به روز هستند. اگر هر یک از گره های خوشه ای از کار بیفتد، داده ها سازگار هستند و از بین نمی روند.
در دسترس بودن بالا، یعنی تحمل خطا با داشتن یک ماکت فعال به دست می آید که در عرض چند ثانیه پس از شکست رهبر فعلی و ارائه درخواست ها، به عنوان یک رهبر جدید آماده است.
4.5. ثبات
هم ثبات پایگاه داده و هم ثبات تراکنش در cdrLIS تضمین شده است. سازگاری پایگاه داده با محدودیت های یکپارچگی معنایی مشخص شده به عنوان مجموعه ای از قوانین یکپارچگی ساختاری با استفاده از ادعاهای SQL و مجموعه ای از محدودیت های رفتاری تعبیه شده در بسته های cdrLIS Go به دست می آید.
تراکنش ها یک لایه انتزاعی هستند که به برنامه اجازه می دهد وانمود کند که مشکلات و خطاهای همزمان (هم سخت افزار و هم نرم افزار) وجود ندارد. سازگاری تراکنش به عملیات تراکنش های همزمان اشاره دارد، به عنوان مثال، اطمینان از سازگاری پایگاه داده در صورت وقوع دسترسی و خرابی همزمان. به موجب NewSQL DBMS ما، سختترین سطح جداسازی تراکنش، جداسازی عکس فوری قابل سریالسازی [ 53 ]، تضمین شده است. جداسازی عکس فوری سریالسازی، اجرای تراکنش سریالی را برای همه تراکنشهای متعهد شبیهسازی میکند. به عنوان مثال، گویی تراکنشها بهجای همزمانی، یکی پس از دیگری بهصورت سریالی انجام شدهاند. علاوه بر این، یک تراکنش تراکنش دیگر را مسدود نمی کند: خواندن SQL به روز رسانی SQL را مسدود نمی کند و بالعکس.
به منظور تضمین تحمل خطا در سیستم های توزیع شده در صورت خرابی گره ها، سازگاری قوی تراکنش ذاتاً مستلزم آن است که به روز رسانی ها باید به طور همزمان در چندین گره انجام شوند. ایده اصلی پشت ثبات تراکنش قوی (همچنین به عنوان خطی پذیری یا سازگاری اتمی شناخته می شود) ساده است: ایجاد یک سیستم توزیع شده به گونه ای که گویی تنها یک پایگاه داده وجود دارد و تمام عملیات CRUD روی آن اتمی هستند [ 26 ]. با این حال، تکثیر پارتیشنها در سراسر گرهها مشکلات سازگاری را ایجاد میکند که هر سیستم توزیع شده باید به طور موثر حل کند.
اجماع یک مؤلفه کلیدی برای ارائه خدمات تحملپذیر خطا مانند ذخیرهسازی دادههای تکراری همزمان و تراکنشهای اتمی غیرمسدود است. در نتیجه، سیستمهای NewSQL از پروتکلهای اجماع، به عنوان مثال، Paxos [ 54 ، 55 ] یا الگوریتم اجماع Raft استفاده میکنند تا در صورت وجود خرابی، سازگاری قوی ایجاد کنند. الگوریتمهای اجماع، یک خوشه پایگاه داده را قادر میسازد تا بهعنوان یک گروه منسجم کار کند که میتواند از شکستهای تعداد کمی از گرهها جان سالم به در ببرد. �تی). این از طریق مکانیسم رأی اکثریت به دست می آید: هر تغییری در داده ها مستلزم موافقت اکثریت گره ها با تغییر است.
در مورد ما، الگوریتم Raft [ 56 ] با انتخاب یک رهبر، و سپس دادن مسئولیت کامل برای مدیریت گزارش تکراری، به اجماع دست می یابد. رهبر ورودیهای log را از کلاینتها میپذیرد، آنها را روی دنبالکنندگان تکرار میکند، و به آنها میگوید چه زمانی میتوان ورودیهای ثبت را در ماشینهای حالتشان اعمال کرد. پیروان منفعل هستند: آنها فقط به درخواست های رهبران پاسخ می دهند. پرس و جوهای مشتری توسط رهبر مدیریت می شود: اگر مشتری درخواستی را برای فالوور ارسال کند، دنبال کننده آن را به رهبر هدایت می کند. اگر یک رهبر شکست بخورد یا از سایر گره ها جدا شود، یک رهبر جدید انتخاب می شود.
5. نتیجه گیری ها
محاسبات توزیع شده و معماری اشتراک هیچ بسیار محبوب شدند، از جمله سیستمهای پردازش داده جدید، پلتفرمها، چارچوبها و NoSQL و NewSQL DBMS با مقیاسپذیری افقی و قابلیتهای تحمل خطا. این سیستم های پردازش و مدیریت داده های جدید از مقادیر زیادی سخت افزار کالا برای ذخیره، مدیریت و تجزیه و تحلیل داده ها به روشی بسیار توزیع شده، مقیاس پذیر و مقرون به صرفه استفاده می کنند. ویژگی کلیدی NoSQL DBMS نادیده گرفتن قابلیتهای تراکنش ACID و مدل رابطه (شیء) به نفع سازگاری نهایی و سایر مدلهای داده است. با این حال، بسیاری از برنامههای کاربردی سازمانهای حیاتی، از جمله LIS، نمیتوانند از تراکنش و الزامات سازگاری دقیق چشم پوشی کنند و در نتیجه قادر به استفاده از NoSQL DBMS نیستند.
برنامه ها و سیستم های OLTP فشرده داده، از جمله LIS، باید در درجه اول به عنوان سیستم های انعطاف پذیر، مقیاس پذیر و قابل نگهداری طراحی و اجرا شوند که ثبات را تضمین می کنند. آنها باید بر اساس پارادایم “سرمایه گذاری در انعطاف پذیری داده/سیستم، نه بازیابی فاجعه” ساخته شوند، بنابراین زیرساخت های پشتیبان پیچیده و گران قیمت را حذف کنند. NewSQL DBMS دقیقاً برای این اهداف طراحی و توسعه یافته است و باید در طراحی، ساخت و استقرار نسل بعدی LIS به طور جدی مورد توجه قرار گیرد. اگرچه برای پشتیبانی از سیستمهای OLTP با بار کاری ACID-transaction، مقیاسپذیری و انعطافپذیری طراحی شدهاند، اما DBMS های توزیع شده NewSQL هنوز در حوزه LA به کار گرفته نشدهاند.
در این مقاله، ما چارچوب اصلی سازگار با LADM عمومی و توسعهپذیر و نمونه اولیه LIS سازگار، توزیعشده و انعطافپذیر را بر اساس سیستم مدیریت پایگاه داده NewSQL ارائه کردهایم. چارچوب هسته عمومی Go ما را می توان در دو جهت گسترش داد: (i) برای پشتیبانی از انواع خاصی از واحدهای فضایی، به عنوان مثال، پروفایل های فضایی (مبتنی بر چند ضلعی، مبتنی بر توپولوژیک، یا مشابه). و (ii) برای حمایت از اجرای یک نمایه کشور خاص. این چارچوب همچنین عمومی است به این معنا که می تواند در ساخت LIS توزیع شده و متمرکز و همچنین سایر برنامه های کاربردی در حوزه مدیریت زمین از جمله ابزارهای جمع آوری داده ها استفاده شود.
به عنوان کار آینده، ما قصد داریم چارچوب عمومی خود را با پروفایل های فضایی مبتنی بر چند ضلعی و توپولوژیکی دو بعدی گسترش دهیم. کارهای آتی اضافی نیز شامل بهبود عملکرد، به عنوان مثال، پارتیشن بندی فضایی داده ها در میان گره ها در سطح پایگاه داده، و توسعه برای پشتیبانی از واحدهای فضایی سه بعدی خواهد بود.
منابع
- استون بریکر، م. Çetintemel، U. “یک اندازه برای همه”: ایده ای که زمان آن فرا رسیده و رفته است. در کارکرد پایگاههای داده: حکمت عملگرایانه مایکل استونبریکر . برودی، ام ال، اد. ACM/Morgan & Claypool: نیویورک، نیویورک، ایالات متحده آمریکا، 2019؛ صص 441-462. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- داوودیان، ع. چن، ال. لیو، ام. نظرسنجی در فروشگاه های NoSQL. کامپیوتر ACM. Surv. 2018 , 51 . [ Google Scholar ] [ CrossRef ]
- Stonebraker، M. فرصت های جدید برای SQL جدید. اشتراک. ACM 2012 ، 55 ، 10-11. [ Google Scholar ] [ CrossRef ]
- گارسیا-مولینا، اچ. اولمان، جی دی. Widom, J. Database Systems-The Complete Book , 2nd ed.; تحصیلات پیرسون: لندن، انگلستان، 2009. [ Google Scholar ]
- اوزسو، MT; Valduriez, P. Principles of Distributed Database Systems , 4th ed.; Springer: برلین، آلمان، 2020. [ Google Scholar ] [ CrossRef ]
- بنیاد نرم افزار آپاچی آپاچی هادوپ. 2020. در دسترس آنلاین: https://hadoop.apache.org (در 4 مارس 2020 قابل دسترسی است).
- بنیاد نرم افزار آپاچی آپاچی اسپارک. 2020. در دسترس آنلاین: https://spark.apache.org (در 4 مارس 2020 قابل دسترسی است).
- بنیاد نرم افزار آپاچی آپاچی فلینک. 2020. در دسترس آنلاین: https://flink.apache.org (در 4 مارس 2020 قابل دسترسی است).
- الدوی، ا. Mokbel، MF SpatialHadoop: یک چارچوب MapReduce برای داده های مکانی. در مجموعه مقالات سی و یکمین کنفرانس بین المللی IEEE در مهندسی داده، ICDE 2015، سئول، کره، 13-17 آوریل 2015. Gehrke, J., Lehner, W., Shim, K., Cha, SK, Lohman, GM, Eds. IEEE Computer Society: Piscataway, NJ, USA, 2015; صص 1352–1363. [ Google Scholar ] [ CrossRef ]
- بلوسی، ا. میگلیورینی، اس. Eldawy، A. پارتیشن بندی مبتنی بر چولگی در SpatialHadoop. ISPRS Int. J. Geo-Inform. 2020 ، 9 ، 201. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یو، جی. ژانگ، ز. Sarwat، M. مدیریت داده های فضایی در آپاچی اسپارک: دیدگاه GeoSpark و فراتر از آن. GeoInformatica 2019 ، 23 ، 37–78. [ Google Scholar ] [ CrossRef ]
- گالیچ، ز. مسکوویچ، ای. Osmanovic، D. پردازش داده های حرکتی بزرگ به عنوان جریان های داده های مکانی-زمانی. GeoInformatica 2017 ، 21 ، 263-291. [ Google Scholar ] [ CrossRef ]
- پاولو، ا. Aslett, M. واقعاً چه چیزی با NewSQL جدید است؟ SIGMOD Rec. 2016 ، 45 ، 45-55. [ Google Scholar ] [ CrossRef ]
- بنت، آر.ام. پیکرینگ، ام. سارجنت، جی. دگرگونی ها، انتقال ها یا داستان های بلند؟ بررسی جهانی جذب و تأثیر NoSQL، بلاک چین و تجزیه و تحلیل داده های بزرگ در بخش مدیریت زمین. سیاست کاربری زمین 2019 ، 83 ، 435-448. [ Google Scholar ] [ CrossRef ]
- ISO 19152:2012 اطلاعات جغرافیایی — مدل دامنه مدیریت اراضی (LADM) ; سازمان بین المللی استاندارد: ژنو، سوئیس، 2012.
- لمن، سی. ون اوستروم، پی. Bennett, R. مدل دامنه مدیریت زمین. سیاست کاربری زمین 2015 ، 49 ، 535-545. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کالوجیانی، ای. کلانتری، م. دیموپولو، ای. van Oosterom، P. LADM توسعه پروفایل های کشور: جنبه هایی که باید منعکس و در نظر گرفته شوند. در مجموعه مقالات هشتمین کارگاه مدل دامنه مدیریت زمین، کوالالامپور، مالزی، 1 تا 3 اکتبر 2019؛ van Oosterom, P., Lemmen, C., Rahman, AA, Eds.; فدراسیون بین المللی نقشه برداران (FIG): کپنهاگ، دانمارک، 2019؛ ص 287-302. [ Google Scholar ]
- یینگ، اس. گوا، آر. لی، ال. ون اوستروم، پی. لدوکس، اچ. Stoter, J. طراحی و توسعه نمونه اولیه سیستم کاداستر سه بعدی بر اساس توپولوژی LADM و 3D. در مجموعه مقالات دومین کارگاه بین المللی کاداسترهای سه بعدی، دلفت، هلند، 16-18 نوامبر 2011. ص 167-188. [ Google Scholar ]
- واندیشوا، ن. ساپلنیکوف، اس. ون اوستروم، پی. دی وریس، ام. اسپایرینگ، بی. واترز، آر. هوگوین، ا. پنکوف، وی. نمونه اولیه و پایلوت کاداستر سه بعدی در فدراسیون روسیه. در مجموعه مقالات هفته کاری FIG 2012، رم، ایتالیا، 6 تا 10 اکتبر 2012. صص 1-16. [ Google Scholar ]
- زولکیفلی، NA; رحمان، ع.ا. جمیل، ح. تنگ، CH; قهوهای مایل به زرد، LC; Looi، KS; چان، KL; Van Oosterom، P. توسعه یک نمونه اولیه برای ارزیابی نمایه کشور LADM مالزی. در مجموعه مقالات کنگره FIG 2014، کوالالامپور، مالزی، 16-21 ژوئن 2014; صص 1-18. [ Google Scholar ]
- Visnjevac، N.; میهایلوویچ، آر. سوسکیچ، م. سیویتینوویچ، ز. Bajat، B. نمونه اولیه سیستم کاداستر سه بعدی بر اساس یک پایگاه داده NoSQL و یک برنامه تجسم جاوا اسکریپت. ISPRS Int. J. Geo-Inform. 2019 ، 8 ، 227. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کالوجیانی، ای. دیموپولو، ای. van Oosterom، P. اجرای نمونه اولیه LADM سه بعدی در INTERLIS. در پیشرفت در ژئو اطلاعات سه بعدی ; عبدالرحمن، ع.، ویرایش; Springer: برلین، آلمان، 2017; صص 137-157. [ Google Scholar ]
- ون استین، ام. Tanenbaum, A. Distributed Systems , 3rd ed.; CreateSpace Independent Publishing Platform: Scotts Valley, CA, USA, 2018. [ Google Scholar ]
- ویوتی، پی. Vukolic، M. سازگاری در سیستم های ذخیره سازی توزیع شده غیرمعامله ای. کامپیوتر ACM. Surv. 2016 ، 49 ، 19:1-19:34. [ Google Scholar ] [ CrossRef ]
- ون استین، م. Tanenbaum، AS مقدمه ای کوتاه بر سیستم های توزیع شده. Computing 2016 , 98 , 967-1009. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Kleppmann, M. طراحی برنامه های کاربردی داده فشرده: ایده های بزرگ پشت سیستم های قابل اعتماد، مقیاس پذیر و قابل نگهداری . O’Reilly: نیوتن، MA، ایالات متحده آمریکا، 2017. [ Google Scholar ]
- MariaDB. ClustrixDB. 2020. در دسترس آنلاین: https://clustrix.com (در 24 مارس 2020 قابل دسترسی است).
- آزمایشگاه سوسک دی بی. سوسک DB. 2020. در دسترس آنلاین: https://www.cockroachlabs.com/product/ (در 24 مارس 2020 قابل دسترسی است).
- Fauna, Inc. FaunaDB. 2020. در دسترس آنلاین: https://fauna.com (در 24 مارس 2020 قابل دسترسی است).
- کمپر، ا. Neumann, T. HyPer: یک سیستم پایگاه داده حافظه اصلی ترکیبی OLTP&OLAP بر اساس تصاویر فوری حافظه مجازی. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی مهندسی داده، ICDE 2011، هانوفر، آلمان، 11-16 آوریل 2011. Abiteboul, S., Böhm, K., Koch, C., Tan, K., Eds.; IEEE Computer Society: Piscataway, NJ, USA, 2011; ص 195-206. [ Google Scholar ] [ CrossRef ]
- Shamgunov، N. سیستم پایگاه داده درون حافظه MemSQL. در مجموعه مقالات دومین کارگاه بین المللی در مدیریت داده های حافظه و تجزیه و تحلیل، IMDM 2014، هانگژو، چین، 1 سپتامبر 2014. [ Google Scholar ]
- MemSQL Inc. MemSQL. 2020. در دسترس آنلاین: https://www.memsql.com (در 24 مارس 2020 قابل دسترسی است).
- NuoDB, Inc. NuoDB. در دسترس آنلاین: https://www.nuodb.com (در 24 مارس 2020 قابل دسترسی است).
- لی، جی. موله، م. می، ن. فاربر، اف. سیکا، وی. پلاتنر، اچ. کروگر، جی. Grund، M. پردازش تراکنش با عملکرد بالا در SAP HANA. IEEE Data Eng. گاو نر 2013 ، 36 ، 28-33. [ Google Scholar ]
- کوربت، جی سی. دین، جی. اپستاین، ام. فیکس، ا. فراست، سی. فورمن، جی جی. قماوت، س. گوبارف، آ. هایزر، سی. هوچشیلد، پی. و همکاران آچار: پایگاه داده جهانی توزیع شده گوگل. ACM Trans. محاسبه کنید. سیستم 2013 ، 31 ، 8:1-8:22. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- PingCAP Inc. TiDB. 2020. در دسترس آنلاین: https://pingcap.com/en/ (در 24 مارس 2020 قابل دسترسی است).
- استون بریکر، م. ویزبرگ، A. DBMS حافظه اصلی VoltDB. IEEE Data Eng. گاو نر 2013 ، 36 ، 21-27. [ Google Scholar ]
- Yugabyte, Inc. YugabyteDB. 2020. در دسترس آنلاین: https://www.yugabyte.com (در 24 مارس 2020 قابل دسترسی است).
- دونوان، AAA؛ Kernighan، BW The Go زبان برنامه نویسی ; ادیسون-وسلی: بوستون، MA، ایالات متحده آمریکا، 2016. [ Google Scholar ]
- Google Inc. Go. 2020. در دسترس آنلاین: https://golang.org (در 7 آوریل 2020 قابل دسترسی است).
- سامرفیلد، ام. برنامه نویسی در Go ; ادیسون-وسلی: بوستون، MA، ایالات متحده آمریکا، 2016. [ Google Scholar ]
- اسمیت، پی. گوگئوس. 2020. در دسترس آنلاین: https://github.com/paulsmith/gogeos (در 10 مارس 2020 قابل دسترسی است).
- OSGeo. GEOS—موتور هندسه، منبع باز. در دسترس آنلاین: https://trac.osgeo.org/geos/ (در 10 مارس 2020 قابل دسترسی است).
- اطلاعات جغرافیایی — دسترسی به ویژگی های ساده — قسمت 2: گزینه SQL ; سازمان بین المللی استاندارد: ژنو، سوئیس، 2004.
- ایرلند، سی. باورز، دی. نیوتن، ام. واو، ک. طبقهبندی عدم تطابق امپدانس شی – رابطهای. در مجموعه مقالات اولین کنفرانس بین المللی پیشرفت در پایگاه های داده، دانش و کاربردهای داده، DBKDS 2009، Gosier، گوادلوپ، فرانسه، 1-6 مارس 2009. Chen, Q., Cuzzocrea, A., Hara, T., Hunt, E., Popescu, M., Eds. IEEE Computer Society: Piscataway, NJ, USA, 2009; صص 36-43. [ Google Scholar ] [ CrossRef ]
- پاترئون. پکیج Gorm. 2020. در دسترس آنلاین: https://pkg.go.dev/github.com/jinzhu/gorm (در 10 مارس 2020 قابل دسترسی است).
- گالیچ، ز. Vuzem، M. cdrLIS. 2020. در دسترس آنلاین: https://github.com/cdrlis/cdrLIS (در 8 مه 2020 قابل دسترسی است).
- لمن، سی. ون اوستروم، پی. کلانتری، م. اونگر، ای. De Zeeuw, C. OGC Paper on Administration Land ; کنسرسیوم فضایی باز: Wayland، MA، ایالات متحده آمریکا، 2019؛ در دسترس آنلاین: https://docs.opengeospatial.org/wp/18-008r1/18-008r1.html (در 3 ژوئیه 2020 قابل دسترسی است).
- فیس بوک. RocksDB. 2020. در دسترس آنلاین: https://rocksdb.org (در 3 ژوئن 2020 قابل دسترسی است).
- داکر شرکت داکر. 2020. در دسترس آنلاین: https://www.docker.com (در 3 ژوئن 2020 قابل دسترسی است).
- بنیاد لینوکس کوبرنتیس 2020. در دسترس آنلاین: https://kubernetes.io (در 3 ژوئن 2020 قابل دسترسی است).
- بروور، E. CAP دوازده سال بعد: چگونه “قوانین” تغییر کرده است. کامپیوتر 2012 ، 49 ، 23-29. [ Google Scholar ] [ CrossRef ]
- کیهیل، ام جی. روم، یو. Fekete، AD Serializable جداسازی برای پایگاه داده های عکس فوری. ACM Trans. سیستم پایگاه داده 2009 ، 34 ، 20:1-20:42. [ Google Scholar ] [ CrossRef ]
- Lamport، L. پارلمان پاره وقت. ACM Trans. محاسبه کنید. سیستم 1998 ، 16 ، 133-169. [ Google Scholar ] [ CrossRef ]
- ون رنس، آر. Altinbuken، D. Paxos ساخت متوسط پیچیده. کامپیوتر ACM. Surv. 2015 ، 47 ، 42:1-42:36. [ Google Scholar ] [ CrossRef ]
- اونگارو، دی. Ousterhout، JK در جستجوی یک الگوریتم اجماع قابل درک. در مجموعه مقالات کنفرانس فنی سالانه USENIX 2014، USENIX ATC’14، فیلادلفیا، PA، ایالات متحده آمریکا، 19-20 ژوئن 2014. Gibson, G., Zeldovich, N., Eds. انجمن USENIX: برکلی، کالیفرنیا، ایالات متحده آمریکا، 2014; صص 305-319. [ Google Scholar ]
شکل 1. مدل نهاد-رابطه (ER) cdrLIS.
شکل 2. نمودار توالی UML: ایجاد LASpatialUnit .
شکل 3. معماری توزیع شده تک سایتی.

شکل 4. نمونه ای از پارتیشن بندی افقی.
شکل 5. نمونه ای از ترکیب تکرار و پارتیشن بندی در یک خوشه با چهار گره.


بدون دیدگاه